Decision Trees from large Databases: SLIQ
|
|
|
- Clifford Flowers
- 9 years ago
- Views:
Transcription
1 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values for every attribute Build the tree breadth-first, not depth-first. Original reference: M. Mehta et. al.: SLIQ: A Fast Scalable Classifier for Data Mining

2 SLIQ: Gini Index To determine the best split, SLIQ uses the Gini- Index instead of Information Gain. For a training set L with n distinct classes: Gini L = 1 p j 2 j=1 n p j is the relative frequency of value j After a binary split of the set L into sets L 1 and L 2 the index becomes: Gini split L = L 1 L Gini L 1 + L 2 L Gini L 2 Gini-Index behaves similarly to Information Gain. 42

3 Compare: Information Gain vs. Gini Index Which split is better? [29 +, 35 -] yes x 1 x 2 no H L, y = log log = 0.99 [29 +, 35 -] [21+, 5 -] [8+, 30 -] [18+, 33 -] [11+, 2 -] IG L, x 1 = H L x 1 =yes, y H L x 1 =no, y 0.26 IG L, x 2 = H L x 2 =yes, y H L x 2 =no, y Gini x1 L = Gini L x 1 =yes Gini L x 1 =no 0.32 Gini x2 L = Gini L x 2 =yes Gini L x 2 =no yes no 0.33
![99 [29 +, 35 -] [21+, 5 -] [8+, 30 -] [18+, 33 -] [11+, 2 -] IG L, x 1 = 0.](/docs-images/48/18871751/images/page_3.jpg "99 26 64 H L x 1 =yes, y + 38 64 H L x 1 =no, y 0.26 IG L, x 2 = 0.99 51 64 H L x 2 =yes, y + 13 64 H L x 2 =no, y 0.")
4 SLIQ Algorithm 1. Start Pre-sorting of the samples. 2. As long as the stop criterion has not been reached 1. For every attribute 1. Place all nodes into a class histogram. 2. Start evaluation of the splits. 2. Choose a split. 3. Update the decision tree; for each new node update its class list (nodes). 44
.")
5 SLIQ (1st Substep) Pre-sorting of the samples: 1. For each attribute: create an attribute list with columns for the value, sample-id and class. 2. Create a class list with columns for the sample-id, class and leaf node. 3. Iterate over all training samples: For each attribute Insert its attribute values, sample-id and class (sorted by attribute value) into the attribute list. Insert the sample-id, the class and the leaf node (sorted by sample-id) into the class list. 45

6 SLIQ: Example 46
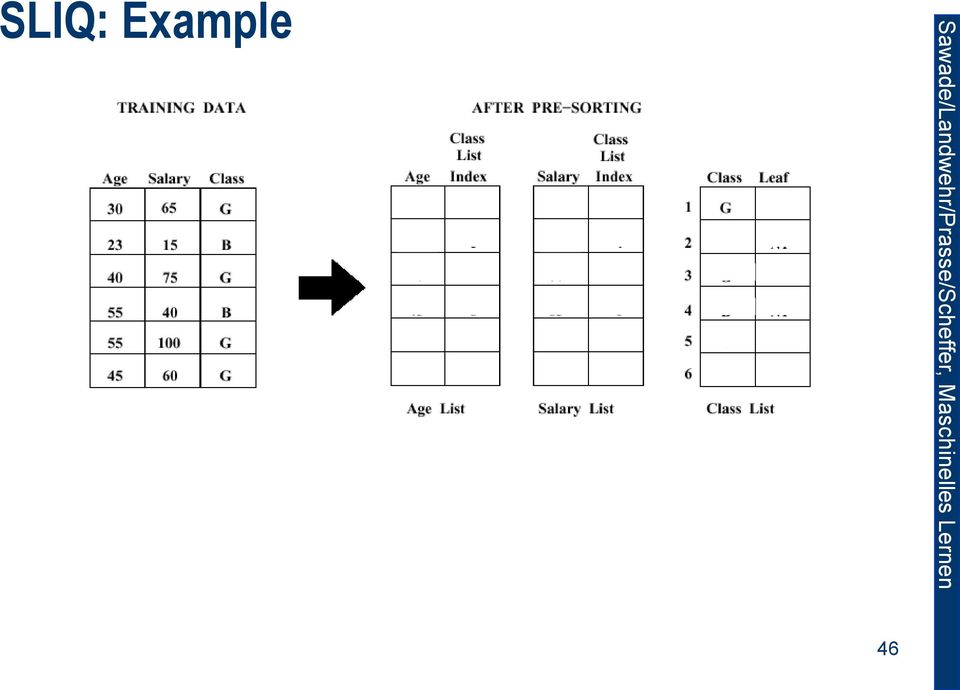
7 SLIQ: Example 47

8 SLIQ Algorithm 1. Start Pre-sorting of the samples. 2. As long as the stop criterion has not been reached 1. For every attribute 1. Place all nodes into a class histogram. 2. Start evaluation of the splits. 2. Choose a split. 3. Update the decision tree; for each new node update its class list (nodes). 48
.")
9 SLIQ (2nd Substep) Evaluation of the splits. 1. For each node, and for all attributes 1. Construct a histogram (for each class the histogram saves the count of samples before and after the split). 2. For each attribute A 1. For each value v (traverse the attribute list for A) 1. Find the entry in the class list (provides the class and node). 2. Update the histogram for the node. 3. Assess the split (if its a maximum, record it!) 49
. 2. Update the histogram for the node. 3.")
10 SLIQ: Example 50
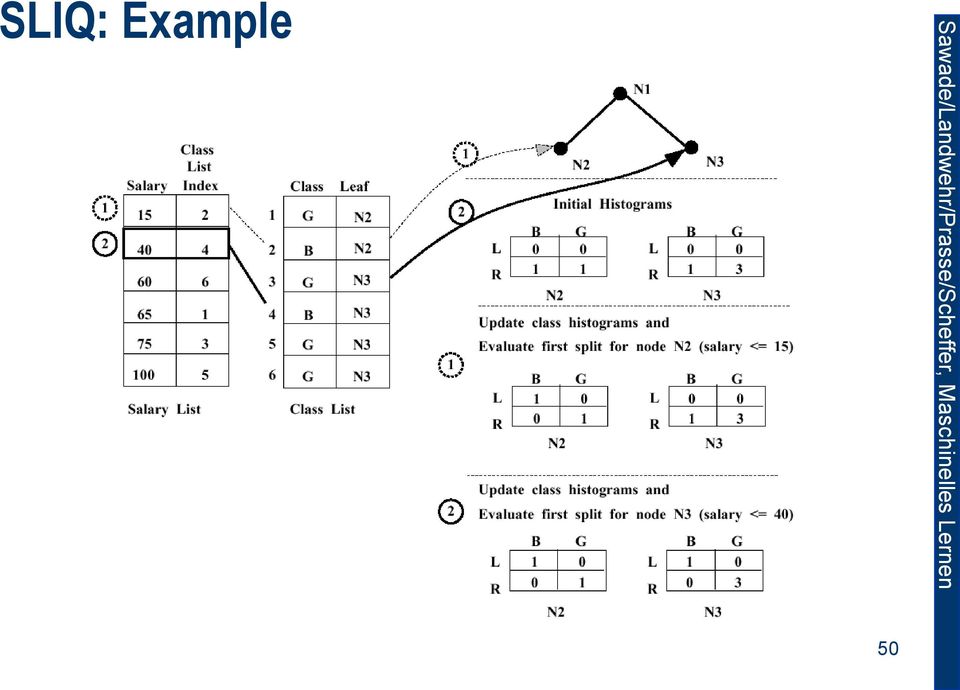
11 SLIQ Algorithm 1. Start Pre-sorting of the samples. 2. As long as the stop criterion has not been reached 1. For every attribute 1. Place all nodes into a class histogram. 2. Start evaluation of the splits. 2. Choose a split. 3. Update the decision tree; for each new node update its class list (nodes). 51
.")
12 SLIQ (3rd Substep) Update the Class list (nodes). 1. Traverse the attribute list of the attribute used in the node. 2. For each entry (value, ID) 3. Find the matching entry (ID, class, node) in the class list. 4. Apply the split criterion emitting a new node. 5. Replace the corresponding class list entry with (ID, class, new node). 52
 in the class list. 4.")
13 SLIQ: Example 53
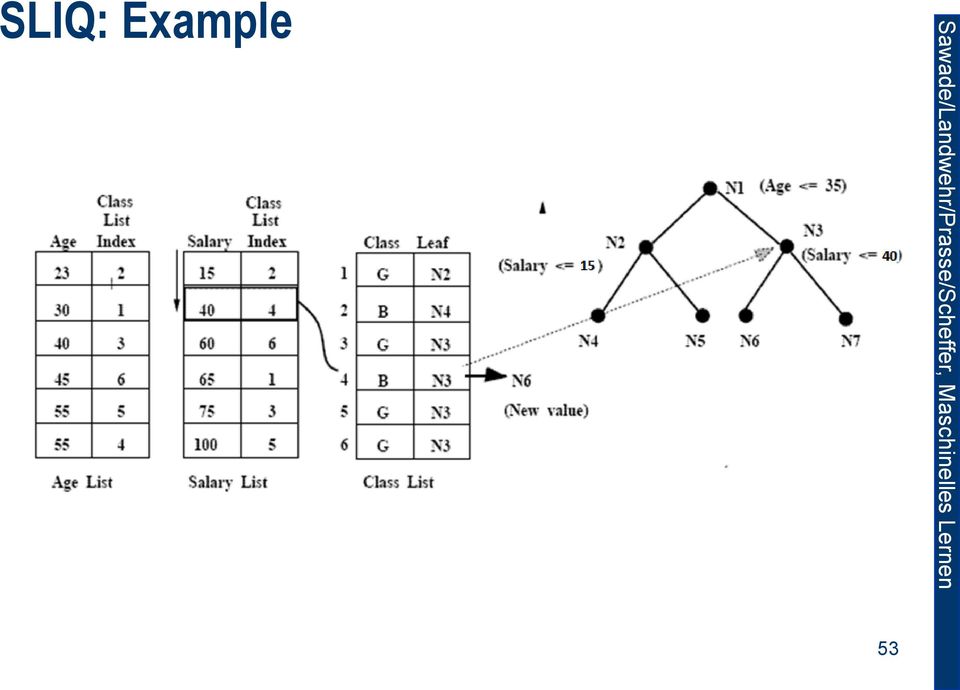
14 SLIQ: Data Structures Data structures in memory? Swappable data structures? Data structures in a database? 54

15 SLIQ- Pruning Minimum Description Length (MDL): the best model for a given data set minimizes the sum of the length the encoded data by the model plus the length of the model. cost M, D = cost D M + cost M cost M = cost of the model (length). How large is the decision tree? cost D M = cost to describe the data with the model. How many classification errors are incurred? 55

16 Pruning MDL Example I Assume: 16 binary attributes and 3 classes cost M, D = cost D M + cost M Cost for the encoding of an internal node: log 2 (m) = log 2 16 = 4 Cost for the encoding of a leaf: log 2 (k) = log 2 (3) = 2 Cost for the encoding of a classification error for n training data points: log 2 (n) 7 Errors C 1 C 2 C 3 56
 7 Errors C 1 C 2 C")
17 Pruning MDL Example II Which tree is better? 7 Errors Tree 1: Tree 2: C 1 C 1 C 2 C 3 Internal nodes Leaves Errors 4 Errors C 2 C 1 C 2 Cost for tree 1: log 2 n = log 2 n Cost for tree 2: log 2 n = log 2 n If n < 16, then tree 1 is better. If n > 16, then tree 2 is better. C 3 57

18 SLIQ Properties Running time for the initialization (pre-sorting): O n log n for each attribute Much of the data must not be kept in main memory. Good scalability. If the class list does not fit in main memory then SLIQ no longer works. Alternative: SPRINT Can handle numerical and discrete attributes. Parallelization of the process is possible. 58

19 Regression Trees ID3, C4.5, SLIQ: Solve classification problems. Goal: low error rate + small tree Attribute can be continuous (except for ID3), but their prediction is discrete. Regression: the prediction is continuously valued. Goal: low quadratic error rate + simple model. n 2 SSE = j=1 y j f x j Methods we will now examine: Regression trees, Linear Regression, Model trees. 59

20 Regression Trees Input: L = x 1, y 1,, x n, y n, continuous y. Desired result: f: X Y Algorithm CART It was developed simultaneously & independently from C4.5. Terminal nodes incorporate continuous values. Algorithm like C4.5. For classification, there are slightly different criteria (Gini instead of IG), but otherwise little difference. Information Gain (& Gini) only work for classification. Question: What is a split criterion for Regression? Original reference: L. Breiman et. al.: Classification and Regression Trees
, but otherwise little difference.")
21 Regression Trees Goal: small quadratic error (SSE) + small tree. Examples L arrive at the current node. SSE at the current node: SSE L = x,y L y y 2 where y = 1 y L x,y L. With which test should the data be split? Criterion for test nodes x v : SSE Red L, x v = SSE L SSE L x v SSE L x>v SSE-Reduction through the test. Stop Criterion: Do not make a new split unless the SSE will be reduced by at least some minimum threshold. If so, then create a terminal node with mean m of L. 61
22 CART- Example Which split is better? L = [2,3,4,10,11,12] SSE L = 100 ja nein SSE L = y y 2 x,y L where y = 1 L x 1 x 2 L = [2,3,4,10,11,12] ja nein L 1 = [2,3] L 2 =[4,10,11,12] L 1 =[2,4,10] L 2 =[3,11,12] SSE L 1 = 0,5 SSE L 2 = 38,75 SSE L 1 = 34,67 SSE L 2 = 48,67 x,y L y 62
23 Linear Regression Regression trees: constant prediction at every leaf node. Linear Regression: Global model of a linear dependence between x and y. Standard method. Useful by itself and it serves as a building block for Model trees. 63
24 Linear Regression Input: L = x 1, y 1,, x n, y n Desired result: a linear model, f x = w T x + c Normal vector Residuals Points along the Regression line are perpendicular to the normal vector. 64
25 Model Trees Decision trees but with a linear regression model at each leaf node
26 Model Trees Decision trees but with a linear regression model at each leaf node. yes ja yes ja x <.9 x <.5 x < 1.1 no nein yes no nein nein no
27 Model Trees: Creation of new Test Nodes Fit a linear regression of all samples that are filtered to the current node. Compute the regression s SSE. Iterate over all possible tests (like C4.5): Fit a linear regression for the subset of samples on the left branch, & compute SSE left. Fit a linear regression for the subset of samples on the right branch, & compute SSE right. Choose the test with the largest reduction SSE SSE left SSE right. Stop-Criterion: If the SSE is not reduced by at least a minimum threshold, don t create a new test. 67
28 Missing Attribute Values Problem: Training data with missing attributes. What if we test an attribute A for which an attribute value does not exist for every sample? These training samples receive a substitute attribute value which occurs most frequently for A among the samples at node n. These training samples receive a substitute attribute value, which most samples with the same classification have. 68
29 Attributes with Costs Example: Medical diagnosis A blood test costs more than taking one s pulse Question: How can you learn a tree that is consistent with the training data at a low cost? Solution: Replace Information Gain with: Tan and Schlimmer (1990): Nunez (1988): IG 2 L,x Cost A 2 IG L,x 1 Cost A +1 w Parameter w 0,1 controls the impact of the cost. 69
30 Bootstrapping Simple resampling method. Generates many variants of a training set L. Bootstrap Algorithm: Repeat k = 1 M times: Generate a sample dataset L k of size n from L: The sampled dataset is drawn uniformly with replacement from the original set of samples. Compute model θ k for dataset L k Return the parameters generated by the bootstrap: θ = θ 1,, θ M 70
31 Bootstrapping - Example x = , x = 4,46 x = x = x = , x = 4,13, x = 4,64, x = 1,74 71
32 Bagging Learning Robust Trees Bagging = Bootstrap aggregating Bagging Algorithm: Repeat k = 1 M times : Generate a sample dataset L k from L. Compute model θ k for dataset L k. Combine the M learned predictive models: Classification problems: Voting Regression problems: Mean value Original reference: L.Breiman: Bagging Predictors e.g. a model tree 72
33 Random Forests Repeat: Draw randomly n samples, uniformly with replacement, from the training set. Randomly select m < m features Learn decision tree (without pruning) Classification: Maximum over all trees (Voting) Regression: Average over all trees Original reference: L. Breiman: Random Forests Bootstrap 73
34 Usages of Decision Trees Medical Diagnosis. In face recognition. As part of more complex systems. 74
35 Decision Tree - Advantages Easy to interpret. Can be efficiently learned from many samples. SLIQ, SPRINT Many Applications. High Accuracy. 75
36 Decision Tree - Disadvantages Not robust against noise Tendency to overfit Unstable 76
37 Summary of Decision Trees Classification: Prediction of discrete values. Discrete attributes: ID3. Continuous attributes: C4.5. Scalable to large databases: SLIQ, SPRINT. Regression: Prediction of continuous values. Regression trees: constant value predicted at each leaf. Model trees: a linear model is contained in each leaf. 77
Classification and Prediction
 Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Data Mining Classification: Decision Trees
 Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Knowledge Discovery and Data Mining. Bootstrap review. Bagging Important Concepts. Notes. Lecture 19 - Bagging. Tom Kelsey. Notes
 Knowledge Discovery and Data Mining Lecture 19 - Bagging Tom Kelsey School of Computer Science University of St Andrews http://tom.host.cs.st-andrews.ac.uk [email protected] Tom Kelsey ID5059-19-B &
Knowledge Discovery and Data Mining Lecture 19 - Bagging Tom Kelsey School of Computer Science University of St Andrews http://tom.host.cs.st-andrews.ac.uk [email protected] Tom Kelsey ID5059-19-B &
Data Mining for Knowledge Management. Classification
 1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
COMP3420: Advanced Databases and Data Mining. Classification and prediction: Introduction and Decision Tree Induction
 COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
Model Combination. 24 Novembre 2009
 Model Combination 24 Novembre 2009 Datamining 1 2009-2010 Plan 1 Principles of model combination 2 Resampling methods Bagging Random Forests Boosting 3 Hybrid methods Stacking Generic algorithm for mulistrategy
Model Combination 24 Novembre 2009 Datamining 1 2009-2010 Plan 1 Principles of model combination 2 Resampling methods Bagging Random Forests Boosting 3 Hybrid methods Stacking Generic algorithm for mulistrategy
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data mining techniques: decision trees
 Data mining techniques: decision trees 1/39 Agenda Rule systems Building rule systems vs rule systems Quick reference 2/39 1 Agenda Rule systems Building rule systems vs rule systems Quick reference 3/39
Data mining techniques: decision trees 1/39 Agenda Rule systems Building rule systems vs rule systems Quick reference 2/39 1 Agenda Rule systems Building rule systems vs rule systems Quick reference 3/39
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Gerry Hobbs, Department of Statistics, West Virginia University
 Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
ENSEMBLE DECISION TREE CLASSIFIER FOR BREAST CANCER DATA
 ENSEMBLE DECISION TREE CLASSIFIER FOR BREAST CANCER DATA D.Lavanya 1 and Dr.K.Usha Rani 2 1 Research Scholar, Department of Computer Science, Sree Padmavathi Mahila Visvavidyalayam, Tirupati, Andhra Pradesh,
ENSEMBLE DECISION TREE CLASSIFIER FOR BREAST CANCER DATA D.Lavanya 1 and Dr.K.Usha Rani 2 1 Research Scholar, Department of Computer Science, Sree Padmavathi Mahila Visvavidyalayam, Tirupati, Andhra Pradesh,
Lecture 10: Regression Trees
 Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Lecture 10: Regression Trees 36-350: Data Mining October 11, 2006 Reading: Textbook, sections 5.2 and 10.5. The next three lectures are going to be about a particular kind of nonlinear predictive model,
Data Mining Techniques Chapter 6: Decision Trees
 Data Mining Techniques Chapter 6: Decision Trees What is a classification decision tree?.......................................... 2 Visualizing decision trees...................................................
Data Mining Techniques Chapter 6: Decision Trees What is a classification decision tree?.......................................... 2 Visualizing decision trees...................................................
Using multiple models: Bagging, Boosting, Ensembles, Forests
 Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Comparative Analysis of Serial Decision Tree Classification Algorithms
 Comparative Analysis of Serial Decision Tree Classification Algorithms Matthew N. Anyanwu Department of Computer Science The University of Memphis, Memphis, TN 38152, U.S.A manyanwu @memphis.edu Sajjan
Comparative Analysis of Serial Decision Tree Classification Algorithms Matthew N. Anyanwu Department of Computer Science The University of Memphis, Memphis, TN 38152, U.S.A manyanwu @memphis.edu Sajjan
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Data Mining with R. Decision Trees and Random Forests. Hugh Murrell
 Data Mining with R Decision Trees and Random Forests Hugh Murrell reference books These slides are based on a book by Graham Williams: Data Mining with Rattle and R, The Art of Excavating Data for Knowledge
Data Mining with R Decision Trees and Random Forests Hugh Murrell reference books These slides are based on a book by Graham Williams: Data Mining with Rattle and R, The Art of Excavating Data for Knowledge
CI6227: Data Mining. Lesson 11b: Ensemble Learning. Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore.
 CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
How To Make A Credit Risk Model For A Bank Account
 TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző [email protected] 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző [email protected] 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
Fast Analytics on Big Data with H20
 Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER. Copyr i g ht 2013, SAS Ins titut e Inc. All rights res er ve d.
 EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER ANALYTICS LIFECYCLE Evaluate & Monitor Model Formulate Problem Data Preparation Deploy Model Data Exploration Validate Models
EXPLORING & MODELING USING INTERACTIVE DECISION TREES IN SAS ENTERPRISE MINER ANALYTICS LIFECYCLE Evaluate & Monitor Model Formulate Problem Data Preparation Deploy Model Data Exploration Validate Models
Data Mining Methods: Applications for Institutional Research
 Data Mining Methods: Applications for Institutional Research Nora Galambos, PhD Office of Institutional Research, Planning & Effectiveness Stony Brook University NEAIR Annual Conference Philadelphia 2014
Data Mining Methods: Applications for Institutional Research Nora Galambos, PhD Office of Institutional Research, Planning & Effectiveness Stony Brook University NEAIR Annual Conference Philadelphia 2014
Classifying Large Data Sets Using SVMs with Hierarchical Clusters. Presented by :Limou Wang
 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
CLOUDS: A Decision Tree Classifier for Large Datasets
 CLOUDS: A Decision Tree Classifier for Large Datasets Khaled Alsabti Department of EECS Syracuse University Sanjay Ranka Department of CISE University of Florida Vineet Singh Information Technology Lab
CLOUDS: A Decision Tree Classifier for Large Datasets Khaled Alsabti Department of EECS Syracuse University Sanjay Ranka Department of CISE University of Florida Vineet Singh Information Technology Lab
Comparison of Data Mining Techniques used for Financial Data Analysis
 Comparison of Data Mining Techniques used for Financial Data Analysis Abhijit A. Sawant 1, P. M. Chawan 2 1 Student, 2 Associate Professor, Department of Computer Technology, VJTI, Mumbai, INDIA Abstract
Comparison of Data Mining Techniques used for Financial Data Analysis Abhijit A. Sawant 1, P. M. Chawan 2 1 Student, 2 Associate Professor, Department of Computer Technology, VJTI, Mumbai, INDIA Abstract
CS570 Data Mining Classification: Ensemble Methods
 CS570 Data Mining Classification: Ensemble Methods Cengiz Günay Dept. Math & CS, Emory University Fall 2013 Some slides courtesy of Han-Kamber-Pei, Tan et al., and Li Xiong Günay (Emory) Classification:
CS570 Data Mining Classification: Ensemble Methods Cengiz Günay Dept. Math & CS, Emory University Fall 2013 Some slides courtesy of Han-Kamber-Pei, Tan et al., and Li Xiong Günay (Emory) Classification:
L25: Ensemble learning
 L25: Ensemble learning Introduction Methods for constructing ensembles Combination strategies Stacked generalization Mixtures of experts Bagging Boosting CSCE 666 Pattern Analysis Ricardo Gutierrez-Osuna
L25: Ensemble learning Introduction Methods for constructing ensembles Combination strategies Stacked generalization Mixtures of experts Bagging Boosting CSCE 666 Pattern Analysis Ricardo Gutierrez-Osuna
Introduction to Machine Learning and Data Mining. Prof. Dr. Igor Trajkovski [email protected]
 Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trajkovski [email protected] Ensembles 2 Learning Ensembles Learn multiple alternative definitions of a concept using different training
Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trajkovski [email protected] Ensembles 2 Learning Ensembles Learn multiple alternative definitions of a concept using different training
Learning Example. Machine learning and our focus. Another Example. An example: data (loan application) The data and the goal
 The data and the goal") Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Random forest algorithm in big data environment
 Random forest algorithm in big data environment Yingchun Liu * School of Economics and Management, Beihang University, Beijing 100191, China Received 1 September 2014, www.cmnt.lv Abstract Random forest
Random forest algorithm in big data environment Yingchun Liu * School of Economics and Management, Beihang University, Beijing 100191, China Received 1 September 2014, www.cmnt.lv Abstract Random forest
Decision-Tree Learning
 Decision-Tree Learning Introduction ID3 Attribute selection Entropy, Information, Information Gain Gain Ratio C4.5 Decision Trees TDIDT: Top-Down Induction of Decision Trees Numeric Values Missing Values
Decision-Tree Learning Introduction ID3 Attribute selection Entropy, Information, Information Gain Gain Ratio C4.5 Decision Trees TDIDT: Top-Down Induction of Decision Trees Numeric Values Missing Values
Event driven trading new studies on innovative way. of trading in Forex market. Michał Osmoła INIME live 23 February 2016
 Event driven trading new studies on innovative way of trading in Forex market Michał Osmoła INIME live 23 February 2016 Forex market From Wikipedia: The foreign exchange market (Forex, FX, or currency
Event driven trading new studies on innovative way of trading in Forex market Michał Osmoła INIME live 23 February 2016 Forex market From Wikipedia: The foreign exchange market (Forex, FX, or currency
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Supervised Feature Selection & Unsupervised Dimensionality Reduction
 Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.7 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Linear Regression Other Regression Models References Introduction Introduction Numerical prediction is
Data Mining Part 5. Prediction 5.7 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Linear Regression Other Regression Models References Introduction Introduction Numerical prediction is
Classification and Regression by randomforest
 Vol. 2/3, December 02 18 Classification and Regression by randomforest Andy Liaw and Matthew Wiener Introduction Recently there has been a lot of interest in ensemble learning methods that generate many
Vol. 2/3, December 02 18 Classification and Regression by randomforest Andy Liaw and Matthew Wiener Introduction Recently there has been a lot of interest in ensemble learning methods that generate many
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Evaluating the Accuracy of a Classifier Holdout, random subsampling, crossvalidation, and the bootstrap are common techniques for
Knowledge Discovery and Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Evaluating the Accuracy of a Classifier Holdout, random subsampling, crossvalidation, and the bootstrap are common techniques for
Classification On The Clouds Using MapReduce
 Classification On The Clouds Using MapReduce Simão Martins Instituto Superior Técnico Lisbon, Portugal [email protected] Cláudia Antunes Instituto Superior Técnico Lisbon, Portugal [email protected]
Classification On The Clouds Using MapReduce Simão Martins Instituto Superior Técnico Lisbon, Portugal [email protected] Cláudia Antunes Instituto Superior Técnico Lisbon, Portugal [email protected]
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation. Lecture Notes for Chapter 4. Introduction to Data Mining
 Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data
Data Mining Classification: Basic Concepts, Decision Trees, and Model Evaluation Lecture Notes for Chapter 4 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data
Beating the MLB Moneyline
 Beating the MLB Moneyline Leland Chen [email protected] Andrew He [email protected] 1 Abstract Sports forecasting is a challenging task that has similarities to stock market prediction, requiring time-series
Beating the MLB Moneyline Leland Chen [email protected] Andrew He [email protected] 1 Abstract Sports forecasting is a challenging task that has similarities to stock market prediction, requiring time-series
Leveraging Ensemble Models in SAS Enterprise Miner
 ABSTRACT Paper SAS133-2014 Leveraging Ensemble Models in SAS Enterprise Miner Miguel Maldonado, Jared Dean, Wendy Czika, and Susan Haller SAS Institute Inc. Ensemble models combine two or more models to
ABSTRACT Paper SAS133-2014 Leveraging Ensemble Models in SAS Enterprise Miner Miguel Maldonado, Jared Dean, Wendy Czika, and Susan Haller SAS Institute Inc. Ensemble models combine two or more models to
Predicting Flight Delays
 Predicting Flight Delays Dieterich Lawson [email protected] William Castillo [email protected] Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Predicting Flight Delays Dieterich Lawson [email protected] William Castillo [email protected] Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier
 A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier G.T. Prasanna Kumari Associate Professor, Dept of Computer Science and Engineering, Gokula Krishna College of Engg, Sullurpet-524121,
A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier G.T. Prasanna Kumari Associate Professor, Dept of Computer Science and Engineering, Gokula Krishna College of Engg, Sullurpet-524121,
Automatic Resolver Group Assignment of IT Service Desk Outsourcing
 Automatic Resolver Group Assignment of IT Service Desk Outsourcing in Banking Business Padej Phomasakha Na Sakolnakorn*, Phayung Meesad ** and Gareth Clayton*** Abstract This paper proposes a framework
Automatic Resolver Group Assignment of IT Service Desk Outsourcing in Banking Business Padej Phomasakha Na Sakolnakorn*, Phayung Meesad ** and Gareth Clayton*** Abstract This paper proposes a framework
Introduction to Learning & Decision Trees
 Artificial Intelligence: Representation and Problem Solving 5-38 April 0, 2007 Introduction to Learning & Decision Trees Learning and Decision Trees to learning What is learning? - more than just memorizing
Artificial Intelligence: Representation and Problem Solving 5-38 April 0, 2007 Introduction to Learning & Decision Trees Learning and Decision Trees to learning What is learning? - more than just memorizing
A NEW DECISION TREE METHOD FOR DATA MINING IN MEDICINE
 A NEW DECISION TREE METHOD FOR DATA MINING IN MEDICINE Kasra Madadipouya 1 1 Department of Computing and Science, Asia Pacific University of Technology & Innovation ABSTRACT Today, enormous amount of data
A NEW DECISION TREE METHOD FOR DATA MINING IN MEDICINE Kasra Madadipouya 1 1 Department of Computing and Science, Asia Pacific University of Technology & Innovation ABSTRACT Today, enormous amount of data
Applied Multivariate Analysis - Big data analytics
 Applied Multivariate Analysis - Big data analytics Nathalie Villa-Vialaneix [email protected] http://www.nathalievilla.org M1 in Economics and Economics and Statistics Toulouse School of
Applied Multivariate Analysis - Big data analytics Nathalie Villa-Vialaneix [email protected] http://www.nathalievilla.org M1 in Economics and Economics and Statistics Toulouse School of
Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms
 Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms Yin Zhao School of Mathematical Sciences Universiti Sains Malaysia (USM) Penang, Malaysia Yahya
Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms Yin Zhao School of Mathematical Sciences Universiti Sains Malaysia (USM) Penang, Malaysia Yahya
Why Ensembles Win Data Mining Competitions
 Why Ensembles Win Data Mining Competitions A Predictive Analytics Center of Excellence (PACE) Tech Talk November 14, 2012 Dean Abbott Abbott Analytics, Inc. Blog: http://abbottanalytics.blogspot.com URL:
Why Ensembles Win Data Mining Competitions A Predictive Analytics Center of Excellence (PACE) Tech Talk November 14, 2012 Dean Abbott Abbott Analytics, Inc. Blog: http://abbottanalytics.blogspot.com URL:
Machine Learning and Data Mining. Regression Problem. (adapted from) Prof. Alexander Ihler
 Prof. Alexander Ihler") Machine Learning and Data Mining Regression Problem (adapted from) Prof. Alexander Ihler Overview Regression Problem Definition and define parameters ϴ. Prediction using ϴ as parameters Measure the error
Machine Learning and Data Mining Regression Problem (adapted from) Prof. Alexander Ihler Overview Regression Problem Definition and define parameters ϴ. Prediction using ϴ as parameters Measure the error
ENHANCED CONFIDENCE INTERPRETATIONS OF GP BASED ENSEMBLE MODELING RESULTS
 ENHANCED CONFIDENCE INTERPRETATIONS OF GP BASED ENSEMBLE MODELING RESULTS Michael Affenzeller (a), Stephan M. Winkler (b), Stefan Forstenlechner (c), Gabriel Kronberger (d), Michael Kommenda (e), Stefan
ENHANCED CONFIDENCE INTERPRETATIONS OF GP BASED ENSEMBLE MODELING RESULTS Michael Affenzeller (a), Stephan M. Winkler (b), Stefan Forstenlechner (c), Gabriel Kronberger (d), Michael Kommenda (e), Stefan
D-optimal plans in observational studies
 D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
Chapter 11 Boosting. Xiaogang Su Department of Statistics University of Central Florida - 1 -
 Chapter 11 Boosting Xiaogang Su Department of Statistics University of Central Florida - 1 - Perturb and Combine (P&C) Methods have been devised to take advantage of the instability of trees to create
Chapter 11 Boosting Xiaogang Su Department of Statistics University of Central Florida - 1 - Perturb and Combine (P&C) Methods have been devised to take advantage of the instability of trees to create
An Introduction to Data Mining. Big Data World. Related Fields and Disciplines. What is Data Mining? 2/12/2015
 An Introduction to Data Mining for Wind Power Management Spring 2015 Big Data World Every minute: Google receives over 4 million search queries Facebook users share almost 2.5 million pieces of content
An Introduction to Data Mining for Wind Power Management Spring 2015 Big Data World Every minute: Google receives over 4 million search queries Facebook users share almost 2.5 million pieces of content
An Overview and Evaluation of Decision Tree Methodology
 An Overview and Evaluation of Decision Tree Methodology ASA Quality and Productivity Conference Terri Moore Motorola Austin, TX [email protected] Carole Jesse Cargill, Inc. Wayzata, MN [email protected]
An Overview and Evaluation of Decision Tree Methodology ASA Quality and Productivity Conference Terri Moore Motorola Austin, TX [email protected] Carole Jesse Cargill, Inc. Wayzata, MN [email protected]
Decision Trees. JERZY STEFANOWSKI Institute of Computing Science Poznań University of Technology. Doctoral School, Catania-Troina, April, 2008
 Decision Trees JERZY STEFANOWSKI Institute of Computing Science Poznań University of Technology Doctoral School, Catania-Troina, April, 2008 Aims of this module The decision tree representation. The basic
Decision Trees JERZY STEFANOWSKI Institute of Computing Science Poznań University of Technology Doctoral School, Catania-Troina, April, 2008 Aims of this module The decision tree representation. The basic
HYBRID PROBABILITY BASED ENSEMBLES FOR BANKRUPTCY PREDICTION
 HYBRID PROBABILITY BASED ENSEMBLES FOR BANKRUPTCY PREDICTION Chihli Hung 1, Jing Hong Chen 2, Stefan Wermter 3, 1,2 Department of Management Information Systems, Chung Yuan Christian University, Taiwan
HYBRID PROBABILITY BASED ENSEMBLES FOR BANKRUPTCY PREDICTION Chihli Hung 1, Jing Hong Chen 2, Stefan Wermter 3, 1,2 Department of Management Information Systems, Chung Yuan Christian University, Taiwan
Insurance Analytics - analýza dat a prediktivní modelování v pojišťovnictví. Pavel Kříž. Seminář z aktuárských věd MFF 4.
 Insurance Analytics - analýza dat a prediktivní modelování v pojišťovnictví Pavel Kříž Seminář z aktuárských věd MFF 4. dubna 2014 Summary 1. Application areas of Insurance Analytics 2. Insurance Analytics
Insurance Analytics - analýza dat a prediktivní modelování v pojišťovnictví Pavel Kříž Seminář z aktuárských věd MFF 4. dubna 2014 Summary 1. Application areas of Insurance Analytics 2. Insurance Analytics
DECISION TREE INDUCTION FOR FINANCIAL FRAUD DETECTION USING ENSEMBLE LEARNING TECHNIQUES
 DECISION TREE INDUCTION FOR FINANCIAL FRAUD DETECTION USING ENSEMBLE LEARNING TECHNIQUES Vijayalakshmi Mahanra Rao 1, Yashwant Prasad Singh 2 Multimedia University, Cyberjaya, MALAYSIA 1 [email protected]
DECISION TREE INDUCTION FOR FINANCIAL FRAUD DETECTION USING ENSEMBLE LEARNING TECHNIQUES Vijayalakshmi Mahanra Rao 1, Yashwant Prasad Singh 2 Multimedia University, Cyberjaya, MALAYSIA 1 [email protected]
Generalizing Random Forests Principles to other Methods: Random MultiNomial Logit, Random Naive Bayes, Anita Prinzie & Dirk Van den Poel
 Generalizing Random Forests Principles to other Methods: Random MultiNomial Logit, Random Naive Bayes, Anita Prinzie & Dirk Van den Poel Copyright 2008 All rights reserved. Random Forests Forest of decision
Generalizing Random Forests Principles to other Methods: Random MultiNomial Logit, Random Naive Bayes, Anita Prinzie & Dirk Van den Poel Copyright 2008 All rights reserved. Random Forests Forest of decision
Studying Auto Insurance Data
 Studying Auto Insurance Data Ashutosh Nandeshwar February 23, 2010 1 Introduction To study auto insurance data using traditional and non-traditional tools, I downloaded a well-studied data from http://www.statsci.org/data/general/motorins.
Studying Auto Insurance Data Ashutosh Nandeshwar February 23, 2010 1 Introduction To study auto insurance data using traditional and non-traditional tools, I downloaded a well-studied data from http://www.statsci.org/data/general/motorins.
The Artificial Prediction Market
 The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
Distributed forests for MapReduce-based machine learning
 Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
An Overview of Data Mining: Predictive Modeling for IR in the 21 st Century
 An Overview of Data Mining: Predictive Modeling for IR in the 21 st Century Nora Galambos, PhD Senior Data Scientist Office of Institutional Research, Planning & Effectiveness Stony Brook University AIRPO
An Overview of Data Mining: Predictive Modeling for IR in the 21 st Century Nora Galambos, PhD Senior Data Scientist Office of Institutional Research, Planning & Effectiveness Stony Brook University AIRPO
B-Trees. Algorithms and data structures for external memory as opposed to the main memory B-Trees. B -trees
 B-Trees Algorithms and data structures for external memory as opposed to the main memory B-Trees Previous Lectures Height balanced binary search trees: AVL trees, red-black trees. Multiway search trees:
B-Trees Algorithms and data structures for external memory as opposed to the main memory B-Trees Previous Lectures Height balanced binary search trees: AVL trees, red-black trees. Multiway search trees:
A Data Mining Tutorial
 A Data Mining Tutorial Presented at the Second IASTED International Conference on Parallel and Distributed Computing and Networks (PDCN 98) 14 December 1998 Graham Williams, Markus Hegland and Stephen
A Data Mining Tutorial Presented at the Second IASTED International Conference on Parallel and Distributed Computing and Networks (PDCN 98) 14 December 1998 Graham Williams, Markus Hegland and Stephen
Car Insurance. Havránek, Pokorný, Tomášek
 Car Insurance Havránek, Pokorný, Tomášek Outline Data overview Horizontal approach + Decision tree/forests Vertical (column) approach + Neural networks SVM Data overview Customers Viewed policies Bought
Car Insurance Havránek, Pokorný, Tomášek Outline Data overview Horizontal approach + Decision tree/forests Vertical (column) approach + Neural networks SVM Data overview Customers Viewed policies Bought
IMPLEMENTING CLASSIFICATION FOR INDIAN STOCK MARKET USING CART ALGORITHM WITH B+ TREE
 P 0Tis International Journal of Scientific Engineering and Applied Science (IJSEAS) Volume-2, Issue-, January 206 IMPLEMENTING CLASSIFICATION FOR INDIAN STOCK MARKET USING CART ALGORITHM WITH B+ TREE Kalpna
P 0Tis International Journal of Scientific Engineering and Applied Science (IJSEAS) Volume-2, Issue-, January 206 IMPLEMENTING CLASSIFICATION FOR INDIAN STOCK MARKET USING CART ALGORITHM WITH B+ TREE Kalpna
BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL
 The Fifth International Conference on e-learning (elearning-2014), 22-23 September 2014, Belgrade, Serbia BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL SNJEŽANA MILINKOVIĆ University
The Fifth International Conference on e-learning (elearning-2014), 22-23 September 2014, Belgrade, Serbia BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL SNJEŽANA MILINKOVIĆ University
II. RELATED WORK. Sentiment Mining
 Sentiment Mining Using Ensemble Classification Models Matthew Whitehead and Larry Yaeger Indiana University School of Informatics 901 E. 10th St. Bloomington, IN 47408 {mewhiteh, larryy}@indiana.edu Abstract
Sentiment Mining Using Ensemble Classification Models Matthew Whitehead and Larry Yaeger Indiana University School of Informatics 901 E. 10th St. Bloomington, IN 47408 {mewhiteh, larryy}@indiana.edu Abstract
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Microsoft Azure Machine learning Algorithms
 Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql [email protected] http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql [email protected] http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
Decompose Error Rate into components, some of which can be measured on unlabeled data
 Bias-Variance Theory Decompose Error Rate into components, some of which can be measured on unlabeled data Bias-Variance Decomposition for Regression Bias-Variance Decomposition for Classification Bias-Variance
Bias-Variance Theory Decompose Error Rate into components, some of which can be measured on unlabeled data Bias-Variance Decomposition for Regression Bias-Variance Decomposition for Classification Bias-Variance
Predicting borrowers chance of defaulting on credit loans
 Predicting borrowers chance of defaulting on credit loans Junjie Liang ([email protected]) Abstract Credit score prediction is of great interests to banks as the outcome of the prediction algorithm
Predicting borrowers chance of defaulting on credit loans Junjie Liang ([email protected]) Abstract Credit score prediction is of great interests to banks as the outcome of the prediction algorithm
Feature vs. Classifier Fusion for Predictive Data Mining a Case Study in Pesticide Classification
 Feature vs. Classifier Fusion for Predictive Data Mining a Case Study in Pesticide Classification Henrik Boström School of Humanities and Informatics University of Skövde P.O. Box 408, SE-541 28 Skövde
Feature vs. Classifier Fusion for Predictive Data Mining a Case Study in Pesticide Classification Henrik Boström School of Humanities and Informatics University of Skövde P.O. Box 408, SE-541 28 Skövde
Package bigrf. February 19, 2015
 Version 0.1-11 Date 2014-05-16 Package bigrf February 19, 2015 Title Big Random Forests: Classification and Regression Forests for Large Data Sets Maintainer Aloysius Lim OS_type
Version 0.1-11 Date 2014-05-16 Package bigrf February 19, 2015 Title Big Random Forests: Classification and Regression Forests for Large Data Sets Maintainer Aloysius Lim OS_type
Chapter 26: Data Mining
 Chapter 6: Data Mining (Some slides courtesy of Rich Caruana, Cornell University) Definition Data mining is the exploration and analysis of large quantities of data in order to discover valid, novel, potentially
Chapter 6: Data Mining (Some slides courtesy of Rich Caruana, Cornell University) Definition Data mining is the exploration and analysis of large quantities of data in order to discover valid, novel, potentially
New Work Item for ISO 3534-5 Predictive Analytics (Initial Notes and Thoughts) Introduction
 Introduction") Introduction New Work Item for ISO 3534-5 Predictive Analytics (Initial Notes and Thoughts) Predictive analytics encompasses the body of statistical knowledge supporting the analysis of massive data sets.
Introduction New Work Item for ISO 3534-5 Predictive Analytics (Initial Notes and Thoughts) Predictive analytics encompasses the body of statistical knowledge supporting the analysis of massive data sets.
