Longitudinal Data Analysis
|
|
|
- Eleanore Hoover
- 10 years ago
- Views:
Transcription
1 Longitudinal Data Analysis Acknowledge: Professor Garrett Fitzmaurice INSTRUCTOR: Rino Bellocco Department of Statistics & Quantitative Methods University of Milano-Bicocca Department of Medical Epidemiology and Biostatistics Karolinska Institutet 1

2 ORGANIZATION OF LECTURES Introduction and Overview Longitudinal Data: Basic Concepts Linear Models for Longitudinal Dara Modelling the Mean: Analysis of Response Profiles Modelling the Mean: Parametric Curves Modelling the Covariance Linear Mixed Effects Models Extensions to discrete data: GEE 2

3 LONGITUDINAL DATA ANALYSIS LECTURE 1 3

4 INTRODUCTION Longitudinal Studies: Studies in which individuals are measured repeatedly through time. This course will cover the analysis and interpretation of results from longitudinal studies. Emphasis will be on model development, use of statistical software, and interpretation of results. Theoretical basis for results mentioned but not developed. No calculus or matrix algebra is assumed. 4

5 Features of Longitudinal Data Defining feature: repeated observations on individuals, allowing the direct study of change over time. Primary goal of a longitudinal study is to characterize the change in response and factors that influence change. With repeated measures on individuals, one can capture within-individual change. Note that measurements in a longitudinal study are commensurate, i.e., the same variable is measured repeatedly. 5

6 Longitudinal data require somewhat more sophisticated statistical techniques because the repeated observations are usually (positively) correlated. Sequential nature of the measures implies that certain types of correlation structures are likely to arise. Correlation must be accounted for in order to obtain valid inferences. 6

7 Example 1 Treatment of Lead-Exposed Children (TLC) Trial Exposure to lead during infancy is associated with substantial deficits in tests of cognitive ability Chelation treatment of children with high lead levels usually requires injections and hospitalization A new agent, Succimer, can be given orally Randomized trial examining changes in blood lead level during course of treatment 100 children randomized to placebo or Succimer Measures of blood lead level at baseline, 1, 4 and 6 weeks 7

8 Table 1: Blood lead levels (µg/dl) at baseline, week 1, week 4, and week 6 for 8 randomly selected children. ID Group a Baseline Week 1 Week 4 Week P A A P A A P P a P = Placebo; A = Succimer. 8

9 Table 2: Mean blood lead levels (and standard deviation) at baseline, week 1, week 4, and week 6. Group Baseline Week 1 Week 4 Week 6 Succimer (5.0) (7.7) (7.8) (9.2) Placebo (5.0) (5.5) (5.7) (6.2) 9
 (7.7) (7.8) (9.2) Placebo 26.3 24.7 24.1 23.")
10 Mean blood lead level (mcg/dl) Placebo Succimer Time (weeks) Figure 1: Plot of mean blood lead levels at baseline, week 1, week 4, and week 6 in the succimer and placebo groups. 10

11 Example 2 Six Cities Study of Air Pollution and Health Longitudinal study designed to characterize lung function growth in children and adolescents. Most children were enrolled between the ages of six and seven and measurements were obtained annually until graduation from high school. Focus on a randomly selected subset of the 300 female participants living in Topeka, Kansas. Response variable: Volume of air exhaled in the first second of spiromtry manoeuvre, FEV 1. 11

12 Table 3: Data on age, height, and FEV 1 for a randomly selected girl from the Topeka data set. Subject ID Age Height Time FEV Note: Time represents time since entry to study. 12

13 Log(FEV1/Height) Age (years) Figure 2: Timeplot of log(fev 1 /height) versus age for 50 randomly selected girls from the Topeka data set. 13

14 Example 3 Influence of Menarche on Changes in Body Fat Prospective study on body fat accretion in a cohort of 162 girls from the MIT Growth and Development Study. At start of study, all the girls were pre-menarcheal and non-obese All girls were followed over time according to a schedule of annual measurements until four years after menarche. The final measurement was scheduled on the fourth anniversary of their reported date of menarche. At each examination, a measure of body fatness was obtained based on bioelectric impedance analysis. 14

15 15
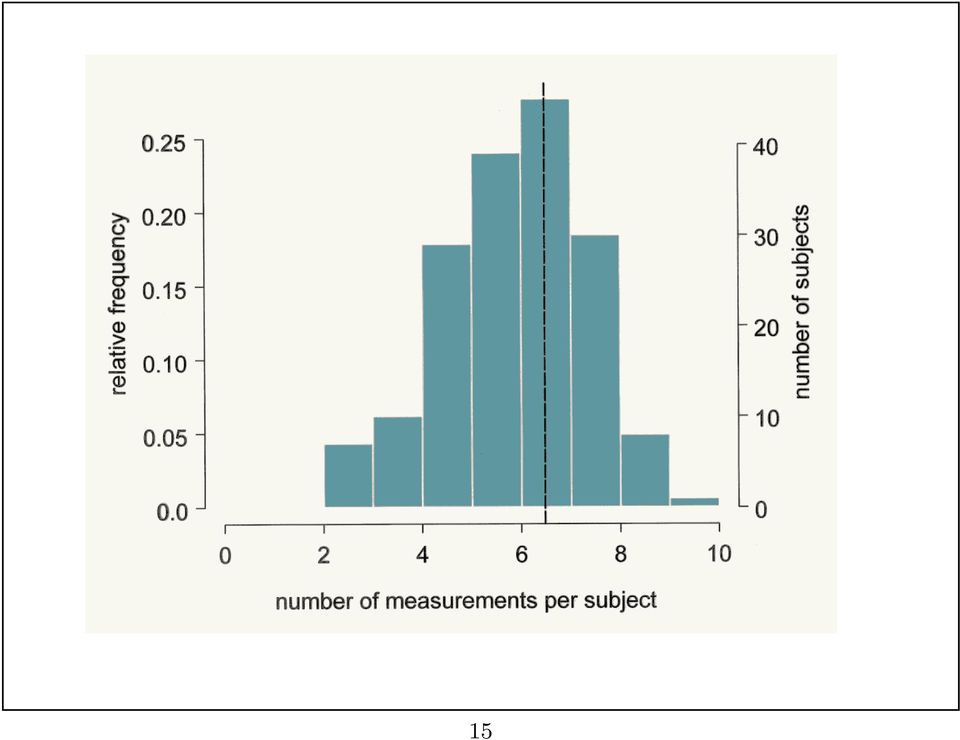
16 Figure 3: Timeplot of percent body fat against age (in years). 16

17 Consider an analysis of the changes in percent body fat before and after menarche. For the purposes of these analyses time is coded as time since menarche and can be positive or negative. Note: measurement protocol is the same for all girls. Study design is almost balanced if timing of measurement is defined as time since baseline measurement. It is inherently unbalanced when timing of measurements is defined as time since a girl experienced menarche. 17

18 40 Percent body fat Time relative to menarche (years) Figure 4: Timeplot of percent body fat against time, relative to age of menarche (in years). 18
. 18")
19 LONGITUDINAL DATA: BASIC CONCEPTS Defining feature of longitudinal studies is that measurements of the same individuals are taken repeatedly through time. Longitudinal studies allow direct study of change over time. The primary goal is to characterize the change in response over time and the factors that influence change. With repeated measures on individuals, we can capture within-individual change. 19

20 A longitudinal study can estimate change with great precision because each individual acts as his/her own control. By comparing each individual s responses at two or more occasions, a longitudinal analysis can remove extraneous, but unavoidable, sources of variability among individuals. This eliminates major sources of variability or noise from the estimation of within-individual change. 20

21 The assessment of within-subject change can only be achieved within a longitudinal study design In a cross-sectional study, we can only obtain estimates of between-individual differences in the response A cross-sectional study may allow comparison among sub-populations that happen to differ in age, but it does not provide any information about how individuals change In a cross-sectional study the effect of ageing is potentially confounded or mixed-up with possible cohort effects 21
22 Terminology Individuals/Subjects: Participants in a longitudinal study are referred to as individuals or subjects. Occasions: In a longitudinal study individuals are measured repeatedly at different occasions or times. The number of repeated observations, and their timing, can vary widely from one longitudinal study to another. When the number and the timing of the repeated measurements are the same for all individuals, the study design is said to be balanced over time. 22
23 Notation Let Y ij denote the response variable for the i th individual (i = 1,..., N) at the j th occasion (j = 1,..., n). If the repeated measures are assumed to be equally-separated in time, this notation will be sufficient. Later, we refine notation to handle the case where repeated measures are unequally-separated and unbalanced over time. We can represent the n observations on the N individuals in a two-dimensional array, with rows corresponding to individuals and columns corresponding to the responses at each occasion. 23
24 Table 4: Tabular representation of longitudinal data, with n repeated observations on N individuals. Occasion Individual n 1 y 11 y 12 y y 1n 2 y 21 y 22 y y 2n N y N1 y N2 y N3... y Nn 24
25 Vector Notation: We can group the n repeated measures on the same individual into a n 1 response vector: Y i = Y i1 Y i2.. Y in Alternatively, we can denote the response vectors Y i as Y i = (Y i1, Y i2,..., Y in ). 25
26 Covariance and Correlation An aspect of longitudinal data that complicates their statistical analysis is that repeated measures on the same individual are usually positively correlated. This violates the fundamental assumption of independence that is the cornerstone of many statistical techniques. What are the potential consequences of not accounting for correlation among longitudinal data in the analysis? An additional, although often overlooked, aspect of longitudinal data that complicates their statistical analysis is heterogeneous variability. 26
27 That is, the variability of the outcome at the end of the study is often discernibly different than the variability at the start of the study. This violates the assumption of homoscedasticity that is the basis for standard linear regression techniques. Thus, there are two aspects of longitudinal data that complicate their statistical analysis: (i) repeated measures on the same individual are usually positively correlated, and (ii) variability is often heterogeneous across measurement occasions. 27
28 Before we can give a formal definition of correlation we need to introduce the notion of expectation. We denote the expectation or mean of Y ij by µ j = E(Y ij ), where E( ) can be thought of as a long-run average. The mean, µ j, provides a measure of the location of the center of the distribution of Y ij. 28
29 The variance provides a measure of the spread or dispersion of the values of Y ij around its respective mean: σj 2 = E[Y ij E(Y ij )] 2 = E(Y ij µ j ) 2. The positive square-root of the variance, σ j, is known as the standard deviation. The covariance between two variables, say Y ij and Y ik, σ jk = E [(Y ij µ j )(Y ik µ k )], is a measure of the linear dependence between Y ij and Y ik. When the covariance is zero, there is no linear dependence between the responses at the two occasions. 29
30 The correlation between Y ij and Y ik is denoted by ρ jk = E [(Y ij µ j )(Y ik µ k )] σ j σ k, where σ j and σ k are the standard deviations of Y ij and Y ik. The correlation, unlike covariance, is a measure of dependence free of scales of measurement of Y ij and Y ik. By definition, correlation must take values between 1 and 1. A correlation of 1 or 1 is obtained when there is a perfect linear relationship between the two variables. 30
31 For the vector of repeated measures, Y i = (Y i1, Y i2,..., Y in ), we define the variance-covariance matrix, Cov(Y i ), Cov Y i1 Y i2. Y in = Var(Y i1 ) Cov(Y i1, Y i2 ) Cov(Y i1, Y in ) Cov(Y i2, Y i1 ) Var(Y i2 ) Cov(Y i2, Y in ) Cov(Y in, Y i1 ) Cov(Y in, Y i2 ) Var(Y in ) = σ 2 1 σ 12 σ 1n σ 21 σ2 2 σ 2n , σ n1 σ n2 σ 2 n where Cov (Y ij, Y ik ) = σ jk = σ kj = Cov(Y ik, Y ij ). 31
32 We can also define the correlation matrix, Corr(Y i ), Corr(Y i ) = 1 ρ 12 ρ 1n ρ 21 1 ρ 2n ρ n1 ρ n2 1. This matrix is also symmetric in the sense that Corr (Y ij, Y ik ) = ρ jk = ρ kj = Corr(Y ik, Y ij ). 32
33 Example: Treatment of Lead-Exposed Children Trial We restrict attention to the data from placebo group Data consist of 4 repeated measurements of blood lead levels obtained at baseline (or week 0), weeks 1, 4, and 6. The inter-dependence (or time-dependence) among the four repeated measures of blood lead level can be examined by constructing a scatter-plot of each pair of repeated measures. Examination of the correlations confirms that they are all positive and tend to decrease with increasing time separation. 33
34 Week Baseline Week Baseline Week Week 1 Week Baseline Week Week 1 Week Week 4 Figure 5: Pairwise scatter-plots of blood lead levels at baseline, week 1, week 4, and week 6 for children in the placebo group. 34
35 Table 5: Estimated covariance matrix for the blood lead levels at baseline, week 1, week 4, and week 6 for children in the placebo group of the TLC trial. Covariance Matrix
36 Table 6: Estimated correlation matrix for the blood lead levels at baseline, week 1, week 4, and week 6 for children in the placebo group of the TLC trial. Correlation Matrix
37 Some Observations about Correlation in Longitudinal Data Empirical observations about the nature of the correlation among repeated measures in longitudinal studies: (i) correlations are positive, (ii) correlations decrease with increasing time separation, (iii) correlations between repeated measures rarely ever approach zero, and (iv) correlation between a pair of repeated measures taken very closely together in time rarely approaches one. 37
38 Consequences of Ignoring Correlation Potential implications of ignoring the correlation among the repeated measures. Consider only the first two repeated measures from the TLC trial, taken at baseline (or week 0) and week 1. Suppose it is of interest to determine whether there has been a change in the mean response over time. A natural estimate of change in the mean response is: ˆδ = ˆµ 2 ˆµ 1 where N ˆµ j = 1 N i=1 Y ij 38
39 For data from TLC trial, estimate of change in the mean response over time in succimer groups is (or ). An expression for the variance of ˆδ is given by [ ] 1 N Var(ˆδ) = Var (Y i2 Y i1) = 1 N N (σ2 1 + σ2 2 2σ 12 ). i=1 We can substitute estimates of variance and covariances into this expression to obtain estimates of variance of ˆδ. Var(ˆδ) = 1 50 [ (15.5)] =
40 Consequences of Ignoring Correlation If we ignored the correlation and proceeded with analysis assuming observations are independent, we would have obtained the following (incorrect) estimate of variance of ˆδ 1 50 [ ] = which is approximately 1.6 times larger. In general, ignoring, the correlation leads to incorrect inferences 40
41 Further Reading: Fitzmaurice GM, Laird NM and Ware JH. (2004) Applied Longitudinal Analysis. Wiley. Chapter 1, Chapter 2 (Sections 2.1, 2.2, 2.3, 2.4) 41
42 APPLIED LONGITUDINAL ANALYSIS LECTURE 2 42
43 LINEAR MODELS FOR LONGITUDINAL DATA Notation: Previously, we assumed a sample of N subjects are measured repeatedly at n occasions. Either by design or happenstance, subjects may not have same number of repeated measures or be measured at same set of occasions. We assume there are n i repeated measurements on the i th subject and each Y ij is observed at time t ij. 43
44 We can group the response variables for the i th subject into a n i 1 vector: Y i = Y i1. Y ini, i = 1,..., N. Associated with Y ij there is a p 1 vector of covariates X ij = X ij1. X ijp, i = 1,..., N; j = 1,..., n i. 44
45 We can group vectors of covariates into a n i p matrix: X i = X i11 X i12 X i1p X i21 X i22 X i2p......, i = 1,..., N. X ini 1 X ini 2 X ini p X i is simply an ordered collection of the values of the p covariates for the i th subject at the n i occasions. 45
46 Throughout this course we consider linear regression models for changes in the mean response over time: Y ij = β 1 X ij1 + β 2 X ij2 + + β p X ijp + e ij, j = 1,..., n i ; where β 1,..., β p are unknown regression coefficients. The e ij are random errors, with mean zero, and represent deviations of the Y ij s from their means, E(Y ij X ij ) = β 1 X ij1 + β 2 X ij2 + + β p X ijp. Typically, although not always, X ij1 = 1 for all i and j, E(Y ij X ij ) = β 1 + β 2 X ij2 + + β p X ijp, and then β 1 is the intercept term in the model. 46
47 Treatment of Lead-Exposed Children Trial For illustrative purposes, consider model that assumes mean blood lead level changes linearly over time, but at a rate that differs by group. Assume two treatment groups have different intercepts and slopes: Y ij = β 1 X ij1 + β 2 X ij2 + β 3 X ij3 + β 4 X ij4 + e ij, where X ij1 = 1 for all i and all j; X ij2 = t j, the week in which the blood lead level was obtained; X ij3 = 1 if the i th subject is assigned to the succimer group and X ij3 = 0 otherwise. X ij4 = t j if the i th subject is assigned to the succimer group and X ij4 = 0 otherwise. Alternatively, X ij4 = X ij2 X ij3. 47
48 Thus, for children in the placebo group E(Y ij X ij ) = β 1 + β 2 t j, where β 1 represents the mean blood lead level at baseline (week = 0) and β 2 is the constant rate of change in mean blood level. Similarly, for children in the succimer group E(Y ij X ij ) = (β 1 + β 3 ) + (β 2 + β 4 )t j, where β 2 + β 4 is the constant rate of change in mean blood level per week. Hypothesis that treatments are equally effective in reducing blood lead levels translated into hypothesis that β 4 = 0. 48
49 To reinforce notation, consider the responses and covariates at the 4 occasions for any individual. For example, the responses at the 4 occasions for ID = 046: The values of the covariates at the 4 occasions for ID = 046: This individual was assigned to treatment with placebo. 49
50 On the other hand, the responses at the 4 occasions for ID = 149: The values of the covariates at the 4 occasions for ID = 149: This individual was assigned to treatment with succimer. 50
51 Distributional Assumptions So far, only assumptions made concern patterns of change in the mean response over time and their relation to covariates. E(Y ij X ij ) = β 1 X ij1 + β 2 X ij2 + + β p X ijp. Next we consider distributional assumptions concerning the random errors, e ij. Note: Y ij is assumed to be comprised of two components, a systematic component, β 1 X ij1 + β 2 X ij2 + + β p X ijp, and a random component, e ij. Assumptions about shape of distribution of e ij translate into assumptions about distribution of Y ij given X ij. 51
52 We assume Y i1,..., Y ini have a multivariate normal distribution, with mean response E(Y ij X ij ) = µ ij = β 1 X ij1 + β 2 X ij2 + + β p X ijp, and covariance matrix, Σ i = Cov(Y i ). Multivariate normal distribution can be considered multivariate analogue of the univariate normal distribution. The multivariate normal distribution is completely specified by the means, µ i1,..., µ ini, and the covariance matrix, Σ i. 52
53 Estimation: Maximum Likelihood A very general approach to estimation is the method of maximum likelihood (ML). Basic idea: use as estimates of β 1,..., β p and Σ i the values that are most probable (or most likely ) for the data that have actually been observed. ML estimates of β 1,..., β p and Σ i are those values that maximize the joint probability of the response variables evaluated at their observed values (the likelihood function). 53
54 The ML estimator of β 1,..., β p is the so-called generalized least squares (GLS) estimator, β 1 (Σ i ),..., β p (Σ i ), β = [ N ( X i Σ 1 ) ] 1 N X i i=1 i=1 ( X i Σ 1 i y i ), and depends on covariance among the repeated measures, Σ i. This is a generalization of the ordinary least squares (OLS) estimator used in standard linear regression. In general, there is no simple expression for ML estimator of Σ i ; instead, ML estimate of Σ i requires iterative techniques. Once ML estimate of Σ i has been obtained, we simply substitute the estimate of Σ i, say Σ i, into the GLS estimator of β 1,..., β p to obtain ML estimates, β 1 ( Σ i ),..., β p ( Σ i ). 54
55 Restricted Maximum Likelihood (REML) Estimation ML estimation of Σ i is known to be biased in small samples. Bias arises because ML estimate has not taken into account the fact that β 1,..., β p is also estimated from the data. Instead we can use a variant on ML estimation, known as restricted maximum likelihood (REML) estimation. When REML estimation is used to estimate Σ i, β 1,..., β p are estimated by the usual GLS estimator, β 1 ( Σ i ),..., β p ( Σ i ), except Σ i is now the REML estimate of Σ i. 55
56 Caution: While REML log-likelihood can be used to compare nested models for the covariance, it should not be used to compare nested regression models for the mean. Instead, nested models for the mean should be compared using likelihood ratio tests based on the ML log-likelihood. 56
57 Modelling Longitudinal Data Longitudinal data present two aspects of the data that require modelling: (i) mean response over time (ii) covariance Models for longitudinal data must jointly specify models for the mean and covariance. Modelling the Mean Two main approaches can be distinguished: (1) analysis of response profiles (2) parametric or semi-parametric curves. 57
58 Modelling the Covariance Three broad approaches can be distinguished: (1) unstructured or arbitrary pattern of covariance (2) covariance pattern models (3) random effects covariance strucutre 58
59 MODELLING THE MEAN: ANALYSIS OF RESPONSE PROFILES Basic idea: Compare groups in terms of mean response profiles over time. Useful for balanced longitudinal designs and when there is a single categorical covariate (perhaps denoting different treatment or exposure groups). Analysis of response profiles can be extended to handle more than a single group factor. Analysis of response profiles can also handle missing data. 59
60 Mean blood lead level (mcg/dl) Placebo Succimer Time (weeks) Figure 6: Mean blood lead levels at baseline, week 1, week 4, and week 6 in the succimer and placebo groups. 60
61 Hypotheses concerning response profiles Given a sequence of n repeated measures on a number of distinct groups of individuals, three main questions: 1. Are the mean response profiles similar in the groups, in the sense that the mean response profiles are parallel? This is a question that concerns the group time interaction effect; see Figure 7(a). 2. Assuming mean response profiles are parallel, are the means constant over time, in the sense that the mean response profiles are flat? This is a question that concerns the time effect; see Figure 7(b). 61
62 3. Assuming that the population mean response profiles are parallel, are they also at the same level in the sense that the mean response profiles for the groups coincide? This is a questions that concerns the group effect; see Figure 7(c). For many longitudinal studies, main interest is in question 1. 62
63 (a) Expected Response Group 1 Group Time (b) Expected Response Group 1 Group Time (c) Expected Response Group 1 Group Time Figure 7: Graphical representation of the null hypotheses of (a) no group time interaction effect, (b) no time effect, and (c) no group effect. 63
64 Table 7: Mean response profile over time in G groups. Measurement Occasion Group n 1 µ 1 (1) µ 2 (1)... µ n (1) 2 µ 1 (2) µ 2 (2)... µ n (2).... g µ 1 (g) µ 2 (g)... µ n (g).... G µ 1 (G) µ 2 (G)... µ n (G) 64
65 Consider two-group case: G = 2 Define j = µ j (1) µ j (2), j = 1,..., n. With G = 2, the first hypothesis in an analysis of response profiles can be expressed as: No group time interaction effect: H 0 : 1 = 2 = = n, (n-1 degrees of freedom) With G 2, the test of the null hypothesis of no group time interaction effect has (G 1) (n 1) degrees of freedom. 65
66 Focus of analysis is on a global test of the null hypothesis that mean response profiles are parallel. This question concerns the group time interaction effect. In testing this hypothesis, both group and time are regarded as categorical covariates (analogous to two-way ANOVA). Analysis of response profiles can be specified as a regression model with indicator variables for group and time. However, correlation and variability among repeated measures on the same individuals must be properly accounted for. 66
67 Dummy or Indicator Variable Coding: Consider a factor with k levels: Define X 1 = 1 if measurement or subject belongs to level 1, and 0 otherwise. Define X 2 = 1 if measurement or subject belongs to level 2, and 0 otherwise. Define X 3,..., X k similarly. Note: In model with intercept term, we only require k 1 indicator variables. The choice of omitted indicator variable (e.g., X 1 ) determines what level of the factor is the reference level (e.g., first level). 67
68 Level X 2 X 3 X 4... X k k
69 For example, this leads to a simple way of expressing the mean response in a regression model (with intercept β 1 ): or (equivalently) Y ij = β 1 + β 2 X 2ij + + β k X kij + ɛ ij µ j = E(Y ij ) = β 1 + β 2 X 2ij + + β k X kij 69
70 Note: Mean response for level 1: µ 1 = β 1 Mean response for level 2: µ 2 = β 1 + β 2. Mean response for level k: µ k = β 1 + β k Equivalently: Level 2 versus Level 1 = β 2 Level 3 versus Level 1 = β 3.. Level k versus Level 1 = β k 70
71 Choice of Reference Level The usual choice of reference group: (i) A natural baseline or comparison group, and/or (ii) group with largest sample size In longitudinal data setting, the baseline or first measurement occasion is a natural reference group for time. 71
72 In summary, analysis of response profiles can be specified as a regression model with indicator variables for group and time. The global test of the null hypothesis of parallel profiles translates into a hypothesis concerning regression coefficients for the group time interaction being equal to zero. Beyond testing the null hypothesis of parallel profiles, the estimated regression coefficients have meaningful interpretations. 72
73 Treatment of Lead-Exposed Children Trial In the TLC Trial there are two groups (placebo and succimer) and four measurement occasions (week 0, 1, 4, 6). Let X 1 = 1 for all children at all occasions. Creating indicator variables for group and time: Group: Let X 2 = 1 if child randomized to succimer, X 2 = 0 otherwise. Time: Let X 3 = 1 if measurement at week 1, X 3 = 0 otherwise Let X 4 = 1 if measurement at week 4, X 4 = 0 otherwise Let X 5 = 1 if measurement at week 6, X 5 = 0 otherwise 73
74 Analysis of response profiles model can be expressed as: Y = β 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +β 5 X 5 +β 6 X 2 X 3 +β 7 X 2 X 4 +β 8 X 2 X 5 +e Test of group time interaction: H 0 : β 6 = β 7 = β 8 = 0. The analysis must also account for the correlation among repeated measures on the same child. The analysis of response profiles estimates separate variances for each occasion (4 variances) and six pairwise correlations. 74
75 Table 8: Estimated covariance matrix for the blood lead levels at baseline, week 1, week 4, and week 6 for the children from the TLC trial. Covariance Matrix
76 Note the discernible increase in the variability in blood lead levels from pre- to post-randomization. This increase in variability from baseline is probably due to: (1) given the treatment group assignment, there may be natural heterogeneity in the individual response trajectories over time, (2) the trial had an inclusion criterion that blood lead levels at baseline were in the range of micrograms/dl. 76
77 Table 9: Tests of fixed effects based on a profile analysis of the blood lead level data at baseline, weeks 1, 4, and 6. EFFECT DF CHI-SQUARE P-VALUE GROUP < WEEK < GROUP*WEEK <
78 Test of the group time interaction is based on (multivariate) Wald test (comparison of estimates to SEs). In TLC trial, question of main interest concerns comparison of groups in terms of patterns of change from baseline. This question translates into test of group time interaction. The test of the group time interaction yields a Wald statistic of 113 with 3 degrees of freedom (p < 0.001). Because this is a global test, it indicates that groups differ but does not tell us how they differ. 78
79 Recall, analysis of response profiles model can be expressed as: Y = β 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +β 5 X 5 +β 6 X 2 X 3 +β 7 X 2 X 4 +β 8 X 2 X 5 +e Test of group time interaction: H 0 : β 6 = β 7 = β 8 = 0. The 3 single df contrasts for group time interaction have direct interpretations in terms of group comparisons of changes from baseline. They indicate that children treated with succimer have greater decrease in mean blood lead levels from baseline at all occasions when compared to children treated with placebo (see Table 10). 79
80 Table 10: Estimated regression coefficients and standard errors based on a profile analysis of the blood lead level data. PARAMETER GROUP WEEK ESTIMATE SE Z INTERCEPT GROUP A WEEK WEEK WEEK GROUP*WEEK A GROUP*WEEK A GROUP*WEEK A
81 Strengths and Weaknesses of Analysis of Response Profiles Strengths: Allows arbitrary patterns in the mean response over time and arbitrary patterns in the covariance. Analysis has a certain robustness since potential risks of bias due to misspecification of models for mean and covariance are minimal. Drawbacks: Requirement that the longitudinal design be balanced. Analysis cannot incorporate mistimed measurements. 81
82 Analysis ignores the time-ordering (time trends) of the repeated measures in a longitudinal study occasion is regarded as a qualitative factor. Produces omnibus tests of effects that may have low power to detect group differences in specific trends in the mean response over time (e.g., linear trends in the mean response). The number of estimated parameters, G n mean parameters and n(n+1) 2 covariance parameters, grows rapidly with the number of measurement occasions. 82
83 Further Reading: Fitzmaurice GM, Laird NM and Ware JH. (2004) Applied Longitudinal Analysis. Wiley. Chapter 3 (Sections 3.1, 3.2, 3.4, 3.5) Chapter 4 (Sections 4.1, 4.2, 4.4, 4.5) Chapter 5 (Sections , 5.8, 5.9) 83
84 APPLIED LONGITUDINAL ANALYSIS LECTURE 3 84
85 MODELLING THE MEAN: PARAMETRIC CURVES Fitting parametric or semi-parametric curves to longitudinal data can be justified on substantive and statistical grounds. Substantively, in many studies true underlying mean response process changes over time in a relatively smooth, monotonically increasing/decreasing pattern. Fitting parsimonious models for mean response results in statistical tests of covariate effects (e.g., treatment time interactions) with greater power than in profile analysis. 85
86 Polynomial Trends in Time Describe the patterns of change in the mean response over time in terms of simple polynomial trends. The means are modelled as an explicit function of time. This approach can handle highly unbalanced designs in a relatively seamless way. For example, mistimed measurements are easily incorporated in the model for the mean response. 86
87 Linear Trends over Time Simplest possible curve for describing changes in the mean response over time is a straight line. Slope has direct interpretation in terms of a constant change in mean response for a single unit change in time. Consider two-group study comparing treatment and control, where changes in mean response are approximately linear: E (Y ij ) = β 1 + β 2 Time ij + β 3 Group i + β 4 Time ij Group i, where Group i = 1 if i th individual assigned to treatment, and Group i = 0 otherwise; and Time ij denotes measurement time for the j th measurement on i th individual. 87
88 Model for the mean for subjects in control group: E (Y ij ) = β 1 + β 2 Time ij, while for subjects in treatment group, E (Y ij ) = (β 1 + β 3 ) + (β 2 + β 4 ) Time ij. Thus, each group s mean response is assumed to change linearly over time (see Figure 8). 88
89 Group 1 Expected Response Group Time Figure 8: Graphical representation of model with linear trends for two groups. 89
90 Quadratic Trends over Time When changes in the mean response over time are not linear, higher-order polynomial trends can be considered. For example, if the means are monotonically increasing or decreasing over the course of the study, but in a curvilinear way, a model with quadratic trends can be considered. In a quadratic trend model the rate of change in the mean response is not constant but depends on time. Rate of change must be expressed in terms of two parameters. 90
91 Consider two-group study example: E (Y ij ) = β 1 + β 2 Time ij + β 3 Time 2 ij + β 4 Group i + β 5 Time ij Group i + β 6 Time 2 ij Group i. Model for subjects in control group: E (Y ij ) = β 1 + β 2 Time ij + β 3 Time 2 ij; while model for subjects in treatment group: E (Y ij ) = (β 1 + β 4 ) + (β 2 + β 5 ) Time ij + (β 3 + β 6 ) Time 2 ij. 91
92 Group 1 Expected Response Group Time Figure 9: Graphical representation of model with quadratic trends for two groups. 92
93 Note: mean response changes at different rate, depending upon Time ij. Rate of change in control group is β 2 + 2β 3 Time ij (derivation of this instantaneous rate of change requires familiarity with calculus). Thus, early in the study when Time ij = 1, rate of change is β 2 + 2β 3 ; while later in the study, say Time ij = 4, rate of change is β 2 + 8β 3. Regression coefficients, (β 2 + β 5 ) and (β 3 + β 6 ), have similar interpretations for treatment group. 93
94 Centering To avoid problems of collinearity it is advisable to center Time j on its mean value prior to the analysis. Replace Time j by its deviation from the mean of (Time 1,Time 2,...,Time n ). Note: centering of Time ij at individual-specific values (e.g., the mean of the n i measurement times for i th individual) should be avoided, as the interpretation of the intercept becomes meaningless. 94
95 Linear Splines If simplest possible curve is a straight line, then one way to extend the curve is to have sequence of joined line segments that produces a piecewise linear pattern. Linear spline models provide flexible way to accommodate many non-linear trends that cannot be approximated by simple polynomials in time. Basic idea: Divide time axis into series of segments and consider piecewise-linear trends, having different slopes but joined at fixed times. Locations where lines are tied together are known as knots. Resulting piecewise-linear curve is called a spline. Piecewise-linear model often called broken-stick model. 95
96 Group 1 Expected Response Group Time Figure 10: Graphical representation of model with linear splines for two groups, with common knot. 96
97 The simplest possible spline model has only one knot. For two-group example, linear spline model with knot at t : E (Y ij ) = β 1 + β 2 Time ij + β 3 (Time ij t ) + + β 4 Group i + β 5 Time ij Group i + β 6 (Time ij t ) + Group i, where (x) + is defined as a function that equals x when x is positive and is equal to zero otherwise. Thus, (Time ij t ) + is equal to (Time ij t ) when Time ij > t and is equal to zero when Time ij t. Note: (Time t ) + can be created as max(time t, 0). 97
98 Model for subjects in control group: E (Y ij ) = β 1 + β 2 Time ij + β 3 (Time ij t ) +. When expressed in terms of mean response prior/after t : E (Y ij ) = β 1 + β 2 Time ij, Time ij t ; E (Y ij ) = (β 1 β 3 t ) + (β 2 + β 3 )Time ij, Time ij > t. Slope prior to t is β 2 and following t is (β 2 + β 3 ). 98
99 Model for subjects in treatment group: E (Y ij ) = (β 1 + β 4 ) + (β 2 + β 5 )Time ij + (β 3 + β 6 )(Time ij t ) +. When expressed in terms of mean response prior/after t : E (Y ij ) = (β 1 + β 4 ) + (β 2 + β 5 )Time ij, Time ij t ; E (Y ij ) = [(β 1 + β 4 ) (β 3 + β 6 )t )] + (β 2 + β 3 + β 5 + β 6 )Time ij, Time ij > t. 99
100 Case Study 1: Vlagtwedde-Vlaardingen Study Epidemiologic study on risk factors for chronic obstructive lung disease. Sample participated in follow-up surveys approximately every 3 years for up to 19 years. Pulmonary function was determined by spirometry: FEV 1. We focus on subset of 133 residents aged 36 or older at entry into study and whose smoking status did not change during follow-up. Each participant was either a current or former smoker. 100
101 3.6 Former Smokers Current Smokers 3.4 Mean FEV1 (liters) Time (years) Figure 11: Mean FEV 1 at baseline (year 0), year 3, year 6, year 9, year 12, year 15, and year 19 in the current and former smoking exposure groups. 101
102 First we consider a linear trend in the mean response over time, with intercepts and slopes that differ for the two smoking exposure groups. We assume an unstructured covariance matrix. Based on the REML estimates of the regression coefficients in Table 11, the mean response for former smokers is E (Y ij ) = Time ij, while for current smokers, E (Y ij ) = ( ) ( ) Time ij = Time ij. 102
103 Table 11: Estimated regression coefficients for linear trend model for FEV 1 data from the Vlagtwedde-Vlaardingen study. Variable Smoking Group Estimate SE Z Intercept Smoke i Current Time ij Smoke i Time ij Current
104 Thus, both groups have a significant decline in mean FEV 1 over time. But there is no discernible difference between the two smoking exposure groups in the constant rate of change. That is, the Smoke i Time ij interaction (i.e., the comparison of the two slopes) is not significant, with Z = 1.42, p > But is the rate of change constant over time? Adequacy of linear trend model can be assessed by including higher-order polynomial trends. 104
105 For example, we can consider a model that allows quadratic trends for changes in FEV 1 over time. Recall that linear trend model is nested within quadratic trend model. The maximized log-likelihoods for models with linear and quadratic trends are presented in Table 12. LRT test statistic, based on ML not REML, can be compared to a chi-squared distribution with 2 degrees of freedom (or 6, the number of parameters in the quadratic trend model, minus 4, the number of parameters in the linear trend model). 105
106 Table 12: Maximized (ML) log-likelihoods for models with linear and quadratic trends for FEV 1 data from the Vlagtwedde-Vlaardingen study. Model 2 (ML) Log-Likelihood Quadratic Trend Model Linear Trend Model Log-Likelihood Ratio: G 2 = 1.3, 2 df (p > 0.50) 106
107 LRT comparing quadratic and linear trend models, produces G 2 = 1.3, with 2 degrees of freedom (p > 0.50). Thus, when compared to quadratic trend model, linear trend model appears to be adequate. Finally, for illustrative purposes, we can make a comparison with a cubic trend model. This produces LRT statistic, G 2 = 4.4, with 4 degrees of freedom (p > 0.35), indicating again that the linear trend model is adequate. 107
108 Case Study 2: Treatment of Lead-Exposed Children Recall data from TLC trial: Trial Children randomized to placebo or Succimer. Measures of blood lead level at baseline, 1, 4 and 6 weeks. The sequence of means over time in each group is displayed in Figure
109 Mean blood lead level (mcg/dl) Placebo Succimer Time (weeks) Figure 12: Mean blood lead levels at baseline, week 1, week 4, and week 6 in the succimer and placebo groups. 109
110 Given that there are non-linearities in the trends over time, higher-order polynomial models (e.g., a quadratic trend model) could be fit to the data. Alternatively, we can accommodate the non-linearity with a piecewise linear model with common knot at week 1, E (Y ij ) = β 1 + β 2 Week ij + β 3 (Week ij 1) + + β 4 Group i Week ij + β 5 Group i (Week ij 1) +, where Group i = 1 if assigned to succimer, and Group i = 0 otherwise. 110
111 In this piecewise linear model, means for subjects in placebo group are E (Y ij ) = β 1 + β 2 Week ij + β 3 (Week ij 1) +, while in the succimer group E (Y ij ) = β 1 + (β 2 + β 4 ) Week ij + (β 3 + β 5 ) (Week ij 1) +. Because of randomization, assume a common mean at baseline (no Group main effect). 111
112 Table 13: Estimated regression coefficients and standard errors based on a piecewise linear model, with knot at week 1. Variable Group Estimate SE Z Intercept Week ij (Week ij 1) Group Week ij A Group (Week ij 1) + A
113 When expressed in terms of mean response prior to/after week 1, estimated means in the placebo group are µ ij = β 1 + β 2 Week ij, Week ij 1; µ ij = ( β 1 β 3 ) + ( β 2 + β 3 ) Week ij, Week ij > 1. Thus, in the placebo group, slope prior to week 1 is β 2 = 1.63 and following week 1 is ( β 2 + β 3 ) = =
114 Similarly, when expressed in terms of the mean response prior to and after week 1, the estimated means for subjects in the succimer group are given by µ ij = β 1 + ( β 2 + β 4 ) Week ij, Week ij 1; µ ij = β 1 ( β 3 + β 5 ) + ( β 2 + β 3 + β 4 + β 5 ) Week ij, Week ij >
115 Estimates of mean blood lead levels for placebo and succimer groups are presented in Table 14. The estimated means appear to adequately fit observed mean response profiles for two treatment groups. Note piecewise linear and quadratic trend models (with common intercept for two groups) are not nested. Because they have same number of parameters, their log-likelihoods (LL) can be directly compared: piecewise linear model fits better than quadratic trend model ( 2 ML LL = for piecewise linear model versus 2 ML LL = for quadratic trend model). 115
116 Table 14: Estimated mean blood lead levels for placebo and succimer groups from linear spline model (knot at week 1). Observed means in parentheses. Group Week 0 Week 1 Week 4 Week 6 Succimer (26.5) (13.5) (15.5) (20.8) Placebo (26.3) (24.7) (24.1) (23.2) 116
117 Further Reading: Fitzmaurice GM, Laird NM and Ware JH. (2004) Applied Longitudinal Analysis. Wiley. Chapter 6 117
118 APPLIED LONGITUDINAL ANALYSIS LECTURE 4 118
119 MODELLING THE COVARIANCE Longitudinal data present two aspects of the data that require modelling: mean response over time and covariance. Although these two aspects of the data can be modelled separately, they are interrelated. Choice of models for mean response and covariance are interdependent. A model for the covariance must be chosen on the basis of some assumed model for the mean response. Covariance between any pair of residuals, say [Y ij µ ij (β)] and [Y ik µ ik (β)], depends on the model for the mean, i.e., depends on β. 119
120 Modelling the Covariance Three broad approaches can be distinguished: (1) unstructured or arbitrary pattern of covariance (2) covariance pattern models (3) random effects covariance structure 120
121 Unstructured Covariance Appropriate when design is balanced and number of measurement occasions is relatively small. No explicit structure is assumed other than homogeneity of covariance across different individuals, Cov(Y i ) = Σ i = Σ. Chief advantage: no assumptions made about the patterns of variances and covariances. 121
122 With n measurement occasions, unstructured covariance matrix has n (n+1) 2 parameters: the n variances and n (n 1)/2 pairwise covariances (or correlations), Cov(Y i ) = σ 2 1 σ σ 1n σ 21 σ σ 2n σ n1 σ n2... σ 2 n. 122
123 Potential drawbacks: Number of covariance parameters grows rapidly with the number of measurement occasions: For n = 3 number of covariance parameters is 6 For n = 5 number of covariance parameters is 15 For n = 10 number of covariance parameters is 55 When number of covariance parameters is large, relative to sample size, estimation is likely to be very unstable. Use of an unstructured covariance is appealing only when N is large relative to n (n+1) 2. Unstructured covariance is problematic when there are mistimed measurements. 123
124 Covariance Pattern Models When attempting to impose some structure on the covariance, a subtle balance needs to be struck. With too little structure there may be too many parameters to be estimated with limited amount of data. With too much structure, potential risk of model misspecification and misleading inferences concerning β. Classic tradeoff between bias and variance. Covariance pattern models have their basis in models for serial correlation originally developed for time series data. 124
125 Compound Symmetry Assumes variance is constant across occasions, say σ 2, and Corr(Y ij, Y i,k ) = ρ for all j and k. 1 ρ ρ... ρ ρ 1 ρ... ρ Cov(Y i ) = σ 2 ρ ρ 1... ρ ρ ρ ρ... 1 Parsimonious: two parameters regardless of number of measurement occasions. Strong assumptions about variance and correlation are usually not valid with longitudinal data. 125
126 Toeplitz Assumes variance is constant across occasions, say σ 2, and Corr(Y ij, Y i,j+k ) = ρ k for all j and k. 1 ρ 1 ρ 2... ρ n 1 ρ 1 1 ρ 1... ρ n 2 Cov(Y i ) = σ 2 ρ 2 ρ ρ n ρ n 1 ρ n 2 ρ n Assumes correlation among responses at adjacent measurement occasions is constant, ρ
127 Toeplitz only appropriate when measurements are made at equal (or approximately equal) intervals of time. Toeplitz covariance has n parameters (1 variance parameter, and n 1 correlation parameters). A special case of the Toeplitz covariance is the (first-order) autoregressive covariance. 127
128 Autoregressive Assumes variance is constant across occasions, say σ 2, and Corr(Y ij, Y i,j+k ) = ρ k for all j and k, and ρ 0. 1 ρ ρ 2... ρ n 1 ρ 1 ρ... ρ n 2 Cov(Y i ) = σ 2 ρ 2 ρ 1... ρ n ρ n 1 ρ n 2 ρ n Parsimonious: only 2 parameters, regardless of number of measurement occasions. Only appropriate when the measurements are made at equal (or approximately equal) intervals of time. 128
129 Compound symmetry, Toeplitz and autoregressive covariances assume variances are constant across time. This assumption can be relaxed by considering versions of these models with heterogeneous variances, Var(Y ij ) = σj 2. A heterogeneous autoregressive covariance pattern: σ1 2 ρσ 1 σ 2 ρ 2 σ 1 σ 3... ρ n 1 σ 1 σ n ρσ 1 σ 2 σ2 2 ρσ 2 σ 3... ρ n 2 σ 2 σ n Cov(Y i ) = ρ 2 σ 1 σ 3 ρσ 2 σ 3 σ ρ n 3 σ 3 σ n , ρ n 1 σ 1 σ n ρ n 2 σ 2 σ n ρ n 3 σ 3 σ n... σ 2 n and has n + 1 parameters (n variance parameters and 1 correlation parameter). 129
130 Banded Assumes correlation is zero beyond some specified interval. For example, a banded covariance pattern with a band size of 3 assumes that Corr(Y ij, Y i,j+k ) = 0 for k 3. It is possible to apply a banded pattern to any of the covariance pattern models considered so far. 130
131 A banded Toeplitz covariance pattern with a band size of 2 is given by, 1 ρ ρ 1 1 ρ Cov(Y i ) = σ 2 0 ρ , where ρ 2 = ρ 3 = = ρ n 1 = 0. Banding makes very strong assumption about how quickly the correlation decays to zero with increasing time separation. 131
132 Exponential When measurement occasions are not equally-spaced over time, autoregressive model can be generalized as follows. Let {t i1,..., t in } denote the observation times for the i th individual and assume that the variance is constant across all measurement occasions, say σ 2, and Corr(Y ij, Y ik ) = ρ t ij t ik, for ρ 0. Correlation between any pair of repeated measures decreases exponentially with the time separations between them. 132
133 Referred to as exponential covariance because it can be re-expressed as Cov(Y ij, Y ik ) = σ 2 ρ t ij t ik = σ 2 exp ( θ t ij t ik ), where θ = log(ρ) or ρ = exp ( θ) for θ 0. Exponential covariance model is invariant under linear transformation of the time scale. If we replace t ij by (a + bt ij ) (e.g., if we replace time measured in weeks by time measured in days ), the same form for the covariance matrix holds. 133
134 Choice among Covariance Pattern Models Choice of models for covariance and mean are interdependent. Choice of model for covariance should be based on a maximal model for the mean that minimizes any potential misspecification. With balanced designs and a very small number of discrete covariates, choose saturated model for the mean response. Saturated model: includes main effects of time (regarded as a within-subject factor) and all other main effects, in addition to their two- and higher-way interactions. 134
135 Maximal model should be in a certain sense the most elaborate model for the mean response that we would consider from a subject-matter point of view. Once maximal model has been chosen, residual variation and covariation can be used to select appropriate model for covariance. For nested covariance pattern models, a likelihood ratio test statistic can be constructed that compares full and reduced models. 135
136 Recall: two models are said to be nested when the reduced model is a special case of the full model. For example, compound symmetry model is nested within the Toeplitz model, since if the former holds the latter must necessarily hold, with ρ 1 = ρ 2 = = ρ n 1. Likelihood ratio test is obtained by taking twice the difference in the respective maximized REML log-likelihoods, G 2 = 2( l full l red ), and comparing statistic to a chi-squared distribution with df equal to difference between the number of covariance parameters in full and reduced models. 136
137 To compare non-nested model, an alternative approach is the Akaike Information Criterion (AIC). According to the AIC, given a set of competing models for the covariance, one should select the model that minimizes AIC = 2(maximized log-likelihood) + 2(number of parameters) = 2( l c), where l is the maximized REML log-likelihood and c is the number of covariance parameters. 137
138 Exercise Therapy Trial subjects were assigned to one of two weightlifting programs to increase muscle strength. treatment 1: number of repetitions of the exercises was increased as subjects became stronger. treatment 2, number of repetitions was held constant but amount of weight was increased as subjects became stronger. Measurements of body strength were taken at baseline and on days 2, 4, 6, 8, 10, and 12. We focus only on measures of strength obtained at baseline (or day 0) and on days 4, 6, 8, and
139 Before considering models for the covariance, it is necessary to choose a maximal model for the mean response. We chose maximal model to be the saturated model for the mean. First, we consider an unstructured covariance matrix. Note that the variance is larger by the end of the study when compared to the variance at baseline. Correlations decrease as the time separation between the repeated measures increases. 139
140 Table 15: Estimated unstructured covariance matrix for the strength data at baseline, day 4, day 6, day 8, and day 12. Day
141 Table 16: Estimated unstructured correlation matrix for the strength data at baseline, day 4, day 6, day 8, and day 12. Day
142 Despite apparent increase in variance over time, we consider an autoregressive model for the correlation. It results in the following estimates of the variance and correlation parameters, σ 2 = and ρ = This model is not very appropriate as data are unequally spaced over time. Consider exponential model for the covariance, where Corr(Y ij, Y ik ) = ρ t ij t ik, for t i = (0, 4, 6, 8, 12) for all subjects. Results: σ 2 = and ρ =
143 Table 17: Estimated autoregressive correlation matrix for the strength data at baseline, day 4, day 6, day 8, and day 12. Day
144 Table 18: Estimated exponential correlation matrix for the strength data at baseline, day 4, day 6, day 8, and day 12. Day
145 There is a hierarchy among the models: autoregressive and exponential are both nested within unstructured. The autoregressive and exponential models are not nested but have the same number of parameters. Any comparison between these two models can be made directly in terms of their maximized log-likelihoods. LRT comparing autoregressive and unstructured covariance, G 2 = = 23.8, with 13 (or 15-2) degrees of freedom (p < 0.05). There is evidence that the autoregressive model does not provide an adequate fit to the covariance. 145
146 LRT comparing exponential and unstructured covariance, yields G 2 = = 21.2, and when compared to a chi-squared distribution with 13 degrees of freedom, p > Exponential covariance provides an adequate fit to the data. Also, in terms of AIC, the exponential model minimizes this criterion. 146
147 Table 19: Comparison of the maximized (REML) loglikelihoods and AIC for the covariance pattern models for the strength data from the exercise therapy trial. Covariance Pattern Model -2 (REML) Log-Likelihood AIC Unstructured Autoregressive Exponential
148 Strengths/Weaknesses of Covariance Pattern Models Covariance pattern models attempt to characterize the covariance with a relatively small number of parameters. However, many models (e.g., autoregressive, Toeplitz, and banded) appropriate only when repeated measurements are obtained at equal intervals and cannot handle irregularly timed measurements. While there is a large selection of models for correlations, choice of models for variances is limited. They are not well-suited for modelling data from inherently unbalanced longitudinal designs. 148
149 Further Reading: Fitzmaurice GM, Laird NM and Ware JH. (2004) Applied Longitudinal Analysis. Wiley. Chapter 7 (Sections , 7.7) 149
150 APPLIED LONGITUDINAL ANALYSIS LECTURE 5 150
151 LINEAR MIXED EFFECTS MODEL So far, we have discussed models for longitudinal data where changes in the mean response can be expressed as, E(Y ij X ij ) = β 1 X ij1 + β 2 X ij2 + + β p X ijp, and where the primary goal is to make inferences about the population regression parameters, β 1,..., β p. Specification of this regression model is completed by making additional assumptions about structure of Cov(Y i ) = Σ i. Next, we consider an alternative, but closely related, approach for analyzing longitudinal data using linear mixed effects models. 151
152 Basic idea: some subset of the regression parameters vary randomly from one individual to another, thereby accounting for sources of natural heterogeneity in the population. Individuals in population are assumed to have their own subject-specific mean response trajectories over time. Distinctive feature: mean response modelled as a combination of population characteristics, β 1,..., β p, assumed to be shared by all individuals, and subject-specific effects that are unique to a particular individual. 152
153 The former are referred to as fixed effects, while the latter are referred to as random effects. The term mixed is used in this context to denote that the model contains both fixed and random effects. Note: It is not only possible to estimate parameters that describe how the mean response changes in the population of interest, but it is also possible to predict how individual-specific response trajectories change over time. 153
154 Example: Random Intercept Model Simplest possible case is the linear model with a randomly varying subject effect (or random intercept). Each subject assumed to have underlying level of response which persists over time, incorporated in linear mixed effects model by regarding this subject effect as random, Y ij = β 1 X ij1 + β 2 X ij2 + + β p X ijp + b i + e ij, where b i is the random subject effect and the e ij are regarded as measurement or sampling errors. Response for i th subject at j th occasion is assumed to differ from population mean by a subject effect, b i, and a within-subject measurement error, e ij. 154
155 Subject-effect and measurement error are assumed to be random, with mean zero, Var (b i ) = σ 2 b and Var (e ij) = σ 2. b i and e ij are assumed to be independent of one another. Model describes conditional mean response trajectory over time for a specific individual, E(Y ij b i ) = β 1 X ij1 + β 2 X ij2 + + β p X ijp + b i, in addition to marginal mean response profile in the population (i.e., averaged over all individuals in population), E(Y ij ) = β 1 X ij1 + β 2 X ij2 + + β p X ijp. 155
156 Y ij = β 1 X ij1 + β 2 X ij2 + + β p X ijp + b i + e ij = (β 1 + b i ) + β 2 X ij2 + + β p X ijp + e ij, where X ij1 = 1 for all i and j, and β 1 is then the fixed effect intercept term in the model. Intercept for the i th individual is β 1 + b i and varies randomly from one individual to another. Because mean of the random effect b i is assumed to be zero, b i represents the deviation of the i th individual s intercept (β 1 + b i ) from the population intercept, β
157 A Response B Time Figure 13: Graphical representation of the marginal and conditional mean responses over time. 157
158 Figure 13 provides graphical representation of model. Marginal mean response over time in the population changes linearly with time (denoted by the solid line). Conditional mean responses for two specific individuals, subjects A and B, deviate from the population trend (denoted by the broken lines). Individual A responds higher than the population average and thus has a positive b i. Individual B responds lower than the population average and has a negative b i. Inclusion of measurement errors, e ij, allows response at any occasion to vary randomly above/below subject-specific trajectories (see Figure 14). 158
159 A Response B Time Figure 14: Graphical representation of the marginal and conditional mean responses over time, plus measurement errors. 159
160 Consider the marginal covariance among the repeated measurements on the same individual. When averaged over the individual-specific effects, the marginal mean of Y ij is given by E(Y ij ) = µ ij = β 1 X ij1 + β 2 X ij2 + + β p X ijp. The marginal covariance among the Y ij is defined in terms of deviations of Y ij from the marginal mean, µ ij. 160
161 For the model with randomly varying intercepts, the marginal covariance has the following compound symmetry pattern σ b 2 + σ2 σb 2 σb 2... σb 2 σ b 2 σb 2 + σ2 σb 2... σ 2 b Cov(Y i ) = σ b 2 σb 2 σb 2 + σ2... σb 2, σb 2 σb 2 σb 2... σb 2 + σ2 and Corr(Y ij, Y ik ) = σ2 b σ 2 b +σ2. This emphasizes an important aspect of mixed effects models: the introduction of a random subject effect, b i, can be seen to induce correlation among the repeated measurements. 161
162 Linear Mixed Effects Model Next, we consider generalizations by allowing additional regression coefficients to vary randomly. By allowing a subset of the regression coefficients to vary randomly, a very flexible, and yet quite parsimonious, class of random effects covariance structures becomes available. In the following we assume there are N individuals on whom we have collected n i repeated observations, with the response variable Y ij measured at time t ij. 162
163 Any of the components of β 1,..., β p can be allowed to vary randomly. The collection of random effects, denoted b i, are assumed to have a multivariate normal distribution with mean zero and covariance matrix G. That is, E(b i ) = 0 and Cov(b i ) = G. Ordinarily, the errors e ij and e ik are assumed to be uncorrelated, with equal variance, σ 2 ; the e ij s can be thought of as sampling or measurement errors. 163
164 Example: Random Intercept and Slope Model Consider model with intercepts and slopes that vary randomly among individuals, Y ij = β 1 + β 2 t ij + b i1 + b i2 t ij + e ij, j = 1,..., n i. This model posits that individuals vary not only in their baseline level of response (when t i1 = 0), but also in terms of their changes in the mean response over time. 164
165 The effects of covariates (e.g. due to treatments, exposures) can be incorporated by allowing mean of intercepts and slopes to depend on covariates. For example, consider two-group study comparing a treatment and a control group: Y ij = β 1 + β 2 t ij + β 3 Group i + β 4 t ij Group i + b i1 + b i2 t ij + e ij, where Group i = 1 if the i th individual assigned to treatment, and Group i = 0 otherwise. 165
166 A Response B Time Figure 15: Graphical representation of the marginal and conditional mean responses over time, plus measurement errors. 166
167 Next, consider the covariance among the responses. Let Var (b i1 ) = g 11, Var (b i2 ) = g 22, and Cov (b i1, b i2 ) = g 12. If we also assume that Cov(e ij, e ik ) = 0 and Var(e ij ) = σ 2, then Var (Y ij ) = Var (b i1 + b i2 t ij + e i ) = Var(b i1 ) + 2t ij Cov(b i1, b i2 ) + t 2 ij Var(b i2) + Var(e i ) = g t ij g 12 + t 2 ij g 22 + σ 2. Similar;y, it can be shown that Cov (Y ij, Y ik ) = g 11 + (t ij + t ik ) g 12 + t ij t ik g 22. Thus, in this model for longitudinal data the covariance matrix, Cov(Y i ), can be expressed as a function of time, t ij. 167
168 Random Effects Covariance Structure Next, we consider form of induced random effects covariance structure in the more general case when Y i = X i β + Z i b i + e i. Recall that we can distinguish the conditional mean of Y i, given b i, E (Y i b i ) = X i β + Z i b i, from the marginal or population-averaged mean of Y i, E (Y i ) = X i β. Similarly, we can distinguish conditional and marginal covariances. 168
169 The conditional covariance of Y i, given b i, is Cov (Y i b i ) = Cov (e i ) = R i, while the marginal covariance of Y i, averaged over the distribution of b i, is given by, Cov (Y i ) = Cov (Z i b i ) + Cov (e i ) = Z i Cov(b i )Z i + Cov(e i ) = Z i GZ i + R i. Even when R i = Cov(e i ) = σ 2 I ni, a diagonal matrix (with all pairwise correlations equal to zero), Cov (Y i ) = Z i GZ i + σ 2 I ni is emphatically not a diagonal matrix. 169
170 Cov (Y i ) will, in general, have non-zero off-diagonal elements, thereby accounting for the correlation among repeated observations on the same individuals. Introduction of random effects, b i, induces correlation among the components of Y i. Cov (Y i ) has been described in terms of a set of covariance parameters, some defining G and some defining R i. Linear mixed effects model allows for the explicit analysis of between-subject (G) and within-subject (R i ) sources of variation in the responses. Finally, note the marginal covariance of Y i is a function of the times of measurement. 170
171 Prediction of Random Effects In many applications, inference is focused on fixed effects, β 1,..., β p. However, we can also estimate (or predict) individual-specific response trajectories over time. We can obtain predictions of the subject-specific effects, b i (or of the subject-specific response trajectories). This is known as best linear unbiased predictor (or BLUP). 171
172 Interestingly, the predicted response trajectory for the i th subject is a weighted combination of estimated population-averaged mean response profile, µ i1,..., µ ini (where µ ij = β 1 X ij1 + β 2 X ij2 + + β p X ijp ), and i th subject s observed response profile Y i1,..., Y ini. This helps to explains why it is often said that empirical BLUP shrinks i th subject s predicted response profile towards population-averaged mean. 172
173 For example, consider the random intercept model Y ij = β 1 X ij1 + β 2 X ij2 + + β p X ijp + b i + e ij, where Var (b i ) = σ 2 b and Var (e ij) = σ 2. It can be shown that the BLUP for b i is: bi = w 1 n i (Y ij µ ij ) +(1 w) 0, where w = n i j=1 n iσ 2 b n i σ 2 b + σ2. That is, a weighted-average of zero (mean of b i ) and the mean residual for the i th subject. Note: Less shrinkage (toward zero) when n i is large and when σ 2 b is large relative to σ2. 173
174 Example: Influence of Menarche on Changes in Body Fat Prospective study on body fat accretion in a cohort of 162 girls from the MIT Growth and Development Study. At start of study, all the girls were pre-menarcheal and non-obese All girls were followed over time according to a schedule of annual measurements until four years after menarche. The final measurement was scheduled on the fourth anniversary of their reported date of menarche. At each examination, a measure of body fatness was obtained based on bioelectric impedance analysis. 174
175 175
176 176
177 Figure 16: Timeplot of percent body fat against age (in years). 177
178 Consider an analysis of the changes in percent body fat before and after menarche. For the purposes of these analyses time is coded as time since menarche and can be positive or negative. Note: measurement protocol is the same for all girls. Study design is balanced if timing of measurement is defined as time since baseline measurement. It is inherently unbalanced when timing of measurements is defined as time since a girl experienced menarche. 178
179 40 Percent body fat Time relative to menarche (years) Figure 17: Timeplot of percent body fat against time, relative to age of menarche (in years). 179
180 Consider hypothesis that %body fat accretion increases linearly with age, but with different slopes before/after menarche. We assume that each girl has a piecewise linear spline growth curve with a knot at the time of menarche. Each girl s growth curve can be described with an intercept and two slopes, one slope for changes in response before menarche, another slope for changes in response after menarche. Note the knot is not a fixed age for all subjects. Let t ij denote time of the j th measurement on i th subject before or after menarche (i.e., t ij = 0 at menarche). 180
181 Figure 18: Graphical representation of piecewise linear trajectory. 181
182 We consider the following linear mixed effects model E(Y ij b i ) = β 1 + β 2 t ij + β 3 (t ij ) + + b i1 + b i2 t ij + b i3 (t ij ) +, where (t ij ) + = t ij if t ij > 0 and (t ij ) + = 0 if t ij 0. (β 1 + b i1 ) is intercept for i th subject and is the true %body fat at menarche (when t ij = 0). Similarly, (β 2 + b i2 ) is i th subject s slope, or rate of change in %body fat during the pre-menarcheal period. Finally, the i th subject s slope during the post-menarcheal period is given by [(β 2 + β 3 ) + (b i2 + b i3 )]. Note: goal of analysis is to assess whether population slopes differ before and after menarche, i.e., H 0 : β 3 =
183 Table 20: Estimated regression coefficients (fixed effects) and standard errors for the percent body fat data. PARAMETER ESTIMATE SE Z INTERCEPT time (time)
184 Table 21: Estimated covariance of the random effects and standard errors for the percent body fat data. PARAMETER ESTIMATE SE Z Var(b i1 ) = g Var(b i2 ) = g Var(b i3 ) = g Cov(b i1, b i2 ) = g Cov(b i1, b i3 ) = g Cov(b i2, b i3 ) = g Var(e i ) = σ
185 Results: Based on magnitude of β 3, relative to its standard error, slopes before and after menarche differ. Estimate of the population mean pre-menarcheal slope is 0.42, which is statistically significant at the 0.05 level. Estimated slope is rather shallow and indicates that the annual rate of body fat accretion is less that 0.5%. Estimate of population mean post-menarcheal slope is 2.46 (with SE = 0.12), which is significant at 0.05 level. Indicates that annual rate of growth in body fat is approximately 2.5%, almost 6 times higher than pre-menarche. 185
186 Estimated variance of b i2 is 1.6, indicating substantial variability from girl to girl in rates of fat accretion during the pre-menarcheal period. Approx. 95% of girls have changes in percent body fat between -2.09% and 2.92% ( i.e., 0.42 ± ). Estimated variance of slopes during post-menarcheal period, Var(b i2 + b i3 ), is 0.88 (or [ ]), indicating less variability in the slopes after menarche. Approx. 95% of girls have changes in percent body fat between 0.62% and 4.30% ( i.e., 2.46 ± ). 186
187 Results indicate that more than 95% of girls are expected to have increases in body fat during the post-menarcheal period. Substantially fewer (approximately 63%) are expected to have increases in body fat during the pre-menarcheal period. There is strong positive correlation (approximately 0.8) between annual measurements of percent body fat. Strength of correlation declines over time, but does not decay to zero even when measurements are taken 8 years apart. 187
188 Table 22: Marginal correlations (off-diagonals) among repeated measures of percent body fat between 4 years pre- and postmenarche, with estimated variances along main diagonal
189 The mixed effects model can be used to obtain estimates of each girl s growth trajectory over time. Figure 19 displays estimated population mean growth curve and predicted (empirical BLUP) growth curves for two girls. Note: two girls differ in the number of measurements obtained (6 and 10 respectively). A noticeable feature of the predicted growth curves is that there is more shrinkage towards the population mean curve when fewer data points are available. 189
190 30 Percent body fat Time relative to menarche (years) Figure 19: Population average curve and empirical BLUPs for two randomly selected girls. 190
191 Predicted growth curve for girl with only 6 data points is pulled closer to the population mean curve. Predicted growth curve for girl with 10 observation follows her data more closely. This becomes more apparent when empirical BLUPs are compared to ordinary least squares (OLS) estimates based only on observations from each girl (see Figure 20). 191
192 30 Percent body fat Time relative to menarche (years) Figure 20: Population average curve, empirical BLUPs, and OLS predictions for two randomly selected girls. 192
193 Additional Questions: 1. Is there non-linearity of curve after menarche? Can add (t 2 ij ) + term to the model as a fixed effect (β) and/or as a random effect (b i ). 2. Does parental obesity affect percent body fat? Does parental obesity affect slope post-menarche? Can allow mean % body fat at menarche and slopes to depend on parental obesity, add more β parameters (fixed effects). 193
194 Further Reading: Fitzmaurice GM, Laird NM and Ware JH. (2004) Applied Longitudinal Analysis. Wiley. Chapter 8 Cnaan A, Slasor P and Laird NM. (1997) Tutorial in Biostatistics: Using the general linear mixed model to analyze unbalanced repeated measures and longitudinal data. Statistics in Medicine, 16: Naumova EN, Must A and Laird NM. (2001) Evaluating the impact of critical periods in longitudinal studies of growth using piecewise mixed effects models. International Journal of Epidemiology, 30:
195 APPLIED LONGITUDINAL ANALYSIS LECTURE 6 195
196 INTRODUCTION TO GENERALIZED LINEAR MODELS FOR LONGITUDINAL DATA So far, focus has been on methods for longitudinal data where response variable is continuous. The main emphasis was on linear models for a vector of responses assumed to have a multivariate normal distribution. Today, we consider non-gaussian responses and generalized linear models. Since binary data are the most common case, we focus heavily on methods for repeated binary data. 196
197 Generalized linear models are a class of regression models; they incude the standard linear regression model but also many other important regression models used in biomedical research: - Linear regression for continuous data - Logistic regression for binary data - Loglinear models for count data In today s lecture, we will review the generalized linear model and show how we can apply generalized linear models in the longitudinal data setting. 197
198 Motivating Example Six Cities Study of Respiratory Illness in Children (Laird, Beck and Ware, 1984) A non-randomized longitudinal study of the health effects of air pollution. Subset of data from Steubenville, Ohio Outcome: Binary indicator of respiratory illness in child Measurement schedule: Four annual measurements at ages 7, 8, 9, and 10. Interested in the influence of maternal smoking on children s respiratory illness. Sample size: 537 children 198
199 199
200 MOTIVATING EXAMPLE Clinical trial of anti-epileptic drug progabide (Thall and Vail, Biometrics, 1990) Randomized, placebo-controlled study of treatment of epileptic seizures with progabide. Patients were randomized to treatment with progabide, or to placebo in addition to standard chemotherapy. Outcome variable: Count of number of seizures Measurement schedule: Baseline measurement during 8 weeks prior to randomization. Four measurements during consecutive two-week intervals. Sample size: 28 epileptics on placebo; 31 epileptics on progabide 200
201 201
202 Summary In longitudinal studies the outcome variable can be: - continuous - binary - count The data set can be incomplete. Subjects may be measured at different occasions. Over the next three days of lectures we will develop statistical methods that can handle all of these cases. 202
203 Generalized Linear Model In generalized linear models: (i) the distribution of the response is assumed to belong to a single family of distributions known as the exponential family, e.g., normal, Bernoulli, binomial, and Poisson distributions. (ii) A transformation of the mean response is then linearly related to the covariates, via an appropriate link function. 203
204 Mean and Variance of Exponential Family Distribution Exponential family distributions share some common statistical properties. The variance of Y i can be expressed in terms of Var (Y i ) = φv(µ i ), where the scale parameter φ > 0. The variance function, v(µ i ), describes how the variance of the response is functionally related to µ i, the mean of Y i. 204
205 Link Function The link function applies a transformation to the mean and then links the covariates to the transformed mean, g(µ i ) = β 1 X i1 + β 2 X i β p X ip = p β j X ij, j=1 where link function g( ) is known function, e.g., log(µ i ). This implies that it is the transformed mean response that changes linearly with changes in the values of the covariates. 205
206 Canonical link and variance functions for the normal, Bernoulli, and Poisson distributions. Distribution Var. Function, v(µ) Canonical Link Normal v(µ) = 1 Identity: µ = η Bernoulli v(µ) = µ(1 µ) Logit: log [ ] µ (1 µ) = η Poisson v(µ) = µ Log: log(µ) = η where η = β 1 X 1 + β 2 X β p X p. 206
207 Common Examples Normal distribution: If we assume that g( ) is the identity function, then g (µ) = µ µ i = β 1 X i1 + β 2 X i β p X ip = p β j X ij j=1 gives the standard linear regression model. We can, however, choose other link functions when they seem appropriate to the application. 207
208 Bernoulli distribution: For the Bernoulli distribution, 0 < µ i < 1, so we would prefer a link function that transforms the interval [0, 1] on to the entire real line [, ]. There are several possibilities: logit : η i = ln [(µ i / (1 µ i ))] probit : η i = Φ 1 (µ i ) where Φ( ) is the standard normal cumulative distribution function. Another possibility is the complementary log-log link function: η i = ln [ ln (1 µ i )] 208
209 GENERALIZED LINEAR MODELS FOR LONGITUDINAL DATA Next, we consider a general approach for analyzing longitudinal responses. Marginal models can be considered an extensions of generalized linear models to correlated data. The main focus will be on discrete response data, e.g. count data or binary responses. 209
210 MARGINAL MODELS The basic premise of marginal models is to make inferences about population averages. The term marginal is used here to emphasize that the mean response modelled is conditional only on covariates and not on other responses or random effects. A feature of marginal models is that the models for the mean and the covariance are specified separately. 210
211 Notation Assume sample of N subjects are measured repeatedly over time. We let Y ij denote the response variable for the i th subject on the j th measurement occasion. Y ij can be continuous, binary, or a count. Associated with each response, Y ij, there is a p 1 vector of covariates, X ij. 211
212 The focus of marginal models is on inferences about population averages. The marginal expectation, µ ij = E (Y ij ), of each response is modelled as a function of covariates. Specifically, with marginal models we make the following three assumptions: 212
213 1. the marginal expectation of the response, µ ij, depends on covariates, X ij, through a known link function g (µ ij ) = η ij = β 1 X ij1 + β 2 X ij β p X ijp 2. the marginal variance of Y ij depends on the marginal mean according to V ar (Y ij ) = υ (µ ij ) φ where υ (µ ij ) is a known variance function and φ is a scale parameter that may need to be estimated. 3. the within-subject association among the responses is a function of the means and perhaps of additional parameters, say α, that may also need to be estimated. 213
214 Illustrative Examples of Marginal Models: Example 1. Continuous responses: 1. µ ij = η ij = β 1 X ij1 + β 2 X ij β p X ijp (i.e. linear regression) 2. V ar (Y ij ) = φ j (i.e. heterogeneous variance) 3. Corr (Y ij, Y ik ) = α k j (0 α 1) (i.e. autoregressive correlation) 214
215 Example 2. Binary responses: 1. Logit (µ ij ) = η ij = β 1 X ij1 + β 2 X ij β p X ijp (i.e. logistic regression) 2. V ar (Y ij ) = µ ij (1 µ ij ) (i.e. Bernoulli variance) 3. Corr (Y ij, Y ik ) = α jk (i.e. unstructured correlation) 215
216 Example 3. Count data: 1. Log (µ ij ) = η ij = β 1 X ij1 + β 2 X ij β p X ijp (i.e. Poisson regression) 2. V ar (Y ij ) = µ ij φ (i.e. extra-poisson variance) 3. Corr (Y ij, Y ik ) = α (i.e. compound symmetry correlation) 216
217 Interpretation of Marginal Model Parameters: The regression parameters, β, have population-averaged interpretations: - describe the effect of covariates on the marginal expectations or average responses - contrast the means in sub-populations that share common covariate values Of note, nature or magnitude of the correlation does not alter the interpretation of β. 217
218 Summary Focus of marginal models is inferences about population averages. Regression parameters, β, have population-averaged interpretations (where averaging is over all individuals within subgroups of the population): - describe effect of covariates on the average responses - contrast means in sub-populations that share common covariate values = Marginal models are most useful for population-level inferences. Marginal models should not be used to make inferences about individuals ( ecological fallacy ). 218
219 Statistical Inference for Marginal Models Maximum Likelihood (ML): Unfortunately, with discrete response data there is no analogue of the multivariate normal distribution. In the absence of a convenient likelihood function for discrete data, there is no unified likelihood-based approach for marginal models. Recall: In linear models for normal responses, specifying the means and the covariance matrix fully determines the likelihood. 219
220 This is not the case with discrete response data. To specify the likelihood for multivariate discrete data, additional assumptions about higher-order moments are required. Even when additional assumptions are made, the likelihood is often intractable. 220
221 To illustrate some of the problems, consider a discrete response, Y ij, having C categories. The joint distribution of Y i = (Y i1, Y i2,..., Y in ) is multinomial, with a C n joint probability vector. For example, when C = 5 and n = 10, the joint probability vector is of length 10,000,000. Problem: Computations grow exponentially with n and ML quickly becomes impractical. Solution: We will consider an alternative approach to estimation - Generalized Estimating Equations (GEE). 221
222 Generalized Estimating Equations Avoid making distributional assumptions about Y i altogether. Potential advantages: Empirical researcher does not have to be concerned that the distribution of Y i closely approximates some multivariate distribution. It circumvents the need to specify models for the three-way, four-way and higher-way associations among the responses. It leads to a method of estimation, known as generalized estimating equations (GEE). 222
223 The GEE approach has become an extremely popular method for analyzing longitudinal data. It provides a flexible approach for modelling the mean and the pairwise within-subject association structure. It can handle inherently unbalanced designs and missing data with ease. GEE approach is computationally straightforward and has been implemented in existing, widely-available statistical software. 223
224 Recall, marginal models make following three assumptions: 1. the marginal expectation of the response, µ ij, depends on covariates, X ij, through a known link function g (µ ij ) = η ij = X ijβ = β 1 X ij1 + β 2 X ij β p X ijp 2. the marginal variance of Y ij depends on the marginal mean according to V ar (Y ij ) = υ (µ ij ) φ where υ (µ ij ) is a known variance function and φ is a scale parameter that may need to be estimated. 3. the within-subject association among the responses is a function of the means and perhaps of additional parameters, say α, that may also need to be estimated. 224
225 For example, when the vector of parameters α represents the pairwise correlations among the responses, the covariances among the responses depend on µ ij (β), φ, and α: V i = A 1 2 i Corr(Y i )A 1 2 i, where A i is a diagonal matrix with Var (Y ij ) = φ v (µ ij ) along the diagonal (and A 1 2 i is a diagonal matrix with the standard deviations, φ v (µ ij ), along the diagonal), and Corr(Y i ) is the correlation matrix. 225
226 The GEE estimator of β solves the following generalized estimating equations N i=1 D V 1 i (y i µ i ) = 0, where V i is the so-called working covariance matrix. By working covariance matrix we mean that V i approximates the true underlying covariance matrix for Y i. That is, V i Cov (Y i ), recognizing that V i Cov (Y i ) unless the models for the variances and the within-subject associations are correct. D i = µ i / β is the so-called derivative matrix (of µ i with respect to the components of β). 226
227 D i is a matrix that transforms from the original units of Y i (and µ i ) to the units of g(µ ij ). The n i p derivative matrix D i is given by, µ i1 / β 1 µ i1 / β 2... µ i1 / β p D i = , µ ini / β 1 µ ini / β 2... µ ini / β p and is only a function of β (since the µ ij only depend on β). 227
228 Therefore the generalized estimating equations depend on both β and α. Because the generalized estimating equations depend on both β and α, an iterative two-stage estimation procedure is required: 1. Given current estimates of α and φ, an estimate of β is obtained as the solution to the generalized estimating equations 2. Given current estimate of β, estimates of α and φ are obtained based on the standardized residuals, r ij = (Y ij µ ij ) /υ ( µ ij ) 1/2 228
229 For example, φ can be estimated by 1/ (Nn) N i=1 n j=1 r 2 ij Alternatively, to take account of the p regression parameters estimated, φ can be estimated by 1/ (Nn p) N i=1 n j=1 r 2 ij 229
230 The correlation parameters, α, can be estimated in a similar way, depending on the working assumption about the correlation. For example, unstructured correlations, α jk = Corr (Y ij, Y ik ), can be estimated by α jk = (1/N) φ 1 N r ij r ik i=1 Finally, in the two-stage estimation procedure we iterate between steps 1) and 2) until convergence has been achieved. 230
231 Properties of GEE estimators: β, the solution to the generalized estimating equations, has the following properties: 1. β is consistent estimate of β (with high probability, it is close to β) 2. In large samples, β has a multivariate normal distribution 3. Cov( β) = B 1 MB 1 231
232 where B = M = N i=1 N i=1 D iv i 1 D i D iv 1 i Cov (Y i ) Vi 1 D i Note that B and M can be estimated by replacing α, φ, and β by their estimates, and replacing Cov (Y i ) by (Y i µ i ) (Y i µ i ). That is, we can use the empirical or so-called sandwich variance estimator. 232
233 In summary, the GEE estimators have the following attractive properties: 1. In many cases β is almost efficient when compared to MLE. For example, GEE has same form as likelihood equations for multivariate normal models and also certain models for discrete data 2. β is consistent even if the covariance of Yi has been misspecified 3. Standard errors for β can be obtained using the empirical or so-called sandwich estimator 233
234 Example: Six Cities Study of Respiratory Illness in Children. A non-randomized longitudinal study of the health effects of air pollution. Subset of data from one of the participating cities: Steubenville, Ohio Outcome variable: Binary indicator of respiratory infections in child. Measurements on the children were taken annually at ages 7, 8, 9, and 10. Interested in changes in the rates of respiratory illness and the influence of maternal smoking. 234
235 Assume marginal probability of infection follows a logistic model, logit(µ ij ) = β 1 + β 2 age ij + β 3 smoke i + β 4 age smoke i where age ij = child s age - 9; and smoke i = 1 if child s mother smokes, 0 otherwise. Also, we assume that var(y ij ) = µ ij (1 µ ij ) Need to make assumptions about within-subject association, e.g., Corr(Y ij, Y ik ) = α jk ( unstructured ). 235
236 Stata Commands for GEE. infile id smoke age y using wheeze.dat. replace age=age-9. generate sm_age=smoke*age. tsset id age. xtgee y smoke age sm_age,family(binomial) link(logit) corr(unstr) robust Iteration 1: tolerance = Iteration 2: tolerance = Iteration 3: tolerance = 9.376e-07 GEE population-averaged model Number of obs = 2148 Group and time vars: id age Number of groups = 537 Link: logit Obs per group: min = 4 Family: binomial avg = 4.0 Correlation: unstructured max = 4 Wald chi2(3) = 8.80 Scale parameter: 1 Prob > chi2 = (Std. Err. adjusted for clustering on id) 236
237 Semi-robust y Coef. Std. Err. z P> z [95% Conf. Interval] smoke age sm_age _cons xtcorr Estimated within-id correlation matrix R: c1 c2 c3 c4 r r r r xtgee y smoke age,family(binomial) link(logit) corr(unstr) robust 237
238 GEE population-averaged model Number of obs = 2148 Group and time vars: id age Number of groups = 537 Link: logit Obs per group: min = 4 Family: binomial avg = 4.0 Correlation: unstructured max = 4 Wald chi2(2) = 8.90 Scale parameter: 1 Prob > chi2 = (Std. Err. adjusted for clustering on id) Semi-robust y Coef. Std. Err. z P> z [95% Conf. Interval] smoke age _cons predict yhat 238
239 (option mu assumed; exp(xb)/(1+exp(xb))). list smoke age yhat if (smoke==0) smoke age yhat list smoke age yhat if (smoke==1) smoke age yhat
240 Thus, there is evidence that the rates of respiratory infection decline with age, but the rates do not appear to depend on whether a child s mother smokes. Can fit model exluding age smoke interaction. For a child whose mother does not smoke, the predicted probability of infection at ages 7, 8, 9, and 10 is 0.160, 0.145, 0.131, and respectively. While for a child whose mother does smoke, the predicted probability of infection at ages 7, 8, 9, and 10 is 0.197, 0.179, 0.163, and respectively. 240
241 Summary The GEE approach has become an extremely popular method for analyzing longitudinal data. It provides a flexible approach for modelling the mean and the pairwise within-subject association structure. It can handle inherently unbalanced designs and missing data with ease. GEE approach is computationally straightforward and has been implemented in existing, widely-available statistical software. 241
242 Further Reading: Fitzmaurice GM, Laird NM and Ware JH. (2004) Applied Longitudinal Analysis. Wiley. Chapter 10 (Sections 10.1, 10.2, 10.3) Chapter 11 (Sections 11.1, 11.2, 11.3, 11.4) 242
Chapter 1. Longitudinal Data Analysis. 1.1 Introduction
 Chapter 1 Longitudinal Data Analysis 1.1 Introduction One of the most common medical research designs is a pre-post study in which a single baseline health status measurement is obtained, an intervention
Chapter 1 Longitudinal Data Analysis 1.1 Introduction One of the most common medical research designs is a pre-post study in which a single baseline health status measurement is obtained, an intervention
Analysis of Correlated Data. Patrick J. Heagerty PhD Department of Biostatistics University of Washington
 Analysis of Correlated Data Patrick J Heagerty PhD Department of Biostatistics University of Washington Heagerty, 6 Course Outline Examples of longitudinal data Correlation and weighting Exploratory data
Analysis of Correlated Data Patrick J Heagerty PhD Department of Biostatistics University of Washington Heagerty, 6 Course Outline Examples of longitudinal data Correlation and weighting Exploratory data
STATISTICA Formula Guide: Logistic Regression. Table of Contents
 : Table of Contents... 1 Overview of Model... 1 Dispersion... 2 Parameterization... 3 Sigma-Restricted Model... 3 Overparameterized Model... 4 Reference Coding... 4 Model Summary (Summary Tab)... 5 Summary
: Table of Contents... 1 Overview of Model... 1 Dispersion... 2 Parameterization... 3 Sigma-Restricted Model... 3 Overparameterized Model... 4 Reference Coding... 4 Model Summary (Summary Tab)... 5 Summary
Overview of Methods for Analyzing Cluster-Correlated Data. Garrett M. Fitzmaurice
 Overview of Methods for Analyzing Cluster-Correlated Data Garrett M. Fitzmaurice Laboratory for Psychiatric Biostatistics, McLean Hospital Department of Biostatistics, Harvard School of Public Health Outline
Overview of Methods for Analyzing Cluster-Correlated Data Garrett M. Fitzmaurice Laboratory for Psychiatric Biostatistics, McLean Hospital Department of Biostatistics, Harvard School of Public Health Outline
Statistical Models in R
 Statistical Models in R Some Examples Steven Buechler Department of Mathematics 276B Hurley Hall; 1-6233 Fall, 2007 Outline Statistical Models Structure of models in R Model Assessment (Part IA) Anova
Statistical Models in R Some Examples Steven Buechler Department of Mathematics 276B Hurley Hall; 1-6233 Fall, 2007 Outline Statistical Models Structure of models in R Model Assessment (Part IA) Anova
Introduction to Longitudinal Data Analysis
 Introduction to Longitudinal Data Analysis Longitudinal Data Analysis Workshop Section 1 University of Georgia: Institute for Interdisciplinary Research in Education and Human Development Section 1: Introduction
Introduction to Longitudinal Data Analysis Longitudinal Data Analysis Workshop Section 1 University of Georgia: Institute for Interdisciplinary Research in Education and Human Development Section 1: Introduction
Introduction to Regression and Data Analysis
 Statlab Workshop Introduction to Regression and Data Analysis with Dan Campbell and Sherlock Campbell October 28, 2008 I. The basics A. Types of variables Your variables may take several forms, and it
Statlab Workshop Introduction to Regression and Data Analysis with Dan Campbell and Sherlock Campbell October 28, 2008 I. The basics A. Types of variables Your variables may take several forms, and it
15.062 Data Mining: Algorithms and Applications Matrix Math Review
 .6 Data Mining: Algorithms and Applications Matrix Math Review The purpose of this document is to give a brief review of selected linear algebra concepts that will be useful for the course and to develop
.6 Data Mining: Algorithms and Applications Matrix Math Review The purpose of this document is to give a brief review of selected linear algebra concepts that will be useful for the course and to develop
Individual Growth Analysis Using PROC MIXED Maribeth Johnson, Medical College of Georgia, Augusta, GA
 Paper P-702 Individual Growth Analysis Using PROC MIXED Maribeth Johnson, Medical College of Georgia, Augusta, GA ABSTRACT Individual growth models are designed for exploring longitudinal data on individuals
Paper P-702 Individual Growth Analysis Using PROC MIXED Maribeth Johnson, Medical College of Georgia, Augusta, GA ABSTRACT Individual growth models are designed for exploring longitudinal data on individuals
11. Analysis of Case-control Studies Logistic Regression
 Research methods II 113 11. Analysis of Case-control Studies Logistic Regression This chapter builds upon and further develops the concepts and strategies described in Ch.6 of Mother and Child Health:
Research methods II 113 11. Analysis of Case-control Studies Logistic Regression This chapter builds upon and further develops the concepts and strategies described in Ch.6 of Mother and Child Health:
UNDERSTANDING THE TWO-WAY ANOVA
 UNDERSTANDING THE e have seen how the one-way ANOVA can be used to compare two or more sample means in studies involving a single independent variable. This can be extended to two independent variables
UNDERSTANDING THE e have seen how the one-way ANOVA can be used to compare two or more sample means in studies involving a single independent variable. This can be extended to two independent variables
NCSS Statistical Software Principal Components Regression. In ordinary least squares, the regression coefficients are estimated using the formula ( )
") Chapter 340 Principal Components Regression Introduction is a technique for analyzing multiple regression data that suffer from multicollinearity. When multicollinearity occurs, least squares estimates
Chapter 340 Principal Components Regression Introduction is a technique for analyzing multiple regression data that suffer from multicollinearity. When multicollinearity occurs, least squares estimates
Least Squares Estimation
 Least Squares Estimation SARA A VAN DE GEER Volume 2, pp 1041 1045 in Encyclopedia of Statistics in Behavioral Science ISBN-13: 978-0-470-86080-9 ISBN-10: 0-470-86080-4 Editors Brian S Everitt & David
Least Squares Estimation SARA A VAN DE GEER Volume 2, pp 1041 1045 in Encyclopedia of Statistics in Behavioral Science ISBN-13: 978-0-470-86080-9 ISBN-10: 0-470-86080-4 Editors Brian S Everitt & David
An Introduction to Modeling Longitudinal Data
 An Introduction to Modeling Longitudinal Data Session I: Basic Concepts and Looking at Data Robert Weiss Department of Biostatistics UCLA School of Public Health [email protected] August 2010 Robert Weiss
An Introduction to Modeling Longitudinal Data Session I: Basic Concepts and Looking at Data Robert Weiss Department of Biostatistics UCLA School of Public Health [email protected] August 2010 Robert Weiss
DEPARTMENT OF PSYCHOLOGY UNIVERSITY OF LANCASTER MSC IN PSYCHOLOGICAL RESEARCH METHODS ANALYSING AND INTERPRETING DATA 2 PART 1 WEEK 9
 DEPARTMENT OF PSYCHOLOGY UNIVERSITY OF LANCASTER MSC IN PSYCHOLOGICAL RESEARCH METHODS ANALYSING AND INTERPRETING DATA 2 PART 1 WEEK 9 Analysis of covariance and multiple regression So far in this course,
DEPARTMENT OF PSYCHOLOGY UNIVERSITY OF LANCASTER MSC IN PSYCHOLOGICAL RESEARCH METHODS ANALYSING AND INTERPRETING DATA 2 PART 1 WEEK 9 Analysis of covariance and multiple regression So far in this course,
HLM software has been one of the leading statistical packages for hierarchical
 Introductory Guide to HLM With HLM 7 Software 3 G. David Garson HLM software has been one of the leading statistical packages for hierarchical linear modeling due to the pioneering work of Stephen Raudenbush
Introductory Guide to HLM With HLM 7 Software 3 G. David Garson HLM software has been one of the leading statistical packages for hierarchical linear modeling due to the pioneering work of Stephen Raudenbush
SYSTEMS OF REGRESSION EQUATIONS
 SYSTEMS OF REGRESSION EQUATIONS 1. MULTIPLE EQUATIONS y nt = x nt n + u nt, n = 1,...,N, t = 1,...,T, x nt is 1 k, and n is k 1. This is a version of the standard regression model where the observations
SYSTEMS OF REGRESSION EQUATIONS 1. MULTIPLE EQUATIONS y nt = x nt n + u nt, n = 1,...,N, t = 1,...,T, x nt is 1 k, and n is k 1. This is a version of the standard regression model where the observations
Overview of Violations of the Basic Assumptions in the Classical Normal Linear Regression Model
 Overview of Violations of the Basic Assumptions in the Classical Normal Linear Regression Model 1 September 004 A. Introduction and assumptions The classical normal linear regression model can be written
Overview of Violations of the Basic Assumptions in the Classical Normal Linear Regression Model 1 September 004 A. Introduction and assumptions The classical normal linear regression model can be written
Longitudinal Data Analyses Using Linear Mixed Models in SPSS: Concepts, Procedures and Illustrations
 Research Article TheScientificWorldJOURNAL (2011) 11, 42 76 TSW Child Health & Human Development ISSN 1537-744X; DOI 10.1100/tsw.2011.2 Longitudinal Data Analyses Using Linear Mixed Models in SPSS: Concepts,
Research Article TheScientificWorldJOURNAL (2011) 11, 42 76 TSW Child Health & Human Development ISSN 1537-744X; DOI 10.1100/tsw.2011.2 Longitudinal Data Analyses Using Linear Mixed Models in SPSS: Concepts,
Chapter 15. Mixed Models. 15.1 Overview. A flexible approach to correlated data.
 Chapter 15 Mixed Models A flexible approach to correlated data. 15.1 Overview Correlated data arise frequently in statistical analyses. This may be due to grouping of subjects, e.g., students within classrooms,
Chapter 15 Mixed Models A flexible approach to correlated data. 15.1 Overview Correlated data arise frequently in statistical analyses. This may be due to grouping of subjects, e.g., students within classrooms,
Elements of statistics (MATH0487-1)
") Elements of statistics (MATH0487-1) Prof. Dr. Dr. K. Van Steen University of Liège, Belgium December 10, 2012 Introduction to Statistics Basic Probability Revisited Sampling Exploratory Data Analysis -
Elements of statistics (MATH0487-1) Prof. Dr. Dr. K. Van Steen University of Liège, Belgium December 10, 2012 Introduction to Statistics Basic Probability Revisited Sampling Exploratory Data Analysis -
Overview. Longitudinal Data Variation and Correlation Different Approaches. Linear Mixed Models Generalized Linear Mixed Models
 Overview 1 Introduction Longitudinal Data Variation and Correlation Different Approaches 2 Mixed Models Linear Mixed Models Generalized Linear Mixed Models 3 Marginal Models Linear Models Generalized Linear
Overview 1 Introduction Longitudinal Data Variation and Correlation Different Approaches 2 Mixed Models Linear Mixed Models Generalized Linear Mixed Models 3 Marginal Models Linear Models Generalized Linear
Regression III: Advanced Methods
 Lecture 16: Generalized Additive Models Regression III: Advanced Methods Bill Jacoby Michigan State University http://polisci.msu.edu/jacoby/icpsr/regress3 Goals of the Lecture Introduce Additive Models
Lecture 16: Generalized Additive Models Regression III: Advanced Methods Bill Jacoby Michigan State University http://polisci.msu.edu/jacoby/icpsr/regress3 Goals of the Lecture Introduce Additive Models
Poisson Models for Count Data
 Chapter 4 Poisson Models for Count Data In this chapter we study log-linear models for count data under the assumption of a Poisson error structure. These models have many applications, not only to the
Chapter 4 Poisson Models for Count Data In this chapter we study log-linear models for count data under the assumption of a Poisson error structure. These models have many applications, not only to the
An analysis method for a quantitative outcome and two categorical explanatory variables.
 Chapter 11 Two-Way ANOVA An analysis method for a quantitative outcome and two categorical explanatory variables. If an experiment has a quantitative outcome and two categorical explanatory variables that
Chapter 11 Two-Way ANOVA An analysis method for a quantitative outcome and two categorical explanatory variables. If an experiment has a quantitative outcome and two categorical explanatory variables that
Algebra 1 Course Information
 Course Information Course Description: Students will study patterns, relations, and functions, and focus on the use of mathematical models to understand and analyze quantitative relationships. Through
Course Information Course Description: Students will study patterns, relations, and functions, and focus on the use of mathematical models to understand and analyze quantitative relationships. Through
Simple Predictive Analytics Curtis Seare
 Using Excel to Solve Business Problems: Simple Predictive Analytics Curtis Seare Copyright: Vault Analytics July 2010 Contents Section I: Background Information Why use Predictive Analytics? How to use
Using Excel to Solve Business Problems: Simple Predictive Analytics Curtis Seare Copyright: Vault Analytics July 2010 Contents Section I: Background Information Why use Predictive Analytics? How to use
Linear Mixed-Effects Modeling in SPSS: An Introduction to the MIXED Procedure
 Technical report Linear Mixed-Effects Modeling in SPSS: An Introduction to the MIXED Procedure Table of contents Introduction................................................................ 1 Data preparation
Technical report Linear Mixed-Effects Modeling in SPSS: An Introduction to the MIXED Procedure Table of contents Introduction................................................................ 1 Data preparation
Tips for surviving the analysis of survival data. Philip Twumasi-Ankrah, PhD
 Tips for surviving the analysis of survival data Philip Twumasi-Ankrah, PhD Big picture In medical research and many other areas of research, we often confront continuous, ordinal or dichotomous outcomes
Tips for surviving the analysis of survival data Philip Twumasi-Ankrah, PhD Big picture In medical research and many other areas of research, we often confront continuous, ordinal or dichotomous outcomes
Multivariate Normal Distribution
 Multivariate Normal Distribution Lecture 4 July 21, 2011 Advanced Multivariate Statistical Methods ICPSR Summer Session #2 Lecture #4-7/21/2011 Slide 1 of 41 Last Time Matrices and vectors Eigenvalues
Multivariate Normal Distribution Lecture 4 July 21, 2011 Advanced Multivariate Statistical Methods ICPSR Summer Session #2 Lecture #4-7/21/2011 Slide 1 of 41 Last Time Matrices and vectors Eigenvalues
E(y i ) = x T i β. yield of the refined product as a percentage of crude specific gravity vapour pressure ASTM 10% point ASTM end point in degrees F
 = x T i β. yield of the refined product as a percentage of crude specific gravity vapour pressure ASTM 10% point ASTM end point in degrees F") Random and Mixed Effects Models (Ch. 10) Random effects models are very useful when the observations are sampled in a highly structured way. The basic idea is that the error associated with any linear,
Random and Mixed Effects Models (Ch. 10) Random effects models are very useful when the observations are sampled in a highly structured way. The basic idea is that the error associated with any linear,
Introduction to General and Generalized Linear Models
 Introduction to General and Generalized Linear Models General Linear Models - part I Henrik Madsen Poul Thyregod Informatics and Mathematical Modelling Technical University of Denmark DK-2800 Kgs. Lyngby
Introduction to General and Generalized Linear Models General Linear Models - part I Henrik Madsen Poul Thyregod Informatics and Mathematical Modelling Technical University of Denmark DK-2800 Kgs. Lyngby
South Carolina College- and Career-Ready (SCCCR) Probability and Statistics
 Probability and Statistics") South Carolina College- and Career-Ready (SCCCR) Probability and Statistics South Carolina College- and Career-Ready Mathematical Process Standards The South Carolina College- and Career-Ready (SCCCR)
South Carolina College- and Career-Ready (SCCCR) Probability and Statistics South Carolina College- and Career-Ready Mathematical Process Standards The South Carolina College- and Career-Ready (SCCCR)
Service courses for graduate students in degree programs other than the MS or PhD programs in Biostatistics.
 Course Catalog In order to be assured that all prerequisites are met, students must acquire a permission number from the education coordinator prior to enrolling in any Biostatistics course. Courses are
Course Catalog In order to be assured that all prerequisites are met, students must acquire a permission number from the education coordinator prior to enrolling in any Biostatistics course. Courses are
Linear Models and Conjoint Analysis with Nonlinear Spline Transformations
 Linear Models and Conjoint Analysis with Nonlinear Spline Transformations Warren F. Kuhfeld Mark Garratt Abstract Many common data analysis models are based on the general linear univariate model, including
Linear Models and Conjoint Analysis with Nonlinear Spline Transformations Warren F. Kuhfeld Mark Garratt Abstract Many common data analysis models are based on the general linear univariate model, including
SAS Software to Fit the Generalized Linear Model
 SAS Software to Fit the Generalized Linear Model Gordon Johnston, SAS Institute Inc., Cary, NC Abstract In recent years, the class of generalized linear models has gained popularity as a statistical modeling
SAS Software to Fit the Generalized Linear Model Gordon Johnston, SAS Institute Inc., Cary, NC Abstract In recent years, the class of generalized linear models has gained popularity as a statistical modeling
CORRELATED TO THE SOUTH CAROLINA COLLEGE AND CAREER-READY FOUNDATIONS IN ALGEBRA
 We Can Early Learning Curriculum PreK Grades 8 12 INSIDE ALGEBRA, GRADES 8 12 CORRELATED TO THE SOUTH CAROLINA COLLEGE AND CAREER-READY FOUNDATIONS IN ALGEBRA April 2016 www.voyagersopris.com Mathematical
We Can Early Learning Curriculum PreK Grades 8 12 INSIDE ALGEBRA, GRADES 8 12 CORRELATED TO THE SOUTH CAROLINA COLLEGE AND CAREER-READY FOUNDATIONS IN ALGEBRA April 2016 www.voyagersopris.com Mathematical
Marketing Mix Modelling and Big Data P. M Cain
 1) Introduction Marketing Mix Modelling and Big Data P. M Cain Big data is generally defined in terms of the volume and variety of structured and unstructured information. Whereas structured data is stored
1) Introduction Marketing Mix Modelling and Big Data P. M Cain Big data is generally defined in terms of the volume and variety of structured and unstructured information. Whereas structured data is stored
CONTENTS OF DAY 2. II. Why Random Sampling is Important 9 A myth, an urban legend, and the real reason NOTES FOR SUMMER STATISTICS INSTITUTE COURSE
 1 2 CONTENTS OF DAY 2 I. More Precise Definition of Simple Random Sample 3 Connection with independent random variables 3 Problems with small populations 8 II. Why Random Sampling is Important 9 A myth,
1 2 CONTENTS OF DAY 2 I. More Precise Definition of Simple Random Sample 3 Connection with independent random variables 3 Problems with small populations 8 II. Why Random Sampling is Important 9 A myth,
Algebra 1 2008. Academic Content Standards Grade Eight and Grade Nine Ohio. Grade Eight. Number, Number Sense and Operations Standard
 Academic Content Standards Grade Eight and Grade Nine Ohio Algebra 1 2008 Grade Eight STANDARDS Number, Number Sense and Operations Standard Number and Number Systems 1. Use scientific notation to express
Academic Content Standards Grade Eight and Grade Nine Ohio Algebra 1 2008 Grade Eight STANDARDS Number, Number Sense and Operations Standard Number and Number Systems 1. Use scientific notation to express
DESCRIPTIVE STATISTICS AND EXPLORATORY DATA ANALYSIS
 DESCRIPTIVE STATISTICS AND EXPLORATORY DATA ANALYSIS SEEMA JAGGI Indian Agricultural Statistics Research Institute Library Avenue, New Delhi - 110 012 [email protected] 1. Descriptive Statistics Statistics
DESCRIPTIVE STATISTICS AND EXPLORATORY DATA ANALYSIS SEEMA JAGGI Indian Agricultural Statistics Research Institute Library Avenue, New Delhi - 110 012 [email protected] 1. Descriptive Statistics Statistics
Multivariate Analysis of Variance (MANOVA): I. Theory
: I. Theory") Gregory Carey, 1998 MANOVA: I - 1 Multivariate Analysis of Variance (MANOVA): I. Theory Introduction The purpose of a t test is to assess the likelihood that the means for two groups are sampled from the
Gregory Carey, 1998 MANOVA: I - 1 Multivariate Analysis of Variance (MANOVA): I. Theory Introduction The purpose of a t test is to assess the likelihood that the means for two groups are sampled from the
MULTIPLE REGRESSION AND ISSUES IN REGRESSION ANALYSIS
 MULTIPLE REGRESSION AND ISSUES IN REGRESSION ANALYSIS MSR = Mean Regression Sum of Squares MSE = Mean Squared Error RSS = Regression Sum of Squares SSE = Sum of Squared Errors/Residuals α = Level of Significance
MULTIPLE REGRESSION AND ISSUES IN REGRESSION ANALYSIS MSR = Mean Regression Sum of Squares MSE = Mean Squared Error RSS = Regression Sum of Squares SSE = Sum of Squared Errors/Residuals α = Level of Significance
DATA INTERPRETATION AND STATISTICS
 PholC60 September 001 DATA INTERPRETATION AND STATISTICS Books A easy and systematic introductory text is Essentials of Medical Statistics by Betty Kirkwood, published by Blackwell at about 14. DESCRIPTIVE
PholC60 September 001 DATA INTERPRETATION AND STATISTICS Books A easy and systematic introductory text is Essentials of Medical Statistics by Betty Kirkwood, published by Blackwell at about 14. DESCRIPTIVE
Multivariate Logistic Regression
 1 Multivariate Logistic Regression As in univariate logistic regression, let π(x) represent the probability of an event that depends on p covariates or independent variables. Then, using an inv.logit formulation
1 Multivariate Logistic Regression As in univariate logistic regression, let π(x) represent the probability of an event that depends on p covariates or independent variables. Then, using an inv.logit formulation
Simple Linear Regression Inference
 Simple Linear Regression Inference 1 Inference requirements The Normality assumption of the stochastic term e is needed for inference even if it is not a OLS requirement. Therefore we have: Interpretation
Simple Linear Regression Inference 1 Inference requirements The Normality assumption of the stochastic term e is needed for inference even if it is not a OLS requirement. Therefore we have: Interpretation
Auxiliary Variables in Mixture Modeling: 3-Step Approaches Using Mplus
 Auxiliary Variables in Mixture Modeling: 3-Step Approaches Using Mplus Tihomir Asparouhov and Bengt Muthén Mplus Web Notes: No. 15 Version 8, August 5, 2014 1 Abstract This paper discusses alternatives
Auxiliary Variables in Mixture Modeling: 3-Step Approaches Using Mplus Tihomir Asparouhov and Bengt Muthén Mplus Web Notes: No. 15 Version 8, August 5, 2014 1 Abstract This paper discusses alternatives
Additional sources Compilation of sources: http://lrs.ed.uiuc.edu/tseportal/datacollectionmethodologies/jin-tselink/tselink.htm
 Mgt 540 Research Methods Data Analysis 1 Additional sources Compilation of sources: http://lrs.ed.uiuc.edu/tseportal/datacollectionmethodologies/jin-tselink/tselink.htm http://web.utk.edu/~dap/random/order/start.htm
Mgt 540 Research Methods Data Analysis 1 Additional sources Compilation of sources: http://lrs.ed.uiuc.edu/tseportal/datacollectionmethodologies/jin-tselink/tselink.htm http://web.utk.edu/~dap/random/order/start.htm
Linear Models for Continuous Data
 Chapter 2 Linear Models for Continuous Data The starting point in our exploration of statistical models in social research will be the classical linear model. Stops along the way include multiple linear
Chapter 2 Linear Models for Continuous Data The starting point in our exploration of statistical models in social research will be the classical linear model. Stops along the way include multiple linear
Section 14 Simple Linear Regression: Introduction to Least Squares Regression
 Slide 1 Section 14 Simple Linear Regression: Introduction to Least Squares Regression There are several different measures of statistical association used for understanding the quantitative relationship
Slide 1 Section 14 Simple Linear Regression: Introduction to Least Squares Regression There are several different measures of statistical association used for understanding the quantitative relationship
A Basic Introduction to Missing Data
 John Fox Sociology 740 Winter 2014 Outline Why Missing Data Arise Why Missing Data Arise Global or unit non-response. In a survey, certain respondents may be unreachable or may refuse to participate. Item
John Fox Sociology 740 Winter 2014 Outline Why Missing Data Arise Why Missing Data Arise Global or unit non-response. In a survey, certain respondents may be unreachable or may refuse to participate. Item
10. Analysis of Longitudinal Studies Repeat-measures analysis
 Research Methods II 99 10. Analysis of Longitudinal Studies Repeat-measures analysis This chapter builds on the concepts and methods described in Chapters 7 and 8 of Mother and Child Health: Research methods.
Research Methods II 99 10. Analysis of Longitudinal Studies Repeat-measures analysis This chapter builds on the concepts and methods described in Chapters 7 and 8 of Mother and Child Health: Research methods.
Simple Regression Theory II 2010 Samuel L. Baker
 SIMPLE REGRESSION THEORY II 1 Simple Regression Theory II 2010 Samuel L. Baker Assessing how good the regression equation is likely to be Assignment 1A gets into drawing inferences about how close the
SIMPLE REGRESSION THEORY II 1 Simple Regression Theory II 2010 Samuel L. Baker Assessing how good the regression equation is likely to be Assignment 1A gets into drawing inferences about how close the
Assignments Analysis of Longitudinal data: a multilevel approach
 Assignments Analysis of Longitudinal data: a multilevel approach Frans E.S. Tan Department of Methodology and Statistics University of Maastricht The Netherlands Maastricht, Jan 2007 Correspondence: Frans
Assignments Analysis of Longitudinal data: a multilevel approach Frans E.S. Tan Department of Methodology and Statistics University of Maastricht The Netherlands Maastricht, Jan 2007 Correspondence: Frans
Applied Statistics. J. Blanchet and J. Wadsworth. Institute of Mathematics, Analysis, and Applications EPF Lausanne
 Applied Statistics J. Blanchet and J. Wadsworth Institute of Mathematics, Analysis, and Applications EPF Lausanne An MSc Course for Applied Mathematicians, Fall 2012 Outline 1 Model Comparison 2 Model
Applied Statistics J. Blanchet and J. Wadsworth Institute of Mathematics, Analysis, and Applications EPF Lausanne An MSc Course for Applied Mathematicians, Fall 2012 Outline 1 Model Comparison 2 Model
Normality Testing in Excel
 Normality Testing in Excel By Mark Harmon Copyright 2011 Mark Harmon No part of this publication may be reproduced or distributed without the express permission of the author. [email protected]
Normality Testing in Excel By Mark Harmon Copyright 2011 Mark Harmon No part of this publication may be reproduced or distributed without the express permission of the author. [email protected]
Statistical Models in R
 Statistical Models in R Some Examples Steven Buechler Department of Mathematics 276B Hurley Hall; 1-6233 Fall, 2007 Outline Statistical Models Linear Models in R Regression Regression analysis is the appropriate
Statistical Models in R Some Examples Steven Buechler Department of Mathematics 276B Hurley Hall; 1-6233 Fall, 2007 Outline Statistical Models Linear Models in R Regression Regression analysis is the appropriate
Penalized regression: Introduction
 Penalized regression: Introduction Patrick Breheny August 30 Patrick Breheny BST 764: Applied Statistical Modeling 1/19 Maximum likelihood Much of 20th-century statistics dealt with maximum likelihood
Penalized regression: Introduction Patrick Breheny August 30 Patrick Breheny BST 764: Applied Statistical Modeling 1/19 Maximum likelihood Much of 20th-century statistics dealt with maximum likelihood
Basic Statistics and Data Analysis for Health Researchers from Foreign Countries
 Basic Statistics and Data Analysis for Health Researchers from Foreign Countries Volkert Siersma [email protected] The Research Unit for General Practice in Copenhagen Dias 1 Content Quantifying association
Basic Statistics and Data Analysis for Health Researchers from Foreign Countries Volkert Siersma [email protected] The Research Unit for General Practice in Copenhagen Dias 1 Content Quantifying association
POLYNOMIAL AND MULTIPLE REGRESSION. Polynomial regression used to fit nonlinear (e.g. curvilinear) data into a least squares linear regression model.
 data into a least squares linear regression model.") Polynomial Regression POLYNOMIAL AND MULTIPLE REGRESSION Polynomial regression used to fit nonlinear (e.g. curvilinear) data into a least squares linear regression model. It is a form of linear regression
Polynomial Regression POLYNOMIAL AND MULTIPLE REGRESSION Polynomial regression used to fit nonlinear (e.g. curvilinear) data into a least squares linear regression model. It is a form of linear regression
3. Data Analysis, Statistics, and Probability
 3. Data Analysis, Statistics, and Probability Data and probability sense provides students with tools to understand information and uncertainty. Students ask questions and gather and use data to answer
3. Data Analysis, Statistics, and Probability Data and probability sense provides students with tools to understand information and uncertainty. Students ask questions and gather and use data to answer
2. Simple Linear Regression
 Research methods - II 3 2. Simple Linear Regression Simple linear regression is a technique in parametric statistics that is commonly used for analyzing mean response of a variable Y which changes according
Research methods - II 3 2. Simple Linear Regression Simple linear regression is a technique in parametric statistics that is commonly used for analyzing mean response of a variable Y which changes according
Case Study in Data Analysis Does a drug prevent cardiomegaly in heart failure?
 Case Study in Data Analysis Does a drug prevent cardiomegaly in heart failure? Harvey Motulsky [email protected] This is the first case in what I expect will be a series of case studies. While I mention
Case Study in Data Analysis Does a drug prevent cardiomegaly in heart failure? Harvey Motulsky [email protected] This is the first case in what I expect will be a series of case studies. While I mention
Chapter 13 Introduction to Linear Regression and Correlation Analysis
 Chapter 3 Student Lecture Notes 3- Chapter 3 Introduction to Linear Regression and Correlation Analsis Fall 2006 Fundamentals of Business Statistics Chapter Goals To understand the methods for displaing
Chapter 3 Student Lecture Notes 3- Chapter 3 Introduction to Linear Regression and Correlation Analsis Fall 2006 Fundamentals of Business Statistics Chapter Goals To understand the methods for displaing
Curriculum Map Statistics and Probability Honors (348) Saugus High School Saugus Public Schools 2009-2010
 Saugus High School Saugus Public Schools 2009-2010") Curriculum Map Statistics and Probability Honors (348) Saugus High School Saugus Public Schools 2009-2010 Week 1 Week 2 14.0 Students organize and describe distributions of data by using a number of different
Curriculum Map Statistics and Probability Honors (348) Saugus High School Saugus Public Schools 2009-2010 Week 1 Week 2 14.0 Students organize and describe distributions of data by using a number of different
This can dilute the significance of a departure from the null hypothesis. We can focus the test on departures of a particular form.
 One-Degree-of-Freedom Tests Test for group occasion interactions has (number of groups 1) number of occasions 1) degrees of freedom. This can dilute the significance of a departure from the null hypothesis.
One-Degree-of-Freedom Tests Test for group occasion interactions has (number of groups 1) number of occasions 1) degrees of freedom. This can dilute the significance of a departure from the null hypothesis.
Basic Concepts in Research and Data Analysis
 Basic Concepts in Research and Data Analysis Introduction: A Common Language for Researchers...2 Steps to Follow When Conducting Research...3 The Research Question... 3 The Hypothesis... 4 Defining the
Basic Concepts in Research and Data Analysis Introduction: A Common Language for Researchers...2 Steps to Follow When Conducting Research...3 The Research Question... 3 The Hypothesis... 4 Defining the
A Primer on Mathematical Statistics and Univariate Distributions; The Normal Distribution; The GLM with the Normal Distribution
 A Primer on Mathematical Statistics and Univariate Distributions; The Normal Distribution; The GLM with the Normal Distribution PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 4: September
A Primer on Mathematical Statistics and Univariate Distributions; The Normal Distribution; The GLM with the Normal Distribution PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 4: September
2013 MBA Jump Start Program. Statistics Module Part 3
 2013 MBA Jump Start Program Module 1: Statistics Thomas Gilbert Part 3 Statistics Module Part 3 Hypothesis Testing (Inference) Regressions 2 1 Making an Investment Decision A researcher in your firm just
2013 MBA Jump Start Program Module 1: Statistics Thomas Gilbert Part 3 Statistics Module Part 3 Hypothesis Testing (Inference) Regressions 2 1 Making an Investment Decision A researcher in your firm just
business statistics using Excel OXFORD UNIVERSITY PRESS Glyn Davis & Branko Pecar
 business statistics using Excel Glyn Davis & Branko Pecar OXFORD UNIVERSITY PRESS Detailed contents Introduction to Microsoft Excel 2003 Overview Learning Objectives 1.1 Introduction to Microsoft Excel
business statistics using Excel Glyn Davis & Branko Pecar OXFORD UNIVERSITY PRESS Detailed contents Introduction to Microsoft Excel 2003 Overview Learning Objectives 1.1 Introduction to Microsoft Excel
Interaction between quantitative predictors
 Interaction between quantitative predictors In a first-order model like the ones we have discussed, the association between E(y) and a predictor x j does not depend on the value of the other predictors
Interaction between quantitative predictors In a first-order model like the ones we have discussed, the association between E(y) and a predictor x j does not depend on the value of the other predictors
COMMON CORE STATE STANDARDS FOR
 COMMON CORE STATE STANDARDS FOR Mathematics (CCSSM) High School Statistics and Probability Mathematics High School Statistics and Probability Decisions or predictions are often based on data numbers in
COMMON CORE STATE STANDARDS FOR Mathematics (CCSSM) High School Statistics and Probability Mathematics High School Statistics and Probability Decisions or predictions are often based on data numbers in
Fairfield Public Schools
 Mathematics Fairfield Public Schools AP Statistics AP Statistics BOE Approved 04/08/2014 1 AP STATISTICS Critical Areas of Focus AP Statistics is a rigorous course that offers advanced students an opportunity
Mathematics Fairfield Public Schools AP Statistics AP Statistics BOE Approved 04/08/2014 1 AP STATISTICS Critical Areas of Focus AP Statistics is a rigorous course that offers advanced students an opportunity
X X X a) perfect linear correlation b) no correlation c) positive correlation (r = 1) (r = 0) (0 < r < 1)
 perfect linear correlation b) no correlation c) positive correlation (r = 1) (r = 0) (0 < r < 1)") CORRELATION AND REGRESSION / 47 CHAPTER EIGHT CORRELATION AND REGRESSION Correlation and regression are statistical methods that are commonly used in the medical literature to compare two or more variables.
CORRELATION AND REGRESSION / 47 CHAPTER EIGHT CORRELATION AND REGRESSION Correlation and regression are statistical methods that are commonly used in the medical literature to compare two or more variables.
Biostatistics: Types of Data Analysis
 Biostatistics: Types of Data Analysis Theresa A Scott, MS Vanderbilt University Department of Biostatistics [email protected] http://biostat.mc.vanderbilt.edu/theresascott Theresa A Scott, MS
Biostatistics: Types of Data Analysis Theresa A Scott, MS Vanderbilt University Department of Biostatistics [email protected] http://biostat.mc.vanderbilt.edu/theresascott Theresa A Scott, MS
What is the purpose of this document? What is in the document? How do I send Feedback?
 This document is designed to help North Carolina educators teach the Common Core (Standard Course of Study). NCDPI staff are continually updating and improving these tools to better serve teachers. Statistics
This document is designed to help North Carolina educators teach the Common Core (Standard Course of Study). NCDPI staff are continually updating and improving these tools to better serve teachers. Statistics
Statistics in Retail Finance. Chapter 6: Behavioural models
 Statistics in Retail Finance 1 Overview > So far we have focussed mainly on application scorecards. In this chapter we shall look at behavioural models. We shall cover the following topics:- Behavioural
Statistics in Retail Finance 1 Overview > So far we have focussed mainly on application scorecards. In this chapter we shall look at behavioural models. We shall cover the following topics:- Behavioural
Statistics Graduate Courses
 Statistics Graduate Courses STAT 7002--Topics in Statistics-Biological/Physical/Mathematics (cr.arr.).organized study of selected topics. Subjects and earnable credit may vary from semester to semester.
Statistics Graduate Courses STAT 7002--Topics in Statistics-Biological/Physical/Mathematics (cr.arr.).organized study of selected topics. Subjects and earnable credit may vary from semester to semester.
Indices of Model Fit STRUCTURAL EQUATION MODELING 2013
 Indices of Model Fit STRUCTURAL EQUATION MODELING 2013 Indices of Model Fit A recommended minimal set of fit indices that should be reported and interpreted when reporting the results of SEM analyses:
Indices of Model Fit STRUCTURAL EQUATION MODELING 2013 Indices of Model Fit A recommended minimal set of fit indices that should be reported and interpreted when reporting the results of SEM analyses:
the points are called control points approximating curve
 Chapter 4 Spline Curves A spline curve is a mathematical representation for which it is easy to build an interface that will allow a user to design and control the shape of complex curves and surfaces.
Chapter 4 Spline Curves A spline curve is a mathematical representation for which it is easy to build an interface that will allow a user to design and control the shape of complex curves and surfaces.
Multivariate Analysis of Ecological Data
 Multivariate Analysis of Ecological Data MICHAEL GREENACRE Professor of Statistics at the Pompeu Fabra University in Barcelona, Spain RAUL PRIMICERIO Associate Professor of Ecology, Evolutionary Biology
Multivariate Analysis of Ecological Data MICHAEL GREENACRE Professor of Statistics at the Pompeu Fabra University in Barcelona, Spain RAUL PRIMICERIO Associate Professor of Ecology, Evolutionary Biology
Biostatistics Short Course Introduction to Longitudinal Studies
 Biostatistics Short Course Introduction to Longitudinal Studies Zhangsheng Yu Division of Biostatistics Department of Medicine Indiana University School of Medicine Zhangsheng Yu (Indiana University) Longitudinal
Biostatistics Short Course Introduction to Longitudinal Studies Zhangsheng Yu Division of Biostatistics Department of Medicine Indiana University School of Medicine Zhangsheng Yu (Indiana University) Longitudinal
The Basic Two-Level Regression Model
 2 The Basic Two-Level Regression Model The multilevel regression model has become known in the research literature under a variety of names, such as random coefficient model (de Leeuw & Kreft, 1986; Longford,
2 The Basic Two-Level Regression Model The multilevel regression model has become known in the research literature under a variety of names, such as random coefficient model (de Leeuw & Kreft, 1986; Longford,
Clustering in the Linear Model
 Short Guides to Microeconometrics Fall 2014 Kurt Schmidheiny Universität Basel Clustering in the Linear Model 2 1 Introduction Clustering in the Linear Model This handout extends the handout on The Multiple
Short Guides to Microeconometrics Fall 2014 Kurt Schmidheiny Universität Basel Clustering in the Linear Model 2 1 Introduction Clustering in the Linear Model This handout extends the handout on The Multiple
Review of the Methods for Handling Missing Data in. Longitudinal Data Analysis
 Int. Journal of Math. Analysis, Vol. 5, 2011, no. 1, 1-13 Review of the Methods for Handling Missing Data in Longitudinal Data Analysis Michikazu Nakai and Weiming Ke Department of Mathematics and Statistics
Int. Journal of Math. Analysis, Vol. 5, 2011, no. 1, 1-13 Review of the Methods for Handling Missing Data in Longitudinal Data Analysis Michikazu Nakai and Weiming Ke Department of Mathematics and Statistics
Analysis of Variance. MINITAB User s Guide 2 3-1
 3 Analysis of Variance Analysis of Variance Overview, 3-2 One-Way Analysis of Variance, 3-5 Two-Way Analysis of Variance, 3-11 Analysis of Means, 3-13 Overview of Balanced ANOVA and GLM, 3-18 Balanced
3 Analysis of Variance Analysis of Variance Overview, 3-2 One-Way Analysis of Variance, 3-5 Two-Way Analysis of Variance, 3-11 Analysis of Means, 3-13 Overview of Balanced ANOVA and GLM, 3-18 Balanced
Institute of Actuaries of India Subject CT3 Probability and Mathematical Statistics
 Institute of Actuaries of India Subject CT3 Probability and Mathematical Statistics For 2015 Examinations Aim The aim of the Probability and Mathematical Statistics subject is to provide a grounding in
Institute of Actuaries of India Subject CT3 Probability and Mathematical Statistics For 2015 Examinations Aim The aim of the Probability and Mathematical Statistics subject is to provide a grounding in
Technical report. in SPSS AN INTRODUCTION TO THE MIXED PROCEDURE
 Linear mixedeffects modeling in SPSS AN INTRODUCTION TO THE MIXED PROCEDURE Table of contents Introduction................................................................3 Data preparation for MIXED...................................................3
Linear mixedeffects modeling in SPSS AN INTRODUCTION TO THE MIXED PROCEDURE Table of contents Introduction................................................................3 Data preparation for MIXED...................................................3
Recall this chart that showed how most of our course would be organized:
 Chapter 4 One-Way ANOVA Recall this chart that showed how most of our course would be organized: Explanatory Variable(s) Response Variable Methods Categorical Categorical Contingency Tables Categorical
Chapter 4 One-Way ANOVA Recall this chart that showed how most of our course would be organized: Explanatory Variable(s) Response Variable Methods Categorical Categorical Contingency Tables Categorical
Business Statistics. Successful completion of Introductory and/or Intermediate Algebra courses is recommended before taking Business Statistics.
 Business Course Text Bowerman, Bruce L., Richard T. O'Connell, J. B. Orris, and Dawn C. Porter. Essentials of Business, 2nd edition, McGraw-Hill/Irwin, 2008, ISBN: 978-0-07-331988-9. Required Computing
Business Course Text Bowerman, Bruce L., Richard T. O'Connell, J. B. Orris, and Dawn C. Porter. Essentials of Business, 2nd edition, McGraw-Hill/Irwin, 2008, ISBN: 978-0-07-331988-9. Required Computing
Parametric and Nonparametric: Demystifying the Terms
 Parametric and Nonparametric: Demystifying the Terms By Tanya Hoskin, a statistician in the Mayo Clinic Department of Health Sciences Research who provides consultations through the Mayo Clinic CTSA BERD
Parametric and Nonparametric: Demystifying the Terms By Tanya Hoskin, a statistician in the Mayo Clinic Department of Health Sciences Research who provides consultations through the Mayo Clinic CTSA BERD
Fitting Subject-specific Curves to Grouped Longitudinal Data
 Fitting Subject-specific Curves to Grouped Longitudinal Data Djeundje, Viani Heriot-Watt University, Department of Actuarial Mathematics & Statistics Edinburgh, EH14 4AS, UK E-mail: [email protected] Currie,
Fitting Subject-specific Curves to Grouped Longitudinal Data Djeundje, Viani Heriot-Watt University, Department of Actuarial Mathematics & Statistics Edinburgh, EH14 4AS, UK E-mail: [email protected] Currie,
LAGUARDIA COMMUNITY COLLEGE CITY UNIVERSITY OF NEW YORK DEPARTMENT OF MATHEMATICS, ENGINEERING, AND COMPUTER SCIENCE
 LAGUARDIA COMMUNITY COLLEGE CITY UNIVERSITY OF NEW YORK DEPARTMENT OF MATHEMATICS, ENGINEERING, AND COMPUTER SCIENCE MAT 119 STATISTICS AND ELEMENTARY ALGEBRA 5 Lecture Hours, 2 Lab Hours, 3 Credits Pre-
LAGUARDIA COMMUNITY COLLEGE CITY UNIVERSITY OF NEW YORK DEPARTMENT OF MATHEMATICS, ENGINEERING, AND COMPUTER SCIENCE MAT 119 STATISTICS AND ELEMENTARY ALGEBRA 5 Lecture Hours, 2 Lab Hours, 3 Credits Pre-
Use of deviance statistics for comparing models
 A likelihood-ratio test can be used under full ML. The use of such a test is a quite general principle for statistical testing. In hierarchical linear models, the deviance test is mostly used for multiparameter
A likelihood-ratio test can be used under full ML. The use of such a test is a quite general principle for statistical testing. In hierarchical linear models, the deviance test is mostly used for multiparameter
Introduction to Structural Equation Modeling (SEM) Day 4: November 29, 2012
 Day 4: November 29, 2012") Introduction to Structural Equation Modeling (SEM) Day 4: November 29, 202 ROB CRIBBIE QUANTITATIVE METHODS PROGRAM DEPARTMENT OF PSYCHOLOGY COORDINATOR - STATISTICAL CONSULTING SERVICE COURSE MATERIALS
Introduction to Structural Equation Modeling (SEM) Day 4: November 29, 202 ROB CRIBBIE QUANTITATIVE METHODS PROGRAM DEPARTMENT OF PSYCHOLOGY COORDINATOR - STATISTICAL CONSULTING SERVICE COURSE MATERIALS
II. DISTRIBUTIONS distribution normal distribution. standard scores
 Appendix D Basic Measurement And Statistics The following information was developed by Steven Rothke, PhD, Department of Psychology, Rehabilitation Institute of Chicago (RIC) and expanded by Mary F. Schmidt,
Appendix D Basic Measurement And Statistics The following information was developed by Steven Rothke, PhD, Department of Psychology, Rehabilitation Institute of Chicago (RIC) and expanded by Mary F. Schmidt,
Systematic Reviews and Meta-analyses
 Systematic Reviews and Meta-analyses Introduction A systematic review (also called an overview) attempts to summarize the scientific evidence related to treatment, causation, diagnosis, or prognosis of
Systematic Reviews and Meta-analyses Introduction A systematic review (also called an overview) attempts to summarize the scientific evidence related to treatment, causation, diagnosis, or prognosis of
GLM I An Introduction to Generalized Linear Models
 GLM I An Introduction to Generalized Linear Models CAS Ratemaking and Product Management Seminar March 2009 Presented by: Tanya D. Havlicek, Actuarial Assistant 0 ANTITRUST Notice The Casualty Actuarial
GLM I An Introduction to Generalized Linear Models CAS Ratemaking and Product Management Seminar March 2009 Presented by: Tanya D. Havlicek, Actuarial Assistant 0 ANTITRUST Notice The Casualty Actuarial