Fast Iterative Graph Computation with Resource Aware Graph Parallel Abstraction
|
|
|
- Diane Hancock
- 10 years ago
- Views:
Transcription
1 Human connectome. Gerhard et al., Frontiers in Neuroinformatics 5(3), NA = mol 1 Paul Burkhardt, Chris Waring An NSA Big Graph experiment Fast Iterative Graph Computation with Resource Aware Graph Parallel Abstraction Yang Zhou, Ling Liu, Kisung Lee, Calton Pu, Qi Zhang Distributed Data Intensive Systems Lab (DiSL) School of Computer Science Georgia Institute of Technology
 School of Computer Science Georgia")
2 GraphLego: Motivation Graphs are everywhere: Internet, Web, Road networks, Protein Interaction Networks, Utility Grids Scale of Graphs studied in literature: billions of edges, tens/hundreds of GBs [Paul Burkhardt, Chris Waring 2013] Brain Scale: 100 billion vertices, 100 trillion edges 2

3 Existing Graph Processing Systems HPDC 15 Single PC Systems GraphLab [Low et al., UAI'10] GraphChi [Kyrola et al., OSDI'12] X-Stream [Roy et al., SOSP'13] TurboGraph [Han et al., KDD 13] Distributed Shared Memory Systems Pregel [Malewicz et al., SIGMOD'10] Giraph/Hama Apache Software Foundation Distributed GraphLab [Low et al., VLDB'12] PowerGraph [Gonzalez et al., OSDI'12] SPARK-GraphX [Gonzalez et al., OSDI'14] 3
![, KDD 13] Distributed Shared Memory Systems Pregel [Malewicz et al.](/docs-images/45/10357248/images/page_3.jpg ", SIGMOD'10] Giraph/Hama Apache Software Foundation Distributed GraphLab [Low et al.")
4 Vertex-centric Computation Model Think like a vertex vertex_scatter(vertex v) send updates over outgoing edges of v vertex_gather(vertex v) apply updates from inbound edges of v repeat the computation iterations for all vertices v vertex_scatter(v) for all vertices v vertex_gather(v) 4
 for all")
5 Edge-centric Computation Model (X-Stream) HPDC 15 Think like an edge (source vertex and destination vertex) edge_scatter(edge e) send update over e (from source vertex to destination vertex) update_gather(update u) apply update u to u.destination repeat the computation iterations for all edges e edge_scatter(e) for all updates u update_gather(u) 5
 for all")
6 Challenges of Big Graphs HPDC 15 Graph size v.s. limited resource Handling big graphs with billions of vertices and edges in memory may require hundreds of gigabytes of DRAM High-degree vertices In uk-union with 133.6M vertices: the maximum indegree is 6,366,525 and the maximum outdegree is 22,429 Skewed vertex degree distribution In Yahoo web with 1.4B vertices: the average vertex degree is 4.7, 49% of the vertices have degree zero and the maximum indegree is 7,637,656 Skewed edge weight distribution In DBLP with 0.96M vertices: among 389 coauthors of Elisa Bertino, she has only one coauthored paper with 198 coauthors, two coauthored papers with 74 coauthors, three coauthored papers with 30 coauthors, and coauthored paper larger than 4 with 87 coauthors 6

7 Real-world Big Graphs 7

8 Graph Processing Systems: Challenges Diverse types of processed graphs Simple graph: not allow for parallel edges (multiple edges) between a pair of vertices Multigraph: allow for parallel edges between a pair of vertices Different kinds of graph applications Matrix-vector multiplication and graph traversal with the cost of O(n 2 ) Matrix-matrix multiplication with the cost of O(n 3 ) Random access It is inefficient for both access and storage. A bunch of random accesses are necessary but would hurt the performance of graph processing systems Workload imbalance The time of computing on a vertex and its edges is much faster than the time to access to the vertex state and its edge data in memory or on disk The computation workloads on different vertices are significantly imbalanced due to the highly skewed vertex degree distribution. 8

9 GraphLego: Our Approach Flexible multi-level hierarchical graph parallel abstractions Model a large graph as a 3D cube with source vertex, destination vertex and edge weight as the dimensions Partitioning a big graph by: slice, strip, dice based graph partitioning Access Locality Optimization Dice-based data placement: store a large graph on disk by minimizing nonsequential disk access and enabling more structured in-memory access Construct partition-to-chunk index and vertex-to-partition index to facilitate fast access to slices, strips and dices implement partition-level in-memory gzip compression to optimize disk I/Os Optimization for Partitioning Parameters Build a regression-based learning model to discover the latent relationship between the number of partitions and the runtime 9

10 Modeling a Graph as a 3D Cube Model a directed graph G=(V,E,W) as a 3D cube I=(S,D,E,W) with source vertices (S=V), destination vertices (D=V) and edge weights (W) as the three dimensions 10
 and edge weights (W) as the three")
11 Multi-level Hierarchical Graph Parallel Abstractions 11

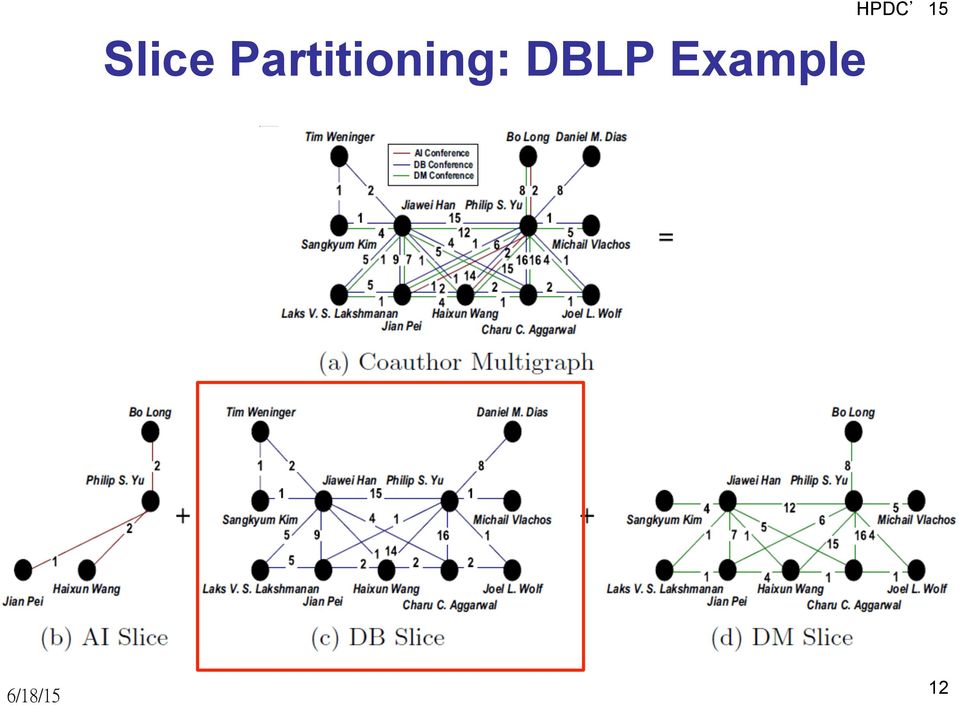
12 Slice Partitioning: DBLP Example HPDC 15 12
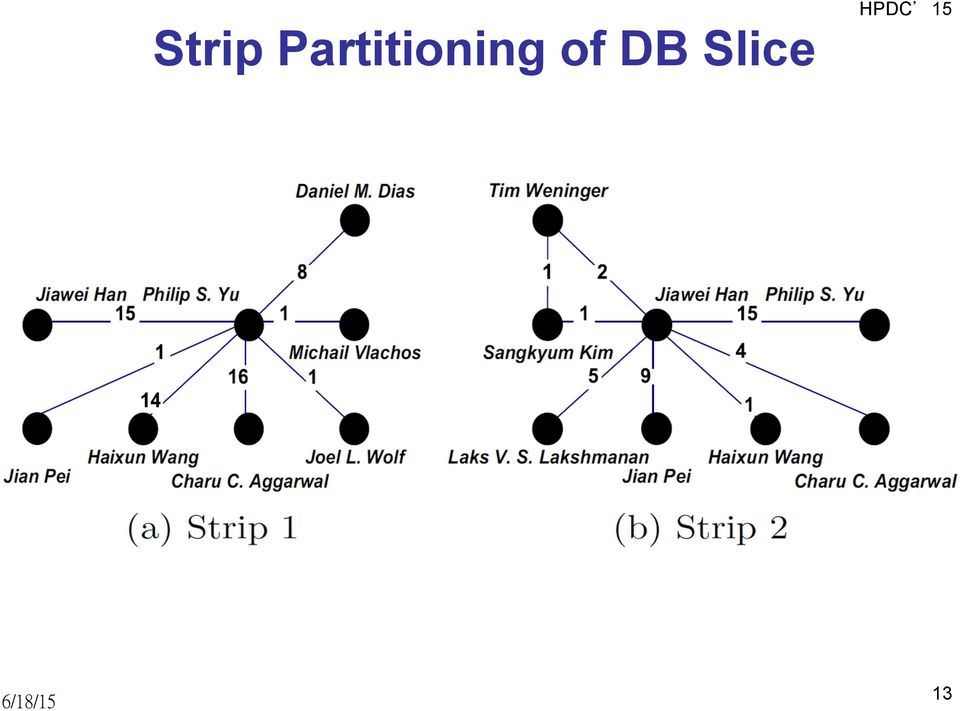
13 Strip Partitioning of DB Slice HPDC 15 13
14 Dice Partitioning: An Example HPDC 15 SVP: v1,v2,v3, v5,v6,v7, v11, v12, v15 DVP: v2,v3,v4,v5,v6, v7,v8,v9,v10,v11, v12,v13,v14,v15.v16 14

15 Dice Partition Storage (OEDs) HPDC 15 15
")
16 Advantage: Multi-level Hierarchical Graph Parallel Abstractions HPDC 15 Choose smaller subgraph blocks such as dice partition or strip partition to balance the parallel computation efficiency among partition blocks Use larger subgraph blocks such as slice partition or strip partition to maximize sequential access and minimize random access 16

17 Programmable Interface vertex centric programming API, such as Scatter and Gather. Scatter vertex updates to outgoing edges Gather vertex updates from neighbor vertices and incoming edges Compile iterative algorithms into a sequence of internal function (routine) calls that understand the internal data structures for accessing the graph by different types of subgraph partition blocks 17

18 Partition-to-chunk Index Vertex-to-partition Index HPDC 15 The dice-level index is a dense index that maps a dice ID and its DVP (or SVP) to the chunks on disk where the corresponding dice partition is stored physically The strip-level index is a two level sparse index, which maps a strip ID to the dice-level index-blocks and then map each dice ID to the dice partition chunks in the physical storage The slice level index is a three-level sparse index with slice index blocks at the top, strip index blocks at the middle and dice index blocks at the bottom, enabling fast retrieval of dices with a slice-specific condition 18

19 Partition-level Compression HPDC 15 Iterative computations on large graphs incur nontrivial cost for the I/O processing The I/O processing of Twitter dataset on a PC with 4 CPU cores and 16GB memory takes 50.2% of the total running time for PageRank (5 iterations) Apply in-memory gzip compression to transform each graph partition block into a compressed format before storing them on disk 19
 Apply in-memory gzip compression to")
20 Configuration of Partitioning Parameters User definition Simple estimation Regression-based learning Construct a polynomial regression model to model the nonlinear relationship between independent variables p, q, r (partition parameters) and dependent variable T (runtime) with latent coefficient α ijk and error term ε The goal of regression-based learning is to determine the latent α ijk and ε to get the function between p, q, r and T Select m limited samples of (p l, q l, r l, T l ) (1 l m) from the existing experiment results Solve m linear equations consisting of m selected samples to generate the concrete α ijk and ε Utilize a successive convex approximation method (SCA) to find the optimal solution (i.e., the minimum runtime T) of the above polynomial function and the optimal parameters (i.e., p, q and r) when T is minimum 20
 to find the optimal solution (i.e., the minimum runtime T) of the above polynomial function and the optimal parameters (i.")
21 Experimental Evaluation Computer server Intel Core i GHz, 16 GB RAM, 1 TB hard drive, Linux 64-bit Graph parallel systems GraphLab [Low et al., UAI'10] GraphChi [Kyrola et al., OSDI'12] X-Stream [Roy et al., SOSP'13] Graph applications 21
22 Execution Efficiency on Single Graph 22
23 Execution Efficiency on Multiple Graphs 23
24 Decision of #Partitions HPDC 15 24
25 Efficiency of Regression-based Learning 25
26 GraphLego: Resource Aware GPS Flexible multi-level hierarchical graph parallel abstractions Model a large graph as a 3D cube with source vertex, destination vertex and edge weight as the dimensions Partitioning a big graph by: slice, strip, dice based graph partitioning Access Locality Optimization Dice-based data placement: store a large graph on disk by minimizing non-sequential disk access and enabling more structured in-memory access Construct partition-to-chunk index and vertex-to-partition index to facilitate fast access to slices, strips and dices implement partition-level in-memory gzip compression to optimize disk I/ Os Optimization for Partitioning Parameters Build a regression-based learning model to discover the latent relationship between the number of partitions and the runtime 26
27 Questions Open Source: 27
Big Graph Processing: Some Background
 Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
Software tools for Complex Networks Analysis. Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team
 Team") Software tools for Complex Networks Analysis Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team MOTIVATION Why do we need tools? Source : nature.com Visualization Properties extraction
Software tools for Complex Networks Analysis Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team MOTIVATION Why do we need tools? Source : nature.com Visualization Properties extraction
LARGE-SCALE GRAPH PROCESSING IN THE BIG DATA WORLD. Dr. Buğra Gedik, Ph.D.
 LARGE-SCALE GRAPH PROCESSING IN THE BIG DATA WORLD Dr. Buğra Gedik, Ph.D. MOTIVATION Graph data is everywhere Relationships between people, systems, and the nature Interactions between people, systems,
LARGE-SCALE GRAPH PROCESSING IN THE BIG DATA WORLD Dr. Buğra Gedik, Ph.D. MOTIVATION Graph data is everywhere Relationships between people, systems, and the nature Interactions between people, systems,
MMap: Fast Billion-Scale Graph Computation on a PC via Memory Mapping
 : Fast Billion-Scale Graph Computation on a PC via Memory Mapping Zhiyuan Lin, Minsuk Kahng, Kaeser Md. Sabrin, Duen Horng (Polo) Chau Georgia Tech Atlanta, Georgia {zlin48, kahng, kmsabrin, polo}@gatech.edu
: Fast Billion-Scale Graph Computation on a PC via Memory Mapping Zhiyuan Lin, Minsuk Kahng, Kaeser Md. Sabrin, Duen Horng (Polo) Chau Georgia Tech Atlanta, Georgia {zlin48, kahng, kmsabrin, polo}@gatech.edu
An NSA Big Graph experiment. Paul Burkhardt, Chris Waring. May 20, 2013
 U.S. National Security Agency Research Directorate - R6 Technical Report NSA-RD-2013-056002v1 May 20, 2013 Graphs are everywhere! A graph is a collection of binary relationships, i.e. networks of pairwise
U.S. National Security Agency Research Directorate - R6 Technical Report NSA-RD-2013-056002v1 May 20, 2013 Graphs are everywhere! A graph is a collection of binary relationships, i.e. networks of pairwise
Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing
 /35 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
/35 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
SIGMOD RWE Review Towards Proximity Pattern Mining in Large Graphs
 SIGMOD RWE Review Towards Proximity Pattern Mining in Large Graphs Fabian Hueske, TU Berlin June 26, 21 1 Review This document is a review report on the paper Towards Proximity Pattern Mining in Large
SIGMOD RWE Review Towards Proximity Pattern Mining in Large Graphs Fabian Hueske, TU Berlin June 26, 21 1 Review This document is a review report on the paper Towards Proximity Pattern Mining in Large
Asking Hard Graph Questions. Paul Burkhardt. February 3, 2014
 Beyond Watson: Predictive Analytics and Big Data U.S. National Security Agency Research Directorate - R6 Technical Report February 3, 2014 300 years before Watson there was Euler! The first (Jeopardy!)
Beyond Watson: Predictive Analytics and Big Data U.S. National Security Agency Research Directorate - R6 Technical Report February 3, 2014 300 years before Watson there was Euler! The first (Jeopardy!)
MapGraph. A High Level API for Fast Development of High Performance Graphic Analytics on GPUs. http://mapgraph.io
 MapGraph A High Level API for Fast Development of High Performance Graphic Analytics on GPUs http://mapgraph.io Zhisong Fu, Michael Personick and Bryan Thompson SYSTAP, LLC Outline Motivations MapGraph
MapGraph A High Level API for Fast Development of High Performance Graphic Analytics on GPUs http://mapgraph.io Zhisong Fu, Michael Personick and Bryan Thompson SYSTAP, LLC Outline Motivations MapGraph
Systems and Algorithms for Big Data Analytics
 Systems and Algorithms for Big Data Analytics YAN, Da Email: [email protected] My Research Graph Data Distributed Graph Processing Spatial Data Spatial Query Processing Uncertain Data Querying & Mining
Systems and Algorithms for Big Data Analytics YAN, Da Email: [email protected] My Research Graph Data Distributed Graph Processing Spatial Data Spatial Query Processing Uncertain Data Querying & Mining
Large-Scale Data Processing
 Large-Scale Data Processing Eiko Yoneki [email protected] http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Large-Scale Data Processing Eiko Yoneki [email protected] http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Presto/Blockus: Towards Scalable R Data Analysis
 /Blockus: Towards Scalable R Data Analysis Andrew A. Chien University of Chicago and Argonne ational Laboratory IRIA-UIUC-AL Joint Institute Potential Collaboration ovember 19, 2012 ovember 19, 2012 Andrew
/Blockus: Towards Scalable R Data Analysis Andrew A. Chien University of Chicago and Argonne ational Laboratory IRIA-UIUC-AL Joint Institute Potential Collaboration ovember 19, 2012 ovember 19, 2012 Andrew
Scalable Data Analysis in R. Lee E. Edlefsen Chief Scientist UserR! 2011
 Scalable Data Analysis in R Lee E. Edlefsen Chief Scientist UserR! 2011 1 Introduction Our ability to collect and store data has rapidly been outpacing our ability to analyze it We need scalable data analysis
Scalable Data Analysis in R Lee E. Edlefsen Chief Scientist UserR! 2011 1 Introduction Our ability to collect and store data has rapidly been outpacing our ability to analyze it We need scalable data analysis
GraySort on Apache Spark by Databricks
 GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
GraySort on Apache Spark by Databricks Reynold Xin, Parviz Deyhim, Ali Ghodsi, Xiangrui Meng, Matei Zaharia Databricks Inc. Apache Spark Sorting in Spark Overview Sorting Within a Partition Range Partitioner
Big RDF Data Partitioning and Processing using hadoop in Cloud
 Big RDF Data Partitioning and Processing using hadoop in Cloud Tejas Bharat Thorat Dept. of Computer Engineering MIT Academy of Engineering, Alandi, Pune, India Prof.Ranjana R.Badre Dept. of Computer Engineering
Big RDF Data Partitioning and Processing using hadoop in Cloud Tejas Bharat Thorat Dept. of Computer Engineering MIT Academy of Engineering, Alandi, Pune, India Prof.Ranjana R.Badre Dept. of Computer Engineering
An Experimental Comparison of Pregel-like Graph Processing Systems
 An Experimental Comparison of Pregel-like Graph Processing Systems Minyang Han, Khuzaima Daudjee, Khaled Ammar, M. Tamer Özsu, Xingfang Wang, Tianqi Jin David R. Cheriton School of Computer Science, University
An Experimental Comparison of Pregel-like Graph Processing Systems Minyang Han, Khuzaima Daudjee, Khaled Ammar, M. Tamer Özsu, Xingfang Wang, Tianqi Jin David R. Cheriton School of Computer Science, University
Graph Processing and Social Networks
 Graph Processing and Social Networks Presented by Shu Jiayu, Yang Ji Department of Computer Science and Engineering The Hong Kong University of Science and Technology 2015/4/20 1 Outline Background Graph
Graph Processing and Social Networks Presented by Shu Jiayu, Yang Ji Department of Computer Science and Engineering The Hong Kong University of Science and Technology 2015/4/20 1 Outline Background Graph
A Survey on: Efficient and Customizable Data Partitioning for Distributed Big RDF Data Processing using hadoop in Cloud.
 A Survey on: Efficient and Customizable Data Partitioning for Distributed Big RDF Data Processing using hadoop in Cloud. Tejas Bharat Thorat Prof.RanjanaR.Badre Computer Engineering Department Computer
A Survey on: Efficient and Customizable Data Partitioning for Distributed Big RDF Data Processing using hadoop in Cloud. Tejas Bharat Thorat Prof.RanjanaR.Badre Computer Engineering Department Computer
GraphChi: Large-Scale Graph Computation on Just a PC
 GraphChi: Large-Scale Graph Computation on Just a PC Aapo Kyrola Carnegie Mellon University [email protected] Guy Blelloch Carnegie Mellon University [email protected] Carlos Guestrin University of Washington
GraphChi: Large-Scale Graph Computation on Just a PC Aapo Kyrola Carnegie Mellon University [email protected] Guy Blelloch Carnegie Mellon University [email protected] Carlos Guestrin University of Washington
Distributed R for Big Data
 Distributed R for Big Data Indrajit Roy, HP Labs November 2013 Team: Shivara m Erik Kyungyon g Alvin Rob Vanish A Big Data story Once upon a time, a customer in distress had. 2+ billion rows of financial
Distributed R for Big Data Indrajit Roy, HP Labs November 2013 Team: Shivara m Erik Kyungyon g Alvin Rob Vanish A Big Data story Once upon a time, a customer in distress had. 2+ billion rows of financial
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Massive Data Analysis Using Fast I/O
 Abstract Massive Data Analysis Using Fast I/O Da Zheng Department of Computer Science The Johns Hopkins University Baltimore, Maryland, 21218 [email protected] The advance of new I/O technologies has tremendously
Abstract Massive Data Analysis Using Fast I/O Da Zheng Department of Computer Science The Johns Hopkins University Baltimore, Maryland, 21218 [email protected] The advance of new I/O technologies has tremendously
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Analysis of Web Archives. Vinay Goel Senior Data Engineer
 Analysis of Web Archives Vinay Goel Senior Data Engineer Internet Archive Established in 1996 501(c)(3) non profit organization 20+ PB (compressed) of publicly accessible archival material Technology partner
Analysis of Web Archives Vinay Goel Senior Data Engineer Internet Archive Established in 1996 501(c)(3) non profit organization 20+ PB (compressed) of publicly accessible archival material Technology partner
A1 and FARM scalable graph database on top of a transactional memory layer
 A1 and FARM scalable graph database on top of a transactional memory layer Miguel Castro, Aleksandar Dragojević, Dushyanth Narayanan, Ed Nightingale, Alex Shamis Richie Khanna, Matt Renzelmann Chiranjeeb
A1 and FARM scalable graph database on top of a transactional memory layer Miguel Castro, Aleksandar Dragojević, Dushyanth Narayanan, Ed Nightingale, Alex Shamis Richie Khanna, Matt Renzelmann Chiranjeeb
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany MapReduce II MapReduce II 1 / 33 Outline 1. Introduction
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany MapReduce II MapReduce II 1 / 33 Outline 1. Introduction
Ringo: Interactive Graph Analytics on Big-Memory Machines
 Ringo: Interactive Graph Analytics on Big-Memory Machines Yonathan Perez, Rok Sosič, Arijit Banerjee, Rohan Puttagunta, Martin Raison, Pararth Shah, Jure Leskovec Stanford University {yperez, rok, arijitb,
Ringo: Interactive Graph Analytics on Big-Memory Machines Yonathan Perez, Rok Sosič, Arijit Banerjee, Rohan Puttagunta, Martin Raison, Pararth Shah, Jure Leskovec Stanford University {yperez, rok, arijitb,
GeoGrid Project and Experiences with Hadoop
 GeoGrid Project and Experiences with Hadoop Gong Zhang and Ling Liu Distributed Data Intensive Systems Lab (DiSL) Center for Experimental Computer Systems Research (CERCS) Georgia Institute of Technology
GeoGrid Project and Experiences with Hadoop Gong Zhang and Ling Liu Distributed Data Intensive Systems Lab (DiSL) Center for Experimental Computer Systems Research (CERCS) Georgia Institute of Technology
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
Data Backup and Archiving with Enterprise Storage Systems
 Data Backup and Archiving with Enterprise Storage Systems Slavjan Ivanov 1, Igor Mishkovski 1 1 Faculty of Computer Science and Engineering Ss. Cyril and Methodius University Skopje, Macedonia [email protected],
Data Backup and Archiving with Enterprise Storage Systems Slavjan Ivanov 1, Igor Mishkovski 1 1 Faculty of Computer Science and Engineering Ss. Cyril and Methodius University Skopje, Macedonia [email protected],
Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing
 : A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat Karim Awara Amani Alonazi Hani Jamjoom Dan Williams Panos Kalnis King Abdullah University of Science and Technology,
: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat Karim Awara Amani Alonazi Hani Jamjoom Dan Williams Panos Kalnis King Abdullah University of Science and Technology,
Machine Learning over Big Data
 Machine Learning over Big Presented by Fuhao Zou [email protected] Jue 16, 2014 Huazhong University of Science and Technology Contents 1 2 3 4 Role of Machine learning Challenge of Big Analysis Distributed
Machine Learning over Big Presented by Fuhao Zou [email protected] Jue 16, 2014 Huazhong University of Science and Technology Contents 1 2 3 4 Role of Machine learning Challenge of Big Analysis Distributed
Big Data and Scripting Systems beyond Hadoop
 Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Recommended hardware system configurations for ANSYS users
 Recommended hardware system configurations for ANSYS users The purpose of this document is to recommend system configurations that will deliver high performance for ANSYS users across the entire range
Recommended hardware system configurations for ANSYS users The purpose of this document is to recommend system configurations that will deliver high performance for ANSYS users across the entire range
Evaluating partitioning of big graphs
 Evaluating partitioning of big graphs Fredrik Hallberg, Joakim Candefors, Micke Soderqvist [email protected], [email protected], [email protected] Royal Institute of Technology, Stockholm, Sweden Abstract. Distributed
Evaluating partitioning of big graphs Fredrik Hallberg, Joakim Candefors, Micke Soderqvist [email protected], [email protected], [email protected] Royal Institute of Technology, Stockholm, Sweden Abstract. Distributed
Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software
 WHITEPAPER Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software SanDisk ZetaScale software unlocks the full benefits of flash for In-Memory Compute and NoSQL applications
WHITEPAPER Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software SanDisk ZetaScale software unlocks the full benefits of flash for In-Memory Compute and NoSQL applications
Four Orders of Magnitude: Running Large Scale Accumulo Clusters. Aaron Cordova Accumulo Summit, June 2014
 Four Orders of Magnitude: Running Large Scale Accumulo Clusters Aaron Cordova Accumulo Summit, June 2014 Scale, Security, Schema Scale to scale 1 - (vt) to change the size of something let s scale the
Four Orders of Magnitude: Running Large Scale Accumulo Clusters Aaron Cordova Accumulo Summit, June 2014 Scale, Security, Schema Scale to scale 1 - (vt) to change the size of something let s scale the
The Power of Relationships
 The Power of Relationships Opportunities and Challenges in Big Data Intel Labs Cluster Computing Architecture Legal Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO
The Power of Relationships Opportunities and Challenges in Big Data Intel Labs Cluster Computing Architecture Legal Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO
KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS
 ABSTRACT KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS In many real applications, RDF (Resource Description Framework) has been widely used as a W3C standard to describe data in the Semantic Web. In practice,
ABSTRACT KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS In many real applications, RDF (Resource Description Framework) has been widely used as a W3C standard to describe data in the Semantic Web. In practice,
MapReduce and Distributed Data Analysis. Sergei Vassilvitskii Google Research
 MapReduce and Distributed Data Analysis Google Research 1 Dealing With Massive Data 2 2 Dealing With Massive Data Polynomial Memory Sublinear RAM Sketches External Memory Property Testing 3 3 Dealing With
MapReduce and Distributed Data Analysis Google Research 1 Dealing With Massive Data 2 2 Dealing With Massive Data Polynomial Memory Sublinear RAM Sketches External Memory Property Testing 3 3 Dealing With
Optimization and analysis of large scale data sorting algorithm based on Hadoop
 Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Main Memory Data Warehouses
 Main Memory Data Warehouses Robert Wrembel Poznan University of Technology Institute of Computing Science [email protected] www.cs.put.poznan.pl/rwrembel Lecture outline Teradata Data Warehouse
Main Memory Data Warehouses Robert Wrembel Poznan University of Technology Institute of Computing Science [email protected] www.cs.put.poznan.pl/rwrembel Lecture outline Teradata Data Warehouse
InfiniteGraph: The Distributed Graph Database
 A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
Maximizing SQL Server Virtualization Performance
 Maximizing SQL Server Virtualization Performance Michael Otey Senior Technical Director Windows IT Pro SQL Server Pro 1 What this presentation covers Host configuration guidelines CPU, RAM, networking
Maximizing SQL Server Virtualization Performance Michael Otey Senior Technical Director Windows IT Pro SQL Server Pro 1 What this presentation covers Host configuration guidelines CPU, RAM, networking
NoSQL Performance Test In-Memory Performance Comparison of SequoiaDB, Cassandra, and MongoDB
 bankmark UG (haftungsbeschränkt) Bahnhofstraße 1 9432 Passau Germany www.bankmark.de [email protected] T +49 851 25 49 49 F +49 851 25 49 499 NoSQL Performance Test In-Memory Performance Comparison of SequoiaDB,
bankmark UG (haftungsbeschränkt) Bahnhofstraße 1 9432 Passau Germany www.bankmark.de [email protected] T +49 851 25 49 49 F +49 851 25 49 499 NoSQL Performance Test In-Memory Performance Comparison of SequoiaDB,
Scaling from Datacenter to Client
 Scaling from Datacenter to Client KeunSoo Jo Sr. Manager Memory Product Planning Samsung Semiconductor Audio-Visual Sponsor Outline SSD Market Overview & Trends - Enterprise What brought us to NVMe Technology
Scaling from Datacenter to Client KeunSoo Jo Sr. Manager Memory Product Planning Samsung Semiconductor Audio-Visual Sponsor Outline SSD Market Overview & Trends - Enterprise What brought us to NVMe Technology
Overview on Graph Datastores and Graph Computing Systems. -- Litao Deng (Cloud Computing Group) 06-08-2012
 06-08-2012") Overview on Graph Datastores and Graph Computing Systems -- Litao Deng (Cloud Computing Group) 06-08-2012 Graph - Everywhere 1: Friendship Graph 2: Food Graph 3: Internet Graph Most of the relationships
Overview on Graph Datastores and Graph Computing Systems -- Litao Deng (Cloud Computing Group) 06-08-2012 Graph - Everywhere 1: Friendship Graph 2: Food Graph 3: Internet Graph Most of the relationships
Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing. October 29th, 2015
 E6893 Big Data Analytics Lecture 8: Spark Streams and Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing
E6893 Big Data Analytics Lecture 8: Spark Streams and Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing
Mining Large Datasets: Case of Mining Graph Data in the Cloud
 Mining Large Datasets: Case of Mining Graph Data in the Cloud Sabeur Aridhi PhD in Computer Science with Laurent d Orazio, Mondher Maddouri and Engelbert Mephu Nguifo 16/05/2014 Sabeur Aridhi Mining Large
Mining Large Datasets: Case of Mining Graph Data in the Cloud Sabeur Aridhi PhD in Computer Science with Laurent d Orazio, Mondher Maddouri and Engelbert Mephu Nguifo 16/05/2014 Sabeur Aridhi Mining Large
How To Store Data On An Ocora Nosql Database On A Flash Memory Device On A Microsoft Flash Memory 2 (Iomemory)
") WHITE PAPER Oracle NoSQL Database and SanDisk Offer Cost-Effective Extreme Performance for Big Data 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Abstract... 3 What Is Big Data?...
WHITE PAPER Oracle NoSQL Database and SanDisk Offer Cost-Effective Extreme Performance for Big Data 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Abstract... 3 What Is Big Data?...
From GWS to MapReduce: Google s Cloud Technology in the Early Days
 Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu [email protected] MapReduce/Hadoop
Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu [email protected] MapReduce/Hadoop
SCAN: A Structural Clustering Algorithm for Networks
 SCAN: A Structural Clustering Algorithm for Networks Xiaowei Xu, Nurcan Yuruk, Zhidan Feng (University of Arkansas at Little Rock) Thomas A. J. Schweiger (Acxiom Corporation) Networks scaling: #edges connected
SCAN: A Structural Clustering Algorithm for Networks Xiaowei Xu, Nurcan Yuruk, Zhidan Feng (University of Arkansas at Little Rock) Thomas A. J. Schweiger (Acxiom Corporation) Networks scaling: #edges connected
Social Media Mining. Graph Essentials
 Graph Essentials Graph Basics Measures Graph and Essentials Metrics 2 2 Nodes and Edges A network is a graph nodes, actors, or vertices (plural of vertex) Connections, edges or ties Edge Node Measures
Graph Essentials Graph Basics Measures Graph and Essentials Metrics 2 2 Nodes and Edges A network is a graph nodes, actors, or vertices (plural of vertex) Connections, edges or ties Edge Node Measures
! E6893 Big Data Analytics Lecture 9:! Linked Big Data Graph Computing (I)
") ! E6893 Big Data Analytics Lecture 9:! Linked Big Data Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
! E6893 Big Data Analytics Lecture 9:! Linked Big Data Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
A Performance Evaluation of Open Source Graph Databases. Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader
 A Performance Evaluation of Open Source Graph Databases Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader Overview Motivation Options Evaluation Results Lessons Learned Moving Forward
A Performance Evaluation of Open Source Graph Databases Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader Overview Motivation Options Evaluation Results Lessons Learned Moving Forward
Preview of Oracle Database 12c In-Memory Option. Copyright 2013, Oracle and/or its affiliates. All rights reserved.
 Preview of Oracle Database 12c In-Memory Option 1 The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any
Preview of Oracle Database 12c In-Memory Option 1 The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any
RevoScaleR Speed and Scalability
 EXECUTIVE WHITE PAPER RevoScaleR Speed and Scalability By Lee Edlefsen Ph.D., Chief Scientist, Revolution Analytics Abstract RevoScaleR, the Big Data predictive analytics library included with Revolution
EXECUTIVE WHITE PAPER RevoScaleR Speed and Scalability By Lee Edlefsen Ph.D., Chief Scientist, Revolution Analytics Abstract RevoScaleR, the Big Data predictive analytics library included with Revolution
LLAMA: Efficient Graph Analytics Using Large Multiversioned Arrays
 LLAMA: Efficient Graph Analytics Using Large Multiversioned Arrays Peter Macko # 1, Virendra J. Marathe 2, Daniel W. Margo #3, Margo I. Seltzer # 4 # School of Engineering and Applied Sciences, Harvard
LLAMA: Efficient Graph Analytics Using Large Multiversioned Arrays Peter Macko # 1, Virendra J. Marathe 2, Daniel W. Margo #3, Margo I. Seltzer # 4 # School of Engineering and Applied Sciences, Harvard
Parallels Cloud Server 6.0
 Parallels Cloud Server 6.0 Parallels Cloud Storage I/O Benchmarking Guide September 05, 2014 Copyright 1999-2014 Parallels IP Holdings GmbH and its affiliates. All rights reserved. Parallels IP Holdings
Parallels Cloud Server 6.0 Parallels Cloud Storage I/O Benchmarking Guide September 05, 2014 Copyright 1999-2014 Parallels IP Holdings GmbH and its affiliates. All rights reserved. Parallels IP Holdings
Colgate-Palmolive selects SAP HANA to improve the speed of business analytics with IBM and SAP
 selects SAP HANA to improve the speed of business analytics with IBM and SAP Founded in 1806, is a global consumer products company which sells nearly $17 billion annually in personal care, home care,
selects SAP HANA to improve the speed of business analytics with IBM and SAP Founded in 1806, is a global consumer products company which sells nearly $17 billion annually in personal care, home care,
An Empirical Study of Two MIS Algorithms
 An Empirical Study of Two MIS Algorithms Email: Tushar Bisht and Kishore Kothapalli International Institute of Information Technology, Hyderabad Hyderabad, Andhra Pradesh, India 32. [email protected],
An Empirical Study of Two MIS Algorithms Email: Tushar Bisht and Kishore Kothapalli International Institute of Information Technology, Hyderabad Hyderabad, Andhra Pradesh, India 32. [email protected],
EMC Unified Storage for Microsoft SQL Server 2008
 EMC Unified Storage for Microsoft SQL Server 2008 Enabled by EMC CLARiiON and EMC FAST Cache Reference Copyright 2010 EMC Corporation. All rights reserved. Published October, 2010 EMC believes the information
EMC Unified Storage for Microsoft SQL Server 2008 Enabled by EMC CLARiiON and EMC FAST Cache Reference Copyright 2010 EMC Corporation. All rights reserved. Published October, 2010 EMC believes the information
Using In-Memory Computing to Simplify Big Data Analytics
 SCALEOUT SOFTWARE Using In-Memory Computing to Simplify Big Data Analytics by Dr. William Bain, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 T he big data revolution is upon us, fed
SCALEOUT SOFTWARE Using In-Memory Computing to Simplify Big Data Analytics by Dr. William Bain, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 T he big data revolution is upon us, fed
Benchmarking Cassandra on Violin
 Technical White Paper Report Technical Report Benchmarking Cassandra on Violin Accelerating Cassandra Performance and Reducing Read Latency With Violin Memory Flash-based Storage Arrays Version 1.0 Abstract
Technical White Paper Report Technical Report Benchmarking Cassandra on Violin Accelerating Cassandra Performance and Reducing Read Latency With Violin Memory Flash-based Storage Arrays Version 1.0 Abstract
Rethinking SIMD Vectorization for In-Memory Databases
 SIGMOD 215, Melbourne, Victoria, Australia Rethinking SIMD Vectorization for In-Memory Databases Orestis Polychroniou Columbia University Arun Raghavan Oracle Labs Kenneth A. Ross Columbia University Latest
SIGMOD 215, Melbourne, Victoria, Australia Rethinking SIMD Vectorization for In-Memory Databases Orestis Polychroniou Columbia University Arun Raghavan Oracle Labs Kenneth A. Ross Columbia University Latest
Common Patterns and Pitfalls for Implementing Algorithms in Spark. Hossein Falaki @mhfalaki [email protected]
 Common Patterns and Pitfalls for Implementing Algorithms in Spark Hossein Falaki @mhfalaki [email protected] Challenges of numerical computation over big data When applying any algorithm to big data
Common Patterns and Pitfalls for Implementing Algorithms in Spark Hossein Falaki @mhfalaki [email protected] Challenges of numerical computation over big data When applying any algorithm to big data
Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks
 WHITE PAPER July 2014 Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks Contents Executive Summary...2 Background...3 InfiniteGraph...3 High Performance
WHITE PAPER July 2014 Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks Contents Executive Summary...2 Background...3 InfiniteGraph...3 High Performance
Outline. Motivation. Motivation. MapReduce & GraphLab: Programming Models for Large-Scale Parallel/Distributed Computing 2/28/2013
 MapReduce & GraphLab: Programming Models for Large-Scale Parallel/Distributed Computing Iftekhar Naim Outline Motivation MapReduce Overview Design Issues & Abstractions Examples and Results Pros and Cons
MapReduce & GraphLab: Programming Models for Large-Scale Parallel/Distributed Computing Iftekhar Naim Outline Motivation MapReduce Overview Design Issues & Abstractions Examples and Results Pros and Cons
STINGER: High Performance Data Structure for Streaming Graphs
 STINGER: High Performance Data Structure for Streaming Graphs David Ediger Rob McColl Jason Riedy David A. Bader Georgia Institute of Technology Atlanta, GA, USA Abstract The current research focus on
STINGER: High Performance Data Structure for Streaming Graphs David Ediger Rob McColl Jason Riedy David A. Bader Georgia Institute of Technology Atlanta, GA, USA Abstract The current research focus on
EFFICIENT GEAR-SHIFTING FOR A POWER-PROPORTIONAL DISTRIBUTED DATA-PLACEMENT METHOD
 EFFICIENT GEAR-SHIFTING FOR A POWER-PROPORTIONAL DISTRIBUTED DATA-PLACEMENT METHOD 2014/1/27 Hieu Hanh Le, Satoshi Hikida and Haruo Yokota Tokyo Institute of Technology 1.1 Background 2 Commodity-based
EFFICIENT GEAR-SHIFTING FOR A POWER-PROPORTIONAL DISTRIBUTED DATA-PLACEMENT METHOD 2014/1/27 Hieu Hanh Le, Satoshi Hikida and Haruo Yokota Tokyo Institute of Technology 1.1 Background 2 Commodity-based
FPGA-based Multithreading for In-Memory Hash Joins
 FPGA-based Multithreading for In-Memory Hash Joins Robert J. Halstead, Ildar Absalyamov, Walid A. Najjar, Vassilis J. Tsotras University of California, Riverside Outline Background What are FPGAs Multithreaded
FPGA-based Multithreading for In-Memory Hash Joins Robert J. Halstead, Ildar Absalyamov, Walid A. Najjar, Vassilis J. Tsotras University of California, Riverside Outline Background What are FPGAs Multithreaded
Graph Database Proof of Concept Report
 Objectivity, Inc. Graph Database Proof of Concept Report Managing The Internet of Things Table of Contents Executive Summary 3 Background 3 Proof of Concept 4 Dataset 4 Process 4 Query Catalog 4 Environment
Objectivity, Inc. Graph Database Proof of Concept Report Managing The Internet of Things Table of Contents Executive Summary 3 Background 3 Proof of Concept 4 Dataset 4 Process 4 Query Catalog 4 Environment
A Novel Cloud Based Elastic Framework for Big Data Preprocessing
 School of Systems Engineering A Novel Cloud Based Elastic Framework for Big Data Preprocessing Omer Dawelbeit and Rachel McCrindle October 21, 2014 University of Reading 2008 www.reading.ac.uk Overview
School of Systems Engineering A Novel Cloud Based Elastic Framework for Big Data Preprocessing Omer Dawelbeit and Rachel McCrindle October 21, 2014 University of Reading 2008 www.reading.ac.uk Overview
Scalable Cloud Computing Solutions for Next Generation Sequencing Data
 Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Juwei Shi, Yunjie Qiu, Umar Farooq Minhas, Limei Jiao, Chen Wang, Berthold Reinwald, and Fatma Özcan IBM Research China IBM Almaden
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Juwei Shi, Yunjie Qiu, Umar Farooq Minhas, Limei Jiao, Chen Wang, Berthold Reinwald, and Fatma Özcan IBM Research China IBM Almaden
Using Synology SSD Technology to Enhance System Performance Synology Inc.
 Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_SSD_Cache_WP_ 20140512 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges...
Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_SSD_Cache_WP_ 20140512 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges...
Static Data Mining Algorithm with Progressive Approach for Mining Knowledge
 Global Journal of Business Management and Information Technology. Volume 1, Number 2 (2011), pp. 85-93 Research India Publications http://www.ripublication.com Static Data Mining Algorithm with Progressive
Global Journal of Business Management and Information Technology. Volume 1, Number 2 (2011), pp. 85-93 Research India Publications http://www.ripublication.com Static Data Mining Algorithm with Progressive
A Study on Workload Imbalance Issues in Data Intensive Distributed Computing
 A Study on Workload Imbalance Issues in Data Intensive Distributed Computing Sven Groot 1, Kazuo Goda 1, and Masaru Kitsuregawa 1 University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8505, Japan Abstract.
A Study on Workload Imbalance Issues in Data Intensive Distributed Computing Sven Groot 1, Kazuo Goda 1, and Masaru Kitsuregawa 1 University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8505, Japan Abstract.
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics
 Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
How To Cluster Of Complex Systems
 Entropy based Graph Clustering: Application to Biological and Social Networks Edward C Kenley Young-Rae Cho Department of Computer Science Baylor University Complex Systems Definition Dynamically evolving
Entropy based Graph Clustering: Application to Biological and Social Networks Edward C Kenley Young-Rae Cho Department of Computer Science Baylor University Complex Systems Definition Dynamically evolving
Two Parts. Filesystem Interface. Filesystem design. Interface the user sees. Implementing the interface
 File Management Two Parts Filesystem Interface Interface the user sees Organization of the files as seen by the user Operations defined on files Properties that can be read/modified Filesystem design Implementing
File Management Two Parts Filesystem Interface Interface the user sees Organization of the files as seen by the user Operations defined on files Properties that can be read/modified Filesystem design Implementing
GraphQ: Graph Query Processing with Abstraction Refinement Scalable and Programmable Analytics over Very Large Graphs on a Single PC
 GraphQ: Graph Query Processing with Abstraction Refinement Scalable and Programmable Analytics over Very Large Graphs on a Single PC Kai Wang and Guoqing Xu, University of California, Irvine; Zhendong
GraphQ: Graph Query Processing with Abstraction Refinement Scalable and Programmable Analytics over Very Large Graphs on a Single PC Kai Wang and Guoqing Xu, University of California, Irvine; Zhendong
Understanding Data Locality in VMware Virtual SAN
 Understanding Data Locality in VMware Virtual SAN July 2014 Edition T E C H N I C A L M A R K E T I N G D O C U M E N T A T I O N Table of Contents Introduction... 2 Virtual SAN Design Goals... 3 Data
Understanding Data Locality in VMware Virtual SAN July 2014 Edition T E C H N I C A L M A R K E T I N G D O C U M E N T A T I O N Table of Contents Introduction... 2 Virtual SAN Design Goals... 3 Data
SAP HANA. SAP HANA Performance Efficient Speed and Scale-Out for Real-Time Business Intelligence
 SAP HANA SAP HANA Performance Efficient Speed and Scale-Out for Real-Time Business Intelligence SAP HANA Performance Table of Contents 3 Introduction 4 The Test Environment Database Schema Test Data System
SAP HANA SAP HANA Performance Efficient Speed and Scale-Out for Real-Time Business Intelligence SAP HANA Performance Table of Contents 3 Introduction 4 The Test Environment Database Schema Test Data System
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Introduction to Graph Mining
 Introduction to Graph Mining What is a graph? A graph G = (V,E) is a set of vertices V and a set (possibly empty) E of pairs of vertices e 1 = (v 1, v 2 ), where e 1 E and v 1, v 2 V. Edges may contain
Introduction to Graph Mining What is a graph? A graph G = (V,E) is a set of vertices V and a set (possibly empty) E of pairs of vertices e 1 = (v 1, v 2 ), where e 1 E and v 1, v 2 V. Edges may contain
IOS110. Virtualization 5/27/2014 1
 IOS110 Virtualization 5/27/2014 1 Agenda What is Virtualization? Types of Virtualization. Advantages and Disadvantages. Virtualization software Hyper V What is Virtualization? Virtualization Refers to
IOS110 Virtualization 5/27/2014 1 Agenda What is Virtualization? Types of Virtualization. Advantages and Disadvantages. Virtualization software Hyper V What is Virtualization? Virtualization Refers to
APPM4720/5720: Fast algorithms for big data. Gunnar Martinsson The University of Colorado at Boulder
 APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search