Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 9. Introduction to Data Mining
|
|
|
- Madison Black
- 10 years ago
- Views:
Transcription
1 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 9 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1

2 Hierarchical Clustering: Revisited Creates nested clusters Agglomerative clustering algorithms vary in terms of how the proximity of two clusters are computed u MIN (single link): susceptible to noise/outliers u MAX/GROUP AVERAGE: may not work well with non-globular clusters CURE algorithm tries to handle both problems Often starts with a proximity matrix A type of graph-based algorithm

3 CURE: Another Hierarchical Approach Uses a number of points to represent a cluster Representative points are found by selecting a constant number of points from a cluster and then shrinking them toward the center of the cluster Cluster similarity is the similarity of the closest pair of representative points from different clusters

4 CURE Shrinking representative points toward the center helps avoid problems with noise and outliers CURE is better able to handle clusters of arbitrary shapes and sizes

5 Experimental Results: CURE Picture from CURE, Guha, Rastogi, Shim.

6 Experimental Results: CURE (centroid) (single link) Picture from CURE, Guha, Rastogi, Shim.

7 CURE Cannot Handle Differing Densities Original Points CURE

8 Graph-Based Clustering Graph-Based clustering uses the proximity graph Start with the proximity matrix Consider each point as a node in a graph Each edge between two nodes has a weight which is the proximity between the two points Initially the proximity graph is fully connected MIN (single-link) and MAX (complete-link) can be viewed as starting with this graph In the simplest case, clusters are connected components in the graph.
 can be viewed as starting with this graph In the simplest case, clusters are connected")
9 Graph-Based Clustering: Sparsification The amount of data that needs to be processed is drastically reduced Sparsification can eliminate more than 99% of the entries in a proximity matrix The amount of time required to cluster the data is drastically reduced The size of the problems that can be handled is increased

10 Graph-Based Clustering: Sparsification Clustering may work better Sparsification techniques keep the connections to the most similar (nearest) neighbors of a point while breaking the connections to less similar points. The nearest neighbors of a point tend to belong to the same class as the point itself. This reduces the impact of noise and outliers and sharpens the distinction between clusters. Sparsification facilitates the use of graph partitioning algorithms (or algorithms based on graph partitioning algorithms. Chameleon and Hypergraph-based Clustering

11 Sparsification in the Clustering Process

12 Limitations of Current Merging Schemes Existing merging schemes in hierarchical clustering algorithms are static in nature MIN or CURE: u merge two clusters based on their closeness (or minimum distance) GROUP-AVERAGE: u merge two clusters based on their average connectivity

13 Limitations of Current Merging Schemes (a) (b) (c) (d) Closeness schemes will merge (a) and (b) Average connectivity schemes will merge (c) and (d)

14 Chameleon: Clustering Using Dynamic Modeling Adapt to the characteristics of the data set to find the natural clusters Use a dynamic model to measure the similarity between clusters Main property is the relative closeness and relative interconnectivity of the cluster Two clusters are combined if the resulting cluster shares certain properties with the constituent clusters The merging scheme preserves self-similarity One of the areas of application is spatial data

15 Characteristics of Spatial Data Sets Clusters are defined as densely populated regions of the space Clusters have arbitrary shapes, orientation, and non-uniform sizes Difference in densities across clusters and variation in density within clusters Existence of special artifacts (streaks) and noise The clustering algorithm must address the above characteristics and also require minimal supervision.

16 Chameleon: Steps Preprocessing Step: Represent the Data by a Graph Given a set of points, construct the k-nearest-neighbor (k-nn) graph to capture the relationship between a point and its k nearest neighbors Concept of neighborhood is captured dynamically (even if region is sparse) Phase 1: Use a multilevel graph partitioning algorithm on the graph to find a large number of clusters of well-connected vertices Each cluster should contain mostly points from one true cluster, i.e., is a sub-cluster of a real cluster

17 Chameleon: Steps Phase 2: Use Hierarchical Agglomerative Clustering to merge sub-clusters Two clusters are combined if the resulting cluster shares certain properties with the constituent clusters Two key properties used to model cluster similarity: u Relative Interconnectivity: Absolute interconnectivity of two clusters normalized by the internal connectivity of the clusters u Relative Closeness: Absolute closeness of two clusters normalized by the internal closeness of the clusters

