Semi-Supervised Support Vector Machines and Application to Spam Filtering
|
|
|
- Mervin Hardy
- 9 years ago
- Views:
Transcription


1 Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery Challenge

2 1 Introduction 2 Training a S 3 VM Why It Matters Some S 3 VM Training Methods Gradient-based Optimization The Continuation S 3 VM 3 Overview of SSL Assumptions of SSL A Crude Overview of SSL Combining Methods 4 Application to Spam Filtering Naive Application Proper Model Selection 5 Conclusions

3 find a linear classification boundary

4
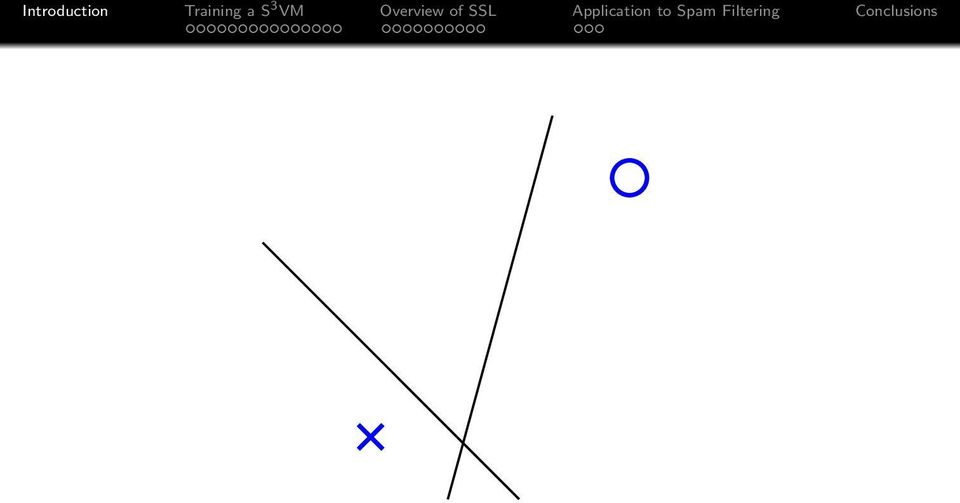
5 not robust wrt input noise!

6 SVM: maximum margin classifier w min w,b 1 2 w w } {{ } regularizer s.t. y i (w x i + b) 1

7 S 3 VM (TSVM): semi-supervised (transductive) SVM min w,b,(y j ) 1 2 w w } {{ } regularizer s.t. y i (w x i + b) 1 y j (w x j + b) 1
 1 y j (w x j +")
8 soft margin S 3 VM min w,b,(y j ),(ξ k ) 1 2 w w +C i ξ i +C j ξ j s.t. ξ i 0 ξ j 0 y i (w x i + b) 1 ξ i y j (w x j + b) 1 ξ j
 1 ξ")
9 Two Moons toy data easy for human (0% error) hard for S 3 VMs! S 3 VM optimization method test error objective value global min. {Branch & Bound 0.0% 7.81 find local minima CCCP S 3 VM light S 3 VM cs 3 VM 64.0% 66.2% 59.3% 45.7% objective function is good for SSL try to find better local minima!

10 min w,b,(y j ),(ξ k ) s.t. 1 2 w w + C i ξ i + C j ξ j y i (w x i + b) 1 ξ i ξ i 0 y j (w x j + b) 1 ξ j ξ j 0 Mixed Integer Programming [Bennett, Demiriz; NIPS 1998] global optimum found by standard optimization packages (eg CPLEX) combinatorial & NP-hard! only works for small sized problems
![ξ j ξ j 0 Mixed Integer Programming [Bennett, Demiriz; NIPS 1998] global](/docs-images/48/19682369/images/page_10.jpg "optimum found by standard optimization packages (eg CPLEX) combinatorial")
11 min w,b,(y j ),(ξ k ) s.t. 1 2 w w + C i ξ i + C j ξ j y i (w x i + b) 1 ξ i ξ i 0 y j (w x j + b) 1 ξ j ξ j 0 S 3 VM light [T. Joachims; ICML 1999] train SVM on labeled points, predict y j s in prediction, always make sure that #{y j = +1} # unlabeled points = #{y i = +1} # labeled points (1) with stepwise increasing C do 1 train SVM on all points, using labels (y i ), (y j ) 2 predict new y j s s.t. balancing constraint (*)
![Joachims; ICML 1999] train SVM on labeled points, predict y j s in prediction, always make sure that #{y j](/docs-images/48/19682369/images/page_11.jpg "= +1} # unlabeled points = #{y i = +1} # labeled points (1) with stepwise increasing C do 1 train SVM on")
12 min w,b,(y j ),(ξ k ) s.t. 1 2 w w + C i ξ i + C j ξ j y i (w x i + b) 1 ξ i ξ i 0 y j (w x j + b) 1 ξ j ξ j 0 Balancing constraint required to avoid degenerate solutions!

13 min w,b,(y j ),(ξ k ) s.t. Effective Loss Functions ξ j = { ξ i = min min y j {+1, 1} 1 2 w w + C i ξ i + C j ξ j y i (w x i + b) 1 ξ i ξ i 0 y j (w x j + b) 1 ξ j ξ j 0 } 1 y i (w x i + b), 0 { } 1 y j (w x j + b), 0 loss functions ξ i y i (w x i + b) ξ j w x j + b
, 0 { } 1 y j (w x j + b), 0 loss functions ξ i 0")
14 min w,b,(y j ),(ξ k ) s.t. 1 2 w w + C i ξ i + C j ξ j y i (w x i + b) 1 ξ i ξ i 0 y j (w x j + b) 1 ξ j ξ j 0 Resolving the Constraints 1 2 w w + C i ) l l (y i (w x i + b) + C j ) l u (w x j + b loss functions l l l u
 l l (y i (w x i + b) + C j ) l u (w x j + b loss")
15 1 2 w w + C i ) l l (y i (w x i + b) + C j ) l u (w x j + b CCCP-S 3 VM [R. Collobert et al.; ICML 2006] CCCP: Concave Convex Procedure objective = convex function + concave function starting from SVM solution, iterate: 1 approximate concave part by linear function at given point 2 solve resulting convex problem [Fung, Mangasarian; 1999] similar approach restricted to linear S 3 VMs

16 1 2 w w + C i ) l l (y i (w x i + b) + C j ) l u (w x j + b S 3 VM as Unconstrained Differentiable Optimization Problem original loss functions l l l u smooth loss functions l l l u

17 1 2 w w + C i ) l l (y i (w x i + b) + C j ) l u (w x j + b S 3 VM [Chapelle, Zien; AISTATS 2005] simply do gradient descent! thereby stepwise increase C conts 3 VM [Chapelle et al.; ICML 2006]... in more detail on next slides!

18 1 2 w w + C i ) l l (y i (w x i + b) + C j ) l u (w x j + b Hard Balancing Constraint S 3 VM light constraint equivalent constraint #{y j = +1} # unlabeled points = 1 ( ) sign w x j + b m j } {{ } average prediction #{y i = +1} # labeled points = 1 y i n i } {{ } average label

19 Making the Balancing Constraint Linear hard / non-linear soft / linear 1 ( ) sign w x j + b m j } {{ } average prediction = 1 w x j + b m j } {{ } mean output on unlabeled points 1 y i n i } {{ } average label = 1 y i n i } {{ } average label Implementing the linear soft balancing: center the unlabeled data: j x j = 0 just fix b; unconstrained optimization over w!

20 The Continuation Method in a Nutshell Procedure 1 smooth function until convex 2 find minimum 3 track minimum while decreasing amount of smoothing Illustration

21 Smoothing the S 3 VM Objective f ( ) Convolution of f ( ) with Gaussian of width γ/2: f γ (w) = (πγ) d/2 f (w t) exp( t 2 /γ)dt Closed form solution! Smoothing Sequence choose γ 0 > γ 1 >... γ p 1 > γ p = 0 choose γ 0 such that f γ0 ( ) is convex choose γ p 1 such that f γp 1 ( ) f γp ( ) = f ( ) p = 10 steps (equidistant on log scale) sufficient
22 Handling Non-Linearity Consider non-linear map Φ(x), kernel k(x i, x j ) = Φ(x i ) Φ(x j ). Representer Theorem: S 3 VM solution is in span E of data points E := span{φ(x i )} = R n+m Implementation 1 expand basis vectors v i of E: v i = k A ik Φ(x k ) 2 orthonormality gives: (A A) 1 = K solve for A, eg by KPCA or Choleski 3 project data Φ(x i ) on basis V = (v j ) j : x i = V Φ(x i ) = (A) i
 similar results for other hyperparameter settings [Chapelle, Chi, Zien; ICML")
23 Comparison of S 3 VM Optimization Methods averaged over splits (and pairs of classes) fixed hyperparams (close to hard margin) similar results for other hyperparameter settings [Chapelle, Chi, Zien; ICML 2006]
