CSC 177 Fall 2014 Team Project Final Report
|
|
|
- Marjory Spencer
- 9 years ago
- Views:
Transcription
1 CSC 177 Fall 2014 Team Project Final Report Project Title, Data Mining on Farmers Market Data Instructor: Dr. Meiliu Lu Team Members: Yogesh Isawe Kalindi Mehta Aditi Kulkarni

2 CSc 177 DM Project Cover Page Due pm (Submit it to the CSC Department office before 5pm 12/15/14 Or to the instructor at 5:15pm in RVR 5029) Student(s) Name : Aditi Kulkarni, Kalindi Mehta, Yogesh Isawe Grade Title of the project: Data Mining on Farmers Market Hand-in-check list: A hardcopy of final report (without appendix) with cover page for the term project An electronic copy on a CD including all of important writings of your term project Project oral presentation power point file with improvement made based on comments of the class and instructor during oral presentation. Project final report (100%) containing the following parts, font >= 11: 1. objective statement of the term project (1/3-1/2 page); 2. background information (1 page); 3. design principle of your data mining system/ scope of study (1/3 1/2 page); 4. implementation issues and solutions/ survey results/ diagrams/ tables (3-5 pages); 5. summary of learning experience such as experiments and readings (1/2-1 page); 6. References (authors, title, publishing source data, date of publication, URL) and you should quote each reference in your report text. 7. Appendix (optional) containing a set of supporting material such as examples, sample demo sessions, and any information that reflects your effort regarding the project.
 containing the following parts, font >= 11: 1. objective statement of the term project (1/3-1/2 page); 2. background information (1 page); 3.")
3 TABLE OF CONTENTS Chapter 1. OBJECTIVE 2. BACK GROUND INFORMATION 3. DESIGN PRINCIPLES 4. IMPLEMENTATION ISSUES AND SOLUTIONS 5. SUMMARY OF LEARNING EXPERIENCE 6. FUTURE SCOPE 7. REFERENCES

4 1. Abstract Data set consists of Location of U.S. Farmers Market, Goods availability at the market as per season. We have created a data mart that can provide the information and answers questions. We have designed questions to address two types of users Consumer and Government officials. For data mining project, we are working on the same data to find patterns. 2. Objective Using data mining tool WEKA to do a multi-step data mining exercise. Interpreting the data well, understanding the structure of the data using one or more data mining algorithms, and presenting the findings. Mining data to extract knowledge from available data. To explore alternative data mining tools such as Rapidminer. 3. Background Information In data mining project we are mining US Farmers Market data to extract knowledge. Here we are using WEKA tool to mine the data. Data source for data is Original dataset consists of 8000 records with 41 different attributes related to farmers market. Our primary goal is to use different mining tools to apply classification and clustering algorithms. 4. Design Principles The design principles of this project included data cleaning and preprocessing. The first phase of this project includes cleaning the data and makes it compatible to data mining tool, the next phase is to apply data mining algorithms to get classification and clustering results and study these algorithms. The Data is cleaned and pre-processed manually by checking all the attribute entries and made changes using Microsoft Office Excel. Using WEKA -Data Mining tool, based on the structure and type of DB, we applied following algorithms: 1. Classification Algorithms: a. Logistic Algorithm b. J48 (Decision Tree) 2. Clustering Algorithms: a. Expectation Maximization (EM) Algorithm b. K-Means Algorithm 5. Implementation

5 To mine data we have followed KDD process. Following are steps we followed: 1. Data Preprocessing: As it is real time data, it is noisy data and need preprocessing. To make it easy to handle, we have trimmed original data to 1907 rows. We are using 35 attributes out of 41. Season attribute was not consistent throughout the data. In some records it was mention as date or duration of months. To make it consistent we added two columns named Season start and season end. Some special characters were used in data which is not accepted by Weka so we remove these characters or replace with appropriate one. 2. Import preprocessed data in Weka. 3. Applied Classification and Clustering algorithms as mention below: Based on the structure of Data Set and type of DB, specific algorithms can only yield the results that interpret data well. 6. Classification Algorithms We used same database for data mining projects and data warehousing project. As the database is very vast and distributive with many independent and with few dependent attributes. After analyzing database, we come to conclusion that to apply different data mining algorithms on different sets of attributes from the database, to interpret data well. Two broad sets formed for the data mining project are; 1. Goods Prediction and Clustering: Location + Season Information + Goods Available

6 Basic Classification Histogram In the above diagram we can select different goods from class and visualize distribution of that selected good for all the states or season. Red- Interprets particular good is available Blue- Interprets particular good is not available

7 2. Nutrition Program Prediction and Clustering: Location + Season Information + Nutrition Programs For nutrition programs we find out what program is available at which market location and during what season. Red- Interprets particular nutrition program is available Blue- Interprets particular nutrition program is not available

8 All the instances from the dataset are visualized based on two conditions for each of the above attributes, i.e. whether the nutrition program is available (red) or not (blue). 6.1 Logistic Algorithm Highly regarded classical statistical technique for making predictions. Logistic Algorithm assigns weightage to the attributes in the Data Set. And uses the logistic regression formula to predict how accurately a particular attribute value can be determined for the future instances. Thus using relative (interdependent) attributes increases prediction capability as oppose to using all the data available. Since using independent attributes would affect assignment of weightage which is used to formulate the prediction accuracy. To apply logistic algorithm classification on Goods data Set of relevant attributes i.e. dependent are used. Logistic algorithm then assigns weightage to all attributes in dataset.
 attributes increases prediction capability as oppose to using all the data available.")
9 Then these weightages are run through logistic regression formula to predict the attribute under consideration in this example wine

10 Logistic Algorithm for class Wine Thus from the above diagram we interpret that using Logistic Classification Algorithm can predict next/ future instance of wine with 88.8% accuracy, given the dependent relations among all the attributes, that we used for this example.(location +season+all goods) Similarly, for the nutrition program we use location + season + nutrition program related dataset. And predict accuracy for the SFNMP in following example, the algorithm can predicts future instance of SFNMP with 83.4% accuracy.
 Similarly, for the nutrition program we use location + season + nutrition program related dataset.")
11 Logistic Algorithm for class SFNMP Logistic Algorithm for class WICcash 6.2 J48 Algorithm (Decision Tree)
")
12 Logistic Algorithms cannot predict numeric values. Whereas J48 Algorithm can predict both nominal and numeric attribute values. J48 algorithm uses most relevant attribute from the dataset to determine the prediction values, thus it s better to have all the attributes rather that only relevant attributes, as we did in logistic algorithm. Using all the data set for J48 Algorithm, the prediction efficiency increases. J48 Algorithms visualizes result in the form of Decision Tree, where most relevant attributes are used for prediction of particular attribute s future-instance value. Using this tree rules can be formed J48 Algorithm on Bake-goods From the above diagram, Bake-goods can be predicted with 94% accuracy using the attribute Vegetables which is determined as most relative by J48.

