Hadoop and Map-Reduce. Swati Gore
|
|
|
- Kathryn Clark
- 10 years ago
- Views:
Transcription
1 Hadoop and Map-Reduce Swati Gore

2 Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort

3 Why Hadoop?

4 Existing Data Analysis Architecture
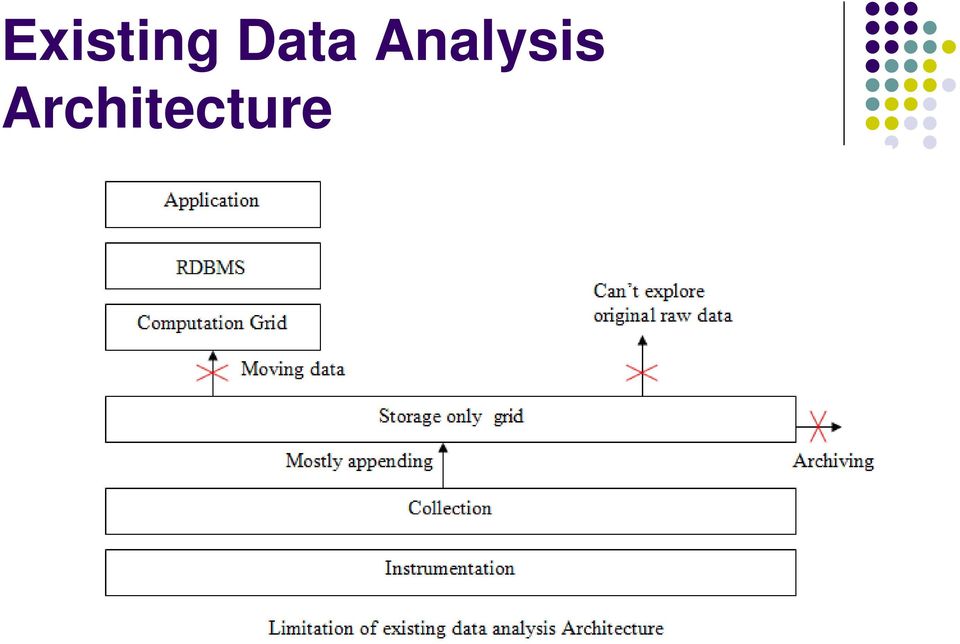
5 Existing Data Analysis Architecture Instrumentation and Collection layer: obtains raw data from different sources like web server, cache registers, mobile devices, system logs etc and dumped on the storage grid. Storage grid: Store the raw data collected by Instrumentation and Collection layer. ETL Computation: Performs Extract Transform Load functions. Extract: Reading data from storage grid

6 Transform: Converting extracted data to the required form. In this case from unstructured to structured form. Load: Writing the transformed data to the target database. RDBMS: Like Oracle. Application Layer: Various applications that act on the data stored on RDBMS and obtain required information.

7 Existing Data Analysis Architecture

8 Limitations! Three limitations: 1. Moving stored data from storage grid to computation grid. 2. Lost of original raw data. Can not use it for any new information 3. Archiving leading to death of data

9 Hadoop Overview Hadoop in a nut shell is an operating system. Has two major components HDFS: Hadoop Distributed File System Map-Reduce: Application that works on the data stored in HDFS and act as resources scheduler.

10 Hadoop Overview

11 Benefits of Hadoop over existing architectures Existing architecture employs Schema-on- Write (RDBMS) model Create Schema Transform data so as to fits it into this schema. Load data. Obtain required information. Efficient for compression, indexing, partitioning but difficult to adapt to changes.

12 Example of Schema-on-Write Student database UIN NAME DEPARTMENT GPA 1 TIM CS JOHN ECE Percentage of students getting placed?

13 Steps needed to adapt to new requirements Convince management to allow major change in existing database. Change the schema. Get required data. Then get desired information.

14 Hadoop: Schema-on-read model Data is simply copied to the file without any transformation. Transformation done only when data is queried. Thus adapting to changes becomes very easy.

15 Schema-on-read vs Schemaon-Write Thus both systems have their pros and cons. Even though SQL is good enough for solving complex data mining problems it still can t help us with say, image processing. Similarly Hadoop s Schema-on-read is not suited for ACID transactions like bank transactions

16 Thus existing architecture is like you are given all ingredients chopped and ready to use for cooking. You need to make the dish. Whereas in Hadoop you have direct access to the pantry so you can choose any type of ingredients and make any dish you like.

17 Schema-on-Write take less time but it restricts ability while Schema-on-read does not impose any restriction, allowing us to make the best of raw objects.

18 Languages used in Hadoop Hadoop gives us the flexibility to use any language to write our algorithms. We use Java Map-Reduce, Streaming Map- Reduce (works with any programming language like C++, Python), Crunch (Google), Pig latin (Yahoo), Hive (Facebook), Oozie (links all together). We don t have to stick to SQL.
, Crunch (Google), Pig latin (Yahoo), Hive")
19 Hadoop Architecture This architecture consists of three major components - the Client, the Master node and the slave nodes. Client: can be any organization which has a lot of unstructured data from different sources like web server, cache registers, mobile devices, system logs etc. and wants to analyze this data.

20 Master node Responsible for two functionalities: 1. Distributing data obtained form the client to the HDFS 2. And assigning tasks to Map-Reduce layer.

21 Master Node
22 These functions are handled by two different nodes: Name Node: helps in coordinating HDFS Job Tracker: helps in coordinating parallel execution of Map-Reduce.
23 Slave Node
24 Slave Node Slave node consists of Data Node and Task Tracker. There are number slave nodes in a Hadoop cluster. These nodes communicate and receive instructions for the Master nodes and perform the assigned tasks.
25
26 Working Job Tracker
27 Name Node Name Node is a critical component of the HDFS. Responsible for the distribution of the data throughout the Hadoop cluster. Obtains the data from client machine divides it in to chunks. Distributes same data chunk to three different data nodes leading to data redundancy.
28 Name Node s Role Keeps track of What chucks belong to a file and which Data Node holds its copy. cluster s storage capacity. Making sure each chunk of file has the minimum number of copies in the cluster as required. Directs clients for write or read operation Schedule and execute Map Reduce jobs.
29 Job Tracker Client submitted Map-Reduce logic. Responsible for scheduling the task to the slave nodes. Job Tracker consults the Name Node and assigns the task to the nodes which has the data on which this task would be performed.
30 Data Node One of the slave node part Responsible to store the chunk of that assigned to it by the Name Node.
31 Task Tracker Other part of slave node. Has the actual logic to perform the task. Performs the task (Map and reduce functions) on the data assigned to it by Master Node.
32 Map-Reduce Function Map: Takes a single <key, value> pair, and produces zero or more new <key, value> pairs that may be of different type. Reduce: Works on the output of Map function and produces desired result.
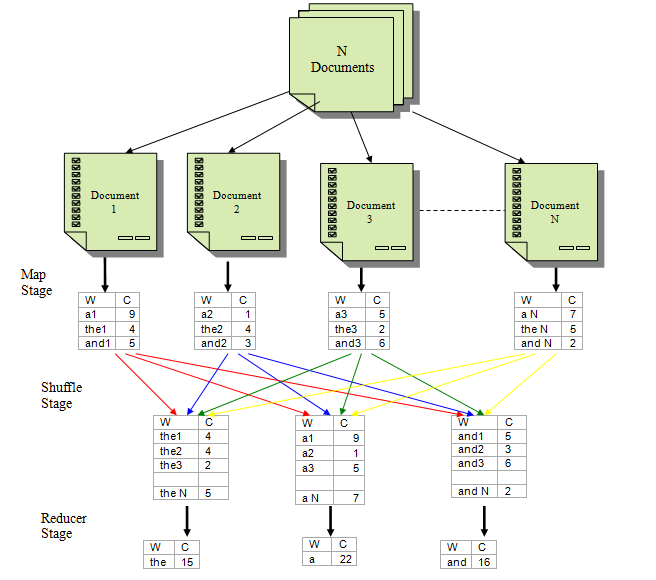
33
34 Fault Tolerance A system is said to be fault tolerant if can continue to work properly and does not lose any data when some component crashes. HDFS achieves this by data redundancy.
35 Failure of Slave Node
36 Data Node failure Data Node send a periodic heartbeat to Name Node. Missing heartbeat helps detected Data Node failure. In such a case Name Node removes the crashed Data Node from the cluster and redistributes its chunks to other surviving Data Nodes.
37 Task Tracker Failure Just like Data Node, Task Tracker s failure is detected by the Job Tracker after missing its heartbeat. Job Tracker then decides the next step: It may reschedule the job elsewhere or It may mark specific record to avoid or It may blacklist this Task Tracker as unreliable.
38 Failure of Master Node
39 Name Node failure Since Name Node contains all the important information required for the data distribution and computation, If it crashes, HDFS could fail. To overcome this single point failure Hadoop introduced the Backup Node.
40 Backup Node Backup Node regularly contacts Name Node and maintains an up to date snapshots of Name Node's directory information. When Name Node fails Backup helps to revive the Name Node.
41 Job Tracker Failure Again a single point failure If it goes down, all running jobs fail. In the latest Hadoop architecture Job Tracker is split into application logic such that there can be a number of masters having different logic. Thus the cluster is capable of supporting different application logic.
42 Name Node s rack-aware policy A large Hadoop clusters is arranged in racks. Name Node assigns data blocks that involves minimum data flow across the racks. But it also keeps in mind that replicas need to be spread out enough to improve fault tolerance.
43 Drawbacks/ limitations Since Name Node is the single point for storage and management of metadata, this can be a bottleneck for supporting a huge number of files, especially a large number of small files. For a very robust system replica distribution should be on totally separate racks.
44 But would lead to high communication overhead especially during write operation, as all replicas must be updated. Thus HDFS write two of the replicas on different nodes of the same rack and write the other one on a totally separate rack.
45 Why Map-Reduce not MPI? Firstly Map-Reduce provides a transparent and efficient mechanism to handle fault where as errors in MPI are considered fatal and only way to handle them is to abort the job. Secondly in order for MPI to support Map-Reduce operations, it would need variable-sized reduction function because Reducer in Map-Reduce can return values that are of a different size than the input values, e.g., string concatenations.
46 The basic difference is that Map-Reduce and MPI were developed by two different communities that are traditionally disjoint and were developed to cater different needs and capabilities. As the interests of both converge they can benefit by taking advantage of these respective technologies.
47 Benefits of using Hadoop Firstly since both map and reduce functions can run in parallel, allow the runtime to be reduces to several optimizations. Secondly Map-Reduce is fault resiliency which allows the application developer to focus on the important algorithmic aspects of his problem while ignoring issues like data distribution, synchronization, parallel execution, fault tolerance, and monitoring. Lastly be using Apache Hadoop, we avoid paying expensive software licenses; get flexibility to modify source code to meet our evolving needs; and avail themselves of leading-edge innovations coming from the worldwide Hadoop community.
48 The Communication Protocols All HDFS communication protocols are built on top of the TCP protocol. A client establishes a TCP connection with the Name Node machine. Once the connection is set they talk using the Client Protocol. Similarly the Data Nodes talk to the Name Node using the Data Node Protocol. Both the Client Protocol and the Data Node Protocol use Remote Procedure Call (RPC) abstraction.

49 The Communication Protocols
50 Companies using Hadoop Netflix s movie recommendation algorithm uses Hive (underneath using Hadoop, HDFS & Map-Reduce) for query processing and Business Intelligence. The Yahoo! Search Webmap is a Hadoop application that runs on a more than 10,000 core Linux cluster and produces data that is now used in every Yahoo! Web search query. Facebook uses largest Hadoop cluster in the world with 21 PB of storage.
51 Applications of Map-Reduce distributed grep distributed sort web link-graph reversal term-vector per host web access log stats inverted index construction document clustering machine learning statistical machine translation
52 Distributed Sort Suppose we want to sort 1 million entries in a student database based on their age (Age- Name). We want to sort using Age.
53 Flow Chart
54 Reducer Stage Slave Node Slave Node merges resultant lists obtained from the Map stage. Sorted list of million students
55 Now we can ask a question that if there is only one reducer where the results are combined, how does it that advantage of the distributed framework? Won t merging 1 million entries at one node cause processes to slow down?
56 The answer is yes! But it turns out that it is more efficient to merge partially sorted listed to produce a sorted list then to sort complete list. The reducers work is very simple it just looks at the smallest elements from the all the lists it obtained as input and pick the one that is the smallest.
57 We can parallelize reducers work but dividing the resultant list in batches of two between a number of reducers. Each of them would merge two lists. Thus the final reducer would be responsible to merge only two lists.
58
59 In any other architecture this parallel execution would be restricted due to the topology which has to be defined before the execution starts. Where as in Hadoop cluster we are not bound by this restriction, the data distribution and execution is not the programmer s responsibility, its taken care by HDFS. Programmer just has to make sure the mapper and reducer functions are written in accordance with the Map-Reduce paradigm.
60 CDH: Cloudera s Distribution Including Apache Hadoop Hadoop is only the kernel. Just like in Linux. We can get the kernel from kernel.org but there is Red Hat which is the distribution which has the kernel, libs, apache web server, xwindows which make it a complete product. Cloudera does the same for Hadoop. It adds HBase, Apache Flume, Hive, Oozie, installer which is not open source but is free, we just need to submit the IP addresses of different system and it takes care of the rest of the installation.
61 Conclusion Hadoop is an operating system that spans over a grid of computers providing an economically scalable solution for storing and processing large amount of structured and unstructured data over long period of time. Hadoop architecture provides a lot of flexibility which traditional systems didn t. It is very easy to add information, adapt to changing needs. It can answers queries which are very difficult to solve using RDBMS. Hadoop is inexpensive as compared to the other data store solution available in the market making it very attractive. It also uses commodity hardware, open-source software.
62 Questions? Thank You
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Big Data Too Big To Ignore
 Big Data Too Big To Ignore Geert! Big Data Consultant and Manager! Currently finishing a 3 rd Big Data project! IBM & Cloudera Certified! IBM & Microsoft Big Data Partner 2 Agenda! Defining Big Data! Introduction
Big Data Too Big To Ignore Geert! Big Data Consultant and Manager! Currently finishing a 3 rd Big Data project! IBM & Cloudera Certified! IBM & Microsoft Big Data Partner 2 Agenda! Defining Big Data! Introduction
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Big Data: Tools and Technologies in Big Data
 Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Hadoop Introduction. Olivier Renault Solution Engineer - Hortonworks
 Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Constructing a Data Lake: Hadoop and Oracle Database United!
 Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Constructing a Data Lake: Hadoop and Oracle Database United! Sharon Sophia Stephen Big Data PreSales Consultant February 21, 2015 Safe Harbor The following is intended to outline our general product direction.
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Peers Techno log ies Pv t. L td. HADOOP
 Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
MapReduce with Apache Hadoop Analysing Big Data
 MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside [email protected] About Journey Dynamics Founded in 2006 to develop software technology to address the issues
MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside [email protected] About Journey Dynamics Founded in 2006 to develop software technology to address the issues
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
<Insert Picture Here> Big Data
 Big Data Kevin Kalmbach Principal Sales Consultant, Public Sector Engineered Systems Program Agenda What is Big Data and why it is important? What is your Big
Big Data Kevin Kalmbach Principal Sales Consultant, Public Sector Engineered Systems Program Agenda What is Big Data and why it is important? What is your Big
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
The Inside Scoop on Hadoop
 The Inside Scoop on Hadoop Orion Gebremedhin National Solutions Director BI & Big Data, Neudesic LLC. VTSP Microsoft Corp. [email protected] [email protected] @OrionGM The Inside Scoop
The Inside Scoop on Hadoop Orion Gebremedhin National Solutions Director BI & Big Data, Neudesic LLC. VTSP Microsoft Corp. [email protected] [email protected] @OrionGM The Inside Scoop
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Oracle s Big Data solutions. Roger Wullschleger. <Insert Picture Here>
 s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
s Big Data solutions Roger Wullschleger DBTA Workshop on Big Data, Cloud Data Management and NoSQL 10. October 2012, Stade de Suisse, Berne 1 The following is intended to outline
Getting Started with Hadoop. Raanan Dagan Paul Tibaldi
 Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM
 HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS
 A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Case Study : 3 different hadoop cluster deployments
 Case Study : 3 different hadoop cluster deployments Lee moon soo [email protected] HDFS as a Storage Last 4 years, our HDFS clusters, stored Customer 1500 TB+ data safely served 375,000 TB+ data to customer
Case Study : 3 different hadoop cluster deployments Lee moon soo [email protected] HDFS as a Storage Last 4 years, our HDFS clusters, stored Customer 1500 TB+ data safely served 375,000 TB+ data to customer
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13
 Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Big Data Analytics with MapReduce VL Implementierung von Datenbanksystemen 05-Feb-13 Astrid Rheinländer Wissensmanagement in der Bioinformatik What is Big Data? collection of data sets so large and complex
Log Mining Based on Hadoop s Map and Reduce Technique
 Log Mining Based on Hadoop s Map and Reduce Technique ABSTRACT: Anuja Pandit Department of Computer Science, [email protected] Amruta Deshpande Department of Computer Science, [email protected]
Log Mining Based on Hadoop s Map and Reduce Technique ABSTRACT: Anuja Pandit Department of Computer Science, [email protected] Amruta Deshpande Department of Computer Science, [email protected]
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Storage Options for Hadoop Sam Fineberg, HP Storage
 Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop
 Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop Kanchan A. Khedikar Department of Computer Science & Engineering Walchand Institute of Technoloy, Solapur, Maharashtra,
Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop Kanchan A. Khedikar Department of Computer Science & Engineering Walchand Institute of Technoloy, Solapur, Maharashtra,
Hadoop Distributed File System. Jordan Prosch, Matt Kipps
 Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
MySQL and Hadoop. Percona Live 2014 Chris Schneider
 MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Alternatives to HIVE SQL in Hadoop File Structure
 Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
White Paper. Big Data and Hadoop. Abhishek S, Java COE. Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP
 White Paper Big Data and Hadoop Abhishek S, Java COE www.marlabs.com Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP Table of contents Abstract.. 1 Introduction. 2 What is Big
White Paper Big Data and Hadoop Abhishek S, Java COE www.marlabs.com Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP Table of contents Abstract.. 1 Introduction. 2 What is Big
Extending the Enterprise Data Warehouse with Hadoop Robert Lancaster. Nov 7, 2012
 Extending the Enterprise Data Warehouse with Hadoop Robert Lancaster Nov 7, 2012 Who I Am Robert Lancaster Solutions Architect, Hotel Supply Team [email protected] @rob1lancaster Organizer of Chicago
Extending the Enterprise Data Warehouse with Hadoop Robert Lancaster Nov 7, 2012 Who I Am Robert Lancaster Solutions Architect, Hotel Supply Team [email protected] @rob1lancaster Organizer of Chicago
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: [email protected] Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Big Data. White Paper. Big Data Executive Overview WP-BD-10312014-01. Jafar Shunnar & Dan Raver. Page 1 Last Updated 11-10-2014
 White Paper Big Data Executive Overview WP-BD-10312014-01 By Jafar Shunnar & Dan Raver Page 1 Last Updated 11-10-2014 Table of Contents Section 01 Big Data Facts Page 3-4 Section 02 What is Big Data? Page
White Paper Big Data Executive Overview WP-BD-10312014-01 By Jafar Shunnar & Dan Raver Page 1 Last Updated 11-10-2014 Table of Contents Section 01 Big Data Facts Page 3-4 Section 02 What is Big Data? Page
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA USING HDFS MS.
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A REVIEW ON HIGH PERFORMANCE DATA STORAGE ARCHITECTURE OF BIGDATA USING HDFS MS.
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Forensic Clusters: Advanced Processing with Open Source Software. Jon Stewart Geoff Black
 Forensic Clusters: Advanced Processing with Open Source Software Jon Stewart Geoff Black Who We Are Mac Lightbox Guidance alum Mr. EnScript C++ & Java Developer Fortune 100 Financial NCIS (DDK/ManTech)
Forensic Clusters: Advanced Processing with Open Source Software Jon Stewart Geoff Black Who We Are Mac Lightbox Guidance alum Mr. EnScript C++ & Java Developer Fortune 100 Financial NCIS (DDK/ManTech)
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani
 A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
Infomatics. Big-Data and Hadoop Developer Training with Oracle WDP
 Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Data Mining in the Swamp
 WHITE PAPER Page 1 of 8 Data Mining in the Swamp Taming Unruly Data with Cloud Computing By John Brothers Business Intelligence is all about making better decisions from the data you have. However, all
WHITE PAPER Page 1 of 8 Data Mining in the Swamp Taming Unruly Data with Cloud Computing By John Brothers Business Intelligence is all about making better decisions from the data you have. However, all
marlabs driving digital agility WHITEPAPER Big Data and Hadoop
 marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science
 A Seminar report On Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED BY: www.studymafia.org
A Seminar report On Hadoop Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: www.studymafia.org SUBMITTED BY: www.studymafia.org
Hadoop: Distributed Data Processing. Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010
 Hadoop: Distributed Data Processing Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010 Outline Scaling for Large Data Processing What is Hadoop? HDFS and MapReduce
Hadoop: Distributed Data Processing Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010 Outline Scaling for Large Data Processing What is Hadoop? HDFS and MapReduce
W H I T E P A P E R. Deriving Intelligence from Large Data Using Hadoop and Applying Analytics. Abstract
 W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Map Reduce / Hadoop / HDFS
 Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop
 Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
ITG Software Engineering
 Introduction to Cloudera Course ID: Page 1 Last Updated 12/15/2014 Introduction to Cloudera Course : This 5 day course introduces the student to the Hadoop architecture, file system, and the Hadoop Ecosystem.
Introduction to Cloudera Course ID: Page 1 Last Updated 12/15/2014 Introduction to Cloudera Course : This 5 day course introduces the student to the Hadoop architecture, file system, and the Hadoop Ecosystem.
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Suresh Lakavath csir urdip Pune, India [email protected].
 A Big Data Hadoop Architecture for Online Analysis. Suresh Lakavath csir urdip Pune, India [email protected]. Ramlal Naik L Acme Tele Power LTD Haryana, India [email protected]. Abstract Big Data
A Big Data Hadoop Architecture for Online Analysis. Suresh Lakavath csir urdip Pune, India [email protected]. Ramlal Naik L Acme Tele Power LTD Haryana, India [email protected]. Abstract Big Data
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Cost-Effective Business Intelligence with Red Hat and Open Source
 Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,