Hadoop for MySQL DBAs. Copyright 2011 Cloudera. All rights reserved. Not to be reproduced without prior written consent.
|
|
|
- Abel Lang
- 8 years ago
- Views:
Transcription


1 Hadoop for MySQL DBAs + 1

2 About me Sarah Sproehnle, Director of Educational Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years sarah@cloudera.com 2

3 What is Hadoop? An open-source framework for storing and processing data on a cluster of computers Based on Google's whitepapers of the Google File System and MapReduce Scales linearly (proven to scale to 1000s of nodes) Built-in high availability Designed for batch processing Optimized for streaming reads 3
 Built-in high")
4 Why Hadoop? Volume Big data is whatever size that is difficult for you to manage with traditional systems Velocity Can injest terabytes/day Variety Structured and/or complext data 4

5 Use cases for Hadoop Recommendation engine Netflix recommends movies last.fm recommends music Ad targeting, log processing, search optimization ContextWeb, ebay and Orbitz Machine learning and classification Yahoo! Mail's spam detection financial industry: identify fraud, credit risk Graph analysis Facebook, LinkedIn and eharmony suggest connections 5

6 How does Hadoop work? Spreads your data onto tens, hundreds or thousands of machines using the Hadoop Distributed File System (HDFS) Built-in redundancy (replication) for fault-tolerance Machines will fail! HDD MTBF 1000 days, 1000 disks = 1 failure every day Read and process data with MapReduce Processing is sent to the data Many "map" tasks each work on a slice of the data Failed tasks are automatically restarted on another node 6


7 MapReduce Example - Word Count map(key, value) foreach (word in value) output (word, 1) Key and value represent a row of data : key is the byte offset, value is a line Intermediate output: the, 1 cat, 1 in, 1 the, 1 hat, 1 7

 cat, (1,1,1) in, (1,1,1,1,1,1).")
8 Reduce phase reduce(key, list) sum the list output(key, sum) Hadoop aggregates the keys and calls reduce for each unique key: the, (1,1,1,1,1,1 1) cat, (1,1,1) in, (1,1,1,1,1,1)... Final result: the, cat, 1204 in,
.")
9 So where does this fit in? 9

10 Example data pipeline 1. Use MySQL for real-time read/write data access (e.g., websites) 2. Cron job occasionally "Sqoops" data into Hadoop 3. Flume aggregates web logs and loads them into Hadoop 4. Use MapReduce to transform data, run batch analysis, join data, etc 5. Export the transformed results to OLAP or OLTP environment 10

11 Hadoop vs. MySQL MySQL Data capacity TB+ (may require sharding) PB+ Data per query GB? PB+ Hadoop Read/write Random read/write Sequential scans, Appendonly Query language SQL Java MapReduce, scripting languages, HiveQL Transactions Yes No Indexes Yes No Latency Sub-second (hopefully) Minutes to hours Data structure Structured Structured or un-structured 11
 Minutes to hours Data structure Structured Structured or")
12 Sqoop: SQL-to-Hadoop Open source software Parallel import/export between Hadoop and various RDBMSes Default implementation is JDBC-based Optimized for MySQL (built-in) Optimized connectors for Oracle, Netezza, Teradata (others coming) Freely available (but not open source) at cloudera.com 12
 Freely available (but not open source) at")
13 How Sqoop works 13
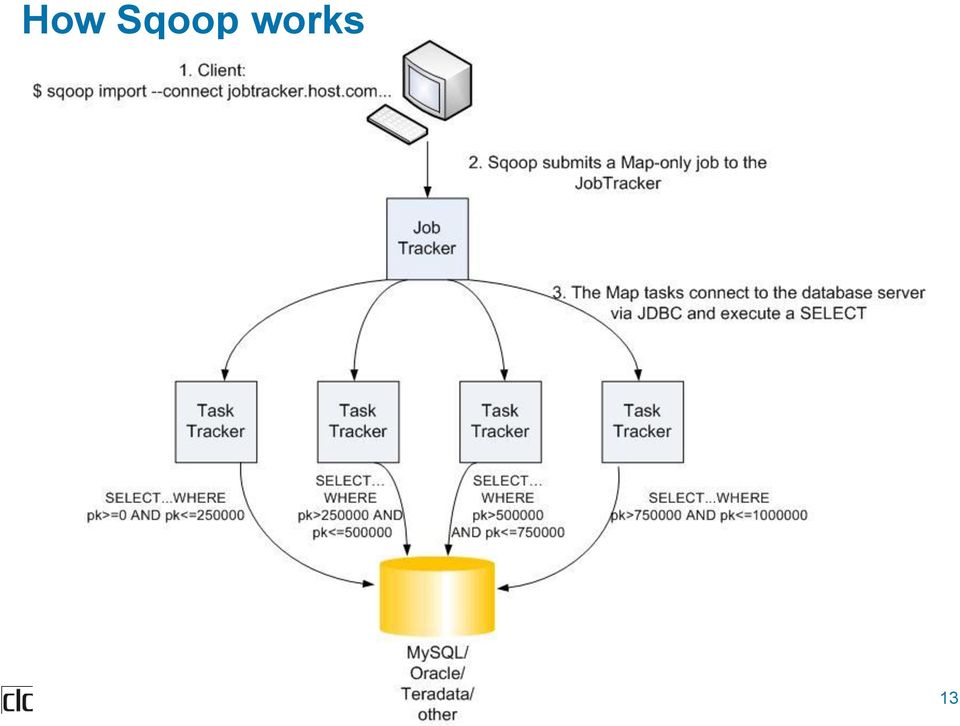
14 "Sqooping" your tables into Hadoop $ sqoop import --connect jdbc:mysql://foo.com/db --table orders --fields-terminated-by '\t' --lines-terminated-by '\n' This command will submit a Hadoop job that queries your MySQL server at foo.com and reads rows from db.orders Resulting TSV files are stored in Hadoop's Distributed File System 14

15 Other features Other features : Choose which tables, rows (--where) or columns to import Configurable parallelization Specify the number of connections (--num-mappers) Specify the column to split on (--split-by) MySQL optimization (uses parallel mysqldump commands) LOBs can be inline or a separate file Incremental loads (with TIMESTAMP or AUTO_INCREMENT ) Integration with Hive and HBase 15
 Integration with Hive")
16 Exporting data $ sqoop export --connect jdbc:mysql://foo.com/db --table bar --export-dir /hdfs_path/bar_data Target table must already exist Assumes comma-separated fields Use --fields-terminated-by and --lines-terminated-by Can use a staging table (--staging-table) Failed jobs can have unpredictable results otherwise 16
 Failed jobs can")
17 Now what? Once your data is in Hadoop, you can write MapReduce code or Hive Looks like SQL (kinda) Adds structural metadata on top of files in HDFS Table names, file format, column definitions, partitions, etc Provides a command-line very similar to the mysql cli 17

18 Sqoop + Hive $ sqoop import --connect jdbc:mysql://foo.com/db --table orders --hive-import By including --hive-import, Sqoop will create a Hive table definition for the data Alternatively, you can issue CREAT E TABLE statements for data that is already in HDFS 18

19 Hive $ hive hive> SHOW TABLES;... hive> SELECT locationid, sum(cost) AS sales FROM orders GROUP BY locationid ORDER BY sales LIMIT 100; 19

20 Demo $ sqoop import --connect jdbc:mysql://localhost/world --username root --table City --hive-import $ sqoop import --connect jdbc:mysql://localhost/world --username root --table Country --hive-import $ hadoop fs -ls /user/hive/warehouse $ hadoop fs -cat /user/hive/warehouse/city/*0 more $ hive SHOW TABLES; SELECT * FROM city LIMIT 10; SELECT countrycode, sum(population) as people FROM city WHERE population > GROUP BY countrycode ORDER BY people DESC LIMIT 10; SELECT code, sum(ci.population) as people FROM city ci JOIN country co ON ci.countrycode = co.code WHERE continent = 'North America' GROUP BY code ORDER BY people desc LIMIT 10; 20
 as people FROM city ci JOIN country co ON ci.countrycode = co.")
21 Thanks! 21
MySQL and Hadoop. Percona Live 2014 Chris Schneider
 MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
<Insert Picture Here> Big Data
 Big Data Kevin Kalmbach Principal Sales Consultant, Public Sector Engineered Systems Program Agenda What is Big Data and why it is important? What is your Big
Big Data Kevin Kalmbach Principal Sales Consultant, Public Sector Engineered Systems Program Agenda What is Big Data and why it is important? What is your Big
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Hadoop and MySQL for Big Data
 Hadoop and MySQL for Big Data Alexander Rubin October 9, 2013 About Me Alexander Rubin, Principal Consultant, Percona Working with MySQL for over 10 years Started at MySQL AB, Sun Microsystems, Oracle
Hadoop and MySQL for Big Data Alexander Rubin October 9, 2013 About Me Alexander Rubin, Principal Consultant, Percona Working with MySQL for over 10 years Started at MySQL AB, Sun Microsystems, Oracle
HOW TO LIVE WITH THE ELEPHANT IN THE SERVER ROOM APACHE HADOOP WORKSHOP
 HOW TO LIVE WITH THE ELEPHANT IN THE SERVER ROOM APACHE HADOOP WORKSHOP AGENDA Introduction What is Hadoop and the rationale behind it Hadoop Distributed File System (HDFS) and MapReduce Common Hadoop
HOW TO LIVE WITH THE ELEPHANT IN THE SERVER ROOM APACHE HADOOP WORKSHOP AGENDA Introduction What is Hadoop and the rationale behind it Hadoop Distributed File System (HDFS) and MapReduce Common Hadoop
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani
 A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Apache Hadoop: Past, Present, and Future
 The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
project collects data from national events, both natural and manmade, to be stored and evaluated by
 Joseph Sebastian CS 2994 Spring 2014 Undergraduate Research Final Paper GOALS The goal of my research was to assist the Integrated Digital Event Archive (IDEAL) team in transferring their Twitter data
Joseph Sebastian CS 2994 Spring 2014 Undergraduate Research Final Paper GOALS The goal of my research was to assist the Integrated Digital Event Archive (IDEAL) team in transferring their Twitter data
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Apache Sqoop. A Data Transfer Tool for Hadoop
 Apache Sqoop A Data Transfer Tool for Hadoop Arvind Prabhakar, Cloudera Inc. Sept 21, 2011 What is Sqoop? Allows easy import and export of data from structured data stores: o Relational Database o Enterprise
Apache Sqoop A Data Transfer Tool for Hadoop Arvind Prabhakar, Cloudera Inc. Sept 21, 2011 What is Sqoop? Allows easy import and export of data from structured data stores: o Relational Database o Enterprise
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
MapReduce with Apache Hadoop Analysing Big Data
 MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside gavin.heavyside@journeydynamics.com About Journey Dynamics Founded in 2006 to develop software technology to address the issues
MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside gavin.heavyside@journeydynamics.com About Journey Dynamics Founded in 2006 to develop software technology to address the issues
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop: Distributed Data Processing. Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010
 Hadoop: Distributed Data Processing Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010 Outline Scaling for Large Data Processing What is Hadoop? HDFS and MapReduce
Hadoop: Distributed Data Processing Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010 Outline Scaling for Large Data Processing What is Hadoop? HDFS and MapReduce
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh miles@inf.ed.ac.uk October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh miles@inf.ed.ac.uk October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
MySQL and Hadoop: Big Data Integration. Shubhangi Garg & Neha Kumari MySQL Engineering
 MySQL and Hadoop: Big Data Integration Shubhangi Garg & Neha Kumari MySQL Engineering 1Copyright 2013, Oracle and/or its affiliates. All rights reserved. Agenda Design rationale Implementation Installation
MySQL and Hadoop: Big Data Integration Shubhangi Garg & Neha Kumari MySQL Engineering 1Copyright 2013, Oracle and/or its affiliates. All rights reserved. Agenda Design rationale Implementation Installation
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
Constructing a Data Lake: Hadoop and Oracle Database United!
 Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Qsoft Inc www.qsoft-inc.com
 Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Putting Apache Kafka to Use!
 Putting Apache Kafka to Use! Building a Real-time Data Platform for Event Streams! JAY KREPS, CONFLUENT! A Couple of Themes! Theme 1: Rise of Events! Theme 2: Immutability Everywhere! Level! Example! Immutable
Putting Apache Kafka to Use! Building a Real-time Data Platform for Event Streams! JAY KREPS, CONFLUENT! A Couple of Themes! Theme 1: Rise of Events! Theme 2: Immutability Everywhere! Level! Example! Immutable
Introduction to Apache Cassandra
 Introduction to Apache Cassandra White Paper BY DATASTAX CORPORATION JULY 2013 1 Table of Contents Abstract 3 Introduction 3 Built by Necessity 3 The Architecture of Cassandra 4 Distributing and Replicating
Introduction to Apache Cassandra White Paper BY DATASTAX CORPORATION JULY 2013 1 Table of Contents Abstract 3 Introduction 3 Built by Necessity 3 The Architecture of Cassandra 4 Distributing and Replicating
Can the Elephants Handle the NoSQL Onslaught?
 Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Scaling Up 2 CSE 6242 / CX 4242. Duen Horng (Polo) Chau Georgia Tech. HBase, Hive
 Chau Georgia Tech. HBase, Hive") CSE 6242 / CX 4242 Scaling Up 2 HBase, Hive Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 2 HBase, Hive Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Scaling Up HBase, Hive, Pegasus
 CSE 6242 A / CS 4803 DVA Mar 7, 2013 Scaling Up HBase, Hive, Pegasus Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 A / CS 4803 DVA Mar 7, 2013 Scaling Up HBase, Hive, Pegasus Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK hdpguru@gmail.com Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK hdpguru@gmail.com Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
Infomatics. Big-Data and Hadoop Developer Training with Oracle WDP
 Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer timo.aaltonen@tut.fi Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer timo.aaltonen@tut.fi Assistants: Henri Terho and Antti
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Play with Big Data on the Shoulders of Open Source
 OW2 Open Source Corporate Network Meeting Play with Big Data on the Shoulders of Open Source Liu Jie Technology Center of Software Engineering Institute of Software, Chinese Academy of Sciences 2012-10-19
OW2 Open Source Corporate Network Meeting Play with Big Data on the Shoulders of Open Source Liu Jie Technology Center of Software Engineering Institute of Software, Chinese Academy of Sciences 2012-10-19
Big Data and Industrial Internet
 Big Data and Industrial Internet Keijo Heljanko Department of Computer Science and Helsinki Institute for Information Technology HIIT School of Science, Aalto University keijo.heljanko@aalto.fi 16.6-2015
Big Data and Industrial Internet Keijo Heljanko Department of Computer Science and Helsinki Institute for Information Technology HIIT School of Science, Aalto University keijo.heljanko@aalto.fi 16.6-2015
SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP. Eva Andreasson Cloudera
 PROBLEMS USING HADOOP. Eva Andreasson Cloudera") SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP Eva Andreasson Cloudera Most FAQ: Super-Quick Overview! The Apache Hadoop Ecosystem a Zoo! Oozie ZooKeeper Hue Impala Solr Hive Pig Mahout HBase MapReduce
SOLVING REAL AND BIG (DATA) PROBLEMS USING HADOOP Eva Andreasson Cloudera Most FAQ: Super-Quick Overview! The Apache Hadoop Ecosystem a Zoo! Oozie ZooKeeper Hue Impala Solr Hive Pig Mahout HBase MapReduce
OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS)
") Use Data from a Hadoop Cluster with Oracle Database Hands-On Lab Lab Structure Acronyms: OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS) All files are
Use Data from a Hadoop Cluster with Oracle Database Hands-On Lab Lab Structure Acronyms: OLH: Oracle Loader for Hadoop OSCH: Oracle SQL Connector for Hadoop Distributed File System (HDFS) All files are
Big Data Too Big To Ignore
 Big Data Too Big To Ignore Geert! Big Data Consultant and Manager! Currently finishing a 3 rd Big Data project! IBM & Cloudera Certified! IBM & Microsoft Big Data Partner 2 Agenda! Defining Big Data! Introduction
Big Data Too Big To Ignore Geert! Big Data Consultant and Manager! Currently finishing a 3 rd Big Data project! IBM & Cloudera Certified! IBM & Microsoft Big Data Partner 2 Agenda! Defining Big Data! Introduction
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
Big Data Technologies Compared June 2014
 Big Data Technologies Compared June 2014 Agenda What is Big Data Big Data Technology Comparison Summary Other Big Data Technologies Questions 2 What is Big Data by Example The SKA Telescope is a new development
Big Data Technologies Compared June 2014 Agenda What is Big Data Big Data Technology Comparison Summary Other Big Data Technologies Questions 2 What is Big Data by Example The SKA Telescope is a new development
I/O Considerations in Big Data Analytics
 Library of Congress I/O Considerations in Big Data Analytics 26 September 2011 Marshall Presser Federal Field CTO EMC, Data Computing Division 1 Paradigms in Big Data Structured (relational) data Very
Library of Congress I/O Considerations in Big Data Analytics 26 September 2011 Marshall Presser Federal Field CTO EMC, Data Computing Division 1 Paradigms in Big Data Structured (relational) data Very
BIG DATA TECHNOLOGY. Hadoop Ecosystem
 BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Introduction to Apache Hadoop
 Introduction to Apache Hadoop 201203 01-1 Chapter 1 Introduction 01-2 Introduction Course Logistics About Apache Hadoop About Cloudera Conclusion 01-3 Logistics! Course start and end time! Breaks! Restrooms
Introduction to Apache Hadoop 201203 01-1 Chapter 1 Introduction 01-2 Introduction Course Logistics About Apache Hadoop About Cloudera Conclusion 01-3 Logistics! Course start and end time! Breaks! Restrooms
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
An Oracle White Paper November 2010. Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics
 An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
Getting Started with Hadoop. Raanan Dagan Paul Tibaldi
 Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
From Dolphins to Elephants: Real-Time MySQL to Hadoop Replication with Tungsten
 From Dolphins to Elephants: Real-Time MySQL to Hadoop Replication with Tungsten MC Brown, Director of Documentation Linas Virbalas, Senior Software Engineer. About Tungsten Replicator Open source drop-in
From Dolphins to Elephants: Real-Time MySQL to Hadoop Replication with Tungsten MC Brown, Director of Documentation Linas Virbalas, Senior Software Engineer. About Tungsten Replicator Open source drop-in
L1: Introduction to Hadoop
 L1: Introduction to Hadoop Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
L1: Introduction to Hadoop Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform interactive execution of map reduce jobs Pig is the name of the system Pig Latin is the
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform interactive execution of map reduce jobs Pig is the name of the system Pig Latin is the
Agenda. ! Strengths of PostgreSQL. ! Strengths of Hadoop. ! Hadoop Community. ! Use Cases
 Postgres & Hadoop Agenda! Strengths of PostgreSQL! Strengths of Hadoop! Hadoop Community! Use Cases Best of Both World Postgres Hadoop World s most advanced open source database solution Enterprise class
Postgres & Hadoop Agenda! Strengths of PostgreSQL! Strengths of Hadoop! Hadoop Community! Use Cases Best of Both World Postgres Hadoop World s most advanced open source database solution Enterprise class
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Move Data from Oracle to Hadoop and Gain New Business Insights
 Move Data from Oracle to Hadoop and Gain New Business Insights Written by Lenka Vanek, senior director of engineering, Dell Software Abstract Today, the majority of data for transaction processing resides
Move Data from Oracle to Hadoop and Gain New Business Insights Written by Lenka Vanek, senior director of engineering, Dell Software Abstract Today, the majority of data for transaction processing resides
White Paper: Hadoop for Intelligence Analysis
 CTOlabs.com White Paper: Hadoop for Intelligence Analysis July 2011 A White Paper providing context, tips and use cases on the topic of analysis over large quantities of data. Inside: Apache Hadoop and
CTOlabs.com White Paper: Hadoop for Intelligence Analysis July 2011 A White Paper providing context, tips and use cases on the topic of analysis over large quantities of data. Inside: Apache Hadoop and
Unlocking Hadoop for Your Rela4onal DB. Kathleen Ting @kate_ting Technical Account Manager, Cloudera Sqoop PMC Member BigData.
 Unlocking Hadoop for Your Rela4onal DB Kathleen Ting @kate_ting Technical Account Manager, Cloudera Sqoop PMC Member BigData.be April 4, 2014 Who Am I? Started 3 yr ago as 1 st Cloudera Support Eng Now
Unlocking Hadoop for Your Rela4onal DB Kathleen Ting @kate_ting Technical Account Manager, Cloudera Sqoop PMC Member BigData.be April 4, 2014 Who Am I? Started 3 yr ago as 1 st Cloudera Support Eng Now
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
 Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
Hadoop Introduction. Olivier Renault Solution Engineer - Hortonworks
 Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Big Data on AWS. Services Overview. Bernie Nallamotu Principle Solutions Architect
 on AWS Services Overview Bernie Nallamotu Principle Solutions Architect \ So what is it? When your data sets become so large that you have to start innovating around how to collect, store, organize, analyze
on AWS Services Overview Bernie Nallamotu Principle Solutions Architect \ So what is it? When your data sets become so large that you have to start innovating around how to collect, store, organize, analyze
Peers Techno log ies Pv t. L td. HADOOP
 Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
WA2341 Hadoop Programming EVALUATION ONLY
 WA2341 Hadoop Programming Web Age Solutions Inc. USA: 1-877-517-6540 Canada: 1-866-206-4644 Web: http://www.webagesolutions.com The following terms are trademarks of other companies: Java and all Java-based
WA2341 Hadoop Programming Web Age Solutions Inc. USA: 1-877-517-6540 Canada: 1-866-206-4644 Web: http://www.webagesolutions.com The following terms are trademarks of other companies: Java and all Java-based
Practical Hadoop by Example
 Practical Hadoop by Example for relational database professioanals Alex Gorbachev 12-Mar-2013 New York, NY Alex Gorbachev Chief Technology Officer at Pythian Blogger OakTable Network member Oracle ACE
Practical Hadoop by Example for relational database professioanals Alex Gorbachev 12-Mar-2013 New York, NY Alex Gorbachev Chief Technology Officer at Pythian Blogger OakTable Network member Oracle ACE
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM
 HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Alexander Rubin Principle Architect, Percona April 18, 2015. Using Hadoop Together with MySQL for Data Analysis
 Alexander Rubin Principle Architect, Percona April 18, 2015 Using Hadoop Together with MySQL for Data Analysis About Me Alexander Rubin, Principal Consultant, Percona Working with MySQL for over 10 years
Alexander Rubin Principle Architect, Percona April 18, 2015 Using Hadoop Together with MySQL for Data Analysis About Me Alexander Rubin, Principal Consultant, Percona Working with MySQL for over 10 years
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP)
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP)
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Pro Apache Hadoop. Second Edition. Sameer Wadkar. Madhu Siddalingaiah
 Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
MapReduce and Distributed Data Analysis. Sergei Vassilvitskii Google Research
 MapReduce and Distributed Data Analysis Google Research 1 Dealing With Massive Data 2 2 Dealing With Massive Data Polynomial Memory Sublinear RAM Sketches External Memory Property Testing 3 3 Dealing With
MapReduce and Distributed Data Analysis Google Research 1 Dealing With Massive Data 2 2 Dealing With Massive Data Polynomial Memory Sublinear RAM Sketches External Memory Property Testing 3 3 Dealing With