Big Data Analytics Hadoop and Spark
|
|
|
- Rodger Osborne
- 7 years ago
- Views:
Transcription


1 Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1

2 What is Big Data? 2

3 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time. Big data "size" is a constantly moving target, as of 2012 ranging from a few dozen terabytes to many petabytes of data. Big data is a set of techniques and technologies that require new forms of integration to uncover large hidden values from large datasets that are diverse, complex, and of a massive scale. (From Wikipedia) 3

4 What is Big Data? Volume. Value. Variety. Velocity - the speed of generation of data. Variability - the inconsistency which can be shown by the data at times. Veracity - the quality of the data being captured can vary greatly. Complexity - data management can become a very complex process, especially when large volumes of data come from multiple sources. (From Wikipedia) 4

5 How to analyze Big Data? 5

6 Map/Reduce 6

7 Map/Reduce MapReduce is a framework for processing parallelizable problems across huge datasets using a large number of computers (nodes), collectively referred to as a cluster. Map step: Each worker node applies the "map()" function to the local data, and writes the output to a temporary storage. A master node orchestrates that for redundant copies of input data, only one is processed. Shuffle step: Worker nodes redistribute data based on the output keys (produced by the "map()" function), such that all data belonging to one key is located on the same worker node. Reduce step: Worker nodes now process each group of output data, per key, in parallel. (From Wikipedia) 7
\" function), such that all data belonging to one key is located on the same")
8 Basic Example: Word Count (Spark & Python) 8

9 Basic Example: Word Count (Spark & Scala) 9

10 Map/Reduce Parallel Computing No dependency among data Data can be split into equal-size chunks Each process can work on a chunk Master/worker approach Master: Initializes array and splits it according to # of workers Sends each worker the sub-array Receives the results from each worker Worker: Receives a sub-array from master Perfoms processing Sends results to master 10

11 11

12 12

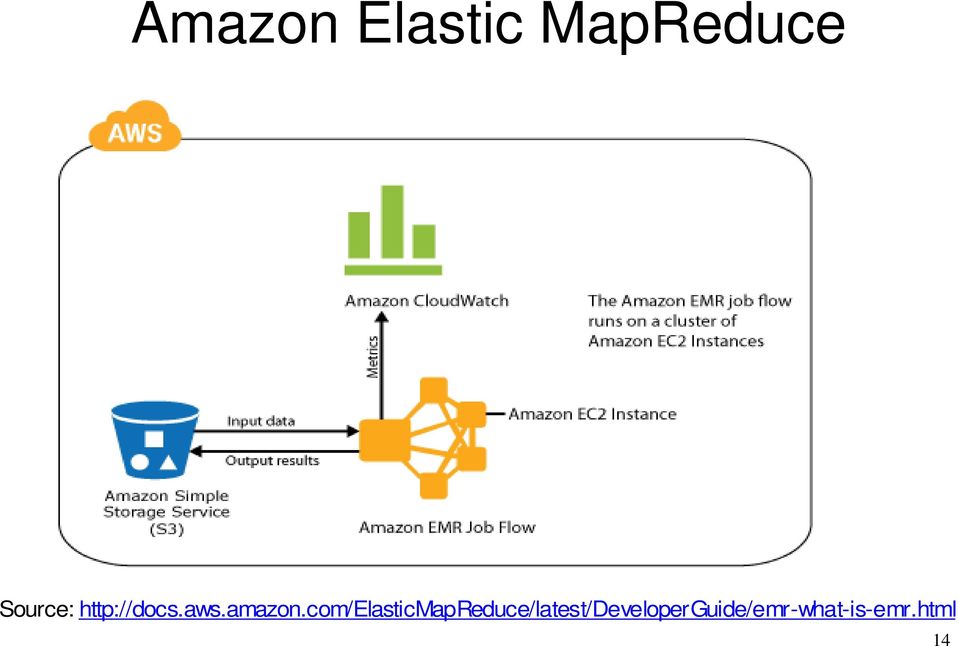
13 Map/Reduce History Invented by Google: Uses: Inspired by functional programming languages map and reduce functions Seminal paper: Dean, Jeffrey & Ghemawat, Sanjay (OSDI 2004), "MapReduce: Simplified Data Processing on Large Clusters" Used at Google to completely regenerate Google's index of the World Wide Web. It replaced the old ad-hoc programs that updated the index and ran the various analysis distributed pattern-based searching, distributed sorting, web link-graph reversal, term-vector per host, web access log stats, inverted index construction, document clustering, machine learning, statistical machine translation Apache Hadoop: Open source implementation matches Google s specifications Amazon Elastic MapReduce running on Amazon EC2 13

14 Amazon Elastic MapReduce Source: 14
15 HDFS Architecture Source 15

16 Hadoop & Object Storage 16

17 Apache Spark Apache Spark is a fast and general open-source engine for large-scale data processing. Includes the following libraries: SPARK SQL, SPARK Streaming, MLlib (Machine Learning) and GraphX (graph processing). Spark capable to run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. Spark can run on Apache Mesos or Hadoop 2's YARN cluster manager, and can read any existing Hadoop data. Written in Scala language (a Java like, executed in Java VM) Apache Spark is built by a wide set of developers from over 50 companies. Since the project started in 2009, more than 400 developers have contributed to Spark. 17

18 Spark vs. Hadoop 18

19 Spark Cluster Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext (SC) object in your main. SC can connect to several types of resource cluster managers (either Spark s own standalone cluster manager or Mesos/YARN), which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are worker processes that run computations and store data for your application. Next, it sends your application code (JAR or Python files) to the executors. Finally, SC sends tasks for the executors to run. 19

20 Spark Cluster Example: Log Mining 20

21 Spark Cluster Example: Log Mining 21
22 Spark Cluster Example: Log Mining 22

23 Spark RDD 23
24 Spark & Scala: Creating RDD 24
25 Spark & Scala: Basic Transformations 25
26 Spark & Scala: Basic Actions 26
27 Spark & Scala: Key-Value Operations 27
28 Goal: Example: Spark Map/Reduce Find number of distinct names per "first letter". 28
29 Goal: Example: Spark Map/Reduce Find number of distinct names per "first letter". 29
30 Example: Spark Map/Reduce 30
31 Example: Page Rank 31
32 Example: Page Rank 32
33 33
34 [ ] A = [ ] [ ] [ ] [1] V = [1] [1] [1] B = 0.85*A U = 0.15*V B*V+U =? 34
35 [ ] A = [ ] [ ] [ ] [1] V = [1] [1] [1] B = 0.85*A U = 0.15*V [1.85 ] B*V+U = [1.0 ] [0.575] [0.575] 35
36 [ ] A = [ ] [ ] [ ] [1] V = [1] [1] [1] B = 0.85*A U = 0.15*V B*(B*V+U)+U =? 36
37 [ ] A = [ ] [ ] [ ] [1] V = [1] [1] [1] B = 0.85*A U = 0.15*V [1.31] B*(B*V+U)+U = [1.72] [0.39] [0.58] B*(B*(B*V+U)+U)+U =... 37
38 [ ] A = [ ] [ ] [ ] [1] V = [1] [1] [1] B = 0.85*A U = 0.15*V At the k-th step: B k V +(B k 1 +B k B 2 +B+I) U=B k V +(I B k ) (I B) 1 U For k=10: [1.43] [1.37] [0.46] [0.73] 38
39 [ ] A = [ ] [ ] [ ] [1] V = [1] [1] [1] B = 0.85*A U = 0.15*V Where k goes to infinity: [1.44] (I-B)^(-1)*U = [1.37] [0.46] [0.73] B k V 0 B k V+(I B k ) (I B) 1 U (I B) 1 U 39
40 [ ] A = [ ] B=0.85*A [ ] [ ] Characteristic polynomial of A: x 4 0.5x x 0.25 A is diagonalizable, 1 is the largest eigen value of A (in its absolute value), 1 corresponds to the eigen vector: [1.0 ] E = [1.0 ] [0.25] [0.5 ] Where k goes to infinity: A k V ce B k V 0 40
41 Example: Page Rank 41
42 Example: Page Rank 42
43 43
44 44
45 45
46 46
47 Spark Streaming Spark Streaming is an extension of the core Spark API that allows high-throughput, fault-tolerant stream processing of live data streams. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches. 47
48 48
49 Machine Learning: K-Means clustering (from Wikipedia) 49
50 Goal: Example: Spark MLLib & Geolocation Segment tweets into clusters by geolocation using Spark MLLib K-means clustering 50
51 Example: Spark MLLib & Geolocation 51
52 Example: Spark MLLib & Geolocation 52
53 The Next Generation
54 References Papers: Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica, Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, NSDI 2012, April Videos and Presentations: Spark workshop hosted by Stanford ICME, April Reza Zadeh, Patrick Wendell, Holden Karau, Hossein Falaki, Xianguri Meng, Spark summit Matei Zaharia, Aaaron Davidson, Paul Krzyzanowski, "Distributed systems": // Links:
55 55
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Architectures for massive data management
 Architectures for massive data management Apache Spark Albert Bifet albert.bifet@telecom-paristech.fr October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
Architectures for massive data management Apache Spark Albert Bifet albert.bifet@telecom-paristech.fr October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
CSE-E5430 Scalable Cloud Computing Lecture 11
 CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 30.11-2015 1/24 Distributed Coordination Systems Consensus
CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 30.11-2015 1/24 Distributed Coordination Systems Consensus
Spark. Fast, Interactive, Language- Integrated Cluster Computing
 Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
From GWS to MapReduce: Google s Cloud Technology in the Early Days
 Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu lingu@ieee.org MapReduce/Hadoop
Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu lingu@ieee.org MapReduce/Hadoop
Apache Spark and Distributed Programming
 Apache Spark and Distributed Programming Concurrent Programming Keijo Heljanko Department of Computer Science University School of Science November 25th, 2015 Slides by Keijo Heljanko Apache Spark Apache
Apache Spark and Distributed Programming Concurrent Programming Keijo Heljanko Department of Computer Science University School of Science November 25th, 2015 Slides by Keijo Heljanko Apache Spark Apache
Big Data Processing. Patrick Wendell Databricks
 Big Data Processing Patrick Wendell Databricks About me Committer and PMC member of Apache Spark Former PhD student at Berkeley Left Berkeley to help found Databricks Now managing open source work at Databricks
Big Data Processing Patrick Wendell Databricks About me Committer and PMC member of Apache Spark Former PhD student at Berkeley Left Berkeley to help found Databricks Now managing open source work at Databricks
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC sujee@elephantscale.com http://elephantscale.com
 Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC sujee@elephantscale.com http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC sujee@elephantscale.com http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
How To Create A Data Visualization With Apache Spark And Zeppelin 2.5.3.5
 Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Unified Big Data Analytics Pipeline. 连 城 lian@databricks.com
 Unified Big Data Analytics Pipeline 连 城 lian@databricks.com What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 lian@databricks.com What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University](/thumbs/26/8135278.jpg "CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
Spark ΕΡΓΑΣΤΗΡΙΟ 10. Prepared by George Nikolaides 4/19/2015 1
 Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
VariantSpark: Applying Spark-based machine learning methods to genomic information
 VariantSpark: Applying Spark-based machine learning methods to genomic information Aidan R. O BRIEN a a,1 and Denis C. BAUER a CSIRO, Health and Biosecurity Flagship Abstract. Genomic information is increasingly
VariantSpark: Applying Spark-based machine learning methods to genomic information Aidan R. O BRIEN a a,1 and Denis C. BAUER a CSIRO, Health and Biosecurity Flagship Abstract. Genomic information is increasingly
Spark and Shark. High- Speed In- Memory Analytics over Hadoop and Hive Data
 Spark and Shark High- Speed In- Memory Analytics over Hadoop and Hive Data Matei Zaharia, in collaboration with Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Cliff Engle, Michael Franklin, Haoyuan Li,
Spark and Shark High- Speed In- Memory Analytics over Hadoop and Hive Data Matei Zaharia, in collaboration with Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Cliff Engle, Michael Franklin, Haoyuan Li,
Apache Spark 11/10/15. Context. Reminder. Context. What is Spark? A GrowingStack
 Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Brave New World: Hadoop vs. Spark
 Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Spark and the Big Data Library
 Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Introduction to Parallel Programming and MapReduce
 Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Learning. Spark LIGHTNING-FAST DATA ANALYTICS. Holden Karau, Andy Konwinski, Patrick Wendell & Matei Zaharia
 Compliments of Learning Spark LIGHTNING-FAST DATA ANALYTICS Holden Karau, Andy Konwinski, Patrick Wendell & Matei Zaharia Bring Your Big Data to Life Big Data Integration and Analytics Learn how to power
Compliments of Learning Spark LIGHTNING-FAST DATA ANALYTICS Holden Karau, Andy Konwinski, Patrick Wendell & Matei Zaharia Bring Your Big Data to Life Big Data Integration and Analytics Learn how to power
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Big Data Analytics with Spark and Oscar BAO. Tamas Jambor, Lead Data Scientist at Massive Analytic
 Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
FP-Hadoop: Efficient Execution of Parallel Jobs Over Skewed Data
 FP-Hadoop: Efficient Execution of Parallel Jobs Over Skewed Data Miguel Liroz-Gistau, Reza Akbarinia, Patrick Valduriez To cite this version: Miguel Liroz-Gistau, Reza Akbarinia, Patrick Valduriez. FP-Hadoop:
FP-Hadoop: Efficient Execution of Parallel Jobs Over Skewed Data Miguel Liroz-Gistau, Reza Akbarinia, Patrick Valduriez To cite this version: Miguel Liroz-Gistau, Reza Akbarinia, Patrick Valduriez. FP-Hadoop:
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Introduction to Spark
 Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics
 E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
ANALYSIS OF BILL OF MATERIAL DATA USING KAFKA AND SPARK
 44 ANALYSIS OF BILL OF MATERIAL DATA USING KAFKA AND SPARK Ashwitha Jain *, Dr. Venkatramana Bhat P ** * Student, Department of Computer Science & Engineering, Mangalore Institute of Technology & Engineering
44 ANALYSIS OF BILL OF MATERIAL DATA USING KAFKA AND SPARK Ashwitha Jain *, Dr. Venkatramana Bhat P ** * Student, Department of Computer Science & Engineering, Mangalore Institute of Technology & Engineering
Fast and Expressive Big Data Analytics with Python. Matei Zaharia UC BERKELEY
 Fast and Expressive Big Data Analytics with Python Matei Zaharia UC Berkeley / MIT UC BERKELEY spark-project.org What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop
Fast and Expressive Big Data Analytics with Python Matei Zaharia UC Berkeley / MIT UC BERKELEY spark-project.org What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Spark: Cluster Computing with Working Sets
 Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Spark Application on AWS EC2 Cluster:
 Spark Application on AWS EC2 Cluster: ImageNet dataset classification using Multinomial Naive Bayes Classifier Chao-Hsuan Shen, Patrick Loomis, John Geevarghese 1 Acknowledgements Special thanks to professor
Spark Application on AWS EC2 Cluster: ImageNet dataset classification using Multinomial Naive Bayes Classifier Chao-Hsuan Shen, Patrick Loomis, John Geevarghese 1 Acknowledgements Special thanks to professor
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Big Data and Scripting Systems beyond Hadoop
 Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Improving MapReduce Performance in Heterogeneous Environments
 UC Berkeley Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony Joseph, Randy Katz, Ion Stoica University of California at Berkeley Motivation 1. MapReduce
UC Berkeley Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony Joseph, Randy Katz, Ion Stoica University of California at Berkeley Motivation 1. MapReduce
Big Data. Lyle Ungar, University of Pennsylvania
 Big Data Big data will become a key basis of competition, underpinning new waves of productivity growth, innovation, and consumer surplus. McKinsey Data Scientist: The Sexiest Job of the 21st Century -
Big Data Big data will become a key basis of competition, underpinning new waves of productivity growth, innovation, and consumer surplus. McKinsey Data Scientist: The Sexiest Job of the 21st Century -
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Accelerating Hadoop MapReduce Using an In-Memory Data Grid
 Accelerating Hadoop MapReduce Using an In-Memory Data Grid By David L. Brinker and William L. Bain, ScaleOut Software, Inc. 2013 ScaleOut Software, Inc. 12/27/2012 H adoop has been widely embraced for
Accelerating Hadoop MapReduce Using an In-Memory Data Grid By David L. Brinker and William L. Bain, ScaleOut Software, Inc. 2013 ScaleOut Software, Inc. 12/27/2012 H adoop has been widely embraced for
Machine- Learning Summer School - 2015
 Machine- Learning Summer School - 2015 Big Data Programming David Franke Vast.com hbp://www.cs.utexas.edu/~dfranke/ Goals for Today Issues to address when you have big data Understand two popular big data
Machine- Learning Summer School - 2015 Big Data Programming David Franke Vast.com hbp://www.cs.utexas.edu/~dfranke/ Goals for Today Issues to address when you have big data Understand two popular big data
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
This is a brief tutorial that explains the basics of Spark SQL programming.
 About the Tutorial Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types
About the Tutorial Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types
BIG DATA ANALYTICS For REAL TIME SYSTEM
 BIG DATA ANALYTICS For REAL TIME SYSTEM Where does big data come from? Big Data is often boiled down to three main varieties: Transactional data these include data from invoices, payment orders, storage
BIG DATA ANALYTICS For REAL TIME SYSTEM Where does big data come from? Big Data is often boiled down to three main varieties: Transactional data these include data from invoices, payment orders, storage
BIG DATA APPLICATIONS
 BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
DduP Towards a Deduplication Framework utilising Apache Spark
 DduP Towards a Deduplication Framework utilising Apache Spark Niklas Wilcke Datenbanken und Informationssysteme (ISYS) University of Hamburg Vogt-Koelln-Strasse 30 22527 Hamburg 1wilcke@informatik.uni-hamburg.de
DduP Towards a Deduplication Framework utilising Apache Spark Niklas Wilcke Datenbanken und Informationssysteme (ISYS) University of Hamburg Vogt-Koelln-Strasse 30 22527 Hamburg 1wilcke@informatik.uni-hamburg.de
A SURVEY ON MAPREDUCE IN CLOUD COMPUTING
 A SURVEY ON MAPREDUCE IN CLOUD COMPUTING Dr.M.Newlin Rajkumar 1, S.Balachandar 2, Dr.V.Venkatesakumar 3, T.Mahadevan 4 1 Asst. Prof, Dept. of CSE,Anna University Regional Centre, Coimbatore, newlin_rajkumar@yahoo.co.in
A SURVEY ON MAPREDUCE IN CLOUD COMPUTING Dr.M.Newlin Rajkumar 1, S.Balachandar 2, Dr.V.Venkatesakumar 3, T.Mahadevan 4 1 Asst. Prof, Dept. of CSE,Anna University Regional Centre, Coimbatore, newlin_rajkumar@yahoo.co.in
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
HiBench Introduction. Carson Wang (carson.wang@intel.com) Software & Services Group
 Software & Services Group") HiBench Introduction Carson Wang (carson.wang@intel.com) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
HiBench Introduction Carson Wang (carson.wang@intel.com) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
Hybrid Software Architectures for Big Data. Laurence.Hubert@hurence.com @hurence http://www.hurence.com
 Hybrid Software Architectures for Big Data Laurence.Hubert@hurence.com @hurence http://www.hurence.com Headquarters : Grenoble Pure player Expert level consulting Training R&D Big Data X-data hot-line
Hybrid Software Architectures for Big Data Laurence.Hubert@hurence.com @hurence http://www.hurence.com Headquarters : Grenoble Pure player Expert level consulting Training R&D Big Data X-data hot-line
Beyond Hadoop with Apache Spark and BDAS
 Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Big Data Storage, Management and challenges. Ahmed Ali-Eldin
 Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Spark: Making Big Data Interactive & Real-Time
 Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Optimization and analysis of large scale data sorting algorithm based on Hadoop
 Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Big Data Frameworks Course. Prof. Sasu Tarkoma 10.3.2015
 Big Data Frameworks Course Prof. Sasu Tarkoma 10.3.2015 Contents Course Overview Lectures Assignments/Exercises Course Overview This course examines current and emerging Big Data frameworks with focus
Big Data Frameworks Course Prof. Sasu Tarkoma 10.3.2015 Contents Course Overview Lectures Assignments/Exercises Course Overview This course examines current and emerging Big Data frameworks with focus
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Real Time Data Processing using Spark Streaming
 Real Time Data Processing using Spark Streaming Hari Shreedharan, Software Engineer @ Cloudera Committer/PMC Member, Apache Flume Committer, Apache Sqoop Contributor, Apache Spark Author, Using Flume (O
Real Time Data Processing using Spark Streaming Hari Shreedharan, Software Engineer @ Cloudera Committer/PMC Member, Apache Flume Committer, Apache Sqoop Contributor, Apache Spark Author, Using Flume (O
Apache Flink Next-gen data analysis. Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Managing large clusters resources
 Managing large clusters resources ID2210 Gautier Berthou (SICS) Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth
Managing large clusters resources ID2210 Gautier Berthou (SICS) Big Processing with No Locality Job( /crawler/bot/jd.io/1 ) submi t Workflow Manager Compute Grid Node Job This doesn t scale. Bandwidth
Enhancing Dataset Processing in Hadoop YARN Performance for Big Data Applications
 Enhancing Dataset Processing in Hadoop YARN Performance for Big Data Applications Ahmed Abdulhakim Al-Absi, Dae-Ki Kang and Myong-Jong Kim Abstract In Hadoop MapReduce distributed file system, as the input
Enhancing Dataset Processing in Hadoop YARN Performance for Big Data Applications Ahmed Abdulhakim Al-Absi, Dae-Ki Kang and Myong-Jong Kim Abstract In Hadoop MapReduce distributed file system, as the input
Conquering Big Data with BDAS (Berkeley Data Analytics)
") UC BERKELEY Conquering Big Data with BDAS (Berkeley Data Analytics) Ion Stoica UC Berkeley / Databricks / Conviva Extracting Value from Big Data Insights, diagnosis, e.g.,» Why is user engagement dropping?»
UC BERKELEY Conquering Big Data with BDAS (Berkeley Data Analytics) Ion Stoica UC Berkeley / Databricks / Conviva Extracting Value from Big Data Insights, diagnosis, e.g.,» Why is user engagement dropping?»
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
International Journal of Advanced Engineering Research and Applications (IJAERA) ISSN: 2454-2377 Vol. 1, Issue 6, October 2015. Big Data and Hadoop
 ISSN: 2454-2377 Vol. 1, Issue 6, October 2015. Big Data and Hadoop") ISSN: 2454-2377, October 2015 Big Data and Hadoop Simmi Bagga 1 Satinder Kaur 2 1 Assistant Professor, Sant Hira Dass Kanya MahaVidyalaya, Kala Sanghian, Distt Kpt. INDIA E-mail: simmibagga12@gmail.com
ISSN: 2454-2377, October 2015 Big Data and Hadoop Simmi Bagga 1 Satinder Kaur 2 1 Assistant Professor, Sant Hira Dass Kanya MahaVidyalaya, Kala Sanghian, Distt Kpt. INDIA E-mail: simmibagga12@gmail.com
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Suresh Lakavath csir urdip Pune, India lsureshit@gmail.com.
 A Big Data Hadoop Architecture for Online Analysis. Suresh Lakavath csir urdip Pune, India lsureshit@gmail.com. Ramlal Naik L Acme Tele Power LTD Haryana, India ramlalnaik@gmail.com. Abstract Big Data
A Big Data Hadoop Architecture for Online Analysis. Suresh Lakavath csir urdip Pune, India lsureshit@gmail.com. Ramlal Naik L Acme Tele Power LTD Haryana, India ramlalnaik@gmail.com. Abstract Big Data
Spark Application Carousel. Spark Summit East 2015
 Spark Application Carousel Spark Summit East 2015 About Today s Talk About Me: Vida Ha - Solutions Engineer at Databricks. Goal: For beginning/early intermediate Spark Developers. Motivate you to start
Spark Application Carousel Spark Summit East 2015 About Today s Talk About Me: Vida Ha - Solutions Engineer at Databricks. Goal: For beginning/early intermediate Spark Developers. Motivate you to start
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics
 Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
Big Systems, Big Data
 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
Hadoop Evolution In Organizations. Mark Vervuurt Cluster Data Science & Analytics
 In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science
 A Seminar report On Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED BY: www.studymafia.org
A Seminar report On Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED BY: www.studymafia.org
Ali Ghodsi Head of PM and Engineering Databricks
 Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Big Data on Microsoft Platform
 Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Keywords: Big Data, HDFS, Map Reduce, Hadoop
 Volume 5, Issue 7, July 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Configuration Tuning
Volume 5, Issue 7, July 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Configuration Tuning
Big Data Rethink Algos and Architecture. Scott Marsh Manager R&D Personal Lines Auto Pricing
 Big Data Rethink Algos and Architecture Scott Marsh Manager R&D Personal Lines Auto Pricing Agenda History Map Reduce Algorithms History Google talks about their solutions to their problems Map Reduce:
Big Data Rethink Algos and Architecture Scott Marsh Manager R&D Personal Lines Auto Pricing Agenda History Map Reduce Algorithms History Google talks about their solutions to their problems Map Reduce:
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
COMP9321 Web Application Engineering
 COMP9321 Web Application Engineering Semester 2, 2015 Dr. Amin Beheshti Service Oriented Computing Group, CSE, UNSW Australia Week 11 (Part II) http://webapps.cse.unsw.edu.au/webcms2/course/index.php?cid=2411
COMP9321 Web Application Engineering Semester 2, 2015 Dr. Amin Beheshti Service Oriented Computing Group, CSE, UNSW Australia Week 11 (Part II) http://webapps.cse.unsw.edu.au/webcms2/course/index.php?cid=2411