How To Create A Map And Reduce Function In A Microsoft Microsoft Hadoop (Minorodeo) (Mino) And Hadooper
|
|
|
- Christopher Casey
- 5 years ago
- Views:
Transcription
1 Introduction to MapReduce, Hadoop, & Spark Jonathan Carroll-Nellenback Center for Integrated Research Computing

2 Big Data Outline Analytics Map Reduce Programming Model Hadoop Ecosystem HDFS, Pig, Hive, Oosize, Sqoop, HBase, Yarn Spark

3 Big Data Volume Too big for typical database software tools to capture, store, manage, and analyze (TB, PB, EB) Velocity Real time streaming data Variety Structured & Unstructured (documents, graphs, videos, audio etc...) Veracity How trustworthy is the data Value How useful is the data

4 Big Data Analytics Descriptive analytics What happened Predictive analytics What will happen Prescriptive analytics What to do going forward Social media analytics Mine social media data to discover sentiment, behavior patterns, individual preferences Entity analytics Analyze common types of events, people, things, transactions, and relationships Cognitive computing IBM Watson (simulation of human thought processes natural language processing, pattern recognition, data mining)

5 Map Reduce Map Reduce Programming Model (Google) map[k1, V1] => List [K2, V2] reduce[k2, List[V2]] => List[K3, V3]
![map[k1, V1] => List [K2, V2]](/docs-images/44/23166191/images/page_5.jpg "reduce[k2, List[V2]] =>")
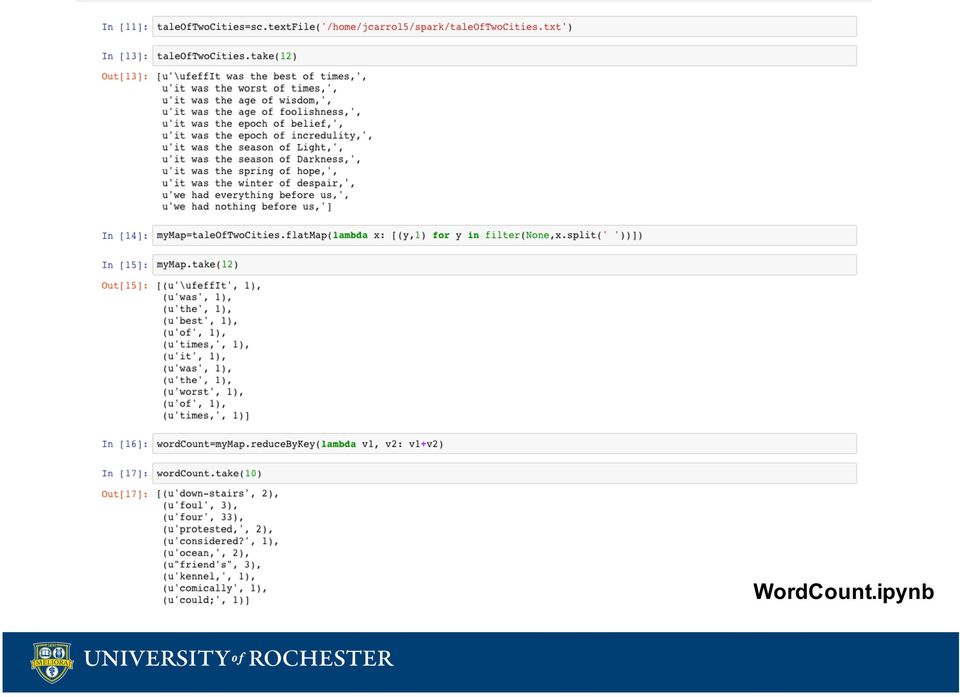
6 Word Count Map Reduce Programming Model map[k1, V1] => List [K2, V2] reduce[k2, List[V2]] => List[K3, V3] Count occurrences of words in document K1 = line number V1 = text Map returns a list of words and the number 1 K2 = word V2 = 1 Reduce adds up values for each key K3 = word V3 = number of occurrences K1 V1 1 It was the best of times, 2 It was the worst of times, 3 it was the age of wisdom, 4 it was the age of foolishness, 5 it was the epoch of belief, 6 it was the epoch of incredulity, 7 it was the season of Light, 8 it was the season of Darkness, K2 V2 K3 V3 It 1 It 10 was 1 was 12 the 1 the 100 best 1 best 10 of 1 of 50 times 1 times 15 It 1 age 4 was 1 wisdom 3

7 Image credit: Broomfield Technology Consultants

8 WordCount.ipynb
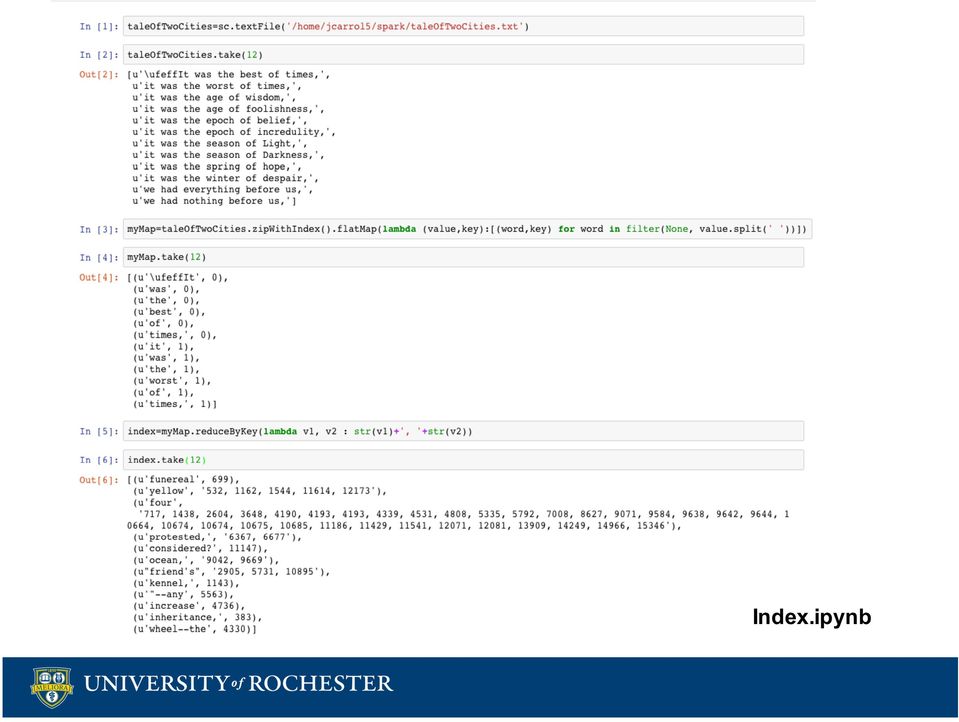
9 Generate Index Map Reduce Programming Model map[k1, V1] => List [K2, V2] reduce[k2, List[V2]] => List[K3, V3] List all lines that a word appears on K1 = line number V1 = text Map returns a list of words and the line number K2 = word V2 = line # Reduce concatenates values for each key K3 = word V3 = list of line # s K1 V1 1 It was the best of times, 2 It was the worst of times, 3 it was the age of wisdom, 4 it was the age of foolishness, 5 it was the epoch of belief, 6 it was the epoch of incredulity, 7 it was the season of Light, 8 it was the season of Darkness, K2 V2 K3 V3 It 1 It 1,2,3,... was 1 was 1,2,3,... the 1 the 1,2,3,... best 1 best 1 of 1 of 1,2,3,... times 1 times 1,2 It 2 age 3,4, was 2 wisdom 3

10 Index.ipynb
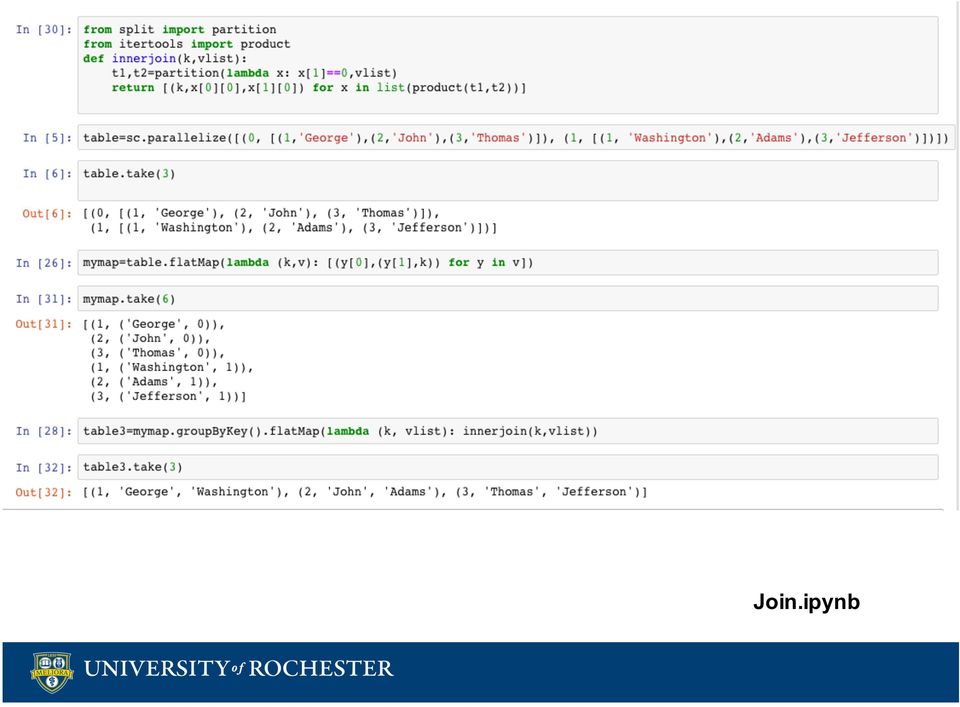
11 Join Tables Map Reduce Programming Model map[k1, V1] => List [K2, V2] reduce[k2, List[V2]] => List[K3, V3] Join two tables using a key K1 = tableid V1 = row of data Map returns a list of words and the line number K2 = value to join on V2 = row and tableid Reduce does an outer/inner product on each set of rows from different tableids K3 = none V3 = outer product from each set of rows first 1 George 2 John 3 Thomas K1 + = last 1 Washington 2 Adams 3 Jefferson V1 first 1 George first 2 John first 3 Thomas last 1 Washington last 2 Adams last 3 Jefferson

12 Join Tables Map Reduce Programming Model map[k1, V1] => List [K2, V2] reduce[k2, List[V2]] => List[K3, V3] Join two tables using a key K1 = tableid V1 = row of data Map returns a list of words and the line number K2 = value to join on V2 = row and tableid Reduce does an outer/inner product on each set of rows from different tableids K3 = none V3 = outer product from each set of rows K1 V1 first 1 George first 2 John first 3 Thomas last 1 Washington last 2 Adams last 3 Jefferson K2 V2 1 first George 2 first John 3 first Thomas 1 last Washington 2 last Adams 3 last Jefferson K3 V3 1 George Washington 2 John Adams 3 Thomas Jefferson

13 Join.ipynb
14 Join Tables Collecting data for each join key within a single partition allows for any type of join (left, right, inner, outer) Tables don t have to have same number of columns K1 V1 first 1 George 1789 first 2 John 1797 first 3 Thomas 1801 last 1 Washington last 2 Adams last 3 Jefferson K2 V2 1 first George first John first Thomas last Washington 2 last Adams 3 last Jefferson K3 V3 1 George Washington John Adams Thomas Jefferson 1801

15 Map Reduce Map Reduce Programming Model map[k1, V1] => List [K2, V2] reduce[k2, List[V2]] => List[K3, V3] Group by key Shuffle Initial key value pairs are partitioned across multiple nodes Mapping can occur locally Grouping by key involves data shuffling prior to reduce If reduction operator is associative and commutative, then no need to group data for each key K2 on the same partition. Reduction can happen within each partition and then across partitions.

16 Hadoop Ecosystem Hadoop Framework Hadoop MapReduce HDFS (Hadoop Distributed File System) Fault tolerant Designed for Batch processing Large datasets Simple coherency model: file content cannot be updated just appended Hadoop YARN Resource management and job scheduler Additional packages Pig Procedural language (pig latin) to express map and reduce processes Hive Provides SQL interface on top of MapReduce HBase Column-oriented key-value store on top of HDFS Sqoop Allows for efficiently moving data from relational database to HDFS

17 Apache Spark Runs in memory Main Components Spark Core MapReduce Spark SQL Database Spark Streaming Real-time analysis of streaming data Spark MLlib Distributed machine learning library Spark GraphX Distributed graph processing framework Procedural style interface similar to PigLatin Libraries available for Python, R, Scala, Java Supports lazy evaluation Map operations (transformations) only occur when needed by a reduction Reductions (actions) are scheduled to run within a MapReduce cluster. Can choose to cache intermediate results Comes with standalone native Spark cluster, or can interface with YARN Can connect to HDFS, GPFS, Cassandra, Amazon S3, etc...

18 Jupyter Web application that allows for the creation and sharing of documents that contain live code, equations, visualizations, and explanatory text. Supports Julia, Python, and R Jupyter + Python + Spark = Easy interactive big-data analytics

19 Spark+Jupyter on Bluehive Install X2go following instructions for your OS under Getting Started Guide Getting Started Connecting using <OS> Connecting using a Graphical User Interface

20 Spark+Jupyter on Bluehive Open a terminal on Head node (under Applications : System Tools ) Copy over directory containing sample files. cp -r /public/jcarrol5/csc461. cd CSC461 Run the command init_jupyter.sh which will 1.) create a self-signed key for the jupyter web app 2.) prompt you for a password to secure your jupyter notebook server 3.) update your jupyter notebook configuration file
 create a self-signed key for the jupyter web app 2.")
21 Spark+Jupyter on Bluehive Run the command interactive -p debug -t 60 --exclusive This will request an interactive session on a compute node in the debug partition for 60 minutes. Run the script start-spark-jupyter This will start a stand-alone spark cluster within your job s allocation and launch your jupyter notebook initialized with the spark context (sc) and spark SQL context (sqlcontext) Note the url of the spark master ( and the Jupyter Notebook ( Open firefox web browser (under Applications : Internet) Connect to the Jupyter Notebook (and the Spark master)
22 Spark Data structures Spark Core: RDD Resilient Distributed Data Set RDD Each element is just a value (iestring) MapRDD Each element is a key-value pair - though the value can be anything. RowRDD Each element in the RDD is a Row object with some schema Spark SQL: DataFrame Column oriented distributed data set (Hive). Supports SQL queries as well as procedural operations (join, select,.)
23 Wegmans Data The Wegmans.ipynb notebook contains example code that loads data from text files into an RDD of strings maps that onto a RDD of Rows Transforms the RowRDDs into DataFrames Performs SQL queries as well as procedural queries Performs Market Basket Analysis to find sets of frequent items
24 Spark modules Core RDD SQL DataFrames Streaming Supports continuous inflow of data mllib Machine Learning Library Statistics Classification/Regression Collaborative Filtering ALS Clustering (ie k-means) Dimensionality Reduction (SVD / PCA) Frequent pattern mining (FP-growth) GraphX Supports operations on graphs (maptripletes, groupedges, pagerank, connectedcomponents, )
25 Homework Modify the word count example to count letters instead of words in the taleoftwocities.txt file Modify the Wegmans.ipynb Jupyter notebook to calculate the top 20 grossing products sold by Wegmans. Calculate the average number of products in each transaction. Repeat the basket analysis but using item category names instead of item names. Determine what items are frequently bought with CARBONATED SODA POP
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Spark ΕΡΓΑΣΤΗΡΙΟ 10. Prepared by George Nikolaides 4/19/2015 1
 Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Spark ΕΡΓΑΣΤΗΡΙΟ 10 Prepared by George Nikolaides 4/19/2015 1 Introduction to Apache Spark Another cluster computing framework Developed in the AMPLab at UC Berkeley Started in 2009 Open-sourced in 2010
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Big Data Analytics with Spark and Oscar BAO. Tamas Jambor, Lead Data Scientist at Massive Analytic
 Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
Architectures for massive data management
 Architectures for massive data management Apache Spark Albert Bifet [email protected] October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
Architectures for massive data management Apache Spark Albert Bifet [email protected] October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
How To Create A Data Visualization With Apache Spark And Zeppelin 2.5.3.5
 Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Big Data Analytics Hadoop and Spark
 Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Apache Spark 11/10/15. Context. Reminder. Context. What is Spark? A GrowingStack
 Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University](/thumbs/26/8135278.jpg "CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
Introduction to Spark
 Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Oracle Big Data Fundamentals Ed 1 NEW
 Oracle University Contact Us: +90 212 329 6779 Oracle Big Data Fundamentals Ed 1 NEW Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big
Oracle University Contact Us: +90 212 329 6779 Oracle Big Data Fundamentals Ed 1 NEW Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
BIG DATA TECHNOLOGY. Hadoop Ecosystem
 BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Unified Big Data Analytics Pipeline. 连 城 [email protected]
 Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Spark and the Big Data Library
 Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Ali Ghodsi Head of PM and Engineering Databricks
 Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform Pig is the name of the system Pig Latin is the provided programming language Pig Latin is
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Introduction to Big Data Training
 Introduction to Big Data Training The quickest way to be introduce with NOSQL/BIG DATA offerings Learn and experience Big Data Solutions including Hadoop HDFS, Map Reduce, NoSQL DBs: Document Based DB
Introduction to Big Data Training The quickest way to be introduce with NOSQL/BIG DATA offerings Learn and experience Big Data Solutions including Hadoop HDFS, Map Reduce, NoSQL DBs: Document Based DB
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com
 Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
BIG DATA APPLICATIONS
 BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Big Data Approaches. Making Sense of Big Data. Ian Crosland. Jan 2016
 Big Data Approaches Making Sense of Big Data Ian Crosland Jan 2016 Accelerate Big Data ROI Even firms that are investing in Big Data are still struggling to get the most from it. Make Big Data Accessible
Big Data Approaches Making Sense of Big Data Ian Crosland Jan 2016 Accelerate Big Data ROI Even firms that are investing in Big Data are still struggling to get the most from it. Make Big Data Accessible
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Big Data on Microsoft Platform
 Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK OVERVIEW ON BIG DATA SYSTEMATIC TOOLS MR. SACHIN D. CHAVHAN 1, PROF. S. A. BHURA
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK OVERVIEW ON BIG DATA SYSTEMATIC TOOLS MR. SACHIN D. CHAVHAN 1, PROF. S. A. BHURA
This is a brief tutorial that explains the basics of Spark SQL programming.
 About the Tutorial Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types
About the Tutorial Apache Spark is a lightning-fast cluster computing designed for fast computation. It was built on top of Hadoop MapReduce and it extends the MapReduce model to efficiently use more types
Big Data and Data Science: Behind the Buzz Words
 Big Data and Data Science: Behind the Buzz Words Peggy Brinkmann, FCAS, MAAA Actuary Milliman, Inc. April 1, 2014 Contents Big data: from hype to value Deconstructing data science Managing big data Analyzing
Big Data and Data Science: Behind the Buzz Words Peggy Brinkmann, FCAS, MAAA Actuary Milliman, Inc. April 1, 2014 Contents Big data: from hype to value Deconstructing data science Managing big data Analyzing
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
ITG Software Engineering
 Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Big Data and Industrial Internet
 Big Data and Industrial Internet Keijo Heljanko Department of Computer Science and Helsinki Institute for Information Technology HIIT School of Science, Aalto University [email protected] 16.6-2015
Big Data and Industrial Internet Keijo Heljanko Department of Computer Science and Helsinki Institute for Information Technology HIIT School of Science, Aalto University [email protected] 16.6-2015
Apache Spark and Distributed Programming
 Apache Spark and Distributed Programming Concurrent Programming Keijo Heljanko Department of Computer Science University School of Science November 25th, 2015 Slides by Keijo Heljanko Apache Spark Apache
Apache Spark and Distributed Programming Concurrent Programming Keijo Heljanko Department of Computer Science University School of Science November 25th, 2015 Slides by Keijo Heljanko Apache Spark Apache
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Hadoop Evolution In Organizations. Mark Vervuurt Cluster Data Science & Analytics
 In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
TRAINING PROGRAM ON BIGDATA/HADOOP
 Course: Training on Bigdata/Hadoop with Hands-on Course Duration / Dates / Time: 4 Days / 24th - 27th June 2015 / 9:30-17:30 Hrs Venue: Eagle Photonics Pvt Ltd First Floor, Plot No 31, Sector 19C, Vashi,
Course: Training on Bigdata/Hadoop with Hands-on Course Duration / Dates / Time: 4 Days / 24th - 27th June 2015 / 9:30-17:30 Hrs Venue: Eagle Photonics Pvt Ltd First Floor, Plot No 31, Sector 19C, Vashi,
Spark. Fast, Interactive, Language- Integrated Cluster Computing
 Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Certification Study Guide. MapR Certified Spark Developer Study Guide
 Certification Study Guide MapR Certified Spark Developer Study Guide 1 CONTENTS About MapR Study Guides... 3 MapR Certified Spark Developer (MCSD)... 3 SECTION 1 WHAT S ON THE EXAM?... 5 1. Load and Inspect
Certification Study Guide MapR Certified Spark Developer Study Guide 1 CONTENTS About MapR Study Guides... 3 MapR Certified Spark Developer (MCSD)... 3 SECTION 1 WHAT S ON THE EXAM?... 5 1. Load and Inspect
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
HDFS. Hadoop Distributed File System
 HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
Infomatics. Big-Data and Hadoop Developer Training with Oracle WDP
 Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform interactive execution of map reduce jobs Pig is the name of the system Pig Latin is the
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform interactive execution of map reduce jobs Pig is the name of the system Pig Latin is the
Native Connectivity to Big Data Sources in MSTR 10
 Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
BIG DATA HADOOP TRAINING
 BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
Machine- Learning Summer School - 2015
 Machine- Learning Summer School - 2015 Big Data Programming David Franke Vast.com hbp://www.cs.utexas.edu/~dfranke/ Goals for Today Issues to address when you have big data Understand two popular big data
Machine- Learning Summer School - 2015 Big Data Programming David Franke Vast.com hbp://www.cs.utexas.edu/~dfranke/ Goals for Today Issues to address when you have big data Understand two popular big data
Case Study : 3 different hadoop cluster deployments
 Case Study : 3 different hadoop cluster deployments Lee moon soo [email protected] HDFS as a Storage Last 4 years, our HDFS clusters, stored Customer 1500 TB+ data safely served 375,000 TB+ data to customer
Case Study : 3 different hadoop cluster deployments Lee moon soo [email protected] HDFS as a Storage Last 4 years, our HDFS clusters, stored Customer 1500 TB+ data safely served 375,000 TB+ data to customer
Hadoop: The Definitive Guide
 FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
Big Data at Spotify. Anders Arpteg, Ph D Analytics Machine Learning, Spotify
 Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed)
Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed)
You should have a working knowledge of the Microsoft Windows platform. A basic knowledge of programming is helpful but not required.
 What is this course about? This course is an overview of Big Data tools and technologies. It establishes a strong working knowledge of the concepts, techniques, and products associated with Big Data. Attendees
What is this course about? This course is an overview of Big Data tools and technologies. It establishes a strong working knowledge of the concepts, techniques, and products associated with Big Data. Attendees
Brave New World: Hadoop vs. Spark
 Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Big Data and Analytics: Challenges and Opportunities
 Big Data and Analytics: Challenges and Opportunities Dr. Amin Beheshti Lecturer and Senior Research Associate University of New South Wales, Australia (Service Oriented Computing Group, CSE) Talk: Sharif
Big Data and Analytics: Challenges and Opportunities Dr. Amin Beheshti Lecturer and Senior Research Associate University of New South Wales, Australia (Service Oriented Computing Group, CSE) Talk: Sharif
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
Big Systems, Big Data
 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us
 DATA INTELLIGENCE FOR ALL Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us Christopher Nguyen, PhD Co-Founder & CEO Agenda 1. Challenges & Motivation 2. DDF Overview 3. DDF Design
DATA INTELLIGENCE FOR ALL Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us Christopher Nguyen, PhD Co-Founder & CEO Agenda 1. Challenges & Motivation 2. DDF Overview 3. DDF Design
Native Connectivity to Big Data Sources in MicroStrategy 10. Presented by: Raja Ganapathy
 Native Connectivity to Big Data Sources in MicroStrategy 10 Presented by: Raja Ganapathy Agenda MicroStrategy supports several data sources, including Hadoop Why Hadoop? How does MicroStrategy Analytics
Native Connectivity to Big Data Sources in MicroStrategy 10 Presented by: Raja Ganapathy Agenda MicroStrategy supports several data sources, including Hadoop Why Hadoop? How does MicroStrategy Analytics
CSE-E5430 Scalable Cloud Computing Lecture 11
 CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 30.11-2015 1/24 Distributed Coordination Systems Consensus
CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 30.11-2015 1/24 Distributed Coordination Systems Consensus
Monitis Project Proposals for AUA. September 2014, Yerevan, Armenia
 Monitis Project Proposals for AUA September 2014, Yerevan, Armenia Distributed Log Collecting and Analysing Platform Project Specifications Category: Big Data and NoSQL Software Requirements: Apache Hadoop
Monitis Project Proposals for AUA September 2014, Yerevan, Armenia Distributed Log Collecting and Analysing Platform Project Specifications Category: Big Data and NoSQL Software Requirements: Apache Hadoop
Unlocking the True Value of Hadoop with Open Data Science
 Unlocking the True Value of Hadoop with Open Data Science Kristopher Overholt Solution Architect Big Data Tech 2016 MinneAnalytics June 7, 2016 Overview Overview of Open Data Science Python and the Big