24 Why would unlabeled data be useful at all? Uniform data do not help.
25 Why would unlabeled data be useful at all? Uniform data do not help.
26 Cluster Assumption Points in the same cluster are likely to be of the same class. Algorithmic idea: Low Density Separation
27 Manifold Assumption The data lie on (close to) a low-dimensional manifold. [images from The Geometric Basis of Semi-Supervised Learning, Sindhwani, Belkin, Niyogi in Semi-Supervised Learning Chapelle, Schölkopf, Zien] Algorithmic idea: use Nearest-Neighbor Graph
28 Assumption: Independent Views Exist There exist subsets of features, called views, each of which is independent of the others given the class; is sufficient for classification. view 2 view 1 Algorithmic idea: Co-Training
29 Assumption Approach Example Algorithm Cluster Assumption Low Density Separation S 3 VM; Entropy Regularization; Data-Dependent Regularization;... Manifold Assumption Graphbased Methods build weighted graph (w kl ) min w kl (y k y l ) 2 (y j ) k l relax y j to be real QP Independent Views Co-Training train two predictors y (1) j, y (2) j couple objectives by adding j ( y (1) j y (2) j ) 2
30 Discriminative Learning (Diagnostic Paradigm) model p(y x) (or just boundary: { x p(y x) = 1 2 } ) examples: S 3 VM, graph-based methods Generative Learning (Sampling Paradigm) model p(x y) predict via Bayes: p(y x) = missing data problem p(y)p(x y) y p(y )p(x y ) EM algorithm (expectation-maximization) is a natural tool successful for text data [Nigam et al.; Machine Learning, 2000]
31 SSL Book MIT Press, Sept edited by B. Schölkopf, O. Chapelle, A. Zien contains many state-of-art algorithms by top researchers extensive SSL benchmark online material: sample chapters benchmark data more information
32 SSL Book Text Benchmark error [%] AUC [%] l=10 l=100 l=10 l=100 1-NN SVM MVU + 1-NN LEM + 1-NN QC + CMN Discrete Reg TSVM SGT Cluster-Kernel LDS Laplacian RLS
33 Combining S 3 VM with Graph-based Regularizer LapSVM [1]: modify kernel using graph, then train SVM combination with S 3 VM even better [2] MNIST, 3 vs 5 [1] Beyond the Point Clound ; Sindhwani, Niyogi, Belkin; ICML 2005 [2] A Continuation Method for S 3 VM ; Chapelle, Chi, Zien; ICML 2006 Combining S 3 VM with Co-Training SSL for Structured Output Variables ; Brefeld, Scheffer; ICML 2006
34 min w,b,(y j ),(ξ k ) s.t. 1 2 w w + C i ξ i + C j ξ j y i (w x i + b) 1 ξ i ξ i 0 y j (w x j + b) 1 ξ j ξ j 0 How to set C? data fitting, y i w x i 1, and regularization, min w 2 : w x i = O(1) w 2 Var[x] 1 balance influence: w 2 Cξ i C Var[x] 1 How to set C? C = C C # unlabeled points = λ # labeled points C
35 Naive Application: Transductive setting on each user/inbox: use inbox of given user as unlabeled data test data = unlabeled data Guess the model: Var[x] 1, so set C = 1 C = C linear kernel Results: AUC (rank) [rank in unofficial list] task A task B S 3 VM light 94.53% (4) [6] 92.34% (2) [4] S 3 VM 96.72% (1) [3] 93.74% (2) [4] conts 3 VM 96.01% (1) [3] 93.56% (2) [4]
36 Model selection: C {10 2, 10 1, 10 0, 10 +1, } C {10 2, 10 1, 10 0, 10 +1, } C cross-validation (3-fold for task A; 5-fold for task B) Results: AUC for conts 3 VM task A task B C = C = 1 (guessed model) 96.01% 93.56% model selection 89.31% 90.09% significant drop in accuracy! CV relys on iid assumption: that the data are independent identically distributed
37 Take Home Messages S 3 VM implements low density separation (margin maximization) optimization technique matters (non-convex objective) works well for text classification (texts form clusters) S 3 VM-based hybrids may be even better for spam filtering, further methods needed to cope with non-iid situation (mail inboxes)! Thank you!
Support Vector Machine (SVM)
") Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Online Semi-Supervised Learning
 Online Semi-Supervised Learning Andrew B. Goldberg, Ming Li, Xiaojin Zhu [email protected] Computer Sciences University of Wisconsin Madison Xiaojin Zhu (Univ. Wisconsin-Madison) Online Semi-Supervised
Online Semi-Supervised Learning Andrew B. Goldberg, Ming Li, Xiaojin Zhu [email protected] Computer Sciences University of Wisconsin Madison Xiaojin Zhu (Univ. Wisconsin-Madison) Online Semi-Supervised
Tree based ensemble models regularization by convex optimization
 Tree based ensemble models regularization by convex optimization Bertrand Cornélusse, Pierre Geurts and Louis Wehenkel Department of Electrical Engineering and Computer Science University of Liège B-4000
Tree based ensemble models regularization by convex optimization Bertrand Cornélusse, Pierre Geurts and Louis Wehenkel Department of Electrical Engineering and Computer Science University of Liège B-4000
LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING. ----Changsheng Liu 10-30-2014
 LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING ----Changsheng Liu 10-30-2014 Agenda Semi Supervised Learning Topics in Semi Supervised Learning Label Propagation Local and global consistency Graph
LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING ----Changsheng Liu 10-30-2014 Agenda Semi Supervised Learning Topics in Semi Supervised Learning Label Propagation Local and global consistency Graph
An Introduction to Machine Learning
 An Introduction to Machine Learning L5: Novelty Detection and Regression Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia [email protected] Tata Institute, Pune,
An Introduction to Machine Learning L5: Novelty Detection and Regression Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia [email protected] Tata Institute, Pune,
Statistical Machine Learning
 Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Maximum Margin Clustering
 Maximum Margin Clustering Linli Xu James Neufeld Bryce Larson Dale Schuurmans University of Waterloo University of Alberta Abstract We propose a new method for clustering based on finding maximum margin
Maximum Margin Clustering Linli Xu James Neufeld Bryce Larson Dale Schuurmans University of Waterloo University of Alberta Abstract We propose a new method for clustering based on finding maximum margin
Simple and efficient online algorithms for real world applications
 Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Graph-based Semi-supervised Learning
 Graph-based Semi-supervised Learning Zoubin Ghahramani Department of Engineering University of Cambridge, UK [email protected] http://learning.eng.cam.ac.uk/zoubin/ MLSS 2012 La Palma Motivation Large
Graph-based Semi-supervised Learning Zoubin Ghahramani Department of Engineering University of Cambridge, UK [email protected] http://learning.eng.cam.ac.uk/zoubin/ MLSS 2012 La Palma Motivation Large
Support Vector Machines Explained
 March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Introduction to Support Vector Machines. Colin Campbell, Bristol University
 Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Christfried Webers. Canberra February June 2015
 c Statistical Group and College of Engineering and Computer Science Canberra February June (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 829 c Part VIII Linear Classification 2 Logistic
c Statistical Group and College of Engineering and Computer Science Canberra February June (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 829 c Part VIII Linear Classification 2 Logistic
Learning with Local and Global Consistency
 Learning with Local and Global Consistency Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf Max Planck Institute for Biological Cybernetics, 7276 Tuebingen, Germany
Learning with Local and Global Consistency Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf Max Planck Institute for Biological Cybernetics, 7276 Tuebingen, Germany
Learning with Local and Global Consistency
 Learning with Local and Global Consistency Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf Max Planck Institute for Biological Cybernetics, 7276 Tuebingen, Germany
Learning with Local and Global Consistency Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf Max Planck Institute for Biological Cybernetics, 7276 Tuebingen, Germany
Lecture 6: Logistic Regression
 Lecture 6: CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 13, 2011 Outline Outline Classification task Data : X = [x 1,..., x m]: a n m matrix of data points in R n. y { 1,
Lecture 6: CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 13, 2011 Outline Outline Classification task Data : X = [x 1,..., x m]: a n m matrix of data points in R n. y { 1,
Learning Gaussian process models from big data. Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu
 Learning Gaussian process models from big data Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu Machine learning seminar at University of Cambridge, July 4 2012 Data A lot of
Learning Gaussian process models from big data Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu Machine learning seminar at University of Cambridge, July 4 2012 Data A lot of
Logistic Regression. Vibhav Gogate The University of Texas at Dallas. Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld.
 Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC)
") large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
Introduction to Machine Learning Lecture 1. Mehryar Mohri Courant Institute and Google Research [email protected]
 Introduction to Machine Learning Lecture 1 Mehryar Mohri Courant Institute and Google Research [email protected] Introduction Logistics Prerequisites: basics concepts needed in probability and statistics
Introduction to Machine Learning Lecture 1 Mehryar Mohri Courant Institute and Google Research [email protected] Introduction Logistics Prerequisites: basics concepts needed in probability and statistics
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
Lecture 3: Linear methods for classification
 Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
203.4770: Introduction to Machine Learning Dr. Rita Osadchy
 203.4770: Introduction to Machine Learning Dr. Rita Osadchy 1 Outline 1. About the Course 2. What is Machine Learning? 3. Types of problems and Situations 4. ML Example 2 About the course Course Homepage:
203.4770: Introduction to Machine Learning Dr. Rita Osadchy 1 Outline 1. About the Course 2. What is Machine Learning? 3. Types of problems and Situations 4. ML Example 2 About the course Course Homepage:
Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics
 Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics Part I: Factorizations and Statistical Modeling/Inference Amnon Shashua School of Computer Science & Eng. The Hebrew University
Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics Part I: Factorizations and Statistical Modeling/Inference Amnon Shashua School of Computer Science & Eng. The Hebrew University
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Support Vector Machines with Clustering for Training with Very Large Datasets
 Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France [email protected] Massimiliano
Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France [email protected] Massimiliano
Predict Influencers in the Social Network
 Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, [email protected] Department of Electrical Engineering, Stanford University Abstract Given two persons
Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, [email protected] Department of Electrical Engineering, Stanford University Abstract Given two persons
Several Views of Support Vector Machines
 Several Views of Support Vector Machines Ryan M. Rifkin Honda Research Institute USA, Inc. Human Intention Understanding Group 2007 Tikhonov Regularization We are considering algorithms of the form min
Several Views of Support Vector Machines Ryan M. Rifkin Honda Research Institute USA, Inc. Human Intention Understanding Group 2007 Tikhonov Regularization We are considering algorithms of the form min
Early defect identification of semiconductor processes using machine learning
 STANFORD UNIVERISTY MACHINE LEARNING CS229 Early defect identification of semiconductor processes using machine learning Friday, December 16, 2011 Authors: Saul ROSA Anton VLADIMIROV Professor: Dr. Andrew
STANFORD UNIVERISTY MACHINE LEARNING CS229 Early defect identification of semiconductor processes using machine learning Friday, December 16, 2011 Authors: Saul ROSA Anton VLADIMIROV Professor: Dr. Andrew
Acknowledgments. Data Mining with Regression. Data Mining Context. Overview. Colleagues
 Data Mining with Regression Teaching an old dog some new tricks Acknowledgments Colleagues Dean Foster in Statistics Lyle Ungar in Computer Science Bob Stine Department of Statistics The School of the
Data Mining with Regression Teaching an old dog some new tricks Acknowledgments Colleagues Dean Foster in Statistics Lyle Ungar in Computer Science Bob Stine Department of Statistics The School of the
A semi-supervised Spam mail detector
 A semi-supervised Spam mail detector Bernhard Pfahringer Department of Computer Science, University of Waikato, Hamilton, New Zealand Abstract. This document describes a novel semi-supervised approach
A semi-supervised Spam mail detector Bernhard Pfahringer Department of Computer Science, University of Waikato, Hamilton, New Zealand Abstract. This document describes a novel semi-supervised approach
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Classification with Hybrid Generative/Discriminative Models
 Classification with Hybrid Generative/Discriminative Models Rajat Raina, Yirong Shen, Andrew Y. Ng Computer Science Department Stanford University Stanford, CA 94305 Andrew McCallum Department of Computer
Classification with Hybrid Generative/Discriminative Models Rajat Raina, Yirong Shen, Andrew Y. Ng Computer Science Department Stanford University Stanford, CA 94305 Andrew McCallum Department of Computer
Probabilistic Models for Big Data. Alex Davies and Roger Frigola University of Cambridge 13th February 2014
 Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
1 Maximum likelihood estimation
 COS 424: Interacting with Data Lecturer: David Blei Lecture #4 Scribes: Wei Ho, Michael Ye February 14, 2008 1 Maximum likelihood estimation 1.1 MLE of a Bernoulli random variable (coin flips) Given N
COS 424: Interacting with Data Lecturer: David Blei Lecture #4 Scribes: Wei Ho, Michael Ye February 14, 2008 1 Maximum likelihood estimation 1.1 MLE of a Bernoulli random variable (coin flips) Given N
HT2015: SC4 Statistical Data Mining and Machine Learning
 HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
Machine Learning for Medical Image Analysis. A. Criminisi & the InnerEye team @ MSRC
 Machine Learning for Medical Image Analysis A. Criminisi & the InnerEye team @ MSRC Medical image analysis the goal Automatic, semantic analysis and quantification of what observed in medical scans Brain
Machine Learning for Medical Image Analysis A. Criminisi & the InnerEye team @ MSRC Medical image analysis the goal Automatic, semantic analysis and quantification of what observed in medical scans Brain
Machine Learning in Spam Filtering
 Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov [email protected] Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov [email protected] Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
A Simple Introduction to Support Vector Machines
 A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
Machine Learning. CUNY Graduate Center, Spring 2013. Professor Liang Huang. [email protected]
 Machine Learning CUNY Graduate Center, Spring 2013 Professor Liang Huang [email protected] http://acl.cs.qc.edu/~lhuang/teaching/machine-learning Logistics Lectures M 9:30-11:30 am Room 4419 Personnel
Machine Learning CUNY Graduate Center, Spring 2013 Professor Liang Huang [email protected] http://acl.cs.qc.edu/~lhuang/teaching/machine-learning Logistics Lectures M 9:30-11:30 am Room 4419 Personnel
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Feature Selection & Unsupervised Dimensionality Reduction
 Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Manifold Learning with Variational Auto-encoder for Medical Image Analysis
 Manifold Learning with Variational Auto-encoder for Medical Image Analysis Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill [email protected] Abstract Manifold
Manifold Learning with Variational Auto-encoder for Medical Image Analysis Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill [email protected] Abstract Manifold
Distributed Structured Prediction for Big Data
 Distributed Structured Prediction for Big Data A. G. Schwing ETH Zurich [email protected] T. Hazan TTI Chicago M. Pollefeys ETH Zurich R. Urtasun TTI Chicago Abstract The biggest limitations of learning
Distributed Structured Prediction for Big Data A. G. Schwing ETH Zurich [email protected] T. Hazan TTI Chicago M. Pollefeys ETH Zurich R. Urtasun TTI Chicago Abstract The biggest limitations of learning
Interactive Machine Learning. Maria-Florina Balcan
 Interactive Machine Learning Maria-Florina Balcan Machine Learning Image Classification Document Categorization Speech Recognition Protein Classification Branch Prediction Fraud Detection Spam Detection
Interactive Machine Learning Maria-Florina Balcan Machine Learning Image Classification Document Categorization Speech Recognition Protein Classification Branch Prediction Fraud Detection Spam Detection
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Classifying Large Data Sets Using SVMs with Hierarchical Clusters. Presented by :Limou Wang
 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Lecture 2: The SVM classifier
 Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function
Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function
Direct Loss Minimization for Structured Prediction
 Direct Loss Minimization for Structured Prediction David McAllester TTI-Chicago [email protected] Tamir Hazan TTI-Chicago [email protected] Joseph Keshet TTI-Chicago [email protected] Abstract In discriminative
Direct Loss Minimization for Structured Prediction David McAllester TTI-Chicago [email protected] Tamir Hazan TTI-Chicago [email protected] Joseph Keshet TTI-Chicago [email protected] Abstract In discriminative
Robust personalizable spam filtering via local and global discrimination modeling
 Knowl Inf Syst DOI 10.1007/s10115-012-0477-x REGULAR PAPER Robust personalizable spam filtering via local and global discrimination modeling Khurum Nazir Junejo Asim Karim Received: 29 June 2010 / Revised:
Knowl Inf Syst DOI 10.1007/s10115-012-0477-x REGULAR PAPER Robust personalizable spam filtering via local and global discrimination modeling Khurum Nazir Junejo Asim Karim Received: 29 June 2010 / Revised:
Making Sense of the Mayhem: Machine Learning and March Madness
 Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University [email protected] [email protected] I. Introduction III. Model The goal of our research
Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University [email protected] [email protected] I. Introduction III. Model The goal of our research
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Big Data - Lecture 1 Optimization reminders
 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Schedule Introduction Major issues Examples Mathematics
Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Schedule Introduction Major issues Examples Mathematics
Nonlinear Optimization: Algorithms 3: Interior-point methods
 Nonlinear Optimization: Algorithms 3: Interior-point methods INSEAD, Spring 2006 Jean-Philippe Vert Ecole des Mines de Paris [email protected] Nonlinear optimization c 2006 Jean-Philippe Vert,
Nonlinear Optimization: Algorithms 3: Interior-point methods INSEAD, Spring 2006 Jean-Philippe Vert Ecole des Mines de Paris [email protected] Nonlinear optimization c 2006 Jean-Philippe Vert,
CSE 473: Artificial Intelligence Autumn 2010
 CSE 473: Artificial Intelligence Autumn 2010 Machine Learning: Naive Bayes and Perceptron Luke Zettlemoyer Many slides over the course adapted from Dan Klein. 1 Outline Learning: Naive Bayes and Perceptron
CSE 473: Artificial Intelligence Autumn 2010 Machine Learning: Naive Bayes and Perceptron Luke Zettlemoyer Many slides over the course adapted from Dan Klein. 1 Outline Learning: Naive Bayes and Perceptron
Logistic Regression. Jia Li. Department of Statistics The Pennsylvania State University. Logistic Regression
 Logistic Regression Department of Statistics The Pennsylvania State University Email: [email protected] Logistic Regression Preserve linear classification boundaries. By the Bayes rule: Ĝ(x) = arg max
Logistic Regression Department of Statistics The Pennsylvania State University Email: [email protected] Logistic Regression Preserve linear classification boundaries. By the Bayes rule: Ĝ(x) = arg max
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Logistic Regression for Spam Filtering
 Logistic Regression for Spam Filtering Nikhila Arkalgud February 14, 28 Abstract The goal of the spam filtering problem is to identify an email as a spam or not spam. One of the classic techniques used
Logistic Regression for Spam Filtering Nikhila Arkalgud February 14, 28 Abstract The goal of the spam filtering problem is to identify an email as a spam or not spam. One of the classic techniques used
Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh
 Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh Peter Richtárik Week 3 Randomized Coordinate Descent With Arbitrary Sampling January 27, 2016 1 / 30 The Problem
Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh Peter Richtárik Week 3 Randomized Coordinate Descent With Arbitrary Sampling January 27, 2016 1 / 30 The Problem
Model Trees for Classification of Hybrid Data Types
 Model Trees for Classification of Hybrid Data Types Hsing-Kuo Pao, Shou-Chih Chang, and Yuh-Jye Lee Dept. of Computer Science & Information Engineering, National Taiwan University of Science & Technology,
Model Trees for Classification of Hybrid Data Types Hsing-Kuo Pao, Shou-Chih Chang, and Yuh-Jye Lee Dept. of Computer Science & Information Engineering, National Taiwan University of Science & Technology,
Support Vector Machines
 Support Vector Machines Charlie Frogner 1 MIT 2011 1 Slides mostly stolen from Ryan Rifkin (Google). Plan Regularization derivation of SVMs. Analyzing the SVM problem: optimization, duality. Geometric
Support Vector Machines Charlie Frogner 1 MIT 2011 1 Slides mostly stolen from Ryan Rifkin (Google). Plan Regularization derivation of SVMs. Analyzing the SVM problem: optimization, duality. Geometric
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Gaussian Mixture Models Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Gaussian Mixture Models Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
10-601. Machine Learning. http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
 10-601 Machine Learning http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html Course data All up-to-date info is on the course web page: http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
10-601 Machine Learning http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html Course data All up-to-date info is on the course web page: http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
CS 688 Pattern Recognition Lecture 4. Linear Models for Classification
 CS 688 Pattern Recognition Lecture 4 Linear Models for Classification Probabilistic generative models Probabilistic discriminative models 1 Generative Approach ( x ) p C k p( C k ) Ck p ( ) ( x Ck ) p(
CS 688 Pattern Recognition Lecture 4 Linear Models for Classification Probabilistic generative models Probabilistic discriminative models 1 Generative Approach ( x ) p C k p( C k ) Ck p ( ) ( x Ck ) p(
CS 2750 Machine Learning. Lecture 1. Machine Learning. http://www.cs.pitt.edu/~milos/courses/cs2750/ CS 2750 Machine Learning.
 Lecture Machine Learning Milos Hauskrecht [email protected] 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht [email protected] 539 Sennott
Lecture Machine Learning Milos Hauskrecht [email protected] 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht [email protected] 539 Sennott
Discrete Optimization
 Discrete Optimization [Chen, Batson, Dang: Applied integer Programming] Chapter 3 and 4.1-4.3 by Johan Högdahl and Victoria Svedberg Seminar 2, 2015-03-31 Todays presentation Chapter 3 Transforms using
Discrete Optimization [Chen, Batson, Dang: Applied integer Programming] Chapter 3 and 4.1-4.3 by Johan Högdahl and Victoria Svedberg Seminar 2, 2015-03-31 Todays presentation Chapter 3 Transforms using
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
Local features and matching. Image classification & object localization
 Overview Instance level search Local features and matching Efficient visual recognition Image classification & object localization Category recognition Image classification: assigning a class label to
Overview Instance level search Local features and matching Efficient visual recognition Image classification & object localization Category recognition Image classification: assigning a class label to
Probabilistic Linear Classification: Logistic Regression. Piyush Rai IIT Kanpur
 Probabilistic Linear Classification: Logistic Regression Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 18, 2016 Probabilistic Machine Learning (CS772A) Probabilistic Linear Classification:
Probabilistic Linear Classification: Logistic Regression Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 18, 2016 Probabilistic Machine Learning (CS772A) Probabilistic Linear Classification:
17.3.1 Follow the Perturbed Leader
 CS787: Advanced Algorithms Topic: Online Learning Presenters: David He, Chris Hopman 17.3.1 Follow the Perturbed Leader 17.3.1.1 Prediction Problem Recall the prediction problem that we discussed in class.
CS787: Advanced Algorithms Topic: Online Learning Presenters: David He, Chris Hopman 17.3.1 Follow the Perturbed Leader 17.3.1.1 Prediction Problem Recall the prediction problem that we discussed in class.
Maximum-Margin Matrix Factorization
 Maximum-Margin Matrix Factorization Nathan Srebro Dept. of Computer Science University of Toronto Toronto, ON, CANADA [email protected] Jason D. M. Rennie Tommi S. Jaakkola Computer Science and Artificial
Maximum-Margin Matrix Factorization Nathan Srebro Dept. of Computer Science University of Toronto Toronto, ON, CANADA [email protected] Jason D. M. Rennie Tommi S. Jaakkola Computer Science and Artificial
Machine Learning and Data Analysis overview. Department of Cybernetics, Czech Technical University in Prague. http://ida.felk.cvut.
 Machine Learning and Data Analysis overview Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz psyllabus Lecture Lecturer Content 1. J. Kléma Introduction,
Machine Learning and Data Analysis overview Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz psyllabus Lecture Lecturer Content 1. J. Kléma Introduction,
Robust Personalizable Spam Filtering Via Local and Global Discrimination Modeling
 Robust Personalizable Spam Filtering Via Local and Global Discrimination Modeling Khurum Nazir Junejo Asim Karim Department of Computer Science LUMS School of Science and Engineering Lahore, Pakistan [email protected]
Robust Personalizable Spam Filtering Via Local and Global Discrimination Modeling Khurum Nazir Junejo Asim Karim Department of Computer Science LUMS School of Science and Engineering Lahore, Pakistan [email protected]
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Pa8ern Recogni6on. and Machine Learning. Chapter 4: Linear Models for Classifica6on
 Pa8ern Recogni6on and Machine Learning Chapter 4: Linear Models for Classifica6on Represen'ng the target values for classifica'on If there are only two classes, we typically use a single real valued output
Pa8ern Recogni6on and Machine Learning Chapter 4: Linear Models for Classifica6on Represen'ng the target values for classifica'on If there are only two classes, we typically use a single real valued output
Decompose Error Rate into components, some of which can be measured on unlabeled data
 Bias-Variance Theory Decompose Error Rate into components, some of which can be measured on unlabeled data Bias-Variance Decomposition for Regression Bias-Variance Decomposition for Classification Bias-Variance
Bias-Variance Theory Decompose Error Rate into components, some of which can be measured on unlabeled data Bias-Variance Decomposition for Regression Bias-Variance Decomposition for Classification Bias-Variance
These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
 course textbook Pattern Recognition and Machine Learning by Christopher Bishop") Music and Machine Learning (IFT6080 Winter 08) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher
Music and Machine Learning (IFT6080 Winter 08) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher
Introduction to Online Learning Theory
 Introduction to Online Learning Theory Wojciech Kot lowski Institute of Computing Science, Poznań University of Technology IDSS, 04.06.2013 1 / 53 Outline 1 Example: Online (Stochastic) Gradient Descent
Introduction to Online Learning Theory Wojciech Kot lowski Institute of Computing Science, Poznań University of Technology IDSS, 04.06.2013 1 / 53 Outline 1 Example: Online (Stochastic) Gradient Descent
Cross-validation for detecting and preventing overfitting
 Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
The Artificial Prediction Market
 The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S
 e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard
Gaussian Processes in Machine Learning
 Gaussian Processes in Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics, 72076 Tübingen, Germany [email protected] WWW home page: http://www.tuebingen.mpg.de/ carl