13 Decision Tree for Bake goods Where attribute vegetable is not alone used to predict the bakegoods, but other relevant attributes such as prepared and soap. Rules that can be formed from the above decision tree are; 1. If Vegetables=Yes then Bake-goods=Yes 2. If Vegetables=No And Prepared=Yes then Bake-goods=Yes 3. If Vegetables=No And Prepared=No And Soap=Yes then Bake-goods=Yes 4. If Vegetables=No And Prepared=No And Soap=No then Bake-goods=No Next diagram shows Prediction of instance of Herb with 90.8% accuracy.

14 J48 Algorithm for class Herbs In the case of Herb J48 again chooses most relevant attribute vegetable, but then there are other attributes from dataset to form the rules. These attributes are jams, eggs, seafood, prepared. Rules can be formed similar to above case using following decision tree.

15 Decision Tree for Herbs class

16 J48 Algorithm for class SNAP

17 Decision Tree SNAP
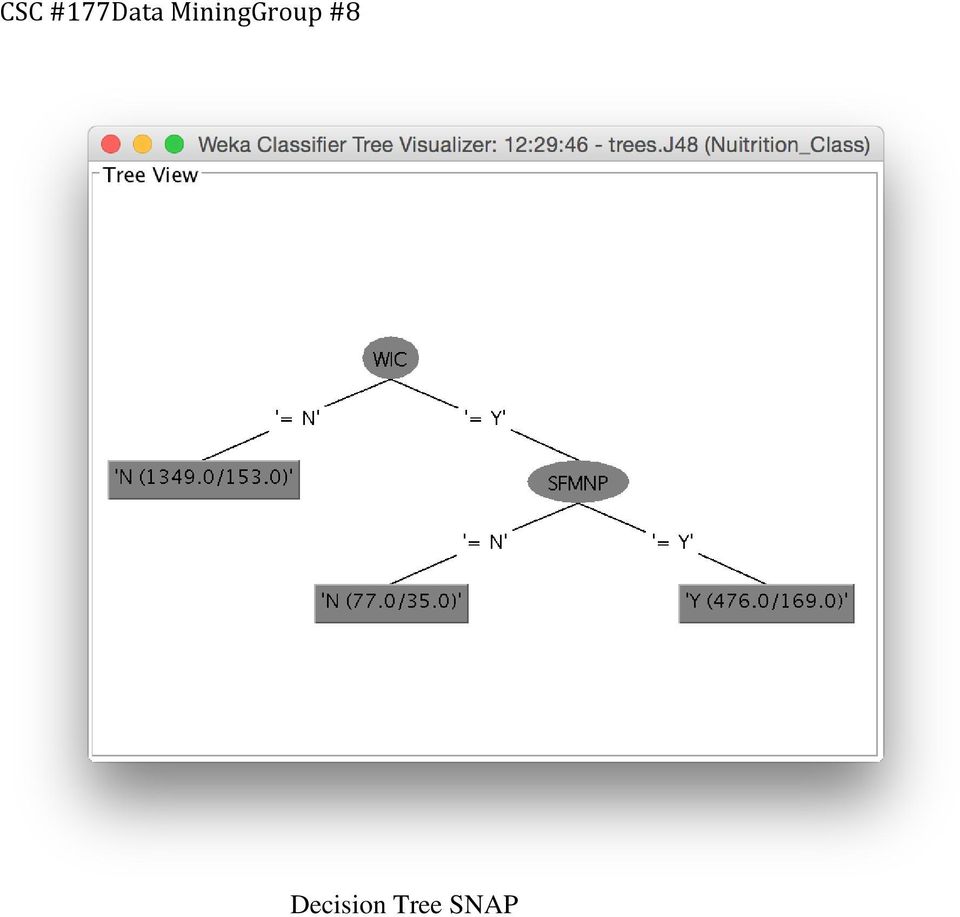
18 J48 Algorithm for class WIC

19 7. Clustering Algorithms Decision Tree for WIC Clustering algorithms are applied to set of similar data, to interpret data well. We created two sets of attributes; 1. All Goods 2. Nutrition Programs Number of distinct values for attributes are two, Yes/No (Y/N). Thus numbers of clusters used for both EM and K-Means algorithm are two.
.")
20 Basic clustering histogram for goods Basic clustering histogram for Nutrition Program 7.1 EM Algorithm


21 Properties to choose for applying clustering algorithm, where we can specify various algorithm values so as to interpret data well. NumClusters: Number cluster for clustering. In EM algorithm we don t need to specify the number. EM algorithm determines number of clusters based on data. Thus the value is -1 that means algorithm will form number clusters based on datasets. Seed: Provides the virtualization method to choose initial random center value around which algorithm forms cluster. Depending on the vastness and distributive nature of data, we keep the value 100. Thus from the above diagram, EM forms two clusters, the reason for two clusters might be based on various distinct values in dataset.

22 EM Algorithm Applied for Nutrition Program 7.2 Simple K-Means Second clustering algorithm we used is simple K-Means algorithm. Properties for simple K-Means:

23 numclusters : In case of K-Means algorithm we do have to specify number of clusters to form. We input number of clusters two here, so as to compare results with EM-Algorithm which determined based on dataset, to form two clusters. Seed: For comparing EM Algorithm result with K-Means result and for better chance at forming clusters we make this value 100.
24 Simple K-Means Applied for Nutrition Program By comparing both the clustering results for Nutrition Program We get nearly similar result with ~70% instances in one cluster and ~30% instances in another cluster. Following diagram shows the clustering algorithms applied on Goods Data

25 1st cluster: 51% instances 2nd cluster: 49% insrtances EM Algorithm Applied for Goods Simple K-Means applied on Goods 1st cluster: 57% instances 2nd cluster: 43% instances
26 Here we do not get similar clustering as that we have seen in case of Nutrition Program. This might the effect of vastness and distributive nature of Goods dataset. 8. Summary of learning experience such as experiments and readings Learned Data Mining tool such as WEKA Got better understanding of classification algorithms such as J 48, Logistic Regression algorithm Learned different Clustering algorithms as EM, Simple K-Means Learned real time application and analysis of result for algorithms Team work advantages Read many articles to get clear idea of how to do data mining 9. References Data Source: Weka Tutorial: Rapid Miner Tutorial: 2WJLWfbp_JWgg5It1O6
Data Mining and Data Warehousing on US Farmer s Data
 Data Mining and Data Warehousing on US Farmer s Data Guide: Dr. Meiliu Lu Presented By, Yogesh Isawe Kalindi Mehta Aditi Kulkarni * Data Warehousing Project * Introduction * Background * Technologies Explored
Data Mining and Data Warehousing on US Farmer s Data Guide: Dr. Meiliu Lu Presented By, Yogesh Isawe Kalindi Mehta Aditi Kulkarni * Data Warehousing Project * Introduction * Background * Technologies Explored
CSC 177 Data warehouse and Mining project. Pooja Vora Vishma Shah Guided by Prof. Meiliu lu
 CSC 177 Data warehouse and Mining project Pooja Vora Vishma Shah Guided by Prof. Meiliu lu Agenda Data Warehouse Project Introduction Background Scope of study Implementation Data Cleaning and Preprocessing
CSC 177 Data warehouse and Mining project Pooja Vora Vishma Shah Guided by Prof. Meiliu lu Agenda Data Warehouse Project Introduction Background Scope of study Implementation Data Cleaning and Preprocessing
An Introduction to WEKA. As presented by PACE
 An Introduction to WEKA As presented by PACE Download and Install WEKA Website: http://www.cs.waikato.ac.nz/~ml/weka/index.html 2 Content Intro and background Exploring WEKA Data Preparation Creating Models/
An Introduction to WEKA As presented by PACE Download and Install WEKA Website: http://www.cs.waikato.ac.nz/~ml/weka/index.html 2 Content Intro and background Exploring WEKA Data Preparation Creating Models/
Introduction Predictive Analytics Tools: Weka
 Introduction Predictive Analytics Tools: Weka Predictive Analytics Center of Excellence San Diego Supercomputer Center University of California, San Diego Tools Landscape Considerations Scale User Interface
Introduction Predictive Analytics Tools: Weka Predictive Analytics Center of Excellence San Diego Supercomputer Center University of California, San Diego Tools Landscape Considerations Scale User Interface
COC131 Data Mining - Clustering
 COC131 Data Mining - Clustering Martin D. Sykora [email protected] Tutorial 05, Friday 20th March 2009 1. Fire up Weka (Waikako Environment for Knowledge Analysis) software, launch the explorer window
COC131 Data Mining - Clustering Martin D. Sykora [email protected] Tutorial 05, Friday 20th March 2009 1. Fire up Weka (Waikako Environment for Knowledge Analysis) software, launch the explorer window
Pentaho Data Mining Last Modified on January 22, 2007
 Pentaho Data Mining Copyright 2007 Pentaho Corporation. Redistribution permitted. All trademarks are the property of their respective owners. For the latest information, please visit our web site at www.pentaho.org
Pentaho Data Mining Copyright 2007 Pentaho Corporation. Redistribution permitted. All trademarks are the property of their respective owners. For the latest information, please visit our web site at www.pentaho.org
DBTech Pro Workshop. Knowledge Discovery from Databases (KDD) Including Data Warehousing and Data Mining. Georgios Evangelidis
 Including Data Warehousing and Data Mining. Georgios Evangelidis") DBTechNet DBTech Pro Workshop Knowledge Discovery from Databases (KDD) Including Data Warehousing and Data Mining Dimitris A. Dervos [email protected] http://aetos.it.teithe.gr/~dad Georgios Evangelidis
DBTechNet DBTech Pro Workshop Knowledge Discovery from Databases (KDD) Including Data Warehousing and Data Mining Dimitris A. Dervos [email protected] http://aetos.it.teithe.gr/~dad Georgios Evangelidis
Index Contents Page No. Introduction . Data Mining & Knowledge Discovery
 Index Contents Page No. 1. Introduction 1 1.1 Related Research 2 1.2 Objective of Research Work 3 1.3 Why Data Mining is Important 3 1.4 Research Methodology 4 1.5 Research Hypothesis 4 1.6 Scope 5 2.
Index Contents Page No. 1. Introduction 1 1.1 Related Research 2 1.2 Objective of Research Work 3 1.3 Why Data Mining is Important 3 1.4 Research Methodology 4 1.5 Research Hypothesis 4 1.6 Scope 5 2.
Classification of Titanic Passenger Data and Chances of Surviving the Disaster Data Mining with Weka and Kaggle Competition Data
 Proceedings of Student-Faculty Research Day, CSIS, Pace University, May 2 nd, 2014 Classification of Titanic Passenger Data and Chances of Surviving the Disaster Data Mining with Weka and Kaggle Competition
Proceedings of Student-Faculty Research Day, CSIS, Pace University, May 2 nd, 2014 Classification of Titanic Passenger Data and Chances of Surviving the Disaster Data Mining with Weka and Kaggle Competition
Data Mining for Customer Service Support. Senioritis Seminar Presentation Megan Boice Jay Carter Nick Linke KC Tobin
 Data Mining for Customer Service Support Senioritis Seminar Presentation Megan Boice Jay Carter Nick Linke KC Tobin Traditional Hotline Services Problem Traditional Customer Service Support (manufacturing)
Data Mining for Customer Service Support Senioritis Seminar Presentation Megan Boice Jay Carter Nick Linke KC Tobin Traditional Hotline Services Problem Traditional Customer Service Support (manufacturing)
