W. Heath Rushing Adsurgo LLC. Harness the Power of Text Analytics: Unstructured Data Analysis for Healthcare. Session H-1 JTCC: October 23, 2015
|
|
|
- Rosaline Jackson
- 8 years ago
- Views:
Transcription

1 W. Heath Rushing Adsurgo LLC Harness the Power of Text Analytics: Unstructured Data Analysis for Healthcare Session H-1 JTCC: October 23, 2015

2 Outline Demonstration: Recent article on cnn.com Introduction to Text Mining Text Mining String Processing Natural Language Processing Statistical Approaches Clustering Application Examples Workers Compensation Fraud Detection 10,000 Patient Records References 2

3 What is Text Mining? Text mining: semi-automated process of detecting patterns (useful information and knowledge) from large amounts of unstructured data sources Text analytics: methods used for intelligent analyses of textual data; a larger set of activities around inference steps of discovering information, grouping documents, summarizing information, etc. 3 Gary Miner, et al. Practical Text Mining and Statistical Analysis for Non-structured Text Data Applications. Academic Press: Oxford, 2012.

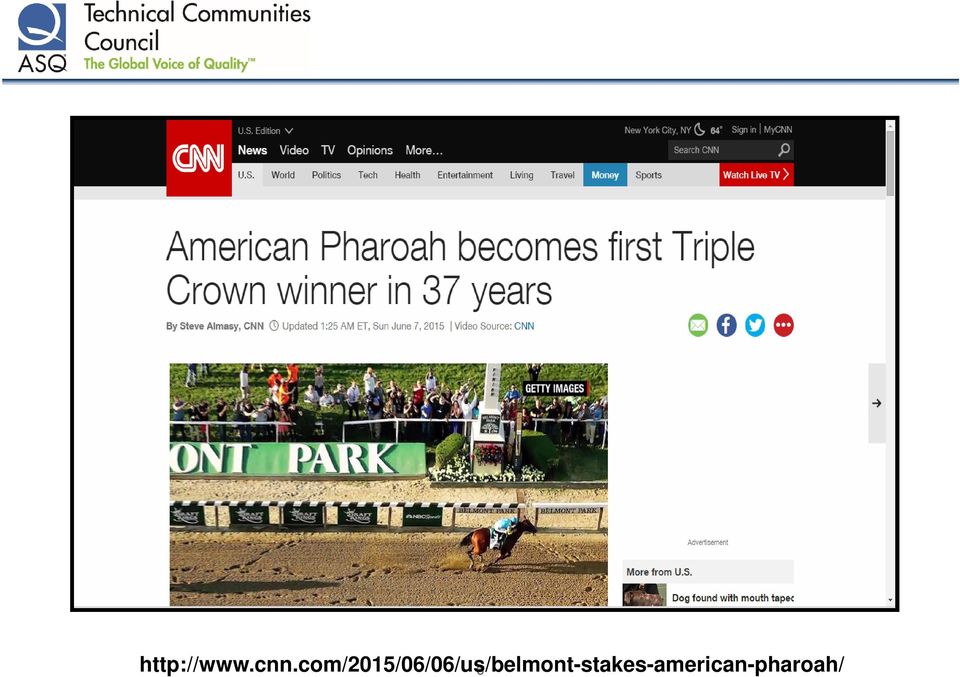
4 Warm Up Consider the word counts of a recent article on cnn.com Can you get the general idea of what might have happened by these frequencies alone? 4


5 Warm Up More Insight 5

6 6
7 Extracting Numerical Representations of Text In order to analyze text in a systematic and structured way, we first need to develop a numerical representation of the text. Obviously, there is not a unique solution to this problem. The appropriate mapping of text- >numbers depends on the goal of the study. 7

8 Development of Enabling Technology Reduction of Dimensionality and Feature Selection Statistical Approaches Graphical Capabilities 8 Gary Miner, et al. Practical Text Mining and Statistical Analysis for Non-structured Text Data Applications. Academic Press: Oxford, 2012.

9 Text Mining in Healthcare Fraud detection in medical insurance claims. Analysis of Medline. 1 Reduction of medical errors in electronic clinical records. 2 Analysis of text from patient records, prescriptions, and doctor notes. 2 Extract data related to adverse events. 3 Healthcare claims processing Raja U., Mitchell T., Day T., and Hardin JM. Text Mining in Healthcare: Applications and Opportunities, Journal of Healthcare Information Management Summer, 22(3): Botsis T., Nguyen MD., Woo EJ., Markatou M., Ball R. Text mining for the Vaccine Adverse Event Reporting System: medical text classification using informative feature selection. Journal of Am Med Inform Assoc Sep- Oct;18(5): Popwich, F. Using Text Mining and Natural Language Processing for Health Care Claims Processing. SIGKDD Explorations. June 2005; 7(5):

10 Simple Example Car Accidents Slid on ice into a curb. Driving too fast in a dust storm, hit the curb. Low-budget tires failed after bumping curb. We will use the three car accident descriptions above to illustrate text processing. 10

11 Bag of Words Approach Using a bag of words approach, we disregard the ordering of the words in each document as well as their grammatical properties. While this may seem simplistic, it has been shown to give excellent results in many applications. 11

12 Processing Text Within each document, we will first Isolate individual words Remove punctuation Normalize case (convert all characters to lowercase) Remove numbers Later, we will discuss further processing of the words. 12

13 Isolate Words Document 1 Document 2 Document 3 Slid Driving Low-budget on too tire ice fast failed into in after a a bumping curb. dust curb. storm, hit the curb. Notice that punctuation is concatenated to adjacent terms. 13

14 Remove Punctuation Document 1 Document 2 Document 3 Slid Driving Lowbudget on too tire ice fast failed into in after a a bumping curb dust curb storm hit the curb 14

15 Normalize Case Document 1 Document 2 Document 3 slid driving lowbudget on too tire ice fast failed into in after a a bumping curb dust curb storm hit the curb 15

16 Zipf s Law and Term Frequency Counts When counting frequency of terms in a corpus, the frequency of a word will be roughly proportional to its rank. 16

17 Natural Language Processing After extracting the tokens from a document, it is typically useful to Remove stopwords (most frequent words). Stem the text. Remove words with character length below a minimum or above a maximum. Remove words that appear in only a few documents (most infrequent words). 17

18 Remove Stopwords Document 1 Document 2 Document 3 slid driving lowbudget ice fast tire curb dust failed storm bumping hit curb curb 18

19 Stem Text Document 1 Document 2 Document 3 slid drive lowbudget ice fast tire curb dust fail storm bump hit curb curb 19

20 Representing Text with Numbers To find clusters of documents or to use the information present in the documents in a predictive model, we need a numerical representation of the text. Using the bag of words approach, we create a document term matrix (DTM). Each document is represented by a row, and each token is represented by a column. The components of the matrix represent how many times each token appears in each document. 20

21 Document Term Matrix Doc bump curb drive dust fail fast hit ice lowbud get slid storm tire
22 Transformations of the DTM Frequency (local) weights Binary: Useful if there is a lot of variance in the lengths of the documents in the corpus. Ternary/Frequency: Some researchers have found that distinguishing between terms that appear only once in a document vs. those that appear multiple time can improve results. Log: Dampens the presence of high counts in longer documents without sacrificing as much information as the binary weighting scheme. 22
23 Transformations of the DTM Term (global) weights Term Frequency - Inverse Document Frequency (tfidf) Shrinks the weight of terms that appear in many documents while also inflating the weight of terms that appear in only a few documents Sometimes makes interpretation of results more difficult, but can give better predictive performance. In practice, it is best to try different weighting schemes: there is no need to pick only one! 23
24 Inverse Document Frequency idf down-weights terms that appear in many documents. The idf for term t is D idf = log df D is the number of documents in the corpus. df is the number of documents containing term t. If a term appears in every document, its idf is 0. 24
25 tf-idf Doc bump curb drive dust fail fast hit ice lowbud get slid storm tire
26 Singular Value Decomposition The DTM is usually very large, though sparse. Working directly with the DTM requires software capable of performing sparse matrix algebra. Even then, most of the terms represent noise variables. This presents a complication for regression methods. 26
27 Example - Patient Records 10,000 simulated patient records Primary objective: To determine if certain words or phrases are associated with this particular hospital. Secondary objective: To determine if certain words or phrases are associated with any particular race, language, or marital status. 27
28 Full DTM is Sparse 28
29 Singular Value Decomposition The reduced-rank singular value decomposition (SVD) provides us with a dimensionality reduction technique. The SVD reduces the DTM to a (dense) matrix with fewer columns. The new (orthogonal) columns are linear combinations of the rows in the original DTM, selected to preserve as much of the structure of the original DTM as possible. 29
30 SVD Example SVD finds a new set of orthogonal basis vectors such that each additional dimension accounts for as much of the variation of the data as possible. X2 SVD1 SVD2 30 X1
31 Latent Semantic Analysis In natural language processing, the use of a rankreduced SVD is referred to as latent semantic analysis (LSA). A popular LSA technique is to plot the corpus dictionary using the first two vectors resulting from the SVD. Similar words (words that either appear frequently in the same documents, or appear frequently with common sets of words throughout the corpus) are plotted together, and a rough interpretation can often be assigned to dimensions appearing in the plot. 31
32 SVD1 vs. SVD2 The words appearing close to each other appear together frequently (or appear independently with a common set of words) in documents in the corpus. 32
33 Clustering Once we have produced either a DTM or an SVD of a DTM, we may use the resulting numeric columns with clustering algorithms to answer questions such as Which groups of documents are most similar? Which documents are most similar to a particular document? Which groups of terms tend to appear either together in the same documents or together with the same words? Which terms are most similar to a particular term? Are certain clusters of documents more strongly related to other variables (e.g. income, cost, fraudulent activity) than other clusters? 33
34 Text Mining Example Workers Compensation Data: 3,037 workers compensation insurance claims. Objective: Use text mining and document clustering techniques to find evidence of potential fraud cases in a large set of claims. 34
35 References Textbooks: Gary Miner, et al. Practical Text Mining and Statistical Analysis for Non-structured Text Data Applications. Academic Press: Oxford, Text Analytics Using SAS Text Miner. SAS Institute: Cary, Websites: Papers: Botsis T., Nguyen MD., Woo EJ., Markatou M., Ball R. Text mining for the Vaccine Adverse Event Reporting System: medical text classification using informative feature selection. Journal of Am Med Inform Assoc Sep-Oct;18(5): Popwich, F. Using Text Mining and Natural Language Processing for Health Care Claims Processing. SIGKDD Explorations. June 2005; 7(5): Raja U., Mitchell T., Day T., and Hardin JM. Text Mining in Healthcare: Applications and Opportunities, Journal of Healthcare Information Management Summer, 22(3):
Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC
 Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC 1. Introduction A popular rule of thumb suggests that
Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC 1. Introduction A popular rule of thumb suggests that
Search Engines. Stephen Shaw <stesh@netsoc.tcd.ie> 18th of February, 2014. Netsoc
 Search Engines Stephen Shaw Netsoc 18th of February, 2014 Me M.Sc. Artificial Intelligence, University of Edinburgh Would recommend B.A. (Mod.) Computer Science, Linguistics, French,
Search Engines Stephen Shaw Netsoc 18th of February, 2014 Me M.Sc. Artificial Intelligence, University of Edinburgh Would recommend B.A. (Mod.) Computer Science, Linguistics, French,
dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING
 dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING ABSTRACT In most CRM (Customer Relationship Management) systems, information on
dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING ABSTRACT In most CRM (Customer Relationship Management) systems, information on
TF-IDF. David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt
 TF-IDF David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt Administrative Homework 3 available soon Assignment 2 available soon Popular media article
TF-IDF David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt Administrative Homework 3 available soon Assignment 2 available soon Popular media article
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Text mining & Information Retrieval Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Text mining & Information Retrieval Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki
CAPTURING THE VALUE OF UNSTRUCTURED DATA: INTRODUCTION TO TEXT MINING
 CAPTURING THE VALUE OF UNSTRUCTURED DATA: INTRODUCTION TO TEXT MINING Mary-Elizabeth ( M-E ) Eddlestone Principal Systems Engineer, Analytics SAS Customer Loyalty, SAS Institute, Inc. Is there valuable
CAPTURING THE VALUE OF UNSTRUCTURED DATA: INTRODUCTION TO TEXT MINING Mary-Elizabeth ( M-E ) Eddlestone Principal Systems Engineer, Analytics SAS Customer Loyalty, SAS Institute, Inc. Is there valuable
CHAPTER VII CONCLUSIONS
 CHAPTER VII CONCLUSIONS To do successful research, you don t need to know everything, you just need to know of one thing that isn t known. -Arthur Schawlow In this chapter, we provide the summery of the
CHAPTER VII CONCLUSIONS To do successful research, you don t need to know everything, you just need to know of one thing that isn t known. -Arthur Schawlow In this chapter, we provide the summery of the
Text Mining with R Twitter Data Analysis 1
 Text Mining with R Twitter Data Analysis 1 Yanchang Zhao http://www.rdatamining.com R and Data Mining Workshop for the Master of Business Analytics course, Deakin University, Melbourne 28 May 2015 1 Presented
Text Mining with R Twitter Data Analysis 1 Yanchang Zhao http://www.rdatamining.com R and Data Mining Workshop for the Master of Business Analytics course, Deakin University, Melbourne 28 May 2015 1 Presented
Mining Text Data: An Introduction
 Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
C o p yr i g ht 2015, S A S I nstitute Inc. A l l r i g hts r eser v ed. INTRODUCTION TO SAS TEXT MINER
 INTRODUCTION TO SAS TEXT MINER TODAY S AGENDA INTRODUCTION TO SAS TEXT MINER Define data mining Overview of SAS Enterprise Miner Describe text analytics and define text data mining Text Mining Process
INTRODUCTION TO SAS TEXT MINER TODAY S AGENDA INTRODUCTION TO SAS TEXT MINER Define data mining Overview of SAS Enterprise Miner Describe text analytics and define text data mining Text Mining Process
Big Data Analytics and Healthcare
 Big Data Analytics and Healthcare Anup Kumar, Professor and Director of MINDS Lab Computer Engineering and Computer Science Department University of Louisville Road Map Introduction Data Sources Structured
Big Data Analytics and Healthcare Anup Kumar, Professor and Director of MINDS Lab Computer Engineering and Computer Science Department University of Louisville Road Map Introduction Data Sources Structured
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #18: Dimensionality Reduc7on
 Data Management Systems. B. Aditya Prakash Lecture #18: Dimensionality Reduc7on") CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #18: Dimensionality Reduc7on Dimensionality Reduc=on Assump=on: Data lies on or near a low d- dimensional subspace Axes of this subspace
CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #18: Dimensionality Reduc7on Dimensionality Reduc=on Assump=on: Data lies on or near a low d- dimensional subspace Axes of this subspace
Big Data Text Mining and Visualization. Anton Heijs
 Copyright 2007 by Treparel Information Solutions BV. This report nor any part of it may be copied, circulated, quoted without prior written approval from Treparel7 Treparel Information Solutions BV Delftechpark
Copyright 2007 by Treparel Information Solutions BV. This report nor any part of it may be copied, circulated, quoted without prior written approval from Treparel7 Treparel Information Solutions BV Delftechpark
APPM4720/5720: Fast algorithms for big data. Gunnar Martinsson The University of Colorado at Boulder
 APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
Clustering and Classification of Maintenance Logs using Text Data Mining
 Clustering and Classification of Maintenance Logs using Text Data Mining Brett Edwards Michael Zatorsky Richi Nayak CRC for Integrated Engineering Asset Management Faculty of Information Technology Queensland
Clustering and Classification of Maintenance Logs using Text Data Mining Brett Edwards Michael Zatorsky Richi Nayak CRC for Integrated Engineering Asset Management Faculty of Information Technology Queensland
Lecture 5: Singular Value Decomposition SVD (1)
") EEM3L1: Numerical and Analytical Techniques Lecture 5: Singular Value Decomposition SVD (1) EE3L1, slide 1, Version 4: 25-Sep-02 Motivation for SVD (1) SVD = Singular Value Decomposition Consider the system
EEM3L1: Numerical and Analytical Techniques Lecture 5: Singular Value Decomposition SVD (1) EE3L1, slide 1, Version 4: 25-Sep-02 Motivation for SVD (1) SVD = Singular Value Decomposition Consider the system
Predictive Analytics Certificate Program
 Information Technologies Programs Predictive Analytics Certificate Program Accelerate Your Career Offered in partnership with: University of California, Irvine Extension s professional certificate and
Information Technologies Programs Predictive Analytics Certificate Program Accelerate Your Career Offered in partnership with: University of California, Irvine Extension s professional certificate and
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Introduction to basic Text Mining in R.
 Introduction to basic Text Mining in R. As published in Benchmarks RSS Matters, January 2014 http://web3.unt.edu/benchmarks/issues/2014/01/rss-matters Jon Starkweather, PhD 1 Jon Starkweather, PhD jonathan.starkweather@unt.edu
Introduction to basic Text Mining in R. As published in Benchmarks RSS Matters, January 2014 http://web3.unt.edu/benchmarks/issues/2014/01/rss-matters Jon Starkweather, PhD 1 Jon Starkweather, PhD jonathan.starkweather@unt.edu
Using LSI for Implementing Document Management Systems Turning unstructured data from a liability to an asset.
 White Paper Using LSI for Implementing Document Management Systems Turning unstructured data from a liability to an asset. Using LSI for Implementing Document Management Systems By Mike Harrison, Director,
White Paper Using LSI for Implementing Document Management Systems Turning unstructured data from a liability to an asset. Using LSI for Implementing Document Management Systems By Mike Harrison, Director,
2015 Workshops for Professors
 SAS Education Grow with us Offered by the SAS Global Academic Program Supporting teaching, learning and research in higher education 2015 Workshops for Professors 1 Workshops for Professors As the market
SAS Education Grow with us Offered by the SAS Global Academic Program Supporting teaching, learning and research in higher education 2015 Workshops for Professors 1 Workshops for Professors As the market
Statistical Feature Selection Techniques for Arabic Text Categorization
 Statistical Feature Selection Techniques for Arabic Text Categorization Rehab M. Duwairi Department of Computer Information Systems Jordan University of Science and Technology Irbid 22110 Jordan Tel. +962-2-7201000
Statistical Feature Selection Techniques for Arabic Text Categorization Rehab M. Duwairi Department of Computer Information Systems Jordan University of Science and Technology Irbid 22110 Jordan Tel. +962-2-7201000
Latent Semantic Indexing with Selective Query Expansion Abstract Introduction
 Latent Semantic Indexing with Selective Query Expansion Andy Garron April Kontostathis Department of Mathematics and Computer Science Ursinus College Collegeville PA 19426 Abstract This article describes
Latent Semantic Indexing with Selective Query Expansion Andy Garron April Kontostathis Department of Mathematics and Computer Science Ursinus College Collegeville PA 19426 Abstract This article describes
Decision Support Systems
 Decision Support Systems 50 (2011) 511 521 Contents lists available at ScienceDirect Decision Support Systems journal homepage: www.elsevier.com/locate/dss Exploring determinants of voting for the helpfulness
Decision Support Systems 50 (2011) 511 521 Contents lists available at ScienceDirect Decision Support Systems journal homepage: www.elsevier.com/locate/dss Exploring determinants of voting for the helpfulness
Text Mining and Analysis
 Text Mining and Analysis Practical Methods, Examples, and Case Studies Using SAS Goutam Chakraborty, Murali Pagolu, Satish Garla From Text Mining and Analysis. Full book available for purchase here. Contents
Text Mining and Analysis Practical Methods, Examples, and Case Studies Using SAS Goutam Chakraborty, Murali Pagolu, Satish Garla From Text Mining and Analysis. Full book available for purchase here. Contents
BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES
 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 123 CHAPTER 7 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 7.1 Introduction Even though using SVM presents
BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 123 CHAPTER 7 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 7.1 Introduction Even though using SVM presents
SAS Software to Fit the Generalized Linear Model
 SAS Software to Fit the Generalized Linear Model Gordon Johnston, SAS Institute Inc., Cary, NC Abstract In recent years, the class of generalized linear models has gained popularity as a statistical modeling
SAS Software to Fit the Generalized Linear Model Gordon Johnston, SAS Institute Inc., Cary, NC Abstract In recent years, the class of generalized linear models has gained popularity as a statistical modeling
Content-Based Recommendation
 Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
A Statistical Text Mining Method for Patent Analysis
 A Statistical Text Mining Method for Patent Analysis Department of Statistics Cheongju University, shjun@cju.ac.kr Abstract Most text data from diverse document databases are unsuitable for analytical
A Statistical Text Mining Method for Patent Analysis Department of Statistics Cheongju University, shjun@cju.ac.kr Abstract Most text data from diverse document databases are unsuitable for analytical
Search and Information Retrieval
 Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features
 Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features Charlie Berger, MS Eng, MBA Sr. Director Product Management, Data Mining and Advanced Analytics charlie.berger@oracle.com www.twitter.com/charliedatamine
Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features Charlie Berger, MS Eng, MBA Sr. Director Product Management, Data Mining and Advanced Analytics charlie.berger@oracle.com www.twitter.com/charliedatamine
Web Mining. Margherita Berardi LACAM. Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it
 Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
M15_BERE8380_12_SE_C15.7.qxd 2/21/11 3:59 PM Page 1. 15.7 Analytics and Data Mining 1
 M15_BERE8380_12_SE_C15.7.qxd 2/21/11 3:59 PM Page 1 15.7 Analytics and Data Mining 15.7 Analytics and Data Mining 1 Section 1.5 noted that advances in computing processing during the past 40 years have
M15_BERE8380_12_SE_C15.7.qxd 2/21/11 3:59 PM Page 1 15.7 Analytics and Data Mining 15.7 Analytics and Data Mining 1 Section 1.5 noted that advances in computing processing during the past 40 years have
Principal Component Analysis
 Principal Component Analysis ERS70D George Fernandez INTRODUCTION Analysis of multivariate data plays a key role in data analysis. Multivariate data consists of many different attributes or variables recorded
Principal Component Analysis ERS70D George Fernandez INTRODUCTION Analysis of multivariate data plays a key role in data analysis. Multivariate data consists of many different attributes or variables recorded
Introduction. A. Bellaachia Page: 1
 Introduction 1. Objectives... 3 2. What is Data Mining?... 4 3. Knowledge Discovery Process... 5 4. KD Process Example... 7 5. Typical Data Mining Architecture... 8 6. Database vs. Data Mining... 9 7.
Introduction 1. Objectives... 3 2. What is Data Mining?... 4 3. Knowledge Discovery Process... 5 4. KD Process Example... 7 5. Typical Data Mining Architecture... 8 6. Database vs. Data Mining... 9 7.
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING
 A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING Sumit Goswami 1 and Mayank Singh Shishodia 2 1 Indian Institute of Technology-Kharagpur, Kharagpur, India sumit_13@yahoo.com 2 School of Computer
A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING Sumit Goswami 1 and Mayank Singh Shishodia 2 1 Indian Institute of Technology-Kharagpur, Kharagpur, India sumit_13@yahoo.com 2 School of Computer
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter
 VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
How To Create A Text Mining Model For An Auto Analyst
 Paper 003-29 Text Mining Warranty and Call Center Data: Early Warning for Product Quality Awareness John Wallace, Business Researchers, Inc., San Francisco, CA Tracy Cermack, American Honda Motor Co.,
Paper 003-29 Text Mining Warranty and Call Center Data: Early Warning for Product Quality Awareness John Wallace, Business Researchers, Inc., San Francisco, CA Tracy Cermack, American Honda Motor Co.,
AN SQL EXTENSION FOR LATENT SEMANTIC ANALYSIS
 Advances in Information Mining ISSN: 0975 3265 & E-ISSN: 0975 9093, Vol. 3, Issue 1, 2011, pp-19-25 Available online at http://www.bioinfo.in/contents.php?id=32 AN SQL EXTENSION FOR LATENT SEMANTIC ANALYSIS
Advances in Information Mining ISSN: 0975 3265 & E-ISSN: 0975 9093, Vol. 3, Issue 1, 2011, pp-19-25 Available online at http://www.bioinfo.in/contents.php?id=32 AN SQL EXTENSION FOR LATENT SEMANTIC ANALYSIS
1 o Semestre 2007/2008
 Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 Outline 1 2 3 4 5 Exploiting Text How is text exploited? Two main directions Extraction Extraction
Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 Outline 1 2 3 4 5 Exploiting Text How is text exploited? Two main directions Extraction Extraction
Clustering Technique in Data Mining for Text Documents
 Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Technical Report. The KNIME Text Processing Feature:
 Technical Report The KNIME Text Processing Feature: An Introduction Dr. Killian Thiel Dr. Michael Berthold Killian.Thiel@uni-konstanz.de Michael.Berthold@uni-konstanz.de Copyright 2012 by KNIME.com AG
Technical Report The KNIME Text Processing Feature: An Introduction Dr. Killian Thiel Dr. Michael Berthold Killian.Thiel@uni-konstanz.de Michael.Berthold@uni-konstanz.de Copyright 2012 by KNIME.com AG
Data, Measurements, Features
 Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Introduction to Information Retrieval http://informationretrieval.org
 Introduction to Information Retrieval http://informationretrieval.org IIR 6&7: Vector Space Model Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-08-29 Schütze:
Introduction to Information Retrieval http://informationretrieval.org IIR 6&7: Vector Space Model Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-08-29 Schütze:
Homework 4 Statistics W4240: Data Mining Columbia University Due Tuesday, October 29 in Class
 Problem 1. (10 Points) James 6.1 Problem 2. (10 Points) James 6.3 Problem 3. (10 Points) James 6.5 Problem 4. (15 Points) James 6.7 Problem 5. (15 Points) James 6.10 Homework 4 Statistics W4240: Data Mining
Problem 1. (10 Points) James 6.1 Problem 2. (10 Points) James 6.3 Problem 3. (10 Points) James 6.5 Problem 4. (15 Points) James 6.7 Problem 5. (15 Points) James 6.10 Homework 4 Statistics W4240: Data Mining
FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT MINING SYSTEM
 International Journal of Innovative Computing, Information and Control ICIC International c 0 ISSN 34-48 Volume 8, Number 8, August 0 pp. 4 FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT
International Journal of Innovative Computing, Information and Control ICIC International c 0 ISSN 34-48 Volume 8, Number 8, August 0 pp. 4 FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT
Text Analytics. A business guide
 Text Analytics A business guide February 2014 Contents 3 The Business Value of Text Analytics 4 What is Text Analytics? 6 Text Analytics Methods 8 Unstructured Meets Structured Data 9 Business Application
Text Analytics A business guide February 2014 Contents 3 The Business Value of Text Analytics 4 What is Text Analytics? 6 Text Analytics Methods 8 Unstructured Meets Structured Data 9 Business Application
Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning
 in Semi-supervised Learning Reducing Dimension and Maintaining Meaning") Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013 Outline Introduction to NMF Applications Motivations NMF as a middle step
Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013 Outline Introduction to NMF Applications Motivations NMF as a middle step
Server Load Prediction
 Server Load Prediction Suthee Chaidaroon (unsuthee@stanford.edu) Joon Yeong Kim (kim64@stanford.edu) Jonghan Seo (jonghan@stanford.edu) Abstract Estimating server load average is one of the methods that
Server Load Prediction Suthee Chaidaroon (unsuthee@stanford.edu) Joon Yeong Kim (kim64@stanford.edu) Jonghan Seo (jonghan@stanford.edu) Abstract Estimating server load average is one of the methods that
Mining Text Data for Useful Information in Higher Education John Zilvinskis Indiana University
 Mining Text Data for Useful Information in Higher Education John Zilvinskis Indiana University Institutional Researchers Credo We have not succeeded in answering all our problems indeed we sometimes feel
Mining Text Data for Useful Information in Higher Education John Zilvinskis Indiana University Institutional Researchers Credo We have not succeeded in answering all our problems indeed we sometimes feel
3/17/2009. Knowledge Management BIKM eclassifier Integrated BIKM Tools
 Paper by W. F. Cody J. T. Kreulen V. Krishna W. S. Spangler Presentation by Dylan Chi Discussion by Debojit Dhar THE INTEGRATION OF BUSINESS INTELLIGENCE AND KNOWLEDGE MANAGEMENT BUSINESS INTELLIGENCE
Paper by W. F. Cody J. T. Kreulen V. Krishna W. S. Spangler Presentation by Dylan Chi Discussion by Debojit Dhar THE INTEGRATION OF BUSINESS INTELLIGENCE AND KNOWLEDGE MANAGEMENT BUSINESS INTELLIGENCE
Machine Learning for Data Science (CS4786) Lecture 1
 Lecture 1") Machine Learning for Data Science (CS4786) Lecture 1 Tu-Th 10:10 to 11:25 AM Hollister B14 Instructors : Lillian Lee and Karthik Sridharan ROUGH DETAILS ABOUT THE COURSE Diagnostic assignment 0 is out:
Machine Learning for Data Science (CS4786) Lecture 1 Tu-Th 10:10 to 11:25 AM Hollister B14 Instructors : Lillian Lee and Karthik Sridharan ROUGH DETAILS ABOUT THE COURSE Diagnostic assignment 0 is out:
Bagged Ensemble Classifiers for Sentiment Classification of Movie Reviews
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 3 Issue 2 February, 2014 Page No. 3951-3961 Bagged Ensemble Classifiers for Sentiment Classification of Movie
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 3 Issue 2 February, 2014 Page No. 3951-3961 Bagged Ensemble Classifiers for Sentiment Classification of Movie
Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study
 Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study Aron Henriksson 1, Martin Hassel 1, and Maria Kvist 1,2 1 Department of Computer and System Sciences
Diagnosis Code Assignment Support Using Random Indexing of Patient Records A Qualitative Feasibility Study Aron Henriksson 1, Martin Hassel 1, and Maria Kvist 1,2 1 Department of Computer and System Sciences
Data Warehousing and Data Mining in Business Applications
 133 Data Warehousing and Data Mining in Business Applications Eesha Goel CSE Deptt. GZS-PTU Campus, Bathinda. Abstract Information technology is now required in all aspect of our lives that helps in business
133 Data Warehousing and Data Mining in Business Applications Eesha Goel CSE Deptt. GZS-PTU Campus, Bathinda. Abstract Information technology is now required in all aspect of our lives that helps in business
Web Data Mining: A Case Study. Abstract. Introduction
 Web Data Mining: A Case Study Samia Jones Galveston College, Galveston, TX 77550 Omprakash K. Gupta Prairie View A&M, Prairie View, TX 77446 okgupta@pvamu.edu Abstract With an enormous amount of data stored
Web Data Mining: A Case Study Samia Jones Galveston College, Galveston, TX 77550 Omprakash K. Gupta Prairie View A&M, Prairie View, TX 77446 okgupta@pvamu.edu Abstract With an enormous amount of data stored
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 3, 2014 Text Analytics (Text Mining) LSI (uses SVD), Visualization Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey
CSE 6242 / CX 4242 Apr 3, 2014 Text Analytics (Text Mining) LSI (uses SVD), Visualization Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP
 Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
SIMOnt: A Security Information Management Ontology Framework
 SIMOnt: A Security Information Management Ontology Framework Muhammad Abulaish 1,#, Syed Irfan Nabi 1,3, Khaled Alghathbar 1 & Azeddine Chikh 2 1 Centre of Excellence in Information Assurance, King Saud
SIMOnt: A Security Information Management Ontology Framework Muhammad Abulaish 1,#, Syed Irfan Nabi 1,3, Khaled Alghathbar 1 & Azeddine Chikh 2 1 Centre of Excellence in Information Assurance, King Saud
Review Jeopardy. Blue vs. Orange. Review Jeopardy
 Review Jeopardy Blue vs. Orange Review Jeopardy Jeopardy Round Lectures 0-3 Jeopardy Round $200 How could I measure how far apart (i.e. how different) two observations, y 1 and y 2, are from each other?
Review Jeopardy Blue vs. Orange Review Jeopardy Jeopardy Round Lectures 0-3 Jeopardy Round $200 How could I measure how far apart (i.e. how different) two observations, y 1 and y 2, are from each other?
Mammoth Scale Machine Learning!
 Mammoth Scale Machine Learning! Speaker: Robin Anil, Apache Mahout PMC Member! OSCON"10! Portland, OR! July 2010! Quick Show of Hands!# Are you fascinated about ML?!# Have you used ML?!# Do you have Gigabytes
Mammoth Scale Machine Learning! Speaker: Robin Anil, Apache Mahout PMC Member! OSCON"10! Portland, OR! July 2010! Quick Show of Hands!# Are you fascinated about ML?!# Have you used ML?!# Do you have Gigabytes
D-optimal plans in observational studies
 D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
Advanced In-Database Analytics
 Advanced In-Database Analytics Tallinn, Sept. 25th, 2012 Mikko-Pekka Bertling, BDM Greenplum EMEA 1 That sounds complicated? 2 Who can tell me how best to solve this 3 What are the main mathematical functions??
Advanced In-Database Analytics Tallinn, Sept. 25th, 2012 Mikko-Pekka Bertling, BDM Greenplum EMEA 1 That sounds complicated? 2 Who can tell me how best to solve this 3 What are the main mathematical functions??
Hexaware E-book on Predictive Analytics
 Hexaware E-book on Predictive Analytics Business Intelligence & Analytics Actionable Intelligence Enabled Published on : Feb 7, 2012 Hexaware E-book on Predictive Analytics What is Data mining? Data mining,
Hexaware E-book on Predictive Analytics Business Intelligence & Analytics Actionable Intelligence Enabled Published on : Feb 7, 2012 Hexaware E-book on Predictive Analytics What is Data mining? Data mining,
Data Mining Yelp Data - Predicting rating stars from review text
 Data Mining Yelp Data - Predicting rating stars from review text Rakesh Chada Stony Brook University rchada@cs.stonybrook.edu Chetan Naik Stony Brook University cnaik@cs.stonybrook.edu ABSTRACT The majority
Data Mining Yelp Data - Predicting rating stars from review text Rakesh Chada Stony Brook University rchada@cs.stonybrook.edu Chetan Naik Stony Brook University cnaik@cs.stonybrook.edu ABSTRACT The majority
DATA ANALYSIS II. Matrix Algorithms
 DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
Data Mining Techniques
 TIMELY. PRACTICAL. RELIABLE. Data Mining Techniques For Marketing, Sales, and Customer Relationship Management Third Edition Gordon S. Linoff Michael J. A. Berry Chapter 21 n Listen Carefully to What Your
TIMELY. PRACTICAL. RELIABLE. Data Mining Techniques For Marketing, Sales, and Customer Relationship Management Third Edition Gordon S. Linoff Michael J. A. Berry Chapter 21 n Listen Carefully to What Your
A Survey of Text Mining Techniques and Applications
 60 JOURNAL OF EMERGING TECHNOLOGIES IN WEB INTELLIGENCE, VOL. 1, NO. 1, AUGUST 2009 A Survey of Text Mining Techniques and Applications Vishal Gupta Lecturer Computer Science & Engineering, University
60 JOURNAL OF EMERGING TECHNOLOGIES IN WEB INTELLIGENCE, VOL. 1, NO. 1, AUGUST 2009 A Survey of Text Mining Techniques and Applications Vishal Gupta Lecturer Computer Science & Engineering, University
Spam Filtering Based on Latent Semantic Indexing
 Spam Filtering Based on Latent Semantic Indexing Wilfried N. Gansterer Andreas G. K. Janecek Robert Neumayer Abstract In this paper, a study on the classification performance of a vector space model (VSM)
Spam Filtering Based on Latent Semantic Indexing Wilfried N. Gansterer Andreas G. K. Janecek Robert Neumayer Abstract In this paper, a study on the classification performance of a vector space model (VSM)
The Big Data Paradigm Shift. Insight Through Automation
 The Big Data Paradigm Shift Insight Through Automation Agenda The Problem Emcien s Solution: Algorithms solve data related business problems How Does the Technology Work? Case Studies 2013 Emcien, Inc.
The Big Data Paradigm Shift Insight Through Automation Agenda The Problem Emcien s Solution: Algorithms solve data related business problems How Does the Technology Work? Case Studies 2013 Emcien, Inc.
Mining a Corpus of Job Ads
 Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
SEIZE THE DATA. 2015 SEIZE THE DATA. 2015
 1 Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. Deep dive into Haven Predictive Analytics Powered by HP Distributed R and
1 Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. Deep dive into Haven Predictive Analytics Powered by HP Distributed R and
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
5.5 Copyright 2011 Pearson Education, Inc. publishing as Prentice Hall. Figure 5-2
 Class Announcements TIM 50 - Business Information Systems Lecture 15 Database Assignment 2 posted Due Tuesday 5/26 UC Santa Cruz May 19, 2015 Database: Collection of related files containing records on
Class Announcements TIM 50 - Business Information Systems Lecture 15 Database Assignment 2 posted Due Tuesday 5/26 UC Santa Cruz May 19, 2015 Database: Collection of related files containing records on
Analytics on Big Data
 Analytics on Big Data Riccardo Torlone Università Roma Tre Credits: Mohamed Eltabakh (WPI) Analytics The discovery and communication of meaningful patterns in data (Wikipedia) It relies on data analysis
Analytics on Big Data Riccardo Torlone Università Roma Tre Credits: Mohamed Eltabakh (WPI) Analytics The discovery and communication of meaningful patterns in data (Wikipedia) It relies on data analysis
Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression
 Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression Saikat Maitra and Jun Yan Abstract: Dimension reduction is one of the major tasks for multivariate
Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression Saikat Maitra and Jun Yan Abstract: Dimension reduction is one of the major tasks for multivariate
BUILDING A PREDICTIVE MODEL AN EXAMPLE OF A PRODUCT RECOMMENDATION ENGINE
 BUILDING A PREDICTIVE MODEL AN EXAMPLE OF A PRODUCT RECOMMENDATION ENGINE Alex Lin Senior Architect Intelligent Mining alin@intelligentmining.com Outline Predictive modeling methodology k-nearest Neighbor
BUILDING A PREDICTIVE MODEL AN EXAMPLE OF A PRODUCT RECOMMENDATION ENGINE Alex Lin Senior Architect Intelligent Mining alin@intelligentmining.com Outline Predictive modeling methodology k-nearest Neighbor
STATISTICA. Financial Institutions. Case Study: Credit Scoring. and
 Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
DATA MINING TECHNIQUES AND APPLICATIONS
 DATA MINING TECHNIQUES AND APPLICATIONS Mrs. Bharati M. Ramageri, Lecturer Modern Institute of Information Technology and Research, Department of Computer Application, Yamunanagar, Nigdi Pune, Maharashtra,
DATA MINING TECHNIQUES AND APPLICATIONS Mrs. Bharati M. Ramageri, Lecturer Modern Institute of Information Technology and Research, Department of Computer Application, Yamunanagar, Nigdi Pune, Maharashtra,
How Organisations Are Using Data Mining Techniques To Gain a Competitive Advantage John Spooner SAS UK
 How Organisations Are Using Data Mining Techniques To Gain a Competitive Advantage John Spooner SAS UK Agenda Analytics why now? The process around data and text mining Case Studies The Value of Information
How Organisations Are Using Data Mining Techniques To Gain a Competitive Advantage John Spooner SAS UK Agenda Analytics why now? The process around data and text mining Case Studies The Value of Information
SYMMETRIC EIGENFACES MILI I. SHAH
 SYMMETRIC EIGENFACES MILI I. SHAH Abstract. Over the years, mathematicians and computer scientists have produced an extensive body of work in the area of facial analysis. Several facial analysis algorithms
SYMMETRIC EIGENFACES MILI I. SHAH Abstract. Over the years, mathematicians and computer scientists have produced an extensive body of work in the area of facial analysis. Several facial analysis algorithms
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization
 A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca ablancogo@upsa.es Spain Manuel Martín-Merino Universidad
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca ablancogo@upsa.es Spain Manuel Martín-Merino Universidad
1 Example of Time Series Analysis by SSA 1
 1 Example of Time Series Analysis by SSA 1 Let us illustrate the 'Caterpillar'-SSA technique [1] by the example of time series analysis. Consider the time series FORT (monthly volumes of fortied wine sales
1 Example of Time Series Analysis by SSA 1 Let us illustrate the 'Caterpillar'-SSA technique [1] by the example of time series analysis. Consider the time series FORT (monthly volumes of fortied wine sales
Paper 3508-2015. Downtime of a truck = Truck repair end date - Truck repair start date
 Paper 3508-2015 Using Text from Repair Tickets of a Truck Manufacturing Company to Predict Factors that Contribute to Truck Downtime Ayush Priyadarshi and Dr. Goutam Chakraborty, Oklahoma State University
Paper 3508-2015 Using Text from Repair Tickets of a Truck Manufacturing Company to Predict Factors that Contribute to Truck Downtime Ayush Priyadarshi and Dr. Goutam Chakraborty, Oklahoma State University
text data analytics insights unstructured predictive improve source Extracting Value from Unstructured Data use behavior characteristics customer
 models time techniques segmentation topics characteristics customer strong major processing value performance example intelligence changing better algorithms operational Data multiple Text unstructured
models time techniques segmentation topics characteristics customer strong major processing value performance example intelligence changing better algorithms operational Data multiple Text unstructured
Why is Internal Audit so Hard?
 Why is Internal Audit so Hard? 2 2014 Why is Internal Audit so Hard? 3 2014 Why is Internal Audit so Hard? Waste Abuse Fraud 4 2014 Waves of Change 1 st Wave Personal Computers Electronic Spreadsheets
Why is Internal Audit so Hard? 2 2014 Why is Internal Audit so Hard? 3 2014 Why is Internal Audit so Hard? Waste Abuse Fraud 4 2014 Waves of Change 1 st Wave Personal Computers Electronic Spreadsheets
Statistical Challenges with Big Data in Management Science
 Statistical Challenges with Big Data in Management Science Arnab Kumar Laha Indian Institute of Management Ahmedabad Analytics vs Reporting Competitive Advantage Reporting Prescriptive Analytics (Decision
Statistical Challenges with Big Data in Management Science Arnab Kumar Laha Indian Institute of Management Ahmedabad Analytics vs Reporting Competitive Advantage Reporting Prescriptive Analytics (Decision
Identifying SPAM with Predictive Models
 Identifying SPAM with Predictive Models Dan Steinberg and Mikhaylo Golovnya Salford Systems 1 Introduction The ECML-PKDD 2006 Discovery Challenge posed a topical problem for predictive modelers: how to
Identifying SPAM with Predictive Models Dan Steinberg and Mikhaylo Golovnya Salford Systems 1 Introduction The ECML-PKDD 2006 Discovery Challenge posed a topical problem for predictive modelers: how to
What Are They Thinking? With Oracle Application Express and Oracle Data Miner
 What Are They Thinking? With Oracle Application Express and Oracle Data Miner Roel Hartman Brendan Tierney Agenda Who are we The Scenario Graphs & Charts in APEX - Live Demo Oracle Data Miner & DBA tasks
What Are They Thinking? With Oracle Application Express and Oracle Data Miner Roel Hartman Brendan Tierney Agenda Who are we The Scenario Graphs & Charts in APEX - Live Demo Oracle Data Miner & DBA tasks
Exam in course TDT4215 Web Intelligence - Solutions and guidelines -
 English Student no:... Page 1 of 12 Contact during the exam: Geir Solskinnsbakk Phone: 94218 Exam in course TDT4215 Web Intelligence - Solutions and guidelines - Friday May 21, 2010 Time: 0900-1300 Allowed
English Student no:... Page 1 of 12 Contact during the exam: Geir Solskinnsbakk Phone: 94218 Exam in course TDT4215 Web Intelligence - Solutions and guidelines - Friday May 21, 2010 Time: 0900-1300 Allowed
SPATIAL DATA CLASSIFICATION AND DATA MINING
 , pp.-40-44. Available online at http://www. bioinfo. in/contents. php?id=42 SPATIAL DATA CLASSIFICATION AND DATA MINING RATHI J.B. * AND PATIL A.D. Department of Computer Science & Engineering, Jawaharlal
, pp.-40-44. Available online at http://www. bioinfo. in/contents. php?id=42 SPATIAL DATA CLASSIFICATION AND DATA MINING RATHI J.B. * AND PATIL A.D. Department of Computer Science & Engineering, Jawaharlal
STATISTICAL ANALYSIS OF SOCIAL NETWORKS. Agostino Di Ciaccio, Giovanni Maria Giorgi
 Rivista Italiana di Economia Demografia e Statistica Volume LXVII n. 3/4 Luglio-Dicembre 2013 STATISTICAL ANALYSIS OF SOCIAL NETWORKS Agostino Di Ciaccio, Giovanni Maria Giorgi 1. Introduction The marked
Rivista Italiana di Economia Demografia e Statistica Volume LXVII n. 3/4 Luglio-Dicembre 2013 STATISTICAL ANALYSIS OF SOCIAL NETWORKS Agostino Di Ciaccio, Giovanni Maria Giorgi 1. Introduction The marked
Linear Algebra Review. Vectors
 Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka kosecka@cs.gmu.edu http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa Cogsci 8F Linear Algebra review UCSD Vectors The length
Linear Algebra Review By Tim K. Marks UCSD Borrows heavily from: Jana Kosecka kosecka@cs.gmu.edu http://cs.gmu.edu/~kosecka/cs682.html Virginia de Sa Cogsci 8F Linear Algebra review UCSD Vectors The length
Why are Organizations Interested?
 SAS Text Analytics Mary-Elizabeth ( M-E ) Eddlestone SAS Customer Loyalty M-E.Eddlestone@sas.com +1 (607) 256-7929 Why are Organizations Interested? Text Analytics 2009: User Perspectives on Solutions
SAS Text Analytics Mary-Elizabeth ( M-E ) Eddlestone SAS Customer Loyalty M-E.Eddlestone@sas.com +1 (607) 256-7929 Why are Organizations Interested? Text Analytics 2009: User Perspectives on Solutions
Knowledge Discovery from patents using KMX Text Analytics
 Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs anton.heijs@treparel.com Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs anton.heijs@treparel.com Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
In this presentation, you will be introduced to data mining and the relationship with meaningful use.
 In this presentation, you will be introduced to data mining and the relationship with meaningful use. Data mining refers to the art and science of intelligent data analysis. It is the application of machine
In this presentation, you will be introduced to data mining and the relationship with meaningful use. Data mining refers to the art and science of intelligent data analysis. It is the application of machine
Comparison of Standard and Zipf-Based Document Retrieval Heuristics
 Comparison of Standard and Zipf-Based Document Retrieval Heuristics Benjamin Hoffmann Universität Stuttgart, Institut für Formale Methoden der Informatik Universitätsstr. 38, D-70569 Stuttgart, Germany
Comparison of Standard and Zipf-Based Document Retrieval Heuristics Benjamin Hoffmann Universität Stuttgart, Institut für Formale Methoden der Informatik Universitätsstr. 38, D-70569 Stuttgart, Germany