Data Preprocessing. Week 2
|
|
|
- Clyde Armstrong
- 9 years ago
- Views:
Transcription
1 Data Preprocessing Week 2

2 Topics Data Types Data Repositories Data Preprocessing Present homework assignment #1

3 Team Homework Assignment #2 Read pp , pp , and pp the text book. Do Examples 5.3, 5.4, 5.8, 5.9, and Exercise 5.5. Write an R program to verify your answer for Exercise 5.5. Refer to pp of the lab book. Explore frequent pattern mining tools and play them for Exercise 5.5 Prepare for the results of the homework assignment. Due date beginning gof the lecture on Friday February 11 th.

4 Team Homework Assignment #3 Prepare for the one page description i of your group project topic Prepare for presentation using slides Due date beginning of the lecture on Friday February 11 th.

5 Figure 1.4 Dataa Mining as a step in the process of knowledge discovery

6 Why Data Preprocessing Is Important? Welcome to the Real World! No quality data, no quality mining results! Preprocessing is one of the most critical steps in a data mining process 6

7 Major Tasks in Data Preprocessing Figure 2.1 Forms of data preprocessing 7

8 Why Data Preprocessing is Beneficial to Data Mining? i Less data data mining methods can learn faster Higher accuracy data mining methods can generalize better Simple results they are easier to understand Fewer attributes For the next round of data collection, saving can be made by removing redundant and irrelevant features 8

9 Data Cleaning 9
10 Remarks on Data Cleaning Data cleaning is one of the biggest problems in data warehousing Ralph Kimball Data cleaning is the number one problem in data warehousing DCI survey 10

11 Why Data Is Dirty? Incomplete, noisy, and inconsistent i data are commonplace properties of large real world databases. (p. 48) There are many possible reasons for noisy data. (p. 48) 11

12 Types of Dirty Data Cleaning Methods Missing values Fill in missing values Noisy data (incorrect values) Identify outliers and smooth out noisy data 12

13 Methods for Missing Values (1) Ignore the tuple Fillin in the missing value manually Use a global constant to fill in the missing value 13

14 Methods for Missing Values (2) Use the attribute mean to fill in the missing value Use the attribute mean for all samples belonging to the same class as the given tuple Use the most probable value to fill in the missing value 14

15 Methods for Noisy Data Binning Regression Clustering 15

16 Binning 16

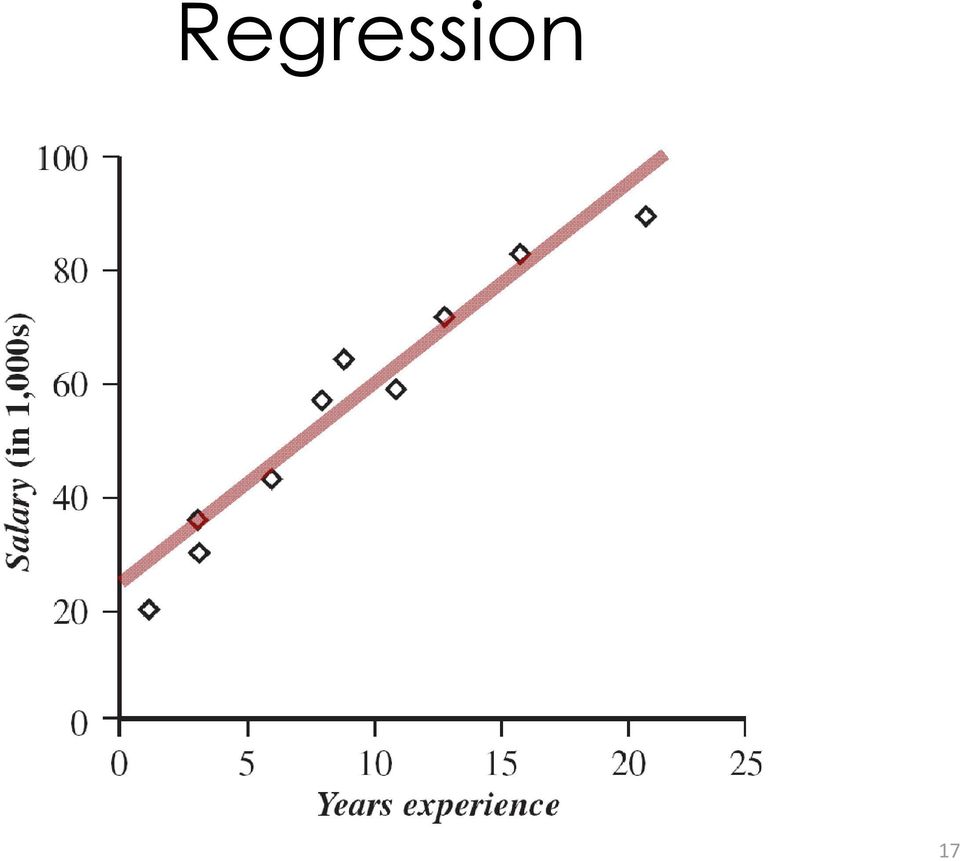
17 Regression 17
18 Clustering Figure 2.12 A 2 D plot of customer data with respect to customer locations in a city, showing three data clusters. Each cluster centroid is marked with a +, representing the average point on space that t cluster. Outliers may be detected dt tdas values that t fall flloutside tid of the sets of clusters. 18

19 Data Integration 19

20 Data Integration Schema integration and object matching Entity identification problem Redundant data (between attributes) occur often when integration of multiple databases Redundant attributes may be able to be detected by correlation lti analysis, and chi square method 20

21 Schema Integration and Object Matching custom_id and cust_number Schema conflict H and S, and 1 and 2 for pay_type in one database Value conflict Solutions meta dt data (data about tdt) data) 21
22 Detecting Redundancy (1) If an attributed can be derived from another attribute or a set of attributes, it may be redundant 22
23 Detecting Redundancy (2) Some redundancies can be detected by correlation analysis Correlation coefficient for numeric data Chi square test for categorical data These can be also used for data reduction 23
24 Chi-square Test For categorical (discrete) data, a correlation relationship between two attributes, A and B, can be discovered by a χ2 test Given the degree of freedom, the value of χ2 is used to decide correlation based on a significance level 24
25 Chi-square Test for Categorical Data ( Observed Expected) χ 2 = Expected 2 χ2χ 2 c r ( = e oij eij i= 1 j= 1 ij ) 2 e ij count( A = ai) count( B = b ) N j = p. 68 The larger the Χ 2 value, the more likely the variables are related. 25
26 Chi-square Test male female Total fiction non_fiction Total Table2.2 A 2 X 2 contingency table for the data of Example 2.1. Are gender and preferred_reading correlated? The χ2 statistic tests the hypothesis that gender and preferred_reading are independent. The test is based on a significant level, with (r 1) x (c 1) degree of freedom. 26
27 Table of Percentage Points of the χ2 2 Distribution ib ti 27
28 Correlation Coefficient Correlation Coefficient ) ( ) )( ( 1 1 N i i i N i i i B N A a b B b A a 1 1, = = = = B A i B A i B A N N r σ σ σ σ 1, +1 B A r p
29 29
30 Data Transformation 30
31 Data Transformation/Consolidation Smoothing Aggregation Generalization Normaliza on Attribute construc on 31
32 Smoothing Remove noise from the data Binning, regression, and clustering 32
33 Data Normalization Min-max normalization v v min A ' = ( new _ maxa new _ mina) + max A minaa new _ min A z-score normalization v' = v μa σa Normalization by decimal scaling v v'= 10 j where j is the smallest integer such that Max( ν ) < 1 33
34 Data Normalization Suppose that the minimum and maximum values for attribute income are $12,000 and $98,000, respectively. We would like to map income to the range [0.0, 0 1.0]. 10] Do Min max normalization, z score normalization, and decimal scaling for the attribute income 34
35 Attribution Construction New attributes are constructed from given attributes and added in order to help improve accuracy and understanding of structure in high dimension data Example Add the attribute area based on the attributes height and width 35
36 Data Reduction 36
37 Data Reduction Data reduction techniques can be applied to obtain a reduced representation of the data set that ismuch smallerin volume, yet closely maintains the integrity of the original data 37
38 Data Reduction (Data Cube)Aggregation Attribute (Subset) Selection Dimensionality Reduction Numerosity Reduction Data Discretization Concept thierarchy Generation 38
39 The Curse of Dimensionality (1) Size The size of a data set yielding the same density of data points in an n dimensional space increase exponentially with dimensions Radius A larger radius is needed to enclose a faction of the data points in a high dimensional space 39
40 The Curse of Dimensionality (2) Distance Almost every point is closer to an edge than to another sample point in a high dimensional space Outlier Almost every point is an outlier in a high dimensional space 40
41 Data Cube Aggregation Summarize (aggregate) data based on dimensions The resulting data set is smaller in volume, without loss of informationnecessary necessary for analysis task Concept hierarchies may exist for each attribute, allowing the analysis of data at multiple levels of abstraction 41
42 Data Aggregation Figure 2.13 Sales data for a given branch of AllElectronics for the years 2002 to On the left, the sales are shown per quarter. On the right, the data are aggregated to provide the annual sales 42
43 Data Cube Provide fast access to pre computed, summarized data, thereby benefiting on line analyticalprocessing aswell as data mining 43
44 Data Cube - Example Figure 2.14 A data cube for sales at AllElectronics 44
45 Attribute Subset Selection (1) Attribute selection can help in the phases of data mining (knowledge discovery) process By attribute selection, we can improve data mining performance (speed of learning, predictive i accuracy, or simplicity i of rules) we can visualize the data for model selected we reduce dimensionality and remove noise. 45
46 Attribute Subset Selection (2) Attribute (Feature) selection is a search problem Search directions (Sequential) Forward selection (Sequential) Backward selection (elimination) Bidirectional selection Decision i tree algorithm (induction) 46
47 Attribute Subset Selection (3) Attribute (Feature) selection is a search problem Search strategies Eh Exhaustive search Heuristic search Selection criteria Statistic significance Information gain etc. 47
48 Attribute Subset Selection (4) Figure Greedy (heuristic) methods for attribute subset selection 48
49 Data Discretization Rd Reduce the number of values for a given continuous attribute by dividing the range of the attributeinto into intervals Interval labels can then be used to replace actual ldt data values Split (top down) vs. merge (bottom up) Discretization can be performed recursively on an attribute 49/51
50 Why Discretization is Used? Reduce data size. Transforming quantitative data to qualitative data. 50
51 Interval Merge by χ 2 Analysis Merging based (bottom up) Merge: Find the best neighboring intervals and merge them to form larger intervals recursively ChiMerge [Kerber AAAI 1992, See also Liu et al. DMKD 2002] 51/51
52 Initially, each distinct value of a numerical attribute A is considered to be one interval χ 2 tests are performed for every pair of adjacent intervals Adjacent intervals with the least χ 2 values are merged together, since low χ 2 values for a pair indicate similar class distributions This mergeprocess proceeds recursively until a predefined stopping criterion is met 52
53 Entropy-Based Discretization The goal of this algorithm is to find the split with the maximum information gain. The boundary that minimizes the entropy over all possible boundaries is selected The process is recursively applied to partitions obtained until some stopping criterion is met Such a boundary may reduce data size and improve classification accuracy 53/51
54 What is Entropy? The entropy is a measure of the uncertainty associated with a random variable As uncertainty and or randomness increases for a result set so does the entropy Values range from 0 1 to represent the entropy of information 54
55 Entropy Example 55
56 Entropy Example 56
57 Entropy Example (cont d) 57
58 Calculating Entropy For m classes: Entropy ( S) For 2 classes: = m i= 1 p i log 2 p i Entropy( S) = p p 1 log 2 p1 p2 log 2 Calculated based on the class distribution of the samples in set S. p i is the probability of class i in S m is the number of classes (class values) 2 58
59 Calculating Entropy From Split Entropy of subsets S 1 and S 2 are calculated. The calculations are weighted by their probability of being in set S and summed. In formula below, S is the set T is the value used to split S into S 1 and S 2 S1 S2 E ( S, T ) = Entropy( S1) + Entropy( S2) S S 59
60 Calculating Information Gain Information Gain Gi = Difference in entropy bt between original set (S) and weighted split (S 1 + S 2 ) Gain( S, T ) = Entopy( S) E( S, T ) Gain( S,56) = Gain ( S,56) = compare to Gain( S,46) =
61 Numeric Concept Hierarchy A concept hierarchy for a given numerical attribute defines a discretization of the attribute Recursively reduce the data by collecting and replacing low level concepts by higher level concepts 61
62 A Concept Hierarchy for the Attribute Price Figure A concept hierarchy for the attribute price. 62/51
63 Segmentation by Natural Partitioning A simply rule can be used to segment numeric data into relatively l uniform, natural intervals If an interval covers 3, 6, 7 or 9 distinct values at the most significant digit, partition the range into 3 equi width intervals If it covers 2, 4, or 8 distinct values at the most significant digit, partition the range into 4 intervals If it covers 1, 5, or 10 distinct values at the most significant digit, partition the range into 5 intervals 63/51
64 64 Figure Automatic generation of a concept Hierarchy for profit based on rule.
65 Concept Hierarchy Generation for Categorical Data Specification of a partial ordering of attributes explicitly at the schema level by users or experts Specification of a portion of a hierarchy by explicit data grouping Specification of a set of attributes, but not of their partial ordering 65
66 Automatic Concept Hierarchy Generation country province or state city street 15 distinct valules 365 distinct values 3,567 distinct values 674,339 distinct values Based on the number of distinct values per attributes, p95 p.95 66
67 Data preprocessing Data cleaning Data integration Data trasnformation Data reduction Missing values Noisy data Entity ID problem Redundancy Smoothing Aggregation Generailization Normalization Attribute Construction Data cube aggregation Attribute subset selection Dimensionality reduction Numerosity Reduction Data discretization Concept hierarchy Use the most probable value to fill in the missing value (and five other methods) Binning; Regression; Clusttering Metadata Correlationanalysis analysis (Correlation coefficient, chi square test) Data cleaning Data reduction Data reduction Min max; z score; decimal scaling Data cube store multidimensional aggregated information Stepwise forward selection; stepwise backward selection; combination; decision tree induction Discrete wavelet trasnforms (DWT); Principle components analysis (PCA); Regression and log linear models; histograms; clustering; sampling Binning; i historgram analysis; entropy based discretization; Interval merging by chi square analysis; cluster analysis; intuitive partitioning Concept hierarchy generation 67
Data Mining: Data Preprocessing. I211: Information infrastructure II
 Data Mining: Data Preprocessing I211: Information infrastructure II 10 What is Data? Collection of data objects and their attributes Attributes An attribute is a property or characteristic of an object
Data Mining: Data Preprocessing I211: Information infrastructure II 10 What is Data? Collection of data objects and their attributes Attributes An attribute is a property or characteristic of an object
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 3: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 3: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major
Medical Information Management & Mining. You Chen Jan,15, 2013 [email protected]
 Medical Information Management & Mining You Chen Jan,15, 2013 [email protected] 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Medical Information Management & Mining You Chen Jan,15, 2013 [email protected] 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Data cleaning and Data preprocessing
 Data cleaning and Data preprocessing Nguyen Hung Son This presentation was prepared on the basis of the following public materials: 1. Jiawei Han and Micheline Kamber, Data mining, concept and techniques
Data cleaning and Data preprocessing Nguyen Hung Son This presentation was prepared on the basis of the following public materials: 1. Jiawei Han and Micheline Kamber, Data mining, concept and techniques
Data Exploration and Preprocessing. Data Mining and Text Mining (UIC 583 @ Politecnico di Milano)
") Data Exploration and Preprocessing Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
Data Exploration and Preprocessing Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
Knowledge Discovery and Data Mining. Structured vs. Non-Structured Data
 Knowledge Discovery and Data Mining Unit # 2 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric or alphanumeric values.
Knowledge Discovery and Data Mining Unit # 2 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric or alphanumeric values.
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Data Mining: A Preprocessing Engine
 Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Standardization and Its Effects on K-Means Clustering Algorithm
 Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
IMPROVING DATA INTEGRATION FOR DATA WAREHOUSE: A DATA MINING APPROACH
 IMPROVING DATA INTEGRATION FOR DATA WAREHOUSE: A DATA MINING APPROACH Kalinka Mihaylova Kaloyanova St. Kliment Ohridski University of Sofia, Faculty of Mathematics and Informatics Sofia 1164, Bulgaria
IMPROVING DATA INTEGRATION FOR DATA WAREHOUSE: A DATA MINING APPROACH Kalinka Mihaylova Kaloyanova St. Kliment Ohridski University of Sofia, Faculty of Mathematics and Informatics Sofia 1164, Bulgaria
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 8/05/2005 1 What is data exploration? A preliminary
Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 8/05/2005 1 What is data exploration? A preliminary
Data Mining and Knowledge Discovery in Databases (KDD) State of the Art. Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland
 State of the Art. Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland") Data Mining and Knowledge Discovery in Databases (KDD) State of the Art Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland 1 Conference overview 1. Overview of KDD and data mining 2. Data
Data Mining and Knowledge Discovery in Databases (KDD) State of the Art Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland 1 Conference overview 1. Overview of KDD and data mining 2. Data
COM CO P 5318 Da t Da a t Explora Explor t a ion and Analysis y Chapte Chapt r e 3
 COMP 5318 Data Exploration and Analysis Chapter 3 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping
COMP 5318 Data Exploration and Analysis Chapter 3 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping
Data Mining Classification: Decision Trees
 Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
BUSINESS ANALYTICS. Data Pre-processing. Lecture 3. Information Systems and Machine Learning Lab. University of Hildesheim.
 Tomáš Horváth BUSINESS ANALYTICS Lecture 3 Data Pre-processing Information Systems and Machine Learning Lab University of Hildesheim Germany Overview The aim of this lecture is to describe some data pre-processing
Tomáš Horváth BUSINESS ANALYTICS Lecture 3 Data Pre-processing Information Systems and Machine Learning Lab University of Hildesheim Germany Overview The aim of this lecture is to describe some data pre-processing
Data Mining Techniques Chapter 6: Decision Trees
 Data Mining Techniques Chapter 6: Decision Trees What is a classification decision tree?.......................................... 2 Visualizing decision trees...................................................
Data Mining Techniques Chapter 6: Decision Trees What is a classification decision tree?.......................................... 2 Visualizing decision trees...................................................
Customer Classification And Prediction Based On Data Mining Technique
 Customer Classification And Prediction Based On Data Mining Technique Ms. Neethu Baby 1, Mrs. Priyanka L.T 2 1 M.E CSE, Sri Shakthi Institute of Engineering and Technology, Coimbatore 2 Assistant Professor
Customer Classification And Prediction Based On Data Mining Technique Ms. Neethu Baby 1, Mrs. Priyanka L.T 2 1 M.E CSE, Sri Shakthi Institute of Engineering and Technology, Coimbatore 2 Assistant Professor
Lecture 10: Regression Trees
 Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Chapter 20: Data Analysis
 Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
A Survey on Pre-processing and Post-processing Techniques in Data Mining
 , pp. 99-128 http://dx.doi.org/10.14257/ijdta.2014.7.4.09 A Survey on Pre-processing and Post-processing Techniques in Data Mining Divya Tomar and Sonali Agarwal Indian Institute of Information Technology,
, pp. 99-128 http://dx.doi.org/10.14257/ijdta.2014.7.4.09 A Survey on Pre-processing and Post-processing Techniques in Data Mining Divya Tomar and Sonali Agarwal Indian Institute of Information Technology,
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Data Mining for Knowledge Management. Classification
 1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
Learning Example. Machine learning and our focus. Another Example. An example: data (loan application) The data and the goal
 The data and the goal") Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Index Contents Page No. Introduction . Data Mining & Knowledge Discovery
 Index Contents Page No. 1. Introduction 1 1.1 Related Research 2 1.2 Objective of Research Work 3 1.3 Why Data Mining is Important 3 1.4 Research Methodology 4 1.5 Research Hypothesis 4 1.6 Scope 5 2.
Index Contents Page No. 1. Introduction 1 1.1 Related Research 2 1.2 Objective of Research Work 3 1.3 Why Data Mining is Important 3 1.4 Research Methodology 4 1.5 Research Hypothesis 4 1.6 Scope 5 2.
Concept and Applications of Data Mining. Week 1
 Concept and Applications of Data Mining Week 1 Topics Introduction Syllabus Data Mining Concepts Team Organization Introduction Session Your name and major The dfiiti definition of dt data mining i Your
Concept and Applications of Data Mining Week 1 Topics Introduction Syllabus Data Mining Concepts Team Organization Introduction Session Your name and major The dfiiti definition of dt data mining i Your
Clustering. Adrian Groza. Department of Computer Science Technical University of Cluj-Napoca
 Clustering Adrian Groza Department of Computer Science Technical University of Cluj-Napoca Outline 1 Cluster Analysis What is Datamining? Cluster Analysis 2 K-means 3 Hierarchical Clustering What is Datamining?
Clustering Adrian Groza Department of Computer Science Technical University of Cluj-Napoca Outline 1 Cluster Analysis What is Datamining? Cluster Analysis 2 K-means 3 Hierarchical Clustering What is Datamining?
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Principles of Data Mining by Hand&Mannila&Smyth
 Principles of Data Mining by Hand&Mannila&Smyth Slides for Textbook Ari Visa,, Institute of Signal Processing Tampere University of Technology October 4, 2010 Data Mining: Concepts and Techniques 1 Differences
Principles of Data Mining by Hand&Mannila&Smyth Slides for Textbook Ari Visa,, Institute of Signal Processing Tampere University of Technology October 4, 2010 Data Mining: Concepts and Techniques 1 Differences
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Building Data Cubes and Mining Them. Jelena Jovanovic Email: [email protected]
 Building Data Cubes and Mining Them Jelena Jovanovic Email: [email protected] KDD Process KDD is an overall process of discovering useful knowledge from data. Data mining is a particular step in the
Building Data Cubes and Mining Them Jelena Jovanovic Email: [email protected] KDD Process KDD is an overall process of discovering useful knowledge from data. Data mining is a particular step in the
Discretization: An Enabling Technique
 Data Mining and Knowledge Discovery, 6, 393 423, 2002 c 2002 Kluwer Academic Publishers. Manufactured in The Netherlands. Discretization: An Enabling Technique HUAN LIU FARHAD HUSSAIN CHEW LIM TAN MANORANJAN
Data Mining and Knowledge Discovery, 6, 393 423, 2002 c 2002 Kluwer Academic Publishers. Manufactured in The Netherlands. Discretization: An Enabling Technique HUAN LIU FARHAD HUSSAIN CHEW LIM TAN MANORANJAN
Supervised Feature Selection & Unsupervised Dimensionality Reduction
 Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
COMP3420: Advanced Databases and Data Mining. Classification and prediction: Introduction and Decision Tree Induction
 COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
Cluster Analysis. Isabel M. Rodrigues. Lisboa, 2014. Instituto Superior Técnico
 Instituto Superior Técnico Lisboa, 2014 Introduction: Cluster analysis What is? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Instituto Superior Técnico Lisboa, 2014 Introduction: Cluster analysis What is? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Exploratory Data Analysis
 Exploratory Data Analysis Johannes Schauer [email protected] Institute of Statistics Graz University of Technology Steyrergasse 17/IV, 8010 Graz www.statistics.tugraz.at February 12, 2008 Introduction
Exploratory Data Analysis Johannes Schauer [email protected] Institute of Statistics Graz University of Technology Steyrergasse 17/IV, 8010 Graz www.statistics.tugraz.at February 12, 2008 Introduction
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
Descriptive statistics Statistical inference statistical inference, statistical induction and inferential statistics
 Descriptive statistics is the discipline of quantitatively describing the main features of a collection of data. Descriptive statistics are distinguished from inferential statistics (or inductive statistics),
Descriptive statistics is the discipline of quantitatively describing the main features of a collection of data. Descriptive statistics are distinguished from inferential statistics (or inductive statistics),
OLAP and Data Mining. Data Warehousing and End-User Access Tools. Introducing OLAP. Introducing OLAP
 Data Warehousing and End-User Access Tools OLAP and Data Mining Accompanying growth in data warehouses is increasing demands for more powerful access tools providing advanced analytical capabilities. Key
Data Warehousing and End-User Access Tools OLAP and Data Mining Accompanying growth in data warehouses is increasing demands for more powerful access tools providing advanced analytical capabilities. Key
Clustering. 15-381 Artificial Intelligence Henry Lin. Organizing data into clusters such that there is
 Clustering 15-381 Artificial Intelligence Henry Lin Modified from excellent slides of Eamonn Keogh, Ziv Bar-Joseph, and Andrew Moore What is Clustering? Organizing data into clusters such that there is
Clustering 15-381 Artificial Intelligence Henry Lin Modified from excellent slides of Eamonn Keogh, Ziv Bar-Joseph, and Andrew Moore What is Clustering? Organizing data into clusters such that there is
Divide-n-Discover Discretization based Data Exploration Framework for Healthcare Analytics
 for Healthcare Analytics Si-Chi Chin,KiyanaZolfaghar,SenjutiBasuRoy,AnkurTeredesai,andPaulAmoroso Institute of Technology, The University of Washington -Tacoma,900CommerceStreet,Tacoma,WA980-00,U.S.A.
for Healthcare Analytics Si-Chi Chin,KiyanaZolfaghar,SenjutiBasuRoy,AnkurTeredesai,andPaulAmoroso Institute of Technology, The University of Washington -Tacoma,900CommerceStreet,Tacoma,WA980-00,U.S.A.
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER. Copyr i g ht 2013, SAS Ins titut e Inc. All rights res er ve d.
 EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER ANALYTICS LIFECYCLE Evaluate & Monitor Model Formulate Problem Data Preparation Deploy Model Data Exploration Validate Models
EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER ANALYTICS LIFECYCLE Evaluate & Monitor Model Formulate Problem Data Preparation Deploy Model Data Exploration Validate Models
Clustering & Visualization
 Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Classification and Prediction
 Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Assessment. Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall
 Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
Automatic Photo Quality Assessment Presenter: Yupu Zhang, Guoliang Jin, Tuo Wang Computer Vision 2008 Fall Estimating i the photorealism of images: Distinguishing i i paintings from photographs h Florin
An Overview of Knowledge Discovery Database and Data mining Techniques
 An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
A fast, powerful data mining workbench designed for small to midsize organizations
 FACT SHEET SAS Desktop Data Mining for Midsize Business A fast, powerful data mining workbench designed for small to midsize organizations What does SAS Desktop Data Mining for Midsize Business do? Business
FACT SHEET SAS Desktop Data Mining for Midsize Business A fast, powerful data mining workbench designed for small to midsize organizations What does SAS Desktop Data Mining for Midsize Business do? Business
Cluster Analysis: Advanced Concepts
 Cluster Analysis: Advanced Concepts and dalgorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 08/06/2006 1 Introduction to Data Mining 08/06/2006 1 Outline Prototype-based Fuzzy c-means
Cluster Analysis: Advanced Concepts and dalgorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 08/06/2006 1 Introduction to Data Mining 08/06/2006 1 Outline Prototype-based Fuzzy c-means
Data Mining. Knowledge Discovery, Data Warehousing and Machine Learning Final remarks. Lecturer: JERZY STEFANOWSKI
 Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: [email protected] Data Mining a step in A KDD Process Data mining:
Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: [email protected] Data Mining a step in A KDD Process Data mining:
Data Exploration Data Visualization
 Data Exploration Data Visualization What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping to select
Data Exploration Data Visualization What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping to select
Exploratory data analysis (Chapter 2) Fall 2011
 Fall 2011") Exploratory data analysis (Chapter 2) Fall 2011 Data Examples Example 1: Survey Data 1 Data collected from a Stat 371 class in Fall 2005 2 They answered questions about their: gender, major, year in school,
Exploratory data analysis (Chapter 2) Fall 2011 Data Examples Example 1: Survey Data 1 Data collected from a Stat 371 class in Fall 2005 2 They answered questions about their: gender, major, year in school,
How To Solve The Kd Cup 2010 Challenge
 A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China [email protected] [email protected]
A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China [email protected] [email protected]
Decision Trees What Are They?
 Decision Trees What Are They? Introduction...1 Using Decision Trees with Other Modeling Approaches...5 Why Are Decision Trees So Useful?...8 Level of Measurement... 11 Introduction Decision trees are a
Decision Trees What Are They? Introduction...1 Using Decision Trees with Other Modeling Approaches...5 Why Are Decision Trees So Useful?...8 Level of Measurement... 11 Introduction Decision trees are a
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP
 Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Introduction to Data Mining
 Introduction to Data Mining 1 Why Data Mining? Explosive Growth of Data Data collection and data availability Automated data collection tools, Internet, smartphones, Major sources of abundant data Business:
Introduction to Data Mining 1 Why Data Mining? Explosive Growth of Data Data collection and data availability Automated data collection tools, Internet, smartphones, Major sources of abundant data Business:
Data Mining: Concepts and Techniques. Jiawei Han. Micheline Kamber. Simon Fräser University К MORGAN KAUFMANN PUBLISHERS. AN IMPRINT OF Elsevier
 Data Mining: Concepts and Techniques Jiawei Han Micheline Kamber Simon Fräser University К MORGAN KAUFMANN PUBLISHERS AN IMPRINT OF Elsevier Contents Foreword Preface xix vii Chapter I Introduction I I.
Data Mining: Concepts and Techniques Jiawei Han Micheline Kamber Simon Fräser University К MORGAN KAUFMANN PUBLISHERS AN IMPRINT OF Elsevier Contents Foreword Preface xix vii Chapter I Introduction I I.
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Slides by Tan, Steinbach, Kumar adapted by Michael Hahsler
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Slides by Tan, Steinbach, Kumar adapted by Michael Hahsler Topics Exploratory Data Analysis Summary Statistics Visualization What is data exploration?
Data Mining: Exploring Data Lecture Notes for Chapter 3 Slides by Tan, Steinbach, Kumar adapted by Michael Hahsler Topics Exploratory Data Analysis Summary Statistics Visualization What is data exploration?
DATA VERIFICATION IN ETL PROCESSES
 KNOWLEDGE ENGINEERING: PRINCIPLES AND TECHNIQUES Proceedings of the International Conference on Knowledge Engineering, Principles and Techniques, KEPT2007 Cluj-Napoca (Romania), June 6 8, 2007, pp. 282
KNOWLEDGE ENGINEERING: PRINCIPLES AND TECHNIQUES Proceedings of the International Conference on Knowledge Engineering, Principles and Techniques, KEPT2007 Cluj-Napoca (Romania), June 6 8, 2007, pp. 282
Normality Testing in Excel
 Normality Testing in Excel By Mark Harmon Copyright 2011 Mark Harmon No part of this publication may be reproduced or distributed without the express permission of the author. [email protected]
Normality Testing in Excel By Mark Harmon Copyright 2011 Mark Harmon No part of this publication may be reproduced or distributed without the express permission of the author. [email protected]
Designing a learning system
 Lecture Designing a learning system Milos Hauskrecht [email protected] 539 Sennott Square, x4-8845 http://.cs.pitt.edu/~milos/courses/cs750/ Design of a learning system (first vie) Application or Testing
Lecture Designing a learning system Milos Hauskrecht [email protected] 539 Sennott Square, x4-8845 http://.cs.pitt.edu/~milos/courses/cs750/ Design of a learning system (first vie) Application or Testing
Using Data Mining for Mobile Communication Clustering and Characterization
 Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Multiple Linear Regression in Data Mining
 Multiple Linear Regression in Data Mining Contents 2.1. A Review of Multiple Linear Regression 2.2. Illustration of the Regression Process 2.3. Subset Selection in Linear Regression 1 2 Chap. 2 Multiple
Multiple Linear Regression in Data Mining Contents 2.1. A Review of Multiple Linear Regression 2.2. Illustration of the Regression Process 2.3. Subset Selection in Linear Regression 1 2 Chap. 2 Multiple
Chapter 7. Cluster Analysis
 Chapter 7. Cluster Analysis. What is Cluster Analysis?. A Categorization of Major Clustering Methods. Partitioning Methods. Hierarchical Methods 5. Density-Based Methods 6. Grid-Based Methods 7. Model-Based
Chapter 7. Cluster Analysis. What is Cluster Analysis?. A Categorization of Major Clustering Methods. Partitioning Methods. Hierarchical Methods 5. Density-Based Methods 6. Grid-Based Methods 7. Model-Based
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Clustering Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Clustering Algorithms K-means and its variants Hierarchical clustering
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Clustering Algorithms K-means and its variants Hierarchical clustering
Rule based Classification of BSE Stock Data with Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 4, Number 1 (2012), pp. 1-9 International Research Publication House http://www.irphouse.com Rule based Classification
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 4, Number 1 (2012), pp. 1-9 International Research Publication House http://www.irphouse.com Rule based Classification
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Data Mining: An Overview. David Madigan http://www.stat.columbia.edu/~madigan
 Data Mining: An Overview David Madigan http://www.stat.columbia.edu/~madigan Overview Brief Introduction to Data Mining Data Mining Algorithms Specific Eamples Algorithms: Disease Clusters Algorithms:
Data Mining: An Overview David Madigan http://www.stat.columbia.edu/~madigan Overview Brief Introduction to Data Mining Data Mining Algorithms Specific Eamples Algorithms: Disease Clusters Algorithms:
STATISTICA Formula Guide: Logistic Regression. Table of Contents
 : Table of Contents... 1 Overview of Model... 1 Dispersion... 2 Parameterization... 3 Sigma-Restricted Model... 3 Overparameterized Model... 4 Reference Coding... 4 Model Summary (Summary Tab)... 5 Summary
: Table of Contents... 1 Overview of Model... 1 Dispersion... 2 Parameterization... 3 Sigma-Restricted Model... 3 Overparameterized Model... 4 Reference Coding... 4 Model Summary (Summary Tab)... 5 Summary
ETL PROCESS IN DATA WAREHOUSE
 ETL PROCESS IN DATA WAREHOUSE OUTLINE ETL : Extraction, Transformation, Loading Capture/Extract Scrub or data cleansing Transform Load and Index ETL OVERVIEW Extraction Transformation Loading ETL ETL is
ETL PROCESS IN DATA WAREHOUSE OUTLINE ETL : Extraction, Transformation, Loading Capture/Extract Scrub or data cleansing Transform Load and Index ETL OVERVIEW Extraction Transformation Loading ETL ETL is
Robust Outlier Detection Technique in Data Mining: A Univariate Approach
 Robust Outlier Detection Technique in Data Mining: A Univariate Approach Singh Vijendra and Pathak Shivani Faculty of Engineering and Technology Mody Institute of Technology and Science Lakshmangarh, Sikar,
Robust Outlier Detection Technique in Data Mining: A Univariate Approach Singh Vijendra and Pathak Shivani Faculty of Engineering and Technology Mody Institute of Technology and Science Lakshmangarh, Sikar,
STT315 Chapter 4 Random Variables & Probability Distributions KM. Chapter 4.5, 6, 8 Probability Distributions for Continuous Random Variables
 Chapter 4.5, 6, 8 Probability Distributions for Continuous Random Variables Discrete vs. continuous random variables Examples of continuous distributions o Uniform o Exponential o Normal Recall: A random
Chapter 4.5, 6, 8 Probability Distributions for Continuous Random Variables Discrete vs. continuous random variables Examples of continuous distributions o Uniform o Exponential o Normal Recall: A random
Comparative Analysis of Supervised and Unsupervised Discretization Techniques
 , Vol., No. 3, 0 Comparative Analysis of Supervised and Unsupervised Discretization Techniques Rajashree Dash, Rajib Lochan Paramguru, Rasmita Dash 3, Department of Computer Science and Engineering, ITER,Siksha
, Vol., No. 3, 0 Comparative Analysis of Supervised and Unsupervised Discretization Techniques Rajashree Dash, Rajib Lochan Paramguru, Rasmita Dash 3, Department of Computer Science and Engineering, ITER,Siksha
Data W a Ware r house house and and OLAP Week 5 1
 Data Warehouse and OLAP Week 5 1 Midterm I Friday, March 4 Scope Homework assignments 1 4 Open book Team Homework Assignment #7 Read pp. 121 139, 146 150 of the text book. Do Examples 3.8, 3.10 and Exercise
Data Warehouse and OLAP Week 5 1 Midterm I Friday, March 4 Scope Homework assignments 1 4 Open book Team Homework Assignment #7 Read pp. 121 139, 146 150 of the text book. Do Examples 3.8, 3.10 and Exercise
Lecture 6 - Data Mining Processes
 Lecture 6 - Data Mining Processes Dr. Songsri Tangsripairoj Dr.Benjarath Pupacdi Faculty of ICT, Mahidol University 1 Cross-Industry Standard Process for Data Mining (CRISP-DM) Example Application: Telephone
Lecture 6 - Data Mining Processes Dr. Songsri Tangsripairoj Dr.Benjarath Pupacdi Faculty of ICT, Mahidol University 1 Cross-Industry Standard Process for Data Mining (CRISP-DM) Example Application: Telephone
Exercise 1.12 (Pg. 22-23)
") Individuals: The objects that are described by a set of data. They may be people, animals, things, etc. (Also referred to as Cases or Records) Variables: The characteristics recorded about each individual.
Individuals: The objects that are described by a set of data. They may be people, animals, things, etc. (Also referred to as Cases or Records) Variables: The characteristics recorded about each individual.
Statistics Chapter 2
 Statistics Chapter 2 Frequency Tables A frequency table organizes quantitative data. partitions data into classes (intervals). shows how many data values are in each class. Test Score Number of Students
Statistics Chapter 2 Frequency Tables A frequency table organizes quantitative data. partitions data into classes (intervals). shows how many data values are in each class. Test Score Number of Students
PREDICTING STUDENTS PERFORMANCE USING ID3 AND C4.5 CLASSIFICATION ALGORITHMS
 PREDICTING STUDENTS PERFORMANCE USING ID3 AND C4.5 CLASSIFICATION ALGORITHMS Kalpesh Adhatrao, Aditya Gaykar, Amiraj Dhawan, Rohit Jha and Vipul Honrao ABSTRACT Department of Computer Engineering, Fr.
PREDICTING STUDENTS PERFORMANCE USING ID3 AND C4.5 CLASSIFICATION ALGORITHMS Kalpesh Adhatrao, Aditya Gaykar, Amiraj Dhawan, Rohit Jha and Vipul Honrao ABSTRACT Department of Computer Engineering, Fr.
K-Means Cluster Analysis. Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1
 K-Means Cluster Analsis Chapter 3 PPDM Class Tan,Steinbach, Kumar Introduction to Data Mining 4/18/4 1 What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar
K-Means Cluster Analsis Chapter 3 PPDM Class Tan,Steinbach, Kumar Introduction to Data Mining 4/18/4 1 What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar
Professor Anita Wasilewska. Classification Lecture Notes
 Professor Anita Wasilewska Classification Lecture Notes Classification (Data Mining Book Chapters 5 and 7) PART ONE: Supervised learning and Classification Data format: training and test data Concept,
Professor Anita Wasilewska Classification Lecture Notes Classification (Data Mining Book Chapters 5 and 7) PART ONE: Supervised learning and Classification Data format: training and test data Concept,
International Journal of Computer Science Trends and Technology (IJCST) Volume 2 Issue 3, May-Jun 2014
 Volume 2 Issue 3, May-Jun 2014") RESEARCH ARTICLE OPEN ACCESS A Survey of Data Mining: Concepts with Applications and its Future Scope Dr. Zubair Khan 1, Ashish Kumar 2, Sunny Kumar 3 M.Tech Research Scholar 2. Department of Computer
RESEARCH ARTICLE OPEN ACCESS A Survey of Data Mining: Concepts with Applications and its Future Scope Dr. Zubair Khan 1, Ashish Kumar 2, Sunny Kumar 3 M.Tech Research Scholar 2. Department of Computer
Neural Networks Lesson 5 - Cluster Analysis
 Neural Networks Lesson 5 - Cluster Analysis Prof. Michele Scarpiniti INFOCOM Dpt. - Sapienza University of Rome http://ispac.ing.uniroma1.it/scarpiniti/index.htm [email protected] Rome, 29
Neural Networks Lesson 5 - Cluster Analysis Prof. Michele Scarpiniti INFOCOM Dpt. - Sapienza University of Rome http://ispac.ing.uniroma1.it/scarpiniti/index.htm [email protected] Rome, 29
Data Warehousing und Data Mining
 Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
How To Cluster
 Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 by Tan, Steinbach, Kumar 1 What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 by Tan, Steinbach, Kumar 1 What is Cluster Analysis? Finding groups of objects such that the objects in a group will
TOWARDS SIMPLE, EASY TO UNDERSTAND, AN INTERACTIVE DECISION TREE ALGORITHM
 TOWARDS SIMPLE, EASY TO UNDERSTAND, AN INTERACTIVE DECISION TREE ALGORITHM Thanh-Nghi Do College of Information Technology, Cantho University 1 Ly Tu Trong Street, Ninh Kieu District Cantho City, Vietnam
TOWARDS SIMPLE, EASY TO UNDERSTAND, AN INTERACTIVE DECISION TREE ALGORITHM Thanh-Nghi Do College of Information Technology, Cantho University 1 Ly Tu Trong Street, Ninh Kieu District Cantho City, Vietnam
Review of Modern Techniques of Qualitative Data Clustering
 Review of Modern Techniques of Qualitative Data Clustering Sergey Cherevko and Andrey Malikov The North Caucasus Federal University, Institute of Information Technology and Telecommunications [email protected],
Review of Modern Techniques of Qualitative Data Clustering Sergey Cherevko and Andrey Malikov The North Caucasus Federal University, Institute of Information Technology and Telecommunications [email protected],
A Review of Data Mining Techniques
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 4, April 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 4, April 2014,
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Multimedia Databases. Wolf-Tilo Balke Philipp Wille Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.
 Multimedia Databases Wolf-Tilo Balke Philipp Wille Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 14 Previous Lecture 13 Indexes for Multimedia Data 13.1
Multimedia Databases Wolf-Tilo Balke Philipp Wille Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 14 Previous Lecture 13 Indexes for Multimedia Data 13.1
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization
 A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca [email protected] Spain Manuel Martín-Merino Universidad
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca [email protected] Spain Manuel Martín-Merino Universidad
Data Mining with R. Decision Trees and Random Forests. Hugh Murrell
 Data Mining with R Decision Trees and Random Forests Hugh Murrell reference books These slides are based on a book by Graham Williams: Data Mining with Rattle and R, The Art of Excavating Data for Knowledge
Data Mining with R Decision Trees and Random Forests Hugh Murrell reference books These slides are based on a book by Graham Williams: Data Mining with Rattle and R, The Art of Excavating Data for Knowledge
Java Modules for Time Series Analysis
 Java Modules for Time Series Analysis Agenda Clustering Non-normal distributions Multifactor modeling Implied ratings Time series prediction 1. Clustering + Cluster 1 Synthetic Clustering + Time series
Java Modules for Time Series Analysis Agenda Clustering Non-normal distributions Multifactor modeling Implied ratings Time series prediction 1. Clustering + Cluster 1 Synthetic Clustering + Time series
IBM SPSS Direct Marketing 23
 IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
Data Mining. Cluster Analysis: Advanced Concepts and Algorithms
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 More Clustering Methods Prototype-based clustering Density-based clustering Graph-based
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 More Clustering Methods Prototype-based clustering Density-based clustering Graph-based
Insurance Analytics - analýza dat a prediktivní modelování v pojišťovnictví. Pavel Kříž. Seminář z aktuárských věd MFF 4.
 Insurance Analytics - analýza dat a prediktivní modelování v pojišťovnictví Pavel Kříž Seminář z aktuárských věd MFF 4. dubna 2014 Summary 1. Application areas of Insurance Analytics 2. Insurance Analytics
Insurance Analytics - analýza dat a prediktivní modelování v pojišťovnictví Pavel Kříž Seminář z aktuárských věd MFF 4. dubna 2014 Summary 1. Application areas of Insurance Analytics 2. Insurance Analytics