Data Mining and Knowledge Discovery in Databases (KDD) State of the Art. Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland
 State of the Art. Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland") Data Mining and Knowledge Discovery in Databases (KDD) State of the Art Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland 1 Conference overview 1. Overview of KDD and data mining 2. Data
Data Mining and Knowledge Discovery in Databases (KDD) State of the Art Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland 1 Conference overview 1. Overview of KDD and data mining 2. Data
Université de Montpellier 2 Hugo Alatrista-Salas : [email protected]
 Université de Montpellier 2 Hugo Alatrista-Salas : [email protected] WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Université de Montpellier 2 Hugo Alatrista-Salas : [email protected] WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Data Mining Application in Direct Marketing: Identifying Hot Prospects for Banking Product
 Data Mining Application in Direct Marketing: Identifying Hot Prospects for Banking Product Sagarika Prusty Web Data Mining (ECT 584),Spring 2013 DePaul University,Chicago [email protected] Keywords:
Data Mining Application in Direct Marketing: Identifying Hot Prospects for Banking Product Sagarika Prusty Web Data Mining (ECT 584),Spring 2013 DePaul University,Chicago [email protected] Keywords:
Data Mining Project Report. Document Clustering. Meryem Uzun-Per
 Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
COURSE RECOMMENDER SYSTEM IN E-LEARNING
 International Journal of Computer Science and Communication Vol. 3, No. 1, January-June 2012, pp. 159-164 COURSE RECOMMENDER SYSTEM IN E-LEARNING Sunita B Aher 1, Lobo L.M.R.J. 2 1 M.E. (CSE)-II, Walchand
International Journal of Computer Science and Communication Vol. 3, No. 1, January-June 2012, pp. 159-164 COURSE RECOMMENDER SYSTEM IN E-LEARNING Sunita B Aher 1, Lobo L.M.R.J. 2 1 M.E. (CSE)-II, Walchand
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R
 Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Introduction to Data Mining and Machine Learning Techniques. Iza Moise, Evangelos Pournaras, Dirk Helbing
 Introduction to Data Mining and Machine Learning Techniques Iza Moise, Evangelos Pournaras, Dirk Helbing Iza Moise, Evangelos Pournaras, Dirk Helbing 1 Overview Main principles of data mining Definition
Introduction to Data Mining and Machine Learning Techniques Iza Moise, Evangelos Pournaras, Dirk Helbing Iza Moise, Evangelos Pournaras, Dirk Helbing 1 Overview Main principles of data mining Definition
City University of Hong Kong. Information on a Course offered by Department of Information Systems with effect from Semester B in 2013 / 2014
 City University of Hong Kong Information on a Course offered by Department of Information Systems with effect from Semester B in 2013 / 2014 Part I Course Title: Course Code: Course Duration: Business
City University of Hong Kong Information on a Course offered by Department of Information Systems with effect from Semester B in 2013 / 2014 Part I Course Title: Course Code: Course Duration: Business
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Data Mining + Business Intelligence. Integration, Design and Implementation
 Data Mining + Business Intelligence Integration, Design and Implementation ABOUT ME Vijay Kotu Data, Business, Technology, Statistics BUSINESS INTELLIGENCE - Result Making data accessible Wider distribution
Data Mining + Business Intelligence Integration, Design and Implementation ABOUT ME Vijay Kotu Data, Business, Technology, Statistics BUSINESS INTELLIGENCE - Result Making data accessible Wider distribution
In this tutorial, we try to build a roc curve from a logistic regression.
 Subject In this tutorial, we try to build a roc curve from a logistic regression. Regardless the software we used, even for commercial software, we have to prepare the following steps when we want build
Subject In this tutorial, we try to build a roc curve from a logistic regression. Regardless the software we used, even for commercial software, we have to prepare the following steps when we want build
Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features
 Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features Charlie Berger, MS Eng, MBA Sr. Director Product Management, Data Mining and Advanced Analytics [email protected] www.twitter.com/charliedatamine
Oracle Advanced Analytics 12c & SQLDEV/Oracle Data Miner 4.0 New Features Charlie Berger, MS Eng, MBA Sr. Director Product Management, Data Mining and Advanced Analytics [email protected] www.twitter.com/charliedatamine
BIDM Project. Predicting the contract type for IT/ITES outsourcing contracts
 BIDM Project Predicting the contract type for IT/ITES outsourcing contracts N a n d i n i G o v i n d a r a j a n ( 6 1 2 1 0 5 5 6 ) The authors believe that data modelling can be used to predict if an
BIDM Project Predicting the contract type for IT/ITES outsourcing contracts N a n d i n i G o v i n d a r a j a n ( 6 1 2 1 0 5 5 6 ) The authors believe that data modelling can be used to predict if an
DATA MINING, DIRTY DATA, AND COSTS (Research-in-Progress)
") DATA MINING, DIRTY DATA, AND COSTS (Research-in-Progress) Leo Pipino University of Massachusetts Lowell [email protected] David Kopcso Babson College [email protected] Abstract: A series of simulations
DATA MINING, DIRTY DATA, AND COSTS (Research-in-Progress) Leo Pipino University of Massachusetts Lowell [email protected] David Kopcso Babson College [email protected] Abstract: A series of simulations
In this presentation, you will be introduced to data mining and the relationship with meaningful use.
 In this presentation, you will be introduced to data mining and the relationship with meaningful use. Data mining refers to the art and science of intelligent data analysis. It is the application of machine
In this presentation, you will be introduced to data mining and the relationship with meaningful use. Data mining refers to the art and science of intelligent data analysis. It is the application of machine
Lecture: Mon 13:30 14:50 Fri 9:00-10:20 ( LTH, Lift 27-28) Lab: Fri 12:00-12:50 (Rm. 4116)
 Lab: Fri 12:00-12:50 (Rm. 4116)") Business Intelligence and Data Mining ISOM 3360: Spring 203 Instructor Contact Office Hours Course Schedule and Classroom Course Webpage Jia Jia, ISOM Email: [email protected] Office: Rm 336 (Lift 3-) Begin
Business Intelligence and Data Mining ISOM 3360: Spring 203 Instructor Contact Office Hours Course Schedule and Classroom Course Webpage Jia Jia, ISOM Email: [email protected] Office: Rm 336 (Lift 3-) Begin
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
An Overview of Knowledge Discovery Database and Data mining Techniques
 An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
A Regression Approach for Forecasting Vendor Revenue in Telecommunication Industries
 A Regression Approach for Forecasting Vendor Revenue in Telecommunication Industries Aida Mustapha *1, Farhana M. Fadzil #2 * Faculty of Computer Science and Information Technology, Universiti Tun Hussein
A Regression Approach for Forecasting Vendor Revenue in Telecommunication Industries Aida Mustapha *1, Farhana M. Fadzil #2 * Faculty of Computer Science and Information Technology, Universiti Tun Hussein
Final Project Report
 CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
Numerical Algorithms Group
 Title: Summary: Using the Component Approach to Craft Customized Data Mining Solutions One definition of data mining is the non-trivial extraction of implicit, previously unknown and potentially useful
Title: Summary: Using the Component Approach to Craft Customized Data Mining Solutions One definition of data mining is the non-trivial extraction of implicit, previously unknown and potentially useful
College of Health and Human Services. Fall 2013. Syllabus
 College of Health and Human Services Fall 2013 Syllabus information placement Instructor description objectives HAP 780 : Data Mining in Health Care Time: Mondays, 7.20pm 10pm (except for 3 rd lecture
College of Health and Human Services Fall 2013 Syllabus information placement Instructor description objectives HAP 780 : Data Mining in Health Care Time: Mondays, 7.20pm 10pm (except for 3 rd lecture
Data Mining. Knowledge Discovery, Data Warehousing and Machine Learning Final remarks. Lecturer: JERZY STEFANOWSKI
 Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: [email protected] Data Mining a step in A KDD Process Data mining:
Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: [email protected] Data Mining a step in A KDD Process Data mining:
DHL Data Mining Project. Customer Segmentation with Clustering
 DHL Data Mining Project Customer Segmentation with Clustering Timothy TAN Chee Yong Aditya Hridaya MISRA Jeffery JI Jun Yao 3/30/2010 DHL Data Mining Project Table of Contents Introduction to DHL and the
DHL Data Mining Project Customer Segmentation with Clustering Timothy TAN Chee Yong Aditya Hridaya MISRA Jeffery JI Jun Yao 3/30/2010 DHL Data Mining Project Table of Contents Introduction to DHL and the
not possible or was possible at a high cost for collecting the data.
 Data Mining and Knowledge Discovery Generating knowledge from data Knowledge Discovery Data Mining White Paper Organizations collect a vast amount of data in the process of carrying out their day-to-day
Data Mining and Knowledge Discovery Generating knowledge from data Knowledge Discovery Data Mining White Paper Organizations collect a vast amount of data in the process of carrying out their day-to-day
CONTENTS PREFACE 1 INTRODUCTION 1 2 DATA VISUALIZATION 19
 PREFACE xi 1 INTRODUCTION 1 1.1 Overview 1 1.2 Definition 1 1.3 Preparation 2 1.3.1 Overview 2 1.3.2 Accessing Tabular Data 3 1.3.3 Accessing Unstructured Data 3 1.3.4 Understanding the Variables and Observations
PREFACE xi 1 INTRODUCTION 1 1.1 Overview 1 1.2 Definition 1 1.3 Preparation 2 1.3.1 Overview 2 1.3.2 Accessing Tabular Data 3 1.3.3 Accessing Unstructured Data 3 1.3.4 Understanding the Variables and Observations
King Saud University
 King Saud University College of Computer and Information Sciences Department of Computer Science CSC 493 Selected Topics in Computer Science (3-0-1) - Elective Course CECS 493 Selected Topics: DATA MINING
King Saud University College of Computer and Information Sciences Department of Computer Science CSC 493 Selected Topics in Computer Science (3-0-1) - Elective Course CECS 493 Selected Topics: DATA MINING
The Prophecy-Prototype of Prediction modeling tool
 The Prophecy-Prototype of Prediction modeling tool Ms. Ashwini Dalvi 1, Ms. Dhvni K.Shah 2, Ms. Rujul B.Desai 3, Ms. Shraddha M.Vora 4, Mr. Vaibhav G.Tailor 5 Department of Information Technology, Mumbai
The Prophecy-Prototype of Prediction modeling tool Ms. Ashwini Dalvi 1, Ms. Dhvni K.Shah 2, Ms. Rujul B.Desai 3, Ms. Shraddha M.Vora 4, Mr. Vaibhav G.Tailor 5 Department of Information Technology, Mumbai
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP
 Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Introduction to Data Mining
 Introduction to Data Mining Jay Urbain Credits: Nazli Goharian & David Grossman @ IIT Outline Introduction Data Pre-processing Data Mining Algorithms Naïve Bayes Decision Tree Neural Network Association
Introduction to Data Mining Jay Urbain Credits: Nazli Goharian & David Grossman @ IIT Outline Introduction Data Pre-processing Data Mining Algorithms Naïve Bayes Decision Tree Neural Network Association
BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL
 The Fifth International Conference on e-learning (elearning-2014), 22-23 September 2014, Belgrade, Serbia BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL SNJEŽANA MILINKOVIĆ University
The Fifth International Conference on e-learning (elearning-2014), 22-23 September 2014, Belgrade, Serbia BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL SNJEŽANA MILINKOVIĆ University
Data Mining with SQL Server Data Tools
 Data Mining with SQL Server Data Tools Data mining tasks include classification (directed/supervised) models as well as (undirected/unsupervised) models of association analysis and clustering. 1 Data Mining
Data Mining with SQL Server Data Tools Data mining tasks include classification (directed/supervised) models as well as (undirected/unsupervised) models of association analysis and clustering. 1 Data Mining
Data mining techniques: decision trees
 Data mining techniques: decision trees 1/39 Agenda Rule systems Building rule systems vs rule systems Quick reference 2/39 1 Agenda Rule systems Building rule systems vs rule systems Quick reference 3/39
Data mining techniques: decision trees 1/39 Agenda Rule systems Building rule systems vs rule systems Quick reference 2/39 1 Agenda Rule systems Building rule systems vs rule systems Quick reference 3/39
STATISTICA. Financial Institutions. Case Study: Credit Scoring. and
 Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
Data Mining. SPSS Clementine 12.0. 1. Clementine Overview. Spring 2010 Instructor: Dr. Masoud Yaghini. Clementine
 Data Mining SPSS 12.0 1. Overview Spring 2010 Instructor: Dr. Masoud Yaghini Introduction Types of Models Interface Projects References Outline Introduction Introduction Three of the common data mining
Data Mining SPSS 12.0 1. Overview Spring 2010 Instructor: Dr. Masoud Yaghini Introduction Types of Models Interface Projects References Outline Introduction Introduction Three of the common data mining
How To Solve The Kd Cup 2010 Challenge
 A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China [email protected] [email protected]
A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China [email protected] [email protected]
Strategic Management System for Effective Health Care Planning (SMS-EHCP)
") 674 Strategic Management System for Effective Health Care Planning (SMS-EHCP) 1 O. I. Omotoso, 2 I. A. Adeyanju, 3 S. A. Ibraheem 4 K. S. Ibrahim 1,2,3,4 Department of Computer Science and Engineering,
674 Strategic Management System for Effective Health Care Planning (SMS-EHCP) 1 O. I. Omotoso, 2 I. A. Adeyanju, 3 S. A. Ibraheem 4 K. S. Ibrahim 1,2,3,4 Department of Computer Science and Engineering,
Gerry Hobbs, Department of Statistics, West Virginia University
 Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Management Decision Making. Hadi Hosseini CS 330 David R. Cheriton School of Computer Science University of Waterloo July 14, 2011
 Management Decision Making Hadi Hosseini CS 330 David R. Cheriton School of Computer Science University of Waterloo July 14, 2011 Management decision making Decision making Spreadsheet exercise Data visualization,
Management Decision Making Hadi Hosseini CS 330 David R. Cheriton School of Computer Science University of Waterloo July 14, 2011 Management decision making Decision making Spreadsheet exercise Data visualization,
Syllabus. HMI 7437: Data Warehousing and Data/Text Mining for Healthcare
 Syllabus HMI 7437: Data Warehousing and Data/Text Mining for Healthcare 1. Instructor Illhoi Yoo, Ph.D Office: 404 Clark Hall Email: [email protected] Office hours: TBA Classroom: TBA Class hours: TBA
Syllabus HMI 7437: Data Warehousing and Data/Text Mining for Healthcare 1. Instructor Illhoi Yoo, Ph.D Office: 404 Clark Hall Email: [email protected] Office hours: TBA Classroom: TBA Class hours: TBA
Data Mining is sometimes referred to as KDD and DM and KDD tend to be used as synonyms
 Data Mining Techniques forcrm Data Mining The non-trivial extraction of novel, implicit, and actionable knowledge from large datasets. Extremely large datasets Discovery of the non-obvious Useful knowledge
Data Mining Techniques forcrm Data Mining The non-trivial extraction of novel, implicit, and actionable knowledge from large datasets. Extremely large datasets Discovery of the non-obvious Useful knowledge
2015 Workshops for Professors
 SAS Education Grow with us Offered by the SAS Global Academic Program Supporting teaching, learning and research in higher education 2015 Workshops for Professors 1 Workshops for Professors As the market
SAS Education Grow with us Offered by the SAS Global Academic Program Supporting teaching, learning and research in higher education 2015 Workshops for Professors 1 Workshops for Professors As the market
ON INTEGRATING UNSUPERVISED AND SUPERVISED CLASSIFICATION FOR CREDIT RISK EVALUATION
 ISSN 9 X INFORMATION TECHNOLOGY AND CONTROL, 00, Vol., No.A ON INTEGRATING UNSUPERVISED AND SUPERVISED CLASSIFICATION FOR CREDIT RISK EVALUATION Danuta Zakrzewska Institute of Computer Science, Technical
ISSN 9 X INFORMATION TECHNOLOGY AND CONTROL, 00, Vol., No.A ON INTEGRATING UNSUPERVISED AND SUPERVISED CLASSIFICATION FOR CREDIT RISK EVALUATION Danuta Zakrzewska Institute of Computer Science, Technical
An Introduction to Data Mining
 An Introduction to Intel Beijing [email protected] January 17, 2014 Outline 1 DW Overview What is Notable Application of Conference, Software and Applications Major Process in 2 Major Tasks in Detail
An Introduction to Intel Beijing [email protected] January 17, 2014 Outline 1 DW Overview What is Notable Application of Conference, Software and Applications Major Process in 2 Major Tasks in Detail
IT462 Lab 5: Clustering with MS SQL Server
 IT462 Lab 5: Clustering with MS SQL Server This lab should give you the chance to practice some of the data mining techniques you've learned in class. Preliminaries: For this lab, you will use the SQL
IT462 Lab 5: Clustering with MS SQL Server This lab should give you the chance to practice some of the data mining techniques you've learned in class. Preliminaries: For this lab, you will use the SQL
Course Syllabus. Purposes of Course:
 Course Syllabus Eco 5385.701 Predictive Analytics for Economists Summer 2014 TTh 6:00 8:50 pm and Sat. 12:00 2:50 pm First Day of Class: Tuesday, June 3 Last Day of Class: Tuesday, July 1 251 Maguire Building
Course Syllabus Eco 5385.701 Predictive Analytics for Economists Summer 2014 TTh 6:00 8:50 pm and Sat. 12:00 2:50 pm First Day of Class: Tuesday, June 3 Last Day of Class: Tuesday, July 1 251 Maguire Building
Web Mining as a Tool for Understanding Online Learning
 Web Mining as a Tool for Understanding Online Learning Jiye Ai University of Missouri Columbia Columbia, MO USA [email protected] James Laffey University of Missouri Columbia Columbia, MO USA [email protected]
Web Mining as a Tool for Understanding Online Learning Jiye Ai University of Missouri Columbia Columbia, MO USA [email protected] James Laffey University of Missouri Columbia Columbia, MO USA [email protected]
Decision Trees from large Databases: SLIQ
 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
INTRODUCTION TO DATA MINING SAS ENTERPRISE MINER
 INTRODUCTION TO DATA MINING SAS ENTERPRISE MINER Mary-Elizabeth ( M-E ) Eddlestone Principal Systems Engineer, Analytics SAS Customer Loyalty, SAS Institute, Inc. AGENDA Overview/Introduction to Data Mining
INTRODUCTION TO DATA MINING SAS ENTERPRISE MINER Mary-Elizabeth ( M-E ) Eddlestone Principal Systems Engineer, Analytics SAS Customer Loyalty, SAS Institute, Inc. AGENDA Overview/Introduction to Data Mining
K-means Clustering Technique on Search Engine Dataset using Data Mining Tool
 International Journal of Information and Computation Technology. ISSN 0974-2239 Volume 3, Number 6 (2013), pp. 505-510 International Research Publications House http://www. irphouse.com /ijict.htm K-means
International Journal of Information and Computation Technology. ISSN 0974-2239 Volume 3, Number 6 (2013), pp. 505-510 International Research Publications House http://www. irphouse.com /ijict.htm K-means
Microsoft Azure Machine learning Algorithms
 Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql [email protected] http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql [email protected] http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
