2
|
|
|
- Quentin Davidson
- 9 years ago
- Views:
Transcription

1 1

2 2

3 3

4 4

5 5
 Intel Wide Dynamic Execution (this includes the OOO capabilities of")
6 For Description of these Features see The following Features Greatly affect Performance Monitoring The New Performance Monitoring Unit (New Counters, New Meanings) Intel Wide Dynamic Execution (this includes the OOO capabilities of the processor) Adds complexity for performance analysis Intel Hyper-Threading Technology Adds complexity for performance analysis if you can it is easier to turn it off during performance analysis Intel Turbo Boost Technology Adds complexity for performance analysis if you can it is easier to turn it off during performance analysis The Features of the Integrated Memory Controller/Smart Memory Access/QPI/8 MB Intel Smart Cache Adds More things which can be/need to be measured on Nehalem 6
 INST_RETIRED.ANY_P CPU_CLK_UNHALTED.THREAD_P CPU_CLK_UNHALTED.")
7 The 3 Fixed Counters = INST_RETIRED.ANY CPU_CLK_UNHALTED.THREAD CPU_CLK_UNHALTED.REF Note- each of these counters has a corresponding Programmable version (which will use a general purpose counter) INST_RETIRED.ANY_P CPU_CLK_UNHALTED.THREAD_P CPU_CLK_UNHALTED.REF_P Note: The New capabilities to measure uncore events is not supported by Vtune. And the new information gathered when measuring certain events (i.e. Load Latency in the PEBS record) is not supported by VTune analyzer. 7

8 Both Intel Hyper-Threading Technology and Intel Turbo Boost Technology can be enabled or disabled through BIOS on most platforms. Contact with the system vendor or manufacturer for the specifics of any platform before attempting this. Incorrectly modifying bios settings from those supplied by the manufacturer can result in rendering the system completely unusable and may void the warranty. Don t forget to re-enable these features once you are through with the software optimization process! 8

9 Note: While VTune analyzer can also be helpful in threading an application, this slideset is not aimed at the process of introducing threads. The process described here could be used either before or after threading. Intel Thread Profiler is another performance analysis tool included with Intel Vtune Performance Analyzer for Windows that can help determine the efficiency of a parallel algorithm. Remember for all upcoming slides that you should only focus on hotspots! Only try to determine efficiency, identify causes, and optimize in hotspots! 9

10 For Intel Core i7 processors, the CPU_CLK_UNHALTED.THREAD counter measures unhalted clockticks on a per thread basis. So for each tick of the CPU's clock, the counter will count 2 ticks if Hyper-Threading is enabled, 1 tick if Hyper-Threading is disabled. There is no per-core clocktick counter. There is also a CPU_CLK_UNHALTED.REF counter, which counts unhalted clockticks per thread, at the reference frequency for the CPU. In other words, the CPU_CLK_UNHALTED.REF counter should not increase or decrease as a result of frequency changes due to Turbo Mode or Speedstep Technology.

11 % Execution Stalled and Changes in CPI methods rely on VTune s sampling. The Code Examination method relies on using Intel s capability as a source/disassembly viewer.

12 The UOPS_EXECUTED.CORE_STALL_CYCLES counter measures when the EXECUTION stage of the pipeline is stalled. This counter counts per CORE, not per thread. This has implications for doing performance analysis with Intel Hyper-Threading enabled. For example, if Intel Hyper- Threading is enabled, you won t be able to tell if the stall cycles are evenly distributed across the threads or just occurring on one thread. For this reason it can be easier to interpret performance data taken while Intel Hyper-Threading is disabled. (And enabled again after optimizations are completed). Note: Optimized code (i.e: SSE instructions) may actually lower the CPI, and increase stall % but it will increase the performance. CPI and Stalls is just general guidance of efficiency the real measure of efficiency is work taking less time work is not something that can be measured by the CPU

13 Note that CPI is a ratio! Cycles per instruction. So if the code size changes for a binary, CPI will change. In general, if CPI reduces as a result of optimizations, that is good, and if it increases, that is bad. However there are exceptions! Some code can have a very low CPI but still be inefficient because more instructions are executed than are needed. This problem is discussed using the Code Examination method for determining efficiency. Another Note: CPI will be doubled if using Intel Hyper-threading. With Intel Hyper-Threading enabled, there are actually 2 different definitions of CPI. We call them "Per Thread CPI" and "Per Core CPI". The Per Thread CPI will be twice the Per Core CPI. Only convert between per Thread and per Core CPI when viewing aggregate CPIs (summed for all logical threads). Note: Optimized code (i.e: SSE instructions) may actually lower the CPI, and increase stall % but it will increase the performance. CPI and Stalls is just general guidance of efficiency the real measure of efficiency is work taking less time work is not something that can be measured by the CPU

14 This method involves looking at the disassembly to make sure the most efficient instruction streams are generated. This can be complex and can require an expert knowledge of the Intel instruction set and compiler technology. What we have done is describe how to find the 2 most easy-to-detect and easy-to-fix issues in the next 2 slides.

15 *Advanced Note: Intel SSE included movups but On previous IA-32 and Intel 64 processors movups was not the best way to load data from memory. Now on Intel Core i7 processors movups and movupd is as fast as movaps and movapd on aligned data so therefore when the Intel Compiler uses /QxSSE4.2 it removes the if condition to check for aligned data. Speeding up loops and reducing the # of instructions to implement. + addss is a s(calar) Intel SSE instruction which is better than x87 instructions- but is not as good as packed SSE instructions. 15

16 16

17 These are issues that result in stall cycles and high CPI. It is important to go through these in order, as we have placed the most likely problem areas in front.

18

19 Note that all applications will have some branch mispredicts. As much as 10% of branches being mispredicted could be considered normal, depending on the application. However anything above 10% should be investigated. With branch mispredicts, it is not the number of mispredicts that is the problem but the impact. The equations above show how to determine the impact of the mispredicts on the front-end (with instruction starvation) and the back-end (with wasted execution cycles given to wrongly speculated code).

20 The pipeline for the Intel Core i7 processor consists of many stages. Some stages are collectively referred to as the front-end these are the stages responsible for fetching, decoding, and issuing instructions and micro-operations. The back-end contains the stages responsible for dispatching, executing, and retiring instructions and micro-operations. These 2 parts of the pipeline are de-coupled and separated by a buffer (in fact buffering is used throughout the pipeline) so, when the front-end is stalled, it does NOT necessarily mean the back-end is stalled. Front-end stalls are a problem when they are causing instruction starvation, meaning no micro-operations are being issued to the back-end. If instruction starvation occurs for a long enough period of time, the back-end may stall.

21 This counter only measures 4K False Store Forwarding but if 4k False Store Forwarding is detected your code is probably being impacted by Set Associative Cache issues, 4K false Store Forwarding, and potentially even Memory bank issues all resulting in more cache misses and slower data access. 4k False Store Forwarding: In order to speed things up - when the CPU is processing Stores and Loads it uses a subset of the address to determine if the store forward optimization can occur if the bits are the same it starts to process the load. Later on it will fully resolve the addresses and determine that the load is not from the same address as the store, resulting in the processor needing to fetch the appropriate data. Set Associative Cache issue. Set Associative Caches are organized into ways. If 2 data elements are in memory at addresses which are 2 N apart such that they fall in the same set then they will take 2 entries in that set on a 4 way set associative cache - the 5 th access that tries to occupy the same slot will force one of the other entries out of the cache. Turning a large Multi KB/MB cache into a N entry cache. The Level 1, Level 2, and Level 3 Caches of different SKU s of processors have different Cache Sizes Line Sizes Associativity Skipping through memory at exactly 2 n boundaries (2K,4K, 16K 256K) will cause the cache to evict entries more quickly. The exact size depends on the processor and the cache. Memory Bank Issues Typically (and for best performance) computers are installed with multiple DIMMs for the RAM No single dimm can keep up with requests from the CPU. The system determines which data goes to which dimm via some bits in the address. Skipping through memory large 2N may cause all or most of the accesses to hit the same dimm. 21

22 FP_ASSIST.ALL: It would be nice to use this counter but that counter only works for x87 code (Some of the manuals misreport that this event works on SSE code) UOPS_DECODED.MS: Counts the number of Uops decoded by the Microcode Sequencer, MS. The MS delivers uops when the instruction is more than 4 uops long or a microcode assist is occurring There is no public definitive list of events/instructions that will cause this to fire if there is a high % of uop_dedoded.ms than try to deduce why the processor is issuing extra instructions or causing an exception in your code. 1 UOP does not necessarily equal to one cycle but the result is close enough to determine if it is affecting your overall time. 22

23 On target data locality to TLB size: this is accomplished via data blocking and trying to minimize random access patterns. Note: this is more likely to occur with server applications or applications with a large random dataset

24 24

25 25
26 26

27 27
28 28
29 29
30 30
31 31
32 32

33 33
34 34

35 35
36 36
37 37
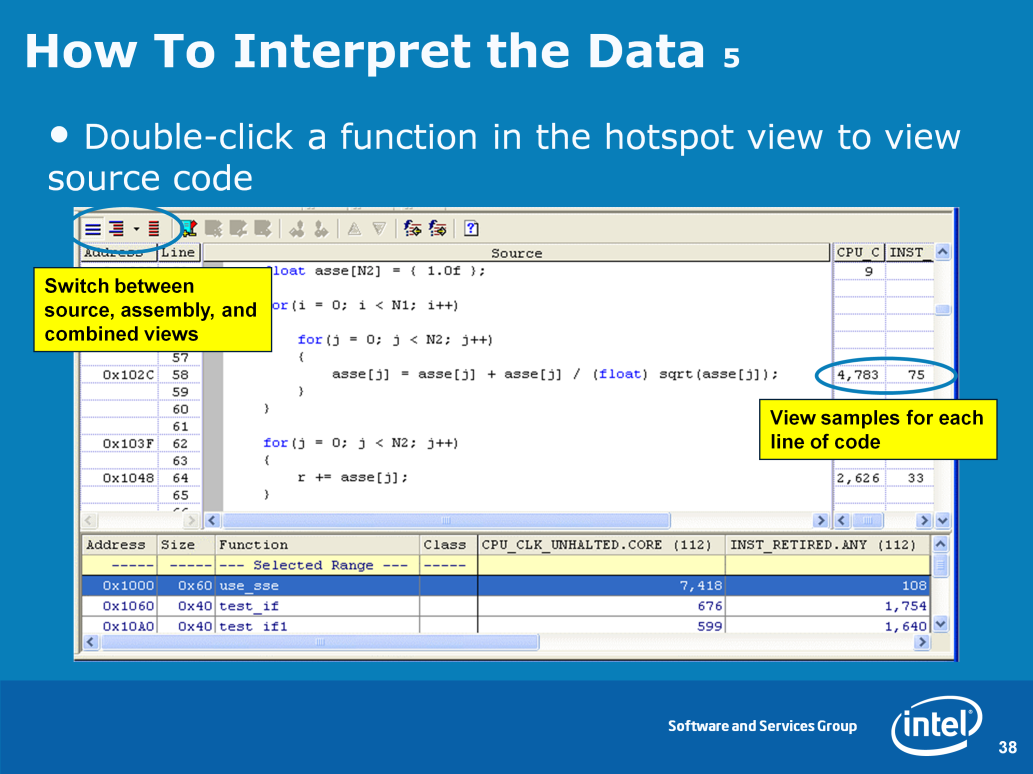
38 38
39 39
40 40
41 41

42 42
 More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
Performance Analysis Guide for Intel Core i7 Processor and Intel Xeon 5500 processors By Dr David Levinthal PhD. Version 1.0
 Performance Analysis Guide for Intel Core i7 Processor and Intel Xeon 5500 processors By Dr David Levinthal PhD. Version 1.0 1 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
Performance Analysis Guide for Intel Core i7 Processor and Intel Xeon 5500 processors By Dr David Levinthal PhD. Version 1.0 1 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
Performance Analysis of Dual Core, Core 2 Duo and Core i3 Intel Processor
 Performance Analysis of Dual Core, Core 2 Duo and Core i3 Intel Processor Taiwo O. Ojeyinka Department of Computer Science, Adekunle Ajasin University, Akungba-Akoko Ondo State, Nigeria. Olusola Olajide
Performance Analysis of Dual Core, Core 2 Duo and Core i3 Intel Processor Taiwo O. Ojeyinka Department of Computer Science, Adekunle Ajasin University, Akungba-Akoko Ondo State, Nigeria. Olusola Olajide
Putting it all together: Intel Nehalem. http://www.realworldtech.com/page.cfm?articleid=rwt040208182719
 Putting it all together: Intel Nehalem http://www.realworldtech.com/page.cfm?articleid=rwt040208182719 Intel Nehalem Review entire term by looking at most recent microprocessor from Intel Nehalem is code
Putting it all together: Intel Nehalem http://www.realworldtech.com/page.cfm?articleid=rwt040208182719 Intel Nehalem Review entire term by looking at most recent microprocessor from Intel Nehalem is code
INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER
 Course on: Advanced Computer Architectures INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER Prof. Cristina Silvano Politecnico di Milano [email protected] Prof. Silvano, Politecnico di Milano
Course on: Advanced Computer Architectures INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER Prof. Cristina Silvano Politecnico di Milano [email protected] Prof. Silvano, Politecnico di Milano
POWER8 Performance Analysis
 POWER8 Performance Analysis Satish Kumar Sadasivam Senior Performance Engineer, Master Inventor IBM Systems and Technology Labs [email protected] #OpenPOWERSummit Join the conversation at #OpenPOWERSummit
POWER8 Performance Analysis Satish Kumar Sadasivam Senior Performance Engineer, Master Inventor IBM Systems and Technology Labs [email protected] #OpenPOWERSummit Join the conversation at #OpenPOWERSummit
CS:APP Chapter 4 Computer Architecture. Wrap-Up. William J. Taffe Plymouth State University. using the slides of
 CS:APP Chapter 4 Computer Architecture Wrap-Up William J. Taffe Plymouth State University using the slides of Randal E. Bryant Carnegie Mellon University Overview Wrap-Up of PIPE Design Performance analysis
CS:APP Chapter 4 Computer Architecture Wrap-Up William J. Taffe Plymouth State University using the slides of Randal E. Bryant Carnegie Mellon University Overview Wrap-Up of PIPE Design Performance analysis
Bindel, Spring 2010 Applications of Parallel Computers (CS 5220) Week 1: Wednesday, Jan 27
 Week 1: Wednesday, Jan 27") Logistics Week 1: Wednesday, Jan 27 Because of overcrowding, we will be changing to a new room on Monday (Snee 1120). Accounts on the class cluster (crocus.csuglab.cornell.edu) will be available next week.
Logistics Week 1: Wednesday, Jan 27 Because of overcrowding, we will be changing to a new room on Monday (Snee 1120). Accounts on the class cluster (crocus.csuglab.cornell.edu) will be available next week.
Application Note 195. ARM11 performance monitor unit. Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007
 Application Note 195 ARM11 performance monitor unit Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007 Copyright 2007 ARM Limited. All rights reserved. Application Note
Application Note 195 ARM11 performance monitor unit Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007 Copyright 2007 ARM Limited. All rights reserved. Application Note
Multithreading Lin Gao cs9244 report, 2006
 Multithreading Lin Gao cs9244 report, 2006 2 Contents 1 Introduction 5 2 Multithreading Technology 7 2.1 Fine-grained multithreading (FGMT)............. 8 2.2 Coarse-grained multithreading (CGMT)............
Multithreading Lin Gao cs9244 report, 2006 2 Contents 1 Introduction 5 2 Multithreading Technology 7 2.1 Fine-grained multithreading (FGMT)............. 8 2.2 Coarse-grained multithreading (CGMT)............
Hardware performance monitoring. Zoltán Majó
 Hardware performance monitoring Zoltán Majó 1 Question Did you take any of these lectures: Computer Architecture and System Programming How to Write Fast Numerical Code Design of Parallel and High Performance
Hardware performance monitoring Zoltán Majó 1 Question Did you take any of these lectures: Computer Architecture and System Programming How to Write Fast Numerical Code Design of Parallel and High Performance
Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x
![Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x](/thumbs/25/6459870.jpg "Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x") Software Pipelining for (i=1, i
Software Pipelining for (i=1, i
what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored?
 Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Basics of VTune Performance Analyzer. Intel Software College. Objectives. VTune Performance Analyzer. Agenda
 Objectives At the completion of this module, you will be able to: Understand the intended purpose and usage models supported by the VTune Performance Analyzer. Identify hotspots by drilling down through
Objectives At the completion of this module, you will be able to: Understand the intended purpose and usage models supported by the VTune Performance Analyzer. Identify hotspots by drilling down through
Multi-core architectures. Jernej Barbic 15-213, Spring 2007 May 3, 2007
 Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
IA-64 Application Developer s Architecture Guide
 IA-64 Application Developer s Architecture Guide The IA-64 architecture was designed to overcome the performance limitations of today s architectures and provide maximum headroom for the future. To achieve
IA-64 Application Developer s Architecture Guide The IA-64 architecture was designed to overcome the performance limitations of today s architectures and provide maximum headroom for the future. To achieve
HyperThreading Support in VMware ESX Server 2.1
 HyperThreading Support in VMware ESX Server 2.1 Summary VMware ESX Server 2.1 now fully supports Intel s new Hyper-Threading Technology (HT). This paper explains the changes that an administrator can expect
HyperThreading Support in VMware ESX Server 2.1 Summary VMware ESX Server 2.1 now fully supports Intel s new Hyper-Threading Technology (HT). This paper explains the changes that an administrator can expect
Generations of the computer. processors.
 . Piotr Gwizdała 1 Contents 1 st Generation 2 nd Generation 3 rd Generation 4 th Generation 5 th Generation 6 th Generation 7 th Generation 8 th Generation Dual Core generation Improves and actualizations
. Piotr Gwizdała 1 Contents 1 st Generation 2 nd Generation 3 rd Generation 4 th Generation 5 th Generation 6 th Generation 7 th Generation 8 th Generation Dual Core generation Improves and actualizations
Solution: start more than one instruction in the same clock cycle CPI < 1 (or IPC > 1, Instructions per Cycle) Two approaches:
 Two approaches:") Multiple-Issue Processors Pipelining can achieve CPI close to 1 Mechanisms for handling hazards Static or dynamic scheduling Static or dynamic branch handling Increase in transistor counts (Moore s Law):
Multiple-Issue Processors Pipelining can achieve CPI close to 1 Mechanisms for handling hazards Static or dynamic scheduling Static or dynamic branch handling Increase in transistor counts (Moore s Law):
Binary search tree with SIMD bandwidth optimization using SSE
 Binary search tree with SIMD bandwidth optimization using SSE Bowen Zhang, Xinwei Li 1.ABSTRACT In-memory tree structured index search is a fundamental database operation. Modern processors provide tremendous
Binary search tree with SIMD bandwidth optimization using SSE Bowen Zhang, Xinwei Li 1.ABSTRACT In-memory tree structured index search is a fundamental database operation. Modern processors provide tremendous
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
PROBLEMS #20,R0,R1 #$3A,R2,R4
 506 CHAPTER 8 PIPELINING (Corrisponde al cap. 11 - Introduzione al pipelining) PROBLEMS 8.1 Consider the following sequence of instructions Mul And #20,R0,R1 #3,R2,R3 #$3A,R2,R4 R0,R2,R5 In all instructions,
506 CHAPTER 8 PIPELINING (Corrisponde al cap. 11 - Introduzione al pipelining) PROBLEMS 8.1 Consider the following sequence of instructions Mul And #20,R0,R1 #3,R2,R3 #$3A,R2,R4 R0,R2,R5 In all instructions,
Using Synology SSD Technology to Enhance System Performance Synology Inc.
 Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_SSD_Cache_WP_ 20140512 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges...
Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_SSD_Cache_WP_ 20140512 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges...
"JAGUAR AMD s Next Generation Low Power x86 Core. Jeff Rupley, AMD Fellow Chief Architect / Jaguar Core August 28, 2012
 "JAGUAR AMD s Next Generation Low Power x86 Core Jeff Rupley, AMD Fellow Chief Architect / Jaguar Core August 28, 2012 TWO X86 CORES TUNED FOR TARGET MARKETS Mainstream Client and Server Markets Bulldozer
"JAGUAR AMD s Next Generation Low Power x86 Core Jeff Rupley, AMD Fellow Chief Architect / Jaguar Core August 28, 2012 TWO X86 CORES TUNED FOR TARGET MARKETS Mainstream Client and Server Markets Bulldozer
Get an Easy Performance Boost Even with Unthreaded Apps. with Intel Parallel Studio XE for Windows*
 Get an Easy Performance Boost Even with Unthreaded Apps for Windows* Can recompiling just one file make a difference? Yes, in many cases it can! Often, you can achieve a major performance boost by recompiling
Get an Easy Performance Boost Even with Unthreaded Apps for Windows* Can recompiling just one file make a difference? Yes, in many cases it can! Often, you can achieve a major performance boost by recompiling
Programming Guide. Intel Microarchitecture Codename Nehalem Performance Monitoring Unit Programming Guide (Nehalem Core PMU)
") Programming Guide Intel Microarchitecture Codename Nehalem Performance Monitoring Unit Programming Guide (Nehalem Core PMU) Table of Contents 1. About this document... 8 2. Nehalem-based PMU Architecture...
Programming Guide Intel Microarchitecture Codename Nehalem Performance Monitoring Unit Programming Guide (Nehalem Core PMU) Table of Contents 1. About this document... 8 2. Nehalem-based PMU Architecture...
(Refer Slide Time: 00:01:16 min)
") Digital Computer Organization Prof. P. K. Biswas Department of Electronic & Electrical Communication Engineering Indian Institute of Technology, Kharagpur Lecture No. # 04 CPU Design: Tirning & Control
Digital Computer Organization Prof. P. K. Biswas Department of Electronic & Electrical Communication Engineering Indian Institute of Technology, Kharagpur Lecture No. # 04 CPU Design: Tirning & Control
Pitfalls of Object Oriented Programming
 Sony Computer Entertainment Europe Research & Development Division Pitfalls of Object Oriented Programming Tony Albrecht Technical Consultant Developer Services A quick look at Object Oriented (OO) programming
Sony Computer Entertainment Europe Research & Development Division Pitfalls of Object Oriented Programming Tony Albrecht Technical Consultant Developer Services A quick look at Object Oriented (OO) programming
CPU Session 1. Praktikum Parallele Rechnerarchtitekturen. Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1
 CPU Session 1 Praktikum Parallele Rechnerarchtitekturen Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1 Overview Types of Parallelism in Modern Multi-Core CPUs o Multicore
CPU Session 1 Praktikum Parallele Rechnerarchtitekturen Praktikum Parallele Rechnerarchitekturen / Johannes Hofmann April 14, 2015 1 Overview Types of Parallelism in Modern Multi-Core CPUs o Multicore
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging
 Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
Chapter 1 Computer System Overview
 Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
Performance Monitoring of the Software Frameworks for LHC Experiments
 Proceedings of the First EELA-2 Conference R. mayo et al. (Eds.) CIEMAT 2009 2009 The authors. All rights reserved Performance Monitoring of the Software Frameworks for LHC Experiments William A. Romero
Proceedings of the First EELA-2 Conference R. mayo et al. (Eds.) CIEMAT 2009 2009 The authors. All rights reserved Performance Monitoring of the Software Frameworks for LHC Experiments William A. Romero
Random Access Memory (RAM) Types of RAM. RAM Random Access Memory Jamie Tees SDRAM. Micro-DIMM SO-DIMM
 Types of RAM. RAM Random Access Memory Jamie Tees SDRAM. Micro-DIMM SO-DIMM") Random Access Memory (RAM) Sends/Receives data quickly between CPU This is way quicker than using just the HDD RAM holds temporary data used by any open application or active / running process Multiple
Random Access Memory (RAM) Sends/Receives data quickly between CPU This is way quicker than using just the HDD RAM holds temporary data used by any open application or active / running process Multiple
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING
 COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
AMD GPU Architecture. OpenCL Tutorial, PPAM 2009. Dominik Behr September 13th, 2009
 AMD GPU Architecture OpenCL Tutorial, PPAM 2009 Dominik Behr September 13th, 2009 Overview AMD GPU architecture How OpenCL maps on GPU and CPU How to optimize for AMD GPUs and CPUs in OpenCL 2 AMD GPU
AMD GPU Architecture OpenCL Tutorial, PPAM 2009 Dominik Behr September 13th, 2009 Overview AMD GPU architecture How OpenCL maps on GPU and CPU How to optimize for AMD GPUs and CPUs in OpenCL 2 AMD GPU
Using Synology SSD Technology to Enhance System Performance Synology Inc.
 Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_WP_ 20121112 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD
Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_WP_ 20121112 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD
İSTANBUL AYDIN UNIVERSITY
 İSTANBUL AYDIN UNIVERSITY FACULTY OF ENGİNEERİNG SOFTWARE ENGINEERING THE PROJECT OF THE INSTRUCTION SET COMPUTER ORGANIZATION GÖZDE ARAS B1205.090015 Instructor: Prof. Dr. HASAN HÜSEYİN BALIK DECEMBER
İSTANBUL AYDIN UNIVERSITY FACULTY OF ENGİNEERİNG SOFTWARE ENGINEERING THE PROJECT OF THE INSTRUCTION SET COMPUTER ORGANIZATION GÖZDE ARAS B1205.090015 Instructor: Prof. Dr. HASAN HÜSEYİN BALIK DECEMBER
The Intel VTune Performance Analyzer
 The Intel VTune Performance Analyzer Focusing on Vtune for Intel Itanium running Linux* OS Copyright 2002 Intel Corporation. All rights reserved. VTune and the Intel logo are trademarks or registered trademarks
The Intel VTune Performance Analyzer Focusing on Vtune for Intel Itanium running Linux* OS Copyright 2002 Intel Corporation. All rights reserved. VTune and the Intel logo are trademarks or registered trademarks
Advanced Computer Architecture-CS501. Computer Systems Design and Architecture 2.1, 2.2, 3.2
 Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Static Scheduling. option #1: dynamic scheduling (by the hardware) option #2: static scheduling (by the compiler) ECE 252 / CPS 220 Lecture Notes
 option #2: static scheduling (by the compiler) ECE 252 / CPS 220 Lecture Notes") basic pipeline: single, in-order issue first extension: multiple issue (superscalar) second extension: scheduling instructions for more ILP option #1: dynamic scheduling (by the hardware) option #2: static
basic pipeline: single, in-order issue first extension: multiple issue (superscalar) second extension: scheduling instructions for more ILP option #1: dynamic scheduling (by the hardware) option #2: static
Intel Core i3-2120 Processor (3M Cache, 3.30 GHz)
") *Trademarks Intel Core i3-2120 Processor (3M Cache, 3.30 GHz) COMPARE PRODUCTS Intel Corporation All Essentials Memory Specifications Essentials Status Launched Add to Compare Compare w (0) Graphics Specifications
*Trademarks Intel Core i3-2120 Processor (3M Cache, 3.30 GHz) COMPARE PRODUCTS Intel Corporation All Essentials Memory Specifications Essentials Status Launched Add to Compare Compare w (0) Graphics Specifications
Processing Multiple Buffers in Parallel to Increase Performance on Intel Architecture Processors
 White Paper Vinodh Gopal Jim Guilford Wajdi Feghali Erdinc Ozturk Gil Wolrich Martin Dixon IA Architects Intel Corporation Processing Multiple Buffers in Parallel to Increase Performance on Intel Architecture
White Paper Vinodh Gopal Jim Guilford Wajdi Feghali Erdinc Ozturk Gil Wolrich Martin Dixon IA Architects Intel Corporation Processing Multiple Buffers in Parallel to Increase Performance on Intel Architecture
Introduction Disks RAID Tertiary storage. Mass Storage. CMSC 412, University of Maryland. Guest lecturer: David Hovemeyer.
 Guest lecturer: David Hovemeyer November 15, 2004 The memory hierarchy Red = Level Access time Capacity Features Registers nanoseconds 100s of bytes fixed Cache nanoseconds 1-2 MB fixed RAM nanoseconds
Guest lecturer: David Hovemeyer November 15, 2004 The memory hierarchy Red = Level Access time Capacity Features Registers nanoseconds 100s of bytes fixed Cache nanoseconds 1-2 MB fixed RAM nanoseconds
Measuring Cache and Memory Latency and CPU to Memory Bandwidth
 White Paper Joshua Ruggiero Computer Systems Engineer Intel Corporation Measuring Cache and Memory Latency and CPU to Memory Bandwidth For use with Intel Architecture December 2008 1 321074 Executive Summary
White Paper Joshua Ruggiero Computer Systems Engineer Intel Corporation Measuring Cache and Memory Latency and CPU to Memory Bandwidth For use with Intel Architecture December 2008 1 321074 Executive Summary
ATI Radeon 4800 series Graphics. Michael Doggett Graphics Architecture Group Graphics Product Group
 ATI Radeon 4800 series Graphics Michael Doggett Graphics Architecture Group Graphics Product Group Graphics Processing Units ATI Radeon HD 4870 AMD Stream Computing Next Generation GPUs 2 Radeon 4800 series
ATI Radeon 4800 series Graphics Michael Doggett Graphics Architecture Group Graphics Product Group Graphics Processing Units ATI Radeon HD 4870 AMD Stream Computing Next Generation GPUs 2 Radeon 4800 series
This Unit: Putting It All Together. CIS 501 Computer Architecture. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 11: Putting It All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Amir Roth with contributions by Milo
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 11: Putting It All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Amir Roth with contributions by Milo
Intel Pentium 4 Processor on 90nm Technology
 Intel Pentium 4 Processor on 90nm Technology Ronak Singhal August 24, 2004 Hot Chips 16 1 1 Agenda Netburst Microarchitecture Review Microarchitecture Features Hyper-Threading Technology SSE3 Intel Extended
Intel Pentium 4 Processor on 90nm Technology Ronak Singhal August 24, 2004 Hot Chips 16 1 1 Agenda Netburst Microarchitecture Review Microarchitecture Features Hyper-Threading Technology SSE3 Intel Extended
Memory management basics (1) Requirements (1) Objectives. Operating Systems Part of E1.9 - Principles of Computers and Software Engineering
 Requirements (1) Objectives. Operating Systems Part of E1.9 - Principles of Computers and Software Engineering") Memory management basics (1) Requirements (1) Operating Systems Part of E1.9 - Principles of Computers and Software Engineering Lecture 7: Memory Management I Memory management intends to satisfy the following
Memory management basics (1) Requirements (1) Operating Systems Part of E1.9 - Principles of Computers and Software Engineering Lecture 7: Memory Management I Memory management intends to satisfy the following
Operating Systems. 05. Threads. Paul Krzyzanowski. Rutgers University. Spring 2015
 Operating Systems 05. Threads Paul Krzyzanowski Rutgers University Spring 2015 February 9, 2015 2014-2015 Paul Krzyzanowski 1 Thread of execution Single sequence of instructions Pointed to by the program
Operating Systems 05. Threads Paul Krzyzanowski Rutgers University Spring 2015 February 9, 2015 2014-2015 Paul Krzyzanowski 1 Thread of execution Single sequence of instructions Pointed to by the program
This Unit: Multithreading (MT) CIS 501 Computer Architecture. Performance And Utilization. Readings
 CIS 501 Computer Architecture. Performance And Utilization. Readings") This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
Operating Systems, 6 th ed. Test Bank Chapter 7
 True / False Questions: Chapter 7 Memory Management 1. T / F In a multiprogramming system, main memory is divided into multiple sections: one for the operating system (resident monitor, kernel) and one
True / False Questions: Chapter 7 Memory Management 1. T / F In a multiprogramming system, main memory is divided into multiple sections: one for the operating system (resident monitor, kernel) and one
EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000. ILP Execution
 EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000 Lecture #11: Wednesday, 3 May 2000 Lecturer: Ben Serebrin Scribe: Dean Liu ILP Execution
EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000 Lecture #11: Wednesday, 3 May 2000 Lecturer: Ben Serebrin Scribe: Dean Liu ILP Execution
Interpreters and virtual machines. Interpreters. Interpreters. Why interpreters? Tree-based interpreters. Text-based interpreters
 Interpreters and virtual machines Michel Schinz 2007 03 23 Interpreters Interpreters Why interpreters? An interpreter is a program that executes another program, represented as some kind of data-structure.
Interpreters and virtual machines Michel Schinz 2007 03 23 Interpreters Interpreters Why interpreters? An interpreter is a program that executes another program, represented as some kind of data-structure.
Secondary Storage. Any modern computer system will incorporate (at least) two levels of storage: magnetic disk/optical devices/tape systems
 two levels of storage: magnetic disk/optical devices/tape systems") 1 Any modern computer system will incorporate (at least) two levels of storage: primary storage: typical capacity cost per MB $3. typical access time burst transfer rate?? secondary storage: typical capacity
1 Any modern computer system will incorporate (at least) two levels of storage: primary storage: typical capacity cost per MB $3. typical access time burst transfer rate?? secondary storage: typical capacity
RevoScaleR Speed and Scalability
 EXECUTIVE WHITE PAPER RevoScaleR Speed and Scalability By Lee Edlefsen Ph.D., Chief Scientist, Revolution Analytics Abstract RevoScaleR, the Big Data predictive analytics library included with Revolution
EXECUTIVE WHITE PAPER RevoScaleR Speed and Scalability By Lee Edlefsen Ph.D., Chief Scientist, Revolution Analytics Abstract RevoScaleR, the Big Data predictive analytics library included with Revolution
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
361 Computer Architecture Lecture 14: Cache Memory
 1 361 Computer Architecture Lecture 14 Memory cache.1 The Motivation for s Memory System Processor DRAM Motivation Large memories (DRAM) are slow Small memories (SRAM) are fast Make the average access
1 361 Computer Architecture Lecture 14 Memory cache.1 The Motivation for s Memory System Processor DRAM Motivation Large memories (DRAM) are slow Small memories (SRAM) are fast Make the average access
Base Conversion written by Cathy Saxton
 Base Conversion written by Cathy Saxton 1. Base 10 In base 10, the digits, from right to left, specify the 1 s, 10 s, 100 s, 1000 s, etc. These are powers of 10 (10 x ): 10 0 = 1, 10 1 = 10, 10 2 = 100,
Base Conversion written by Cathy Saxton 1. Base 10 In base 10, the digits, from right to left, specify the 1 s, 10 s, 100 s, 1000 s, etc. These are powers of 10 (10 x ): 10 0 = 1, 10 1 = 10, 10 2 = 100,
Distribution One Server Requirements
 Distribution One Server Requirements Introduction Welcome to the Hardware Configuration Guide. The goal of this guide is to provide a practical approach to sizing your Distribution One application and
Distribution One Server Requirements Introduction Welcome to the Hardware Configuration Guide. The goal of this guide is to provide a practical approach to sizing your Distribution One application and
ClearPath MCP Software Series Compatibility Guide
 ClearPath Software Series Compatibility Guide Overview The ClearPath Software Series is designed to deliver new cost and performance competitive attributes and to continue to advance environment attributes
ClearPath Software Series Compatibility Guide Overview The ClearPath Software Series is designed to deliver new cost and performance competitive attributes and to continue to advance environment attributes
x64 Servers: Do you want 64 or 32 bit apps with that server?
 TMurgent Technologies x64 Servers: Do you want 64 or 32 bit apps with that server? White Paper by Tim Mangan TMurgent Technologies February, 2006 Introduction New servers based on what is generally called
TMurgent Technologies x64 Servers: Do you want 64 or 32 bit apps with that server? White Paper by Tim Mangan TMurgent Technologies February, 2006 Introduction New servers based on what is generally called
AMD Opteron Quad-Core
 AMD Opteron Quad-Core a brief overview Daniele Magliozzi Politecnico di Milano Opteron Memory Architecture native quad-core design (four cores on a single die for more efficient data sharing) enhanced
AMD Opteron Quad-Core a brief overview Daniele Magliozzi Politecnico di Milano Opteron Memory Architecture native quad-core design (four cores on a single die for more efficient data sharing) enhanced
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
HY345 Operating Systems
 HY345 Operating Systems Recitation 2 - Memory Management Solutions Panagiotis Papadopoulos [email protected] Problem 7 Consider the following C program: int X[N]; int step = M; //M is some predefined constant
HY345 Operating Systems Recitation 2 - Memory Management Solutions Panagiotis Papadopoulos [email protected] Problem 7 Consider the following C program: int X[N]; int step = M; //M is some predefined constant
The Quest for Speed - Memory. Cache Memory. A Solution: Memory Hierarchy. Memory Hierarchy
 The Quest for Speed - Memory Cache Memory CSE 4, Spring 25 Computer Systems http://www.cs.washington.edu/4 If all memory accesses (IF/lw/sw) accessed main memory, programs would run 20 times slower And
The Quest for Speed - Memory Cache Memory CSE 4, Spring 25 Computer Systems http://www.cs.washington.edu/4 If all memory accesses (IF/lw/sw) accessed main memory, programs would run 20 times slower And
Overview. CISC Developments. RISC Designs. CISC Designs. VAX: Addressing Modes. Digital VAX
 Overview CISC Developments Over Twenty Years Classic CISC design: Digital VAX VAXÕs RISC successor: PRISM/Alpha IntelÕs ubiquitous 80x86 architecture Ð 8086 through the Pentium Pro (P6) RJS 2/3/97 Philosophy
Overview CISC Developments Over Twenty Years Classic CISC design: Digital VAX VAXÕs RISC successor: PRISM/Alpha IntelÕs ubiquitous 80x86 architecture Ð 8086 through the Pentium Pro (P6) RJS 2/3/97 Philosophy
Unit A451: Computer systems and programming. Section 2: Computing Hardware 1/5: Central Processing Unit
 Unit A451: Computer systems and programming Section 2: Computing Hardware 1/5: Central Processing Unit Section Objectives Candidates should be able to: (a) State the purpose of the CPU (b) Understand the
Unit A451: Computer systems and programming Section 2: Computing Hardware 1/5: Central Processing Unit Section Objectives Candidates should be able to: (a) State the purpose of the CPU (b) Understand the
Slide Set 8. for ENCM 369 Winter 2015 Lecture Section 01. Steve Norman, PhD, PEng
 Slide Set 8 for ENCM 369 Winter 2015 Lecture Section 01 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary Winter Term, 2015 ENCM 369 W15 Section
Slide Set 8 for ENCM 369 Winter 2015 Lecture Section 01 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary Winter Term, 2015 ENCM 369 W15 Section
A Unified View of Virtual Machines
 A Unified View of Virtual Machines First ACM/USENIX Conference on Virtual Execution Environments J. E. Smith June 2005 Introduction Why are virtual machines interesting? They allow transcending of interfaces
A Unified View of Virtual Machines First ACM/USENIX Conference on Virtual Execution Environments J. E. Smith June 2005 Introduction Why are virtual machines interesting? They allow transcending of interfaces
Quiz for Chapter 1 Computer Abstractions and Technology 3.10
 Date: 3.10 Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Date: 3.10 Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Configuring Memory on the HP Business Desktop dx5150
 Configuring Memory on the HP Business Desktop dx5150 Abstract... 2 Glossary of Terms... 2 Introduction... 2 Main Memory Configuration... 3 Single-channel vs. Dual-channel... 3 Memory Type and Speed...
Configuring Memory on the HP Business Desktop dx5150 Abstract... 2 Glossary of Terms... 2 Introduction... 2 Main Memory Configuration... 3 Single-channel vs. Dual-channel... 3 Memory Type and Speed...
FPGA-based Multithreading for In-Memory Hash Joins
 FPGA-based Multithreading for In-Memory Hash Joins Robert J. Halstead, Ildar Absalyamov, Walid A. Najjar, Vassilis J. Tsotras University of California, Riverside Outline Background What are FPGAs Multithreaded
FPGA-based Multithreading for In-Memory Hash Joins Robert J. Halstead, Ildar Absalyamov, Walid A. Najjar, Vassilis J. Tsotras University of California, Riverside Outline Background What are FPGAs Multithreaded
Intel Media Server Studio - Metrics Monitor (v1.1.0) Reference Manual
 Reference Manual") Intel Media Server Studio - Metrics Monitor (v1.1.0) Reference Manual Overview Metrics Monitor is part of Intel Media Server Studio 2015 for Linux Server. Metrics Monitor is a user space shared library
Intel Media Server Studio - Metrics Monitor (v1.1.0) Reference Manual Overview Metrics Monitor is part of Intel Media Server Studio 2015 for Linux Server. Metrics Monitor is a user space shared library
GIVE YOUR ORACLE DBAs THE BACKUPS THEY REALLY WANT
 Why Data Domain Series GIVE YOUR ORACLE DBAs THE BACKUPS THEY REALLY WANT Why you should take the time to read this paper Speed up backups (Up to 58.7 TB/hr, Data Domain systems are about 1.5 times faster
Why Data Domain Series GIVE YOUR ORACLE DBAs THE BACKUPS THEY REALLY WANT Why you should take the time to read this paper Speed up backups (Up to 58.7 TB/hr, Data Domain systems are about 1.5 times faster
Computer Organization and Components
 Computer Organization and Components IS5, fall 25 Lecture : Pipelined Processors ssociate Professor, KTH Royal Institute of Technology ssistant Research ngineer, University of California, Berkeley Slides
Computer Organization and Components IS5, fall 25 Lecture : Pipelined Processors ssociate Professor, KTH Royal Institute of Technology ssistant Research ngineer, University of California, Berkeley Slides
Using Synology SSD Technology to Enhance System Performance. Based on DSM 5.2
 Using Synology SSD Technology to Enhance System Performance Based on DSM 5.2 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD Cache as Solution...
Using Synology SSD Technology to Enhance System Performance Based on DSM 5.2 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD Cache as Solution...
EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES
 ABSTRACT EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES Tyler Cossentine and Ramon Lawrence Department of Computer Science, University of British Columbia Okanagan Kelowna, BC, Canada [email protected]
ABSTRACT EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES Tyler Cossentine and Ramon Lawrence Department of Computer Science, University of British Columbia Okanagan Kelowna, BC, Canada [email protected]
The Bus (PCI and PCI-Express)
") 4 Jan, 2008 The Bus (PCI and PCI-Express) The CPU, memory, disks, and all the other devices in a computer have to be able to communicate and exchange data. The technology that connects them is called the
4 Jan, 2008 The Bus (PCI and PCI-Express) The CPU, memory, disks, and all the other devices in a computer have to be able to communicate and exchange data. The technology that connects them is called the
SUBJECT: SOLIDWORKS HARDWARE RECOMMENDATIONS - 2013 UPDATE
 SUBJECT: SOLIDWORKS RECOMMENDATIONS - 2013 UPDATE KEYWORDS:, CORE, PROCESSOR, GRAPHICS, DRIVER, RAM, STORAGE SOLIDWORKS RECOMMENDATIONS - 2013 UPDATE Below is a summary of key components of an ideal SolidWorks
SUBJECT: SOLIDWORKS RECOMMENDATIONS - 2013 UPDATE KEYWORDS:, CORE, PROCESSOR, GRAPHICS, DRIVER, RAM, STORAGE SOLIDWORKS RECOMMENDATIONS - 2013 UPDATE Below is a summary of key components of an ideal SolidWorks
Logical Operations. Control Unit. Contents. Arithmetic Operations. Objectives. The Central Processing Unit: Arithmetic / Logic Unit.
 Objectives The Central Processing Unit: What Goes on Inside the Computer Chapter 4 Identify the components of the central processing unit and how they work together and interact with memory Describe how
Objectives The Central Processing Unit: What Goes on Inside the Computer Chapter 4 Identify the components of the central processing unit and how they work together and interact with memory Describe how
Chapter 2 Basic Structure of Computers. Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan
 Chapter 2 Basic Structure of Computers Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Functional Units Basic Operational Concepts Bus Structures Software
Chapter 2 Basic Structure of Computers Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Functional Units Basic Operational Concepts Bus Structures Software
Legal Notices and Important Information
 Legal Notices and Important Information Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor family, not across different processor families.
Legal Notices and Important Information Intel processor numbers are not a measure of performance. Processor numbers differentiate features within each processor family, not across different processor families.
Driving force. What future software needs. Potential research topics
 Improving Software Robustness and Efficiency Driving force Processor core clock speed reach practical limit ~4GHz (power issue) Percentage of sustainable # of active transistors decrease; Increase in #
Improving Software Robustness and Efficiency Driving force Processor core clock speed reach practical limit ~4GHz (power issue) Percentage of sustainable # of active transistors decrease; Increase in #
Load Testing and Monitoring Web Applications in a Windows Environment
 OpenDemand Systems, Inc. Load Testing and Monitoring Web Applications in a Windows Environment Introduction An often overlooked step in the development and deployment of Web applications on the Windows
OpenDemand Systems, Inc. Load Testing and Monitoring Web Applications in a Windows Environment Introduction An often overlooked step in the development and deployment of Web applications on the Windows
Enhancing SQL Server Performance
 Enhancing SQL Server Performance Bradley Ball, Jason Strate and Roger Wolter In the ever-evolving data world, improving database performance is a constant challenge for administrators. End user satisfaction
Enhancing SQL Server Performance Bradley Ball, Jason Strate and Roger Wolter In the ever-evolving data world, improving database performance is a constant challenge for administrators. End user satisfaction
Low Power AMD Athlon 64 and AMD Opteron Processors
 Low Power AMD Athlon 64 and AMD Opteron Processors Hot Chips 2004 Presenter: Marius Evers Block Diagram of AMD Athlon 64 and AMD Opteron Based on AMD s 8 th generation architecture AMD Athlon 64 and AMD
Low Power AMD Athlon 64 and AMD Opteron Processors Hot Chips 2004 Presenter: Marius Evers Block Diagram of AMD Athlon 64 and AMD Opteron Based on AMD s 8 th generation architecture AMD Athlon 64 and AMD
Chapter 4 System Unit Components. Discovering Computers 2012. Your Interactive Guide to the Digital World
 Chapter 4 System Unit Components Discovering Computers 2012 Your Interactive Guide to the Digital World Objectives Overview Differentiate among various styles of system units on desktop computers, notebook
Chapter 4 System Unit Components Discovering Computers 2012 Your Interactive Guide to the Digital World Objectives Overview Differentiate among various styles of system units on desktop computers, notebook
Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) [email protected] http://www.mzahran.com
 mzahran@cs.nyu.edu http://www.mzahran.com") CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) [email protected] http://www.mzahran.com Modern GPU
CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) [email protected] http://www.mzahran.com Modern GPU
Q. Consider a dynamic instruction execution (an execution trace, in other words) that consists of repeats of code in this pattern:
 that consists of repeats of code in this pattern:") Pipelining HW Q. Can a MIPS SW instruction executing in a simple 5-stage pipelined implementation have a data dependency hazard of any type resulting in a nop bubble? If so, show an example; if not, prove
Pipelining HW Q. Can a MIPS SW instruction executing in a simple 5-stage pipelined implementation have a data dependency hazard of any type resulting in a nop bubble? If so, show an example; if not, prove
Computer Architecture TDTS10
 why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
Multicore Processor and GPU. Jia Rao Assistant Professor in CS http://cs.uccs.edu/~jrao/
 Multicore Processor and GPU Jia Rao Assistant Professor in CS http://cs.uccs.edu/~jrao/ Moore s Law The number of transistors on integrated circuits doubles approximately every two years! CPU performance
Multicore Processor and GPU Jia Rao Assistant Professor in CS http://cs.uccs.edu/~jrao/ Moore s Law The number of transistors on integrated circuits doubles approximately every two years! CPU performance
Breakthrough AES Performance with. Intel AES New Instructions
 White Paper Breakthrough AES Performance with Intel AES New Instructions Kahraman Akdemir, Martin Dixon, Wajdi Feghali, Patrick Fay, Vinodh Gopal, Jim Guilford, Erdinc Ozturk, Gil Wolrich, Ronen Zohar
White Paper Breakthrough AES Performance with Intel AES New Instructions Kahraman Akdemir, Martin Dixon, Wajdi Feghali, Patrick Fay, Vinodh Gopal, Jim Guilford, Erdinc Ozturk, Gil Wolrich, Ronen Zohar
Boundless Security Systems, Inc.
 Boundless Security Systems, Inc. sharper images with better access and easier installation Product Overview Product Summary Data Sheet Control Panel client live and recorded viewing, and search software
Boundless Security Systems, Inc. sharper images with better access and easier installation Product Overview Product Summary Data Sheet Control Panel client live and recorded viewing, and search software
Rethinking SIMD Vectorization for In-Memory Databases
 SIGMOD 215, Melbourne, Victoria, Australia Rethinking SIMD Vectorization for In-Memory Databases Orestis Polychroniou Columbia University Arun Raghavan Oracle Labs Kenneth A. Ross Columbia University Latest
SIGMOD 215, Melbourne, Victoria, Australia Rethinking SIMD Vectorization for In-Memory Databases Orestis Polychroniou Columbia University Arun Raghavan Oracle Labs Kenneth A. Ross Columbia University Latest
AMD PhenomII. Architecture for Multimedia System -2010. Prof. Cristina Silvano. Group Member: Nazanin Vahabi 750234 Kosar Tayebani 734923
 AMD PhenomII Architecture for Multimedia System -2010 Prof. Cristina Silvano Group Member: Nazanin Vahabi 750234 Kosar Tayebani 734923 Outline Introduction Features Key architectures References AMD Phenom
AMD PhenomII Architecture for Multimedia System -2010 Prof. Cristina Silvano Group Member: Nazanin Vahabi 750234 Kosar Tayebani 734923 Outline Introduction Features Key architectures References AMD Phenom