Performance Optimization Strategies For GPU-Accelerated Applications
|
|
|
- Bennett Stafford
- 7 years ago
- Views:
Transcription
1 Performance Optimization Strategies For GPU-Accelerated Applications
2 Performance Opportunities Application level opportunities Overall GPU utilization and efficiency Memory copy efficiency Kernel level opportunities Instruction and memory latency hiding / reduction Efficient use of memory bandwidth Efficient use of compute resources
3 Identifying Performance Opportunities NVIDIA Nsight Eclipse Edition (nsight) NVIDIA Visual Profiler (nvvp) nvprof command-line profiler
4 Automatic Performance Analysis NEW in 5.5 Step-by-step optimization guidance

5 Improved Analysis Visualization NEW in 5.5 More clearly present optimization opportunities
6 Command-Line Metric Collection NEW in 5.5 Collect metrics using nvprof $ nvprof --metrics gld_throughput,flops_dp minife -nx 50 -ny 50 -nz 50 ==24954== Profiling application: minife -nx 50 -ny 50 -nz 50 ==24954== Profiling result: ==24954== Metric result: Invocations Metric Name Metric Description Min Max Avg Kernel: void launch_closure_by_value<...>(double) 100 gld_throughput Global Load Throughput MB/s MB/s MB/s 100 flops_dp FLOPS(Double) Kernel: void spmv_ell_kernel<double, int>(int*, double*,...) 51 gld_throughput Global Load Throughput GB/s GB/s GB/s 51 flops_dp FLOPS(Double) Kernel: void add_to_diagonal_kernel<...>(int, doublescalartype,...) 1 gld_throughput Global Load Throughput GB/s GB/s GB/s 1 flops_dp FLOPS(Double)
7 Optimization Scenarios Full application Optimize overall GPU utilization, efficiency, etc. Optimize individual kernels, most likely optimization candidates first Algorithm Using a test harness Optimize individual kernels Iterate
8 Outline: Kernel Optimization Discuss an overall application optimization strategy Based on identifying primary performance limiter Discuss common optimization opportunities How to use CUDA profiling tools Execute optimization strategy Identify optimization opportunities

9 Identifying Candidate Kernels Analysis system estimates which kernels are best candidates for speedup Execution time, achieved occupancy
10 Primary Performance Bound Most likely limiter to performance for a kernel Memory bandwidth Compute resources Instruction and memory latency Primary bound should be addressed first Often beneficial to examine secondary bounds as well
11 Calculating Performance Bounds Memory bandwidth utilization Compute resource utilization High utilization value likely performance limiter Low utilization value likely not performance limiter Taken together to determine performance bound
12 Memory Bandwidth Utilization Traffic to/from each memory subsystem, relative to peak Maximum utilization of any memory subsystem L1/Shared Memory L2 Cache Texture Cache Device Memory System Memory (via PCIe) nvprof metrics: l2_utilization, texture_utilization, sysmem_utlization,
13 Compute Resource Utilization Number of instructions issued, relative to peak capabilities of GPU Some resources shared across all instructions Some resources specific to instruction classes : integer, FP, control-flow, etc. Maximum utilization of any resource nvprof metrics: issue_slot_utilization, int_fu_utilization, fp_fu_utlization,
14 Calculating Performance Bounds Utilizations Both high compute and memory highly utilized Compute Memory
15 Calculating Performance Bounds Utilizations Memory high, compute low memory bandwidth bound Compute Memory
16 Calculating Performance Bounds Utilizations Compute high, memory low compute resource bound Compute Memory
17 Calculating Performance Bounds Utilizations Both low latency bound Compute Memory

18 Visual Profiler: Performance Bound
19 Bound-Specific Optimization Analysis Memory Bandwidth Bound Compute Bound Latency Bound
20 Bound-Specific Optimization Analysis Memory Bandwidth Bound Compute Bound Latency Bound

21 Memory Bandwidth Bound
22 Memory Bandwidths Understand memory usage patterns of kernel L1/Shared Memory L2 Cache Texture Cache Device Memory System Memory (via PCIe) nvprof metrics: gld_throughput, tex_cache_throughput,, l2_read_transactions, sysmem_read_transactions,

23
24 Memory Access Pattern And Alignment Access pattern Sequential: 1 memory access for entire warp Strided: up to 32 memory accesses for warp Alignment nvprof metrics: gld_efficiency, gst_efficiency, shared_efficiency

25 Visual Profiler: Memory Efficiency
26 Bound-Specific Optimization Analysis Memory Bandwidth Bound Compute Bound Latency Bound
27 Warp Execution Efficiency All threads in warp may not execute instruction Divergent branch Divergent predication 1 of 32 threads = 3% 32 of 32 threads = 100% nvprof metrics: warp_execution_efficiency, warp_nonpred_execution_efficiency (SM3.0+)
28 Visual Profiler: Warp Execution Efficiency

29 Visual Profiler: Warp Execution Efficiency

30 Bound-Specific Optimization Analysis Memory Bandwidth Bound Compute Bound Latency Bound
31 Latency Memory load : delay from when load instruction executed until data returns Arithmetic : delay from when instruction starts until result produced A = Waiting for A = A
32 Hiding Latency SM can do many things at once Time Warp 0 Warp 2 Warp 3 Warp 0 Warp 6 Warp 1 Warp 4 Warp 5 Warp 2 Warp 0 waiting SM still busy Can hide latency as long as there are enough
33 Occupancy Occupancy is the ratio of the number of active warps per multiprocessor to the maximum number of possible active warps Theoretical occupancy, upper bound based on: Threads / block Shared memory usage / block Register usage / thread Achieved occupancy Actual measured occupancy of running kernel (active_warps / active_cycles) / MAX_WARPS_PER_SM nvprof metrics: achieved_occupancy

34 Low Theoretical Occupancy # warps on SM = # blocks on SM # warps per block If low Not enough blocks in kernel # blocks on SM limited by threads, shared memory, registers CUDA Best Practices Guide has extensive discussion on improving occupancy

35 Visual Profiler: Low Theoretical Occupancy

36 Visual Profiler: Low Theoretical Occupancy
37 SM0 SM1 Low Achieved Occupancy In theory kernel allows enough warps on each SM Time Block 0 Block 6 Block 1 Block 7 Block 2 Block 8 Block 3 Block 9 Block 4 Block 10 Block 5 Block 11
38 SM0 SM1 Low Achieved Occupancy In theory kernel allows enough warps on each SM In practice have low achieved occupancy Likely cause is that all SMs do not remain equally busy over duration of kernel execution Time Block 0 Block 1 Block 2 Block 6 Block 7 Block 8 Block 3 Block 4 Block 5 Block 11 Block 9 Block 10
39 Latency Bound, Not Occupancy Haar wavelet decomposition Excellent occupancy : 100% theoretical, 91% achieved Still latency bound
40 Lots Of Warps, Not Enough Can Execute SM can do many things at once Warp Idle No ready warp Warp Time Idle
41 Latency Bound, Instruction Stalls
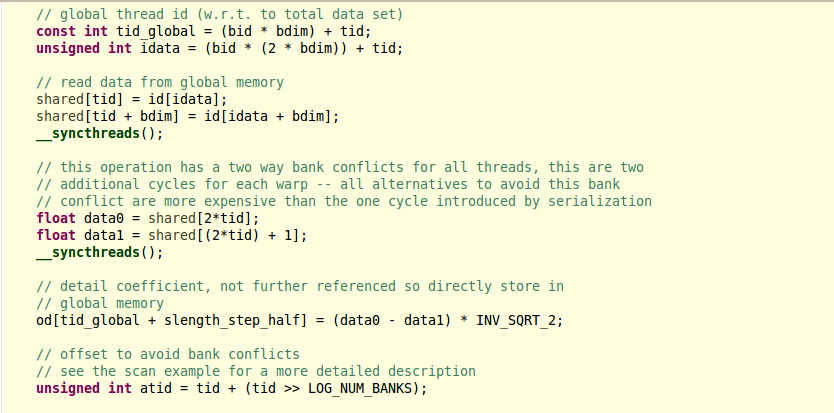
42 syncthreads Stall
43 Summary: Kernel Optimization Application optimization strategy based on primary performance limiter Memory bandwidth Compute resources Instruction and memory latency Common optimization opportunities Use CUDA profiling tools to identify optimization opportunities Guided analysis
44 Next Steps Download free CUDA Toolkit: Join the community: developer.nvidia.com/join Post at Developer Zone Forums: devtalk.nvidia.com Visit Expert Table and Developer Demo Stations S Performance Optimization: Programming Guidelines and GPU Architecture Details Behind Them Thur. 3/21, 9am, Room 210H GTC On-Demand website for all GTC talks
Guided Performance Analysis with the NVIDIA Visual Profiler
 Guided Performance Analysis with the NVIDIA Visual Profiler Identifying Performance Opportunities NVIDIA Nsight Eclipse Edition (nsight) NVIDIA Visual Profiler (nvvp) nvprof command-line profiler Guided
Guided Performance Analysis with the NVIDIA Visual Profiler Identifying Performance Opportunities NVIDIA Nsight Eclipse Edition (nsight) NVIDIA Visual Profiler (nvvp) nvprof command-line profiler Guided
CUDA Optimization with NVIDIA Tools. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Tools Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nvidia Tools 2 What Does the Application
CUDA Optimization with NVIDIA Tools Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nvidia Tools 2 What Does the Application
Optimizing Application Performance with CUDA Profiling Tools
 Optimizing Application Performance with CUDA Profiling Tools Why Profile? Application Code GPU Compute-Intensive Functions Rest of Sequential CPU Code CPU 100 s of cores 10,000 s of threads Great memory
Optimizing Application Performance with CUDA Profiling Tools Why Profile? Application Code GPU Compute-Intensive Functions Rest of Sequential CPU Code CPU 100 s of cores 10,000 s of threads Great memory
GPU Performance Analysis and Optimisation
 GPU Performance Analysis and Optimisation Thomas Bradley, NVIDIA Corporation Outline What limits performance? Analysing performance: GPU profiling Exposing sufficient parallelism Optimising for Kepler
GPU Performance Analysis and Optimisation Thomas Bradley, NVIDIA Corporation Outline What limits performance? Analysing performance: GPU profiling Exposing sufficient parallelism Optimising for Kepler
NVIDIA Tools For Profiling And Monitoring. David Goodwin
 NVIDIA Tools For Profiling And Monitoring David Goodwin Outline CUDA Profiling and Monitoring Libraries Tools Technologies Directions CScADS Summer 2012 Workshop on Performance Tools for Extreme Scale
NVIDIA Tools For Profiling And Monitoring David Goodwin Outline CUDA Profiling and Monitoring Libraries Tools Technologies Directions CScADS Summer 2012 Workshop on Performance Tools for Extreme Scale
E6895 Advanced Big Data Analytics Lecture 14:! NVIDIA GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
GPU Computing with CUDA Lecture 4 - Optimizations. Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile
 GPU Computing with CUDA Lecture 4 - Optimizations Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 3 Control flow Coalescing Latency hiding
GPU Computing with CUDA Lecture 4 - Optimizations Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 3 Control flow Coalescing Latency hiding
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
OpenCL Optimization. San Jose 10/2/2009 Peng Wang, NVIDIA
 OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
CUDA Tools for Debugging and Profiling. Jiri Kraus (NVIDIA)
") Mitglied der Helmholtz-Gemeinschaft CUDA Tools for Debugging and Profiling Jiri Kraus (NVIDIA) GPU Programming@Jülich Supercomputing Centre Jülich 7-9 April 2014 What you will learn How to use cuda-memcheck
Mitglied der Helmholtz-Gemeinschaft CUDA Tools for Debugging and Profiling Jiri Kraus (NVIDIA) GPU Programming@Jülich Supercomputing Centre Jülich 7-9 April 2014 What you will learn How to use cuda-memcheck
GPU Computing with CUDA Lecture 2 - CUDA Memories. Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile
 GPU Computing with CUDA Lecture 2 - CUDA Memories Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 1 Warp scheduling CUDA Memory hierarchy
GPU Computing with CUDA Lecture 2 - CUDA Memories Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 1 Warp scheduling CUDA Memory hierarchy
CUDA SKILLS. Yu-Hang Tang. June 23-26, 2015 CSRC, Beijing
 CUDA SKILLS Yu-Hang Tang June 23-26, 2015 CSRC, Beijing day1.pdf at /home/ytang/slides Referece solutions coming soon Online CUDA API documentation http://docs.nvidia.com/cuda/index.html Yu-Hang Tang @
CUDA SKILLS Yu-Hang Tang June 23-26, 2015 CSRC, Beijing day1.pdf at /home/ytang/slides Referece solutions coming soon Online CUDA API documentation http://docs.nvidia.com/cuda/index.html Yu-Hang Tang @
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GP-GPUs. Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1
 Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
GPU Tools Sandra Wienke
 Sandra Wienke Center for Computing and Communication, RWTH Aachen University MATSE HPC Battle 2012/13 Rechen- und Kommunikationszentrum (RZ) Agenda IDE Eclipse Debugging (CUDA) TotalView Profiling (CUDA
Sandra Wienke Center for Computing and Communication, RWTH Aachen University MATSE HPC Battle 2012/13 Rechen- und Kommunikationszentrum (RZ) Agenda IDE Eclipse Debugging (CUDA) TotalView Profiling (CUDA
ultra fast SOM using CUDA
 ultra fast SOM using CUDA SOM (Self-Organizing Map) is one of the most popular artificial neural network algorithms in the unsupervised learning category. Sijo Mathew Preetha Joy Sibi Rajendra Manoj A
ultra fast SOM using CUDA SOM (Self-Organizing Map) is one of the most popular artificial neural network algorithms in the unsupervised learning category. Sijo Mathew Preetha Joy Sibi Rajendra Manoj A
Graphics Cards and Graphics Processing Units. Ben Johnstone Russ Martin November 15, 2011
 Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
GPU Architectures. A CPU Perspective. Data Parallelism: What is it, and how to exploit it? Workload characteristics
 GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
1. If we need to use each thread to calculate one output element of a vector addition, what would
 Quiz questions Lecture 2: 1. If we need to use each thread to calculate one output element of a vector addition, what would be the expression for mapping the thread/block indices to data index: (A) i=threadidx.x
Quiz questions Lecture 2: 1. If we need to use each thread to calculate one output element of a vector addition, what would be the expression for mapping the thread/block indices to data index: (A) i=threadidx.x
OpenCL Programming for the CUDA Architecture. Version 2.3
 OpenCL Programming for the CUDA Architecture Version 2.3 8/31/2009 In general, there are multiple ways of implementing a given algorithm in OpenCL and these multiple implementations can have vastly different
OpenCL Programming for the CUDA Architecture Version 2.3 8/31/2009 In general, there are multiple ways of implementing a given algorithm in OpenCL and these multiple implementations can have vastly different
ANDROID DEVELOPER TOOLS TRAINING GTC 2014. Sébastien Dominé, NVIDIA
 ANDROID DEVELOPER TOOLS TRAINING GTC 2014 Sébastien Dominé, NVIDIA AGENDA NVIDIA Developer Tools Introduction Multi-core CPU tools Graphics Developer Tools Compute Developer Tools NVIDIA Developer Tools
ANDROID DEVELOPER TOOLS TRAINING GTC 2014 Sébastien Dominé, NVIDIA AGENDA NVIDIA Developer Tools Introduction Multi-core CPU tools Graphics Developer Tools Compute Developer Tools NVIDIA Developer Tools
GPU Parallel Computing Architecture and CUDA Programming Model
 GPU Parallel Computing Architecture and CUDA Programming Model John Nickolls Outline Why GPU Computing? GPU Computing Architecture Multithreading and Arrays Data Parallel Problem Decomposition Parallel
GPU Parallel Computing Architecture and CUDA Programming Model John Nickolls Outline Why GPU Computing? GPU Computing Architecture Multithreading and Arrays Data Parallel Problem Decomposition Parallel
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
CUDA Basics. Murphy Stein New York University
 CUDA Basics Murphy Stein New York University Overview Device Architecture CUDA Programming Model Matrix Transpose in CUDA Further Reading What is CUDA? CUDA stands for: Compute Unified Device Architecture
CUDA Basics Murphy Stein New York University Overview Device Architecture CUDA Programming Model Matrix Transpose in CUDA Further Reading What is CUDA? CUDA stands for: Compute Unified Device Architecture
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Applications to Computational Financial and GPU Computing. May 16th. Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61
 F# Applications to Computational Financial and GPU Computing May 16th Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61 Today! Why care about F#? Just another fashion?! Three success stories! How Alea.cuBase
F# Applications to Computational Financial and GPU Computing May 16th Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61 Today! Why care about F#? Just another fashion?! Three success stories! How Alea.cuBase
Chapter 12: Multiprocessor Architectures. Lesson 01: Performance characteristics of Multiprocessor Architectures and Speedup
 Chapter 12: Multiprocessor Architectures Lesson 01: Performance characteristics of Multiprocessor Architectures and Speedup Objective Be familiar with basic multiprocessor architectures and be able to
Chapter 12: Multiprocessor Architectures Lesson 01: Performance characteristics of Multiprocessor Architectures and Speedup Objective Be familiar with basic multiprocessor architectures and be able to
Introduction to GPU Architecture
 Introduction to GPU Architecture Ofer Rosenberg, PMTS SW, OpenCL Dev. Team AMD Based on From Shader Code to a Teraflop: How GPU Shader Cores Work, By Kayvon Fatahalian, Stanford University Content 1. Three
Introduction to GPU Architecture Ofer Rosenberg, PMTS SW, OpenCL Dev. Team AMD Based on From Shader Code to a Teraflop: How GPU Shader Cores Work, By Kayvon Fatahalian, Stanford University Content 1. Three
Next Generation GPU Architecture Code-named Fermi
 Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
NVIDIA GeForce GTX 580 GPU Datasheet
 NVIDIA GeForce GTX 580 GPU Datasheet NVIDIA GeForce GTX 580 GPU Datasheet 3D Graphics Full Microsoft DirectX 11 Shader Model 5.0 support: o NVIDIA PolyMorph Engine with distributed HW tessellation engines
NVIDIA GeForce GTX 580 GPU Datasheet NVIDIA GeForce GTX 580 GPU Datasheet 3D Graphics Full Microsoft DirectX 11 Shader Model 5.0 support: o NVIDIA PolyMorph Engine with distributed HW tessellation engines
TEGRA X1 DEVELOPER TOOLS SEBASTIEN DOMINE, SR. DIRECTOR SW ENGINEERING
 TEGRA X1 DEVELOPER TOOLS SEBASTIEN DOMINE, SR. DIRECTOR SW ENGINEERING NVIDIA DEVELOPER TOOLS BUILD. DEBUG. PROFILE. C/C++ IDE INTEGRATION STANDALONE TOOLS HARDWARE SUPPORT CPU AND GPU DEBUGGING & PROFILING
TEGRA X1 DEVELOPER TOOLS SEBASTIEN DOMINE, SR. DIRECTOR SW ENGINEERING NVIDIA DEVELOPER TOOLS BUILD. DEBUG. PROFILE. C/C++ IDE INTEGRATION STANDALONE TOOLS HARDWARE SUPPORT CPU AND GPU DEBUGGING & PROFILING
GPU Hardware Performance. Fall 2015
 Fall 2015 Atomic operations performs read-modify-write operations on shared or global memory no interference with other threads for 32-bit and 64-bit integers (c. c. 1.2), float addition (c. c. 2.0) using
Fall 2015 Atomic operations performs read-modify-write operations on shared or global memory no interference with other threads for 32-bit and 64-bit integers (c. c. 1.2), float addition (c. c. 2.0) using
GPU Hardware and Programming Models. Jeremy Appleyard, September 2015
 GPU Hardware and Programming Models Jeremy Appleyard, September 2015 A brief history of GPUs In this talk Hardware Overview Programming Models Ask questions at any point! 2 A Brief History of GPUs 3 Once
GPU Hardware and Programming Models Jeremy Appleyard, September 2015 A brief history of GPUs In this talk Hardware Overview Programming Models Ask questions at any point! 2 A Brief History of GPUs 3 Once
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING
 COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
GPGPU Computing. Yong Cao
 GPGPU Computing Yong Cao Why Graphics Card? It s powerful! A quiet trend Copyright 2009 by Yong Cao Why Graphics Card? It s powerful! Processor Processing Units FLOPs per Unit Clock Speed Processing Power
GPGPU Computing Yong Cao Why Graphics Card? It s powerful! A quiet trend Copyright 2009 by Yong Cao Why Graphics Card? It s powerful! Processor Processing Units FLOPs per Unit Clock Speed Processing Power
Programming GPUs with CUDA
 Programming GPUs with CUDA Max Grossman Department of Computer Science Rice University johnmc@rice.edu COMP 422 Lecture 23 12 April 2016 Why GPUs? Two major trends GPU performance is pulling away from
Programming GPUs with CUDA Max Grossman Department of Computer Science Rice University johnmc@rice.edu COMP 422 Lecture 23 12 April 2016 Why GPUs? Two major trends GPU performance is pulling away from
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Towards Fast SQL Query Processing in DB2 BLU Using GPUs A Technology Demonstration. Sina Meraji sinamera@ca.ibm.com
 Towards Fast SQL Query Processing in DB2 BLU Using GPUs A Technology Demonstration Sina Meraji sinamera@ca.ibm.com Please Note IBM s statements regarding its plans, directions, and intent are subject to
Towards Fast SQL Query Processing in DB2 BLU Using GPUs A Technology Demonstration Sina Meraji sinamera@ca.ibm.com Please Note IBM s statements regarding its plans, directions, and intent are subject to
HIGH PERFORMANCE CONSULTING COURSE OFFERINGS
 Performance 1(6) HIGH PERFORMANCE CONSULTING COURSE OFFERINGS LEARN TO TAKE ADVANTAGE OF POWERFUL GPU BASED ACCELERATOR TECHNOLOGY TODAY 2006 2013 Nvidia GPUs Intel CPUs CONTENTS Acronyms and Terminology...
Performance 1(6) HIGH PERFORMANCE CONSULTING COURSE OFFERINGS LEARN TO TAKE ADVANTAGE OF POWERFUL GPU BASED ACCELERATOR TECHNOLOGY TODAY 2006 2013 Nvidia GPUs Intel CPUs CONTENTS Acronyms and Terminology...
GPU-based Decompression for Medical Imaging Applications
 GPU-based Decompression for Medical Imaging Applications Al Wegener, CTO Samplify Systems 160 Saratoga Ave. Suite 150 Santa Clara, CA 95051 sales@samplify.com (888) LESS-BITS +1 (408) 249-1500 1 Outline
GPU-based Decompression for Medical Imaging Applications Al Wegener, CTO Samplify Systems 160 Saratoga Ave. Suite 150 Santa Clara, CA 95051 sales@samplify.com (888) LESS-BITS +1 (408) 249-1500 1 Outline
15-418 Final Project Report. Trading Platform Server
 15-418 Final Project Report Yinghao Wang yinghaow@andrew.cmu.edu May 8, 214 Trading Platform Server Executive Summary The final project will implement a trading platform server that provides back-end support
15-418 Final Project Report Yinghao Wang yinghaow@andrew.cmu.edu May 8, 214 Trading Platform Server Executive Summary The final project will implement a trading platform server that provides back-end support
ANALYSIS OF RSA ALGORITHM USING GPU PROGRAMMING
 ANALYSIS OF RSA ALGORITHM USING GPU PROGRAMMING Sonam Mahajan 1 and Maninder Singh 2 1 Department of Computer Science Engineering, Thapar University, Patiala, India 2 Department of Computer Science Engineering,
ANALYSIS OF RSA ALGORITHM USING GPU PROGRAMMING Sonam Mahajan 1 and Maninder Singh 2 1 Department of Computer Science Engineering, Thapar University, Patiala, India 2 Department of Computer Science Engineering,
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC
 OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
NVIDIA CUDA Software and GPU Parallel Computing Architecture. David B. Kirk, Chief Scientist
 NVIDIA CUDA Software and GPU Parallel Computing Architecture David B. Kirk, Chief Scientist Outline Applications of GPU Computing CUDA Programming Model Overview Programming in CUDA The Basics How to Get
NVIDIA CUDA Software and GPU Parallel Computing Architecture David B. Kirk, Chief Scientist Outline Applications of GPU Computing CUDA Programming Model Overview Programming in CUDA The Basics How to Get
LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR
 LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR Frédéric Kuznik, frederic.kuznik@insa lyon.fr 1 Framework Introduction Hardware architecture CUDA overview Implementation details A simple case:
LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR Frédéric Kuznik, frederic.kuznik@insa lyon.fr 1 Framework Introduction Hardware architecture CUDA overview Implementation details A simple case:
Texture Cache Approximation on GPUs
 Texture Cache Approximation on GPUs Mark Sutherland Joshua San Miguel Natalie Enright Jerger {suther68,enright}@ece.utoronto.ca, joshua.sanmiguel@mail.utoronto.ca 1 Our Contribution GPU Core Cache Cache
Texture Cache Approximation on GPUs Mark Sutherland Joshua San Miguel Natalie Enright Jerger {suther68,enright}@ece.utoronto.ca, joshua.sanmiguel@mail.utoronto.ca 1 Our Contribution GPU Core Cache Cache
Stream Processing on GPUs Using Distributed Multimedia Middleware
 Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
GPU Computing - CUDA
 GPU Computing - CUDA A short overview of hardware and programing model Pierre Kestener 1 1 CEA Saclay, DSM, Maison de la Simulation Saclay, June 12, 2012 Atelier AO and GPU 1 / 37 Content Historical perspective
GPU Computing - CUDA A short overview of hardware and programing model Pierre Kestener 1 1 CEA Saclay, DSM, Maison de la Simulation Saclay, June 12, 2012 Atelier AO and GPU 1 / 37 Content Historical perspective
Intro to GPU computing. Spring 2015 Mark Silberstein, 048661, Technion 1
 Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
GPU File System Encryption Kartik Kulkarni and Eugene Linkov
 GPU File System Encryption Kartik Kulkarni and Eugene Linkov 5/10/2012 SUMMARY. We implemented a file system that encrypts and decrypts files. The implementation uses the AES algorithm computed through
GPU File System Encryption Kartik Kulkarni and Eugene Linkov 5/10/2012 SUMMARY. We implemented a file system that encrypts and decrypts files. The implementation uses the AES algorithm computed through
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
Accelerating Wavelet-Based Video Coding on Graphics Hardware
 Wladimir J. van der Laan, Andrei C. Jalba, and Jos B.T.M. Roerdink. Accelerating Wavelet-Based Video Coding on Graphics Hardware using CUDA. In Proc. 6th International Symposium on Image and Signal Processing
Wladimir J. van der Laan, Andrei C. Jalba, and Jos B.T.M. Roerdink. Accelerating Wavelet-Based Video Coding on Graphics Hardware using CUDA. In Proc. 6th International Symposium on Image and Signal Processing
GPU Computing with CUDA Lecture 3 - Efficient Shared Memory Use. Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile
 GPU Computing with CUDA Lecture 3 - Efficient Shared Memory Use Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 2 Shared memory in detail
GPU Computing with CUDA Lecture 3 - Efficient Shared Memory Use Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 2 Shared memory in detail
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data
 Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
CudaDMA: Optimizing GPU Memory Bandwidth via Warp Specialization
 CudaDMA: Optimizing GPU Memory Bandwidth via Warp Specialization Michael Bauer Stanford University mebauer@cs.stanford.edu Henry Cook UC Berkeley hcook@cs.berkeley.edu Brucek Khailany NVIDIA Research bkhailany@nvidia.com
CudaDMA: Optimizing GPU Memory Bandwidth via Warp Specialization Michael Bauer Stanford University mebauer@cs.stanford.edu Henry Cook UC Berkeley hcook@cs.berkeley.edu Brucek Khailany NVIDIA Research bkhailany@nvidia.com
MONTE-CARLO SIMULATION OF AMERICAN OPTIONS WITH GPUS. Julien Demouth, NVIDIA
 MONTE-CARLO SIMULATION OF AMERICAN OPTIONS WITH GPUS Julien Demouth, NVIDIA STAC-A2 BENCHMARK STAC-A2 Benchmark Developed by banks Macro and micro, performance and accuracy Pricing and Greeks for American
MONTE-CARLO SIMULATION OF AMERICAN OPTIONS WITH GPUS Julien Demouth, NVIDIA STAC-A2 BENCHMARK STAC-A2 Benchmark Developed by banks Macro and micro, performance and accuracy Pricing and Greeks for American
Introduction to GPGPU. Tiziano Diamanti t.diamanti@cineca.it
 t.diamanti@cineca.it Agenda From GPUs to GPGPUs GPGPU architecture CUDA programming model Perspective projection Vectors that connect the vanishing point to every point of the 3D model will intersecate
t.diamanti@cineca.it Agenda From GPUs to GPGPUs GPGPU architecture CUDA programming model Perspective projection Vectors that connect the vanishing point to every point of the 3D model will intersecate
Interactive Level-Set Deformation On the GPU
 Interactive Level-Set Deformation On the GPU Institute for Data Analysis and Visualization University of California, Davis Problem Statement Goal Interactive system for deformable surface manipulation
Interactive Level-Set Deformation On the GPU Institute for Data Analysis and Visualization University of California, Davis Problem Statement Goal Interactive system for deformable surface manipulation
CUDA Programming. Week 4. Shared memory and register
 CUDA Programming Week 4. Shared memory and register Outline Shared memory and bank confliction Memory padding Register allocation Example of matrix-matrix multiplication Homework SHARED MEMORY AND BANK
CUDA Programming Week 4. Shared memory and register Outline Shared memory and bank confliction Memory padding Register allocation Example of matrix-matrix multiplication Homework SHARED MEMORY AND BANK
DSS. Diskpool and cloud storage benchmarks used in IT-DSS. Data & Storage Services. Geoffray ADDE
 DSS Data & Diskpool and cloud storage benchmarks used in IT-DSS CERN IT Department CH-1211 Geneva 23 Switzerland www.cern.ch/it Geoffray ADDE DSS Outline I- A rational approach to storage systems evaluation
DSS Data & Diskpool and cloud storage benchmarks used in IT-DSS CERN IT Department CH-1211 Geneva 23 Switzerland www.cern.ch/it Geoffray ADDE DSS Outline I- A rational approach to storage systems evaluation
Profiler User's Guide
 Version 2016 www.pgroup.com TABLE OF CONTENTS Profiling Overview... iv What's New... iv Terminology... v Chapter 1. Preparing An Application For Profiling...1 1.1. Focused Profiling...1 1.2. Marking Regions
Version 2016 www.pgroup.com TABLE OF CONTENTS Profiling Overview... iv What's New... iv Terminology... v Chapter 1. Preparing An Application For Profiling...1 1.1. Focused Profiling...1 1.2. Marking Regions
Clustering Billions of Data Points Using GPUs
 Clustering Billions of Data Points Using GPUs Ren Wu ren.wu@hp.com Bin Zhang bin.zhang2@hp.com Meichun Hsu meichun.hsu@hp.com ABSTRACT In this paper, we report our research on using GPUs to accelerate
Clustering Billions of Data Points Using GPUs Ren Wu ren.wu@hp.com Bin Zhang bin.zhang2@hp.com Meichun Hsu meichun.hsu@hp.com ABSTRACT In this paper, we report our research on using GPUs to accelerate
GPU Programming Strategies and Trends in GPU Computing
 GPU Programming Strategies and Trends in GPU Computing André R. Brodtkorb 1 Trond R. Hagen 1,2 Martin L. Sætra 2 1 SINTEF, Dept. Appl. Math., P.O. Box 124, Blindern, NO-0314 Oslo, Norway 2 Center of Mathematics
GPU Programming Strategies and Trends in GPU Computing André R. Brodtkorb 1 Trond R. Hagen 1,2 Martin L. Sætra 2 1 SINTEF, Dept. Appl. Math., P.O. Box 124, Blindern, NO-0314 Oslo, Norway 2 Center of Mathematics
Oracle Applications Release 10.7 NCA Network Performance for the Enterprise. An Oracle White Paper January 1998
 Oracle Applications Release 10.7 NCA Network Performance for the Enterprise An Oracle White Paper January 1998 INTRODUCTION Oracle has quickly integrated web technologies into business applications, becoming
Oracle Applications Release 10.7 NCA Network Performance for the Enterprise An Oracle White Paper January 1998 INTRODUCTION Oracle has quickly integrated web technologies into business applications, becoming
Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com
 mzahran@cs.nyu.edu http://www.mzahran.com") CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Modern GPU
CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Modern GPU
Optimization. NVIDIA OpenCL Best Practices Guide. Version 1.0
 Optimization NVIDIA OpenCL Best Practices Guide Version 1.0 August 10, 2009 NVIDIA OpenCL Best Practices Guide REVISIONS Original release: July 2009 ii August 16, 2009 Table of Contents Preface... v What
Optimization NVIDIA OpenCL Best Practices Guide Version 1.0 August 10, 2009 NVIDIA OpenCL Best Practices Guide REVISIONS Original release: July 2009 ii August 16, 2009 Table of Contents Preface... v What
Speeding up GPU-based password cracking
 Speeding up GPU-based password cracking SHARCS 2012 Martijn Sprengers 1,2 Lejla Batina 2,3 Sprengers.Martijn@kpmg.nl KPMG IT Advisory 1 Radboud University Nijmegen 2 K.U. Leuven 3 March 17-18, 2012 Who
Speeding up GPU-based password cracking SHARCS 2012 Martijn Sprengers 1,2 Lejla Batina 2,3 Sprengers.Martijn@kpmg.nl KPMG IT Advisory 1 Radboud University Nijmegen 2 K.U. Leuven 3 March 17-18, 2012 Who
Radeon GPU Architecture and the Radeon 4800 series. Michael Doggett Graphics Architecture Group June 27, 2008
 Radeon GPU Architecture and the series Michael Doggett Graphics Architecture Group June 27, 2008 Graphics Processing Units Introduction GPU research 2 GPU Evolution GPU started as a triangle rasterizer
Radeon GPU Architecture and the series Michael Doggett Graphics Architecture Group June 27, 2008 Graphics Processing Units Introduction GPU research 2 GPU Evolution GPU started as a triangle rasterizer
Parallel Firewalls on General-Purpose Graphics Processing Units
 Parallel Firewalls on General-Purpose Graphics Processing Units Manoj Singh Gaur and Vijay Laxmi Kamal Chandra Reddy, Ankit Tharwani, Ch.Vamshi Krishna, Lakshminarayanan.V Department of Computer Engineering
Parallel Firewalls on General-Purpose Graphics Processing Units Manoj Singh Gaur and Vijay Laxmi Kamal Chandra Reddy, Ankit Tharwani, Ch.Vamshi Krishna, Lakshminarayanan.V Department of Computer Engineering
Advanced CUDA Webinar. Memory Optimizations
 Advanced CUDA Webinar Memory Optimizations Outline Overview Hardware Memory Optimizations Data transfers between host and device Device memory optimizations Summary Measuring performance effective bandwidth
Advanced CUDA Webinar Memory Optimizations Outline Overview Hardware Memory Optimizations Data transfers between host and device Device memory optimizations Summary Measuring performance effective bandwidth
Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter
 Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter Daniel Weingaertner Informatics Department Federal University of Paraná - Brazil Hochschule Regensburg 02.05.2011 Daniel
Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter Daniel Weingaertner Informatics Department Federal University of Paraná - Brazil Hochschule Regensburg 02.05.2011 Daniel
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
#OpenPOWERSummit. Join the conversation at #OpenPOWERSummit 1
 XLC/C++ and GPU Programming on Power Systems Kelvin Li, Kit Barton, John Keenleyside IBM {kli, kbarton, keenley}@ca.ibm.com John Ashley NVIDIA jashley@nvidia.com #OpenPOWERSummit Join the conversation
XLC/C++ and GPU Programming on Power Systems Kelvin Li, Kit Barton, John Keenleyside IBM {kli, kbarton, keenley}@ca.ibm.com John Ashley NVIDIA jashley@nvidia.com #OpenPOWERSummit Join the conversation
Experiences on using GPU accelerators for data analysis in ROOT/RooFit
 Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Deep Dive: Maximizing EC2 & EBS Performance
 Deep Dive: Maximizing EC2 & EBS Performance Tom Maddox, Solutions Architect 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved What we ll cover Amazon EBS overview Volumes Snapshots
Deep Dive: Maximizing EC2 & EBS Performance Tom Maddox, Solutions Architect 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved What we ll cover Amazon EBS overview Volumes Snapshots
CUDA Debugging. GPGPU Workshop, August 2012. Sandra Wienke Center for Computing and Communication, RWTH Aachen University
 CUDA Debugging GPGPU Workshop, August 2012 Sandra Wienke Center for Computing and Communication, RWTH Aachen University Nikolay Piskun, Chris Gottbrath Rogue Wave Software Rechen- und Kommunikationszentrum
CUDA Debugging GPGPU Workshop, August 2012 Sandra Wienke Center for Computing and Communication, RWTH Aachen University Nikolay Piskun, Chris Gottbrath Rogue Wave Software Rechen- und Kommunikationszentrum
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Amin Safi Faculty of Mathematics, TU dortmund January 22, 2016 Table of Contents Set
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Amin Safi Faculty of Mathematics, TU dortmund January 22, 2016 Table of Contents Set
NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X
 NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X DU-05348-001_v6.5 August 2014 Installation and Verification on Mac OS X TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2. About
NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X DU-05348-001_v6.5 August 2014 Installation and Verification on Mac OS X TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2. About
NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X
 NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X DU-05348-001_v5.5 July 2013 Installation and Verification on Mac OS X TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2. About
NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X DU-05348-001_v5.5 July 2013 Installation and Verification on Mac OS X TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2. About
Packet-based Network Traffic Monitoring and Analysis with GPUs
 Packet-based Network Traffic Monitoring and Analysis with GPUs Wenji Wu, Phil DeMar wenji@fnal.gov, demar@fnal.gov GPU Technology Conference 2014 March 24-27, 2014 SAN JOSE, CALIFORNIA Background Main
Packet-based Network Traffic Monitoring and Analysis with GPUs Wenji Wu, Phil DeMar wenji@fnal.gov, demar@fnal.gov GPU Technology Conference 2014 March 24-27, 2014 SAN JOSE, CALIFORNIA Background Main
The Yin and Yang of Processing Data Warehousing Queries on GPU Devices
 The Yin and Yang of Processing Data Warehousing Queries on GPU Devices Yuan Yuan Rubao Lee Xiaodong Zhang Department of Computer Science and Engineering The Ohio State University {yuanyu, liru, zhang}@cse.ohio-state.edu
The Yin and Yang of Processing Data Warehousing Queries on GPU Devices Yuan Yuan Rubao Lee Xiaodong Zhang Department of Computer Science and Engineering The Ohio State University {yuanyu, liru, zhang}@cse.ohio-state.edu
How To Test Your Code On A Cuda Gdb (Gdb) On A Linux Computer With A Gbd (Gbd) And Gbbd Gbdu (Gdb) (Gdu) (Cuda
 On A Linux Computer With A Gbd (Gbd) And Gbbd Gbdu (Gdb) (Gdu) (Cuda") Mitglied der Helmholtz-Gemeinschaft Hands On CUDA Tools and Performance-Optimization JSC GPU Programming Course 26. März 2011 Dominic Eschweiler Outline of This Talk Introduction Setup CUDA-GDB Profiling
Mitglied der Helmholtz-Gemeinschaft Hands On CUDA Tools and Performance-Optimization JSC GPU Programming Course 26. März 2011 Dominic Eschweiler Outline of This Talk Introduction Setup CUDA-GDB Profiling
~ Greetings from WSU CAPPLab ~
 ~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
Delivering Quality in Software Performance and Scalability Testing
 Delivering Quality in Software Performance and Scalability Testing Abstract Khun Ban, Robert Scott, Kingsum Chow, and Huijun Yan Software and Services Group, Intel Corporation {khun.ban, robert.l.scott,
Delivering Quality in Software Performance and Scalability Testing Abstract Khun Ban, Robert Scott, Kingsum Chow, and Huijun Yan Software and Services Group, Intel Corporation {khun.ban, robert.l.scott,
Path Tracing Overview
 Path Tracing Overview Cast a ray from the camera through the pixel At hit point, evaluate material Determine new incoming direction Update path throughput Cast a shadow ray towards a light source Cast
Path Tracing Overview Cast a ray from the camera through the pixel At hit point, evaluate material Determine new incoming direction Update path throughput Cast a shadow ray towards a light source Cast
GPU for Scientific Computing. -Ali Saleh
 1 GPU for Scientific Computing -Ali Saleh Contents Introduction What is GPU GPU for Scientific Computing K-Means Clustering K-nearest Neighbours When to use GPU and when not Commercial Programming GPU
1 GPU for Scientific Computing -Ali Saleh Contents Introduction What is GPU GPU for Scientific Computing K-Means Clustering K-nearest Neighbours When to use GPU and when not Commercial Programming GPU
Using Many-Core Hardware to Correlate Radio Astronomy Signals
 Using Many-Core Hardware to Correlate Radio Astronomy Signals Rob V. van Nieuwpoort ASTRON, Netherlands Institute for Radio Astronomy Dwingeloo, The Netherlands nieuwpoort@astron.nl Categories and Subject
Using Many-Core Hardware to Correlate Radio Astronomy Signals Rob V. van Nieuwpoort ASTRON, Netherlands Institute for Radio Astronomy Dwingeloo, The Netherlands nieuwpoort@astron.nl Categories and Subject
A STUDY OF PARALLEL SORTING ALGORITHMS. USING CUDA AND OpenMP
 A STUDY OF PARALLEL SORTING ALGORITHMS USING CUDA AND OpenMP A MASTER S THESIS IN SOFTWARE ENGINEERING ATILIM UNIVERSITY by Hakan GÖKAHMETOĞLU OCTOBER 2015 A STUDY OF PARALLEL SORTING ALGORITHMS USING
A STUDY OF PARALLEL SORTING ALGORITHMS USING CUDA AND OpenMP A MASTER S THESIS IN SOFTWARE ENGINEERING ATILIM UNIVERSITY by Hakan GÖKAHMETOĞLU OCTOBER 2015 A STUDY OF PARALLEL SORTING ALGORITHMS USING
High Performance Matrix Inversion with Several GPUs
 High Performance Matrix Inversion on a Multi-core Platform with Several GPUs Pablo Ezzatti 1, Enrique S. Quintana-Ortí 2 and Alfredo Remón 2 1 Centro de Cálculo-Instituto de Computación, Univ. de la República
High Performance Matrix Inversion on a Multi-core Platform with Several GPUs Pablo Ezzatti 1, Enrique S. Quintana-Ortí 2 and Alfredo Remón 2 1 Centro de Cálculo-Instituto de Computación, Univ. de la República
NVIDIA CUDA GETTING STARTED GUIDE FOR MICROSOFT WINDOWS
 NVIDIA CUDA GETTING STARTED GUIDE FOR MICROSOFT WINDOWS DU-05349-001_v6.0 February 2014 Installation and Verification on TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2.
NVIDIA CUDA GETTING STARTED GUIDE FOR MICROSOFT WINDOWS DU-05349-001_v6.0 February 2014 Installation and Verification on TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2.
Efficient Parallel Graph Exploration on Multi-Core CPU and GPU
 Efficient Parallel Graph Exploration on Multi-Core CPU and GPU Pervasive Parallelism Laboratory Stanford University Sungpack Hong, Tayo Oguntebi, and Kunle Olukotun Graph and its Applications Graph Fundamental
Efficient Parallel Graph Exploration on Multi-Core CPU and GPU Pervasive Parallelism Laboratory Stanford University Sungpack Hong, Tayo Oguntebi, and Kunle Olukotun Graph and its Applications Graph Fundamental
ATI Radeon 4800 series Graphics. Michael Doggett Graphics Architecture Group Graphics Product Group
 ATI Radeon 4800 series Graphics Michael Doggett Graphics Architecture Group Graphics Product Group Graphics Processing Units ATI Radeon HD 4870 AMD Stream Computing Next Generation GPUs 2 Radeon 4800 series
ATI Radeon 4800 series Graphics Michael Doggett Graphics Architecture Group Graphics Product Group Graphics Processing Units ATI Radeon HD 4870 AMD Stream Computing Next Generation GPUs 2 Radeon 4800 series
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK
 HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Intro, GPU Computing February 9, 2012 Dan Negrut, 2012 ME964 UW-Madison "The Internet is a great way to get on the net. US Senator Bob Dole
ME964 High Performance Computing for Engineering Applications Intro, GPU Computing February 9, 2012 Dan Negrut, 2012 ME964 UW-Madison "The Internet is a great way to get on the net. US Senator Bob Dole
Speeding Up RSA Encryption Using GPU Parallelization
 2014 Fifth International Conference on Intelligent Systems, Modelling and Simulation Speeding Up RSA Encryption Using GPU Parallelization Chu-Hsing Lin, Jung-Chun Liu, and Cheng-Chieh Li Department of
2014 Fifth International Conference on Intelligent Systems, Modelling and Simulation Speeding Up RSA Encryption Using GPU Parallelization Chu-Hsing Lin, Jung-Chun Liu, and Cheng-Chieh Li Department of
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Practical Performance Understanding the Performance of Your Application
 Neil Masson IBM Java Service Technical Lead 25 th September 2012 Practical Performance Understanding the Performance of Your Application 1 WebSphere User Group: Practical Performance Understand the Performance
Neil Masson IBM Java Service Technical Lead 25 th September 2012 Practical Performance Understanding the Performance of Your Application 1 WebSphere User Group: Practical Performance Understand the Performance