Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning
|
|
|
- Gertrude Paul
- 10 years ago
- Views:
Transcription
1 Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013

2 Outline Introduction to NMF Applications Motivations NMF as a middle step in a semi-supervised learning framework Support vector machines Random forests Future directions and Q&A

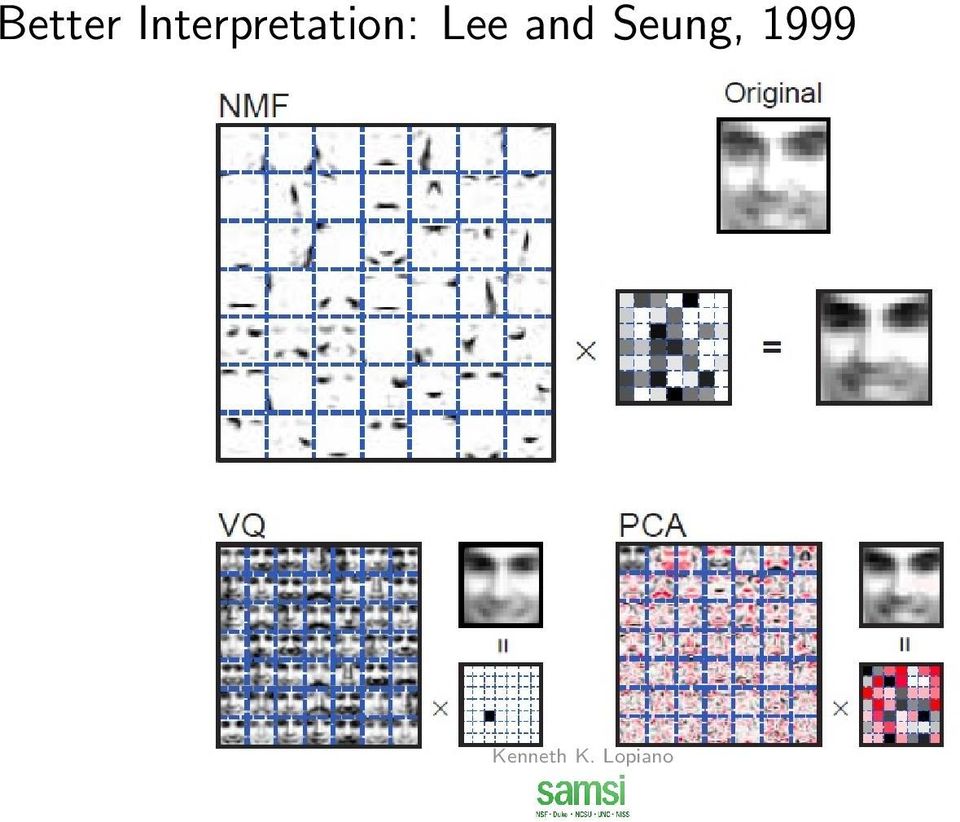
3 Introduction Consider a matrix X p n s.t. X i,j 0 i, j Non-standard interpretation for statisticians Rows are features Columns are samples Non-negative matrix factorization X p n = W p k H k n + E p n W R p k + - Basis Matrix H R k n + - Coefficient Matrix E - Error matrix Advantage: NMF decomposes original matrix into a parts based representation that gives better interpretation of factoring matrices for non-negative data

4 Better Interpretation: Lee and Seung, 1999
5 Why do we care? Many real world applications - some in health care! 1. Text mining - document clustering, topic detection and trend tracking 2. Image analysis - feature representation, sparse coding, video tracking, image compression, image reconstruction, semi-supervised learning 3. Social/Interaction networks - community detection, recommendation systems 4. Bioinformatics - -omics data analysis 5. Acoustic Signal Processing - blind source separation 6. Data clustering...to name a few!

6 Community Detection H can be interpreted as indicating community membership Illustrated here using a cell phone network of 177 cell towers in DR matrix of normalized call flows (i.e., ij th element = proportion of calls from i to j.) y Kenneth 70.5 K. Lopiano x
 y 18.")
7 Community Detection Clear separation in captial city - West is higher income, east is lower income y x


8 Metagenomics: Brunet et al. Efficient method for identification of distinct molecular patterns and provides a powerful method for class discovery


9 Audio Source Separation: Battenberg and Wessel Matrix - number of positive frequency bins by number of analysis frames CUDA implementation...the newer Geforce GTX 280, with 30 multiprocessors at 1.3GHz, runs the CUDA implementation over 30x faster than the optimized Matlab implementation

10 So it matters - now what? Can I estimate W and H? How is this done? What are the properties of my estimators? A fruitful area of research related to NMF has been related to developing algorithms to answer these questions, however, I am not interested in improving/comparing algorithms. I am interested in using the algorithms in different applications and understanding the unique benefits of NMF.

11 Loss Functions For completeness - a brief review Frobenius norm KL Divergence min W,H i,j min W,H ( Xij X ij log X WH 2 F s.t. W, H 0 (WH) ij s.t. W, H 0 ) X ij + (WH) ij Sparsity constraints on H (similarly defined for sparsity on W) min W,H many more... n X WH 2 F + η W 2 F + β H(:, j) 2 1 s.t. W 0, H 0 j=1
 X ij + (WH) ij Sparsity constraints on H (similarly defined for")

12 Algorithms

13 NMF for Partially Labeled Data NMF is an unsupervised learning algorithm to reduce dimension of original data Question: Suppose some observations are labeled (e.g., diseased versus not diseased). If the weight vectors are used as covariates in a statistical learning framework, then does NMF give any clear advantages over other dimension reduction techniques (e.g., PCA)?
?")
14 Semi-Supervised Dimensionality Reduction NMF is an unsupervised learning algorithm to reduce dimension of original data Goal: Incorporate information from labeled examples to estimate the rank of the lower dimensional data. Example: MNIST Data - Comparing 4s and 9s - n = 13782, p = 784 pixels, m = 11791, Y i, i = 1,..., m, is an indicator the i th observations is a 4 or 9. Use NMF to project the observations from 784 dimensions to k = 8, 16, 32, 64, 128, and 256 dimensions (multiplicative updates algorithm) Use support vector machines to train a classifier using The full training data: observations and 784 covariates The reduced training data: observations and k dimensions Predict the class membership of n m = 1991 validation observations

15 Semi-Supervised Dimensionality Reduction NMF is an unsupervised learning algorithm to reduce dimension of original data Goal: Incorporate information from labeled examples to estimate the rank of the lower dimensional data. Example: MNIST Data - Comparing 4s and 9s - n = 13782, p = 784 pixels, m = 11791, Y i, i = 1,..., m, is an indicator the i th observations is a 4 or 9. Use NMF to project the observations from 784 dimensions to k = 8, 16, 32, 64, 128, and 256 dimensions (multiplicative updates algorithm) Use support vector machines to train a classifier using The full training data: observations and 784 covariates The reduced training data: observations and k dimensions Predict the class membership of n m = 1991 validation observations

16 Semi-Supervised Dimensionality Reduction NMF is an unsupervised learning algorithm to reduce dimension of original data Goal: Incorporate information from labeled examples to estimate the rank of the lower dimensional data. Example: MNIST Data - Comparing 4s and 9s - n = 13782, p = 784 pixels, m = 11791, Y i, i = 1,..., m, is an indicator the i th observations is a 4 or 9. Use NMF to project the observations from 784 dimensions to k = 8, 16, 32, 64, 128, and 256 dimensions (multiplicative updates algorithm) Use support vector machines to train a classifier using The full training data: observations and 784 covariates The reduced training data: observations and k dimensions Predict the class membership of n m = 1991 validation observations

17 Semi-Supervised Dimensionality Reduction NMF is an unsupervised learning algorithm to reduce dimension of original data Goal: Incorporate information from labeled examples to estimate the rank of the lower dimensional data. Example: MNIST Data - Comparing 4s and 9s - n = 13782, p = 784 pixels, m = 11791, Y i, i = 1,..., m, is an indicator the i th observations is a 4 or 9. Use NMF to project the observations from 784 dimensions to k = 8, 16, 32, 64, 128, and 256 dimensions (multiplicative updates algorithm) Use support vector machines to train a classifier using The full training data: observations and 784 covariates The reduced training data: observations and k dimensions Predict the class membership of n m = 1991 validation observations

18 Semi-Supervised Dimensionality Reduction NMF is an unsupervised learning algorithm to reduce dimension of original data Goal: Incorporate information from labeled examples to estimate the rank of the lower dimensional data. Example: MNIST Data - Comparing 4s and 9s - n = 13782, p = 784 pixels, m = 11791, Y i, i = 1,..., m, is an indicator the i th observations is a 4 or 9. Use NMF to project the observations from 784 dimensions to k = 8, 16, 32, 64, 128, and 256 dimensions (multiplicative updates algorithm) Use support vector machines to train a classifier using The full training data: observations and 784 covariates The reduced training data: observations and k dimensions Predict the class membership of n m = 1991 validation observations

19 Semi-Supervised Dimensionality Reduction NMF is an unsupervised learning algorithm to reduce dimension of original data Goal: Incorporate information from labeled examples to estimate the rank of the lower dimensional data. Example: MNIST Data - Comparing 4s and 9s - n = 13782, p = 784 pixels, m = 11791, Y i, i = 1,..., m, is an indicator the i th observations is a 4 or 9. Use NMF to project the observations from 784 dimensions to k = 8, 16, 32, 64, 128, and 256 dimensions (multiplicative updates algorithm) Use support vector machines to train a classifier using The full training data: observations and 784 covariates The reduced training data: observations and k dimensions Predict the class membership of n m = 1991 validation observations

20 Semi-Supervised Dimensionality Reduction NMF is an unsupervised learning algorithm to reduce dimension of original data Goal: Incorporate information from labeled examples to estimate the rank of the lower dimensional data. Example: MNIST Data - Comparing 4s and 9s - n = 13782, p = 784 pixels, m = 11791, Y i, i = 1,..., m, is an indicator the i th observations is a 4 or 9. Use NMF to project the observations from 784 dimensions to k = 8, 16, 32, 64, 128, and 256 dimensions (multiplicative updates algorithm) Use support vector machines to train a classifier using The full training data: observations and 784 covariates The reduced training data: observations and k dimensions Predict the class membership of n m = 1991 validation observations

21 Results Prediction Error in Reduced Dimension Prediction Error (%) NMF PC Full Dimension k
22 Idea - Reducing Dimension and Maintaining Meaning NMF gives factors that are more interpretable than those obtained from PCA or SVD. Does this mean that the importance of the variables in the reduced dimension can be interpreted?
23 Random Forests and Variable Importance Random forest - machine learning algorithm used for classification and regression - many decision trees are trained to many samples of the original data and combined to form final classification rules (details omitted here) Variable importance measures can be used to identify which variables are important for the learning task. Gini Impurity - I = 1 2 i=1 f i 2, f i = fraction of items labeled i in the set Gini importance - Every time a split of a node is made on a variable the gini impurity criterion for the two descendent nodes is less than the parent node. Adding up the gini decreases for each individual variable over all trees in the forest gives a fast variable importance... Kenneth breiman/randomforests/cc K. Lopiano home.htm
24 Results k = 32, 64, 128 Random forest using k factors obtained through NMF and first k principal components The 4 most important variables are plotted for both NMF and PCA
25 Examples Example 4 Mean 4r Example 9 Mean 9
26 Results k=32,64,and 128 k=32,64,and 128 k=32,64,and 128 k=32,64,and 128
27 Results k = 32 k=32 k=32 k=32 k=32
28 Results k = 64 k=64 k=64 k=64 k=64
29 Results k = 128 k=128 k=128 k=128 k=128
30 Moving forward NMF as a middle step - classification or prediction as final step More examples - genetics and medical imaging With prediction or classification in mind - minimize mean squared prediction error and cross validation to choose k
31 References Battenberg, E. and Wessel, D. (2009) Accelerating non-negative matrix factorization for audio source separation on multi-core and many core architectures Proceedings of the 10th International Society for Music Information Retrieval Conference (ISMIR 2009) Brunet et al. (2004) Metagenes and molecular pattern discovery using matrix factorization. PNAS. vol 101, no 12. Jiang, X. et al. (2012) A non-negative matrix factorization framework for identifying modular paterns in metagenomic profile data. Journal of Mathematical Biology. vol 64. pp Kim, J. and Park, H. (2008) Sparse NMF for Clustering. hpark/papers/gt-cse pdf Mazack, M. (2009) Non-Negative Matrix Factorization with Applications to Handwritten Digit Recognition, Working Paper, University of Minnesota. nmf paper.pdf Wang, F et al. (2010) Community discovery using NMF. Data Mining and Knowledge Discovery
BIOINF 585 Fall 2015 Machine Learning for Systems Biology & Clinical Informatics http://www.ccmb.med.umich.edu/node/1376
 Course Director: Dr. Kayvan Najarian (DCM&B, [email protected]) Lectures: Labs: Mondays and Wednesdays 9:00 AM -10:30 AM Rm. 2065 Palmer Commons Bldg. Wednesdays 10:30 AM 11:30 AM (alternate weeks) Rm.
Course Director: Dr. Kayvan Najarian (DCM&B, [email protected]) Lectures: Labs: Mondays and Wednesdays 9:00 AM -10:30 AM Rm. 2065 Palmer Commons Bldg. Wednesdays 10:30 AM 11:30 AM (alternate weeks) Rm.
Medical Information Management & Mining. You Chen Jan,15, 2013 [email protected]
 Medical Information Management & Mining You Chen Jan,15, 2013 [email protected] 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Medical Information Management & Mining You Chen Jan,15, 2013 [email protected] 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches
 Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Data, Measurements, Features
 Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Data, Measurements, Features Middle East Technical University Dep. of Computer Engineering 2009 compiled by V. Atalay What do you think of when someone says Data? We might abstract the idea that data are
Unsupervised and supervised dimension reduction: Algorithms and connections
 Unsupervised and supervised dimension reduction: Algorithms and connections Jieping Ye Department of Computer Science and Engineering Evolutionary Functional Genomics Center The Biodesign Institute Arizona
Unsupervised and supervised dimension reduction: Algorithms and connections Jieping Ye Department of Computer Science and Engineering Evolutionary Functional Genomics Center The Biodesign Institute Arizona
Component Ordering in Independent Component Analysis Based on Data Power
 Component Ordering in Independent Component Analysis Based on Data Power Anne Hendrikse Raymond Veldhuis University of Twente University of Twente Fac. EEMCS, Signals and Systems Group Fac. EEMCS, Signals
Component Ordering in Independent Component Analysis Based on Data Power Anne Hendrikse Raymond Veldhuis University of Twente University of Twente Fac. EEMCS, Signals and Systems Group Fac. EEMCS, Signals
Exploratory data analysis for microarray data
 Eploratory data analysis for microarray data Anja von Heydebreck Ma Planck Institute for Molecular Genetics, Dept. Computational Molecular Biology, Berlin, Germany [email protected] Visualization
Eploratory data analysis for microarray data Anja von Heydebreck Ma Planck Institute for Molecular Genetics, Dept. Computational Molecular Biology, Berlin, Germany [email protected] Visualization
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Machine Learning: Overview
 Machine Learning: Overview Why Learning? Learning is a core of property of being intelligent. Hence Machine learning is a core subarea of Artificial Intelligence. There is a need for programs to behave
Machine Learning: Overview Why Learning? Learning is a core of property of being intelligent. Hence Machine learning is a core subarea of Artificial Intelligence. There is a need for programs to behave
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Sparse Nonnegative Matrix Factorization for Clustering
 Sparse Nonnegative Matrix Factorization for Clustering Jingu Kim and Haesun Park College of Computing Georgia Institute of Technology 266 Ferst Drive, Atlanta, GA 30332, USA {jingu, hpark}@cc.gatech.edu
Sparse Nonnegative Matrix Factorization for Clustering Jingu Kim and Haesun Park College of Computing Georgia Institute of Technology 266 Ferst Drive, Atlanta, GA 30332, USA {jingu, hpark}@cc.gatech.edu
Methodology for Emulating Self Organizing Maps for Visualization of Large Datasets
 Methodology for Emulating Self Organizing Maps for Visualization of Large Datasets Macario O. Cordel II and Arnulfo P. Azcarraga College of Computer Studies *Corresponding Author: [email protected]
Methodology for Emulating Self Organizing Maps for Visualization of Large Datasets Macario O. Cordel II and Arnulfo P. Azcarraga College of Computer Studies *Corresponding Author: [email protected]
CS Master Level Courses and Areas COURSE DESCRIPTIONS. CSCI 521 Real-Time Systems. CSCI 522 High Performance Computing
 CS Master Level Courses and Areas The graduate courses offered may change over time, in response to new developments in computer science and the interests of faculty and students; the list of graduate
CS Master Level Courses and Areas The graduate courses offered may change over time, in response to new developments in computer science and the interests of faculty and students; the list of graduate
Class-specific Sparse Coding for Learning of Object Representations
 Class-specific Sparse Coding for Learning of Object Representations Stephan Hasler, Heiko Wersing, and Edgar Körner Honda Research Institute Europe GmbH Carl-Legien-Str. 30, 63073 Offenbach am Main, Germany
Class-specific Sparse Coding for Learning of Object Representations Stephan Hasler, Heiko Wersing, and Edgar Körner Honda Research Institute Europe GmbH Carl-Legien-Str. 30, 63073 Offenbach am Main, Germany
A Survey on Outlier Detection Techniques for Credit Card Fraud Detection
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 2, Ver. VI (Mar-Apr. 2014), PP 44-48 A Survey on Outlier Detection Techniques for Credit Card Fraud
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 2, Ver. VI (Mar-Apr. 2014), PP 44-48 A Survey on Outlier Detection Techniques for Credit Card Fraud
NAVIGATING SCIENTIFIC LITERATURE A HOLISTIC PERSPECTIVE. Venu Govindaraju
 NAVIGATING SCIENTIFIC LITERATURE A HOLISTIC PERSPECTIVE Venu Govindaraju BIOMETRICS DOCUMENT ANALYSIS PATTERN RECOGNITION 8/24/2015 ICDAR- 2015 2 Towards a Globally Optimal Approach for Learning Deep Unsupervised
NAVIGATING SCIENTIFIC LITERATURE A HOLISTIC PERSPECTIVE Venu Govindaraju BIOMETRICS DOCUMENT ANALYSIS PATTERN RECOGNITION 8/24/2015 ICDAR- 2015 2 Towards a Globally Optimal Approach for Learning Deep Unsupervised
Fast Analytics on Big Data with H20
 Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
Fast Analytics on Big Data with H20 0xdata.com, h2o.ai Tomas Nykodym, Petr Maj Team About H2O and 0xdata H2O is a platform for distributed in memory predictive analytics and machine learning Pure Java,
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 3, 2014 Text Analytics (Text Mining) LSI (uses SVD), Visualization Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey
CSE 6242 / CX 4242 Apr 3, 2014 Text Analytics (Text Mining) LSI (uses SVD), Visualization Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey
Efficient online learning of a non-negative sparse autoencoder
 and Machine Learning. Bruges (Belgium), 28-30 April 2010, d-side publi., ISBN 2-93030-10-2. Efficient online learning of a non-negative sparse autoencoder Andre Lemme, R. Felix Reinhart and Jochen J. Steil
and Machine Learning. Bruges (Belgium), 28-30 April 2010, d-side publi., ISBN 2-93030-10-2. Efficient online learning of a non-negative sparse autoencoder Andre Lemme, R. Felix Reinhart and Jochen J. Steil
Statistical Data Mining. Practical Assignment 3 Discriminant Analysis and Decision Trees
 Statistical Data Mining Practical Assignment 3 Discriminant Analysis and Decision Trees In this practical we discuss linear and quadratic discriminant analysis and tree-based classification techniques.
Statistical Data Mining Practical Assignment 3 Discriminant Analysis and Decision Trees In this practical we discuss linear and quadratic discriminant analysis and tree-based classification techniques.
RANDOM PROJECTIONS FOR SEARCH AND MACHINE LEARNING
 = + RANDOM PROJECTIONS FOR SEARCH AND MACHINE LEARNING Stefan Savev Berlin Buzzwords June 2015 KEYWORD-BASED SEARCH Document Data 300 unique words per document 300 000 words in vocabulary Data sparsity:
= + RANDOM PROJECTIONS FOR SEARCH AND MACHINE LEARNING Stefan Savev Berlin Buzzwords June 2015 KEYWORD-BASED SEARCH Document Data 300 unique words per document 300 000 words in vocabulary Data sparsity:
An Introduction to Data Mining. Big Data World. Related Fields and Disciplines. What is Data Mining? 2/12/2015
 An Introduction to Data Mining for Wind Power Management Spring 2015 Big Data World Every minute: Google receives over 4 million search queries Facebook users share almost 2.5 million pieces of content
An Introduction to Data Mining for Wind Power Management Spring 2015 Big Data World Every minute: Google receives over 4 million search queries Facebook users share almost 2.5 million pieces of content
Statistical machine learning, high dimension and big data
 Statistical machine learning, high dimension and big data S. Gaïffas 1 14 mars 2014 1 CMAP - Ecole Polytechnique Agenda for today Divide and Conquer principle for collaborative filtering Graphical modelling,
Statistical machine learning, high dimension and big data S. Gaïffas 1 14 mars 2014 1 CMAP - Ecole Polytechnique Agenda for today Divide and Conquer principle for collaborative filtering Graphical modelling,
SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING
 AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
Integrated Data Mining Strategy for Effective Metabolomic Data Analysis
 The First International Symposium on Optimization and Systems Biology (OSB 07) Beijing, China, August 8 10, 2007 Copyright 2007 ORSC & APORC pp. 45 51 Integrated Data Mining Strategy for Effective Metabolomic
The First International Symposium on Optimization and Systems Biology (OSB 07) Beijing, China, August 8 10, 2007 Copyright 2007 ORSC & APORC pp. 45 51 Integrated Data Mining Strategy for Effective Metabolomic
Using multiple models: Bagging, Boosting, Ensembles, Forests
 Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
D-optimal plans in observational studies
 D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
D-optimal plans in observational studies Constanze Pumplün Stefan Rüping Katharina Morik Claus Weihs October 11, 2005 Abstract This paper investigates the use of Design of Experiments in observational
APPM4720/5720: Fast algorithms for big data. Gunnar Martinsson The University of Colorado at Boulder
 APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
APPM4720/5720: Fast algorithms for big data Gunnar Martinsson The University of Colorado at Boulder Course objectives: The purpose of this course is to teach efficient algorithms for processing very large
Programming Exercise 3: Multi-class Classification and Neural Networks
 Programming Exercise 3: Multi-class Classification and Neural Networks Machine Learning November 4, 2011 Introduction In this exercise, you will implement one-vs-all logistic regression and neural networks
Programming Exercise 3: Multi-class Classification and Neural Networks Machine Learning November 4, 2011 Introduction In this exercise, you will implement one-vs-all logistic regression and neural networks
Supervised Feature Selection & Unsupervised Dimensionality Reduction
 Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set
 EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set Amhmed A. Bhih School of Electrical and Electronic Engineering Princy Johnson School of Electrical and Electronic Engineering Martin
EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set Amhmed A. Bhih School of Electrical and Electronic Engineering Princy Johnson School of Electrical and Electronic Engineering Martin
Mehtap Ergüven Abstract of Ph.D. Dissertation for the degree of PhD of Engineering in Informatics
 INTERNATIONAL BLACK SEA UNIVERSITY COMPUTER TECHNOLOGIES AND ENGINEERING FACULTY ELABORATION OF AN ALGORITHM OF DETECTING TESTS DIMENSIONALITY Mehtap Ergüven Abstract of Ph.D. Dissertation for the degree
INTERNATIONAL BLACK SEA UNIVERSITY COMPUTER TECHNOLOGIES AND ENGINEERING FACULTY ELABORATION OF AN ALGORITHM OF DETECTING TESTS DIMENSIONALITY Mehtap Ergüven Abstract of Ph.D. Dissertation for the degree
CS 5614: (Big) Data Management Systems. B. Aditya Prakash Lecture #18: Dimensionality Reduc7on
 Data Management Systems. B. Aditya Prakash Lecture #18: Dimensionality Reduc7on") CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #18: Dimensionality Reduc7on Dimensionality Reduc=on Assump=on: Data lies on or near a low d- dimensional subspace Axes of this subspace
CS 5614: (Big) Data Management Systems B. Aditya Prakash Lecture #18: Dimensionality Reduc7on Dimensionality Reduc=on Assump=on: Data lies on or near a low d- dimensional subspace Axes of this subspace
Supervised and unsupervised learning - 1
 Chapter 3 Supervised and unsupervised learning - 1 3.1 Introduction The science of learning plays a key role in the field of statistics, data mining, artificial intelligence, intersecting with areas in
Chapter 3 Supervised and unsupervised learning - 1 3.1 Introduction The science of learning plays a key role in the field of statistics, data mining, artificial intelligence, intersecting with areas in
Network Machine Learning Research Group. Intended status: Informational October 19, 2015 Expires: April 21, 2016
 Network Machine Learning Research Group S. Jiang Internet-Draft Huawei Technologies Co., Ltd Intended status: Informational October 19, 2015 Expires: April 21, 2016 Abstract Network Machine Learning draft-jiang-nmlrg-network-machine-learning-00
Network Machine Learning Research Group S. Jiang Internet-Draft Huawei Technologies Co., Ltd Intended status: Informational October 19, 2015 Expires: April 21, 2016 Abstract Network Machine Learning draft-jiang-nmlrg-network-machine-learning-00
Final Project Report
 CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
Distributed forests for MapReduce-based machine learning
 Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
New Ensemble Combination Scheme
 New Ensemble Combination Scheme Namhyoung Kim, Youngdoo Son, and Jaewook Lee, Member, IEEE Abstract Recently many statistical learning techniques are successfully developed and used in several areas However,
New Ensemble Combination Scheme Namhyoung Kim, Youngdoo Son, and Jaewook Lee, Member, IEEE Abstract Recently many statistical learning techniques are successfully developed and used in several areas However,
Big Data Text Mining and Visualization. Anton Heijs
 Copyright 2007 by Treparel Information Solutions BV. This report nor any part of it may be copied, circulated, quoted without prior written approval from Treparel7 Treparel Information Solutions BV Delftechpark
Copyright 2007 by Treparel Information Solutions BV. This report nor any part of it may be copied, circulated, quoted without prior written approval from Treparel7 Treparel Information Solutions BV Delftechpark
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU
 Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Machine Learning and Pattern Recognition Logistic Regression
 Machine Learning and Pattern Recognition Logistic Regression Course Lecturer:Amos J Storkey Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh Crichton Street,
Machine Learning and Pattern Recognition Logistic Regression Course Lecturer:Amos J Storkey Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh Crichton Street,
CS 2750 Machine Learning. Lecture 1. Machine Learning. http://www.cs.pitt.edu/~milos/courses/cs2750/ CS 2750 Machine Learning.
 Lecture Machine Learning Milos Hauskrecht [email protected] 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht [email protected] 539 Sennott
Lecture Machine Learning Milos Hauskrecht [email protected] 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht [email protected] 539 Sennott
Multidimensional data analysis
 Multidimensional data analysis Ella Bingham Dept of Computer Science, University of Helsinki [email protected] June 2008 The Finnish Graduate School in Astronomy and Space Physics Summer School
Multidimensional data analysis Ella Bingham Dept of Computer Science, University of Helsinki [email protected] June 2008 The Finnish Graduate School in Astronomy and Space Physics Summer School
BUILDING A PREDICTIVE MODEL AN EXAMPLE OF A PRODUCT RECOMMENDATION ENGINE
 BUILDING A PREDICTIVE MODEL AN EXAMPLE OF A PRODUCT RECOMMENDATION ENGINE Alex Lin Senior Architect Intelligent Mining [email protected] Outline Predictive modeling methodology k-nearest Neighbor
BUILDING A PREDICTIVE MODEL AN EXAMPLE OF A PRODUCT RECOMMENDATION ENGINE Alex Lin Senior Architect Intelligent Mining [email protected] Outline Predictive modeling methodology k-nearest Neighbor
Data Mining Applications in Fund Raising
 Data Mining Applications in Fund Raising Nafisseh Heiat Data mining tools make it possible to apply mathematical models to the historical data to manipulate and discover new information. In this study,
Data Mining Applications in Fund Raising Nafisseh Heiat Data mining tools make it possible to apply mathematical models to the historical data to manipulate and discover new information. In this study,
Image Compression through DCT and Huffman Coding Technique
 International Journal of Current Engineering and Technology E-ISSN 2277 4106, P-ISSN 2347 5161 2015 INPRESSCO, All Rights Reserved Available at http://inpressco.com/category/ijcet Research Article Rahul
International Journal of Current Engineering and Technology E-ISSN 2277 4106, P-ISSN 2347 5161 2015 INPRESSCO, All Rights Reserved Available at http://inpressco.com/category/ijcet Research Article Rahul
TIETS34 Seminar: Data Mining on Biometric identification
 TIETS34 Seminar: Data Mining on Biometric identification Youming Zhang Computer Science, School of Information Sciences, 33014 University of Tampere, Finland [email protected] Course Description Content
TIETS34 Seminar: Data Mining on Biometric identification Youming Zhang Computer Science, School of Information Sciences, 33014 University of Tampere, Finland [email protected] Course Description Content
Science Navigation Map: An Interactive Data Mining Tool for Literature Analysis
 Science Navigation Map: An Interactive Data Mining Tool for Literature Analysis Yu Liu School of Software [email protected] Zhen Huang School of Software [email protected] Yufeng Chen School of Computer
Science Navigation Map: An Interactive Data Mining Tool for Literature Analysis Yu Liu School of Software [email protected] Zhen Huang School of Software [email protected] Yufeng Chen School of Computer
Machine Learning for Medical Image Analysis. A. Criminisi & the InnerEye team @ MSRC
 Machine Learning for Medical Image Analysis A. Criminisi & the InnerEye team @ MSRC Medical image analysis the goal Automatic, semantic analysis and quantification of what observed in medical scans Brain
Machine Learning for Medical Image Analysis A. Criminisi & the InnerEye team @ MSRC Medical image analysis the goal Automatic, semantic analysis and quantification of what observed in medical scans Brain
Object Recognition and Template Matching
 Object Recognition and Template Matching Template Matching A template is a small image (sub-image) The goal is to find occurrences of this template in a larger image That is, you want to find matches of
Object Recognition and Template Matching Template Matching A template is a small image (sub-image) The goal is to find occurrences of this template in a larger image That is, you want to find matches of
BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES
 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 123 CHAPTER 7 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 7.1 Introduction Even though using SVM presents
BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 123 CHAPTER 7 BEHAVIOR BASED CREDIT CARD FRAUD DETECTION USING SUPPORT VECTOR MACHINES 7.1 Introduction Even though using SVM presents
Recognition. Sanja Fidler CSC420: Intro to Image Understanding 1 / 28
 Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP
 Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 3: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 3: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major
How To Make A Credit Risk Model For A Bank Account
 TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző [email protected] 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző [email protected] 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
Statistical Analysis. NBAF-B Metabolomics Masterclass. Mark Viant
 Statistical Analysis NBAF-B Metabolomics Masterclass Mark Viant 1. Introduction 2. Univariate analysis Overview of lecture 3. Unsupervised multivariate analysis Principal components analysis (PCA) Interpreting
Statistical Analysis NBAF-B Metabolomics Masterclass Mark Viant 1. Introduction 2. Univariate analysis Overview of lecture 3. Unsupervised multivariate analysis Principal components analysis (PCA) Interpreting
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization
 A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca [email protected] Spain Manuel Martín-Merino Universidad
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca [email protected] Spain Manuel Martín-Merino Universidad
Clustering Very Large Data Sets with Principal Direction Divisive Partitioning
 Clustering Very Large Data Sets with Principal Direction Divisive Partitioning David Littau 1 and Daniel Boley 2 1 University of Minnesota, Minneapolis MN 55455 [email protected] 2 University of Minnesota,
Clustering Very Large Data Sets with Principal Direction Divisive Partitioning David Littau 1 and Daniel Boley 2 1 University of Minnesota, Minneapolis MN 55455 [email protected] 2 University of Minnesota,
Support Vector Machines with Clustering for Training with Very Large Datasets
 Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France [email protected] Massimiliano
Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France [email protected] Massimiliano
Data Preprocessing. Week 2
 Data Preprocessing Week 2 Topics Data Types Data Repositories Data Preprocessing Present homework assignment #1 Team Homework Assignment #2 Read pp. 227 240, pp. 250 250, and pp. 259 263 the text book.
Data Preprocessing Week 2 Topics Data Types Data Repositories Data Preprocessing Present homework assignment #1 Team Homework Assignment #2 Read pp. 227 240, pp. 250 250, and pp. 259 263 the text book.
Learning, Sparsity and Big Data
 Learning, Sparsity and Big Data M. Magdon-Ismail (Joint Work) January 22, 2014. Out-of-Sample is What Counts NO YES A pattern exists We don t know it We have data to learn it Tested on new cases? Teaching
Learning, Sparsity and Big Data M. Magdon-Ismail (Joint Work) January 22, 2014. Out-of-Sample is What Counts NO YES A pattern exists We don t know it We have data to learn it Tested on new cases? Teaching
Data Mining in Web Search Engine Optimization and User Assisted Rank Results
 Data Mining in Web Search Engine Optimization and User Assisted Rank Results Minky Jindal Institute of Technology and Management Gurgaon 122017, Haryana, India Nisha kharb Institute of Technology and Management
Data Mining in Web Search Engine Optimization and User Assisted Rank Results Minky Jindal Institute of Technology and Management Gurgaon 122017, Haryana, India Nisha kharb Institute of Technology and Management
DATA ANALYSIS II. Matrix Algorithms
 DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
Map-Reduce for Machine Learning on Multicore
 Map-Reduce for Machine Learning on Multicore Chu, et al. Problem The world is going multicore New computers - dual core to 12+-core Shift to more concurrent programming paradigms and languages Erlang,
Map-Reduce for Machine Learning on Multicore Chu, et al. Problem The world is going multicore New computers - dual core to 12+-core Shift to more concurrent programming paradigms and languages Erlang,
Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics
 Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics Part I: Factorizations and Statistical Modeling/Inference Amnon Shashua School of Computer Science & Eng. The Hebrew University
Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics Part I: Factorizations and Statistical Modeling/Inference Amnon Shashua School of Computer Science & Eng. The Hebrew University
Adaptive Framework for Network Traffic Classification using Dimensionality Reduction and Clustering
 IV International Congress on Ultra Modern Telecommunications and Control Systems 22 Adaptive Framework for Network Traffic Classification using Dimensionality Reduction and Clustering Antti Juvonen, Tuomo
IV International Congress on Ultra Modern Telecommunications and Control Systems 22 Adaptive Framework for Network Traffic Classification using Dimensionality Reduction and Clustering Antti Juvonen, Tuomo
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Discriminant non-stationary signal features clustering using hard and fuzzy cluster labeling
 Ghoraani and Krishnan EURASIP Journal on Advances in Signal Processing 2012, 2012:250 RESEARCH Open Access Discriminant non-stationary signal features clustering using hard and fuzzy cluster labeling Behnaz
Ghoraani and Krishnan EURASIP Journal on Advances in Signal Processing 2012, 2012:250 RESEARCH Open Access Discriminant non-stationary signal features clustering using hard and fuzzy cluster labeling Behnaz
Principal Component Analysis
 Principal Component Analysis ERS70D George Fernandez INTRODUCTION Analysis of multivariate data plays a key role in data analysis. Multivariate data consists of many different attributes or variables recorded
Principal Component Analysis ERS70D George Fernandez INTRODUCTION Analysis of multivariate data plays a key role in data analysis. Multivariate data consists of many different attributes or variables recorded
Introduction to Machine Learning Using Python. Vikram Kamath
 Introduction to Machine Learning Using Python Vikram Kamath Contents: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Introduction/Definition Where and Why ML is used Types of Learning Supervised Learning Linear Regression
Introduction to Machine Learning Using Python Vikram Kamath Contents: 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Introduction/Definition Where and Why ML is used Types of Learning Supervised Learning Linear Regression
Big Data Summarization Using Semantic. Feture for IoT on Cloud
 Contemporary Engineering Sciences, Vol. 7, 2014, no. 22, 1095-1103 HIKARI Ltd, www.m-hikari.com http://dx.doi.org/10.12988/ces.2014.49137 Big Data Summarization Using Semantic Feture for IoT on Cloud Yoo-Kang
Contemporary Engineering Sciences, Vol. 7, 2014, no. 22, 1095-1103 HIKARI Ltd, www.m-hikari.com http://dx.doi.org/10.12988/ces.2014.49137 Big Data Summarization Using Semantic Feture for IoT on Cloud Yoo-Kang
Machine learning for algo trading
 Machine learning for algo trading An introduction for nonmathematicians Dr. Aly Kassam Overview High level introduction to machine learning A machine learning bestiary What has all this got to do with
Machine learning for algo trading An introduction for nonmathematicians Dr. Aly Kassam Overview High level introduction to machine learning A machine learning bestiary What has all this got to do with
Web Log Data Sparsity Analysis and Performance Evaluation for OLAP
 Web Log Data Sparsity Analysis and Performance Evaluation for OLAP Ji-Hyun Kim, Hwan-Seung Yong Department of Computer Science and Engineering Ewha Womans University 11-1 Daehyun-dong, Seodaemun-gu, Seoul,
Web Log Data Sparsity Analysis and Performance Evaluation for OLAP Ji-Hyun Kim, Hwan-Seung Yong Department of Computer Science and Engineering Ewha Womans University 11-1 Daehyun-dong, Seodaemun-gu, Seoul,
Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression
 Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression Saikat Maitra and Jun Yan Abstract: Dimension reduction is one of the major tasks for multivariate
Principle Component Analysis and Partial Least Squares: Two Dimension Reduction Techniques for Regression Saikat Maitra and Jun Yan Abstract: Dimension reduction is one of the major tasks for multivariate
Wavelet analysis. Wavelet requirements. Example signals. Stationary signal 2 Hz + 10 Hz + 20Hz. Zero mean, oscillatory (wave) Fast decay (let)
 Fast decay (let)") Wavelet analysis In the case of Fourier series, the orthonormal basis is generated by integral dilation of a single function e jx Every 2π-periodic square-integrable function is generated by a superposition
Wavelet analysis In the case of Fourier series, the orthonormal basis is generated by integral dilation of a single function e jx Every 2π-periodic square-integrable function is generated by a superposition
01219211 Software Development Training Camp 1 (0-3) Prerequisite : 01204214 Program development skill enhancement camp, at least 48 person-hours.
 Prerequisite : 01204214 Program development skill enhancement camp, at least 48 person-hours.") (International Program) 01219141 Object-Oriented Modeling and Programming 3 (3-0) Object concepts, object-oriented design and analysis, object-oriented analysis relating to developing conceptual models
(International Program) 01219141 Object-Oriented Modeling and Programming 3 (3-0) Object concepts, object-oriented design and analysis, object-oriented analysis relating to developing conceptual models
6. Cholesky factorization
 6. Cholesky factorization EE103 (Fall 2011-12) triangular matrices forward and backward substitution the Cholesky factorization solving Ax = b with A positive definite inverse of a positive definite matrix
6. Cholesky factorization EE103 (Fall 2011-12) triangular matrices forward and backward substitution the Cholesky factorization solving Ax = b with A positive definite inverse of a positive definite matrix
Decision Trees from large Databases: SLIQ
 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Introduction to Pattern Recognition
 Introduction to Pattern Recognition Selim Aksoy Department of Computer Engineering Bilkent University [email protected] CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Introduction to Pattern Recognition Selim Aksoy Department of Computer Engineering Bilkent University [email protected] CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Standardization and Its Effects on K-Means Clustering Algorithm
 Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
Soft Clustering with Projections: PCA, ICA, and Laplacian
 1 Soft Clustering with Projections: PCA, ICA, and Laplacian David Gleich and Leonid Zhukov Abstract In this paper we present a comparison of three projection methods that use the eigenvectors of a matrix
1 Soft Clustering with Projections: PCA, ICA, and Laplacian David Gleich and Leonid Zhukov Abstract In this paper we present a comparison of three projection methods that use the eigenvectors of a matrix
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
Classification Problems
 Classification Read Chapter 4 in the text by Bishop, except omit Sections 4.1.6, 4.1.7, 4.2.4, 4.3.3, 4.3.5, 4.3.6, 4.4, and 4.5. Also, review sections 1.5.1, 1.5.2, 1.5.3, and 1.5.4. Classification Problems
Classification Read Chapter 4 in the text by Bishop, except omit Sections 4.1.6, 4.1.7, 4.2.4, 4.3.3, 4.3.5, 4.3.6, 4.4, and 4.5. Also, review sections 1.5.1, 1.5.2, 1.5.3, and 1.5.4. Classification Problems
Probabilistic Latent Semantic Analysis (plsa)
") Probabilistic Latent Semantic Analysis (plsa) SS 2008 Bayesian Networks Multimedia Computing, Universität Augsburg [email protected] www.multimedia-computing.{de,org} References
Probabilistic Latent Semantic Analysis (plsa) SS 2008 Bayesian Networks Multimedia Computing, Universität Augsburg [email protected] www.multimedia-computing.{de,org} References
Using Data Mining for Mobile Communication Clustering and Characterization
 Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Unsupervised Data Mining (Clustering)
") Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Unsupervised Data Mining (Clustering) Javier Béjar KEMLG December 01 Javier Béjar (KEMLG) Unsupervised Data Mining (Clustering) December 01 1 / 51 Introduction Clustering in KDD One of the main tasks in
Maschinelles Lernen mit MATLAB
 Maschinelles Lernen mit MATLAB Jérémy Huard Applikationsingenieur The MathWorks GmbH 2015 The MathWorks, Inc. 1 Machine Learning is Everywhere Image Recognition Speech Recognition Stock Prediction Medical
Maschinelles Lernen mit MATLAB Jérémy Huard Applikationsingenieur The MathWorks GmbH 2015 The MathWorks, Inc. 1 Machine Learning is Everywhere Image Recognition Speech Recognition Stock Prediction Medical
FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT MINING SYSTEM
 International Journal of Innovative Computing, Information and Control ICIC International c 0 ISSN 34-48 Volume 8, Number 8, August 0 pp. 4 FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT
International Journal of Innovative Computing, Information and Control ICIC International c 0 ISSN 34-48 Volume 8, Number 8, August 0 pp. 4 FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT
How To Cluster
 Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Leveraging Ensemble Models in SAS Enterprise Miner
 ABSTRACT Paper SAS133-2014 Leveraging Ensemble Models in SAS Enterprise Miner Miguel Maldonado, Jared Dean, Wendy Czika, and Susan Haller SAS Institute Inc. Ensemble models combine two or more models to
ABSTRACT Paper SAS133-2014 Leveraging Ensemble Models in SAS Enterprise Miner Miguel Maldonado, Jared Dean, Wendy Czika, and Susan Haller SAS Institute Inc. Ensemble models combine two or more models to
Review Jeopardy. Blue vs. Orange. Review Jeopardy
 Review Jeopardy Blue vs. Orange Review Jeopardy Jeopardy Round Lectures 0-3 Jeopardy Round $200 How could I measure how far apart (i.e. how different) two observations, y 1 and y 2, are from each other?
Review Jeopardy Blue vs. Orange Review Jeopardy Jeopardy Round Lectures 0-3 Jeopardy Round $200 How could I measure how far apart (i.e. how different) two observations, y 1 and y 2, are from each other?
Group Testing a tool of protecting Network Security
 Group Testing a tool of protecting Network Security Hung-Lin Fu 傅 恆 霖 Department of Applied Mathematics, National Chiao Tung University, Hsin Chu, Taiwan Group testing (General Model) Consider a set N
Group Testing a tool of protecting Network Security Hung-Lin Fu 傅 恆 霖 Department of Applied Mathematics, National Chiao Tung University, Hsin Chu, Taiwan Group testing (General Model) Consider a set N
Big Text Data Clustering using Class Labels and Semantic Feature Based on Hadoop of Cloud Computing
 Vol.8, No.4 (214), pp.1-1 http://dx.doi.org/1.14257/ijseia.214.8.4.1 Big Text Data Clustering using Class Labels and Semantic Feature Based on Hadoop of Cloud Computing Yong-Il Kim 1, Yoo-Kang Ji 2 and
Vol.8, No.4 (214), pp.1-1 http://dx.doi.org/1.14257/ijseia.214.8.4.1 Big Text Data Clustering using Class Labels and Semantic Feature Based on Hadoop of Cloud Computing Yong-Il Kim 1, Yoo-Kang Ji 2 and
Comparative Analysis of EM Clustering Algorithm and Density Based Clustering Algorithm Using WEKA tool.
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 9, Issue 8 (January 2014), PP. 19-24 Comparative Analysis of EM Clustering Algorithm
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 9, Issue 8 (January 2014), PP. 19-24 Comparative Analysis of EM Clustering Algorithm
Clustering Big Data. Anil K. Jain. (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012
 Department of Computer Science Michigan State University November 29, 2012") Clustering Big Data Anil K. Jain (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012 Outline Big Data How to extract information? Data clustering
Clustering Big Data Anil K. Jain (with Radha Chitta and Rong Jin) Department of Computer Science Michigan State University November 29, 2012 Outline Big Data How to extract information? Data clustering