Big Data at Spotify. Anders Arpteg, Ph D Analytics Machine Learning, Spotify
|
|
|
- Edith Chapman
- 10 years ago
- Views:
Transcription
 speed Logistic regression in Scikit vs Spark SGD optimizer in Spark General thoughts so")
1 Big Data at Spotify Anders Arpteg, Ph D Analytics Machine Learning, Spotify Quickly about me Quickly about Spotify What is all the data used for? Quickly about Spark Hadoop MR vs Spark Need for (distributed) speed Logistic regression in Scikit vs Spark SGD optimizer in Spark General thoughts so far Demo?

2 Quickly about me 1995 University of Kalmar 1997 The Buyer's Guide 2000 Ph D student, Kalmar + Linköping 2005 Assistant Professor, Kalmar 2007 Venture capital, research project 2007 TestFreaks, Pricerunner 15,000+ sites worldwide 2011 Campanja, AI-team Optimized Netflix worldwide 2013 Spotify, Graph data lead 2014 Spotify, Analytics ML manager

3 Quickly about Spotify 75+ million monthly active users Launched in 58 different countries 20+ million paying subscribers 30+ million licensed songs 20,000 new songs every day 1,5+ billion playlists created 14 TB of user/service-related log data per day Expands to 170 TB per day node Hadoop cluster 50 PB of storage capacity, 48 TB of memory capacity
4 What is all the data used for? Reporting to labels and right holders Product Features Browse, search, radio, related artists, A/B Testing Catalog quality Artist disambiguation, track deduplication Business Analytics KPI, DAU, MAU, SUBS, conversion, retention, NPS analysis, understand the users User funnel, awareness, activation, conversion, retention Marketing, growth, consumer insights Operational Analysis

5 A/B Testing

6 Spotify data architecture

7 The discovery data pipeline

8 Collaborative filtering Approximate 60M users x 4M songs with 40 latent factors, ALS In short, minimize the cost function:

9 Next-generation Data Analytics Analytics Traditional statistical analysis Statistical significance with ~1000 users Centralized relational databases Analytics Big Data Moving algorithms to data Make it possible to handle big data Volume, Variety, and Velocity Analytics Machine Learning & Real-time Simplify distributed data processing Decrease latency between incoming data and decision Intelligent distributed machine learning algorithms
10 Next-generation Data Analytics (2) Hadoop 2+, YARN application Killing classical Map/Reduce Iterative algorithms in Spark, Tez, and Flink Streaming data (not just music) Kafka, Storm, och Spark Streaming Lambda architecture Improved storage formats Columnar data storage Parquet, ORC Simplified machine learning toolkits Scikit-learn, Spark MLlib, IPython notebooks, R Ubiquitous machine learning, ML for everyone Better tools for datawarehousing and dashboarding

11 Quickly about classical map/reduce

12 Quickly about classical map/reduce (2)

13 Quickly about Spark

14 Quickly about Spark (2)
15 Spark Example with the RDD API Array of data distributed of workers Same API as normal arrays Transforming: map, filter, reducebykey, groupbykey,... Joining: joinbykey, leftouterjoin, cogroup, zip,.. Actions: count, saveasavro, saveastext,... Failure recovery, reruns failed tasks

16 Spark Example with the DataFrame API Higher level of abstraction than RDD Make use of schema-free data sources Dynamic schema-awareness Additional optimizations performed automatically Same performance in Python as in Scala Similar API as Pandas and R

17 Quickly about Spark (5)
18 Problem Definition + Hypothesis Improve user targeting for house ads P(C A) Identify users that are likely to convert given that they ve seen house ads Target less people with house ads, and retain as many conversions as possible Hypothesis By making use of information about users behaviour, demographics, and ad data, it will be possible to estimate likelihood of conversion with a logistic regression model. Alternative algorithms Navie Bayes, Decision Trees, Boosted Trees Random Forest, SVM,
19 Evaluation of the model
20 Need for (distributed) speed Steps to build the model Extract data for training Transform data into features Train the model using the features Evaluate the performance of the model Tune the parameters Extract data for prediction Transform prediction data into features Predict probability of conversion for all the users Main tools used IPython notebook Scikit learn library Spark + MLlib
21 Running data extraction in Spark
22 More often like this

23 Quickly about Logistic Regression

24 Logistic Regression in Scikit-learn L2 regularized optimization problem in liblinear Newton Raphson solver

25 Logistic Regression in Spark Stochastic gradient descent Params: step size, use intercept, regularization, batch size
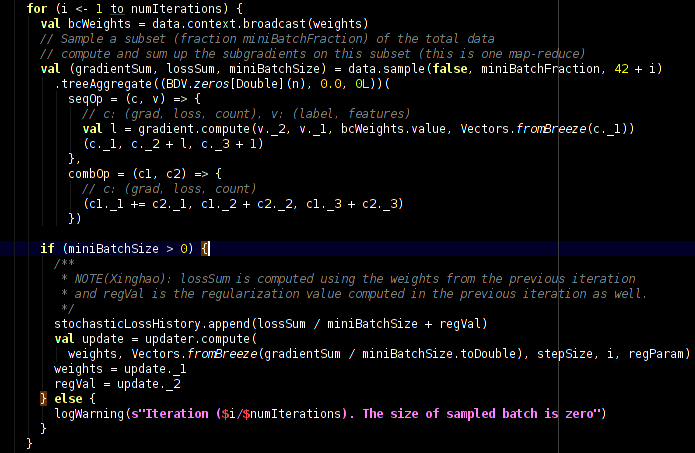
26 SGD implementation in Spark

27 Calculation of the gradient

28 Updating of the weights
29 SGD Convergence
30 Learning rate (step size) tuning
31 Regularizaton tuning
32 Thoughts about Spark Advantages with Spark General purpose engine (batch, streaming, sql, graph) Faster Yarn engine, DAG optimization and less IO High level machine learning library RDD, failure recovery, data locality Generic caching and accumulators Nice development environment, local debugging,... Huge community and activity Disadvantages and things to consider Still rather immature, unexpected error messages Beware number of executors Avoid references to outer classes Be careful about partition tunining

33 Thanks!
34 Deep learning for identifying similar songs
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Fast and Expressive Big Data Analytics with Python. Matei Zaharia UC BERKELEY
 Fast and Expressive Big Data Analytics with Python Matei Zaharia UC Berkeley / MIT UC BERKELEY spark-project.org What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop
Fast and Expressive Big Data Analytics with Python Matei Zaharia UC Berkeley / MIT UC BERKELEY spark-project.org What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop
Big Data Analytics with Spark and Oscar BAO. Tamas Jambor, Lead Data Scientist at Massive Analytic
 Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Big Data Analytics with Spark and Oscar BAO Tamas Jambor, Lead Data Scientist at Massive Analytic About me Building a scalable Machine Learning platform at MA Worked in Big Data and Data Science in the
Unified Big Data Analytics Pipeline. 连 城 [email protected]
 Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Spark: Making Big Data Interactive & Real-Time
 Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Spark: Making Big Data Interactive & Real-Time Matei Zaharia UC Berkeley / MIT www.spark-project.org What is Spark? Fast and expressive cluster computing system compatible with Apache Hadoop Improves efficiency
Apache Spark 11/10/15. Context. Reminder. Context. What is Spark? A GrowingStack
 Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
The Internet of Things and Big Data: Intro
 The Internet of Things and Big Data: Intro John Berns, Solutions Architect, APAC - MapR Technologies April 22 nd, 2014 1 What This Is; What This Is Not It s not specific to IoT It s not about any specific
The Internet of Things and Big Data: Intro John Berns, Solutions Architect, APAC - MapR Technologies April 22 nd, 2014 1 What This Is; What This Is Not It s not specific to IoT It s not about any specific
Apache Flink Next-gen data analysis. Kostas Tzoumas [email protected] @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas [email protected] @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas [email protected] @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How To Create A Data Visualization With Apache Spark And Zeppelin 2.5.3.5
 Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com
 Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Apache Spark : Fast and Easy Data Processing Sujee Maniyam Elephant Scale LLC [email protected] http://elephantscale.com Spark Fast & Expressive Cluster computing engine Compatible with Hadoop Came
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Ali Ghodsi Head of PM and Engineering Databricks
 Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Spark and the Big Data Library
 Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
Spark and the Big Data Library Reza Zadeh Thanks to Matei Zaharia Problem Data growing faster than processing speeds Only solution is to parallelize on large clusters» Wide use in both enterprises and
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics
 E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Beyond Hadoop with Apache Spark and BDAS
 Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Beyond Hadoop with Apache Spark and BDAS Khanderao Kand Principal Technologist, Guavus 12 April GITPRO World 2014 Palo Alto, CA Credit: Some stajsjcs and content came from presentajons from publicly shared
Bayesian networks - Time-series models - Apache Spark & Scala
 Bayesian networks - Time-series models - Apache Spark & Scala Dr John Sandiford, CTO Bayes Server Data Science London Meetup - November 2014 1 Contents Introduction Bayesian networks Latent variables Anomaly
Bayesian networks - Time-series models - Apache Spark & Scala Dr John Sandiford, CTO Bayes Server Data Science London Meetup - November 2014 1 Contents Introduction Bayesian networks Latent variables Anomaly
CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University](/thumbs/26/8135278.jpg "CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
Spark and Shark. High- Speed In- Memory Analytics over Hadoop and Hive Data
 Spark and Shark High- Speed In- Memory Analytics over Hadoop and Hive Data Matei Zaharia, in collaboration with Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Cliff Engle, Michael Franklin, Haoyuan Li,
Spark and Shark High- Speed In- Memory Analytics over Hadoop and Hive Data Matei Zaharia, in collaboration with Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Cliff Engle, Michael Franklin, Haoyuan Li,
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Unlocking the True Value of Hadoop with Open Data Science
 Unlocking the True Value of Hadoop with Open Data Science Kristopher Overholt Solution Architect Big Data Tech 2016 MinneAnalytics June 7, 2016 Overview Overview of Open Data Science Python and the Big
Unlocking the True Value of Hadoop with Open Data Science Kristopher Overholt Solution Architect Big Data Tech 2016 MinneAnalytics June 7, 2016 Overview Overview of Open Data Science Python and the Big
Scalable Machine Learning - or what to do with all that Big Data infrastructure
 - or what to do with all that Big Data infrastructure TU Berlin blog.mikiobraun.de Strata+Hadoop World London, 2015 1 Complex Data Analysis at Scale Click-through prediction Personalized Spam Detection
- or what to do with all that Big Data infrastructure TU Berlin blog.mikiobraun.de Strata+Hadoop World London, 2015 1 Complex Data Analysis at Scale Click-through prediction Personalized Spam Detection
Big Data Approaches. Making Sense of Big Data. Ian Crosland. Jan 2016
 Big Data Approaches Making Sense of Big Data Ian Crosland Jan 2016 Accelerate Big Data ROI Even firms that are investing in Big Data are still struggling to get the most from it. Make Big Data Accessible
Big Data Approaches Making Sense of Big Data Ian Crosland Jan 2016 Accelerate Big Data ROI Even firms that are investing in Big Data are still struggling to get the most from it. Make Big Data Accessible
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
HADOOP. Revised 10/19/2015
 HADOOP Revised 10/19/2015 This Page Intentionally Left Blank Table of Contents Hortonworks HDP Developer: Java... 1 Hortonworks HDP Developer: Apache Pig and Hive... 2 Hortonworks HDP Developer: Windows...
HADOOP Revised 10/19/2015 This Page Intentionally Left Blank Table of Contents Hortonworks HDP Developer: Java... 1 Hortonworks HDP Developer: Apache Pig and Hive... 2 Hortonworks HDP Developer: Windows...
Architectures for massive data management
 Architectures for massive data management Apache Spark Albert Bifet [email protected] October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
Architectures for massive data management Apache Spark Albert Bifet [email protected] October 20, 2015 Spark Motivation Apache Spark Figure: IBM and Apache Spark What is Apache Spark Apache
SEIZE THE DATA. 2015 SEIZE THE DATA. 2015
 1 Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. BIG DATA CONFERENCE 2015 Boston August 10-13 Predicting and reducing deforestation
1 Copyright 2015 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice. BIG DATA CONFERENCE 2015 Boston August 10-13 Predicting and reducing deforestation
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us
 DATA INTELLIGENCE FOR ALL Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us Christopher Nguyen, PhD Co-Founder & CEO Agenda 1. Challenges & Motivation 2. DDF Overview 3. DDF Design
DATA INTELLIGENCE FOR ALL Distributed DataFrame on Spark: Simplifying Big Data For The Rest Of Us Christopher Nguyen, PhD Co-Founder & CEO Agenda 1. Challenges & Motivation 2. DDF Overview 3. DDF Design
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Spark. Fast, Interactive, Language- Integrated Cluster Computing
 Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Spark Fast, Interactive, Language- Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica UC
Big Data Infrastructure at Spotify
 Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure June 12, 2013 2 Agenda Let s talk about Data Infrastructure, how we did it, what we learned and how we ve failed Some Context
Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure June 12, 2013 2 Agenda Let s talk about Data Infrastructure, how we did it, what we learned and how we ve failed Some Context
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Data Analytics at NERSC. Joaquin Correa [email protected] NERSC Data and Analytics Services
 Data Analytics at NERSC Joaquin Correa [email protected] NERSC Data and Analytics Services NERSC User Meeting August, 2015 Data analytics at NERSC Science Applications Climate, Cosmology, Kbase, Materials,
Data Analytics at NERSC Joaquin Correa [email protected] NERSC Data and Analytics Services NERSC User Meeting August, 2015 Data analytics at NERSC Science Applications Climate, Cosmology, Kbase, Materials,
Introduction to Spark
 Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
Introduction to Spark Shannon Quinn (with thanks to Paco Nathan and Databricks) Quick Demo Quick Demo API Hooks Scala / Java All Java libraries *.jar http://www.scala- lang.org Python Anaconda: https://
MLlib: Scalable Machine Learning on Spark
 MLlib: Scalable Machine Learning on Spark Xiangrui Meng Collaborators: Ameet Talwalkar, Evan Sparks, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia, Rean Griffith, John Duchi, Joseph
MLlib: Scalable Machine Learning on Spark Xiangrui Meng Collaborators: Ameet Talwalkar, Evan Sparks, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia, Rean Griffith, John Duchi, Joseph
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
Making big data simple with Databricks
 Making big data simple with Databricks We are Databricks, the company behind Spark Founded by the creators of Apache Spark in 2013 Data 75% Share of Spark code contributed by Databricks in 2014 Value Created
Making big data simple with Databricks We are Databricks, the company behind Spark Founded by the creators of Apache Spark in 2013 Data 75% Share of Spark code contributed by Databricks in 2014 Value Created
Big Data Research in Berlin BBDC and Apache Flink
 Big Data Research in Berlin BBDC and Apache Flink Tilmann Rabl [email protected] dima.tu-berlin.de bbdc.berlin 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2015 Agenda About Data Management,
Big Data Research in Berlin BBDC and Apache Flink Tilmann Rabl [email protected] dima.tu-berlin.de bbdc.berlin 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2015 Agenda About Data Management,
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta [email protected] Radu Chilom [email protected] Buzzwords Berlin - 2015 Big data analytics / machine
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta [email protected] Radu Chilom [email protected] Buzzwords Berlin - 2015 Big data analytics / machine
How to use Big Data in Industry 4.0 implementations. LAURI ILISON, PhD Head of Big Data and Machine Learning
 How to use Big Data in Industry 4.0 implementations LAURI ILISON, PhD Head of Big Data and Machine Learning Big Data definition? Big Data is about structured vs unstructured data Big Data is about Volume
How to use Big Data in Industry 4.0 implementations LAURI ILISON, PhD Head of Big Data and Machine Learning Big Data definition? Big Data is about structured vs unstructured data Big Data is about Volume
DATA SCIENCE CURRICULUM WEEK 1 ONLINE PRE-WORK INSTALLING PACKAGES COMMAND LINE CODE EDITOR PYTHON STATISTICS PROJECT O5 PROJECT O3 PROJECT O2
 DATA SCIENCE CURRICULUM Before class even begins, students start an at-home pre-work phase. When they convene in class, students spend the first eight weeks doing iterative, project-centered skill acquisition.
DATA SCIENCE CURRICULUM Before class even begins, students start an at-home pre-work phase. When they convene in class, students spend the first eight weeks doing iterative, project-centered skill acquisition.
Streaming items through a cluster with Spark Streaming
 Streaming items through a cluster with Spark Streaming Tathagata TD Das @tathadas CME 323: Distributed Algorithms and Optimization Stanford, May 6, 2015 Who am I? > Project Management Committee (PMC) member
Streaming items through a cluster with Spark Streaming Tathagata TD Das @tathadas CME 323: Distributed Algorithms and Optimization Stanford, May 6, 2015 Who am I? > Project Management Committee (PMC) member
Spark: Cluster Computing with Working Sets
 Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
Spark: Cluster Computing with Working Sets Outline Why? Mesos Resilient Distributed Dataset Spark & Scala Examples Uses Why? MapReduce deficiencies: Standard Dataflows are Acyclic Prevents Iterative Jobs
CSE-E5430 Scalable Cloud Computing Lecture 11
 CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 30.11-2015 1/24 Distributed Coordination Systems Consensus
CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 30.11-2015 1/24 Distributed Coordination Systems Consensus
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming. by Dibyendu Bhattacharya
 Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Big Data and Scripting Systems beyond Hadoop
 Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
Big Data and Scripting Systems beyond Hadoop 1, 2, ZooKeeper distributed coordination service many problems are shared among distributed systems ZooKeeper provides an implementation that solves these avoid
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Big Data by the numbers
 COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
COMP 598 Applied Machine Learning Lecture 21: Parallelization methods for large-scale machine learning! Instructor: ([email protected]) TAs: Pierre-Luc Bacon ([email protected]) Ryan Lowe ([email protected])
1. The orange button 2. Audio Type 3. Close apps 4. Enlarge my screen 5. Headphones 6. Questions Pane. SparkR 2
 SparkR 1. The orange button 2. Audio Type 3. Close apps 4. Enlarge my screen 5. Headphones 6. Questions Pane SparkR 2 Lecture slides and/or video will be made available within one week Live Demonstration
SparkR 1. The orange button 2. Audio Type 3. Close apps 4. Enlarge my screen 5. Headphones 6. Questions Pane SparkR 2 Lecture slides and/or video will be made available within one week Live Demonstration
Up Your R Game. James Taylor, Decision Management Solutions Bill Franks, Teradata
 Up Your R Game James Taylor, Decision Management Solutions Bill Franks, Teradata Today s Speakers James Taylor Bill Franks CEO Chief Analytics Officer Decision Management Solutions Teradata 7/28/14 3 Polling
Up Your R Game James Taylor, Decision Management Solutions Bill Franks, Teradata Today s Speakers James Taylor Bill Franks CEO Chief Analytics Officer Decision Management Solutions Teradata 7/28/14 3 Polling
Upcoming Announcements
 Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC [email protected] Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC [email protected] Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Productionizing a 24/7 Spark Streaming Service on YARN
 Productionizing a 24/7 Spark Streaming Service on YARN Issac Buenrostro, Arup Malakar Spark Summit 2014 July 1, 2014 About Ooyala Cross-device video analytics and monetization products and services Founded
Productionizing a 24/7 Spark Streaming Service on YARN Issac Buenrostro, Arup Malakar Spark Summit 2014 July 1, 2014 About Ooyala Cross-device video analytics and monetization products and services Founded
Hybrid Software Architectures for Big Data. [email protected] @hurence http://www.hurence.com
 Hybrid Software Architectures for Big Data [email protected] @hurence http://www.hurence.com Headquarters : Grenoble Pure player Expert level consulting Training R&D Big Data X-data hot-line
Hybrid Software Architectures for Big Data [email protected] @hurence http://www.hurence.com Headquarters : Grenoble Pure player Expert level consulting Training R&D Big Data X-data hot-line
Analytics on Spark & Shark @Yahoo
 Analytics on Spark & Shark @Yahoo PRESENTED BY Tim Tully December 3, 2013 Overview Legacy / Current Hadoop Architecture Reflection / Pain Points Why the movement towards Spark / Shark New Hybrid Environment
Analytics on Spark & Shark @Yahoo PRESENTED BY Tim Tully December 3, 2013 Overview Legacy / Current Hadoop Architecture Reflection / Pain Points Why the movement towards Spark / Shark New Hybrid Environment
From Spark to Ignition:
 From Spark to Ignition: Fueling Your Business on Real-Time Analytics Eric Frenkiel, MemSQL CEO June 29, 2015 San Francisco, CA What s in Store For This Presentation? 1. MemSQL: A real-time database for
From Spark to Ignition: Fueling Your Business on Real-Time Analytics Eric Frenkiel, MemSQL CEO June 29, 2015 San Francisco, CA What s in Store For This Presentation? 1. MemSQL: A real-time database for
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Apache Flink. Fast and Reliable Large-Scale Data Processing
 Apache Flink Fast and Reliable Large-Scale Data Processing Fabian Hueske @fhueske 1 What is Apache Flink? Distributed Data Flow Processing System Focused on large-scale data analytics Real-time stream
Apache Flink Fast and Reliable Large-Scale Data Processing Fabian Hueske @fhueske 1 What is Apache Flink? Distributed Data Flow Processing System Focused on large-scale data analytics Real-time stream
Machine Learning over Big Data
 Machine Learning over Big Presented by Fuhao Zou [email protected] Jue 16, 2014 Huazhong University of Science and Technology Contents 1 2 3 4 Role of Machine learning Challenge of Big Analysis Distributed
Machine Learning over Big Presented by Fuhao Zou [email protected] Jue 16, 2014 Huazhong University of Science and Technology Contents 1 2 3 4 Role of Machine learning Challenge of Big Analysis Distributed
Brave New World: Hadoop vs. Spark
 Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Brave New World: Hadoop vs. Spark Dr. Kurt Stockinger Associate Professor of Computer Science Director of Studies in Data Science Zurich University of Applied Sciences Datalab Seminar, Zurich, Oct. 7,
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Big Data Analytics Hadoop and Spark
 Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Big Data Analytics Hadoop and Spark Shelly Garion, Ph.D. IBM Research Haifa 1 What is Big Data? 2 What is Big Data? Big data usually includes data sets with sizes beyond the ability of commonly used software
Monitis Project Proposals for AUA. September 2014, Yerevan, Armenia
 Monitis Project Proposals for AUA September 2014, Yerevan, Armenia Distributed Log Collecting and Analysing Platform Project Specifications Category: Big Data and NoSQL Software Requirements: Apache Hadoop
Monitis Project Proposals for AUA September 2014, Yerevan, Armenia Distributed Log Collecting and Analysing Platform Project Specifications Category: Big Data and NoSQL Software Requirements: Apache Hadoop
Pulsar Realtime Analytics At Scale. Tony Ng April 14, 2015
 Pulsar Realtime Analytics At Scale Tony Ng April 14, 2015 Big Data Trends Bigger data volumes More data sources DBs, logs, behavioral & business event streams, sensors Faster analysis Next day to hours
Pulsar Realtime Analytics At Scale Tony Ng April 14, 2015 Big Data Trends Bigger data volumes More data sources DBs, logs, behavioral & business event streams, sensors Faster analysis Next day to hours
Big Data Analytics. An Introduction. Oliver Fuchsberger University of Paderborn 2014
 Big Data Analytics An Introduction Oliver Fuchsberger University of Paderborn 2014 Table of Contents I. Introduction & Motivation What is Big Data Analytics? Why is it so important? II. Techniques & Solutions
Big Data Analytics An Introduction Oliver Fuchsberger University of Paderborn 2014 Table of Contents I. Introduction & Motivation What is Big Data Analytics? Why is it so important? II. Techniques & Solutions
Databricks. A Primer
 Databricks A Primer Who is Databricks? Databricks was founded by the team behind Apache Spark, the most active open source project in the big data ecosystem today. Our mission at Databricks is to dramatically
Databricks A Primer Who is Databricks? Databricks was founded by the team behind Apache Spark, the most active open source project in the big data ecosystem today. Our mission at Databricks is to dramatically
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Designing Agile Data Pipelines. Ashish Singh Software Engineer, Cloudera
 Designing Agile Data Pipelines Ashish Singh Software Engineer, Cloudera About Me Software Engineer @ Cloudera Contributed to Kafka, Hive, Parquet and Sentry Used to work in HPC @singhasdev 204 Cloudera,
Designing Agile Data Pipelines Ashish Singh Software Engineer, Cloudera About Me Software Engineer @ Cloudera Contributed to Kafka, Hive, Parquet and Sentry Used to work in HPC @singhasdev 204 Cloudera,
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Big Data Analytics with Cassandra, Spark & MLLib
 Big Data Analytics with Cassandra, Spark & MLLib Matthias Niehoff AGENDA Spark Basics In A Cluster Cassandra Spark Connector Use Cases Spark Streaming Spark SQL Spark MLLib Live Demo CQL QUERYING LANGUAGE
Big Data Analytics with Cassandra, Spark & MLLib Matthias Niehoff AGENDA Spark Basics In A Cluster Cassandra Spark Connector Use Cases Spark Streaming Spark SQL Spark MLLib Live Demo CQL QUERYING LANGUAGE
Big Data Processing. Patrick Wendell Databricks
 Big Data Processing Patrick Wendell Databricks About me Committer and PMC member of Apache Spark Former PhD student at Berkeley Left Berkeley to help found Databricks Now managing open source work at Databricks
Big Data Processing Patrick Wendell Databricks About me Committer and PMC member of Apache Spark Former PhD student at Berkeley Left Berkeley to help found Databricks Now managing open source work at Databricks
Spark Application Carousel. Spark Summit East 2015
 Spark Application Carousel Spark Summit East 2015 About Today s Talk About Me: Vida Ha - Solutions Engineer at Databricks. Goal: For beginning/early intermediate Spark Developers. Motivate you to start
Spark Application Carousel Spark Summit East 2015 About Today s Talk About Me: Vida Ha - Solutions Engineer at Databricks. Goal: For beginning/early intermediate Spark Developers. Motivate you to start
Journée Thématique Big Data 13/03/2015
 Journée Thématique Big Data 13/03/2015 1 Agenda About Flaminem What Do We Want To Predict? What Is The Machine Learning Theory Behind It? How Does It Work In Practice? What Is Happening When Data Gets
Journée Thématique Big Data 13/03/2015 1 Agenda About Flaminem What Do We Want To Predict? What Is The Machine Learning Theory Behind It? How Does It Work In Practice? What Is Happening When Data Gets
Reference Architecture, Requirements, Gaps, Roles
 Reference Architecture, Requirements, Gaps, Roles The contents of this document are an excerpt from the brainstorming document M0014. The purpose is to show how a detailed Big Data Reference Architecture
Reference Architecture, Requirements, Gaps, Roles The contents of this document are an excerpt from the brainstorming document M0014. The purpose is to show how a detailed Big Data Reference Architecture
Data-Intensive Applications on HPC Using Hadoop, Spark and RADICAL-Cybertools
 Data-Intensive Applications on HPC Using Hadoop, Spark and RADICAL-Cybertools Shantenu Jha, Andre Luckow, Ioannis Paraskevakos RADICAL, Rutgers, http://radical.rutgers.edu Agenda 1. Motivation and Background
Data-Intensive Applications on HPC Using Hadoop, Spark and RADICAL-Cybertools Shantenu Jha, Andre Luckow, Ioannis Paraskevakos RADICAL, Rutgers, http://radical.rutgers.edu Agenda 1. Motivation and Background
TE's Analytics on Hadoop and SAP HANA Using SAP Vora
 TE's Analytics on Hadoop and SAP HANA Using SAP Vora Naveen Narra Senior Manager TE Connectivity Santha Kumar Rajendran Enterprise Data Architect TE Balaji Krishna - Director, SAP HANA Product Mgmt. -
TE's Analytics on Hadoop and SAP HANA Using SAP Vora Naveen Narra Senior Manager TE Connectivity Santha Kumar Rajendran Enterprise Data Architect TE Balaji Krishna - Director, SAP HANA Product Mgmt. -
Big Data Use Case: Business Analytics
 Big Data Use Case: Business Analytics Starting point A telecommunications company wants to allude to the topic of Big Data. The established Big Data working group has access to the data stock of the enterprise
Big Data Use Case: Business Analytics Starting point A telecommunications company wants to allude to the topic of Big Data. The established Big Data working group has access to the data stock of the enterprise
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Databricks. A Primer
 Databricks A Primer Who is Databricks? Databricks vision is to empower anyone to easily build and deploy advanced analytics solutions. The company was founded by the team who created Apache Spark, a powerful
Databricks A Primer Who is Databricks? Databricks vision is to empower anyone to easily build and deploy advanced analytics solutions. The company was founded by the team who created Apache Spark, a powerful
COMP9321 Web Application Engineering
 COMP9321 Web Application Engineering Semester 2, 2015 Dr. Amin Beheshti Service Oriented Computing Group, CSE, UNSW Australia Week 11 (Part II) http://webapps.cse.unsw.edu.au/webcms2/course/index.php?cid=2411
COMP9321 Web Application Engineering Semester 2, 2015 Dr. Amin Beheshti Service Oriented Computing Group, CSE, UNSW Australia Week 11 (Part II) http://webapps.cse.unsw.edu.au/webcms2/course/index.php?cid=2411
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics
 Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at [email protected].
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at [email protected].
Big Data and Industrial Internet
 Big Data and Industrial Internet Keijo Heljanko Department of Computer Science and Helsinki Institute for Information Technology HIIT School of Science, Aalto University [email protected] 16.6-2015
Big Data and Industrial Internet Keijo Heljanko Department of Computer Science and Helsinki Institute for Information Technology HIIT School of Science, Aalto University [email protected] 16.6-2015
Next-Gen Big Data Analytics using the Spark stack
 Next-Gen Big Data Analytics using the Spark stack Jason Dai Chief Architect of Big Data Technologies Software and Services Group, Intel Agenda Overview Apache Spark stack Next-gen big data analytics Our
Next-Gen Big Data Analytics using the Spark stack Jason Dai Chief Architect of Big Data Technologies Software and Services Group, Intel Agenda Overview Apache Spark stack Next-gen big data analytics Our
Architectures for massive data management
 Architectures for massive data management Apache Kafka, Samza, Storm Albert Bifet [email protected] October 20, 2015 Stream Engine Motivation Digital Universe EMC Digital Universe with
Architectures for massive data management Apache Kafka, Samza, Storm Albert Bifet [email protected] October 20, 2015 Stream Engine Motivation Digital Universe EMC Digital Universe with
Data Science in the Wild
 Data Science in the Wild Lecture 4 59 Apache Spark 60 1 What is Spark? Not a modified version of Hadoop Separate, fast, MapReduce-like engine In-memory data storage for very fast iterative queries General
Data Science in the Wild Lecture 4 59 Apache Spark 60 1 What is Spark? Not a modified version of Hadoop Separate, fast, MapReduce-like engine In-memory data storage for very fast iterative queries General
BIG DATA ANALYTICS For REAL TIME SYSTEM
 BIG DATA ANALYTICS For REAL TIME SYSTEM Where does big data come from? Big Data is often boiled down to three main varieties: Transactional data these include data from invoices, payment orders, storage
BIG DATA ANALYTICS For REAL TIME SYSTEM Where does big data come from? Big Data is often boiled down to three main varieties: Transactional data these include data from invoices, payment orders, storage
The Top 10 7 Hadoop Patterns and Anti-patterns. Alex Holmes @
 The Top 10 7 Hadoop Patterns and Anti-patterns Alex Holmes @ whoami Alex Holmes Software engineer Working on distributed systems for many years Hadoop since 2008 @grep_alex grepalex.com what s hadoop...
The Top 10 7 Hadoop Patterns and Anti-patterns Alex Holmes @ whoami Alex Holmes Software engineer Working on distributed systems for many years Hadoop since 2008 @grep_alex grepalex.com what s hadoop...
Let the data speak to you. Look Who s Peeking at Your Paycheck. Big Data. What is Big Data? The Artemis project: Saving preemies using Big Data
 CS535 Big Data W1.A.1 CS535 BIG DATA W1.A.2 Let the data speak to you Medication Adherence Score How likely people are to take their medication, based on: How long people have lived at the same address
CS535 Big Data W1.A.1 CS535 BIG DATA W1.A.2 Let the data speak to you Medication Adherence Score How likely people are to take their medication, based on: How long people have lived at the same address
Embracing Spark as the Scalable Data Analytics Platform for the Enterprise
 Embracing Spark as the Scalable Data Analytics Platform for the Enterprise Matthew J. Glickman GS.com/Engineering Spark Summit East 2015 1 How did we get here today? Strata + Hadoop World October 2014
Embracing Spark as the Scalable Data Analytics Platform for the Enterprise Matthew J. Glickman GS.com/Engineering Spark Summit East 2015 1 How did we get here today? Strata + Hadoop World October 2014
Advanced In-Database Analytics
 Advanced In-Database Analytics Tallinn, Sept. 25th, 2012 Mikko-Pekka Bertling, BDM Greenplum EMEA 1 That sounds complicated? 2 Who can tell me how best to solve this 3 What are the main mathematical functions??
Advanced In-Database Analytics Tallinn, Sept. 25th, 2012 Mikko-Pekka Bertling, BDM Greenplum EMEA 1 That sounds complicated? 2 Who can tell me how best to solve this 3 What are the main mathematical functions??
HPE Vertica & Hadoop. Tapping Innovation to Turbocharge Your Big Data. #SeizeTheData
 HPE Vertica & Hadoop Tapping Innovation to Turbocharge Your Big Data #SeizeTheData The HPE Vertica portfolio One Vertica Engine running on Cloud, Bare Metal, or Hadoop Data Nodes HPE Vertica OnDemand &
HPE Vertica & Hadoop Tapping Innovation to Turbocharge Your Big Data #SeizeTheData The HPE Vertica portfolio One Vertica Engine running on Cloud, Bare Metal, or Hadoop Data Nodes HPE Vertica OnDemand &
Parallel Data Mining. Team 2 Flash Coders Team Research Investigation Presentation 2. Foundations of Parallel Computing Oct 2014
 Parallel Data Mining Team 2 Flash Coders Team Research Investigation Presentation 2 Foundations of Parallel Computing Oct 2014 Agenda Overview of topic Analysis of research papers Software design Overview
Parallel Data Mining Team 2 Flash Coders Team Research Investigation Presentation 2 Foundations of Parallel Computing Oct 2014 Agenda Overview of topic Analysis of research papers Software design Overview
HiBench Introduction. Carson Wang ([email protected]) Software & Services Group
 Software & Services Group") HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
HiBench Introduction Carson Wang ([email protected]) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
Mobile Monetization Scenario Design & Big Data. Arther Wu Senior Director of Monetization and Business Operation
 Mobile Monetization Scenario Design & Big Data Arther Wu Senior Director of Monetization and Business Operation Agenda Quick update of Cheetah Mobile Ad Scenario Design Big Data / Relation with Advertising
Mobile Monetization Scenario Design & Big Data Arther Wu Senior Director of Monetization and Business Operation Agenda Quick update of Cheetah Mobile Ad Scenario Design Big Data / Relation with Advertising
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document