MapReduce. from the paper. MapReduce: Simplified Data Processing on Large Clusters (2004)
|
|
|
- Ronald Bishop
- 10 years ago
- Views:
Transcription
1 MapReduce from the paper MapReduce: Simplified Data Processing on Large Clusters (2004)

2 What it is MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.

3 map and reduce functions map(string key, String value): reduce(string key, Iterator values) map (k1,v1) list(k2,v2) reduce (k2,list(v2)) list(v2)
 reduce (k2,list(v2))")
4 sample problem: word counting counting the number of occurences of each word in a large collection of documents map(string key, String value): // key: document name (k1=filename) // value: document contents (v1) for each word w (= k2) in value: EmitIntermediate(w, "1" (= v2) );
 for each word w (= k2) in value: EmitIntermediate(w,")
5 sample problem: word counting reduce(string key, String value): // key: word (= k2) // value: list of v2 = list of "1" for each word w (= k2) in value: EmitIntermediate(w, "1" (= v2) );
 in value: EmitIntermediate(w, \"1\" (=")
6 sample problem: distributed grep grep (pattern matching according to a regular expression) in a large collection of documents map: k1 = filename k2 = line that matches pattern v2 = filename + linenumber within file reduce: output of k2 list(v2)

7 sample: URL access frequency counting the number of occurences of each URL in a large collection of documents which contain URL lists map: k1 = filename k2 = URL v2 = 1 reduce: for each k2: size (list(v2) )

8 sample: reverse web link graph all references to a Web page, given a large collection of documents which contain <source-url, target-url> pairs map: k1 = filename k2 = target-url v2 = source-url reduce: for each k2: output list(v2)

9 execution of a map reduce process

10 execution of a map reduce process The MapReduce library in the user program first shards the input files into M pieces of typically 16 megabytes to 64 megabytes (MB) per piece. It then starts up many copies of the program on a cluster of machines. One of the copies of the program is special: the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task. A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key/value pairs produced by the Map function are buffered in memory. Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.

11 execution of a map reduce process When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. If the amount of intermediate data is too large to fit in memory, an external sort is used. The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user's Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition. When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the MapReduce call in the user program returns back to the user code. After successful completion, the output of the MapReduce execution is available in the R output files.

12 master data structures For each map task and reduce task: the state (idle, in-progress, or completed), and the identity of the worker machine (for non-idle tasks) for each completed map task: the locations and sizes of the R intermediate file regions produced by the map task.

13 fault tolerance (1) worker failure: timeout check: master pings every worker periodically; if no response is received from a worker in a certain amount of time, the master marks the worker as failed. When a map task is executed first by worker A and then later executed by worker B (because A failed), all workers executing reduce tasks are notified of the reexecution. Any reduce task that has not already read the data from worker A will read the data from worker B. master failure: MapReduce computation aborted if the master fails. Clients can check for this condition and retry the MapReduce operation if they desire.

14 fault tolerance (2) straggling workers: a machine takes an unusually long time to complete one of the map or reduce tasks in the computation. general mechanism to alleviate the problem of stragglers: When a MapReduce operation is close to completion, the master schedules backup executions of the remaining inprogress tasks. The task is marked as completed whenever either the primary or the backup execution completes.

15 fault tolerance (3) bad records: sometimes there are bugs in user code that cause the Map or Reduce functions to crash deterministically on certain records sometimes it is acceptable to ignore a few records, for example when doing statistical analysis on a large data set. Each worker process installs a signal handler that catches segmentation violations and bus errors. when the master has seen more than one failure on a particular record, it indicates that the record should be skipped when it issues the next re-execution of the corresponding Map or Reduce task

16 optimizations combiner function: in some cases, there is significant repetition in the intermediate keys produced by each map task, and the userspecified Reduce function is commutative and associative thus, the intermediate keys should be processed locally combiner function = reduce function except for output destination (intermediate file for combiner) the Combiner function is executed on each machine that performs a map task
 the Combiner function is executed on each machine that")
17 sample: distributed grep The grep program scans through byte records, searching for a relatively rare three-character pattern (the pattern occurs in 92,337 records). The input is split into approximately 64MB pieces (M = 15000), and the en- tire output is placed in one file (R = 1).
, and the")
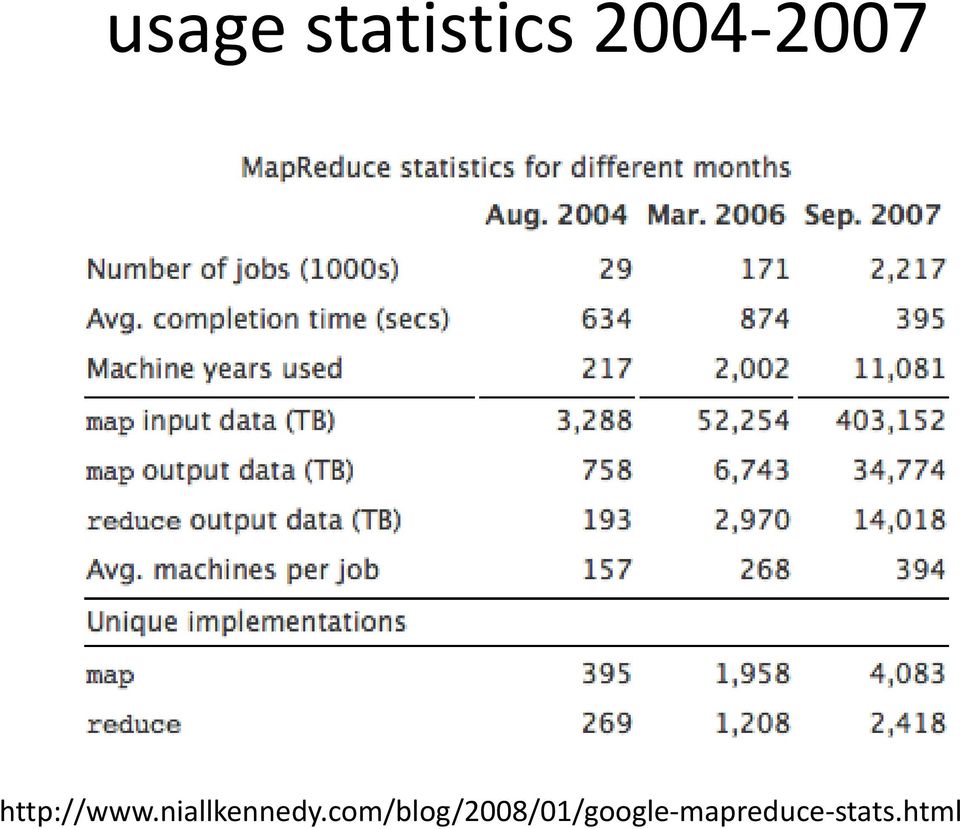
18 usage statistics
Introduction to Parallel Programming and MapReduce
 Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
MapReduce (in the cloud)
") MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Big Data Storage, Management and challenges. Ahmed Ali-Eldin
 Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
MapReduce is a programming model and an associated implementation for processing
 MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat Abstract MapReduce is a programming model and an associated implementation for processing and generating large
MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat Abstract MapReduce is a programming model and an associated implementation for processing and generating large
Map Reduce / Hadoop / HDFS
 Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
MapReduce. MapReduce and SQL Injections. CS 3200 Final Lecture. Introduction. MapReduce. Programming Model. Example
 MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
ImprovedApproachestoHandleBigdatathroughHadoop
 Global Journal of Computer Science and Technology: C Software & Data Engineering Volume 14 Issue 9 Version 1.0 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals
Global Journal of Computer Science and Technology: C Software & Data Engineering Volume 14 Issue 9 Version 1.0 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat [email protected], [email protected] Google, Inc. Abstract MapReduce is a programming model and an associated implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat [email protected], [email protected] Google, Inc. Abstract MapReduce is a programming model and an associated implementation
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat [email protected], [email protected] Google, Inc. Abstract MapReduce is a programming model and an associated implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat [email protected], [email protected] Google, Inc. Abstract MapReduce is a programming model and an associated implementation
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
Data Management in the Cloud MAP/REDUCE. Map/Reduce. Programming model Examples Execution model Criticism Iterative map/reduce
 Data Management in the Cloud MAP/REDUCE 117 Programming model Examples Execution model Criticism Iterative map/reduce Map/Reduce 118 Motivation Background and Requirements computations are conceptually
Data Management in the Cloud MAP/REDUCE 117 Programming model Examples Execution model Criticism Iterative map/reduce Map/Reduce 118 Motivation Background and Requirements computations are conceptually
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
From GWS to MapReduce: Google s Cloud Technology in the Early Days
 Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu [email protected] MapReduce/Hadoop
Large-Scale Distributed Systems From GWS to MapReduce: Google s Cloud Technology in the Early Days Part II: MapReduce in a Datacenter COMP6511A Spring 2014 HKUST Lin Gu [email protected] MapReduce/Hadoop
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
16.1 MAPREDUCE. For personal use only, not for distribution. 333
 For personal use only, not for distribution. 333 16.1 MAPREDUCE Initially designed by the Google labs and used internally by Google, the MAPREDUCE distributed programming model is now promoted by several
For personal use only, not for distribution. 333 16.1 MAPREDUCE Initially designed by the Google labs and used internally by Google, the MAPREDUCE distributed programming model is now promoted by several
A programming model in Cloud: MapReduce
 A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
MapReduce Jeffrey Dean and Sanjay Ghemawat. Background context
 MapReduce Jeffrey Dean and Sanjay Ghemawat Background context BIG DATA!! o Large-scale services generate huge volumes of data: logs, crawls, user databases, web site content, etc. o Very useful to be able
MapReduce Jeffrey Dean and Sanjay Ghemawat Background context BIG DATA!! o Large-scale services generate huge volumes of data: logs, crawls, user databases, web site content, etc. o Very useful to be able
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Data Science in the Wild
 Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
Data Science in the Wild Lecture 3 Some slides are taken from J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 1 Data Science and Big Data Big Data: the data cannot
Outline. Motivation. Motivation. MapReduce & GraphLab: Programming Models for Large-Scale Parallel/Distributed Computing 2/28/2013
 MapReduce & GraphLab: Programming Models for Large-Scale Parallel/Distributed Computing Iftekhar Naim Outline Motivation MapReduce Overview Design Issues & Abstractions Examples and Results Pros and Cons
MapReduce & GraphLab: Programming Models for Large-Scale Parallel/Distributed Computing Iftekhar Naim Outline Motivation MapReduce Overview Design Issues & Abstractions Examples and Results Pros and Cons
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
Advanced Data Management Technologies
 ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
Introduc)on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan [email protected]
on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan sriram@sdsc.edu") Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan [email protected] Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan [email protected] Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13
 Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Big Application Execution on Cloud using Hadoop Distributed File System
 Big Application Execution on Cloud using Hadoop Distributed File System Ashkan Vates*, Upendra, Muwafaq Rahi Ali RPIIT Campus, Bastara Karnal, Haryana, India ---------------------------------------------------------------------***---------------------------------------------------------------------
Big Application Execution on Cloud using Hadoop Distributed File System Ashkan Vates*, Upendra, Muwafaq Rahi Ali RPIIT Campus, Bastara Karnal, Haryana, India ---------------------------------------------------------------------***---------------------------------------------------------------------
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
CS246: Mining Massive Datasets Jure Leskovec, Stanford University. http://cs246.stanford.edu
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2 CPU Memory Machine Learning, Statistics Classical Data Mining Disk 3 20+ billion web pages x 20KB = 400+ TB
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2 CPU Memory Machine Learning, Statistics Classical Data Mining Disk 3 20+ billion web pages x 20KB = 400+ TB
Sriram Krishnan, Ph.D. [email protected]
 Sriram Krishnan, Ph.D. [email protected] (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Sriram Krishnan, Ph.D. [email protected] (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
2.1 Hadoop a. Hadoop Installation & Configuration
 2. Implementation 2.1 Hadoop a. Hadoop Installation & Configuration First of all, we need to install Java Sun 6, and it is preferred to be version 6 not 7 for running Hadoop. Type the following commands
2. Implementation 2.1 Hadoop a. Hadoop Installation & Configuration First of all, we need to install Java Sun 6, and it is preferred to be version 6 not 7 for running Hadoop. Type the following commands
Lecture Data Warehouse Systems
 Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
HPC & Big Data. Adam S.Z Belloum Software and Network engineering group University of Amsterdam
 HPC & Big Data Adam S.Z Belloum Software and Network engineering group University of Amsterdam 1 Introduc)on to MapReduce programing model 2 Content Introduc)on Master/Worker approach MapReduce Examples
