Big Data Storage, Management and challenges. Ahmed Ali-Eldin
|
|
|
- Rosaline Scott
- 10 years ago
- Views:
Transcription
1 Big Data Storage, Management and challenges Ahmed Ali-Eldin

2 (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big Data Map-Reduce (Hadoop) Under the Hood (DS at work) Paxos for consensus Chubby (Google s implementation) ZooKeeper (Yahoo s implementation. Last Year) How to transfer Big Data Kafka (LinkedIn s solution)

3 What is Big Data? Big data is data that exceeds the processing capacity of conventional database systems. The data is too big, moves too fast, or doesn t fit the strictures of your database architectures. To gain value from this data, you must choose an alternative way to process it. Edd Dumbill

4 What is Big Data? It is Big Brother s (Orwell s 1984) enabler to watch the people of Oceania Every day, humans create 2.5 quintillion (10 21 ) bytes of data (quote from IBM) 100 hours of video are uploaded to YouTube every minute. All needs to be stored. All needs to be searched 350 million new photos each day uploaded to FB 25 to 30 Petabytes of data needs to be stored by the LHC Much much much more is produced per day (at least 1 petabyte per day that is filtered data)

5 Big Data Storage

6 Quick Review on ACID Atomicity if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged Consistency any transaction will bring the database from one valid state to another Isolation concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially Durability once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors.

7 CAP Theorem For a Distributed system (and database) you can mainain two of three properties: Consistency Availability Partition tolerance

8 BASE: A newer data storage paradigm Maintaining ACID is impossible for highly distributed data stores You never want to sacrifice availability Basically Available, Soft state, Eventual consistency

9

10

11

12

13

14

15

16

17

18

19
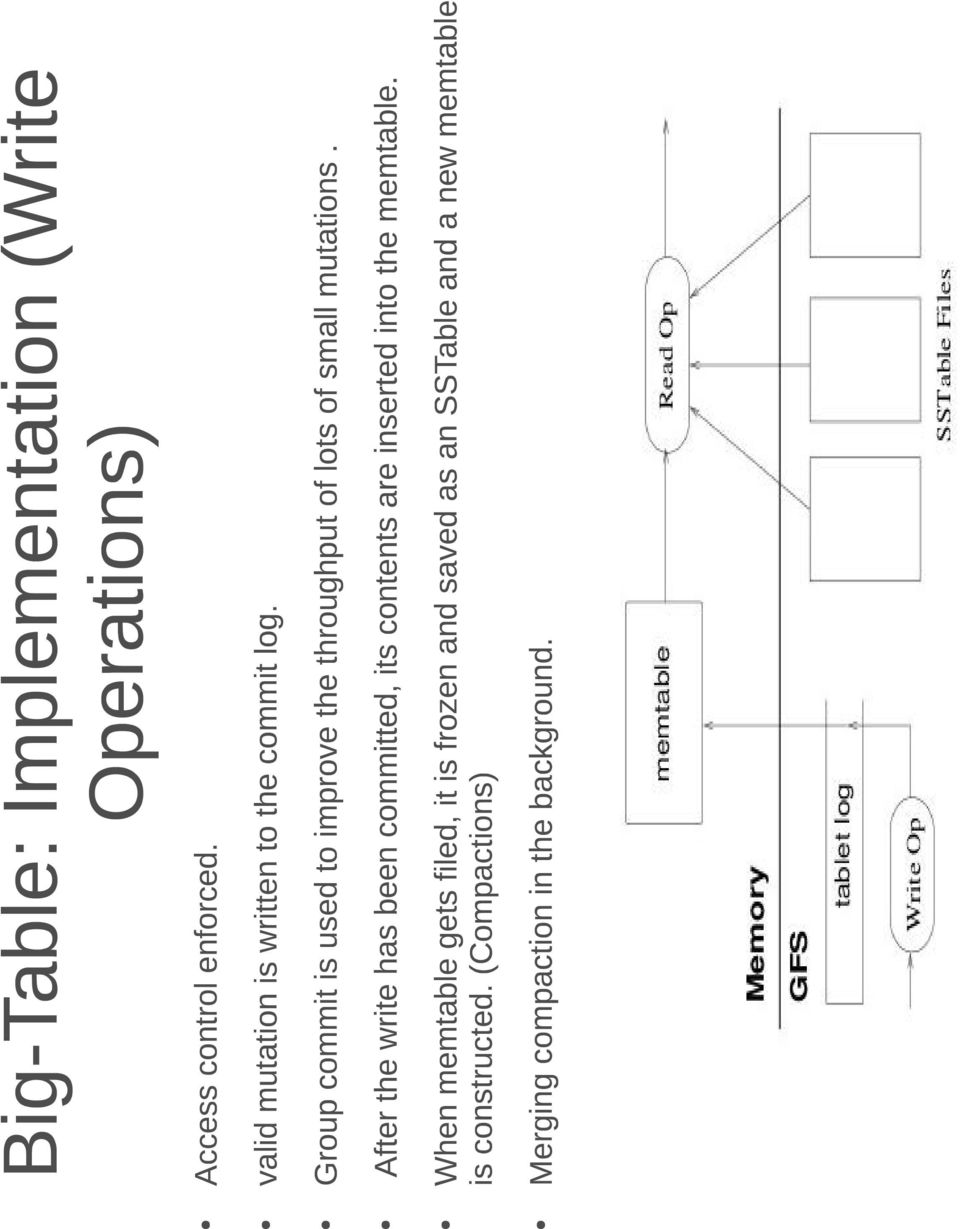
20

21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 Great Ideas in Computing Lecture 3: MapReduce
36 Example: Counting Words Count the most popular terms on the Internet: Sounds easy Why not this? CountWords(internet): hash_map<string, int> word_count; for each page in internet: for each word in page: word_count[word] += 1
37 Motivation: Large-Scale Data Processing Example: 20+ billion web pages x 20KB = 400+ ~1,000 hard drives just to store the web terabytes One computer can read MB/sec from disk ~four months to read the web Even more to do something with the data
38 Large-Scale Data Processing 1. Problems: 1. Time 2. Errors / Problems 2. Solution: 1. Distribute processing on many machines
39 Indexing Algorithm Input: Billions of documents (html) Distributed across many machines Indexing Pipeline Output: Index of terms: word1 -> document 1, document 2, etc
40 Link Reversal Input: Billions of documents (html) Distributed across many machines Link Reversal Output: Incoming links for each document: URL1 -> URL2, URL3, URL5,

