Big Data Interpolation: An Effcient Sampling Alternative for Sensor Data Aggregation
|
|
|
- Henry Bennett
- 8 years ago
- Views:
Transcription
1 Big Data Interpolation: An Effcient Sampling Alternative for Sensor Data Aggregation Hadassa Daltrophe, Shlomi Dolev, Zvi Lotker Ben-Gurion University

2 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Data Random Sample with Unrestricted Noise Byzantine elimination Conclusion 2

3 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Data Random Sample with Unrestricted Noise Byzantine elimination Conclusion 3

4 Motivation Given a large set of measurment sensor data we would like to capture the essence of the data gathered by the sensor.

5 Motivation Given a large set of measurment sensor data we would like to capture the essence of the data gathered by the sensors.

6 Big Data Age The abstraction of big data becomes one of the most important tasks in the presence of the enormous amount of data produced these days. military surveillance, medical records, photography archives, video archives 6

7 Motivations Given a large set of measurment sensor data we would like to capture the essence of the data gathered by the sensors.

8 Data Aggregation Compute a function- COUNT, SUM, AVERAGE,... Condition queries ( Where temp > 35 ) Focus on specific domin
 Focus on specific")
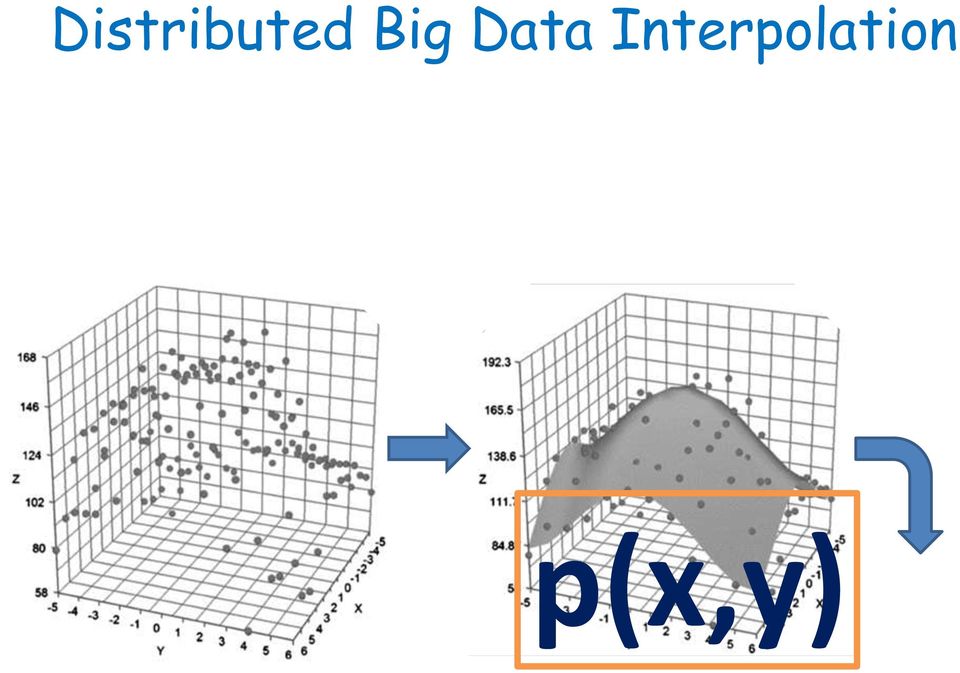
9 Distributed Big Data Interpolation Our goal is to represent every value of the data by a single (abstracting) function.

10 Distributed Big Data Interpolation Given a (sampled) set of values, we interpolate the datapoints to define a polynomial that would represent the data. data. p(x,y)

11 Distributed Big Data Interpolation Given a (sampled) set of values, we interpolate the datapoints to define a polynomial that would represent the data. data. p(x,y)

12 Distributed Big Data Interpolation p(x,y)
13 Distributed Big Data Interpolation Weierstrass approximation Theorem: for any given ε > 0, there exists a polynomial p such that p f ε p(x,y)-???
-?")
14 Distributed Big Data Interpolation The interpolation task would carried out by local data centers. The local polynomials are merged to a global one by interpolation in a hierarchical manner.

15 Challenges In practice, the data can be noisy and even Byzantine, where the Byzantine data represents an adversarial value that is not limited to being close to the correct measured data.

16 Polynomial Fitting to Noisy and Byzantine Data noise parameter δ Byzantine bound t Sample of k dimension datapoints p d (x)= y ± δ for at least N- t points Different polynomial degree d

17 Definition: Polynomial Fitting to Noisy and Byzantine Data problem Given a sample S of k dimension datapoints x 1i,, x ki N i=1 f defined on those points and a function f(x 1i,, x ki ) = y i, a noise parameter δ > 0, and Byzantine bound t we have to find a polynomial p of total degree d satisfying: p(x 1,, x k ) [y δ, y + δ] for at least N- t points
 [y δ, y + δ] for at least N- t")
18 Polynomial Fitting to Noisy and Byzantine Data

19 Polynomial Fitting to Noisy and Error Correcting Code approach: Byzantine elimination via polynomial division. Handle multidimensional general data Tolerated to discrete-noise and Byzantine appearance. Byzantine Data

20 Polynomial Fitting to Noisy and Byzantine Data Error Correcting Code approach: Byzantine elimunation via polynomial division Handle multidimensional general data Tolerated to discrete-noise and Byzantine appearance Curve-fitting & approximation approach: Noise decreasing using linear programming. Handle random sample with unrestricted noise.

21 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Reconstruction Random Sample with Unrestricted Noise Noise decreasing using linear programming Byzantine elimination Conclusions 21
22 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Reconstruction Random Sample with Unrestricted Noise Noise decreasing using linear programming Byzantine elimination Conclusions 22
23 Welch and Berlekamp (WB) Algorithm [Welch & Berlekamp, 1986]
24 Welch and Berlekamp (WB) Algorithm Handle Byzantine data No noise Using error-locating polynomial, e. e(x i ) = 0 whenever p(x i ) y i. defining the polynomial q x = p x e x solve q(x i ) = y i e(x i ) for all i p x can be found by p x = q x /e(x) [Welch & Berlekamp, 1986]
25 WB Algorithm : 2D data 3D polynomial reconstruction Multidimensional data reconstruction
26 3D polynomial reconstruction
27 3D polynomial reconstruction Byzantine appearance
28 3D polynomial reconstruction N Input:t, d, x i, y i, z i i=1 Output: p x, y deg p = d Step 1: compute e x, q x, y (deg e = t, deg q = d + t) by solving: q(x i, y i ) = z i e(x i ) 1 i N Step 2: p x, y = q(x, y)/e(x)
29 3D polynomial reconstruction Claim 2.4 (Time complexity): Given d + t + 2 N = t + data samples, we can reconstruct d + t p x, y using O(N ω ) running time. (where ω is the matrix multiplication complexity)
30 3D polynomial reconstruction Proof: m variate polynomial with degree d d + m d terms. Necessary to have d + t + 2 d + t distinct points. Step 1: We have N linear equation in at most N variables, which we can be solve e.g., by Gaussian elimination in time O(N ω ). Step 2: The general problem -can be done using the Gröbner base. Since the divider is a univariate polynomial, we can mimic long division can be implemented in O NlogN running time
31 3D polynomial reconstruction Multidimensional data reconstruction
32 3D polynomial reconstruction e and q are x-variate polynomial Using Gröbner bases we can implement the polynomial division at close to O(NlogN) time Noise: dismiss it by consistently insert a vector of possible noise, reconstruct the polynomial, and test it by the original dataset S. Multidimensional data reconstruction
33 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Reconstruction Random Sample with Unrestricted Noise Noise decreasing using linear programming Byzantine elimination Conclusions 33
34 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Reconstruction Random Sample with Unrestricted Noise Noise decreasing using linear programming Byzantine elimination Conclusions 34
35 Random Sample with Unrestricted Noise Most research has used the L 2 norm of noise (LS). Not suffice the adversarial noise Extend Arora & Khot (2002) to handle L noise
36 Random Sample with Unrestricted Noise Small noise at every point & large noise occasionally Too many polynomials agreeing with the given data. Thus, our goal is to find a polynomial p that is δ-approximation of f p q δ
37 Random Sample with Unrestricted Noise Given a random sample N x i, y i, f(x i, y i ) = z i i=1 We assume by rescaling the data that each x i, y i, z i 1,1. Define a linear programming system (LP) with the fitting polynomial as its solution.
38 Random Sample with Unrestricted Noise Noise parameter move to Chebyshev's representation of the polynomial- T i, T j ( ) each of its coefficients is at most 2 due to Chebyshev
39 Random Sample with Unrestricted Noise the output of the LP minimization p is the respected δ-approximation of f i. e., f p δ
40 Random Sample with Unrestricted Noise Bernstein-Markov Theorem applies (p f) O(d 2 ) Let ε denote the largest distance between two successive points (x 1, y 1 ),, (x S, y S ) Every interval of size ε contains at least one of the datapoints (forming ε-net). With high probability log S ε = O = O(δ/d 2 ) S Due to the LP constraint p, f differ by at most δ on the points in the ε -net, p f 2δ + O εd 2 = cδ p is the respected δ-approximation of f
41 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Reconstruction Random Sample with Unrestricted Noise Noise decreasing using linear programming Byzantine elimination Conclusions 41
42 Byzantine elimination For any point, consider a small sqaure interval Ʌ. Due to the derivative bound, the true value of the polynomial is essentialy constant over Ʌ. we can eliminate the byzantine appearance.
43 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Reconstruction Random Sample with Unrestricted Noise Noise decreasing using linear programming Byzantine elimination Conclusions 43
44 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Reconstruction Random Sample with Unrestricted Noise Noise decreasing using linear programming Byzantine elimination Conclusions 44
45 General Byzantine data with Discrete Finite Noise Solving linear system Polynomial division N = t + d + t + 2 d + t constant δ Random Byzantine Sample with Unrestricted LP Noise minimization N = d4 δ log 1 δ
46 Outline Introduction Motivation Problem definition General data with Discrete Finite Noise Welsh & Berlekamp Algorithm Multidimensional Reconstruction Random Sample with Unrestricted Noise Noise decreasing using linear programming Byzantine elimination Conclusions 46
47 Conclusions Presented the concept of data interpolation in the scope of sensor data aggregation as well as the new big data challenge.
48 Conclusions Constructs a polynomial using the WB method as a subroutine. Tolerated to discrete-noise and Byzantine multi-dimensional data. Presented a multivariate analogue of the WB method. Using linear programing minimization we reconstruct an unknown multi-dimensional polynomial. Detail the way to eliminate the Byzantine appearance.
49 Thank you...
50 e is multivariate or univariate Given that p has m=2 variable, deg(p)=1 the data contain t = 2 Byzantine appearance When e univariate: When e is bivariate: Both give the same expected solution: back
51 Random Sample with Unrestricted Noise proof: Since using Bernstein-Markov theorem We get thus:
52 Random Sample with Unrestricted Noise From symmetric consideration By construction, p takes all values in [-1,1] for all points in I, and the distance between successive points of I is 2/ I (I is equidistant). The claim follows from the fact that the derivative p by denition gives the rate of change in p
53 Random Sample with Unrestricted Noise This follows from Bernstein-Markov and the estimate
54 3D polynomial reconstruction Claim 2.2 (Correctness): There exist a pair of polynomials e(x) and q(x, y) that satisfy Step 1 such that q x, y = p x, y e(x) proof: If e x i = 0, then q x i, y i = z i e x i = 0. When e(x i ) 0, we know p(x i, y i ) = z i and so we still have p x i, y i e x i = z i e(x i ), as desired.
55 3D polynomial reconstruction
56 3D polynomial reconstruction
57 3D polynomial reconstruction Claim 2.2 (Correctness): There exist a pair of polynomials e(x) and q(x, y) that satisfy Step 1 such that q x, y = p x, y e(x)
58 3D polynomial reconstruction Claim 2.3 (Uniqueness): If any two distinct solutions q 1 x, y ; e 1 x q 2 x, y ; e 2 x satisfy Step 1, then they will satisfy q 1 (x, y)/e 1 (x)= q 2 (x, y)/e 2 (x)
59 3D polynomial reconstruction Claim 2.2 (Correctness): There exist a pair of polynomials e(x) and q(x, y) that satisfy Step 1 such that q x, y = p x, y e(x) Claim 2.3 (Uniqueness): If any two distinct solutions q 1 x, y ; e 1 x q 2 x, y ; e 2 x satisfy Step 1, then they will satisfy q 1 (x, y)/e 1 (x)= q 2 (x, y)/e 2 (x)
