Introduction to Spark
|
|
|
- Cory Hopkins
- 9 years ago
- Views:
Transcription
1 Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks)

2 Quick Demo

3 Quick Demo

4 API Hooks Scala / Java All Java libraries *.jar lang.org Python Anaconda: store.continuum.io/ cshop/anaconda/

5 Introduction

6 Start Spark on a cluster Submit code to be run on it Spark Structure

7

8

9

10

11
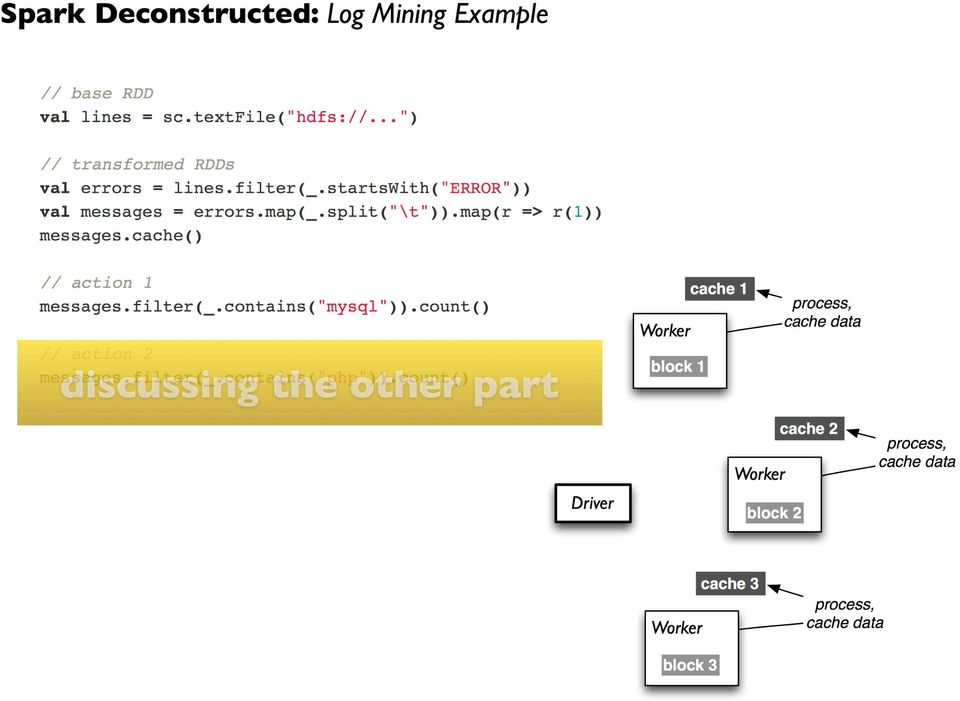
12

13

14

15

16 Another Perspective

17 Step by step

18 Step by step

19 Step by step

20 Example: WordCount

21 Example: WordCount
22 Limitations of MapReduce Performance bottlenecks not all jobs can be cast as batch processes Graphs? Programming in Hadoop is hard Boilerplate boilerplate everywhere
23 Initial Workaround: Specialization
24 Along Came Spark Spark s goal was to generalize MapReduce to support new applications within the same engine Two additions: Fast data sharing General DAGs (directed acyclic graphs) Best of both worlds: easy to program & more efzicient engine in general
25 Codebase Size
26 More on Spark More general Supports map/reduce paradigm Supports vertex- based paradigm General compute engine (DAG) More API hooks Scala, Java, and Python More interfaces Batch (Hadoop), real- time (Storm), and interactive (???)
27 Interactive Shells Spark creates a SparkContext object (cluster information) For either shell: sc External programs use a static constructor to instantiate the context
28 Interactive Shells spark-shell --master
29 Interactive Shells Master connects to the cluster manager, which allocates resources across applications Acquires executors on cluster nodes: worker processes to run computations and store data Sends app code to executors Sends tasks for executors to run
30 Resilient Distributed Datasets (RDDs) Resilient Distributed Datasets (RDDs) are primary data abstraction in Spark Fault- tolerant Can be operated on in parallel 1. Parallelized Collections 2. Hadoop datasets Two types of RDD operations 1. Transformations (lazy) 2. Actions (immediate)
31 Resilient Distributed Datasets (RDDs)
32 Resilient Distributed Datasets (RDDs) Can create RDDs from any Zile stored in HDFS Local Zilesystem Amazon S3 HBase Text Ziles, SequenceFiles, or any other Hadoop InputFormat Any directory or glob /data/201414*
33 Resilient Distributed Datasets (RDDs) Transformations Create a new RDD from an existing one Lazily evaluated: results are not immediately computed Pipeline of subsequent transformations can be optimized Lost data partitions can be recovered
34 Resilient Distributed Datasets (RDDs)
35 Resilient Distributed Datasets (RDDs)
36 Resilient Distributed Datasets (RDDs)
37 Resilient Distributed Datasets (RDDs)
38 Closures in Java
39 Resilient Distributed Datasets (RDDs) Actions Create a new RDD from an existing one Eagerly evaluated: results are immediately computed Applies previous transformations (cache results?)
40 Resilient Distributed Datasets (RDDs)
41 Resilient Distributed Datasets (RDDs)
42 Resilient Distributed Datasets (RDDs)
43 Resilient Distributed Datasets (RDDs) Spark can persist / cache an RDD in memory across operations Each slice is persisted in memory and reused in subsequent actions involving that RDD Cache provides fault- tolerance: if partition is lost, it will be recomputed using transformations that created it
44 Resilient Distributed Datasets (RDDs)
45 Resilient Distributed Datasets (RDDs)
46 Broadcast Variables Spark s version of Hadoop s DistributedCache Read- only variable cached on each node Spark [internally] distributed broadcast variables in such a way to minimize communication cost
47 Broadcast Variables
48 Accumulators Spark s version of Hadoop s Counter Variables that can only be added through an associative operation Native support of numeric accumulator types and standard mutable collections Users can extend to new types Only driver program can read accumulator value
49 Accumulators