41 Any Algorithm Input: Billions of? Distributed across many machines? Output:?
42 Before MapReduce Each team needed to understand distributed computing Extra code Extra complexity...
43 Algorithm Requirements: Has to be scalable (terabytes of data) Has to be fast Has to be fault-tolerant Has to be easy to implement and flexible The solution: MapReduce: a distributed algorithm
44 MapReduce: Introduction MapReduce is a programming model and an associated implementation for processing and generating large data sets. Can run on thousands of machines Can process terabytes of information (input / output) It is fault-tolerant It is easy to implement
45 MapReduce Model Programming model inspired by functional language primitives, e.g., LISP 1. Read a lot of data 2. Map: extract something you care about from each record 3. Shuffle and Sort 4. Reduce: aggregate, summarize, filter, or transform 5. Write the results Outline stays the same, map and reduce change
46 MapReduce: Logical Diagram INPUT Grouping MAP Intermediate data G REDU CE OUTPUT
47 Programming Model Input & Output: each a set of key/value pairs Programmer specifies two functions: map (in_key, in_value) -> list(out_key, intermediate_value) Processes input key/value pair Produces set of intermediate pairs GROUPING reduce (out_key, list(intermediate_value)) -> list (out_value) Combines all intermediate values for a particular key Produces a set of merged output values (usually just one)
48 MapReduce: Logical Diagram INPUT Grouping MAP Intermediate data G REDU CE OUTPUT
49 MapReduce: Map Phase First, the MAP function: Programmer supplies this function map (in_key, in_value) -> list(out_key, intermediate_value) Input = any pair (e.g., URL, document) Output = list of pairs (key/value)
50 MapReduce: Map Example Example: word counting <URL, document text> -> Output: list(<word, count>) E.g. for one document <URL, nile university is the best university > Output -> list(<nile, 1>, <university, 1>, <is, 1>, <the, 1>, <best, 1>, <university, 1> ) For another document <URL, "UNIX is simple and elegant"> Output -> list(<unix, 1>, <is, 1>, <simple, 1>...)
51 MapReduce: Map Example Example: word counting <URL, document text> Output: list(<word, count>) Code: Map(string input_key, string input_value): // key: document URL // value: document text for each word in input_value: OutputIntermediate(word, 1 );
52 MapReduce: Logical Diagram INPUT Grouping MAP Intermediate data G REDU CE OUTPUT
53 MapReduce: Grouping The GROUPING (or combining) This happens automatically (by the library) Put all values for same key together For our example: <nile, list(1)> <university, list(1, 1)> <the, list(1)> <is, list(1, 1)> <best, list(1)>...

54 MapReduce: Logical Diagram INPUT Grouping MAP Intermediate data G REDU CE OUTPUT
55 MapReduce: Reduce Last phase is REDUCE Takes the output from grouping: reduce (out_key, list(intermediate_value)) -> list (out_value)
56 MapReduce: Reduce Example Example (word-counting): <university, list(1, 1)> <university, 2> Reduce(string key, List values): // key: word, same for input and output // values: list of counts int sum = 0; for each v in values: sum += v; Output(sum);
57 MapReduce: Word Count Want to count how many times each word occurs MAP: Input: <DocumentId, Full Text> For time a word occurs: Output: <Word, 1> REDUCE: Input: <Word, list(1, 1, )> Sum over each word: Output <Word, Count>
58 MapReduce: Grep (search) Want to search terabytes of documents for where a word occurs MAP: Input: <DocumentId, Full Text> For each line where the word occurs: Output: <DocumentId, LineNumber> REDUCE: Input: <DocumentId, list(linenumber)> Do nothing (output == input)
59 MapReduce: Link Reversal Want to build a reverse-link index MAP: Input: <source_url, Full Text> For each outgoing link <a href= (destination_url ) >: Output: <destination_url, source_url> REDUCE: Input: < destination_url, list(source_url)> Join source_url Output: for each URL, a list of all other URLs that link to it.
60 MapReduce Usage Index construction Web access log stats, e.g., search trends (Google Zeitgeist) Distributed grep Distributed sort Most popular terms on the Internet Document clustering (news, products, etc.) Find all the pages that link to each document (link reversal) Machine learning Statistical machine translation
61 Why complicate things?
62 MapReduce: Parallelism Each Map call is independent (parallelize) Run M different Map tasks (each takes a chunk of input) Each Reduce call is independent (parallelize) Run R different Reduce tasks (each produces a chunk of output)
63 MapReduce: Parallelism
64 Framework User: Map function (used in Map Phase) Reduce function (used in Reduce Phase) Options (Map tasks, Reduce tasks, Workers, Input, Output) Framework: Execute map and reduce phase (distributedly) Collect/move data: input intermediate output data Handle faults Dynamic load-balancing and scheduling
65 MapReduce: Scheduling One master, many workers Input data split into M map tasks (16-64MB in size) Reduce phase partitioned into R reduce tasks Tasks are assigned to workers dynamically Often: M =200,000; R =4,000; workers=2,000 Master assigns each map task to a free worker Considers locality of data to worker when assigning task Worker reads task input (often from local disk!) Worker produces R local files containing intermediate k/v pairs Master assigns each reduce task to a free worker Worker reads intermediate k/v pairs from map workers Worker sorts & applies user s Reduce op to produce the output
66 MapReduce: The Master One machine is the Master Controls other machines (workers), start or stop MAP/REDUCE Keeps track of progress of each worker Stores location of input, output of each worker There are MAP workers and REDUCE workers
67 MapReduce: Parallelism

68 MapReduce: Map Parallelism MAP worker1 MAP output 1 MAP output 2 Input #1 Input #2 Input #3 MAP worker2 MAP output 1 MAP output 2 MAP worker3 MAP output 1 MAP output 2
69 MapReduce: Map Parallelism MAP output is split for REDUCERs by key Bins for keys E.g. keys starting (a m) output1, (n z) output2 (Usually use <hash(key) modulo (# of reducers)> for more random partition) MAP worker1 MAP output 1 MAP output 2

70 MapReduce: Reduce Parallelism MAP worker1 MAP output 1 MAP output 2 REDUCE worker1 MAP worker2 M1 M2 MAP worker3 M1 M2 REDUCE worker2

71 MapReduce: Reduce Parallelism Each REDUCE worker reads one section of input from all MAP workers Performs GROUPing Performs reducing Stores output REDUCE worker1 Output 1
72 MapReduce: Fault Tolerance More machines = more chance of failure Probability of one machine failing p (small) If each machine fails independently, chance of any one out of k machine failing 1 - (1 p)n (larger than p) If p = 0.01, probability of one failure: 1 machine machines machines machines machines 0.99
73 MapReduce: Fault Tolerance If one machine fails, the program should not fail If many machines fail, the program should not fail
74 MapReduce: Fault Tolerance Worker fails (happens often): Master checks workers If worker responds as failed, or does not respond: Master restarts on different machine Bad input: Master keeps track of bad input Asks workers to skip bad input Master fails (happens rarely): Can abort operation Or, can restart master on a different machine
75 MapReduce: Optimizations No REDUCE can start until all MAPs are complete (bottleneck) Sometimes one machine is really slow (bad RAM, corrupted disk, etc) Master notices slow machines Executes input on another machine Uses output of machine that finishes first Other optimizations Locality optimization Intermediate data compression
76 Task Granularity and Pipelining Fine granularity tasks: many more map tasks than machines e.g., 200,000 map/5000 reduce tasks w/ 2000 machines Minimizes time for fault recovery Can pipeline grouping with map execution Better dynamic load balancing
77 MapReduce: Performance Using 1,800 machines: Two 2GHz Intel Xeon 4GB RAM Two 160GB disks Gigabit Ethernet MR_Grep scanned 1 terabyte in 100 seconds MR_Sort sorted 1 terabyte of 100 byte records in 14 minutes
78 Conclusion The internet is composed of billions of documents To process that information, we need to use distributed algorithms and run processes in parallel MapReduce has proven to be a useful abstraction Greatly simplifies large-scale computations at Google Fun to use: focus on problem, let library deal w/ messy details
79 MapReduce: Beyond Google Hadoop: Open-source implementation of MapReduce MapReduce implementations in C++, Java, Python, Perl, Ruby, Erlang... Most companies that run distributed algorithms have an implementation of MapReduce (Facebook, Nokia, MySpace,...)
80 For Next Class: Read the Google Labs MapReduce paper (by Ghemawat and Dean)
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
MapReduce. from the paper. MapReduce: Simplified Data Processing on Large Clusters (2004)
") MapReduce from the paper MapReduce: Simplified Data Processing on Large Clusters (2004) What it is MapReduce is a programming model and an associated implementation for processing and generating large
MapReduce from the paper MapReduce: Simplified Data Processing on Large Clusters (2004) What it is MapReduce is a programming model and an associated implementation for processing and generating large
Map Reduce / Hadoop / HDFS
 Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
MapReduce: Simplified Data Processing on Large Clusters. Jeff Dean, Sanjay Ghemawat Google, Inc.
 MapReduce: Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Motivation: Large Scale Data Processing Many tasks: Process lots of data to produce other data Want to use
MapReduce: Simplified Data Processing on Large Clusters Jeff Dean, Sanjay Ghemawat Google, Inc. Motivation: Large Scale Data Processing Many tasks: Process lots of data to produce other data Want to use
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Lecture Data Warehouse Systems
 Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
MapReduce (in the cloud)
") MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
Recap. CSE 486/586 Distributed Systems Data Analytics. Example 1: Scientific Data. Two Questions We ll Answer. Data Analytics. Example 2: Web Data C 1
 ecap Distributed Systems Data Analytics Steve Ko Computer Sciences and Engineering University at Buffalo PC enables programmers to call functions in remote processes. IDL (Interface Definition Language)
ecap Distributed Systems Data Analytics Steve Ko Computer Sciences and Engineering University at Buffalo PC enables programmers to call functions in remote processes. IDL (Interface Definition Language)
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Introduction to Parallel Programming and MapReduce
 Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Introduction to Parallel Programming and MapReduce Audience and Pre-Requisites This tutorial covers the basics of parallel programming and the MapReduce programming model. The pre-requisites are significant
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Architectures for massive data management
 Architectures for massive data management Apache Kafka, Samza, Storm Albert Bifet [email protected] October 20, 2015 Stream Engine Motivation Digital Universe EMC Digital Universe with
Architectures for massive data management Apache Kafka, Samza, Storm Albert Bifet [email protected] October 20, 2015 Stream Engine Motivation Digital Universe EMC Digital Universe with
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
CS246: Mining Massive Datasets Jure Leskovec, Stanford University. http://cs246.stanford.edu
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2 CPU Memory Machine Learning, Statistics Classical Data Mining Disk 3 20+ billion web pages x 20KB = 400+ TB
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2 CPU Memory Machine Learning, Statistics Classical Data Mining Disk 3 20+ billion web pages x 20KB = 400+ TB
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
A programming model in Cloud: MapReduce
 A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
16.1 MAPREDUCE. For personal use only, not for distribution. 333
 For personal use only, not for distribution. 333 16.1 MAPREDUCE Initially designed by the Google labs and used internally by Google, the MAPREDUCE distributed programming model is now promoted by several
For personal use only, not for distribution. 333 16.1 MAPREDUCE Initially designed by the Google labs and used internally by Google, the MAPREDUCE distributed programming model is now promoted by several
MapReduce. MapReduce and SQL Injections. CS 3200 Final Lecture. Introduction. MapReduce. Programming Model. Example
 MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
The Hadoop Framework
 The Hadoop Framework Nils Braden University of Applied Sciences Gießen-Friedberg Wiesenstraße 14 35390 Gießen [email protected] Abstract. The Hadoop Framework offers an approach to large-scale
The Hadoop Framework Nils Braden University of Applied Sciences Gießen-Friedberg Wiesenstraße 14 35390 Gießen [email protected] Abstract. The Hadoop Framework offers an approach to large-scale
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Big Systems, Big Data
 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Advanced Data Management Technologies
 ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
ADMT 2015/16 Unit 15 J. Gamper 1/53 Advanced Data Management Technologies Unit 15 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
The Performance Characteristics of MapReduce Applications on Scalable Clusters
 The Performance Characteristics of MapReduce Applications on Scalable Clusters Kenneth Wottrich Denison University Granville, OH 43023 [email protected] ABSTRACT Many cluster owners and operators have
The Performance Characteristics of MapReduce Applications on Scalable Clusters Kenneth Wottrich Denison University Granville, OH 43023 [email protected] ABSTRACT Many cluster owners and operators have
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensive Computing. University of Florida, CISE Department Prof.
 CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensie Computing Uniersity of Florida, CISE Department Prof. Daisy Zhe Wang Map/Reduce: Simplified Data Processing on Large Clusters Parallel/Distributed
CIS 4930/6930 Spring 2014 Introduction to Data Science /Data Intensie Computing Uniersity of Florida, CISE Department Prof. Daisy Zhe Wang Map/Reduce: Simplified Data Processing on Large Clusters Parallel/Distributed
Performance and Energy Efficiency of. Hadoop deployment models
 Performance and Energy Efficiency of Hadoop deployment models Contents Review: What is MapReduce Review: What is Hadoop Hadoop Deployment Models Metrics Experiment Results Summary MapReduce Introduced
Performance and Energy Efficiency of Hadoop deployment models Contents Review: What is MapReduce Review: What is Hadoop Hadoop Deployment Models Metrics Experiment Results Summary MapReduce Introduced
Introduction to Cloud Computing
 Introduction to Cloud Computing MapReduce and Hadoop 15 319, spring 2010 17 th Lecture, Mar 16 th Majd F. Sakr Lecture Goals Transition to MapReduce from Functional Programming Understand the origins of
Introduction to Cloud Computing MapReduce and Hadoop 15 319, spring 2010 17 th Lecture, Mar 16 th Majd F. Sakr Lecture Goals Transition to MapReduce from Functional Programming Understand the origins of
Big Data Processing in the Cloud. Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center
 Big Data Processing in the Cloud Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center Data is ONLY as useful as the decisions it enables 2 Data is ONLY as useful as the decisions it enables
Big Data Processing in the Cloud Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center Data is ONLY as useful as the decisions it enables 2 Data is ONLY as useful as the decisions it enables
MAPREDUCE Programming Model
 CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT
 LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT Samira Daneshyar 1 and Majid Razmjoo 2 1,2 School of Computer Science, Centre of Software Technology and Management (SOFTEM),
LARGE-SCALE DATA PROCESSING USING MAPREDUCE IN CLOUD COMPUTING ENVIRONMENT Samira Daneshyar 1 and Majid Razmjoo 2 1,2 School of Computer Science, Centre of Software Technology and Management (SOFTEM),
Hadoop and Map-reduce computing
 Hadoop and Map-reduce computing 1 Introduction This activity contains a great deal of background information and detailed instructions so that you can refer to it later for further activities and homework.
Hadoop and Map-reduce computing 1 Introduction This activity contains a great deal of background information and detailed instructions so that you can refer to it later for further activities and homework.
CS54100: Database Systems
 CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
CS54100: Database Systems Cloud Databases: The Next Post- Relational World 18 April 2012 Prof. Chris Clifton Beyond RDBMS The Relational Model is too limiting! Simple data model doesn t capture semantics
Big Data Analytics* Outline. Issues. Big Data
 Outline Big Data Analytics* Big Data Data Analytics: Challenges and Issues Misconceptions Big Data Infrastructure Scalable Distributed Computing: Hadoop Programming in Hadoop: MapReduce Paradigm Example
Outline Big Data Analytics* Big Data Data Analytics: Challenges and Issues Misconceptions Big Data Infrastructure Scalable Distributed Computing: Hadoop Programming in Hadoop: MapReduce Paradigm Example
Parallel Programming Map-Reduce. Needless to Say, We Need Machine Learning for Big Data
 Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
Case Study 2: Document Retrieval Parallel Programming Map-Reduce Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 31 st, 2013 Carlos Guestrin
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
MapReduce and Hadoop Distributed File System
 MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) [email protected] http://www.cse.buffalo.edu/faculty/bina Partially
MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) [email protected] http://www.cse.buffalo.edu/faculty/bina Partially
The Google File System
 The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
BIG DATA, MAPREDUCE & HADOOP
 BIG, MAPREDUCE & HADOOP LARGE SCALE DISTRIBUTED SYSTEMS By Jean-Pierre Lozi A tutorial for the LSDS class LARGE SCALE DISTRIBUTED SYSTEMS BIG, MAPREDUCE & HADOOP 1 OBJECTIVES OF THIS LAB SESSION The LSDS
BIG, MAPREDUCE & HADOOP LARGE SCALE DISTRIBUTED SYSTEMS By Jean-Pierre Lozi A tutorial for the LSDS class LARGE SCALE DISTRIBUTED SYSTEMS BIG, MAPREDUCE & HADOOP 1 OBJECTIVES OF THIS LAB SESSION The LSDS
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13
 Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected]
 Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected] Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team [email protected] Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Optimization and analysis of large scale data sorting algorithm based on Hadoop
 Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
Optimization and analysis of large scale sorting algorithm based on Hadoop Zhuo Wang, Longlong Tian, Dianjie Guo, Xiaoming Jiang Institute of Information Engineering, Chinese Academy of Sciences {wangzhuo,
CS 378 Big Data Programming
 CS 378 Big Data Programming Lecture 2 Map- Reduce CS 378 - Fall 2015 Big Data Programming 1 MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is
CS 378 Big Data Programming Lecture 2 Map- Reduce CS 378 - Fall 2015 Big Data Programming 1 MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is
Big Data Analytics Hadoop and Spark
 Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Improving MapReduce Performance in Heterogeneous Environments
 UC Berkeley Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony Joseph, Randy Katz, Ion Stoica University of California at Berkeley Motivation 1. MapReduce
UC Berkeley Improving MapReduce Performance in Heterogeneous Environments Matei Zaharia, Andy Konwinski, Anthony Joseph, Randy Katz, Ion Stoica University of California at Berkeley Motivation 1. MapReduce
Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu
 Yabo (Arber) Xu") Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
MapReduce Jeffrey Dean and Sanjay Ghemawat. Background context
 MapReduce Jeffrey Dean and Sanjay Ghemawat Background context BIG DATA!! o Large-scale services generate huge volumes of data: logs, crawls, user databases, web site content, etc. o Very useful to be able
MapReduce Jeffrey Dean and Sanjay Ghemawat Background context BIG DATA!! o Large-scale services generate huge volumes of data: logs, crawls, user databases, web site content, etc. o Very useful to be able
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Distributed File System V I J A Y R A O
 MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
CS 4604: Introduc0on to Database Management Systems. B. Aditya Prakash Lecture #13: NoSQL and MapReduce
 CS 4604: Introduc0on to Database Management Systems B. Aditya Prakash Lecture #13: NoSQL and MapReduce Announcements HW4 is out You have to use the PGSQL server START EARLY!! We can not help if everyone
CS 4604: Introduc0on to Database Management Systems B. Aditya Prakash Lecture #13: NoSQL and MapReduce Announcements HW4 is out You have to use the PGSQL server START EARLY!! We can not help if everyone
Lecture 10 - Functional programming: Hadoop and MapReduce
 Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
CS 378 Big Data Programming. Lecture 2 Map- Reduce
 CS 378 Big Data Programming Lecture 2 Map- Reduce MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is processed But viewed in small increments
CS 378 Big Data Programming Lecture 2 Map- Reduce MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is processed But viewed in small increments
Scalable Cloud Computing Solutions for Next Generation Sequencing Data
 Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA USING HDFS MS.
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA USING HDFS MS.
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop/MapReduce. Object-oriented framework presentation CSCI 5448 Casey McTaggart
 Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
Hadoop/MapReduce Object-oriented framework presentation CSCI 5448 Casey McTaggart What is Apache Hadoop? Large scale, open source software framework Yahoo! has been the largest contributor to date Dedicated
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
A bit about Hadoop. Luca Pireddu. March 9, 2012. CRS4Distributed Computing Group. [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18
 Luca Pireddu March 9, 2012 1 / 18") A bit about Hadoop Luca Pireddu CRS4Distributed Computing Group March 9, 2012 [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18 Often seen problems Often seen problems Low parallelism I/O is
A bit about Hadoop Luca Pireddu CRS4Distributed Computing Group March 9, 2012 [email protected] (CRS4) Luca Pireddu March 9, 2012 1 / 18 Often seen problems Often seen problems Low parallelism I/O is
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
Comparison of Different Implementation of Inverted Indexes in Hadoop
 Comparison of Different Implementation of Inverted Indexes in Hadoop Hediyeh Baban, S. Kami Makki, and Stefan Andrei Department of Computer Science Lamar University Beaumont, Texas (hbaban, kami.makki,
Comparison of Different Implementation of Inverted Indexes in Hadoop Hediyeh Baban, S. Kami Makki, and Stefan Andrei Department of Computer Science Lamar University Beaumont, Texas (hbaban, kami.makki,
Big Data Buzzwords From A to Z. By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012
 Big Data Buzzwords From A to Z By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012 Big Data Buzzwords Big data is one of the, well, biggest trends in IT today, and it has spawned a whole new generation
Big Data Buzzwords From A to Z By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012 Big Data Buzzwords Big data is one of the, well, biggest trends in IT today, and it has spawned a whole new generation
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Big Data by the numbers
 COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
Four Orders of Magnitude: Running Large Scale Accumulo Clusters. Aaron Cordova Accumulo Summit, June 2014
 Four Orders of Magnitude: Running Large Scale Accumulo Clusters Aaron Cordova Accumulo Summit, June 2014 Scale, Security, Schema Scale to scale 1 - (vt) to change the size of something let s scale the
Four Orders of Magnitude: Running Large Scale Accumulo Clusters Aaron Cordova Accumulo Summit, June 2014 Scale, Security, Schema Scale to scale 1 - (vt) to change the size of something let s scale the
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Agenda. Some Examples from Yahoo! Hadoop. Some Examples from Yahoo! Crawling. Cloud (data) management Ahmed Ali-Eldin. First part: Second part:
 management Ahmed Ali-Eldin. First part: Second part:") Cloud (data) management Ahmed Ali-Eldin First part: ZooKeeper (Yahoo!) Agenda A highly available, scalable, distributed, configuration, consensus, group membership, leader election, naming, and coordination
Cloud (data) management Ahmed Ali-Eldin First part: ZooKeeper (Yahoo!) Agenda A highly available, scalable, distributed, configuration, consensus, group membership, leader election, naming, and coordination
Forensic Clusters: Advanced Processing with Open Source Software. Jon Stewart Geoff Black
 Forensic Clusters: Advanced Processing with Open Source Software Jon Stewart Geoff Black Who We Are Mac Lightbox Guidance alum Mr. EnScript C++ & Java Developer Fortune 100 Financial NCIS (DDK/ManTech)
Forensic Clusters: Advanced Processing with Open Source Software Jon Stewart Geoff Black Who We Are Mac Lightbox Guidance alum Mr. EnScript C++ & Java Developer Fortune 100 Financial NCIS (DDK/ManTech)
Large-Scale Data Sets Clustering Based on MapReduce and Hadoop
 Journal of Computational Information Systems 7: 16 (2011) 5956-5963 Available at http://www.jofcis.com Large-Scale Data Sets Clustering Based on MapReduce and Hadoop Ping ZHOU, Jingsheng LEI, Wenjun YE
Journal of Computational Information Systems 7: 16 (2011) 5956-5963 Available at http://www.jofcis.com Large-Scale Data Sets Clustering Based on MapReduce and Hadoop Ping ZHOU, Jingsheng LEI, Wenjun YE
Hadoop WordCount Explained! IT332 Distributed Systems
 Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Big Table A Distributed Storage System For Data
 Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,