Amazon-style shopping cart analysis using MapReduce on a Hadoop cluster. Dan Şerban
|
|
|
- Stephany Waters
- 9 years ago
- Views:
Transcription

1 Amazon-style shopping cart analysis using MapReduce on a Hadoop cluster Dan Şerban

2 Agenda :: Introduction - Real-world uses of MapReduce - The origins of Hadoop - Hadoop facts and architecture :: Part 1 - Deploying Hadoop :: Part 2 - MapReduce is machine learning :: Q&A


3 Why shopping cart analysis is useful to amazon.com


4 Linkedin and Google Reader


5 The origins of Hadoop :: Hadoop got its start in Nutch :: A few enthusiastic developers were attempting to build an open source web search engine and having trouble managing computations running on even a handful of computers :: Once Google published their GoogleFS and MapReduce whitepapers, the way forward became clear :: Google had devised systems to solve precisely the problems the Nutch project was facing :: Thus, Hadoop was born

6 Hadoop facts :: Hadoop is a distributed computing platform for processing extremely large amounts of data :: Hadoop is divided into two main components: - the MapReduce runtime - the Hadoop Distributed File System (HDFS) :: The MapReduce runtime allows the user to submit MapReduce jobs :: The HDFS is a distributed file system that provides a logical interface for persistent and redundant storage of large data :: Hadoop also provides the HadoopStreaming library that leverages STDIN and STDOUT so you can write mappers and reducers in your programming language of choice

7 Hadoop facts :: Hadoop is based on the principle of moving computation to where the data is :: Data stored on the Hadoop Distributed File System is broken up into chunks and replicated across the cluster providing fault tolerant parallel processing and redundancy for both the data and the jobs :: Computation takes the form of a job which consists of a map phase and a reduce phase :: Data is initially processed by map functions which run in parallel across the cluster :: Map output is in the form of key-value pairs :: The reduce phase then aggregates the map results :: The reduce phase typically happens in multiple consecutive waves until the job is complete

8 Hadoop architecture
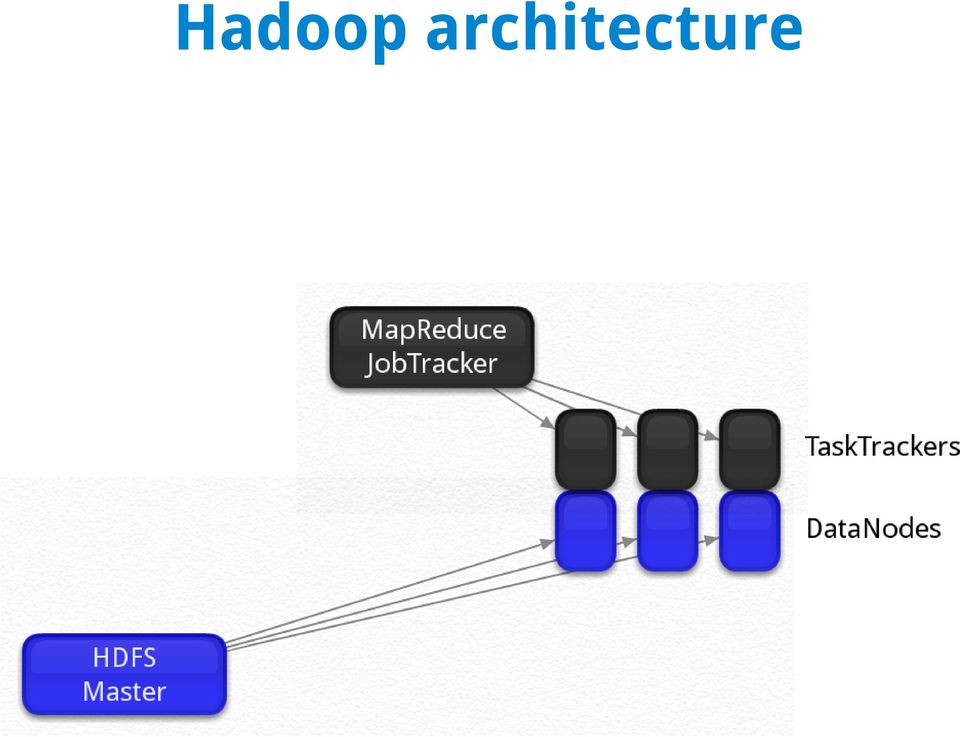
9 Part 1: Configuring and deploying the Hadoop cluster


10 Hands-on with Hadoop

11 core-site.xml - before
12 core-site.xml - after
13 hdfs-site.xml - before
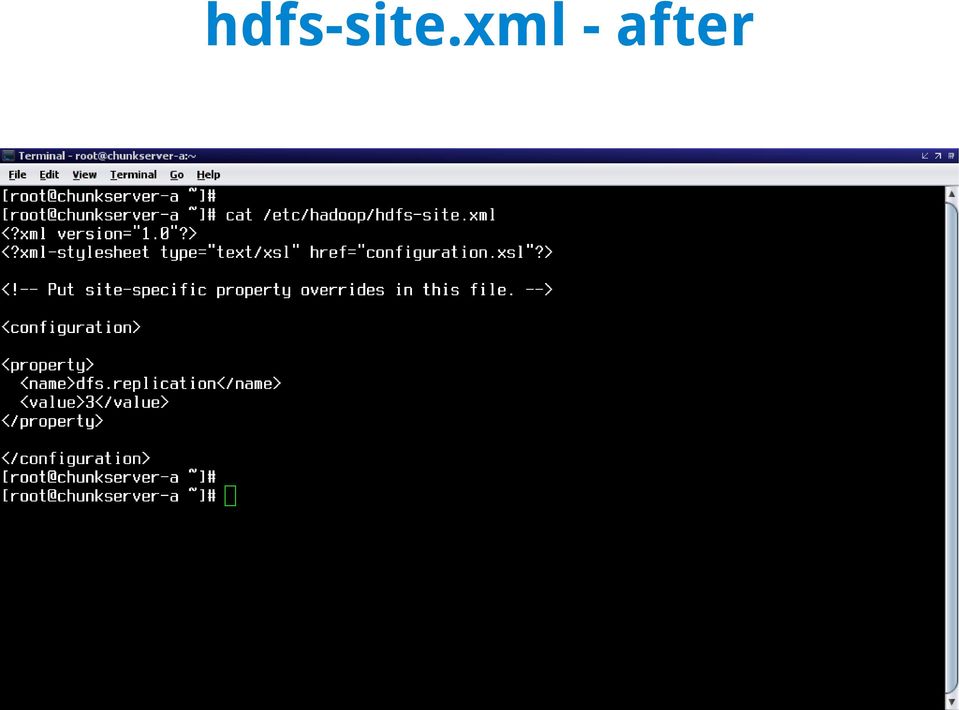
14 hdfs-site.xml - after
15 mapred-site.xml - before

16 mapred-site.xml - after

17 Setting up SSH :: needs to be able to ssh* into: - hadoop@hadoop-master - hadoop@chunkserver-a - hadoop@chunkserver-b - hadoop@chunkserver-c :: hadoop@job-tracker needs to be able to ssh* into: - hadoop@job-tracker - hadoop@chunkserver-a - hadoop@chunkserver-b - hadoop@chunkserver-c *Passwordless-ly and passphraseless-ly


18 Hands-on with Hadoop

19 Hands-on with Hadoop


20 Hands-on with Hadoop

21 Hands-on with Hadoop

22 Hands-on with Hadoop

23 Hands-on with Hadoop
24 Hands-on with Hadoop
25 Part 2: MapReduce is machine learning

26 Rolling your own self-hosted alternative to...
27 Hands-on with MapReduce

28 Hands-on with MapReduce
29 Hands-on with MapReduce
30 mapper.py #!/usr/bin/python import sys for line in sys.stdin: line = line.strip() IDs = line.split() for firstid in IDs: for secondid in IDs: if secondid > firstid: print '%s_%s\t%s' % (firstid, secondid, 1)
31 reducer.py #!/usr/bin/python import sys subtotals = {} for line in sys.stdin: line = line.strip() word = line.split('\t')[0] count = int(line.split('\t')[1]) subtotals[word] = subtotals.get(word, 0) + count for k, v in subtotals.items(): print "%s\t%s" % (k, v)

32 Hands-on with MapReduce

33 Hands-on with MapReduce

34 Hands-on with MapReduce

35 Hands-on with MapReduce

36 Hands-on with MapReduce
37 Other MapReduce use cases :: :: :: :: :: :: :: :: :: :: Google Suggest Video recommendations (YouTube) ClickStream Analysis (large web properties) Spam filtering and contextual advertising (Yahoo) Fraud detection (ebay, CC companies) Firewall log analysis to discover exfiltration and other undesirable (possibly malware-related) activity Finding patterns in social data, analyzing likes and building a search engine on top of them (FaceBook) Discovering microblogging trends and opinion leaders, analyzing who follows who (Twitter) Plain old supermarket shopping basket analysis The semantic web
38 Questions / Feedback

39 Bonus slide: Making of SQLite DB
Hadoop. MPDL-Frühstück 9. Dezember 2013 MPDL INTERN
 Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Introduction to Hadoop on the SDSC Gordon Data Intensive Cluster"
 Introduction to Hadoop on the SDSC Gordon Data Intensive Cluster" Mahidhar Tatineni SDSC Summer Institute August 06, 2013 Overview "" Hadoop framework extensively used for scalable distributed processing
Introduction to Hadoop on the SDSC Gordon Data Intensive Cluster" Mahidhar Tatineni SDSC Summer Institute August 06, 2013 Overview "" Hadoop framework extensively used for scalable distributed processing
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1 Review and Motivation Agenda Assignment Information Introduction
Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1 Review and Motivation Agenda Assignment Information Introduction
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
L1: Introduction to Hadoop
 L1: Introduction to Hadoop Feng Li [email protected] School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
L1: Introduction to Hadoop Feng Li [email protected] School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
Simple Parallel Computing in R Using Hadoop
 Simple Parallel Computing in R Using Hadoop Stefan Theußl WU Vienna University of Economics and Business Augasse 2 6, 1090 Vienna [email protected] 30.06.2009 Agenda Problem & Motivation The MapReduce
Simple Parallel Computing in R Using Hadoop Stefan Theußl WU Vienna University of Economics and Business Augasse 2 6, 1090 Vienna [email protected] 30.06.2009 Agenda Problem & Motivation The MapReduce
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Getting Started with Hadoop with Amazon s Elastic MapReduce
 Getting Started with Hadoop with Amazon s Elastic MapReduce Scott Hendrickson [email protected] http://drskippy.net/projects/emr-hadoopmeetup.pdf Boulder/Denver Hadoop Meetup 8 July 2010 Scott Hendrickson
Getting Started with Hadoop with Amazon s Elastic MapReduce Scott Hendrickson [email protected] http://drskippy.net/projects/emr-hadoopmeetup.pdf Boulder/Denver Hadoop Meetup 8 July 2010 Scott Hendrickson
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
BIG DATA USING HADOOP
 + Breakaway Session By Johnson Iyilade, Ph.D. University of Saskatchewan, Canada 23-July, 2015 BIG DATA USING HADOOP + Outline n Framing the Problem Hadoop Solves n Meet Hadoop n Storage with HDFS n Data
+ Breakaway Session By Johnson Iyilade, Ph.D. University of Saskatchewan, Canada 23-July, 2015 BIG DATA USING HADOOP + Outline n Framing the Problem Hadoop Solves n Meet Hadoop n Storage with HDFS n Data
Hadoop. Bioinformatics Big Data
 Hadoop Bioinformatics Big Data Paolo D Onorio De Meo Mattia D Antonio [email protected] [email protected] Big Data Too much information! Big Data Explosive data growth proliferation of data capture
Hadoop Bioinformatics Big Data Paolo D Onorio De Meo Mattia D Antonio [email protected] [email protected] Big Data Too much information! Big Data Explosive data growth proliferation of data capture
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Introduction To Hive
 Introduction To Hive How to use Hive in Amazon EC2 CS 341: Project in Mining Massive Data Sets Hyung Jin(Evion) Kim Stanford University References: Cloudera Tutorials, CS345a session slides, Hadoop - The
Introduction To Hive How to use Hive in Amazon EC2 CS 341: Project in Mining Massive Data Sets Hyung Jin(Evion) Kim Stanford University References: Cloudera Tutorials, CS345a session slides, Hadoop - The
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Beyond Web Application Log Analysis using Apache TM Hadoop. A Whitepaper by Orzota, Inc.
 Beyond Web Application Log Analysis using Apache TM Hadoop A Whitepaper by Orzota, Inc. 1 Web Applications As more and more software moves to a Software as a Service (SaaS) model, the web application has
Beyond Web Application Log Analysis using Apache TM Hadoop A Whitepaper by Orzota, Inc. 1 Web Applications As more and more software moves to a Software as a Service (SaaS) model, the web application has
Big Data : Experiments with Apache Hadoop and JBoss Community projects
 Big Data : Experiments with Apache Hadoop and JBoss Community projects About the speaker Anil Saldhana is Lead Security Architect at JBoss. Founder of PicketBox and PicketLink. Interested in using Big
Big Data : Experiments with Apache Hadoop and JBoss Community projects About the speaker Anil Saldhana is Lead Security Architect at JBoss. Founder of PicketBox and PicketLink. Interested in using Big
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Cloud Computing. Chapter 8. 8.1 Hadoop
 Chapter 8 Cloud Computing In cloud computing, the idea is that a large corporation that has many computers could sell time on them, for example to make profitable use of excess capacity. The typical customer
Chapter 8 Cloud Computing In cloud computing, the idea is that a large corporation that has many computers could sell time on them, for example to make profitable use of excess capacity. The typical customer
Big Data. White Paper. Big Data Executive Overview WP-BD-10312014-01. Jafar Shunnar & Dan Raver. Page 1 Last Updated 11-10-2014
 White Paper Big Data Executive Overview WP-BD-10312014-01 By Jafar Shunnar & Dan Raver Page 1 Last Updated 11-10-2014 Table of Contents Section 01 Big Data Facts Page 3-4 Section 02 What is Big Data? Page
White Paper Big Data Executive Overview WP-BD-10312014-01 By Jafar Shunnar & Dan Raver Page 1 Last Updated 11-10-2014 Table of Contents Section 01 Big Data Facts Page 3-4 Section 02 What is Big Data? Page
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop 101. Lars George. NoSQL- Ma4ers, Cologne April 26, 2013
 Hadoop 101 Lars George NoSQL- Ma4ers, Cologne April 26, 2013 1 What s Ahead? Overview of Apache Hadoop (and related tools) What it is Why it s relevant How it works No prior experience needed Feel free
Hadoop 101 Lars George NoSQL- Ma4ers, Cologne April 26, 2013 1 What s Ahead? Overview of Apache Hadoop (and related tools) What it is Why it s relevant How it works No prior experience needed Feel free
CS455 - Lab 10. Thilina Buddhika. April 6, 2015
 Thilina Buddhika April 6, 2015 Agenda Course Logistics Quiz 8 Review Giga Sort - FAQ Census Data Analysis - Introduction Implementing Custom Data Types in Hadoop Course Logistics HW3-PC Component 1 (Giga
Thilina Buddhika April 6, 2015 Agenda Course Logistics Quiz 8 Review Giga Sort - FAQ Census Data Analysis - Introduction Implementing Custom Data Types in Hadoop Course Logistics HW3-PC Component 1 (Giga
Hadoop/MapReduce Workshop. Dan Mazur, McGill HPC [email protected] [email protected] July 10, 2014
 Hadoop/MapReduce Workshop Dan Mazur, McGill HPC [email protected] [email protected] July 10, 2014 1 Outline Hadoop introduction and motivation Python review HDFS - The Hadoop Filesystem MapReduce
Hadoop/MapReduce Workshop Dan Mazur, McGill HPC [email protected] [email protected] July 10, 2014 1 Outline Hadoop introduction and motivation Python review HDFS - The Hadoop Filesystem MapReduce
Yuji Shirasaki (JVO NAOJ)
") Yuji Shirasaki (JVO NAOJ) A big table : 20 billions of photometric data from various survey SDSS, TWOMASS, USNO-b1.0,GSC2.3,Rosat, UKIDSS, SDS(Subaru Deep Survey), VVDS (VLT), GDDS (Gemini), RXTE, GOODS,
Yuji Shirasaki (JVO NAOJ) A big table : 20 billions of photometric data from various survey SDSS, TWOMASS, USNO-b1.0,GSC2.3,Rosat, UKIDSS, SDS(Subaru Deep Survey), VVDS (VLT), GDDS (Gemini), RXTE, GOODS,
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Package hive. January 10, 2011
 Package hive January 10, 2011 Version 0.1-9 Date 2011-01-09 Title Hadoop InteractiVE Description Hadoop InteractiVE, is an R extension facilitating distributed computing via the MapReduce paradigm. It
Package hive January 10, 2011 Version 0.1-9 Date 2011-01-09 Title Hadoop InteractiVE Description Hadoop InteractiVE, is an R extension facilitating distributed computing via the MapReduce paradigm. It
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
NoSQL for SQL Professionals William McKnight
 NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Extreme computing lab exercises Session one
 Extreme computing lab exercises Session one Michail Basios ([email protected]) Stratis Viglas ([email protected]) 1 Getting started First you need to access the machine where you will be doing all
Extreme computing lab exercises Session one Michail Basios ([email protected]) Stratis Viglas ([email protected]) 1 Getting started First you need to access the machine where you will be doing all
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
Hadoop Streaming. Table of contents
 Table of contents 1 Hadoop Streaming...3 2 How Streaming Works... 3 3 Streaming Command Options...4 3.1 Specifying a Java Class as the Mapper/Reducer... 5 3.2 Packaging Files With Job Submissions... 5
Table of contents 1 Hadoop Streaming...3 2 How Streaming Works... 3 3 Streaming Command Options...4 3.1 Specifying a Java Class as the Mapper/Reducer... 5 3.2 Packaging Files With Job Submissions... 5
Sector vs. Hadoop. A Brief Comparison Between the Two Systems
 Sector vs. Hadoop A Brief Comparison Between the Two Systems Background Sector is a relatively new system that is broadly comparable to Hadoop, and people want to know what are the differences. Is Sector
Sector vs. Hadoop A Brief Comparison Between the Two Systems Background Sector is a relatively new system that is broadly comparable to Hadoop, and people want to know what are the differences. Is Sector
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
How To Analyze Network Traffic With Mapreduce On A Microsoft Server On A Linux Computer (Ahem) On A Network (Netflow) On An Ubuntu Server On An Ipad Or Ipad (Netflower) On Your Computer
 On A Network (Netflow) On An Ubuntu Server On An Ipad Or Ipad (Netflower) On Your Computer") A Comparative Survey Based on Processing Network Traffic Data Using Hadoop Pig and Typical Mapreduce Anjali P P and Binu A Department of Information Technology, Rajagiri School of Engineering and Technology,
A Comparative Survey Based on Processing Network Traffic Data Using Hadoop Pig and Typical Mapreduce Anjali P P and Binu A Department of Information Technology, Rajagiri School of Engineering and Technology,
Are You Ready for Big Data?
 Are You Ready for Big Data? Jim Gallo National Director, Business Analytics February 11, 2013 Agenda What is Big Data? How do you leverage Big Data in your company? How do you prepare for a Big Data initiative?
Are You Ready for Big Data? Jim Gallo National Director, Business Analytics February 11, 2013 Agenda What is Big Data? How do you leverage Big Data in your company? How do you prepare for a Big Data initiative?
The Big Data Ecosystem at LinkedIn Roshan Sumbaly, Jay Kreps, and Sam Shah LinkedIn
 The Big Data Ecosystem at LinkedIn Roshan Sumbaly, Jay Kreps, and Sam Shah LinkedIn Presented by :- Ishank Kumar Aakash Patel Vishnu Dev Yadav CONTENT Abstract Introduction Related work The Ecosystem Ingress
The Big Data Ecosystem at LinkedIn Roshan Sumbaly, Jay Kreps, and Sam Shah LinkedIn Presented by :- Ishank Kumar Aakash Patel Vishnu Dev Yadav CONTENT Abstract Introduction Related work The Ecosystem Ingress
Hadoop 2.2.0 MultiNode Cluster Setup
 Hadoop 2.2.0 MultiNode Cluster Setup Sunil Raiyani Jayam Modi June 7, 2014 Sunil Raiyani Jayam Modi Hadoop 2.2.0 MultiNode Cluster Setup June 7, 2014 1 / 14 Outline 4 Starting Daemons 1 Pre-Requisites
Hadoop 2.2.0 MultiNode Cluster Setup Sunil Raiyani Jayam Modi June 7, 2014 Sunil Raiyani Jayam Modi Hadoop 2.2.0 MultiNode Cluster Setup June 7, 2014 1 / 14 Outline 4 Starting Daemons 1 Pre-Requisites
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
HADOOP CLUSTER SETUP GUIDE:
 HADOOP CLUSTER SETUP GUIDE: Passwordless SSH Sessions: Before we start our installation, we have to ensure that passwordless SSH Login is possible to any of the Linux machines of CS120. In order to do
HADOOP CLUSTER SETUP GUIDE: Passwordless SSH Sessions: Before we start our installation, we have to ensure that passwordless SSH Login is possible to any of the Linux machines of CS120. In order to do
16.1 MAPREDUCE. For personal use only, not for distribution. 333
 For personal use only, not for distribution. 333 16.1 MAPREDUCE Initially designed by the Google labs and used internally by Google, the MAPREDUCE distributed programming model is now promoted by several
For personal use only, not for distribution. 333 16.1 MAPREDUCE Initially designed by the Google labs and used internally by Google, the MAPREDUCE distributed programming model is now promoted by several
Using an In-Memory Data Grid for Near Real-Time Data Analysis
 SCALEOUT SOFTWARE Using an In-Memory Data Grid for Near Real-Time Data Analysis by Dr. William Bain, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 IN today s competitive world, businesses
SCALEOUT SOFTWARE Using an In-Memory Data Grid for Near Real-Time Data Analysis by Dr. William Bain, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 IN today s competitive world, businesses
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000
 Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000 Alexandra Carpen-Amarie Diana Moise Bogdan Nicolae KerData Team, INRIA Outline
Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000 Alexandra Carpen-Amarie Diana Moise Bogdan Nicolae KerData Team, INRIA Outline
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Hadoop/MapReduce Workshop
 Hadoop/MapReduce Workshop Dan Mazur [email protected] Simon Nderitu [email protected] [email protected] August 14, 2015 1 Outline Hadoop introduction and motivation Python review HDFS
Hadoop/MapReduce Workshop Dan Mazur [email protected] Simon Nderitu [email protected] [email protected] August 14, 2015 1 Outline Hadoop introduction and motivation Python review HDFS
How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup)
") How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup) Author : Vignesh Prajapati Categories : Hadoop Date : February 22, 2015 Since you have reached on this blogpost of Setting up Multinode Hadoop
How to install Apache Hadoop 2.6.0 in Ubuntu (Multi node setup) Author : Vignesh Prajapati Categories : Hadoop Date : February 22, 2015 Since you have reached on this blogpost of Setting up Multinode Hadoop
Sunnie Chung. Cleveland State University
 Sunnie Chung Cleveland State University Data Scientist Big Data Processing Data Mining 2 INTERSECT of Computer Scientists and Statisticians with Knowledge of Data Mining AND Big data Processing Skills:
Sunnie Chung Cleveland State University Data Scientist Big Data Processing Data Mining 2 INTERSECT of Computer Scientists and Statisticians with Knowledge of Data Mining AND Big data Processing Skills:
Real-time Analytics at Facebook: Data Freeway and Puma. Zheng Shao 12/2/2011
 Real-time Analytics at Facebook: Data Freeway and Puma Zheng Shao 12/2/2011 Agenda 1 Analytics and Real-time 2 Data Freeway 3 Puma 4 Future Works Analytics and Real-time what and why Facebook Insights
Real-time Analytics at Facebook: Data Freeway and Puma Zheng Shao 12/2/2011 Agenda 1 Analytics and Real-time 2 Data Freeway 3 Puma 4 Future Works Analytics and Real-time what and why Facebook Insights
MapReduce and Hadoop Distributed File System V I J A Y R A O
 MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Extreme computing lab exercises Session one
 Extreme computing lab exercises Session one Miles Osborne (original: Sasa Petrovic) October 23, 2012 1 Getting started First you need to access the machine where you will be doing all the work. Do this
Extreme computing lab exercises Session one Miles Osborne (original: Sasa Petrovic) October 23, 2012 1 Getting started First you need to access the machine where you will be doing all the work. Do this
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Real-time Big Data Analytics with Storm
 Ron Bodkin Founder & CEO, Think Big June 2013 Real-time Big Data Analytics with Storm Leading Provider of Data Science and Engineering Services Accelerating Your Time to Value IMAGINE Strategy and Roadmap
Ron Bodkin Founder & CEO, Think Big June 2013 Real-time Big Data Analytics with Storm Leading Provider of Data Science and Engineering Services Accelerating Your Time to Value IMAGINE Strategy and Roadmap
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Processing of Hadoop using Highly Available NameNode
 Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
HDFS Cluster Installation Automation for TupleWare
 HDFS Cluster Installation Automation for TupleWare Xinyi Lu Department of Computer Science Brown University Providence, RI 02912 [email protected] March 26, 2014 Abstract TupleWare[1] is a C++ Framework
HDFS Cluster Installation Automation for TupleWare Xinyi Lu Department of Computer Science Brown University Providence, RI 02912 [email protected] March 26, 2014 Abstract TupleWare[1] is a C++ Framework
Analysing Large Web Log Files in a Hadoop Distributed Cluster Environment
 Analysing Large Files in a Hadoop Distributed Cluster Environment S Saravanan, B Uma Maheswari Department of Computer Science and Engineering, Amrita School of Engineering, Amrita Vishwa Vidyapeetham,
Analysing Large Files in a Hadoop Distributed Cluster Environment S Saravanan, B Uma Maheswari Department of Computer Science and Engineering, Amrita School of Engineering, Amrita Vishwa Vidyapeetham,
Hadoop (pseudo-distributed) installation and configuration
 installation and configuration") Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Hadoop (pseudo-distributed) installation and configuration 1. Operating systems. Linux-based systems are preferred, e.g., Ubuntu or Mac OS X. 2. Install Java. For Linux, you should download JDK 8 under
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
CDH AND BUSINESS CONTINUITY:
 WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Networking in the Hadoop Cluster
 Hadoop and other distributed systems are increasingly the solution of choice for next generation data volumes. A high capacity, any to any, easily manageable networking layer is critical for peak Hadoop
Hadoop and other distributed systems are increasingly the solution of choice for next generation data volumes. A high capacity, any to any, easily manageable networking layer is critical for peak Hadoop
Using In-Memory Computing to Simplify Big Data Analytics
 SCALEOUT SOFTWARE Using In-Memory Computing to Simplify Big Data Analytics by Dr. William Bain, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 T he big data revolution is upon us, fed
SCALEOUT SOFTWARE Using In-Memory Computing to Simplify Big Data Analytics by Dr. William Bain, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 T he big data revolution is upon us, fed
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
CS242 PROJECT. Presented by Moloud Shahbazi Spring 2015
 CS242 PROJECT Presented by Moloud Shahbazi Spring 2015 AGENDA Project Overview Data Collection Indexing Big Data Processing PROJECT- PART1 1.1 Data Collection: 5G < data size < 10G Deliverables: Document
CS242 PROJECT Presented by Moloud Shahbazi Spring 2015 AGENDA Project Overview Data Collection Indexing Big Data Processing PROJECT- PART1 1.1 Data Collection: 5G < data size < 10G Deliverables: Document
Hadoop 2.6.0 Setup Walkthrough
 Hadoop 2.6.0 Setup Walkthrough This document provides information about working with Hadoop 2.6.0. 1 Setting Up Configuration Files... 2 2 Setting Up The Environment... 2 3 Additional Notes... 3 4 Selecting
Hadoop 2.6.0 Setup Walkthrough This document provides information about working with Hadoop 2.6.0. 1 Setting Up Configuration Files... 2 2 Setting Up The Environment... 2 3 Additional Notes... 3 4 Selecting
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Log Mining Based on Hadoop s Map and Reduce Technique
 Log Mining Based on Hadoop s Map and Reduce Technique ABSTRACT: Anuja Pandit Department of Computer Science, [email protected] Amruta Deshpande Department of Computer Science, [email protected]
Log Mining Based on Hadoop s Map and Reduce Technique ABSTRACT: Anuja Pandit Department of Computer Science, [email protected] Amruta Deshpande Department of Computer Science, [email protected]
Infrastructures for big data
 Infrastructures for big data Rasmus Pagh 1 Today s lecture Three technologies for handling big data: MapReduce (Hadoop) BigTable (and descendants) Data stream algorithms Alternatives to (some uses of)
Infrastructures for big data Rasmus Pagh 1 Today s lecture Three technologies for handling big data: MapReduce (Hadoop) BigTable (and descendants) Data stream algorithms Alternatives to (some uses of)
A bit about Hadoop. Luca Pireddu. March 9, 2012. CRS4Distributed Computing Group. [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18
 Luca Pireddu March 9, 2012 1 / 18") A bit about Hadoop Luca Pireddu CRS4Distributed Computing Group March 9, 2012 [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18 Often seen problems Often seen problems Low parallelism I/O is
A bit about Hadoop Luca Pireddu CRS4Distributed Computing Group March 9, 2012 [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18 Often seen problems Often seen problems Low parallelism I/O is
Big Data: Tools and Technologies in Big Data
 Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Storage, Management and challenges. Ahmed Ali-Eldin
 Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Hadoop for MySQL DBAs. Copyright 2011 Cloudera. All rights reserved. Not to be reproduced without prior written consent.
 Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years [email protected] 2 What is Hadoop? An open-source
Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years [email protected] 2 What is Hadoop? An open-source
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: [email protected] Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
How to properly misuse Hadoop. Marcel Huntemann NERSC tutorial session 2/12/13
 How to properly misuse Hadoop Marcel Huntemann NERSC tutorial session 2/12/13 History Created by Doug Cutting (also creator of Apache Lucene). 2002 Origin in Apache Nutch (open source web search engine).
How to properly misuse Hadoop Marcel Huntemann NERSC tutorial session 2/12/13 History Created by Doug Cutting (also creator of Apache Lucene). 2002 Origin in Apache Nutch (open source web search engine).
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
map/reduce connected components
 1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains