Map Reduce / Hadoop / HDFS
|
|
|
- David Cameron
- 10 years ago
- Views:
Transcription
1 Chapter 3: Map Reduce / Hadoop / HDFS 97

2 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98

3 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN Today Next week 99

4 Overview Distributed File Systems - Difference to RDBMS - Parallel Computing Architecture 100

5 Distributed File Systems Past - most computing is done on a single processor: - one main memory - one cache - one local disk, New Challenges: - Files must be stored redundantly: - If one node fails, all of its files would be unavailable until the node is replaced (see File Management) - Computations must be divided into tasks: - a task can be restarted without affecting other tasks (see ) - use of commodity hardware 101
 - use of commodity")
6 Distributed File Systems - Drawbacks of RDBMS - Database system are difficult to scale. - Database systems are difficult to configure and maintain - Diversification in available systems complicates its selection - Peak provisioning leads to unnecessary costs - Advantages of NoSQL systems: - Elastic scaling - Less administration - Better economics - Flexible data models 102

7 Distributed File Systems Parallel computing architecture - Referred as cluster computing - Physical Organisation: - compute nodes are stored on racks (8-64) - nodes on a single rack connected by a network Switch Rack Rack Rack Rack Racks of servers (and switches at the top), at Google s Mayes County, Oklahoma data center [extremetech.com] Nodes within a rack are connected by a network, typically gigabit Ethernet 103

8 Distributed File Systems Parallel computing architecture Large-Scale File-System Organisation: - Characteristics: - files are several terabytes in size (Facebook s daily logs: 60TB; 1000 genomes project: 200TB; Google Web Index; 10+ PB) - files are rarely updated - Reads and appends are common Exemplary distributed file systems: - Google File System (GFS) - Hadoop Distributed File System (HDFS, by Apache) - CloudStore - HDF5 - S3 (Amazon EC2) - 104
 - Hadoop Distributed File System (HDFS, by Apache) - CloudStore - HDF5")
9 Distributed File Systems Parallel computing architecture - Large-Scale File-System Organisation: - Organisation: - files are divided into chunks (typically 16-64MB in size) - chunks are replicated n times (i.e default in HDFS: n=3) at n different nodes (optimally: replicas are located on different racks optimising fault tolerance) - how to find files? - existence of a master node - holds a meta-file (directory) about location of all copies of a file -> all participants using the DFS know where copies are located 105

10 Overview -Motivation - Programming Model - Recap Functional Programming - Examples 106

11 Motivation: - Comparison to Other Systems vs. RDBMS RDBMS Data size Petabytes Gigabytes Access Batch Interactive and Batch Updates Write once, read many times Read & Write many times Structure Dynamic schema Static schema Integrity Low High (normalized data) Scaling Linear Non linear 107

12 Motivation: - Comparison to Other Systems vs. Grid Computing - Accessing large data volumes becomes a problem in High performance computing (HPC), as the network bandwidth is the bottleneck <-> Data Locality in - in HPC, programmers have to explicitly handle the data flow <-> operates only in higher level, i.e. data flow is implicit -handling partial failures <-> as a shared-nothingarchitecture (no dependence of tasks); detects failures and reschedules missing operations 108

13 Motivation: Large Scale Data Processing In General: - can be used to manage large-scale computations in a way that is tolerant of hardware faults - System itself manages automatic parallelisation and distribution, I/O scheduling, coordination of tasks that are implemented in map() and reduce() and copes with unexpected system failures or stragglers - several implementations: Google s internal implementation, open-source implementation Hadoop (using HDFS), 109

14 Programming Model - General Processing - Input & Output: each a set of key/value pairs - Programmer specifies two functions: map (in_key, in_value) -> list (out_key, intermediate_value) Processes input key/value pair; one Map()-Call for every pair Produces a set of intermediate pairs reduce (out_key, list(intermediate_value)) -> list (out_value) combines all intermediate values for a particular key; one Reduce()-call per unique key produces a set of merged output values (usually just one output value) 110
-call per unique key produces a set of merged output values (usually just one output")
15 Programming Model Recap: Functional Programming - is inspired by similar primitives in LISP, SML, Haskell and other languages - The general idea of higher order functions (map and fold) in functional programming (FP) languages are transferred in the environment of : - map in <-> map in FP - reduce in <-> fold in FP 111

16 Programming Model Recap: Functional Programming - MAP: - 2 parameters: applies a function on each element of a list - the type of the elements within the result list can differ from the type of the input list - the size of the result list remains the same In Haskell: Example: map :: (a >b) > [a] > [b] map f [] = [] map f (x:xs) = f x : map f xs *Main> map (\x > (x,1)) [ Big, Data, Management, and, Analysis ] [( Big,1),( Data,1),( Management,1),( and,1),( Analysis,1)] 112
![list remains the same In Haskell: Example: map :: (a >b) > [a] > [b] map f [] = [] map f (x:xs) = f x : map f xs](/docs-images/52/12216670/images/page_16.jpg "*Main> map (\x > (x,1)) [ Big, Data, Management, and, Analysis ] [( Big,1),( Data,1),( Management,1),( and,1),(")
17 Programming Model Recap: Functional Programming - FOLD: - 3 parameters: traverse a list and apply a function f() to each element plus an accumulator. f() returns the next accumulator value - in functional programming: foldl and foldr In Haskell (analog foldr): foldl :: (b >a >b) > b > [a] > b foldl f acc [] = acc foldl f acc (x:xs) = fold f (f acc x) xs Example: *Main> foldl (\acc (key,value) > acc + value) 0 [( Big, 1), ( Big, 1), ( Big,1)] 3 113
 > b > [a] > b foldl f acc [] = acc foldl f acc (x:xs) = fold f (f acc x) xs Example: *Main>")
18 Programming Model - General Processing of - 1. Chunks from a DFS are attached to Map tasks turning each chunk into a sequence of key-value pairs key-value pairs are collected by a master controller and sorted by key. The keys are divided among all Reduce tasks Reduce tasks work on each key separately and combine all the values associated with a specific key. 114

19 Programming Model - High-level diagram 115
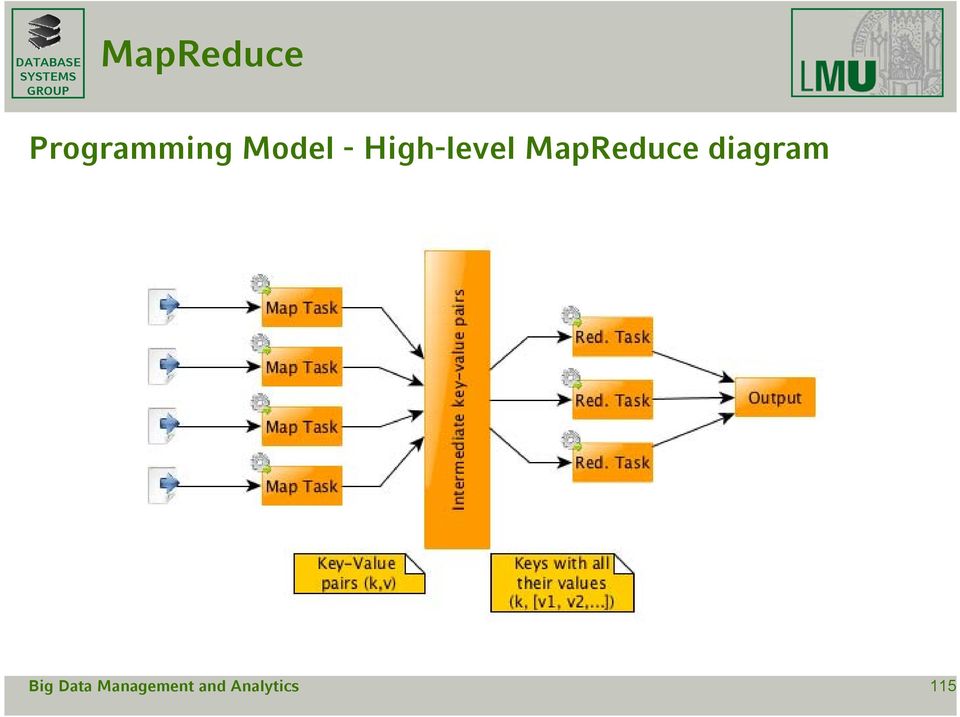
20 Programming Model - High-level diagram 116
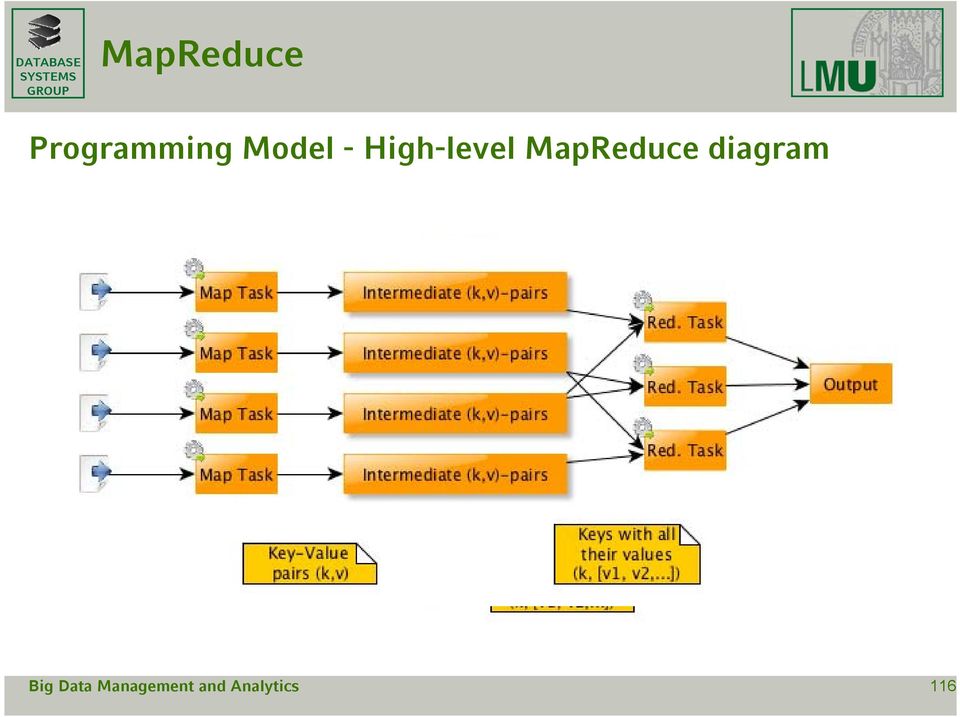
21 Programming Model - General Processing - Programmer s task: specify map() and reduce(); - environment takes care of: - Partitioning the input data - Scheduling - Shuffle and Sort (performing the group-by-key step) - Handling machine failures and stragglers - Managing of required inter-machine communication 117
22 Programming Model - General Processing Partitioning the input data - data files are divided into blocks (default in GFS/HDFS: 64 MB) and replicas of each are stored on different nodes - Master schedules map() tasks in close proximity to data storage - map() tasks are executed physically on the same machine where one replica of an input file is storaged (or, at least on the same rack -> communication via network switch) - > Goal: conserve network bandwidth (c.f Grid Computing) > achieves to read input data at local disk speed, rather than limiting read rate by rack switches 118
23 Programming Model - General Processing Scheduling - One master, many workers - split input data into M map tasks - reduce phase partitioned into R tasks - tasks are assigned to workers dynamically - Master assigns each map task to a free worker - considers proximity of data to worker - > worker reads task input (optimal: from local disk) - > output: files containing intermediate (key,value)-pairs sorted by key - Master assigns each reduce task to a free worker - worker reads intermediate (key, value)-pairs - worker merges and applies reduce()-function for output 119
24 Programming Model - General Processing Shuffle and Sort (performing the group-by-key step) - input to every reducer is sorted by key - Shuffle: sort and transfer the map outputs to the reducers as inputs - Mappers need to separate output intended for different reducers - Reducers need to collect their data from all(!) mappers - keys at each reducer are processed in order 120
25 Programming Model - General Processing Shuffle and Sort (performing the group-by-key step) Quelle: Oreilly, Hadoop The Definitive Guide 3rd Edition, May
26 Programming Model - General Processing Handling machine failures and stragglers - General: master pings workers periodically to detect failures - Map worker failure - Map tasks completed or in-progress at worker are reset to idle - all reduce workers will be notified about any re-execution - Reduce worker failure - only in-progress tasks at worker will be re-executed - > output stored in global FS - Master failure - master node is replicated itself. Backup master recovers last updated log files (metafile) and continues - if no backup master -> MR task is aborted and client is notified 122
27 Programming Model - General Processing Handling machine failures and stragglers - Failures
28 Programming Model - General Processing Handling machine failures and stragglers - Stragglers - slow workers lengthen the termination of a task - close to completion, backup copies of the remaining in-progress tasks are created - Causes: hardware degradation, software misconfiguration, - if a task is running slower than expected, another equivalent task will be launched as backup -> speculative execution of tasks - when a task completes successfully, any duplicate task are killed 124
29 Programming Model - General Processing Handling machine failures and stragglers - Stragglers
30 Programming Model - General Processing Managing required inter-machine communication - Task status (idle, in-progress, completed) - Idle tasks get scheduled as workers become available - In completion of a map task, the worker sends the location and sizes of its intermediate files to the master - Master pushes this info to reducers - Fault tolerance: master pings workers periodically to detect failures 126
31 Programming Model - General Processing - Workflow Workflow of (as original implemented by Google): 1. Initiate the environment on a cluster of machines 2. One Master, the rest are workers that are assigned tasks by the master 3. A map task reads the contents of an input split and passes them to the MAP-function. The results are buffered in memory 4. The buffered (key,value)-pairs are written to local disk. The location of these (intermediate) files are passed back to the master 5. A reduce worker who has been notified by the master, uses remote procedure calls to read the buffered data. 6. Reduce worker iterates over the sorted intermediate (key,value)-pairs and passes them to the REDUCE-function > On completion of all tasks, the master notifies the user program. 127
32 Programming Model - Low-level diagram 128
33 Example #1 WordCount - Setting: text documents, e.g. web server logs - Task: count occurrence of distinct words appearing in the input file, e.g find popular URLs in server logs Challenges: - File is too large for to fit in a single machines s memory - parallel execution > Solution: Apply 129
34 Example #1 WordCount - Goal: Count word occurrence in a set of documents - Input: Wer A sagt, muss auch B sagen! Wer B sagt, braucht B nicht nochmal sagen! map (k1, v1) > list (k2, v2) map (String key, String value): //key:document name //value: content of document for each word w in value do: emitintermediate(w, 1 ) reduce (k2, list(v2)) > list(v2) reduce (String key, Iterator values): //key:a word //values: a list of counts int result = 0; for each v in values do: result += parseint(v); emit(result.tostring()) 130
35 Example #1 WordCount In a parallel environment: worker: 2 131
36 Example #2 k-means Randomly initialize k centers: Classify: Assign each point to nearest centre: Recenter: becomes centroid of its points: 132
37 Example #2 k-means - - Scheme 133
38 Example #2 k-means - Classification Step As Map Classify: Assign each point to nearest center: Map: Input: - subset of d-dimensional objects of in each mapper - initial set of centroids Output: - list of objects assigned to nearest centroid. This list will later be read by the reducer program 134
39 Example #2 k-means - Classification Step As Map Classify: Assign each point to nearest center: for all x_i in M do bestcentroid <- null mindist <- inf for all c in C do dist <- l2dist(x, c) if bestcentroid == null dist < mindist then mindist <- dist bestcentroid <- c endif endfor outputlist << (bestcentroid, x_i) endfor return outputlist 135
40 Example #2 k-means - Recenter Step as Reduce Recenter: becomes centroid of its points: Note: equivalent to averaging its points! Reduce: Input: - list of (key,value)-pairs, where key = bestcentroid and value = objects assigned to this centroid Output: - (key,value), where key = oldcentroid and value = newbestcentroid, which is the new centroid calculated for that bestcentroid 136
41 Example #2 k-means - Recenter Step as Reduce Recenter: becomes centroid of its points: assignmentlist <- outputlists // lists from mappers are merged together (shuffle) for all (key,values) in assignmentlist do newcentroid, sumofobjects, numofobjects <- null for all obj in values do sumofobjects += obj numofobjects ++ endfor newcentroid <- (sumofobjects / numofobjects) newcentroidlist << (key, newcentroid) endfor return newcentroidlist 137
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
MapReduce (in the cloud)
") MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
CS246: Mining Massive Datasets Jure Leskovec, Stanford University. http://cs246.stanford.edu
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2 CPU Memory Machine Learning, Statistics Classical Data Mining Disk 3 20+ billion web pages x 20KB = 400+ TB
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2 CPU Memory Machine Learning, Statistics Classical Data Mining Disk 3 20+ billion web pages x 20KB = 400+ TB
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13
 Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Big Data Storage, Management and challenges. Ahmed Ali-Eldin
 Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
MapReduce. from the paper. MapReduce: Simplified Data Processing on Large Clusters (2004)
") MapReduce from the paper MapReduce: Simplified Data Processing on Large Clusters (2004) What it is MapReduce is a programming model and an associated implementation for processing and generating large
MapReduce from the paper MapReduce: Simplified Data Processing on Large Clusters (2004) What it is MapReduce is a programming model and an associated implementation for processing and generating large
MapReduce and the New Software Stack
 20 Chapter 2 MapReduce and the New Software Stack Modern data-mining applications, often called big-data analysis, require us to manage immense amounts of data quickly. In many of these applications, the
20 Chapter 2 MapReduce and the New Software Stack Modern data-mining applications, often called big-data analysis, require us to manage immense amounts of data quickly. In many of these applications, the
Big Data. Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich
 Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich First, an Announcement There will be a repetition exercise group on Wednesday this week. TAs will answer your questions on SQL, relational
Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich First, an Announcement There will be a repetition exercise group on Wednesday this week. TAs will answer your questions on SQL, relational
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
MapReduce. MapReduce and SQL Injections. CS 3200 Final Lecture. Introduction. MapReduce. Programming Model. Example
 MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Advanced Data Management Technologies
 ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Data Science in the Wild
 Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
and HDFS for Big Data Applications Serge Blazhievsky Nice Systems
 Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
Introduction PRESENTATION to Hadoop, TITLE GOES MapReduce HERE and HDFS for Big Data Applications Serge Blazhievsky Nice Systems SNIA Legal Notice The material contained in this tutorial is copyrighted
16.1 MAPREDUCE. For personal use only, not for distribution. 333
 For personal use only, not for distribution. 333 16.1 MAPREDUCE Initially designed by the Google labs and used internally by Google, the MAPREDUCE distributed programming model is now promoted by several
For personal use only, not for distribution. 333 16.1 MAPREDUCE Initially designed by the Google labs and used internally by Google, the MAPREDUCE distributed programming model is now promoted by several
Lecture Data Warehouse Systems
 Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics
 Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Big Data by the numbers
 COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Intro to Map/Reduce a.k.a. Hadoop
 Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Big Application Execution on Cloud using Hadoop Distributed File System
 Big Application Execution on Cloud using Hadoop Distributed File System Ashkan Vates*, Upendra, Muwafaq Rahi Ali RPIIT Campus, Bastara Karnal, Haryana, India ---------------------------------------------------------------------***---------------------------------------------------------------------
Big Application Execution on Cloud using Hadoop Distributed File System Ashkan Vates*, Upendra, Muwafaq Rahi Ali RPIIT Campus, Bastara Karnal, Haryana, India ---------------------------------------------------------------------***---------------------------------------------------------------------
Introduction to Parallel Programming and MapReduce
 Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT
 LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT Samira Daneshyar 1 and Majid Razmjoo 2 1,2 School of Computer Science, Centre of Software Technology and Management (SOFTEM),
LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT Samira Daneshyar 1 and Majid Razmjoo 2 1,2 School of Computer Science, Centre of Software Technology and Management (SOFTEM),
Parallel Programming Map-Reduce. Needless to Say, We Need Machine Learning for Big Data
 Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
What Is Datacenter (Warehouse) Computing. Distributed and Parallel Technology. Datacenter Computing Application Programming
 Computing. Distributed and Parallel Technology. Datacenter Computing Application Programming") Distributed and Parallel Technology Datacenter and Warehouse Computing Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University, Edinburgh 0 Based on earlier versions by
Distributed and Parallel Technology Datacenter and Warehouse Computing Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University, Edinburgh 0 Based on earlier versions by
Distributed File Systems
 Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
CS 378 Big Data Programming. Lecture 2 Map- Reduce
 CS 378 Big Data Programming Lecture 2 Map- Reduce MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is processed But viewed in small increments
CS 378 Big Data Programming Lecture 2 Map- Reduce MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is processed But viewed in small increments
MapReduce: Simplified Data Processing on Large Clusters. Jeff Dean, Sanjay Ghemawat Google, Inc.
 MapReduce: Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Motivation: Large Scale Data Processing Many tasks: Process lots of data to produce other data Want to use
MapReduce: Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Motivation: Large Scale Data Processing Many tasks: Process lots of data to produce other data Want to use
Recap. CSE 486/586 Distributed Systems Data Analytics. Example 1: Scientific Data. Two Questions We ll Answer. Data Analytics. Example 2: Web Data C 1
 ecap Distributed Systems Data Analytics Steve Ko Computer Sciences and Engineering University at Buffalo PC enables programmers to call functions in remote processes. IDL (Interface Definition Language)
ecap Distributed Systems Data Analytics Steve Ko Computer Sciences and Engineering University at Buffalo PC enables programmers to call functions in remote processes. IDL (Interface Definition Language)
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
CS 378 Big Data Programming
 CS 378 Big Data Programming Lecture 2 Map- Reduce CS 378 - Fall 2015 Big Data Programming 1 MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is
CS 378 Big Data Programming Lecture 2 Map- Reduce CS 378 - Fall 2015 Big Data Programming 1 MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Hadoop Cluster Applications
 Hadoop Overview Data analytics has become a key element of the business decision process over the last decade. Classic reporting on a dataset stored in a database was sufficient until recently, but yesterday
Hadoop Overview Data analytics has become a key element of the business decision process over the last decade. Classic reporting on a dataset stored in a database was sufficient until recently, but yesterday
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA USING HDFS MS.
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA USING HDFS MS.
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensive Computing. University of Florida, CISE Department Prof.
 CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensie Computing Uniersity of Florida, CISE Department Prof. Daisy Zhe Wang Map/Reduce: Simplified Data Processing on Large Clusters Parallel/Distributed
CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensie Computing Uniersity of Florida, CISE Department Prof. Daisy Zhe Wang Map/Reduce: Simplified Data Processing on Large Clusters Parallel/Distributed
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
MAPREDUCE Programming Model
 CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Storage Architectures for Big Data in the Cloud
 Storage Architectures for Big Data in the Cloud Sam Fineberg HP Storage CT Office/ May 2013 Overview Introduction What is big data? Big Data I/O Hadoop/HDFS SAN Distributed FS Cloud Summary Research Areas
Storage Architectures for Big Data in the Cloud Sam Fineberg HP Storage CT Office/ May 2013 Overview Introduction What is big data? Big Data I/O Hadoop/HDFS SAN Distributed FS Cloud Summary Research Areas
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Cloud Computing using MapReduce, Hadoop, Spark
 Cloud Computing using MapReduce, Hadoop, Spark Benjamin Hindman [email protected] Why this talk? At some point, you ll have enough data to run your parallel algorithms on multiple computers SPMD (e.g.,
Cloud Computing using MapReduce, Hadoop, Spark Benjamin Hindman [email protected] Why this talk? At some point, you ll have enough data to run your parallel algorithms on multiple computers SPMD (e.g.,
Hypertable Architecture Overview
 WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
The Hadoop Framework
 The Hadoop Framework Nils Braden University of Applied Sciences Gießen-Friedberg Wiesenstraße 14 35390 Gießen [email protected] Abstract. The Hadoop Framework offers an approach to large-scale
The Hadoop Framework Nils Braden University of Applied Sciences Gießen-Friedberg Wiesenstraße 14 35390 Gießen [email protected] Abstract. The Hadoop Framework offers an approach to large-scale
Sriram Krishnan, Ph.D. [email protected]
 Sriram Krishnan, Ph.D. [email protected] (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Sriram Krishnan, Ph.D. [email protected] (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Big Systems, Big Data
 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
A programming model in Cloud: MapReduce
 A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
HADOOP PERFORMANCE TUNING
 PERFORMANCE TUNING Abstract This paper explains tuning of Hadoop configuration parameters which directly affects Map-Reduce job performance under various conditions, to achieve maximum performance. The
PERFORMANCE TUNING Abstract This paper explains tuning of Hadoop configuration parameters which directly affects Map-Reduce job performance under various conditions, to achieve maximum performance. The
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
BBM467 Data Intensive ApplicaAons
 Hace7epe Üniversitesi Bilgisayar Mühendisliği Bölümü BBM467 Data Intensive ApplicaAons Dr. Fuat Akal [email protected] Problem How do you scale up applicaaons? Run jobs processing 100 s of terabytes
Hace7epe Üniversitesi Bilgisayar Mühendisliği Bölümü BBM467 Data Intensive ApplicaAons Dr. Fuat Akal [email protected] Problem How do you scale up applicaaons? Run jobs processing 100 s of terabytes
R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5
 Distributed data processing in heterogeneous cloud environments R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5 1 [email protected], 2 [email protected],
Distributed data processing in heterogeneous cloud environments R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5 1 [email protected], 2 [email protected],
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
marlabs driving digital agility WHITEPAPER Big Data and Hadoop
 marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability