Apache Hadoop new way for the company to store and analyze big data
|
|
|
- Poppy Small
- 10 years ago
- Views:
Transcription

1 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer


2 Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File System Hadoop MapReduce Hadoop Ecosystem Running Hadoop 2

3 What is big Data? Big data is a popular term used to describe the exponential growth and availability of data, both structured and unstructured When dealing with larger datasets, organizations face difficulties in being able to create, manipulate, and manage big data, basic there are 2 problem with big data How to store and work with large volumes of data. And most importantly, how to interpret and analyze this data, Hadoop appears on the market as a solution to these problems, providing a way to store and process this data 3

4 What is hadoop? Hadoop is an open source software that provides a framework written in Java to allow for the distributed processing of large data sets across clusters built with commodity hardware. Design can go from few nodes to thousands of nodes in a flexible Hadoop is a distributed system using a master-slave architecture, Using to store your Hadoop Distributed File System (HDFS) And MapReduce algorithms for computing Both MapReduce and the Hadoop Distributed File System are designed so that node failures are automatically handled by the framework 4

5 Who uses Hadoop? 5

6 Hadoop Architecture 6

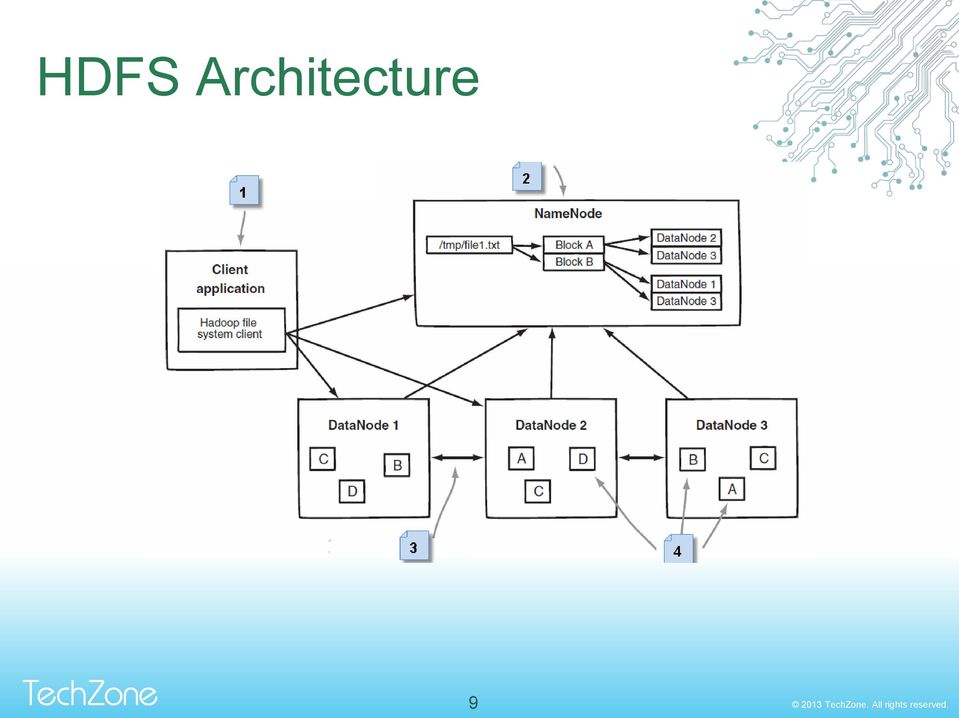
7 Hadoop Distributed File System HDFS is a distributed file system designed to run on commodity hardware HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets Write-once-read-many access model for files HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode and many DataNodes 7

8 Hadoop Distributed File System NameNode A master server that manages the file system namespace and regulates access to files by clients. Executes file system namespace operations like opening, closing, and renaming files and directories and determines the mapping of blocks to DataNodes. Keep in memory the file system metadata and control file blocks that each DataNode DataNodes They are responsible for serving read and write requests from the file system s clients. They also perform block creation, deletion, and replication upon instruction from the NameNode. 8

9 HDFS Architecture 9
10 Hadoop MapReduce It is a software framework for easily writing applications which process vast amounts of data (multi-terabyte datasets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner. MapReduce divides workloads up into multiple tasks that can be executed in parallel. Typically the compute nodes and the storage nodes are the same 10

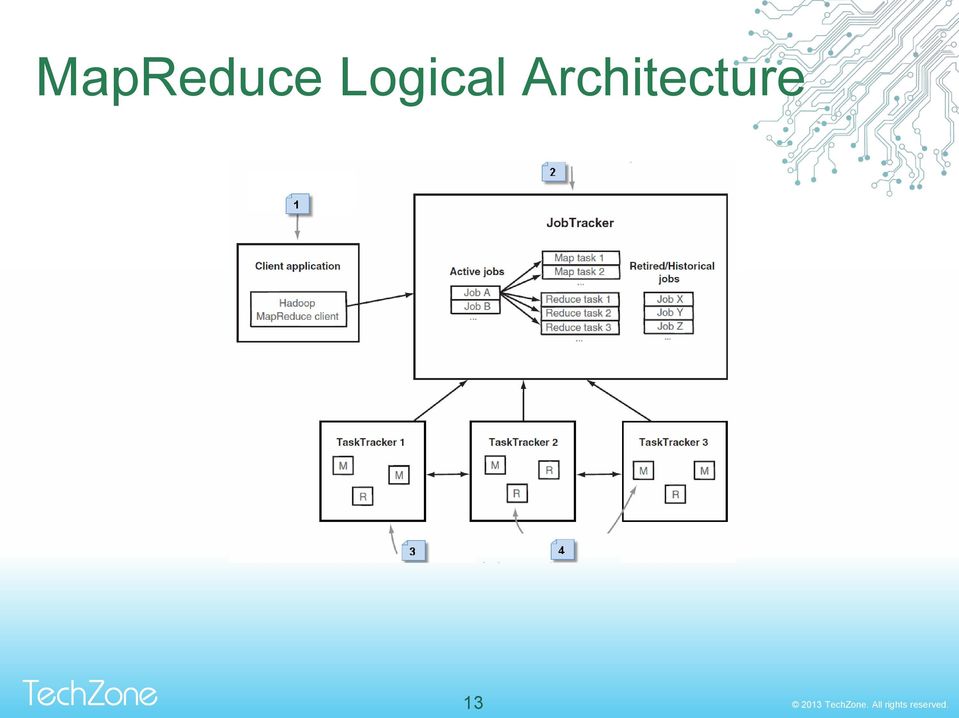
11 Hadoop MapReduce The Map/Reduce framework consists of a single master JobTracker and many TaskTracker one per cluster-node. The master is responsible for scheduling the jobs' component tasks on the slaves, monitoring them and re-executing the failed tasks. The slaves execute the tasks as directed by the master. Two main phases: Map and Reduce: Map step: Master node receives and divides a task into smaller tasks which distributes to other nodes to process them. Reduce step: The master node collects all the responses received and combines them to generate the output. 11

12 Hadoop MapReduce MapReduce job is converted into map and reduce tasks Developers need ONLY to implement the Map and Reduce classes 12

13 MapReduce Logical Architecture 13
14 Hadoop ecosystem 14

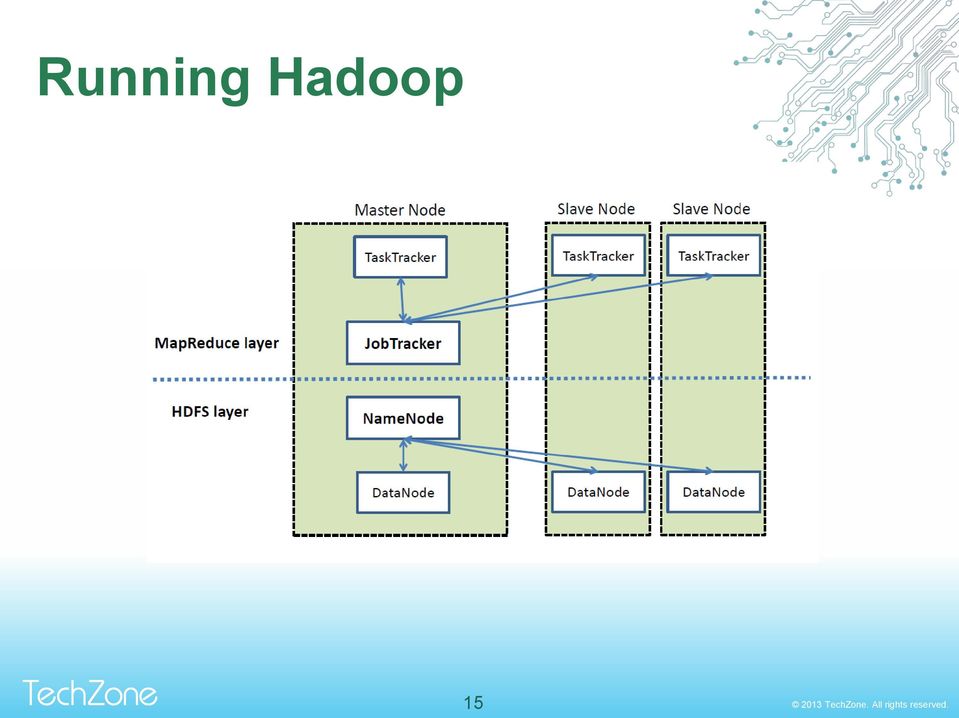
15 Running Hadoop 15
16 Hadoop Cluster Installation Supported Platforms GNU/Linux is supported as a development and production platform Win32 is supported as a development platform. Distributed operation has not been well tested on Win32 Required Software Java 1.6 or +, preferably from Sun, must be installed. ssh must be installed and sshd must be running to use the Hadoop scripts that manage remote Hadoop daemons. To get a Hadoop distribution, download a recent stable release from one of the Apache Download Mirrors 16

17 Hadoop Cluster Installation Installing a Hadoop cluster typically involves unpacking the software on all the machines in the cluster The root of the distribution is referred to as HADOOP_HOME Configuration Files hadoop-env.sh Master and slave configuration (master only): conf/masters and conf/slaves Site-specific configuration (all machines): conf/core-site.xml, conf/hdfs-site.xml and conf/mapred-site.xml. 17
: conf/masters and conf/slaves Site-specific")
 HDFS daemons: bin/start-dfs.sh MapReduce daemons: bin/start-mapred.sh The following Java processes should run on master and salve 18")
18 Hadoop Cluster Installation Formatting the HDFS filesystem via the NameNode /usr/local/hadoop/bin/hadoop namenode format Starting your multi-node cluster (only master server) HDFS daemons: bin/start-dfs.sh MapReduce daemons: bin/start-mapred.sh The following Java processes should run on master and salve 18

19 Hadoop Cluster Installation Stopping the multi-node cluster (only master server) MapReduce daemons: bin/stop-mapred.sh HDFS daemons: bin/stop-dfs.sh If there are any errors, examine the log files in the /logs/ directory. hadoop-hduser-namenode-hadoopsrv2.log, hadoop-hduserdatanode-hadoopsrv2.log, hadoop-hduser-tasktracker-hadoopsrv2.log Hadoop Web Interfaces web UI of the NameNode daemon web UI of the JobTracker daemon web UI of the TaskTracker daemon 19


20 Hadoop Cluster Setup common problems Problem 1 Starting a hadoop cluster a warning message is raised: $HADOOP_HOME is deprecated So to resolve that in.bashrc file, replace the "HADOOP_HOME" variable with "HADOOP_PREFIX" variable. Problem 2 java.io.ioexception: Incompatible namespaceids: If you have formatted the namenode twice. In this case the namespaceid is not replicated to the DataNodes (/app/hadoop/tmp/dfs/name/current/version) 20


21 Running a MapReduce job We will use the WordCount example job which reads text files and counts how often words occur. Download example input data Copy local example data to HDFS bin/hadoop dfs -copyfromlocal /tmp/inputtext/ /user/hduser/inputtext bin/hadoop dfs -ls /user/hduser 21
22 Running a MapReduce job Run the MapReduce job bin/hadoop jar hadoop-examples jar wordcount /user/hduser/input-text /user/hduser/results-output bin/hadoop dfs -ls /user/hduser Retrieve the job result from HDFS bin/hadoop dfs -cat /user/hduser/results-output/part-r mkdir /tmp/results-output bin/hadoop dfs -getmerge /user/hduser/results-output /tmp/resultsoutput 22
23 Running a MapReduce job Retrieve the job result from HDFS head /tmp/results-output/results-output 23

24 Q&A 24

25 25
Setup Hadoop On Ubuntu Linux. ---Multi-Node Cluster
 Setup Hadoop On Ubuntu Linux ---Multi-Node Cluster We have installed the JDK and Hadoop for you. The JAVA_HOME is /usr/lib/jvm/java/jdk1.6.0_22 The Hadoop home is /home/user/hadoop-0.20.2 1. Network Edit
Setup Hadoop On Ubuntu Linux ---Multi-Node Cluster We have installed the JDK and Hadoop for you. The JAVA_HOME is /usr/lib/jvm/java/jdk1.6.0_22 The Hadoop home is /home/user/hadoop-0.20.2 1. Network Edit
Single Node Setup. Table of contents
 Table of contents 1 Purpose... 2 2 Prerequisites...2 2.1 Supported Platforms...2 2.2 Required Software... 2 2.3 Installing Software...2 3 Download...2 4 Prepare to Start the Hadoop Cluster... 3 5 Standalone
Table of contents 1 Purpose... 2 2 Prerequisites...2 2.1 Supported Platforms...2 2.2 Required Software... 2 2.3 Installing Software...2 3 Download...2 4 Prepare to Start the Hadoop Cluster... 3 5 Standalone
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Running Hadoop On Ubuntu Linux (Multi-Node Cluster) - Michael G...
 - Michael G...") Go Home About Contact Blog Code Publications DMOZ100k06 Photography Running Hadoop On Ubuntu Linux (Multi-Node Cluster) From Michael G. Noll Contents 1 What we want to do 2 Tutorial approach and structure
Go Home About Contact Blog Code Publications DMOZ100k06 Photography Running Hadoop On Ubuntu Linux (Multi-Node Cluster) From Michael G. Noll Contents 1 What we want to do 2 Tutorial approach and structure
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
2.1 Hadoop a. Hadoop Installation & Configuration
 2. Implementation 2.1 Hadoop a. Hadoop Installation & Configuration First of all, we need to install Java Sun 6, and it is preferred to be version 6 not 7 for running Hadoop. Type the following commands
2. Implementation 2.1 Hadoop a. Hadoop Installation & Configuration First of all, we need to install Java Sun 6, and it is preferred to be version 6 not 7 for running Hadoop. Type the following commands
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
TP1: Getting Started with Hadoop
 TP1: Getting Started with Hadoop Alexandru Costan MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development of web
TP1: Getting Started with Hadoop Alexandru Costan MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development of web
研 發 專 案 原 始 程 式 碼 安 裝 及 操 作 手 冊. Version 0.1
 102 年 度 國 科 會 雲 端 計 算 與 資 訊 安 全 技 術 研 發 專 案 原 始 程 式 碼 安 裝 及 操 作 手 冊 Version 0.1 總 計 畫 名 稱 : 行 動 雲 端 環 境 動 態 群 組 服 務 研 究 與 創 新 應 用 子 計 畫 一 : 行 動 雲 端 群 組 服 務 架 構 與 動 態 群 組 管 理 (NSC 102-2218-E-259-003) 計
102 年 度 國 科 會 雲 端 計 算 與 資 訊 安 全 技 術 研 發 專 案 原 始 程 式 碼 安 裝 及 操 作 手 冊 Version 0.1 總 計 畫 名 稱 : 行 動 雲 端 環 境 動 態 群 組 服 務 研 究 與 創 新 應 用 子 計 畫 一 : 行 動 雲 端 群 組 服 務 架 構 與 動 態 群 組 管 理 (NSC 102-2218-E-259-003) 計
Research Laboratory. Java Web Crawler & Hadoop MapReduce Anri Morchiladze && Bachana Dolidze Supervisor Nodar Momtselidze
 Research Laboratory Java Web Crawler & Hadoop MapReduce Anri Morchiladze && Bachana Dolidze Supervisor Nodar Momtselidze 1. Java Web Crawler Description Java Code 2. MapReduce Overview Example of mapreduce
Research Laboratory Java Web Crawler & Hadoop MapReduce Anri Morchiladze && Bachana Dolidze Supervisor Nodar Momtselidze 1. Java Web Crawler Description Java Code 2. MapReduce Overview Example of mapreduce
How To Install Hadoop 1.2.1.1 From Apa Hadoop 1.3.2 To 1.4.2 (Hadoop)
") Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1 Review and Motivation Agenda Assignment Information Introduction
Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1 Review and Motivation Agenda Assignment Information Introduction
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM
 IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM Sugandha Agarwal 1, Pragya Jain 2 1,2 Department of Computer Science & Engineering ASET, Amity University, Noida,
IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM Sugandha Agarwal 1, Pragya Jain 2 1,2 Department of Computer Science & Engineering ASET, Amity University, Noida,
Single Node Hadoop Cluster Setup
 Single Node Hadoop Cluster Setup This document describes how to create Hadoop Single Node cluster in just 30 Minutes on Amazon EC2 cloud. You will learn following topics. Click Here to watch these steps
Single Node Hadoop Cluster Setup This document describes how to create Hadoop Single Node cluster in just 30 Minutes on Amazon EC2 cloud. You will learn following topics. Click Here to watch these steps
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment
 CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Installation and Configuration Documentation
 Installation and Configuration Documentation Release 1.0.1 Oshin Prem October 08, 2015 Contents 1 HADOOP INSTALLATION 3 1.1 SINGLE-NODE INSTALLATION................................... 3 1.2 MULTI-NODE
Installation and Configuration Documentation Release 1.0.1 Oshin Prem October 08, 2015 Contents 1 HADOOP INSTALLATION 3 1.1 SINGLE-NODE INSTALLATION................................... 3 1.2 MULTI-NODE
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Hadoop (pseudo-distributed) installation and configuration
 installation and configuration") Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Hadoop Lab Notes. Nicola Tonellotto November 15, 2010
 Hadoop Lab Notes Nicola Tonellotto November 15, 2010 2 Contents 1 Hadoop Setup 4 1.1 Prerequisites........................................... 4 1.2 Installation............................................
Hadoop Lab Notes Nicola Tonellotto November 15, 2010 2 Contents 1 Hadoop Setup 4 1.1 Prerequisites........................................... 4 1.2 Installation............................................
MapReduce. Tushar B. Kute, http://tusharkute.com
 MapReduce Tushar B. Kute, http://tusharkute.com What is MapReduce? MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity
MapReduce Tushar B. Kute, http://tusharkute.com What is MapReduce? MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity
Introduction to Cloud Computing
 Introduction to Cloud Computing Qloud Demonstration 15 319, spring 2010 3 rd Lecture, Jan 19 th Suhail Rehman Time to check out the Qloud! Enough Talk! Time for some Action! Finally you can have your own
Introduction to Cloud Computing Qloud Demonstration 15 319, spring 2010 3 rd Lecture, Jan 19 th Suhail Rehman Time to check out the Qloud! Enough Talk! Time for some Action! Finally you can have your own
Hadoop 2.2.0 MultiNode Cluster Setup
 Hadoop 2.2.0 MultiNode Cluster Setup Sunil Raiyani Jayam Modi June 7, 2014 Sunil Raiyani Jayam Modi Hadoop 2.2.0 MultiNode Cluster Setup June 7, 2014 1 / 14 Outline 4 Starting Daemons 1 Pre-Requisites
Hadoop 2.2.0 MultiNode Cluster Setup Sunil Raiyani Jayam Modi June 7, 2014 Sunil Raiyani Jayam Modi Hadoop 2.2.0 MultiNode Cluster Setup June 7, 2014 1 / 14 Outline 4 Starting Daemons 1 Pre-Requisites
Hadoop Setup. 1 Cluster
 In order to use HadoopUnit (described in Sect. 3.3.3), a Hadoop cluster needs to be setup. This cluster can be setup manually with physical machines in a local environment, or in the cloud. Creating a
In order to use HadoopUnit (described in Sect. 3.3.3), a Hadoop cluster needs to be setup. This cluster can be setup manually with physical machines in a local environment, or in the cloud. Creating a
Hadoop Distributed File System. Dhruba Borthakur June, 2007
 Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
HDFS Users Guide. Table of contents
 Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
Data Analytics. CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL. All rights reserved.
 2011, Parallel Systems Architecture Lab, EPFL. All rights reserved.") Data Analytics CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL All rights reserved. The data analytics benchmark relies on using the Hadoop MapReduce framework
Data Analytics CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL All rights reserved. The data analytics benchmark relies on using the Hadoop MapReduce framework
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney") Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Sriram Krishnan, Ph.D. [email protected]
 Sriram Krishnan, Ph.D. [email protected] (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Sriram Krishnan, Ph.D. [email protected] (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Lecture 2 (08/31, 09/02, 09/09): Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015
: Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015") Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science
 A Seminar report On Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED BY: www.studymafia.org
A Seminar report On Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED BY: www.studymafia.org
HADOOP - MULTI NODE CLUSTER
 HADOOP - MULTI NODE CLUSTER http://www.tutorialspoint.com/hadoop/hadoop_multi_node_cluster.htm Copyright tutorialspoint.com This chapter explains the setup of the Hadoop Multi-Node cluster on a distributed
HADOOP - MULTI NODE CLUSTER http://www.tutorialspoint.com/hadoop/hadoop_multi_node_cluster.htm Copyright tutorialspoint.com This chapter explains the setup of the Hadoop Multi-Node cluster on a distributed
Big Data 2012 Hadoop Tutorial
 Big Data 2012 Hadoop Tutorial Oct 19th, 2012 Martin Kaufmann Systems Group, ETH Zürich 1 Contact Exercise Session Friday 14.15 to 15.00 CHN D 46 Your Assistant Martin Kaufmann Office: CAB E 77.2 E-Mail:
Big Data 2012 Hadoop Tutorial Oct 19th, 2012 Martin Kaufmann Systems Group, ETH Zürich 1 Contact Exercise Session Friday 14.15 to 15.00 CHN D 46 Your Assistant Martin Kaufmann Office: CAB E 77.2 E-Mail:
map/reduce connected components
 1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
Intro to Map/Reduce a.k.a. Hadoop
 Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Intro to Map/Reduce a.k.a. Hadoop Based on: Mining of Massive Datasets by Ra jaraman and Ullman, Cambridge University Press, 2011 Data Mining for the masses by North, Global Text Project, 2012 Slides by
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
Running Kmeans Mapreduce code on Amazon AWS
 Running Kmeans Mapreduce code on Amazon AWS Pseudo Code Input: Dataset D, Number of clusters k Output: Data points with cluster memberships Step 1: for iteration = 1 to MaxIterations do Step 2: Mapper:
Running Kmeans Mapreduce code on Amazon AWS Pseudo Code Input: Dataset D, Number of clusters k Output: Data points with cluster memberships Step 1: for iteration = 1 to MaxIterations do Step 2: Mapper:
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms
 Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
Tutorial- Counting Words in File(s) using MapReduce
 using MapReduce") Tutorial- Counting Words in File(s) using MapReduce 1 Overview This document serves as a tutorial to setup and run a simple application in Hadoop MapReduce framework. A job in Hadoop MapReduce usually
Tutorial- Counting Words in File(s) using MapReduce 1 Overview This document serves as a tutorial to setup and run a simple application in Hadoop MapReduce framework. A job in Hadoop MapReduce usually
HADOOP INTO CLOUD: A RESEARCH
 HADOOP INTO CLOUD: A RESEARCH Prof.M.S.Malkar H.O.D, PCP, Pune [email protected] Ms.Misha Ann Alexander M.E.Student, LecturerPCP,Pune [email protected] Abstract- Hadoop and cloud has gained
HADOOP INTO CLOUD: A RESEARCH Prof.M.S.Malkar H.O.D, PCP, Pune [email protected] Ms.Misha Ann Alexander M.E.Student, LecturerPCP,Pune [email protected] Abstract- Hadoop and cloud has gained
Set JAVA PATH in Linux Environment. Edit.bashrc and add below 2 lines $vi.bashrc export JAVA_HOME=/usr/lib/jvm/java-7-oracle/
 Download the Hadoop tar. Download the Java from Oracle - Unpack the Comparisons -- $tar -zxvf hadoop-2.6.0.tar.gz $tar -zxf jdk1.7.0_60.tar.gz Set JAVA PATH in Linux Environment. Edit.bashrc and add below
Download the Hadoop tar. Download the Java from Oracle - Unpack the Comparisons -- $tar -zxvf hadoop-2.6.0.tar.gz $tar -zxf jdk1.7.0_60.tar.gz Set JAVA PATH in Linux Environment. Edit.bashrc and add below
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.
 EDUREKA Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.0 Cluster edureka! 11/12/2013 A guide to Install and Configure
EDUREKA Apache Hadoop 2.0 Installation and Single Node Cluster Configuration on Ubuntu A guide to install and setup Single-Node Apache Hadoop 2.0 Cluster edureka! 11/12/2013 A guide to Install and Configure
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
MapReduce, Hadoop and Amazon AWS
 MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
Big Data Storage Options for Hadoop Sam Fineberg, HP Storage
 Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
From Relational to Hadoop Part 1: Introduction to Hadoop. Gwen Shapira, Cloudera and Danil Zburivsky, Pythian
 From Relational to Hadoop Part 1: Introduction to Hadoop Gwen Shapira, Cloudera and Danil Zburivsky, Pythian Tutorial Logistics 2 Got VM? 3 Grab a USB USB contains: Cloudera QuickStart VM Slides Exercises
From Relational to Hadoop Part 1: Introduction to Hadoop Gwen Shapira, Cloudera and Danil Zburivsky, Pythian Tutorial Logistics 2 Got VM? 3 Grab a USB USB contains: Cloudera QuickStart VM Slides Exercises
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200
 CCD-410, CCA-410 and CCB-400 and DS-200") Hadoop Learning Resources 1 Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200 Author: Hadoop Learning Resource Hadoop Training in Just $60/3000INR
Hadoop Learning Resources 1 Hadoop Certification (Developer, Administrator HBase & Data Science) CCD-410, CCA-410 and CCB-400 and DS-200 Author: Hadoop Learning Resource Hadoop Training in Just $60/3000INR
Reduction of Data at Namenode in HDFS using harballing Technique
 Reduction of Data at Namenode in HDFS using harballing Technique Vaibhav Gopal Korat, Kumar Swamy Pamu [email protected] [email protected] Abstract HDFS stands for the Hadoop Distributed File System.
Reduction of Data at Namenode in HDFS using harballing Technique Vaibhav Gopal Korat, Kumar Swamy Pamu [email protected] [email protected] Abstract HDFS stands for the Hadoop Distributed File System.
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
MAP/REDUCE DESIGN AND IMPLEMENTATION OF APRIORIALGORITHM FOR HANDLING VOLUMINOUS DATA-SETS
 MAP/REDUCE DESIGN AND IMPLEMENTATION OF APRIORIALGORITHM FOR HANDLING VOLUMINOUS DATA-SETS Anjan K Koundinya 1,Srinath N K 1,K A K Sharma 1, Kiran Kumar 1, Madhu M N 1 and Kiran U Shanbag 1 1 Department
MAP/REDUCE DESIGN AND IMPLEMENTATION OF APRIORIALGORITHM FOR HANDLING VOLUMINOUS DATA-SETS Anjan K Koundinya 1,Srinath N K 1,K A K Sharma 1, Kiran Kumar 1, Madhu M N 1 and Kiran U Shanbag 1 1 Department
International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Integration Of Virtualization With Hadoop Tools
 Integration Of Virtualization With Hadoop Tools Aparna Raj K [email protected] Kamaldeep Kaur [email protected] Uddipan Dutta [email protected] V Venkat Sandeep [email protected] Technical
Integration Of Virtualization With Hadoop Tools Aparna Raj K [email protected] Kamaldeep Kaur [email protected] Uddipan Dutta [email protected] V Venkat Sandeep [email protected] Technical
RDMA for Apache Hadoop 0.9.9 User Guide
 0.9.9 User Guide HIGH-PERFORMANCE BIG DATA TEAM http://hibd.cse.ohio-state.edu NETWORK-BASED COMPUTING LABORATORY DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING THE OHIO STATE UNIVERSITY Copyright (c)
0.9.9 User Guide HIGH-PERFORMANCE BIG DATA TEAM http://hibd.cse.ohio-state.edu NETWORK-BASED COMPUTING LABORATORY DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING THE OHIO STATE UNIVERSITY Copyright (c)
HPC (High-Performance the Computing) for Big Data on Cloud: Opportunities and Challenges
 for Big Data on Cloud: Opportunities and Challenges") HPC (High-Performance the Computing) for Big Data on Cloud: Opportunities and Challenges Mohamed Riduan Abid Abstract Big data and Cloud computing are emerging as new promising technologies, gaining noticeable
HPC (High-Performance the Computing) for Big Data on Cloud: Opportunities and Challenges Mohamed Riduan Abid Abstract Big data and Cloud computing are emerging as new promising technologies, gaining noticeable
Integrating SAP BusinessObjects with Hadoop. Using a multi-node Hadoop Cluster
 Integrating SAP BusinessObjects with Hadoop Using a multi-node Hadoop Cluster May 17, 2013 SAP BO HADOOP INTEGRATION Contents 1. Installing a Single Node Hadoop Server... 2 2. Configuring a Multi-Node
Integrating SAP BusinessObjects with Hadoop Using a multi-node Hadoop Cluster May 17, 2013 SAP BO HADOOP INTEGRATION Contents 1. Installing a Single Node Hadoop Server... 2 2. Configuring a Multi-Node
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
How to properly misuse Hadoop. Marcel Huntemann NERSC tutorial session 2/12/13
 How to properly misuse Hadoop Marcel Huntemann NERSC tutorial session 2/12/13 History Created by Doug Cutting (also creator of Apache Lucene). 2002 Origin in Apache Nutch (open source web search engine).
How to properly misuse Hadoop Marcel Huntemann NERSC tutorial session 2/12/13 History Created by Doug Cutting (also creator of Apache Lucene). 2002 Origin in Apache Nutch (open source web search engine).
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay
 Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay Dipojjwal Ray Sandeep Prasad 1 Introduction In installation manual we listed out the steps for hadoop-1.0.3 and hadoop-
Hadoop Tutorial Group 7 - Tools For Big Data Indian Institute of Technology Bombay Dipojjwal Ray Sandeep Prasad 1 Introduction In installation manual we listed out the steps for hadoop-1.0.3 and hadoop-
HADOOP MOCK TEST HADOOP MOCK TEST I
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the Cloud
 A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the Cloud Thuy D. Nguyen, Cynthia E. Irvine, Jean Khosalim Department of Computer Science Ground System Architectures Workshop
A Multilevel Secure MapReduce Framework for Cross-Domain Information Sharing in the Cloud Thuy D. Nguyen, Cynthia E. Irvine, Jean Khosalim Department of Computer Science Ground System Architectures Workshop
How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup)
") How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup) Author : Vignesh Prajapati Categories : Hadoop Date : February 22, 2015 Since you have reached on this blogpost of Setting up Multinode Hadoop
How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup) Author : Vignesh Prajapati Categories : Hadoop Date : February 22, 2015 Since you have reached on this blogpost of Setting up Multinode Hadoop
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Big Data Analysis using Hadoop components like Flume, MapReduce, Pig and Hive
 Big Data Analysis using Hadoop components like Flume, MapReduce, Pig and Hive E. Laxmi Lydia 1,Dr. M.Ben Swarup 2 1 Associate Professor, Department of Computer Science and Engineering, Vignan's Institute
Big Data Analysis using Hadoop components like Flume, MapReduce, Pig and Hive E. Laxmi Lydia 1,Dr. M.Ben Swarup 2 1 Associate Professor, Department of Computer Science and Engineering, Vignan's Institute
HSearch Installation
 To configure HSearch you need to install Hadoop, Hbase, Zookeeper, HSearch and Tomcat. 1. Add the machines ip address in the /etc/hosts to access all the servers using name as shown below. 2. Allow all
To configure HSearch you need to install Hadoop, Hbase, Zookeeper, HSearch and Tomcat. 1. Add the machines ip address in the /etc/hosts to access all the servers using name as shown below. 2. Allow all
http://www.paper.edu.cn
 5 10 15 20 25 30 35 A platform for massive railway information data storage # SHAN Xu 1, WANG Genying 1, LIU Lin 2** (1. Key Laboratory of Communication and Information Systems, Beijing Municipal Commission
5 10 15 20 25 30 35 A platform for massive railway information data storage # SHAN Xu 1, WANG Genying 1, LIU Lin 2** (1. Key Laboratory of Communication and Information Systems, Beijing Municipal Commission
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
The objective of this lab is to learn how to set up an environment for running distributed Hadoop applications.
 Lab 9: Hadoop Development The objective of this lab is to learn how to set up an environment for running distributed Hadoop applications. Introduction Hadoop can be run in one of three modes: Standalone
Lab 9: Hadoop Development The objective of this lab is to learn how to set up an environment for running distributed Hadoop applications. Introduction Hadoop can be run in one of three modes: Standalone
Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud
 Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud Aditya Jadhav, Mahesh Kukreja E-mail: [email protected] & [email protected] Abstract : In the information industry,
Parallel Data Mining and Assurance Service Model Using Hadoop in Cloud Aditya Jadhav, Mahesh Kukreja E-mail: [email protected] & [email protected] Abstract : In the information industry,
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath