Bigtable is a proven design Underpins 100+ Google services:
|
|
|
- Elijah Norton
- 8 years ago
- Views:
Transcription
1 Mastering Massive Data Volumes with Hypertable Doug Judd

2 Talk Outline Overview Architecture Performance Evaluation Case Studies

3 Hypertable Overview Massively Scalable Database Modeled after Google s Bigtable Open Source (GPL 2 license) High Performance Implementation (C++) Thrift Interface for all popular High Level Languages: Java, Ruby, Python, PHP, etc Project started March Zvents

4 Bigtable: the infrastructure that Google is built on Bigtable is a proven design Underpins 100+ Google services: YouTube, Blogger, Google Earth, Google Maps, Orkut, Gmail, Google Analytics, Google Book Search, Google Code, Crawl Database Part of larger scalable computing stack: Bigtable + GFS + MapReduce Provides strong consistency

5 Hypertable In Use Today

6 Architecture

7 System Overview
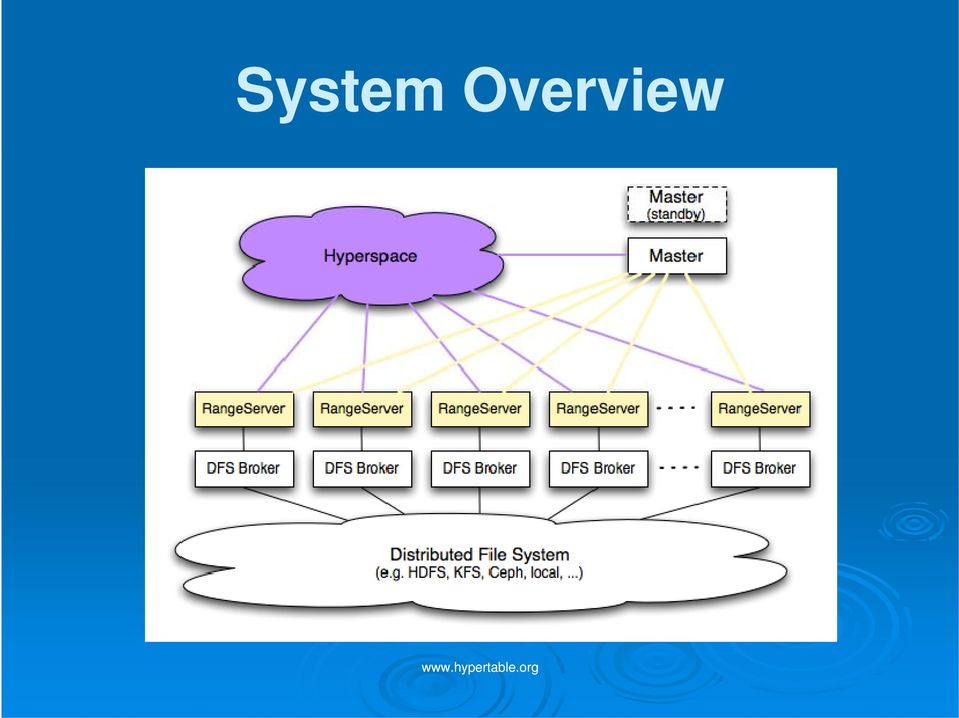
8 Data Model Sparse, two-dimensional table with cell versions Cells are identified by a 4-part key Row (string) Column Family Column Qualifier (string) Timestamp
")
9 Table: Visual Representation

10 Table: Actual Representation

11 Anatomy of a Key Column Family is represented with 1 byte Timestamp and revision are stored big-endian ones- compliment Simple byte-wise comparison