50 Key/Value Pairs
51 Resources Original slide deck: itas_workshop.pdf Code samples: f2c c9610eac1d 8ae5b9509a08c08a1132
Spark ΕΡΓΑΣΤΗΡΙΟ 10. Prepared by George Nikolaides 4/19/2015 1
 Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Introduction to Big Data with Apache Spark UC BERKELEY
 Introduction to Big Data with Apache Spark UC BERKELEY This Lecture Programming Spark Resilient Distributed Datasets (RDDs) Creating an RDD Spark Transformations and Actions Spark Programming Model Python
Introduction to Big Data with Apache Spark UC BERKELEY This Lecture Programming Spark Resilient Distributed Datasets (RDDs) Creating an RDD Spark Transformations and Actions Spark Programming Model Python
Unified Big Data Analytics Pipeline. 连 城 [email protected]
 Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Architectures for massive data management
 Architectures for massive data management Apache Spark Albert Bifet [email protected] October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
Architectures for massive data management Apache Spark Albert Bifet [email protected] October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Apache Spark and Distributed Programming
 Apache Spark and Distributed Programming Concurrent Programming Keijo Heljanko Department of Computer Science University School of Science November 25th, 2015 Slides by Keijo Heljanko Apache Spark Apache
Apache Spark and Distributed Programming Concurrent Programming Keijo Heljanko Department of Computer Science University School of Science November 25th, 2015 Slides by Keijo Heljanko Apache Spark Apache
Big Data Frameworks: Scala and Spark Tutorial
 Big Data Frameworks: Scala and Spark Tutorial 13.03.2015 Eemil Lagerspetz, Ella Peltonen Professor Sasu Tarkoma These slides: http://is.gd/bigdatascala www.cs.helsinki.fi Functional Programming Functional
Big Data Frameworks: Scala and Spark Tutorial 13.03.2015 Eemil Lagerspetz, Ella Peltonen Professor Sasu Tarkoma These slides: http://is.gd/bigdatascala www.cs.helsinki.fi Functional Programming Functional
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com
 Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Flink Next-gen data analysis. Kostas Tzoumas [email protected] @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas [email protected] @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas [email protected] @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Spark. Fast, Interactive, Language- Integrated Cluster Computing
 Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Data Science in the Wild
 Data Science in the Wild Lecture 4 59 Apache Spark 60 1 What is Spark? Not a modified version of Hadoop Separate, fast, MapReduce-like engine In-memory data storage for very fast iterative queries General
Data Science in the Wild Lecture 4 59 Apache Spark 60 1 What is Spark? Not a modified version of Hadoop Separate, fast, MapReduce-like engine In-memory data storage for very fast iterative queries General
Beyond Hadoop with Apache Spark and BDAS
 Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University](/thumbs/26/8135278.jpg "CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
Real Time Data Processing using Spark Streaming
 Real Time Data Processing using Spark Streaming Hari Shreedharan, Software Engineer @ Cloudera Committer/PMC Member, Apache Flume Committer, Apache Sqoop Contributor, Apache Spark Author, Using Flume (O
Real Time Data Processing using Spark Streaming Hari Shreedharan, Software Engineer @ Cloudera Committer/PMC Member, Apache Flume Committer, Apache Sqoop Contributor, Apache Spark Author, Using Flume (O
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics
 E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
Fast and Expressive Big Data Analytics with Python. Matei Zaharia UC BERKELEY
 Fast and Expressive Big Data Analytics with Python Matei Zaharia UC Berkeley / MIT UC BERKELEY spark-project.org What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop
Fast and Expressive Big Data Analytics with Python Matei Zaharia UC Berkeley / MIT UC BERKELEY spark-project.org What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Big Data Analytics with Spark and Oscar BAO. Tamas Jambor, Lead Data Scientist at Massive Analytic
 Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Big Data and Scripting Systems beyond Hadoop
 Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Spark: Making Big Data Interactive & Real-Time
 Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Apache Spark 11/10/15. Context. Reminder. Context. What is Spark? A GrowingStack
 Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Spark: Cluster Computing with Working Sets
 Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Streaming items through a cluster with Spark Streaming
 Streaming items through a cluster with Spark Streaming Tathagata TD Das @tathadas CME 323: Distributed Algorithms and Optimization Stanford, May 6, 2015 Who am I? > Project Management Committee (PMC) member
Streaming items through a cluster with Spark Streaming Tathagata TD Das @tathadas CME 323: Distributed Algorithms and Optimization Stanford, May 6, 2015 Who am I? > Project Management Committee (PMC) member
LAB 2 SPARK / D-STREAM PROGRAMMING SCIENTIFIC APPLICATIONS FOR IOT WORKSHOP
 LAB 2 SPARK / D-STREAM PROGRAMMING SCIENTIFIC APPLICATIONS FOR IOT WORKSHOP ICTP, Trieste, March 24th 2015 The objectives of this session are: Understand the Spark RDD programming model Familiarize with
LAB 2 SPARK / D-STREAM PROGRAMMING SCIENTIFIC APPLICATIONS FOR IOT WORKSHOP ICTP, Trieste, March 24th 2015 The objectives of this session are: Understand the Spark RDD programming model Familiarize with
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Brave New World: Hadoop vs. Spark
 Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming. by Dibyendu Bhattacharya
 Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Spark and the Big Data Library
 Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Machine- Learning Summer School - 2015
 Machine- Learning Summer School - 2015 Big Data Programming David Franke Vast.com hbp://www.cs.utexas.edu/~dfranke/ Goals for Today Issues to address when you have big data Understand two popular big data
Machine- Learning Summer School - 2015 Big Data Programming David Franke Vast.com hbp://www.cs.utexas.edu/~dfranke/ Goals for Today Issues to address when you have big data Understand two popular big data
BIG DATA APPLICATIONS
 BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
Big Data Analytics Hadoop and Spark
 Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Hadoop: The Definitive Guide
 FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source
 - In- Memory Data Fabric Fast Data Meets Open Source") Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org @apacheignite @dsetrakyan Agenda About In- Memory
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org @apacheignite @dsetrakyan Agenda About In- Memory
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
CSE-E5430 Scalable Cloud Computing Lecture 11
 CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 30.11-2015 1/24 Distributed Coordination Systems Consensus
CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 30.11-2015 1/24 Distributed Coordination Systems Consensus
Using Apache Spark Pat McDonough - Databricks
 Using Apache Spark Pat McDonough - Databricks Apache Spark spark.incubator.apache.org github.com/apache/incubator-spark [email protected] The Spark Community +You! INTRODUCTION TO APACHE
Using Apache Spark Pat McDonough - Databricks Apache Spark spark.incubator.apache.org github.com/apache/incubator-spark [email protected] The Spark Community +You! INTRODUCTION TO APACHE
SPARK USE CASE IN TELCO. Apache Spark Night 9-2-2014! Chance Coble!
 SPARK USE CASE IN TELCO Apache Spark Night 9-2-2014! Chance Coble! Use Case Profile Telecommunications company Shared business problems/pain Scalable analytics infrastructure is a problem Pushing infrastructure
SPARK USE CASE IN TELCO Apache Spark Night 9-2-2014! Chance Coble! Use Case Profile Telecommunications company Shared business problems/pain Scalable analytics infrastructure is a problem Pushing infrastructure
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Spark and Shark. High- Speed In- Memory Analytics over Hadoop and Hive Data
 Spark and Shark High- Speed In- Memory Analytics over Hadoop and Hive Data Matei Zaharia, in collaboration with Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Cliff Engle, Michael Franklin, Haoyuan Li,
Spark and Shark High- Speed In- Memory Analytics over Hadoop and Hive Data Matei Zaharia, in collaboration with Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Cliff Engle, Michael Franklin, Haoyuan Li,
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Beyond Hadoop MapReduce Apache Tez and Apache Spark
 Beyond Hadoop MapReduce Apache Tez and Apache Spark Prakasam Kannan Computer Science Department San Jose State University San Jose, CA 95192 408-924-1000 [email protected] ABSTRACT Hadoop MapReduce
Beyond Hadoop MapReduce Apache Tez and Apache Spark Prakasam Kannan Computer Science Department San Jose State University San Jose, CA 95192 408-924-1000 [email protected] ABSTRACT Hadoop MapReduce
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
1. The orange button 2. Audio Type 3. Close apps 4. Enlarge my screen 5. Headphones 6. Questions Pane. SparkR 2
 SparkR 1. The orange button 2. Audio Type 3. Close apps 4. Enlarge my screen 5. Headphones 6. Questions Pane SparkR 2 Lecture slides and/or video will be made available within one week Live Demonstration
SparkR 1. The orange button 2. Audio Type 3. Close apps 4. Enlarge my screen 5. Headphones 6. Questions Pane SparkR 2 Lecture slides and/or video will be made available within one week Live Demonstration
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
What We Can Do in the Cloud (2) -Tutorial for Cloud Computing Course- Mikael Fernandus Simalango WISE Research Lab Ajou University, South Korea
 -Tutorial for Cloud Computing Course- Mikael Fernandus Simalango WISE Research Lab Ajou University, South Korea") What We Can Do in the Cloud (2) -Tutorial for Cloud Computing Course- Mikael Fernandus Simalango WISE Research Lab Ajou University, South Korea Overview Riding Google App Engine Taming Hadoop Summary Riding
What We Can Do in the Cloud (2) -Tutorial for Cloud Computing Course- Mikael Fernandus Simalango WISE Research Lab Ajou University, South Korea Overview Riding Google App Engine Taming Hadoop Summary Riding
Learning. Spark LIGHTNING-FAST DATA ANALYTICS. Holden Karau, Andy Konwinski, Patrick Wendell & Matei Zaharia
 Compliments of Learning Spark LIGHTNING-FAST DATA ANALYTICS Holden Karau, Andy Konwinski, Patrick Wendell & Matei Zaharia Bring Your Big Data to Life Big Data Integration and Analytics Learn how to power
Compliments of Learning Spark LIGHTNING-FAST DATA ANALYTICS Holden Karau, Andy Konwinski, Patrick Wendell & Matei Zaharia Bring Your Big Data to Life Big Data Integration and Analytics Learn how to power
Embracing Spark as the Scalable Data Analytics Platform for the Enterprise
 Embracing Spark as the Scalable Data Analytics Platform for the Enterprise Matthew J. Glickman GS.com/Engineering Spark Summit East 2015 1 How did we get here today? Strata + Hadoop World October 2014
Embracing Spark as the Scalable Data Analytics Platform for the Enterprise Matthew J. Glickman GS.com/Engineering Spark Summit East 2015 1 How did we get here today? Strata + Hadoop World October 2014
GridGain In- Memory Data Fabric: UlCmate Speed and Scale for TransacCons and AnalyCcs
 GridGain In- Memory Data Fabric: UlCmate Speed and Scale for TransacCons and AnalyCcs DMITRIY SETRAKYAN Founder & EVP Engineering @dsetrakyan www.gridgain.com #gridgain Agenda EvoluCon of In- Memory CompuCng
GridGain In- Memory Data Fabric: UlCmate Speed and Scale for TransacCons and AnalyCcs DMITRIY SETRAKYAN Founder & EVP Engineering @dsetrakyan www.gridgain.com #gridgain Agenda EvoluCon of In- Memory CompuCng
Spark Application Carousel. Spark Summit East 2015
 Spark Application Carousel Spark Summit East 2015 About Today s Talk About Me: Vida Ha - Solutions Engineer at Databricks. Goal: For beginning/early intermediate Spark Developers. Motivate you to start
Spark Application Carousel Spark Summit East 2015 About Today s Talk About Me: Vida Ha - Solutions Engineer at Databricks. Goal: For beginning/early intermediate Spark Developers. Motivate you to start
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Case Study : 3 different hadoop cluster deployments
 Case Study : 3 different hadoop cluster deployments Lee moon soo [email protected] HDFS as a Storage Last 4 years, our HDFS clusters, stored Customer 1500 TB+ data safely served 375,000 TB+ data to customer
Case Study : 3 different hadoop cluster deployments Lee moon soo [email protected] HDFS as a Storage Last 4 years, our HDFS clusters, stored Customer 1500 TB+ data safely served 375,000 TB+ data to customer
Pro Apache Hadoop. Second Edition. Sameer Wadkar. Madhu Siddalingaiah
 Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Implementation of Spark Cluster Technique with SCALA
 International Journal of Scientific and Research Publications, Volume 2, Issue 11, November 2012 1 Implementation of Spark Cluster Technique with SCALA Tarun Kumawat 1, Pradeep Kumar Sharma 2, Deepak Verma
International Journal of Scientific and Research Publications, Volume 2, Issue 11, November 2012 1 Implementation of Spark Cluster Technique with SCALA Tarun Kumawat 1, Pradeep Kumar Sharma 2, Deepak Verma
Hybrid Software Architectures for Big Data. [email protected] @hurence http://www.hurence.com
 Hybrid Software Architectures for Big Data [email protected] @hurence http://www.hurence.com Headquarters : Grenoble Pure player Expert level consulting Training R&D Big Data X-data hot-line
Hybrid Software Architectures for Big Data [email protected] @hurence http://www.hurence.com Headquarters : Grenoble Pure player Expert level consulting Training R&D Big Data X-data hot-line
Introduc8on to Apache Spark
 Introduc8on to Apache Spark Jordan Volz, Systems Engineer @ Cloudera 1 Analyzing Data on Large Data Sets Python, R, etc. are popular tools among data scien8sts/analysts, sta8s8cians, etc. Why are these
Introduc8on to Apache Spark Jordan Volz, Systems Engineer @ Cloudera 1 Analyzing Data on Large Data Sets Python, R, etc. are popular tools among data scien8sts/analysts, sta8s8cians, etc. Why are these
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
HiBench Introduction. Carson Wang ([email protected]) Software & Services Group
 Software & Services Group") HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
How To Understand The Programing Framework For Distributed Computing
 Survey on Frameworks for Distributed Computing: Hadoop, Spark and Storm Telmo da Silva Morais Student of Doctoral Program of Informatics Engineering Faculty of Engineering, University of Porto Porto, Portugal
Survey on Frameworks for Distributed Computing: Hadoop, Spark and Storm Telmo da Silva Morais Student of Doctoral Program of Informatics Engineering Faculty of Engineering, University of Porto Porto, Portugal
The Top 10 7 Hadoop Patterns and Anti-patterns. Alex Holmes @
 The Top 10 7 Hadoop Patterns and Anti-patterns Alex Holmes @ whoami Alex Holmes Software engineer Working on distributed systems for many years Hadoop since 2008 @grep_alex grepalex.com what s hadoop...
The Top 10 7 Hadoop Patterns and Anti-patterns Alex Holmes @ whoami Alex Holmes Software engineer Working on distributed systems for many years Hadoop since 2008 @grep_alex grepalex.com what s hadoop...
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Primer. 1 Why Big Data? Alex Sverdlov [email protected]
 Big Data Primer Alex Sverdlov [email protected] 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Big Data Primer Alex Sverdlov [email protected] 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
ITG Software Engineering
 Introduction to Cloudera Course ID: Page 1 Last Updated 12/15/2014 Introduction to Cloudera Course : This 5 day course introduces the student to the Hadoop architecture, file system, and the Hadoop Ecosystem.
Introduction to Cloudera Course ID: Page 1 Last Updated 12/15/2014 Introduction to Cloudera Course : This 5 day course introduces the student to the Hadoop architecture, file system, and the Hadoop Ecosystem.
Big Data at Spotify. Anders Arpteg, Ph D Analytics Machine Learning, Spotify
 Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed)
Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed)
Kafka & Redis for Big Data Solutions
 Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Disco: Beyond MapReduce
 Disco: Beyond MapReduce Prashanth Mundkur Nokia Mar 22, 2013 Outline BigData/MapReduce Disco Disco Pipeline Model Disco Roadmap BigData/MapReduce Data too big to fit in RAM/disk of any single machine Analyze
Disco: Beyond MapReduce Prashanth Mundkur Nokia Mar 22, 2013 Outline BigData/MapReduce Disco Disco Pipeline Model Disco Roadmap BigData/MapReduce Data too big to fit in RAM/disk of any single machine Analyze
How To Create A Data Visualization With Apache Spark And Zeppelin 2.5.3.5
 Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source
 - In- Memory Data Fabric Fast Data Meets Open Source") Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org #apacheignite Agenda Apache Ignite (tm) In- Memory
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org #apacheignite Agenda Apache Ignite (tm) In- Memory
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
This is a brief tutorial that explains the basics of Spark SQL programming.
 About the Tutorial Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types
About the Tutorial Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect
 Huibert Aalbers Senior Certified Executive IT Architect") The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
Writing Standalone Spark Programs
 Writing Standalone Spark Programs Matei Zaharia UC Berkeley www.spark- project.org UC BERKELEY Outline Setting up for Spark development Example: PageRank PageRank in Java Testing and debugging Building
Writing Standalone Spark Programs Matei Zaharia UC Berkeley www.spark- project.org UC BERKELEY Outline Setting up for Spark development Example: PageRank PageRank in Java Testing and debugging Building
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Real-time Big Data Analytics with Storm
 Ron Bodkin Founder & CEO, Think Big June 2013 Real-time Big Data Analytics with Storm Leading Provider of Data Science and Engineering Services Accelerating Your Time to Value IMAGINE Strategy and Roadmap
Ron Bodkin Founder & CEO, Think Big June 2013 Real-time Big Data Analytics with Storm Leading Provider of Data Science and Engineering Services Accelerating Your Time to Value IMAGINE Strategy and Roadmap
How To Choose A Data Flow Pipeline From A Data Processing Platform
 S N A P L O G I C T E C H N O L O G Y B R I E F SNAPLOGIC BIG DATA INTEGRATION PROCESSING PLATFORMS 2 W Fifth Avenue Fourth Floor, San Mateo CA, 94402 telephone: 888.494.1570 www.snaplogic.com Big Data
S N A P L O G I C T E C H N O L O G Y B R I E F SNAPLOGIC BIG DATA INTEGRATION PROCESSING PLATFORMS 2 W Fifth Avenue Fourth Floor, San Mateo CA, 94402 telephone: 888.494.1570 www.snaplogic.com Big Data
t] open source Hadoop Beginner's Guide ij$ data avalanche Garry Turkington Learn how to crunch big data to extract meaning from
![t] open source Hadoop Beginner's Guide ij$ data avalanche Garry Turkington Learn how to crunch big data to extract meaning from](/thumbs/26/7239192.jpg "t] open source Hadoop Beginner's Guide ij$ data avalanche Garry Turkington Learn how to crunch big data to extract meaning from") Hadoop Beginner's Guide Learn how to crunch big data to extract meaning from data avalanche Garry Turkington [ PUBLISHING t] open source I I community experience distilled ftu\ ij$ BIRMINGHAMMUMBAI ')
Hadoop Beginner's Guide Learn how to crunch big data to extract meaning from data avalanche Garry Turkington [ PUBLISHING t] open source I I community experience distilled ftu\ ij$ BIRMINGHAMMUMBAI ')
HDFS. Hadoop Distributed File System
 HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
A bit about Hadoop. Luca Pireddu. March 9, 2012. CRS4Distributed Computing Group. [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18
 Luca Pireddu March 9, 2012 1 / 18") A bit about Hadoop Luca Pireddu CRS4Distributed Computing Group March 9, 2012 [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18 Often seen problems Often seen problems Low parallelism I/O is
A bit about Hadoop Luca Pireddu CRS4Distributed Computing Group March 9, 2012 [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18 Often seen problems Often seen problems Low parallelism I/O is
3 Reasons Enterprises Struggle with Storm & Spark Streaming and Adopt DataTorrent RTS
 . 3 Reasons Enterprises Struggle with Storm & Spark Streaming and Adopt DataTorrent RTS Deliver fast actionable business insights for data scientists, rapid application creation for developers and enterprise-grade
. 3 Reasons Enterprises Struggle with Storm & Spark Streaming and Adopt DataTorrent RTS Deliver fast actionable business insights for data scientists, rapid application creation for developers and enterprise-grade
Certification Study Guide. MapR Certified Spark Developer Study Guide
 Certification Study Guide MapR Certified Spark Developer Study Guide 1 CONTENTS About MapR Study Guides... 3 MapR Certified Spark Developer (MCSD)... 3 SECTION 1 WHAT S ON THE EXAM?... 5 1. Load and Inspect
Certification Study Guide MapR Certified Spark Developer Study Guide 1 CONTENTS About MapR Study Guides... 3 MapR Certified Spark Developer (MCSD)... 3 SECTION 1 WHAT S ON THE EXAM?... 5 1. Load and Inspect
Unlocking the True Value of Hadoop with Open Data Science
 Unlocking the True Value of Hadoop with Open Data Science Kristopher Overholt Solution Architect Big Data Tech 2016 MinneAnalytics June 7, 2016 Overview Overview of Open Data Science Python and the Big
Unlocking the True Value of Hadoop with Open Data Science Kristopher Overholt Solution Architect Big Data Tech 2016 MinneAnalytics June 7, 2016 Overview Overview of Open Data Science Python and the Big
Energy Efficient MapReduce
 Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
Productionizing a 24/7 Spark Streaming Service on YARN
 Productionizing a 24/7 Spark Streaming Service on YARN Issac Buenrostro, Arup Malakar Spark Summit 2014 July 1, 2014 About Ooyala Cross-device video analytics and monetization products and services Founded
Productionizing a 24/7 Spark Streaming Service on YARN Issac Buenrostro, Arup Malakar Spark Summit 2014 July 1, 2014 About Ooyala Cross-device video analytics and monetization products and services Founded
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
University of Maryland. Tuesday, February 2, 2010
 Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
CS 378 Big Data Programming. Lecture 2 Map- Reduce
 CS 378 Big Data Programming Lecture 2 Map- Reduce MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is processed But viewed in small increments
CS 378 Big Data Programming Lecture 2 Map- Reduce MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is processed But viewed in small increments
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: [email protected] Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...