Gaussian Processes in Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics, 72076 Tübingen, Germany [email protected] WWW home page: http://www.tuebingen.mpg.de/ carl
Linear Models for Classification
 Linear Models for Classification Sumeet Agarwal, EEL709 (Most figures from Bishop, PRML) Approaches to classification Discriminant function: Directly assigns each data point x to a particular class Ci
Linear Models for Classification Sumeet Agarwal, EEL709 (Most figures from Bishop, PRML) Approaches to classification Discriminant function: Directly assigns each data point x to a particular class Ci
Probabilistic user behavior models in online stores for recommender systems
 Probabilistic user behavior models in online stores for recommender systems Tomoharu Iwata Abstract Recommender systems are widely used in online stores because they are expected to improve both user
Probabilistic user behavior models in online stores for recommender systems Tomoharu Iwata Abstract Recommender systems are widely used in online stores because they are expected to improve both user
MACHINE LEARNING IN HIGH ENERGY PHYSICS
 MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
On Entropy in Network Traffic Anomaly Detection
 On Entropy in Network Traffic Anomaly Detection Jayro Santiago-Paz, Deni Torres-Roman. Cinvestav, Campus Guadalajara, Mexico November 2015 Jayro Santiago-Paz, Deni Torres-Roman. 1/19 On Entropy in Network
On Entropy in Network Traffic Anomaly Detection Jayro Santiago-Paz, Deni Torres-Roman. Cinvestav, Campus Guadalajara, Mexico November 2015 Jayro Santiago-Paz, Deni Torres-Roman. 1/19 On Entropy in Network
Machine Learning in Computer Vision A Tutorial. Ajay Joshi, Anoop Cherian and Ravishankar Shivalingam Dept. of Computer Science, UMN
 Machine Learning in Computer Vision A Tutorial Ajay Joshi, Anoop Cherian and Ravishankar Shivalingam Dept. of Computer Science, UMN Outline Introduction Supervised Learning Unsupervised Learning Semi-Supervised
Machine Learning in Computer Vision A Tutorial Ajay Joshi, Anoop Cherian and Ravishankar Shivalingam Dept. of Computer Science, UMN Outline Introduction Supervised Learning Unsupervised Learning Semi-Supervised
Network Intrusion Detection using Semi Supervised Support Vector Machine
 Network Intrusion Detection using Semi Supervised Support Vector Machine Jyoti Haweliya Department of Computer Engineering Institute of Engineering & Technology, Devi Ahilya University Indore, India ABSTRACT
Network Intrusion Detection using Semi Supervised Support Vector Machine Jyoti Haweliya Department of Computer Engineering Institute of Engineering & Technology, Devi Ahilya University Indore, India ABSTRACT
Part III: Machine Learning. CS 188: Artificial Intelligence. Machine Learning This Set of Slides. Parameter Estimation. Estimation: Smoothing
 CS 188: Artificial Intelligence Lecture 20: Dynamic Bayes Nets, Naïve Bayes Pieter Abbeel UC Berkeley Slides adapted from Dan Klein. Part III: Machine Learning Up until now: how to reason in a model and
CS 188: Artificial Intelligence Lecture 20: Dynamic Bayes Nets, Naïve Bayes Pieter Abbeel UC Berkeley Slides adapted from Dan Klein. Part III: Machine Learning Up until now: how to reason in a model and
Visualization by Linear Projections as Information Retrieval
 Visualization by Linear Projections as Information Retrieval Jaakko Peltonen Helsinki University of Technology, Department of Information and Computer Science, P. O. Box 5400, FI-0015 TKK, Finland [email protected]
Visualization by Linear Projections as Information Retrieval Jaakko Peltonen Helsinki University of Technology, Department of Information and Computer Science, P. O. Box 5400, FI-0015 TKK, Finland [email protected]
Attribution. Modified from Stuart Russell s slides (Berkeley) Parts of the slides are inspired by Dan Klein s lecture material for CS 188 (Berkeley)
 Parts of the slides are inspired by Dan Klein s lecture material for CS 188 (Berkeley)") Machine Learning 1 Attribution Modified from Stuart Russell s slides (Berkeley) Parts of the slides are inspired by Dan Klein s lecture material for CS 188 (Berkeley) 2 Outline Inductive learning Decision
Machine Learning 1 Attribution Modified from Stuart Russell s slides (Berkeley) Parts of the slides are inspired by Dan Klein s lecture material for CS 188 (Berkeley) 2 Outline Inductive learning Decision
Semi-supervised Sentiment Classification in Resource-Scarce Language: A Comparative Study
 一 般 社 団 法 人 電 子 情 報 通 信 学 会 THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEERS 信 学 技 報 IE IC E Technical Report Semi-supervised Sentiment Classification in Resource-Scarce Language:
一 般 社 団 法 人 電 子 情 報 通 信 学 会 THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEERS 信 学 技 報 IE IC E Technical Report Semi-supervised Sentiment Classification in Resource-Scarce Language:
Predicting the Stock Market with News Articles
 Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Introduction to Machine Learning and Data Mining. Prof. Dr. Igor Trajkovski [email protected]
 Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trakovski [email protected] Neural Networks 2 Neural Networks Analogy to biological neural systems, the most robust learning systems
Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trakovski [email protected] Neural Networks 2 Neural Networks Analogy to biological neural systems, the most robust learning systems
Principles of Dat Da a t Mining Pham Tho Hoan [email protected] [email protected]. n
 Principles of Data Mining Pham Tho Hoan [email protected] References [1] David Hand, Heikki Mannila and Padhraic Smyth, Principles of Data Mining, MIT press, 2002 [2] Jiawei Han and Micheline Kamber,
Principles of Data Mining Pham Tho Hoan [email protected] References [1] David Hand, Heikki Mannila and Padhraic Smyth, Principles of Data Mining, MIT press, 2002 [2] Jiawei Han and Micheline Kamber,