MapGraph. A High Level API for Fast Development of High Performance Graphic Analytics on GPUs.
|
|
|
- Linette Sherman
- 10 years ago
- Views:
Transcription
1 MapGraph A High Level API for Fast Development of High Performance Graphic Analytics on GPUs Zhisong Fu, Michael Personick and Bryan Thompson SYSTAP, LLC

2 Outline Motivations MapGraph overview Results Summary

3 Million Traversed Edges per Second GPUs A Game Changer for Graph Analytics? Graphs are everywhere in data, also getting bigger and bigger GPUs may be the technology that finally delivers real-time analytics on large graphs 10x flops over CPU 10x memory bandwidth This is a hard problem Irregular memory access Load imbalance Significant speed up over CPU on BFS [Merrill2013] Over 10x speedup over CPU Average Traversal Depth NVIDIA Tesla C2050 Multicore per socket Sequential

4 Low-level VS. High-level Low-level approach BFS: [Merrill2013] PageRank: [Duong2012] SSSP: [Davidson2014] High-level approach GraphLab [Low2012] Medusa [Zhong2013] Totem [Gharaibeh2013] Pros: High performance Cons: Difficulty to develop Reinvent the wheels Pros: High programmability Cons: Low Performance
![[Davidson2014] High-level approach GraphLab [Low2012] Medusa [Zhong2013]](/docs-images/42/2885213/images/page_4.jpg "Totem [Gharaibeh2013] Pros: High performance Cons: Difficulty to develop")
5 MapGraph High-level graph processing framework High programmability: only C++ sequential GPU architecture Optimization techniques CUDA, OpenCL High performance Comparable to low-level approach

6 GAS Abstraction Gather

7 GAS Abstraction Gather Apply
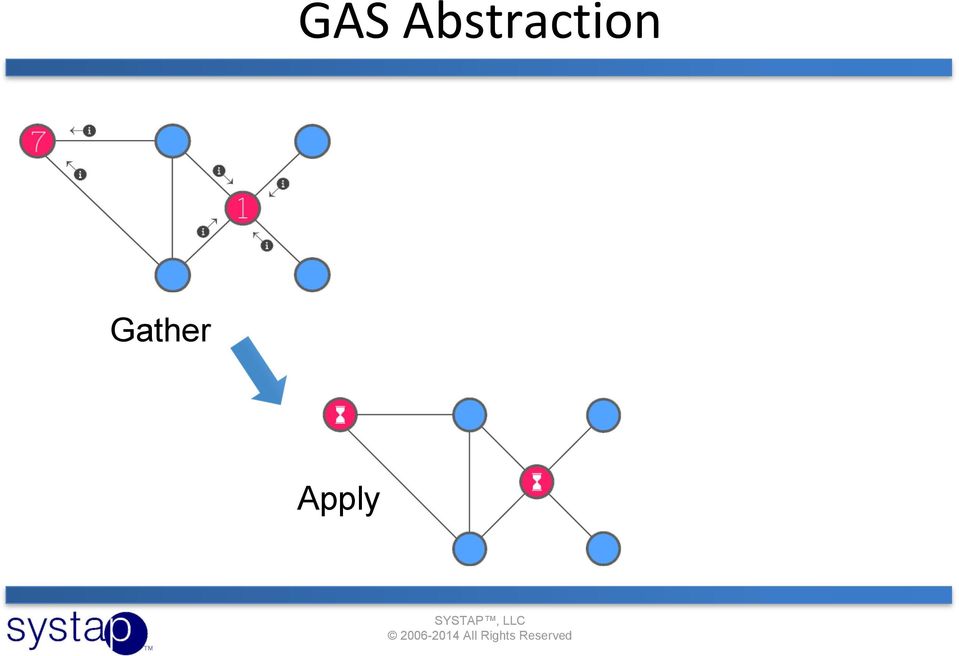
8 GAS Abstraction Gather Scatter = Expand + Contract Apply

9 GAS Abstraction Frontier size > 0 Gather Scatter = Expand + Contract Apply


10 MapGraph Runtime Pipeline

11 MTEPS Experiment Datasets Dataset #vertices #edges Max Degree MTEPS (BFS) Webbase 1,000,005 3,105, Delaunay 2,097,152 6,291,408 4, Bitcoin 6,297,539 28,143,065 4,075, Wiki 3,566,907 45,030,389 7, Kron 1,048,576 89,239, ,505 1,871 2,000 1,800 1,600 1,400 1,200 1, Webbase Delaunay Bitcoin Wiki Kron

12 Speedup Results: Compare to Other GPU implementations MapGraph Speedups vs Other GPU Implementations Medusa B40c Webbase Delaunay Bitcoin Wiki Kron 12

13 Speedup BFS Results: Compare to GraphLab 1, MapGraph Speedup vs GraphLab (BFS) GL-2 GL-4 GL-8 GL-12 MPG Webbase Delaunay Bitcoin Wiki Kron 13

14 Speedup PageRank Results: Compare to GraphLab MapGraph Speedup vs GraphLab (PR) GL-2 GL-4 GL-8 GL-12 MPG 0.10 Webbase Delaunay Bitcoin Wiki Kron

15 MapGraph API Gather gatheroveredges gather_edge gather_sum gather_vertex Scatter = Expand + Contract expandoveredges Expand expand_vertex expand_edge Contract contract Apply apply

16 Example: PageRank Implementation Gather, Apply, Scatter phases User Data VertexType Gather Apply Expand gatheroveredges gather_edge gather_sum apply expandoveredges expand_vertex expand_edge float* d_ranks; int* d_num_out_edge; return GATHER_IN_EDGES; float nb_rank = d_dists[neighbor_id]; new_rank = nb_rank / d_num_out_edge[neighbor_id]; return left + right; float old_value = d_ranks[vertex_id]; float new_value = 0.15f + (1.0f f) * gathervalue; changed = fabs(old_value new_value) >= 0.01f; d_dists[vertex_id] = new_value; return EXPAND_OUT_EDGES; return changed; frontier = neighbor_id;
![= nb_rank / d_num_out_edge[neighbor_id]; return left + right; float old_value = d_ranks[vertex_id]; float new_value = 0.15f + (1.0f - 0.](/docs-images/42/2885213/images/page_16.jpg "15f) * gathervalue; changed = fabs(old_value new_value) >= 0.")
17 Source vertex ids in-edges Future Work GPU cluster: 2D partitioning (aka vertex cuts) In collaboration with SCI Institute of the University of Utah Compute grid defined over virtual nodes. Patches assigned to virtual nodes based on source and target identifier of the edge. Topology, message and data compression target vertex ids out-edges

18 Summary MapGraph: high-level graph processing framework High programmability: GAS abstraction Simple and flexible API High performance: Hybrid scheduling strategy Structure Of Arrays

19 Acknowledgement This work was (partially) funded by the DARPA XDATA program under AFRL Contract #FA C This work is also supported by the DARPA under Contract No. D14PC Many thanks to Dr. Christopher White for the support.

Frog: Asynchronous Graph Processing on GPU with Hybrid Coloring Model
 X. SHI ET AL. 1 Frog: Asynchronous Graph Processing on GPU with Hybrid Coloring Model Xuanhua Shi 1, Xuan Luo 1, Junling Liang 1, Peng Zhao 1, Sheng Di 2, Bingsheng He 3, and Hai Jin 1 1 Services Computing
X. SHI ET AL. 1 Frog: Asynchronous Graph Processing on GPU with Hybrid Coloring Model Xuanhua Shi 1, Xuan Luo 1, Junling Liang 1, Peng Zhao 1, Sheng Di 2, Bingsheng He 3, and Hai Jin 1 1 Services Computing
HIGH PERFORMANCE BIG DATA ANALYTICS
 HIGH PERFORMANCE BIG DATA ANALYTICS Kunle Olukotun Electrical Engineering and Computer Science Stanford University June 2, 2014 Explosion of Data Sources Sensors DoD is swimming in sensors and drowning
HIGH PERFORMANCE BIG DATA ANALYTICS Kunle Olukotun Electrical Engineering and Computer Science Stanford University June 2, 2014 Explosion of Data Sources Sensors DoD is swimming in sensors and drowning
Fast Iterative Graph Computation with Resource Aware Graph Parallel Abstraction
 Human connectome. Gerhard et al., Frontiers in Neuroinformatics 5(3), 2011 2 NA = 6.022 1023 mol 1 Paul Burkhardt, Chris Waring An NSA Big Graph experiment Fast Iterative Graph Computation with Resource
Human connectome. Gerhard et al., Frontiers in Neuroinformatics 5(3), 2011 2 NA = 6.022 1023 mol 1 Paul Burkhardt, Chris Waring An NSA Big Graph experiment Fast Iterative Graph Computation with Resource
Programming models for heterogeneous computing. Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga
 Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Graphics Cards and Graphics Processing Units. Ben Johnstone Russ Martin November 15, 2011
 Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Parallel Computing: Strategies and Implications. Dori Exterman CTO IncrediBuild.
 Parallel Computing: Strategies and Implications Dori Exterman CTO IncrediBuild. In this session we will discuss Multi-threaded vs. Multi-Process Choosing between Multi-Core or Multi- Threaded development
Parallel Computing: Strategies and Implications Dori Exterman CTO IncrediBuild. In this session we will discuss Multi-threaded vs. Multi-Process Choosing between Multi-Core or Multi- Threaded development
LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR
 LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR Frédéric Kuznik, frederic.kuznik@insa lyon.fr 1 Framework Introduction Hardware architecture CUDA overview Implementation details A simple case:
LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR Frédéric Kuznik, frederic.kuznik@insa lyon.fr 1 Framework Introduction Hardware architecture CUDA overview Implementation details A simple case:
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Green-Marl: A DSL for Easy and Efficient Graph Analysis
 Green-Marl: A DSL for Easy and Efficient Graph Analysis Sungpack Hong*, Hassan Chafi* +, Eric Sedlar +, and Kunle Olukotun* *Pervasive Parallelism Lab, Stanford University + Oracle Labs Graph Analysis
Green-Marl: A DSL for Easy and Efficient Graph Analysis Sungpack Hong*, Hassan Chafi* +, Eric Sedlar +, and Kunle Olukotun* *Pervasive Parallelism Lab, Stanford University + Oracle Labs Graph Analysis
Software tools for Complex Networks Analysis. Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team
 Team") Software tools for Complex Networks Analysis Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team MOTIVATION Why do we need tools? Source : nature.com Visualization Properties extraction
Software tools for Complex Networks Analysis Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team MOTIVATION Why do we need tools? Source : nature.com Visualization Properties extraction
Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries
 Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries Shin Morishima 1 and Hiroki Matsutani 1,2,3 1Keio University, 3 14 1 Hiyoshi, Kohoku ku, Yokohama, Japan 2National Institute
Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries Shin Morishima 1 and Hiroki Matsutani 1,2,3 1Keio University, 3 14 1 Hiyoshi, Kohoku ku, Yokohama, Japan 2National Institute
NVIDIA Tools For Profiling And Monitoring. David Goodwin
 NVIDIA Tools For Profiling And Monitoring David Goodwin Outline CUDA Profiling and Monitoring Libraries Tools Technologies Directions CScADS Summer 2012 Workshop on Performance Tools for Extreme Scale
NVIDIA Tools For Profiling And Monitoring David Goodwin Outline CUDA Profiling and Monitoring Libraries Tools Technologies Directions CScADS Summer 2012 Workshop on Performance Tools for Extreme Scale
NVIDIA CUDA Software and GPU Parallel Computing Architecture. David B. Kirk, Chief Scientist
 NVIDIA CUDA Software and GPU Parallel Computing Architecture David B. Kirk, Chief Scientist Outline Applications of GPU Computing CUDA Programming Model Overview Programming in CUDA The Basics How to Get
NVIDIA CUDA Software and GPU Parallel Computing Architecture David B. Kirk, Chief Scientist Outline Applications of GPU Computing CUDA Programming Model Overview Programming in CUDA The Basics How to Get
Computer Graphics Hardware An Overview
 Computer Graphics Hardware An Overview Graphics System Monitor Input devices CPU/Memory GPU Raster Graphics System Raster: An array of picture elements Based on raster-scan TV technology The screen (and
Computer Graphics Hardware An Overview Graphics System Monitor Input devices CPU/Memory GPU Raster Graphics System Raster: An array of picture elements Based on raster-scan TV technology The screen (and
Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing
 /35 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
/35 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC
 OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
GPGPU Computing. Yong Cao
 GPGPU Computing Yong Cao Why Graphics Card? It s powerful! A quiet trend Copyright 2009 by Yong Cao Why Graphics Card? It s powerful! Processor Processing Units FLOPs per Unit Clock Speed Processing Power
GPGPU Computing Yong Cao Why Graphics Card? It s powerful! A quiet trend Copyright 2009 by Yong Cao Why Graphics Card? It s powerful! Processor Processing Units FLOPs per Unit Clock Speed Processing Power
Efficient Parallel Graph Exploration on Multi-Core CPU and GPU
 Efficient Parallel Graph Exploration on Multi-Core CPU and GPU Pervasive Parallelism Laboratory Stanford University Sungpack Hong, Tayo Oguntebi, and Kunle Olukotun Graph and its Applications Graph Fundamental
Efficient Parallel Graph Exploration on Multi-Core CPU and GPU Pervasive Parallelism Laboratory Stanford University Sungpack Hong, Tayo Oguntebi, and Kunle Olukotun Graph and its Applications Graph Fundamental
The Evolution of Computer Graphics. SVP, Content & Technology, NVIDIA
 The Evolution of Computer Graphics Tony Tamasi SVP, Content & Technology, NVIDIA Graphics Make great images intricate shapes complex optical effects seamless motion Make them fast invent clever techniques
The Evolution of Computer Graphics Tony Tamasi SVP, Content & Technology, NVIDIA Graphics Make great images intricate shapes complex optical effects seamless motion Make them fast invent clever techniques
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
L20: GPU Architecture and Models
 L20: GPU Architecture and Models scribe(s): Abdul Khalifa 20.1 Overview GPUs (Graphics Processing Units) are large parallel structure of processing cores capable of rendering graphics efficiently on displays.
L20: GPU Architecture and Models scribe(s): Abdul Khalifa 20.1 Overview GPUs (Graphics Processing Units) are large parallel structure of processing cores capable of rendering graphics efficiently on displays.
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs
 Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
Optimizing GPU-based application performance for the HP for the HP ProLiant SL390s G7 server
 Optimizing GPU-based application performance for the HP for the HP ProLiant SL390s G7 server Technology brief Introduction... 2 GPU-based computing... 2 ProLiant SL390s GPU-enabled architecture... 2 Optimizing
Optimizing GPU-based application performance for the HP for the HP ProLiant SL390s G7 server Technology brief Introduction... 2 GPU-based computing... 2 ProLiant SL390s GPU-enabled architecture... 2 Optimizing
Introducing PgOpenCL A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child
 Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
World s fastest database and big data analytics platform
 World s fastest database and big data analytics platform www.map-d.com @datarefined 33 Concord Ave, Suite 6, Cambridge, MA 238 Todd Mostak Tom Graham Ι Ι [email protected] [email protected] Ι Ι + 67 83 76 + 67
World s fastest database and big data analytics platform www.map-d.com @datarefined 33 Concord Ave, Suite 6, Cambridge, MA 238 Todd Mostak Tom Graham Ι Ι [email protected] [email protected] Ι Ι + 67 83 76 + 67
A general-purpose virtualization service for HPC on cloud computing: an application to GPUs
 A general-purpose virtualization service for HPC on cloud computing: an application to GPUs R.Montella, G.Coviello, G.Giunta* G. Laccetti #, F. Isaila, J. Garcia Blas *Department of Applied Science University
A general-purpose virtualization service for HPC on cloud computing: an application to GPUs R.Montella, G.Coviello, G.Giunta* G. Laccetti #, F. Isaila, J. Garcia Blas *Department of Applied Science University
NVIDIA GRID OVERVIEW SERVER POWERED BY NVIDIA GRID. WHY GPUs FOR VIRTUAL DESKTOPS AND APPLICATIONS? WHAT IS A VIRTUAL DESKTOP?
 NVIDIA GRID OVERVIEW Imagine if responsive Windows and rich multimedia experiences were available via virtual desktop infrastructure, even those with intensive graphics needs. NVIDIA makes this possible
NVIDIA GRID OVERVIEW Imagine if responsive Windows and rich multimedia experiences were available via virtual desktop infrastructure, even those with intensive graphics needs. NVIDIA makes this possible
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville CS 594 Lecture Notes March 4, 2015 1/18 Outline! Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville CS 594 Lecture Notes March 4, 2015 1/18 Outline! Introduction - Hardware
MapReduce and Distributed Data Analysis. Sergei Vassilvitskii Google Research
 MapReduce and Distributed Data Analysis Google Research 1 Dealing With Massive Data 2 2 Dealing With Massive Data Polynomial Memory Sublinear RAM Sketches External Memory Property Testing 3 3 Dealing With
MapReduce and Distributed Data Analysis Google Research 1 Dealing With Massive Data 2 2 Dealing With Massive Data Polynomial Memory Sublinear RAM Sketches External Memory Property Testing 3 3 Dealing With
Introduction to GP-GPUs. Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1
 Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Enhancing Cloud-based Servers by GPU/CPU Virtualization Management
 Enhancing Cloud-based Servers by GPU/CPU Virtualiz Management Tin-Yu Wu 1, Wei-Tsong Lee 2, Chien-Yu Duan 2 Department of Computer Science and Inform Engineering, Nal Ilan University, Taiwan, ROC 1 Department
Enhancing Cloud-based Servers by GPU/CPU Virtualiz Management Tin-Yu Wu 1, Wei-Tsong Lee 2, Chien-Yu Duan 2 Department of Computer Science and Inform Engineering, Nal Ilan University, Taiwan, ROC 1 Department
Chapter 2 Parallel Architecture, Software And Performance
 Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Big Graph Processing: Some Background
 Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS
 AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS") A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 [email protected] THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 [email protected] THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
Real-Time Realistic Rendering. Michael Doggett Docent Department of Computer Science Lund university
 Real-Time Realistic Rendering Michael Doggett Docent Department of Computer Science Lund university 30-5-2011 Visually realistic goal force[d] us to completely rethink the entire rendering process. Cook
Real-Time Realistic Rendering Michael Doggett Docent Department of Computer Science Lund university 30-5-2011 Visually realistic goal force[d] us to completely rethink the entire rendering process. Cook
Parallel Computing. Benson Muite. [email protected] http://math.ut.ee/ benson. https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage
 Parallel Computing Benson Muite [email protected] http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
Parallel Computing Benson Muite [email protected] http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
GPU Parallel Computing Architecture and CUDA Programming Model
 GPU Parallel Computing Architecture and CUDA Programming Model John Nickolls Outline Why GPU Computing? GPU Computing Architecture Multithreading and Arrays Data Parallel Problem Decomposition Parallel
GPU Parallel Computing Architecture and CUDA Programming Model John Nickolls Outline Why GPU Computing? GPU Computing Architecture Multithreading and Arrays Data Parallel Problem Decomposition Parallel
Parallel Firewalls on General-Purpose Graphics Processing Units
 Parallel Firewalls on General-Purpose Graphics Processing Units Manoj Singh Gaur and Vijay Laxmi Kamal Chandra Reddy, Ankit Tharwani, Ch.Vamshi Krishna, Lakshminarayanan.V Department of Computer Engineering
Parallel Firewalls on General-Purpose Graphics Processing Units Manoj Singh Gaur and Vijay Laxmi Kamal Chandra Reddy, Ankit Tharwani, Ch.Vamshi Krishna, Lakshminarayanan.V Department of Computer Engineering
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles [email protected] hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles [email protected] hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Le langage OCaml et la programmation des GPU
 Le langage OCaml et la programmation des GPU GPU programming with OCaml Mathias Bourgoin - Emmanuel Chailloux - Jean-Luc Lamotte Le projet OpenGPU : un an plus tard Ecole Polytechnique - 8 juin 2011 Outline
Le langage OCaml et la programmation des GPU GPU programming with OCaml Mathias Bourgoin - Emmanuel Chailloux - Jean-Luc Lamotte Le projet OpenGPU : un an plus tard Ecole Polytechnique - 8 juin 2011 Outline
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK
 HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
HPC Wales Skills Academy Course Catalogue 2015
 HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
Cluster Monitoring and Management Tools RAJAT PHULL, NVIDIA SOFTWARE ENGINEER ROB TODD, NVIDIA SOFTWARE ENGINEER
 Cluster Monitoring and Management Tools RAJAT PHULL, NVIDIA SOFTWARE ENGINEER ROB TODD, NVIDIA SOFTWARE ENGINEER MANAGE GPUS IN THE CLUSTER Administrators, End users Middleware Engineers Monitoring/Management
Cluster Monitoring and Management Tools RAJAT PHULL, NVIDIA SOFTWARE ENGINEER ROB TODD, NVIDIA SOFTWARE ENGINEER MANAGE GPUS IN THE CLUSTER Administrators, End users Middleware Engineers Monitoring/Management
CUDA in the Cloud Enabling HPC Workloads in OpenStack With special thanks to Andrew Younge (Indiana Univ.) and Massimo Bernaschi (IAC-CNR)
 and Massimo Bernaschi (IAC-CNR)") CUDA in the Cloud Enabling HPC Workloads in OpenStack John Paul Walters Computer Scien5st, USC Informa5on Sciences Ins5tute [email protected] With special thanks to Andrew Younge (Indiana Univ.) and Massimo
CUDA in the Cloud Enabling HPC Workloads in OpenStack John Paul Walters Computer Scien5st, USC Informa5on Sciences Ins5tute [email protected] With special thanks to Andrew Younge (Indiana Univ.) and Massimo
InfiniteGraph: The Distributed Graph Database
 A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
An Introduction to Parallel Computing/ Programming
 An Introduction to Parallel Computing/ Programming Vicky Papadopoulou Lesta Astrophysics and High Performance Computing Research Group (http://ahpc.euc.ac.cy) Dep. of Computer Science and Engineering European
An Introduction to Parallel Computing/ Programming Vicky Papadopoulou Lesta Astrophysics and High Performance Computing Research Group (http://ahpc.euc.ac.cy) Dep. of Computer Science and Engineering European
Introduction GPU Hardware GPU Computing Today GPU Computing Example Outlook Summary. GPU Computing. Numerical Simulation - from Models to Software
 GPU Computing Numerical Simulation - from Models to Software Andreas Barthels JASS 2009, Course 2, St. Petersburg, Russia Prof. Dr. Sergey Y. Slavyanov St. Petersburg State University Prof. Dr. Thomas
GPU Computing Numerical Simulation - from Models to Software Andreas Barthels JASS 2009, Course 2, St. Petersburg, Russia Prof. Dr. Sergey Y. Slavyanov St. Petersburg State University Prof. Dr. Thomas
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
Optimizing AAA Games for Mobile Platforms
 Optimizing AAA Games for Mobile Platforms Niklas Smedberg Senior Engine Programmer, Epic Games Who Am I A.k.a. Smedis Epic Games, Unreal Engine 15 years in the industry 30 years of programming C64 demo
Optimizing AAA Games for Mobile Platforms Niklas Smedberg Senior Engine Programmer, Epic Games Who Am I A.k.a. Smedis Epic Games, Unreal Engine 15 years in the industry 30 years of programming C64 demo
15-418 Final Project Report. Trading Platform Server
 15-418 Final Project Report Yinghao Wang [email protected] May 8, 214 Trading Platform Server Executive Summary The final project will implement a trading platform server that provides back-end support
15-418 Final Project Report Yinghao Wang [email protected] May 8, 214 Trading Platform Server Executive Summary The final project will implement a trading platform server that provides back-end support
Big Data Systems CS 5965/6965 FALL 2015
 Big Data Systems CS 5965/6965 FALL 2015 Today General course overview Expectations from this course Q&A Introduction to Big Data Assignment #1 General Course Information Course Web Page http://www.cs.utah.edu/~hari/teaching/fall2015.html
Big Data Systems CS 5965/6965 FALL 2015 Today General course overview Expectations from this course Q&A Introduction to Big Data Assignment #1 General Course Information Course Web Page http://www.cs.utah.edu/~hari/teaching/fall2015.html
Turbomachinery CFD on many-core platforms experiences and strategies
 Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
Applications to Computational Financial and GPU Computing. May 16th. Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61
 F# Applications to Computational Financial and GPU Computing May 16th Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61 Today! Why care about F#? Just another fashion?! Three success stories! How Alea.cuBase
F# Applications to Computational Financial and GPU Computing May 16th Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61 Today! Why care about F#? Just another fashion?! Three success stories! How Alea.cuBase
E6895 Advanced Big Data Analytics Lecture 14:! NVIDIA GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
Image Analytics on Big Data In Motion Implementation of Image Analytics CCL in Apache Kafka and Storm
 Image Analytics on Big Data In Motion Implementation of Image Analytics CCL in Apache Kafka and Storm Lokesh Babu Rao 1 C. Elayaraja 2 1PG Student, Dept. of ECE, Dhaanish Ahmed College of Engineering,
Image Analytics on Big Data In Motion Implementation of Image Analytics CCL in Apache Kafka and Storm Lokesh Babu Rao 1 C. Elayaraja 2 1PG Student, Dept. of ECE, Dhaanish Ahmed College of Engineering,
Petascale Visualization: Approaches and Initial Results
 Petascale Visualization: Approaches and Initial Results James Ahrens Li-Ta Lo, Boonthanome Nouanesengsy, John Patchett, Allen McPherson Los Alamos National Laboratory LA-UR- 08-07337 Operated by Los Alamos
Petascale Visualization: Approaches and Initial Results James Ahrens Li-Ta Lo, Boonthanome Nouanesengsy, John Patchett, Allen McPherson Los Alamos National Laboratory LA-UR- 08-07337 Operated by Los Alamos
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany MapReduce II MapReduce II 1 / 33 Outline 1. Introduction
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany MapReduce II MapReduce II 1 / 33 Outline 1. Introduction
Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) [email protected] http://www.mzahran.com
 mzahran@cs.nyu.edu http://www.mzahran.com") CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) [email protected] http://www.mzahran.com Modern GPU
CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) [email protected] http://www.mzahran.com Modern GPU
Jean-Pierre Panziera Teratec 2011
 Technologies for the future HPC systems Jean-Pierre Panziera Teratec 2011 3 petaflop systems : TERA 100, CURIE & IFERC Tera100 Curie IFERC 1.25 PetaFlops 256 TB ory 30 PB disk storage 140 000+ Xeon cores
Technologies for the future HPC systems Jean-Pierre Panziera Teratec 2011 3 petaflop systems : TERA 100, CURIE & IFERC Tera100 Curie IFERC 1.25 PetaFlops 256 TB ory 30 PB disk storage 140 000+ Xeon cores
Embedded Systems: map to FPGA, GPU, CPU?
 Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven [email protected] Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven [email protected] Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
A1 and FARM scalable graph database on top of a transactional memory layer
 A1 and FARM scalable graph database on top of a transactional memory layer Miguel Castro, Aleksandar Dragojević, Dushyanth Narayanan, Ed Nightingale, Alex Shamis Richie Khanna, Matt Renzelmann Chiranjeeb
A1 and FARM scalable graph database on top of a transactional memory layer Miguel Castro, Aleksandar Dragojević, Dushyanth Narayanan, Ed Nightingale, Alex Shamis Richie Khanna, Matt Renzelmann Chiranjeeb
Big Data Mining Services and Knowledge Discovery Applications on Clouds
 Big Data Mining Services and Knowledge Discovery Applications on Clouds Domenico Talia DIMES, Università della Calabria & DtoK Lab Italy [email protected] Data Availability or Data Deluge? Some decades
Big Data Mining Services and Knowledge Discovery Applications on Clouds Domenico Talia DIMES, Università della Calabria & DtoK Lab Italy [email protected] Data Availability or Data Deluge? Some decades
Writing Applications for the GPU Using the RapidMind Development Platform
 Writing Applications for the GPU Using the RapidMind Development Platform Contents Introduction... 1 Graphics Processing Units... 1 RapidMind Development Platform... 2 Writing RapidMind Enabled Applications...
Writing Applications for the GPU Using the RapidMind Development Platform Contents Introduction... 1 Graphics Processing Units... 1 RapidMind Development Platform... 2 Writing RapidMind Enabled Applications...
High Performance Cloud: a MapReduce and GPGPU Based Hybrid Approach
 High Performance Cloud: a MapReduce and GPGPU Based Hybrid Approach Beniamino Di Martino, Antonio Esposito and Andrea Barbato Department of Industrial and Information Engineering Second University of Naples
High Performance Cloud: a MapReduce and GPGPU Based Hybrid Approach Beniamino Di Martino, Antonio Esposito and Andrea Barbato Department of Industrial and Information Engineering Second University of Naples
CSE 564: Visualization. GPU Programming (First Steps) GPU Generations. Klaus Mueller. Computer Science Department Stony Brook University
 GPU Generations. Klaus Mueller. Computer Science Department Stony Brook University") GPU Generations CSE 564: Visualization GPU Programming (First Steps) Klaus Mueller Computer Science Department Stony Brook University For the labs, 4th generation is desirable Graphics Hardware Pipeline
GPU Generations CSE 564: Visualization GPU Programming (First Steps) Klaus Mueller Computer Science Department Stony Brook University For the labs, 4th generation is desirable Graphics Hardware Pipeline
LARGE-SCALE GRAPH PROCESSING IN THE BIG DATA WORLD. Dr. Buğra Gedik, Ph.D.
 LARGE-SCALE GRAPH PROCESSING IN THE BIG DATA WORLD Dr. Buğra Gedik, Ph.D. MOTIVATION Graph data is everywhere Relationships between people, systems, and the nature Interactions between people, systems,
LARGE-SCALE GRAPH PROCESSING IN THE BIG DATA WORLD Dr. Buğra Gedik, Ph.D. MOTIVATION Graph data is everywhere Relationships between people, systems, and the nature Interactions between people, systems,
ACCELERATING SELECT WHERE AND SELECT JOIN QUERIES ON A GPU
 Computer Science 14 (2) 2013 http://dx.doi.org/10.7494/csci.2013.14.2.243 Marcin Pietroń Pawe l Russek Kazimierz Wiatr ACCELERATING SELECT WHERE AND SELECT JOIN QUERIES ON A GPU Abstract This paper presents
Computer Science 14 (2) 2013 http://dx.doi.org/10.7494/csci.2013.14.2.243 Marcin Pietroń Pawe l Russek Kazimierz Wiatr ACCELERATING SELECT WHERE AND SELECT JOIN QUERIES ON A GPU Abstract This paper presents
Hardware design for ray tracing
 Hardware design for ray tracing Jae-sung Yoon Introduction Realtime ray tracing performance has recently been achieved even on single CPU. [Wald et al. 2001, 2002, 2004] However, higher resolutions, complex
Hardware design for ray tracing Jae-sung Yoon Introduction Realtime ray tracing performance has recently been achieved even on single CPU. [Wald et al. 2001, 2002, 2004] However, higher resolutions, complex
Verteilte Systeme - Overview
 - Overview Prof. Dr.-Ing. Torben Weis Building BC, 4 th Floor, Room 407 http://www.vs.uni-due.de Scientific Staff Christopher Boelmann Sebastian Schuster Matthäus Wander Working Areas Networked systems
- Overview Prof. Dr.-Ing. Torben Weis Building BC, 4 th Floor, Room 407 http://www.vs.uni-due.de Scientific Staff Christopher Boelmann Sebastian Schuster Matthäus Wander Working Areas Networked systems
OpenACC 2.0 and the PGI Accelerator Compilers
 OpenACC 2.0 and the PGI Accelerator Compilers Michael Wolfe The Portland Group [email protected] This presentation discusses the additions made to the OpenACC API in Version 2.0. I will also present
OpenACC 2.0 and the PGI Accelerator Compilers Michael Wolfe The Portland Group [email protected] This presentation discusses the additions made to the OpenACC API in Version 2.0. I will also present
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU
 Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Accelerating Intensity Layer Based Pencil Filter Algorithm using CUDA
 Accelerating Intensity Layer Based Pencil Filter Algorithm using CUDA Dissertation submitted in partial fulfillment of the requirements for the degree of Master of Technology, Computer Engineering by Amol
Accelerating Intensity Layer Based Pencil Filter Algorithm using CUDA Dissertation submitted in partial fulfillment of the requirements for the degree of Master of Technology, Computer Engineering by Amol
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o [email protected]
 Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o [email protected] Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o [email protected] Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
High Performance CUDA Accelerated Local Optimization in Traveling Salesman Problem
 High Performance CUDA Accelerated Local Optimization in Traveling Salesman Problem Kamil Rocki, PhD Department of Computer Science Graduate School of Information Science and Technology The University of
High Performance CUDA Accelerated Local Optimization in Traveling Salesman Problem Kamil Rocki, PhD Department of Computer Science Graduate School of Information Science and Technology The University of
www.xenon.com.au STORAGE HIGH SPEED INTERCONNECTS HIGH PERFORMANCE COMPUTING VISUALISATION GPU COMPUTING
 www.xenon.com.au STORAGE HIGH SPEED INTERCONNECTS HIGH PERFORMANCE COMPUTING GPU COMPUTING VISUALISATION XENON Accelerating Exploration Mineral, oil and gas exploration is an expensive and challenging
www.xenon.com.au STORAGE HIGH SPEED INTERCONNECTS HIGH PERFORMANCE COMPUTING GPU COMPUTING VISUALISATION XENON Accelerating Exploration Mineral, oil and gas exploration is an expensive and challenging
NVIDIA VIDEO ENCODER 5.0
 NVIDIA VIDEO ENCODER 5.0 NVENC_DA-06209-001_v06 November 2014 Application Note NVENC - NVIDIA Hardware Video Encoder 5.0 NVENC_DA-06209-001_v06 i DOCUMENT CHANGE HISTORY NVENC_DA-06209-001_v06 Version
NVIDIA VIDEO ENCODER 5.0 NVENC_DA-06209-001_v06 November 2014 Application Note NVENC - NVIDIA Hardware Video Encoder 5.0 NVENC_DA-06209-001_v06 i DOCUMENT CHANGE HISTORY NVENC_DA-06209-001_v06 Version
Coping with Complexity: CPUs, GPUs and Real-world Applications
 Coping with Complexity: CPUs, GPUs and Real-world Applications Leonel Sousa, Frederico Pratas, Svetislav Momcilovic and Aleksandar Ilic 9 th Scheduling for Large Scale Systems Workshop Lyon, France July
Coping with Complexity: CPUs, GPUs and Real-world Applications Leonel Sousa, Frederico Pratas, Svetislav Momcilovic and Aleksandar Ilic 9 th Scheduling for Large Scale Systems Workshop Lyon, France July
Presto/Blockus: Towards Scalable R Data Analysis
 /Blockus: Towards Scalable R Data Analysis Andrew A. Chien University of Chicago and Argonne ational Laboratory IRIA-UIUC-AL Joint Institute Potential Collaboration ovember 19, 2012 ovember 19, 2012 Andrew
/Blockus: Towards Scalable R Data Analysis Andrew A. Chien University of Chicago and Argonne ational Laboratory IRIA-UIUC-AL Joint Institute Potential Collaboration ovember 19, 2012 ovember 19, 2012 Andrew
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics
 Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
 WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data
 Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles [email protected] Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles [email protected] Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
A survey on platforms for big data analytics
 Singh and Reddy Journal of Big Data 2014, 1:8 SURVEY PAPER Open Access A survey on platforms for big data analytics Dilpreet Singh and Chandan K Reddy * * Correspondence: [email protected] Department
Singh and Reddy Journal of Big Data 2014, 1:8 SURVEY PAPER Open Access A survey on platforms for big data analytics Dilpreet Singh and Chandan K Reddy * * Correspondence: [email protected] Department
GPU for Scientific Computing. -Ali Saleh
 1 GPU for Scientific Computing -Ali Saleh Contents Introduction What is GPU GPU for Scientific Computing K-Means Clustering K-nearest Neighbours When to use GPU and when not Commercial Programming GPU
1 GPU for Scientific Computing -Ali Saleh Contents Introduction What is GPU GPU for Scientific Computing K-Means Clustering K-nearest Neighbours When to use GPU and when not Commercial Programming GPU
GPU Architectures. A CPU Perspective. Data Parallelism: What is it, and how to exploit it? Workload characteristics
 GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
GPU Programming in Computer Vision
 Computer Vision Group Prof. Daniel Cremers GPU Programming in Computer Vision Preliminary Meeting Thomas Möllenhoff, Robert Maier, Caner Hazirbas What you will learn in the practical course Introduction
Computer Vision Group Prof. Daniel Cremers GPU Programming in Computer Vision Preliminary Meeting Thomas Möllenhoff, Robert Maier, Caner Hazirbas What you will learn in the practical course Introduction
Retargeting PLAPACK to Clusters with Hardware Accelerators
 Retargeting PLAPACK to Clusters with Hardware Accelerators Manuel Fogué 1 Francisco Igual 1 Enrique S. Quintana-Ortí 1 Robert van de Geijn 2 1 Departamento de Ingeniería y Ciencia de los Computadores.
Retargeting PLAPACK to Clusters with Hardware Accelerators Manuel Fogué 1 Francisco Igual 1 Enrique S. Quintana-Ortí 1 Robert van de Geijn 2 1 Departamento de Ingeniería y Ciencia de los Computadores.