Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
|
|
|
- Silas Booker
- 10 years ago
- Views:
Transcription


1 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015

2 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib algorithms MLlib MLlib on PICO

3 Hadoop Apache Hadoop is an open-source software framework written in Java for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware. All the modules in Hadoop are designed with a fundamental assumption that hardware failures (of individual machines, or racks of machines) are commonplace and thus should be automatically handled in software by the framework. The core of Apache Hadoop consists of a storage part (Hadoop Distributed File System (HDFS)) and a processing part (MapReduce).

4 Hadoop Hadoop splits files into large blocks and distributes them amongst the nodes in the cluster. To process the data, Hadoop MapReduce transfers packaged code for nodes to process in parallel, based on the data each node needs to process. This approach takes advantage of data locality (nodes manipulating the data that they have on hand) to allow the data to be processed faster and more efficiently than it would be in a more conventional supercomputer architecture that relies on a parallel file system where computation and data are connected via high-speed networking.

5 Hadoop Core Components HDFS Hadoop Distributed File System(Storage) Distributed across nodes Natively redundant Name Node tracks locations. MapReduce (Processing) Splits a task across processors near the data & assembles results Self-Healing, High Bandwidth Clustered storage JobTracker manages the TaskTrackers

6 Hadoop Core Components


7 HDFS Architecture NameNode master of the system maintains and manages the blocks which are present on the DataNodes DataNodes slaves which are deployed on each machine and provide the actual storage responsible for serving read and write requests for the clients

8 NameNode Metadata Metadata in Memory The entire Metadata is in main memory No demand paging of FS meta-data Types of Metadata List of files List of Blocks for each file List of DataNode for each block File attributes, e.g. access time, replication factor A Transaction Log Records file creations, file deletions etc. Secondary NameNode: Not a hot standby for the NameNode Connects to NameNodeevery hour* Housekeeping, backup of NameNode metadata Saved metadata can build a failed NameNode

9 JobTracker and TaskTracker JobTracker Manages MapReduce jobs, distribute individual tasks (map/reduce) to machines running the TaskTracker Instantiates and monitors individual Map and Reduce tasks When a TaskTracker receives a request to run a task, it instantiates a separate JVM for that task Can run multiple tasks at the same time depending on the hardware resources

10 JobTracker takes care of: JobTracker task status: (idle, in-progress, completed) scheduling idle tasks as resources (managed by tasktrackers) become available gathering location and size of each intermediate file produced by the Map tasks sending this info to the reducer tasks JobTracker pings tasktrackers periodically to detect failures: if a Map failure occurs: Map tasks completed or in-progress are reset to idle Reduce tasks are notified when the map task is rescheduled on another tasktracker if Reduce failure occurs: Only in-progress tasks are reset to idle JobTracker failure MapReduce task is aborted and client is notified

11 Hadoop MapReduce MapReduce is an high-level programming model and implementation for largescale parallel data processing. A MapReduce program consists of two functions (inspired by primitives of functional programming language): MAP function: Input: (input key, value) Output: bag of (intermediate key, value) REDUCE function: Input: (intermediate key, bag of values) Output: bag of output (values) System executes the program in two steps: the MAP function is applied in parallel to all (input key, value) pairs in the input file the system will group all pairs with the same intermediate key ( shuffle ), and passes the bag of values to the REDUCE function
 pairs in the input file the system will group all pairs with the same intermediate key ( shuffle ), and")
12 Word count example
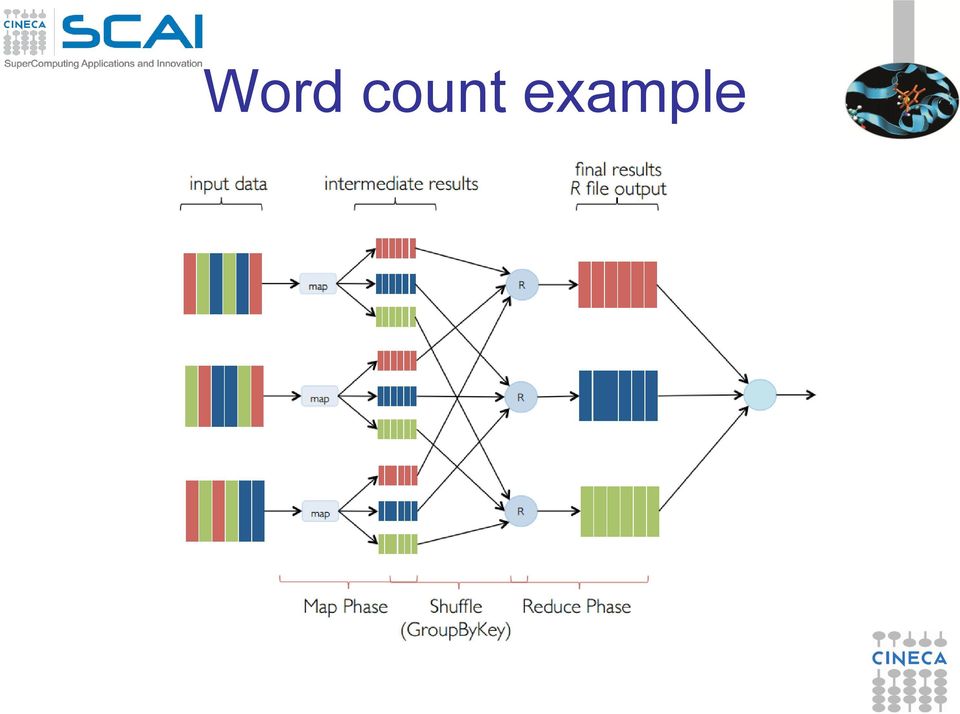

13 Word count example

14 Importing data in Hadoop Copy Commands put:copy file(s) from local file system to destination file system. It can also read from stdin and writes to destination file system. hadoop dfs put iris.txt hdfs://<target Namenode> copyfromlocal: Similar to put command, except that the source is restricted to a local file reference. hadoop dfs copyfromlocal iris.txt hdfs://<target Namenode> distcp: Distributed Copy to move data between clusters, used for backup and recovery. hadoop distcphdfs://<source NN> hdfs://<target NN>

15 Sqoop Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured data stores such as relational databases. Imports individual tables or entire databases to HDFS. Generates Java classes to allow you to interact with your imported data. Provides the ability to import from SQL databases straight into your Hive data warehouse

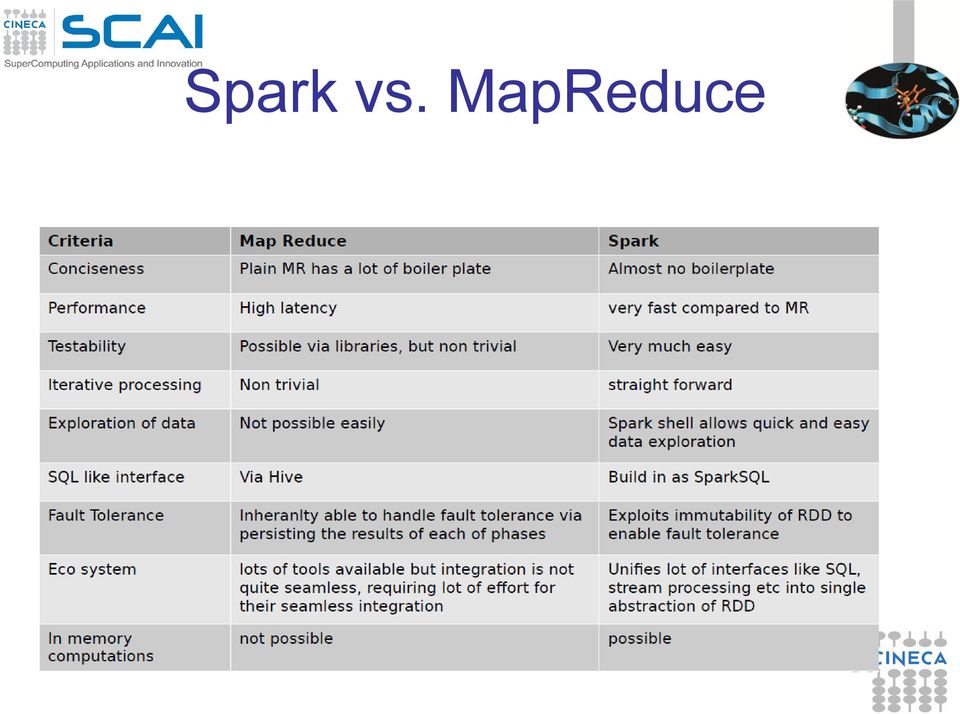
16 Apache Spark Apache Spark is a fast and general engine for large-scale data processing. Apache Spark is a multi-purpose platform for use cases that span investigative, as well as operational analytics. Apache Spark is an execution engine that broadens the type of computing workloads Hadoop can handle, while also tuning the performance of the big data framework. Apache Spark has numerous advantages over Hadoop's MapReduce execution engine, in both the speed with which it carries out batch processing jobs and the wider range of computing workloads it can handle.

17 Apache Spark Features Spark has a number of features that make it a compelling cross over platform for investigative as well as operational analytics: Spark comes with a Machine-Learning Library, MLlib Being Scala-based, Spark embeds in any JVM-based operational system, but can also be used interactively in a way that will feel familiar to R and Python users. For Java programmers, Scala still presents a learning curve. But at least, any Java library can be used from within Scala. Spark s RDD (Resilient Distributed Dataset) abstraction resembles Crunch s PCollection, which has proved a useful abstraction in Hadoop that will already be familiar to Crunch developers.(crunch can even be used on top of Spark.) Spark imitates Scala s collections API and functional style, which is a boon to Java and Scala developers,but also some what familiar to developers coming from Python. Scala is also a compelling choice for statistical computing.
 abstraction resembles Crunch s PCollection, which has proved a useful abstraction in Hadoop that will already be familiar to Crunch developers.")

18 Spark vs. MapReduce
19 Apache Spark Architecture Spark solves similar problems as Hadoop MapReduce does but with a fast in memory approach and a clean functional style API. With its ability to integrate with Hadoop and inbuilt tools for interactive query analysis(shark), large-scale graph processing and analysis(bagel), and real-time analysis(spark Streaming), it can be interactively used to quickly process and query big datasets. Fast Data Processing with Spark covers how to write distributed mapreduce style programs with Spark.
, and real-time analysis(spark Streaming), it can be interactively used to quickly process and query big")
20 MapReduce issues MapReduce let users write parallel computations using a set of high-level operators without having to worry about: distribution fault tolerance abstractions for accessing a cluster s computational resources but lacks abstractions for leveraging distributed memory between two MR jobs writes results to an external stable storage system, e.g., HDFS! Inefficient for an important class of emerging applications: iterative algorithms those that reuse intermediate results across multiple computations e.g. Machine learning and graph algorithms interactive data mining where a user runs multiple ad-hoc queries on the same subset of the data

21 Improving over MapReduce Not relying on a rigid map-then-reduce format, its engine can execute a more general directed acyclic graph (DAG) of operators. Spark can pass them directly to the next step in the pipeline in situations where MapReduce must write out intermediate results to the distributed filesystem. It extends this capability with a rich set of transformations that enable users to express computation more naturally. It has a strong developer focus and streamlined API that can represent complex pipelines in a few lines of code.
22 Improving over MapReduce Spark extends its predecessors with in-memory processing. Its Resilient Distributed Dataset (RDD) abstraction enables developers to materialize any point in a processing pipeline into memory across the cluster. Hadoop workloads are typically centered around the concept of doing batch jobs on large amounts of data, and typically it s not used for interactive querying. Spark, in contrast, has the ability to chainsaw through large amounts of data, store pared-down views of the data in structures called Resilient Distributed Datasets (RDDs), and do interactive queries with sub-second response times.
23 MLlib MLlib is a Spark subproject providing machine learning primitives: initial contribution from AMPLab, UC Berkeley shipped with Spark since version 0.8 MLlib s goal is to make practical machine learning (ML) scalable and easy. Besides new algorithms and performance improvements that we have seen in each release, a great deal of time and effort has been spent on making MLlib easy.
24 Why MLlib It is built on Apache Spark, a fast and general engine for large-scale data processing. Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. MLlib provides APIs in three languages: Python, Java, and Scala, along with user guide and example code, to ease the learning curve for users coming from different backgrounds
25 MLlib Algorithms classification: logistic regression, naive Bayes, decision tree, ensemble of trees (random forests) regression: generalized linear regression (GLM) collaborative filtering: alternating least squares (ALS) clustering: k-means, gaussian mixture, power iteration clustering, latent Dirichelt allocation decomposition: singular value decomposition (SVD), principal component analysis, singular value decompostion
26 Examples with MLlib Clustering KDD 99 cup Decision tree covtype
27 KDD Cup 99 data This is the data set used for The Third International Knowledge Discovery and Data Mining Tools Competition, which was held in conjunction with KDD-99 The Fifth International Conference on Knowledge Discovery and Data Mining. The competition task was to build a network intrusion detector, a predictive model capable of distinguishing between ``bad'' connections, called intrusions or attacks, and ``good'' normal connections. This database contains a standard set of data to be audited, which includes a wide variety of intrusions simulated in a military network environment.
28 Covtype data The data set used in this chapter is the well-known Covtype data set, available online as a compressed CSV-format data file, covtype.data.gz, and accompanying info file, covtype.info. The data set records the types of forest covering parcels of land in Colorado, USA. Each example contains several features describing each parcel of land, like its elevation, slope, distance to water, shade, and soil type, along with the known forest type covering the land. The forest cover type is to be predicted from the rest of the features, of which there are 54 in total. This data set has been used in research, and even a Kaggle competition. It is an interesting data set to explore in this chapter because it contains both categorical and numeric features. There are 581,012 examples in the data set, which does not exactly qualify as big data, but is large enough to be manageable as an example and still highlight some issues of scale.
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Spark and the Big Data Library
 Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Unified Big Data Analytics Pipeline. 连 城 [email protected]
 Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Big Data Analytics with Spark and Oscar BAO. Tamas Jambor, Lead Data Scientist at Massive Analytic
 Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Big Data by the numbers
 COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Fast Analytics on Big Data with H20
 Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Spark. Fast, Interactive, Language- Integrated Cluster Computing
 Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com
 Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Getting Started with Hadoop. Raanan Dagan Paul Tibaldi
 Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Apache Spark 11/10/15. Context. Reminder. Context. What is Spark? A GrowingStack
 Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
HDFS. Hadoop Distributed File System
 HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ. Cloudera World Japan November 2014
 Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ Cloudera World Japan November 2014 WANdisco Background WANdisco: Wide Area Network Distributed Computing Enterprise ready, high availability
Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ Cloudera World Japan November 2014 WANdisco Background WANdisco: Wide Area Network Distributed Computing Enterprise ready, high availability
Map Reduce / Hadoop / HDFS
 Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Brave New World: Hadoop vs. Spark
 Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
HiBench Introduction. Carson Wang ([email protected]) Software & Services Group
 Software & Services Group") HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science
 A Seminar report On Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED BY: www.studymafia.org
A Seminar report On Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED BY: www.studymafia.org
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Spark: Making Big Data Interactive & Real-Time
 Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,[email protected]
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Managing large clusters resources
 Managing large clusters resources ID2210 Gautier Berthou (SICS) Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth
Managing large clusters resources ID2210 Gautier Berthou (SICS) Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
SEIZE THE DATA. 2015 SEIZE THE DATA. 2015
 1 Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. BIG DATA CONFERENCE 2015 Boston August 10-13 Predicting and reducing deforestation
1 Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. BIG DATA CONFERENCE 2015 Boston August 10-13 Predicting and reducing deforestation
Spark ΕΡΓΑΣΤΗΡΙΟ 10. Prepared by George Nikolaides 4/19/2015 1
 Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
HadoopRDF : A Scalable RDF Data Analysis System
 HadoopRDF : A Scalable RDF Data Analysis System Yuan Tian 1, Jinhang DU 1, Haofen Wang 1, Yuan Ni 2, and Yong Yu 1 1 Shanghai Jiao Tong University, Shanghai, China {tian,dujh,whfcarter}@apex.sjtu.edu.cn
HadoopRDF : A Scalable RDF Data Analysis System Yuan Tian 1, Jinhang DU 1, Haofen Wang 1, Yuan Ni 2, and Yong Yu 1 1 Shanghai Jiao Tong University, Shanghai, China {tian,dujh,whfcarter}@apex.sjtu.edu.cn
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
MLlib: Scalable Machine Learning on Spark
 MLlib: Scalable Machine Learning on Spark Xiangrui Meng Collaborators: Ameet Talwalkar, Evan Sparks, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia, Rean Griffith, John Duchi, Joseph
MLlib: Scalable Machine Learning on Spark Xiangrui Meng Collaborators: Ameet Talwalkar, Evan Sparks, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia, Rean Griffith, John Duchi, Joseph
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Shark Installation Guide Week 3 Report. Ankush Arora
 Shark Installation Guide Week 3 Report Ankush Arora Last Updated: May 31,2014 CONTENTS Contents 1 Introduction 1 1.1 Shark..................................... 1 1.2 Apache Spark.................................
Shark Installation Guide Week 3 Report Ankush Arora Last Updated: May 31,2014 CONTENTS Contents 1 Introduction 1 1.1 Shark..................................... 1 1.2 Apache Spark.................................
CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University](/thumbs/26/8135278.jpg "CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
Advanced In-Database Analytics
 Advanced In-Database Analytics Tallinn, Sept. 25th, 2012 Mikko-Pekka Bertling, BDM Greenplum EMEA 1 That sounds complicated? 2 Who can tell me how best to solve this 3 What are the main mathematical functions??
Advanced In-Database Analytics Tallinn, Sept. 25th, 2012 Mikko-Pekka Bertling, BDM Greenplum EMEA 1 That sounds complicated? 2 Who can tell me how best to solve this 3 What are the main mathematical functions??
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
CDH AND BUSINESS CONTINUITY:
 WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS
 A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Introduction to Spark
 Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
Big Data Analytics Hadoop and Spark
 Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics
 E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo
 Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
Sensor Network Messaging Service Hive/Hadoop Mr. Apichon Witayangkurn [email protected] Department of Civil Engineering The University of Tokyo Contents 1 Introduction 2 What & Why Sensor Network
NETWORK TRAFFIC ANALYSIS: HADOOP PIG VS TYPICAL MAPREDUCE
 NETWORK TRAFFIC ANALYSIS: HADOOP PIG VS TYPICAL MAPREDUCE Anjali P P 1 and Binu A 2 1 Department of Information Technology, Rajagiri School of Engineering and Technology, Kochi. M G University, Kerala
NETWORK TRAFFIC ANALYSIS: HADOOP PIG VS TYPICAL MAPREDUCE Anjali P P 1 and Binu A 2 1 Department of Information Technology, Rajagiri School of Engineering and Technology, Kochi. M G University, Kerala
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
Architectures for massive data management
 Architectures for massive data management Apache Spark Albert Bifet [email protected] October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
Architectures for massive data management Apache Spark Albert Bifet [email protected] October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
Big Data and Data Science: Behind the Buzz Words
 Big Data and Data Science: Behind the Buzz Words Peggy Brinkmann, FCAS, MAAA Actuary Milliman, Inc. April 1, 2014 Contents Big data: from hype to value Deconstructing data science Managing big data Analyzing
Big Data and Data Science: Behind the Buzz Words Peggy Brinkmann, FCAS, MAAA Actuary Milliman, Inc. April 1, 2014 Contents Big data: from hype to value Deconstructing data science Managing big data Analyzing
Hadoop Cluster Applications
 Hadoop Overview Data analytics has become a key element of the business decision process over the last decade. Classic reporting on a dataset stored in a database was sufficient until recently, but yesterday
Hadoop Overview Data analytics has become a key element of the business decision process over the last decade. Classic reporting on a dataset stored in a database was sufficient until recently, but yesterday
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Big Data at Spotify. Anders Arpteg, Ph D Analytics Machine Learning, Spotify
 Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed)
Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed)
Oracle Big Data Fundamentals Ed 1 NEW
 Oracle University Contact Us: +90 212 329 6779 Oracle Big Data Fundamentals Ed 1 NEW Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big
Oracle University Contact Us: +90 212 329 6779 Oracle Big Data Fundamentals Ed 1 NEW Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
How To Create A Data Visualization With Apache Spark And Zeppelin 2.5.3.5
 Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data