12 Scaling (part I)

13 Scaling (part II)

14 Scaling (part III)

15 Request est Routing

16 Insert Handling

17 Query Handling
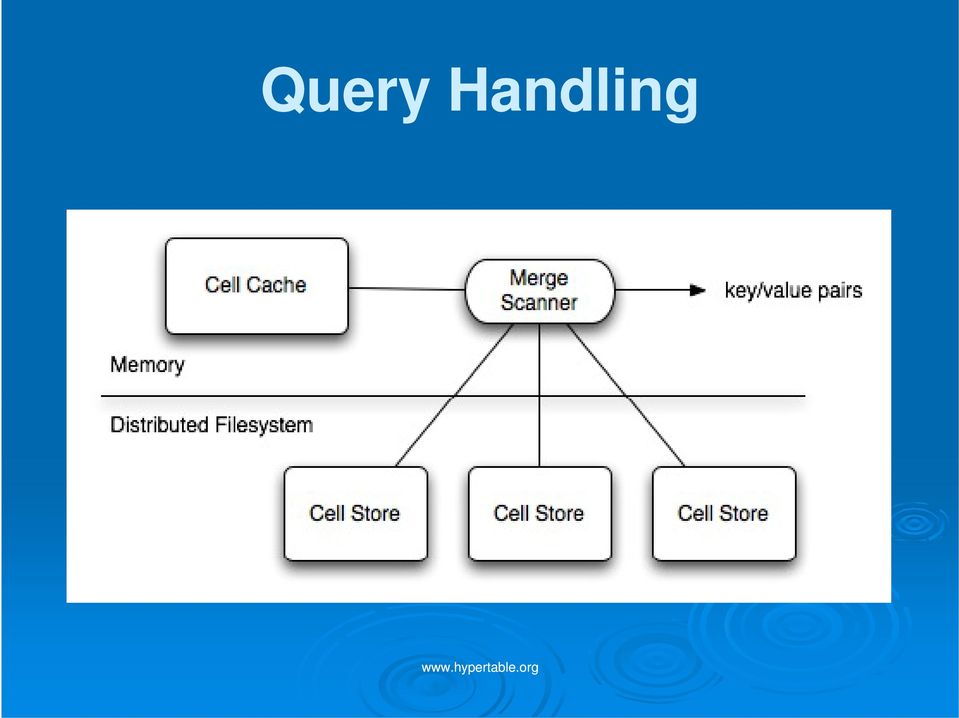
18 CellStore Format Immutable file containing i sorted sequence of key/value pairs Sequence of 65K blocks of compressed key/value pairs

19 Compression Cell Store blocks are compressed Commit Log updates are compressed Supported Compression Schemes zlib (--best and --fast) lzo quicklz bmz none
 lzo")
20 Block Cache Caching Caches CellStore blocks Blocks are cached uncompressed Dynamically adjusted size based on workload Query Cache Caches query results

21 Bloom Filter Probabilistic bili data structure t associated with every CellStore Tells you if key is definitively not present
22 Dynamic Memory Allocation
23 Performance Evaluation
24 Setup Modeled after Test described in Bigtable paper 1 Test Dispatcher, 4 Test Clients, 4 Tablet Servers Test was written entirely in Java Hardware 1 X 1.8 GHz Dual-core Opteron 10 GB RAM 3X 250GB SATA drives Software HDFS running on all 10 nodes, 3X replication HBase Hypertable
25 Latency
26 Throughput Test Random Read Zipfian 80 GB 925 Random Read Zipfian 20 GB 777 Random Read Zipfian 2.5 GB 100 Random Write 10KB values 51 Random Write 1KB values 102 Random Write 100 byte values 427 Random Write 10 byte values 931 Sequential Read 10KB values 1060 Sequential Read 1KB values 68 Sequential Read 100 byte values 129 Scan 10KB values 2 Scan 1KB values 58 Scan 100 byte values 75 Scan 10 byte values 220 Hypertable Advantage Relative to HBase (%)
27 Detailed Report h t /?
28 Case Studies
29 Zvents Longest running Hypertable deployment Analytics Platform - Reporting Per-listing page view graphs Change log Ruby on Rails - HyperRecord
30 Rediff.com rediffmail SPAM classification Several hundred front-end web servers tens of millions requests/day Peak rate 500 queries/s 99.99% sub-second second response time
31 Best Fit Use Cases Serve massive data sets to live applications It s ordered - good for applications that need to scan over data ranges (e.g. time series data) Typical workflow: logs -> HDFS -> MapReduce -> Hypertable
32 Resources Project site: Twitter: hypertable Commercial Support:
33 Q&A
Hypertable Architecture Overview
 WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
Distributed storage for structured data
 Distributed storage for structured data Dennis Kafura CS5204 Operating Systems 1 Overview Goals scalability petabytes of data thousands of machines applicability to Google applications Google Analytics
Distributed storage for structured data Dennis Kafura CS5204 Operating Systems 1 Overview Goals scalability petabytes of data thousands of machines applicability to Google applications Google Analytics
Hypertable Goes Realtime at Baidu. Yang Dong yangdong01@baidu.com Sherlock Yang(http://weibo.com/u/2624357843)
") Hypertable Goes Realtime at Baidu Yang Dong yangdong01@baidu.com Sherlock Yang(http://weibo.com/u/2624357843) Agenda Motivation Related Work Model Design Evaluation Conclusion 2 Agenda Motivation Related
Hypertable Goes Realtime at Baidu Yang Dong yangdong01@baidu.com Sherlock Yang(http://weibo.com/u/2624357843) Agenda Motivation Related Work Model Design Evaluation Conclusion 2 Agenda Motivation Related
Big Table A Distributed Storage System For Data
 Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
NoSQL Data Base Basics
 NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
NoSQL: Going Beyond Structured Data and RDBMS
 NoSQL: Going Beyond Structured Data and RDBMS Scenario Size of data >> disk or memory space on a single machine Store data across many machines Retrieve data from many machines Machine = Commodity machine
NoSQL: Going Beyond Structured Data and RDBMS Scenario Size of data >> disk or memory space on a single machine Store data across many machines Retrieve data from many machines Machine = Commodity machine
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Similarity Search in a Very Large Scale Using Hadoop and HBase
 Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
HBase A Comprehensive Introduction. James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367
 CIT 367") HBase A Comprehensive Introduction James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367 Overview Overview: History Began as project by Powerset to process massive
HBase A Comprehensive Introduction James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367 Overview Overview: History Began as project by Powerset to process massive
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Can the Elephants Handle the NoSQL Onslaught?
 Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Xiaoming Gao Hui Li Thilina Gunarathne
 Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Future Prospects of Scalable Cloud Computing
 Future Prospects of Scalable Cloud Computing Keijo Heljanko Department of Information and Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 7.3-2012 1/17 Future Cloud Topics Beyond
Future Prospects of Scalable Cloud Computing Keijo Heljanko Department of Information and Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 7.3-2012 1/17 Future Cloud Topics Beyond
Four Orders of Magnitude: Running Large Scale Accumulo Clusters. Aaron Cordova Accumulo Summit, June 2014
 Four Orders of Magnitude: Running Large Scale Accumulo Clusters Aaron Cordova Accumulo Summit, June 2014 Scale, Security, Schema Scale to scale 1 - (vt) to change the size of something let s scale the
