Parallel Programming Multicore systems
|
|
|
- Mavis Quinn
- 7 years ago
- Views:
Transcription

1 FYS3240 PC-based instrumentation and microcontrollers Parallel Programming Multicore systems Spring 2013 Lecture #9 Bekkeng,

2 Introduction Until recently, innovations in processor technology have resulted in computers with CPUs that operate at higher clock rates. However, as clock rates approach their theoretical physical limits, companies are developing new processors with multiple processing cores. P = ACV 2 f (P is consumed power, A is active chip area, C is the switched capacitance, f is frequency and V is voltage). With these multicore processors the best performance and highest throughput is achieved by using parallel programming techniques This requires knowledge and suitable programming tools to take advantage of the multicore processors

3 Multiprocessors & Multicore Processors Multiprocessor systems contain multiple CPUs that are not on the same chip Multicore Processors contain any number of multiple CPUs on a single chip The multiprocessor system has a divided cache with long-interconnects The multicore processors share the cache with short interconnects
4 Hyper-threading Hyper-threading is a technology that was introduced by Intel, with the primary purpose of improving support for multithreaded code. Under certain workloads hyper-threading technology provides a more efficient use of CPU resources by executing threads in parallel on a single processor. Hyper-threading works by duplicating certain sections of the processor. A hyper-threading equipped processor (core) pretends to be two "logical" processors to the host operating system, allowing the operating system to schedule two threads or processes simultaneously. E.g. Pentium 4, Xeon, Core i5 and Core i7 processors implement hyper-threading.

5 FPGAs FPGA = Field Programmable Gate Array VHDL for programming of FPGAs is part of FYS4220! Contains huge amount of programmable gates that can be programmed into many parallel hardware paths FPGAs are truly parallel in nature so different processing operations do not have to compete for the same resources (no thread prioritization as typical to most common operating system)

6 How LabVIEW Implements Multithreading Parallel code paths on a block diagram can execute in unique threads LabVIEW automatically divides each application into multiple execution threads (originally introduced in 1998 with LabVIEW 5.0)

7 LabVIEW Example: DAQ Two separate tasks that are not dependent on one another for data will run in parallel without the need for any extra programming.
")
8 How LabVIEW Implements Multithreading II Automatic Multithreading using LabVIEW Execution System (Implicit Parallelism / Threading)
 Dedicate time-critical tasks to a single CPU In computing, FLOPS (floating-point operations per second) is a measure of a computer's")
9 Multicore Programming Goals Increase code execution speed (# of FLOPS) Maintain rate of execution but increase data throughput Evenly balance tasks across available CPUs (fair distribution of processing load) Dedicate time-critical tasks to a single CPU In computing, FLOPS (floating-point operations per second) is a measure of a computer's performance
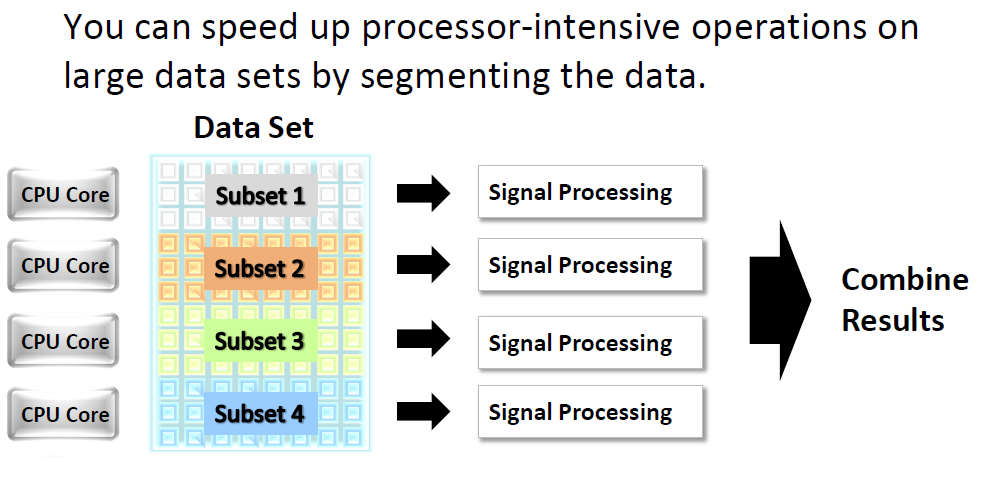
10 Data Parallelism
11 Example: Data Parallelism in LabVIEW Mult. Split Combine A standard implementation of matrix multiplication in LabVIEW does not use data parallelism Data parallelism; by dividing the matrix in half the operation can be computed simultaneously on two CPU cores. With 1000 x 1000 matrices used for the input matrices:

12 Data Flow Many applications involve sequential, multistep algorithms
13 LabVIEW: Sequential data flow Sim Signal processing Write The five tasks run in the same thread because they are connected sequentially
14 Data Flow Parallelism - Pipelining Applying pipelining can increase performance Increase throughput (amount of data processed in a given time period) Pipelining Strategy:

15 Pipelining in LabVIEW

16 Producer-consumer loops and pipelining using queues Note: Pipelined processing does introduce latency between input and output! In general, the CPU and data bus operate most efficiently when processing large blocks of data

17 Pipelining increases latency Pipelining increase throughput but it also introduces additional latency
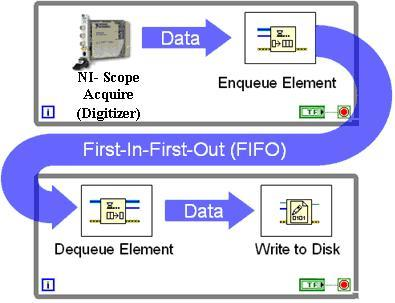
18 Producer-Consumer for DAQ