18 Experimental Results: CHAMELEON
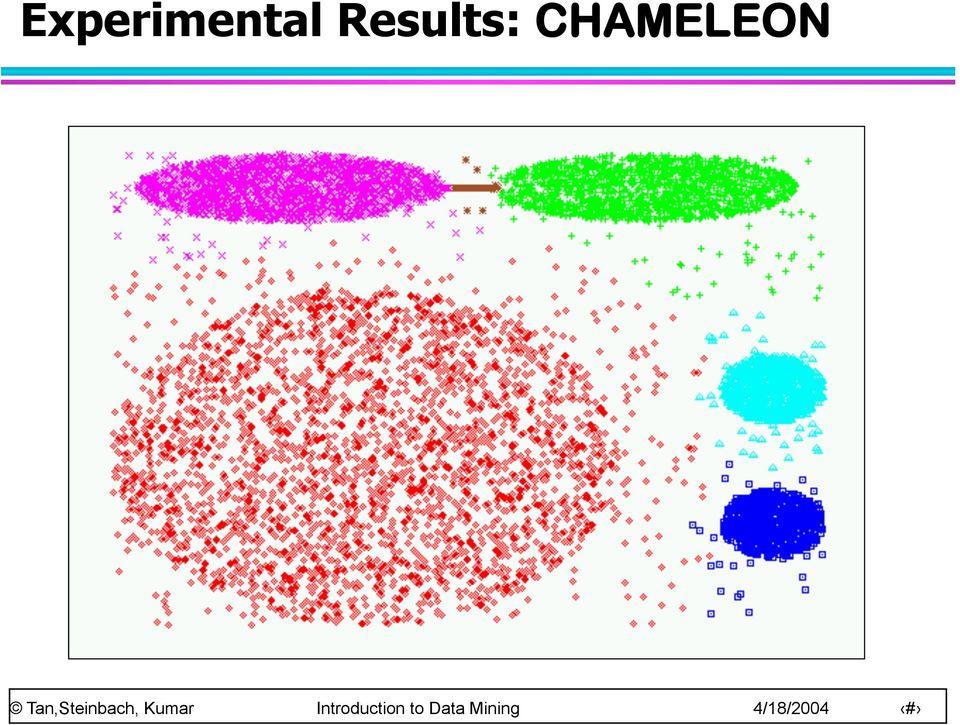
19 Experimental Results: CHAMELEON
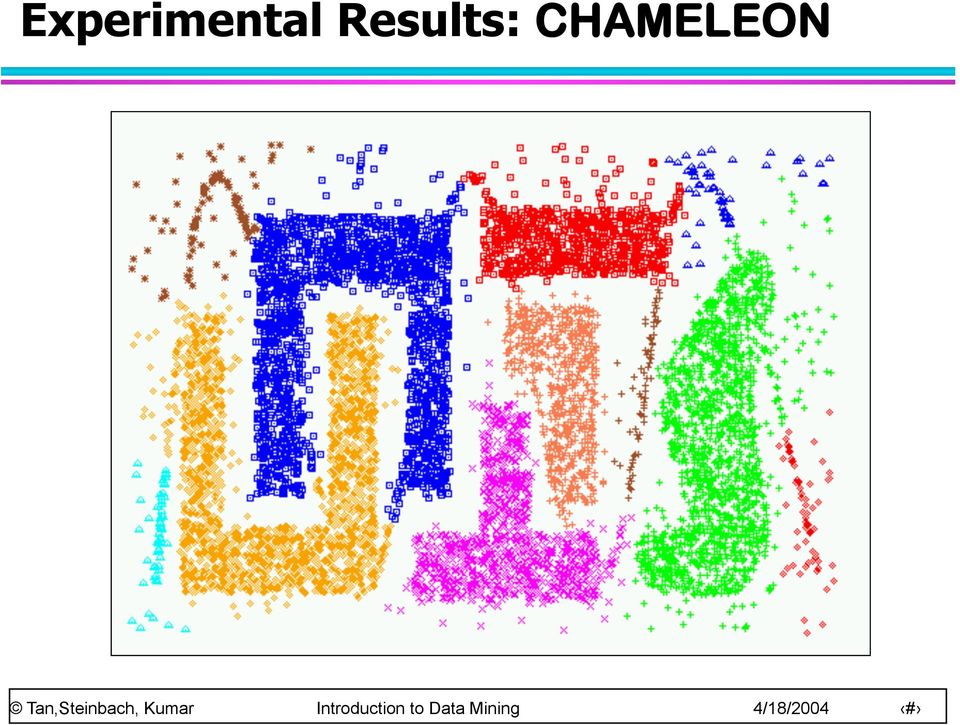
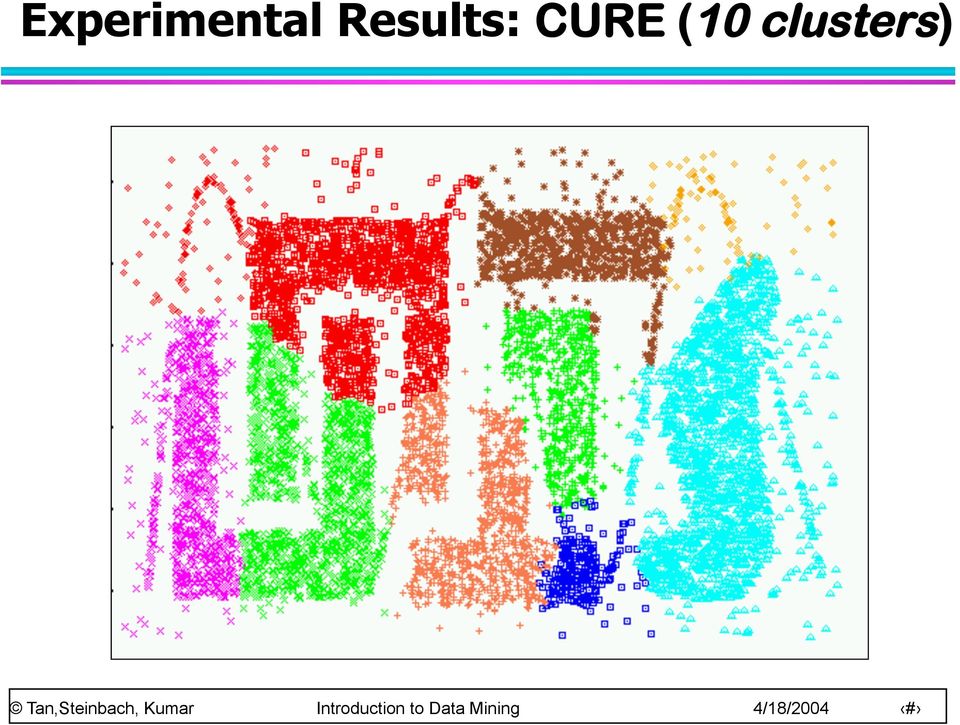
20 Experimental Results: CURE (10 clusters)
21 Experimental Results: CURE (15 clusters)
22 Experimental Results: CHAMELEON
23 Experimental Results: CURE (9 clusters)
24 Experimental Results: CURE (15 clusters)
25 Shared Near Neighbor Approach SNN graph: the weight of an edge is the number of shared neighbors between vertices given that the vertices are connected i j i j 4
26 Creating the SNN Graph Sparse Graph Shared Near Neighbor Graph Link weights are similarities between neighboring points Link weights are number of Shared Nearest Neighbors
27 ROCK (RObust Clustering using links) Clustering algorithm for data with categorical and Boolean attributes A pair of points is defined to be neighbors if their similarity is greater than some threshold Use a hierarchical clustering scheme to cluster the data. 1. Obtain a sample of points from the data set 2. Compute the link value for each set of points, i.e., transform the original similarities (computed by Jaccard coefficient) into similarities that reflect the number of shared neighbors between points 3. Perform an agglomerative hierarchical clustering on the data using the number of shared neighbors as similarity measure and maximizing the shared neighbors objective function 4. Assign the remaining points to the clusters that have been found
28 Jarvis-Patrick Clustering First, the k-nearest neighbors of all points are found In graph terms this can be regarded as breaking all but the k strongest links from a point to other points in the proximity graph A pair of points is put in the same cluster if any two points share more than T neighbors and the two points are in each others k nearest neighbor list For instance, we might choose a nearest neighbor list of size 20 and put points in the same cluster if they share more than 10 near neighbors Jarvis-Patrick clustering is too brittle
29 When Jarvis-Patrick Works Reasonably Well Original Points Jarvis Patrick Clustering 6 shared neighbors out of 20
30 When Jarvis-Patrick Does NOT Work Well Smallest threshold, T, that does not merge clusters. Threshold of T - 1
31 SNN Clustering Algorithm 1. Compute the similarity matrix This corresponds to a similarity graph with data points for nodes and edges whose weights are the similarities between data points 2. Sparsify the similarity matrix by keeping only the k most similar neighbors This corresponds to only keeping the k strongest links of the similarity graph 3. Construct the shared nearest neighbor graph from the sparsified similarity matrix. At this point, we could apply a similarity threshold and find the connected components to obtain the clusters (Jarvis-Patrick algorithm) 4. Find the SNN density of each Point. Using a user specified parameters, Eps, find the number points that have an SNN similarity of Eps or greater to each point. This is the SNN density of the point
32 SNN Clustering Algorithm 5. Find the core points Using a user specified parameter, MinPts, find the core points, i.e., all points that have an SNN density greater than MinPts 6. Form clusters from the core points If two core points are within a radius, Eps, of each other they are place in the same cluster 7. Discard all noise points All non-core points that are not within a radius of Eps of a core point are discarded 8. Assign all non-noise, non-core points to clusters This can be done by assigning such points to the nearest core point (Note that steps 4-8 are DBSCAN)
33 SNN Density a) All Points b) High SNN Density c) Medium SNN Density d) Low SNN Density
34 SNN Clustering Can Handle Differing Densities Original Points SNN Clustering
35 SNN Clustering Can Handle Other Difficult Situations
36 Finding Clusters of Time Series In Spatio-Temporal Data latitude SLP Clusters via Shared Nearest Neighbor Clustering (100 NN, ) longitude SNN Clusters of SLP. latitude 90 SNN Density of SLP Time Series Data longitude SNN Density of Points on the Globe.
37 Features and Limitations of SNN Clustering Does not cluster all the points Complexity of SNN Clustering is high O( n * time to find numbers of neighbor within Eps) In worst case, this is O(n 2 ) For lower dimensions, there are more efficient ways to find the nearest neighbors u u R* Tree k-d Trees
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 9. Introduction to Data Mining
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 9 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 9 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004
Cluster Analysis: Advanced Concepts
 Cluster Analysis: Advanced Concepts and dalgorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 08/06/2006 1 Introduction to Data Mining 08/06/2006 1 Outline Prototype-based Fuzzy c-means
Cluster Analysis: Advanced Concepts and dalgorithms Dr. Hui Xiong Rutgers University Introduction to Data Mining 08/06/2006 1 Introduction to Data Mining 08/06/2006 1 Outline Prototype-based Fuzzy c-means
Data Mining. Cluster Analysis: Advanced Concepts and Algorithms
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 More Clustering Methods Prototype-based clustering Density-based clustering Graph-based
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 More Clustering Methods Prototype-based clustering Density-based clustering Graph-based
Clustering. Data Mining. Abraham Otero. Data Mining. Agenda
 Clustering 1/46 Agenda Introduction Distance K-nearest neighbors Hierarchical clustering Quick reference 2/46 1 Introduction It seems logical that in a new situation we should act in a similar way as in
Clustering 1/46 Agenda Introduction Distance K-nearest neighbors Hierarchical clustering Quick reference 2/46 1 Introduction It seems logical that in a new situation we should act in a similar way as in
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Clustering Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Clustering Algorithms K-means and its variants Hierarchical clustering
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Clustering Algorithms K-means and its variants Hierarchical clustering
Data Mining Clustering (2) Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining
 Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining") Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining /8/ What is Cluster
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 by Tan, Steinbach, Kumar 1 What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 by Tan, Steinbach, Kumar 1 What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Clustering. Adrian Groza. Department of Computer Science Technical University of Cluj-Napoca
 Clustering Adrian Groza Department of Computer Science Technical University of Cluj-Napoca Outline 1 Cluster Analysis What is Datamining? Cluster Analysis 2 K-means 3 Hierarchical Clustering What is Datamining?
Clustering Adrian Groza Department of Computer Science Technical University of Cluj-Napoca Outline 1 Cluster Analysis What is Datamining? Cluster Analysis 2 K-means 3 Hierarchical Clustering What is Datamining?
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What is
Data Mining Cluster Analsis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining b Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What is
GraphZip: A Fast and Automatic Compression Method for Spatial Data Clustering
 GraphZip: A Fast and Automatic Compression Method for Spatial Data Clustering Yu Qian Kang Zhang Department of Computer Science, The University of Texas at Dallas, Richardson, TX 75083-0688, USA {yxq012100,
GraphZip: A Fast and Automatic Compression Method for Spatial Data Clustering Yu Qian Kang Zhang Department of Computer Science, The University of Texas at Dallas, Richardson, TX 75083-0688, USA {yxq012100,
K-Means Cluster Analysis. Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1
 K-Means Cluster Analsis Chapter 3 PPDM Class Tan,Steinbach, Kumar Introduction to Data Mining 4/18/4 1 What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar
K-Means Cluster Analsis Chapter 3 PPDM Class Tan,Steinbach, Kumar Introduction to Data Mining 4/18/4 1 What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar
Cluster Analysis. Alison Merikangas Data Analysis Seminar 18 November 2009
 Cluster Analysis Alison Merikangas Data Analysis Seminar 18 November 2009 Overview What is cluster analysis? Types of cluster Distance functions Clustering methods Agglomerative K-means Density-based Interpretation
Cluster Analysis Alison Merikangas Data Analysis Seminar 18 November 2009 Overview What is cluster analysis? Types of cluster Distance functions Clustering methods Agglomerative K-means Density-based Interpretation
Clustering UE 141 Spring 2013
 Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
Clustering UE 141 Spring 013 Jing Gao SUNY Buffalo 1 Definition of Clustering Finding groups of obects such that the obects in a group will be similar (or related) to one another and different from (or
An Introduction to Cluster Analysis for Data Mining
 An Introduction to Cluster Analysis for Data Mining 10/02/2000 11:42 AM 1. INTRODUCTION... 4 1.1. Scope of This Paper... 4 1.2. What Cluster Analysis Is... 4 1.3. What Cluster Analysis Is Not... 5 2. OVERVIEW...
An Introduction to Cluster Analysis for Data Mining 10/02/2000 11:42 AM 1. INTRODUCTION... 4 1.1. Scope of This Paper... 4 1.2. What Cluster Analysis Is... 4 1.3. What Cluster Analysis Is Not... 5 2. OVERVIEW...
Chapter 7. Cluster Analysis
 Chapter 7. Cluster Analysis. What is Cluster Analysis?. A Categorization of Major Clustering Methods. Partitioning Methods. Hierarchical Methods 5. Density-Based Methods 6. Grid-Based Methods 7. Model-Based
Chapter 7. Cluster Analysis. What is Cluster Analysis?. A Categorization of Major Clustering Methods. Partitioning Methods. Hierarchical Methods 5. Density-Based Methods 6. Grid-Based Methods 7. Model-Based
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analsis: Basic Concepts and Algorithms What does it mean clustering? Applications Tpes of clustering K-means Intuition Algorithm Choosing initial centroids Bisecting K-means Post-processing Strengths
Cluster Analsis: Basic Concepts and Algorithms What does it mean clustering? Applications Tpes of clustering K-means Intuition Algorithm Choosing initial centroids Bisecting K-means Post-processing Strengths
Clustering methods for Big data analysis
 Clustering methods for Big data analysis Keshav Sanse, Meena Sharma Abstract Today s age is the age of data. Nowadays the data is being produced at a tremendous rate. In order to make use of this large-scale
Clustering methods for Big data analysis Keshav Sanse, Meena Sharma Abstract Today s age is the age of data. Nowadays the data is being produced at a tremendous rate. In order to make use of this large-scale
Example: Document Clustering. Clustering: Definition. Notion of a Cluster can be Ambiguous. Types of Clusterings. Hierarchical Clustering
 Overview Prognostic Models and Data Mining in Medicine, part I Cluster Analsis What is Cluster Analsis? K-Means Clustering Hierarchical Clustering Cluster Validit Eample: Microarra data analsis 6 Summar
Overview Prognostic Models and Data Mining in Medicine, part I Cluster Analsis What is Cluster Analsis? K-Means Clustering Hierarchical Clustering Cluster Validit Eample: Microarra data analsis 6 Summar
Cluster Analysis: Basic Concepts and Algorithms
 8 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
8 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
A Comparative Analysis of Various Clustering Techniques used for Very Large Datasets
 A Comparative Analysis of Various Clustering Techniques used for Very Large Datasets Preeti Baser, Assistant Professor, SJPIBMCA, Gandhinagar, Gujarat, India 382 007 Research Scholar, R. K. University,
A Comparative Analysis of Various Clustering Techniques used for Very Large Datasets Preeti Baser, Assistant Professor, SJPIBMCA, Gandhinagar, Gujarat, India 382 007 Research Scholar, R. K. University,
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Clustering Techniques: A Brief Survey of Different Clustering Algorithms
 Clustering Techniques: A Brief Survey of Different Clustering Algorithms Deepti Sisodia Technocrates Institute of Technology, Bhopal, India Lokesh Singh Technocrates Institute of Technology, Bhopal, India
Clustering Techniques: A Brief Survey of Different Clustering Algorithms Deepti Sisodia Technocrates Institute of Technology, Bhopal, India Lokesh Singh Technocrates Institute of Technology, Bhopal, India
SCAN: A Structural Clustering Algorithm for Networks
 SCAN: A Structural Clustering Algorithm for Networks Xiaowei Xu, Nurcan Yuruk, Zhidan Feng (University of Arkansas at Little Rock) Thomas A. J. Schweiger (Acxiom Corporation) Networks scaling: #edges connected
SCAN: A Structural Clustering Algorithm for Networks Xiaowei Xu, Nurcan Yuruk, Zhidan Feng (University of Arkansas at Little Rock) Thomas A. J. Schweiger (Acxiom Corporation) Networks scaling: #edges connected
On Data Clustering Analysis: Scalability, Constraints and Validation
 On Data Clustering Analysis: Scalability, Constraints and Validation Osmar R. Zaïane, Andrew Foss, Chi-Hoon Lee, and Weinan Wang University of Alberta, Edmonton, Alberta, Canada Summary. Clustering is
On Data Clustering Analysis: Scalability, Constraints and Validation Osmar R. Zaïane, Andrew Foss, Chi-Hoon Lee, and Weinan Wang University of Alberta, Edmonton, Alberta, Canada Summary. Clustering is
An Analysis on Density Based Clustering of Multi Dimensional Spatial Data
 An Analysis on Density Based Clustering of Multi Dimensional Spatial Data K. Mumtaz 1 Assistant Professor, Department of MCA Vivekanandha Institute of Information and Management Studies, Tiruchengode,
An Analysis on Density Based Clustering of Multi Dimensional Spatial Data K. Mumtaz 1 Assistant Professor, Department of MCA Vivekanandha Institute of Information and Management Studies, Tiruchengode,
ROCK: A Robust Clustering Algorithm for Categorical Attributes
 ROCK: A Robust Clustering Algorithm for Categorical Attributes Sudipto Guha Stanford University Stanford, CA 94305 [email protected] Rajeev Rastogi Bell Laboratories Murray Hill, NJ 07974 [email protected]
ROCK: A Robust Clustering Algorithm for Categorical Attributes Sudipto Guha Stanford University Stanford, CA 94305 [email protected] Rajeev Rastogi Bell Laboratories Murray Hill, NJ 07974 [email protected]
Concept of Cluster Analysis
 RESEARCH PAPER ON CLUSTER TECHNIQUES OF DATA VARIATIONS Er. Arpit Gupta 1,Er.Ankit Gupta 2,Er. Amit Mishra 3 [email protected], [email protected],[email protected] Faculty Of Engineering
RESEARCH PAPER ON CLUSTER TECHNIQUES OF DATA VARIATIONS Er. Arpit Gupta 1,Er.Ankit Gupta 2,Er. Amit Mishra 3 [email protected], [email protected],[email protected] Faculty Of Engineering
On Clustering Validation Techniques
 Journal of Intelligent Information Systems, 17:2/3, 107 145, 2001 c 2001 Kluwer Academic Publishers. Manufactured in The Netherlands. On Clustering Validation Techniques MARIA HALKIDI [email protected] YANNIS
Journal of Intelligent Information Systems, 17:2/3, 107 145, 2001 c 2001 Kluwer Academic Publishers. Manufactured in The Netherlands. On Clustering Validation Techniques MARIA HALKIDI [email protected] YANNIS
A comparison of various clustering methods and algorithms in data mining
 Volume :2, Issue :5, 32-36 May 2015 www.allsubjectjournal.com e-issn: 2349-4182 p-issn: 2349-5979 Impact Factor: 3.762 R.Tamilselvi B.Sivasakthi R.Kavitha Assistant Professor A comparison of various clustering
Volume :2, Issue :5, 32-36 May 2015 www.allsubjectjournal.com e-issn: 2349-4182 p-issn: 2349-5979 Impact Factor: 3.762 R.Tamilselvi B.Sivasakthi R.Kavitha Assistant Professor A comparison of various clustering
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 8/05/2005 1 What is data exploration? A preliminary
Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 8/05/2005 1 What is data exploration? A preliminary
How To Cluster
 Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Mining Process Using Clustering: A Survey
 Data Mining Process Using Clustering: A Survey Mohamad Saraee Department of Electrical and Computer Engineering Isfahan University of Techno1ogy, Isfahan, 84156-83111 [email protected] Najmeh Ahmadian
Data Mining Process Using Clustering: A Survey Mohamad Saraee Department of Electrical and Computer Engineering Isfahan University of Techno1ogy, Isfahan, 84156-83111 [email protected] Najmeh Ahmadian
Territorial Analysis for Ratemaking. Philip Begher, Dario Biasini, Filip Branitchev, David Graham, Erik McCracken, Rachel Rogers and Alex Takacs
 Territorial Analysis for Ratemaking by Philip Begher, Dario Biasini, Filip Branitchev, David Graham, Erik McCracken, Rachel Rogers and Alex Takacs Department of Statistics and Applied Probability University
Territorial Analysis for Ratemaking by Philip Begher, Dario Biasini, Filip Branitchev, David Graham, Erik McCracken, Rachel Rogers and Alex Takacs Department of Statistics and Applied Probability University
Public Transportation BigData Clustering
 Public Transportation BigData Clustering Preliminary Communication Tomislav Galba J.J. Strossmayer University of Osijek Faculty of Electrical Engineering Cara Hadriana 10b, 31000 Osijek, Croatia [email protected]
Public Transportation BigData Clustering Preliminary Communication Tomislav Galba J.J. Strossmayer University of Osijek Faculty of Electrical Engineering Cara Hadriana 10b, 31000 Osijek, Croatia [email protected]
2 Basic Concepts and Techniques of Cluster Analysis
 The Challenges of Clustering High Dimensional Data * Michael Steinbach, Levent Ertöz, and Vipin Kumar Abstract Cluster analysis divides data into groups (clusters) for the purposes of summarization or
The Challenges of Clustering High Dimensional Data * Michael Steinbach, Levent Ertöz, and Vipin Kumar Abstract Cluster analysis divides data into groups (clusters) for the purposes of summarization or
Clustering on Large Numeric Data Sets Using Hierarchical Approach Birch
 Global Journal of Computer Science and Technology Software & Data Engineering Volume 12 Issue 12 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global
Global Journal of Computer Science and Technology Software & Data Engineering Volume 12 Issue 12 Version 1.0 Year 2012 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global
Reference Books. Data Mining. Supervised vs. Unsupervised Learning. Classification: Definition. Classification k-nearest neighbors
 Classification k-nearest neighbors Data Mining Dr. Engin YILDIZTEPE Reference Books Han, J., Kamber, M., Pei, J., (2011). Data Mining: Concepts and Techniques. Third edition. San Francisco: Morgan Kaufmann
Classification k-nearest neighbors Data Mining Dr. Engin YILDIZTEPE Reference Books Han, J., Kamber, M., Pei, J., (2011). Data Mining: Concepts and Techniques. Third edition. San Francisco: Morgan Kaufmann
Distances, Clustering, and Classification. Heatmaps
 Distances, Clustering, and Classification Heatmaps 1 Distance Clustering organizes things that are close into groups What does it mean for two genes to be close? What does it mean for two samples to be
Distances, Clustering, and Classification Heatmaps 1 Distance Clustering organizes things that are close into groups What does it mean for two genes to be close? What does it mean for two samples to be
Data Mining Project Report. Document Clustering. Meryem Uzun-Per
 Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Chapter ML:XI (continued)
") Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Data Clustering Techniques Qualifying Oral Examination Paper
 Data Clustering Techniques Qualifying Oral Examination Paper Periklis Andritsos University of Toronto Department of Computer Science [email protected] March 11, 2002 1 Introduction During a cholera
Data Clustering Techniques Qualifying Oral Examination Paper Periklis Andritsos University of Toronto Department of Computer Science [email protected] March 11, 2002 1 Introduction During a cholera
. Learn the number of classes and the structure of each class using similarity between unlabeled training patterns
 Outline Part 1: of data clustering Non-Supervised Learning and Clustering : Problem formulation cluster analysis : Taxonomies of Clustering Techniques : Data types and Proximity Measures : Difficulties
Outline Part 1: of data clustering Non-Supervised Learning and Clustering : Problem formulation cluster analysis : Taxonomies of Clustering Techniques : Data types and Proximity Measures : Difficulties
SoSe 2014: M-TANI: Big Data Analytics
 SoSe 2014: M-TANI: Big Data Analytics Lecture 4 21/05/2014 Sead Izberovic Dr. Nikolaos Korfiatis Agenda Recap from the previous session Clustering Introduction Distance mesures Hierarchical Clustering
SoSe 2014: M-TANI: Big Data Analytics Lecture 4 21/05/2014 Sead Izberovic Dr. Nikolaos Korfiatis Agenda Recap from the previous session Clustering Introduction Distance mesures Hierarchical Clustering
A Study on the Hierarchical Data Clustering Algorithm Based on Gravity Theory
 A Study on the Hierarchical Data Clustering Algorithm Based on Gravity Theory Yen-Jen Oyang, Chien-Yu Chen, and Tsui-Wei Yang Department of Computer Science and Information Engineering National Taiwan
A Study on the Hierarchical Data Clustering Algorithm Based on Gravity Theory Yen-Jen Oyang, Chien-Yu Chen, and Tsui-Wei Yang Department of Computer Science and Information Engineering National Taiwan
A Comparative Study of clustering algorithms Using weka tools
 A Comparative Study of clustering algorithms Using weka tools Bharat Chaudhari 1, Manan Parikh 2 1,2 MECSE, KITRC KALOL ABSTRACT Data clustering is a process of putting similar data into groups. A clustering
A Comparative Study of clustering algorithms Using weka tools Bharat Chaudhari 1, Manan Parikh 2 1,2 MECSE, KITRC KALOL ABSTRACT Data clustering is a process of putting similar data into groups. A clustering
Clustering. 15-381 Artificial Intelligence Henry Lin. Organizing data into clusters such that there is
 Clustering 15-381 Artificial Intelligence Henry Lin Modified from excellent slides of Eamonn Keogh, Ziv Bar-Joseph, and Andrew Moore What is Clustering? Organizing data into clusters such that there is
Clustering 15-381 Artificial Intelligence Henry Lin Modified from excellent slides of Eamonn Keogh, Ziv Bar-Joseph, and Andrew Moore What is Clustering? Organizing data into clusters such that there is
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Categorical Data Visualization and Clustering Using Subjective Factors
 Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Clustering. Clustering. What is Clustering? What is Clustering? What is Clustering? Types of Data in Cluster Analysis
 What is Clustering? Clustering Tpes of Data in Cluster Analsis Clustering A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods What is Clustering? Clustering of data is
What is Clustering? Clustering Tpes of Data in Cluster Analsis Clustering A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods What is Clustering? Clustering of data is
PERFORMANCE ANALYSIS OF CLUSTERING ALGORITHMS IN DATA MINING IN WEKA
 PERFORMANCE ANALYSIS OF CLUSTERING ALGORITHMS IN DATA MINING IN WEKA Prakash Singh 1, Aarohi Surya 2 1 Department of Finance, IIM Lucknow, Lucknow, India 2 Department of Computer Science, LNMIIT, Jaipur,
PERFORMANCE ANALYSIS OF CLUSTERING ALGORITHMS IN DATA MINING IN WEKA Prakash Singh 1, Aarohi Surya 2 1 Department of Finance, IIM Lucknow, Lucknow, India 2 Department of Computer Science, LNMIIT, Jaipur,
Summary Data Mining & Process Mining (1BM46) Content. Made by S.P.T. Ariesen
 Content. Made by S.P.T. Ariesen") Summary Data Mining & Process Mining (1BM46) Made by S.P.T. Ariesen Content Data Mining part... 2 Lecture 1... 2 Lecture 2:... 4 Lecture 3... 7 Lecture 4... 9 Process mining part... 13 Lecture 5... 13
Summary Data Mining & Process Mining (1BM46) Made by S.P.T. Ariesen Content Data Mining part... 2 Lecture 1... 2 Lecture 2:... 4 Lecture 3... 7 Lecture 4... 9 Process mining part... 13 Lecture 5... 13
Cluster Analysis. Isabel M. Rodrigues. Lisboa, 2014. Instituto Superior Técnico
 Instituto Superior Técnico Lisboa, 2014 Introduction: Cluster analysis What is? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Instituto Superior Técnico Lisboa, 2014 Introduction: Cluster analysis What is? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
BIRCH: An Efficient Data Clustering Method For Very Large Databases
 BIRCH: An Efficient Data Clustering Method For Very Large Databases Tian Zhang, Raghu Ramakrishnan, Miron Livny CPSC 504 Presenter: Discussion Leader: Sophia (Xueyao) Liang HelenJr, Birches. Online Image.
BIRCH: An Efficient Data Clustering Method For Very Large Databases Tian Zhang, Raghu Ramakrishnan, Miron Livny CPSC 504 Presenter: Discussion Leader: Sophia (Xueyao) Liang HelenJr, Birches. Online Image.
Medical Information Management & Mining. You Chen Jan,15, 2013 [email protected]
 Medical Information Management & Mining You Chen Jan,15, 2013 [email protected] 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Medical Information Management & Mining You Chen Jan,15, 2013 [email protected] 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Comparison and Analysis of Various Clustering Methods in Data mining On Education data set Using the weak tool
 Comparison and Analysis of Various Clustering Metho in Data mining On Education data set Using the weak tool Abstract:- Data mining is used to find the hidden information pattern and relationship between
Comparison and Analysis of Various Clustering Metho in Data mining On Education data set Using the weak tool Abstract:- Data mining is used to find the hidden information pattern and relationship between
How To Perform An Ensemble Analysis
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY 10598 Outlier Ensembles Keynote, Outlier Detection and Description Workshop, 2013 Based on the ACM SIGKDD Explorations Position Paper: Outlier
Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY 10598 Outlier Ensembles Keynote, Outlier Detection and Description Workshop, 2013 Based on the ACM SIGKDD Explorations Position Paper: Outlier
Classification algorithm in Data mining: An Overview
 Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Linköpings Universitet - ITN TNM033 2011-11-30 DBSCAN. A Density-Based Spatial Clustering of Application with Noise
 DBSCAN A Density-Based Spatial Clustering of Application with Noise Henrik Bäcklund (henba892), Anders Hedblom (andh893), Niklas Neijman (nikne866) 1 1. Introduction Today data is received automatically
DBSCAN A Density-Based Spatial Clustering of Application with Noise Henrik Bäcklund (henba892), Anders Hedblom (andh893), Niklas Neijman (nikne866) 1 1. Introduction Today data is received automatically
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Unsupervised Learning and Data Mining. Unsupervised Learning and Data Mining. Clustering. Supervised Learning. Supervised Learning
 Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS
 UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 [email protected] What is Learning? "Learning denotes changes in a system that enable
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 [email protected] What is Learning? "Learning denotes changes in a system that enable
Cluster Analysis: Basic Concepts and Methods
 10 Cluster Analysis: Basic Concepts and Methods Imagine that you are the Director of Customer Relationships at AllElectronics, and you have five managers working for you. You would like to organize all
10 Cluster Analysis: Basic Concepts and Methods Imagine that you are the Director of Customer Relationships at AllElectronics, and you have five managers working for you. You would like to organize all
COM CO P 5318 Da t Da a t Explora Explor t a ion and Analysis y Chapte Chapt r e 3
 COMP 5318 Data Exploration and Analysis Chapter 3 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping
COMP 5318 Data Exploration and Analysis Chapter 3 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping
Data Mining: A Preprocessing Engine
 Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
King Saud University
 King Saud University College of Computer and Information Sciences Department of Computer Science CSC 493 Selected Topics in Computer Science (3-0-1) - Elective Course CECS 493 Selected Topics: DATA MINING
King Saud University College of Computer and Information Sciences Department of Computer Science CSC 493 Selected Topics in Computer Science (3-0-1) - Elective Course CECS 493 Selected Topics: DATA MINING
An Overview of Knowledge Discovery Database and Data mining Techniques
 An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
B490 Mining the Big Data. 2 Clustering
 B490 Mining the Big Data 2 Clustering Qin Zhang 1-1 Motivations Group together similar documents/webpages/images/people/proteins/products One of the most important problems in machine learning, pattern
B490 Mining the Big Data 2 Clustering Qin Zhang 1-1 Motivations Group together similar documents/webpages/images/people/proteins/products One of the most important problems in machine learning, pattern
A Two-Step Method for Clustering Mixed Categroical and Numeric Data
 Tamkang Journal of Science and Engineering, Vol. 13, No. 1, pp. 11 19 (2010) 11 A Two-Step Method for Clustering Mixed Categroical and Numeric Data Ming-Yi Shih*, Jar-Wen Jheng and Lien-Fu Lai Department
Tamkang Journal of Science and Engineering, Vol. 13, No. 1, pp. 11 19 (2010) 11 A Two-Step Method for Clustering Mixed Categroical and Numeric Data Ming-Yi Shih*, Jar-Wen Jheng and Lien-Fu Lai Department
SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING
 AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
Clustering Data Streams
 Clustering Data Streams Mohamed Elasmar Prashant Thiruvengadachari Javier Salinas Martin [email protected] [email protected] [email protected] Introduction: Data mining is the science of extracting
Clustering Data Streams Mohamed Elasmar Prashant Thiruvengadachari Javier Salinas Martin [email protected] [email protected] [email protected] Introduction: Data mining is the science of extracting
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Data Clustering Using Data Mining Techniques
 Data Clustering Using Data Mining Techniques S.R.Pande 1, Ms. S.S.Sambare 2, V.M.Thakre 3 Department of Computer Science, SSES Amti's Science College, Congressnagar, Nagpur, India 1 Department of Computer
Data Clustering Using Data Mining Techniques S.R.Pande 1, Ms. S.S.Sambare 2, V.M.Thakre 3 Department of Computer Science, SSES Amti's Science College, Congressnagar, Nagpur, India 1 Department of Computer
A Survey of Clustering Techniques
 A Survey of Clustering Techniques Pradeep Rai Asst. Prof., CSE Department, Kanpur Institute of Technology, Kanpur-0800 (India) Shubha Singh Asst. Prof., MCA Department, Kanpur Institute of Technology,
A Survey of Clustering Techniques Pradeep Rai Asst. Prof., CSE Department, Kanpur Institute of Technology, Kanpur-0800 (India) Shubha Singh Asst. Prof., MCA Department, Kanpur Institute of Technology,
Protein Protein Interaction Networks
 Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Distances between Clustering, Hierarchical Clustering
 Distances between Clustering, Hierarchical Clustering 36-350, Data Mining 14 September 2009 Contents 1 Distances Between Partitions 1 2 Hierarchical clustering 2 2.1 Ward s method............................
Distances between Clustering, Hierarchical Clustering 36-350, Data Mining 14 September 2009 Contents 1 Distances Between Partitions 1 2 Hierarchical clustering 2 2.1 Ward s method............................
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Classification Techniques (1)
") 10 10 Overview Classification Techniques (1) Today Classification Problem Classification based on Regression Distance-based Classification (KNN) Net Lecture Decision Trees Classification using Rules Quality
10 10 Overview Classification Techniques (1) Today Classification Problem Classification based on Regression Distance-based Classification (KNN) Net Lecture Decision Trees Classification using Rules Quality
International Journal of Advance Research in Computer Science and Management Studies
 Volume 3, Issue 11, November 2015 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Volume 3, Issue 11, November 2015 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Clustering and Outlier Detection
 Clustering and Outlier Detection Application Examples Customer segmentation How to partition customers into groups so that customers in each group are similar, while customers in different groups are dissimilar?
Clustering and Outlier Detection Application Examples Customer segmentation How to partition customers into groups so that customers in each group are similar, while customers in different groups are dissimilar?
Identifying erroneous data using outlier detection techniques
 Identifying erroneous data using outlier detection techniques Wei Zhuang 1, Yunqing Zhang 2 and J. Fred Grassle 2 1 Department of Computer Science, Rutgers, the State University of New Jersey, Piscataway,
Identifying erroneous data using outlier detection techniques Wei Zhuang 1, Yunqing Zhang 2 and J. Fred Grassle 2 1 Department of Computer Science, Rutgers, the State University of New Jersey, Piscataway,
Clustering Via Decision Tree Construction
 Clustering Via Decision Tree Construction Bing Liu 1, Yiyuan Xia 2, and Philip S. Yu 3 1 Department of Computer Science, University of Illinois at Chicago, 851 S. Morgan Street, Chicago, IL 60607-7053.
Clustering Via Decision Tree Construction Bing Liu 1, Yiyuan Xia 2, and Philip S. Yu 3 1 Department of Computer Science, University of Illinois at Chicago, 851 S. Morgan Street, Chicago, IL 60607-7053.
Unsupervised learning: Clustering
 Unsupervised learning: Clustering Salissou Moutari Centre for Statistical Science and Operational Research CenSSOR 17 th September 2013 Unsupervised learning: Clustering 1/52 Outline 1 Introduction What
Unsupervised learning: Clustering Salissou Moutari Centre for Statistical Science and Operational Research CenSSOR 17 th September 2013 Unsupervised learning: Clustering 1/52 Outline 1 Introduction What
Robust Outlier Detection Technique in Data Mining: A Univariate Approach
 Robust Outlier Detection Technique in Data Mining: A Univariate Approach Singh Vijendra and Pathak Shivani Faculty of Engineering and Technology Mody Institute of Technology and Science Lakshmangarh, Sikar,
Robust Outlier Detection Technique in Data Mining: A Univariate Approach Singh Vijendra and Pathak Shivani Faculty of Engineering and Technology Mody Institute of Technology and Science Lakshmangarh, Sikar,
Modifying Insurance Rating Territories Via Clustering
 Modifying Insurance Rating Territories Via Clustering Quncai Zou, New Jersey Manufacturers Insurance Company, West Trenton, NJ Ryan Diehl, New Jersey Manufacturers Insurance Company, West Trenton, NJ ABSTRACT
Modifying Insurance Rating Territories Via Clustering Quncai Zou, New Jersey Manufacturers Insurance Company, West Trenton, NJ Ryan Diehl, New Jersey Manufacturers Insurance Company, West Trenton, NJ ABSTRACT
Classifying Large Data Sets Using SVMs with Hierarchical Clusters. Presented by :Limou Wang
 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Well-Separated Pair Decomposition for the Unit-disk Graph Metric and its Applications
 Well-Separated Pair Decomposition for the Unit-disk Graph Metric and its Applications Jie Gao Department of Computer Science Stanford University Joint work with Li Zhang Systems Research Center Hewlett-Packard
Well-Separated Pair Decomposition for the Unit-disk Graph Metric and its Applications Jie Gao Department of Computer Science Stanford University Joint work with Li Zhang Systems Research Center Hewlett-Packard