Lecture: Pipelining Extensions. Topics: control hazards, multi-cycle instructions, pipelining equations
|
|
|
- Francis Stevenson
- 8 years ago
- Views:
Transcription
1 Lecture: Pipelining Extensions Topics: control hazards, multi-cycle instructions, pipelining equations 1

2 Problem 6 Show the instruction occupying each stage in each cycle (with bypassing) if I1 is R1+R2 R3 and I2 is R3+R4 R5 and I3 is R3+R8 R9. Identify the input latch for each input operand. CYC-1 CYC-2 CYC-3 CYC-4 CYC-5 CYC-6 CYC-7 CYC-8 IF I1 IF I2 IF I3 IF I4 IF I5 IF IF IF D/R ALU D/R I1 ALU D/R I2 ALU I1 D/R I3 ALU I2 D/R I4 L3 L3 L4 L3 L5 L3 ALU I3 D/R ALU D/R ALU D/R ALU DM DM DM DM I1 DM I2 DM I3 DM DM RW RW RW RW RW I1 RW I2 RW I3 RW

3 Problem 7 Consider this 8-stage pipeline (RR and RW take a full cycle) IF DE RR AL AL DM DM RW For the following pairs of instructions, how many stalls will the 2 nd instruction experience (with and without bypassing)? ADD R1+R2 R3 ADD R3+R4 R5 without: 5 with: 1 LD [R1] R2 ADD R2+R3 R4 without: 5 with: 3 LD [R1] R2 SD [R2] R3 without: 5 with: 3 LD [R1] R2 SD [R3] R2 without: 5 with: 1 3

4 Hazards Structural Hazards Data Hazards Control Hazards 4

5 Control Hazards Simple techniques to handle control hazard stalls: for every branch, introduce a stall cycle (note: every 6 th instruction is a branch on average!) assume the branch is not taken and start fetching the next instruction if the branch is taken, need hardware to cancel the effect of the wrong-path instructions predict the next PC and fetch that instr if the prediction is wrong, cancel the effect of the wrong-path instructions fetch the next instruction (branch delay slot) and execute it anyway if the instruction turns out to be on the correct path, useful work was done if the instruction turns out to be on the wrong path, hopefully program state is not lost 5

6 Branch Delay Slots 6
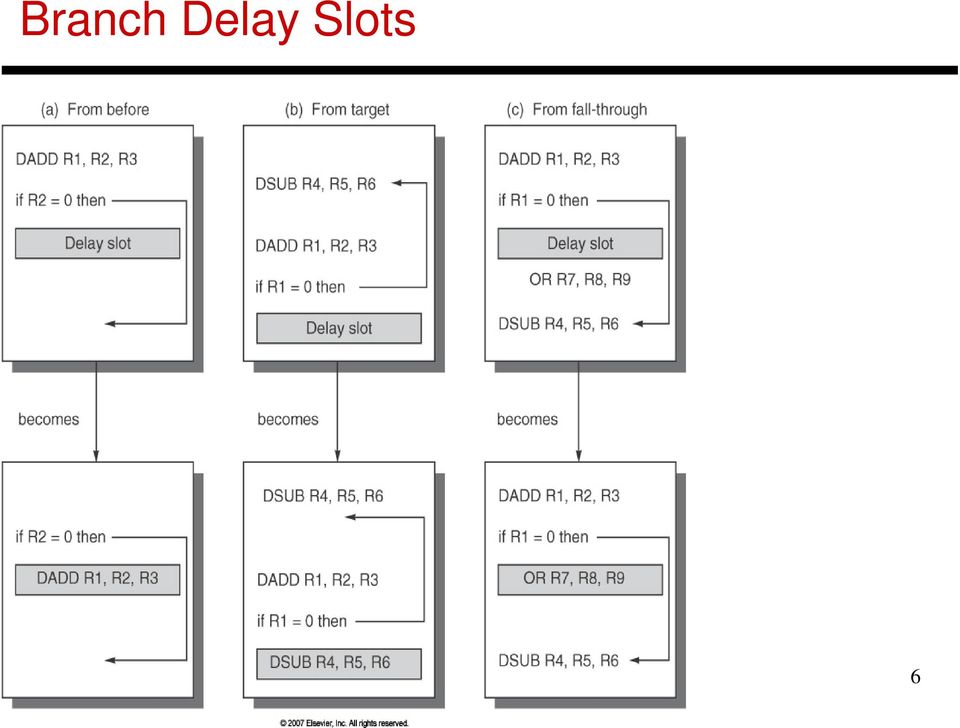
7 Problem 1 Consider a branch that is taken 80% of the time. On average, how many stalls are introduced for this branch for each approach below: Stall fetch until branch outcome is known Assume not-taken and squash if the branch is taken Assume a branch delay slot o You can t find anything to put in the delay slot o An instr before the branch is put in the delay slot o An instr from the taken side is put in the delay slot o An instr from the not-taken side is put in the slot 7

8 Problem 1 Consider a branch that is taken 80% of the time. On average, how many stalls are introduced for this branch for each approach below: Stall fetch until branch outcome is known 1 Assume not-taken and squash if the branch is taken 0.8 Assume a branch delay slot o You can t find anything to put in the delay slot 1 o An instr before the branch is put in the delay slot 0 o An instr from the taken side is put in the slot 0.2 o An instr from the not-taken side is put in the slot 0.8 8

9 Multicycle Instructions 9
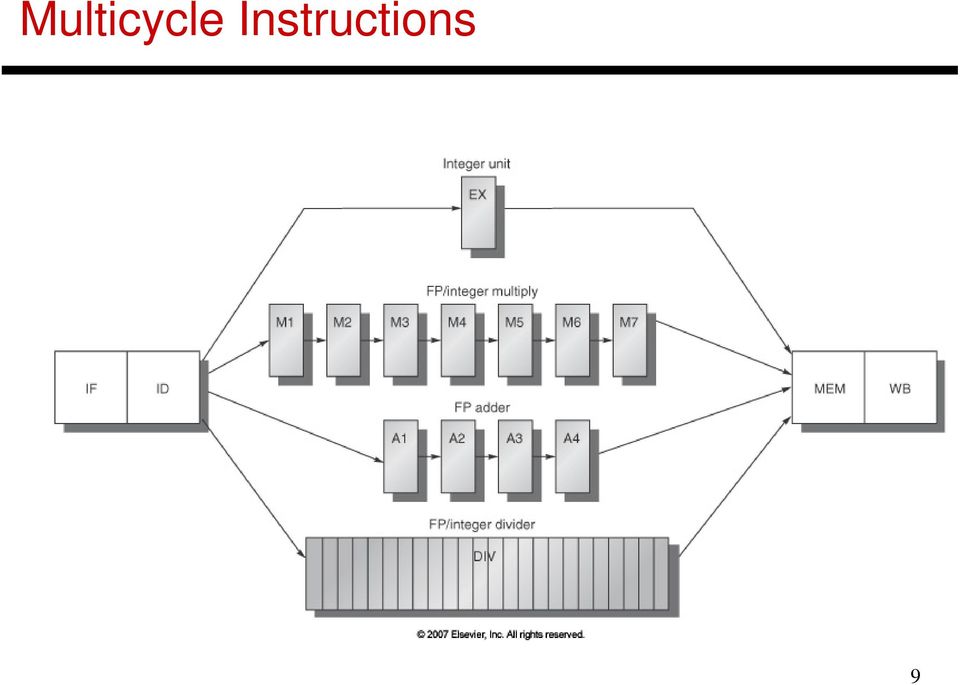
10 Effects of Multicycle Instructions Potentially multiple writes to the register file in a cycle Frequent RAW hazards WAW hazards (WAR hazards not possible) Imprecise exceptions because of o-o-o instr completion Note: Can also increase the width of the processor: handle multiple instructions at the same time: for example, fetch two instructions, read registers for both, execute both, etc. 10