19 Producer-Consumer LabVIEW example

20 Multicore Programming Challenges Thread Synchronization Race Conditions Deadlocks Shared resources Data transfer between processor cores

21 Synchronization in LabVIEW Synchronization mechanisms in LabVIEW: Notifiers Queues Semaphores Rendezvous Occurrences

22 Data Transfer between cores Physical distance between processors and the quality of the processor connections can have large effect on execution speed

23 Unbalanced vs. balanced Parallel Tasks Unbalanced Balanced
24 Pipelining and balancing In order to gain the most performance increase possible from pipelining, individual stages must be carefully balanced so that no single stage takes a much longer time to complete than other stages. In addition, any data transfer between pipeline stages should be minimized to avoid decreased performance due to memory access from multiple cores. Not optimal for pipelining! Move tasks from Stage 1 to Stage 2 until both stages take approximately equal times to execute
25 Conclusions PC-based instrumentation benefit greatly from advances in multicore processor technology and improved data bus speeds. As new CPUs improve performance by adding multiple processing cores, parallel or pipelined processing structures are necessary to maximize CPU efficiency. You can achieve significant performance improvements by structuring algorithms to take advantage of parallel processing.
Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com
 mzahran@cs.nyu.edu http://www.mzahran.com") CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Modern GPU
CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Modern GPU
Multicore Programming with LabVIEW Technical Resource Guide
 Multicore Programming with LabVIEW Technical Resource Guide 2 INTRODUCTORY TOPICS UNDERSTANDING PARALLEL HARDWARE: MULTIPROCESSORS, HYPERTHREADING, DUAL- CORE, MULTICORE AND FPGAS... 5 DIFFERENCES BETWEEN
Multicore Programming with LabVIEW Technical Resource Guide 2 INTRODUCTORY TOPICS UNDERSTANDING PARALLEL HARDWARE: MULTIPROCESSORS, HYPERTHREADING, DUAL- CORE, MULTICORE AND FPGAS... 5 DIFFERENCES BETWEEN
Multi-core architectures. Jernej Barbic 15-213, Spring 2007 May 3, 2007
 Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Chapter 07: Instruction Level Parallelism VLIW, Vector, Array and Multithreaded Processors. Lesson 05: Array Processors
 Chapter 07: Instruction Level Parallelism VLIW, Vector, Array and Multithreaded Processors Lesson 05: Array Processors Objective To learn how the array processes in multiple pipelines 2 Array Processor
Chapter 07: Instruction Level Parallelism VLIW, Vector, Array and Multithreaded Processors Lesson 05: Array Processors Objective To learn how the array processes in multiple pipelines 2 Array Processor
Course Development of Programming for General-Purpose Multicore Processors
 Course Development of Programming for General-Purpose Multicore Processors Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University Richmond, VA 23284 wzhang4@vcu.edu
Course Development of Programming for General-Purpose Multicore Processors Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University Richmond, VA 23284 wzhang4@vcu.edu
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Thread level parallelism
 Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
FPGA-based Multithreading for In-Memory Hash Joins
 FPGA-based Multithreading for In-Memory Hash Joins Robert J. Halstead, Ildar Absalyamov, Walid A. Najjar, Vassilis J. Tsotras University of California, Riverside Outline Background What are FPGAs Multithreaded
FPGA-based Multithreading for In-Memory Hash Joins Robert J. Halstead, Ildar Absalyamov, Walid A. Najjar, Vassilis J. Tsotras University of California, Riverside Outline Background What are FPGAs Multithreaded
Open Flow Controller and Switch Datasheet
 Open Flow Controller and Switch Datasheet California State University Chico Alan Braithwaite Spring 2013 Block Diagram Figure 1. High Level Block Diagram The project will consist of a network development
Open Flow Controller and Switch Datasheet California State University Chico Alan Braithwaite Spring 2013 Block Diagram Figure 1. High Level Block Diagram The project will consist of a network development
Chapter 2: OS Overview
 Chapter 2: OS Overview CmSc 335 Operating Systems 1. Operating system objectives and functions Operating systems control and support the usage of computer systems. a. usage users of a computer system:
Chapter 2: OS Overview CmSc 335 Operating Systems 1. Operating system objectives and functions Operating systems control and support the usage of computer systems. a. usage users of a computer system:
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging
 Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
Unit A451: Computer systems and programming. Section 2: Computing Hardware 1/5: Central Processing Unit
 Unit A451: Computer systems and programming Section 2: Computing Hardware 1/5: Central Processing Unit Section Objectives Candidates should be able to: (a) State the purpose of the CPU (b) Understand the
Unit A451: Computer systems and programming Section 2: Computing Hardware 1/5: Central Processing Unit Section Objectives Candidates should be able to: (a) State the purpose of the CPU (b) Understand the
Chapter 2 Logic Gates and Introduction to Computer Architecture
 Chapter 2 Logic Gates and Introduction to Computer Architecture 2.1 Introduction The basic components of an Integrated Circuit (IC) is logic gates which made of transistors, in digital system there are
Chapter 2 Logic Gates and Introduction to Computer Architecture 2.1 Introduction The basic components of an Integrated Circuit (IC) is logic gates which made of transistors, in digital system there are
1. Memory technology & Hierarchy
 1. Memory technology & Hierarchy RAM types Advances in Computer Architecture Andy D. Pimentel Memory wall Memory wall = divergence between CPU and RAM speed We can increase bandwidth by introducing concurrency
1. Memory technology & Hierarchy RAM types Advances in Computer Architecture Andy D. Pimentel Memory wall Memory wall = divergence between CPU and RAM speed We can increase bandwidth by introducing concurrency
Historically, Huge Performance Gains came from Huge Clock Frequency Increases Unfortunately.
 Historically, Huge Performance Gains came from Huge Clock Frequency Increases Unfortunately. Hardware Solution Evolution of Computer Architectures Micro-Scopic View Clock Rate Limits Have Been Reached
Historically, Huge Performance Gains came from Huge Clock Frequency Increases Unfortunately. Hardware Solution Evolution of Computer Architectures Micro-Scopic View Clock Rate Limits Have Been Reached
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
Multi-core and Linux* Kernel
 Multi-core and Linux* Kernel Suresh Siddha Intel Open Source Technology Center Abstract Semiconductor technological advances in the recent years have led to the inclusion of multiple CPU execution cores
Multi-core and Linux* Kernel Suresh Siddha Intel Open Source Technology Center Abstract Semiconductor technological advances in the recent years have led to the inclusion of multiple CPU execution cores
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Scheduling. Scheduling. Scheduling levels. Decision to switch the running process can take place under the following circumstances:
 Scheduling Scheduling Scheduling levels Long-term scheduling. Selects which jobs shall be allowed to enter the system. Only used in batch systems. Medium-term scheduling. Performs swapin-swapout operations
Scheduling Scheduling Scheduling levels Long-term scheduling. Selects which jobs shall be allowed to enter the system. Only used in batch systems. Medium-term scheduling. Performs swapin-swapout operations
Embedded Parallel Computing
 Embedded Parallel Computing Lecture 5 - The anatomy of a modern multiprocessor, the multicore processors Tomas Nordström Course webpage:: Course responsible and examiner: Tomas
Embedded Parallel Computing Lecture 5 - The anatomy of a modern multiprocessor, the multicore processors Tomas Nordström Course webpage:: Course responsible and examiner: Tomas
Intro to GPU computing. Spring 2015 Mark Silberstein, 048661, Technion 1
 Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Software and the Concurrency Revolution
 Software and the Concurrency Revolution A: The world s fastest supercomputer, with up to 4 processors, 128MB RAM, 942 MFLOPS (peak). 2 Q: What is a 1984 Cray X-MP? (Or a fractional 2005 vintage Xbox )
Software and the Concurrency Revolution A: The world s fastest supercomputer, with up to 4 processors, 128MB RAM, 942 MFLOPS (peak). 2 Q: What is a 1984 Cray X-MP? (Or a fractional 2005 vintage Xbox )
~ Greetings from WSU CAPPLab ~
 ~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
Chapter 2 Parallel Computer Architecture
 Chapter 2 Parallel Computer Architecture The possibility for a parallel execution of computations strongly depends on the architecture of the execution platform. This chapter gives an overview of the general
Chapter 2 Parallel Computer Architecture The possibility for a parallel execution of computations strongly depends on the architecture of the execution platform. This chapter gives an overview of the general
Multithreading Lin Gao cs9244 report, 2006
 Multithreading Lin Gao cs9244 report, 2006 2 Contents 1 Introduction 5 2 Multithreading Technology 7 2.1 Fine-grained multithreading (FGMT)............. 8 2.2 Coarse-grained multithreading (CGMT)............
Multithreading Lin Gao cs9244 report, 2006 2 Contents 1 Introduction 5 2 Multithreading Technology 7 2.1 Fine-grained multithreading (FGMT)............. 8 2.2 Coarse-grained multithreading (CGMT)............
Testing Database Performance with HelperCore on Multi-Core Processors
 Project Report on Testing Database Performance with HelperCore on Multi-Core Processors Submitted by Mayuresh P. Kunjir M.E. (CSA) Mahesh R. Bale M.E. (CSA) Under Guidance of Dr. T. Matthew Jacob Problem
Project Report on Testing Database Performance with HelperCore on Multi-Core Processors Submitted by Mayuresh P. Kunjir M.E. (CSA) Mahesh R. Bale M.E. (CSA) Under Guidance of Dr. T. Matthew Jacob Problem
CHAPTER 1 INTRODUCTION
 1 CHAPTER 1 INTRODUCTION 1.1 MOTIVATION OF RESEARCH Multicore processors have two or more execution cores (processors) implemented on a single chip having their own set of execution and architectural recourses.
1 CHAPTER 1 INTRODUCTION 1.1 MOTIVATION OF RESEARCH Multicore processors have two or more execution cores (processors) implemented on a single chip having their own set of execution and architectural recourses.
Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat
 Rik van Riel Sr. Software Engineer, Red Hat") Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat Why Computers Are Getting Slower The traditional approach better performance Why computers are
Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat Why Computers Are Getting Slower The traditional approach better performance Why computers are
HP ProLiant Gen8 vs Gen9 Server Blades on Data Warehouse Workloads
 HP ProLiant Gen8 vs Gen9 Server Blades on Data Warehouse Workloads Gen9 Servers give more performance per dollar for your investment. Executive Summary Information Technology (IT) organizations face increasing
HP ProLiant Gen8 vs Gen9 Server Blades on Data Warehouse Workloads Gen9 Servers give more performance per dollar for your investment. Executive Summary Information Technology (IT) organizations face increasing
Parallelism and Cloud Computing
 Parallelism and Cloud Computing Kai Shen Parallel Computing Parallel computing: Process sub tasks simultaneously so that work can be completed faster. For instances: divide the work of matrix multiplication
Parallelism and Cloud Computing Kai Shen Parallel Computing Parallel computing: Process sub tasks simultaneously so that work can be completed faster. For instances: divide the work of matrix multiplication
Parallel Computing 37 (2011) 26 41. Contents lists available at ScienceDirect. Parallel Computing. journal homepage: www.elsevier.
 26 41. Contents lists available at ScienceDirect. Parallel Computing. journal homepage: www.elsevier.") Parallel Computing 37 (2011) 26 41 Contents lists available at ScienceDirect Parallel Computing journal homepage: www.elsevier.com/locate/parco Architectural support for thread communications in multi-core
Parallel Computing 37 (2011) 26 41 Contents lists available at ScienceDirect Parallel Computing journal homepage: www.elsevier.com/locate/parco Architectural support for thread communications in multi-core
Measuring Cache and Memory Latency and CPU to Memory Bandwidth
 White Paper Joshua Ruggiero Computer Systems Engineer Intel Corporation Measuring Cache and Memory Latency and CPU to Memory Bandwidth For use with Intel Architecture December 2008 1 321074 Executive Summary
White Paper Joshua Ruggiero Computer Systems Engineer Intel Corporation Measuring Cache and Memory Latency and CPU to Memory Bandwidth For use with Intel Architecture December 2008 1 321074 Executive Summary
HyperThreading Support in VMware ESX Server 2.1
 HyperThreading Support in VMware ESX Server 2.1 Summary VMware ESX Server 2.1 now fully supports Intel s new Hyper-Threading Technology (HT). This paper explains the changes that an administrator can expect
HyperThreading Support in VMware ESX Server 2.1 Summary VMware ESX Server 2.1 now fully supports Intel s new Hyper-Threading Technology (HT). This paper explains the changes that an administrator can expect
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Architectural Level Power Consumption of Network on Chip. Presenter: YUAN Zheng
 Architectural Level Power Consumption of Network Presenter: YUAN Zheng Why Architectural Low Power Design? High-speed and large volume communication among different parts on a chip Problem: Power consumption
Architectural Level Power Consumption of Network Presenter: YUAN Zheng Why Architectural Low Power Design? High-speed and large volume communication among different parts on a chip Problem: Power consumption
VHDL DESIGN OF EDUCATIONAL, MODERN AND OPEN- ARCHITECTURE CPU
 VHDL DESIGN OF EDUCATIONAL, MODERN AND OPEN- ARCHITECTURE CPU Martin Straka Doctoral Degree Programme (1), FIT BUT E-mail: strakam@fit.vutbr.cz Supervised by: Zdeněk Kotásek E-mail: kotasek@fit.vutbr.cz
VHDL DESIGN OF EDUCATIONAL, MODERN AND OPEN- ARCHITECTURE CPU Martin Straka Doctoral Degree Programme (1), FIT BUT E-mail: strakam@fit.vutbr.cz Supervised by: Zdeněk Kotásek E-mail: kotasek@fit.vutbr.cz
Interconnection Networks
 Advanced Computer Architecture (0630561) Lecture 15 Interconnection Networks Prof. Kasim M. Al-Aubidy Computer Eng. Dept. Interconnection Networks: Multiprocessors INs can be classified based on: 1. Mode
Advanced Computer Architecture (0630561) Lecture 15 Interconnection Networks Prof. Kasim M. Al-Aubidy Computer Eng. Dept. Interconnection Networks: Multiprocessors INs can be classified based on: 1. Mode
This Unit: Multithreading (MT) CIS 501 Computer Architecture. Performance And Utilization. Readings
 CIS 501 Computer Architecture. Performance And Utilization. Readings") This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Solving Network Challenges
 Solving Network hallenges n Advanced Multicore Sos Presented by: Tim Pontius Multicore So Network hallenges Many heterogeneous cores: various protocols, data width, address maps, bandwidth, clocking, etc.
Solving Network hallenges n Advanced Multicore Sos Presented by: Tim Pontius Multicore So Network hallenges Many heterogeneous cores: various protocols, data width, address maps, bandwidth, clocking, etc.
Four Keys to Successful Multicore Optimization for Machine Vision. White Paper
 Four Keys to Successful Multicore Optimization for Machine Vision White Paper Optimizing a machine vision application for multicore PCs can be a complex process with unpredictable results. Developers need
Four Keys to Successful Multicore Optimization for Machine Vision White Paper Optimizing a machine vision application for multicore PCs can be a complex process with unpredictable results. Developers need
E6895 Advanced Big Data Analytics Lecture 14:! NVIDIA GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
Control 2004, University of Bath, UK, September 2004
 Control, University of Bath, UK, September ID- IMPACT OF DEPENDENCY AND LOAD BALANCING IN MULTITHREADING REAL-TIME CONTROL ALGORITHMS M A Hossain and M O Tokhi Department of Computing, The University of
Control, University of Bath, UK, September ID- IMPACT OF DEPENDENCY AND LOAD BALANCING IN MULTITHREADING REAL-TIME CONTROL ALGORITHMS M A Hossain and M O Tokhi Department of Computing, The University of
Architectures and Platforms
 Hardware/Software Codesign Arch&Platf. - 1 Architectures and Platforms 1. Architecture Selection: The Basic Trade-Offs 2. General Purpose vs. Application-Specific Processors 3. Processor Specialisation
Hardware/Software Codesign Arch&Platf. - 1 Architectures and Platforms 1. Architecture Selection: The Basic Trade-Offs 2. General Purpose vs. Application-Specific Processors 3. Processor Specialisation
Enabling Technologies for Distributed and Cloud Computing
 Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
Parallel Computing for Data Science
 Parallel Computing for Data Science With Examples in R, C++ and CUDA Norman Matloff University of California, Davis USA (g) CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint
Parallel Computing for Data Science With Examples in R, C++ and CUDA Norman Matloff University of California, Davis USA (g) CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint
Symmetric Multiprocessing
 Multicore Computing A multi-core processor is a processing system composed of two or more independent cores. One can describe it as an integrated circuit to which two or more individual processors (called
Multicore Computing A multi-core processor is a processing system composed of two or more independent cores. One can describe it as an integrated circuit to which two or more individual processors (called
Sequential Performance Analysis with Callgrind and KCachegrind
 Sequential Performance Analysis with Callgrind and KCachegrind 2 nd Parallel Tools Workshop, HLRS, Stuttgart, July 7/8, 2008 Josef Weidendorfer Lehrstuhl für Rechnertechnik und Rechnerorganisation Institut
Sequential Performance Analysis with Callgrind and KCachegrind 2 nd Parallel Tools Workshop, HLRS, Stuttgart, July 7/8, 2008 Josef Weidendorfer Lehrstuhl für Rechnertechnik und Rechnerorganisation Institut
Configuring and using DDR3 memory with HP ProLiant Gen8 Servers
 Engineering white paper, 2 nd Edition Configuring and using DDR3 memory with HP ProLiant Gen8 Servers Best Practice Guidelines for ProLiant servers with Intel Xeon processors Table of contents Introduction
Engineering white paper, 2 nd Edition Configuring and using DDR3 memory with HP ProLiant Gen8 Servers Best Practice Guidelines for ProLiant servers with Intel Xeon processors Table of contents Introduction
Improving System Scalability of OpenMP Applications Using Large Page Support
 Improving Scalability of OpenMP Applications on Multi-core Systems Using Large Page Support Ranjit Noronha and Dhabaleswar K. Panda Network Based Computing Laboratory (NBCL) The Ohio State University Outline
Improving Scalability of OpenMP Applications on Multi-core Systems Using Large Page Support Ranjit Noronha and Dhabaleswar K. Panda Network Based Computing Laboratory (NBCL) The Ohio State University Outline
Overview Motivating Examples Interleaving Model Semantics of Correctness Testing, Debugging, and Verification
 Introduction Overview Motivating Examples Interleaving Model Semantics of Correctness Testing, Debugging, and Verification Advanced Topics in Software Engineering 1 Concurrent Programs Characterized by
Introduction Overview Motivating Examples Interleaving Model Semantics of Correctness Testing, Debugging, and Verification Advanced Topics in Software Engineering 1 Concurrent Programs Characterized by
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
CS 159 Two Lecture Introduction. Parallel Processing: A Hardware Solution & A Software Challenge
 CS 159 Two Lecture Introduction Parallel Processing: A Hardware Solution & A Software Challenge We re on the Road to Parallel Processing Outline Hardware Solution (Day 1) Software Challenge (Day 2) Opportunities
CS 159 Two Lecture Introduction Parallel Processing: A Hardware Solution & A Software Challenge We re on the Road to Parallel Processing Outline Hardware Solution (Day 1) Software Challenge (Day 2) Opportunities
CHAPTER 2: HARDWARE BASICS: INSIDE THE BOX
 CHAPTER 2: HARDWARE BASICS: INSIDE THE BOX Multiple Choice: 1. Processing information involves: A. accepting information from the outside world. B. communication with another computer. C. performing arithmetic
CHAPTER 2: HARDWARE BASICS: INSIDE THE BOX Multiple Choice: 1. Processing information involves: A. accepting information from the outside world. B. communication with another computer. C. performing arithmetic
Sequential Performance Analysis with Callgrind and KCachegrind
 Sequential Performance Analysis with Callgrind and KCachegrind 4 th Parallel Tools Workshop, HLRS, Stuttgart, September 7/8, 2010 Josef Weidendorfer Lehrstuhl für Rechnertechnik und Rechnerorganisation
Sequential Performance Analysis with Callgrind and KCachegrind 4 th Parallel Tools Workshop, HLRS, Stuttgart, September 7/8, 2010 Josef Weidendorfer Lehrstuhl für Rechnertechnik und Rechnerorganisation
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM
 ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM 1 The ARM architecture processors popular in Mobile phone systems 2 ARM Features ARM has 32-bit architecture but supports 16 bit
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM 1 The ARM architecture processors popular in Mobile phone systems 2 ARM Features ARM has 32-bit architecture but supports 16 bit
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Emerging IT and Energy Star PC Specification Version 4.0: Opportunities and Risks. ITI/EPA Energy Star Workshop June 21, 2005 Donna Sadowy, AMD
 Emerging IT and Energy Star PC Specification Version 4.0: Opportunities and Risks ITI/EPA Energy Star Workshop June 21, 2005 Donna Sadowy, AMD Defining the Goal The ITI members and EPA share a common goal:
Emerging IT and Energy Star PC Specification Version 4.0: Opportunities and Risks ITI/EPA Energy Star Workshop June 21, 2005 Donna Sadowy, AMD Defining the Goal The ITI members and EPA share a common goal:
Operating Systems 4 th Class
 Operating Systems 4 th Class Lecture 1 Operating Systems Operating systems are essential part of any computer system. Therefore, a course in operating systems is an essential part of any computer science
Operating Systems 4 th Class Lecture 1 Operating Systems Operating systems are essential part of any computer system. Therefore, a course in operating systems is an essential part of any computer science
15-418 Final Project Report. Trading Platform Server
 15-418 Final Project Report Yinghao Wang yinghaow@andrew.cmu.edu May 8, 214 Trading Platform Server Executive Summary The final project will implement a trading platform server that provides back-end support
15-418 Final Project Report Yinghao Wang yinghaow@andrew.cmu.edu May 8, 214 Trading Platform Server Executive Summary The final project will implement a trading platform server that provides back-end support
Virtuoso and Database Scalability
 Virtuoso and Database Scalability By Orri Erling Table of Contents Abstract Metrics Results Transaction Throughput Initializing 40 warehouses Serial Read Test Conditions Analysis Working Set Effect of
Virtuoso and Database Scalability By Orri Erling Table of Contents Abstract Metrics Results Transaction Throughput Initializing 40 warehouses Serial Read Test Conditions Analysis Working Set Effect of
Lesson 7: SYSTEM-ON. SoC) AND USE OF VLSI CIRCUIT DESIGN TECHNOLOGY. Chapter-1L07: "Embedded Systems - ", Raj Kamal, Publs.: McGraw-Hill Education
 AND USE OF VLSI CIRCUIT DESIGN TECHNOLOGY. Chapter-1L07: Embedded Systems - , Raj Kamal, Publs.: McGraw-Hill Education") Lesson 7: SYSTEM-ON ON-CHIP (SoC( SoC) AND USE OF VLSI CIRCUIT DESIGN TECHNOLOGY 1 VLSI chip Integration of high-level components Possess gate-level sophistication in circuits above that of the counter,
Lesson 7: SYSTEM-ON ON-CHIP (SoC( SoC) AND USE OF VLSI CIRCUIT DESIGN TECHNOLOGY 1 VLSI chip Integration of high-level components Possess gate-level sophistication in circuits above that of the counter,
Reconfigurable Architecture Requirements for Co-Designed Virtual Machines
 Reconfigurable Architecture Requirements for Co-Designed Virtual Machines Kenneth B. Kent University of New Brunswick Faculty of Computer Science Fredericton, New Brunswick, Canada ken@unb.ca Micaela Serra
Reconfigurable Architecture Requirements for Co-Designed Virtual Machines Kenneth B. Kent University of New Brunswick Faculty of Computer Science Fredericton, New Brunswick, Canada ken@unb.ca Micaela Serra
CYCLIC: A LOCALITY-PRESERVING LOAD-BALANCING ALGORITHM FOR PDES ON SHARED MEMORY MULTIPROCESSORS
 Computing and Informatics, Vol. 31, 2012, 1255 1278 CYCLIC: A LOCALITY-PRESERVING LOAD-BALANCING ALGORITHM FOR PDES ON SHARED MEMORY MULTIPROCESSORS Antonio García-Dopico, Antonio Pérez Santiago Rodríguez,
Computing and Informatics, Vol. 31, 2012, 1255 1278 CYCLIC: A LOCALITY-PRESERVING LOAD-BALANCING ALGORITHM FOR PDES ON SHARED MEMORY MULTIPROCESSORS Antonio García-Dopico, Antonio Pérez Santiago Rodríguez,
Agenda. Michele Taliercio, Il circuito Integrato, Novembre 2001
 Agenda Introduzione Il mercato Dal circuito integrato al System on a Chip (SoC) La progettazione di un SoC La tecnologia Una fabbrica di circuiti integrati 28 How to handle complexity G The engineering
Agenda Introduzione Il mercato Dal circuito integrato al System on a Chip (SoC) La progettazione di un SoC La tecnologia Una fabbrica di circuiti integrati 28 How to handle complexity G The engineering
CPU Session 1. Praktikum Parallele Rechnerarchtitekturen. Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1
 CPU Session 1 Praktikum Parallele Rechnerarchtitekturen Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1 Overview Types of Parallelism in Modern Multi-Core CPUs o Multicore
CPU Session 1 Praktikum Parallele Rechnerarchtitekturen Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1 Overview Types of Parallelism in Modern Multi-Core CPUs o Multicore
Best Practises for LabVIEW FPGA Design Flow. uk.ni.com ireland.ni.com
 Best Practises for LabVIEW FPGA Design Flow 1 Agenda Overall Application Design Flow Host, Real-Time and FPGA LabVIEW FPGA Architecture Development FPGA Design Flow Common FPGA Architectures Testing and
Best Practises for LabVIEW FPGA Design Flow 1 Agenda Overall Application Design Flow Host, Real-Time and FPGA LabVIEW FPGA Architecture Development FPGA Design Flow Common FPGA Architectures Testing and
CSE 6040 Computing for Data Analytics: Methods and Tools
 CSE 6040 Computing for Data Analytics: Methods and Tools Lecture 12 Computer Architecture Overview and Why it Matters DA KUANG, POLO CHAU GEORGIA TECH FALL 2014 Fall 2014 CSE 6040 COMPUTING FOR DATA ANALYSIS
CSE 6040 Computing for Data Analytics: Methods and Tools Lecture 12 Computer Architecture Overview and Why it Matters DA KUANG, POLO CHAU GEORGIA TECH FALL 2014 Fall 2014 CSE 6040 COMPUTING FOR DATA ANALYSIS
Low Power AMD Athlon 64 and AMD Opteron Processors
 Low Power AMD Athlon 64 and AMD Opteron Processors Hot Chips 2004 Presenter: Marius Evers Block Diagram of AMD Athlon 64 and AMD Opteron Based on AMD s 8 th generation architecture AMD Athlon 64 and AMD
Low Power AMD Athlon 64 and AMD Opteron Processors Hot Chips 2004 Presenter: Marius Evers Block Diagram of AMD Athlon 64 and AMD Opteron Based on AMD s 8 th generation architecture AMD Athlon 64 and AMD
Performance evaluation
 Performance evaluation Arquitecturas Avanzadas de Computadores - 2547021 Departamento de Ingeniería Electrónica y de Telecomunicaciones Facultad de Ingeniería 2015-1 Bibliography and evaluation Bibliography
Performance evaluation Arquitecturas Avanzadas de Computadores - 2547021 Departamento de Ingeniería Electrónica y de Telecomunicaciones Facultad de Ingeniería 2015-1 Bibliography and evaluation Bibliography
Operating System Impact on SMT Architecture
 Operating System Impact on SMT Architecture The work published in An Analysis of Operating System Behavior on a Simultaneous Multithreaded Architecture, Josh Redstone et al., in Proceedings of the 9th
Operating System Impact on SMT Architecture The work published in An Analysis of Operating System Behavior on a Simultaneous Multithreaded Architecture, Josh Redstone et al., in Proceedings of the 9th
ELEC 5260/6260/6266 Embedded Computing Systems
 ELEC 5260/6260/6266 Embedded Computing Systems Spring 2016 Victor P. Nelson Text: Computers as Components, 3 rd Edition Prof. Marilyn Wolf (Georgia Tech) Course Topics Embedded system design & modeling
ELEC 5260/6260/6266 Embedded Computing Systems Spring 2016 Victor P. Nelson Text: Computers as Components, 3 rd Edition Prof. Marilyn Wolf (Georgia Tech) Course Topics Embedded system design & modeling
Communicating with devices
 Introduction to I/O Where does the data for our CPU and memory come from or go to? Computers communicate with the outside world via I/O devices. Input devices supply computers with data to operate on.
Introduction to I/O Where does the data for our CPU and memory come from or go to? Computers communicate with the outside world via I/O devices. Input devices supply computers with data to operate on.
Introduction to the NI Real-Time Hypervisor
 Introduction to the NI Real-Time Hypervisor 1 Agenda 1) NI Real-Time Hypervisor overview 2) Basics of virtualization technology 3) Configuring and using Real-Time Hypervisor systems 4) Performance and
Introduction to the NI Real-Time Hypervisor 1 Agenda 1) NI Real-Time Hypervisor overview 2) Basics of virtualization technology 3) Configuring and using Real-Time Hypervisor systems 4) Performance and
Let s put together a Manual Processor
 Lecture 14 Let s put together a Manual Processor Hardware Lecture 14 Slide 1 The processor Inside every computer there is at least one processor which can take an instruction, some operands and produce
Lecture 14 Let s put together a Manual Processor Hardware Lecture 14 Slide 1 The processor Inside every computer there is at least one processor which can take an instruction, some operands and produce
Load Balancing & DFS Primitives for Efficient Multicore Applications
 Load Balancing & DFS Primitives for Efficient Multicore Applications M. Grammatikakis, A. Papagrigoriou, P. Petrakis, G. Kornaros, I. Christophorakis TEI of Crete This work is implemented through the Operational
Load Balancing & DFS Primitives for Efficient Multicore Applications M. Grammatikakis, A. Papagrigoriou, P. Petrakis, G. Kornaros, I. Christophorakis TEI of Crete This work is implemented through the Operational
OpenCL Programming for the CUDA Architecture. Version 2.3
 OpenCL Programming for the CUDA Architecture Version 2.3 8/31/2009 In general, there are multiple ways of implementing a given algorithm in OpenCL and these multiple implementations can have vastly different
OpenCL Programming for the CUDA Architecture Version 2.3 8/31/2009 In general, there are multiple ways of implementing a given algorithm in OpenCL and these multiple implementations can have vastly different
Optimizing Shared Resource Contention in HPC Clusters
 Optimizing Shared Resource Contention in HPC Clusters Sergey Blagodurov Simon Fraser University Alexandra Fedorova Simon Fraser University Abstract Contention for shared resources in HPC clusters occurs
Optimizing Shared Resource Contention in HPC Clusters Sergey Blagodurov Simon Fraser University Alexandra Fedorova Simon Fraser University Abstract Contention for shared resources in HPC clusters occurs
ultra fast SOM using CUDA
 ultra fast SOM using CUDA SOM (Self-Organizing Map) is one of the most popular artificial neural network algorithms in the unsupervised learning category. Sijo Mathew Preetha Joy Sibi Rajendra Manoj A
ultra fast SOM using CUDA SOM (Self-Organizing Map) is one of the most popular artificial neural network algorithms in the unsupervised learning category. Sijo Mathew Preetha Joy Sibi Rajendra Manoj A
ADVANCED COMPUTER ARCHITECTURE: Parallelism, Scalability, Programmability
 ADVANCED COMPUTER ARCHITECTURE: Parallelism, Scalability, Programmability * Technische Hochschule Darmstadt FACHBEREiCH INTORMATIK Kai Hwang Professor of Electrical Engineering and Computer Science University
ADVANCED COMPUTER ARCHITECTURE: Parallelism, Scalability, Programmability * Technische Hochschule Darmstadt FACHBEREiCH INTORMATIK Kai Hwang Professor of Electrical Engineering and Computer Science University
CHAPTER 7: The CPU and Memory
 CHAPTER 7: The CPU and Memory The Architecture of Computer Hardware, Systems Software & Networking: An Information Technology Approach 4th Edition, Irv Englander John Wiley and Sons 2010 PowerPoint slides
CHAPTER 7: The CPU and Memory The Architecture of Computer Hardware, Systems Software & Networking: An Information Technology Approach 4th Edition, Irv Englander John Wiley and Sons 2010 PowerPoint slides
Vorlesung Rechnerarchitektur 2 Seite 178 DASH
 Vorlesung Rechnerarchitektur 2 Seite 178 Architecture for Shared () The -architecture is a cache coherent, NUMA multiprocessor system, developed at CSL-Stanford by John Hennessy, Daniel Lenoski, Monica
Vorlesung Rechnerarchitektur 2 Seite 178 Architecture for Shared () The -architecture is a cache coherent, NUMA multiprocessor system, developed at CSL-Stanford by John Hennessy, Daniel Lenoski, Monica
EECS 750: Advanced Operating Systems. 01/28 /2015 Heechul Yun
 EECS 750: Advanced Operating Systems 01/28 /2015 Heechul Yun 1 Recap: Completely Fair Scheduler(CFS) Each task maintains its virtual time V i = E i 1 w i, where E is executed time, w is a weight Pick the
EECS 750: Advanced Operating Systems 01/28 /2015 Heechul Yun 1 Recap: Completely Fair Scheduler(CFS) Each task maintains its virtual time V i = E i 1 w i, where E is executed time, w is a weight Pick the
Hardware and Software
 Hardware and Software 1 Hardware and Software: A complete design Hardware and software support each other Sometimes it is necessary to shift functions from software to hardware or the other way around
Hardware and Software 1 Hardware and Software: A complete design Hardware and software support each other Sometimes it is necessary to shift functions from software to hardware or the other way around
Hunting Asynchronous CDC Violations in the Wild
 Hunting Asynchronous Violations in the Wild Chris Kwok Principal Engineer May 4, 2015 is the #2 Verification Problem Why is a Big Problem: 10 or More Clock Domains are Common Even FPGA Users Are Suffering
Hunting Asynchronous Violations in the Wild Chris Kwok Principal Engineer May 4, 2015 is the #2 Verification Problem Why is a Big Problem: 10 or More Clock Domains are Common Even FPGA Users Are Suffering
Advanced Computer Architecture-CS501. Computer Systems Design and Architecture 2.1, 2.2, 3.2
 Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Rethinking SIMD Vectorization for In-Memory Databases
 SIGMOD 215, Melbourne, Victoria, Australia Rethinking SIMD Vectorization for In-Memory Databases Orestis Polychroniou Columbia University Arun Raghavan Oracle Labs Kenneth A. Ross Columbia University Latest
SIGMOD 215, Melbourne, Victoria, Australia Rethinking SIMD Vectorization for In-Memory Databases Orestis Polychroniou Columbia University Arun Raghavan Oracle Labs Kenneth A. Ross Columbia University Latest
路 論 Chapter 15 System-Level Physical Design
 Introduction to VLSI Circuits and Systems 路 論 Chapter 15 System-Level Physical Design Dept. of Electronic Engineering National Chin-Yi University of Technology Fall 2007 Outline Clocked Flip-flops CMOS
Introduction to VLSI Circuits and Systems 路 論 Chapter 15 System-Level Physical Design Dept. of Electronic Engineering National Chin-Yi University of Technology Fall 2007 Outline Clocked Flip-flops CMOS
Computer Organization
 Computer Organization and Architecture Designing for Performance Ninth Edition William Stallings International Edition contributions by R. Mohan National Institute of Technology, Tiruchirappalli PEARSON
Computer Organization and Architecture Designing for Performance Ninth Edition William Stallings International Edition contributions by R. Mohan National Institute of Technology, Tiruchirappalli PEARSON
The Evolution of CCD Clock Sequencers at MIT: Looking to the Future through History
 The Evolution of CCD Clock Sequencers at MIT: Looking to the Future through History John P. Doty, Noqsi Aerospace, Ltd. This work is Copyright 2007 Noqsi Aerospace, Ltd. This work is licensed under the
The Evolution of CCD Clock Sequencers at MIT: Looking to the Future through History John P. Doty, Noqsi Aerospace, Ltd. This work is Copyright 2007 Noqsi Aerospace, Ltd. This work is licensed under the
David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems
 David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems About me David Rioja Redondo Telecommunication Engineer - Universidad de Alcalá >2 years building and managing clusters UPM
David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems About me David Rioja Redondo Telecommunication Engineer - Universidad de Alcalá >2 years building and managing clusters UPM
Design Cycle for Microprocessors
 Cycle for Microprocessors Raúl Martínez Intel Barcelona Research Center Cursos de Verano 2010 UCLM Intel Corporation, 2010 Agenda Introduction plan Architecture Microarchitecture Logic Silicon ramp Types
Cycle for Microprocessors Raúl Martínez Intel Barcelona Research Center Cursos de Verano 2010 UCLM Intel Corporation, 2010 Agenda Introduction plan Architecture Microarchitecture Logic Silicon ramp Types
Chapter 1 Computer System Overview
 Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
ARM Webinar series. ARM Based SoC. Abey Thomas
 ARM Webinar series ARM Based SoC Verification Abey Thomas Agenda About ARM and ARM IP ARM based SoC Verification challenges Verification planning and strategy IP Connectivity verification Performance verification
ARM Webinar series ARM Based SoC Verification Abey Thomas Agenda About ARM and ARM IP ARM based SoC Verification challenges Verification planning and strategy IP Connectivity verification Performance verification
CPU Scheduling Outline
 CPU Scheduling Outline What is scheduling in the OS? What are common scheduling criteria? How to evaluate scheduling algorithms? What are common scheduling algorithms? How is thread scheduling different
CPU Scheduling Outline What is scheduling in the OS? What are common scheduling criteria? How to evaluate scheduling algorithms? What are common scheduling algorithms? How is thread scheduling different
Graph Analytics in Big Data. John Feo Pacific Northwest National Laboratory
 Graph Analytics in Big Data John Feo Pacific Northwest National Laboratory 1 A changing World The breadth of problems requiring graph analytics is growing rapidly Large Network Systems Social Networks
Graph Analytics in Big Data John Feo Pacific Northwest National Laboratory 1 A changing World The breadth of problems requiring graph analytics is growing rapidly Large Network Systems Social Networks