Unlocking the True Value of Hadoop with Open Data Science Kristopher Overholt Solution Architect Big Data Tech 2016 MinneAnalytics June 7, 2016 Overview Overview of Open Data Science Python and the Big
Real Time Data Processing using Spark Streaming
 Real Time Data Processing using Spark Streaming Hari Shreedharan, Software Engineer @ Cloudera Committer/PMC Member, Apache Flume Committer, Apache Sqoop Contributor, Apache Spark Author, Using Flume (O
Real Time Data Processing using Spark Streaming Hari Shreedharan, Software Engineer @ Cloudera Committer/PMC Member, Apache Flume Committer, Apache Sqoop Contributor, Apache Spark Author, Using Flume (O
Information Builders Mission & Value Proposition
 Value 10/06/2015 2015 MapR Technologies 2015 MapR Technologies 1 Information Builders Mission & Value Proposition Economies of Scale & Increasing Returns (Note: Not to be confused with diminishing returns
Value 10/06/2015 2015 MapR Technologies 2015 MapR Technologies 1 Information Builders Mission & Value Proposition Economies of Scale & Increasing Returns (Note: Not to be confused with diminishing returns
BIG DATA - HADOOP PROFESSIONAL amron
 0 Training Details Course Duration: 30-35 hours training + assignments + actual project based case studies Training Materials: All attendees will receive: Assignment after each module, video recording
0 Training Details Course Duration: 30-35 hours training + assignments + actual project based case studies Training Materials: All attendees will receive: Assignment after each module, video recording
Big Data. Lyle Ungar, University of Pennsylvania
 Big Data Big data will become a key basis of competition, underpinning new waves of productivity growth, innovation, and consumer surplus. McKinsey Data Scientist: The Sexiest Job of the 21st Century -
Big Data Big data will become a key basis of competition, underpinning new waves of productivity growth, innovation, and consumer surplus. McKinsey Data Scientist: The Sexiest Job of the 21st Century -
Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu
 Yabo (Arber) Xu") Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
Getting Started with Hadoop with Amazon s Elastic MapReduce
 Getting Started with Hadoop with Amazon s Elastic MapReduce Scott Hendrickson [email protected] http://drskippy.net/projects/emr-hadoopmeetup.pdf Boulder/Denver Hadoop Meetup 8 July 2010 Scott Hendrickson
Getting Started with Hadoop with Amazon s Elastic MapReduce Scott Hendrickson [email protected] http://drskippy.net/projects/emr-hadoopmeetup.pdf Boulder/Denver Hadoop Meetup 8 July 2010 Scott Hendrickson
COMP9321 Web Application Engineering
 COMP9321 Web Application Engineering Semester 2, 2015 Dr. Amin Beheshti Service Oriented Computing Group, CSE, UNSW Australia Week 11 (Part II) http://webapps.cse.unsw.edu.au/webcms2/course/index.php?cid=2411
COMP9321 Web Application Engineering Semester 2, 2015 Dr. Amin Beheshti Service Oriented Computing Group, CSE, UNSW Australia Week 11 (Part II) http://webapps.cse.unsw.edu.au/webcms2/course/index.php?cid=2411
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Hive Interview Questions
 HADOOPEXAM LEARNING RESOURCES Hive Interview Questions www.hadoopexam.com Please visit www.hadoopexam.com for various resources for BigData/Hadoop/Cassandra/MongoDB/Node.js/Scala etc. 1 Professional Training
HADOOPEXAM LEARNING RESOURCES Hive Interview Questions www.hadoopexam.com Please visit www.hadoopexam.com for various resources for BigData/Hadoop/Cassandra/MongoDB/Node.js/Scala etc. 1 Professional Training
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Big Data Explained. An introduction to Big Data Science.
 Big Data Explained An introduction to Big Data Science. 1 Presentation Agenda What is Big Data Why learn Big Data Who is it for How to start learning Big Data When to learn it Objective and Benefits of
Big Data Explained An introduction to Big Data Science. 1 Presentation Agenda What is Big Data Why learn Big Data Who is it for How to start learning Big Data When to learn it Objective and Benefits of
Chukwa, Hadoop subproject, 37, 131 Cloud enabled big data, 4 Codd s 12 rules, 1 Column-oriented databases, 18, 52 Compression pattern, 83 84
 Index A Amazon Web Services (AWS), 50, 58 Analytics engine, 21 22 Apache Kafka, 38, 131 Apache S4, 38, 131 Apache Sqoop, 37, 131 Appliance pattern, 104 105 Application architecture, big data analytics
Index A Amazon Web Services (AWS), 50, 58 Analytics engine, 21 22 Apache Kafka, 38, 131 Apache S4, 38, 131 Apache Sqoop, 37, 131 Appliance pattern, 104 105 Application architecture, big data analytics
A programming model in Cloud: MapReduce
 A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value