Classifying Large Data Sets Using SVMs with Hierarchical Clusters. Presented by :Limou Wang
|
|
|
- Matthew Garrett
- 7 years ago
- Views:
Transcription
1 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang
2 Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental Evaluation Conclusion & Future work
3 SVM Overview What is Support Vector Machine? analyze data & recognize patterns How does SVM work? Training phase : Given a sequence of training examples, find a hyperplane that separate these data points. Predicting phase : When a new data points arrive, correctly classifies it.
 does")
4 SVM Overview Example : H1(blue) & H2(red) separate the data points H3(green) does not

5 SVM Overview Maximum Margin Principle Samples on the margin are called support vectors
6 Motivation SVM has been promising methods However, training time of the standard SVM is O(N 3 ) Therefore, not scalable for very large data sets
7 Hierarchical micro-clustering algorithm Goals Minimize running time and data scans, thus formulating the problem for large data sets Clustering decisions made without scanning the whole data Exploit the non uniformity of data treat dense areas as one, and remove outliers (noise)
8 Hierarchical micro-clustering algorithm Clustering Feature (CF) CF is a compact storage for data on points in a cluster Has enough information to calculate the intracluster distances Additivity theorem allows us to merge subclusters
9 Hierarchical micro-clustering algorithm CF (contd.) Given N d-dimensional data points in a cluster: {Xi} where i = 1, 2,, N, CF = ( N, LS, SS) N is the number of data points in the cluster, LS is the linear sum of the N data points, SS is the square sum of the N data points.
10 Hierarchical micro-clustering algorithm CF Tree Comprising of a root node, non-leaf nodes and leaf nodes Two parameters : branching factor b & threshold t Non-leaf node at most b entries Radius of an leaf node entry must less than t
11 Hierarchical micro-clustering algorithm CF Tree (contd.) Example Thus, CF Tree is a compact representation of a large data set
12 Hierarchical micro-clustering algorithm CF Tree (contd.) Algorithm : 1. Identifying the appropriate leaf Root -> closet centroid 2. Modifying the leaf Absorb, add an entry or split 3. Modifying the path to the leaf Recursively back to the root
13 Hierarchical micro-clustering algorithm CF Tree (contd.) Outlier handling : After building the CF tree, remove the entries that contains far fewer data points than the average Running time : If we only consider the dependence of the size of the data set, the computation complexity of the algorithm is O(N)
14 Clustering-Based SVM (CB-SVM) Train data using the hierarchical micro-cluster 1. Construct two CF trees 2. Train an SVM boundary function from the centroids of the root entries 3. Decluster the entries near the boundary into the next level 4. Update the SVM boundary function from the centroids of the entries in the training set, repeat 3 until nothing is accumulated
15 Clustering-Based SVM (CB-SVM) Decluster the low-margin cluster : Let D s be the distance from the boundary to the centroid of a support cluster D i be the distance from the boundary to the centroid of a cluster E i Then if D i R i < D s E i is considered to be a low margin cluster
16 Clustering-Based SVM (CB-SVM) Next, we look at how CB-SVM works
17 Clustering-Based SVM (CB-SVM)
18 Clustering-Based SVM (CB-SVM) Running time : Let r = s / b s : average number of support entries 0 < r << 1 Therefore, CB-SVM trains from leaf entries is O(b 2h ) If the # of leaf entries = number of data points, It trains 1/r 2h-2 faster than the standard SVM which is a huge improvement in performance compared with the standard SVM as the data set becomes larger
19 Experimental Evaluation Environment : All experiments are done in a Pentium III 800Mhz machine with 906MB memory Premise : Perform binary classification on 2 dimensional data sets Note : training and testing data are drawn from the same distribution
20 Experimental Evaluation
21 Experimental Evaluation
22 Experimental Evaluation

23 Experimental Evaluation
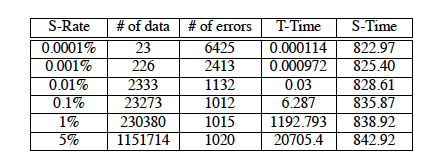
24 Experimental Evaluation
25 Conclusion & Future work CB-SVM very scalable for large data sets Generating high classification accuracy However, Limited to the usage of linear kernels Radius and distances will not be preserved in a high-dimensional feature space Future work Constructing an efficient indexing structure for nonlinear kernels
26 Questions? Thank you!
BIRCH: An Efficient Data Clustering Method For Very Large Databases
 BIRCH: An Efficient Data Clustering Method For Very Large Databases Tian Zhang, Raghu Ramakrishnan, Miron Livny CPSC 504 Presenter: Discussion Leader: Sophia (Xueyao) Liang HelenJr, Birches. Online Image.
BIRCH: An Efficient Data Clustering Method For Very Large Databases Tian Zhang, Raghu Ramakrishnan, Miron Livny CPSC 504 Presenter: Discussion Leader: Sophia (Xueyao) Liang HelenJr, Birches. Online Image.
Making SVMs Scalable to Large Data Sets using Hierarchical Cluster Indexing
 SUBMISSION TO DATA MINING AND KNOWLEDGE DISCOVERY: AN INTERNATIONAL JOURNAL, MAY. 2005 100 Making SVMs Scalable to Large Data Sets using Hierarchical Cluster Indexing Hwanjo Yu, Jiong Yang, Jiawei Han,
SUBMISSION TO DATA MINING AND KNOWLEDGE DISCOVERY: AN INTERNATIONAL JOURNAL, MAY. 2005 100 Making SVMs Scalable to Large Data Sets using Hierarchical Cluster Indexing Hwanjo Yu, Jiong Yang, Jiawei Han,
Classifying Large Data Sets Using SVMs with Hierarchical Clusters
 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Hwanjo Yu Department of Computer Science University of Illinois Urbana-Champaign, IL 61801 USA hwanjoyu@uiuc.edu Jiong Yang Department
Classifying Large Data Sets Using SVMs with Hierarchical Clusters Hwanjo Yu Department of Computer Science University of Illinois Urbana-Champaign, IL 61801 USA hwanjoyu@uiuc.edu Jiong Yang Department
Clustering on Large Numeric Data Sets Using Hierarchical Approach Birch
 Global Journal of Computer Science and Technology Software & Data Engineering Volume 12 Issue 12 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global
Global Journal of Computer Science and Technology Software & Data Engineering Volume 12 Issue 12 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global
Data Mining. Cluster Analysis: Advanced Concepts and Algorithms
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 More Clustering Methods Prototype-based clustering Density-based clustering Graph-based
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 More Clustering Methods Prototype-based clustering Density-based clustering Graph-based
Echidna: Efficient Clustering of Hierarchical Data for Network Traffic Analysis
 Echidna: Efficient Clustering of Hierarchical Data for Network Traffic Analysis Abdun Mahmood, Christopher Leckie, Parampalli Udaya Department of Computer Science and Software Engineering University of
Echidna: Efficient Clustering of Hierarchical Data for Network Traffic Analysis Abdun Mahmood, Christopher Leckie, Parampalli Udaya Department of Computer Science and Software Engineering University of
Clustering. Data Mining. Abraham Otero. Data Mining. Agenda
 Clustering 1/46 Agenda Introduction Distance K-nearest neighbors Hierarchical clustering Quick reference 2/46 1 Introduction It seems logical that in a new situation we should act in a similar way as in
Clustering 1/46 Agenda Introduction Distance K-nearest neighbors Hierarchical clustering Quick reference 2/46 1 Introduction It seems logical that in a new situation we should act in a similar way as in
A Survey of Classification Techniques in the Area of Big Data.
 A Survey of Classification Techniques in the Area of Big Data. 1PrafulKoturwar, 2 SheetalGirase, 3 Debajyoti Mukhopadhyay 1Reseach Scholar, Department of Information Technology 2Assistance Professor,Department
A Survey of Classification Techniques in the Area of Big Data. 1PrafulKoturwar, 2 SheetalGirase, 3 Debajyoti Mukhopadhyay 1Reseach Scholar, Department of Information Technology 2Assistance Professor,Department
Introduction to Support Vector Machines. Colin Campbell, Bristol University
 Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Classification and Prediction
 Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Clustering UE 141 Spring 2013
 Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
Support Vector Machines with Clustering for Training with Very Large Datasets
 Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France theodoros.evgeniou@insead.fr Massimiliano
Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France theodoros.evgeniou@insead.fr Massimiliano
Decision Trees from large Databases: SLIQ
 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Artificial Neural Networks and Support Vector Machines. CS 486/686: Introduction to Artificial Intelligence
 Artificial Neural Networks and Support Vector Machines CS 486/686: Introduction to Artificial Intelligence 1 Outline What is a Neural Network? - Perceptron learners - Multi-layer networks What is a Support
Artificial Neural Networks and Support Vector Machines CS 486/686: Introduction to Artificial Intelligence 1 Outline What is a Neural Network? - Perceptron learners - Multi-layer networks What is a Support
Lecture 10: Regression Trees
 Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
The SPSS TwoStep Cluster Component
 White paper technical report The SPSS TwoStep Cluster Component A scalable component enabling more efficient customer segmentation Introduction The SPSS TwoStep Clustering Component is a scalable cluster
White paper technical report The SPSS TwoStep Cluster Component A scalable component enabling more efficient customer segmentation Introduction The SPSS TwoStep Clustering Component is a scalable cluster
Clustering & Visualization
 Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Clustering Via Decision Tree Construction
 Clustering Via Decision Tree Construction Bing Liu 1, Yiyuan Xia 2, and Philip S. Yu 3 1 Department of Computer Science, University of Illinois at Chicago, 851 S. Morgan Street, Chicago, IL 60607-7053.
Clustering Via Decision Tree Construction Bing Liu 1, Yiyuan Xia 2, and Philip S. Yu 3 1 Department of Computer Science, University of Illinois at Chicago, 851 S. Morgan Street, Chicago, IL 60607-7053.
A fast multi-class SVM learning method for huge databases
 www.ijcsi.org 544 A fast multi-class SVM learning method for huge databases Djeffal Abdelhamid 1, Babahenini Mohamed Chaouki 2 and Taleb-Ahmed Abdelmalik 3 1,2 Computer science department, LESIA Laboratory,
www.ijcsi.org 544 A fast multi-class SVM learning method for huge databases Djeffal Abdelhamid 1, Babahenini Mohamed Chaouki 2 and Taleb-Ahmed Abdelmalik 3 1,2 Computer science department, LESIA Laboratory,
Support Vector Machine (SVM)
") Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Data Mining for Knowledge Management. Classification
 1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
Data Mining Techniques Chapter 6: Decision Trees
 Data Mining Techniques Chapter 6: Decision Trees What is a classification decision tree?.......................................... 2 Visualizing decision trees...................................................
Data Mining Techniques Chapter 6: Decision Trees What is a classification decision tree?.......................................... 2 Visualizing decision trees...................................................
COMP3420: Advanced Databases and Data Mining. Classification and prediction: Introduction and Decision Tree Induction
 COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES
 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 123 CHAPTER 7 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 7.1 Introduction Even though using SVM presents
BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 123 CHAPTER 7 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 7.1 Introduction Even though using SVM presents
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
A Non-Linear Schema Theorem for Genetic Algorithms
 A Non-Linear Schema Theorem for Genetic Algorithms William A Greene Computer Science Department University of New Orleans New Orleans, LA 70148 bill@csunoedu 504-280-6755 Abstract We generalize Holland
A Non-Linear Schema Theorem for Genetic Algorithms William A Greene Computer Science Department University of New Orleans New Orleans, LA 70148 bill@csunoedu 504-280-6755 Abstract We generalize Holland
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Cluster Analysis: Advanced Concepts
 Cluster Analysis: Advanced Concepts and dalgorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 08/06/2006 1 Introduction to Data Mining 08/06/2006 1 Outline Prototype-based Fuzzy c-means
Cluster Analysis: Advanced Concepts and dalgorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 08/06/2006 1 Introduction to Data Mining 08/06/2006 1 Outline Prototype-based Fuzzy c-means
DATABASE DESIGN - 1DL400
 DATABASE DESIGN - 1DL400 Spring 2015 A course on modern database systems!! http://www.it.uu.se/research/group/udbl/kurser/dbii_vt15/ Kjell Orsborn! Uppsala Database Laboratory! Department of Information
DATABASE DESIGN - 1DL400 Spring 2015 A course on modern database systems!! http://www.it.uu.se/research/group/udbl/kurser/dbii_vt15/ Kjell Orsborn! Uppsala Database Laboratory! Department of Information
Using multiple models: Bagging, Boosting, Ensembles, Forests
 Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing and Developing E-mail Classifier
 International Journal of Recent Technology and Engineering (IJRTE) ISSN: 2277-3878, Volume-1, Issue-6, January 2013 Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing
International Journal of Recent Technology and Engineering (IJRTE) ISSN: 2277-3878, Volume-1, Issue-6, January 2013 Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing
Learning Example. Machine learning and our focus. Another Example. An example: data (loan application) The data and the goal
 The data and the goal") Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Philosophies and Advances in Scaling Mining Algorithms to Large Databases
 Philosophies and Advances in Scaling Mining Algorithms to Large Databases Paul Bradley Apollo Data Technologies paul@apollodatatech.com Raghu Ramakrishnan UW-Madison raghu@cs.wisc.edu Johannes Gehrke Cornell
Philosophies and Advances in Scaling Mining Algorithms to Large Databases Paul Bradley Apollo Data Technologies paul@apollodatatech.com Raghu Ramakrishnan UW-Madison raghu@cs.wisc.edu Johannes Gehrke Cornell
Predictive Dynamix Inc
 Predictive Modeling Technology Predictive modeling is concerned with analyzing patterns and trends in historical and operational data in order to transform data into actionable decisions. This is accomplished
Predictive Modeling Technology Predictive modeling is concerned with analyzing patterns and trends in historical and operational data in order to transform data into actionable decisions. This is accomplished
Euclidean Minimum Spanning Trees Based on Well Separated Pair Decompositions Chaojun Li. Advised by: Dave Mount. May 22, 2014
 Euclidean Minimum Spanning Trees Based on Well Separated Pair Decompositions Chaojun Li Advised by: Dave Mount May 22, 2014 1 INTRODUCTION In this report we consider the implementation of an efficient
Euclidean Minimum Spanning Trees Based on Well Separated Pair Decompositions Chaojun Li Advised by: Dave Mount May 22, 2014 1 INTRODUCTION In this report we consider the implementation of an efficient
Classification algorithm in Data mining: An Overview
 Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Neural Networks and Support Vector Machines
 INF5390 - Kunstig intelligens Neural Networks and Support Vector Machines Roar Fjellheim INF5390-13 Neural Networks and SVM 1 Outline Neural networks Perceptrons Neural networks Support vector machines
INF5390 - Kunstig intelligens Neural Networks and Support Vector Machines Roar Fjellheim INF5390-13 Neural Networks and SVM 1 Outline Neural networks Perceptrons Neural networks Support vector machines
Clustering through Decision Tree Construction in Geology
 Nonlinear Analysis: Modelling and Control, 2001, v. 6, No. 2, 29-41 Clustering through Decision Tree Construction in Geology Received: 22.10.2001 Accepted: 31.10.2001 A. Juozapavičius, V. Rapševičius Faculty
Nonlinear Analysis: Modelling and Control, 2001, v. 6, No. 2, 29-41 Clustering through Decision Tree Construction in Geology Received: 22.10.2001 Accepted: 31.10.2001 A. Juozapavičius, V. Rapševičius Faculty
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Chapter 4 Data Mining A Short Introduction. 2006/7, Karl Aberer, EPFL-IC, Laboratoire de systèmes d'informations répartis Data Mining - 1
 Chapter 4 Data Mining A Short Introduction 2006/7, Karl Aberer, EPFL-IC, Laboratoire de systèmes d'informations répartis Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining
Chapter 4 Data Mining A Short Introduction 2006/7, Karl Aberer, EPFL-IC, Laboratoire de systèmes d'informations répartis Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining
Content-Based Recommendation
 Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Vector storage and access; algorithms in GIS. This is lecture 6
 Vector storage and access; algorithms in GIS This is lecture 6 Vector data storage and access Vectors are built from points, line and areas. (x,y) Surface: (x,y,z) Vector data access Access to vector
Vector storage and access; algorithms in GIS This is lecture 6 Vector data storage and access Vectors are built from points, line and areas. (x,y) Surface: (x,y,z) Vector data access Access to vector
Knowledge Discovery from patents using KMX Text Analytics
 Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs anton.heijs@treparel.com Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs anton.heijs@treparel.com Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches
 Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Validity Measure of Cluster Based On the Intra-Cluster and Inter-Cluster Distance
 International Journal of Electronics and Computer Science Engineering 2486 Available Online at www.ijecse.org ISSN- 2277-1956 Validity Measure of Cluster Based On the Intra-Cluster and Inter-Cluster Distance
International Journal of Electronics and Computer Science Engineering 2486 Available Online at www.ijecse.org ISSN- 2277-1956 Validity Measure of Cluster Based On the Intra-Cluster and Inter-Cluster Distance
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Scalable Developments for Big Data Analytics in Remote Sensing
 Scalable Developments for Big Data Analytics in Remote Sensing Federated Systems and Data Division Research Group High Productivity Data Processing Dr.-Ing. Morris Riedel et al. Research Group Leader,
Scalable Developments for Big Data Analytics in Remote Sensing Federated Systems and Data Division Research Group High Productivity Data Processing Dr.-Ing. Morris Riedel et al. Research Group Leader,
EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER. Copyr i g ht 2013, SAS Ins titut e Inc. All rights res er ve d.
 EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER ANALYTICS LIFECYCLE Evaluate & Monitor Model Formulate Problem Data Preparation Deploy Model Data Exploration Validate Models
EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER ANALYTICS LIFECYCLE Evaluate & Monitor Model Formulate Problem Data Preparation Deploy Model Data Exploration Validate Models
Feature Selection using Integer and Binary coded Genetic Algorithm to improve the performance of SVM Classifier
 Feature Selection using Integer and Binary coded Genetic Algorithm to improve the performance of SVM Classifier D.Nithya a, *, V.Suganya b,1, R.Saranya Irudaya Mary c,1 Abstract - This paper presents,
Feature Selection using Integer and Binary coded Genetic Algorithm to improve the performance of SVM Classifier D.Nithya a, *, V.Suganya b,1, R.Saranya Irudaya Mary c,1 Abstract - This paper presents,
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 by Tan, Steinbach, Kumar 1 What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 by Tan, Steinbach, Kumar 1 What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Support Vector Machines
 Support Vector Machines Charlie Frogner 1 MIT 2011 1 Slides mostly stolen from Ryan Rifkin (Google). Plan Regularization derivation of SVMs. Analyzing the SVM problem: optimization, duality. Geometric
Support Vector Machines Charlie Frogner 1 MIT 2011 1 Slides mostly stolen from Ryan Rifkin (Google). Plan Regularization derivation of SVMs. Analyzing the SVM problem: optimization, duality. Geometric
COPYRIGHTED MATERIAL. Contents. List of Figures. Acknowledgments
 Contents List of Figures Foreword Preface xxv xxiii xv Acknowledgments xxix Chapter 1 Fraud: Detection, Prevention, and Analytics! 1 Introduction 2 Fraud! 2 Fraud Detection and Prevention 10 Big Data for
Contents List of Figures Foreword Preface xxv xxiii xv Acknowledgments xxix Chapter 1 Fraud: Detection, Prevention, and Analytics! 1 Introduction 2 Fraud! 2 Fraud Detection and Prevention 10 Big Data for
LCs for Binary Classification
 Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Data Mining Clustering (2) Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining
 Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining") Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
Data Mining Classification: Decision Trees
 Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Going Big in Data Dimensionality:
 LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS DATABASE Going Big in Data Dimensionality: Challenges and Solutions for Mining High Dimensional Data Peer Kröger Lehrstuhl für
LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS DATABASE Going Big in Data Dimensionality: Challenges and Solutions for Mining High Dimensional Data Peer Kröger Lehrstuhl für
Clustering. Chapter 7. 7.1 Introduction to Clustering Techniques. 7.1.1 Points, Spaces, and Distances
 240 Chapter 7 Clustering Clustering is the process of examining a collection of points, and grouping the points into clusters according to some distance measure. The goal is that points in the same cluster
240 Chapter 7 Clustering Clustering is the process of examining a collection of points, and grouping the points into clusters according to some distance measure. The goal is that points in the same cluster
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Clustering. 15-381 Artificial Intelligence Henry Lin. Organizing data into clusters such that there is
 Clustering 15-381 Artificial Intelligence Henry Lin Modified from excellent slides of Eamonn Keogh, Ziv Bar-Joseph, and Andrew Moore What is Clustering? Organizing data into clusters such that there is
Clustering 15-381 Artificial Intelligence Henry Lin Modified from excellent slides of Eamonn Keogh, Ziv Bar-Joseph, and Andrew Moore What is Clustering? Organizing data into clusters such that there is
Classification of Bad Accounts in Credit Card Industry
 Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition
Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition
Classification and Prediction techniques using Machine Learning for Anomaly Detection.
 Classification and Prediction techniques using Machine Learning for Anomaly Detection. Pradeep Pundir, Dr.Virendra Gomanse,Narahari Krishnamacharya. *( Department of Computer Engineering, Jagdishprasad
Classification and Prediction techniques using Machine Learning for Anomaly Detection. Pradeep Pundir, Dr.Virendra Gomanse,Narahari Krishnamacharya. *( Department of Computer Engineering, Jagdishprasad
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Fast Matching of Binary Features
 Fast Matching of Binary Features Marius Muja and David G. Lowe Laboratory for Computational Intelligence University of British Columbia, Vancouver, Canada {mariusm,lowe}@cs.ubc.ca Abstract There has been
Fast Matching of Binary Features Marius Muja and David G. Lowe Laboratory for Computational Intelligence University of British Columbia, Vancouver, Canada {mariusm,lowe}@cs.ubc.ca Abstract There has been
AUTOMATION OF ENERGY DEMAND FORECASTING. Sanzad Siddique, B.S.
 AUTOMATION OF ENERGY DEMAND FORECASTING by Sanzad Siddique, B.S. A Thesis submitted to the Faculty of the Graduate School, Marquette University, in Partial Fulfillment of the Requirements for the Degree
AUTOMATION OF ENERGY DEMAND FORECASTING by Sanzad Siddique, B.S. A Thesis submitted to the Faculty of the Graduate School, Marquette University, in Partial Fulfillment of the Requirements for the Degree
SURVEY OF TEXT CLASSIFICATION ALGORITHMS FOR SPAM FILTERING
 I J I T E ISSN: 2229-7367 3(1-2), 2012, pp. 233-237 SURVEY OF TEXT CLASSIFICATION ALGORITHMS FOR SPAM FILTERING K. SARULADHA 1 AND L. SASIREKA 2 1 Assistant Professor, Department of Computer Science and
I J I T E ISSN: 2229-7367 3(1-2), 2012, pp. 233-237 SURVEY OF TEXT CLASSIFICATION ALGORITHMS FOR SPAM FILTERING K. SARULADHA 1 AND L. SASIREKA 2 1 Assistant Professor, Department of Computer Science and
Neural Networks Lesson 5 - Cluster Analysis
 Neural Networks Lesson 5 - Cluster Analysis Prof. Michele Scarpiniti INFOCOM Dpt. - Sapienza University of Rome http://ispac.ing.uniroma1.it/scarpiniti/index.htm michele.scarpiniti@uniroma1.it Rome, 29
Neural Networks Lesson 5 - Cluster Analysis Prof. Michele Scarpiniti INFOCOM Dpt. - Sapienza University of Rome http://ispac.ing.uniroma1.it/scarpiniti/index.htm michele.scarpiniti@uniroma1.it Rome, 29
R-trees. R-Trees: A Dynamic Index Structure For Spatial Searching. R-Tree. Invariants
 R-Trees: A Dynamic Index Structure For Spatial Searching A. Guttman R-trees Generalization of B+-trees to higher dimensions Disk-based index structure Occupancy guarantee Multiple search paths Insertions
R-Trees: A Dynamic Index Structure For Spatial Searching A. Guttman R-trees Generalization of B+-trees to higher dimensions Disk-based index structure Occupancy guarantee Multiple search paths Insertions
Application of Face Recognition to Person Matching in Trains
 Application of Face Recognition to Person Matching in Trains May 2008 Objective Matching of person Context : in trains Using face recognition and face detection algorithms With a video-surveillance camera
Application of Face Recognition to Person Matching in Trains May 2008 Objective Matching of person Context : in trains Using face recognition and face detection algorithms With a video-surveillance camera
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Binary Coded Web Access Pattern Tree in Education Domain
 Binary Coded Web Access Pattern Tree in Education Domain C. Gomathi P.G. Department of Computer Science Kongu Arts and Science College Erode-638-107, Tamil Nadu, India E-mail: kc.gomathi@gmail.com M. Moorthi
Binary Coded Web Access Pattern Tree in Education Domain C. Gomathi P.G. Department of Computer Science Kongu Arts and Science College Erode-638-107, Tamil Nadu, India E-mail: kc.gomathi@gmail.com M. Moorthi
Lecture 2: The SVM classifier
 Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function
Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function
The basic data mining algorithms introduced may be enhanced in a number of ways.
 DATA MINING TECHNOLOGIES AND IMPLEMENTATIONS The basic data mining algorithms introduced may be enhanced in a number of ways. Data mining algorithms have traditionally assumed data is memory resident,
DATA MINING TECHNOLOGIES AND IMPLEMENTATIONS The basic data mining algorithms introduced may be enhanced in a number of ways. Data mining algorithms have traditionally assumed data is memory resident,
Clustering Data Streams
 Clustering Data Streams Mohamed Elasmar Prashant Thiruvengadachari Javier Salinas Martin gtg091e@mail.gatech.edu tprashant@gmail.com javisal1@gatech.edu Introduction: Data mining is the science of extracting
Clustering Data Streams Mohamed Elasmar Prashant Thiruvengadachari Javier Salinas Martin gtg091e@mail.gatech.edu tprashant@gmail.com javisal1@gatech.edu Introduction: Data mining is the science of extracting
Steven C.H. Hoi. School of Computer Engineering Nanyang Technological University Singapore
 Steven C.H. Hoi School of Computer Engineering Nanyang Technological University Singapore Acknowledgments: Peilin Zhao, Jialei Wang, Hao Xia, Jing Lu, Rong Jin, Pengcheng Wu, Dayong Wang, etc. 2 Agenda
Steven C.H. Hoi School of Computer Engineering Nanyang Technological University Singapore Acknowledgments: Peilin Zhao, Jialei Wang, Hao Xia, Jing Lu, Rong Jin, Pengcheng Wu, Dayong Wang, etc. 2 Agenda
Predicting Flight Delays
 Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
The Operational Value of Social Media Information. Social Media and Customer Interaction
 The Operational Value of Social Media Information Dennis J. Zhang (Kellogg School of Management) Ruomeng Cui (Kelley School of Business) Santiago Gallino (Tuck School of Business) Antonio Moreno-Garcia
The Operational Value of Social Media Information Dennis J. Zhang (Kellogg School of Management) Ruomeng Cui (Kelley School of Business) Santiago Gallino (Tuck School of Business) Antonio Moreno-Garcia
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Support Vector Machines Explained
 March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Extension of Decision Tree Algorithm for Stream Data Mining Using Real Data
 Fifth International Workshop on Computational Intelligence & Applications IEEE SMC Hiroshima Chapter, Hiroshima University, Japan, November 10, 11 & 12, 2009 Extension of Decision Tree Algorithm for Stream
Fifth International Workshop on Computational Intelligence & Applications IEEE SMC Hiroshima Chapter, Hiroshima University, Japan, November 10, 11 & 12, 2009 Extension of Decision Tree Algorithm for Stream
Big Data and Scripting. Part 4: Memory Hierarchies
 1, Big Data and Scripting Part 4: Memory Hierarchies 2, Model and Definitions memory size: M machine words total storage (on disk) of N elements (N is very large) disk size unlimited (for our considerations)
1, Big Data and Scripting Part 4: Memory Hierarchies 2, Model and Definitions memory size: M machine words total storage (on disk) of N elements (N is very large) disk size unlimited (for our considerations)
Forecasting and Hedging in the Foreign Exchange Markets
 Christian Ullrich Forecasting and Hedging in the Foreign Exchange Markets 4u Springer Contents Part I Introduction 1 Motivation 3 2 Analytical Outlook 7 2.1 Foreign Exchange Market Predictability 7 2.2
Christian Ullrich Forecasting and Hedging in the Foreign Exchange Markets 4u Springer Contents Part I Introduction 1 Motivation 3 2 Analytical Outlook 7 2.1 Foreign Exchange Market Predictability 7 2.2
Authors. Data Clustering: Algorithms and Applications
 Authors Data Clustering: Algorithms and Applications 2 Contents 1 Grid-based Clustering 1 Wei Cheng, Wei Wang, and Sandra Batista 1.1 Introduction................................... 1 1.2 The Classical
Authors Data Clustering: Algorithms and Applications 2 Contents 1 Grid-based Clustering 1 Wei Cheng, Wei Wang, and Sandra Batista 1.1 Introduction................................... 1 1.2 The Classical
Outline BST Operations Worst case Average case Balancing AVL Red-black B-trees. Binary Search Trees. Lecturer: Georgy Gimel farb
 Binary Search Trees Lecturer: Georgy Gimel farb COMPSCI 220 Algorithms and Data Structures 1 / 27 1 Properties of Binary Search Trees 2 Basic BST operations The worst-case time complexity of BST operations
Binary Search Trees Lecturer: Georgy Gimel farb COMPSCI 220 Algorithms and Data Structures 1 / 27 1 Properties of Binary Search Trees 2 Basic BST operations The worst-case time complexity of BST operations
Comparison of machine learning methods for intelligent tutoring systems
 Comparison of machine learning methods for intelligent tutoring systems Wilhelmiina Hämäläinen 1 and Mikko Vinni 1 Department of Computer Science, University of Joensuu, P.O. Box 111, FI-80101 Joensuu
Comparison of machine learning methods for intelligent tutoring systems Wilhelmiina Hämäläinen 1 and Mikko Vinni 1 Department of Computer Science, University of Joensuu, P.O. Box 111, FI-80101 Joensuu
MHI3000 Big Data Analytics for Health Care Final Project Report
 MHI3000 Big Data Analytics for Health Care Final Project Report Zhongtian Fred Qiu (1002274530) http://gallery.azureml.net/details/81ddb2ab137046d4925584b5095ec7aa 1. Data pre-processing The data given
MHI3000 Big Data Analytics for Health Care Final Project Report Zhongtian Fred Qiu (1002274530) http://gallery.azureml.net/details/81ddb2ab137046d4925584b5095ec7aa 1. Data pre-processing The data given
Krishna Institute of Engineering & Technology, Ghaziabad Department of Computer Application MCA-213 : DATA STRUCTURES USING C
 Tutorial#1 Q 1:- Explain the terms data, elementary item, entity, primary key, domain, attribute and information? Also give examples in support of your answer? Q 2:- What is a Data Type? Differentiate
Tutorial#1 Q 1:- Explain the terms data, elementary item, entity, primary key, domain, attribute and information? Also give examples in support of your answer? Q 2:- What is a Data Type? Differentiate
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 10 th, 2013 Wolf-Tilo Balke and Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 10 th, 2013 Wolf-Tilo Balke and Kinda El Maarry Institut für Informationssysteme Technische Universität Braunschweig
Beating the MLB Moneyline
 Beating the MLB Moneyline Leland Chen llxchen@stanford.edu Andrew He andu@stanford.edu 1 Abstract Sports forecasting is a challenging task that has similarities to stock market prediction, requiring time-series
Beating the MLB Moneyline Leland Chen llxchen@stanford.edu Andrew He andu@stanford.edu 1 Abstract Sports forecasting is a challenging task that has similarities to stock market prediction, requiring time-series
Recognition. Sanja Fidler CSC420: Intro to Image Understanding 1 / 28
 Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Intrusion Detection via Machine Learning for SCADA System Protection
 Intrusion Detection via Machine Learning for SCADA System Protection S.L.P. Yasakethu Department of Computing, University of Surrey, Guildford, GU2 7XH, UK. s.l.yasakethu@surrey.ac.uk J. Jiang Department
Intrusion Detection via Machine Learning for SCADA System Protection S.L.P. Yasakethu Department of Computing, University of Surrey, Guildford, GU2 7XH, UK. s.l.yasakethu@surrey.ac.uk J. Jiang Department
Smart-Sample: An Efficient Algorithm for Clustering Large High-Dimensional Datasets
 Smart-Sample: An Efficient Algorithm for Clustering Large High-Dimensional Datasets Dudu Lazarov, Gil David, Amir Averbuch School of Computer Science, Tel-Aviv University Tel-Aviv 69978, Israel Abstract
Smart-Sample: An Efficient Algorithm for Clustering Large High-Dimensional Datasets Dudu Lazarov, Gil David, Amir Averbuch School of Computer Science, Tel-Aviv University Tel-Aviv 69978, Israel Abstract
Character Image Patterns as Big Data
 22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
Machine Learning in Spam Filtering
 Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov kt@ut.ee Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov kt@ut.ee Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
A Simple Introduction to Support Vector Machines
 A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
The Artificial Prediction Market
 The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory