Lecture 2: The SVM classifier
|
|
|
- Sheila Pierce
- 9 years ago
- Views:
Transcription
1 Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function Slack variables Loss functions revisited Optimization

2 Binary Classification Given training data (x i,y i )fori =1...N,with x i R d and y i { 1, 1}, learnaclassifier f(x) such that ( 0 yi =+1 f(x i ) < 0 y i = 1 i.e. y i f(x i ) > 0 for a correct classification.
 such that ( 0 yi =+1 f(x i ) < 0 y i = 1 i.e.")
3 Linear separability linearly separable not linearly separable

4 Linear classifiers A linear classifier has the form f(x) =0 X 2 f(x) =w > x + b f(x) < 0 f(x) > 0 X 1 in 2D the discriminant is a line is the normal to the line, and b the bias is known as the weight vector

5 Linear classifiers A linear classifier has the form f(x) =0 f(x) =w > x + b in 3D the discriminant is a plane, and in nd it is a hyperplane For a K-NN classifier it was necessary to `carry the training data For a linear classifier, the training data is used to learn w and then discarded Only w is needed for classifying new data

6 The Perceptron Classifier Given linearly separable data x i labelled into two categories y i = {-1,1}, find a weight vector w such that the discriminant function f(x i )=w > x i + b separates the categories for i = 1,.., N how can we find this separating hyperplane? The Perceptron Algorithm Write classifier as f(x i )= w > x i + w 0 = w > x i where w =( w,w 0 ), x i =( x i, 1) Initialize w = 0 Cycle though the data points { x i, y i } if x i is misclassified then w w + α sign(f(x i )) x i Until all the data is correctly classified
) x i Until all the data is correctly")
7 For example in 2D Initialize w = 0 Cycle though the data points { x i, y i } if x i is misclassified then Until all the data is correctly classified w w + α sign(f(x i )) x i before update after update X 2 X 2 w w x i X 1 X 1 NB after convergence w = P N i α i x i

8 8 Perceptron example if the data is linearly separable, then the algorithm will converge convergence can be slow separating line close to training data we would prefer a larger margin for generalization

9 What is the best w? maximum margin solution: most stable under perturbations of the inputs

10 f(x) = X i Support Vector Machine linearly separable data w T x + b = 0 b w Support Vector Support Vector w α i y i (x i > x)+b support vectors
+b support")
11 SVM sketch derivation Since w > x + b =0andc(w > x + b) =0define the same plane, we have the freedom to choose the normalization of w Choose normalization such that w > x + +b =+1andw > x + b = 1 for the positive and negative support vectors respectively Then the margin is given by w w. ³ w > ³ x + x x + x = w = 2 w

12 Support Vector Machine linearly separable data Margin = 2 w Support Vector Support Vector w T x + b = 1 w w T x + b = 0 w T x + b = -1

13 SVM Optimization Learning the SVM can be formulated as an optimization: max w 2 w subject to w > x i +b 1 if y i =+1 1 if y i = 1 for i =1...N Or equivalently min w w 2 subject to y i ³ w > x i + b 1fori =1...N This is a quadratic optimization problem subject to linear constraints and there is a unique minimum

14 Linear separability again: What is the best w? the points can be linearly separated but there is a very narrow margin but possibly the large margin solution is better, even though one constraint is violated In general there is a trade off between the margin and the number of mistakes on the training data

15 Introduce slack variables ξ i 0 for 0 < ξ 1 point is between margin and correct side of hyperplane. This is a margin violation Misclassified point ξ i w > 2 w ξ i w < 1 w Margin = 2 w for ξ > 1 point is misclassified Support Vector Support Vector = 0 w T x + b = 1 w w T x + b = 0 w T x + b = -1

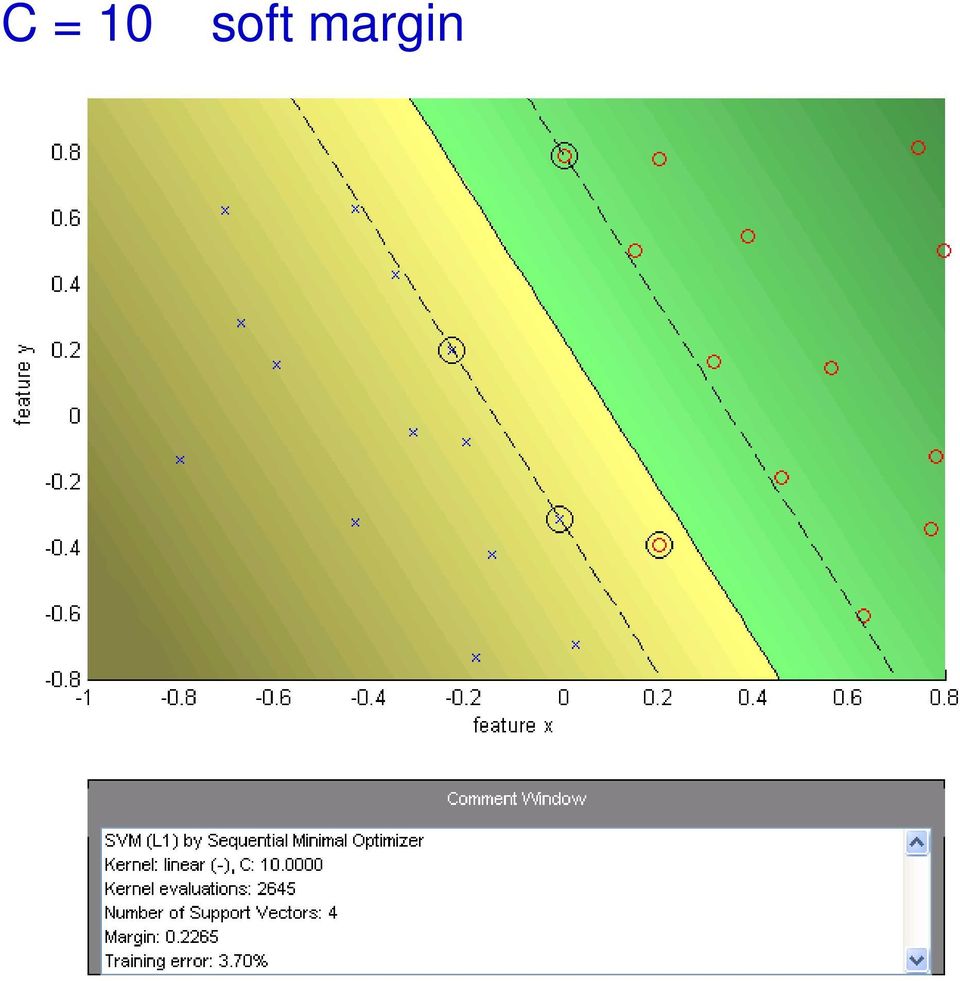
16 The optimization problem becomes Soft margin solution subject to min w R d,ξ i R w 2 +C + NX ξ i i y i ³ w > x i + b 1 ξ i for i =1...N Every constraint can be satisfied if ξ i is sufficiently large C is a regularization parameter: small C allows constraints to be easily ignored large margin large C makes constraints hard to ignore narrow margin C = enforces all constraints: hard margin This is still a quadratic optimization problem and there is a unique minimum. Note, there is only one parameter, C.

17 feature y feature x data is linearly separable but only with a narrow margin

18 C = Infinity hard margin

19 C = 10 soft margin
20 Application: Pedestrian detection in Computer Vision Objective: detect (localize) standing humans in an image cf face detection with a sliding window classifier reduces object detection to binary classification does an image window contain a person or not? Method: the HOG detector

21 Training data and features Positive data 1208 positive window examples Negative data 1218 negative window examples (initially)
22 Feature: histogram of oriented gradients (HOG) image dominant direction HOG tile window into 8 x 8 pixel cells each cell represented by HOG frequency orientation Feature vector dimension = 16 x 8 (for tiling) x 8 (orientations) = 1024
23
24 Averaged positive examples
25 Algorithm Training (Learning) Represent each example window by a HOG feature vector x i R d, with d = 1024 Train a SVM classifier Testing (Detection) Sliding window classifier f(x) =w > x + b
26 Dalal and Triggs, CVPR 2005
27 Learned model f (x) = w>x + b Slide from Deva Ramanan
28 Slide from Deva Ramanan
29 Optimization Learning an SVM has been formulated as a constrained optimization problem over w and ξ min w R d,ξ i R w 2 + C + NX i ξ i subject to y i ³ w > x i + b 1 ξ i for i =1...N The constraint y i ³ w > x i + b 1 ξ i, can be written more concisely as y i f(x i ) 1 ξ i which, together with ξ i 0, is equivalent to ξ i =max(0, 1 y i f(x i )) Hence the learning problem is equivalent to the unconstrained optimization problem over w min w R w 2 + C d regularization NX i max (0, 1 y i f(x i )) loss function
30 Loss function min w 2 + C w R d NX i max (0, 1 y i f(x i )) loss function w T x + b = 0 Points are in three categories: 1. y i f(x i ) > 1 Point is outside margin. No contribution to loss 2. y i f(x i )=1 Point is on margin. No contribution to loss. As in hard margin case. 3. y i f(x i ) < 1 Point violates margin constraint. Contributes to loss Support Vector w Support Vector
31 Loss functions y i f(x i ) SVM uses hinge loss an approximation to the 0-1 loss max (0, 1 y i f(x i ))
32 Optimization continued min w R d C N X i max (0, 1 y i f(x i )) + w 2 local minimum global minimum Does this cost function have a unique solution? Does the solution depend on the starting point of an iterative optimization algorithm (such as gradient descent)? If the cost function is convex, then a locally optimal point is globally optimal (provided the optimization is over a convex set, which it is in our case)
33 Convex functions
34 Convex function examples convex Not convex A non-negative sum of convex functions is convex
35 + SVM min w R d C N X i max (0, 1 y i f(x i )) + w 2 convex
36 Gradient (or steepest) descent algorithm for SVM To minimize a cost function C(w) use the iterative update where η is the learning rate. First, rewrite the optimization problem as an average min w C(w) = λ 2 w N = 1 N NX i w t+1 w t η t w C(w t ) NX i max (0, 1 y i f(x i )) µ λ 2 w 2 +max(0, 1 y i f(x i )) (with λ =2/(NC) up to an overall scale of the problem) and f(x) =w > x + b Because the hinge loss is not differentiable, a sub-gradient is computed
37 Sub-gradient for hinge loss L(x i,y i ; w) =max(0, 1 y i f(x i )) f(x i )=w > x i + b L w = y ix i L w =0 y i f(x i )
38 Sub-gradient descent algorithm for SVM C(w) = 1 N NX i µ λ 2 w 2 + L(x i,y i ; w) The iterative update is w t+1 w t η wt C(w t ) where η is the learning rate. w t η 1 N NX i (λw t + w L(x i,y i ; w t )) Then each iteration t involves cycling through the training data with the updates: w t+1 w t η(λw t y i x i ) if y i f(x i ) < 1 w t ηλw t otherwise In the Pegasos algorithm the learning rate is set at η t = 1 λt
39 Pegasos Stochastic Gradient Descent Algorithm Randomly sample from the training data energy
40 Background reading and more Next lecture see that the SVM can be expressed as a sum over the support vectors: f(x) = X i α i y i (x i > x)+b support vectors On web page: links to SVM tutorials and video lectures MATLAB SVM demo
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S
 e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard
Support Vector Machine (SVM)
") Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machines
 Support Vector Machines Charlie Frogner 1 MIT 2011 1 Slides mostly stolen from Ryan Rifkin (Google). Plan Regularization derivation of SVMs. Analyzing the SVM problem: optimization, duality. Geometric
Support Vector Machines Charlie Frogner 1 MIT 2011 1 Slides mostly stolen from Ryan Rifkin (Google). Plan Regularization derivation of SVMs. Analyzing the SVM problem: optimization, duality. Geometric
Statistical Machine Learning
 Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
A Simple Introduction to Support Vector Machines
 A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
Probabilistic Linear Classification: Logistic Regression. Piyush Rai IIT Kanpur
 Probabilistic Linear Classification: Logistic Regression Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 18, 2016 Probabilistic Machine Learning (CS772A) Probabilistic Linear Classification:
Probabilistic Linear Classification: Logistic Regression Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 18, 2016 Probabilistic Machine Learning (CS772A) Probabilistic Linear Classification:
Machine Learning in Spam Filtering
 Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov [email protected] Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov [email protected] Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Support Vector Machines Explained
 March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Lecture 6: Logistic Regression
 Lecture 6: CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 13, 2011 Outline Outline Classification task Data : X = [x 1,..., x m]: a n m matrix of data points in R n. y { 1,
Lecture 6: CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 13, 2011 Outline Outline Classification task Data : X = [x 1,..., x m]: a n m matrix of data points in R n. y { 1,
Lecture 3. Linear Programming. 3B1B Optimization Michaelmas 2015 A. Zisserman. Extreme solutions. Simplex method. Interior point method
 Lecture 3 3B1B Optimization Michaelmas 2015 A. Zisserman Linear Programming Extreme solutions Simplex method Interior point method Integer programming and relaxation The Optimization Tree Linear Programming
Lecture 3 3B1B Optimization Michaelmas 2015 A. Zisserman Linear Programming Extreme solutions Simplex method Interior point method Integer programming and relaxation The Optimization Tree Linear Programming
Introduction to Support Vector Machines. Colin Campbell, Bristol University
 Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
Several Views of Support Vector Machines
 Several Views of Support Vector Machines Ryan M. Rifkin Honda Research Institute USA, Inc. Human Intention Understanding Group 2007 Tikhonov Regularization We are considering algorithms of the form min
Several Views of Support Vector Machines Ryan M. Rifkin Honda Research Institute USA, Inc. Human Intention Understanding Group 2007 Tikhonov Regularization We are considering algorithms of the form min
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 269 Class Project Report
 Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 69 Class Project Report Junhua Mao and Lunbo Xu University of California, Los Angeles [email protected] and lunbo
Automatic 3D Reconstruction via Object Detection and 3D Transformable Model Matching CS 69 Class Project Report Junhua Mao and Lunbo Xu University of California, Los Angeles [email protected] and lunbo
Local features and matching. Image classification & object localization
 Overview Instance level search Local features and matching Efficient visual recognition Image classification & object localization Category recognition Image classification: assigning a class label to
Overview Instance level search Local features and matching Efficient visual recognition Image classification & object localization Category recognition Image classification: assigning a class label to
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
AIMS Big data. AIMS Big data. Outline. Outline. Lecture 5: Structured-output learning January 7, 2015 Andrea Vedaldi
 AMS Big data AMS Big data Lecture 5: Structured-output learning January 7, 5 Andrea Vedaldi. Discriminative learning. Discriminative learning 3. Hashing and kernel maps 4. Learning representations 5. Structured-output
AMS Big data AMS Big data Lecture 5: Structured-output learning January 7, 5 Andrea Vedaldi. Discriminative learning. Discriminative learning 3. Hashing and kernel maps 4. Learning representations 5. Structured-output
CS 688 Pattern Recognition Lecture 4. Linear Models for Classification
 CS 688 Pattern Recognition Lecture 4 Linear Models for Classification Probabilistic generative models Probabilistic discriminative models 1 Generative Approach ( x ) p C k p( C k ) Ck p ( ) ( x Ck ) p(
CS 688 Pattern Recognition Lecture 4 Linear Models for Classification Probabilistic generative models Probabilistic discriminative models 1 Generative Approach ( x ) p C k p( C k ) Ck p ( ) ( x Ck ) p(
Linear Programming Notes V Problem Transformations
 Linear Programming Notes V Problem Transformations 1 Introduction Any linear programming problem can be rewritten in either of two standard forms. In the first form, the objective is to maximize, the material
Linear Programming Notes V Problem Transformations 1 Introduction Any linear programming problem can be rewritten in either of two standard forms. In the first form, the objective is to maximize, the material
Distributed Machine Learning and Big Data
 Distributed Machine Learning and Big Data Sourangshu Bhattacharya Dept. of Computer Science and Engineering, IIT Kharagpur. http://cse.iitkgp.ac.in/~sourangshu/ August 21, 2015 Sourangshu Bhattacharya
Distributed Machine Learning and Big Data Sourangshu Bhattacharya Dept. of Computer Science and Engineering, IIT Kharagpur. http://cse.iitkgp.ac.in/~sourangshu/ August 21, 2015 Sourangshu Bhattacharya
Artificial Neural Networks and Support Vector Machines. CS 486/686: Introduction to Artificial Intelligence
 Artificial Neural Networks and Support Vector Machines CS 486/686: Introduction to Artificial Intelligence 1 Outline What is a Neural Network? - Perceptron learners - Multi-layer networks What is a Support
Artificial Neural Networks and Support Vector Machines CS 486/686: Introduction to Artificial Intelligence 1 Outline What is a Neural Network? - Perceptron learners - Multi-layer networks What is a Support
Duality in General Programs. Ryan Tibshirani Convex Optimization 10-725/36-725
 Duality in General Programs Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: duality in linear programs Given c R n, A R m n, b R m, G R r n, h R r : min x R n c T x max u R m, v R r b T
Duality in General Programs Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: duality in linear programs Given c R n, A R m n, b R m, G R r n, h R r : min x R n c T x max u R m, v R r b T
Machine Learning and Pattern Recognition Logistic Regression
 Machine Learning and Pattern Recognition Logistic Regression Course Lecturer:Amos J Storkey Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh Crichton Street,
Machine Learning and Pattern Recognition Logistic Regression Course Lecturer:Amos J Storkey Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh Crichton Street,
Date: April 12, 2001. Contents
 2 Lagrange Multipliers Date: April 12, 2001 Contents 2.1. Introduction to Lagrange Multipliers......... p. 2 2.2. Enhanced Fritz John Optimality Conditions...... p. 12 2.3. Informative Lagrange Multipliers...........
2 Lagrange Multipliers Date: April 12, 2001 Contents 2.1. Introduction to Lagrange Multipliers......... p. 2 2.2. Enhanced Fritz John Optimality Conditions...... p. 12 2.3. Informative Lagrange Multipliers...........
These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
 course textbook Pattern Recognition and Machine Learning by Christopher Bishop") Music and Machine Learning (IFT6080 Winter 08) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher
Music and Machine Learning (IFT6080 Winter 08) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher
Numerisches Rechnen. (für Informatiker) M. Grepl J. Berger & J.T. Frings. Institut für Geometrie und Praktische Mathematik RWTH Aachen
 M. Grepl J. Berger & J.T. Frings. Institut für Geometrie und Praktische Mathematik RWTH Aachen") (für Informatiker) M. Grepl J. Berger & J.T. Frings Institut für Geometrie und Praktische Mathematik RWTH Aachen Wintersemester 2010/11 Problem Statement Unconstrained Optimality Conditions Constrained
(für Informatiker) M. Grepl J. Berger & J.T. Frings Institut für Geometrie und Praktische Mathematik RWTH Aachen Wintersemester 2010/11 Problem Statement Unconstrained Optimality Conditions Constrained
An Introduction to Machine Learning
 An Introduction to Machine Learning L5: Novelty Detection and Regression Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia [email protected] Tata Institute, Pune,
An Introduction to Machine Learning L5: Novelty Detection and Regression Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia [email protected] Tata Institute, Pune,
Online learning of multi-class Support Vector Machines
 IT 12 061 Examensarbete 30 hp November 2012 Online learning of multi-class Support Vector Machines Xuan Tuan Trinh Institutionen för informationsteknologi Department of Information Technology Abstract
IT 12 061 Examensarbete 30 hp November 2012 Online learning of multi-class Support Vector Machines Xuan Tuan Trinh Institutionen för informationsteknologi Department of Information Technology Abstract
4.1 Introduction - Online Learning Model
 Computational Learning Foundations Fall semester, 2010 Lecture 4: November 7, 2010 Lecturer: Yishay Mansour Scribes: Elad Liebman, Yuval Rochman & Allon Wagner 1 4.1 Introduction - Online Learning Model
Computational Learning Foundations Fall semester, 2010 Lecture 4: November 7, 2010 Lecturer: Yishay Mansour Scribes: Elad Liebman, Yuval Rochman & Allon Wagner 1 4.1 Introduction - Online Learning Model
Big Data - Lecture 1 Optimization reminders
 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Schedule Introduction Major issues Examples Mathematics
Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Schedule Introduction Major issues Examples Mathematics
Nonlinear Programming Methods.S2 Quadratic Programming
 Nonlinear Programming Methods.S2 Quadratic Programming Operations Research Models and Methods Paul A. Jensen and Jonathan F. Bard A linearly constrained optimization problem with a quadratic objective
Nonlinear Programming Methods.S2 Quadratic Programming Operations Research Models and Methods Paul A. Jensen and Jonathan F. Bard A linearly constrained optimization problem with a quadratic objective
In this section, we will consider techniques for solving problems of this type.
 Constrained optimisation roblems in economics typically involve maximising some quantity, such as utility or profit, subject to a constraint for example income. We shall therefore need techniques for solving
Constrained optimisation roblems in economics typically involve maximising some quantity, such as utility or profit, subject to a constraint for example income. We shall therefore need techniques for solving
Wes, Delaram, and Emily MA751. Exercise 4.5. 1 p(x; β) = [1 p(xi ; β)] = 1 p(x. y i [βx i ] log [1 + exp {βx i }].
![Wes, Delaram, and Emily MA751. Exercise 4.5. 1 p(x; β) = [1 p(xi ; β)] = 1 p(x. y i [βx i ] log [1 + exp {βx i }].](/thumbs/30/14087801.jpg "Wes, Delaram, and Emily MA751. Exercise 4.5. 1 p(x; β) = [1 p(xi ; β)] = 1 p(x. y i [βx i ] log [1 + exp {βx i }].") Wes, Delaram, and Emily MA75 Exercise 4.5 Consider a two-class logistic regression problem with x R. Characterize the maximum-likelihood estimates of the slope and intercept parameter if the sample for
Wes, Delaram, and Emily MA75 Exercise 4.5 Consider a two-class logistic regression problem with x R. Characterize the maximum-likelihood estimates of the slope and intercept parameter if the sample for
Recognizing Cats and Dogs with Shape and Appearance based Models. Group Member: Chu Wang, Landu Jiang
 Recognizing Cats and Dogs with Shape and Appearance based Models Group Member: Chu Wang, Landu Jiang Abstract Recognizing cats and dogs from images is a challenging competition raised by Kaggle platform
Recognizing Cats and Dogs with Shape and Appearance based Models Group Member: Chu Wang, Landu Jiang Abstract Recognizing cats and dogs from images is a challenging competition raised by Kaggle platform
Walrasian Demand. u(x) where B(p, w) = {x R n + : p x w}.
 where B(p, w) = {x R n + : p x w}.") Walrasian Demand Econ 2100 Fall 2015 Lecture 5, September 16 Outline 1 Walrasian Demand 2 Properties of Walrasian Demand 3 An Optimization Recipe 4 First and Second Order Conditions Definition Walrasian
Walrasian Demand Econ 2100 Fall 2015 Lecture 5, September 16 Outline 1 Walrasian Demand 2 Properties of Walrasian Demand 3 An Optimization Recipe 4 First and Second Order Conditions Definition Walrasian
Linear Models for Classification
 Linear Models for Classification Sumeet Agarwal, EEL709 (Most figures from Bishop, PRML) Approaches to classification Discriminant function: Directly assigns each data point x to a particular class Ci
Linear Models for Classification Sumeet Agarwal, EEL709 (Most figures from Bishop, PRML) Approaches to classification Discriminant function: Directly assigns each data point x to a particular class Ci
CONSTRAINED NONLINEAR PROGRAMMING
 149 CONSTRAINED NONLINEAR PROGRAMMING We now turn to methods for general constrained nonlinear programming. These may be broadly classified into two categories: 1. TRANSFORMATION METHODS: In this approach
149 CONSTRAINED NONLINEAR PROGRAMMING We now turn to methods for general constrained nonlinear programming. These may be broadly classified into two categories: 1. TRANSFORMATION METHODS: In this approach
Lecture 3: Linear methods for classification
 Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Lecture 8 February 4
 ICS273A: Machine Learning Winter 2008 Lecture 8 February 4 Scribe: Carlos Agell (Student) Lecturer: Deva Ramanan 8.1 Neural Nets 8.1.1 Logistic Regression Recall the logistic function: g(x) = 1 1 + e θt
ICS273A: Machine Learning Winter 2008 Lecture 8 February 4 Scribe: Carlos Agell (Student) Lecturer: Deva Ramanan 8.1 Neural Nets 8.1.1 Logistic Regression Recall the logistic function: g(x) = 1 1 + e θt
A NEW LOOK AT CONVEX ANALYSIS AND OPTIMIZATION
 1 A NEW LOOK AT CONVEX ANALYSIS AND OPTIMIZATION Dimitri Bertsekas M.I.T. FEBRUARY 2003 2 OUTLINE Convexity issues in optimization Historical remarks Our treatment of the subject Three unifying lines of
1 A NEW LOOK AT CONVEX ANALYSIS AND OPTIMIZATION Dimitri Bertsekas M.I.T. FEBRUARY 2003 2 OUTLINE Convexity issues in optimization Historical remarks Our treatment of the subject Three unifying lines of
Machine Learning Final Project Spam Email Filtering
 Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Introduction to Online Learning Theory
 Introduction to Online Learning Theory Wojciech Kot lowski Institute of Computing Science, Poznań University of Technology IDSS, 04.06.2013 1 / 53 Outline 1 Example: Online (Stochastic) Gradient Descent
Introduction to Online Learning Theory Wojciech Kot lowski Institute of Computing Science, Poznań University of Technology IDSS, 04.06.2013 1 / 53 Outline 1 Example: Online (Stochastic) Gradient Descent
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
AdaBoost. Jiri Matas and Jan Šochman. Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz
 AdaBoost Jiri Matas and Jan Šochman Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Presentation Outline: AdaBoost algorithm Why is of interest? How it works? Why
AdaBoost Jiri Matas and Jan Šochman Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Presentation Outline: AdaBoost algorithm Why is of interest? How it works? Why
LCs for Binary Classification
 Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Nonlinear Optimization: Algorithms 3: Interior-point methods
 Nonlinear Optimization: Algorithms 3: Interior-point methods INSEAD, Spring 2006 Jean-Philippe Vert Ecole des Mines de Paris [email protected] Nonlinear optimization c 2006 Jean-Philippe Vert,
Nonlinear Optimization: Algorithms 3: Interior-point methods INSEAD, Spring 2006 Jean-Philippe Vert Ecole des Mines de Paris [email protected] Nonlinear optimization c 2006 Jean-Philippe Vert,
Derivative Free Optimization
 Department of Mathematics Derivative Free Optimization M.J.D. Powell LiTH-MAT-R--2014/02--SE Department of Mathematics Linköping University S-581 83 Linköping, Sweden. Three lectures 1 on Derivative Free
Department of Mathematics Derivative Free Optimization M.J.D. Powell LiTH-MAT-R--2014/02--SE Department of Mathematics Linköping University S-581 83 Linköping, Sweden. Three lectures 1 on Derivative Free
What is Linear Programming?
 Chapter 1 What is Linear Programming? An optimization problem usually has three essential ingredients: a variable vector x consisting of a set of unknowns to be determined, an objective function of x to
Chapter 1 What is Linear Programming? An optimization problem usually has three essential ingredients: a variable vector x consisting of a set of unknowns to be determined, an objective function of x to
Week 1: Introduction to Online Learning
 Week 1: Introduction to Online Learning 1 Introduction This is written based on Prediction, Learning, and Games (ISBN: 2184189 / -21-8418-9 Cesa-Bianchi, Nicolo; Lugosi, Gabor 1.1 A Gentle Start Consider
Week 1: Introduction to Online Learning 1 Introduction This is written based on Prediction, Learning, and Games (ISBN: 2184189 / -21-8418-9 Cesa-Bianchi, Nicolo; Lugosi, Gabor 1.1 A Gentle Start Consider
Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh
 Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh Peter Richtárik Week 3 Randomized Coordinate Descent With Arbitrary Sampling January 27, 2016 1 / 30 The Problem
Modern Optimization Methods for Big Data Problems MATH11146 The University of Edinburgh Peter Richtárik Week 3 Randomized Coordinate Descent With Arbitrary Sampling January 27, 2016 1 / 30 The Problem
Classifying Large Data Sets Using SVMs with Hierarchical Clusters. Presented by :Limou Wang
 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
15 Kuhn -Tucker conditions
 5 Kuhn -Tucker conditions Consider a version of the consumer problem in which quasilinear utility x 2 + 4 x 2 is maximised subject to x +x 2 =. Mechanically applying the Lagrange multiplier/common slopes
5 Kuhn -Tucker conditions Consider a version of the consumer problem in which quasilinear utility x 2 + 4 x 2 is maximised subject to x +x 2 =. Mechanically applying the Lagrange multiplier/common slopes
2.3 Convex Constrained Optimization Problems
 42 CHAPTER 2. FUNDAMENTAL CONCEPTS IN CONVEX OPTIMIZATION Theorem 15 Let f : R n R and h : R R. Consider g(x) = h(f(x)) for all x R n. The function g is convex if either of the following two conditions
42 CHAPTER 2. FUNDAMENTAL CONCEPTS IN CONVEX OPTIMIZATION Theorem 15 Let f : R n R and h : R R. Consider g(x) = h(f(x)) for all x R n. The function g is convex if either of the following two conditions
Simple and efficient online algorithms for real world applications
 Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Max Flow. Lecture 4. Optimization on graphs. C25 Optimization Hilary 2013 A. Zisserman. Max-flow & min-cut. The augmented path algorithm
 Lecture 4 C5 Optimization Hilary 03 A. Zisserman Optimization on graphs Max-flow & min-cut The augmented path algorithm Optimization for binary image graphs Applications Max Flow Given: a weighted directed
Lecture 4 C5 Optimization Hilary 03 A. Zisserman Optimization on graphs Max-flow & min-cut The augmented path algorithm Optimization for binary image graphs Applications Max Flow Given: a weighted directed
Support Vector Machines
 CS229 Lecture notes Andrew Ng Part V Support Vector Machines This set of notes presents the Support Vector Machine (SVM) learning algorithm. SVMs are among the best (and many believe are indeed the best)
CS229 Lecture notes Andrew Ng Part V Support Vector Machines This set of notes presents the Support Vector Machine (SVM) learning algorithm. SVMs are among the best (and many believe are indeed the best)
Dual Methods for Total Variation-Based Image Restoration
 Dual Methods for Total Variation-Based Image Restoration Jamylle Carter Institute for Mathematics and its Applications University of Minnesota, Twin Cities Ph.D. (Mathematics), UCLA, 2001 Advisor: Tony
Dual Methods for Total Variation-Based Image Restoration Jamylle Carter Institute for Mathematics and its Applications University of Minnesota, Twin Cities Ph.D. (Mathematics), UCLA, 2001 Advisor: Tony
Foundations of Machine Learning On-Line Learning. Mehryar Mohri Courant Institute and Google Research [email protected]
 Foundations of Machine Learning On-Line Learning Mehryar Mohri Courant Institute and Google Research [email protected] Motivation PAC learning: distribution fixed over time (training and test). IID assumption.
Foundations of Machine Learning On-Line Learning Mehryar Mohri Courant Institute and Google Research [email protected] Motivation PAC learning: distribution fixed over time (training and test). IID assumption.
Making Sense of the Mayhem: Machine Learning and March Madness
 Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University [email protected] [email protected] I. Introduction III. Model The goal of our research
Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University [email protected] [email protected] I. Introduction III. Model The goal of our research
Machine Learning. CUNY Graduate Center, Spring 2013. Professor Liang Huang. [email protected]
 Machine Learning CUNY Graduate Center, Spring 2013 Professor Liang Huang [email protected] http://acl.cs.qc.edu/~lhuang/teaching/machine-learning Logistics Lectures M 9:30-11:30 am Room 4419 Personnel
Machine Learning CUNY Graduate Center, Spring 2013 Professor Liang Huang [email protected] http://acl.cs.qc.edu/~lhuang/teaching/machine-learning Logistics Lectures M 9:30-11:30 am Room 4419 Personnel
The Steepest Descent Algorithm for Unconstrained Optimization and a Bisection Line-search Method
 The Steepest Descent Algorithm for Unconstrained Optimization and a Bisection Line-search Method Robert M. Freund February, 004 004 Massachusetts Institute of Technology. 1 1 The Algorithm The problem
The Steepest Descent Algorithm for Unconstrained Optimization and a Bisection Line-search Method Robert M. Freund February, 004 004 Massachusetts Institute of Technology. 1 1 The Algorithm The problem
Linear Classification. Volker Tresp Summer 2015
 Linear Classification Volker Tresp Summer 2015 1 Classification Classification is the central task of pattern recognition Sensors supply information about an object: to which class do the object belong
Linear Classification Volker Tresp Summer 2015 1 Classification Classification is the central task of pattern recognition Sensors supply information about an object: to which class do the object belong
Proximal mapping via network optimization
 L. Vandenberghe EE236C (Spring 23-4) Proximal mapping via network optimization minimum cut and maximum flow problems parametric minimum cut problem application to proximal mapping Introduction this lecture:
L. Vandenberghe EE236C (Spring 23-4) Proximal mapping via network optimization minimum cut and maximum flow problems parametric minimum cut problem application to proximal mapping Introduction this lecture:
LECTURE: INTRO TO LINEAR PROGRAMMING AND THE SIMPLEX METHOD, KEVIN ROSS MARCH 31, 2005
 LECTURE: INTRO TO LINEAR PROGRAMMING AND THE SIMPLEX METHOD, KEVIN ROSS MARCH 31, 2005 DAVID L. BERNICK [email protected] 1. Overview Typical Linear Programming problems Standard form and converting
LECTURE: INTRO TO LINEAR PROGRAMMING AND THE SIMPLEX METHOD, KEVIN ROSS MARCH 31, 2005 DAVID L. BERNICK [email protected] 1. Overview Typical Linear Programming problems Standard form and converting
Logistic Regression for Spam Filtering
 Logistic Regression for Spam Filtering Nikhila Arkalgud February 14, 28 Abstract The goal of the spam filtering problem is to identify an email as a spam or not spam. One of the classic techniques used
Logistic Regression for Spam Filtering Nikhila Arkalgud February 14, 28 Abstract The goal of the spam filtering problem is to identify an email as a spam or not spam. One of the classic techniques used
Numerical methods for American options
 Lecture 9 Numerical methods for American options Lecture Notes by Andrzej Palczewski Computational Finance p. 1 American options The holder of an American option has the right to exercise it at any moment
Lecture 9 Numerical methods for American options Lecture Notes by Andrzej Palczewski Computational Finance p. 1 American options The holder of an American option has the right to exercise it at any moment
Epipolar Geometry. Readings: See Sections 10.1 and 15.6 of Forsyth and Ponce. Right Image. Left Image. e(p ) Epipolar Lines. e(q ) q R.
 Epipolar Lines. e(q ) q R.") Epipolar Geometry We consider two perspective images of a scene as taken from a stereo pair of cameras (or equivalently, assume the scene is rigid and imaged with a single camera from two different locations).
Epipolar Geometry We consider two perspective images of a scene as taken from a stereo pair of cameras (or equivalently, assume the scene is rigid and imaged with a single camera from two different locations).
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches
 Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
International Doctoral School Algorithmic Decision Theory: MCDA and MOO
 International Doctoral School Algorithmic Decision Theory: MCDA and MOO Lecture 2: Multiobjective Linear Programming Department of Engineering Science, The University of Auckland, New Zealand Laboratoire
International Doctoral School Algorithmic Decision Theory: MCDA and MOO Lecture 2: Multiobjective Linear Programming Department of Engineering Science, The University of Auckland, New Zealand Laboratoire
Natural Language Processing. Today. Logistic Regression Models. Lecture 13 10/6/2015. Jim Martin. Multinomial Logistic Regression
 Natural Language Processing Lecture 13 10/6/2015 Jim Martin Today Multinomial Logistic Regression Aka log-linear models or maximum entropy (maxent) Components of the model Learning the parameters 10/1/15
Natural Language Processing Lecture 13 10/6/2015 Jim Martin Today Multinomial Logistic Regression Aka log-linear models or maximum entropy (maxent) Components of the model Learning the parameters 10/1/15
MVA ENS Cachan. Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos [email protected]
 Machine Learning for Computer Vision 1 MVA ENS Cachan Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos [email protected] Department of Applied Mathematics Ecole Centrale Paris Galen
Machine Learning for Computer Vision 1 MVA ENS Cachan Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos [email protected] Department of Applied Mathematics Ecole Centrale Paris Galen
Two-Stage Stochastic Linear Programs
 Two-Stage Stochastic Linear Programs Operations Research Anthony Papavasiliou 1 / 27 Two-Stage Stochastic Linear Programs 1 Short Reviews Probability Spaces and Random Variables Convex Analysis 2 Deterministic
Two-Stage Stochastic Linear Programs Operations Research Anthony Papavasiliou 1 / 27 Two-Stage Stochastic Linear Programs 1 Short Reviews Probability Spaces and Random Variables Convex Analysis 2 Deterministic
Loss Functions for Preference Levels: Regression with Discrete Ordered Labels
 Loss Functions for Preference Levels: Regression with Discrete Ordered Labels Jason D. M. Rennie Massachusetts Institute of Technology Comp. Sci. and Artificial Intelligence Laboratory Cambridge, MA 9,
Loss Functions for Preference Levels: Regression with Discrete Ordered Labels Jason D. M. Rennie Massachusetts Institute of Technology Comp. Sci. and Artificial Intelligence Laboratory Cambridge, MA 9,
Lecture 2: August 29. Linear Programming (part I)
") 10-725: Convex Optimization Fall 2013 Lecture 2: August 29 Lecturer: Barnabás Póczos Scribes: Samrachana Adhikari, Mattia Ciollaro, Fabrizio Lecci Note: LaTeX template courtesy of UC Berkeley EECS dept.
10-725: Convex Optimization Fall 2013 Lecture 2: August 29 Lecturer: Barnabás Póczos Scribes: Samrachana Adhikari, Mattia Ciollaro, Fabrizio Lecci Note: LaTeX template courtesy of UC Berkeley EECS dept.
Support Vector Machines with Clustering for Training with Very Large Datasets
 Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France [email protected] Massimiliano
Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France [email protected] Massimiliano
Semi-Supervised Support Vector Machines and Application to Spam Filtering
 Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery
Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery
Mean-Shift Tracking with Random Sampling
 1 Mean-Shift Tracking with Random Sampling Alex Po Leung, Shaogang Gong Department of Computer Science Queen Mary, University of London, London, E1 4NS Abstract In this work, boosting the efficiency of
1 Mean-Shift Tracking with Random Sampling Alex Po Leung, Shaogang Gong Department of Computer Science Queen Mary, University of London, London, E1 4NS Abstract In this work, boosting the efficiency of
Introduction to Machine Learning and Data Mining. Prof. Dr. Igor Trajkovski [email protected]
 Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trakovski [email protected] Neural Networks 2 Neural Networks Analogy to biological neural systems, the most robust learning systems
Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trakovski [email protected] Neural Networks 2 Neural Networks Analogy to biological neural systems, the most robust learning systems
Efficient online learning of a non-negative sparse autoencoder
 and Machine Learning. Bruges (Belgium), 28-30 April 2010, d-side publi., ISBN 2-93030-10-2. Efficient online learning of a non-negative sparse autoencoder Andre Lemme, R. Felix Reinhart and Jochen J. Steil
and Machine Learning. Bruges (Belgium), 28-30 April 2010, d-side publi., ISBN 2-93030-10-2. Efficient online learning of a non-negative sparse autoencoder Andre Lemme, R. Felix Reinhart and Jochen J. Steil
DUOL: A Double Updating Approach for Online Learning
 : A Double Updating Approach for Online Learning Peilin Zhao School of Comp. Eng. Nanyang Tech. University Singapore 69798 [email protected] Steven C.H. Hoi School of Comp. Eng. Nanyang Tech. University
: A Double Updating Approach for Online Learning Peilin Zhao School of Comp. Eng. Nanyang Tech. University Singapore 69798 [email protected] Steven C.H. Hoi School of Comp. Eng. Nanyang Tech. University
Machine Learning Big Data using Map Reduce
 Machine Learning Big Data using Map Reduce By Michael Bowles, PhD Where Does Big Data Come From? -Web data (web logs, click histories) -e-commerce applications (purchase histories) -Retail purchase histories
Machine Learning Big Data using Map Reduce By Michael Bowles, PhD Where Does Big Data Come From? -Web data (web logs, click histories) -e-commerce applications (purchase histories) -Retail purchase histories
Distance Metric Learning for Large Margin Nearest Neighbor Classification
 Journal of Machine Learning Research 10 (2009) 207-244 Submitted 12/07; Revised 9/08; Published 2/09 Distance Metric Learning for Large Margin Nearest Neighbor Classification Kilian Q. Weinberger Yahoo!
Journal of Machine Learning Research 10 (2009) 207-244 Submitted 12/07; Revised 9/08; Published 2/09 Distance Metric Learning for Large Margin Nearest Neighbor Classification Kilian Q. Weinberger Yahoo!
CHAPTER 3 SECURITY CONSTRAINED OPTIMAL SHORT-TERM HYDROTHERMAL SCHEDULING
 60 CHAPTER 3 SECURITY CONSTRAINED OPTIMAL SHORT-TERM HYDROTHERMAL SCHEDULING 3.1 INTRODUCTION Optimal short-term hydrothermal scheduling of power systems aims at determining optimal hydro and thermal generations
60 CHAPTER 3 SECURITY CONSTRAINED OPTIMAL SHORT-TERM HYDROTHERMAL SCHEDULING 3.1 INTRODUCTION Optimal short-term hydrothermal scheduling of power systems aims at determining optimal hydro and thermal generations
A fast multi-class SVM learning method for huge databases
 www.ijcsi.org 544 A fast multi-class SVM learning method for huge databases Djeffal Abdelhamid 1, Babahenini Mohamed Chaouki 2 and Taleb-Ahmed Abdelmalik 3 1,2 Computer science department, LESIA Laboratory,
www.ijcsi.org 544 A fast multi-class SVM learning method for huge databases Djeffal Abdelhamid 1, Babahenini Mohamed Chaouki 2 and Taleb-Ahmed Abdelmalik 3 1,2 Computer science department, LESIA Laboratory,
CSC 411: Lecture 07: Multiclass Classification
 CSC 411: Lecture 07: Multiclass Classification Class based on Raquel Urtasun & Rich Zemel s lectures Sanja Fidler University of Toronto Feb 1, 2016 Urtasun, Zemel, Fidler (UofT) CSC 411: 07-Multiclass
CSC 411: Lecture 07: Multiclass Classification Class based on Raquel Urtasun & Rich Zemel s lectures Sanja Fidler University of Toronto Feb 1, 2016 Urtasun, Zemel, Fidler (UofT) CSC 411: 07-Multiclass
Table 1: Summary of the settings and parameters employed by the additive PA algorithm for classification, regression, and uniclass.
 Online Passive-Aggressive Algorithms Koby Crammer Ofer Dekel Shai Shalev-Shwartz Yoram Singer School of Computer Science & Engineering The Hebrew University, Jerusalem 91904, Israel {kobics,oferd,shais,singer}@cs.huji.ac.il
Online Passive-Aggressive Algorithms Koby Crammer Ofer Dekel Shai Shalev-Shwartz Yoram Singer School of Computer Science & Engineering The Hebrew University, Jerusalem 91904, Israel {kobics,oferd,shais,singer}@cs.huji.ac.il
Large Scale Learning to Rank
 Large Scale Learning to Rank D. Sculley Google, Inc. [email protected] Abstract Pairwise learning to rank methods such as RankSVM give good performance, but suffer from the computational burden of optimizing
Large Scale Learning to Rank D. Sculley Google, Inc. [email protected] Abstract Pairwise learning to rank methods such as RankSVM give good performance, but suffer from the computational burden of optimizing
Duality of linear conic problems
 Duality of linear conic problems Alexander Shapiro and Arkadi Nemirovski Abstract It is well known that the optimal values of a linear programming problem and its dual are equal to each other if at least
Duality of linear conic problems Alexander Shapiro and Arkadi Nemirovski Abstract It is well known that the optimal values of a linear programming problem and its dual are equal to each other if at least
Recovery of primal solutions from dual subgradient methods for mixed binary linear programming; a branch-and-bound approach
 MASTER S THESIS Recovery of primal solutions from dual subgradient methods for mixed binary linear programming; a branch-and-bound approach PAULINE ALDENVIK MIRJAM SCHIERSCHER Department of Mathematical
MASTER S THESIS Recovery of primal solutions from dual subgradient methods for mixed binary linear programming; a branch-and-bound approach PAULINE ALDENVIK MIRJAM SCHIERSCHER Department of Mathematical
GenOpt (R) Generic Optimization Program User Manual Version 3.0.0β1
 Generic Optimization Program User Manual Version 3.0.0β1") (R) User Manual Environmental Energy Technologies Division Berkeley, CA 94720 http://simulationresearch.lbl.gov Michael Wetter [email protected] February 20, 2009 Notice: This work was supported by the U.S.
(R) User Manual Environmental Energy Technologies Division Berkeley, CA 94720 http://simulationresearch.lbl.gov Michael Wetter [email protected] February 20, 2009 Notice: This work was supported by the U.S.
Probabilistic Models for Big Data. Alex Davies and Roger Frigola University of Cambridge 13th February 2014
 Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Machine learning challenges for big data
 Machine learning challenges for big data Francis Bach SIERRA Project-team, INRIA - Ecole Normale Supérieure Joint work with R. Jenatton, J. Mairal, G. Obozinski, N. Le Roux, M. Schmidt - December 2012
Machine learning challenges for big data Francis Bach SIERRA Project-team, INRIA - Ecole Normale Supérieure Joint work with R. Jenatton, J. Mairal, G. Obozinski, N. Le Roux, M. Schmidt - December 2012
Pattern Analysis. Logistic Regression. 12. Mai 2009. Joachim Hornegger. Chair of Pattern Recognition Erlangen University
 Pattern Analysis Logistic Regression 12. Mai 2009 Joachim Hornegger Chair of Pattern Recognition Erlangen University Pattern Analysis 2 / 43 1 Logistic Regression Posteriors and the Logistic Function Decision
Pattern Analysis Logistic Regression 12. Mai 2009 Joachim Hornegger Chair of Pattern Recognition Erlangen University Pattern Analysis 2 / 43 1 Logistic Regression Posteriors and the Logistic Function Decision
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j
 Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Object Detection with Discriminatively Trained Part Based Models
 1 Object Detection with Discriminatively Trained Part Based Models Pedro F. Felzenszwalb, Ross B. Girshick, David McAllester and Deva Ramanan Abstract We describe an object detection system based on mixtures
1 Object Detection with Discriminatively Trained Part Based Models Pedro F. Felzenszwalb, Ross B. Girshick, David McAllester and Deva Ramanan Abstract We describe an object detection system based on mixtures
LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING. ----Changsheng Liu 10-30-2014
 LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING ----Changsheng Liu 10-30-2014 Agenda Semi Supervised Learning Topics in Semi Supervised Learning Label Propagation Local and global consistency Graph
LABEL PROPAGATION ON GRAPHS. SEMI-SUPERVISED LEARNING ----Changsheng Liu 10-30-2014 Agenda Semi Supervised Learning Topics in Semi Supervised Learning Label Propagation Local and global consistency Graph
constraint. Let us penalize ourselves for making the constraint too big. We end up with a
 Chapter 4 Constrained Optimization 4.1 Equality Constraints (Lagrangians) Suppose we have a problem: Maximize 5, (x 1, 2) 2, 2(x 2, 1) 2 subject to x 1 +4x 2 =3 If we ignore the constraint, we get the
Chapter 4 Constrained Optimization 4.1 Equality Constraints (Lagrangians) Suppose we have a problem: Maximize 5, (x 1, 2) 2, 2(x 2, 1) 2 subject to x 1 +4x 2 =3 If we ignore the constraint, we get the