HPC & Big Data Adam S.Z Belloum Software and Network engineering group University of Amsterdam 1 Introduc)on to MapReduce programing model 2 Content Introduc)on Master/Worker approach MapReduce Examples
Hadoop Design and k-means Clustering
 Hadoop Design and k-means Clustering Kenneth Heafield Google Inc January 15, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise
Hadoop Design and k-means Clustering Kenneth Heafield Google Inc January 15, 2008 Example code from Hadoop 0.13.1 used under the Apache License Version 2.0 and modified for presentation. Except as otherwise
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics
 Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
Convex Optimization for Big Data: Lecture 2: Frameworks for Big Data Analytics Sabeur Aridhi Aalto University, Finland Sabeur Aridhi Frameworks for Big Data Analytics 1 / 59 Introduction Contents 1 Introduction
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Big Data by the numbers
 COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
marlabs driving digital agility WHITEPAPER Big Data and Hadoop
 marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
MapReduce: Simplified Data Processing on Large Clusters. Jeff Dean, Sanjay Ghemawat Google, Inc.
 MapReduce: Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Motivation: Large Scale Data Processing Many tasks: Process lots of data to produce other data Want to use
MapReduce: Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Motivation: Large Scale Data Processing Many tasks: Process lots of data to produce other data Want to use
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
White Paper. Big Data and Hadoop. Abhishek S, Java COE. Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP
 White Paper Big Data and Hadoop Abhishek S, Java COE www.marlabs.com Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP Table of contents Abstract.. 1 Introduction. 2 What is Big
White Paper Big Data and Hadoop Abhishek S, Java COE www.marlabs.com Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP Table of contents Abstract.. 1 Introduction. 2 What is Big
MAPREDUCE Programming Model
 CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
MapReduce and the New Software Stack
 20 Chapter 2 MapReduce and the New Software Stack Modern data-mining applications, often called big-data analysis, require us to manage immense amounts of data quickly. In many of these applications, the
20 Chapter 2 MapReduce and the New Software Stack Modern data-mining applications, often called big-data analysis, require us to manage immense amounts of data quickly. In many of these applications, the
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Big Data. Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich
 Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich First, an Announcement There will be a repetition exercise group on Wednesday this week. TAs will answer your questions on SQL, relational
Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich First, an Announcement There will be a repetition exercise group on Wednesday this week. TAs will answer your questions on SQL, relational
Lecture 10 - Functional programming: Hadoop and MapReduce
 Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
The Performance of MapReduce: An In-depth Study
 The Performance of MapReduce: An In-depth Study Dawei Jiang Beng Chin Ooi Lei Shi Sai Wu School of Computing National University of Singapore {jiangdw, ooibc, shilei, wusai}@comp.nus.edu.sg ABSTRACT MapReduce
The Performance of MapReduce: An In-depth Study Dawei Jiang Beng Chin Ooi Lei Shi Sai Wu School of Computing National University of Singapore {jiangdw, ooibc, shilei, wusai}@comp.nus.edu.sg ABSTRACT MapReduce
Cloud Computing using MapReduce, Hadoop, Spark
 Cloud Computing using MapReduce, Hadoop, Spark Benjamin Hindman [email protected] Why this talk? At some point, you ll have enough data to run your parallel algorithms on multiple computers SPMD (e.g.,
Cloud Computing using MapReduce, Hadoop, Spark Benjamin Hindman [email protected] Why this talk? At some point, you ll have enough data to run your parallel algorithms on multiple computers SPMD (e.g.,
Comparison of Different Implementation of Inverted Indexes in Hadoop
 Comparison of Different Implementation of Inverted Indexes in Hadoop Hediyeh Baban, S. Kami Makki, and Stefan Andrei Department of Computer Science Lamar University Beaumont, Texas (hbaban, kami.makki,
Comparison of Different Implementation of Inverted Indexes in Hadoop Hediyeh Baban, S. Kami Makki, and Stefan Andrei Department of Computer Science Lamar University Beaumont, Texas (hbaban, kami.makki,
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
How To Write A Map In Java (Java) On A Microsoft Powerbook 2.5 (Ahem) On An Ipa (Aeso) Or Ipa 2.4 (Aseo) On Your Computer Or Your Computer
 On A Microsoft Powerbook 2.5 (Ahem) On An Ipa (Aeso) Or Ipa 2.4 (Aseo) On Your Computer Or Your Computer") Lab 0 - Introduction to Hadoop/Eclipse/Map/Reduce CSE 490h - Winter 2007 To Do 1. Eclipse plug in introduction Dennis Quan, IBM 2. Read this hand out. 3. Get Eclipse set up on your machine. 4. Load the
Lab 0 - Introduction to Hadoop/Eclipse/Map/Reduce CSE 490h - Winter 2007 To Do 1. Eclipse plug in introduction Dennis Quan, IBM 2. Read this hand out. 3. Get Eclipse set up on your machine. 4. Load the
Principles of Software Construction: Objects, Design, and Concurrency. Distributed System Design, Part 2. MapReduce. Charlie Garrod Christian Kästner
 Principles of Software Construction: Objects, Design, and Concurrency Distributed System Design, Part 2. MapReduce Spring 2014 Charlie Garrod Christian Kästner School of Computer Science Administrivia
Principles of Software Construction: Objects, Design, and Concurrency Distributed System Design, Part 2. MapReduce Spring 2014 Charlie Garrod Christian Kästner School of Computer Science Administrivia
Big Data Processing in the Cloud. Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center
 Big Data Processing in the Cloud Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center Data is ONLY as useful as the decisions it enables 2 Data is ONLY as useful as the decisions it enables
Big Data Processing in the Cloud Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center Data is ONLY as useful as the decisions it enables 2 Data is ONLY as useful as the decisions it enables
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Parameterizable benchmarking framework for designing a MapReduce performance model
 CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. (2014) Published online in Wiley Online Library (wileyonlinelibrary.com)..3229 SPECIAL ISSUE PAPER Parameterizable
CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. (2014) Published online in Wiley Online Library (wileyonlinelibrary.com)..3229 SPECIAL ISSUE PAPER Parameterizable
Distributed and Cloud Computing
 Distributed and Cloud Computing K. Hwang, G. Fox and J. Dongarra Chapter 6: Cloud Programming and Software Environments Part 1 Adapted from Kai Hwang, University of Southern California with additions from
Distributed and Cloud Computing K. Hwang, G. Fox and J. Dongarra Chapter 6: Cloud Programming and Software Environments Part 1 Adapted from Kai Hwang, University of Southern California with additions from
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Optimization and analysis of large scale data sorting algorithm based on Hadoop
 Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
MapReduce and Hadoop Distributed File System
 MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) [email protected] http://www.cse.buffalo.edu/faculty/bina Partially
MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) [email protected] http://www.cse.buffalo.edu/faculty/bina Partially
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
StreamStorage: High-throughput and Scalable Storage Technology for Streaming Data
 : High-throughput and Scalable Storage Technology for Streaming Data Munenori Maeda Toshihiro Ozawa Real-time analytical processing (RTAP) of vast amounts of time-series data from sensors, server logs,
: High-throughput and Scalable Storage Technology for Streaming Data Munenori Maeda Toshihiro Ozawa Real-time analytical processing (RTAP) of vast amounts of time-series data from sensors, server logs,
Hadoop Distributed File System Propagation Adapter for Nimbus
 University of Victoria Faculty of Engineering Coop Workterm Report Hadoop Distributed File System Propagation Adapter for Nimbus Department of Physics University of Victoria Victoria, BC Matthew Vliet
University of Victoria Faculty of Engineering Coop Workterm Report Hadoop Distributed File System Propagation Adapter for Nimbus Department of Physics University of Victoria Victoria, BC Matthew Vliet
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Analysis and Modeling of MapReduce s Performance on Hadoop YARN
 Analysis and Modeling of MapReduce s Performance on Hadoop YARN Qiuyi Tang Dept. of Mathematics and Computer Science Denison University [email protected] Dr. Thomas C. Bressoud Dept. of Mathematics and
Analysis and Modeling of MapReduce s Performance on Hadoop YARN Qiuyi Tang Dept. of Mathematics and Computer Science Denison University [email protected] Dr. Thomas C. Bressoud Dept. of Mathematics and
A METHODOLOGY FOR IDENTIFYING THE RELATIONSHIP BETWEEN PERFORMANCE FACTORS FOR CLOUD COMPUTING APPLICATIONS
 A METHODOLOGY FOR IDENTIFYING THE RELATIONSHIP BETWEEN PERFORMANCE FACTORS FOR CLOUD COMPUTING APPLICATIONS Luis Bautista 1, 2, Alain April 2, Alain Abran 2 1 Department of Electronic Systems, Autonomous
A METHODOLOGY FOR IDENTIFYING THE RELATIONSHIP BETWEEN PERFORMANCE FACTORS FOR CLOUD COMPUTING APPLICATIONS Luis Bautista 1, 2, Alain April 2, Alain Abran 2 1 Department of Electronic Systems, Autonomous
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
The Google File System
 The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
Architectures for massive data management
 Architectures for massive data management Apache Kafka, Samza, Storm Albert Bifet [email protected] October 20, 2015 Stream Engine Motivation Digital Universe EMC Digital Universe with
Architectures for massive data management Apache Kafka, Samza, Storm Albert Bifet [email protected] October 20, 2015 Stream Engine Motivation Digital Universe EMC Digital Universe with
5 SCS Deployment Infrastructure in Use
 5 SCS Deployment Infrastructure in Use Currently, an increasing adoption of cloud computing resources as the base to build IT infrastructures is enabling users to build flexible, scalable, and low-cost
5 SCS Deployment Infrastructure in Use Currently, an increasing adoption of cloud computing resources as the base to build IT infrastructures is enabling users to build flexible, scalable, and low-cost
University of Maryland. Tuesday, February 2, 2010
 Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Hadoop MapReduce Tutorial - Reduce Comp variability in Data Stamps
 Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Getting Started with Hadoop with Amazon s Elastic MapReduce
 Getting Started with Hadoop with Amazon s Elastic MapReduce Scott Hendrickson [email protected] http://drskippy.net/projects/emr-hadoopmeetup.pdf Boulder/Denver Hadoop Meetup 8 July 2010 Scott Hendrickson
Getting Started with Hadoop with Amazon s Elastic MapReduce Scott Hendrickson [email protected] http://drskippy.net/projects/emr-hadoopmeetup.pdf Boulder/Denver Hadoop Meetup 8 July 2010 Scott Hendrickson
Viswanath Nandigam Sriram Krishnan Chaitan Baru
 Viswanath Nandigam Sriram Krishnan Chaitan Baru Traditional Database Implementations for large-scale spatial data Data Partitioning Spatial Extensions Pros and Cons Cloud Computing Introduction Relevance
Viswanath Nandigam Sriram Krishnan Chaitan Baru Traditional Database Implementations for large-scale spatial data Data Partitioning Spatial Extensions Pros and Cons Cloud Computing Introduction Relevance
CS 4604: Introduc0on to Database Management Systems. B. Aditya Prakash Lecture #13: NoSQL and MapReduce
 CS 4604: Introduc0on to Database Management Systems B. Aditya Prakash Lecture #13: NoSQL and MapReduce Announcements HW4 is out You have to use the PGSQL server START EARLY!! We can not help if everyone
CS 4604: Introduc0on to Database Management Systems B. Aditya Prakash Lecture #13: NoSQL and MapReduce Announcements HW4 is out You have to use the PGSQL server START EARLY!! We can not help if everyone
Hadoop WordCount Explained! IT332 Distributed Systems
 Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,