CISC 360. Computer Architecture. Seth Morecraft Course Web Site:
|
|
|
- Alyson Hensley
- 9 years ago
- Views:
Transcription
1 CISC 360 Computer Architecture Seth Morecraft Course Web Site:
2 Static & Dynamic Scheduling Scheduling: act of finding independent instructions Static done at compile time by the compiler (software) Dynamic done at runtime by the processor (hardware)
3 Code Scheduling Why schedule code? Scalar pipelines: fill in load-to-use delay slots to improve CPI Superscalar: place independent instructions together As above, load-to-use delay slots Allow multiple-issue decode logic to let them execute at the same time
4 Compiler Scheduling Compiler can schedule (move) instructions to reduce stalls Basic pipeline scheduling: eliminate back-toback load-use pairs Example code sequence: a = b + c; d = f e;
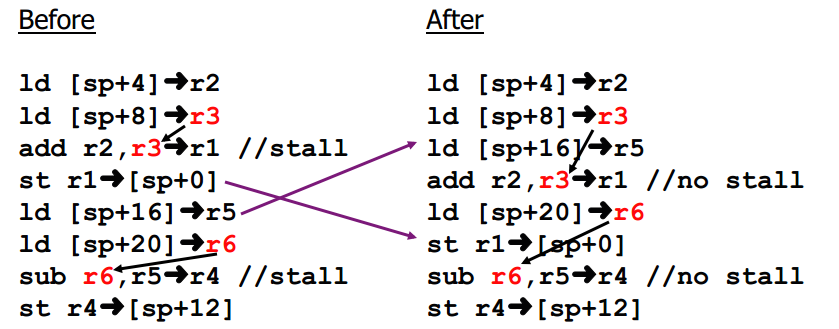
5 Compiler Scheduling
6 Compiler Scheduling Requires Large scheduling scope Independent instruction to put between loaduse pairs + Original example: large scope, two independent computations This example: small scope, one computation
7 Compiler Scheduling Requires Compiler can create larger scheduling scopes For example: loop unrolling & function inlining * Side Note: Branches can really mess this up
8 Compiler Scheduling Requires Enough registers To hold additional live values Example code contains 7 different values (including sp) Before: max 3 values live at any time 3 registers enough After: max 4 values live 3 registers not enough
9 Compiler Scheduling Requires Alias analysis Ability to tell whether load/store reference same memory locations Effectively, whether load/store can be rearranged Must be conservative
10 Compiler Scheduling Limitations Scheduling scope Example: can t generally move memory operations past branches Limited number of registers (set by ISA) Inexact memory aliasing information Often prevents reordering of loads above stores by compiler Caches misses (or any runtime event) confound scheduling How can the compiler know which loads will miss? Can impact the compiler s scheduling decisions
11 Can Hardware Overcome These Limits? Dynamically-scheduled processors Also called out-of-order processors Hardware re-schedules insns within a sliding window of VonNeumann insns As with pipelining and superscalar, ISA unchanged Same hardware/software interface, appearance of in-order
12 Can Hardware Overcome These Limits? Increases scheduling scope Does loop unrolling transparently! Uses branch prediction to unroll branches Examples: Pentium Pro/II/III (3-wide), Core 2 (4-wide), Alpha (4-wide), MIPS R10000 (4-wide), Power5 (5-wide)
13 Out-of-Order to the Rescue Dynamic scheduling done by the hardware Still superscalar, but now out-of-order, too Allows instructions to issue when dependences are ready
14 Out-of-Order Execution Also call Dynamic scheduling Done by the hardware on-the-fly during execution Looks at a window of instructions waiting to execute Each cycle, picks the next ready instruction(s)
15 Out-of-Order Execution Two steps to enable out-of-order execution: Step #1: Register renaming to avoid false dependencies Step #2: Dynamically schedule to enforce true dependencies Key to understanding out-of-order execution: Data dependencies
 WAR (Write After Read) = anti-dependence (false) WAW & WAR are false, Can be totally eliminated by")
16 Dependence types RAW (Read After Write) = true dependence (true) WAW (Write After Write) = output dependence (false) WAR (Write After Read) = anti-dependence (false) WAW & WAR are false, Can be totally eliminated by renaming
17 Step #1: Register Renaming To eliminate register conflicts/hazards Architected vs Physical registers level of indirection Names: r1,r2,r3 Locations: p1,p2,p3,p4,p5,p6,p7 Original mapping: r1 p1, r2 p2, r3 p3, p4 p7 are available
18 Step #1: Register Renaming Renaming conceptually write each register once + Removes false dependences + Leaves true dependences intact! When to reuse a physical register? After overwriting insn done
19 Register Renaming Two key data structures: maptable[architectural_reg] => physical_reg Free list: allocate (new) & free registers (implemented as a queue) Algorithm: at decode stage for each instruction, lookup (LUT) or map At commit Once all older instructions have committed, free register
20 Also Have Dependencies via Memory WAR/WAW are false dependencies - But can t rename memory in same way as registers Why? Address are not known at rename Need to use other tricks
21 Store Queue (SQ) Solves two problems Allows for recovery of speculative stores Allows out-of-order stores Store Queue (SQ) At dispatch, each store is given a slot in the Store Queue First-in-first-out (FIFO) queue Each entry contains: address, value, and age
22 Store Queue (SQ) Operation: Dispatch (in-order): allocate entry in SQ (stall if full) Execute (out-of-order): write store value into store queue Commit (in-order): read value from SQ and write into data cache Branch recovery: remove entries from the store queue
23 Memory Forwarding Loads also search the Store Queue (in parallel with cache access) Conceptually like register bypassing, but different implementation Why? Addresses unknown until execute
24 Memory WAR Hazards Need to make sure that load doesn t read store s result Need to get values based on program order not execution order Bad solution: require all stores/loads to execute in-order Good solution: add age fields to store queue (SQ) Loads read matching address that is earlier (or older ) than it Another reason the SQ is a FIFO queue
25 Load Queue Detects load ordering violations Load execution: Write address into Load Queue Also note any store forwarded from here Store execution: Search Load Queue Younger load with same addr? Didn t forward from younger store? (optimization for full renaming)
26 Store Queue + Load Queue Store Queue: handles forwarding Entry per store dispatch, commit) Written by stores (@ execute) Searched by loads (@ execute) Read from to write data cache (@ commit)
27 Store Queue + Load Queue Load Queue: detects ordering violations Entry per load dispatch, commit) Written by loads (@ execute) Searched by stores (@ execute) Both together Allows aggressive load scheduling Stores don t constrain load execution
28 Step #2: Dynamic Scheduling Instructions fetch/decoded/renamed into Instruction Buffer Also called instruction window or instruction scheduler Instructions (conceptually) check ready bits every cycle Execute oldest ready instruction, set output as ready
29 Dynamic Scheduling Operation (Recap) Dynamic scheduling Totally in the hardware (not visible to software) Also called out-of-order execution (OoO) Fetch many instructions into instruction window Use branch prediction to speculate past (multiple) branches Flush pipeline on branch misprediction
30 Dynamic Scheduling Operation (Recap) Rename registers to avoid false dependencies Execute instructions as soon as possible Register dependencies are known Handling memory dependencies more tricky Commit instructions in order Anything strange happens before commit, just flush the pipeline
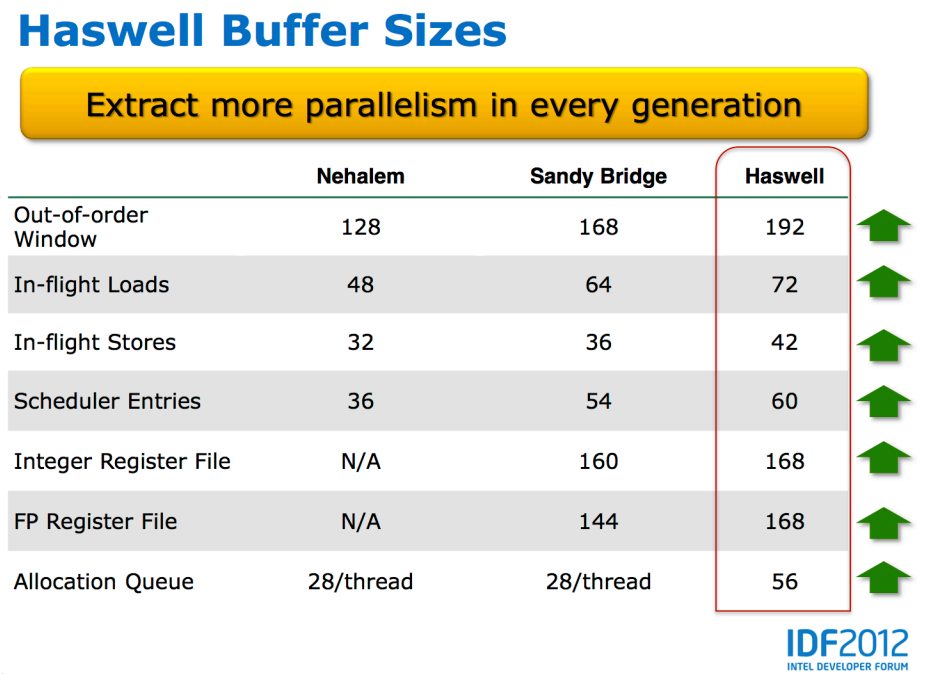
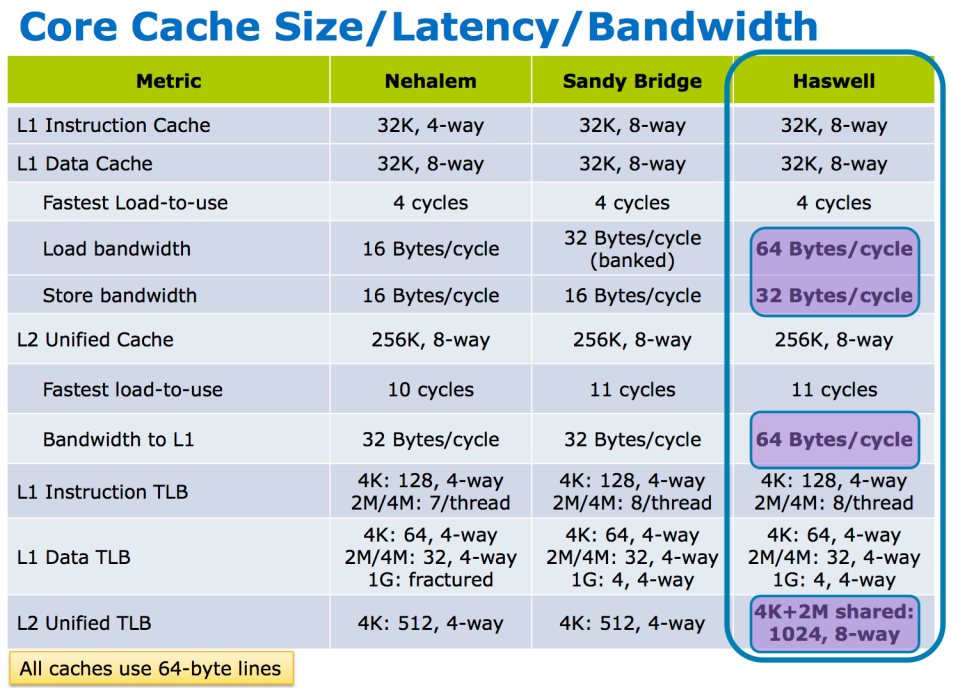
31 How much out-of-order? Core i7 Sandy Bridge : 68-entry reorder buffer, 160 integer registers, 54-entry scheduler
32
33
34
35 Out of Order: Benefits Allows speculative re-ordering Loads / stores Branch prediction to look past branches Done by hardware Compiler may want different schedule for different hw configs Hardware has only its own configuration to deal with
36 Out of Order: Benefits Schedule can change due to cache misses Different schedule optimal from on cache hit Memory-level parallelism Executes around cache misses to find independent instructions Finds and initiates independent misses, reducing memory latency Especially good at hiding L2 hits (~12 cycles in Core i7)
37 Challenges for Out-of-Order Cores Design complexity More complicated than in-order? Certainly! But, we have managed to overcome the design complexity Clock frequency Can we build a high ILP machine at high clock frequency? Yes, with some additional pipe stages, clever design
38 Challenges for Out-of-Order Cores Limits to (efficiently) scaling the window and ILP Large physical register file Fast register renaming/wakeup/select/load queue/store queue Active areas of micro-architectural research Branch & memory depend. prediction (limits effective window size) 95% branch mis-prediction: 1 in 20 branches, or 1 in 100 insn. Plus all the issues of build wide in-order superscalar Power efficiency Today, even mobile phone chips are out-of-order cores

39 Wrap-up: Hardware vs. Software Scheduling Static scheduling Performed by compiler, limited in several ways Dynamic scheduling Performed by the hardware, overcomes limitations Static limitation dynamic mitigation Number of registers in the ISA register renaming Scheduling scope branch prediction & speculation Inexact memory aliasing information speculative memory ops Unknown latencies of cache misses execute when ready Which to do? Compiler does what it can, hardware the rest Why? dynamic scheduling needed to sustain more than 2-way issue Helps with hiding memory latency (execute around misses) Intel Core i7 is four-wide execute w/ scheduling window of 100+ Even mobile phones have dynamic scheduled cores (ARM A9)
INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER
 Course on: Advanced Computer Architectures INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER Prof. Cristina Silvano Politecnico di Milano [email protected] Prof. Silvano, Politecnico di Milano
Course on: Advanced Computer Architectures INSTRUCTION LEVEL PARALLELISM PART VII: REORDER BUFFER Prof. Cristina Silvano Politecnico di Milano [email protected] Prof. Silvano, Politecnico di Milano
 More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
VLIW Processors. VLIW Processors
 1 VLIW Processors VLIW ( very long instruction word ) processors instructions are scheduled by the compiler a fixed number of operations are formatted as one big instruction (called a bundle) usually LIW
1 VLIW Processors VLIW ( very long instruction word ) processors instructions are scheduled by the compiler a fixed number of operations are formatted as one big instruction (called a bundle) usually LIW
Pipelining Review and Its Limitations
 Pipelining Review and Its Limitations Yuri Baida [email protected] [email protected] October 16, 2010 Moscow Institute of Physics and Technology Agenda Review Instruction set architecture Basic
Pipelining Review and Its Limitations Yuri Baida [email protected] [email protected] October 16, 2010 Moscow Institute of Physics and Technology Agenda Review Instruction set architecture Basic
Solution: start more than one instruction in the same clock cycle CPI < 1 (or IPC > 1, Instructions per Cycle) Two approaches:
 Two approaches:") Multiple-Issue Processors Pipelining can achieve CPI close to 1 Mechanisms for handling hazards Static or dynamic scheduling Static or dynamic branch handling Increase in transistor counts (Moore s Law):
Multiple-Issue Processors Pipelining can achieve CPI close to 1 Mechanisms for handling hazards Static or dynamic scheduling Static or dynamic branch handling Increase in transistor counts (Moore s Law):
Overview. CISC Developments. RISC Designs. CISC Designs. VAX: Addressing Modes. Digital VAX
 Overview CISC Developments Over Twenty Years Classic CISC design: Digital VAX VAXÕs RISC successor: PRISM/Alpha IntelÕs ubiquitous 80x86 architecture Ð 8086 through the Pentium Pro (P6) RJS 2/3/97 Philosophy
Overview CISC Developments Over Twenty Years Classic CISC design: Digital VAX VAXÕs RISC successor: PRISM/Alpha IntelÕs ubiquitous 80x86 architecture Ð 8086 through the Pentium Pro (P6) RJS 2/3/97 Philosophy
Static Scheduling. option #1: dynamic scheduling (by the hardware) option #2: static scheduling (by the compiler) ECE 252 / CPS 220 Lecture Notes
 option #2: static scheduling (by the compiler) ECE 252 / CPS 220 Lecture Notes") basic pipeline: single, in-order issue first extension: multiple issue (superscalar) second extension: scheduling instructions for more ILP option #1: dynamic scheduling (by the hardware) option #2: static
basic pipeline: single, in-order issue first extension: multiple issue (superscalar) second extension: scheduling instructions for more ILP option #1: dynamic scheduling (by the hardware) option #2: static
WAR: Write After Read
 WAR: Write After Read write-after-read (WAR) = artificial (name) dependence add R1, R2, R3 sub R2, R4, R1 or R1, R6, R3 problem: add could use wrong value for R2 can t happen in vanilla pipeline (reads
WAR: Write After Read write-after-read (WAR) = artificial (name) dependence add R1, R2, R3 sub R2, R4, R1 or R1, R6, R3 problem: add could use wrong value for R2 can t happen in vanilla pipeline (reads
Administration. Instruction scheduling. Modern processors. Examples. Simplified architecture model. CS 412 Introduction to Compilers
 CS 4 Introduction to Compilers ndrew Myers Cornell University dministration Prelim tomorrow evening No class Wednesday P due in days Optional reading: Muchnick 7 Lecture : Instruction scheduling pr 0 Modern
CS 4 Introduction to Compilers ndrew Myers Cornell University dministration Prelim tomorrow evening No class Wednesday P due in days Optional reading: Muchnick 7 Lecture : Instruction scheduling pr 0 Modern
Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x
![Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x](/thumbs/25/6459870.jpg "Software Pipelining. for (i=1, i<100, i++) { x := A[i]; x := x+1; A[i] := x") Software Pipelining for (i=1, i
Software Pipelining for (i=1, i
Computer Architecture TDTS10
 why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000. ILP Execution
 EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000 Lecture #11: Wednesday, 3 May 2000 Lecturer: Ben Serebrin Scribe: Dean Liu ILP Execution
EE482: Advanced Computer Organization Lecture #11 Processor Architecture Stanford University Wednesday, 31 May 2000 Lecture #11: Wednesday, 3 May 2000 Lecturer: Ben Serebrin Scribe: Dean Liu ILP Execution
CS:APP Chapter 4 Computer Architecture. Wrap-Up. William J. Taffe Plymouth State University. using the slides of
 CS:APP Chapter 4 Computer Architecture Wrap-Up William J. Taffe Plymouth State University using the slides of Randal E. Bryant Carnegie Mellon University Overview Wrap-Up of PIPE Design Performance analysis
CS:APP Chapter 4 Computer Architecture Wrap-Up William J. Taffe Plymouth State University using the slides of Randal E. Bryant Carnegie Mellon University Overview Wrap-Up of PIPE Design Performance analysis
This Unit: Multithreading (MT) CIS 501 Computer Architecture. Performance And Utilization. Readings
 CIS 501 Computer Architecture. Performance And Utilization. Readings") This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
This Unit: Multithreading (MT) CIS 501 Computer Architecture Unit 10: Hardware Multithreading Application OS Compiler Firmware CU I/O Memory Digital Circuits Gates & Transistors Why multithreading (MT)?
Energy-Efficient, High-Performance Heterogeneous Core Design
 Energy-Efficient, High-Performance Heterogeneous Core Design Raj Parihar Core Design Session, MICRO - 2012 Advanced Computer Architecture Lab, UofR, Rochester April 18, 2013 Raj Parihar Energy-Efficient,
Energy-Efficient, High-Performance Heterogeneous Core Design Raj Parihar Core Design Session, MICRO - 2012 Advanced Computer Architecture Lab, UofR, Rochester April 18, 2013 Raj Parihar Energy-Efficient,
Computer Organization and Components
 Computer Organization and Components IS5, fall 25 Lecture : Pipelined Processors ssociate Professor, KTH Royal Institute of Technology ssistant Research ngineer, University of California, Berkeley Slides
Computer Organization and Components IS5, fall 25 Lecture : Pipelined Processors ssociate Professor, KTH Royal Institute of Technology ssistant Research ngineer, University of California, Berkeley Slides
The Microarchitecture of Superscalar Processors
 The Microarchitecture of Superscalar Processors James E. Smith Department of Electrical and Computer Engineering 1415 Johnson Drive Madison, WI 53706 ph: (608)-265-5737 fax:(608)-262-1267 email: [email protected]
The Microarchitecture of Superscalar Processors James E. Smith Department of Electrical and Computer Engineering 1415 Johnson Drive Madison, WI 53706 ph: (608)-265-5737 fax:(608)-262-1267 email: [email protected]
CPU Performance Equation
 CPU Performance Equation C T I T ime for task = C T I =Average # Cycles per instruction =Time per cycle =Instructions per task Pipelining e.g. 3-5 pipeline steps (ARM, SA, R3000) Attempt to get C down
CPU Performance Equation C T I T ime for task = C T I =Average # Cycles per instruction =Time per cycle =Instructions per task Pipelining e.g. 3-5 pipeline steps (ARM, SA, R3000) Attempt to get C down
PROBLEMS #20,R0,R1 #$3A,R2,R4
 506 CHAPTER 8 PIPELINING (Corrisponde al cap. 11 - Introduzione al pipelining) PROBLEMS 8.1 Consider the following sequence of instructions Mul And #20,R0,R1 #3,R2,R3 #$3A,R2,R4 R0,R2,R5 In all instructions,
506 CHAPTER 8 PIPELINING (Corrisponde al cap. 11 - Introduzione al pipelining) PROBLEMS 8.1 Consider the following sequence of instructions Mul And #20,R0,R1 #3,R2,R3 #$3A,R2,R4 R0,R2,R5 In all instructions,
<Insert Picture Here> T4: A Highly Threaded Server-on-a-Chip with Native Support for Heterogeneous Computing
 T4: A Highly Threaded Server-on-a-Chip with Native Support for Heterogeneous Computing Robert Golla Senior Hardware Architect Paul Jordan Senior Principal Hardware Engineer Oracle
T4: A Highly Threaded Server-on-a-Chip with Native Support for Heterogeneous Computing Robert Golla Senior Hardware Architect Paul Jordan Senior Principal Hardware Engineer Oracle
2
 1 2 3 4 5 For Description of these Features see http://download.intel.com/products/processor/corei7/prod_brief.pdf The following Features Greatly affect Performance Monitoring The New Performance Monitoring
1 2 3 4 5 For Description of these Features see http://download.intel.com/products/processor/corei7/prod_brief.pdf The following Features Greatly affect Performance Monitoring The New Performance Monitoring
A Lab Course on Computer Architecture
 A Lab Course on Computer Architecture Pedro López José Duato Depto. de Informática de Sistemas y Computadores Facultad de Informática Universidad Politécnica de Valencia Camino de Vera s/n, 46071 - Valencia,
A Lab Course on Computer Architecture Pedro López José Duato Depto. de Informática de Sistemas y Computadores Facultad de Informática Universidad Politécnica de Valencia Camino de Vera s/n, 46071 - Valencia,
Q. Consider a dynamic instruction execution (an execution trace, in other words) that consists of repeats of code in this pattern:
 that consists of repeats of code in this pattern:") Pipelining HW Q. Can a MIPS SW instruction executing in a simple 5-stage pipelined implementation have a data dependency hazard of any type resulting in a nop bubble? If so, show an example; if not, prove
Pipelining HW Q. Can a MIPS SW instruction executing in a simple 5-stage pipelined implementation have a data dependency hazard of any type resulting in a nop bubble? If so, show an example; if not, prove
Module: Software Instruction Scheduling Part I
 Module: Software Instruction Scheduling Part I Sudhakar Yalamanchili, Georgia Institute of Technology Reading for this Module Loop Unrolling and Instruction Scheduling Section 2.2 Dependence Analysis Section
Module: Software Instruction Scheduling Part I Sudhakar Yalamanchili, Georgia Institute of Technology Reading for this Module Loop Unrolling and Instruction Scheduling Section 2.2 Dependence Analysis Section
POWER8 Performance Analysis
 POWER8 Performance Analysis Satish Kumar Sadasivam Senior Performance Engineer, Master Inventor IBM Systems and Technology Labs [email protected] #OpenPOWERSummit Join the conversation at #OpenPOWERSummit
POWER8 Performance Analysis Satish Kumar Sadasivam Senior Performance Engineer, Master Inventor IBM Systems and Technology Labs [email protected] #OpenPOWERSummit Join the conversation at #OpenPOWERSummit
Thread level parallelism
 Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
Instruction Set Architecture. or How to talk to computers if you aren t in Star Trek
 Instruction Set Architecture or How to talk to computers if you aren t in Star Trek The Instruction Set Architecture Application Compiler Instr. Set Proc. Operating System I/O system Instruction Set Architecture
Instruction Set Architecture or How to talk to computers if you aren t in Star Trek The Instruction Set Architecture Application Compiler Instr. Set Proc. Operating System I/O system Instruction Set Architecture
Advanced Computer Architecture-CS501. Computer Systems Design and Architecture 2.1, 2.2, 3.2
 Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Checkpoint Processing and Recovery: Towards Scalable Large Instruction Window Processors
 Checkpoint Processing and Recovery: Towards Scalable Large Instruction Window Processors Haitham Akkary Ravi Rajwar Srikanth T. Srinivasan Microprocessor Research Labs, Intel Corporation Hillsboro, Oregon
Checkpoint Processing and Recovery: Towards Scalable Large Instruction Window Processors Haitham Akkary Ravi Rajwar Srikanth T. Srinivasan Microprocessor Research Labs, Intel Corporation Hillsboro, Oregon
IA-64 Application Developer s Architecture Guide
 IA-64 Application Developer s Architecture Guide The IA-64 architecture was designed to overcome the performance limitations of today s architectures and provide maximum headroom for the future. To achieve
IA-64 Application Developer s Architecture Guide The IA-64 architecture was designed to overcome the performance limitations of today s architectures and provide maximum headroom for the future. To achieve
OC By Arsene Fansi T. POLIMI 2008 1
 IBM POWER 6 MICROPROCESSOR OC By Arsene Fansi T. POLIMI 2008 1 WHAT S IBM POWER 6 MICROPOCESSOR The IBM POWER6 microprocessor powers the new IBM i-series* and p-series* systems. It s based on IBM POWER5
IBM POWER 6 MICROPROCESSOR OC By Arsene Fansi T. POLIMI 2008 1 WHAT S IBM POWER 6 MICROPOCESSOR The IBM POWER6 microprocessor powers the new IBM i-series* and p-series* systems. It s based on IBM POWER5
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
CS521 CSE IITG 11/23/2012
 CS521 CSE TG 11/23/2012 A Sahu 1 Degree of overlap Serial, Overlapped, d, Super pipelined/superscalar Depth Shallow, Deep Structure Linear, Non linear Scheduling of operations Static, Dynamic A Sahu slide
CS521 CSE TG 11/23/2012 A Sahu 1 Degree of overlap Serial, Overlapped, d, Super pipelined/superscalar Depth Shallow, Deep Structure Linear, Non linear Scheduling of operations Static, Dynamic A Sahu slide
Bindel, Spring 2010 Applications of Parallel Computers (CS 5220) Week 1: Wednesday, Jan 27
 Week 1: Wednesday, Jan 27") Logistics Week 1: Wednesday, Jan 27 Because of overcrowding, we will be changing to a new room on Monday (Snee 1120). Accounts on the class cluster (crocus.csuglab.cornell.edu) will be available next week.
Logistics Week 1: Wednesday, Jan 27 Because of overcrowding, we will be changing to a new room on Monday (Snee 1120). Accounts on the class cluster (crocus.csuglab.cornell.edu) will be available next week.
CS352H: Computer Systems Architecture
 CS352H: Computer Systems Architecture Topic 9: MIPS Pipeline - Hazards October 1, 2009 University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell Data Hazards in ALU Instructions
CS352H: Computer Systems Architecture Topic 9: MIPS Pipeline - Hazards October 1, 2009 University of Texas at Austin CS352H - Computer Systems Architecture Fall 2009 Don Fussell Data Hazards in ALU Instructions
ELE 356 Computer Engineering II. Section 1 Foundations Class 6 Architecture
 ELE 356 Computer Engineering II Section 1 Foundations Class 6 Architecture History ENIAC Video 2 tj History Mechanical Devices Abacus 3 tj History Mechanical Devices The Antikythera Mechanism Oldest known
ELE 356 Computer Engineering II Section 1 Foundations Class 6 Architecture History ENIAC Video 2 tj History Mechanical Devices Abacus 3 tj History Mechanical Devices The Antikythera Mechanism Oldest known
Software implementation of Post-Quantum Cryptography
 Software implementation of Post-Quantum Cryptography Peter Schwabe Radboud University Nijmegen, The Netherlands October 20, 2013 ASCrypto 2013, Florianópolis, Brazil Part I Optimizing cryptographic software
Software implementation of Post-Quantum Cryptography Peter Schwabe Radboud University Nijmegen, The Netherlands October 20, 2013 ASCrypto 2013, Florianópolis, Brazil Part I Optimizing cryptographic software
Instruction Set Design
 Instruction Set Design Instruction Set Architecture: to what purpose? ISA provides the level of abstraction between the software and the hardware One of the most important abstraction in CS It s narrow,
Instruction Set Design Instruction Set Architecture: to what purpose? ISA provides the level of abstraction between the software and the hardware One of the most important abstraction in CS It s narrow,
SOC architecture and design
 SOC architecture and design system-on-chip (SOC) processors: become components in a system SOC covers many topics processor: pipelined, superscalar, VLIW, array, vector storage: cache, embedded and external
SOC architecture and design system-on-chip (SOC) processors: become components in a system SOC covers many topics processor: pipelined, superscalar, VLIW, array, vector storage: cache, embedded and external
on an system with an infinite number of processors. Calculate the speedup of
 1. Amdahl s law Three enhancements with the following speedups are proposed for a new architecture: Speedup1 = 30 Speedup2 = 20 Speedup3 = 10 Only one enhancement is usable at a time. a) If enhancements
1. Amdahl s law Three enhancements with the following speedups are proposed for a new architecture: Speedup1 = 30 Speedup2 = 20 Speedup3 = 10 Only one enhancement is usable at a time. a) If enhancements
Performance evaluation
 Performance evaluation Arquitecturas Avanzadas de Computadores - 2547021 Departamento de Ingeniería Electrónica y de Telecomunicaciones Facultad de Ingeniería 2015-1 Bibliography and evaluation Bibliography
Performance evaluation Arquitecturas Avanzadas de Computadores - 2547021 Departamento de Ingeniería Electrónica y de Telecomunicaciones Facultad de Ingeniería 2015-1 Bibliography and evaluation Bibliography
Instruction scheduling
 Instruction ordering Instruction scheduling Advanced Compiler Construction Michel Schinz 2015 05 21 When a compiler emits the instructions corresponding to a program, it imposes a total order on them.
Instruction ordering Instruction scheduling Advanced Compiler Construction Michel Schinz 2015 05 21 When a compiler emits the instructions corresponding to a program, it imposes a total order on them.
Technical Report. Complexity-effective superscalar embedded processors using instruction-level distributed processing. Ian Caulfield.
 Technical Report UCAM-CL-TR-707 ISSN 1476-2986 Number 707 Computer Laboratory Complexity-effective superscalar embedded processors using instruction-level distributed processing Ian Caulfield December
Technical Report UCAM-CL-TR-707 ISSN 1476-2986 Number 707 Computer Laboratory Complexity-effective superscalar embedded processors using instruction-level distributed processing Ian Caulfield December
Multithreading Lin Gao cs9244 report, 2006
 Multithreading Lin Gao cs9244 report, 2006 2 Contents 1 Introduction 5 2 Multithreading Technology 7 2.1 Fine-grained multithreading (FGMT)............. 8 2.2 Coarse-grained multithreading (CGMT)............
Multithreading Lin Gao cs9244 report, 2006 2 Contents 1 Introduction 5 2 Multithreading Technology 7 2.1 Fine-grained multithreading (FGMT)............. 8 2.2 Coarse-grained multithreading (CGMT)............
BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA
 BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA AGENDA INTRO TO BEAGLEBONE BLACK HARDWARE & SPECS CORTEX-A8 ARMV7 PROCESSOR PROS & CONS VS RASPBERRY PI WHEN TO USE BEAGLEBONE BLACK Single
BEAGLEBONE BLACK ARCHITECTURE MADELEINE DAIGNEAU MICHELLE ADVENA AGENDA INTRO TO BEAGLEBONE BLACK HARDWARE & SPECS CORTEX-A8 ARMV7 PROCESSOR PROS & CONS VS RASPBERRY PI WHEN TO USE BEAGLEBONE BLACK Single
Intel Pentium 4 Processor on 90nm Technology
 Intel Pentium 4 Processor on 90nm Technology Ronak Singhal August 24, 2004 Hot Chips 16 1 1 Agenda Netburst Microarchitecture Review Microarchitecture Features Hyper-Threading Technology SSE3 Intel Extended
Intel Pentium 4 Processor on 90nm Technology Ronak Singhal August 24, 2004 Hot Chips 16 1 1 Agenda Netburst Microarchitecture Review Microarchitecture Features Hyper-Threading Technology SSE3 Intel Extended
Exploring the Design of the Cortex-A15 Processor ARM s next generation mobile applications processor. Travis Lanier Senior Product Manager
 Exploring the Design of the Cortex-A15 Processor ARM s next generation mobile applications processor Travis Lanier Senior Product Manager 1 Cortex-A15: Next Generation Leadership Cortex-A class multi-processor
Exploring the Design of the Cortex-A15 Processor ARM s next generation mobile applications processor Travis Lanier Senior Product Manager 1 Cortex-A15: Next Generation Leadership Cortex-A class multi-processor
Putting it all together: Intel Nehalem. http://www.realworldtech.com/page.cfm?articleid=rwt040208182719
 Putting it all together: Intel Nehalem http://www.realworldtech.com/page.cfm?articleid=rwt040208182719 Intel Nehalem Review entire term by looking at most recent microprocessor from Intel Nehalem is code
Putting it all together: Intel Nehalem http://www.realworldtech.com/page.cfm?articleid=rwt040208182719 Intel Nehalem Review entire term by looking at most recent microprocessor from Intel Nehalem is code
Execution Cycle. Pipelining. IF and ID Stages. Simple MIPS Instruction Formats
 Execution Cycle Pipelining CSE 410, Spring 2005 Computer Systems http://www.cs.washington.edu/410 1. Instruction Fetch 2. Instruction Decode 3. Execute 4. Memory 5. Write Back IF and ID Stages 1. Instruction
Execution Cycle Pipelining CSE 410, Spring 2005 Computer Systems http://www.cs.washington.edu/410 1. Instruction Fetch 2. Instruction Decode 3. Execute 4. Memory 5. Write Back IF and ID Stages 1. Instruction
"JAGUAR AMD s Next Generation Low Power x86 Core. Jeff Rupley, AMD Fellow Chief Architect / Jaguar Core August 28, 2012
 "JAGUAR AMD s Next Generation Low Power x86 Core Jeff Rupley, AMD Fellow Chief Architect / Jaguar Core August 28, 2012 TWO X86 CORES TUNED FOR TARGET MARKETS Mainstream Client and Server Markets Bulldozer
"JAGUAR AMD s Next Generation Low Power x86 Core Jeff Rupley, AMD Fellow Chief Architect / Jaguar Core August 28, 2012 TWO X86 CORES TUNED FOR TARGET MARKETS Mainstream Client and Server Markets Bulldozer
Unit 4: Performance & Benchmarking. Performance Metrics. This Unit. CIS 501: Computer Architecture. Performance: Latency vs.
 This Unit CIS 501: Computer Architecture Unit 4: Performance & Benchmarking Metrics Latency and throughput Speedup Averaging CPU Performance Performance Pitfalls Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'Pennsylvania'
This Unit CIS 501: Computer Architecture Unit 4: Performance & Benchmarking Metrics Latency and throughput Speedup Averaging CPU Performance Performance Pitfalls Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'Pennsylvania'
Week 1 out-of-class notes, discussions and sample problems
 Week 1 out-of-class notes, discussions and sample problems Although we will primarily concentrate on RISC processors as found in some desktop/laptop computers, here we take a look at the varying types
Week 1 out-of-class notes, discussions and sample problems Although we will primarily concentrate on RISC processors as found in some desktop/laptop computers, here we take a look at the varying types
Pipeline Hazards. Arvind Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by Arvind and Krste Asanovic
 1 Pipeline Hazards Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by and Krste Asanovic 6.823 L6-2 Technology Assumptions A small amount of very fast memory
1 Pipeline Hazards Computer Science and Artificial Intelligence Laboratory M.I.T. Based on the material prepared by and Krste Asanovic 6.823 L6-2 Technology Assumptions A small amount of very fast memory
Software Pipelining by Modulo Scheduling. Philip Sweany University of North Texas
 Software Pipelining by Modulo Scheduling Philip Sweany University of North Texas Overview Opportunities for Loop Optimization Software Pipelining Modulo Scheduling Resource and Dependence Constraints Scheduling
Software Pipelining by Modulo Scheduling Philip Sweany University of North Texas Overview Opportunities for Loop Optimization Software Pipelining Modulo Scheduling Resource and Dependence Constraints Scheduling
Boosting Beyond Static Scheduling in a Superscalar Processor
 Boosting Beyond Static Scheduling in a Superscalar Processor Michael D. Smith, Monica S. Lam, and Mark A. Horowitz Computer Systems Laboratory Stanford University, Stanford CA 94305-4070 May 1990 1 Introduction
Boosting Beyond Static Scheduling in a Superscalar Processor Michael D. Smith, Monica S. Lam, and Mark A. Horowitz Computer Systems Laboratory Stanford University, Stanford CA 94305-4070 May 1990 1 Introduction
LSN 2 Computer Processors
 LSN 2 Computer Processors Department of Engineering Technology LSN 2 Computer Processors Microprocessors Design Instruction set Processor organization Processor performance Bandwidth Clock speed LSN 2
LSN 2 Computer Processors Department of Engineering Technology LSN 2 Computer Processors Microprocessors Design Instruction set Processor organization Processor performance Bandwidth Clock speed LSN 2
Coming Challenges in Microarchitecture and Architecture
 Coming Challenges in Microarchitecture and Architecture RONNY RONEN, SENIOR MEMBER, IEEE, AVI MENDELSON, MEMBER, IEEE, KONRAD LAI, SHIH-LIEN LU, MEMBER, IEEE, FRED POLLACK, AND JOHN P. SHEN, FELLOW, IEEE
Coming Challenges in Microarchitecture and Architecture RONNY RONEN, SENIOR MEMBER, IEEE, AVI MENDELSON, MEMBER, IEEE, KONRAD LAI, SHIH-LIEN LU, MEMBER, IEEE, FRED POLLACK, AND JOHN P. SHEN, FELLOW, IEEE
EE282 Computer Architecture and Organization Midterm Exam February 13, 2001. (Total Time = 120 minutes, Total Points = 100)
") EE282 Computer Architecture and Organization Midterm Exam February 13, 2001 (Total Time = 120 minutes, Total Points = 100) Name: (please print) Wolfe - Solution In recognition of and in the spirit of the
EE282 Computer Architecture and Organization Midterm Exam February 13, 2001 (Total Time = 120 minutes, Total Points = 100) Name: (please print) Wolfe - Solution In recognition of and in the spirit of the
Introduction to RISC Processor. ni logic Pvt. Ltd., Pune
 Introduction to RISC Processor ni logic Pvt. Ltd., Pune AGENDA What is RISC & its History What is meant by RISC Architecture of MIPS-R4000 Processor Difference Between RISC and CISC Pros and Cons of RISC
Introduction to RISC Processor ni logic Pvt. Ltd., Pune AGENDA What is RISC & its History What is meant by RISC Architecture of MIPS-R4000 Processor Difference Between RISC and CISC Pros and Cons of RISC
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
In the Beginning... 1964 -- The first ISA appears on the IBM System 360 In the good old days
 RISC vs CISC 66 In the Beginning... 1964 -- The first ISA appears on the IBM System 360 In the good old days Initially, the focus was on usability by humans. Lots of user-friendly instructions (remember
RISC vs CISC 66 In the Beginning... 1964 -- The first ISA appears on the IBM System 360 In the good old days Initially, the focus was on usability by humans. Lots of user-friendly instructions (remember
The Pentium 4 and the G4e: An Architectural Comparison
 The Pentium 4 and the G4e: An Architectural Comparison Part I by Jon Stokes Copyright Ars Technica, LLC 1998-2001. The following disclaimer applies to the information, trademarks, and logos contained in
The Pentium 4 and the G4e: An Architectural Comparison Part I by Jon Stokes Copyright Ars Technica, LLC 1998-2001. The following disclaimer applies to the information, trademarks, and logos contained in
Pentium vs. Power PC Computer Architecture and PCI Bus Interface
 Pentium vs. Power PC Computer Architecture and PCI Bus Interface CSE 3322 1 Pentium vs. Power PC Computer Architecture and PCI Bus Interface Nowadays, there are two major types of microprocessors in the
Pentium vs. Power PC Computer Architecture and PCI Bus Interface CSE 3322 1 Pentium vs. Power PC Computer Architecture and PCI Bus Interface Nowadays, there are two major types of microprocessors in the
Rethinking SIMD Vectorization for In-Memory Databases
 SIGMOD 215, Melbourne, Victoria, Australia Rethinking SIMD Vectorization for In-Memory Databases Orestis Polychroniou Columbia University Arun Raghavan Oracle Labs Kenneth A. Ross Columbia University Latest
SIGMOD 215, Melbourne, Victoria, Australia Rethinking SIMD Vectorization for In-Memory Databases Orestis Polychroniou Columbia University Arun Raghavan Oracle Labs Kenneth A. Ross Columbia University Latest
Processor Architectures
 ECPE 170 Jeff Shafer University of the Pacific Processor Architectures 2 Schedule Exam 3 Tuesday, December 6 th Caches Virtual Memory Input / Output OperaKng Systems Compilers & Assemblers Processor Architecture
ECPE 170 Jeff Shafer University of the Pacific Processor Architectures 2 Schedule Exam 3 Tuesday, December 6 th Caches Virtual Memory Input / Output OperaKng Systems Compilers & Assemblers Processor Architecture
Design Cycle for Microprocessors
 Cycle for Microprocessors Raúl Martínez Intel Barcelona Research Center Cursos de Verano 2010 UCLM Intel Corporation, 2010 Agenda Introduction plan Architecture Microarchitecture Logic Silicon ramp Types
Cycle for Microprocessors Raúl Martínez Intel Barcelona Research Center Cursos de Verano 2010 UCLM Intel Corporation, 2010 Agenda Introduction plan Architecture Microarchitecture Logic Silicon ramp Types
NVIDIA Tegra 4 Family CPU Architecture
 Whitepaper NVIDIA Tegra 4 Family CPU Architecture 4-PLUS-1 Quad core 1 Table of Contents... 1 Introduction... 3 NVIDIA Tegra 4 Family of Mobile Processors... 3 Benchmarking CPU Performance... 4 Tegra 4
Whitepaper NVIDIA Tegra 4 Family CPU Architecture 4-PLUS-1 Quad core 1 Table of Contents... 1 Introduction... 3 NVIDIA Tegra 4 Family of Mobile Processors... 3 Benchmarking CPU Performance... 4 Tegra 4
Lecture: Pipelining Extensions. Topics: control hazards, multi-cycle instructions, pipelining equations
 Lecture: Pipelining Extensions Topics: control hazards, multi-cycle instructions, pipelining equations 1 Problem 6 Show the instruction occupying each stage in each cycle (with bypassing) if I1 is R1+R2
Lecture: Pipelining Extensions Topics: control hazards, multi-cycle instructions, pipelining equations 1 Problem 6 Show the instruction occupying each stage in each cycle (with bypassing) if I1 is R1+R2
what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored?
 Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Introduction to Microprocessors
 Introduction to Microprocessors Yuri Baida [email protected] [email protected] October 2, 2010 Moscow Institute of Physics and Technology Agenda Background and History What is a microprocessor?
Introduction to Microprocessors Yuri Baida [email protected] [email protected] October 2, 2010 Moscow Institute of Physics and Technology Agenda Background and History What is a microprocessor?
! Metrics! Latency and throughput. ! Reporting performance! Benchmarking and averaging. ! CPU performance equation & performance trends
 This Unit CIS 501 Computer Architecture! Metrics! Latency and throughput! Reporting performance! Benchmarking and averaging Unit 2: Performance! CPU performance equation & performance trends CIS 501 (Martin/Roth):
This Unit CIS 501 Computer Architecture! Metrics! Latency and throughput! Reporting performance! Benchmarking and averaging Unit 2: Performance! CPU performance equation & performance trends CIS 501 (Martin/Roth):
High Performance Processor Architecture. André Seznec IRISA/INRIA ALF project-team
 High Performance Processor Architecture André Seznec IRISA/INRIA ALF project-team 1 2 Moore s «Law» Nb of transistors on a micro processor chip doubles every 18 months 1972: 2000 transistors (Intel 4004)
High Performance Processor Architecture André Seznec IRISA/INRIA ALF project-team 1 2 Moore s «Law» Nb of transistors on a micro processor chip doubles every 18 months 1972: 2000 transistors (Intel 4004)
Data Dependences. A data dependence occurs whenever one instruction needs a value produced by another.
 Data Hazards 1 Hazards: Key Points Hazards cause imperfect pipelining They prevent us from achieving CPI = 1 They are generally causes by counter flow data pennces in the pipeline Three kinds Structural
Data Hazards 1 Hazards: Key Points Hazards cause imperfect pipelining They prevent us from achieving CPI = 1 They are generally causes by counter flow data pennces in the pipeline Three kinds Structural
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM
 ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM 1 The ARM architecture processors popular in Mobile phone systems 2 ARM Features ARM has 32-bit architecture but supports 16 bit
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-12: ARM 1 The ARM architecture processors popular in Mobile phone systems 2 ARM Features ARM has 32-bit architecture but supports 16 bit
Five Families of ARM Processor IP
 ARM1026EJ-S Synthesizable ARM10E Family Processor Core Eric Schorn CPU Product Manager ARM Austin Design Center Five Families of ARM Processor IP Performance ARM preserves SW & HW investment through code
ARM1026EJ-S Synthesizable ARM10E Family Processor Core Eric Schorn CPU Product Manager ARM Austin Design Center Five Families of ARM Processor IP Performance ARM preserves SW & HW investment through code
Instruction Set Architecture (ISA)
") Instruction Set Architecture (ISA) * Instruction set architecture of a machine fills the semantic gap between the user and the machine. * ISA serves as the starting point for the design of a new machine
Instruction Set Architecture (ISA) * Instruction set architecture of a machine fills the semantic gap between the user and the machine. * ISA serves as the starting point for the design of a new machine
ARM Microprocessor and ARM-Based Microcontrollers
 ARM Microprocessor and ARM-Based Microcontrollers Nguatem William 24th May 2006 A Microcontroller-Based Embedded System Roadmap 1 Introduction ARM ARM Basics 2 ARM Extensions Thumb Jazelle NEON & DSP Enhancement
ARM Microprocessor and ARM-Based Microcontrollers Nguatem William 24th May 2006 A Microcontroller-Based Embedded System Roadmap 1 Introduction ARM ARM Basics 2 ARM Extensions Thumb Jazelle NEON & DSP Enhancement
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING
 COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
Multi-core architectures. Jernej Barbic 15-213, Spring 2007 May 3, 2007
 Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Pipeline Hazards. Structure hazard Data hazard. ComputerArchitecture_PipelineHazard1
 Pipeline Hazards Structure hazard Data hazard Pipeline hazard: the major hurdle A hazard is a condition that prevents an instruction in the pipe from executing its next scheduled pipe stage Taxonomy of
Pipeline Hazards Structure hazard Data hazard Pipeline hazard: the major hurdle A hazard is a condition that prevents an instruction in the pipe from executing its next scheduled pipe stage Taxonomy of
Chapter 5 Instructor's Manual
 The Essentials of Computer Organization and Architecture Linda Null and Julia Lobur Jones and Bartlett Publishers, 2003 Chapter 5 Instructor's Manual Chapter Objectives Chapter 5, A Closer Look at Instruction
The Essentials of Computer Organization and Architecture Linda Null and Julia Lobur Jones and Bartlett Publishers, 2003 Chapter 5 Instructor's Manual Chapter Objectives Chapter 5, A Closer Look at Instruction
Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University [email protected].
 Chih Wei Liu 劉 志 尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.") Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University [email protected] Review Computers in mid 50 s Hardware was expensive
Computer Architecture Lecture 2: Instruction Set Principles (Appendix A) Chih Wei Liu 劉 志 尉 National Chiao Tung University [email protected] Review Computers in mid 50 s Hardware was expensive
Using Power to Improve C Programming Education
 Using Power to Improve C Programming Education Jonas Skeppstedt Department of Computer Science Lund University Lund, Sweden [email protected] jonasskeppstedt.net jonasskeppstedt.net [email protected]
Using Power to Improve C Programming Education Jonas Skeppstedt Department of Computer Science Lund University Lund, Sweden [email protected] jonasskeppstedt.net jonasskeppstedt.net [email protected]
Wiggins/Redstone: An On-line Program Specializer
 Wiggins/Redstone: An On-line Program Specializer Dean Deaver Rick Gorton Norm Rubin {dean.deaver,rick.gorton,norm.rubin}@compaq.com Hot Chips 11 Wiggins/Redstone 1 W/R is a Software System That: u Makes
Wiggins/Redstone: An On-line Program Specializer Dean Deaver Rick Gorton Norm Rubin {dean.deaver,rick.gorton,norm.rubin}@compaq.com Hot Chips 11 Wiggins/Redstone 1 W/R is a Software System That: u Makes
İSTANBUL AYDIN UNIVERSITY
 İSTANBUL AYDIN UNIVERSITY FACULTY OF ENGİNEERİNG SOFTWARE ENGINEERING THE PROJECT OF THE INSTRUCTION SET COMPUTER ORGANIZATION GÖZDE ARAS B1205.090015 Instructor: Prof. Dr. HASAN HÜSEYİN BALIK DECEMBER
İSTANBUL AYDIN UNIVERSITY FACULTY OF ENGİNEERİNG SOFTWARE ENGINEERING THE PROJECT OF THE INSTRUCTION SET COMPUTER ORGANIZATION GÖZDE ARAS B1205.090015 Instructor: Prof. Dr. HASAN HÜSEYİN BALIK DECEMBER
Comparative Performance Review of SHA-3 Candidates
 Comparative Performance Review of the SHA-3 Second-Round Candidates Cryptolog International Second SHA-3 Candidate Conference Outline sphlib sphlib sphlib is an open-source implementation of many hash
Comparative Performance Review of the SHA-3 Second-Round Candidates Cryptolog International Second SHA-3 Candidate Conference Outline sphlib sphlib sphlib is an open-source implementation of many hash
Lecture 17: Virtual Memory II. Goals of virtual memory
 Lecture 17: Virtual Memory II Last Lecture: Introduction to virtual memory Today Review and continue virtual memory discussion Lecture 17 1 Goals of virtual memory Make it appear as if each process has:
Lecture 17: Virtual Memory II Last Lecture: Introduction to virtual memory Today Review and continue virtual memory discussion Lecture 17 1 Goals of virtual memory Make it appear as if each process has:
Computer Organization and Architecture. Characteristics of Memory Systems. Chapter 4 Cache Memory. Location CPU Registers and control unit memory
 Computer Organization and Architecture Chapter 4 Cache Memory Characteristics of Memory Systems Note: Appendix 4A will not be covered in class, but the material is interesting reading and may be used in
Computer Organization and Architecture Chapter 4 Cache Memory Characteristics of Memory Systems Note: Appendix 4A will not be covered in class, but the material is interesting reading and may be used in
A Survey on ARM Cortex A Processors. Wei Wang Tanima Dey
 A Survey on ARM Cortex A Processors Wei Wang Tanima Dey 1 Overview of ARM Processors Focusing on Cortex A9 & Cortex A15 ARM ships no processors but only IP cores For SoC integration Targeting markets:
A Survey on ARM Cortex A Processors Wei Wang Tanima Dey 1 Overview of ARM Processors Focusing on Cortex A9 & Cortex A15 ARM ships no processors but only IP cores For SoC integration Targeting markets:
Putting Checkpoints to Work in Thread Level Speculative Execution
 Putting Checkpoints to Work in Thread Level Speculative Execution Salman Khan E H U N I V E R S I T Y T O H F G R E D I N B U Doctor of Philosophy Institute of Computing Systems Architecture School of
Putting Checkpoints to Work in Thread Level Speculative Execution Salman Khan E H U N I V E R S I T Y T O H F G R E D I N B U Doctor of Philosophy Institute of Computing Systems Architecture School of
Vector Architectures
 EE482C: Advanced Computer Organization Lecture #11 Stream Processor Architecture Stanford University Thursday, 9 May 2002 Lecture #11: Thursday, 9 May 2002 Lecturer: Prof. Bill Dally Scribe: James Bonanno
EE482C: Advanced Computer Organization Lecture #11 Stream Processor Architecture Stanford University Thursday, 9 May 2002 Lecture #11: Thursday, 9 May 2002 Lecturer: Prof. Bill Dally Scribe: James Bonanno
Performance Impacts of Non-blocking Caches in Out-of-order Processors
 Performance Impacts of Non-blocking Caches in Out-of-order Processors Sheng Li; Ke Chen; Jay B. Brockman; Norman P. Jouppi HP Laboratories HPL-2011-65 Keyword(s): Non-blocking cache; MSHR; Out-of-order
Performance Impacts of Non-blocking Caches in Out-of-order Processors Sheng Li; Ke Chen; Jay B. Brockman; Norman P. Jouppi HP Laboratories HPL-2011-65 Keyword(s): Non-blocking cache; MSHR; Out-of-order
Categories and Subject Descriptors C.1.1 [Processor Architecture]: Single Data Stream Architectures. General Terms Performance, Design.
![Categories and Subject Descriptors C.1.1 [Processor Architecture]: Single Data Stream Architectures. General Terms Performance, Design.](/thumbs/29/13762795.jpg "Categories and Subject Descriptors C.1.1 [Processor Architecture]: Single Data Stream Architectures. General Terms Performance, Design.") Enhancing Memory Level Parallelism via Recovery-Free Value Prediction Huiyang Zhou Thomas M. Conte Department of Electrical and Computer Engineering North Carolina State University 1-919-513-2014 {hzhou,
Enhancing Memory Level Parallelism via Recovery-Free Value Prediction Huiyang Zhou Thomas M. Conte Department of Electrical and Computer Engineering North Carolina State University 1-919-513-2014 {hzhou,
A Predictive Model for Cache-Based Side Channels in Multicore and Multithreaded Microprocessors
 A Predictive Model for Cache-Based Side Channels in Multicore and Multithreaded Microprocessors Leonid Domnitser, Nael Abu-Ghazaleh and Dmitry Ponomarev Department of Computer Science SUNY-Binghamton {lenny,
A Predictive Model for Cache-Based Side Channels in Multicore and Multithreaded Microprocessors Leonid Domnitser, Nael Abu-Ghazaleh and Dmitry Ponomarev Department of Computer Science SUNY-Binghamton {lenny,