Data Mining. Cluster Analysis: Advanced Concepts and Algorithms
|
|
|
- Hubert O’Neal’
- 10 years ago
- Views:
Transcription
1 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/ More Clustering Methods Prototype-based clustering Density-based clustering Graph-based clustering Scalable Clustering

2 Prototype-based Clustering Fuzzy c-means: objects are allowed to belong to more than one cluster EM (Expectation-Maximization): a cluster is modeled as a statistical distribution SOM (Self-Organizing Maps): clusters are constrained to have fixed relationships Fuzzy c-means A collection of fuzzy clusters is a subset of all possible fuzzy subsets of the set of data points. Each point is assigned a weight for each cluster. The sum of the weight for each point is 1. Each cluster contains at least one point but not all points. Difference from K-means: instead of updating centroid and reassign points, c-means updates the centroid and the weight.

3 Clustering using Mixture Models Mixture model: using statistical distributions to model data, with each distribution corresponds to a cluster Maximum Likelihood principle: parameters for distribution are fixed but unknown best parameters are obtained by maximizing the probability of obtaining the samples observed

4 Likelihood Function: likelihood function for a data set that contains n points: k n P( D θ ) = = P( xk θ ) k = 1 P( D θ ) is called the likelihood of θ w.r.t. the set of samples D) log-likelihood function: l ( θ) = log P( D θ) Distribution parameters ˆ θ = arg log-likelihood is given by: k n = = θl = k 1 θ max θ θ log P( x l( ) that maximize the k θ ) = 0
 log-likelihood function: l ( θ) = log P( D θ) Distribution")
5 The EM Algorithm Select an initial set of model parameters Repeat Expectation Step: for each object, calculate the probability that each object belongs to each distribution Maximization Step: Given the probabilities from the expectation step, find the new estimates of the parameters that maximize the expected likelihood Until the parameters do not change K-means is a special case of EM for Gaussian distributions with equal covariance but different means Left cluster corresponds to Gaussian distribution with center at (-4,1) and std=2 Right cluster corresponds to Gaussian distribution with center at (0,0), and std=0.5
 and std=2 Right cluster corresponds to Gaussian distribution with center at (0,0), and")
6 SOM Centroids have a pre-determined topographic ordering relationship For each data point, its closest centroid and centroids in the neighborhood are updated Output is a set of centroids with clusters implicitly defined.

7 Density-based Clustering Grid-based clustering: define a set of grid cells assign data points to the appropriate cells and compute the density of each cell eliminate cells with low density merge adjacent cells to form clusters CLIQUE: cluster data points using a subset of attributes DENCLUE: use kernel density function

8 CLIQUE Partition each dimension into the same number of equal width interval and partition an m-dimensional data space into non-overlapping rectangular units Repeatedly generate k-dimensional subspace cells from k-1-dimensional subspace cells and eliminate non-dense cells Merge adjacent cells to form clusters DENCLUE Influence or kernel function: each data point has an influence that extends over a range Density function: sum of all kernel function associated with each data point

9 DENCLUE Find density attractor x* which is the local maximum of the density function Associate points to a density attractor x* that maximize the increase in density Each density attractor and data points associated with it represents a cluster Discard a cluster if its density attractor has a density less than ξ Combine clusters that are connected Points that are attracted to smaller maxima are considered outliers Graph-based Clustering Graph-Based clustering uses the proximity graph Start with the proximity matrix Consider each data point as a node in a graph Each edge between two nodes has a weight which is the proximity between the two data points In the simplest case, clusters are connected components in the graph Graph-based clustering algorithms: Chameleon Shared Nearest Neighbor and SNN density

10 Chameleon Adapt to the characteristics of the data set to find the natural clusters Use a dynamic model to measure the similarity between clusters Main property is the relative closeness and relative interconnectivity of the cluster Two clusters are combined if the resulting cluster shares certain properties with the constituent clusters The merging scheme preserves self-similarity One of the areas of application is spatial data Characteristics of Spatial Data Sets Clusters are defined as densely populated regions of the space Clusters have arbitrary shapes, orientation, and non-uniform sizes Difference in densities across clusters and variation in density within clusters Existence of special artifacts (streaks) and noise The clustering algorithm must address the above characteristics and also require minimal supervision.
 and noise The clustering algorithm must address the above")
11 Chameleon Preprocessing Step: Represent the Data by a Graph Given a set of points, construct the k-nearest-neighbor (k-nn) graph to capture the relationship between a point and its k nearest neighbors Concept of neighborhood is captured dynamically (even if region is sparse) Phase 1: Use a multilevel graph partitioning algorithm on the graph to find a large number of clusters of well-connected vertices Each cluster should contain mostly points from one true cluster, i.e., is a sub-cluster of a real cluster Chameleon Phase 2: Use Hierarchical Agglomerative Clustering to merge sub-clusters Two clusters are combined if the resulting cluster shares certain properties with the constituent clusters Two key properties used to model cluster similarity: u Relative Interconnectivity: Absolute interconnectivity of two clusters normalized by the internal connectivity of the clusters u Relative Closeness: Absolute closeness of two clusters normalized by the internal closeness of the clusters

12 Shared Near Neighbor SNN graph: the weight of an edge is the number of shared neighbors between vertices given that the vertices are connected i j i j 4 SNN Density Clustering 1. Compute the similarity matrix This corresponds to a similarity graph with data points for nodes and edges whose weights are the similarities between data points 2. Sparsify the similarity matrix by keeping only the k most similar neighbors This corresponds to only keeping the k strongest links of the similarity graph 3. Construct the shared nearest neighbor graph from the sparsified similarity matrix. At this point, we could apply a similarity threshold and find the connected components to obtain the clusters (Jarvis-Patrick algorithm) 4. Find the SNN density of each Point. Using a user specified parameters, Eps, find the number points that have an SNN similarity of Eps or greater to each point. This is the SNN density of the point

13 SNN Density Clustering 5. Find the core points Using a user specified parameter, MinPts, find the core points, i.e., all points that have an SNN density greater than MinPts 6. Form clusters from the core points If two core points are within a radius, Eps, of each other they are place in the same cluster 7. Discard all noise points All non-core points that are not within a radius of Eps of a core point are discarded 8. Assign all non-noise, non-core points to clusters This can be done by assigning such points to the nearest core point (Note that steps 4-8 are DBSCAN) Scalable Clustering Algorithms Handles large amount of data BIRCH CURE
 Scalable")
14 BIRCH Balanced Iterative Reducing and Clustering using Hierarchies Minimized I/O cost (1 or 2 scan) Clustering Feature: N number of points in a cluster LS linear sum of points in a cluster SS square sum of points in a cluster CF-tree Similar to B+-tree Each node corresponds to one page Parameters: B branching factor T threshold Non-leaf node contains at most B CF entries of its child Leaf node each entry s diameter (or radius) has to be less than T, number of entries per node is determined by the page size and entry size. A leaf node represents a cluster made up of all the subclusters represented by its entries.

15 CF-tree BIRCH Algorithm
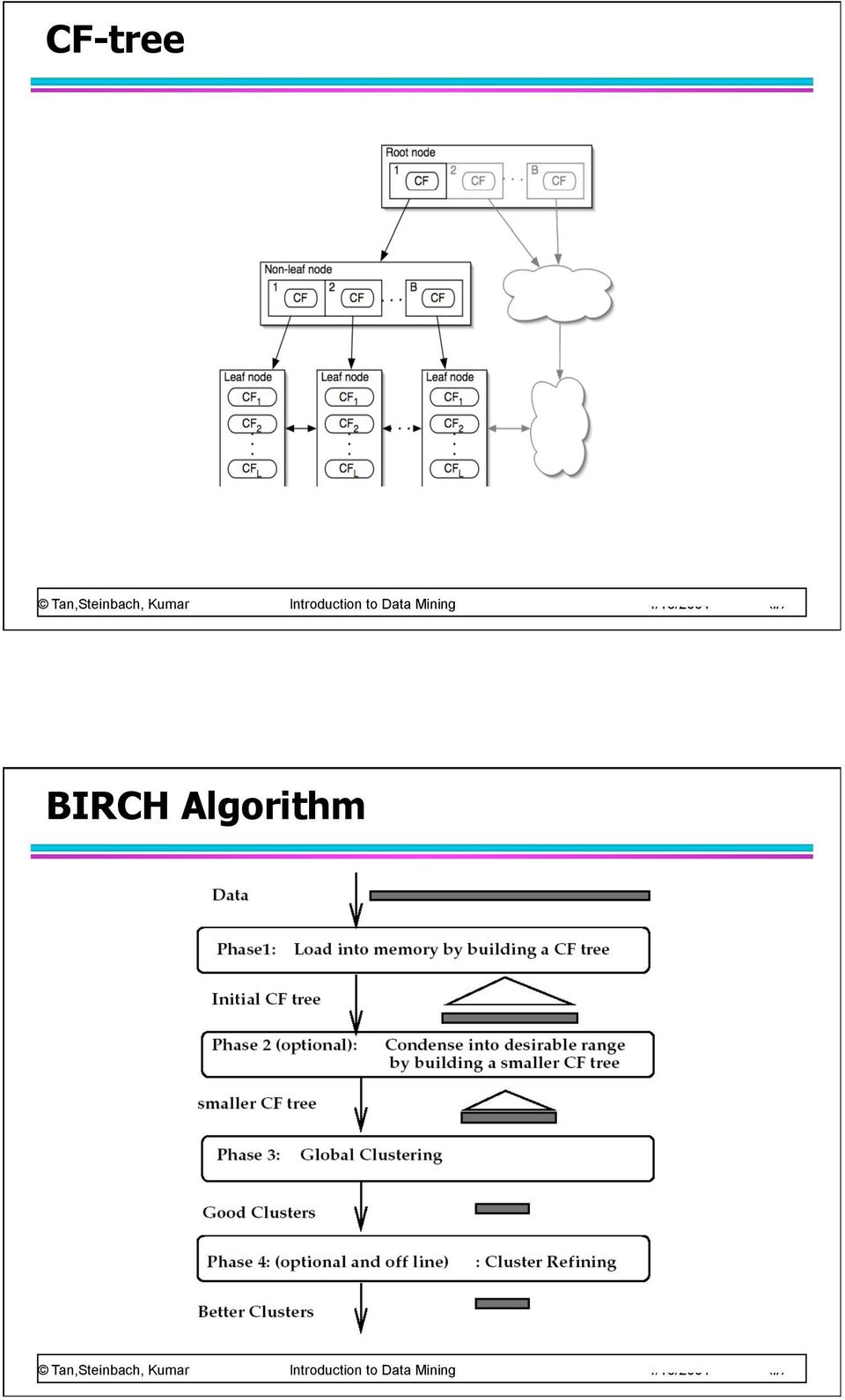
16 BIRCH Algorithm Phase 1: Start with initial threshold and insert points into the tree If run out of memory, increase threshold value, and rebuild a smaller tree by reinserting values from older tree and then other values Remove outliers while rebuilding tree Phase 2: Optional prepare the tree for Phase 3 Removes outliers, and grouping clusters BIRCH Algorithm Phase 3: Cluster all leaf nodes on the CF values according to an existing algorithm (e.g. agglomerative hierarchical clustering) Phase 4: Optional refine clusters Perform additional passes over the dataset and reassign data points to the closest centroid Recalculate the centroids and redistributing the items.

17 An Example of the CF-tree Initially, the data points in one cluster. root A A An Example of the CF-tree The data arrives, and a check is made whether the size of the cluster does not exceed T. root A A T

18 An Example of the CF-tree If the cluster size grows too big, the cluster is split into two clusters, and the points are redistributed. A root B B A T An Example of the CF-tree At each node of the tree, the CF tree keeps information about the mean of the cluster, and the mean of the sum of squares to compute the size of the clusters efficiently. A root B A B

19 CURE Uses a number of points to represent a cluster Representative points are found by selecting a constant number of points from a cluster and then shrinking them toward the center of the cluster Cluster similarity is the similarity of the closest pair of representative points from different clusters CURE Shrinking representative points toward the center helps avoid problems with noise and outliers CURE is better able to handle clusters of arbitrary shapes and sizes

Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 9. Introduction to Data Mining
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 9 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 9 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
Cluster Analysis: Advanced Concepts
 Cluster Analysis: Advanced Concepts and dalgorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 08/06/2006 1 Introduction to Data Mining 08/06/2006 1 Outline Prototype-based Fuzzy c-means
Cluster Analysis: Advanced Concepts and dalgorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 08/06/2006 1 Introduction to Data Mining 08/06/2006 1 Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 9. Introduction to Data Mining
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 9 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 9 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
BIRCH: An Efficient Data Clustering Method For Very Large Databases
 BIRCH: An Efficient Data Clustering Method For Very Large Databases Tian Zhang, Raghu Ramakrishnan, Miron Livny CPSC 504 Presenter: Discussion Leader: Sophia (Xueyao) Liang HelenJr, Birches. Online Image.
BIRCH: An Efficient Data Clustering Method For Very Large Databases Tian Zhang, Raghu Ramakrishnan, Miron Livny CPSC 504 Presenter: Discussion Leader: Sophia (Xueyao) Liang HelenJr, Birches. Online Image.
Clustering. Data Mining. Abraham Otero. Data Mining. Agenda
 Clustering 1/46 Agenda Introduction Distance K-nearest neighbors Hierarchical clustering Quick reference 2/46 1 Introduction It seems logical that in a new situation we should act in a similar way as in
Clustering 1/46 Agenda Introduction Distance K-nearest neighbors Hierarchical clustering Quick reference 2/46 1 Introduction It seems logical that in a new situation we should act in a similar way as in
Data Clustering Techniques Qualifying Oral Examination Paper
 Data Clustering Techniques Qualifying Oral Examination Paper Periklis Andritsos University of Toronto Department of Computer Science [email protected] March 11, 2002 1 Introduction During a cholera
Data Clustering Techniques Qualifying Oral Examination Paper Periklis Andritsos University of Toronto Department of Computer Science [email protected] March 11, 2002 1 Introduction During a cholera
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 by Tan, Steinbach, Kumar 1 What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 by Tan, Steinbach, Kumar 1 What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Clustering UE 141 Spring 2013
 Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Clustering Techniques: A Brief Survey of Different Clustering Algorithms
 Clustering Techniques: A Brief Survey of Different Clustering Algorithms Deepti Sisodia Technocrates Institute of Technology, Bhopal, India Lokesh Singh Technocrates Institute of Technology, Bhopal, India
Clustering Techniques: A Brief Survey of Different Clustering Algorithms Deepti Sisodia Technocrates Institute of Technology, Bhopal, India Lokesh Singh Technocrates Institute of Technology, Bhopal, India
Classifying Large Data Sets Using SVMs with Hierarchical Clusters. Presented by :Limou Wang
 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Clustering. Adrian Groza. Department of Computer Science Technical University of Cluj-Napoca
 Clustering Adrian Groza Department of Computer Science Technical University of Cluj-Napoca Outline 1 Cluster Analysis What is Datamining? Cluster Analysis 2 K-means 3 Hierarchical Clustering What is Datamining?
Clustering Adrian Groza Department of Computer Science Technical University of Cluj-Napoca Outline 1 Cluster Analysis What is Datamining? Cluster Analysis 2 K-means 3 Hierarchical Clustering What is Datamining?
Clustering methods for Big data analysis
 Clustering methods for Big data analysis Keshav Sanse, Meena Sharma Abstract Today s age is the age of data. Nowadays the data is being produced at a tremendous rate. In order to make use of this large-scale
Clustering methods for Big data analysis Keshav Sanse, Meena Sharma Abstract Today s age is the age of data. Nowadays the data is being produced at a tremendous rate. In order to make use of this large-scale
Data Mining Clustering (2) Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining
 Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining") Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
An Introduction to Cluster Analysis for Data Mining
 An Introduction to Cluster Analysis for Data Mining 10/02/2000 11:42 AM 1. INTRODUCTION... 4 1.1. Scope of This Paper... 4 1.2. What Cluster Analysis Is... 4 1.3. What Cluster Analysis Is Not... 5 2. OVERVIEW...
An Introduction to Cluster Analysis for Data Mining 10/02/2000 11:42 AM 1. INTRODUCTION... 4 1.1. Scope of This Paper... 4 1.2. What Cluster Analysis Is... 4 1.3. What Cluster Analysis Is Not... 5 2. OVERVIEW...
Clustering & Visualization
 Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Chapter 7. Cluster Analysis
 Chapter 7. Cluster Analysis. What is Cluster Analysis?. A Categorization of Major Clustering Methods. Partitioning Methods. Hierarchical Methods 5. Density-Based Methods 6. Grid-Based Methods 7. Model-Based
Chapter 7. Cluster Analysis. What is Cluster Analysis?. A Categorization of Major Clustering Methods. Partitioning Methods. Hierarchical Methods 5. Density-Based Methods 6. Grid-Based Methods 7. Model-Based
The SPSS TwoStep Cluster Component
 White paper technical report The SPSS TwoStep Cluster Component A scalable component enabling more efficient customer segmentation Introduction The SPSS TwoStep Clustering Component is a scalable cluster
White paper technical report The SPSS TwoStep Cluster Component A scalable component enabling more efficient customer segmentation Introduction The SPSS TwoStep Clustering Component is a scalable cluster
Cluster Analysis: Basic Concepts and Algorithms
 8 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
8 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
Cluster Analysis. Alison Merikangas Data Analysis Seminar 18 November 2009
 Cluster Analysis Alison Merikangas Data Analysis Seminar 18 November 2009 Overview What is cluster analysis? Types of cluster Distance functions Clustering methods Agglomerative K-means Density-based Interpretation
Cluster Analysis Alison Merikangas Data Analysis Seminar 18 November 2009 Overview What is cluster analysis? Types of cluster Distance functions Clustering methods Agglomerative K-means Density-based Interpretation
A comparison of various clustering methods and algorithms in data mining
 Volume :2, Issue :5, 32-36 May 2015 www.allsubjectjournal.com e-issn: 2349-4182 p-issn: 2349-5979 Impact Factor: 3.762 R.Tamilselvi B.Sivasakthi R.Kavitha Assistant Professor A comparison of various clustering
Volume :2, Issue :5, 32-36 May 2015 www.allsubjectjournal.com e-issn: 2349-4182 p-issn: 2349-5979 Impact Factor: 3.762 R.Tamilselvi B.Sivasakthi R.Kavitha Assistant Professor A comparison of various clustering
A Comparative Analysis of Various Clustering Techniques used for Very Large Datasets
 A Comparative Analysis of Various Clustering Techniques used for Very Large Datasets Preeti Baser, Assistant Professor, SJPIBMCA, Gandhinagar, Gujarat, India 382 007 Research Scholar, R. K. University,
A Comparative Analysis of Various Clustering Techniques used for Very Large Datasets Preeti Baser, Assistant Professor, SJPIBMCA, Gandhinagar, Gujarat, India 382 007 Research Scholar, R. K. University,
On Clustering Validation Techniques
 Journal of Intelligent Information Systems, 17:2/3, 107 145, 2001 c 2001 Kluwer Academic Publishers. Manufactured in The Netherlands. On Clustering Validation Techniques MARIA HALKIDI [email protected] YANNIS
Journal of Intelligent Information Systems, 17:2/3, 107 145, 2001 c 2001 Kluwer Academic Publishers. Manufactured in The Netherlands. On Clustering Validation Techniques MARIA HALKIDI [email protected] YANNIS
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
An Analysis on Density Based Clustering of Multi Dimensional Spatial Data
 An Analysis on Density Based Clustering of Multi Dimensional Spatial Data K. Mumtaz 1 Assistant Professor, Department of MCA Vivekanandha Institute of Information and Management Studies, Tiruchengode,
An Analysis on Density Based Clustering of Multi Dimensional Spatial Data K. Mumtaz 1 Assistant Professor, Department of MCA Vivekanandha Institute of Information and Management Studies, Tiruchengode,
Cluster Analysis: Basic Concepts and Methods
 10 Cluster Analysis: Basic Concepts and Methods Imagine that you are the Director of Customer Relationships at AllElectronics, and you have five managers working for you. You would like to organize all
10 Cluster Analysis: Basic Concepts and Methods Imagine that you are the Director of Customer Relationships at AllElectronics, and you have five managers working for you. You would like to organize all
2 Basic Concepts and Techniques of Cluster Analysis
 The Challenges of Clustering High Dimensional Data * Michael Steinbach, Levent Ertöz, and Vipin Kumar Abstract Cluster analysis divides data into groups (clusters) for the purposes of summarization or
The Challenges of Clustering High Dimensional Data * Michael Steinbach, Levent Ertöz, and Vipin Kumar Abstract Cluster analysis divides data into groups (clusters) for the purposes of summarization or
Clustering. 15-381 Artificial Intelligence Henry Lin. Organizing data into clusters such that there is
 Clustering 15-381 Artificial Intelligence Henry Lin Modified from excellent slides of Eamonn Keogh, Ziv Bar-Joseph, and Andrew Moore What is Clustering? Organizing data into clusters such that there is
Clustering 15-381 Artificial Intelligence Henry Lin Modified from excellent slides of Eamonn Keogh, Ziv Bar-Joseph, and Andrew Moore What is Clustering? Organizing data into clusters such that there is
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Clustering Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Clustering Algorithms K-means and its variants Hierarchical clustering
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Clustering Algorithms K-means and its variants Hierarchical clustering
K-Means Cluster Analysis. Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1
 K-Means Cluster Analsis Chapter 3 PPDM Class Tan,Steinbach, Kumar Introduction to Data Mining 4/18/4 1 What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar
K-Means Cluster Analsis Chapter 3 PPDM Class Tan,Steinbach, Kumar Introduction to Data Mining 4/18/4 1 What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar
Comparison and Analysis of Various Clustering Methods in Data mining On Education data set Using the weak tool
 Comparison and Analysis of Various Clustering Metho in Data mining On Education data set Using the weak tool Abstract:- Data mining is used to find the hidden information pattern and relationship between
Comparison and Analysis of Various Clustering Metho in Data mining On Education data set Using the weak tool Abstract:- Data mining is used to find the hidden information pattern and relationship between
Clustering and Outlier Detection
 Clustering and Outlier Detection Application Examples Customer segmentation How to partition customers into groups so that customers in each group are similar, while customers in different groups are dissimilar?
Clustering and Outlier Detection Application Examples Customer segmentation How to partition customers into groups so that customers in each group are similar, while customers in different groups are dissimilar?
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
SCAN: A Structural Clustering Algorithm for Networks
 SCAN: A Structural Clustering Algorithm for Networks Xiaowei Xu, Nurcan Yuruk, Zhidan Feng (University of Arkansas at Little Rock) Thomas A. J. Schweiger (Acxiom Corporation) Networks scaling: #edges connected
SCAN: A Structural Clustering Algorithm for Networks Xiaowei Xu, Nurcan Yuruk, Zhidan Feng (University of Arkansas at Little Rock) Thomas A. J. Schweiger (Acxiom Corporation) Networks scaling: #edges connected
GraphZip: A Fast and Automatic Compression Method for Spatial Data Clustering
 GraphZip: A Fast and Automatic Compression Method for Spatial Data Clustering Yu Qian Kang Zhang Department of Computer Science, The University of Texas at Dallas, Richardson, TX 75083-0688, USA {yxq012100,
GraphZip: A Fast and Automatic Compression Method for Spatial Data Clustering Yu Qian Kang Zhang Department of Computer Science, The University of Texas at Dallas, Richardson, TX 75083-0688, USA {yxq012100,
Clustering on Large Numeric Data Sets Using Hierarchical Approach Birch
 Global Journal of Computer Science and Technology Software & Data Engineering Volume 12 Issue 12 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global
Global Journal of Computer Science and Technology Software & Data Engineering Volume 12 Issue 12 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global
Chapter ML:XI (continued)
") Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Echidna: Efficient Clustering of Hierarchical Data for Network Traffic Analysis
 Echidna: Efficient Clustering of Hierarchical Data for Network Traffic Analysis Abdun Mahmood, Christopher Leckie, Parampalli Udaya Department of Computer Science and Software Engineering University of
Echidna: Efficient Clustering of Hierarchical Data for Network Traffic Analysis Abdun Mahmood, Christopher Leckie, Parampalli Udaya Department of Computer Science and Software Engineering University of
Proposed Application of Data Mining Techniques for Clustering Software Projects
 Proposed Application of Data Mining Techniques for Clustering Software Projects HENRIQUE RIBEIRO REZENDE 1 AHMED ALI ABDALLA ESMIN 2 UFLA - Federal University of Lavras DCC - Department of Computer Science
Proposed Application of Data Mining Techniques for Clustering Software Projects HENRIQUE RIBEIRO REZENDE 1 AHMED ALI ABDALLA ESMIN 2 UFLA - Federal University of Lavras DCC - Department of Computer Science
Smart-Sample: An Efficient Algorithm for Clustering Large High-Dimensional Datasets
 Smart-Sample: An Efficient Algorithm for Clustering Large High-Dimensional Datasets Dudu Lazarov, Gil David, Amir Averbuch School of Computer Science, Tel-Aviv University Tel-Aviv 69978, Israel Abstract
Smart-Sample: An Efficient Algorithm for Clustering Large High-Dimensional Datasets Dudu Lazarov, Gil David, Amir Averbuch School of Computer Science, Tel-Aviv University Tel-Aviv 69978, Israel Abstract
Authors. Data Clustering: Algorithms and Applications
 Authors Data Clustering: Algorithms and Applications 2 Contents 1 Grid-based Clustering 1 Wei Cheng, Wei Wang, and Sandra Batista 1.1 Introduction................................... 1 1.2 The Classical
Authors Data Clustering: Algorithms and Applications 2 Contents 1 Grid-based Clustering 1 Wei Cheng, Wei Wang, and Sandra Batista 1.1 Introduction................................... 1 1.2 The Classical
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What is
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What is
A Comparative Study of clustering algorithms Using weka tools
 A Comparative Study of clustering algorithms Using weka tools Bharat Chaudhari 1, Manan Parikh 2 1,2 MECSE, KITRC KALOL ABSTRACT Data clustering is a process of putting similar data into groups. A clustering
A Comparative Study of clustering algorithms Using weka tools Bharat Chaudhari 1, Manan Parikh 2 1,2 MECSE, KITRC KALOL ABSTRACT Data clustering is a process of putting similar data into groups. A clustering
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analsis: Basic Concepts and Algorithms What does it mean clustering? Applications Tpes of clustering K-means Intuition Algorithm Choosing initial centroids Bisecting K-means Post-processing Strengths
Cluster Analsis: Basic Concepts and Algorithms What does it mean clustering? Applications Tpes of clustering K-means Intuition Algorithm Choosing initial centroids Bisecting K-means Post-processing Strengths
Forschungskolleg Data Analytics Methods and Techniques
 Forschungskolleg Data Analytics Methods and Techniques Martin Hahmann, Gunnar Schröder, Phillip Grosse Prof. Dr.-Ing. Wolfgang Lehner Why do we need it? We are drowning in data, but starving for knowledge!
Forschungskolleg Data Analytics Methods and Techniques Martin Hahmann, Gunnar Schröder, Phillip Grosse Prof. Dr.-Ing. Wolfgang Lehner Why do we need it? We are drowning in data, but starving for knowledge!
GE-INTERNATIONAL JOURNAL OF ENGINEERING RESEARCH VOLUME -3, ISSUE-6 (June 2015) IF-4.007 ISSN: (2321-1717) EMERGING CLUSTERING TECHNIQUES ON BIG DATA
 IF-4.007 ISSN: (2321-1717) EMERGING CLUSTERING TECHNIQUES ON BIG DATA") EMERGING CLUSTERING TECHNIQUES ON BIG DATA Pooja Batra Nagpal 1, Sarika Chaudhary 2, Preetishree Patnaik 3 1,2,3 Computer Science/Amity University, India ABSTRACT The term "Big Data" defined as enormous
EMERGING CLUSTERING TECHNIQUES ON BIG DATA Pooja Batra Nagpal 1, Sarika Chaudhary 2, Preetishree Patnaik 3 1,2,3 Computer Science/Amity University, India ABSTRACT The term "Big Data" defined as enormous
Neural Networks Lesson 5 - Cluster Analysis
 Neural Networks Lesson 5 - Cluster Analysis Prof. Michele Scarpiniti INFOCOM Dpt. - Sapienza University of Rome http://ispac.ing.uniroma1.it/scarpiniti/index.htm [email protected] Rome, 29
Neural Networks Lesson 5 - Cluster Analysis Prof. Michele Scarpiniti INFOCOM Dpt. - Sapienza University of Rome http://ispac.ing.uniroma1.it/scarpiniti/index.htm [email protected] Rome, 29
R-trees. R-Trees: A Dynamic Index Structure For Spatial Searching. R-Tree. Invariants
 R-Trees: A Dynamic Index Structure For Spatial Searching A. Guttman R-trees Generalization of B+-trees to higher dimensions Disk-based index structure Occupancy guarantee Multiple search paths Insertions
R-Trees: A Dynamic Index Structure For Spatial Searching A. Guttman R-trees Generalization of B+-trees to higher dimensions Disk-based index structure Occupancy guarantee Multiple search paths Insertions
A Survey of Clustering Algorithms for Big Data: Taxonomy & Empirical Analysis
 TRANSACTIONS ON EMERGING TOPICS IN COMPUTING, 2014 1 A Survey of Clustering Algorithms for Big Data: Taxonomy & Empirical Analysis A. Fahad, N. Alshatri, Z. Tari, Member, IEEE, A. Alamri, I. Khalil A.
TRANSACTIONS ON EMERGING TOPICS IN COMPUTING, 2014 1 A Survey of Clustering Algorithms for Big Data: Taxonomy & Empirical Analysis A. Fahad, N. Alshatri, Z. Tari, Member, IEEE, A. Alamri, I. Khalil A.
Making SVMs Scalable to Large Data Sets using Hierarchical Cluster Indexing
 SUBMISSION TO DATA MINING AND KNOWLEDGE DISCOVERY: AN INTERNATIONAL JOURNAL, MAY. 2005 100 Making SVMs Scalable to Large Data Sets using Hierarchical Cluster Indexing Hwanjo Yu, Jiong Yang, Jiawei Han,
SUBMISSION TO DATA MINING AND KNOWLEDGE DISCOVERY: AN INTERNATIONAL JOURNAL, MAY. 2005 100 Making SVMs Scalable to Large Data Sets using Hierarchical Cluster Indexing Hwanjo Yu, Jiong Yang, Jiawei Han,
. Learn the number of classes and the structure of each class using similarity between unlabeled training patterns
 Outline Part 1: of data clustering Non-Supervised Learning and Clustering : Problem formulation cluster analysis : Taxonomies of Clustering Techniques : Data types and Proximity Measures : Difficulties
Outline Part 1: of data clustering Non-Supervised Learning and Clustering : Problem formulation cluster analysis : Taxonomies of Clustering Techniques : Data types and Proximity Measures : Difficulties
On Data Clustering Analysis: Scalability, Constraints and Validation
 On Data Clustering Analysis: Scalability, Constraints and Validation Osmar R. Zaïane, Andrew Foss, Chi-Hoon Lee, and Weinan Wang University of Alberta, Edmonton, Alberta, Canada Summary. Clustering is
On Data Clustering Analysis: Scalability, Constraints and Validation Osmar R. Zaïane, Andrew Foss, Chi-Hoon Lee, and Weinan Wang University of Alberta, Edmonton, Alberta, Canada Summary. Clustering is
Medical Information Management & Mining. You Chen Jan,15, 2013 [email protected]
 Medical Information Management & Mining You Chen Jan,15, 2013 [email protected] 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Medical Information Management & Mining You Chen Jan,15, 2013 [email protected] 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Outlier Detection in Clustering
 Outlier Detection in Clustering Svetlana Cherednichenko 24.01.2005 University of Joensuu Department of Computer Science Master s Thesis TABLE OF CONTENTS 1. INTRODUCTION...1 1.1. BASIC DEFINITIONS... 1
Outlier Detection in Clustering Svetlana Cherednichenko 24.01.2005 University of Joensuu Department of Computer Science Master s Thesis TABLE OF CONTENTS 1. INTRODUCTION...1 1.1. BASIC DEFINITIONS... 1
Comparative Analysis of EM Clustering Algorithm and Density Based Clustering Algorithm Using WEKA tool.
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 9, Issue 8 (January 2014), PP. 19-24 Comparative Analysis of EM Clustering Algorithm
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 9, Issue 8 (January 2014), PP. 19-24 Comparative Analysis of EM Clustering Algorithm
Data Mining Project Report. Document Clustering. Meryem Uzun-Per
 Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING
 AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
Data Mining: Concepts and Techniques. Jiawei Han. Micheline Kamber. Simon Fräser University К MORGAN KAUFMANN PUBLISHERS. AN IMPRINT OF Elsevier
 Data Mining: Concepts and Techniques Jiawei Han Micheline Kamber Simon Fräser University К MORGAN KAUFMANN PUBLISHERS AN IMPRINT OF Elsevier Contents Foreword Preface xix vii Chapter I Introduction I I.
Data Mining: Concepts and Techniques Jiawei Han Micheline Kamber Simon Fräser University К MORGAN KAUFMANN PUBLISHERS AN IMPRINT OF Elsevier Contents Foreword Preface xix vii Chapter I Introduction I I.
Example: Document Clustering. Clustering: Definition. Notion of a Cluster can be Ambiguous. Types of Clusterings. Hierarchical Clustering
 Overview Prognostic Models and Data Mining in Medicine, part I Cluster Analsis What is Cluster Analsis? K-Means Clustering Hierarchical Clustering Cluster Validit Eample: Microarra data analsis 6 Summar
Overview Prognostic Models and Data Mining in Medicine, part I Cluster Analsis What is Cluster Analsis? K-Means Clustering Hierarchical Clustering Cluster Validit Eample: Microarra data analsis 6 Summar
A Distribution-Based Clustering Algorithm for Mining in Large Spatial Databases
 Published in the Proceedings of 14th International Conference on Data Engineering (ICDE 98) A Distribution-Based Clustering Algorithm for Mining in Large Spatial Databases Xiaowei Xu, Martin Ester, Hans-Peter
Published in the Proceedings of 14th International Conference on Data Engineering (ICDE 98) A Distribution-Based Clustering Algorithm for Mining in Large Spatial Databases Xiaowei Xu, Martin Ester, Hans-Peter
Environmental Remote Sensing GEOG 2021
 Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Unsupervised learning: Clustering
 Unsupervised learning: Clustering Salissou Moutari Centre for Statistical Science and Operational Research CenSSOR 17 th September 2013 Unsupervised learning: Clustering 1/52 Outline 1 Introduction What
Unsupervised learning: Clustering Salissou Moutari Centre for Statistical Science and Operational Research CenSSOR 17 th September 2013 Unsupervised learning: Clustering 1/52 Outline 1 Introduction What
Data Mining: Foundation, Techniques and Applications
 Data Mining: Foundation, Techniques and Applications Lesson 1b :A Quick Overview of Data Mining Li Cuiping( 李 翠 平 ) School of Information Renmin University of China Anthony Tung( 鄧 锦 浩 ) School of Computing
Data Mining: Foundation, Techniques and Applications Lesson 1b :A Quick Overview of Data Mining Li Cuiping( 李 翠 平 ) School of Information Renmin University of China Anthony Tung( 鄧 锦 浩 ) School of Computing
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Unsupervised Learning and Data Mining. Unsupervised Learning and Data Mining. Clustering. Supervised Learning. Supervised Learning
 Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
Data Clustering Using Data Mining Techniques
 Data Clustering Using Data Mining Techniques S.R.Pande 1, Ms. S.S.Sambare 2, V.M.Thakre 3 Department of Computer Science, SSES Amti's Science College, Congressnagar, Nagpur, India 1 Department of Computer
Data Clustering Using Data Mining Techniques S.R.Pande 1, Ms. S.S.Sambare 2, V.M.Thakre 3 Department of Computer Science, SSES Amti's Science College, Congressnagar, Nagpur, India 1 Department of Computer
PERFORMANCE ANALYSIS OF CLUSTERING ALGORITHMS IN DATA MINING IN WEKA
 PERFORMANCE ANALYSIS OF CLUSTERING ALGORITHMS IN DATA MINING IN WEKA Prakash Singh 1, Aarohi Surya 2 1 Department of Finance, IIM Lucknow, Lucknow, India 2 Department of Computer Science, LNMIIT, Jaipur,
PERFORMANCE ANALYSIS OF CLUSTERING ALGORITHMS IN DATA MINING IN WEKA Prakash Singh 1, Aarohi Surya 2 1 Department of Finance, IIM Lucknow, Lucknow, India 2 Department of Computer Science, LNMIIT, Jaipur,
Data Warehousing und Data Mining
 Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS
 UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 [email protected] What is Learning? "Learning denotes changes in a system that enable
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 [email protected] What is Learning? "Learning denotes changes in a system that enable
How To Cluster
 Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Concept of Cluster Analysis
 RESEARCH PAPER ON CLUSTER TECHNIQUES OF DATA VARIATIONS Er. Arpit Gupta 1,Er.Ankit Gupta 2,Er. Amit Mishra 3 [email protected], [email protected],[email protected] Faculty Of Engineering
RESEARCH PAPER ON CLUSTER TECHNIQUES OF DATA VARIATIONS Er. Arpit Gupta 1,Er.Ankit Gupta 2,Er. Amit Mishra 3 [email protected], [email protected],[email protected] Faculty Of Engineering
Public Transportation BigData Clustering
 Public Transportation BigData Clustering Preliminary Communication Tomislav Galba J.J. Strossmayer University of Osijek Faculty of Electrical Engineering Cara Hadriana 10b, 31000 Osijek, Croatia [email protected]
Public Transportation BigData Clustering Preliminary Communication Tomislav Galba J.J. Strossmayer University of Osijek Faculty of Electrical Engineering Cara Hadriana 10b, 31000 Osijek, Croatia [email protected]
Data Mining Process Using Clustering: A Survey
 Data Mining Process Using Clustering: A Survey Mohamad Saraee Department of Electrical and Computer Engineering Isfahan University of Techno1ogy, Isfahan, 84156-83111 [email protected] Najmeh Ahmadian
Data Mining Process Using Clustering: A Survey Mohamad Saraee Department of Electrical and Computer Engineering Isfahan University of Techno1ogy, Isfahan, 84156-83111 [email protected] Najmeh Ahmadian
How To Solve The Cluster Algorithm
 Cluster Algorithms Adriano Cruz [email protected] 28 de outubro de 2013 Adriano Cruz [email protected] () Cluster Algorithms 28 de outubro de 2013 1 / 80 Summary 1 K-Means Adriano Cruz [email protected]
Cluster Algorithms Adriano Cruz [email protected] 28 de outubro de 2013 Adriano Cruz [email protected] () Cluster Algorithms 28 de outubro de 2013 1 / 80 Summary 1 K-Means Adriano Cruz [email protected]
ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING)
 LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING)") ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING) Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ OUTLINE Preliminaries Classification and Clustering Applications
ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING) Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ OUTLINE Preliminaries Classification and Clustering Applications
A Survey of Clustering Techniques
 A Survey of Clustering Techniques Pradeep Rai Asst. Prof., CSE Department, Kanpur Institute of Technology, Kanpur-0800 (India) Shubha Singh Asst. Prof., MCA Department, Kanpur Institute of Technology,
A Survey of Clustering Techniques Pradeep Rai Asst. Prof., CSE Department, Kanpur Institute of Technology, Kanpur-0800 (India) Shubha Singh Asst. Prof., MCA Department, Kanpur Institute of Technology,
A Grid-based Clustering Algorithm using Adaptive Mesh Refinement
 Appears in the 7th Workshop on Mining Scientific and Engineering Datasets 2004 A Grid-based Clustering Algorithm using Adaptive Mesh Refinement Wei-keng Liao Ying Liu Alok Choudhary Abstract Clustering
Appears in the 7th Workshop on Mining Scientific and Engineering Datasets 2004 A Grid-based Clustering Algorithm using Adaptive Mesh Refinement Wei-keng Liao Ying Liu Alok Choudhary Abstract Clustering
Quality Assessment in Spatial Clustering of Data Mining
 Quality Assessment in Spatial Clustering of Data Mining Azimi, A. and M.R. Delavar Centre of Excellence in Geomatics Engineering and Disaster Management, Dept. of Surveying and Geomatics Engineering, Engineering
Quality Assessment in Spatial Clustering of Data Mining Azimi, A. and M.R. Delavar Centre of Excellence in Geomatics Engineering and Disaster Management, Dept. of Surveying and Geomatics Engineering, Engineering
Hadoop SNS. renren.com. Saturday, December 3, 11
 Hadoop SNS renren.com Saturday, December 3, 11 2.2 190 40 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December
Hadoop SNS renren.com Saturday, December 3, 11 2.2 190 40 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December 3, 11 Saturday, December
Classification algorithm in Data mining: An Overview
 Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Advanced Web Usage Mining Algorithm using Neural Network and Principal Component Analysis
 Advanced Web Usage Mining Algorithm using Neural Network and Principal Component Analysis Arumugam, P. and Christy, V Department of Statistics, Manonmaniam Sundaranar University, Tirunelveli, Tamilnadu,
Advanced Web Usage Mining Algorithm using Neural Network and Principal Component Analysis Arumugam, P. and Christy, V Department of Statistics, Manonmaniam Sundaranar University, Tirunelveli, Tamilnadu,
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Linköpings Universitet - ITN TNM033 2011-11-30 DBSCAN. A Density-Based Spatial Clustering of Application with Noise
 DBSCAN A Density-Based Spatial Clustering of Application with Noise Henrik Bäcklund (henba892), Anders Hedblom (andh893), Niklas Neijman (nikne866) 1 1. Introduction Today data is received automatically
DBSCAN A Density-Based Spatial Clustering of Application with Noise Henrik Bäcklund (henba892), Anders Hedblom (andh893), Niklas Neijman (nikne866) 1 1. Introduction Today data is received automatically
Part 2: Community Detection
 Chapter 8: Graph Data Part 2: Community Detection Based on Leskovec, Rajaraman, Ullman 2014: Mining of Massive Datasets Big Data Management and Analytics Outline Community Detection - Social networks -
Chapter 8: Graph Data Part 2: Community Detection Based on Leskovec, Rajaraman, Ullman 2014: Mining of Massive Datasets Big Data Management and Analytics Outline Community Detection - Social networks -
COC131 Data Mining - Clustering
 COC131 Data Mining - Clustering Martin D. Sykora [email protected] Tutorial 05, Friday 20th March 2009 1. Fire up Weka (Waikako Environment for Knowledge Analysis) software, launch the explorer window
COC131 Data Mining - Clustering Martin D. Sykora [email protected] Tutorial 05, Friday 20th March 2009 1. Fire up Weka (Waikako Environment for Knowledge Analysis) software, launch the explorer window
Image Segmentation and Registration
 Image Segmentation and Registration Dr. Christine Tanner ([email protected]) Computer Vision Laboratory, ETH Zürich Dr. Verena Kaynig, Machine Learning Laboratory, ETH Zürich Outline Segmentation
Image Segmentation and Registration Dr. Christine Tanner ([email protected]) Computer Vision Laboratory, ETH Zürich Dr. Verena Kaynig, Machine Learning Laboratory, ETH Zürich Outline Segmentation
Data Mining K-Clustering Problem
 Data Mining K-Clustering Problem Elham Karoussi Supervisor Associate Professor Noureddine Bouhmala This Master s Thesis is carried out as a part of the education at the University of Agder and is therefore
Data Mining K-Clustering Problem Elham Karoussi Supervisor Associate Professor Noureddine Bouhmala This Master s Thesis is carried out as a part of the education at the University of Agder and is therefore
Data Mining. Session 9 Main Theme Clustering. Dr. Jean-Claude Franchitti
 Data Mining Session 9 Main Theme Clustering Dr. Jean-Claude Franchitti New York University Computer Science Department Courant Institute of Mathematical Sciences Adapted from course textbook resources
Data Mining Session 9 Main Theme Clustering Dr. Jean-Claude Franchitti New York University Computer Science Department Courant Institute of Mathematical Sciences Adapted from course textbook resources