Caches (Writing) P & H Chapter 5.2-3, 5.5. Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University
|
|
|
- Jemimah Rosamund Atkinson
- 7 years ago
- Views:
Transcription
1 Caches (Writing) P & H Chapter 5.2-3, 5.5 Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University
2 Goals for Today: caches Writing to the Cache Write-through vs Write-back Cache Parameter Tradeoffs Cache Conscious Programming
3 Writing with Caches
4 Eviction Which cache line should be evicted from the cache to make room for a new line? Direct-mapped no choice, must evict line selected by index Associative caches random: select one of the lines at random round-robin: similar to random FIFO: replace oldest line LRU: replace line that has not been used in the longest time
5 Next Goal What about writes? What happens when the CPU writes to a register and calls a store instruction?!
6 Cached Write Policies Q: How to write data? CPU addr data Cache Memory SRAM DRAM If data is already in the cache No-Write writes invalidate the cache and go directly to memory Write-Through writes go to main memory and cache Write-Back CPU writes only to cache cache writes to main memory later (when block is evicted)
7 What about Stores? Where should you write the result of a store? If that memory location is in the cache? Send it to the cache Should we also send it to memory right away? (write-through policy) Wait until we kick the block out (write-back policy) If it is not in the cache? Allocate the line (put it in the cache)? (write allocate policy) Write it directly to memory without allocation? (no write allocate policy)
8 Write Allocation Policies Q: How to write data? CPU addr data Cache Memory SRAM DRAM If data is not in the cache Write-Allocate allocate a cache line for new data (and maybe write-through) No-Write-Allocate ignore cache, just go to main memory
9 Next Goal Example: How does a write-through cache work? Assume write-allocate.
10 Handling Stores (Write-Through) Using byte addresses in this example! Addr Bus = 5 bits Processor Assume write-allocate policy LB $1 M[ 1 ] LB $2 M[ 7 ] SB $2 M[ 0 ] SB $1 M[ 5 ] LB $2 M[ 10 ] SB $1 M[ 5 ] SB $1 M[ 10 ] $0 $1 $2 $3 Cache Fully Associative Cache 2 cache lines 2 word block 4 bit tag field 1 bit block offset field V tag data 0 0 Misses: 0 Hits: Memory
11 Write-Through (REF 1) Processor Cache Memory LB $1 M[ 1 ] LB $2 M[ 7 ] SB $2 M[ 0 ] SB $1 M[ 5 ] LB $2 M[ 10 ] SB $1 M[ 5 ] SB $1 M[ 10 ] $0 $1 $2 $3 V tag data 0 0 Misses: 0 Hits:
12 How Many Memory References? Write-through performance Each miss (read or write) reads a block from mem Each store writes an item to mem Evictions don t need to write to mem
13 Takeaway A cache with a write-through policy (and writeallocate) reads an entire block (cacheline) from memory on a cache miss and writes only the updated item to memory for a store. Evictions do not need to write to memory.
14 Next Goal Can we also design the cache NOT write all stores immediately to memory? Keep the most current copy in cache, and update memory when that data is evicted (write-back policy)
15 Write-Back Meta-Data V D Tag Byte 1 Byte 2 Byte N V = 1 means the line has valid data D = 1 means the bytes are newer than main memory When allocating line: Set V = 1, D = 0, fill in Tag and Data When writing line: Set D = 1 When evicting line: If D = 0: just set V = 0 If D = 1: write-back Data, then set D = 0, V = 0
16 Write-back Example Example: How does a write-back cache work? Assume write-allocate.
17 Handling Stores (Write-Back) Using byte addresses in this example! Addr Bus = 5 bits Processor Assume write-allocate policy LB $1 M[ 1 ] LB $2 M[ 7 ] SB $2 M[ 0 ] SB $1 M[ 5 ] LB $2 M[ 10 ] SB $1 M[ 5 ] SB $1 M[ 10 ] $0 $1 $2 $3 Cache Fully Associative Cache 2 cache lines 2 word block 3 bit tag field 1 bit block offset field V d tag data 0 0 Misses: 0 Hits: Memory
18 Write-Back (REF 1) Processor Cache Memory LB $1 M[ 1 ] LB $2 M[ 7 ] SB $2 M[ 0 ] SB $1 M[ 5 ] LB $2 M[ 10 ] SB $1 M[ 5 ] SB $1 M[ 10 ] $0 $1 $2 $3 0 0 V d tag data Misses: 0 Hits:
19 How Many Memory References? Write-back performance Each miss (read or write) reads a block from mem Some evictions write a block to mem
20 How Many Memory references? Each miss reads a block Two words in this cache Each evicted dirty cache line writes a block
21 Write-through vs. Write-back Write-through is slower But cleaner (memory always consistent) Write-back is faster But complicated when multi cores sharing memory
22 Takeaway A cache with a write-through policy (and writeallocate) reads an entire block (cacheline) from memory on a cache miss and writes only the updated item to memory for a store. Evictions do not need to write to memory. A cache with a write-back policy (and write-allocate) reads an entire block (cacheline) from memory on a cache miss, may need to write dirty cacheline first. Any writes to memory need to be the entire cacheline since no way to distinguish which word was dirty with only a single dirty bit. Evictions of a dirty cacheline cause a write to memory.
23 Next Goal What are other performance tradeoffs between write-through and write-back? How can we further reduce penalty for cost of writes to memory?
24 Performance: An Example Performance: Write-back versus Write-through Assume: large associative cache, 16-byte lines for (i=1; i<n; i++) A[0] += A[i]; for (i=0; i<n; i++) B[i] = A[i]
25 Performance Tradeoffs Q: Hit time: write-through vs. write-back? Q: Miss penalty: write-through vs. write-back?
26 Write Buffering Q: Writes to main memory are slow! A: Use a write-back buffer A small queue holding dirty lines Add to end upon eviction Remove from front upon completion Q: What does it help? A: short bursts of writes (but not sustained writes) A: fast eviction reduces miss penalty
27 Write-through vs. Write-back Write-through is slower But simpler (memory always consistent) Write-back is almost always faster write-back buffer hides large eviction cost But what about multiple cores with separate caches but sharing memory? Write-back requires a cache coherency protocol Inconsistent views of memory Need to snoop in each other s caches Extremely complex protocols, very hard to get right
28 Cache-coherency Q: Multiple readers and writers? A: Potentially inconsistent views of memory net A A A A CPU L1 L1 A L2 CPU L1 L1 Mem CPU L1 L1 L2 CPU L1 L1 disk Cache coherency protocol May need to snoop on other CPU s cache activity Invalidate cache line when other CPU writes Flush write-back caches before other CPU reads Or the reverse: Before writing/reading Extremely complex protocols, very hard to get right
29 Takeaway A cache with a write-through policy (and write-allocate) reads an entire block (cacheline) from memory on a cache miss and writes only the updated item to memory for a store. Evictions do not need to write to memory. A cache with a write-back policy (and write-allocate) reads an entire block (cacheline) from memory on a cache miss, may need to write dirty cacheline first. Any writes to memory need to be the entire cacheline since no way to distinguish which word was dirty with only a single dirty bit. Evictions of a dirty cacheline cause a write to memory. Write-through is slower, but simpler (memory always consistent)/ Write-back is almost always faster (a write-back buffer can hidee large eviction cost), but will need a coherency protocol to maintain consistency will all levels of cache and memory.
30 Cache Design Tradeoffs
31 Cache Design Need to determine parameters: Cache size Block size (aka line size) Number of ways of set-associativity (1, N, ) Eviction policy Number of levels of caching, parameters for each Separate I-cache from D-cache, or Unified cache Prefetching policies / instructions Write policy
32 A Real Example > dmidecode -t cache Cache Information Configuration: Enabled, Not Socketed, Level 1 Operational Mode: Write Back Installed Size: 128 KB Error Correction Type: None Cache Information Configuration: Enabled, Not Socketed, Level 2 Operational Mode: Varies With Memory Address Installed Size: 6144 KB Error Correction Type: Single-bit ECC > cd /sys/devices/system/cpu/cpu0; grep cache/*/* cache/index0/level:1 cache/index0/type:data cache/index0/ways_of_associativity:8 cache/index0/number_of_sets:64 cache/index0/coherency_line_size:64 cache/index0/size:32k cache/index1/level:1 cache/index1/type:instruction cache/index1/ways_of_associativity:8 cache/index1/number_of_sets:64 cache/index1/coherency_line_size:64 cache/index1/size:32k cache/index2/level:2 cache/index2/type:unified cache/index2/shared_cpu_list:0-1 cache/index2/ways_of_associativity:24 cache/index2/number_of_sets:4096 cache/index2/coherency_line_size:64 cache/index2/size:6144k Dual-core 3.16GHz Intel (purchased in 2011)
33 A Real Example Dual 32K L1 Instruction caches 8-way set associative 64 sets 64 byte line size Dual 32K L1 Data caches Same as above Single 6M L2 Unified cache 24-way set associative (!!!) 4096 sets 64 byte line size 4GB Main memory 1TB Disk Dual-core 3.16GHz Intel (purchased in 2009)
34 Basic Cache Organization Q: How to decide block size?
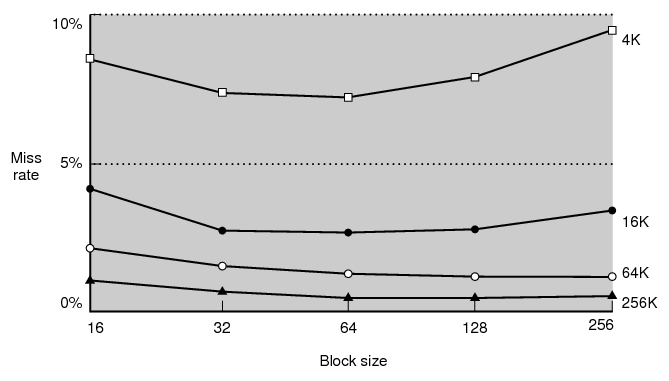
35 Experimental Results
36 Tradeoffs For a given total cache size, larger block sizes mean. fewer lines so fewer tags (and smaller tags for associative caches) so less overhead and fewer cold misses (within-block prefetching ) But also fewer blocks available (for scattered accesses!) so more conflicts and larger miss penalty (time to fetch block)
37 Cache Conscious Programming
38 Cache Conscious Programming // H = 12, W = 10 int A[H][W]; for(x=0; x < W; x++) for(y=0; y < H; y++) sum += A[y][x];
39 Cache Conscious Programming // H = 12, W = 10 int A[H][W]; for(y=0; y < H; y++) for(x=0; x < W; x++) sum += A[y][x];
40 Summary Caching assumptions small working set: 90/10 rule can predict future: spatial & temporal locality Benefits (big & fast) built from (big & slow) + (small & fast) Tradeoffs: associativity, line size, hit cost, miss penalty, hit rate
41 Summary Memory performance matters! often more than CPU performance because it is the bottleneck, and not improving much because most programs move a LOT of data Design space is huge Gambling against program behavior Cuts across all layers: users programs os hardware Multi-core / Multi-Processor is complicated Inconsistent views of memory Extremely complex protocols, very hard to get right
42 Administrivia Prelim1: TODAY, Thursday, March 28 th in evening Time: We will start at 7:30pm sharp, so come early Two Location: PHL101 and UPSB17 If NetID ends with even number, then go to PHL101 (Phillips Hall rm 101) If NetID ends with odd number, then go to UPSB17 (Upson Hall rm B17) Closed Book: NO NOTES, BOOK, ELECTRONICS, CALCULATOR, CELL PHONE Practice prelims are online in CMS Material covered everything up to end of week before spring break Lecture: Lectures 9 to 16 (new since last prelim) Chapter 4: Chapters 4.7 (Data Hazards) and 4.8 (Control Hazards) Chapter 2: Chapter 2.8 and 2.12 (Calling Convention and Linkers), 2.16 and 2.17 (RISC and CISC) Appendix B: B.1 and B.2 (Assemblers), B.3 and B.4 (linkers and loaders), and B.5 and B.6 (Calling Convention and process memory layout) Chapter 5: 5.1 and 5.2 (Caches) HW3, Project1 and Project2
43 Next six weeks Administrivia Week 9 (Mar 25): Prelim2 Week 10 (Apr 1): Project2 due and Lab3 handout Week 11 (Apr 8): Lab3 due and Project3/HW4 handout Week 12 (Apr 15): Project3 design doc due and HW4 due Week 13 (Apr 22): Project3 due and Prelim3 Week 14 (Apr 29): Project4 handout Final Project for class Week 15 (May 6): Project4 design doc due Week 16 (May 13): Project4 due
The Quest for Speed - Memory. Cache Memory. A Solution: Memory Hierarchy. Memory Hierarchy
 The Quest for Speed - Memory Cache Memory CSE 4, Spring 25 Computer Systems http://www.cs.washington.edu/4 If all memory accesses (IF/lw/sw) accessed main memory, programs would run 20 times slower And
The Quest for Speed - Memory Cache Memory CSE 4, Spring 25 Computer Systems http://www.cs.washington.edu/4 If all memory accesses (IF/lw/sw) accessed main memory, programs would run 20 times slower And
361 Computer Architecture Lecture 14: Cache Memory
 1 361 Computer Architecture Lecture 14 Memory cache.1 The Motivation for s Memory System Processor DRAM Motivation Large memories (DRAM) are slow Small memories (SRAM) are fast Make the average access
1 361 Computer Architecture Lecture 14 Memory cache.1 The Motivation for s Memory System Processor DRAM Motivation Large memories (DRAM) are slow Small memories (SRAM) are fast Make the average access
CS/COE1541: Introduction to Computer Architecture. Memory hierarchy. Sangyeun Cho. Computer Science Department University of Pittsburgh
 CS/COE1541: Introduction to Computer Architecture Memory hierarchy Sangyeun Cho Computer Science Department CPU clock rate Apple II MOS 6502 (1975) 1~2MHz Original IBM PC (1981) Intel 8080 4.77MHz Intel
CS/COE1541: Introduction to Computer Architecture Memory hierarchy Sangyeun Cho Computer Science Department CPU clock rate Apple II MOS 6502 (1975) 1~2MHz Original IBM PC (1981) Intel 8080 4.77MHz Intel
Lecture 17: Virtual Memory II. Goals of virtual memory
 Lecture 17: Virtual Memory II Last Lecture: Introduction to virtual memory Today Review and continue virtual memory discussion Lecture 17 1 Goals of virtual memory Make it appear as if each process has:
Lecture 17: Virtual Memory II Last Lecture: Introduction to virtual memory Today Review and continue virtual memory discussion Lecture 17 1 Goals of virtual memory Make it appear as if each process has:
Homework # 2. Solutions. 4.1 What are the differences among sequential access, direct access, and random access?
 ECE337 / CS341, Fall 2005 Introduction to Computer Architecture and Organization Instructor: Victor Manuel Murray Herrera Date assigned: 09/19/05, 05:00 PM Due back: 09/30/05, 8:00 AM Homework # 2 Solutions
ECE337 / CS341, Fall 2005 Introduction to Computer Architecture and Organization Instructor: Victor Manuel Murray Herrera Date assigned: 09/19/05, 05:00 PM Due back: 09/30/05, 8:00 AM Homework # 2 Solutions
Memory ICS 233. Computer Architecture and Assembly Language Prof. Muhamed Mudawar
 Memory ICS 233 Computer Architecture and Assembly Language Prof. Muhamed Mudawar College of Computer Sciences and Engineering King Fahd University of Petroleum and Minerals Presentation Outline Random
Memory ICS 233 Computer Architecture and Assembly Language Prof. Muhamed Mudawar College of Computer Sciences and Engineering King Fahd University of Petroleum and Minerals Presentation Outline Random
Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat
 Rik van Riel Sr. Software Engineer, Red Hat") Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat Why Computers Are Getting Slower The traditional approach better performance Why computers are
Why Computers Are Getting Slower (and what we can do about it) Rik van Riel Sr. Software Engineer, Red Hat Why Computers Are Getting Slower The traditional approach better performance Why computers are
Outline. Cache Parameters. Lecture 5 Cache Operation
 Lecture Cache Operation ECE / Fall Edward F. Gehringer Based on notes by Drs. Eric Rotenberg & Tom Conte of NCSU Outline Review of cache parameters Example of operation of a direct-mapped cache. Example
Lecture Cache Operation ECE / Fall Edward F. Gehringer Based on notes by Drs. Eric Rotenberg & Tom Conte of NCSU Outline Review of cache parameters Example of operation of a direct-mapped cache. Example
Computer Architecture
 Cache Memory Gábor Horváth 2016. április 27. Budapest associate professor BUTE Dept. Of Networked Systems and Services ghorvath@hit.bme.hu It is the memory,... The memory is a serious bottleneck of Neumann
Cache Memory Gábor Horváth 2016. április 27. Budapest associate professor BUTE Dept. Of Networked Systems and Services ghorvath@hit.bme.hu It is the memory,... The memory is a serious bottleneck of Neumann
COMPUTER HARDWARE. Input- Output and Communication Memory Systems
 COMPUTER HARDWARE Input- Output and Communication Memory Systems Computer I/O I/O devices commonly found in Computer systems Keyboards Displays Printers Magnetic Drives Compact disk read only memory (CD-ROM)
COMPUTER HARDWARE Input- Output and Communication Memory Systems Computer I/O I/O devices commonly found in Computer systems Keyboards Displays Printers Magnetic Drives Compact disk read only memory (CD-ROM)
CS 61C: Great Ideas in Computer Architecture Virtual Memory Cont.
 CS 61C: Great Ideas in Computer Architecture Virtual Memory Cont. Instructors: Vladimir Stojanovic & Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/ 1 Bare 5-Stage Pipeline Physical Address PC Inst.
CS 61C: Great Ideas in Computer Architecture Virtual Memory Cont. Instructors: Vladimir Stojanovic & Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/ 1 Bare 5-Stage Pipeline Physical Address PC Inst.
Computer Organization and Architecture. Characteristics of Memory Systems. Chapter 4 Cache Memory. Location CPU Registers and control unit memory
 Computer Organization and Architecture Chapter 4 Cache Memory Characteristics of Memory Systems Note: Appendix 4A will not be covered in class, but the material is interesting reading and may be used in
Computer Organization and Architecture Chapter 4 Cache Memory Characteristics of Memory Systems Note: Appendix 4A will not be covered in class, but the material is interesting reading and may be used in
CSE 160 Lecture 5. The Memory Hierarchy False Sharing Cache Coherence and Consistency. Scott B. Baden
 CSE 160 Lecture 5 The Memory Hierarchy False Sharing Cache Coherence and Consistency Scott B. Baden Using Bang coming down the home stretch Do not use Bang s front end for running mergesort Use batch,
CSE 160 Lecture 5 The Memory Hierarchy False Sharing Cache Coherence and Consistency Scott B. Baden Using Bang coming down the home stretch Do not use Bang s front end for running mergesort Use batch,
The Big Picture. Cache Memory CSE 675.02. Memory Hierarchy (1/3) Disk
 Disk") The Big Picture Cache Memory CSE 5.2 Computer Processor Memory (active) (passive) Control (where ( brain ) programs, Datapath data live ( brawn ) when running) Devices Input Output Keyboard, Mouse Disk,
The Big Picture Cache Memory CSE 5.2 Computer Processor Memory (active) (passive) Control (where ( brain ) programs, Datapath data live ( brawn ) when running) Devices Input Output Keyboard, Mouse Disk,
Virtual Memory. How is it possible for each process to have contiguous addresses and so many of them? A System Using Virtual Addressing
 How is it possible for each process to have contiguous addresses and so many of them? Computer Systems Organization (Spring ) CSCI-UA, Section Instructor: Joanna Klukowska Teaching Assistants: Paige Connelly
How is it possible for each process to have contiguous addresses and so many of them? Computer Systems Organization (Spring ) CSCI-UA, Section Instructor: Joanna Klukowska Teaching Assistants: Paige Connelly
Parallel Processing and Software Performance. Lukáš Marek
 Parallel Processing and Software Performance Lukáš Marek DISTRIBUTED SYSTEMS RESEARCH GROUP http://dsrg.mff.cuni.cz CHARLES UNIVERSITY PRAGUE Faculty of Mathematics and Physics Benchmarking in parallel
Parallel Processing and Software Performance Lukáš Marek DISTRIBUTED SYSTEMS RESEARCH GROUP http://dsrg.mff.cuni.cz CHARLES UNIVERSITY PRAGUE Faculty of Mathematics and Physics Benchmarking in parallel
14.1 Rent-or-buy problem
 CS787: Advanced Algorithms Lecture 14: Online algorithms We now shift focus to a different kind of algorithmic problem where we need to perform some optimization without knowing the input in advance. Algorithms
CS787: Advanced Algorithms Lecture 14: Online algorithms We now shift focus to a different kind of algorithmic problem where we need to perform some optimization without knowing the input in advance. Algorithms
Bindel, Spring 2010 Applications of Parallel Computers (CS 5220) Week 1: Wednesday, Jan 27
 Week 1: Wednesday, Jan 27") Logistics Week 1: Wednesday, Jan 27 Because of overcrowding, we will be changing to a new room on Monday (Snee 1120). Accounts on the class cluster (crocus.csuglab.cornell.edu) will be available next week.
Logistics Week 1: Wednesday, Jan 27 Because of overcrowding, we will be changing to a new room on Monday (Snee 1120). Accounts on the class cluster (crocus.csuglab.cornell.edu) will be available next week.
Using Synology SSD Technology to Enhance System Performance Synology Inc.
 Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_SSD_Cache_WP_ 20140512 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges...
Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_SSD_Cache_WP_ 20140512 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges...
This Unit: Caches. CIS 501 Introduction to Computer Architecture. Motivation. Types of Memory
 This Unit: Caches CIS 5 Introduction to Computer Architecture Unit 3: Storage Hierarchy I: Caches Application OS Compiler Firmware CPU I/O Memory Digital Circuits Gates & Transistors Memory hierarchy concepts
This Unit: Caches CIS 5 Introduction to Computer Architecture Unit 3: Storage Hierarchy I: Caches Application OS Compiler Firmware CPU I/O Memory Digital Circuits Gates & Transistors Memory hierarchy concepts
Secondary Storage. Any modern computer system will incorporate (at least) two levels of storage: magnetic disk/optical devices/tape systems
 two levels of storage: magnetic disk/optical devices/tape systems") 1 Any modern computer system will incorporate (at least) two levels of storage: primary storage: typical capacity cost per MB $3. typical access time burst transfer rate?? secondary storage: typical capacity
1 Any modern computer system will incorporate (at least) two levels of storage: primary storage: typical capacity cost per MB $3. typical access time burst transfer rate?? secondary storage: typical capacity
COS 318: Operating Systems. Virtual Memory and Address Translation
 COS 318: Operating Systems Virtual Memory and Address Translation Today s Topics Midterm Results Virtual Memory Virtualization Protection Address Translation Base and bound Segmentation Paging Translation
COS 318: Operating Systems Virtual Memory and Address Translation Today s Topics Midterm Results Virtual Memory Virtualization Protection Address Translation Base and bound Segmentation Paging Translation
18-548/15-548 Associativity 9/16/98. 7 Associativity. 18-548/15-548 Memory System Architecture Philip Koopman September 16, 1998
 7 Associativity 18-548/15-548 Memory System Architecture Philip Koopman September 16, 1998 Required Reading: Cragon pg. 166-174 Assignments By next class read about data management policies: Cragon 2.2.4-2.2.6,
7 Associativity 18-548/15-548 Memory System Architecture Philip Koopman September 16, 1998 Required Reading: Cragon pg. 166-174 Assignments By next class read about data management policies: Cragon 2.2.4-2.2.6,
Multi-core architectures. Jernej Barbic 15-213, Spring 2007 May 3, 2007
 Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Intel P6 Systemprogrammering 2007 Föreläsning 5 P6/Linux Memory System
 Intel P6 Systemprogrammering 07 Föreläsning 5 P6/Linux ory System Topics P6 address translation Linux memory management Linux page fault handling memory mapping Internal Designation for Successor to Pentium
Intel P6 Systemprogrammering 07 Föreläsning 5 P6/Linux ory System Topics P6 address translation Linux memory management Linux page fault handling memory mapping Internal Designation for Successor to Pentium
Slide Set 8. for ENCM 369 Winter 2015 Lecture Section 01. Steve Norman, PhD, PEng
 Slide Set 8 for ENCM 369 Winter 2015 Lecture Section 01 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary Winter Term, 2015 ENCM 369 W15 Section
Slide Set 8 for ENCM 369 Winter 2015 Lecture Section 01 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary Winter Term, 2015 ENCM 369 W15 Section
Chapter 1 Computer System Overview
 Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
In-Memory Databases Algorithms and Data Structures on Modern Hardware. Martin Faust David Schwalb Jens Krüger Jürgen Müller
 In-Memory Databases Algorithms and Data Structures on Modern Hardware Martin Faust David Schwalb Jens Krüger Jürgen Müller The Free Lunch Is Over 2 Number of transistors per CPU increases Clock frequency
In-Memory Databases Algorithms and Data Structures on Modern Hardware Martin Faust David Schwalb Jens Krüger Jürgen Müller The Free Lunch Is Over 2 Number of transistors per CPU increases Clock frequency
Chapter 12: Multiprocessor Architectures. Lesson 09: Cache Coherence Problem and Cache synchronization solutions Part 1
 Chapter 12: Multiprocessor Architectures Lesson 09: Cache Coherence Problem and Cache synchronization solutions Part 1 Objective To understand cache coherence problem To learn the methods used to solve
Chapter 12: Multiprocessor Architectures Lesson 09: Cache Coherence Problem and Cache synchronization solutions Part 1 Objective To understand cache coherence problem To learn the methods used to solve
Virtual vs Physical Addresses
 Virtual vs Physical Addresses Physical addresses refer to hardware addresses of physical memory. Virtual addresses refer to the virtual store viewed by the process. virtual addresses might be the same
Virtual vs Physical Addresses Physical addresses refer to hardware addresses of physical memory. Virtual addresses refer to the virtual store viewed by the process. virtual addresses might be the same
CISC, RISC, and DSP Microprocessors
 CISC, RISC, and DSP Microprocessors Douglas L. Jones ECE 497 Spring 2000 4/6/00 CISC, RISC, and DSP D.L. Jones 1 Outline Microprocessors circa 1984 RISC vs. CISC Microprocessors circa 1999 Perspective:
CISC, RISC, and DSP Microprocessors Douglas L. Jones ECE 497 Spring 2000 4/6/00 CISC, RISC, and DSP D.L. Jones 1 Outline Microprocessors circa 1984 RISC vs. CISC Microprocessors circa 1999 Perspective:
Discussion Session 9. CS/ECE 552 Ramkumar Ravi 26 Mar 2012
 Discussion Session 9 CS/ECE 55 Ramkumar Ravi 6 Mar CS/ECE 55, Spring Mark your calendar IMPORTANT DATES TODAY 4/ Spring break 4/ HW5 due 4/ Project Demo HW5 discussion Error in mem_system_randbench.v (will
Discussion Session 9 CS/ECE 55 Ramkumar Ravi 6 Mar CS/ECE 55, Spring Mark your calendar IMPORTANT DATES TODAY 4/ Spring break 4/ HW5 due 4/ Project Demo HW5 discussion Error in mem_system_randbench.v (will
Chapter 2 Basic Structure of Computers. Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan
 Chapter 2 Basic Structure of Computers Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Functional Units Basic Operational Concepts Bus Structures Software
Chapter 2 Basic Structure of Computers Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Functional Units Basic Operational Concepts Bus Structures Software
Introduction Disks RAID Tertiary storage. Mass Storage. CMSC 412, University of Maryland. Guest lecturer: David Hovemeyer.
 Guest lecturer: David Hovemeyer November 15, 2004 The memory hierarchy Red = Level Access time Capacity Features Registers nanoseconds 100s of bytes fixed Cache nanoseconds 1-2 MB fixed RAM nanoseconds
Guest lecturer: David Hovemeyer November 15, 2004 The memory hierarchy Red = Level Access time Capacity Features Registers nanoseconds 100s of bytes fixed Cache nanoseconds 1-2 MB fixed RAM nanoseconds
Chapter 11 I/O Management and Disk Scheduling
 Operating Systems: Internals and Design Principles, 6/E William Stallings Chapter 11 I/O Management and Disk Scheduling Dave Bremer Otago Polytechnic, NZ 2008, Prentice Hall I/O Devices Roadmap Organization
Operating Systems: Internals and Design Principles, 6/E William Stallings Chapter 11 I/O Management and Disk Scheduling Dave Bremer Otago Polytechnic, NZ 2008, Prentice Hall I/O Devices Roadmap Organization
Price/performance Modern Memory Hierarchy
 Lecture 21: Storage Administration Take QUIZ 15 over P&H 6.1-4, 6.8-9 before 11:59pm today Project: Cache Simulator, Due April 29, 2010 NEW OFFICE HOUR TIME: Tuesday 1-2, McKinley Last Time Exam discussion
Lecture 21: Storage Administration Take QUIZ 15 over P&H 6.1-4, 6.8-9 before 11:59pm today Project: Cache Simulator, Due April 29, 2010 NEW OFFICE HOUR TIME: Tuesday 1-2, McKinley Last Time Exam discussion
Main Memory. Memories. Hauptspeicher. SIMM: single inline memory module 72 Pins. DIMM: dual inline memory module 168 Pins
 23 Memories Main Memory 2 Hauptspeicher SIMM: single inline memory module 72 Pins DIMM: dual inline memory module 68 Pins / Statische RAMs schnell aber teuer / Dynamische RAMs höhere Integration möglich
23 Memories Main Memory 2 Hauptspeicher SIMM: single inline memory module 72 Pins DIMM: dual inline memory module 68 Pins / Statische RAMs schnell aber teuer / Dynamische RAMs höhere Integration möglich
Intel X38 Express Chipset Memory Technology and Configuration Guide
 Intel X38 Express Chipset Memory Technology and Configuration Guide White Paper January 2008 Document Number: 318469-002 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE,
Intel X38 Express Chipset Memory Technology and Configuration Guide White Paper January 2008 Document Number: 318469-002 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE,
Data Storage - I: Memory Hierarchies & Disks
 Data Storage - I: Memory Hierarchies & Disks W7-C, Spring 2005 Updated by M. Naci Akkøk, 27.02.2004 and 23.02.2005, based upon slides by Pål Halvorsen, 11.3.2002. Contains slides from: Hector Garcia-Molina,
Data Storage - I: Memory Hierarchies & Disks W7-C, Spring 2005 Updated by M. Naci Akkøk, 27.02.2004 and 23.02.2005, based upon slides by Pål Halvorsen, 11.3.2002. Contains slides from: Hector Garcia-Molina,
Chapter 11 I/O Management and Disk Scheduling
 Operatin g Systems: Internals and Design Principle s Chapter 11 I/O Management and Disk Scheduling Seventh Edition By William Stallings Operating Systems: Internals and Design Principles An artifact can
Operatin g Systems: Internals and Design Principle s Chapter 11 I/O Management and Disk Scheduling Seventh Edition By William Stallings Operating Systems: Internals and Design Principles An artifact can
The Orca Chip... Heart of IBM s RISC System/6000 Value Servers
 The Orca Chip... Heart of IBM s RISC System/6000 Value Servers Ravi Arimilli IBM RISC System/6000 Division 1 Agenda. Server Background. Cache Heirarchy Performance Study. RS/6000 Value Server System Structure.
The Orca Chip... Heart of IBM s RISC System/6000 Value Servers Ravi Arimilli IBM RISC System/6000 Division 1 Agenda. Server Background. Cache Heirarchy Performance Study. RS/6000 Value Server System Structure.
Intel DPDK Boosts Server Appliance Performance White Paper
 Intel DPDK Boosts Server Appliance Performance Intel DPDK Boosts Server Appliance Performance Introduction As network speeds increase to 40G and above, both in the enterprise and data center, the bottlenecks
Intel DPDK Boosts Server Appliance Performance Intel DPDK Boosts Server Appliance Performance Introduction As network speeds increase to 40G and above, both in the enterprise and data center, the bottlenecks
Processor Architectures
 ECPE 170 Jeff Shafer University of the Pacific Processor Architectures 2 Schedule Exam 3 Tuesday, December 6 th Caches Virtual Memory Input / Output OperaKng Systems Compilers & Assemblers Processor Architecture
ECPE 170 Jeff Shafer University of the Pacific Processor Architectures 2 Schedule Exam 3 Tuesday, December 6 th Caches Virtual Memory Input / Output OperaKng Systems Compilers & Assemblers Processor Architecture
A Deduplication File System & Course Review
 A Deduplication File System & Course Review Kai Li 12/13/12 Topics A Deduplication File System Review 12/13/12 2 Traditional Data Center Storage Hierarchy Clients Network Server SAN Storage Remote mirror
A Deduplication File System & Course Review Kai Li 12/13/12 Topics A Deduplication File System Review 12/13/12 2 Traditional Data Center Storage Hierarchy Clients Network Server SAN Storage Remote mirror
What is a bus? A Bus is: Advantages of Buses. Disadvantage of Buses. Master versus Slave. The General Organization of a Bus
 Datorteknik F1 bild 1 What is a bus? Slow vehicle that many people ride together well, true... A bunch of wires... A is: a shared communication link a single set of wires used to connect multiple subsystems
Datorteknik F1 bild 1 What is a bus? Slow vehicle that many people ride together well, true... A bunch of wires... A is: a shared communication link a single set of wires used to connect multiple subsystems
Board Notes on Virtual Memory
 Board Notes on Virtual Memory Part A: Why Virtual Memory? - Letʼs user program size exceed the size of the physical address space - Supports protection o Donʼt know which program might share memory at
Board Notes on Virtual Memory Part A: Why Virtual Memory? - Letʼs user program size exceed the size of the physical address space - Supports protection o Donʼt know which program might share memory at
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING
 COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
COMPUTER ORGANIZATION ARCHITECTURES FOR EMBEDDED COMPUTING 2013/2014 1 st Semester Sample Exam January 2014 Duration: 2h00 - No extra material allowed. This includes notes, scratch paper, calculator, etc.
Operating Systems. Virtual Memory
 Operating Systems Virtual Memory Virtual Memory Topics. Memory Hierarchy. Why Virtual Memory. Virtual Memory Issues. Virtual Memory Solutions. Locality of Reference. Virtual Memory with Segmentation. Page
Operating Systems Virtual Memory Virtual Memory Topics. Memory Hierarchy. Why Virtual Memory. Virtual Memory Issues. Virtual Memory Solutions. Locality of Reference. Virtual Memory with Segmentation. Page
Computer Organization and Architecture
 Computer Organization and Architecture Chapter 11 Instruction Sets: Addressing Modes and Formats Instruction Set Design One goal of instruction set design is to minimize instruction length Another goal
Computer Organization and Architecture Chapter 11 Instruction Sets: Addressing Modes and Formats Instruction Set Design One goal of instruction set design is to minimize instruction length Another goal
This Unit: Putting It All Together. CIS 501 Computer Architecture. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 11: Putting It All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Amir Roth with contributions by Milo
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 11: Putting It All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Amir Roth with contributions by Milo
Intel Pentium 4 Processor on 90nm Technology
 Intel Pentium 4 Processor on 90nm Technology Ronak Singhal August 24, 2004 Hot Chips 16 1 1 Agenda Netburst Microarchitecture Review Microarchitecture Features Hyper-Threading Technology SSE3 Intel Extended
Intel Pentium 4 Processor on 90nm Technology Ronak Singhal August 24, 2004 Hot Chips 16 1 1 Agenda Netburst Microarchitecture Review Microarchitecture Features Hyper-Threading Technology SSE3 Intel Extended
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored?
 Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Database Hardware Selection Guidelines
 Database Hardware Selection Guidelines BRUCE MOMJIAN Database servers have hardware requirements different from other infrastructure software, specifically unique demands on I/O and memory. This presentation
Database Hardware Selection Guidelines BRUCE MOMJIAN Database servers have hardware requirements different from other infrastructure software, specifically unique demands on I/O and memory. This presentation
Virtual Memory Paging
 COS 318: Operating Systems Virtual Memory Paging Kai Li Computer Science Department Princeton University (http://www.cs.princeton.edu/courses/cos318/) Today s Topics Paging mechanism Page replacement algorithms
COS 318: Operating Systems Virtual Memory Paging Kai Li Computer Science Department Princeton University (http://www.cs.princeton.edu/courses/cos318/) Today s Topics Paging mechanism Page replacement algorithms
1. Computer System Structure and Components
 1 Computer System Structure and Components Computer System Layers Various Computer Programs OS System Calls (eg, fork, execv, write, etc) KERNEL/Behavior or CPU Device Drivers Device Controllers Devices
1 Computer System Structure and Components Computer System Layers Various Computer Programs OS System Calls (eg, fork, execv, write, etc) KERNEL/Behavior or CPU Device Drivers Device Controllers Devices
Advanced Computer Architecture-CS501. Computer Systems Design and Architecture 2.1, 2.2, 3.2
 Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
Lecture Handout Computer Architecture Lecture No. 2 Reading Material Vincent P. Heuring&Harry F. Jordan Chapter 2,Chapter3 Computer Systems Design and Architecture 2.1, 2.2, 3.2 Summary 1) A taxonomy of
SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications. Jürgen Primsch, SAP AG July 2011
 SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications Jürgen Primsch, SAP AG July 2011 Why In-Memory? Information at the Speed of Thought Imagine access to business data,
SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications Jürgen Primsch, SAP AG July 2011 Why In-Memory? Information at the Speed of Thought Imagine access to business data,
An Introduction to Computer Science and Computer Organization Comp 150 Fall 2008
 An Introduction to Computer Science and Computer Organization Comp 150 Fall 2008 Computer Science the study of algorithms, including Their formal and mathematical properties Their hardware realizations
An Introduction to Computer Science and Computer Organization Comp 150 Fall 2008 Computer Science the study of algorithms, including Their formal and mathematical properties Their hardware realizations
1. Memory technology & Hierarchy
 1. Memory technology & Hierarchy RAM types Advances in Computer Architecture Andy D. Pimentel Memory wall Memory wall = divergence between CPU and RAM speed We can increase bandwidth by introducing concurrency
1. Memory technology & Hierarchy RAM types Advances in Computer Architecture Andy D. Pimentel Memory wall Memory wall = divergence between CPU and RAM speed We can increase bandwidth by introducing concurrency
Using Synology SSD Technology to Enhance System Performance. Based on DSM 5.2
 Using Synology SSD Technology to Enhance System Performance Based on DSM 5.2 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD Cache as Solution...
Using Synology SSD Technology to Enhance System Performance Based on DSM 5.2 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD Cache as Solution...
The continuum of data management techniques for explicitly managed systems
 The continuum of data management techniques for explicitly managed systems Svetozar Miucin, Craig Mustard Simon Fraser University MCES 2013. Montreal Introduction Explicitly Managed Memory systems lack
The continuum of data management techniques for explicitly managed systems Svetozar Miucin, Craig Mustard Simon Fraser University MCES 2013. Montreal Introduction Explicitly Managed Memory systems lack
File System & Device Drive. Overview of Mass Storage Structure. Moving head Disk Mechanism. HDD Pictures 11/13/2014. CS341: Operating System
 CS341: Operating System Lect 36: 1 st Nov 2014 Dr. A. Sahu Dept of Comp. Sc. & Engg. Indian Institute of Technology Guwahati File System & Device Drive Mass Storage Disk Structure Disk Arm Scheduling RAID
CS341: Operating System Lect 36: 1 st Nov 2014 Dr. A. Sahu Dept of Comp. Sc. & Engg. Indian Institute of Technology Guwahati File System & Device Drive Mass Storage Disk Structure Disk Arm Scheduling RAID
CS3210: Crash consistency. Taesoo Kim
 1 CS3210: Crash consistency Taesoo Kim 2 Administrivia Quiz #2. Lab4-5, Ch 3-6 (read "xv6 book") Open laptop/book, no Internet 3:05pm ~ 4:25-30pm (sharp) NOTE Lab6: 10% bonus, a single lab (bump up your
1 CS3210: Crash consistency Taesoo Kim 2 Administrivia Quiz #2. Lab4-5, Ch 3-6 (read "xv6 book") Open laptop/book, no Internet 3:05pm ~ 4:25-30pm (sharp) NOTE Lab6: 10% bonus, a single lab (bump up your
Configuring Memory on the HP Business Desktop dx5150
 Configuring Memory on the HP Business Desktop dx5150 Abstract... 2 Glossary of Terms... 2 Introduction... 2 Main Memory Configuration... 3 Single-channel vs. Dual-channel... 3 Memory Type and Speed...
Configuring Memory on the HP Business Desktop dx5150 Abstract... 2 Glossary of Terms... 2 Introduction... 2 Main Memory Configuration... 3 Single-channel vs. Dual-channel... 3 Memory Type and Speed...
SDRAM and DRAM Memory Systems Overview
 CHAPTER SDRAM and DRAM Memory Systems Overview Product Numbers: MEM-NPE-32MB=, MEM-NPE-64MB=, MEM-NPE-128MB=, MEM-SD-NPE-32MB=, MEM-SD-NPE-64MB=, MEM-SD-NPE-128MB=, MEM-SD-NSE-256MB=, MEM-NPE-400-128MB=,
CHAPTER SDRAM and DRAM Memory Systems Overview Product Numbers: MEM-NPE-32MB=, MEM-NPE-64MB=, MEM-NPE-128MB=, MEM-SD-NPE-32MB=, MEM-SD-NPE-64MB=, MEM-SD-NPE-128MB=, MEM-SD-NSE-256MB=, MEM-NPE-400-128MB=,
1 Storage Devices Summary
 Chapter 1 Storage Devices Summary Dependability is vital Suitable measures Latency how long to the first bit arrives Bandwidth/throughput how fast does stuff come through after the latency period Obvious
Chapter 1 Storage Devices Summary Dependability is vital Suitable measures Latency how long to the first bit arrives Bandwidth/throughput how fast does stuff come through after the latency period Obvious
89 Fifth Avenue, 7th Floor. New York, NY 10003. www.theedison.com 212.367.7400. White Paper. HP 3PAR Adaptive Flash Cache: A Competitive Comparison
 89 Fifth Avenue, 7th Floor New York, NY 10003 www.theedison.com 212.367.7400 White Paper HP 3PAR Adaptive Flash Cache: A Competitive Comparison Printed in the United States of America Copyright 2014 Edison
89 Fifth Avenue, 7th Floor New York, NY 10003 www.theedison.com 212.367.7400 White Paper HP 3PAR Adaptive Flash Cache: A Competitive Comparison Printed in the United States of America Copyright 2014 Edison
Multiprocessor Cache Coherence
 Multiprocessor Cache Coherence M M BUS P P P P The goal is to make sure that READ(X) returns the most recent value of the shared variable X, i.e. all valid copies of a shared variable are identical. 1.
Multiprocessor Cache Coherence M M BUS P P P P The goal is to make sure that READ(X) returns the most recent value of the shared variable X, i.e. all valid copies of a shared variable are identical. 1.
Chapter 2: Computer-System Structures. Computer System Operation Storage Structure Storage Hierarchy Hardware Protection General System Architecture
 Chapter 2: Computer-System Structures Computer System Operation Storage Structure Storage Hierarchy Hardware Protection General System Architecture Operating System Concepts 2.1 Computer-System Architecture
Chapter 2: Computer-System Structures Computer System Operation Storage Structure Storage Hierarchy Hardware Protection General System Architecture Operating System Concepts 2.1 Computer-System Architecture
Flash for Databases. September 22, 2015 Peter Zaitsev Percona
 Flash for Databases September 22, 2015 Peter Zaitsev Percona In this Presentation Flash technology overview Review some of the available technology What does this mean for databases? Specific opportunities
Flash for Databases September 22, 2015 Peter Zaitsev Percona In this Presentation Flash technology overview Review some of the available technology What does this mean for databases? Specific opportunities
Parallel Computing 37 (2011) 26 41. Contents lists available at ScienceDirect. Parallel Computing. journal homepage: www.elsevier.
 26 41. Contents lists available at ScienceDirect. Parallel Computing. journal homepage: www.elsevier.") Parallel Computing 37 (2011) 26 41 Contents lists available at ScienceDirect Parallel Computing journal homepage: www.elsevier.com/locate/parco Architectural support for thread communications in multi-core
Parallel Computing 37 (2011) 26 41 Contents lists available at ScienceDirect Parallel Computing journal homepage: www.elsevier.com/locate/parco Architectural support for thread communications in multi-core
Navigating Big Data with High-Throughput, Energy-Efficient Data Partitioning
 Application-Specific Architecture Navigating Big Data with High-Throughput, Energy-Efficient Data Partitioning Lisa Wu, R.J. Barker, Martha Kim, and Ken Ross Columbia University Xiaowei Wang Rui Chen Outline
Application-Specific Architecture Navigating Big Data with High-Throughput, Energy-Efficient Data Partitioning Lisa Wu, R.J. Barker, Martha Kim, and Ken Ross Columbia University Xiaowei Wang Rui Chen Outline
The Classical Architecture. Storage 1 / 36
 1 / 36 The Problem Application Data? Filesystem Logical Drive Physical Drive 2 / 36 Requirements There are different classes of requirements: Data Independence application is shielded from physical storage
1 / 36 The Problem Application Data? Filesystem Logical Drive Physical Drive 2 / 36 Requirements There are different classes of requirements: Data Independence application is shielded from physical storage
Central Processing Unit (CPU)
") Central Processing Unit (CPU) CPU is the heart and brain It interprets and executes machine level instructions Controls data transfer from/to Main Memory (MM) and CPU Detects any errors In the following
Central Processing Unit (CPU) CPU is the heart and brain It interprets and executes machine level instructions Controls data transfer from/to Main Memory (MM) and CPU Detects any errors In the following
a storage location directly on the CPU, used for temporary storage of small amounts of data during processing.
 CS143 Handout 18 Summer 2008 30 July, 2008 Processor Architectures Handout written by Maggie Johnson and revised by Julie Zelenski. Architecture Vocabulary Let s review a few relevant hardware definitions:
CS143 Handout 18 Summer 2008 30 July, 2008 Processor Architectures Handout written by Maggie Johnson and revised by Julie Zelenski. Architecture Vocabulary Let s review a few relevant hardware definitions:
CPU Organization and Assembly Language
 COS 140 Foundations of Computer Science School of Computing and Information Science University of Maine October 2, 2015 Outline 1 2 3 4 5 6 7 8 Homework and announcements Reading: Chapter 12 Homework:
COS 140 Foundations of Computer Science School of Computing and Information Science University of Maine October 2, 2015 Outline 1 2 3 4 5 6 7 8 Homework and announcements Reading: Chapter 12 Homework:
Datacenter Operating Systems
 Datacenter Operating Systems CSE451 Simon Peter With thanks to Timothy Roscoe (ETH Zurich) Autumn 2015 This Lecture What s a datacenter Why datacenters Types of datacenters Hyperscale datacenters Major
Datacenter Operating Systems CSE451 Simon Peter With thanks to Timothy Roscoe (ETH Zurich) Autumn 2015 This Lecture What s a datacenter Why datacenters Types of datacenters Hyperscale datacenters Major
Intel 965 Express Chipset Family Memory Technology and Configuration Guide
 Intel 965 Express Chipset Family Memory Technology and Configuration Guide White Paper - For the Intel 82Q965, 82Q963, 82G965 Graphics and Memory Controller Hub (GMCH) and Intel 82P965 Memory Controller
Intel 965 Express Chipset Family Memory Technology and Configuration Guide White Paper - For the Intel 82Q965, 82Q963, 82G965 Graphics and Memory Controller Hub (GMCH) and Intel 82P965 Memory Controller
Solid State Drive Architecture
 Solid State Drive Architecture A comparison and evaluation of data storage mediums Tyler Thierolf Justin Uriarte Outline Introduction Storage Device as Limiting Factor Terminology Internals Interface Architecture
Solid State Drive Architecture A comparison and evaluation of data storage mediums Tyler Thierolf Justin Uriarte Outline Introduction Storage Device as Limiting Factor Terminology Internals Interface Architecture
Performance Guideline for syslog-ng Premium Edition 5 LTS
 Performance Guideline for syslog-ng Premium Edition 5 LTS May 08, 2015 Abstract Performance analysis of syslog-ng Premium Edition Copyright 1996-2015 BalaBit S.a.r.l. Table of Contents 1. Preface... 3
Performance Guideline for syslog-ng Premium Edition 5 LTS May 08, 2015 Abstract Performance analysis of syslog-ng Premium Edition Copyright 1996-2015 BalaBit S.a.r.l. Table of Contents 1. Preface... 3
Intel Q35/Q33, G35/G33/G31, P35/P31 Express Chipset Memory Technology and Configuration Guide
 Intel Q35/Q33, G35/G33/G31, P35/P31 Express Chipset Memory Technology and Configuration Guide White Paper August 2007 Document Number: 316971-002 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION
Intel Q35/Q33, G35/G33/G31, P35/P31 Express Chipset Memory Technology and Configuration Guide White Paper August 2007 Document Number: 316971-002 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION
W4118: segmentation and paging. Instructor: Junfeng Yang
 W4118: segmentation and paging Instructor: Junfeng Yang Outline Memory management goals Segmentation Paging TLB 1 Uni- v.s. multi-programming Simple uniprogramming with a single segment per process Uniprogramming
W4118: segmentation and paging Instructor: Junfeng Yang Outline Memory management goals Segmentation Paging TLB 1 Uni- v.s. multi-programming Simple uniprogramming with a single segment per process Uniprogramming
Using Synology SSD Technology to Enhance System Performance Synology Inc.
 Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_WP_ 20121112 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD
Using Synology SSD Technology to Enhance System Performance Synology Inc. Synology_WP_ 20121112 Table of Contents Chapter 1: Enterprise Challenges and SSD Cache as Solution Enterprise Challenges... 3 SSD
ACCURATE HARDWARE RAID SIMULATOR. A Thesis. Presented to. the Faculty of California Polytechnic State University. San Luis Obispo
 ACCURATE HARDWARE RAID SIMULATOR A Thesis Presented to the Faculty of California Polytechnic State University San Luis Obispo In Partial Fulfillment of the Requirements for the Degree Master of Science
ACCURATE HARDWARE RAID SIMULATOR A Thesis Presented to the Faculty of California Polytechnic State University San Luis Obispo In Partial Fulfillment of the Requirements for the Degree Master of Science
Computers. Hardware. The Central Processing Unit (CPU) CMPT 125: Lecture 1: Understanding the Computer
 CMPT 125: Lecture 1: Understanding the Computer") Computers CMPT 125: Lecture 1: Understanding the Computer Tamara Smyth, tamaras@cs.sfu.ca School of Computing Science, Simon Fraser University January 3, 2009 A computer performs 2 basic functions: 1.
Computers CMPT 125: Lecture 1: Understanding the Computer Tamara Smyth, tamaras@cs.sfu.ca School of Computing Science, Simon Fraser University January 3, 2009 A computer performs 2 basic functions: 1.
Chapter 2 - Computer Organization
 Chapter 2 - Computer Organization CPU organization Basic Elements and Principles Parallelism Memory Storage Hierarchy I/O Fast survey of devices Character Codes Ascii, Unicode Homework: Chapter 1 # 2,
Chapter 2 - Computer Organization CPU organization Basic Elements and Principles Parallelism Memory Storage Hierarchy I/O Fast survey of devices Character Codes Ascii, Unicode Homework: Chapter 1 # 2,
Embedded Parallel Computing
 Embedded Parallel Computing Lecture 5 - The anatomy of a modern multiprocessor, the multicore processors Tomas Nordström Course webpage:: Course responsible and examiner: Tomas
Embedded Parallel Computing Lecture 5 - The anatomy of a modern multiprocessor, the multicore processors Tomas Nordström Course webpage:: Course responsible and examiner: Tomas
A Study of Application Performance with Non-Volatile Main Memory
 A Study of Application Performance with Non-Volatile Main Memory Yiying Zhang, Steven Swanson 2 Memory Storage Fast Slow Volatile In bytes Persistent In blocks Next-Generation Non-Volatile Memory (NVM)
A Study of Application Performance with Non-Volatile Main Memory Yiying Zhang, Steven Swanson 2 Memory Storage Fast Slow Volatile In bytes Persistent In blocks Next-Generation Non-Volatile Memory (NVM)
ELE 356 Computer Engineering II. Section 1 Foundations Class 6 Architecture
 ELE 356 Computer Engineering II Section 1 Foundations Class 6 Architecture History ENIAC Video 2 tj History Mechanical Devices Abacus 3 tj History Mechanical Devices The Antikythera Mechanism Oldest known
ELE 356 Computer Engineering II Section 1 Foundations Class 6 Architecture History ENIAC Video 2 tj History Mechanical Devices Abacus 3 tj History Mechanical Devices The Antikythera Mechanism Oldest known
Switch Fabric Implementation Using Shared Memory
 Order this document by /D Switch Fabric Implementation Using Shared Memory Prepared by: Lakshmi Mandyam and B. Kinney INTRODUCTION Whether it be for the World Wide Web or for an intra office network, today
Order this document by /D Switch Fabric Implementation Using Shared Memory Prepared by: Lakshmi Mandyam and B. Kinney INTRODUCTION Whether it be for the World Wide Web or for an intra office network, today
OC By Arsene Fansi T. POLIMI 2008 1
 IBM POWER 6 MICROPROCESSOR OC By Arsene Fansi T. POLIMI 2008 1 WHAT S IBM POWER 6 MICROPOCESSOR The IBM POWER6 microprocessor powers the new IBM i-series* and p-series* systems. It s based on IBM POWER5
IBM POWER 6 MICROPROCESSOR OC By Arsene Fansi T. POLIMI 2008 1 WHAT S IBM POWER 6 MICROPOCESSOR The IBM POWER6 microprocessor powers the new IBM i-series* and p-series* systems. It s based on IBM POWER5
Intel Data Direct I/O Technology (Intel DDIO): A Primer >
: A Primer >") Intel Data Direct I/O Technology (Intel DDIO): A Primer > Technical Brief February 2012 Revision 1.0 Legal Statements INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE,
Intel Data Direct I/O Technology (Intel DDIO): A Primer > Technical Brief February 2012 Revision 1.0 Legal Statements INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE,
Application Note 195. ARM11 performance monitor unit. Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007
 Application Note 195 ARM11 performance monitor unit Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007 Copyright 2007 ARM Limited. All rights reserved. Application Note
Application Note 195 ARM11 performance monitor unit Document number: ARM DAI 195B Issued: 15th February, 2008 Copyright ARM Limited 2007 Copyright 2007 ARM Limited. All rights reserved. Application Note
NAND Flash FAQ. Eureka Technology. apn5_87. NAND Flash FAQ
 What is NAND Flash? What is the major difference between NAND Flash and other Memory? Structural differences between NAND Flash and NOR Flash What does NAND Flash controller do? How to send command to
What is NAND Flash? What is the major difference between NAND Flash and other Memory? Structural differences between NAND Flash and NOR Flash What does NAND Flash controller do? How to send command to
Caching Mechanisms for Mobile and IOT Devices
 Caching Mechanisms for Mobile and IOT Devices Masafumi Takahashi Toshiba Corporation JEDEC Mobile & IOT Technology Forum Copyright 2016 Toshiba Corporation Background. Unified concept. Outline The first
Caching Mechanisms for Mobile and IOT Devices Masafumi Takahashi Toshiba Corporation JEDEC Mobile & IOT Technology Forum Copyright 2016 Toshiba Corporation Background. Unified concept. Outline The first
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Memory Basics. SRAM/DRAM Basics
 Memory Basics RAM: Random Access Memory historically defined as memory array with individual bit access refers to memory with both Read and Write capabilities ROM: Read Only Memory no capabilities for
Memory Basics RAM: Random Access Memory historically defined as memory array with individual bit access refers to memory with both Read and Write capabilities ROM: Read Only Memory no capabilities for
Storage in Database Systems. CMPSCI 445 Fall 2010
 Storage in Database Systems CMPSCI 445 Fall 2010 1 Storage Topics Architecture and Overview Disks Buffer management Files of records 2 DBMS Architecture Query Parser Query Rewriter Query Optimizer Query
Storage in Database Systems CMPSCI 445 Fall 2010 1 Storage Topics Architecture and Overview Disks Buffer management Files of records 2 DBMS Architecture Query Parser Query Rewriter Query Optimizer Query
Enabling Technologies for Distributed and Cloud Computing
 Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading