Managing large clusters resources
|
|
|
- Isaac Shelton
- 10 years ago
- Views:
Transcription
1 Managing large clusters resources ID2210 Gautier Berthou (SICS)
2 Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth is the bottleneck
3 MapReduce Locality Job( /crawler/bot/jd.io/1 ) submi t Job Tracker Task Tracker Task Tracker Task Tracker Task Tracker Task Tracker Task Tracker Job Job Job Job Job Job DN DN DN DN DN DN R R = esultfile(s) R R
4 First step Single Processing Framework Batch Apps Hadoop 1.x MapReduce (resource mgmt, job scheduler, data processing) HDFS (distributed storage) 4
5 MapReduce Locality Job( /crawler/bot/jd.io/1 ) submi t Job Tracker Task Tracker Task Tracker Task Tracker Task Tracker Task Tracker Task Tracker Job Job Job Job Job Job DN DN DN DN DN DN R R = esultfile(s) R R
6 The Job Tracker Job Distribute the map and reduce tasks on the s of the cluster Ensure fairness of the cluster resource attributions Track the progress of these tasks Authenticate job tenants and make sure that each job is isolated from the others Etc. 6
![Limitations of MapReduce [Zaharia 11] MapReduce is based on an acyclic data flow from stable storage to stable storage.](/docs-images/30/14486421/images/7-0.png "- Slow writes data to HDFS at every stage in the pipeline Acyclic data flow is inefficient for applications that repeatedly reuse a working set of data: - Iterative algorithms (machine learning,")
7 Limitations of MapReduce [Zaharia 11] MapReduce is based on an acyclic data flow from stable storage to stable storage. - Slow writes data to HDFS at every stage in the pipeline Acyclic data flow is inefficient for applications that repeatedly reuse a working set of data: - Iterative algorithms (machine learning, graphs) - Interactive data mining tools (R, Excel, Python) Map Reduce Input Map Output Map Reduce
8 Limitations Only one programming model. The map reduce framework is not using the cluster at its maximum. The job tracker is a bottle neck. The job tracker is a single point of failure. 8
9 Goals for a new Scheduler Being able to run different frameworks Scale Provide advance scheduling policies Run efficiently with different kind of workloads 9
10 Second step Multiple Processing Frameworks Batch, Interactive, Streaming Hadoop 2.x MapReduce (data processing) Others (spark, mpi, giraph, etc) YARN (resource mgmt, job scheduler) HDFS (distributed storage) 10
11 Examples of scheduling Policies Capacity scheduler: - Applications have different levels of priorities. Fair scheduler: - Applications have different levels of priorities. - Used resources can be preempted. Reservation-based scheduler (1) : - Applications can indicate how long they will run and when they have to be finished. (1) Reservation-based Scheduling: If you re late don t blame us!, C. Curino & al., Microsoft tech-report 11
12 Scenario 3 kinds of jobs: - Emergency jobs: need to be run as soon as possible. - Production jobs: have a deadline, a known running time and are very exigent on the s they can be scheduled on. - Best effort jobs: interactive jobs that have lower priority, but on which users expect low latency. 12
13 Capacity scheduler Best effort emergency production Best effort Best effort Best effort Best effort Best effort production Now Production work deadline 13
14 Fair scheduler Best effort emergency Best effort Best production effort Best effort Best effort Now Production work deadline 14
15 Reservation-based scheduler Best effort emergency Best effort production production Best effort Best effort Now Production work deadline 15

16 Scheduler Architectures Omega: flexible, scalable schedulers for large compute clusters, Malte Schwarzkopf & al., EuroSys 13 16
17 The monolithic Scheduler Yarn: - Apache Hadoop YARN: Yet Another Resource Negotiator, V. K. Vavilapalli & al., SoCC 13. Borg: - Large-scale cluster management at Google with Borg, A. Verma & al., EuroSys
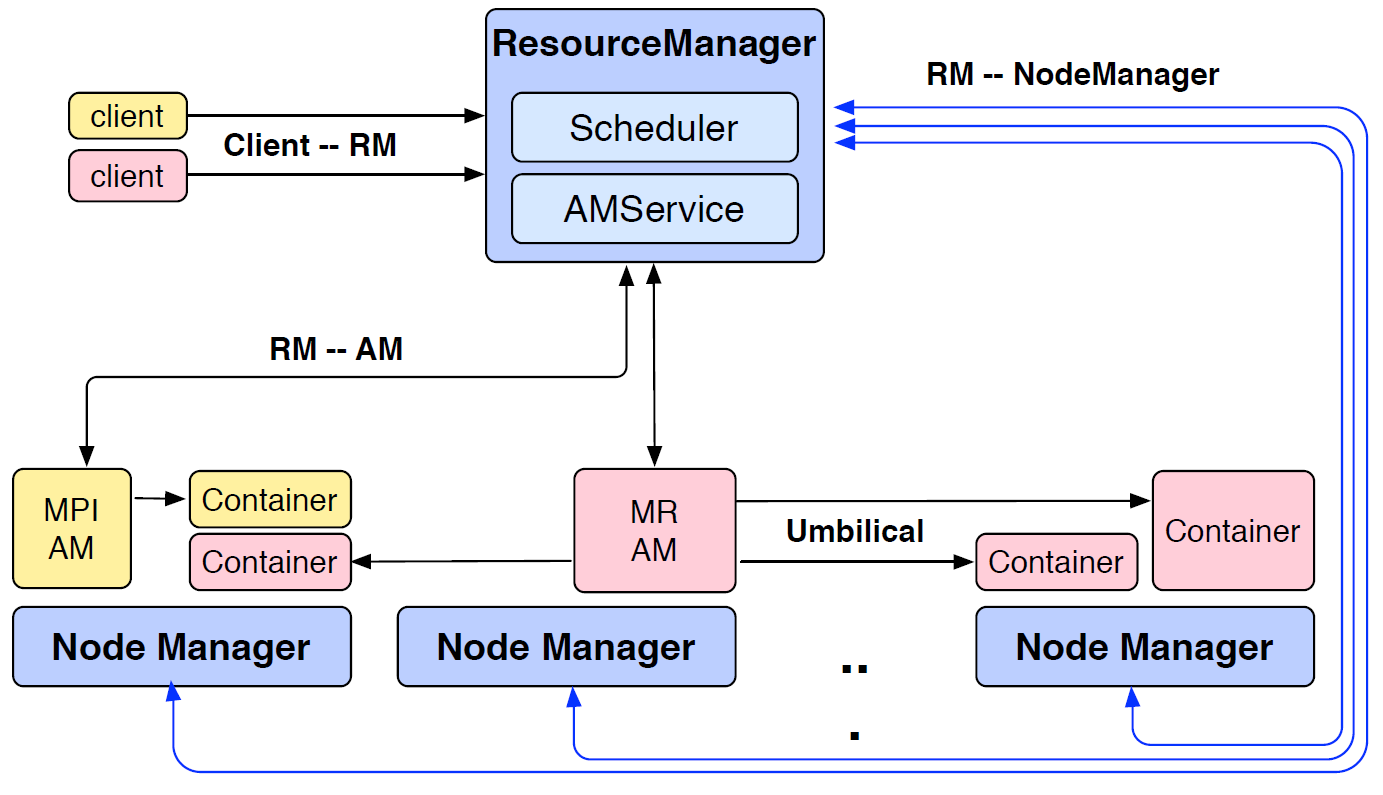
18 Architecture 1/3 18
19 Architecture 2/3 Resources Manager 19
20 Architecture 3/3 zookeeper Standby Master Resources Manager Standby Resources Resources Manager Manager Master Resources Manager 20
21 Pros and Cons Pros: - Fine knowledge of the state of the cluster state -> optimal use of the cluster resources. - Easy to implement new scheduling policies. Cons: - Bottle neck. - The failure of the master scheduler has a big impact on the cluster usage. 21
22 Two level Scheduler Mesos: A Platform for Fine-Grained Resource Sharing in the Center, B. Hindman & al., NSDI 11 22

23 Architecture 1/2 23
24 Architecture 2/2 MapReduce Scheduler Partial State Spark Scheduler Flink Scheduler Mesos Master 24
25 Pros and Cons Pros: - Scale out by adding schedulers. - Concurrent scheduling of tasks. Cons: - Suboptimal use of the cluster. Especially when there exist long running tasks. 25
26 Shared State Scheduler Omega: flexible, scalable schedulers for large compute clusters, M. Schwarzkopf & al. EuroSys 13 26

27 Architecture 1/2 27
28 Architecture 2/2 MapReduce Scheduler Global state` Spark Scheduler Flink Scheduler State Manager 28
29 Architecture 2/2 MapReduce Scheduler Global state Spark Scheduler Conflict Flink Scheduler State Manager 29
30 Pros and Cons Pros - Scalable. - Good use of the cluster resources. Cons - Unpredictable interaction between the different schedulers policies. 30
31 Comparison 31
32 Performance comparison 1/ Simple monolithic Advence monolithic Two-level Shared state 32
33 Performance Comparison 2/ What the previous evaluation does not show about the Two-level scheduling: 33
34 Performance Comparison 3/ Trying to handle more batch jobs in Omega by running several batch schedulers in parallel. How to write an good accepted paper. paper. 34
35 Sum up Two-Level and Shared state Schedulers scale better. Shared state Schedulers use the cluster resources more optimally than Two-level Schedulers. Monolithic Scheduler are a potential Bottleneck. But as Monolithic schedulers are easier to design, allow finer allocation of resources and more advance scheduling policies, they are the ones used in practice. 35
36 Making Yarn more scalable HOPS YARN: a one and a half level scheduler 36
37 Hadoop Yarn HA Implementation zookeeper Standby Master Resources Manager Standby Resources Resources Manager Manager Master Resources Manager 37

38 Hops Yarn HA Implementation3/3 NDB Standby Master Resources Manager Standby Resources Resources Manager Manager Master Resources Manager 38
39 MySQL Cluster (NDB) Shared Nothing DB SQL API NDB API Distributed, In-memory 2-Phase Commit - Replicate DB, not the Log! Real-time - Low TransactionInactive timeouts Commodity Hardware Scales out - Millions of transactions/sec - TB-sized datasets (48 s) Split-Brain solved with Arbitrator Pattern SQL and Native Blocking/Non- Blocking APIs 30+ million update transactions/second on a 30- cluster 39
40 Standby is boring Master Resources Manager Standby Resources Manager Standby Resources Manager 40

41 Dificulties 1/2 41
42 Difficulties 2/2 Pulling from the database when the state is needed is inefficient. Having an independent thread that regularly pull from the database is difficult to tune and cause lock problems. 42
43 Solution Luckily NDB has an event API. 43

44 With streaming Master Resources Manager Standby Resources Manager Standby Resources Manager 44
45 Conclusion There exists three architectures for large cluster resource scheduling: - Monolithic - Two-levels - Shared State Each of these architectures has pros and cons. The monolithic architectur is the one presently used because it is easyer to use and develop. At KTH and SICS we are exploring the possibilities for a new architecture ensuring more scalability while keeping the advantages of the monolithic architecture.
46 References Reservation-based Scheduling: If you re late don t blame us!, C. Curino & al., Microsoft tech-report Omega: flexible, scalable schedulers for large compute clusters, Malte Schwarzkopf & al., EuroSys 13 Apache Hadoop YARN: Yet Another Resource Negotiator, V. K. Vavilapalli & al., SoCC 13. Large-scale cluster management at Google with Borg, A. Verma & al., EuroSys 15. Mesos: A Platform for Fine-Grained Resource Sharing in the Center, B. Hindman & al., NSDI 11
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
YARN Apache Hadoop Next Generation Compute Platform
 YARN Apache Hadoop Next Generation Compute Platform Bikas Saha @bikassaha Hortonworks Inc. 2013 Page 1 Apache Hadoop & YARN Apache Hadoop De facto Big Data open source platform Running for about 5 years
YARN Apache Hadoop Next Generation Compute Platform Bikas Saha @bikassaha Hortonworks Inc. 2013 Page 1 Apache Hadoop & YARN Apache Hadoop De facto Big Data open source platform Running for about 5 years
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Introduction to Hadoop
 Introduction to Hadoop ID2210 Jim Dowling Large Scale Distributed Computing In #Nodes - BitTorrent (millions) - Peer-to-Peer In #Instructions/sec - Teraflops, Petaflops, Exascale - Super-Computing In #Bytes
Introduction to Hadoop ID2210 Jim Dowling Large Scale Distributed Computing In #Nodes - BitTorrent (millions) - Peer-to-Peer In #Instructions/sec - Teraflops, Petaflops, Exascale - Super-Computing In #Bytes
Hadoop Open Platform-as-a-Service (Hops)
") Hadoop Open Platform-as-a-Service (Hops) Academics: PostDocs: PhDs: R/Engineers: Jim Dowling, Seif Haridi Gautier Berthou (SICS) Salman Niazi, Mahmoud Ismail, Kamal Hakimzadeh, Ali Gholami Stig Viaene
Hadoop Open Platform-as-a-Service (Hops) Academics: PostDocs: PhDs: R/Engineers: Jim Dowling, Seif Haridi Gautier Berthou (SICS) Salman Niazi, Mahmoud Ismail, Kamal Hakimzadeh, Ali Gholami Stig Viaene
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Apache Flink Next-gen data analysis. Kostas Tzoumas [email protected] @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas [email protected] @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas [email protected] @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Parallel Computing: Strategies and Implications. Dori Exterman CTO IncrediBuild.
 Parallel Computing: Strategies and Implications Dori Exterman CTO IncrediBuild. In this session we will discuss Multi-threaded vs. Multi-Process Choosing between Multi-Core or Multi- Threaded development
Parallel Computing: Strategies and Implications Dori Exterman CTO IncrediBuild. In this session we will discuss Multi-threaded vs. Multi-Process Choosing between Multi-Core or Multi- Threaded development
Hadoop Open Platform-as-a-Service (Hops)
") Hadoop Open Platform-as-a-Service (Hops) Academics: PostDocs: PhDs: R/Engineers: Jim Dowling, Seif Haridi Gautier Berthou (SICS) Salman Niazi, Mahmoud Ismail, Kamal Hakimzadeh, Ali Gholami Stig Viaene
Hadoop Open Platform-as-a-Service (Hops) Academics: PostDocs: PhDs: R/Engineers: Jim Dowling, Seif Haridi Gautier Berthou (SICS) Salman Niazi, Mahmoud Ismail, Kamal Hakimzadeh, Ali Gholami Stig Viaene
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Big Data and Scripting Systems beyond Hadoop
 Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Energy Efficient MapReduce
 Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Surfing the Data Tsunami: A New Paradigm for Big Data Processing and Analytics
 Surfing the Data Tsunami: A New Paradigm for Big Data Processing and Analytics Dr. Liangxiu Han Future Networks and Distributed Systems Group (FUNDS) School of Computing, Mathematics and Digital Technology,
Surfing the Data Tsunami: A New Paradigm for Big Data Processing and Analytics Dr. Liangxiu Han Future Networks and Distributed Systems Group (FUNDS) School of Computing, Mathematics and Digital Technology,
CSE-E5430 Scalable Cloud Computing Lecture 11
 CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 30.11-2015 1/24 Distributed Coordination Systems Consensus
CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 30.11-2015 1/24 Distributed Coordination Systems Consensus
HiBench Introduction. Carson Wang ([email protected]) Software & Services Group
 Software & Services Group") HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
Data Lake In Action: Real-time, Closed Looped Analytics On Hadoop
 1 Data Lake In Action: Real-time, Closed Looped Analytics On Hadoop 2 Pivotal s Full Approach It s More Than Just Hadoop Pivotal Data Labs 3 Why Pivotal Exists First Movers Solve the Big Data Utility Gap
1 Data Lake In Action: Real-time, Closed Looped Analytics On Hadoop 2 Pivotal s Full Approach It s More Than Just Hadoop Pivotal Data Labs 3 Why Pivotal Exists First Movers Solve the Big Data Utility Gap
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
HDP Hadoop From concept to deployment.
 HDP Hadoop From concept to deployment. Ankur Gupta Senior Solutions Engineer Rackspace: Page 41 27 th Jan 2015 Where are you in your Hadoop Journey? A. Researching our options B. Currently evaluating some
HDP Hadoop From concept to deployment. Ankur Gupta Senior Solutions Engineer Rackspace: Page 41 27 th Jan 2015 Where are you in your Hadoop Journey? A. Researching our options B. Currently evaluating some
Big Data Management and Security
 Big Data Management and Security Audit Concerns and Business Risks Tami Frankenfield Sr. Director, Analytics and Enterprise Data Mercury Insurance What is Big Data? Velocity + Volume + Variety = Value
Big Data Management and Security Audit Concerns and Business Risks Tami Frankenfield Sr. Director, Analytics and Enterprise Data Mercury Insurance What is Big Data? Velocity + Volume + Variety = Value
Comprehensive Analytics on the Hortonworks Data Platform
 Comprehensive Analytics on the Hortonworks Data Platform We do Hadoop. Page 1 Page 2 Back to 2005 Page 3 Vertical Scaling Page 4 Vertical Scaling Page 5 Vertical Scaling Page 6 Horizontal Scaling Page
Comprehensive Analytics on the Hortonworks Data Platform We do Hadoop. Page 1 Page 2 Back to 2005 Page 3 Vertical Scaling Page 4 Vertical Scaling Page 5 Vertical Scaling Page 6 Horizontal Scaling Page
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Apache Hadoop Ecosystem
 Apache Hadoop Ecosystem Rim Moussa ZENITH Team Inria Sophia Antipolis DataScale project [email protected] Context *large scale systems Response time (RIUD ops: one hit, OLTP) Time Processing (analytics:
Apache Hadoop Ecosystem Rim Moussa ZENITH Team Inria Sophia Antipolis DataScale project [email protected] Context *large scale systems Response time (RIUD ops: one hit, OLTP) Time Processing (analytics:
Ali Ghodsi Head of PM and Engineering Databricks
 Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: [email protected] Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Hadoop. MPDL-Frühstück 9. Dezember 2013 MPDL INTERN
 Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Big Data Analytics Hadoop and Spark
 Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Unified Big Data Analytics Pipeline. 连 城 [email protected]
 Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE
 IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
IMPROVED FAIR SCHEDULING ALGORITHM FOR TASKTRACKER IN HADOOP MAP-REDUCE Mr. Santhosh S 1, Mr. Hemanth Kumar G 2 1 PG Scholor, 2 Asst. Professor, Dept. Of Computer Science & Engg, NMAMIT, (India) ABSTRACT
How To Create A Data Visualization With Apache Spark And Zeppelin 2.5.3.5
 Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP. Eva Andreasson Cloudera
 PROBLEMS USING HADOOP. Eva Andreasson Cloudera") SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP Eva Andreasson Cloudera Most FAQ: Super-Quick Overview! The Apache Hadoop Ecosystem a Zoo! Oozie ZooKeeper Hue Impala Solr Hive Pig Mahout HBase MapReduce
SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP Eva Andreasson Cloudera Most FAQ: Super-Quick Overview! The Apache Hadoop Ecosystem a Zoo! Oozie ZooKeeper Hue Impala Solr Hive Pig Mahout HBase MapReduce
#TalendSandbox for Big Data
 Evalua&on von Apache Hadoop mit der #TalendSandbox for Big Data Julien Clarysse @whatdoesdatado @talend 2015 Talend Inc. 1 Connecting the Data-Driven Enterprise 2 Talend Overview Founded in 2006 BRAND
Evalua&on von Apache Hadoop mit der #TalendSandbox for Big Data Julien Clarysse @whatdoesdatado @talend 2015 Talend Inc. 1 Connecting the Data-Driven Enterprise 2 Talend Overview Founded in 2006 BRAND
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert [email protected]/
Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert [email protected]/
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com
 Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
White Paper. Optimizing the Performance Of MySQL Cluster
 White Paper Optimizing the Performance Of MySQL Cluster Table of Contents Introduction and Background Information... 2 Optimal Applications for MySQL Cluster... 3 Identifying the Performance Issues.....
White Paper Optimizing the Performance Of MySQL Cluster Table of Contents Introduction and Background Information... 2 Optimal Applications for MySQL Cluster... 3 Identifying the Performance Issues.....
Computing at Scale: Resource Scheduling Architectural Evolution and Introduction to Fuxi System
 Computing at Scale: Resource Scheduling Architectural Evolution and Introduction to Fuxi System Renyu Yang( 杨 任 宇 ) Supervised by Prof. Jie Xu Ph.D. student@ Beihang University Research Intern @ Alibaba
Computing at Scale: Resource Scheduling Architectural Evolution and Introduction to Fuxi System Renyu Yang( 杨 任 宇 ) Supervised by Prof. Jie Xu Ph.D. student@ Beihang University Research Intern @ Alibaba
Spark. Fast, Interactive, Language- Integrated Cluster Computing
 Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Big Data on Google Cloud
 Big Data on Google Cloud Using Cloud Dataflow, BigQuery, and friends to process data the Cloud way William Vambenepe, Lead Product Manager for Big Data, Google Cloud Platform @vambenepe / [email protected]
Big Data on Google Cloud Using Cloud Dataflow, BigQuery, and friends to process data the Cloud way William Vambenepe, Lead Product Manager for Big Data, Google Cloud Platform @vambenepe / [email protected]
Hybrid Software Architectures for Big Data. [email protected] @hurence http://www.hurence.com
 Hybrid Software Architectures for Big Data [email protected] @hurence http://www.hurence.com Headquarters : Grenoble Pure player Expert level consulting Training R&D Big Data X-data hot-line
Hybrid Software Architectures for Big Data [email protected] @hurence http://www.hurence.com Headquarters : Grenoble Pure player Expert level consulting Training R&D Big Data X-data hot-line
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani
 A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
CDH AND BUSINESS CONTINUITY:
 WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
Cloud Platforms, Challenges & Hadoop. Aditee Rele Karpagam Venkataraman Janani Ravi
 Cloud Platforms, Challenges & Hadoop Aditee Rele Karpagam Venkataraman Janani Ravi Cloud Platform Models Aditee Rele Microsoft Corporation Dec 8, 2010 IT CAPACITY Provisioning IT Capacity Under-supply
Cloud Platforms, Challenges & Hadoop Aditee Rele Karpagam Venkataraman Janani Ravi Cloud Platform Models Aditee Rele Microsoft Corporation Dec 8, 2010 IT CAPACITY Provisioning IT Capacity Under-supply
The Stratosphere Big Data Analytics Platform
 The Stratosphere Big Data Analytics Platform Amir H. Payberah Swedish Institute of Computer Science [email protected] June 4, 2014 Amir H. Payberah (SICS) Stratosphere June 4, 2014 1 / 44 Big Data small data
The Stratosphere Big Data Analytics Platform Amir H. Payberah Swedish Institute of Computer Science [email protected] June 4, 2014 Amir H. Payberah (SICS) Stratosphere June 4, 2014 1 / 44 Big Data small data
Big Graph Analytics on Neo4j with Apache Spark. Michael Hunger Original work by Kenny Bastani Berlin Buzzwords, Open Stage
 Big Graph Analytics on Neo4j with Apache Spark Michael Hunger Original work by Kenny Bastani Berlin Buzzwords, Open Stage My background I only make it to the Open Stages :) Probably because Apache Neo4j
Big Graph Analytics on Neo4j with Apache Spark Michael Hunger Original work by Kenny Bastani Berlin Buzzwords, Open Stage My background I only make it to the Open Stages :) Probably because Apache Neo4j
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Sujee Maniyam, ElephantScale
 Hadoop PRESENTATION 2 : New TITLE and GOES Noteworthy HERE Sujee Maniyam, ElephantScale SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member
Hadoop PRESENTATION 2 : New TITLE and GOES Noteworthy HERE Sujee Maniyam, ElephantScale SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member
Big Data Analytics with Spark and Oscar BAO. Tamas Jambor, Lead Data Scientist at Massive Analytic
 Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing
 YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
Brave New World: Hadoop vs. Spark
 Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Pilot-Streaming: Design Considerations for a Stream Processing Framework for High- Performance Computing
 Pilot-Streaming: Design Considerations for a Stream Processing Framework for High- Performance Computing Andre Luckow, Peter M. Kasson, Shantenu Jha STREAMING 2016, 03/23/2016 RADICAL, Rutgers, http://radical.rutgers.edu
Pilot-Streaming: Design Considerations for a Stream Processing Framework for High- Performance Computing Andre Luckow, Peter M. Kasson, Shantenu Jha STREAMING 2016, 03/23/2016 RADICAL, Rutgers, http://radical.rutgers.edu
The Hadoop Distributed File System
 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
Big Data. White Paper. Big Data Executive Overview WP-BD-10312014-01. Jafar Shunnar & Dan Raver. Page 1 Last Updated 11-10-2014
 White Paper Big Data Executive Overview WP-BD-10312014-01 By Jafar Shunnar & Dan Raver Page 1 Last Updated 11-10-2014 Table of Contents Section 01 Big Data Facts Page 3-4 Section 02 What is Big Data? Page
White Paper Big Data Executive Overview WP-BD-10312014-01 By Jafar Shunnar & Dan Raver Page 1 Last Updated 11-10-2014 Table of Contents Section 01 Big Data Facts Page 3-4 Section 02 What is Big Data? Page
Apache Hama Design Document v0.6
 Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Apache Hama Design Document v0.6 Introduction Hama Architecture BSPMaster GroomServer Zookeeper BSP Task Execution Job Submission Job and Task Scheduling Task Execution Lifecycle Synchronization Fault
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect
 Huibert Aalbers Senior Certified Executive IT Architect") The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II)
") UC BERKELEY Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II) Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter
UC BERKELEY Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II) Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter
Real-Time Analytical Processing (RTAP) Using the Spark Stack. Jason Dai [email protected] Intel Software and Services Group
 Using the Spark Stack. Jason Dai jason.dai@intel.com Intel Software and Services Group") Real-Time Analytical Processing (RTAP) Using the Spark Stack Jason Dai [email protected] Intel Software and Services Group Project Overview Research & open source projects initiated by AMPLab in UC Berkeley
Real-Time Analytical Processing (RTAP) Using the Spark Stack Jason Dai [email protected] Intel Software and Services Group Project Overview Research & open source projects initiated by AMPLab in UC Berkeley
Spark and the Big Data Library
 Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Running a typical ROOT HEP analysis on Hadoop/MapReduce. Stefano Alberto Russo Michele Pinamonti Marina Cobal
 Running a typical ROOT HEP analysis on Hadoop/MapReduce Stefano Alberto Russo Michele Pinamonti Marina Cobal CHEP 2013 Amsterdam 14-18/10/2013 Topics The Hadoop/MapReduce model Hadoop and High Energy Physics
Running a typical ROOT HEP analysis on Hadoop/MapReduce Stefano Alberto Russo Michele Pinamonti Marina Cobal CHEP 2013 Amsterdam 14-18/10/2013 Topics The Hadoop/MapReduce model Hadoop and High Energy Physics
Dominik Wagenknecht Accenture
 Dominik Wagenknecht Accenture Improving Mainframe Performance with Hadoop October 17, 2014 Organizers General Partner Top Media Partner Media Partner Supporters About me Dominik Wagenknecht Accenture Vienna
Dominik Wagenknecht Accenture Improving Mainframe Performance with Hadoop October 17, 2014 Organizers General Partner Top Media Partner Media Partner Supporters About me Dominik Wagenknecht Accenture Vienna
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Upcoming Announcements
 Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC [email protected] Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC [email protected] Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,[email protected]
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
PEPPERDATA IN MULTI-TENANT ENVIRONMENTS
 ..................................... PEPPERDATA IN MULTI-TENANT ENVIRONMENTS technical whitepaper June 2015 SUMMARY OF WHAT S WRITTEN IN THIS DOCUMENT If you are short on time and don t want to read the
..................................... PEPPERDATA IN MULTI-TENANT ENVIRONMENTS technical whitepaper June 2015 SUMMARY OF WHAT S WRITTEN IN THIS DOCUMENT If you are short on time and don t want to read the
Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ. Cloudera World Japan November 2014
 Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ Cloudera World Japan November 2014 WANdisco Background WANdisco: Wide Area Network Distributed Computing Enterprise ready, high availability
Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ Cloudera World Japan November 2014 WANdisco Background WANdisco: Wide Area Network Distributed Computing Enterprise ready, high availability
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
ENABLING GLOBAL HADOOP WITH EMC ELASTIC CLOUD STORAGE
 ENABLING GLOBAL HADOOP WITH EMC ELASTIC CLOUD STORAGE Hadoop Storage-as-a-Service ABSTRACT This White Paper illustrates how EMC Elastic Cloud Storage (ECS ) can be used to streamline the Hadoop data analytics
ENABLING GLOBAL HADOOP WITH EMC ELASTIC CLOUD STORAGE Hadoop Storage-as-a-Service ABSTRACT This White Paper illustrates how EMC Elastic Cloud Storage (ECS ) can be used to streamline the Hadoop data analytics
Data Security in Hadoop
 Data Security in Hadoop Eric Mizell Director, Solution Engineering Page 1 What is Data Security? Data Security for Hadoop allows you to administer a singular policy for authentication of users, authorize
Data Security in Hadoop Eric Mizell Director, Solution Engineering Page 1 What is Data Security? Data Security for Hadoop allows you to administer a singular policy for authentication of users, authorize
GraySort on Apache Spark by Databricks
 GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
Hadoop. Bioinformatics Big Data
 Hadoop Bioinformatics Big Data Paolo D Onorio De Meo Mattia D Antonio [email protected] [email protected] Big Data Too much information! Big Data Explosive data growth proliferation of data capture
Hadoop Bioinformatics Big Data Paolo D Onorio De Meo Mattia D Antonio [email protected] [email protected] Big Data Too much information! Big Data Explosive data growth proliferation of data capture
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)