8. Linear least-squares
 8. Linear least-squares EE13 (Fall 211-12) definition examples and applications solution of a least-squares problem, normal equations 8-1 Definition overdetermined linear equations if b range(a), cannot
8. Linear least-squares EE13 (Fall 211-12) definition examples and applications solution of a least-squares problem, normal equations 8-1 Definition overdetermined linear equations if b range(a), cannot
Influences in low-degree polynomials
 Influences in low-degree polynomials Artūrs Bačkurs December 12, 2012 1 Introduction In 3] it is conjectured that every bounded real polynomial has a highly influential variable The conjecture is known
Influences in low-degree polynomials Artūrs Bačkurs December 12, 2012 1 Introduction In 3] it is conjectured that every bounded real polynomial has a highly influential variable The conjecture is known
1 The Line vs Point Test
 6.875 PCP and Hardness of Approximation MIT, Fall 2010 Lecture 5: Low Degree Testing Lecturer: Dana Moshkovitz Scribe: Gregory Minton and Dana Moshkovitz Having seen a probabilistic verifier for linearity
6.875 PCP and Hardness of Approximation MIT, Fall 2010 Lecture 5: Low Degree Testing Lecturer: Dana Moshkovitz Scribe: Gregory Minton and Dana Moshkovitz Having seen a probabilistic verifier for linearity
Variance Reduction. Pricing American Options. Monte Carlo Option Pricing. Delta and Common Random Numbers
 Variance Reduction The statistical efficiency of Monte Carlo simulation can be measured by the variance of its output If this variance can be lowered without changing the expected value, fewer replications
Variance Reduction The statistical efficiency of Monte Carlo simulation can be measured by the variance of its output If this variance can be lowered without changing the expected value, fewer replications
Inner Product Spaces
 Math 571 Inner Product Spaces 1. Preliminaries An inner product space is a vector space V along with a function, called an inner product which associates each pair of vectors u, v with a scalar u, v, and
Math 571 Inner Product Spaces 1. Preliminaries An inner product space is a vector space V along with a function, called an inner product which associates each pair of vectors u, v with a scalar u, v, and
Basics of Polynomial Theory
 3 Basics of Polynomial Theory 3.1 Polynomial Equations In geodesy and geoinformatics, most observations are related to unknowns parameters through equations of algebraic (polynomial) type. In cases where
3 Basics of Polynomial Theory 3.1 Polynomial Equations In geodesy and geoinformatics, most observations are related to unknowns parameters through equations of algebraic (polynomial) type. In cases where
1 Review of Least Squares Solutions to Overdetermined Systems
 cs4: introduction to numerical analysis /9/0 Lecture 7: Rectangular Systems and Numerical Integration Instructor: Professor Amos Ron Scribes: Mark Cowlishaw, Nathanael Fillmore Review of Least Squares
cs4: introduction to numerical analysis /9/0 Lecture 7: Rectangular Systems and Numerical Integration Instructor: Professor Amos Ron Scribes: Mark Cowlishaw, Nathanael Fillmore Review of Least Squares
The Convolution Operation
 The Convolution Operation Convolution is a very natural mathematical operation which occurs in both discrete and continuous modes of various kinds. We often encounter it in the course of doing other operations
The Convolution Operation Convolution is a very natural mathematical operation which occurs in both discrete and continuous modes of various kinds. We often encounter it in the course of doing other operations
Finding Small Roots of Bivariate Integer Polynomial Equations Revisited
 Finding Small Roots of Bivariate Integer Polynomial Equations Revisited Jean-Sébastien Coron Gemplus Card International 34 rue Guynemer, 92447 Issy-les-Moulineaux, France jean-sebastien.coron@gemplus.com
Finding Small Roots of Bivariate Integer Polynomial Equations Revisited Jean-Sébastien Coron Gemplus Card International 34 rue Guynemer, 92447 Issy-les-Moulineaux, France jean-sebastien.coron@gemplus.com
4.6 Linear Programming duality
 4.6 Linear Programming duality To any minimization (maximization) LP we can associate a closely related maximization (minimization) LP. Different spaces and objective functions but in general same optimal
4.6 Linear Programming duality To any minimization (maximization) LP we can associate a closely related maximization (minimization) LP. Different spaces and objective functions but in general same optimal
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Introduction to Support Vector Machines. Colin Campbell, Bristol University
 Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
POLYNOMIAL HISTOPOLATION, SUPERCONVERGENT DEGREES OF FREEDOM, AND PSEUDOSPECTRAL DISCRETE HODGE OPERATORS
 POLYNOMIAL HISTOPOLATION, SUPERCONVERGENT DEGREES OF FREEDOM, AND PSEUDOSPECTRAL DISCRETE HODGE OPERATORS N. ROBIDOUX Abstract. We show that, given a histogram with n bins possibly non-contiguous or consisting
POLYNOMIAL HISTOPOLATION, SUPERCONVERGENT DEGREES OF FREEDOM, AND PSEUDOSPECTRAL DISCRETE HODGE OPERATORS N. ROBIDOUX Abstract. We show that, given a histogram with n bins possibly non-contiguous or consisting
Joint Exam 1/P Sample Exam 1
 Joint Exam 1/P Sample Exam 1 Take this practice exam under strict exam conditions: Set a timer for 3 hours; Do not stop the timer for restroom breaks; Do not look at your notes. If you believe a question
Joint Exam 1/P Sample Exam 1 Take this practice exam under strict exam conditions: Set a timer for 3 hours; Do not stop the timer for restroom breaks; Do not look at your notes. If you believe a question
Moving Least Squares Approximation
 Chapter 7 Moving Least Squares Approimation An alternative to radial basis function interpolation and approimation is the so-called moving least squares method. As we will see below, in this method the
Chapter 7 Moving Least Squares Approimation An alternative to radial basis function interpolation and approimation is the so-called moving least squares method. As we will see below, in this method the
4.5 Chebyshev Polynomials
 230 CHAP. 4 INTERPOLATION AND POLYNOMIAL APPROXIMATION 4.5 Chebyshev Polynomials We now turn our attention to polynomial interpolation for f (x) over [ 1, 1] based on the nodes 1 x 0 < x 1 < < x N 1. Both
230 CHAP. 4 INTERPOLATION AND POLYNOMIAL APPROXIMATION 4.5 Chebyshev Polynomials We now turn our attention to polynomial interpolation for f (x) over [ 1, 1] based on the nodes 1 x 0 < x 1 < < x N 1. Both
CHAPTER SIX IRREDUCIBILITY AND FACTORIZATION 1. BASIC DIVISIBILITY THEORY
 January 10, 2010 CHAPTER SIX IRREDUCIBILITY AND FACTORIZATION 1. BASIC DIVISIBILITY THEORY The set of polynomials over a field F is a ring, whose structure shares with the ring of integers many characteristics.
January 10, 2010 CHAPTER SIX IRREDUCIBILITY AND FACTORIZATION 1. BASIC DIVISIBILITY THEORY The set of polynomials over a field F is a ring, whose structure shares with the ring of integers many characteristics.
Zeros of a Polynomial Function
 Zeros of a Polynomial Function An important consequence of the Factor Theorem is that finding the zeros of a polynomial is really the same thing as factoring it into linear factors. In this section we
Zeros of a Polynomial Function An important consequence of the Factor Theorem is that finding the zeros of a polynomial is really the same thing as factoring it into linear factors. In this section we
CS 2750 Machine Learning. Lecture 1. Machine Learning. http://www.cs.pitt.edu/~milos/courses/cs2750/ CS 2750 Machine Learning.
 Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Multivariate Normal Distribution
 Multivariate Normal Distribution Lecture 4 July 21, 2011 Advanced Multivariate Statistical Methods ICPSR Summer Session #2 Lecture #4-7/21/2011 Slide 1 of 41 Last Time Matrices and vectors Eigenvalues
Multivariate Normal Distribution Lecture 4 July 21, 2011 Advanced Multivariate Statistical Methods ICPSR Summer Session #2 Lecture #4-7/21/2011 Slide 1 of 41 Last Time Matrices and vectors Eigenvalues
Factorization Algorithms for Polynomials over Finite Fields
 Degree Project Factorization Algorithms for Polynomials over Finite Fields Sajid Hanif, Muhammad Imran 2011-05-03 Subject: Mathematics Level: Master Course code: 4MA11E Abstract Integer factorization is
Degree Project Factorization Algorithms for Polynomials over Finite Fields Sajid Hanif, Muhammad Imran 2011-05-03 Subject: Mathematics Level: Master Course code: 4MA11E Abstract Integer factorization is
Econometrics Simple Linear Regression
 Econometrics Simple Linear Regression Burcu Eke UC3M Linear equations with one variable Recall what a linear equation is: y = b 0 + b 1 x is a linear equation with one variable, or equivalently, a straight
Econometrics Simple Linear Regression Burcu Eke UC3M Linear equations with one variable Recall what a linear equation is: y = b 0 + b 1 x is a linear equation with one variable, or equivalently, a straight
Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs
 CSE599s: Extremal Combinatorics November 21, 2011 Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs Lecturer: Anup Rao 1 An Arithmetic Circuit Lower Bound An arithmetic circuit is just like
CSE599s: Extremal Combinatorics November 21, 2011 Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs Lecturer: Anup Rao 1 An Arithmetic Circuit Lower Bound An arithmetic circuit is just like
Factoring. Factoring 1
 Factoring Factoring 1 Factoring Security of RSA algorithm depends on (presumed) difficulty of factoring o Given N = pq, find p or q and RSA is broken o Rabin cipher also based on factoring Factoring like
Factoring Factoring 1 Factoring Security of RSA algorithm depends on (presumed) difficulty of factoring o Given N = pq, find p or q and RSA is broken o Rabin cipher also based on factoring Factoring like
MA107 Precalculus Algebra Exam 2 Review Solutions
 MA107 Precalculus Algebra Exam 2 Review Solutions February 24, 2008 1. The following demand equation models the number of units sold, x, of a product as a function of price, p. x = 4p + 200 a. Please write
MA107 Precalculus Algebra Exam 2 Review Solutions February 24, 2008 1. The following demand equation models the number of units sold, x, of a product as a function of price, p. x = 4p + 200 a. Please write
FACTORING SPARSE POLYNOMIALS
 FACTORING SPARSE POLYNOMIALS Theorem 1 (Schinzel): Let r be a positive integer, and fix non-zero integers a 0,..., a r. Let F (x 1,..., x r ) = a r x r + + a 1 x 1 + a 0. Then there exist finite sets S
FACTORING SPARSE POLYNOMIALS Theorem 1 (Schinzel): Let r be a positive integer, and fix non-zero integers a 0,..., a r. Let F (x 1,..., x r ) = a r x r + + a 1 x 1 + a 0. Then there exist finite sets S
Algebra 2 Chapter 1 Vocabulary. identity - A statement that equates two equivalent expressions.
 Chapter 1 Vocabulary identity - A statement that equates two equivalent expressions. verbal model- A word equation that represents a real-life problem. algebraic expression - An expression with variables.
Chapter 1 Vocabulary identity - A statement that equates two equivalent expressions. verbal model- A word equation that represents a real-life problem. algebraic expression - An expression with variables.
POLYNOMIAL HISTOPOLATION, SUPERCONVERGENT DEGREES OF FREEDOM, AND PSEUDOSPECTRAL DISCRETE HODGE OPERATORS
 POLYNOMIAL HISTOPOLATION, SUPERCONVERGENT DEGREES OF FREEDOM, AND PSEUDOSPECTRAL DISCRETE HODGE OPERATORS N. ROBIDOUX Abstract. We show that, given a histogram with n bins possibly non-contiguous or consisting
POLYNOMIAL HISTOPOLATION, SUPERCONVERGENT DEGREES OF FREEDOM, AND PSEUDOSPECTRAL DISCRETE HODGE OPERATORS N. ROBIDOUX Abstract. We show that, given a histogram with n bins possibly non-contiguous or consisting
1 Formulating The Low Degree Testing Problem
 6.895 PCP and Hardness of Approximation MIT, Fall 2010 Lecture 5: Linearity Testing Lecturer: Dana Moshkovitz Scribe: Gregory Minton and Dana Moshkovitz In the last lecture, we proved a weak PCP Theorem,
6.895 PCP and Hardness of Approximation MIT, Fall 2010 Lecture 5: Linearity Testing Lecturer: Dana Moshkovitz Scribe: Gregory Minton and Dana Moshkovitz In the last lecture, we proved a weak PCP Theorem,
Notes 11: List Decoding Folded Reed-Solomon Codes
 Introduction to Coding Theory CMU: Spring 2010 Notes 11: List Decoding Folded Reed-Solomon Codes April 2010 Lecturer: Venkatesan Guruswami Scribe: Venkatesan Guruswami At the end of the previous notes,
Introduction to Coding Theory CMU: Spring 2010 Notes 11: List Decoding Folded Reed-Solomon Codes April 2010 Lecturer: Venkatesan Guruswami Scribe: Venkatesan Guruswami At the end of the previous notes,
Lectures 5-6: Taylor Series
 Math 1d Instructor: Padraic Bartlett Lectures 5-: Taylor Series Weeks 5- Caltech 213 1 Taylor Polynomials and Series As we saw in week 4, power series are remarkably nice objects to work with. In particular,
Math 1d Instructor: Padraic Bartlett Lectures 5-: Taylor Series Weeks 5- Caltech 213 1 Taylor Polynomials and Series As we saw in week 4, power series are remarkably nice objects to work with. In particular,
1 VECTOR SPACES AND SUBSPACES
 1 VECTOR SPACES AND SUBSPACES What is a vector? Many are familiar with the concept of a vector as: Something which has magnitude and direction. an ordered pair or triple. a description for quantities such
1 VECTOR SPACES AND SUBSPACES What is a vector? Many are familiar with the concept of a vector as: Something which has magnitude and direction. an ordered pair or triple. a description for quantities such
Introduction to General and Generalized Linear Models
 Introduction to General and Generalized Linear Models General Linear Models - part I Henrik Madsen Poul Thyregod Informatics and Mathematical Modelling Technical University of Denmark DK-2800 Kgs. Lyngby
Introduction to General and Generalized Linear Models General Linear Models - part I Henrik Madsen Poul Thyregod Informatics and Mathematical Modelling Technical University of Denmark DK-2800 Kgs. Lyngby
CITY UNIVERSITY LONDON. BEng Degree in Computer Systems Engineering Part II BSc Degree in Computer Systems Engineering Part III PART 2 EXAMINATION
 No: CITY UNIVERSITY LONDON BEng Degree in Computer Systems Engineering Part II BSc Degree in Computer Systems Engineering Part III PART 2 EXAMINATION ENGINEERING MATHEMATICS 2 (resit) EX2005 Date: August
No: CITY UNIVERSITY LONDON BEng Degree in Computer Systems Engineering Part II BSc Degree in Computer Systems Engineering Part III PART 2 EXAMINATION ENGINEERING MATHEMATICS 2 (resit) EX2005 Date: August
Bindel, Spring 2012 Intro to Scientific Computing (CS 3220) Week 3: Wednesday, Feb 8
 Week 3: Wednesday, Feb 8") Spaces and bases Week 3: Wednesday, Feb 8 I have two favorite vector spaces 1 : R n and the space P d of polynomials of degree at most d. For R n, we have a canonical basis: R n = span{e 1, e 2,..., e
Spaces and bases Week 3: Wednesday, Feb 8 I have two favorite vector spaces 1 : R n and the space P d of polynomials of degree at most d. For R n, we have a canonical basis: R n = span{e 1, e 2,..., e
Some probability and statistics
 Appendix A Some probability and statistics A Probabilities, random variables and their distribution We summarize a few of the basic concepts of random variables, usually denoted by capital letters, X,Y,
Appendix A Some probability and statistics A Probabilities, random variables and their distribution We summarize a few of the basic concepts of random variables, usually denoted by capital letters, X,Y,
Polynomial Factoring. Ramesh Hariharan
 Polynomial Factoring Ramesh Hariharan The Problem Factoring Polynomials overs Integers Factorization is unique (why?) (x^2 + 5x +6) (x+2)(x+3) Time: Polynomial in degree A Related Problem Factoring Integers
Polynomial Factoring Ramesh Hariharan The Problem Factoring Polynomials overs Integers Factorization is unique (why?) (x^2 + 5x +6) (x+2)(x+3) Time: Polynomial in degree A Related Problem Factoring Integers
A Branch and Bound Algorithm for Solving the Binary Bi-level Linear Programming Problem
 A Branch and Bound Algorithm for Solving the Binary Bi-level Linear Programming Problem John Karlof and Peter Hocking Mathematics and Statistics Department University of North Carolina Wilmington Wilmington,
A Branch and Bound Algorithm for Solving the Binary Bi-level Linear Programming Problem John Karlof and Peter Hocking Mathematics and Statistics Department University of North Carolina Wilmington Wilmington,
Recall that two vectors in are perpendicular or orthogonal provided that their dot
 Orthogonal Complements and Projections Recall that two vectors in are perpendicular or orthogonal provided that their dot product vanishes That is, if and only if Example 1 The vectors in are orthogonal
Orthogonal Complements and Projections Recall that two vectors in are perpendicular or orthogonal provided that their dot product vanishes That is, if and only if Example 1 The vectors in are orthogonal
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Applications to Data Smoothing and Image Processing I
 Applications to Data Smoothing and Image Processing I MA 348 Kurt Bryan Signals and Images Let t denote time and consider a signal a(t) on some time interval, say t. We ll assume that the signal a(t) is
Applications to Data Smoothing and Image Processing I MA 348 Kurt Bryan Signals and Images Let t denote time and consider a signal a(t) on some time interval, say t. We ll assume that the signal a(t) is
A Survey on Data Aggregation in Big Data and Cloud Computing
 A Survey on Data Aggregation in Big Data and Cloud Computing N.Karthick 1 and X.Agnes Kalrani 2 1 Department of Computer Science, Karpagam University, Coimbatore, Tamilnadu- 641 021 India. 2 Department
A Survey on Data Aggregation in Big Data and Cloud Computing N.Karthick 1 and X.Agnes Kalrani 2 1 Department of Computer Science, Karpagam University, Coimbatore, Tamilnadu- 641 021 India. 2 Department
March 29, 2011. 171S4.4 Theorems about Zeros of Polynomial Functions
 MAT 171 Precalculus Algebra Dr. Claude Moore Cape Fear Community College CHAPTER 4: Polynomial and Rational Functions 4.1 Polynomial Functions and Models 4.2 Graphing Polynomial Functions 4.3 Polynomial
MAT 171 Precalculus Algebra Dr. Claude Moore Cape Fear Community College CHAPTER 4: Polynomial and Rational Functions 4.1 Polynomial Functions and Models 4.2 Graphing Polynomial Functions 4.3 Polynomial
Application. Outline. 3-1 Polynomial Functions 3-2 Finding Rational Zeros of. Polynomial. 3-3 Approximating Real Zeros of.
 Polynomial and Rational Functions Outline 3-1 Polynomial Functions 3-2 Finding Rational Zeros of Polynomials 3-3 Approximating Real Zeros of Polynomials 3-4 Rational Functions Chapter 3 Group Activity:
Polynomial and Rational Functions Outline 3-1 Polynomial Functions 3-2 Finding Rational Zeros of Polynomials 3-3 Approximating Real Zeros of Polynomials 3-4 Rational Functions Chapter 3 Group Activity:
Lecture 3: Finding integer solutions to systems of linear equations
 Lecture 3: Finding integer solutions to systems of linear equations Algorithmic Number Theory (Fall 2014) Rutgers University Swastik Kopparty Scribe: Abhishek Bhrushundi 1 Overview The goal of this lecture
Lecture 3: Finding integer solutions to systems of linear equations Algorithmic Number Theory (Fall 2014) Rutgers University Swastik Kopparty Scribe: Abhishek Bhrushundi 1 Overview The goal of this lecture
Lecture 11: 0-1 Quadratic Program and Lower Bounds
 Lecture : - Quadratic Program and Lower Bounds (3 units) Outline Problem formulations Reformulation: Linearization & continuous relaxation Branch & Bound Method framework Simple bounds, LP bound and semidefinite
Lecture : - Quadratic Program and Lower Bounds (3 units) Outline Problem formulations Reformulation: Linearization & continuous relaxation Branch & Bound Method framework Simple bounds, LP bound and semidefinite
Mathematical finance and linear programming (optimization)
") Mathematical finance and linear programming (optimization) Geir Dahl September 15, 2009 1 Introduction The purpose of this short note is to explain how linear programming (LP) (=linear optimization) may
Mathematical finance and linear programming (optimization) Geir Dahl September 15, 2009 1 Introduction The purpose of this short note is to explain how linear programming (LP) (=linear optimization) may
A note on companion matrices
 Linear Algebra and its Applications 372 (2003) 325 33 www.elsevier.com/locate/laa A note on companion matrices Miroslav Fiedler Academy of Sciences of the Czech Republic Institute of Computer Science Pod
Linear Algebra and its Applications 372 (2003) 325 33 www.elsevier.com/locate/laa A note on companion matrices Miroslav Fiedler Academy of Sciences of the Czech Republic Institute of Computer Science Pod
Confidence Intervals for the Difference Between Two Means
 Chapter 47 Confidence Intervals for the Difference Between Two Means Introduction This procedure calculates the sample size necessary to achieve a specified distance from the difference in sample means
Chapter 47 Confidence Intervals for the Difference Between Two Means Introduction This procedure calculates the sample size necessary to achieve a specified distance from the difference in sample means
Short Programs for functions on Curves
 Short Programs for functions on Curves Victor S. Miller Exploratory Computer Science IBM, Thomas J. Watson Research Center Yorktown Heights, NY 10598 May 6, 1986 Abstract The problem of deducing a function
Short Programs for functions on Curves Victor S. Miller Exploratory Computer Science IBM, Thomas J. Watson Research Center Yorktown Heights, NY 10598 May 6, 1986 Abstract The problem of deducing a function
Manifold Learning Examples PCA, LLE and ISOMAP
 Manifold Learning Examples PCA, LLE and ISOMAP Dan Ventura October 14, 28 Abstract We try to give a helpful concrete example that demonstrates how to use PCA, LLE and Isomap, attempts to provide some intuition
Manifold Learning Examples PCA, LLE and ISOMAP Dan Ventura October 14, 28 Abstract We try to give a helpful concrete example that demonstrates how to use PCA, LLE and Isomap, attempts to provide some intuition
TOPIC 4: DERIVATIVES
 TOPIC 4: DERIVATIVES 1. The derivative of a function. Differentiation rules 1.1. The slope of a curve. The slope of a curve at a point P is a measure of the steepness of the curve. If Q is a point on the
TOPIC 4: DERIVATIVES 1. The derivative of a function. Differentiation rules 1.1. The slope of a curve. The slope of a curve at a point P is a measure of the steepness of the curve. If Q is a point on the
Quotient Rings and Field Extensions
 Chapter 5 Quotient Rings and Field Extensions In this chapter we describe a method for producing field extension of a given field. If F is a field, then a field extension is a field K that contains F.
Chapter 5 Quotient Rings and Field Extensions In this chapter we describe a method for producing field extension of a given field. If F is a field, then a field extension is a field K that contains F.
Example: Credit card default, we may be more interested in predicting the probabilty of a default than classifying individuals as default or not.
 Statistical Learning: Chapter 4 Classification 4.1 Introduction Supervised learning with a categorical (Qualitative) response Notation: - Feature vector X, - qualitative response Y, taking values in C
Statistical Learning: Chapter 4 Classification 4.1 Introduction Supervised learning with a categorical (Qualitative) response Notation: - Feature vector X, - qualitative response Y, taking values in C
We shall turn our attention to solving linear systems of equations. Ax = b
 59 Linear Algebra We shall turn our attention to solving linear systems of equations Ax = b where A R m n, x R n, and b R m. We already saw examples of methods that required the solution of a linear system
59 Linear Algebra We shall turn our attention to solving linear systems of equations Ax = b where A R m n, x R n, and b R m. We already saw examples of methods that required the solution of a linear system
The Steepest Descent Algorithm for Unconstrained Optimization and a Bisection Line-search Method
 The Steepest Descent Algorithm for Unconstrained Optimization and a Bisection Line-search Method Robert M. Freund February, 004 004 Massachusetts Institute of Technology. 1 1 The Algorithm The problem
The Steepest Descent Algorithm for Unconstrained Optimization and a Bisection Line-search Method Robert M. Freund February, 004 004 Massachusetts Institute of Technology. 1 1 The Algorithm The problem
Two Topics in Parametric Integration Applied to Stochastic Simulation in Industrial Engineering
 Two Topics in Parametric Integration Applied to Stochastic Simulation in Industrial Engineering Department of Industrial Engineering and Management Sciences Northwestern University September 15th, 2014
Two Topics in Parametric Integration Applied to Stochastic Simulation in Industrial Engineering Department of Industrial Engineering and Management Sciences Northwestern University September 15th, 2014
Similarity and Diagonalization. Similar Matrices
 MATH022 Linear Algebra Brief lecture notes 48 Similarity and Diagonalization Similar Matrices Let A and B be n n matrices. We say that A is similar to B if there is an invertible n n matrix P such that
MATH022 Linear Algebra Brief lecture notes 48 Similarity and Diagonalization Similar Matrices Let A and B be n n matrices. We say that A is similar to B if there is an invertible n n matrix P such that
5 Numerical Differentiation
 D. Levy 5 Numerical Differentiation 5. Basic Concepts This chapter deals with numerical approximations of derivatives. The first questions that comes up to mind is: why do we need to approximate derivatives
D. Levy 5 Numerical Differentiation 5. Basic Concepts This chapter deals with numerical approximations of derivatives. The first questions that comes up to mind is: why do we need to approximate derivatives
On the representability of the bi-uniform matroid
 On the representability of the bi-uniform matroid Simeon Ball, Carles Padró, Zsuzsa Weiner and Chaoping Xing August 3, 2012 Abstract Every bi-uniform matroid is representable over all sufficiently large
On the representability of the bi-uniform matroid Simeon Ball, Carles Padró, Zsuzsa Weiner and Chaoping Xing August 3, 2012 Abstract Every bi-uniform matroid is representable over all sufficiently large
15. Symmetric polynomials
 15. Symmetric polynomials 15.1 The theorem 15.2 First examples 15.3 A variant: discriminants 1. The theorem Let S n be the group of permutations of {1,, n}, also called the symmetric group on n things.
15. Symmetric polynomials 15.1 The theorem 15.2 First examples 15.3 A variant: discriminants 1. The theorem Let S n be the group of permutations of {1,, n}, also called the symmetric group on n things.
Lecture 4: AC 0 lower bounds and pseudorandomness
 Lecture 4: AC 0 lower bounds and pseudorandomness Topics in Complexity Theory and Pseudorandomness (Spring 2013) Rutgers University Swastik Kopparty Scribes: Jason Perry and Brian Garnett In this lecture,
Lecture 4: AC 0 lower bounds and pseudorandomness Topics in Complexity Theory and Pseudorandomness (Spring 2013) Rutgers University Swastik Kopparty Scribes: Jason Perry and Brian Garnett In this lecture,
Multivariate Analysis of Ecological Data
 Multivariate Analysis of Ecological Data MICHAEL GREENACRE Professor of Statistics at the Pompeu Fabra University in Barcelona, Spain RAUL PRIMICERIO Associate Professor of Ecology, Evolutionary Biology
Multivariate Analysis of Ecological Data MICHAEL GREENACRE Professor of Statistics at the Pompeu Fabra University in Barcelona, Spain RAUL PRIMICERIO Associate Professor of Ecology, Evolutionary Biology
The p-norm generalization of the LMS algorithm for adaptive filtering
 The p-norm generalization of the LMS algorithm for adaptive filtering Jyrki Kivinen University of Helsinki Manfred Warmuth University of California, Santa Cruz Babak Hassibi California Institute of Technology
The p-norm generalization of the LMS algorithm for adaptive filtering Jyrki Kivinen University of Helsinki Manfred Warmuth University of California, Santa Cruz Babak Hassibi California Institute of Technology
Predict the Popularity of YouTube Videos Using Early View Data
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Department of Mathematics, Indian Institute of Technology, Kharagpur Assignment 2-3, Probability and Statistics, March 2015. Due:-March 25, 2015.
 Department of Mathematics, Indian Institute of Technology, Kharagpur Assignment -3, Probability and Statistics, March 05. Due:-March 5, 05.. Show that the function 0 for x < x+ F (x) = 4 for x < for x
Department of Mathematics, Indian Institute of Technology, Kharagpur Assignment -3, Probability and Statistics, March 05. Due:-March 5, 05.. Show that the function 0 for x < x+ F (x) = 4 for x < for x
Simple and efficient online algorithms for real world applications
 Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Machine Learning and Data Mining. Regression Problem. (adapted from) Prof. Alexander Ihler
 Prof. Alexander Ihler") Machine Learning and Data Mining Regression Problem (adapted from) Prof. Alexander Ihler Overview Regression Problem Definition and define parameters ϴ. Prediction using ϴ as parameters Measure the error
Machine Learning and Data Mining Regression Problem (adapted from) Prof. Alexander Ihler Overview Regression Problem Definition and define parameters ϴ. Prediction using ϴ as parameters Measure the error
University of Lille I PC first year list of exercises n 7. Review
 University of Lille I PC first year list of exercises n 7 Review Exercise Solve the following systems in 4 different ways (by substitution, by the Gauss method, by inverting the matrix of coefficients
University of Lille I PC first year list of exercises n 7 Review Exercise Solve the following systems in 4 different ways (by substitution, by the Gauss method, by inverting the matrix of coefficients
11 Multivariate Polynomials
 CS 487: Intro. to Symbolic Computation Winter 2009: M. Giesbrecht Script 11 Page 1 (These lecture notes were prepared and presented by Dan Roche.) 11 Multivariate Polynomials References: MC: Section 16.6
CS 487: Intro. to Symbolic Computation Winter 2009: M. Giesbrecht Script 11 Page 1 (These lecture notes were prepared and presented by Dan Roche.) 11 Multivariate Polynomials References: MC: Section 16.6
5. Orthogonal matrices
 L Vandenberghe EE133A (Spring 2016) 5 Orthogonal matrices matrices with orthonormal columns orthogonal matrices tall matrices with orthonormal columns complex matrices with orthonormal columns 5-1 Orthonormal
L Vandenberghe EE133A (Spring 2016) 5 Orthogonal matrices matrices with orthonormal columns orthogonal matrices tall matrices with orthonormal columns complex matrices with orthonormal columns 5-1 Orthonormal
EECS 556 Image Processing W 09. Interpolation. Interpolation techniques B splines
 EECS 556 Image Processing W 09 Interpolation Interpolation techniques B splines What is image processing? Image processing is the application of 2D signal processing methods to images Image representation
EECS 556 Image Processing W 09 Interpolation Interpolation techniques B splines What is image processing? Image processing is the application of 2D signal processing methods to images Image representation
Lecture 8. Confidence intervals and the central limit theorem
 Lecture 8. Confidence intervals and the central limit theorem Mathematical Statistics and Discrete Mathematics November 25th, 2015 1 / 15 Central limit theorem Let X 1, X 2,... X n be a random sample of
Lecture 8. Confidence intervals and the central limit theorem Mathematical Statistics and Discrete Mathematics November 25th, 2015 1 / 15 Central limit theorem Let X 1, X 2,... X n be a random sample of
Christfried Webers. Canberra February June 2015
 c Statistical Group and College of Engineering and Computer Science Canberra February June (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 829 c Part VIII Linear Classification 2 Logistic
c Statistical Group and College of Engineering and Computer Science Canberra February June (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 829 c Part VIII Linear Classification 2 Logistic
A Tutorial on Probability Theory
 Paola Sebastiani Department of Mathematics and Statistics University of Massachusetts at Amherst Corresponding Author: Paola Sebastiani. Department of Mathematics and Statistics, University of Massachusetts,
Paola Sebastiani Department of Mathematics and Statistics University of Massachusetts at Amherst Corresponding Author: Paola Sebastiani. Department of Mathematics and Statistics, University of Massachusetts,
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
Prime Numbers and Irreducible Polynomials
 Prime Numbers and Irreducible Polynomials M. Ram Murty The similarity between prime numbers and irreducible polynomials has been a dominant theme in the development of number theory and algebraic geometry.
Prime Numbers and Irreducible Polynomials M. Ram Murty The similarity between prime numbers and irreducible polynomials has been a dominant theme in the development of number theory and algebraic geometry.
Chapter 4: Vector Autoregressive Models
 Chapter 4: Vector Autoregressive Models 1 Contents: Lehrstuhl für Department Empirische of Wirtschaftsforschung Empirical Research and und Econometrics Ökonometrie IV.1 Vector Autoregressive Models (VAR)...
Chapter 4: Vector Autoregressive Models 1 Contents: Lehrstuhl für Department Empirische of Wirtschaftsforschung Empirical Research and und Econometrics Ökonometrie IV.1 Vector Autoregressive Models (VAR)...
Zeros of Polynomial Functions
 Zeros of Polynomial Functions The Rational Zero Theorem If f (x) = a n x n + a n-1 x n-1 + + a 1 x + a 0 has integer coefficients and p/q (where p/q is reduced) is a rational zero, then p is a factor of
Zeros of Polynomial Functions The Rational Zero Theorem If f (x) = a n x n + a n-1 x n-1 + + a 1 x + a 0 has integer coefficients and p/q (where p/q is reduced) is a rational zero, then p is a factor of
Lecture 13 - Basic Number Theory.
 Lecture 13 - Basic Number Theory. Boaz Barak March 22, 2010 Divisibility and primes Unless mentioned otherwise throughout this lecture all numbers are non-negative integers. We say that A divides B, denoted
Lecture 13 - Basic Number Theory. Boaz Barak March 22, 2010 Divisibility and primes Unless mentioned otherwise throughout this lecture all numbers are non-negative integers. We say that A divides B, denoted
Vector and Matrix Norms
 Chapter 1 Vector and Matrix Norms 11 Vector Spaces Let F be a field (such as the real numbers, R, or complex numbers, C) with elements called scalars A Vector Space, V, over the field F is a non-empty
Chapter 1 Vector and Matrix Norms 11 Vector Spaces Let F be a field (such as the real numbers, R, or complex numbers, C) with elements called scalars A Vector Space, V, over the field F is a non-empty
Zeros of Polynomial Functions
 Zeros of Polynomial Functions Objectives: 1.Use the Fundamental Theorem of Algebra to determine the number of zeros of polynomial functions 2.Find rational zeros of polynomial functions 3.Find conjugate
Zeros of Polynomial Functions Objectives: 1.Use the Fundamental Theorem of Algebra to determine the number of zeros of polynomial functions 2.Find rational zeros of polynomial functions 3.Find conjugate
Lecture 3: Linear methods for classification
 Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
4.3 Lagrange Approximation
 206 CHAP. 4 INTERPOLATION AND POLYNOMIAL APPROXIMATION Lagrange Polynomial Approximation 4.3 Lagrange Approximation Interpolation means to estimate a missing function value by taking a weighted average
206 CHAP. 4 INTERPOLATION AND POLYNOMIAL APPROXIMATION Lagrange Polynomial Approximation 4.3 Lagrange Approximation Interpolation means to estimate a missing function value by taking a weighted average
JUST THE MATHS UNIT NUMBER 1.8. ALGEBRA 8 (Polynomials) A.J.Hobson
 A.J.Hobson") JUST THE MATHS UNIT NUMBER 1.8 ALGEBRA 8 (Polynomials) by A.J.Hobson 1.8.1 The factor theorem 1.8.2 Application to quadratic and cubic expressions 1.8.3 Cubic equations 1.8.4 Long division of polynomials
JUST THE MATHS UNIT NUMBER 1.8 ALGEBRA 8 (Polynomials) by A.J.Hobson 1.8.1 The factor theorem 1.8.2 Application to quadratic and cubic expressions 1.8.3 Cubic equations 1.8.4 Long division of polynomials
DIFFERENTIABILITY OF COMPLEX FUNCTIONS. Contents
 DIFFERENTIABILITY OF COMPLEX FUNCTIONS Contents 1. Limit definition of a derivative 1 2. Holomorphic functions, the Cauchy-Riemann equations 3 3. Differentiability of real functions 5 4. A sufficient condition
DIFFERENTIABILITY OF COMPLEX FUNCTIONS Contents 1. Limit definition of a derivative 1 2. Holomorphic functions, the Cauchy-Riemann equations 3 3. Differentiability of real functions 5 4. A sufficient condition
These axioms must hold for all vectors ū, v, and w in V and all scalars c and d.
 DEFINITION: A vector space is a nonempty set V of objects, called vectors, on which are defined two operations, called addition and multiplication by scalars (real numbers), subject to the following axioms
DEFINITION: A vector space is a nonempty set V of objects, called vectors, on which are defined two operations, called addition and multiplication by scalars (real numbers), subject to the following axioms
The degree of a polynomial function is equal to the highest exponent found on the independent variables.
 DETAILED SOLUTIONS AND CONCEPTS - POLYNOMIAL FUNCTIONS Prepared by Ingrid Stewart, Ph.D., College of Southern Nevada Please Send Questions and Comments to ingrid.stewart@csn.edu. Thank you! PLEASE NOTE
DETAILED SOLUTIONS AND CONCEPTS - POLYNOMIAL FUNCTIONS Prepared by Ingrid Stewart, Ph.D., College of Southern Nevada Please Send Questions and Comments to ingrid.stewart@csn.edu. Thank you! PLEASE NOTE
MATH 304 Linear Algebra Lecture 9: Subspaces of vector spaces (continued). Span. Spanning set.
. Span. Spanning set.") MATH 304 Linear Algebra Lecture 9: Subspaces of vector spaces (continued). Span. Spanning set. Vector space A vector space is a set V equipped with two operations, addition V V (x,y) x + y V and scalar
MATH 304 Linear Algebra Lecture 9: Subspaces of vector spaces (continued). Span. Spanning set. Vector space A vector space is a set V equipped with two operations, addition V V (x,y) x + y V and scalar
19 LINEAR QUADRATIC REGULATOR
 19 LINEAR QUADRATIC REGULATOR 19.1 Introduction The simple form of loopshaping in scalar systems does not extend directly to multivariable (MIMO) plants, which are characterized by transfer matrices instead
19 LINEAR QUADRATIC REGULATOR 19.1 Introduction The simple form of loopshaping in scalar systems does not extend directly to multivariable (MIMO) plants, which are characterized by transfer matrices instead
Roots of Polynomials
 Roots of Polynomials (Com S 477/577 Notes) Yan-Bin Jia Sep 24, 2015 A direct corollary of the fundamental theorem of algebra is that p(x) can be factorized over the complex domain into a product a n (x
Roots of Polynomials (Com S 477/577 Notes) Yan-Bin Jia Sep 24, 2015 A direct corollary of the fundamental theorem of algebra is that p(x) can be factorized over the complex domain into a product a n (x
Notes from Week 1: Algorithms for sequential prediction
 CS 683 Learning, Games, and Electronic Markets Spring 2007 Notes from Week 1: Algorithms for sequential prediction Instructor: Robert Kleinberg 22-26 Jan 2007 1 Introduction In this course we will be looking
CS 683 Learning, Games, and Electronic Markets Spring 2007 Notes from Week 1: Algorithms for sequential prediction Instructor: Robert Kleinberg 22-26 Jan 2007 1 Introduction In this course we will be looking
Lecture 9: Introduction to Pattern Analysis
 Lecture 9: Introduction to Pattern Analysis g Features, patterns and classifiers g Components of a PR system g An example g Probability definitions g Bayes Theorem g Gaussian densities Features, patterns
Lecture 9: Introduction to Pattern Analysis g Features, patterns and classifiers g Components of a PR system g An example g Probability definitions g Bayes Theorem g Gaussian densities Features, patterns
Online Outlier Detection in Sensor Data Using Non-Parametric Models
 Online Outlier Detection in Sensor Data Using Non-Parametric Models S. Subramaniam UC Riverside sharmi@cs.ucr.edu T. Palpanas IBM Research themis@us.ibm.com D. Papadopoulos, V. Kalogeraki, D. Gunopulos
Online Outlier Detection in Sensor Data Using Non-Parametric Models S. Subramaniam UC Riverside sharmi@cs.ucr.edu T. Palpanas IBM Research themis@us.ibm.com D. Papadopoulos, V. Kalogeraki, D. Gunopulos
Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh
 Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh Peter Richtárik Week 3 Randomized Coordinate Descent With Arbitrary Sampling January 27, 2016 1 / 30 The Problem
Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh Peter Richtárik Week 3 Randomized Coordinate Descent With Arbitrary Sampling January 27, 2016 1 / 30 The Problem
Breaking The Code. Ryan Lowe. Ryan Lowe is currently a Ball State senior with a double major in Computer Science and Mathematics and
 Breaking The Code Ryan Lowe Ryan Lowe is currently a Ball State senior with a double major in Computer Science and Mathematics and a minor in Applied Physics. As a sophomore, he took an independent study
Breaking The Code Ryan Lowe Ryan Lowe is currently a Ball State senior with a double major in Computer Science and Mathematics and a minor in Applied Physics. As a sophomore, he took an independent study
Dimensionality Reduction: Principal Components Analysis
 Dimensionality Reduction: Principal Components Analysis In data mining one often encounters situations where there are a large number of variables in the database. In such situations it is very likely
Dimensionality Reduction: Principal Components Analysis In data mining one often encounters situations where there are a large number of variables in the database. In such situations it is very likely
The van Hoeij Algorithm for Factoring Polynomials
 The van Hoeij Algorithm for Factoring Polynomials Jürgen Klüners Abstract In this survey we report about a new algorithm for factoring polynomials due to Mark van Hoeij. The main idea is that the combinatorial
The van Hoeij Algorithm for Factoring Polynomials Jürgen Klüners Abstract In this survey we report about a new algorithm for factoring polynomials due to Mark van Hoeij. The main idea is that the combinatorial
How To Prove The Dirichlet Unit Theorem
 Chapter 6 The Dirichlet Unit Theorem As usual, we will be working in the ring B of algebraic integers of a number field L. Two factorizations of an element of B are regarded as essentially the same if
Chapter 6 The Dirichlet Unit Theorem As usual, we will be working in the ring B of algebraic integers of a number field L. Two factorizations of an element of B are regarded as essentially the same if
4.5 Linear Dependence and Linear Independence
 4.5 Linear Dependence and Linear Independence 267 32. {v 1, v 2 }, where v 1, v 2 are collinear vectors in R 3. 33. Prove that if S and S are subsets of a vector space V such that S is a subset of S, then
4.5 Linear Dependence and Linear Independence 267 32. {v 1, v 2 }, where v 1, v 2 are collinear vectors in R 3. 33. Prove that if S and S are subsets of a vector space V such that S is a subset of S, then