SoC Design Lecture 12: MPSoC Multi-Processor System-on-Chip. Shaahin Hessabi Department of Computer Engineering Sharif University of Technology
|
|
|
- Arnold McDowell
- 8 years ago
- Views:
Transcription
1 SoC Design Lecture 12: MPSoC Multi-Processor System-on-Chip Shaahin Hessabi Department of Computer Engineering Sharif University of Technology

2 The Premises The System-on-Chip (SoC) today Heterogeneous ~10 IP s Homogeneous (Multi-processor) ~ 10 µp On-Chip BUS (AMBA, Core Connect, Wishbone, ) IP and µp are sold with proprietary bus interface Near and long-term forecast 100 IP/ µp Buses are non scalable! Physical design issues: signal integrity, power consumption, timing closure Clock issues Is time for the Globally Asynchronous paradigm? (Still locally synchronous) Need for more regular design 2

3 Heterogeneous Today s SoC CPU DSP MEM Interconnection network (BUS) Embedded FPGA Dedicated IP I/O 3
 Embedded FPGA")
4 Maya (Rabaey 00) 4

5 Maya (Rabaey 00) 5

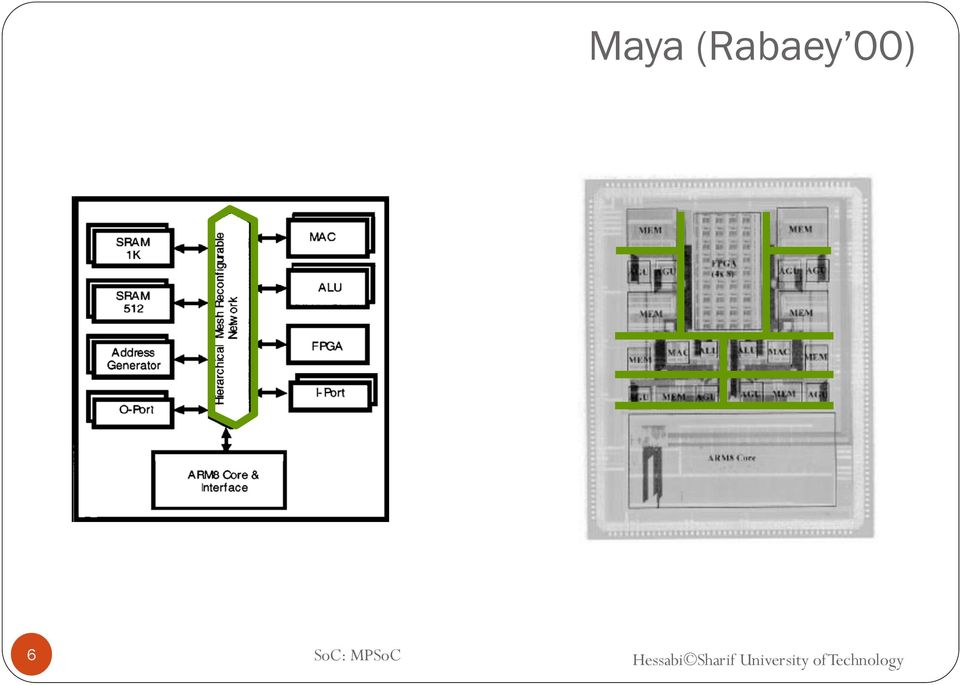
6 Maya (Rabaey 00) 6
7 The Cell Processor Started in mid 2000 by Sony, Toshiba and IBM Sony has PS2 architecture, needs chip for PS3 Toshiba has memory experience, needs chips for HDTV IBM has technical knowledge in processor manufacturing Billions of dollars have been invested high throughput multi purpose processor One of the earliest NoC processors developed to address high-performance distributed computing. Natural human interactions including photorealistic, predictable real-time response, virtualized resource for concurrent activities Heterogeneous Multiprocessing: 9-Core Processor First prototype: 90nm SOI, 8 copper layers 241 million transistors, 235 mm 2 (Rev. DD2) W (prototype) only 6-7 SPEs enabled (manufacturing errors) 1.1V, >4 GHz 7

8 One Power Processor Element (PPE): 64-bit dual-threaded processor based on Power Architecture Contains PXU (power execution unit), L1 and L2 caches. 8 Synergistic Processor Elements (SPEs) SPE contains: independent processor SXU (synergistic execution unit), 256-KB local store (LS) 21M transistors (14M SRAM, 7M logic) Cell Processor Architecture Cell processor is capable of handling 10 simultaneous threads. One Element Interconnection Bus (EIB): coherent bus, organized as four 16-byte-wide rings. One Memory Interface Controller (MIC) One Bus Interface Controller (BIC) One Pervasive Unit (PU) One Power Management Unit (PMU) One Thermal Management Unit (TMU) 8
: coherent bus, organized as four 16-byte-wide rings.")
9 Cell Processor Architecture Components PU: Pervasive Unit (not shown in figure) contains all of the global logic needed for: Basic chip functions Serial peripheral interface (SPI): communicate with an external controller during normal operation Phase-locked loop (PLL): clock generation and distribution logic Power-on-reset (POR): systematically initializes all the units of the processor. Lab debug Fault isolation registers: allow the OS to quickly determine which unit generated an error condition Performance monitor (PFM) Trace logic analyzer (TLA): captures/stores internal signals while chip is running to assist debug Manufacturing test: 11 different test modes, including Array BIST, Memory BIST Logic BIST 9
 Trace logic analyzer (TLA):")
10 Cell Processor Architecture Components (Cont d) PMU and TMU Manage chip power to avoid permanent damage to the chip because of overheating PMU: Power Management Unit allows software controls to reduce chip power when full processing capabilities are not needed. TMU: Thermal Management Unit (not shown) monitors each of the 10 digital thermal sensors (diodes), distributed on the chip, to monitor temperatures in hot spots. controls the chip temperature dynamically and interrupts the PPE when a temperature specified for each element is observed. Software controls the TMU by setting 4 temperature values and the amount of throttling for each sensor in the TMU: 1 st value specifies when the throttling of an element stops 2 nd value specifies when throttling starts 3 rd value specifies when the element is completely stopped 4 th value specifies when the chip s clocks are shut down. 10

11 Cell s Element Interconnect Bus From the trenches: D. Krolak, IBM Well, in the beginning, early in the development process, several people were pushing for a crossbar switch, and the way the bus is architected, you could actually pull out the EIB and put in a crossbar switch if you were willing to devote more silicon space on the chip to wiring. We had to find a balance between connectivity and area, and there just wasn't enough room to put a full crossbar switch in. So we came up with this ring structure which we think is very interesting. It fits within the area constraints and still has very impressive bandwidth. 11

12 4 rings (2 ckwise + 2 counter-ckwise) No token rings, still request/grant arbitrations Cell s Element Interconnect Bus 12

13 Homogeneous SoC (Multiprocessor) CPU CPU CPU CPU MEM MEM MEM MEM Interconnection network (BUS, XBAR) CPU CPU CPU CPU MEM MEM MEM MEM 13
 13")
14 Multiprocessor SoC: Cisco CRS-1 Router CRS-1 Router uses 188 extensible network processors per Silicon Packet Processor chip 16 PPE Clusters of 12 PPEs each 14

15 Multi-Processor Architectures 1. Tightly-coupled multiprocessor systems: Contain multiple CPUs that are connected at the bus level. CPUs may have access to a central shared memory: SMP: symmetric multiprocessor Systems that treat all CPUs equally ASMP: asymmetric multiprocessor or may participate in a memory hierarchy with both local and shared memory NUMA: non-uniform memory access CC-NUMA: cache-coherent NUMA 2. Loosely-coupled multiprocessor systems: Often referred as clusters Based on multiple standalone single or dual processor commodity computers interconnected via a high speed communication system, such as Gigabit ethernet. SMP memory NUMA 15

16 Multiprocessor Communication Architectures Message Passing Separate address space for each processor Processors communicate explicitly via message passing using communication APIs, such as send() or receive(). Create extra communication overhead. Processors have private memories processor 1 cache memory 1 processor 2 cache... interconnection network memory 2 Shared Memory Processors communicate with shared address space Processors communicate implicitly by memory read/write Lower latency widely used in many of today s high performance MPSoCs. SMP or NUMA SMP: Shared Memory Processor or Uniform Memory Access Access to all memory occurred at the same speed for all processors. NUMA: Non-Uniform Memory Access or Distributed Shared Memory Typically interconnection is grid or hypercube. Access to some parts of memory is faster for some processors than other parts of memory. Harder to program, but scales to more processors... processor N cache memory M Shared Memory MultiProcessor 16

17 Bus Based UMA (a) Simplest MP: More than one processor on a single bus connect to memory bus bandwidth becomes a bottleneck. (b) Each processor has a cache to reduce the need to access to memory. (c) To further scale the number of processors, each processor is given private local memory. 17
 To further scale the number of processors, each processor is given")
18 NUMA All memories can be addressed by all processors, but access to a processor s own local memory is faster than access to another processor s remote memory. Looks like a distributed machine, but the interconnection network is usually custom-designed switches and/or buses. 18

19 Multiprocessor SoC: Heterogeneous processors. What is MPSoC? Buses used currently to interconnect modules (processors, memories, etc.) but NoCs are projected to replace buses in future systems. MPSoCs are not chip multiprocessors. Chip multiprocessors are components that take advantage of increased transistor densities to put more processors on a single chip, but they don t try to leverage application needs MPSoCs are custom architectures that balance the constraints of VLSI technology with an application s needs. 19

20 Uniprocessor Need task-level parallelism for performance MPSoC vs. Competitors Real concurrency, not the apparent concurrency of a multitasking OS running on a uniprocessor. Symmetric mutliprocessor (SMP) SMP has the following advantages: Could manufacture the chips in even larger volumes lower price, Uniform platforms and richer tool sets will make software development easier, Symmetry makes it easier to map an application onto the architecture. However, cannot directly apply the scientific computing model to SoCs. SoCs must obey constraints that do not apply to scientific computation: 1. They must perform real-time computations. 2. They must be area-efficient. 3. They must be energy-efficient. 4. They must provide the proper I/O connections. 20

21 1. Real-Time Performance More than high-performance computing: results be available at a predictable rate. Rate variations can often be solved by adding buffer memory, But memory incurs both area and energy consumption costs. Producing results at predictable times requires careful design of hardware: Instruction set, memory system, and system bus. Also careful design of software: to take advantage of features of the hardware, to avoid common problems like excessive reliance on buffering. Many mechanisms provide performance at the expense of making performance less predictable. Snooping caching dynamically manages cache coherency at the cost of less predictable delays since the time required for a memory access depends on the state of several caches. One way to provide predictable and high performance: use a mechanism specialized to the needs of the application: Specialized memory systems or application-specific instructions. Different tasks in an application have different characteristics different parts of the architecture need different hardware structures. 21
22 Heterogeneous multiprocessors are more area-efficient than SMPs. Task-level parallelism is inherently heterogeneous. 2. Area Efficiency Each block does something different and has different computational requirements. A special-purpose PE or a specialized CPU: faster and smaller than a programmable processor. Matching CPU datapath width to the native data sizes of the application saves area. Choosing a cache size and organization to match the application can greatly improve performance. Memory specialization is an important technique for designing efficient architectures. o If some aspects of memory behavior of the application can be predicted, system architect can reflect those characteristics in the architecture. o Example: smaller cache can be used when the application has regular memory access patterns. 22
23 3. Energy Efficiency Most SoC designs are power-sensitive, due to: Environmental considerations (heat dissipation), or System requirements (battery power). Specialization saves power, by stripping away unnecessary features. Particularly true for leakage power consumption. SoCs are mass-market devices due to the economics of VLSI manufacturing. Cost of designing power-saving features for a particular architecture can be compensated due to many times replication during manufacturing. 4. Proper I/O Connections SoC must provide a complete system. Can we implement I/O devices in a generic fashion given enough transistors? To some extent, done for FPGA I/O pads. Due to variety of physical interfaces, difficult to create customizable I/O devices effectively. 23
24 Example: MPSoC from Philips Research For communication needs of consumer electronics SoC with real-time requirements (e.g. settop boxes) Mi: Memories Pi: Programmable dedicated processors MIi: External memory interfaces Ri: Routers Ni: Network interfaces Ref: B. Vermeulen et al., IEEE Communications Magazine, Sept
25 Software Development Design and Manufacturing Challenges Software shipped as part of a chip must be extremely reliable. Must meet design constraints typically reserved for hardware, e.g., hard timing constraints (e.g., real-time operation) and energy consumption. MPSoCs are heterogeneous: harder to program than traditional symmetric multiprocessors. Need customized development environment, including compilers, debuggers, simulators, etc. NoCs resemble external networks, but differ from them in crucial ways Extensive wiring resources: What topologies can best exploit them? Buffers a scarce resource because of area overhead: What flow control method reduce buffer count and router overhead? What circuits (e.g. transceivers) can best exploit the structured wiring of on-chip networks? 25
26 Determining FPGAs vs. software programmability tradeoff Challenges (Cont d.) FPGA fabrics can be used as cores to provide alternative means of programmability Tools for using FPGAs in the design environment are not yet well developed. Security issues, particularly when MPSoC devices connect to the Internet Security breaches can cause malfunctions and must be considered during HW/SW codesign MPSoCs connected into a network of chips, e.g. in automotive/avionics applications Lack of control on external network state, e.g. node failures, reconfiguration. Current MPSoC design is essentially carried out in a closed environment. Silicon debug: Design validation and testing are increasingly insufficient to remove all bugs before first silicon. Design cycle may require expensive respins. 26
27 Microprocessors as the fastest CPUs Collecting several CPUs much easier than redesigning one Multiple users Multiple applications Multi-tasking within an application Responsiveness and/or throughput Share hardware between CPUs Complexity of current microprocessors Do we have enough ideas to sustain 1.5X/yr? Can we deliver such complexity on schedule? Why Multiprocessors? Slow (but steady) improvement in parallel software (scientific apps, databases, OS) Emergence of embedded market driving microprocessors in addition to desktops Embedded functional parallelism 27
28 Bit level parallelism: 1970 to ~ bits, 8 bit, 16 bit, 32 bit microprocessors Instruction level parallelism (ILP): ~1985 through today Pipelining Superscalar VLIW Out-of-Order execution Limits to benefits of ILP? What Level Parallelism? Process Level or thread level parallelism: mainstream for general purpose computing? Servers are parallel High-end desktop dual processor PC Program Level parallelism, or even distributed computing 28
29 SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) Multiple processors on a single data stream SIMD (Single Instruction Multiple Data) Examples: Illiac-IV, CM-2 Simple programming model Low overhead Flexibility All custom integrated circuits (Phrase reused by Intel marketing for media instructions ~ vector) MIMD (Multiple Instruction Multiple Data) Flexible MIMD current winner for MPSoC Popular Categories 29
30 Major MIMD Styles Centralized shared memory Uniform Memory Access (UMA) time or Shared Memory Processor (SMP) 30
31 Distributed memory (memory module with CPU) Get more memory bandwidth, lower memory latency Drawback: Longer communication latency Drawback: Software model more complex Major MIMD Styles (Cont d) 31
32 OS Option 1 Each CPU has its own OS Statically allocate physical memory to each CPU Each CPU runs its own independent OS Share peripherals Each CPU handles its processes system calls Used in early multiprocessor systems Simple to implement Avoids concurrency issues by not sharing Issues: 1. Each processor has its own scheduling queue, and its own memory partition. 2. Consistency is an issue with independent disk buffer caches and potentially shared files. 32
33 Master-Slave Multiprocessors OS mostly runs on a single fixed CPU. User-level applications run on the other CPUs. All system calls are passed to the Master CPU for processing Very little synchronization required Simple to implement Single centralized scheduler to keep all processors busy Memory can be allocated as needed to all CPUs. Issues: Master CPU becomes the bottleneck. OS Option 2 33
34 Symmetric Multiprocessors (SMP) OS Option 3 OS kernel runs on all processors, while load and resources are balanced between all processors. One alternative: A single mutex (mutual exclusion object) that makes the entire kernel a large critical section; Only one CPU is in the kernel at a time; Only slightly better than master-slave Better alternative: Identify independent parts of the kernel and make each of them their own critical section, which allows parallelism in the kernel Issues: A difficult task; Code is mostly similar to uniprocessor code; hard part is identifying independent parts that don t interfere with each other 34
35 Example: Quad-Processor Pentium Pro SMP, bus interconnection. 4 x 200 MHz Intel Pentium Pro processors Kb L1 cache per processor. 512 Kb L2 cache per processor. Snoopy cache coherence. Employed in Compaq, HP, IBM, NetPower. OS: Windows NT, Solaris, Linux, etc. 35
36 1. Fast design time MPSoC Design Goals Very important in typical applications for MPSoC architectures: game/network processors, high-definition video encoding, multimedia hubs, base-band telecom circuits, have particularly tight time-to-market and time window constraints. 2. Higher level abstractions: system-level modeling. Hardware side: RTL models too time consuming to design and verify MPSoCs (cores and associated peripherals) RTL abstraction: designers produce the equivalent of 4 to 10 gates per line of RTL code. A 100 million-gate MPSoC circuit using only RTL code, with 90% code reuse, requires > 1 million lines of code for the remaining 10 million gates. Unrealistic for most MPSoC target markets. A higher abstraction level is needed on the hardware side. Software side: MPSoCs use hundreds of thousands of lines of dedicated software and complex software development environments cannot use mostly low-level programming languages anymore. Higher level abstractions are needed on the software side too. 36
37 MPSoC Design Goals (cont d) 3. Predictability of results High-level abstractions hiding precise circuit behavior (timing information). MPSoCs are mostly targeted for real-time applications accurate performance information must be available at design time. 4. Meeting design metrics High-level design metrics and performance estimation are essential parts in MPSoC design methodologies. System s design metrics are not easy to compose from design metrics of its components. 37
38 Design steps: 1. Design space exploration MPSoC Design Methodologies hardware/software partitioning, selection of architectural platform and components 2. Architecture design Design of components, hardware/software interface design. Design process must consider TTM, system performance, power, and cost. Reuse of predesigned components is necessary for reducing design time, but their integration into a system is challenging. A complete design flow requires multiple capabilities and tools because of the complexity and diversity of applications. 38
39 MPSoC Design Methodologies (cont d) Competing EDA approaches to improve productivity: 1. Top-Down approaches start with an architectural solution, target architecture, or architectural platform: Synthesis from system level models: COSYMA environment for hardware/software co-synthesis, POLIS for Hardware-Software Co-design of Embedded Systems, SpecC, SystemC ODESSEY Platform-based design 2. Bottom-up approach (component-based) starts with a set of components and provides a set of primitives to build application-specific architectures and communication APIs. Goal : allow the integration of heterogeneous processors and communication protocols by using abstract interconnections. Behavior and communication must be separated in the system specification. System communication can be described at a higher level and refined independently of the behavioral system. 2 approaches described previously: standard bus protocol, standard component protocol. 39
40 Synthesis from System Level Models A full design flow from a system-level specification to the RTL architecture 1. Starts with informal model of application Build a more formal (capable to be validated) SoC specification. - System architecture is fixed and HW/SW partitioning is decided. - Produces a golden architecture model: spec of HW components fixed global structure of on-chip network. 3. Design SW. 4. Design HW components. 5. Interconnect HW and SW components while respecting constraints described in golden architecture model. 40
Introduction to System-on-Chip
 Introduction to System-on-Chip COE838: Systems-on-Chip Design http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer Engineering Ryerson University
Introduction to System-on-Chip COE838: Systems-on-Chip Design http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer Engineering Ryerson University
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Parallel Computation Most slides adapted from David Patterson. Some from Mohomed Younis Parallel Computers Definition: A parallel computer is a collection of processing
CMSC 611: Advanced Computer Architecture Parallel Computation Most slides adapted from David Patterson. Some from Mohomed Younis Parallel Computers Definition: A parallel computer is a collection of processing
Making Multicore Work and Measuring its Benefits. Markus Levy, president EEMBC and Multicore Association
 Making Multicore Work and Measuring its Benefits Markus Levy, president EEMBC and Multicore Association Agenda Why Multicore? Standards and issues in the multicore community What is Multicore Association?
Making Multicore Work and Measuring its Benefits Markus Levy, president EEMBC and Multicore Association Agenda Why Multicore? Standards and issues in the multicore community What is Multicore Association?
Architectures and Platforms
 Hardware/Software Codesign Arch&Platf. - 1 Architectures and Platforms 1. Architecture Selection: The Basic Trade-Offs 2. General Purpose vs. Application-Specific Processors 3. Processor Specialisation
Hardware/Software Codesign Arch&Platf. - 1 Architectures and Platforms 1. Architecture Selection: The Basic Trade-Offs 2. General Purpose vs. Application-Specific Processors 3. Processor Specialisation
Principles and characteristics of distributed systems and environments
 Principles and characteristics of distributed systems and environments Definition of a distributed system Distributed system is a collection of independent computers that appears to its users as a single
Principles and characteristics of distributed systems and environments Definition of a distributed system Distributed system is a collection of independent computers that appears to its users as a single
Lecture 23: Multiprocessors
 Lecture 23: Multiprocessors Today s topics: RAID Multiprocessor taxonomy Snooping-based cache coherence protocol 1 RAID 0 and RAID 1 RAID 0 has no additional redundancy (misnomer) it uses an array of disks
Lecture 23: Multiprocessors Today s topics: RAID Multiprocessor taxonomy Snooping-based cache coherence protocol 1 RAID 0 and RAID 1 RAID 0 has no additional redundancy (misnomer) it uses an array of disks
Agenda. Michele Taliercio, Il circuito Integrato, Novembre 2001
 Agenda Introduzione Il mercato Dal circuito integrato al System on a Chip (SoC) La progettazione di un SoC La tecnologia Una fabbrica di circuiti integrati 28 How to handle complexity G The engineering
Agenda Introduzione Il mercato Dal circuito integrato al System on a Chip (SoC) La progettazione di un SoC La tecnologia Una fabbrica di circuiti integrati 28 How to handle complexity G The engineering
What is a System on a Chip?
 What is a System on a Chip? Integration of a complete system, that until recently consisted of multiple ICs, onto a single IC. CPU PCI DSP SRAM ROM MPEG SoC DRAM System Chips Why? Characteristics: Complex
What is a System on a Chip? Integration of a complete system, that until recently consisted of multiple ICs, onto a single IC. CPU PCI DSP SRAM ROM MPEG SoC DRAM System Chips Why? Characteristics: Complex
Design Cycle for Microprocessors
 Cycle for Microprocessors Raúl Martínez Intel Barcelona Research Center Cursos de Verano 2010 UCLM Intel Corporation, 2010 Agenda Introduction plan Architecture Microarchitecture Logic Silicon ramp Types
Cycle for Microprocessors Raúl Martínez Intel Barcelona Research Center Cursos de Verano 2010 UCLM Intel Corporation, 2010 Agenda Introduction plan Architecture Microarchitecture Logic Silicon ramp Types
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Lecture 2 Parallel Programming Platforms
 Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
High Performance Computing. Course Notes 2007-2008. HPC Fundamentals
 High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
ELEC 5260/6260/6266 Embedded Computing Systems
 ELEC 5260/6260/6266 Embedded Computing Systems Spring 2016 Victor P. Nelson Text: Computers as Components, 3 rd Edition Prof. Marilyn Wolf (Georgia Tech) Course Topics Embedded system design & modeling
ELEC 5260/6260/6266 Embedded Computing Systems Spring 2016 Victor P. Nelson Text: Computers as Components, 3 rd Edition Prof. Marilyn Wolf (Georgia Tech) Course Topics Embedded system design & modeling
SOC architecture and design
 SOC architecture and design system-on-chip (SOC) processors: become components in a system SOC covers many topics processor: pipelined, superscalar, VLIW, array, vector storage: cache, embedded and external
SOC architecture and design system-on-chip (SOC) processors: become components in a system SOC covers many topics processor: pipelined, superscalar, VLIW, array, vector storage: cache, embedded and external
EEM870 Embedded System and Experiment Lecture 1: SoC Design Overview
 EEM870 Embedded System and Experiment Lecture 1: SoC Design Overview Wen-Yen Lin, Ph.D. Department of Electrical Engineering Chang Gung University Email: wylin@mail.cgu.edu.tw Feb. 2013 Course Overview
EEM870 Embedded System and Experiment Lecture 1: SoC Design Overview Wen-Yen Lin, Ph.D. Department of Electrical Engineering Chang Gung University Email: wylin@mail.cgu.edu.tw Feb. 2013 Course Overview
7a. System-on-chip design and prototyping platforms
 7a. System-on-chip design and prototyping platforms Labros Bisdounis, Ph.D. Department of Computer and Communication Engineering 1 What is System-on-Chip (SoC)? System-on-chip is an integrated circuit
7a. System-on-chip design and prototyping platforms Labros Bisdounis, Ph.D. Department of Computer and Communication Engineering 1 What is System-on-Chip (SoC)? System-on-chip is an integrated circuit
Introduction to Exploration and Optimization of Multiprocessor Embedded Architectures based on Networks On-Chip
 Introduction to Exploration and Optimization of Multiprocessor Embedded Architectures based on Networks On-Chip Cristina SILVANO silvano@elet.polimi.it Politecnico di Milano, Milano (Italy) Talk Outline
Introduction to Exploration and Optimization of Multiprocessor Embedded Architectures based on Networks On-Chip Cristina SILVANO silvano@elet.polimi.it Politecnico di Milano, Milano (Italy) Talk Outline
Operating Systems 4 th Class
 Operating Systems 4 th Class Lecture 1 Operating Systems Operating systems are essential part of any computer system. Therefore, a course in operating systems is an essential part of any computer science
Operating Systems 4 th Class Lecture 1 Operating Systems Operating systems are essential part of any computer system. Therefore, a course in operating systems is an essential part of any computer science
UNIT 2 CLASSIFICATION OF PARALLEL COMPUTERS
 UNIT 2 CLASSIFICATION OF PARALLEL COMPUTERS Structure Page Nos. 2.0 Introduction 27 2.1 Objectives 27 2.2 Types of Classification 28 2.3 Flynn s Classification 28 2.3.1 Instruction Cycle 2.3.2 Instruction
UNIT 2 CLASSIFICATION OF PARALLEL COMPUTERS Structure Page Nos. 2.0 Introduction 27 2.1 Objectives 27 2.2 Types of Classification 28 2.3 Flynn s Classification 28 2.3.1 Instruction Cycle 2.3.2 Instruction
How To Understand The Concept Of A Distributed System
 Distributed Operating Systems Introduction Ewa Niewiadomska-Szynkiewicz and Adam Kozakiewicz ens@ia.pw.edu.pl, akozakie@ia.pw.edu.pl Institute of Control and Computation Engineering Warsaw University of
Distributed Operating Systems Introduction Ewa Niewiadomska-Szynkiewicz and Adam Kozakiewicz ens@ia.pw.edu.pl, akozakie@ia.pw.edu.pl Institute of Control and Computation Engineering Warsaw University of
Chapter 2 Parallel Architecture, Software And Performance
 Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Outline. Introduction. Multiprocessor Systems on Chip. A MPSoC Example: Nexperia DVP. A New Paradigm: Network on Chip
 Outline Modeling, simulation and optimization of Multi-Processor SoCs (MPSoCs) Università of Verona Dipartimento di Informatica MPSoCs: Multi-Processor Systems on Chip A simulation platform for a MPSoC
Outline Modeling, simulation and optimization of Multi-Processor SoCs (MPSoCs) Università of Verona Dipartimento di Informatica MPSoCs: Multi-Processor Systems on Chip A simulation platform for a MPSoC
Distributed Systems LEEC (2005/06 2º Sem.)
") Distributed Systems LEEC (2005/06 2º Sem.) Introduction João Paulo Carvalho Universidade Técnica de Lisboa / Instituto Superior Técnico Outline Definition of a Distributed System Goals Connecting Users
Distributed Systems LEEC (2005/06 2º Sem.) Introduction João Paulo Carvalho Universidade Técnica de Lisboa / Instituto Superior Técnico Outline Definition of a Distributed System Goals Connecting Users
Symmetric Multiprocessing
 Multicore Computing A multi-core processor is a processing system composed of two or more independent cores. One can describe it as an integrated circuit to which two or more individual processors (called
Multicore Computing A multi-core processor is a processing system composed of two or more independent cores. One can describe it as an integrated circuit to which two or more individual processors (called
Reconfigurable Architecture Requirements for Co-Designed Virtual Machines
 Reconfigurable Architecture Requirements for Co-Designed Virtual Machines Kenneth B. Kent University of New Brunswick Faculty of Computer Science Fredericton, New Brunswick, Canada ken@unb.ca Micaela Serra
Reconfigurable Architecture Requirements for Co-Designed Virtual Machines Kenneth B. Kent University of New Brunswick Faculty of Computer Science Fredericton, New Brunswick, Canada ken@unb.ca Micaela Serra
Computer Systems Structure Input/Output
 Computer Systems Structure Input/Output Peripherals Computer Central Processing Unit Main Memory Computer Systems Interconnection Communication lines Input Output Ward 1 Ward 2 Examples of I/O Devices
Computer Systems Structure Input/Output Peripherals Computer Central Processing Unit Main Memory Computer Systems Interconnection Communication lines Input Output Ward 1 Ward 2 Examples of I/O Devices
ESE566 REPORT3. Design Methodologies for Core-based System-on-Chip HUA TANG OVIDIU CARNU
 ESE566 REPORT3 Design Methodologies for Core-based System-on-Chip HUA TANG OVIDIU CARNU Nov 19th, 2002 ABSTRACT: In this report, we discuss several recent published papers on design methodologies of core-based
ESE566 REPORT3 Design Methodologies for Core-based System-on-Chip HUA TANG OVIDIU CARNU Nov 19th, 2002 ABSTRACT: In this report, we discuss several recent published papers on design methodologies of core-based
Seeking Opportunities for Hardware Acceleration in Big Data Analytics
 Seeking Opportunities for Hardware Acceleration in Big Data Analytics Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto Who
Seeking Opportunities for Hardware Acceleration in Big Data Analytics Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto Who
Real-Time Operating Systems for MPSoCs
 Real-Time Operating Systems for MPSoCs Hiroyuki Tomiyama Graduate School of Information Science Nagoya University http://member.acm.org/~hiroyuki MPSoC 2009 1 Contributors Hiroaki Takada Director and Professor
Real-Time Operating Systems for MPSoCs Hiroyuki Tomiyama Graduate School of Information Science Nagoya University http://member.acm.org/~hiroyuki MPSoC 2009 1 Contributors Hiroaki Takada Director and Professor
Chapter 18: Database System Architectures. Centralized Systems
 Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging
 Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
Achieving Nanosecond Latency Between Applications with IPC Shared Memory Messaging In some markets and scenarios where competitive advantage is all about speed, speed is measured in micro- and even nano-seconds.
Digitale Signalverarbeitung mit FPGA (DSF) Soft Core Prozessor NIOS II Stand Mai 2007. Jens Onno Krah
 Soft Core Prozessor NIOS II Stand Mai 2007. Jens Onno Krah") (DSF) Soft Core Prozessor NIOS II Stand Mai 2007 Jens Onno Krah Cologne University of Applied Sciences www.fh-koeln.de jens_onno.krah@fh-koeln.de NIOS II 1 1 What is Nios II? Altera s Second Generation
(DSF) Soft Core Prozessor NIOS II Stand Mai 2007 Jens Onno Krah Cologne University of Applied Sciences www.fh-koeln.de jens_onno.krah@fh-koeln.de NIOS II 1 1 What is Nios II? Altera s Second Generation
CS550. Distributed Operating Systems (Advanced Operating Systems) Instructor: Xian-He Sun
 Instructor: Xian-He Sun") CS550 Distributed Operating Systems (Advanced Operating Systems) Instructor: Xian-He Sun Email: sun@iit.edu, Phone: (312) 567-5260 Office hours: 2:10pm-3:10pm Tuesday, 3:30pm-4:30pm Thursday at SB229C,
CS550 Distributed Operating Systems (Advanced Operating Systems) Instructor: Xian-He Sun Email: sun@iit.edu, Phone: (312) 567-5260 Office hours: 2:10pm-3:10pm Tuesday, 3:30pm-4:30pm Thursday at SB229C,
A Survey on ARM Cortex A Processors. Wei Wang Tanima Dey
 A Survey on ARM Cortex A Processors Wei Wang Tanima Dey 1 Overview of ARM Processors Focusing on Cortex A9 & Cortex A15 ARM ships no processors but only IP cores For SoC integration Targeting markets:
A Survey on ARM Cortex A Processors Wei Wang Tanima Dey 1 Overview of ARM Processors Focusing on Cortex A9 & Cortex A15 ARM ships no processors but only IP cores For SoC integration Targeting markets:
Principles of Operating Systems CS 446/646
 Principles of Operating Systems CS 446/646 1. Introduction to Operating Systems a. Role of an O/S b. O/S History and Features c. Types of O/S Mainframe systems Desktop & laptop systems Parallel systems
Principles of Operating Systems CS 446/646 1. Introduction to Operating Systems a. Role of an O/S b. O/S History and Features c. Types of O/S Mainframe systems Desktop & laptop systems Parallel systems
COMP 422, Lecture 3: Physical Organization & Communication Costs in Parallel Machines (Sections 2.4 & 2.5 of textbook)
") COMP 422, Lecture 3: Physical Organization & Communication Costs in Parallel Machines (Sections 2.4 & 2.5 of textbook) Vivek Sarkar Department of Computer Science Rice University vsarkar@rice.edu COMP
COMP 422, Lecture 3: Physical Organization & Communication Costs in Parallel Machines (Sections 2.4 & 2.5 of textbook) Vivek Sarkar Department of Computer Science Rice University vsarkar@rice.edu COMP
Computer System Design. System-on-Chip
 Brochure More information from http://www.researchandmarkets.com/reports/2171000/ Computer System Design. System-on-Chip Description: The next generation of computer system designers will be less concerned
Brochure More information from http://www.researchandmarkets.com/reports/2171000/ Computer System Design. System-on-Chip Description: The next generation of computer system designers will be less concerned
CISC, RISC, and DSP Microprocessors
 CISC, RISC, and DSP Microprocessors Douglas L. Jones ECE 497 Spring 2000 4/6/00 CISC, RISC, and DSP D.L. Jones 1 Outline Microprocessors circa 1984 RISC vs. CISC Microprocessors circa 1999 Perspective:
CISC, RISC, and DSP Microprocessors Douglas L. Jones ECE 497 Spring 2000 4/6/00 CISC, RISC, and DSP D.L. Jones 1 Outline Microprocessors circa 1984 RISC vs. CISC Microprocessors circa 1999 Perspective:
Architectural Level Power Consumption of Network on Chip. Presenter: YUAN Zheng
 Architectural Level Power Consumption of Network Presenter: YUAN Zheng Why Architectural Low Power Design? High-speed and large volume communication among different parts on a chip Problem: Power consumption
Architectural Level Power Consumption of Network Presenter: YUAN Zheng Why Architectural Low Power Design? High-speed and large volume communication among different parts on a chip Problem: Power consumption
Low Power AMD Athlon 64 and AMD Opteron Processors
 Low Power AMD Athlon 64 and AMD Opteron Processors Hot Chips 2004 Presenter: Marius Evers Block Diagram of AMD Athlon 64 and AMD Opteron Based on AMD s 8 th generation architecture AMD Athlon 64 and AMD
Low Power AMD Athlon 64 and AMD Opteron Processors Hot Chips 2004 Presenter: Marius Evers Block Diagram of AMD Athlon 64 and AMD Opteron Based on AMD s 8 th generation architecture AMD Athlon 64 and AMD
Codesign: The World Of Practice
 Codesign: The World Of Practice D. Sreenivasa Rao Senior Manager, System Level Integration Group Analog Devices Inc. May 2007 Analog Devices Inc. ADI is focused on high-end signal processing chips and
Codesign: The World Of Practice D. Sreenivasa Rao Senior Manager, System Level Integration Group Analog Devices Inc. May 2007 Analog Devices Inc. ADI is focused on high-end signal processing chips and
3 - Introduction to Operating Systems
 3 - Introduction to Operating Systems Mark Handley What is an Operating System? An OS is a program that: manages the computer hardware. provides the basis on which application programs can be built and
3 - Introduction to Operating Systems Mark Handley What is an Operating System? An OS is a program that: manages the computer hardware. provides the basis on which application programs can be built and
Which ARM Cortex Core Is Right for Your Application: A, R or M?
 Which ARM Cortex Core Is Right for Your Application: A, R or M? Introduction The ARM Cortex series of cores encompasses a very wide range of scalable performance options offering designers a great deal
Which ARM Cortex Core Is Right for Your Application: A, R or M? Introduction The ARM Cortex series of cores encompasses a very wide range of scalable performance options offering designers a great deal
Electronic system-level development: Finding the right mix of solutions for the right mix of engineers.
 Electronic system-level development: Finding the right mix of solutions for the right mix of engineers. Nowadays, System Engineers are placed in the centre of two antagonist flows: microelectronic systems
Electronic system-level development: Finding the right mix of solutions for the right mix of engineers. Nowadays, System Engineers are placed in the centre of two antagonist flows: microelectronic systems
Defining Platform-Based Design. System Definition. Platform Based Design What is it? Platform-Based Design Definitions: Three Perspectives
 Based Design What is it? Question: How many definitions of Based Design are there? Defining -Based Design Answer: How many people to you ask? What does the confusion mean? It is a definition in transition
Based Design What is it? Question: How many definitions of Based Design are there? Defining -Based Design Answer: How many people to you ask? What does the confusion mean? It is a definition in transition
Networked Embedded Systems: Design Challenges
 Networked Embedded Systems: Design Challenges Davide Quaglia Electronic Systems Design Group University of Verona 3 a giornata nazionale di Sintesi Logica, Verona, Jun 21, 2007 Outline Motivation Networked
Networked Embedded Systems: Design Challenges Davide Quaglia Electronic Systems Design Group University of Verona 3 a giornata nazionale di Sintesi Logica, Verona, Jun 21, 2007 Outline Motivation Networked
A Generic Network Interface Architecture for a Networked Processor Array (NePA)
") A Generic Network Interface Architecture for a Networked Processor Array (NePA) Seung Eun Lee, Jun Ho Bahn, Yoon Seok Yang, and Nader Bagherzadeh EECS @ University of California, Irvine Outline Introduction
A Generic Network Interface Architecture for a Networked Processor Array (NePA) Seung Eun Lee, Jun Ho Bahn, Yoon Seok Yang, and Nader Bagherzadeh EECS @ University of California, Irvine Outline Introduction
Study Plan Masters of Science in Computer Engineering and Networks (Thesis Track)
") Plan Number 2009 Study Plan Masters of Science in Computer Engineering and Networks (Thesis Track) I. General Rules and Conditions 1. This plan conforms to the regulations of the general frame of programs
Plan Number 2009 Study Plan Masters of Science in Computer Engineering and Networks (Thesis Track) I. General Rules and Conditions 1. This plan conforms to the regulations of the general frame of programs
Computer Architecture TDTS10
 why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multiprocessor System-on-Chip
 http://www.artistembedded.org/fp6/ ARTIST Workshop at DATE 06 W4: Design Issues in Distributed, CommunicationCentric Systems Modelling Networked Embedded Systems: From MPSoC to Sensor Networks Jan Madsen
http://www.artistembedded.org/fp6/ ARTIST Workshop at DATE 06 W4: Design Issues in Distributed, CommunicationCentric Systems Modelling Networked Embedded Systems: From MPSoC to Sensor Networks Jan Madsen
IBM CELL CELL INTRODUCTION. Project made by: Origgi Alessandro matr. 682197 Teruzzi Roberto matr. 682552 IBM CELL. Politecnico di Milano Como Campus
 Project made by: Origgi Alessandro matr. 682197 Teruzzi Roberto matr. 682552 CELL INTRODUCTION 2 1 CELL SYNERGY Cell is not a collection of different processors, but a synergistic whole Operation paradigms,
Project made by: Origgi Alessandro matr. 682197 Teruzzi Roberto matr. 682552 CELL INTRODUCTION 2 1 CELL SYNERGY Cell is not a collection of different processors, but a synergistic whole Operation paradigms,
Types Of Operating Systems
 Types Of Operating Systems Date 10/01/2004 1/24/2004 Operating Systems 1 Brief history of OS design In the beginning OSes were runtime libraries The OS was just code you linked with your program and loaded
Types Of Operating Systems Date 10/01/2004 1/24/2004 Operating Systems 1 Brief history of OS design In the beginning OSes were runtime libraries The OS was just code you linked with your program and loaded
Infrastructure Matters: POWER8 vs. Xeon x86
 Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
Lizy Kurian John Electrical and Computer Engineering Department, The University of Texas as Austin
 BUS ARCHITECTURES Lizy Kurian John Electrical and Computer Engineering Department, The University of Texas as Austin Keywords: Bus standards, PCI bus, ISA bus, Bus protocols, Serial Buses, USB, IEEE 1394
BUS ARCHITECTURES Lizy Kurian John Electrical and Computer Engineering Department, The University of Texas as Austin Keywords: Bus standards, PCI bus, ISA bus, Bus protocols, Serial Buses, USB, IEEE 1394
Scalability and Classifications
 Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Client/Server Computing Distributed Processing, Client/Server, and Clusters
 Client/Server Computing Distributed Processing, Client/Server, and Clusters Chapter 13 Client machines are generally single-user PCs or workstations that provide a highly userfriendly interface to the
Client/Server Computing Distributed Processing, Client/Server, and Clusters Chapter 13 Client machines are generally single-user PCs or workstations that provide a highly userfriendly interface to the
Distributed Systems. REK s adaptation of Prof. Claypool s adaptation of Tanenbaum s Distributed Systems Chapter 1
 Distributed Systems REK s adaptation of Prof. Claypool s adaptation of Tanenbaum s Distributed Systems Chapter 1 1 The Rise of Distributed Systems! Computer hardware prices are falling and power increasing.!
Distributed Systems REK s adaptation of Prof. Claypool s adaptation of Tanenbaum s Distributed Systems Chapter 1 1 The Rise of Distributed Systems! Computer hardware prices are falling and power increasing.!
Graphics Cards and Graphics Processing Units. Ben Johnstone Russ Martin November 15, 2011
 Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Chapter 2 Parallel Computer Architecture
 Chapter 2 Parallel Computer Architecture The possibility for a parallel execution of computations strongly depends on the architecture of the execution platform. This chapter gives an overview of the general
Chapter 2 Parallel Computer Architecture The possibility for a parallel execution of computations strongly depends on the architecture of the execution platform. This chapter gives an overview of the general
SoC IP Interfaces and Infrastructure A Hybrid Approach
 SoC IP Interfaces and Infrastructure A Hybrid Approach Cary Robins, Shannon Hill ChipWrights, Inc. ABSTRACT System-On-Chip (SoC) designs incorporate more and more Intellectual Property (IP) with each year.
SoC IP Interfaces and Infrastructure A Hybrid Approach Cary Robins, Shannon Hill ChipWrights, Inc. ABSTRACT System-On-Chip (SoC) designs incorporate more and more Intellectual Property (IP) with each year.
Tools Page 1 of 13 ON PROGRAM TRANSLATION. A priori, we have two translation mechanisms available:
 Tools Page 1 of 13 ON PROGRAM TRANSLATION A priori, we have two translation mechanisms available: Interpretation Compilation On interpretation: Statements are translated one at a time and executed immediately.
Tools Page 1 of 13 ON PROGRAM TRANSLATION A priori, we have two translation mechanisms available: Interpretation Compilation On interpretation: Statements are translated one at a time and executed immediately.
A Scalable VISC Processor Platform for Modern Client and Cloud Workloads
 A Scalable VISC Processor Platform for Modern Client and Cloud Workloads Mohammad Abdallah Founder, President and CTO Soft Machines Linley Processor Conference October 7, 2015 Agenda Soft Machines Background
A Scalable VISC Processor Platform for Modern Client and Cloud Workloads Mohammad Abdallah Founder, President and CTO Soft Machines Linley Processor Conference October 7, 2015 Agenda Soft Machines Background
OpenSoC Fabric: On-Chip Network Generator
 OpenSoC Fabric: On-Chip Network Generator Using Chisel to Generate a Parameterizable On-Chip Interconnect Fabric Farzad Fatollahi-Fard, David Donofrio, George Michelogiannakis, John Shalf MODSIM 2014 Presentation
OpenSoC Fabric: On-Chip Network Generator Using Chisel to Generate a Parameterizable On-Chip Interconnect Fabric Farzad Fatollahi-Fard, David Donofrio, George Michelogiannakis, John Shalf MODSIM 2014 Presentation
Overview and History of Operating Systems
 Overview and History of Operating Systems These are the notes for lecture 1. Please review the Syllabus notes before these. Overview / Historical Developments An Operating System... Sits between hardware
Overview and History of Operating Systems These are the notes for lecture 1. Please review the Syllabus notes before these. Overview / Historical Developments An Operating System... Sits between hardware
on-chip and Embedded Software Perspectives and Needs
 Systems-on on-chip and Embedded Software - Perspectives and Needs Miguel Santana Central R&D, STMicroelectronics STMicroelectronics Outline Current trends for SoCs Consequences and challenges Needs: Tackling
Systems-on on-chip and Embedded Software - Perspectives and Needs Miguel Santana Central R&D, STMicroelectronics STMicroelectronics Outline Current trends for SoCs Consequences and challenges Needs: Tackling
Pre-tested System-on-Chip Design. Accelerates PLD Development
 Pre-tested System-on-Chip Design Accelerates PLD Development March 2010 Lattice Semiconductor 5555 Northeast Moore Ct. Hillsboro, Oregon 97124 USA Telephone: (503) 268-8000 www.latticesemi.com 1 Pre-tested
Pre-tested System-on-Chip Design Accelerates PLD Development March 2010 Lattice Semiconductor 5555 Northeast Moore Ct. Hillsboro, Oregon 97124 USA Telephone: (503) 268-8000 www.latticesemi.com 1 Pre-tested
Applying the Benefits of Network on a Chip Architecture to FPGA System Design
 Applying the Benefits of on a Chip Architecture to FPGA System Design WP-01149-1.1 White Paper This document describes the advantages of network on a chip (NoC) architecture in Altera FPGA system design.
Applying the Benefits of on a Chip Architecture to FPGA System Design WP-01149-1.1 White Paper This document describes the advantages of network on a chip (NoC) architecture in Altera FPGA system design.
Centralized Systems. A Centralized Computer System. Chapter 18: Database System Architectures
 Chapter 18: Database System Architectures Centralized Systems! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types! Run on a single computer system and do
Chapter 18: Database System Architectures Centralized Systems! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types! Run on a single computer system and do
Lecture 18: Interconnection Networks. CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012)
") Lecture 18: Interconnection Networks CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Project deadlines: - Mon, April 2: project proposal: 1-2 page writeup - Fri,
Lecture 18: Interconnection Networks CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Project deadlines: - Mon, April 2: project proposal: 1-2 page writeup - Fri,
From Bus and Crossbar to Network-On-Chip. Arteris S.A.
 From Bus and Crossbar to Network-On-Chip Arteris S.A. Copyright 2009 Arteris S.A. All rights reserved. Contact information Corporate Headquarters Arteris, Inc. 1741 Technology Drive, Suite 250 San Jose,
From Bus and Crossbar to Network-On-Chip Arteris S.A. Copyright 2009 Arteris S.A. All rights reserved. Contact information Corporate Headquarters Arteris, Inc. 1741 Technology Drive, Suite 250 San Jose,
All Programmable Logic. Hans-Joachim Gelke Institute of Embedded Systems. Zürcher Fachhochschule
 All Programmable Logic Hans-Joachim Gelke Institute of Embedded Systems Institute of Embedded Systems 31 Assistants 10 Professors 7 Technical Employees 2 Secretaries www.ines.zhaw.ch Research: Education:
All Programmable Logic Hans-Joachim Gelke Institute of Embedded Systems Institute of Embedded Systems 31 Assistants 10 Professors 7 Technical Employees 2 Secretaries www.ines.zhaw.ch Research: Education:
Networking Virtualization Using FPGAs
 Networking Virtualization Using FPGAs Russell Tessier, Deepak Unnikrishnan, Dong Yin, and Lixin Gao Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Massachusetts,
Networking Virtualization Using FPGAs Russell Tessier, Deepak Unnikrishnan, Dong Yin, and Lixin Gao Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Massachusetts,
Hardware Based Virtualization Technologies. Elsie Wahlig elsie.wahlig@amd.com Platform Software Architect
 Hardware Based Virtualization Technologies Elsie Wahlig elsie.wahlig@amd.com Platform Software Architect Outline What is Virtualization? Evolution of Virtualization AMD Virtualization AMD s IO Virtualization
Hardware Based Virtualization Technologies Elsie Wahlig elsie.wahlig@amd.com Platform Software Architect Outline What is Virtualization? Evolution of Virtualization AMD Virtualization AMD s IO Virtualization
Client/Server and Distributed Computing
 Adapted from:operating Systems: Internals and Design Principles, 6/E William Stallings CS571 Fall 2010 Client/Server and Distributed Computing Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Traditional
Adapted from:operating Systems: Internals and Design Principles, 6/E William Stallings CS571 Fall 2010 Client/Server and Distributed Computing Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Traditional
Chapter 1 Computer System Overview
 Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
Overview of Operating Systems Instructor: Dr. Tongping Liu
 Overview of Operating Systems Instructor: Dr. Tongping Liu Thank Dr. Dakai Zhu and Dr. Palden Lama for providing their slides. 1 Lecture Outline Operating System: what is it? Evolution of Computer Systems
Overview of Operating Systems Instructor: Dr. Tongping Liu Thank Dr. Dakai Zhu and Dr. Palden Lama for providing their slides. 1 Lecture Outline Operating System: what is it? Evolution of Computer Systems
Multi-core architectures. Jernej Barbic 15-213, Spring 2007 May 3, 2007
 Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Computer Organization & Architecture Lecture #19
 Computer Organization & Architecture Lecture #19 Input/Output The computer system s I/O architecture is its interface to the outside world. This architecture is designed to provide a systematic means of
Computer Organization & Architecture Lecture #19 Input/Output The computer system s I/O architecture is its interface to the outside world. This architecture is designed to provide a systematic means of
Distributed Operating Systems
 Distributed Operating Systems Prashant Shenoy UMass Computer Science http://lass.cs.umass.edu/~shenoy/courses/677 Lecture 1, page 1 Course Syllabus CMPSCI 677: Distributed Operating Systems Instructor:
Distributed Operating Systems Prashant Shenoy UMass Computer Science http://lass.cs.umass.edu/~shenoy/courses/677 Lecture 1, page 1 Course Syllabus CMPSCI 677: Distributed Operating Systems Instructor:
OC By Arsene Fansi T. POLIMI 2008 1
 IBM POWER 6 MICROPROCESSOR OC By Arsene Fansi T. POLIMI 2008 1 WHAT S IBM POWER 6 MICROPOCESSOR The IBM POWER6 microprocessor powers the new IBM i-series* and p-series* systems. It s based on IBM POWER5
IBM POWER 6 MICROPROCESSOR OC By Arsene Fansi T. POLIMI 2008 1 WHAT S IBM POWER 6 MICROPOCESSOR The IBM POWER6 microprocessor powers the new IBM i-series* and p-series* systems. It s based on IBM POWER5
Design and Implementation of an On-Chip timing based Permutation Network for Multiprocessor system on Chip
 Design and Implementation of an On-Chip timing based Permutation Network for Multiprocessor system on Chip Ms Lavanya Thunuguntla 1, Saritha Sapa 2 1 Associate Professor, Department of ECE, HITAM, Telangana
Design and Implementation of an On-Chip timing based Permutation Network for Multiprocessor system on Chip Ms Lavanya Thunuguntla 1, Saritha Sapa 2 1 Associate Professor, Department of ECE, HITAM, Telangana
Router Architectures
 Router Architectures An overview of router architectures. Introduction What is a Packet Switch? Basic Architectural Components Some Example Packet Switches The Evolution of IP Routers 2 1 Router Components
Router Architectures An overview of router architectures. Introduction What is a Packet Switch? Basic Architectural Components Some Example Packet Switches The Evolution of IP Routers 2 1 Router Components
GEDAE TM - A Graphical Programming and Autocode Generation Tool for Signal Processor Applications
 GEDAE TM - A Graphical Programming and Autocode Generation Tool for Signal Processor Applications Harris Z. Zebrowitz Lockheed Martin Advanced Technology Laboratories 1 Federal Street Camden, NJ 08102
GEDAE TM - A Graphical Programming and Autocode Generation Tool for Signal Processor Applications Harris Z. Zebrowitz Lockheed Martin Advanced Technology Laboratories 1 Federal Street Camden, NJ 08102
Embedded Systems: map to FPGA, GPU, CPU?
 Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven jos@vectorfabrics.com Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven jos@vectorfabrics.com Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
Parallel Digital Signal Processing: An Emerging Market
 Parallel Digital Signal Processing: An Emerging Market Application Report Mitch Reifel and Daniel Chen Digital Signal Processing Products Semiconductor Group SPRA104 February 1994 Printed on Recycled Paper
Parallel Digital Signal Processing: An Emerging Market Application Report Mitch Reifel and Daniel Chen Digital Signal Processing Products Semiconductor Group SPRA104 February 1994 Printed on Recycled Paper
Solving I/O Bottlenecks to Enable Superior Cloud Efficiency
 WHITE PAPER Solving I/O Bottlenecks to Enable Superior Cloud Efficiency Overview...1 Mellanox I/O Virtualization Features and Benefits...2 Summary...6 Overview We already have 8 or even 16 cores on one
WHITE PAPER Solving I/O Bottlenecks to Enable Superior Cloud Efficiency Overview...1 Mellanox I/O Virtualization Features and Benefits...2 Summary...6 Overview We already have 8 or even 16 cores on one
Virtual machine interface. Operating system. Physical machine interface
 Software Concepts User applications Operating system Hardware Virtual machine interface Physical machine interface Operating system: Interface between users and hardware Implements a virtual machine that
Software Concepts User applications Operating system Hardware Virtual machine interface Physical machine interface Operating system: Interface between users and hardware Implements a virtual machine that
Optimizing Configuration and Application Mapping for MPSoC Architectures
 Optimizing Configuration and Application Mapping for MPSoC Architectures École Polytechnique de Montréal, Canada Email : Sebastien.Le-Beux@polymtl.ca 1 Multi-Processor Systems on Chip (MPSoC) Design Trends
Optimizing Configuration and Application Mapping for MPSoC Architectures École Polytechnique de Montréal, Canada Email : Sebastien.Le-Beux@polymtl.ca 1 Multi-Processor Systems on Chip (MPSoC) Design Trends
Chapter 1: Introduction. What is an Operating System?
 Chapter 1: Introduction What is an Operating System? Mainframe Systems Desktop Systems Multiprocessor Systems Distributed Systems Clustered System Real -Time Systems Handheld Systems Computing Environments
Chapter 1: Introduction What is an Operating System? Mainframe Systems Desktop Systems Multiprocessor Systems Distributed Systems Clustered System Real -Time Systems Handheld Systems Computing Environments
Interconnection Networks
 Advanced Computer Architecture (0630561) Lecture 15 Interconnection Networks Prof. Kasim M. Al-Aubidy Computer Eng. Dept. Interconnection Networks: Multiprocessors INs can be classified based on: 1. Mode
Advanced Computer Architecture (0630561) Lecture 15 Interconnection Networks Prof. Kasim M. Al-Aubidy Computer Eng. Dept. Interconnection Networks: Multiprocessors INs can be classified based on: 1. Mode
Contents. Chapter 1. Introduction
 Contents 1. Introduction 2. Computer-System Structures 3. Operating-System Structures 4. Processes 5. Threads 6. CPU Scheduling 7. Process Synchronization 8. Deadlocks 9. Memory Management 10. Virtual
Contents 1. Introduction 2. Computer-System Structures 3. Operating-System Structures 4. Processes 5. Threads 6. CPU Scheduling 7. Process Synchronization 8. Deadlocks 9. Memory Management 10. Virtual
Virtual Machines. www.viplavkambli.com
 1 Virtual Machines A virtual machine (VM) is a "completely isolated guest operating system installation within a normal host operating system". Modern virtual machines are implemented with either software
1 Virtual Machines A virtual machine (VM) is a "completely isolated guest operating system installation within a normal host operating system". Modern virtual machines are implemented with either software
SCSI vs. Fibre Channel White Paper
 SCSI vs. Fibre Channel White Paper 08/27/99 SCSI vs. Fibre Channel Over the past decades, computer s industry has seen radical change in key components. Limitations in speed, bandwidth, and distance have
SCSI vs. Fibre Channel White Paper 08/27/99 SCSI vs. Fibre Channel Over the past decades, computer s industry has seen radical change in key components. Limitations in speed, bandwidth, and distance have
MPSoC Virtual Platforms
 CASTNESS 2007 Workshop MPSoC Virtual Platforms Rainer Leupers Software for Systems on Silicon (SSS) RWTH Aachen University Institute for Integrated Signal Processing Systems Why focus on virtual platforms?
CASTNESS 2007 Workshop MPSoC Virtual Platforms Rainer Leupers Software for Systems on Silicon (SSS) RWTH Aachen University Institute for Integrated Signal Processing Systems Why focus on virtual platforms?
Reliable Systolic Computing through Redundancy
 Reliable Systolic Computing through Redundancy Kunio Okuda 1, Siang Wun Song 1, and Marcos Tatsuo Yamamoto 1 Universidade de São Paulo, Brazil, {kunio,song,mty}@ime.usp.br, http://www.ime.usp.br/ song/
Reliable Systolic Computing through Redundancy Kunio Okuda 1, Siang Wun Song 1, and Marcos Tatsuo Yamamoto 1 Universidade de São Paulo, Brazil, {kunio,song,mty}@ime.usp.br, http://www.ime.usp.br/ song/
independent systems in constant communication what they are, why we care, how they work
 Overview of Presentation Major Classes of Distributed Systems classes of distributed system loosely coupled systems loosely coupled, SMP, Single-system-image Clusters independent systems in constant communication
Overview of Presentation Major Classes of Distributed Systems classes of distributed system loosely coupled systems loosely coupled, SMP, Single-system-image Clusters independent systems in constant communication
Chapter 13 Selected Storage Systems and Interface
 Chapter 13 Selected Storage Systems and Interface Chapter 13 Objectives Appreciate the role of enterprise storage as a distinct architectural entity. Expand upon basic I/O concepts to include storage protocols.
Chapter 13 Selected Storage Systems and Interface Chapter 13 Objectives Appreciate the role of enterprise storage as a distinct architectural entity. Expand upon basic I/O concepts to include storage protocols.