11 Precise Exceptions On an exception: must save PC of instruction where program must resume all instructions after that PC that might be in the pipeline must be converted to NOPs (other instructions continue to execute and may raise exceptions of their own) temporary program state not in memory (in other words, registers) has to be stored in memory potential problems if a later instruction has already modified memory or registers A processor that fulfils all the above conditions is said to provide precise exceptions (useful for debugging and of course, correctness) 11

12 Dealing with these Effects Multiple writes to the register file: increase the number of ports, stall one of the writers during ID, stall one of the writers during WB (the stall will propagate) WAW hazards: detect the hazard during ID and stall the later instruction Imprecise exceptions: buffer the results if they complete early or save more pipeline state so that you can return to exactly the same state that you left at 12

13 Slowdowns from Stalls Perfect pipelining with no hazards an instruction completes every cycle (total cycles ~ num instructions) speedup = increase in clock speed = num pipeline stages With hazards and stalls, some cycles (= stall time) go by during which no instruction completes, and then the stalled instruction completes Total cycles = number of instructions + stall cycles Slowdown because of stalls = 1/ (1 + stall cycles per instr) 13

14 Pipelining Limits Gap between indep instrs: T + Tovh Gap between dep instrs: T + Tovh A B C A B C Gap between indep instrs: T/3 + Tovh Gap between dep instrs: T + 3Tovh A B C D E F A B C D E F Gap between indep instrs: T/6 + Tovh Gap between dep instrs: T + 6Tovh Assume that there is a dependence where the final result of the first instruction is required before starting the second instruction 14

15 Problem 2 Assume an unpipelined processor where it takes 5ns to go through the circuits and 0.1ns for the latch overhead. What is the throughput for 20-stage and 40-stage pipelines? Assume that the P.O.P and P.O.C in the unpipelined processor are separated by 2ns. Assume that half the instructions do not introduce a data hazard and half the instructions depend on their preceding instruction. 15

16 Problem 2 Assume an unpipelined processor where it takes 5ns to go through the circuits and 0.1ns for the latch overhead. What is the throughput for 1-stage, 20-stage and 50-stage pipelines? Assume that the P.O.P and P.O.C in the unpipelined processor are separated by 2ns. Assume that half the instructions do not introduce a data hazard and half the instructions depend on their preceding instruction. 1-stage: 1 instr every 5.1ns 20-stage: first instr takes 0.35ns, the second takes 2.8ns 50-stage: first instr takes 0.2ns, the second takes 4ns 16

17 Title Bullet 17

WAR: Write After Read
 WAR: Write After Read write-after-read (WAR) = artificial (name) dependence add R1, R2, R3 sub R2, R4, R1 or R1, R6, R3 problem: add could use wrong value for R2 can t happen in vanilla pipeline (reads
WAR: Write After Read write-after-read (WAR) = artificial (name) dependence add R1, R2, R3 sub R2, R4, R1 or R1, R6, R3 problem: add could use wrong value for R2 can t happen in vanilla pipeline (reads
Solution: start more than one instruction in the same clock cycle CPI < 1 (or IPC > 1, Instructions per Cycle) Two approaches:
 Two approaches:") Multiple-Issue Processors Pipelining can achieve CPI close to 1 Mechanisms for handling hazards Static or dynamic scheduling Static or dynamic branch handling Increase in transistor counts (Moore s Law):
Multiple-Issue Processors Pipelining can achieve CPI close to 1 Mechanisms for handling hazards Static or dynamic scheduling Static or dynamic branch handling Increase in transistor counts (Moore s Law):
INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER
 Course on: Advanced Computer Architectures INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER Prof. Cristina Silvano Politecnico di Milano cristina.silvano@polimi.it Prof. Silvano, Politecnico di Milano
Course on: Advanced Computer Architectures INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER Prof. Cristina Silvano Politecnico di Milano cristina.silvano@polimi.it Prof. Silvano, Politecnico di Milano
PROBLEMS #20,R0,R1 #$3A,R2,R4
 506 CHAPTER 8 PIPELINING (Corrisponde al cap. 11 - Introduzione al pipelining) PROBLEMS 8.1 Consider the following sequence of instructions Mul And #20,R0,R1 #3,R2,R3 #$3A,R2,R4 R0,R2,R5 In all instructions,
506 CHAPTER 8 PIPELINING (Corrisponde al cap. 11 - Introduzione al pipelining) PROBLEMS 8.1 Consider the following sequence of instructions Mul And #20,R0,R1 #3,R2,R3 #$3A,R2,R4 R0,R2,R5 In all instructions,
Pipeline Hazards. Structure hazard Data hazard. ComputerArchitecture_PipelineHazard1
 Pipeline Hazards Structure hazard Data hazard Pipeline hazard: the major hurdle A hazard is a condition that prevents an instruction in the pipe from executing its next scheduled pipe stage Taxonomy of
Pipeline Hazards Structure hazard Data hazard Pipeline hazard: the major hurdle A hazard is a condition that prevents an instruction in the pipe from executing its next scheduled pipe stage Taxonomy of
UNIVERSITY OF CALIFORNIA, DAVIS Department of Electrical and Computer Engineering. EEC180B Lab 7: MISP Processor Design Spring 1995
 UNIVERSITY OF CALIFORNIA, DAVIS Department of Electrical and Computer Engineering EEC180B Lab 7: MISP Processor Design Spring 1995 Objective: In this lab, you will complete the design of the MISP processor,
UNIVERSITY OF CALIFORNIA, DAVIS Department of Electrical and Computer Engineering EEC180B Lab 7: MISP Processor Design Spring 1995 Objective: In this lab, you will complete the design of the MISP processor,
Pipelining Review and Its Limitations
 Pipelining Review and Its Limitations Yuri Baida yuri.baida@gmail.com yuriy.v.baida@intel.com October 16, 2010 Moscow Institute of Physics and Technology Agenda Review Instruction set architecture Basic
Pipelining Review and Its Limitations Yuri Baida yuri.baida@gmail.com yuriy.v.baida@intel.com October 16, 2010 Moscow Institute of Physics and Technology Agenda Review Instruction set architecture Basic
CS352H: Computer Systems Architecture
 CS352H: Computer Systems Architecture Topic 9: MIPS Pipeline - Hazards October 1, 2009 University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell Data Hazards in ALU Instructions
CS352H: Computer Systems Architecture Topic 9: MIPS Pipeline - Hazards October 1, 2009 University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell Data Hazards in ALU Instructions
Solutions. Solution 4.1. 4.1.1 The values of the signals are as follows:
 4 Solutions Solution 4.1 4.1.1 The values of the signals are as follows: RegWrite MemRead ALUMux MemWrite ALUOp RegMux Branch a. 1 0 0 (Reg) 0 Add 1 (ALU) 0 b. 1 1 1 (Imm) 0 Add 1 (Mem) 0 ALUMux is the
4 Solutions Solution 4.1 4.1.1 The values of the signals are as follows: RegWrite MemRead ALUMux MemWrite ALUOp RegMux Branch a. 1 0 0 (Reg) 0 Add 1 (ALU) 0 b. 1 1 1 (Imm) 0 Add 1 (Mem) 0 ALUMux is the
CPU Performance Equation
 CPU Performance Equation C T I T ime for task = C T I =Average # Cycles per instruction =Time per cycle =Instructions per task Pipelining e.g. 3-5 pipeline steps (ARM, SA, R3000) Attempt to get C down
CPU Performance Equation C T I T ime for task = C T I =Average # Cycles per instruction =Time per cycle =Instructions per task Pipelining e.g. 3-5 pipeline steps (ARM, SA, R3000) Attempt to get C down
Design of Pipelined MIPS Processor. Sept. 24 & 26, 1997
 Design of Pipelined MIPS Processor Sept. 24 & 26, 1997 Topics Instruction processing Principles of pipelining Inserting pipe registers Data Hazards Control Hazards Exceptions MIPS architecture subset R-type
Design of Pipelined MIPS Processor Sept. 24 & 26, 1997 Topics Instruction processing Principles of pipelining Inserting pipe registers Data Hazards Control Hazards Exceptions MIPS architecture subset R-type
Data Dependences. A data dependence occurs whenever one instruction needs a value produced by another.
 Data Hazards 1 Hazards: Key Points Hazards cause imperfect pipelining They prevent us from achieving CPI = 1 They are generally causes by counter flow data pennces in the pipeline Three kinds Structural
Data Hazards 1 Hazards: Key Points Hazards cause imperfect pipelining They prevent us from achieving CPI = 1 They are generally causes by counter flow data pennces in the pipeline Three kinds Structural
Q. Consider a dynamic instruction execution (an execution trace, in other words) that consists of repeats of code in this pattern:
 that consists of repeats of code in this pattern:") Pipelining HW Q. Can a MIPS SW instruction executing in a simple 5-stage pipelined implementation have a data dependency hazard of any type resulting in a nop bubble? If so, show an example; if not, prove
Pipelining HW Q. Can a MIPS SW instruction executing in a simple 5-stage pipelined implementation have a data dependency hazard of any type resulting in a nop bubble? If so, show an example; if not, prove
PROBLEMS. which was discussed in Section 1.6.3.
 22 CHAPTER 1 BASIC STRUCTURE OF COMPUTERS (Corrisponde al cap. 1 - Introduzione al calcolatore) PROBLEMS 1.1 List the steps needed to execute the machine instruction LOCA,R0 in terms of transfers between
22 CHAPTER 1 BASIC STRUCTURE OF COMPUTERS (Corrisponde al cap. 1 - Introduzione al calcolatore) PROBLEMS 1.1 List the steps needed to execute the machine instruction LOCA,R0 in terms of transfers between
 More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
Using Graphics and Animation to Visualize Instruction Pipelining and its Hazards
 Using Graphics and Animation to Visualize Instruction Pipelining and its Hazards Per Stenström, Håkan Nilsson, and Jonas Skeppstedt Department of Computer Engineering, Lund University P.O. Box 118, S-221
Using Graphics and Animation to Visualize Instruction Pipelining and its Hazards Per Stenström, Håkan Nilsson, and Jonas Skeppstedt Department of Computer Engineering, Lund University P.O. Box 118, S-221
Computer Organization and Components
 Computer Organization and Components IS5, fall 25 Lecture : Pipelined Processors ssociate Professor, KTH Royal Institute of Technology ssistant Research ngineer, University of California, Berkeley Slides
Computer Organization and Components IS5, fall 25 Lecture : Pipelined Processors ssociate Professor, KTH Royal Institute of Technology ssistant Research ngineer, University of California, Berkeley Slides
Course on Advanced Computer Architectures
 Course on Advanced Computer Architectures Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, September 3rd, 2015 Prof. C. Silvano EX1A ( 2 points) EX1B ( 2
Course on Advanced Computer Architectures Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, September 3rd, 2015 Prof. C. Silvano EX1A ( 2 points) EX1B ( 2
Advanced Computer Architecture-CS501. Computer Systems Design and Architecture 2.1, 2.2, 3.2
 Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
A Lab Course on Computer Architecture
 A Lab Course on Computer Architecture Pedro López José Duato Depto. de Informática de Sistemas y Computadores Facultad de Informática Universidad Politécnica de Valencia Camino de Vera s/n, 46071 - Valencia,
A Lab Course on Computer Architecture Pedro López José Duato Depto. de Informática de Sistemas y Computadores Facultad de Informática Universidad Politécnica de Valencia Camino de Vera s/n, 46071 - Valencia,
Pipeline Hazards. Arvind Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by Arvind and Krste Asanovic
 1 Pipeline Hazards Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by and Krste Asanovic 6.823 L6-2 Technology Assumptions A small amount of very fast memory
1 Pipeline Hazards Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by and Krste Asanovic 6.823 L6-2 Technology Assumptions A small amount of very fast memory
Central Processing Unit (CPU)
") Central Processing Unit (CPU) CPU is the heart and brain It interprets and executes machine level instructions Controls data transfer from/to Main Memory (MM) and CPU Detects any errors In the following
Central Processing Unit (CPU) CPU is the heart and brain It interprets and executes machine level instructions Controls data transfer from/to Main Memory (MM) and CPU Detects any errors In the following
EE282 Computer Architecture and Organization Midterm Exam February 13, 2001. (Total Time = 120 minutes, Total Points = 100)
") EE282 Computer Architecture and Organization Midterm Exam February 13, 2001 (Total Time = 120 minutes, Total Points = 100) Name: (please print) Wolfe - Solution In recognition of and in the spirit of the
EE282 Computer Architecture and Organization Midterm Exam February 13, 2001 (Total Time = 120 minutes, Total Points = 100) Name: (please print) Wolfe - Solution In recognition of and in the spirit of the
Instruction scheduling
 Instruction ordering Instruction scheduling Advanced Compiler Construction Michel Schinz 2015 05 21 When a compiler emits the instructions corresponding to a program, it imposes a total order on them.
Instruction ordering Instruction scheduling Advanced Compiler Construction Michel Schinz 2015 05 21 When a compiler emits the instructions corresponding to a program, it imposes a total order on them.
Module: Software Instruction Scheduling Part I
 Module: Software Instruction Scheduling Part I Sudhakar Yalamanchili, Georgia Institute of Technology Reading for this Module Loop Unrolling and Instruction Scheduling Section 2.2 Dependence Analysis Section
Module: Software Instruction Scheduling Part I Sudhakar Yalamanchili, Georgia Institute of Technology Reading for this Module Loop Unrolling and Instruction Scheduling Section 2.2 Dependence Analysis Section
CS521 CSE IITG 11/23/2012
 CS521 CSE TG 11/23/2012 A Sahu 1 Degree of overlap Serial, Overlapped, d, Super pipelined/superscalar Depth Shallow, Deep Structure Linear, Non linear Scheduling of operations Static, Dynamic A Sahu slide
CS521 CSE TG 11/23/2012 A Sahu 1 Degree of overlap Serial, Overlapped, d, Super pipelined/superscalar Depth Shallow, Deep Structure Linear, Non linear Scheduling of operations Static, Dynamic A Sahu slide
Chapter 4 Lecture 5 The Microarchitecture Level Integer JAVA Virtual Machine
 Chapter 4 Lecture 5 The Microarchitecture Level Integer JAVA Virtual Machine This is a limited version of a hardware implementation to execute the JAVA programming language. 1 of 23 Structured Computer
Chapter 4 Lecture 5 The Microarchitecture Level Integer JAVA Virtual Machine This is a limited version of a hardware implementation to execute the JAVA programming language. 1 of 23 Structured Computer
Giving credit where credit is due
 CSCE 230J Computer Organization Processor Architecture VI: Wrap-Up Dr. Steve Goddard goddard@cse.unl.edu http://cse.unl.edu/~goddard/courses/csce230j Giving credit where credit is due ost of slides for
CSCE 230J Computer Organization Processor Architecture VI: Wrap-Up Dr. Steve Goddard goddard@cse.unl.edu http://cse.unl.edu/~goddard/courses/csce230j Giving credit where credit is due ost of slides for
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM
 ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM 1 The ARM architecture processors popular in Mobile phone systems 2 ARM Features ARM has 32-bit architecture but supports 16 bit
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM 1 The ARM architecture processors popular in Mobile phone systems 2 ARM Features ARM has 32-bit architecture but supports 16 bit
Chapter 5 Instructor's Manual
 The Essentials of Computer Organization and Architecture Linda Null and Julia Lobur Jones and Bartlett Publishers, 2003 Chapter 5 Instructor's Manual Chapter Objectives Chapter 5, A Closer Look at Instruction
The Essentials of Computer Organization and Architecture Linda Null and Julia Lobur Jones and Bartlett Publishers, 2003 Chapter 5 Instructor's Manual Chapter Objectives Chapter 5, A Closer Look at Instruction
LSN 2 Computer Processors
 LSN 2 Computer Processors Department of Engineering Technology LSN 2 Computer Processors Microprocessors Design Instruction set Processor organization Processor performance Bandwidth Clock speed LSN 2
LSN 2 Computer Processors Department of Engineering Technology LSN 2 Computer Processors Microprocessors Design Instruction set Processor organization Processor performance Bandwidth Clock speed LSN 2
EE361: Digital Computer Organization Course Syllabus
 EE361: Digital Computer Organization Course Syllabus Dr. Mohammad H. Awedh Spring 2014 Course Objectives Simply, a computer is a set of components (Processor, Memory and Storage, Input/Output Devices)
EE361: Digital Computer Organization Course Syllabus Dr. Mohammad H. Awedh Spring 2014 Course Objectives Simply, a computer is a set of components (Processor, Memory and Storage, Input/Output Devices)
VLIW Processors. VLIW Processors
 1 VLIW Processors VLIW ( very long instruction word ) processors instructions are scheduled by the compiler a fixed number of operations are formatted as one big instruction (called a bundle) usually LIW
1 VLIW Processors VLIW ( very long instruction word ) processors instructions are scheduled by the compiler a fixed number of operations are formatted as one big instruction (called a bundle) usually LIW
CS:APP Chapter 4 Computer Architecture. Wrap-Up. William J. Taffe Plymouth State University. using the slides of
 CS:APP Chapter 4 Computer Architecture Wrap-Up William J. Taffe Plymouth State University using the slides of Randal E. Bryant Carnegie Mellon University Overview Wrap-Up of PIPE Design Performance analysis
CS:APP Chapter 4 Computer Architecture Wrap-Up William J. Taffe Plymouth State University using the slides of Randal E. Bryant Carnegie Mellon University Overview Wrap-Up of PIPE Design Performance analysis
Static Scheduling. option #1: dynamic scheduling (by the hardware) option #2: static scheduling (by the compiler) ECE 252 / CPS 220 Lecture Notes
 option #2: static scheduling (by the compiler) ECE 252 / CPS 220 Lecture Notes") basic pipeline: single, in-order issue first extension: multiple issue (superscalar) second extension: scheduling instructions for more ILP option #1: dynamic scheduling (by the hardware) option #2: static
basic pipeline: single, in-order issue first extension: multiple issue (superscalar) second extension: scheduling instructions for more ILP option #1: dynamic scheduling (by the hardware) option #2: static
This Unit: Multithreading (MT) CIS 501 Computer Architecture. Performance And Utilization. Readings
 CIS 501 Computer Architecture. Performance And Utilization. Readings") This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
Introduction to CMOS VLSI Design (E158) Lecture 8: Clocking of VLSI Systems
 Lecture 8: Clocking of VLSI Systems") Harris Introduction to CMOS VLSI Design (E158) Lecture 8: Clocking of VLSI Systems David Harris Harvey Mudd College David_Harris@hmc.edu Based on EE271 developed by Mark Horowitz, Stanford University MAH
Harris Introduction to CMOS VLSI Design (E158) Lecture 8: Clocking of VLSI Systems David Harris Harvey Mudd College David_Harris@hmc.edu Based on EE271 developed by Mark Horowitz, Stanford University MAH
Computer Architecture TDTS10
 why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
An Introduction to the ARM 7 Architecture
 An Introduction to the ARM 7 Architecture Trevor Martin CEng, MIEE Technical Director This article gives an overview of the ARM 7 architecture and a description of its major features for a developer new
An Introduction to the ARM 7 Architecture Trevor Martin CEng, MIEE Technical Director This article gives an overview of the ARM 7 architecture and a description of its major features for a developer new
PART B QUESTIONS AND ANSWERS UNIT I
 PART B QUESTIONS AND ANSWERS UNIT I 1. Explain the architecture of 8085 microprocessor? Logic pin out of 8085 microprocessor Address bus: unidirectional bus, used as high order bus Data bus: bi-directional
PART B QUESTIONS AND ANSWERS UNIT I 1. Explain the architecture of 8085 microprocessor? Logic pin out of 8085 microprocessor Address bus: unidirectional bus, used as high order bus Data bus: bi-directional
Lecture 7: Clocking of VLSI Systems
 Lecture 7: Clocking of VLSI Systems MAH, AEN EE271 Lecture 7 1 Overview Reading Wolf 5.3 Two-Phase Clocking (good description) W&E 5.5.1, 5.5.2, 5.5.3, 5.5.4, 5.5.9, 5.5.10 - Clocking Note: The analysis
Lecture 7: Clocking of VLSI Systems MAH, AEN EE271 Lecture 7 1 Overview Reading Wolf 5.3 Two-Phase Clocking (good description) W&E 5.5.1, 5.5.2, 5.5.3, 5.5.4, 5.5.9, 5.5.10 - Clocking Note: The analysis
picojava TM : A Hardware Implementation of the Java Virtual Machine
 picojava TM : A Hardware Implementation of the Java Virtual Machine Marc Tremblay and Michael O Connor Sun Microelectronics Slide 1 The Java picojava Synergy Java s origins lie in improving the consumer
picojava TM : A Hardware Implementation of the Java Virtual Machine Marc Tremblay and Michael O Connor Sun Microelectronics Slide 1 The Java picojava Synergy Java s origins lie in improving the consumer
The Microarchitecture of Superscalar Processors
 The Microarchitecture of Superscalar Processors James E. Smith Department of Electrical and Computer Engineering 1415 Johnson Drive Madison, WI 53706 ph: (608)-265-5737 fax:(608)-262-1267 email: jes@ece.wisc.edu
The Microarchitecture of Superscalar Processors James E. Smith Department of Electrical and Computer Engineering 1415 Johnson Drive Madison, WI 53706 ph: (608)-265-5737 fax:(608)-262-1267 email: jes@ece.wisc.edu
MACHINE ARCHITECTURE & LANGUAGE
 in the name of God the compassionate, the merciful notes on MACHINE ARCHITECTURE & LANGUAGE compiled by Jumong Chap. 9 Microprocessor Fundamentals A system designer should consider a microprocessor-based
in the name of God the compassionate, the merciful notes on MACHINE ARCHITECTURE & LANGUAGE compiled by Jumong Chap. 9 Microprocessor Fundamentals A system designer should consider a microprocessor-based
BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA
 BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA AGENDA INTRO TO BEAGLEBONE BLACK HARDWARE & SPECS CORTEX-A8 ARMV7 PROCESSOR PROS & CONS VS RASPBERRY PI WHEN TO USE BEAGLEBONE BLACK Single
BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA AGENDA INTRO TO BEAGLEBONE BLACK HARDWARE & SPECS CORTEX-A8 ARMV7 PROCESSOR PROS & CONS VS RASPBERRY PI WHEN TO USE BEAGLEBONE BLACK Single
Administration. Instruction scheduling. Modern processors. Examples. Simplified architecture model. CS 412 Introduction to Compilers
 CS 4 Introduction to Compilers ndrew Myers Cornell University dministration Prelim tomorrow evening No class Wednesday P due in days Optional reading: Muchnick 7 Lecture : Instruction scheduling pr 0 Modern
CS 4 Introduction to Compilers ndrew Myers Cornell University dministration Prelim tomorrow evening No class Wednesday P due in days Optional reading: Muchnick 7 Lecture : Instruction scheduling pr 0 Modern
Instruction Set Architecture. Datapath & Control. Instruction. LC-3 Overview: Memory and Registers. CIT 595 Spring 2010
 Instruction Set Architecture Micro-architecture Datapath & Control CIT 595 Spring 2010 ISA =Programmer-visible components & operations Memory organization Address space -- how may locations can be addressed?
Instruction Set Architecture Micro-architecture Datapath & Control CIT 595 Spring 2010 ISA =Programmer-visible components & operations Memory organization Address space -- how may locations can be addressed?
MICROPROCESSOR AND MICROCOMPUTER BASICS
 Introduction MICROPROCESSOR AND MICROCOMPUTER BASICS At present there are many types and sizes of computers available. These computers are designed and constructed based on digital and Integrated Circuit
Introduction MICROPROCESSOR AND MICROCOMPUTER BASICS At present there are many types and sizes of computers available. These computers are designed and constructed based on digital and Integrated Circuit
Week 1 out-of-class notes, discussions and sample problems
 Week 1 out-of-class notes, discussions and sample problems Although we will primarily concentrate on RISC processors as found in some desktop/laptop computers, here we take a look at the varying types
Week 1 out-of-class notes, discussions and sample problems Although we will primarily concentrate on RISC processors as found in some desktop/laptop computers, here we take a look at the varying types
Execution Cycle. Pipelining. IF and ID Stages. Simple MIPS Instruction Formats
 Execution Cycle Pipelining CSE 410, Spring 2005 Computer Systems http://www.cs.washington.edu/410 1. Instruction Fetch 2. Instruction Decode 3. Execute 4. Memory 5. Write Back IF and ID Stages 1. Instruction
Execution Cycle Pipelining CSE 410, Spring 2005 Computer Systems http://www.cs.washington.edu/410 1. Instruction Fetch 2. Instruction Decode 3. Execute 4. Memory 5. Write Back IF and ID Stages 1. Instruction
Chapter 2 Basic Structure of Computers. Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan
 Chapter 2 Basic Structure of Computers Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Functional Units Basic Operational Concepts Bus Structures Software
Chapter 2 Basic Structure of Computers Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Functional Units Basic Operational Concepts Bus Structures Software
l C-Programming l A real computer language l Data Representation l Everything goes down to bits and bytes l Machine representation Language
 198:211 Computer Architecture Topics: Processor Design Where are we now? C-Programming A real computer language Data Representation Everything goes down to bits and bytes Machine representation Language
198:211 Computer Architecture Topics: Processor Design Where are we now? C-Programming A real computer language Data Representation Everything goes down to bits and bytes Machine representation Language
Delay Time Analysis of Reconfigurable Firewall Unit
 Delay Time Analysis of Reconfigurable Unit Tomoaki SATO C&C Systems Center, Hirosaki University Hirosaki 036-8561 Japan Phichet MOUNGNOUL Faculty of Engineering, King Mongkut's Institute of Technology
Delay Time Analysis of Reconfigurable Unit Tomoaki SATO C&C Systems Center, Hirosaki University Hirosaki 036-8561 Japan Phichet MOUNGNOUL Faculty of Engineering, King Mongkut's Institute of Technology
Let s put together a Manual Processor
 Lecture 14 Let s put together a Manual Processor Hardware Lecture 14 Slide 1 The processor Inside every computer there is at least one processor which can take an instruction, some operands and produce
Lecture 14 Let s put together a Manual Processor Hardware Lecture 14 Slide 1 The processor Inside every computer there is at least one processor which can take an instruction, some operands and produce
Slide Set 8. for ENCM 369 Winter 2015 Lecture Section 01. Steve Norman, PhD, PEng
 Slide Set 8 for ENCM 369 Winter 2015 Lecture Section 01 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary Winter Term, 2015 ENCM 369 W15 Section
Slide Set 8 for ENCM 369 Winter 2015 Lecture Section 01 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary Winter Term, 2015 ENCM 369 W15 Section
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
SIM-PL: Software for teaching computer hardware at secondary schools in the Netherlands
 SIM-PL: Software for teaching computer hardware at secondary schools in the Netherlands Ben Bruidegom, benb@science.uva.nl AMSTEL Instituut Universiteit van Amsterdam Kruislaan 404 NL-1098 SM Amsterdam
SIM-PL: Software for teaching computer hardware at secondary schools in the Netherlands Ben Bruidegom, benb@science.uva.nl AMSTEL Instituut Universiteit van Amsterdam Kruislaan 404 NL-1098 SM Amsterdam
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000. ILP Execution
 EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000 Lecture #11: Wednesday, 3 May 2000 Lecturer: Ben Serebrin Scribe: Dean Liu ILP Execution
EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000 Lecture #11: Wednesday, 3 May 2000 Lecturer: Ben Serebrin Scribe: Dean Liu ILP Execution
StrongARM** SA-110 Microprocessor Instruction Timing
 StrongARM** SA-110 Microprocessor Instruction Timing Application Note September 1998 Order Number: 278194-001 Information in this document is provided in connection with Intel products. No license, express
StrongARM** SA-110 Microprocessor Instruction Timing Application Note September 1998 Order Number: 278194-001 Information in this document is provided in connection with Intel products. No license, express
Quiz for Chapter 1 Computer Abstractions and Technology 3.10
 Date: 3.10 Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Date: 3.10 Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
150127-Microprocessor & Assembly Language
 Chapter 3 Z80 Microprocessor Architecture The Z 80 is one of the most talented 8 bit microprocessors, and many microprocessor-based systems are designed around the Z80. The Z80 microprocessor needs an
Chapter 3 Z80 Microprocessor Architecture The Z 80 is one of the most talented 8 bit microprocessors, and many microprocessor-based systems are designed around the Z80. The Z80 microprocessor needs an
Computer Organization. and Instruction Execution. August 22
 Computer Organization and Instruction Execution August 22 CSC201 Section 002 Fall, 2000 The Main Parts of a Computer CSC201 Section Copyright 2000, Douglas Reeves 2 I/O and Storage Devices (lots of devices,
Computer Organization and Instruction Execution August 22 CSC201 Section 002 Fall, 2000 The Main Parts of a Computer CSC201 Section Copyright 2000, Douglas Reeves 2 I/O and Storage Devices (lots of devices,
Instruction Level Parallelism I: Pipelining
 Instruction Level Parallelism I: Pipelining Readings: H&P Appendix A Instruction Level Parallelism I: Pipelining 1 This Unit: Pipelining Application OS Compiler Firmware CPU I/O Memory Digital Circuits
Instruction Level Parallelism I: Pipelining Readings: H&P Appendix A Instruction Level Parallelism I: Pipelining 1 This Unit: Pipelining Application OS Compiler Firmware CPU I/O Memory Digital Circuits
Chapter 01: Introduction. Lesson 02 Evolution of Computers Part 2 First generation Computers
 Chapter 01: Introduction Lesson 02 Evolution of Computers Part 2 First generation Computers Objective Understand how electronic computers evolved during the first generation of computers First Generation
Chapter 01: Introduction Lesson 02 Evolution of Computers Part 2 First generation Computers Objective Understand how electronic computers evolved during the first generation of computers First Generation
The 104 Duke_ACC Machine
 The 104 Duke_ACC Machine The goal of the next two lessons is to design and simulate a simple accumulator-based processor. The specifications for this processor and some of the QuartusII design components
The 104 Duke_ACC Machine The goal of the next two lessons is to design and simulate a simple accumulator-based processor. The specifications for this processor and some of the QuartusII design components
what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored?
 Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Technical Note. Micron NAND Flash Controller via Xilinx Spartan -3 FPGA. Overview. TN-29-06: NAND Flash Controller on Spartan-3 Overview
 Technical Note TN-29-06: NAND Flash Controller on Spartan-3 Overview Micron NAND Flash Controller via Xilinx Spartan -3 FPGA Overview As mobile product capabilities continue to expand, so does the demand
Technical Note TN-29-06: NAND Flash Controller on Spartan-3 Overview Micron NAND Flash Controller via Xilinx Spartan -3 FPGA Overview As mobile product capabilities continue to expand, so does the demand
A s we saw in Chapter 4, a CPU contains three main sections: the register section,
 6 CPU Design A s we saw in Chapter 4, a CPU contains three main sections: the register section, the arithmetic/logic unit (ALU), and the control unit. These sections work together to perform the sequences
6 CPU Design A s we saw in Chapter 4, a CPU contains three main sections: the register section, the arithmetic/logic unit (ALU), and the control unit. These sections work together to perform the sequences
Addressing The problem. When & Where do we encounter Data? The concept of addressing data' in computations. The implications for our machine design(s)
") Addressing The problem Objectives:- When & Where do we encounter Data? The concept of addressing data' in computations The implications for our machine design(s) Introducing the stack-machine concept Slide
Addressing The problem Objectives:- When & Where do we encounter Data? The concept of addressing data' in computations The implications for our machine design(s) Introducing the stack-machine concept Slide
VHDL DESIGN OF EDUCATIONAL, MODERN AND OPEN- ARCHITECTURE CPU
 VHDL DESIGN OF EDUCATIONAL, MODERN AND OPEN- ARCHITECTURE CPU Martin Straka Doctoral Degree Programme (1), FIT BUT E-mail: strakam@fit.vutbr.cz Supervised by: Zdeněk Kotásek E-mail: kotasek@fit.vutbr.cz
VHDL DESIGN OF EDUCATIONAL, MODERN AND OPEN- ARCHITECTURE CPU Martin Straka Doctoral Degree Programme (1), FIT BUT E-mail: strakam@fit.vutbr.cz Supervised by: Zdeněk Kotásek E-mail: kotasek@fit.vutbr.cz
CSE 141L Computer Architecture Lab Fall 2003. Lecture 2
 CSE 141L Computer Architecture Lab Fall 2003 Lecture 2 Pramod V. Argade CSE141L: Computer Architecture Lab Instructor: TA: Readers: Pramod V. Argade (p2argade@cs.ucsd.edu) Office Hour: Tue./Thu. 9:30-10:30
CSE 141L Computer Architecture Lab Fall 2003 Lecture 2 Pramod V. Argade CSE141L: Computer Architecture Lab Instructor: TA: Readers: Pramod V. Argade (p2argade@cs.ucsd.edu) Office Hour: Tue./Thu. 9:30-10:30
Application Note 195. ARM11 performance monitor unit. Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007
 Application Note 195 ARM11 performance monitor unit Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007 Copyright 2007 ARM Limited. All rights reserved. Application Note
Application Note 195 ARM11 performance monitor unit Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007 Copyright 2007 ARM Limited. All rights reserved. Application Note
Lecture 2: Computer Hardware and Ports. y.alharbi@sau.edu.sa http://faculty.sau.edu.sa/y.alharbi/en
 BMTS 242: Computer and Systems Lecture 2: Computer Hardware and Ports Yousef Alharbi Email Website y.alharbi@sau.edu.sa http://faculty.sau.edu.sa/y.alharbi/en The System Unit McGraw-Hill Copyright 2011
BMTS 242: Computer and Systems Lecture 2: Computer Hardware and Ports Yousef Alharbi Email Website y.alharbi@sau.edu.sa http://faculty.sau.edu.sa/y.alharbi/en The System Unit McGraw-Hill Copyright 2011
A+ Guide to Managing and Maintaining Your PC, 7e. Chapter 1 Introducing Hardware
 A+ Guide to Managing and Maintaining Your PC, 7e Chapter 1 Introducing Hardware Objectives Learn that a computer requires both hardware and software to work Learn about the many different hardware components
A+ Guide to Managing and Maintaining Your PC, 7e Chapter 1 Introducing Hardware Objectives Learn that a computer requires both hardware and software to work Learn about the many different hardware components
2
 1 2 3 4 5 For Description of these Features see http://download.intel.com/products/processor/corei7/prod_brief.pdf The following Features Greatly affect Performance Monitoring The New Performance Monitoring
1 2 3 4 5 For Description of these Features see http://download.intel.com/products/processor/corei7/prod_brief.pdf The following Features Greatly affect Performance Monitoring The New Performance Monitoring
Thread level parallelism
 Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
Levels of Programming Languages. Gerald Penn CSC 324
 Levels of Programming Languages Gerald Penn CSC 324 Levels of Programming Language Microcode Machine code Assembly Language Low-level Programming Language High-level Programming Language Levels of Programming
Levels of Programming Languages Gerald Penn CSC 324 Levels of Programming Language Microcode Machine code Assembly Language Low-level Programming Language High-level Programming Language Levels of Programming
Chapter 4 Register Transfer and Microoperations. Section 4.1 Register Transfer Language
 Chapter 4 Register Transfer and Microoperations Section 4.1 Register Transfer Language Digital systems are composed of modules that are constructed from digital components, such as registers, decoders,
Chapter 4 Register Transfer and Microoperations Section 4.1 Register Transfer Language Digital systems are composed of modules that are constructed from digital components, such as registers, decoders,
Lecture-3 MEMORY: Development of Memory:
 Lecture-3 MEMORY: It is a storage device. It stores program data and the results. There are two kind of memories; semiconductor memories & magnetic memories. Semiconductor memories are faster, smaller,
Lecture-3 MEMORY: It is a storage device. It stores program data and the results. There are two kind of memories; semiconductor memories & magnetic memories. Semiconductor memories are faster, smaller,
Logical Operations. Control Unit. Contents. Arithmetic Operations. Objectives. The Central Processing Unit: Arithmetic / Logic Unit.
 Objectives The Central Processing Unit: What Goes on Inside the Computer Chapter 4 Identify the components of the central processing unit and how they work together and interact with memory Describe how
Objectives The Central Processing Unit: What Goes on Inside the Computer Chapter 4 Identify the components of the central processing unit and how they work together and interact with memory Describe how
TIMING DIAGRAM O 8085
 5 TIMING DIAGRAM O 8085 5.1 INTRODUCTION Timing diagram is the display of initiation of read/write and transfer of data operations under the control of 3-status signals IO / M, S 1, and S 0. As the heartbeat
5 TIMING DIAGRAM O 8085 5.1 INTRODUCTION Timing diagram is the display of initiation of read/write and transfer of data operations under the control of 3-status signals IO / M, S 1, and S 0. As the heartbeat
CHAPTER 7: The CPU and Memory
 CHAPTER 7: The CPU and Memory The Architecture of Computer Hardware, Systems Software & Networking: An Information Technology Approach 4th Edition, Irv Englander John Wiley and Sons 2010 PowerPoint slides
CHAPTER 7: The CPU and Memory The Architecture of Computer Hardware, Systems Software & Networking: An Information Technology Approach 4th Edition, Irv Englander John Wiley and Sons 2010 PowerPoint slides
An Overview of Stack Architecture and the PSC 1000 Microprocessor
 An Overview of Stack Architecture and the PSC 1000 Microprocessor Introduction A stack is an important data handling structure used in computing. Specifically, a stack is a dynamic set of elements in which
An Overview of Stack Architecture and the PSC 1000 Microprocessor Introduction A stack is an important data handling structure used in computing. Specifically, a stack is a dynamic set of elements in which
EC 362 Problem Set #2
 EC 362 Problem Set #2 1) Using Single Precision IEEE 754, what is FF28 0000? 2) Suppose the fraction enhanced of a processor is 40% and the speedup of the enhancement was tenfold. What is the overall speedup?
EC 362 Problem Set #2 1) Using Single Precision IEEE 754, what is FF28 0000? 2) Suppose the fraction enhanced of a processor is 40% and the speedup of the enhancement was tenfold. What is the overall speedup?
Computer organization
 Computer organization Computer design an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs
Computer organization Computer design an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs
PowerPC Microprocessor Clock Modes
 nc. Freescale Semiconductor AN1269 (Freescale Order Number) 1/96 Application Note PowerPC Microprocessor Clock Modes The PowerPC microprocessors offer customers numerous clocking options. An internal phase-lock
nc. Freescale Semiconductor AN1269 (Freescale Order Number) 1/96 Application Note PowerPC Microprocessor Clock Modes The PowerPC microprocessors offer customers numerous clocking options. An internal phase-lock
An Out-of-Order RiSC-16 Tomasulo + Reorder Buffer = Interruptible Out-of-Order
 An Out-of-Order RiSC-16 Tomasulo + Reorder Buffer = Interruptible Out-of-Order ENEE 446: Digital Computer Design, Fall 2000 Prof. Bruce Jacob, http://www.ece.umd.edu/~blj/ This paper describes an out-of-order
An Out-of-Order RiSC-16 Tomasulo + Reorder Buffer = Interruptible Out-of-Order ENEE 446: Digital Computer Design, Fall 2000 Prof. Bruce Jacob, http://www.ece.umd.edu/~blj/ This paper describes an out-of-order
CUDA Optimization with NVIDIA Tools. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Tools Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nvidia Tools 2 What Does the Application
CUDA Optimization with NVIDIA Tools Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nvidia Tools 2 What Does the Application
Remote Copy Technology of ETERNUS6000 and ETERNUS3000 Disk Arrays
 Remote Copy Technology of ETERNUS6000 and ETERNUS3000 Disk Arrays V Tsutomu Akasaka (Manuscript received July 5, 2005) This paper gives an overview of a storage-system remote copy function and the implementation
Remote Copy Technology of ETERNUS6000 and ETERNUS3000 Disk Arrays V Tsutomu Akasaka (Manuscript received July 5, 2005) This paper gives an overview of a storage-system remote copy function and the implementation
Software Pipelining - Modulo Scheduling
 EECS 583 Class 12 Software Pipelining - Modulo Scheduling University of Michigan October 15, 2014 Announcements + Reading Material HW 2 Due this Thursday Today s class reading» Iterative Modulo Scheduling:
EECS 583 Class 12 Software Pipelining - Modulo Scheduling University of Michigan October 15, 2014 Announcements + Reading Material HW 2 Due this Thursday Today s class reading» Iterative Modulo Scheduling:
ECE410 Design Project Spring 2008 Design and Characterization of a CMOS 8-bit Microprocessor Data Path
 ECE410 Design Project Spring 2008 Design and Characterization of a CMOS 8-bit Microprocessor Data Path Project Summary This project involves the schematic and layout design of an 8-bit microprocessor data
ECE410 Design Project Spring 2008 Design and Characterization of a CMOS 8-bit Microprocessor Data Path Project Summary This project involves the schematic and layout design of an 8-bit microprocessor data
Serial Communications
 Serial Communications 1 Serial Communication Introduction Serial communication buses Asynchronous and synchronous communication UART block diagram UART clock requirements Programming the UARTs Operation
Serial Communications 1 Serial Communication Introduction Serial communication buses Asynchronous and synchronous communication UART block diagram UART clock requirements Programming the UARTs Operation
Modbus RTU Communications RX/WX and MRX/MWX
 15 Modbus RTU Communications RX/WX and MRX/MWX In This Chapter.... Network Slave Operation Network Master Operation: RX / WX Network Master Operation: DL06 MRX / MWX 5 2 D0 Modbus Network Slave Operation
15 Modbus RTU Communications RX/WX and MRX/MWX In This Chapter.... Network Slave Operation Network Master Operation: RX / WX Network Master Operation: DL06 MRX / MWX 5 2 D0 Modbus Network Slave Operation
8. Hardware Acceleration and Coprocessing
 July 2011 ED51006-1.2 8. Hardware Acceleration and ED51006-1.2 This chapter discusses how you can use hardware accelerators and coprocessing to create more eicient, higher throughput designs in OPC Builder.
July 2011 ED51006-1.2 8. Hardware Acceleration and ED51006-1.2 This chapter discusses how you can use hardware accelerators and coprocessing to create more eicient, higher throughput designs in OPC Builder.
Overview. CISC Developments. RISC Designs. CISC Designs. VAX: Addressing Modes. Digital VAX
 Overview CISC Developments Over Twenty Years Classic CISC design: Digital VAX VAXÕs RISC successor: PRISM/Alpha IntelÕs ubiquitous 80x86 architecture Ð 8086 through the Pentium Pro (P6) RJS 2/3/97 Philosophy
Overview CISC Developments Over Twenty Years Classic CISC design: Digital VAX VAXÕs RISC successor: PRISM/Alpha IntelÕs ubiquitous 80x86 architecture Ð 8086 through the Pentium Pro (P6) RJS 2/3/97 Philosophy
BASIC COMPUTER ORGANIZATION AND DESIGN
 1 BASIC COMPUTER ORGANIZATION AND DESIGN Instruction Codes Computer Registers Computer Instructions Timing and Control Instruction Cycle Memory Reference Instructions Input-Output and Interrupt Complete
1 BASIC COMPUTER ORGANIZATION AND DESIGN Instruction Codes Computer Registers Computer Instructions Timing and Control Instruction Cycle Memory Reference Instructions Input-Output and Interrupt Complete
IA-64 Application Developer s Architecture Guide
 IA-64 Application Developer s Architecture Guide The IA-64 architecture was designed to overcome the performance limitations of today s architectures and provide maximum headroom for the future. To achieve
IA-64 Application Developer s Architecture Guide The IA-64 architecture was designed to overcome the performance limitations of today s architectures and provide maximum headroom for the future. To achieve
PROGETTO DI SISTEMI ELETTRONICI DIGITALI. Digital Systems Design. Digital Circuits Advanced Topics
 PROGETTO DI SISTEMI ELETTRONICI DIGITALI Digital Systems Design Digital Circuits Advanced Topics 1 Sequential circuit and metastability 2 Sequential circuit - FSM A Sequential circuit contains: Storage
PROGETTO DI SISTEMI ELETTRONICI DIGITALI Digital Systems Design Digital Circuits Advanced Topics 1 Sequential circuit and metastability 2 Sequential circuit - FSM A Sequential circuit contains: Storage
Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.
 Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.") Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Review Computers in mid 50 s Hardware was expensive
Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Review Computers in mid 50 s Hardware was expensive