Chapter 4. Data Hazards in ALU Instructions. The Processor. Consider this sequence: We can resolve hazards with forwarding
|
|
|
- Annabel Primrose Harrell
- 7 years ago
- Views:
Transcription

 We can resolve hazards with forwarding")

1 Chapter 4 The Processor Part III Data Hazards in ALU Instructions Consider this sequence: sub $2, $1,$3$3 and $12,$2,$5 or $13,$6,$2 add $14,$2,$2 sw $15,100($2) We can resolve hazards with forwarding How do we detect when to forward? 4.7 Data a Hazards s: Forward ding vs. Sta alling Chapter 4 The Processor 2





2 Dependencies & Forwarding Chapter 4 The Processor 3 Detecting the Need to Forward Pass register numbers along pipeline e.g., ID/EX.RegisterRs = register number for Rs sitting in ID/EX pipeline register ALU operand register numbers in EX stage are given by ID/EX.RegisterRs, ID/EX.RegisterRt Data hazards when 1a. EX/MEM.RegisterRd = ID/EX.RegisterRs 1b. EX/MEM.RegisterRd = ID/EX.RegisterRt 2a. MEM/WB.RegisterRd = ID/EX.RegisterRs 2b. MEM/WB.RegisterRd = ID/EX.RegisterRt 1. This instr s Rd is next instr s Rs or Rt Fwd from EX/MEM pipeline reg Fwd from MEM/WB pipeline pp reg 2. This instr s Rd is Rs or Rt of instr following next instr Chapter 4 The Processor 4






3 Detecting the Need to Forward But only if forwarding instruction will write to a register! EX/MEM.RegWrite, MEM/WB.RegWrite And only if Rd for that instruction is not $zero EX/MEM.RegisterRd 0, MEM/WB.RegisterRd 0 Chapter 4 The Processor 5 Forwarding Paths Chapter 4 The Processor 6
4 Forwarding Conditions EX hazard if (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) ForwardA = 10 if (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt)) ForwardB = 10 MEM hazard if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01 if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and (MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01 Chapter 4 The Processor 7 Double Data Hazard Consider the sequence: add $1,$1,$2 $2 add $1,$1,$3 add $1,$1,$4 Both hazards occur Want to use the most recent Revise MEM hazard condition Only fwd if EX hazard condition isn t true Chapter 4 The Processor 8
 and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) and (MEM/WB.")
 and (EX/MEM.RegisterRd = ID/EX.")
5 Revised Forwarding Condition MEM hazard not (R-type instr without double hazard) if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs)) and (MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01 if (MEM/WB.RegWrite and (MEM/WB.RegisterRd 0) and not (EX/MEM.RegWrite and (EX/MEM.RegisterRd 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt)) and (MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01 Chapter 4 The Processor 9 Datapath with Forwarding Chapter 4 The Processor 10





 or (ID/EX.")
6 Load-Use Data Hazard Need to stall for one cycle Chapter 4 The Processor 11 Load-Use Hazard Detection Check when using instruction is decoded in ID stage ALU operand register numbers in ID stage are given by IF/ID.RegisterRs, IF/ID.RegisterRt Load-use hazard when load This instr s Rt is next instr s Rs or Rt ID/EX.MemRead and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)) If detected, stall and insert bubble Chapter 4 The Processor 12

 Prevent ent update")




7 How to Stall the Pipeline Force control values in ID/EX register to 0 EX, MEM and WB do nop (no-operation) Prevent ent update of PC and IF/ID register Using instruction is decoded again Following instruction is fetched again 1-cycle stall allows MEM to read data for lw Can subsequently forward to EX stage Chapter 4 The Processor 13 Stall/Bubble in the Pipeline Stall inserted here Chapter 4 The Processor 14
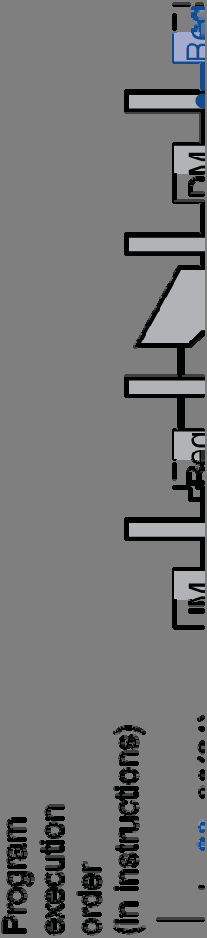







8 Stall/Bubble in the Pipeline Or, more accurately Chapter 4 The Processor 15 Datapath with Hazard Detection Chapter 4 The Processor 16






9 Stalls and Performance The BIG Picture Stalls reduce performance But are required to get correct results Compiler can arrange code to avoid hazards and stalls Requires knowledge of the pipeline structure Chapter 4 The Processor 17 Branch Hazards If branch outcome determined in MEM 4.8 Con ntrol Hazards Flush these instructions (Set control values to 0) PC Chapter 4 The Processor 18
10 Reducing Branch Delay Move hardware to determine outcome to ID stage Target address adder Register comparator Example: branch taken 36: sub $10, $4, $8 40: beq $1, $3, = 44 44: and $12, $2, $5 48: or $13, $2, $6 52: add $14, $4, $2 56: slt $15, $6, $ : lw $4, 50($7) *4 = 72 Chapter 4 The Processor 19 Example: Branch Taken Chapter 4 The Processor 20
11 Example: Branch Taken Chapter 4 The Processor 21 Data Hazards for Branches If a comparison register is a destination of 2 nd or 3 rd preceding ALU instruction add $1, $2, $3 IF ID EX MEM WB add $4, $5, $6 IF ID EX MEM WB IF ID EX MEM WB beq $1, $4, target IF ID EX MEM WB Can resolve using forwarding Chapter 4 The Processor 22
12 Data Hazards for Branches If a comparison register is a destination of preceding ALU instruction or 2 nd preceding load instruction Need 1 stall cycle lw $1, addr IF ID EX MEM WB add $4, $5, $6 IF ID EX MEM WB beq stalled IF ID beq $1, $4, target ID EX MEM WB Chapter 4 The Processor 23 Data Hazards for Branches If a comparison register is a destination of immediately preceding load instruction Need 2 stall cycles lw $1, addr IF ID EX MEM WB beq stalled IF ID beq stalled ID beq $1, $0, target ID EX MEM WB Chapter 4 The Processor 24
13 Dynamic Branch Prediction In deeper and superscalar pipelines, branch penalty is more significant Use dynamic prediction Branch prediction buffer (aka branch history table) Indexed by recent branch instruction addresses Stores outcome (taken/not taken) To execute a branch Check table, expect the same outcome Start fetching from fall-through or target If wrong, flush pipeline and flip prediction Chapter 4 The Processor 25 1-Bit Predictor: Shortcoming Inner loop branches mispredicted twice! outer: inner: beq,, inner beq,, outer Mispredict as taken on last iteration of inner loop Then mispredict as not taken on first iteration of inner loop next time around Chapter 4 The Processor 26








14 2-Bit Predictor Only change prediction on two successive mispredictions Chapter 4 The Processor 27 Calculating the Branch Target Even with predictor, still need to calculate the target address 1-cycle penalty for a taken branch Branch target buffer Cache of target addresses Indexed by PC when instruction fetched If hit and instruction is branch predicted taken, can fetch target immediately Chapter 4 The Processor 28
15 Final Pipelining Datapath and Control Chapter 4 The Processor 29 Exceptions and Interrupts Unexpected events requiring change in flow of control Different ISAs use the terms differently Exception Arises within the CPU Interrupt e.g., undefined opcode, overflow, syscall, From an external I/O controller Dealing with them without sacrificing performance is hard 4.9 Exc eptions Chapter 4 The Processor 30
16 Exceptions in a Pipeline Another form of control hazard Consider overflow on add in EX stage add $1, $2, $1 Prevent $1 from being clobbered Complete previous instructions Flush add and subsequent instructions Set Cause and EPC register values Transfer control to handler Similar to mispredicted branch Use much of the same hardware Chapter 4 The Processor 31 Pipeline with Exceptions Chapter 4 The Processor 32
17 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle Multiple issue Replicate pipeline stages multiple pipelines Start multiple instructions per clock cycle CPI < 1, so use Instructions Per Cycle (IPC) E.g., 4GHz 4-way multiple-issue 16 BIPS, peak CPI = 0.25, peak IPC = 4 But dependencies reduce this in practice 4.10 Pa arallelism and Advan nced Instru uction Lev vel Parallel lism Chapter 4 The Processor 33 Multiple Issue Static multiple issue Compiler groups instructions to be issued together Packages them into issue slots Compiler detects and avoids hazards Dynamic multiple issue CPU examines instruction stream and chooses instructions to issue each cycle Compiler can help by reordering instructions CPU resolves hazards using advanced techniques at runtime Chapter 4 The Processor 34
18 Speculation Guess what to do with an instruction Start operation as soon as possible Check whether guess was right If so, complete the operation If not, roll-back and do the right thing Common to static and dynamic multiple issue Examples Speculate on branch outcome Roll back if path taken is different Speculate on load Roll back if location is updated Chapter 4 The Processor 35 Compiler/Hardware Speculation Compiler can reorder instructions e.g., move load before branch Can include fix-up instructions to recover from incorrect guess Hardware can look ahead for instructions to execute Buffer results until it determines they are actually needed Flush buffers on incorrect speculation Chapter 4 The Processor 36
19 Speculation and Exceptions What if exception occurs on a speculatively e executed ecuted instruction? e.g., speculative load before null-pointer check Static speculation Can add ISA support for deferring exceptions Dynamic speculation Can buffer exceptions until instruction completion (which may not occur) Chapter 4 The Processor 37 Static Multiple Issue Compiler groups instructions into issue packets Group of instructions that can be issued on a single cycle Determined by pipeline resources required Think of an issue packet as a very long instruction Specifies multiple l concurrent operations Very Long Instruction Word (VLIW) Chapter 4 The Processor 38
20 Scheduling Static Multiple Issue Compiler must remove some/all hazards Reorder instructions into issue packets No dependencies with a packet Possibly some dependencies between packets Varies between ISAs; compiler must know! Pad with nop if necessary Chapter 4 The Processor 39 MIPS with Static Dual Issue Two-issue packets One ALU/branch instruction One load/store instruction 64-bit aligned ALU/branch, then load/store Pad an unused instruction with nop Address Instruction type Pipeline Stages n ALU/branch IF ID EX MEM WB n + 4 Load/store IF ID EX MEM WB n + 8 ALU/branch IF ID EX MEM WB n + 12 Load/store IF ID EX MEM WB n + 16 ALU/branch IF ID EX MEM WB n + 20 Load/store IF ID EX MEM WB Chapter 4 The Processor 40



 Split into")


21 MIPS with Static Dual Issue Chapter 4 The Processor 41 Hazards in the Dual-Issue MIPS More instructions executing in parallel EX data hazard Forwarding avoided stalls with single-issue Now can t use ALU result in load/store in same packet add $t0, $s0, $s1 load $s2, 0($t0) Split into two packets, effectively a stall Load-use hazard Still one cycle use latency, but now two instructions More aggressive scheduling required Chapter 4 The Processor 42
22 Scheduling Example Schedule this for dual-issue MIPS Loop: lw $t0, 0($s1) # $t0=array element addu $t0, $t0, $s2 # add scalar in $s2 sw $t0, 0($s1) # store result addi $s1, $s1, 4 # decrement pointer bne $s1, $zero, Loop # branch $s1!=0 ALU/branch Load/store cycle Loop: nop lw $t0, 0($s1) 1 addi $s1, $s1, 4 nop 2 addu $t0, $t0, $s2 nop 3 bne $s1, $zero, Loop sw $t0, 4($s1) 4 IPC = 5/4 = 1.25 (c.f. peak IPC = 2) Chapter 4 The Processor 43 Loop Unrolling Replicate loop body to expose more parallelism Reduces loop-control overhead Use different registers per replication Called register renaming Avoid loop-carried anti-dependencies Store followed by a load of the same register Aka name dependence d Reuse of a register name Chapter 4 The Processor 44
23 Loop Unrolling Example ALU/branch Load/store cycle Loop: addi $s1, $s1, 16 lw $t0, 0($s1) 1 nop lw $t1, 12($s1) 2 addu $t0, $t0, $s2 lw $t2, 8($s1) 3 addu $t1, $t1, $s2 lw $t3, 4($s1) 4 addu $t2, $t2, $s2 sw $t0, 16($s1) 5 addu $t3, $t4, $s2 sw $t1, 12($s1) 6 nop sw $t2, 8($s1) 7 bne $s1, $zero, Loop sw $t3, 4($s1) 8 IPC = 14/8 = 1.75 Closer to 2, but at cost of registers and code size Chapter 4 The Processor 45 Dynamic Multiple Issue Superscalar processors CPU decides whether to issue 0, 1, 2, each cycle Avoiding structural t and data hazards Avoids the need for compiler scheduling Though it may still help Code semantics ensured by the CPU Chapter 4 The Processor 46


 addu $t1, $t0, $t2")





24 Dynamic Pipeline Scheduling Allow the CPU to execute instructions out of order to avoid stalls But commit result to registers in order Example lw $t0, 20($s2) addu $t1, $t0, $t2 sub $s4, $s4, $t3 slti $t5, $s4, 20 Can start sub while addu is waiting for lw Chapter 4 The Processor 47 Dynamically Scheduled CPU Preserves dependencies Hold pending operands Results also sent to any waiting reservation stations Reorders buffer for register writes Can supply operands for issued instructions Chapter 4 The Processor 48
25 Register Renaming Reservation stations and reorder buffer effectively ect e provide register renaming On instruction issue to reservation station If operand is available in register file or reorder buffer Copied to reservation station No longer required in the register; can be overwritten If operand is not yet available It will be provided to the reservation station by a function unit Register update may not be required Chapter 4 The Processor 49 Speculation Predict branch and continue issuing Don t commit until branch outcome determined Load speculation Avoid load and cache miss delay Predict the effective address Predict loaded value Load before completing outstanding stores Bypass stored values to load unit Don t commit load until speculation cleared Chapter 4 The Processor 50
26 Why Do Dynamic Scheduling? Why not just let the compiler schedule code? Not all stalls are predicable e.g., cache misses Can t always schedule around branches Branch outcome is dynamically determined Different implementations of an ISA have different latencies and hazards Chapter 4 The Processor 51 Does Multiple Issue Work? The BIG Picture Yes, but not as much as we d like Programs have real dependencies that limit ILP Some dependencies are hard to eliminate e.g., pointer aliasing Some parallelism is hard to expose Limited window size during instruction issue Memory delays and limited bandwidth Hard to keep pipelines full Speculation can help if done well Chapter 4 The Processor 52










27 Power Efficiency Complexity of dynamic scheduling and speculations requires power Multiple simpler cores may be better Microprocessor Year Clock Rate Pipeline Stages Issue width Out-of-order/ Speculation Cores Power i MHz 5 1 No 1 5W Pentium MHz 5 2 No 1 10W Pentium Pro MHz 10 3 Yes 1 29W P4 Willamette MHz 22 3 Yes 1 75W P4 Prescott MHz 31 3 Yes 1 103W Core MHz 14 4 Yes 2 75W UltraSparc III MHz 14 4 No 1 90W UltraSparc T MHz 6 1 No 8 70W Chapter 4 The Processor 53 The Opteron X4 Microarchitecture 72 physical registers 4.11 Real Stuff: The AMD Opteron X4 (Barcelona) Pipeline Chapter 4 The Processor 54
28 The Opteron X4 Pipeline Flow For integer operations FP is 5 stages longer Up to 106 RISC-ops in progress Bottlenecks Complex instructions with long dependencies Branch mispredictions Memory access delays Chapter 4 The Processor 55 Fallacies Pipelining is easy (!) The basic idea is easy The devil is in the details e.g., detecting data hazards Pipelining is independent of technology So why haven t we always done pipelining? More transistors make more advanced techniques feasible Pipeline-related ISA design needs to take account of technology trends e.g., predicated instructions 4.13 Fa allacies and Pitfalls Chapter 4 The Processor 56
29 Pitfalls Poor ISA design can make pipelining harder e.g., complex instruction sets (VAX, IA-32) Significant overhead to make pipelining work IA-32 micro-op approach e.g., complex addressing modes Register update side effects, memory indirection e.g., delayed branches Advanced pipelines have long delay slots Chapter 4 The Processor 57 Concluding Remarks ISA influences design of datapath and control Datapath and control influence design of ISA Pipelining improves instruction throughput using parallelism More instructions completed per second Latency for each instruction not reduced Hazards: structural, data, control Multiple issue and dynamic scheduling (ILP) Dependencies limit achievable parallelism Complexity leads to the power wall 4.14 Co oncluding Remarks Chapter 4 The Processor 58
CS352H: Computer Systems Architecture
 CS352H: Computer Systems Architecture Topic 9: MIPS Pipeline - Hazards October 1, 2009 University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell Data Hazards in ALU Instructions
CS352H: Computer Systems Architecture Topic 9: MIPS Pipeline - Hazards October 1, 2009 University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell Data Hazards in ALU Instructions
INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER
 Course on: Advanced Computer Architectures INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER Prof. Cristina Silvano Politecnico di Milano cristina.silvano@polimi.it Prof. Silvano, Politecnico di Milano
Course on: Advanced Computer Architectures INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER Prof. Cristina Silvano Politecnico di Milano cristina.silvano@polimi.it Prof. Silvano, Politecnico di Milano
 More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
Pipeline Hazards. Structure hazard Data hazard. ComputerArchitecture_PipelineHazard1
 Pipeline Hazards Structure hazard Data hazard Pipeline hazard: the major hurdle A hazard is a condition that prevents an instruction in the pipe from executing its next scheduled pipe stage Taxonomy of
Pipeline Hazards Structure hazard Data hazard Pipeline hazard: the major hurdle A hazard is a condition that prevents an instruction in the pipe from executing its next scheduled pipe stage Taxonomy of
Design of Pipelined MIPS Processor. Sept. 24 & 26, 1997
 Design of Pipelined MIPS Processor Sept. 24 & 26, 1997 Topics Instruction processing Principles of pipelining Inserting pipe registers Data Hazards Control Hazards Exceptions MIPS architecture subset R-type
Design of Pipelined MIPS Processor Sept. 24 & 26, 1997 Topics Instruction processing Principles of pipelining Inserting pipe registers Data Hazards Control Hazards Exceptions MIPS architecture subset R-type
Q. Consider a dynamic instruction execution (an execution trace, in other words) that consists of repeats of code in this pattern:
 that consists of repeats of code in this pattern:") Pipelining HW Q. Can a MIPS SW instruction executing in a simple 5-stage pipelined implementation have a data dependency hazard of any type resulting in a nop bubble? If so, show an example; if not, prove
Pipelining HW Q. Can a MIPS SW instruction executing in a simple 5-stage pipelined implementation have a data dependency hazard of any type resulting in a nop bubble? If so, show an example; if not, prove
Solution: start more than one instruction in the same clock cycle CPI < 1 (or IPC > 1, Instructions per Cycle) Two approaches:
 Two approaches:") Multiple-Issue Processors Pipelining can achieve CPI close to 1 Mechanisms for handling hazards Static or dynamic scheduling Static or dynamic branch handling Increase in transistor counts (Moore s Law):
Multiple-Issue Processors Pipelining can achieve CPI close to 1 Mechanisms for handling hazards Static or dynamic scheduling Static or dynamic branch handling Increase in transistor counts (Moore s Law):
WAR: Write After Read
 WAR: Write After Read write-after-read (WAR) = artificial (name) dependence add R1, R2, R3 sub R2, R4, R1 or R1, R6, R3 problem: add could use wrong value for R2 can t happen in vanilla pipeline (reads
WAR: Write After Read write-after-read (WAR) = artificial (name) dependence add R1, R2, R3 sub R2, R4, R1 or R1, R6, R3 problem: add could use wrong value for R2 can t happen in vanilla pipeline (reads
Instruction Set Architecture. or How to talk to computers if you aren t in Star Trek
 Instruction Set Architecture or How to talk to computers if you aren t in Star Trek The Instruction Set Architecture Application Compiler Instr. Set Proc. Operating System I/O system Instruction Set Architecture
Instruction Set Architecture or How to talk to computers if you aren t in Star Trek The Instruction Set Architecture Application Compiler Instr. Set Proc. Operating System I/O system Instruction Set Architecture
Course on Advanced Computer Architectures
 Course on Advanced Computer Architectures Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, September 3rd, 2015 Prof. C. Silvano EX1A ( 2 points) EX1B ( 2
Course on Advanced Computer Architectures Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, September 3rd, 2015 Prof. C. Silvano EX1A ( 2 points) EX1B ( 2
Computer Organization and Components
 Computer Organization and Components IS5, fall 25 Lecture : Pipelined Processors ssociate Professor, KTH Royal Institute of Technology ssistant Research ngineer, University of California, Berkeley Slides
Computer Organization and Components IS5, fall 25 Lecture : Pipelined Processors ssociate Professor, KTH Royal Institute of Technology ssistant Research ngineer, University of California, Berkeley Slides
VLIW Processors. VLIW Processors
 1 VLIW Processors VLIW ( very long instruction word ) processors instructions are scheduled by the compiler a fixed number of operations are formatted as one big instruction (called a bundle) usually LIW
1 VLIW Processors VLIW ( very long instruction word ) processors instructions are scheduled by the compiler a fixed number of operations are formatted as one big instruction (called a bundle) usually LIW
Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x
![Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x](/thumbs/25/6459870.jpg "Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x") Software Pipelining for (i=1, i
Software Pipelining for (i=1, i
CS:APP Chapter 4 Computer Architecture. Wrap-Up. William J. Taffe Plymouth State University. using the slides of
 CS:APP Chapter 4 Computer Architecture Wrap-Up William J. Taffe Plymouth State University using the slides of Randal E. Bryant Carnegie Mellon University Overview Wrap-Up of PIPE Design Performance analysis
CS:APP Chapter 4 Computer Architecture Wrap-Up William J. Taffe Plymouth State University using the slides of Randal E. Bryant Carnegie Mellon University Overview Wrap-Up of PIPE Design Performance analysis
Pipeline Hazards. Arvind Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by Arvind and Krste Asanovic
 1 Pipeline Hazards Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by and Krste Asanovic 6.823 L6-2 Technology Assumptions A small amount of very fast memory
1 Pipeline Hazards Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by and Krste Asanovic 6.823 L6-2 Technology Assumptions A small amount of very fast memory
CPU Performance Equation
 CPU Performance Equation C T I T ime for task = C T I =Average # Cycles per instruction =Time per cycle =Instructions per task Pipelining e.g. 3-5 pipeline steps (ARM, SA, R3000) Attempt to get C down
CPU Performance Equation C T I T ime for task = C T I =Average # Cycles per instruction =Time per cycle =Instructions per task Pipelining e.g. 3-5 pipeline steps (ARM, SA, R3000) Attempt to get C down
PROBLEMS #20,R0,R1 #$3A,R2,R4
 506 CHAPTER 8 PIPELINING (Corrisponde al cap. 11 - Introduzione al pipelining) PROBLEMS 8.1 Consider the following sequence of instructions Mul And #20,R0,R1 #3,R2,R3 #$3A,R2,R4 R0,R2,R5 In all instructions,
506 CHAPTER 8 PIPELINING (Corrisponde al cap. 11 - Introduzione al pipelining) PROBLEMS 8.1 Consider the following sequence of instructions Mul And #20,R0,R1 #3,R2,R3 #$3A,R2,R4 R0,R2,R5 In all instructions,
Pipelining Review and Its Limitations
 Pipelining Review and Its Limitations Yuri Baida yuri.baida@gmail.com yuriy.v.baida@intel.com October 16, 2010 Moscow Institute of Physics and Technology Agenda Review Instruction set architecture Basic
Pipelining Review and Its Limitations Yuri Baida yuri.baida@gmail.com yuriy.v.baida@intel.com October 16, 2010 Moscow Institute of Physics and Technology Agenda Review Instruction set architecture Basic
Overview. CISC Developments. RISC Designs. CISC Designs. VAX: Addressing Modes. Digital VAX
 Overview CISC Developments Over Twenty Years Classic CISC design: Digital VAX VAXÕs RISC successor: PRISM/Alpha IntelÕs ubiquitous 80x86 architecture Ð 8086 through the Pentium Pro (P6) RJS 2/3/97 Philosophy
Overview CISC Developments Over Twenty Years Classic CISC design: Digital VAX VAXÕs RISC successor: PRISM/Alpha IntelÕs ubiquitous 80x86 architecture Ð 8086 through the Pentium Pro (P6) RJS 2/3/97 Philosophy
Giving credit where credit is due
 CSCE 230J Computer Organization Processor Architecture VI: Wrap-Up Dr. Steve Goddard goddard@cse.unl.edu http://cse.unl.edu/~goddard/courses/csce230j Giving credit where credit is due ost of slides for
CSCE 230J Computer Organization Processor Architecture VI: Wrap-Up Dr. Steve Goddard goddard@cse.unl.edu http://cse.unl.edu/~goddard/courses/csce230j Giving credit where credit is due ost of slides for
Data Dependences. A data dependence occurs whenever one instruction needs a value produced by another.
 Data Hazards 1 Hazards: Key Points Hazards cause imperfect pipelining They prevent us from achieving CPI = 1 They are generally causes by counter flow data pennces in the pipeline Three kinds Structural
Data Hazards 1 Hazards: Key Points Hazards cause imperfect pipelining They prevent us from achieving CPI = 1 They are generally causes by counter flow data pennces in the pipeline Three kinds Structural
EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000. ILP Execution
 EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000 Lecture #11: Wednesday, 3 May 2000 Lecturer: Ben Serebrin Scribe: Dean Liu ILP Execution
EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000 Lecture #11: Wednesday, 3 May 2000 Lecturer: Ben Serebrin Scribe: Dean Liu ILP Execution
EE282 Computer Architecture and Organization Midterm Exam February 13, 2001. (Total Time = 120 minutes, Total Points = 100)
") EE282 Computer Architecture and Organization Midterm Exam February 13, 2001 (Total Time = 120 minutes, Total Points = 100) Name: (please print) Wolfe - Solution In recognition of and in the spirit of the
EE282 Computer Architecture and Organization Midterm Exam February 13, 2001 (Total Time = 120 minutes, Total Points = 100) Name: (please print) Wolfe - Solution In recognition of and in the spirit of the
Execution Cycle. Pipelining. IF and ID Stages. Simple MIPS Instruction Formats
 Execution Cycle Pipelining CSE 410, Spring 2005 Computer Systems http://www.cs.washington.edu/410 1. Instruction Fetch 2. Instruction Decode 3. Execute 4. Memory 5. Write Back IF and ID Stages 1. Instruction
Execution Cycle Pipelining CSE 410, Spring 2005 Computer Systems http://www.cs.washington.edu/410 1. Instruction Fetch 2. Instruction Decode 3. Execute 4. Memory 5. Write Back IF and ID Stages 1. Instruction
Solutions. Solution 4.1. 4.1.1 The values of the signals are as follows:
 4 Solutions Solution 4.1 4.1.1 The values of the signals are as follows: RegWrite MemRead ALUMux MemWrite ALUOp RegMux Branch a. 1 0 0 (Reg) 0 Add 1 (ALU) 0 b. 1 1 1 (Imm) 0 Add 1 (Mem) 0 ALUMux is the
4 Solutions Solution 4.1 4.1.1 The values of the signals are as follows: RegWrite MemRead ALUMux MemWrite ALUOp RegMux Branch a. 1 0 0 (Reg) 0 Add 1 (ALU) 0 b. 1 1 1 (Imm) 0 Add 1 (Mem) 0 ALUMux is the
Module: Software Instruction Scheduling Part I
 Module: Software Instruction Scheduling Part I Sudhakar Yalamanchili, Georgia Institute of Technology Reading for this Module Loop Unrolling and Instruction Scheduling Section 2.2 Dependence Analysis Section
Module: Software Instruction Scheduling Part I Sudhakar Yalamanchili, Georgia Institute of Technology Reading for this Module Loop Unrolling and Instruction Scheduling Section 2.2 Dependence Analysis Section
Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.
 Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.") Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Review Computers in mid 50 s Hardware was expensive
Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Review Computers in mid 50 s Hardware was expensive
Administration. Instruction scheduling. Modern processors. Examples. Simplified architecture model. CS 412 Introduction to Compilers
 CS 4 Introduction to Compilers ndrew Myers Cornell University dministration Prelim tomorrow evening No class Wednesday P due in days Optional reading: Muchnick 7 Lecture : Instruction scheduling pr 0 Modern
CS 4 Introduction to Compilers ndrew Myers Cornell University dministration Prelim tomorrow evening No class Wednesday P due in days Optional reading: Muchnick 7 Lecture : Instruction scheduling pr 0 Modern
Computer organization
 Computer organization Computer design an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs
Computer organization Computer design an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs
Instruction Set Design
 Instruction Set Design Instruction Set Architecture: to what purpose? ISA provides the level of abstraction between the software and the hardware One of the most important abstraction in CS It s narrow,
Instruction Set Design Instruction Set Architecture: to what purpose? ISA provides the level of abstraction between the software and the hardware One of the most important abstraction in CS It s narrow,
Week 1 out-of-class notes, discussions and sample problems
 Week 1 out-of-class notes, discussions and sample problems Although we will primarily concentrate on RISC processors as found in some desktop/laptop computers, here we take a look at the varying types
Week 1 out-of-class notes, discussions and sample problems Although we will primarily concentrate on RISC processors as found in some desktop/laptop computers, here we take a look at the varying types
Lecture: Pipelining Extensions. Topics: control hazards, multi-cycle instructions, pipelining equations
 Lecture: Pipelining Extensions Topics: control hazards, multi-cycle instructions, pipelining equations 1 Problem 6 Show the instruction occupying each stage in each cycle (with bypassing) if I1 is R1+R2
Lecture: Pipelining Extensions Topics: control hazards, multi-cycle instructions, pipelining equations 1 Problem 6 Show the instruction occupying each stage in each cycle (with bypassing) if I1 is R1+R2
The Microarchitecture of Superscalar Processors
 The Microarchitecture of Superscalar Processors James E. Smith Department of Electrical and Computer Engineering 1415 Johnson Drive Madison, WI 53706 ph: (608)-265-5737 fax:(608)-262-1267 email: jes@ece.wisc.edu
The Microarchitecture of Superscalar Processors James E. Smith Department of Electrical and Computer Engineering 1415 Johnson Drive Madison, WI 53706 ph: (608)-265-5737 fax:(608)-262-1267 email: jes@ece.wisc.edu
Advanced Computer Architecture-CS501. Computer Systems Design and Architecture 2.1, 2.2, 3.2
 Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Static Scheduling. option #1: dynamic scheduling (by the hardware) option #2: static scheduling (by the compiler) ECE 252 / CPS 220 Lecture Notes
 option #2: static scheduling (by the compiler) ECE 252 / CPS 220 Lecture Notes") basic pipeline: single, in-order issue first extension: multiple issue (superscalar) second extension: scheduling instructions for more ILP option #1: dynamic scheduling (by the hardware) option #2: static
basic pipeline: single, in-order issue first extension: multiple issue (superscalar) second extension: scheduling instructions for more ILP option #1: dynamic scheduling (by the hardware) option #2: static
Instruction Set Architecture
 Instruction Set Architecture Consider x := y+z. (x, y, z are memory variables) 1-address instructions 2-address instructions LOAD y (r :=y) ADD y,z (y := y+z) ADD z (r:=r+z) MOVE x,y (x := y) STORE x (x:=r)
Instruction Set Architecture Consider x := y+z. (x, y, z are memory variables) 1-address instructions 2-address instructions LOAD y (r :=y) ADD y,z (y := y+z) ADD z (r:=r+z) MOVE x,y (x := y) STORE x (x:=r)
Intel 8086 architecture
 Intel 8086 architecture Today we ll take a look at Intel s 8086, which is one of the oldest and yet most prevalent processor architectures around. We ll make many comparisons between the MIPS and 8086
Intel 8086 architecture Today we ll take a look at Intel s 8086, which is one of the oldest and yet most prevalent processor architectures around. We ll make many comparisons between the MIPS and 8086
Reduced Instruction Set Computer (RISC)
") Reduced Instruction Set Computer (RISC) Focuses on reducing the number and complexity of instructions of the ISA. RISC Goals RISC: Simplify ISA Simplify CPU Design Better CPU Performance Motivated by simplifying
Reduced Instruction Set Computer (RISC) Focuses on reducing the number and complexity of instructions of the ISA. RISC Goals RISC: Simplify ISA Simplify CPU Design Better CPU Performance Motivated by simplifying
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Central Processing Unit (CPU)
") Central Processing Unit (CPU) CPU is the heart and brain It interprets and executes machine level instructions Controls data transfer from/to Main Memory (MM) and CPU Detects any errors In the following
Central Processing Unit (CPU) CPU is the heart and brain It interprets and executes machine level instructions Controls data transfer from/to Main Memory (MM) and CPU Detects any errors In the following
Boosting Beyond Static Scheduling in a Superscalar Processor
 Boosting Beyond Static Scheduling in a Superscalar Processor Michael D. Smith, Monica S. Lam, and Mark A. Horowitz Computer Systems Laboratory Stanford University, Stanford CA 94305-4070 May 1990 1 Introduction
Boosting Beyond Static Scheduling in a Superscalar Processor Michael D. Smith, Monica S. Lam, and Mark A. Horowitz Computer Systems Laboratory Stanford University, Stanford CA 94305-4070 May 1990 1 Introduction
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM
 ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM 1 The ARM architecture processors popular in Mobile phone systems 2 ARM Features ARM has 32-bit architecture but supports 16 bit
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM 1 The ARM architecture processors popular in Mobile phone systems 2 ARM Features ARM has 32-bit architecture but supports 16 bit
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
LSN 2 Computer Processors
 LSN 2 Computer Processors Department of Engineering Technology LSN 2 Computer Processors Microprocessors Design Instruction set Processor organization Processor performance Bandwidth Clock speed LSN 2
LSN 2 Computer Processors Department of Engineering Technology LSN 2 Computer Processors Microprocessors Design Instruction set Processor organization Processor performance Bandwidth Clock speed LSN 2
18-447 Computer Architecture Lecture 3: ISA Tradeoffs. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 1/18/2013
 18-447 Computer Architecture Lecture 3: ISA Tradeoffs Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 1/18/2013 Reminder: Homeworks for Next Two Weeks Homework 0 Due next Wednesday (Jan 23), right
18-447 Computer Architecture Lecture 3: ISA Tradeoffs Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 1/18/2013 Reminder: Homeworks for Next Two Weeks Homework 0 Due next Wednesday (Jan 23), right
AMD Opteron Quad-Core
 AMD Opteron Quad-Core a brief overview Daniele Magliozzi Politecnico di Milano Opteron Memory Architecture native quad-core design (four cores on a single die for more efficient data sharing) enhanced
AMD Opteron Quad-Core a brief overview Daniele Magliozzi Politecnico di Milano Opteron Memory Architecture native quad-core design (four cores on a single die for more efficient data sharing) enhanced
BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA
 BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA AGENDA INTRO TO BEAGLEBONE BLACK HARDWARE & SPECS CORTEX-A8 ARMV7 PROCESSOR PROS & CONS VS RASPBERRY PI WHEN TO USE BEAGLEBONE BLACK Single
BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA AGENDA INTRO TO BEAGLEBONE BLACK HARDWARE & SPECS CORTEX-A8 ARMV7 PROCESSOR PROS & CONS VS RASPBERRY PI WHEN TO USE BEAGLEBONE BLACK Single
IA-64 Application Developer s Architecture Guide
 IA-64 Application Developer s Architecture Guide The IA-64 architecture was designed to overcome the performance limitations of today s architectures and provide maximum headroom for the future. To achieve
IA-64 Application Developer s Architecture Guide The IA-64 architecture was designed to overcome the performance limitations of today s architectures and provide maximum headroom for the future. To achieve
CS521 CSE IITG 11/23/2012
 CS521 CSE TG 11/23/2012 A Sahu 1 Degree of overlap Serial, Overlapped, d, Super pipelined/superscalar Depth Shallow, Deep Structure Linear, Non linear Scheduling of operations Static, Dynamic A Sahu slide
CS521 CSE TG 11/23/2012 A Sahu 1 Degree of overlap Serial, Overlapped, d, Super pipelined/superscalar Depth Shallow, Deep Structure Linear, Non linear Scheduling of operations Static, Dynamic A Sahu slide
Computer Architecture TDTS10
 why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING
 COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
! Metrics! Latency and throughput. ! Reporting performance! Benchmarking and averaging. ! CPU performance equation & performance trends
 This Unit CIS 501 Computer Architecture! Metrics! Latency and throughput! Reporting performance! Benchmarking and averaging Unit 2: Performance! CPU performance equation & performance trends CIS 501 (Martin/Roth):
This Unit CIS 501 Computer Architecture! Metrics! Latency and throughput! Reporting performance! Benchmarking and averaging Unit 2: Performance! CPU performance equation & performance trends CIS 501 (Martin/Roth):
Performance evaluation
 Performance evaluation Arquitecturas Avanzadas de Computadores - 2547021 Departamento de Ingeniería Electrónica y de Telecomunicaciones Facultad de Ingeniería 2015-1 Bibliography and evaluation Bibliography
Performance evaluation Arquitecturas Avanzadas de Computadores - 2547021 Departamento de Ingeniería Electrónica y de Telecomunicaciones Facultad de Ingeniería 2015-1 Bibliography and evaluation Bibliography
Unit 4: Performance & Benchmarking. Performance Metrics. This Unit. CIS 501: Computer Architecture. Performance: Latency vs.
 This Unit CIS 501: Computer Architecture Unit 4: Performance & Benchmarking Metrics Latency and throughput Speedup Averaging CPU Performance Performance Pitfalls Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'Pennsylvania'
This Unit CIS 501: Computer Architecture Unit 4: Performance & Benchmarking Metrics Latency and throughput Speedup Averaging CPU Performance Performance Pitfalls Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'Pennsylvania'
Technical Report. Complexity-effective superscalar embedded processors using instruction-level distributed processing. Ian Caulfield.
 Technical Report UCAM-CL-TR-707 ISSN 1476-2986 Number 707 Computer Laboratory Complexity-effective superscalar embedded processors using instruction-level distributed processing Ian Caulfield December
Technical Report UCAM-CL-TR-707 ISSN 1476-2986 Number 707 Computer Laboratory Complexity-effective superscalar embedded processors using instruction-level distributed processing Ian Caulfield December
Computer Organization and Architecture
 Computer Organization and Architecture Chapter 11 Instruction Sets: Addressing Modes and Formats Instruction Set Design One goal of instruction set design is to minimize instruction length Another goal
Computer Organization and Architecture Chapter 11 Instruction Sets: Addressing Modes and Formats Instruction Set Design One goal of instruction set design is to minimize instruction length Another goal
CSE 141 Introduction to Computer Architecture Summer Session I, 2005. Lecture 1 Introduction. Pramod V. Argade June 27, 2005
 CSE 141 Introduction to Computer Architecture Summer Session I, 2005 Lecture 1 Introduction Pramod V. Argade June 27, 2005 CSE141: Introduction to Computer Architecture Instructor: Pramod V. Argade (p2argade@cs.ucsd.edu)
CSE 141 Introduction to Computer Architecture Summer Session I, 2005 Lecture 1 Introduction Pramod V. Argade June 27, 2005 CSE141: Introduction to Computer Architecture Instructor: Pramod V. Argade (p2argade@cs.ucsd.edu)
Review: MIPS Addressing Modes/Instruction Formats
 Review: Addressing Modes Addressing mode Example Meaning Register Add R4,R3 R4 R4+R3 Immediate Add R4,#3 R4 R4+3 Displacement Add R4,1(R1) R4 R4+Mem[1+R1] Register indirect Add R4,(R1) R4 R4+Mem[R1] Indexed
Review: Addressing Modes Addressing mode Example Meaning Register Add R4,R3 R4 R4+R3 Immediate Add R4,#3 R4 R4+3 Displacement Add R4,1(R1) R4 R4+Mem[1+R1] Register indirect Add R4,(R1) R4 R4+Mem[R1] Indexed
In the Beginning... 1964 -- The first ISA appears on the IBM System 360 In the good old days
 RISC vs CISC 66 In the Beginning... 1964 -- The first ISA appears on the IBM System 360 In the good old days Initially, the focus was on usability by humans. Lots of user-friendly instructions (remember
RISC vs CISC 66 In the Beginning... 1964 -- The first ISA appears on the IBM System 360 In the good old days Initially, the focus was on usability by humans. Lots of user-friendly instructions (remember
Chapter 2 Topics. 2.1 Classification of Computers & Instructions 2.2 Classes of Instruction Sets 2.3 Informal Description of Simple RISC Computer, SRC
 Chapter 2 Topics 2.1 Classification of Computers & Instructions 2.2 Classes of Instruction Sets 2.3 Informal Description of Simple RISC Computer, SRC See Appendix C for Assembly language information. 2.4
Chapter 2 Topics 2.1 Classification of Computers & Instructions 2.2 Classes of Instruction Sets 2.3 Informal Description of Simple RISC Computer, SRC See Appendix C for Assembly language information. 2.4
A single register, called the accumulator, stores the. operand before the operation, and stores the result. Add y # add y from memory to the acc
 Other architectures Example. Accumulator-based machines A single register, called the accumulator, stores the operand before the operation, and stores the result after the operation. Load x # into acc
Other architectures Example. Accumulator-based machines A single register, called the accumulator, stores the operand before the operation, and stores the result after the operation. Load x # into acc
What is a bus? A Bus is: Advantages of Buses. Disadvantage of Buses. Master versus Slave. The General Organization of a Bus
 Datorteknik F1 bild 1 What is a bus? Slow vehicle that many people ride together well, true... A bunch of wires... A is: a shared communication link a single set of wires used to connect multiple subsystems
Datorteknik F1 bild 1 What is a bus? Slow vehicle that many people ride together well, true... A bunch of wires... A is: a shared communication link a single set of wires used to connect multiple subsystems
High Performance Processor Architecture. André Seznec IRISA/INRIA ALF project-team
 High Performance Processor Architecture André Seznec IRISA/INRIA ALF project-team 1 2 Moore s «Law» Nb of transistors on a micro processor chip doubles every 18 months 1972: 2000 transistors (Intel 4004)
High Performance Processor Architecture André Seznec IRISA/INRIA ALF project-team 1 2 Moore s «Law» Nb of transistors on a micro processor chip doubles every 18 months 1972: 2000 transistors (Intel 4004)
CHAPTER 4 MARIE: An Introduction to a Simple Computer
 CHAPTER 4 MARIE: An Introduction to a Simple Computer 4.1 Introduction 195 4.2 CPU Basics and Organization 195 4.2.1 The Registers 196 4.2.2 The ALU 197 4.2.3 The Control Unit 197 4.3 The Bus 197 4.4 Clocks
CHAPTER 4 MARIE: An Introduction to a Simple Computer 4.1 Introduction 195 4.2 CPU Basics and Organization 195 4.2.1 The Registers 196 4.2.2 The ALU 197 4.2.3 The Control Unit 197 4.3 The Bus 197 4.4 Clocks
Exploring the Design of the Cortex-A15 Processor ARM s next generation mobile applications processor. Travis Lanier Senior Product Manager
 Exploring the Design of the Cortex-A15 Processor ARM s next generation mobile applications processor Travis Lanier Senior Product Manager 1 Cortex-A15: Next Generation Leadership Cortex-A class multi-processor
Exploring the Design of the Cortex-A15 Processor ARM s next generation mobile applications processor Travis Lanier Senior Product Manager 1 Cortex-A15: Next Generation Leadership Cortex-A class multi-processor
Instruction Set Architecture (ISA)
") Instruction Set Architecture (ISA) * Instruction set architecture of a machine fills the semantic gap between the user and the machine. * ISA serves as the starting point for the design of a new machine
Instruction Set Architecture (ISA) * Instruction set architecture of a machine fills the semantic gap between the user and the machine. * ISA serves as the starting point for the design of a new machine
A Lab Course on Computer Architecture
 A Lab Course on Computer Architecture Pedro López José Duato Depto. de Informática de Sistemas y Computadores Facultad de Informática Universidad Politécnica de Valencia Camino de Vera s/n, 46071 - Valencia,
A Lab Course on Computer Architecture Pedro López José Duato Depto. de Informática de Sistemas y Computadores Facultad de Informática Universidad Politécnica de Valencia Camino de Vera s/n, 46071 - Valencia,
Introducción. Diseño de sistemas digitales.1
 Introducción Adapted from: Mary Jane Irwin ( www.cse.psu.edu/~mji ) www.cse.psu.edu/~cg431 [Original from Computer Organization and Design, Patterson & Hennessy, 2005, UCB] Diseño de sistemas digitales.1
Introducción Adapted from: Mary Jane Irwin ( www.cse.psu.edu/~mji ) www.cse.psu.edu/~cg431 [Original from Computer Organization and Design, Patterson & Hennessy, 2005, UCB] Diseño de sistemas digitales.1
Property of ISA vs. Uarch?
 More ISA Property of ISA vs. Uarch? ADD instruction s opcode Number of general purpose registers Number of cycles to execute the MUL instruction Whether or not the machine employs pipelined instruction
More ISA Property of ISA vs. Uarch? ADD instruction s opcode Number of general purpose registers Number of cycles to execute the MUL instruction Whether or not the machine employs pipelined instruction
Exceptions in MIPS. know the exception mechanism in MIPS be able to write a simple exception handler for a MIPS machine
 7 Objectives After completing this lab you will: know the exception mechanism in MIPS be able to write a simple exception handler for a MIPS machine Introduction Branches and jumps provide ways to change
7 Objectives After completing this lab you will: know the exception mechanism in MIPS be able to write a simple exception handler for a MIPS machine Introduction Branches and jumps provide ways to change
SOC architecture and design
 SOC architecture and design system-on-chip (SOC) processors: become components in a system SOC covers many topics processor: pipelined, superscalar, VLIW, array, vector storage: cache, embedded and external
SOC architecture and design system-on-chip (SOC) processors: become components in a system SOC covers many topics processor: pipelined, superscalar, VLIW, array, vector storage: cache, embedded and external
Instruction Set Architecture (ISA) Design. Classification Categories
 Design. Classification Categories") Instruction Set Architecture (ISA) Design Overview» Classify Instruction set architectures» Look at how applications use ISAs» Examine a modern RISC ISA (DLX)» Measurement of ISA usage in real computers
Instruction Set Architecture (ISA) Design Overview» Classify Instruction set architectures» Look at how applications use ISAs» Examine a modern RISC ISA (DLX)» Measurement of ISA usage in real computers
Thread level parallelism
 Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
StrongARM** SA-110 Microprocessor Instruction Timing
 StrongARM** SA-110 Microprocessor Instruction Timing Application Note September 1998 Order Number: 278194-001 Information in this document is provided in connection with Intel products. No license, express
StrongARM** SA-110 Microprocessor Instruction Timing Application Note September 1998 Order Number: 278194-001 Information in this document is provided in connection with Intel products. No license, express
UNIVERSITY OF CALIFORNIA, DAVIS Department of Electrical and Computer Engineering. EEC180B Lab 7: MISP Processor Design Spring 1995
 UNIVERSITY OF CALIFORNIA, DAVIS Department of Electrical and Computer Engineering EEC180B Lab 7: MISP Processor Design Spring 1995 Objective: In this lab, you will complete the design of the MISP processor,
UNIVERSITY OF CALIFORNIA, DAVIS Department of Electrical and Computer Engineering EEC180B Lab 7: MISP Processor Design Spring 1995 Objective: In this lab, you will complete the design of the MISP processor,
This Unit: Multithreading (MT) CIS 501 Computer Architecture. Performance And Utilization. Readings
 CIS 501 Computer Architecture. Performance And Utilization. Readings") This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
Generations of the computer. processors.
 . Piotr Gwizdała 1 Contents 1 st Generation 2 nd Generation 3 rd Generation 4 th Generation 5 th Generation 6 th Generation 7 th Generation 8 th Generation Dual Core generation Improves and actualizations
. Piotr Gwizdała 1 Contents 1 st Generation 2 nd Generation 3 rd Generation 4 th Generation 5 th Generation 6 th Generation 7 th Generation 8 th Generation Dual Core generation Improves and actualizations
Design Cycle for Microprocessors
 Cycle for Microprocessors Raúl Martínez Intel Barcelona Research Center Cursos de Verano 2010 UCLM Intel Corporation, 2010 Agenda Introduction plan Architecture Microarchitecture Logic Silicon ramp Types
Cycle for Microprocessors Raúl Martínez Intel Barcelona Research Center Cursos de Verano 2010 UCLM Intel Corporation, 2010 Agenda Introduction plan Architecture Microarchitecture Logic Silicon ramp Types
Using Graphics and Animation to Visualize Instruction Pipelining and its Hazards
 Using Graphics and Animation to Visualize Instruction Pipelining and its Hazards Per Stenström, Håkan Nilsson, and Jonas Skeppstedt Department of Computer Engineering, Lund University P.O. Box 118, S-221
Using Graphics and Animation to Visualize Instruction Pipelining and its Hazards Per Stenström, Håkan Nilsson, and Jonas Skeppstedt Department of Computer Engineering, Lund University P.O. Box 118, S-221
Computer Performance. Topic 3. Contents. Prerequisite knowledge Before studying this topic you should be able to:
 55 Topic 3 Computer Performance Contents 3.1 Introduction...................................... 56 3.2 Measuring performance............................... 56 3.2.1 Clock Speed.................................
55 Topic 3 Computer Performance Contents 3.1 Introduction...................................... 56 3.2 Measuring performance............................... 56 3.2.1 Clock Speed.................................
Quiz for Chapter 1 Computer Abstractions and Technology 3.10
 Date: 3.10 Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Date: 3.10 Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
CPU Organisation and Operation
 CPU Organisation and Operation The Fetch-Execute Cycle The operation of the CPU 1 is usually described in terms of the Fetch-Execute cycle. 2 Fetch-Execute Cycle Fetch the Instruction Increment the Program
CPU Organisation and Operation The Fetch-Execute Cycle The operation of the CPU 1 is usually described in terms of the Fetch-Execute cycle. 2 Fetch-Execute Cycle Fetch the Instruction Increment the Program
Pentium vs. Power PC Computer Architecture and PCI Bus Interface
 Pentium vs. Power PC Computer Architecture and PCI Bus Interface CSE 3322 1 Pentium vs. Power PC Computer Architecture and PCI Bus Interface Nowadays, there are two major types of microprocessors in the
Pentium vs. Power PC Computer Architecture and PCI Bus Interface CSE 3322 1 Pentium vs. Power PC Computer Architecture and PCI Bus Interface Nowadays, there are two major types of microprocessors in the
Application Note 195. ARM11 performance monitor unit. Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007
 Application Note 195 ARM11 performance monitor unit Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007 Copyright 2007 ARM Limited. All rights reserved. Application Note
Application Note 195 ARM11 performance monitor unit Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007 Copyright 2007 ARM Limited. All rights reserved. Application Note
Design of Digital Circuits (SS16)
") Design of Digital Circuits (SS16) 252-0014-00L (6 ECTS), BSc in CS, ETH Zurich Lecturers: Srdjan Capkun, D-INFK, ETH Zurich Frank K. Gürkaynak, D-ITET, ETH Zurich Labs: Der-Yeuan Yu dyu@inf.ethz.ch Website:
Design of Digital Circuits (SS16) 252-0014-00L (6 ECTS), BSc in CS, ETH Zurich Lecturers: Srdjan Capkun, D-INFK, ETH Zurich Frank K. Gürkaynak, D-ITET, ETH Zurich Labs: Der-Yeuan Yu dyu@inf.ethz.ch Website:
on an system with an infinite number of processors. Calculate the speedup of
 1. Amdahl s law Three enhancements with the following speedups are proposed for a new architecture: Speedup1 = 30 Speedup2 = 20 Speedup3 = 10 Only one enhancement is usable at a time. a) If enhancements
1. Amdahl s law Three enhancements with the following speedups are proposed for a new architecture: Speedup1 = 30 Speedup2 = 20 Speedup3 = 10 Only one enhancement is usable at a time. a) If enhancements
Five Families of ARM Processor IP
 ARM1026EJ-S Synthesizable ARM10E Family Processor Core Eric Schorn CPU Product Manager ARM Austin Design Center Five Families of ARM Processor IP Performance ARM preserves SW & HW investment through code
ARM1026EJ-S Synthesizable ARM10E Family Processor Core Eric Schorn CPU Product Manager ARM Austin Design Center Five Families of ARM Processor IP Performance ARM preserves SW & HW investment through code
Addressing The problem. When & Where do we encounter Data? The concept of addressing data' in computations. The implications for our machine design(s)
") Addressing The problem Objectives:- When & Where do we encounter Data? The concept of addressing data' in computations The implications for our machine design(s) Introducing the stack-machine concept Slide
Addressing The problem Objectives:- When & Where do we encounter Data? The concept of addressing data' in computations The implications for our machine design(s) Introducing the stack-machine concept Slide
Low Power AMD Athlon 64 and AMD Opteron Processors
 Low Power AMD Athlon 64 and AMD Opteron Processors Hot Chips 2004 Presenter: Marius Evers Block Diagram of AMD Athlon 64 and AMD Opteron Based on AMD s 8 th generation architecture AMD Athlon 64 and AMD
Low Power AMD Athlon 64 and AMD Opteron Processors Hot Chips 2004 Presenter: Marius Evers Block Diagram of AMD Athlon 64 and AMD Opteron Based on AMD s 8 th generation architecture AMD Athlon 64 and AMD
2
 1 2 3 4 5 For Description of these Features see http://download.intel.com/products/processor/corei7/prod_brief.pdf The following Features Greatly affect Performance Monitoring The New Performance Monitoring
1 2 3 4 5 For Description of these Features see http://download.intel.com/products/processor/corei7/prod_brief.pdf The following Features Greatly affect Performance Monitoring The New Performance Monitoring
GPU Architectures. A CPU Perspective. Data Parallelism: What is it, and how to exploit it? Workload characteristics
 GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
Coming Challenges in Microarchitecture and Architecture
 Coming Challenges in Microarchitecture and Architecture RONNY RONEN, SENIOR MEMBER, IEEE, AVI MENDELSON, MEMBER, IEEE, KONRAD LAI, SHIH-LIEN LU, MEMBER, IEEE, FRED POLLACK, AND JOHN P. SHEN, FELLOW, IEEE
Coming Challenges in Microarchitecture and Architecture RONNY RONEN, SENIOR MEMBER, IEEE, AVI MENDELSON, MEMBER, IEEE, KONRAD LAI, SHIH-LIEN LU, MEMBER, IEEE, FRED POLLACK, AND JOHN P. SHEN, FELLOW, IEEE
Multithreading Lin Gao cs9244 report, 2006
 Multithreading Lin Gao cs9244 report, 2006 2 Contents 1 Introduction 5 2 Multithreading Technology 7 2.1 Fine-grained multithreading (FGMT)............. 8 2.2 Coarse-grained multithreading (CGMT)............
Multithreading Lin Gao cs9244 report, 2006 2 Contents 1 Introduction 5 2 Multithreading Technology 7 2.1 Fine-grained multithreading (FGMT)............. 8 2.2 Coarse-grained multithreading (CGMT)............
Basic Performance Measurements for AMD Athlon 64, AMD Opteron and AMD Phenom Processors
 Basic Performance Measurements for AMD Athlon 64, AMD Opteron and AMD Phenom Processors Paul J. Drongowski AMD CodeAnalyst Performance Analyzer Development Team Advanced Micro Devices, Inc. Boston Design
Basic Performance Measurements for AMD Athlon 64, AMD Opteron and AMD Phenom Processors Paul J. Drongowski AMD CodeAnalyst Performance Analyzer Development Team Advanced Micro Devices, Inc. Boston Design
Intel Pentium 4 Processor on 90nm Technology
 Intel Pentium 4 Processor on 90nm Technology Ronak Singhal August 24, 2004 Hot Chips 16 1 1 Agenda Netburst Microarchitecture Review Microarchitecture Features Hyper-Threading Technology SSE3 Intel Extended
Intel Pentium 4 Processor on 90nm Technology Ronak Singhal August 24, 2004 Hot Chips 16 1 1 Agenda Netburst Microarchitecture Review Microarchitecture Features Hyper-Threading Technology SSE3 Intel Extended
Embedded System Hardware - Processing (Part II)
") 12 Embedded System Hardware - Processing (Part II) Jian-Jia Chen (Slides are based on Peter Marwedel) Informatik 12 TU Dortmund Germany Springer, 2010 2014 年 11 月 11 日 These slides use Microsoft clip arts.
12 Embedded System Hardware - Processing (Part II) Jian-Jia Chen (Slides are based on Peter Marwedel) Informatik 12 TU Dortmund Germany Springer, 2010 2014 年 11 月 11 日 These slides use Microsoft clip arts.
Streamlining Data Cache Access with Fast Address Calculation
 Streamlining Data Cache Access with Fast Address Calculation Todd M Austin Dionisios N Pnevmatikatos Gurindar S Sohi Computer Sciences Department University of Wisconsin-Madison 2 W Dayton Street Madison,
Streamlining Data Cache Access with Fast Address Calculation Todd M Austin Dionisios N Pnevmatikatos Gurindar S Sohi Computer Sciences Department University of Wisconsin-Madison 2 W Dayton Street Madison,
361 Computer Architecture Lecture 14: Cache Memory
 1 361 Computer Architecture Lecture 14 Memory cache.1 The Motivation for s Memory System Processor DRAM Motivation Large memories (DRAM) are slow Small memories (SRAM) are fast Make the average access
1 361 Computer Architecture Lecture 14 Memory cache.1 The Motivation for s Memory System Processor DRAM Motivation Large memories (DRAM) are slow Small memories (SRAM) are fast Make the average access
A Survey on ARM Cortex A Processors. Wei Wang Tanima Dey
 A Survey on ARM Cortex A Processors Wei Wang Tanima Dey 1 Overview of ARM Processors Focusing on Cortex A9 & Cortex A15 ARM ships no processors but only IP cores For SoC integration Targeting markets:
A Survey on ARM Cortex A Processors Wei Wang Tanima Dey 1 Overview of ARM Processors Focusing on Cortex A9 & Cortex A15 ARM ships no processors but only IP cores For SoC integration Targeting markets:
Chapter 5 Instructor's Manual
 The Essentials of Computer Organization and Architecture Linda Null and Julia Lobur Jones and Bartlett Publishers, 2003 Chapter 5 Instructor's Manual Chapter Objectives Chapter 5, A Closer Look at Instruction
The Essentials of Computer Organization and Architecture Linda Null and Julia Lobur Jones and Bartlett Publishers, 2003 Chapter 5 Instructor's Manual Chapter Objectives Chapter 5, A Closer Look at Instruction