CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #18: Dimensionality Reduc7on
|
|
|
- Derrick Bradley
- 8 years ago
- Views:
Transcription
1 CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #18: Dimensionality Reduc7on

2 Dimensionality Reduc=on Assump=on: Data lies on or near a low d- dimensional subspace Axes of this subspace are effec=ve representa=on of the data 2

3 Dimensionality Reduc=on Compress / reduce dimensionality: 10 6 rows; 10 3 columns; no updates Random access to any cell(s); small error: OK The above matrix is really 2-dimensional. All rows can be reconstructed by scaling [ ] or [ ] 3

4 Rank of a Matrix Q: What is rank of a matrix A? A: Number of linearly independent columns of A For example: Matrix A = has rank r=2 Why? The first two rows are linearly independent, so the rank is at least 2, but all three rows are linearly dependent (the first is equal to the sum of the second and third) so the rank must be less than 3. Why do we care about low rank? We can write A as two basis vectors: [1 2 1] [ ] And new coordinates of : [1 0] [0 1] [1 1] 4
 so the rank must be less than 3.")
5 Rank is Dimensionality Cloud of points 3D space: Think of point posi7ons as a matrix: 1 row per point: A B C A We can rewrite coordinates more efficiently! Old basis vectors: [1 0 0] [0 1 0] [0 0 1] New basis vectors: [1 2 1] [ ] Then A has new coordinates: [1 0]. B: [0 1], C: [1 1] No=ce: We reduced the number of coordinates! 5
![Old basis vectors: [1 0 0] [0 1 0] [0 0 1] New basis vectors: [1 2 1] [- 2-3 1]](/docs-images/45/5095182/images/page_5.jpg "Then A has new coordinates: [1 0].")
6 Dimensionality Reduc=on Goal of dimensionality reduc=on is to discover the axis of data! Rather than representing every point with 2 coordinates we represent each point with 1 coordinate (corresponding to the position of the point on the red line). By doing this we incur a bit of error as the points do not exactly lie on the line 6
.")
7 Why Reduce Dimensions? Why reduce dimensions? Discover hidden correla=ons/topics Words that occur commonly together Remove redundant and noisy features Not all words are useful Interpreta=on and visualiza=on Easier storage and processing of the data 7

8 SVD - Defini=on A [m x n] = U [m x r] Σ [ r x r] (V [n x r] ) T A: Input data matrix m x n matrix (e.g., m documents, n terms) U: Lec singular vectors m x r matrix (m documents, r concepts) Σ: Singular values r x r diagonal matrix (strength of each concept ) (r : rank of the matrix A) V: Right singular vectors n x r matrix (n terms, r concepts) 8
 (r : rank of the")
9 SVD T n n m A m Σ V T U 9
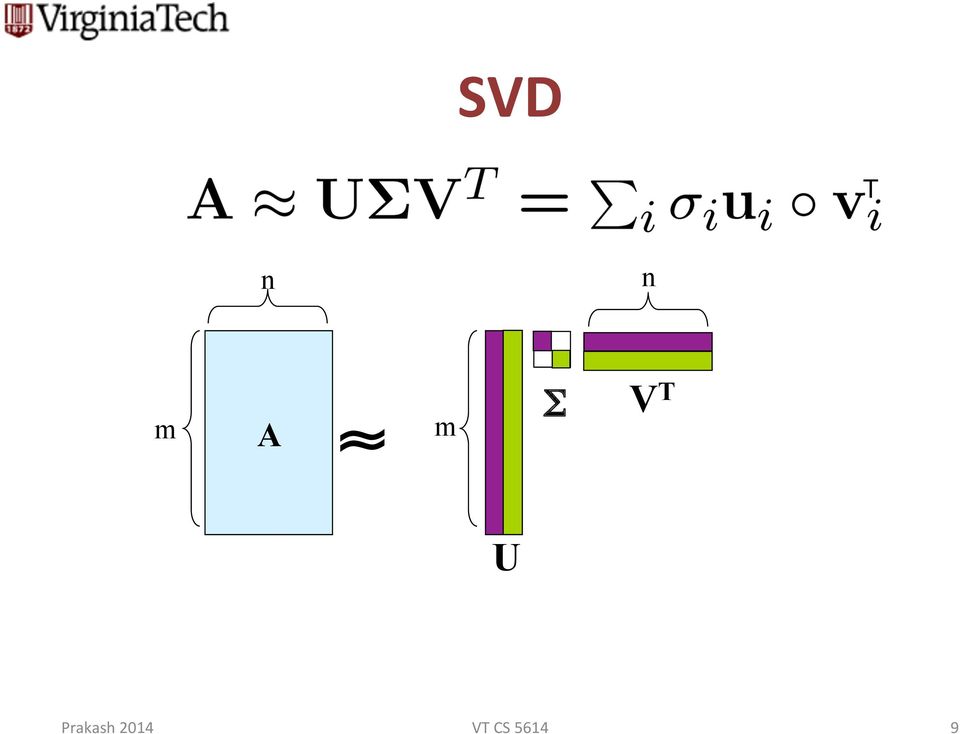
10 SVD T n σ 1 u 1 v 1 σ 2 u 2 v 2 m A + σ i scalar u i vector v i vector 10

11 SVD - Proper=es It is always possible to decompose a real matrix A into A = U Σ V T, where U, Σ, V: unique U, V: column orthonormal U T U = I; V T V = I (I: iden7ty matrix) (Columns are orthogonal unit vectors) Σ: diagonal Entries (singular values) are posi7ve, and sorted in decreasing order (σ 1 σ ) Nice proof of uniqueness: hep:// inf.mpg.de/~bast/ir- seminar- ws04/lecture2.pdf 11
 Nice proof of uniqueness: hep://www.mpi- inf.mpg.de/~bast/ir- seminar- ws04/lecture2.")
12 SciFi Romnce SVD Example: Users- to- Movies A = U Σ V T - example: Users to Movies Matrix Alien Serenity Casablanca Amelie = m U Σ n V T Concepts AKA Latent dimensions AKA Latent factors 12

13 SciFi Romnce SVD Example: Users- to- Movies A = U Σ V T - example: Users to Movies Matrix Alien Serenity Casablanca Amelie = x x

14 SciFi Romnce SVD Example: Users- to- Movies A = U Σ V T - example: Users to Movies Matrix Alien Serenity Casablanca Amelie SciFi- concept = Romance- concept x x

15 SciFi Romnce SVD Example: Users- to- Movies A = U Σ V T - example: Matrix Alien Serenity Casablanca Amelie SciFi- concept = Romance- concept U is user- to- concept similarity matrix x x

16 SVD Example: Users- to- Movies SciFi Romnce A = U Σ V T - example: Matrix Alien Serenity Casablanca Amelie SciFi- concept = x strength of the SciFi- concept x

17 SVD Example: Users- to- Movies SciFi Romnce A = U Σ V T - example: Matrix Alien Serenity Casablanca Amelie SciFi- concept = SciFi- concept V is movie- to- concept similarity matrix x x

18 SVD - Interpreta=on #1 movies, users and concepts : U: user- to- concept similarity matrix V: movie- to- concept similarity matrix Σ: its diagonal elements: strength of each concept 18

19 DIMENSIONALITY REDUCTION WITH SVD

20 SVD Dimensionality Reduc=on Movie 2 rating first right singular vector v 1 Movie 1 rating 20

21 SVD Dimensionality Reduc=on 21
22 SVD - Interpreta=on #2 A = U Σ V T - example: V: movie- to- concept matrix U: user- to- concept matrix Movie 2 rating v 1 first right singular vector Movie 1 rating = x x
23 SVD - Interpreta=on #2 A = U Σ V T - example: variance ( spread ) on the v 1 axis Movie 2 rating v 1 first right singular vector Movie 1 rating = x x
24 SVD - Interpreta=on #2 A = U Σ V T - example: U Σ: Gives the coordinates of the points in the projec7on axis Movie 2 rating v 1 first right singular vector Projection of users on the Sci-Fi axis (U Σ) Τ : Movie 1 rating
25 SVD - Interpreta=on #2 More details Q: How exactly is dim. reduc=on done? = x x
26 SVD - Interpreta=on #2 More details Q: How exactly is dim. reduc=on done? A: Set smallest singular values to zero = x x
27 SVD - Interpreta=on #2 More details Q: How exactly is dim. reduc=on done? A: Set smallest singular values to zero x x
28 SVD - Interpreta=on #2 More details Q: How exactly is dim. reduc=on done? A: Set smallest singular values to zero x x
29 SVD - Interpreta=on #2 More details Q: How exactly is dim. reduc=on done? A: Set smallest singular values to zero x x
30 SVD - Interpreta=on #2 More details Q: How exactly is dim. reduc=on done? A: Set smallest singular values to zero Frobenius norm: ǁ Mǁ F = Σ ij M ij 2 ǁ A-Bǁ F = Σ ij (A ij -B ij ) 2 is small 30
31 SVD Best Low Rank Approx. Sigma A = U V T B is best approximation of A Sigma B = U V T 31
32 SVD Best Low Rank Approx. Theorem: Let A = U Σ V T and B = U S V T where S = diagonal rxr matrix with s i =σ i (i=1 k) else s i =0 then B is a best rank(b)=k approx. to A What do we mean by best : B is a solu=on to min B ǁ A-Bǁ F where rank(b)=k Σ 32
33 Details! SVD Best Low Rank Approx. 33
34 Details! SVD Best Low Rank Approx. 34
35 Details! SVD Best Low Rank Approx. 35
36 SVD - Interpreta=on #2 Equivalent: spectral decomposi=on of the matrix: = u 1 u 2 x σ 1 σ 2 x v 1 v 2 36
37 SVD - Interpreta=on #2 Equivalent: spectral decomposi=on of the matrix n m = u 1 σ 1 v T 1 + σ 2 u 2 vt n x 1 1 x m k terms Assume: σ 1 σ 2 σ Why is setting small σ i to 0 the right thing to do? Vectors u i and v i are unit length, so σ i scales them. So, zeroing small σ i introduces less error. 37
38 SVD - Interpreta=on #2 asd n m = σ 1 u 1 v T 1 + σ 2 u 2 vt Assume: σ 1 σ 2 σ
39 SVD - Complexity To compute SVD: O(nm 2 ) or O(n 2 m) (whichever is less) But: Less work, if we just want singular values or if we want first k singular vectors or if the matrix is sparse Implemented in linear algebra packages like LINPACK, Matlab, SPlus, Mathema7ca... 39
40 SVD - Conclusions so far SVD: A= U Σ V T : unique U: user- to- concept similari7es V: movie- to- concept similari7es Σ : strength of each concept Dimensionality reduc=on: keep the few largest singular values (80-90% of energy ) SVD: picks up linear correla7ons 40
41 Rela=on to Eigen- decomposi=on SVD gives us: A = U Σ V T Eigen- decomposi=on: A = X Λ X T A is symmetric U, V, X are orthonormal (U T U=I), Λ, Σ are diagonal Now let s calculate: AA T = UΣ V T (UΣ V T ) T = UΣ V T (VΣ T U T ) = UΣΣ T U T A T A = V Σ T U T (UΣ V T ) = V ΣΣ T V T 41
42 Rela=on to Eigen- decomposi=on SVD gives us: A = U Σ V T Eigen- decomposi=on: A = X Λ X T A is symmetric U, V, X are orthonormal (U T U=I), Λ, Σ are diagonal Now let s calculate: AA T = UΣ V T (UΣ V T ) T = UΣ V T (VΣ T U T ) = UΣΣ T U T A T A = V Σ T U T (UΣ V T ) = V ΣΣ T V T X Λ 2 X T Shows how to compute SVD using eigenvalue decomposition! X Λ 2 X T 42
43 SVD: Proper=es A A T = U Σ 2 U T A T A = V Σ 2 V T (A T A) k = V Σ 2k V T E.g.: (A T A) 2 = V Σ 2 V T V Σ 2 V T = V Σ 4 V T (A T A) k ~ v 1 σ 1 2k v 1 T for k>>1 43
44 EXAMPLE OF SVD & CONCLUSION
45 SciFi Romnce Case study: How to query? Q: Find users that like Matrix A: Map query into a concept space how? Matrix Alien Serenity Casablanca Amelie = x x
46 Case study: How to query? Q: Find users that like Matrix A: Map query into a concept space how? Matrix Alien Serenity Casablanca Amelie Alien q q = v2 v1 Project into concept space: Inner product with each concept vector v i Matrix 46
47 Case study: How to query? Q: Find users that like Matrix A: Map query into a concept space how? Matrix Alien Serenity Casablanca Amelie Alien q q = v2 v1 q*v 1 Project into concept space: Inner product with each concept vector v i Matrix 47
48 Case study: How to query? Compactly, we have: q concept = q V E.g.: q = Matrix Alien Serenity Casablanca Amelie SciFi- concept x = movie- to- concept similari=es (V) 48
49 Case study: How to query? How would the user d that rated ( Alien, Serenity ) be handled? d concept = d V E.g.: q = Matrix Alien Serenity Casablanca Amelie movie- to- concept similari=es (V) SciFi- concept x =
50 Case study: How to query? Observa=on: User d that rated ( Alien, Serenity ) will be similar to user q that rated ( Matrix ), although d and q have zero ra=ngs in common! Matrix Alien Serenity Casablanca Amelie SciFi- concept d = q = Zero ratings in common Similarity 0 50
51 SVD: Drawbacks + Op=mal low- rank approxima=on in terms of Frobenius norm - Interpretability problem: A singular vector specifies a linear combina7on of all input columns or rows - Lack of sparsity: Singular vectors are dense! = Σ V T U 51
52 CUR DECOMPOSITION
53 CUR Decomposi=on Frobenius norm: ǁ Xǁ F = Σ ij X ij 2 Goal: Express A as a product of matrices C,U,R Make ǁ A- C U Rǁ F small Constraints on C and R: A C U R 53
54 CUR Decomposi=on Goal: Express A as a product of matrices C,U,R Make ǁ A- C U Rǁ F small Constraints on C and R: Frobenius norm: ǁ Xǁ F = Σ ij X ij 2 Pseudo- inverse of the intersec=on of C and R A C U R 54
55 CUR: Provably good approx. to SVD Let: A k be the best rank k approxima7on to A (that is, A k is SVD of A) Theorem [Drineas et al.] CUR in O(m n) 7me achieves ǁ A- CURǁ F ǁ A- A k ǁ F + εǁ Aǁ F with probability at least 1- δ, by picking O(k log(1/δ)/ε 2 ) columns, and O(k 2 log 3 (1/δ)/ε 6 ) rows In practice: Pick 4k cols/rows 55
56 CUR: How it Works Sampling columns (similarly for rows): Note this is a randomized algorithm, same column can be sampled more than once 56
57 Compu=ng U Let W be the intersec7on of sampled columns C and rows R Let SVD of W = X Z Y T Then: U = W + = Y Z + X T Ζ + : reciprocals of non- zero singular values: Ζ + ii =1/ Ζ ii W + is the pseudoinverse A C W R Why pseudoinverse works? W = X Z Y then W -1 = X -1 Z -1 Y -1 Due to orthonomality X -1 =X T and Y -1 =Y T Since Z is diagonal Z -1 = 1/Z ii Thus, if W is nonsingular, pseudoinverse is the true inverse U = W + 57
58 CUR: Provably good approx. to SVD 58
59 CUR: Pros & Cons + Easy interpreta=on Since the basis vectors are actual columns and rows + Sparse basis Since the basis vectors are actual columns and rows - Duplicate columns and rows Columns of large norms will be sampled many 7mes Actual column Singular vector 59
60 Solu=on If we want to get rid of the duplicates: Throw them away Scale (mul7ply) the columns/rows by the square root of the number of duplicates R d R s A C d C s Construct a small U 60
61 SVD vs. CUR sparse and small SVD: A = U Σ V T Huge but sparse Big and dense dense but small CUR: A = C U R Huge but sparse Big but sparse 61
62 SVD vs. CUR: Simple Experiment DBLP bibliographic data Author- to- conference big sparse matrix A ij : Number of papers published by author i at conference j 428K authors (rows), 3659 conferences (columns) Very sparse Want to reduce dimensionality How much 7me does it take? What is the reconstruc7on error? How much space do we need? 62
63 Results: DBLP- big sparse matrix SVD SVD CUR CUR no duplicates SVD CUR CUR no dup CUR Accuracy: 1 rela7ve sum squared errors Space ra=o: #output matrix entries / #input matrix entries CPU =me Sun, Faloutsos: Less is More: Compact Matrix Decomposition for Large Sparse Graphs, SDM
64 What about linearity assump=on? SVD is limited to linear projec=ons: Lower- dimensional linear projec7on that preserves Euclidean distances Non- linear methods: Isomap Data lies on a nonlinear low- dim curve aka manifold Use the distance as measured along the manifold How? Build adjacency graph Geodesic distance is graph distance SVD/PCA the graph pairwise distance matrix 64
65 Further Reading: CUR Drineas et al., Fast Monte Carlo Algorithms for Matrices III: CompuEng a Compressed Approximate Matrix DecomposiEon, SIAM Journal on Compu7ng, J. Sun, Y. Xie, H. Zhang, C. Faloutsos: Less is More: Compact Matrix DecomposiEon for Large Sparse Graphs, SDM 2007 Intra- and interpopulaeon genotype reconstruceon from tagging SNPs, P. Paschou, M. W. Mahoney, A. Javed, J. R. Kidd, A. J. Paks7s, S. Gu, K. K. Kidd, and P. Drineas, Genome Research, 17(1), (2007) Tensor- CUR DecomposiEons For Tensor- Based Data, M. W. Mahoney, M. Maggioni, and P. Drineas, Proc. 12- th Annual SIGKDD, (2006) 65
Linear Algebra Review. Vectors
 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka kosecka@cs.gmu.edu http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa Cogsci 8F Linear Algebra review UCSD Vectors The length
Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka kosecka@cs.gmu.edu http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa Cogsci 8F Linear Algebra review UCSD Vectors The length
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 3, 2014 Text Analytics (Text Mining) LSI (uses SVD), Visualization Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey
CSE 6242 / CX 4242 Apr 3, 2014 Text Analytics (Text Mining) LSI (uses SVD), Visualization Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey
Manifold Learning Examples PCA, LLE and ISOMAP
 Manifold Learning Examples PCA, LLE and ISOMAP Dan Ventura October 14, 28 Abstract We try to give a helpful concrete example that demonstrates how to use PCA, LLE and Isomap, attempts to provide some intuition
Manifold Learning Examples PCA, LLE and ISOMAP Dan Ventura October 14, 28 Abstract We try to give a helpful concrete example that demonstrates how to use PCA, LLE and Isomap, attempts to provide some intuition
Orthogonal Diagonalization of Symmetric Matrices
 MATH10212 Linear Algebra Brief lecture notes 57 Gram Schmidt Process enables us to find an orthogonal basis of a subspace. Let u 1,..., u k be a basis of a subspace V of R n. We begin the process of finding
MATH10212 Linear Algebra Brief lecture notes 57 Gram Schmidt Process enables us to find an orthogonal basis of a subspace. Let u 1,..., u k be a basis of a subspace V of R n. We begin the process of finding
Lecture 5: Singular Value Decomposition SVD (1)
") EEM3L1: Numerical and Analytical Techniques Lecture 5: Singular Value Decomposition SVD (1) EE3L1, slide 1, Version 4: 25-Sep-02 Motivation for SVD (1) SVD = Singular Value Decomposition Consider the system
EEM3L1: Numerical and Analytical Techniques Lecture 5: Singular Value Decomposition SVD (1) EE3L1, slide 1, Version 4: 25-Sep-02 Motivation for SVD (1) SVD = Singular Value Decomposition Consider the system
The Singular Value Decomposition in Symmetric (Löwdin) Orthogonalization and Data Compression
 Orthogonalization and Data Compression") The Singular Value Decomposition in Symmetric (Löwdin) Orthogonalization and Data Compression The SVD is the most generally applicable of the orthogonal-diagonal-orthogonal type matrix decompositions Every
The Singular Value Decomposition in Symmetric (Löwdin) Orthogonalization and Data Compression The SVD is the most generally applicable of the orthogonal-diagonal-orthogonal type matrix decompositions Every
Similarity and Diagonalization. Similar Matrices
 MATH022 Linear Algebra Brief lecture notes 48 Similarity and Diagonalization Similar Matrices Let A and B be n n matrices. We say that A is similar to B if there is an invertible n n matrix P such that
MATH022 Linear Algebra Brief lecture notes 48 Similarity and Diagonalization Similar Matrices Let A and B be n n matrices. We say that A is similar to B if there is an invertible n n matrix P such that
CS3220 Lecture Notes: QR factorization and orthogonal transformations
 CS3220 Lecture Notes: QR factorization and orthogonal transformations Steve Marschner Cornell University 11 March 2009 In this lecture I ll talk about orthogonal matrices and their properties, discuss
CS3220 Lecture Notes: QR factorization and orthogonal transformations Steve Marschner Cornell University 11 March 2009 In this lecture I ll talk about orthogonal matrices and their properties, discuss
Multimedia Databases. Wolf-Tilo Balke Philipp Wille Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.
 Multimedia Databases Wolf-Tilo Balke Philipp Wille Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 14 Previous Lecture 13 Indexes for Multimedia Data 13.1
Multimedia Databases Wolf-Tilo Balke Philipp Wille Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 14 Previous Lecture 13 Indexes for Multimedia Data 13.1
17. Inner product spaces Definition 17.1. Let V be a real vector space. An inner product on V is a function
 17. Inner product spaces Definition 17.1. Let V be a real vector space. An inner product on V is a function, : V V R, which is symmetric, that is u, v = v, u. bilinear, that is linear (in both factors):
17. Inner product spaces Definition 17.1. Let V be a real vector space. An inner product on V is a function, : V V R, which is symmetric, that is u, v = v, u. bilinear, that is linear (in both factors):
α = u v. In other words, Orthogonal Projection
 Orthogonal Projection Given any nonzero vector v, it is possible to decompose an arbitrary vector u into a component that points in the direction of v and one that points in a direction orthogonal to v
Orthogonal Projection Given any nonzero vector v, it is possible to decompose an arbitrary vector u into a component that points in the direction of v and one that points in a direction orthogonal to v
Notes on Symmetric Matrices
 CPSC 536N: Randomized Algorithms 2011-12 Term 2 Notes on Symmetric Matrices Prof. Nick Harvey University of British Columbia 1 Symmetric Matrices We review some basic results concerning symmetric matrices.
CPSC 536N: Randomized Algorithms 2011-12 Term 2 Notes on Symmetric Matrices Prof. Nick Harvey University of British Columbia 1 Symmetric Matrices We review some basic results concerning symmetric matrices.
Nonlinear Iterative Partial Least Squares Method
 Numerical Methods for Determining Principal Component Analysis Abstract Factors Béchu, S., Richard-Plouet, M., Fernandez, V., Walton, J., and Fairley, N. (2016) Developments in numerical treatments for
Numerical Methods for Determining Principal Component Analysis Abstract Factors Béchu, S., Richard-Plouet, M., Fernandez, V., Walton, J., and Fairley, N. (2016) Developments in numerical treatments for
Chapter 6. Orthogonality
 6.3 Orthogonal Matrices 1 Chapter 6. Orthogonality 6.3 Orthogonal Matrices Definition 6.4. An n n matrix A is orthogonal if A T A = I. Note. We will see that the columns of an orthogonal matrix must be
6.3 Orthogonal Matrices 1 Chapter 6. Orthogonality 6.3 Orthogonal Matrices Definition 6.4. An n n matrix A is orthogonal if A T A = I. Note. We will see that the columns of an orthogonal matrix must be
3 Orthogonal Vectors and Matrices
 3 Orthogonal Vectors and Matrices The linear algebra portion of this course focuses on three matrix factorizations: QR factorization, singular valued decomposition (SVD), and LU factorization The first
3 Orthogonal Vectors and Matrices The linear algebra portion of this course focuses on three matrix factorizations: QR factorization, singular valued decomposition (SVD), and LU factorization The first
APPM4720/5720: Fast algorithms for big data. Gunnar Martinsson The University of Colorado at Boulder
 APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
Review Jeopardy. Blue vs. Orange. Review Jeopardy
 Review Jeopardy Blue vs. Orange Review Jeopardy Jeopardy Round Lectures 0-3 Jeopardy Round $200 How could I measure how far apart (i.e. how different) two observations, y 1 and y 2, are from each other?
Review Jeopardy Blue vs. Orange Review Jeopardy Jeopardy Round Lectures 0-3 Jeopardy Round $200 How could I measure how far apart (i.e. how different) two observations, y 1 and y 2, are from each other?
6. Cholesky factorization
 6. Cholesky factorization EE103 (Fall 2011-12) triangular matrices forward and backward substitution the Cholesky factorization solving Ax = b with A positive definite inverse of a positive definite matrix
6. Cholesky factorization EE103 (Fall 2011-12) triangular matrices forward and backward substitution the Cholesky factorization solving Ax = b with A positive definite inverse of a positive definite matrix
1 2 3 1 1 2 x = + x 2 + x 4 1 0 1
 (d) If the vector b is the sum of the four columns of A, write down the complete solution to Ax = b. 1 2 3 1 1 2 x = + x 2 + x 4 1 0 0 1 0 1 2. (11 points) This problem finds the curve y = C + D 2 t which
(d) If the vector b is the sum of the four columns of A, write down the complete solution to Ax = b. 1 2 3 1 1 2 x = + x 2 + x 4 1 0 0 1 0 1 2. (11 points) This problem finds the curve y = C + D 2 t which
1 Introduction to Matrices
 1 Introduction to Matrices In this section, important definitions and results from matrix algebra that are useful in regression analysis are introduced. While all statements below regarding the columns
1 Introduction to Matrices In this section, important definitions and results from matrix algebra that are useful in regression analysis are introduced. While all statements below regarding the columns
Inner Product Spaces and Orthogonality
 Inner Product Spaces and Orthogonality week 3-4 Fall 2006 Dot product of R n The inner product or dot product of R n is a function, defined by u, v a b + a 2 b 2 + + a n b n for u a, a 2,, a n T, v b,
Inner Product Spaces and Orthogonality week 3-4 Fall 2006 Dot product of R n The inner product or dot product of R n is a function, defined by u, v a b + a 2 b 2 + + a n b n for u a, a 2,, a n T, v b,
Orthogonal Projections
 Orthogonal Projections and Reflections (with exercises) by D. Klain Version.. Corrections and comments are welcome! Orthogonal Projections Let X,..., X k be a family of linearly independent (column) vectors
Orthogonal Projections and Reflections (with exercises) by D. Klain Version.. Corrections and comments are welcome! Orthogonal Projections Let X,..., X k be a family of linearly independent (column) vectors
Modélisation et résolutions numérique et symbolique
 Modélisation et résolutions numérique et symbolique via les logiciels Maple et Matlab Jeremy Berthomieu Mohab Safey El Din Stef Graillat Mohab.Safey@lip6.fr Outline Previous course: partial review of what
Modélisation et résolutions numérique et symbolique via les logiciels Maple et Matlab Jeremy Berthomieu Mohab Safey El Din Stef Graillat Mohab.Safey@lip6.fr Outline Previous course: partial review of what
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
Linear Algebraic Equations, SVD, and the Pseudo-Inverse
 Linear Algebraic Equations, SVD, and the Pseudo-Inverse Philip N. Sabes October, 21 1 A Little Background 1.1 Singular values and matrix inversion For non-smmetric matrices, the eigenvalues and singular
Linear Algebraic Equations, SVD, and the Pseudo-Inverse Philip N. Sabes October, 21 1 A Little Background 1.1 Singular values and matrix inversion For non-smmetric matrices, the eigenvalues and singular
BIG Biomedicine and the Foundations of BIG Data Analysis
 BIG Biomedicine and the Foundations of BIG Data Analysis Insider s vs outsider s views (1 of 2) Ques: Genetics vs molecular biology vs biochemistry vs biophysics: What s the difference? Insider s vs outsider
BIG Biomedicine and the Foundations of BIG Data Analysis Insider s vs outsider s views (1 of 2) Ques: Genetics vs molecular biology vs biochemistry vs biophysics: What s the difference? Insider s vs outsider
Torgerson s Classical MDS derivation: 1: Determining Coordinates from Euclidean Distances
 Torgerson s Classical MDS derivation: 1: Determining Coordinates from Euclidean Distances It is possible to construct a matrix X of Cartesian coordinates of points in Euclidean space when we know the Euclidean
Torgerson s Classical MDS derivation: 1: Determining Coordinates from Euclidean Distances It is possible to construct a matrix X of Cartesian coordinates of points in Euclidean space when we know the Euclidean
Differential Privacy Preserving Spectral Graph Analysis
 Differential Privacy Preserving Spectral Graph Analysis Yue Wang, Xintao Wu, and Leting Wu University of North Carolina at Charlotte, {ywang91, xwu, lwu8}@uncc.edu Abstract. In this paper, we focus on
Differential Privacy Preserving Spectral Graph Analysis Yue Wang, Xintao Wu, and Leting Wu University of North Carolina at Charlotte, {ywang91, xwu, lwu8}@uncc.edu Abstract. In this paper, we focus on
15.062 Data Mining: Algorithms and Applications Matrix Math Review
 .6 Data Mining: Algorithms and Applications Matrix Math Review The purpose of this document is to give a brief review of selected linear algebra concepts that will be useful for the course and to develop
.6 Data Mining: Algorithms and Applications Matrix Math Review The purpose of this document is to give a brief review of selected linear algebra concepts that will be useful for the course and to develop
Math 550 Notes. Chapter 7. Jesse Crawford. Department of Mathematics Tarleton State University. Fall 2010
 Math 550 Notes Chapter 7 Jesse Crawford Department of Mathematics Tarleton State University Fall 2010 (Tarleton State University) Math 550 Chapter 7 Fall 2010 1 / 34 Outline 1 Self-Adjoint and Normal Operators
Math 550 Notes Chapter 7 Jesse Crawford Department of Mathematics Tarleton State University Fall 2010 (Tarleton State University) Math 550 Chapter 7 Fall 2010 1 / 34 Outline 1 Self-Adjoint and Normal Operators
Lecture Topic: Low-Rank Approximations
 Lecture Topic: Low-Rank Approximations Low-Rank Approximations We have seen principal component analysis. The extraction of the first principle eigenvalue could be seen as an approximation of the original
Lecture Topic: Low-Rank Approximations Low-Rank Approximations We have seen principal component analysis. The extraction of the first principle eigenvalue could be seen as an approximation of the original
by the matrix A results in a vector which is a reflection of the given
 Eigenvalues & Eigenvectors Example Suppose Then So, geometrically, multiplying a vector in by the matrix A results in a vector which is a reflection of the given vector about the y-axis We observe that
Eigenvalues & Eigenvectors Example Suppose Then So, geometrically, multiplying a vector in by the matrix A results in a vector which is a reflection of the given vector about the y-axis We observe that
Learning, Sparsity and Big Data
 Learning, Sparsity and Big Data M. Magdon-Ismail (Joint Work) January 22, 2014. Out-of-Sample is What Counts NO YES A pattern exists We don t know it We have data to learn it Tested on new cases? Teaching
Learning, Sparsity and Big Data M. Magdon-Ismail (Joint Work) January 22, 2014. Out-of-Sample is What Counts NO YES A pattern exists We don t know it We have data to learn it Tested on new cases? Teaching
Inner product. Definition of inner product
 Math 20F Linear Algebra Lecture 25 1 Inner product Review: Definition of inner product. Slide 1 Norm and distance. Orthogonal vectors. Orthogonal complement. Orthogonal basis. Definition of inner product
Math 20F Linear Algebra Lecture 25 1 Inner product Review: Definition of inner product. Slide 1 Norm and distance. Orthogonal vectors. Orthogonal complement. Orthogonal basis. Definition of inner product
Introduction to Matrix Algebra
 Psychology 7291: Multivariate Statistics (Carey) 8/27/98 Matrix Algebra - 1 Introduction to Matrix Algebra Definitions: A matrix is a collection of numbers ordered by rows and columns. It is customary
Psychology 7291: Multivariate Statistics (Carey) 8/27/98 Matrix Algebra - 1 Introduction to Matrix Algebra Definitions: A matrix is a collection of numbers ordered by rows and columns. It is customary
5. Orthogonal matrices
 L Vandenberghe EE133A (Spring 2016) 5 Orthogonal matrices matrices with orthonormal columns orthogonal matrices tall matrices with orthonormal columns complex matrices with orthonormal columns 5-1 Orthonormal
L Vandenberghe EE133A (Spring 2016) 5 Orthogonal matrices matrices with orthonormal columns orthogonal matrices tall matrices with orthonormal columns complex matrices with orthonormal columns 5-1 Orthonormal
Multidimensional data and factorial methods
 Multidimensional data and factorial methods Bidimensional data x 5 4 3 4 X 3 6 X 3 5 4 3 3 3 4 5 6 x Cartesian plane Multidimensional data n X x x x n X x x x n X m x m x m x nm Factorial plane Interpretation
Multidimensional data and factorial methods Bidimensional data x 5 4 3 4 X 3 6 X 3 5 4 3 3 3 4 5 6 x Cartesian plane Multidimensional data n X x x x n X x x x n X m x m x m x nm Factorial plane Interpretation
Learning Gaussian process models from big data. Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu
 Learning Gaussian process models from big data Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu Machine learning seminar at University of Cambridge, July 4 2012 Data A lot of
Learning Gaussian process models from big data Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu Machine learning seminar at University of Cambridge, July 4 2012 Data A lot of
13 MATH FACTS 101. 2 a = 1. 7. The elements of a vector have a graphical interpretation, which is particularly easy to see in two or three dimensions.
 3 MATH FACTS 0 3 MATH FACTS 3. Vectors 3.. Definition We use the overhead arrow to denote a column vector, i.e., a linear segment with a direction. For example, in three-space, we write a vector in terms
3 MATH FACTS 0 3 MATH FACTS 3. Vectors 3.. Definition We use the overhead arrow to denote a column vector, i.e., a linear segment with a direction. For example, in three-space, we write a vector in terms
Mehtap Ergüven Abstract of Ph.D. Dissertation for the degree of PhD of Engineering in Informatics
 INTERNATIONAL BLACK SEA UNIVERSITY COMPUTER TECHNOLOGIES AND ENGINEERING FACULTY ELABORATION OF AN ALGORITHM OF DETECTING TESTS DIMENSIONALITY Mehtap Ergüven Abstract of Ph.D. Dissertation for the degree
INTERNATIONAL BLACK SEA UNIVERSITY COMPUTER TECHNOLOGIES AND ENGINEERING FACULTY ELABORATION OF AN ALGORITHM OF DETECTING TESTS DIMENSIONALITY Mehtap Ergüven Abstract of Ph.D. Dissertation for the degree
Problem Set 5 Due: In class Thursday, Oct. 18 Late papers will be accepted until 1:00 PM Friday.
 Math 312, Fall 2012 Jerry L. Kazdan Problem Set 5 Due: In class Thursday, Oct. 18 Late papers will be accepted until 1:00 PM Friday. In addition to the problems below, you should also know how to solve
Math 312, Fall 2012 Jerry L. Kazdan Problem Set 5 Due: In class Thursday, Oct. 18 Late papers will be accepted until 1:00 PM Friday. In addition to the problems below, you should also know how to solve
Bindel, Spring 2012 Intro to Scientific Computing (CS 3220) Week 3: Wednesday, Feb 8
 Week 3: Wednesday, Feb 8") Spaces and bases Week 3: Wednesday, Feb 8 I have two favorite vector spaces 1 : R n and the space P d of polynomials of degree at most d. For R n, we have a canonical basis: R n = span{e 1, e 2,..., e
Spaces and bases Week 3: Wednesday, Feb 8 I have two favorite vector spaces 1 : R n and the space P d of polynomials of degree at most d. For R n, we have a canonical basis: R n = span{e 1, e 2,..., e
Similar matrices and Jordan form
 Similar matrices and Jordan form We ve nearly covered the entire heart of linear algebra once we ve finished singular value decompositions we ll have seen all the most central topics. A T A is positive
Similar matrices and Jordan form We ve nearly covered the entire heart of linear algebra once we ve finished singular value decompositions we ll have seen all the most central topics. A T A is positive
Applied Linear Algebra I Review page 1
 Applied Linear Algebra Review 1 I. Determinants A. Definition of a determinant 1. Using sum a. Permutations i. Sign of a permutation ii. Cycle 2. Uniqueness of the determinant function in terms of properties
Applied Linear Algebra Review 1 I. Determinants A. Definition of a determinant 1. Using sum a. Permutations i. Sign of a permutation ii. Cycle 2. Uniqueness of the determinant function in terms of properties
[1] Diagonal factorization
![[1] Diagonal factorization](/thumbs/40/21671034.jpg "[1] Diagonal factorization") 8.03 LA.6: Diagonalization and Orthogonal Matrices [ Diagonal factorization [2 Solving systems of first order differential equations [3 Symmetric and Orthonormal Matrices [ Diagonal factorization Recall:
8.03 LA.6: Diagonalization and Orthogonal Matrices [ Diagonal factorization [2 Solving systems of first order differential equations [3 Symmetric and Orthonormal Matrices [ Diagonal factorization Recall:
DATA ANALYSIS II. Matrix Algorithms
 DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
3. INNER PRODUCT SPACES
 . INNER PRODUCT SPACES.. Definition So far we have studied abstract vector spaces. These are a generalisation of the geometric spaces R and R. But these have more structure than just that of a vector space.
. INNER PRODUCT SPACES.. Definition So far we have studied abstract vector spaces. These are a generalisation of the geometric spaces R and R. But these have more structure than just that of a vector space.
LINEAR ALGEBRA. September 23, 2010
 LINEAR ALGEBRA September 3, 00 Contents 0. LU-decomposition.................................... 0. Inverses and Transposes................................. 0.3 Column Spaces and NullSpaces.............................
LINEAR ALGEBRA September 3, 00 Contents 0. LU-decomposition.................................... 0. Inverses and Transposes................................. 0.3 Column Spaces and NullSpaces.............................
1 VECTOR SPACES AND SUBSPACES
 1 VECTOR SPACES AND SUBSPACES What is a vector? Many are familiar with the concept of a vector as: Something which has magnitude and direction. an ordered pair or triple. a description for quantities such
1 VECTOR SPACES AND SUBSPACES What is a vector? Many are familiar with the concept of a vector as: Something which has magnitude and direction. an ordered pair or triple. a description for quantities such
Metrics on SO(3) and Inverse Kinematics
 and Inverse Kinematics") Mathematical Foundations of Computer Graphics and Vision Metrics on SO(3) and Inverse Kinematics Luca Ballan Institute of Visual Computing Optimization on Manifolds Descent approach d is a ascent direction
Mathematical Foundations of Computer Graphics and Vision Metrics on SO(3) and Inverse Kinematics Luca Ballan Institute of Visual Computing Optimization on Manifolds Descent approach d is a ascent direction
Computational Optical Imaging - Optique Numerique. -- Deconvolution --
 Computational Optical Imaging - Optique Numerique -- Deconvolution -- Winter 2014 Ivo Ihrke Deconvolution Ivo Ihrke Outline Deconvolution Theory example 1D deconvolution Fourier method Algebraic method
Computational Optical Imaging - Optique Numerique -- Deconvolution -- Winter 2014 Ivo Ihrke Deconvolution Ivo Ihrke Outline Deconvolution Theory example 1D deconvolution Fourier method Algebraic method
Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning
 in Semi-supervised Learning Reducing Dimension and Maintaining Meaning") Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013 Outline Introduction to NMF Applications Motivations NMF as a middle step
Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013 Outline Introduction to NMF Applications Motivations NMF as a middle step
Dimensionality Reduction: Principal Components Analysis
 Dimensionality Reduction: Principal Components Analysis In data mining one often encounters situations where there are a large number of variables in the database. In such situations it is very likely
Dimensionality Reduction: Principal Components Analysis In data mining one often encounters situations where there are a large number of variables in the database. In such situations it is very likely
Nimble Algorithms for Cloud Computing. Ravi Kannan, Santosh Vempala and David Woodruff
 Nimble Algorithms for Cloud Computing Ravi Kannan, Santosh Vempala and David Woodruff Cloud computing Data is distributed arbitrarily on many servers Parallel algorithms: time Streaming algorithms: sublinear
Nimble Algorithms for Cloud Computing Ravi Kannan, Santosh Vempala and David Woodruff Cloud computing Data is distributed arbitrarily on many servers Parallel algorithms: time Streaming algorithms: sublinear
CHAPTER 8 FACTOR EXTRACTION BY MATRIX FACTORING TECHNIQUES. From Exploratory Factor Analysis Ledyard R Tucker and Robert C.
 CHAPTER 8 FACTOR EXTRACTION BY MATRIX FACTORING TECHNIQUES From Exploratory Factor Analysis Ledyard R Tucker and Robert C MacCallum 1997 180 CHAPTER 8 FACTOR EXTRACTION BY MATRIX FACTORING TECHNIQUES In
CHAPTER 8 FACTOR EXTRACTION BY MATRIX FACTORING TECHNIQUES From Exploratory Factor Analysis Ledyard R Tucker and Robert C MacCallum 1997 180 CHAPTER 8 FACTOR EXTRACTION BY MATRIX FACTORING TECHNIQUES In
MATH 423 Linear Algebra II Lecture 38: Generalized eigenvectors. Jordan canonical form (continued).
.") MATH 423 Linear Algebra II Lecture 38: Generalized eigenvectors Jordan canonical form (continued) Jordan canonical form A Jordan block is a square matrix of the form λ 1 0 0 0 0 λ 1 0 0 0 0 λ 0 0 J = 0
MATH 423 Linear Algebra II Lecture 38: Generalized eigenvectors Jordan canonical form (continued) Jordan canonical form A Jordan block is a square matrix of the form λ 1 0 0 0 0 λ 1 0 0 0 0 λ 0 0 J = 0
Pa8ern Recogni6on. and Machine Learning. Chapter 4: Linear Models for Classifica6on
 Pa8ern Recogni6on and Machine Learning Chapter 4: Linear Models for Classifica6on Represen'ng the target values for classifica'on If there are only two classes, we typically use a single real valued output
Pa8ern Recogni6on and Machine Learning Chapter 4: Linear Models for Classifica6on Represen'ng the target values for classifica'on If there are only two classes, we typically use a single real valued output
Sketch As a Tool for Numerical Linear Algebra
 Sketching as a Tool for Numerical Linear Algebra (Graph Sparsification) David P. Woodruff presented by Sepehr Assadi o(n) Big Data Reading Group University of Pennsylvania April, 2015 Sepehr Assadi (Penn)
Sketching as a Tool for Numerical Linear Algebra (Graph Sparsification) David P. Woodruff presented by Sepehr Assadi o(n) Big Data Reading Group University of Pennsylvania April, 2015 Sepehr Assadi (Penn)
W. Heath Rushing Adsurgo LLC. Harness the Power of Text Analytics: Unstructured Data Analysis for Healthcare. Session H-1 JTCC: October 23, 2015
 W. Heath Rushing Adsurgo LLC Harness the Power of Text Analytics: Unstructured Data Analysis for Healthcare Session H-1 JTCC: October 23, 2015 Outline Demonstration: Recent article on cnn.com Introduction
W. Heath Rushing Adsurgo LLC Harness the Power of Text Analytics: Unstructured Data Analysis for Healthcare Session H-1 JTCC: October 23, 2015 Outline Demonstration: Recent article on cnn.com Introduction
Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression
 Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression Saikat Maitra and Jun Yan Abstract: Dimension reduction is one of the major tasks for multivariate
Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression Saikat Maitra and Jun Yan Abstract: Dimension reduction is one of the major tasks for multivariate
Numerical Analysis Lecture Notes
 Numerical Analysis Lecture Notes Peter J. Olver 6. Eigenvalues and Singular Values In this section, we collect together the basic facts about eigenvalues and eigenvectors. From a geometrical viewpoint,
Numerical Analysis Lecture Notes Peter J. Olver 6. Eigenvalues and Singular Values In this section, we collect together the basic facts about eigenvalues and eigenvectors. From a geometrical viewpoint,
Multidimensional data analysis
 Multidimensional data analysis Ella Bingham Dept of Computer Science, University of Helsinki ella.bingham@cs.helsinki.fi June 2008 The Finnish Graduate School in Astronomy and Space Physics Summer School
Multidimensional data analysis Ella Bingham Dept of Computer Science, University of Helsinki ella.bingham@cs.helsinki.fi June 2008 The Finnish Graduate School in Astronomy and Space Physics Summer School
Linear Algebra and TI 89
 Linear Algebra and TI 89 Abdul Hassen and Jay Schiffman This short manual is a quick guide to the use of TI89 for Linear Algebra. We do this in two sections. In the first section, we will go over the editing
Linear Algebra and TI 89 Abdul Hassen and Jay Schiffman This short manual is a quick guide to the use of TI89 for Linear Algebra. We do this in two sections. In the first section, we will go over the editing
Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics
 Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics Part I: Factorizations and Statistical Modeling/Inference Amnon Shashua School of Computer Science & Eng. The Hebrew University
Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics Part I: Factorizations and Statistical Modeling/Inference Amnon Shashua School of Computer Science & Eng. The Hebrew University
MATRIX ALGEBRA AND SYSTEMS OF EQUATIONS. + + x 2. x n. a 11 a 12 a 1n b 1 a 21 a 22 a 2n b 2 a 31 a 32 a 3n b 3. a m1 a m2 a mn b m
 MATRIX ALGEBRA AND SYSTEMS OF EQUATIONS 1. SYSTEMS OF EQUATIONS AND MATRICES 1.1. Representation of a linear system. The general system of m equations in n unknowns can be written a 11 x 1 + a 12 x 2 +
MATRIX ALGEBRA AND SYSTEMS OF EQUATIONS 1. SYSTEMS OF EQUATIONS AND MATRICES 1.1. Representation of a linear system. The general system of m equations in n unknowns can be written a 11 x 1 + a 12 x 2 +
CONTROLLABILITY. Chapter 2. 2.1 Reachable Set and Controllability. Suppose we have a linear system described by the state equation
 Chapter 2 CONTROLLABILITY 2 Reachable Set and Controllability Suppose we have a linear system described by the state equation ẋ Ax + Bu (2) x() x Consider the following problem For a given vector x in
Chapter 2 CONTROLLABILITY 2 Reachable Set and Controllability Suppose we have a linear system described by the state equation ẋ Ax + Bu (2) x() x Consider the following problem For a given vector x in
WEEK #3, Lecture 1: Sparse Systems, MATLAB Graphics
 WEEK #3, Lecture 1: Sparse Systems, MATLAB Graphics Visualization of Matrices Good visuals anchor any presentation. MATLAB has a wide variety of ways to display data and calculation results that can be
WEEK #3, Lecture 1: Sparse Systems, MATLAB Graphics Visualization of Matrices Good visuals anchor any presentation. MATLAB has a wide variety of ways to display data and calculation results that can be
Randomized Robust Linear Regression for big data applications
 Randomized Robust Linear Regression for big data applications Yannis Kopsinis 1 Dept. of Informatics & Telecommunications, UoA Thursday, Apr 16, 2015 In collaboration with S. Chouvardas, Harris Georgiou,
Randomized Robust Linear Regression for big data applications Yannis Kopsinis 1 Dept. of Informatics & Telecommunications, UoA Thursday, Apr 16, 2015 In collaboration with S. Chouvardas, Harris Georgiou,
Notes on Orthogonal and Symmetric Matrices MENU, Winter 2013
 Notes on Orthogonal and Symmetric Matrices MENU, Winter 201 These notes summarize the main properties and uses of orthogonal and symmetric matrices. We covered quite a bit of material regarding these topics,
Notes on Orthogonal and Symmetric Matrices MENU, Winter 201 These notes summarize the main properties and uses of orthogonal and symmetric matrices. We covered quite a bit of material regarding these topics,
Linear algebra and the geometry of quadratic equations. Similarity transformations and orthogonal matrices
 MATH 30 Differential Equations Spring 006 Linear algebra and the geometry of quadratic equations Similarity transformations and orthogonal matrices First, some things to recall from linear algebra Two
MATH 30 Differential Equations Spring 006 Linear algebra and the geometry of quadratic equations Similarity transformations and orthogonal matrices First, some things to recall from linear algebra Two
We shall turn our attention to solving linear systems of equations. Ax = b
 59 Linear Algebra We shall turn our attention to solving linear systems of equations Ax = b where A R m n, x R n, and b R m. We already saw examples of methods that required the solution of a linear system
59 Linear Algebra We shall turn our attention to solving linear systems of equations Ax = b where A R m n, x R n, and b R m. We already saw examples of methods that required the solution of a linear system
Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs
 CSE599s: Extremal Combinatorics November 21, 2011 Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs Lecturer: Anup Rao 1 An Arithmetic Circuit Lower Bound An arithmetic circuit is just like
CSE599s: Extremal Combinatorics November 21, 2011 Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs Lecturer: Anup Rao 1 An Arithmetic Circuit Lower Bound An arithmetic circuit is just like
Dimension Reduction. Wei-Ta Chu 2014/10/22. Multimedia Content Analysis, CSIE, CCU
 1 Dimension Reduction Wei-Ta Chu 2014/10/22 2 1.1 Principal Component Analysis (PCA) Widely used in dimensionality reduction, lossy data compression, feature extraction, and data visualization Also known
1 Dimension Reduction Wei-Ta Chu 2014/10/22 2 1.1 Principal Component Analysis (PCA) Widely used in dimensionality reduction, lossy data compression, feature extraction, and data visualization Also known
Examination paper for TMA4205 Numerical Linear Algebra
 Department of Mathematical Sciences Examination paper for TMA4205 Numerical Linear Algebra Academic contact during examination: Markus Grasmair Phone: 97580435 Examination date: December 16, 2015 Examination
Department of Mathematical Sciences Examination paper for TMA4205 Numerical Linear Algebra Academic contact during examination: Markus Grasmair Phone: 97580435 Examination date: December 16, 2015 Examination
NCSS Statistical Software Principal Components Regression. In ordinary least squares, the regression coefficients are estimated using the formula ( )
") Chapter 340 Principal Components Regression Introduction is a technique for analyzing multiple regression data that suffer from multicollinearity. When multicollinearity occurs, least squares estimates
Chapter 340 Principal Components Regression Introduction is a technique for analyzing multiple regression data that suffer from multicollinearity. When multicollinearity occurs, least squares estimates
Vector and Matrix Norms
 Chapter 1 Vector and Matrix Norms 11 Vector Spaces Let F be a field (such as the real numbers, R, or complex numbers, C) with elements called scalars A Vector Space, V, over the field F is a non-empty
Chapter 1 Vector and Matrix Norms 11 Vector Spaces Let F be a field (such as the real numbers, R, or complex numbers, C) with elements called scalars A Vector Space, V, over the field F is a non-empty
MATRIX ALGEBRA AND SYSTEMS OF EQUATIONS
 MATRIX ALGEBRA AND SYSTEMS OF EQUATIONS Systems of Equations and Matrices Representation of a linear system The general system of m equations in n unknowns can be written a x + a 2 x 2 + + a n x n b a
MATRIX ALGEBRA AND SYSTEMS OF EQUATIONS Systems of Equations and Matrices Representation of a linear system The general system of m equations in n unknowns can be written a x + a 2 x 2 + + a n x n b a
Wavelet analysis. Wavelet requirements. Example signals. Stationary signal 2 Hz + 10 Hz + 20Hz. Zero mean, oscillatory (wave) Fast decay (let)
 Fast decay (let)") Wavelet analysis In the case of Fourier series, the orthonormal basis is generated by integral dilation of a single function e jx Every 2π-periodic square-integrable function is generated by a superposition
Wavelet analysis In the case of Fourier series, the orthonormal basis is generated by integral dilation of a single function e jx Every 2π-periodic square-integrable function is generated by a superposition
Recall that two vectors in are perpendicular or orthogonal provided that their dot
 Orthogonal Complements and Projections Recall that two vectors in are perpendicular or orthogonal provided that their dot product vanishes That is, if and only if Example 1 The vectors in are orthogonal
Orthogonal Complements and Projections Recall that two vectors in are perpendicular or orthogonal provided that their dot product vanishes That is, if and only if Example 1 The vectors in are orthogonal
Server Load Prediction
 Server Load Prediction Suthee Chaidaroon (unsuthee@stanford.edu) Joon Yeong Kim (kim64@stanford.edu) Jonghan Seo (jonghan@stanford.edu) Abstract Estimating server load average is one of the methods that
Server Load Prediction Suthee Chaidaroon (unsuthee@stanford.edu) Joon Yeong Kim (kim64@stanford.edu) Jonghan Seo (jonghan@stanford.edu) Abstract Estimating server load average is one of the methods that
(67902) Topics in Theory and Complexity Nov 2, 2006. Lecture 7
 Topics in Theory and Complexity Nov 2, 2006. Lecture 7") (67902) Topics in Theory and Complexity Nov 2, 2006 Lecturer: Irit Dinur Lecture 7 Scribe: Rani Lekach 1 Lecture overview This Lecture consists of two parts In the first part we will refresh the definition
(67902) Topics in Theory and Complexity Nov 2, 2006 Lecturer: Irit Dinur Lecture 7 Scribe: Rani Lekach 1 Lecture overview This Lecture consists of two parts In the first part we will refresh the definition
Clustering Very Large Data Sets with Principal Direction Divisive Partitioning
 Clustering Very Large Data Sets with Principal Direction Divisive Partitioning David Littau 1 and Daniel Boley 2 1 University of Minnesota, Minneapolis MN 55455 littau@cs.umn.edu 2 University of Minnesota,
Clustering Very Large Data Sets with Principal Direction Divisive Partitioning David Littau 1 and Daniel Boley 2 1 University of Minnesota, Minneapolis MN 55455 littau@cs.umn.edu 2 University of Minnesota,
Recall the basic property of the transpose (for any A): v A t Aw = v w, v, w R n.
: v A t Aw = v w, v, w R n.") ORTHOGONAL MATRICES Informally, an orthogonal n n matrix is the n-dimensional analogue of the rotation matrices R θ in R 2. When does a linear transformation of R 3 (or R n ) deserve to be called a rotation?
ORTHOGONAL MATRICES Informally, an orthogonal n n matrix is the n-dimensional analogue of the rotation matrices R θ in R 2. When does a linear transformation of R 3 (or R n ) deserve to be called a rotation?
Au = = = 3u. Aw = = = 2w. so the action of A on u and w is very easy to picture: it simply amounts to a stretching by 3 and 2, respectively.
 Chapter 7 Eigenvalues and Eigenvectors In this last chapter of our exploration of Linear Algebra we will revisit eigenvalues and eigenvectors of matrices, concepts that were already introduced in Geometry
Chapter 7 Eigenvalues and Eigenvectors In this last chapter of our exploration of Linear Algebra we will revisit eigenvalues and eigenvectors of matrices, concepts that were already introduced in Geometry
Numerical Methods I Solving Linear Systems: Sparse Matrices, Iterative Methods and Non-Square Systems
 Numerical Methods I Solving Linear Systems: Sparse Matrices, Iterative Methods and Non-Square Systems Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 Course G63.2010.001 / G22.2420-001,
Numerical Methods I Solving Linear Systems: Sparse Matrices, Iterative Methods and Non-Square Systems Aleksandar Donev Courant Institute, NYU 1 donev@courant.nyu.edu 1 Course G63.2010.001 / G22.2420-001,
Studying E-mail Graphs for Intelligence Monitoring and Analysis in the Absence of Semantic Information
 Studying E-mail Graphs for Intelligence Monitoring and Analysis in the Absence of Semantic Information Petros Drineas, Mukkai S. Krishnamoorthy, Michael D. Sofka Bülent Yener Department of Computer Science,
Studying E-mail Graphs for Intelligence Monitoring and Analysis in the Absence of Semantic Information Petros Drineas, Mukkai S. Krishnamoorthy, Michael D. Sofka Bülent Yener Department of Computer Science,
Syllabus for MATH 191 MATH 191 Topics in Data Science: Algorithms and Mathematical Foundations Department of Mathematics, UCLA Fall Quarter 2015
 Syllabus for MATH 191 MATH 191 Topics in Data Science: Algorithms and Mathematical Foundations Department of Mathematics, UCLA Fall Quarter 2015 Lecture: MWF: 1:00-1:50pm, GEOLOGY 4645 Instructor: Mihai
Syllabus for MATH 191 MATH 191 Topics in Data Science: Algorithms and Mathematical Foundations Department of Mathematics, UCLA Fall Quarter 2015 Lecture: MWF: 1:00-1:50pm, GEOLOGY 4645 Instructor: Mihai
x1 x 2 x 3 y 1 y 2 y 3 x 1 y 2 x 2 y 1 0.
 Cross product 1 Chapter 7 Cross product We are getting ready to study integration in several variables. Until now we have been doing only differential calculus. One outcome of this study will be our ability
Cross product 1 Chapter 7 Cross product We are getting ready to study integration in several variables. Until now we have been doing only differential calculus. One outcome of this study will be our ability
Inner Product Spaces
 Math 571 Inner Product Spaces 1. Preliminaries An inner product space is a vector space V along with a function, called an inner product which associates each pair of vectors u, v with a scalar u, v, and
Math 571 Inner Product Spaces 1. Preliminaries An inner product space is a vector space V along with a function, called an inner product which associates each pair of vectors u, v with a scalar u, v, and
The world s largest matrix computation. (This chapter is out of date and needs a major overhaul.)
") Chapter 7 Google PageRank The world s largest matrix computation. (This chapter is out of date and needs a major overhaul.) One of the reasons why Google TM is such an effective search engine is the PageRank
Chapter 7 Google PageRank The world s largest matrix computation. (This chapter is out of date and needs a major overhaul.) One of the reasons why Google TM is such an effective search engine is the PageRank
Topological Data Analysis Applications to Computer Vision
 Topological Data Analysis Applications to Computer Vision Vitaliy Kurlin, http://kurlin.org Microsoft Research Cambridge and Durham University, UK Topological Data Analysis quantifies topological structures
Topological Data Analysis Applications to Computer Vision Vitaliy Kurlin, http://kurlin.org Microsoft Research Cambridge and Durham University, UK Topological Data Analysis quantifies topological structures
Finite Dimensional Hilbert Spaces and Linear Inverse Problems
 Finite Dimensional Hilbert Spaces and Linear Inverse Problems ECE 174 Lecture Supplement Spring 2009 Ken Kreutz-Delgado Electrical and Computer Engineering Jacobs School of Engineering University of California,
Finite Dimensional Hilbert Spaces and Linear Inverse Problems ECE 174 Lecture Supplement Spring 2009 Ken Kreutz-Delgado Electrical and Computer Engineering Jacobs School of Engineering University of California,
Time Domain and Frequency Domain Techniques For Multi Shaker Time Waveform Replication
 Time Domain and Frequency Domain Techniques For Multi Shaker Time Waveform Replication Thomas Reilly Data Physics Corporation 1741 Technology Drive, Suite 260 San Jose, CA 95110 (408) 216-8440 This paper
Time Domain and Frequency Domain Techniques For Multi Shaker Time Waveform Replication Thomas Reilly Data Physics Corporation 1741 Technology Drive, Suite 260 San Jose, CA 95110 (408) 216-8440 This paper
SYMMETRIC EIGENFACES MILI I. SHAH
 SYMMETRIC EIGENFACES MILI I. SHAH Abstract. Over the years, mathematicians and computer scientists have produced an extensive body of work in the area of facial analysis. Several facial analysis algorithms
SYMMETRIC EIGENFACES MILI I. SHAH Abstract. Over the years, mathematicians and computer scientists have produced an extensive body of work in the area of facial analysis. Several facial analysis algorithms
Subspace Analysis and Optimization for AAM Based Face Alignment
 Subspace Analysis and Optimization for AAM Based Face Alignment Ming Zhao Chun Chen College of Computer Science Zhejiang University Hangzhou, 310027, P.R.China zhaoming1999@zju.edu.cn Stan Z. Li Microsoft
Subspace Analysis and Optimization for AAM Based Face Alignment Ming Zhao Chun Chen College of Computer Science Zhejiang University Hangzhou, 310027, P.R.China zhaoming1999@zju.edu.cn Stan Z. Li Microsoft
Eigenvalues and Eigenvectors
 Chapter 6 Eigenvalues and Eigenvectors 6. Introduction to Eigenvalues Linear equations Ax D b come from steady state problems. Eigenvalues have their greatest importance in dynamic problems. The solution
Chapter 6 Eigenvalues and Eigenvectors 6. Introduction to Eigenvalues Linear equations Ax D b come from steady state problems. Eigenvalues have their greatest importance in dynamic problems. The solution
Mathematics Course 111: Algebra I Part IV: Vector Spaces
 Mathematics Course 111: Algebra I Part IV: Vector Spaces D. R. Wilkins Academic Year 1996-7 9 Vector Spaces A vector space over some field K is an algebraic structure consisting of a set V on which are
Mathematics Course 111: Algebra I Part IV: Vector Spaces D. R. Wilkins Academic Year 1996-7 9 Vector Spaces A vector space over some field K is an algebraic structure consisting of a set V on which are
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Text mining & Information Retrieval Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Text mining & Information Retrieval Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki
Lecture 18 - Clifford Algebras and Spin groups
 Lecture 18 - Clifford Algebras and Spin groups April 5, 2013 Reference: Lawson and Michelsohn, Spin Geometry. 1 Universal Property If V is a vector space over R or C, let q be any quadratic form, meaning
Lecture 18 - Clifford Algebras and Spin groups April 5, 2013 Reference: Lawson and Michelsohn, Spin Geometry. 1 Universal Property If V is a vector space over R or C, let q be any quadratic form, meaning
Lecture Notes 2: Matrices as Systems of Linear Equations
 2: Matrices as Systems of Linear Equations 33A Linear Algebra, Puck Rombach Last updated: April 13, 2016 Systems of Linear Equations Systems of linear equations can represent many things You have probably
2: Matrices as Systems of Linear Equations 33A Linear Algebra, Puck Rombach Last updated: April 13, 2016 Systems of Linear Equations Systems of linear equations can represent many things You have probably