Four Orders of Magnitude: Running Large Scale Accumulo Clusters Aaron Cordova Accumulo Summit, June 2014 Scale, Security, Schema Scale to scale 1 - (vt) to change the size of something let s scale the
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu
 Yabo (Arber) Xu") Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP)
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP)
Analyzing Big Data at. Web 2.0 Expo, 2010 Kevin Weil @kevinweil
 Analyzing Big Data at Web 2.0 Expo, 2010 Kevin Weil @kevinweil Three Challenges Collecting Data Large-Scale Storage and Analysis Rapid Learning over Big Data My Background Studied Mathematics and Physics
Analyzing Big Data at Web 2.0 Expo, 2010 Kevin Weil @kevinweil Three Challenges Collecting Data Large-Scale Storage and Analysis Rapid Learning over Big Data My Background Studied Mathematics and Physics
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
A programming model in Cloud: MapReduce
 A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
Big Data Primer. 1 Why Big Data? Alex Sverdlov alex@theparticle.com
 Big Data Primer Alex Sverdlov alex@theparticle.com 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Big Data Primer Alex Sverdlov alex@theparticle.com 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Big Data. Facebook Wall Data using Graph API. Presented by: Prashant Patel-2556219 Jaykrushna Patel-2619715
 Big Data Facebook Wall Data using Graph API Presented by: Prashant Patel-2556219 Jaykrushna Patel-2619715 Outline Data Source Processing tools for processing our data Big Data Processing System: Mongodb
Big Data Facebook Wall Data using Graph API Presented by: Prashant Patel-2556219 Jaykrushna Patel-2619715 Outline Data Source Processing tools for processing our data Big Data Processing System: Mongodb
Maximum performance, minimal risk for data warehousing
 SYSTEM X SERVERS SOLUTION BRIEF Maximum performance, minimal risk for data warehousing Microsoft Data Warehouse Fast Track for SQL Server 2014 on System x3850 X6 (95TB) The rapid growth of technology has
SYSTEM X SERVERS SOLUTION BRIEF Maximum performance, minimal risk for data warehousing Microsoft Data Warehouse Fast Track for SQL Server 2014 on System x3850 X6 (95TB) The rapid growth of technology has
Real-time Analytics at Facebook: Data Freeway and Puma. Zheng Shao 12/2/2011
 Real-time Analytics at Facebook: Data Freeway and Puma Zheng Shao 12/2/2011 Agenda 1 Analytics and Real-time 2 Data Freeway 3 Puma 4 Future Works Analytics and Real-time what and why Facebook Insights
Real-time Analytics at Facebook: Data Freeway and Puma Zheng Shao 12/2/2011 Agenda 1 Analytics and Real-time 2 Data Freeway 3 Puma 4 Future Works Analytics and Real-time what and why Facebook Insights
L1: Introduction to Hadoop
 L1: Introduction to Hadoop Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
L1: Introduction to Hadoop Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
Amazon Redshift & Amazon DynamoDB Michael Hanisch, Amazon Web Services Erez Hadas-Sonnenschein, clipkit GmbH Witali Stohler, clipkit GmbH 2014-05-15
 Amazon Redshift & Amazon DynamoDB Michael Hanisch, Amazon Web Services Erez Hadas-Sonnenschein, clipkit GmbH Witali Stohler, clipkit GmbH 2014-05-15 2014 Amazon.com, Inc. and its affiliates. All rights
Amazon Redshift & Amazon DynamoDB Michael Hanisch, Amazon Web Services Erez Hadas-Sonnenschein, clipkit GmbH Witali Stohler, clipkit GmbH 2014-05-15 2014 Amazon.com, Inc. and its affiliates. All rights
Criteria to Compare Cloud Computing with Current Database Technology
 Criteria to Compare Cloud Computing with Current Database Technology Jean-Daniel Cryans, Alain April, and Alain Abran École de Technologie Supérieure, 1100 rue Notre-Dame Ouest Montréal, Québec, Canada
Criteria to Compare Cloud Computing with Current Database Technology Jean-Daniel Cryans, Alain April, and Alain Abran École de Technologie Supérieure, 1100 rue Notre-Dame Ouest Montréal, Québec, Canada
Accelerating Cassandra Workloads using SanDisk Solid State Drives
 WHITE PAPER Accelerating Cassandra Workloads using SanDisk Solid State Drives February 2015 951 SanDisk Drive, Milpitas, CA 95035 2015 SanDIsk Corporation. All rights reserved www.sandisk.com Table of
WHITE PAPER Accelerating Cassandra Workloads using SanDisk Solid State Drives February 2015 951 SanDisk Drive, Milpitas, CA 95035 2015 SanDIsk Corporation. All rights reserved www.sandisk.com Table of
Cassandra A Decentralized, Structured Storage System
 Cassandra A Decentralized, Structured Storage System Avinash Lakshman and Prashant Malik Facebook Published: April 2010, Volume 44, Issue 2 Communications of the ACM http://dl.acm.org/citation.cfm?id=1773922
Cassandra A Decentralized, Structured Storage System Avinash Lakshman and Prashant Malik Facebook Published: April 2010, Volume 44, Issue 2 Communications of the ACM http://dl.acm.org/citation.cfm?id=1773922
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, UC Berkeley, Nov 2012
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, UC Berkeley, Nov 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics data 4
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, UC Berkeley, Nov 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics data 4
Oracle s Big Data solutions. Roger Wullschleger. <Insert Picture Here>
 s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM
 Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Yahoo! Cloud Serving Benchmark
 Yahoo! Cloud Serving Benchmark Overview and results March 31, 2010 Brian F. Cooper cooperb@yahoo-inc.com Joint work with Adam Silberstein, Erwin Tam, Raghu Ramakrishnan and Russell Sears System setup and
Yahoo! Cloud Serving Benchmark Overview and results March 31, 2010 Brian F. Cooper cooperb@yahoo-inc.com Joint work with Adam Silberstein, Erwin Tam, Raghu Ramakrishnan and Russell Sears System setup and
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Sentimental Analysis using Hadoop Phase 2: Week 2
 Sentimental Analysis using Hadoop Phase 2: Week 2 MARKET / INDUSTRY, FUTURE SCOPE BY ANKUR UPRIT The key value type basically, uses a hash table in which there exists a unique key and a pointer to a particular
Sentimental Analysis using Hadoop Phase 2: Week 2 MARKET / INDUSTRY, FUTURE SCOPE BY ANKUR UPRIT The key value type basically, uses a hash table in which there exists a unique key and a pointer to a particular
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
bigdata Managing Scale in Ontological Systems
 Managing Scale in Ontological Systems 1 This presentation offers a brief look scale in ontological (semantic) systems, tradeoffs in expressivity and data scale, and both information and systems architectural
Managing Scale in Ontological Systems 1 This presentation offers a brief look scale in ontological (semantic) systems, tradeoffs in expressivity and data scale, and both information and systems architectural
Practical Cassandra. Vitalii Tymchyshyn tivv00@gmail.com @tivv00
 Practical Cassandra NoSQL key-value vs RDBMS why and when Cassandra architecture Cassandra data model Life without joins or HDD space is cheap today Hardware requirements & deployment hints Vitalii Tymchyshyn
Practical Cassandra NoSQL key-value vs RDBMS why and when Cassandra architecture Cassandra data model Life without joins or HDD space is cheap today Hardware requirements & deployment hints Vitalii Tymchyshyn
Media Upload and Sharing Website using HBASE
 A-PDF Merger DEMO : Purchase from www.a-pdf.com to remove the watermark Media Upload and Sharing Website using HBASE Tushar Mahajan Santosh Mukherjee Shubham Mathur Agenda Motivation for the project Introduction
A-PDF Merger DEMO : Purchase from www.a-pdf.com to remove the watermark Media Upload and Sharing Website using HBASE Tushar Mahajan Santosh Mukherjee Shubham Mathur Agenda Motivation for the project Introduction
Hadoop s Entry into the Traditional Analytical DBMS Market. Daniel Abadi Yale University August 3 rd, 2010
 Hadoop s Entry into the Traditional Analytical DBMS Market Daniel Abadi Yale University August 3 rd, 2010 Data, Data, Everywhere Data explosion Web 2.0 more user data More devices that sense data More
Hadoop s Entry into the Traditional Analytical DBMS Market Daniel Abadi Yale University August 3 rd, 2010 Data, Data, Everywhere Data explosion Web 2.0 more user data More devices that sense data More
SQL VS. NO-SQL. Adapted Slides from Dr. Jennifer Widom from Stanford
 SQL VS. NO-SQL Adapted Slides from Dr. Jennifer Widom from Stanford 55 Traditional Databases SQL = Traditional relational DBMS Hugely popular among data analysts Widely adopted for transaction systems
SQL VS. NO-SQL Adapted Slides from Dr. Jennifer Widom from Stanford 55 Traditional Databases SQL = Traditional relational DBMS Hugely popular among data analysts Widely adopted for transaction systems
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
Introduction to Hbase Gkavresis Giorgos 1470
 Introduction to Hbase Gkavresis Giorgos 1470 Agenda What is Hbase Installation About RDBMS Overview of Hbase Why Hbase instead of RDBMS Architecture of Hbase Hbase interface Summarise What is Hbase Hbase
Introduction to Hbase Gkavresis Giorgos 1470 Agenda What is Hbase Installation About RDBMS Overview of Hbase Why Hbase instead of RDBMS Architecture of Hbase Hbase interface Summarise What is Hbase Hbase
The Apache Cassandra storage engine
 The Apache Cassandra storage engine Sylvain Lebresne (sylvain@.com) FOSDEM 12, Brussels 1. What is Apache Cassandra 2. Data Model 3. The storage engine 1. What is Apache Cassandra 2. Data Model 3. The
The Apache Cassandra storage engine Sylvain Lebresne (sylvain@.com) FOSDEM 12, Brussels 1. What is Apache Cassandra 2. Data Model 3. The storage engine 1. What is Apache Cassandra 2. Data Model 3. The
Storage of Structured Data: BigTable and HBase. New Trends In Distributed Systems MSc Software and Systems
 Storage of Structured Data: BigTable and HBase 1 HBase and BigTable HBase is Hadoop's counterpart of Google's BigTable BigTable meets the need for a highly scalable storage system for structured data Provides
Storage of Structured Data: BigTable and HBase 1 HBase and BigTable HBase is Hadoop's counterpart of Google's BigTable BigTable meets the need for a highly scalable storage system for structured data Provides
Scaling Up 2 CSE 6242 / CX 4242. Duen Horng (Polo) Chau Georgia Tech. HBase, Hive
 Chau Georgia Tech. HBase, Hive") CSE 6242 / CX 4242 Scaling Up 2 HBase, Hive Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 2 HBase, Hive Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
Oracle Big Data SQL Technical Update
 Oracle Big Data SQL Technical Update Jean-Pierre Dijcks Oracle Redwood City, CA, USA Keywords: Big Data, Hadoop, NoSQL Databases, Relational Databases, SQL, Security, Performance Introduction This technical
Oracle Big Data SQL Technical Update Jean-Pierre Dijcks Oracle Redwood City, CA, USA Keywords: Big Data, Hadoop, NoSQL Databases, Relational Databases, SQL, Security, Performance Introduction This technical
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems
 Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
An Oracle White Paper June 2012. High Performance Connectors for Load and Access of Data from Hadoop to Oracle Database
 An Oracle White Paper June 2012 High Performance Connectors for Load and Access of Data from Hadoop to Oracle Database Executive Overview... 1 Introduction... 1 Oracle Loader for Hadoop... 2 Oracle Direct
An Oracle White Paper June 2012 High Performance Connectors for Load and Access of Data from Hadoop to Oracle Database Executive Overview... 1 Introduction... 1 Oracle Loader for Hadoop... 2 Oracle Direct
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
NoSQL for SQL Professionals William McKnight
 NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming. by Dibyendu Bhattacharya
 Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Hadoop for MySQL DBAs. Copyright 2011 Cloudera. All rights reserved. Not to be reproduced without prior written consent.
 Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years sarah@cloudera.com 2 What is Hadoop? An open-source
Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years sarah@cloudera.com 2 What is Hadoop? An open-source
Big Fast Data Hadoop acceleration with Flash. June 2013
 Big Fast Data Hadoop acceleration with Flash June 2013 Agenda The Big Data Problem What is Hadoop Hadoop and Flash The Nytro Solution Test Results The Big Data Problem Big Data Output Facebook Traditional
Big Fast Data Hadoop acceleration with Flash June 2013 Agenda The Big Data Problem What is Hadoop Hadoop and Flash The Nytro Solution Test Results The Big Data Problem Big Data Output Facebook Traditional
Fast Data in the Era of Big Data: Tiwtter s Real-Time Related Query Suggestion Architecture
 Fast Data in the Era of Big Data: Tiwtter s Real-Time Related Query Suggestion Architecture Gilad Mishne, Jeff Dalton, Zhenghua Li, Aneesh Sharma, Jimmy Lin Adeniyi Abdul 2522715 Agenda Abstract Introduction
Fast Data in the Era of Big Data: Tiwtter s Real-Time Related Query Suggestion Architecture Gilad Mishne, Jeff Dalton, Zhenghua Li, Aneesh Sharma, Jimmy Lin Adeniyi Abdul 2522715 Agenda Abstract Introduction
BookKeeper. Flavio Junqueira Yahoo! Research, Barcelona. Hadoop in China 2011
 BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: bdg@qburst.com Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Minimize cost and risk for data warehousing
 SYSTEM X SERVERS SOLUTION BRIEF Minimize cost and risk for data warehousing Microsoft Data Warehouse Fast Track for SQL Server 2014 on System x3850 X6 (55TB) Highlights Improve time to value for your data
SYSTEM X SERVERS SOLUTION BRIEF Minimize cost and risk for data warehousing Microsoft Data Warehouse Fast Track for SQL Server 2014 on System x3850 X6 (55TB) Highlights Improve time to value for your data
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Large-Scale Data Processing
 Large-Scale Data Processing Eiko Yoneki eiko.yoneki@cl.cam.ac.uk http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Large-Scale Data Processing Eiko Yoneki eiko.yoneki@cl.cam.ac.uk http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН
 Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН Zettabytes Petabytes ABC Sharding A B C Id Fn Ln Addr 1 Fred Jones Liberty, NY 2 John Smith?????? 122+ NoSQL Database
Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН Zettabytes Petabytes ABC Sharding A B C Id Fn Ln Addr 1 Fred Jones Liberty, NY 2 John Smith?????? 122+ NoSQL Database
How To Store Data On An Ocora Nosql Database On A Flash Memory Device On A Microsoft Flash Memory 2 (Iomemory)
") WHITE PAPER Oracle NoSQL Database and SanDisk Offer Cost-Effective Extreme Performance for Big Data 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Abstract... 3 What Is Big Data?...
WHITE PAPER Oracle NoSQL Database and SanDisk Offer Cost-Effective Extreme Performance for Big Data 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Abstract... 3 What Is Big Data?...
BIG DATA SOLUTION DATA SHEET
 BIG DATA SOLUTION DATA SHEET Highlight. DATA SHEET HGrid247 BIG DATA SOLUTION Exploring your BIG DATA, get some deeper insight. It is possible! Another approach to access your BIG DATA with the latest
BIG DATA SOLUTION DATA SHEET Highlight. DATA SHEET HGrid247 BIG DATA SOLUTION Exploring your BIG DATA, get some deeper insight. It is possible! Another approach to access your BIG DATA with the latest
Can High-Performance Interconnects Benefit Memcached and Hadoop?
 Can High-Performance Interconnects Benefit Memcached and Hadoop? D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Can High-Performance Interconnects Benefit Memcached and Hadoop? D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
How To Handle Big Data With A Data Scientist
 III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com
 REPORT Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com The content of this evaluation guide, including the ideas and concepts contained within, are the property of Splice Machine,
REPORT Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com The content of this evaluation guide, including the ideas and concepts contained within, are the property of Splice Machine,
Facebook: Cassandra. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
Hbase - non SQL Database, Performances Evaluation
 Hbase - non SQL Database, Performances Evaluation 1 Dorin Carstoiu, 2 Elena Lepadatu, 3 Mihai Gaspar 1 Politehnica University of Bucharest, dorin.carstoiu@yahoo.com 2,3 Politehnica University of Bucharest,
Hbase - non SQL Database, Performances Evaluation 1 Dorin Carstoiu, 2 Elena Lepadatu, 3 Mihai Gaspar 1 Politehnica University of Bucharest, dorin.carstoiu@yahoo.com 2,3 Politehnica University of Bucharest,
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
Time series IoT data ingestion into Cassandra using Kaa
 Time series IoT data ingestion into Cassandra using Kaa Andrew Shvayka ashvayka@cybervisiontech.com Agenda Data ingestion challenges Why Kaa? Why Cassandra? Reference architecture overview Hands-on Sandbox
Time series IoT data ingestion into Cassandra using Kaa Andrew Shvayka ashvayka@cybervisiontech.com Agenda Data ingestion challenges Why Kaa? Why Cassandra? Reference architecture overview Hands-on Sandbox
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Open Source for Cloud Infrastructure
 Open Source for Cloud Infrastructure June 29, 2012 Jackson He General Manager, Intel APAC R&D Ltd. Cloud is Here and Expanding More users, more devices, more data & traffic, expanding usages >3B 15B Connected
Open Source for Cloud Infrastructure June 29, 2012 Jackson He General Manager, Intel APAC R&D Ltd. Cloud is Here and Expanding More users, more devices, more data & traffic, expanding usages >3B 15B Connected
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
Benchmarking Cassandra on Violin
 Technical White Paper Report Technical Report Benchmarking Cassandra on Violin Accelerating Cassandra Performance and Reducing Read Latency With Violin Memory Flash-based Storage Arrays Version 1.0 Abstract
Technical White Paper Report Technical Report Benchmarking Cassandra on Violin Accelerating Cassandra Performance and Reducing Read Latency With Violin Memory Flash-based Storage Arrays Version 1.0 Abstract
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Entering the Zettabyte Age Jeffrey Krone
 Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Cost-Effective Business Intelligence with Red Hat and Open Source
 Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
SMALL INDEX LARGE INDEX (SILT)
") Wayne State University ECE 7650: Scalable and Secure Internet Services and Architecture SMALL INDEX LARGE INDEX (SILT) A Memory Efficient High Performance Key Value Store QA REPORT Instructor: Dr. Song
Wayne State University ECE 7650: Scalable and Secure Internet Services and Architecture SMALL INDEX LARGE INDEX (SILT) A Memory Efficient High Performance Key Value Store QA REPORT Instructor: Dr. Song
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23