2. A typical business process
 I. Basic Concepts on ERP 1. Enterprise resource planning (ERP) Enterprise resource planning (ERP) is the planning of how business resources (materials, employees, customers etc.) are acquired and moved
I. Basic Concepts on ERP 1. Enterprise resource planning (ERP) Enterprise resource planning (ERP) is the planning of how business resources (materials, employees, customers etc.) are acquired and moved
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree
 Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
Comparison of K-means and Backpropagation Data Mining Algorithms
 Comparison of K-means and Backpropagation Data Mining Algorithms Nitu Mathuriya, Dr. Ashish Bansal Abstract Data mining has got more and more mature as a field of basic research in computer science and
Comparison of K-means and Backpropagation Data Mining Algorithms Nitu Mathuriya, Dr. Ashish Bansal Abstract Data mining has got more and more mature as a field of basic research in computer science and
Server Load Prediction
 Server Load Prediction Suthee Chaidaroon ([email protected]) Joon Yeong Kim ([email protected]) Jonghan Seo ([email protected]) Abstract Estimating server load average is one of the methods that
Server Load Prediction Suthee Chaidaroon ([email protected]) Joon Yeong Kim ([email protected]) Jonghan Seo ([email protected]) Abstract Estimating server load average is one of the methods that
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Some vendors have a big presence in a particular industry; some are geared toward data scientists, others toward business users.
 Bonus Chapter Ten Major Predictive Analytics Vendors In This Chapter Angoss FICO IBM RapidMiner Revolution Analytics Salford Systems SAP SAS StatSoft, Inc. TIBCO This chapter highlights ten of the major
Bonus Chapter Ten Major Predictive Analytics Vendors In This Chapter Angoss FICO IBM RapidMiner Revolution Analytics Salford Systems SAP SAS StatSoft, Inc. TIBCO This chapter highlights ten of the major
Data Mining Solutions for the Business Environment
 Database Systems Journal vol. IV, no. 4/2013 21 Data Mining Solutions for the Business Environment Ruxandra PETRE University of Economic Studies, Bucharest, Romania [email protected] Over
Database Systems Journal vol. IV, no. 4/2013 21 Data Mining Solutions for the Business Environment Ruxandra PETRE University of Economic Studies, Bucharest, Romania [email protected] Over
Data Mining: Concepts and Techniques. Jiawei Han. Micheline Kamber. Simon Fräser University К MORGAN KAUFMANN PUBLISHERS. AN IMPRINT OF Elsevier
 Data Mining: Concepts and Techniques Jiawei Han Micheline Kamber Simon Fräser University К MORGAN KAUFMANN PUBLISHERS AN IMPRINT OF Elsevier Contents Foreword Preface xix vii Chapter I Introduction I I.
Data Mining: Concepts and Techniques Jiawei Han Micheline Kamber Simon Fräser University К MORGAN KAUFMANN PUBLISHERS AN IMPRINT OF Elsevier Contents Foreword Preface xix vii Chapter I Introduction I I.
Role of Customer Response Models in Customer Solicitation Center s Direct Marketing Campaign
 Role of Customer Response Models in Customer Solicitation Center s Direct Marketing Campaign Arun K Mandapaka, Amit Singh Kushwah, Dr.Goutam Chakraborty Oklahoma State University, OK, USA ABSTRACT Direct
Role of Customer Response Models in Customer Solicitation Center s Direct Marketing Campaign Arun K Mandapaka, Amit Singh Kushwah, Dr.Goutam Chakraborty Oklahoma State University, OK, USA ABSTRACT Direct
WEKA Explorer User Guide for Version 3-4-3
 WEKA Explorer User Guide for Version 3-4-3 Richard Kirkby Eibe Frank November 9, 2004 c 2002, 2004 University of Waikato Contents 1 Launching WEKA 2 2 The WEKA Explorer 2 Section Tabs................................
WEKA Explorer User Guide for Version 3-4-3 Richard Kirkby Eibe Frank November 9, 2004 c 2002, 2004 University of Waikato Contents 1 Launching WEKA 2 2 The WEKA Explorer 2 Section Tabs................................
Audit Analytics. --An innovative course at Rutgers. Qi Liu. Roman Chinchila
 Audit Analytics --An innovative course at Rutgers Qi Liu Roman Chinchila A new certificate in Analytic Auditing Tentative courses: Audit Analytics Special Topics in Audit Analytics Forensic Accounting
Audit Analytics --An innovative course at Rutgers Qi Liu Roman Chinchila A new certificate in Analytic Auditing Tentative courses: Audit Analytics Special Topics in Audit Analytics Forensic Accounting
The basic data mining algorithms introduced may be enhanced in a number of ways.
 DATA MINING TECHNOLOGIES AND IMPLEMENTATIONS The basic data mining algorithms introduced may be enhanced in a number of ways. Data mining algorithms have traditionally assumed data is memory resident,
DATA MINING TECHNOLOGIES AND IMPLEMENTATIONS The basic data mining algorithms introduced may be enhanced in a number of ways. Data mining algorithms have traditionally assumed data is memory resident,
Table of Contents. Chapter No. 1 Introduction 1. iii. xiv. xviii. xix. Page No.
 Table of Contents Title Declaration by the Candidate Certificate of Supervisor Acknowledgement Abstract List of Figures List of Tables List of Abbreviations Chapter Chapter No. 1 Introduction 1 ii iii
Table of Contents Title Declaration by the Candidate Certificate of Supervisor Acknowledgement Abstract List of Figures List of Tables List of Abbreviations Chapter Chapter No. 1 Introduction 1 ii iii
Lowering social cost of car accidents by predicting high-risk drivers
 Lowering social cost of car accidents by predicting high-risk drivers Vannessa Peng Davin Tsai Shu-Min Yeh Why we do this? Traffic accident happened every day. In order to decrease the number of traffic
Lowering social cost of car accidents by predicting high-risk drivers Vannessa Peng Davin Tsai Shu-Min Yeh Why we do this? Traffic accident happened every day. In order to decrease the number of traffic
2 Decision tree + Cross-validation with R (package rpart)
") 1 Subject Using cross-validation for the performance evaluation of decision trees with R, KNIME and RAPIDMINER. This paper takes one of our old study on the implementation of cross-validation for assessing
1 Subject Using cross-validation for the performance evaluation of decision trees with R, KNIME and RAPIDMINER. This paper takes one of our old study on the implementation of cross-validation for assessing
Clustering Marketing Datasets with Data Mining Techniques
 Clustering Marketing Datasets with Data Mining Techniques Özgür Örnek International Burch University, Sarajevo [email protected] Abdülhamit Subaşı International Burch University, Sarajevo [email protected]
Clustering Marketing Datasets with Data Mining Techniques Özgür Örnek International Burch University, Sarajevo [email protected] Abdülhamit Subaşı International Burch University, Sarajevo [email protected]
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Big Data Analysis. Rajen D. Shah (Statistical Laboratory, University of Cambridge) joint work with Nicolai Meinshausen (Seminar für Statistik, ETH
 joint work with Nicolai Meinshausen (Seminar für Statistik, ETH") Big Data Analysis Rajen D Shah (Statistical Laboratory, University of Cambridge) joint work with Nicolai Meinshausen (Seminar für Statistik, ETH Zürich) University of Cambridge Mathematical Sciences Showcase
Big Data Analysis Rajen D Shah (Statistical Laboratory, University of Cambridge) joint work with Nicolai Meinshausen (Seminar für Statistik, ETH Zürich) University of Cambridge Mathematical Sciences Showcase
Data Mining: Overview. What is Data Mining?
 Data Mining: Overview What is Data Mining? Recently * coined term for confluence of ideas from statistics and computer science (machine learning and database methods) applied to large databases in science,
Data Mining: Overview What is Data Mining? Recently * coined term for confluence of ideas from statistics and computer science (machine learning and database methods) applied to large databases in science,
What is Data Mining? MS4424 Data Mining & Modelling. MS4424 Data Mining & Modelling. MS4424 Data Mining & Modelling. MS4424 Data Mining & Modelling
 MS4424 Data Mining & Modelling MS4424 Data Mining & Modelling Lecturer : Dr Iris Yeung Room No : P7509 Tel No : 2788 8566 Email : [email protected] 1 Aims To introduce the basic concepts of data mining
MS4424 Data Mining & Modelling MS4424 Data Mining & Modelling Lecturer : Dr Iris Yeung Room No : P7509 Tel No : 2788 8566 Email : [email protected] 1 Aims To introduce the basic concepts of data mining
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
How Organisations Are Using Data Mining Techniques To Gain a Competitive Advantage John Spooner SAS UK
 How Organisations Are Using Data Mining Techniques To Gain a Competitive Advantage John Spooner SAS UK Agenda Analytics why now? The process around data and text mining Case Studies The Value of Information
How Organisations Are Using Data Mining Techniques To Gain a Competitive Advantage John Spooner SAS UK Agenda Analytics why now? The process around data and text mining Case Studies The Value of Information
Maschinelles Lernen mit MATLAB
 Maschinelles Lernen mit MATLAB Jérémy Huard Applikationsingenieur The MathWorks GmbH 2015 The MathWorks, Inc. 1 Machine Learning is Everywhere Image Recognition Speech Recognition Stock Prediction Medical
Maschinelles Lernen mit MATLAB Jérémy Huard Applikationsingenieur The MathWorks GmbH 2015 The MathWorks, Inc. 1 Machine Learning is Everywhere Image Recognition Speech Recognition Stock Prediction Medical
Data Mining III: Numeric Estimation
 Data Mining III: Numeric Estimation Computer Science 105 Boston University David G. Sullivan, Ph.D. Review: Numeric Estimation Numeric estimation is like classification learning. it involves learning a
Data Mining III: Numeric Estimation Computer Science 105 Boston University David G. Sullivan, Ph.D. Review: Numeric Estimation Numeric estimation is like classification learning. it involves learning a
Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC
 Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC 1. Introduction A popular rule of thumb suggests that
Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC 1. Introduction A popular rule of thumb suggests that
APPM4720/5720: Fast algorithms for big data. Gunnar Martinsson The University of Colorado at Boulder
 APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
CSci 538 Articial Intelligence (Machine Learning and Data Analysis)
") CSci 538 Articial Intelligence (Machine Learning and Data Analysis) Course Syllabus Fall 2015 Instructor Derek Harter, Ph.D., Associate Professor Department of Computer Science Texas A&M University - Commerce
CSci 538 Articial Intelligence (Machine Learning and Data Analysis) Course Syllabus Fall 2015 Instructor Derek Harter, Ph.D., Associate Professor Department of Computer Science Texas A&M University - Commerce
Using Data Mining for Mobile Communication Clustering and Characterization
 Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER. Copyr i g ht 2013, SAS Ins titut e Inc. All rights res er ve d.
 EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER ANALYTICS LIFECYCLE Evaluate & Monitor Model Formulate Problem Data Preparation Deploy Model Data Exploration Validate Models
EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER ANALYTICS LIFECYCLE Evaluate & Monitor Model Formulate Problem Data Preparation Deploy Model Data Exploration Validate Models
Knowledge Discovery in Data with FIT-Miner
 Knowledge Discovery in Data with FIT-Miner Michal Šebek, Martin Hlosta and Jaroslav Zendulka Faculty of Information Technology, Brno University of Technology, Božetěchova 2, Brno {isebek,ihlosta,zendulka}@fit.vutbr.cz
Knowledge Discovery in Data with FIT-Miner Michal Šebek, Martin Hlosta and Jaroslav Zendulka Faculty of Information Technology, Brno University of Technology, Božetěchova 2, Brno {isebek,ihlosta,zendulka}@fit.vutbr.cz
Foundations of Business Intelligence: Databases and Information Management
 Foundations of Business Intelligence: Databases and Information Management Content Problems of managing data resources in a traditional file environment Capabilities and value of a database management
Foundations of Business Intelligence: Databases and Information Management Content Problems of managing data resources in a traditional file environment Capabilities and value of a database management
Clustering Connectionist and Statistical Language Processing
 Clustering Connectionist and Statistical Language Processing Frank Keller [email protected] Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Clustering Connectionist and Statistical Language Processing Frank Keller [email protected] Computerlinguistik Universität des Saarlandes Clustering p.1/21 Overview clustering vs. classification supervised
Improving spam mail filtering using classification algorithms with discretization Filter
 International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) International Journal of Emerging Technologies in Computational
International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) International Journal of Emerging Technologies in Computational