Mixing Hadoop and HPC Workloads on Parallel Filesystems
|
|
|
- Kerry Norman
- 10 years ago
- Views:
Transcription
1 Mixing Hadoop and HPC Workloads on Parallel Filesystems Esteban Molina-Estolano *, Maya Gokhale, Carlos Maltzahn *, John May, John Bent, Scott Brandt * * UC Santa Cruz, ISSDM, PDSI Lawrence Livermore National Laboratory Los Alamos National Laboratory

2 Motivation Strong interest in running both HPC and large-scale data mining workloads on the same infrastructure Hadoop-tailored filesystems (e.g. CloudStore) and highperformance computing filesystems (e.g. PVFS) are tailored to considerably different workloads Existing investments in HPC systems and Hadoop systems should be usable for both workloads Goal: Examine the performance of both types of workloads running concurrently on the same filesystem Goal: collect I/O traces from concurrent workload runs, for parallel filesystem simulator work

3 MapReduce-oriented filesystems Large-scale batch data processing and analysis Single cluster of unreliable commodity machines for both storage and computation Data locality is important for performance Examples: Google FS, Hadoop DFS, CloudStore

4 Hadoop DFS architecture 2"3,,4(567("$'8).%'.9$%!"#$%&'%(!)*%$+,$%(-".),&"/(!"0,$".,$1 "##$%&&"'())$*'$'+",*)-.!

5 High-Performance Computing filesystems 2)3456%$7,$+"&'%(8,+9:.)&3(7)/%;1;.%+; High-throughput, lowlatency workloads!!"#$%&$'()#$*)&+,-(.% -/&0123,.('4-(/56! 7'2$"&02&)'08,60*/'/&0, 2(9*)&0,/15,6&('/#0, 2-)6&0'6+,$"#$%6*005, :'"5#0,:0&.001,&$09! ;3*"2/-,.('4-(/58, 6"9)-/&"(1,2$024*("1&"1#! Architecture: separate compute and storage clusters, high-speed bridge between them Typical workload: simulation checkpointing.$/01#()2314#(% 56'7840((9):%69'( Examples: PVFS, Lustre, PanFS, Ceph!"#$%&'%(!)*%$+,$%(-".),&"/(!"0,$".,$1 "#$%&'()*%(&)+(#,$%-!
6&0'+, Architecture: separate compute and storage clusters, high-speed bridge between them Typical workload: >/1@A simulation")
6 Running each workload on the non-native filesystem Two-sided problem: running HPC workloads on a Hadoop filesystem, and Hadoop workloads on an HPC filesystem Different interfaces: HPC workloads need a POSIX-like interface and shared writes Hadoop is write-once-read-many Different data layout policies

7 Running HPC workloads on a Hadoop filesystem Chosen filesystem: CloudStore Downside of Hadoop s HDFS: no support for shared writes (needed for HPC N-1 workloads) Cloudstore has HDFS-like architecture, and shared write support

8 Running Hadoop workloads on an HPC filesystem Chosen HPC filesystem: PVFS PVFS is open-source and easy to configure Tantisiriroj et al. at CMU have created a shim to run Hadoop on PVFS Shim also adds prefetching, buffering, exposes data layout

9 The two concurrent workloads IOR checkpointing workload writes large amounts of data to disk from many clients N-1 and N-N write patterns Hadoop MapReduce HTTP attack classifier (TFIDF) Using a pre-generated attack model, classify HTTP headers as normal traffic or attack traffic

10
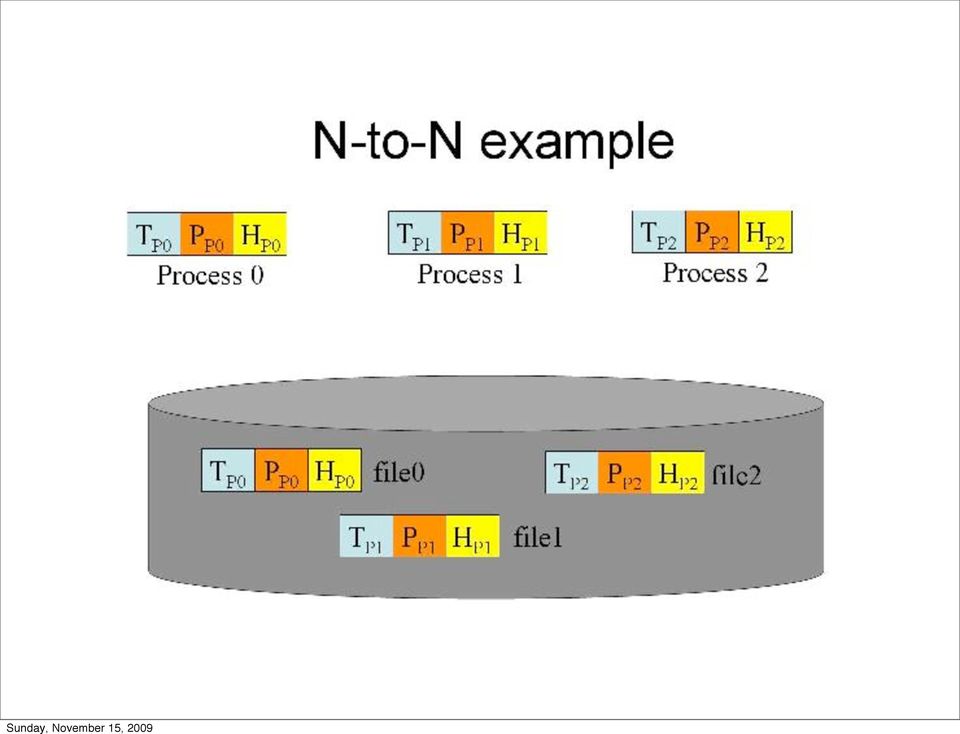
11
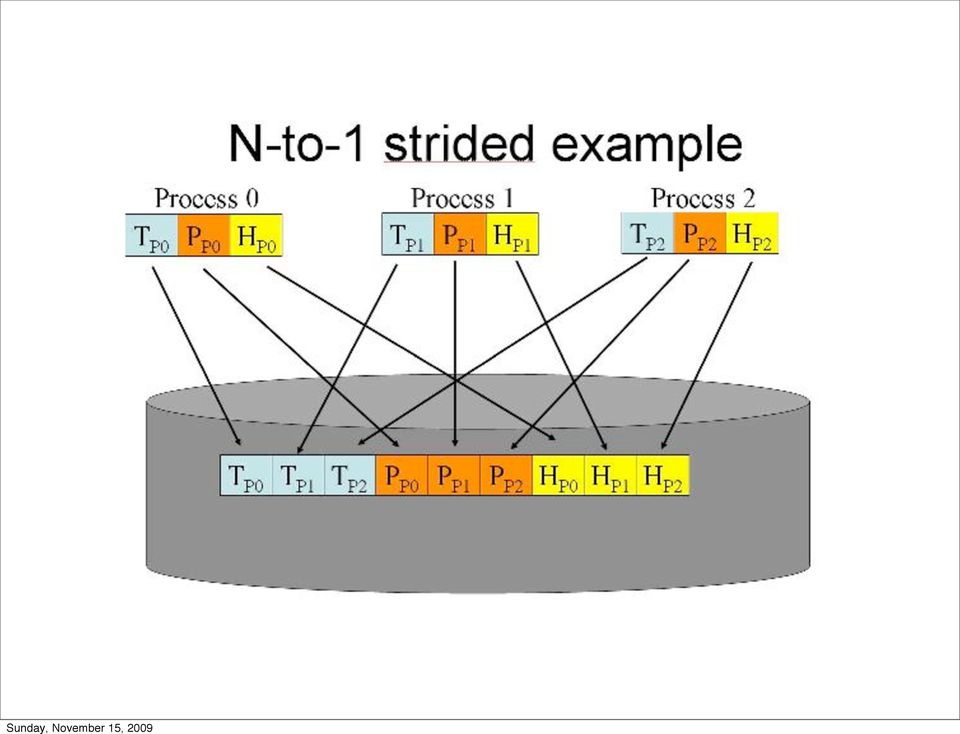
12 Experimental Setup System: 19 nodes, 2-core 2.4 GHz Xeon, 120 GB disks IOR baseline: N-1 strided workload, 64 MB chunks IOR baseline: N-N workload, 64 MB chunks TFIDF baseline: classify 7.2 GB of HTTP headers Mixed workloads: IOR N-1 and TFIDF, IOR N-N and TFIDF Checkpoint size adjusted to make IOR and TFIDF take the same amount of time

13 Performance metrics Throughputs are not comparable between workloads Per-workload throughput: measure how much each job is slowed down by the mixed workload Runtime: compare the runtime of the mixed workload with the runtime of the same jobs run sequentially

14 Hadoop performance results Classification throughput (MB/s) TFIDF classification throughput, standalone and with IOR CloudStore Baseline with IOR N-1 with IOR N-N PVFS

15 IOR performance results Write throughput (MB/s) IOR checkpointing on CloudStore N-1 N-N IOR checkpointing on PVFS Standalone Mixed N-1 N-N

16 Runtime (seconds) Runtime results Runtime comparison of mixed vs. serial workloads Serial runtime Mixed runtime PVFS N-1 PVFS N-N CloudStore N-1 CloudStore N-N

17 Tracing infrastructure We gather traces to use for our parallel filesystem simulator Existing tracing mechanisms (e.g. strace, Pianola, Darshan) don t work well with Java or CloudStore Solution: our own tracing mechanisms for IOR and Hadoop

18 Tracing IOR workloads 2$"')&3(456(#,$7/,"89 Trace shim intercepts I/O calls, sends to stdio!!"#$%&'()*&$#+,-"%'&./0&$#11'2&'%34'&,5&',4)5 #$%&'()*&.$/#' #$%&'()* #$%&'()*&+*,-) #$%&'()*&0.##$ <((8)9>?8;G)>?)A:&9;=) #$%&'()*&1234 #$%&'()*&560.# 89:;< #$%&'()*&73/!"#$%&'%(!)*%$+,$%(-".),&"/(!"0,$".,$1!"
,:DE*;9)F> <((8)9>?8;G)>?)A:&9;=) #$%&'()*&1234 #$%&'()*&560.# 89:;< #$%&'()*&73/!")
19 2$"')&3(4"5,,6(7"68%59'% Tracing Hadoop #$%&'$(+0%.% $'%/ #$%&'$()*'+,-.'/ 56(+7()*'+,-.'/ :6%& ;$%".%!!"#$$%&'(")*+,&-.*/0&1(")2(3*4256-'2/! Tracing shim wraps filesystem interfaces, sends I/O calls! C"-2&9*42-6-'2/-&/$#*9*2#&'$&D("%&E+%>':F>'%>'5'(2"/-& to Hadoop logs! E:F&$%2("'*$+-&4$,,2#&'$&!"#$$%&%2(='"-G&4$,- 56(+70%.% $'%/ 9%:;;3<*;=- #$%&'$(+0%.% $'%/ 56(+70%.% $'%/
*'2%/'@<3):@<-.%$.A.)/'@<'2:A.)/'@<;3'$%.);2B3%$%/@<CCCD<E<$'-4*.<F'*%3-':</-G!\"#$%&'%(!)*%$+,$%(-\".")
20 Tracing overhead Trace data goes to NFS-mounted share (no disk overhead) Small Hadoop reads caused huge tracing overhead Solution: record traces behind read-ahead buffers Overhead (throughput slowdown): IOR checkpointing: 1% TFIDF Hadoop: 5% Mixed workloads: 10%
: IOR checkpointing: 1% TFIDF Hadoop: 5%")
21 Conclusions Each mixed workload component is noticeably slowed, but... If only total runtime matters, the mixed workloads are faster PVFS shows different slowdowns for N-N vs. N-1 workloads Tracing infrastructure: buffering required for small I/O tracing Future work: Run experiments at a larger scale Use experimental results to improve parallel filesystem simulator Investigate scheduling strategies for mixed workloads
22 Questions? Esteban Molina-Estolano:
Performance Analysis of Mixed Distributed Filesystem Workloads
 Performance Analysis of Mixed Distributed Filesystem Workloads Esteban Molina-Estolano, Maya Gokhale, Carlos Maltzahn, John May, John Bent, Scott Brandt Motivation Hadoop-tailored filesystems (e.g. CloudStore)
Performance Analysis of Mixed Distributed Filesystem Workloads Esteban Molina-Estolano, Maya Gokhale, Carlos Maltzahn, John May, John Bent, Scott Brandt Motivation Hadoop-tailored filesystems (e.g. CloudStore)
I/O intensive applications: what are the main differences in the design of the HPC filesystems vs the MapReduce ones?
 I/O intensive applications: what are the main differences in the design of the HPC filesystems vs the MapReduce ones? Matthieu Dorier, Radu Marius Tudoran Master 2 Research ENS Cachan - Brittany extension
I/O intensive applications: what are the main differences in the design of the HPC filesystems vs the MapReduce ones? Matthieu Dorier, Radu Marius Tudoran Master 2 Research ENS Cachan - Brittany extension
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Analysis and Optimization of Massive Data Processing on High Performance Computing Architecture
 Analysis and Optimization of Massive Data Processing on High Performance Computing Architecture He Huang, Shanshan Li, Xiaodong Yi, Feng Zhang, Xiangke Liao and Pan Dong School of Computer Science National
Analysis and Optimization of Massive Data Processing on High Performance Computing Architecture He Huang, Shanshan Li, Xiaodong Yi, Feng Zhang, Xiangke Liao and Pan Dong School of Computer Science National
Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000
 Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000 Alexandra Carpen-Amarie Diana Moise Bogdan Nicolae KerData Team, INRIA Outline
Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000 Alexandra Carpen-Amarie Diana Moise Bogdan Nicolae KerData Team, INRIA Outline
Accelerating and Simplifying Apache
 Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Performance Comparison of Intel Enterprise Edition for Lustre* software and HDFS for MapReduce Applications
 Performance Comparison of Intel Enterprise Edition for Lustre software and HDFS for MapReduce Applications Rekha Singhal, Gabriele Pacciucci and Mukesh Gangadhar 2 Hadoop Introduc-on Open source MapReduce
Performance Comparison of Intel Enterprise Edition for Lustre software and HDFS for MapReduce Applications Rekha Singhal, Gabriele Pacciucci and Mukesh Gangadhar 2 Hadoop Introduc-on Open source MapReduce
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems
 Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
HDFS Space Consolidation
 HDFS Space Consolidation Aastha Mehta*,1,2, Deepti Banka*,1,2, Kartheek Muthyala*,1,2, Priya Sehgal 1, Ajay Bakre 1 *Student Authors 1 Advanced Technology Group, NetApp Inc., Bangalore, India 2 Birla Institute
HDFS Space Consolidation Aastha Mehta*,1,2, Deepti Banka*,1,2, Kartheek Muthyala*,1,2, Priya Sehgal 1, Ajay Bakre 1 *Student Authors 1 Advanced Technology Group, NetApp Inc., Bangalore, India 2 Birla Institute
GeoGrid Project and Experiences with Hadoop
 GeoGrid Project and Experiences with Hadoop Gong Zhang and Ling Liu Distributed Data Intensive Systems Lab (DiSL) Center for Experimental Computer Systems Research (CERCS) Georgia Institute of Technology
GeoGrid Project and Experiences with Hadoop Gong Zhang and Ling Liu Distributed Data Intensive Systems Lab (DiSL) Center for Experimental Computer Systems Research (CERCS) Georgia Institute of Technology
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
Lustre * Filesystem for Cloud and Hadoop *
 OpenFabrics Software User Group Workshop Lustre * Filesystem for Cloud and Hadoop * Robert Read, Intel Lustre * for Cloud and Hadoop * Brief Lustre History and Overview Using Lustre with Hadoop Intel Cloud
OpenFabrics Software User Group Workshop Lustre * Filesystem for Cloud and Hadoop * Robert Read, Intel Lustre * for Cloud and Hadoop * Brief Lustre History and Overview Using Lustre with Hadoop Intel Cloud
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Use of Hadoop File System for Nuclear Physics Analyses in STAR
 1 Use of Hadoop File System for Nuclear Physics Analyses in STAR EVAN SANGALINE UC DAVIS Motivations 2 Data storage a key component of analysis requirements Transmission and storage across diverse resources
1 Use of Hadoop File System for Nuclear Physics Analyses in STAR EVAN SANGALINE UC DAVIS Motivations 2 Data storage a key component of analysis requirements Transmission and storage across diverse resources
BlobSeer: Towards efficient data storage management on large-scale, distributed systems
 : Towards efficient data storage management on large-scale, distributed systems Bogdan Nicolae University of Rennes 1, France KerData Team, INRIA Rennes Bretagne-Atlantique PhD Advisors: Gabriel Antoniu
: Towards efficient data storage management on large-scale, distributed systems Bogdan Nicolae University of Rennes 1, France KerData Team, INRIA Rennes Bretagne-Atlantique PhD Advisors: Gabriel Antoniu
Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage
 White Paper Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage A Benchmark Report August 211 Background Objectivity/DB uses a powerful distributed processing architecture to manage
White Paper Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage A Benchmark Report August 211 Background Objectivity/DB uses a powerful distributed processing architecture to manage
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Linux Performance Optimizations for Big Data Environments
 Linux Performance Optimizations for Big Data Environments Dominique A. Heger Ph.D. DHTechnologies (Performance, Capacity, Scalability) www.dhtusa.com Data Nubes (Big Data, Hadoop, ML) www.datanubes.com
Linux Performance Optimizations for Big Data Environments Dominique A. Heger Ph.D. DHTechnologies (Performance, Capacity, Scalability) www.dhtusa.com Data Nubes (Big Data, Hadoop, ML) www.datanubes.com
Can High-Performance Interconnects Benefit Memcached and Hadoop?
 Can High-Performance Interconnects Benefit Memcached and Hadoop? D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Can High-Performance Interconnects Benefit Memcached and Hadoop? D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 21 Outline
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 21 Outline
Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013
 Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013 * Other names and brands may be claimed as the property of others. Agenda Hadoop Intro Why run Hadoop on Lustre?
Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013 * Other names and brands may be claimed as the property of others. Agenda Hadoop Intro Why run Hadoop on Lustre?
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Data Analytics. CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL. All rights reserved.
 2011, Parallel Systems Architecture Lab, EPFL. All rights reserved.") Data Analytics CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL All rights reserved. The data analytics benchmark relies on using the Hadoop MapReduce framework
Data Analytics CloudSuite1.0 Benchmark Suite Copyright (c) 2011, Parallel Systems Architecture Lab, EPFL All rights reserved. The data analytics benchmark relies on using the Hadoop MapReduce framework
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
BookKeeper. Flavio Junqueira Yahoo! Research, Barcelona. Hadoop in China 2011
 BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
Hadoop s Entry into the Traditional Analytical DBMS Market. Daniel Abadi Yale University August 3 rd, 2010
 Hadoop s Entry into the Traditional Analytical DBMS Market Daniel Abadi Yale University August 3 rd, 2010 Data, Data, Everywhere Data explosion Web 2.0 more user data More devices that sense data More
Hadoop s Entry into the Traditional Analytical DBMS Market Daniel Abadi Yale University August 3 rd, 2010 Data, Data, Everywhere Data explosion Web 2.0 more user data More devices that sense data More
Map Reduce / Hadoop / HDFS
 Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms
 Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
HPCHadoop: MapReduce on Cray X-series
 HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
A Study on Workload Imbalance Issues in Data Intensive Distributed Computing
 A Study on Workload Imbalance Issues in Data Intensive Distributed Computing Sven Groot 1, Kazuo Goda 1, and Masaru Kitsuregawa 1 University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8505, Japan Abstract.
A Study on Workload Imbalance Issues in Data Intensive Distributed Computing Sven Groot 1, Kazuo Goda 1, and Masaru Kitsuregawa 1 University of Tokyo, 4-6-1 Komaba, Meguro-ku, Tokyo 153-8505, Japan Abstract.
RADOS: A Scalable, Reliable Storage Service for Petabyte- scale Storage Clusters
 RADOS: A Scalable, Reliable Storage Service for Petabyte- scale Storage Clusters Sage Weil, Andrew Leung, Scott Brandt, Carlos Maltzahn {sage,aleung,scott,carlosm}@cs.ucsc.edu University of California,
RADOS: A Scalable, Reliable Storage Service for Petabyte- scale Storage Clusters Sage Weil, Andrew Leung, Scott Brandt, Carlos Maltzahn {sage,aleung,scott,carlosm}@cs.ucsc.edu University of California,
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
HADOOP PERFORMANCE TUNING
 PERFORMANCE TUNING Abstract This paper explains tuning of Hadoop configuration parameters which directly affects Map-Reduce job performance under various conditions, to achieve maximum performance. The
PERFORMANCE TUNING Abstract This paper explains tuning of Hadoop configuration parameters which directly affects Map-Reduce job performance under various conditions, to achieve maximum performance. The
A Micro-benchmark Suite for Evaluating Hadoop RPC on High-Performance Networks
 A Micro-benchmark Suite for Evaluating Hadoop RPC on High-Performance Networks Xiaoyi Lu, Md. Wasi- ur- Rahman, Nusrat Islam, and Dhabaleswar K. (DK) Panda Network- Based Compu2ng Laboratory Department
A Micro-benchmark Suite for Evaluating Hadoop RPC on High-Performance Networks Xiaoyi Lu, Md. Wasi- ur- Rahman, Nusrat Islam, and Dhabaleswar K. (DK) Panda Network- Based Compu2ng Laboratory Department
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Cray XC30 Hadoop Platform Jonathan (Bill) Sparks Howard Pritchard Martha Dumler
 Sparks Howard Pritchard Martha Dumler") Cray XC30 Hadoop Platform Jonathan (Bill) Sparks Howard Pritchard Martha Dumler Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Cray XC30 Hadoop Platform Jonathan (Bill) Sparks Howard Pritchard Martha Dumler Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Evaluating HDFS I/O Performance on Virtualized Systems
 Evaluating HDFS I/O Performance on Virtualized Systems Xin Tang [email protected] University of Wisconsin-Madison Department of Computer Sciences Abstract Hadoop as a Service (HaaS) has received increasing
Evaluating HDFS I/O Performance on Virtualized Systems Xin Tang [email protected] University of Wisconsin-Madison Department of Computer Sciences Abstract Hadoop as a Service (HaaS) has received increasing
Duke University http://www.cs.duke.edu/starfish
 Herodotos Herodotou, Harold Lim, Fei Dong, Shivnath Babu Duke University http://www.cs.duke.edu/starfish Practitioners of Big Data Analytics Google Yahoo! Facebook ebay Physicists Biologists Economists
Herodotos Herodotou, Harold Lim, Fei Dong, Shivnath Babu Duke University http://www.cs.duke.edu/starfish Practitioners of Big Data Analytics Google Yahoo! Facebook ebay Physicists Biologists Economists
Hadoop Distributed File System. Dhruba Borthakur June, 2007
 Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Optimize the execution of local physics analysis workflows using Hadoop
 Optimize the execution of local physics analysis workflows using Hadoop INFN CCR - GARR Workshop 14-17 May Napoli Hassen Riahi Giacinto Donvito Livio Fano Massimiliano Fasi Andrea Valentini INFN-PERUGIA
Optimize the execution of local physics analysis workflows using Hadoop INFN CCR - GARR Workshop 14-17 May Napoli Hassen Riahi Giacinto Donvito Livio Fano Massimiliano Fasi Andrea Valentini INFN-PERUGIA
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
The Comprehensive Performance Rating for Hadoop Clusters on Cloud Computing Platform
 The Comprehensive Performance Rating for Hadoop Clusters on Cloud Computing Platform Fong-Hao Liu, Ya-Ruei Liou, Hsiang-Fu Lo, Ko-Chin Chang, and Wei-Tsong Lee Abstract Virtualization platform solutions
The Comprehensive Performance Rating for Hadoop Clusters on Cloud Computing Platform Fong-Hao Liu, Ya-Ruei Liou, Hsiang-Fu Lo, Ko-Chin Chang, and Wei-Tsong Lee Abstract Virtualization platform solutions
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Enabling High performance Big Data platform with RDMA
 Enabling High performance Big Data platform with RDMA Tong Liu HPC Advisory Council Oct 7 th, 2014 Shortcomings of Hadoop Administration tooling Performance Reliability SQL support Backup and recovery
Enabling High performance Big Data platform with RDMA Tong Liu HPC Advisory Council Oct 7 th, 2014 Shortcomings of Hadoop Administration tooling Performance Reliability SQL support Backup and recovery
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
InfoScale Storage & Media Server Workloads
 InfoScale Storage & Media Server Workloads Maximise Performance when Storing and Retrieving Large Amounts of Unstructured Data Carlos Carrero Colin Eldridge Shrinivas Chandukar 1 Table of Contents 01 Introduction
InfoScale Storage & Media Server Workloads Maximise Performance when Storing and Retrieving Large Amounts of Unstructured Data Carlos Carrero Colin Eldridge Shrinivas Chandukar 1 Table of Contents 01 Introduction
HPC and Big Data. EPCC The University of Edinburgh. Adrian Jackson Technical Architect [email protected]
 HPC and Big Data EPCC The University of Edinburgh Adrian Jackson Technical Architect [email protected] EPCC Facilities Technology Transfer European Projects HPC Research Visitor Programmes Training
HPC and Big Data EPCC The University of Edinburgh Adrian Jackson Technical Architect [email protected] EPCC Facilities Technology Transfer European Projects HPC Research Visitor Programmes Training
Research Article Hadoop-Based Distributed Sensor Node Management System
 Distributed Networks, Article ID 61868, 7 pages http://dx.doi.org/1.1155/214/61868 Research Article Hadoop-Based Distributed Node Management System In-Yong Jung, Ki-Hyun Kim, Byong-John Han, and Chang-Sung
Distributed Networks, Article ID 61868, 7 pages http://dx.doi.org/1.1155/214/61868 Research Article Hadoop-Based Distributed Node Management System In-Yong Jung, Ki-Hyun Kim, Byong-John Han, and Chang-Sung
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Investigation of storage options for scientific computing on Grid and Cloud facilities
 Investigation of storage options for scientific computing on Grid and Cloud facilities Overview Hadoop Test Bed Hadoop Evaluation Standard benchmarks Application-based benchmark Blue Arc Evaluation Standard
Investigation of storage options for scientific computing on Grid and Cloud facilities Overview Hadoop Test Bed Hadoop Evaluation Standard benchmarks Application-based benchmark Blue Arc Evaluation Standard
EFFICIENT GEAR-SHIFTING FOR A POWER-PROPORTIONAL DISTRIBUTED DATA-PLACEMENT METHOD
 EFFICIENT GEAR-SHIFTING FOR A POWER-PROPORTIONAL DISTRIBUTED DATA-PLACEMENT METHOD 2014/1/27 Hieu Hanh Le, Satoshi Hikida and Haruo Yokota Tokyo Institute of Technology 1.1 Background 2 Commodity-based
EFFICIENT GEAR-SHIFTING FOR A POWER-PROPORTIONAL DISTRIBUTED DATA-PLACEMENT METHOD 2014/1/27 Hieu Hanh Le, Satoshi Hikida and Haruo Yokota Tokyo Institute of Technology 1.1 Background 2 Commodity-based
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon [email protected] [email protected] XLDB
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon [email protected] [email protected] XLDB
WITH A FUSION POWERED SQL SERVER 2014 IN-MEMORY OLTP DATABASE
 WITH A FUSION POWERED SQL SERVER 2014 IN-MEMORY OLTP DATABASE 1 W W W. F U S I ON I O.COM Table of Contents Table of Contents... 2 Executive Summary... 3 Introduction: In-Memory Meets iomemory... 4 What
WITH A FUSION POWERED SQL SERVER 2014 IN-MEMORY OLTP DATABASE 1 W W W. F U S I ON I O.COM Table of Contents Table of Contents... 2 Executive Summary... 3 Introduction: In-Memory Meets iomemory... 4 What
Snapshots in Hadoop Distributed File System
 Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
OSG Hadoop is packaged into rpms for SL4, SL5 by Caltech BeStMan, gridftp backend
 Hadoop on HEPiX storage test bed at FZK Artem Trunov Karlsruhe Institute of Technology Karlsruhe, Germany KIT The cooperation of Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH) www.kit.edu
Hadoop on HEPiX storage test bed at FZK Artem Trunov Karlsruhe Institute of Technology Karlsruhe, Germany KIT The cooperation of Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH) www.kit.edu
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Michael Thomas, Dorian Kcira California Institute of Technology. CMS Offline & Computing Week
 Michael Thomas, Dorian Kcira California Institute of Technology CMS Offline & Computing Week San Diego, April 20-24 th 2009 Map-Reduce plus the HDFS filesystem implemented in java Map-Reduce is a highly
Michael Thomas, Dorian Kcira California Institute of Technology CMS Offline & Computing Week San Diego, April 20-24 th 2009 Map-Reduce plus the HDFS filesystem implemented in java Map-Reduce is a highly
Comprehending the Tradeoffs between Deploying Oracle Database on RAID 5 and RAID 10 Storage Configurations. Database Solutions Engineering
 Comprehending the Tradeoffs between Deploying Oracle Database on RAID 5 and RAID 10 Storage Configurations A Dell Technical White Paper Database Solutions Engineering By Sudhansu Sekhar and Raghunatha
Comprehending the Tradeoffs between Deploying Oracle Database on RAID 5 and RAID 10 Storage Configurations A Dell Technical White Paper Database Solutions Engineering By Sudhansu Sekhar and Raghunatha