Methods for statistical data analysis with decision trees
 Methods for statistical data analysis with decision trees Problems of the multivariate statistical analysis In realizing the statistical analysis, first of all it is necessary to define which obects and
Methods for statistical data analysis with decision trees Problems of the multivariate statistical analysis In realizing the statistical analysis, first of all it is necessary to define which obects and
The Impact of Big Data on Classic Machine Learning Algorithms. Thomas Jensen, Senior Business Analyst @ Expedia
 The Impact of Big Data on Classic Machine Learning Algorithms Thomas Jensen, Senior Business Analyst @ Expedia Who am I? Senior Business Analyst @ Expedia Working within the competitive intelligence unit
The Impact of Big Data on Classic Machine Learning Algorithms Thomas Jensen, Senior Business Analyst @ Expedia Who am I? Senior Business Analyst @ Expedia Working within the competitive intelligence unit
Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams
 Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams Pramod D. Patil Research Scholar Department of Computer Engineering College of Engg. Pune, University of Pune Parag
Adaptive Classification Algorithm for Concept Drifting Electricity Pricing Data Streams Pramod D. Patil Research Scholar Department of Computer Engineering College of Engg. Pune, University of Pune Parag
Previous Lectures. B-Trees. External storage. Two types of memory. B-trees. Main principles
 B-Trees Algorithms and data structures for external memory as opposed to the main memory B-Trees Previous Lectures Height balanced binary search trees: AVL trees, red-black trees. Multiway search trees:
B-Trees Algorithms and data structures for external memory as opposed to the main memory B-Trees Previous Lectures Height balanced binary search trees: AVL trees, red-black trees. Multiway search trees:
Performance Analysis of Decision Trees
 Performance Analysis of Decision Trees Manpreet Singh Department of Information Technology, Guru Nanak Dev Engineering College, Ludhiana, Punjab, India Sonam Sharma CBS Group of Institutions, New Delhi,India
Performance Analysis of Decision Trees Manpreet Singh Department of Information Technology, Guru Nanak Dev Engineering College, Ludhiana, Punjab, India Sonam Sharma CBS Group of Institutions, New Delhi,India
Better credit models benefit us all
 Better credit models benefit us all Agenda Credit Scoring - Overview Random Forest - Overview Random Forest outperform logistic regression for credit scoring out of the box Interaction term hypothesis
Better credit models benefit us all Agenda Credit Scoring - Overview Random Forest - Overview Random Forest outperform logistic regression for credit scoring out of the box Interaction term hypothesis
Welcome. Data Mining: Updates in Technologies. Xindong Wu. Colorado School of Mines Golden, Colorado 80401, USA
 Welcome Xindong Wu Data Mining: Updates in Technologies Dept of Math and Computer Science Colorado School of Mines Golden, Colorado 80401, USA Email: xwu@ mines.edu Home Page: http://kais.mines.edu/~xwu/
Welcome Xindong Wu Data Mining: Updates in Technologies Dept of Math and Computer Science Colorado School of Mines Golden, Colorado 80401, USA Email: xwu@ mines.edu Home Page: http://kais.mines.edu/~xwu/
Dr. U. Devi Prasad Associate Professor Hyderabad Business School GITAM University, Hyderabad Email: [email protected]
 96 Business Intelligence Journal January PREDICTION OF CHURN BEHAVIOR OF BANK CUSTOMERS USING DATA MINING TOOLS Dr. U. Devi Prasad Associate Professor Hyderabad Business School GITAM University, Hyderabad
96 Business Intelligence Journal January PREDICTION OF CHURN BEHAVIOR OF BANK CUSTOMERS USING DATA MINING TOOLS Dr. U. Devi Prasad Associate Professor Hyderabad Business School GITAM University, Hyderabad
Chapter 20: Data Analysis
 Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Analysis of WEKA Data Mining Algorithm REPTree, Simple Cart and RandomTree for Classification of Indian News
 Analysis of WEKA Data Mining Algorithm REPTree, Simple Cart and RandomTree for Classification of Indian News Sushilkumar Kalmegh Associate Professor, Department of Computer Science, Sant Gadge Baba Amravati
Analysis of WEKA Data Mining Algorithm REPTree, Simple Cart and RandomTree for Classification of Indian News Sushilkumar Kalmegh Associate Professor, Department of Computer Science, Sant Gadge Baba Amravati
The Operational Value of Social Media Information. Social Media and Customer Interaction
 The Operational Value of Social Media Information Dennis J. Zhang (Kellogg School of Management) Ruomeng Cui (Kelley School of Business) Santiago Gallino (Tuck School of Business) Antonio Moreno-Garcia
The Operational Value of Social Media Information Dennis J. Zhang (Kellogg School of Management) Ruomeng Cui (Kelley School of Business) Santiago Gallino (Tuck School of Business) Antonio Moreno-Garcia
6 Classification and Regression Trees, 7 Bagging, and Boosting
 hs24 v.2004/01/03 Prn:23/02/2005; 14:41 F:hs24011.tex; VTEX/ES p. 1 1 Handbook of Statistics, Vol. 24 ISSN: 0169-7161 2005 Elsevier B.V. All rights reserved. DOI 10.1016/S0169-7161(04)24011-1 1 6 Classification
hs24 v.2004/01/03 Prn:23/02/2005; 14:41 F:hs24011.tex; VTEX/ES p. 1 1 Handbook of Statistics, Vol. 24 ISSN: 0169-7161 2005 Elsevier B.V. All rights reserved. DOI 10.1016/S0169-7161(04)24011-1 1 6 Classification
REVIEW OF ENSEMBLE CLASSIFICATION
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IJCSMC, Vol. 2, Issue.
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IJCSMC, Vol. 2, Issue.
Big Data Decision Trees with R
 REVOLUTION ANALYTICS WHITE PAPER Big Data Decision Trees with R By Richard Calaway, Lee Edlefsen, and Lixin Gong Fast, Scalable, Distributable Decision Trees Revolution Analytics RevoScaleR package provides
REVOLUTION ANALYTICS WHITE PAPER Big Data Decision Trees with R By Richard Calaway, Lee Edlefsen, and Lixin Gong Fast, Scalable, Distributable Decision Trees Revolution Analytics RevoScaleR package provides
Ensemble Learning Better Predictions Through Diversity. Todd Holloway ETech 2008
 Ensemble Learning Better Predictions Through Diversity Todd Holloway ETech 2008 Outline Building a classifier (a tutorial example) Neighbor method Major ideas and challenges in classification Ensembles
Ensemble Learning Better Predictions Through Diversity Todd Holloway ETech 2008 Outline Building a classifier (a tutorial example) Neighbor method Major ideas and challenges in classification Ensembles
MHI3000 Big Data Analytics for Health Care Final Project Report
 MHI3000 Big Data Analytics for Health Care Final Project Report Zhongtian Fred Qiu (1002274530) http://gallery.azureml.net/details/81ddb2ab137046d4925584b5095ec7aa 1. Data pre-processing The data given
MHI3000 Big Data Analytics for Health Care Final Project Report Zhongtian Fred Qiu (1002274530) http://gallery.azureml.net/details/81ddb2ab137046d4925584b5095ec7aa 1. Data pre-processing The data given
EFFICIENT CLASSIFICATION OF BIG DATA USING VFDT (VERY FAST DECISION TREE)
") EFFICIENT CLASSIFICATION OF BIG DATA USING VFDT (VERY FAST DECISION TREE) Sourav Roy 1, Brina Patel 2, Samruddhi Purandare 3, Minal Kucheria 4 1 Student, Computer Department, MIT College of Engineering,
EFFICIENT CLASSIFICATION OF BIG DATA USING VFDT (VERY FAST DECISION TREE) Sourav Roy 1, Brina Patel 2, Samruddhi Purandare 3, Minal Kucheria 4 1 Student, Computer Department, MIT College of Engineering,
Classification of Bad Accounts in Credit Card Industry
 Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition
Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition