Big Systems, Big Data
|
|
|
- Barrie Cameron
- 8 years ago
- Views:
Transcription
1 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability, synchronisation) allied with issues of size
 allied with")
2 Big Data Quote from Tim O Reilly, in What is Web 2.0, (2005) data is the next Intel Inside. Hal Varian quote (2009) : The ability to take data to be able to understand it, to process it, to extract value from it, to visualize it, to communicate it that s going to be a hugely important skill in the next decades.

3 Moore s Law From early PCs in 1980s to now Memory has scaled as quickly or more so as CPU cycles processor speed has increased from MHz to GHz memory from MB to GB Reduction in price $1,000 a MB to <$25 a GB

4 Big Data How big is Big? When the size of the data itself becomes part of the problem. Importance of leveraging data Google Facebook LinkedIn Amaxon Google mapping trends, learning from large data sets Analytics the science of analysis

5

6

7 Big Data: need scalable databases Data server I/O bottleneck many writes fast changing data lots of unrelated reads (not in cache) Examples: Facebook, LinkedIn, Flickr, MySpace etc Scaling-up is expensive and doesn t solve the problem Solution: shardingthe database look up using key (e.g. user id) which database to use cost-effective increased complexity

8 Common ShardingSchemes (outline by Dare Obasanjo) Vertical Partitioning segment the application data by having tables related to specific features on their own server. For example, user profile on one database server order history on another reviews and blog on another

9 Common ShardingSchemes Range Based Partitioning: Large data set for a single feature/entity subdivided across multiple servers can use some value range that occurs within entity for predictable partitioning Examples partition by date partition by post-code Needs careful choice of value whose range is used for partitioning If not chosen well then leads to unbalanced servers

10 Common ShardingSchemes Key or Hash Based Partitioning: value from each entity used as input to a hash function whose output determines which database server to use. commonly used for user based partitioning Example Have N servers Have a numeric value, e.g. Student Number Then hashing the numeric value can be done using the Modulo N operation Suitable when fixed number of servers

11 Common ShardingSchemes Directory Based Partitioning: Employ a lookup scheme Maps each entity key to the database server it resides Use directory database or directory web-service for lookup Abstracts away partitioning scheme and actual database used Loose coupling offers advantages in updating, altering number of servers, changing hash function etc

12 ShardingProblems Operations across multiple tables or multiple rows in the same table no longer run on the same server. Joins and Denormalization often not feasible to perform joins that span database shards due to performance constraints since data has to be retrieved from multiple servers

13 ShardingProblems Referential integrity difficult to enforce data integrity constraints such as foreign keys in a shardeddatabase. applications that require referential integrity often have to enforce it in special code and run regular SQL jobs to tidy up. dealing with data inconsistency issues (due to lack of referential integrity and denormalization) can become a significant development cost to the service.

14 Denormalising Denormalise to avoid accessing two shards and doing a join Denormalise: Duplicate some data so that it s available in two shards Efficient to retrieve data Danger of inconsistency data updates need to be duplicates

15 Sharding problems Changing sharding scheme e.g. due to bad choice of partitioning scheme need to change partitioning scheme change and relocate data to different servers downtime, and recode of some applications Directory based partitioning diminishes overhead of changing sharding but is single point of failure

16 Alternatives to relational databases NoSQL databases (Non-Relational databases) (Not Only SQL) includes many different kinds of solution Use tree, graph, key-value pairs rather than tables, fixed schema distributed across many nodes support BASE rather than ACID guarantees eventually consistent flexible schema, denormalized Original examples: BigTableat Google, and Dynamo at Amazon, Cassandra used at Facebook, Twitter, Rackspace, HBase: part of the Apache Hadoopproject

17 Bigdata: Structured vsunstructured data General software engineering data model: describes classes/objects, their properties and relationships (e.g. as might be used to describe real-world entities in the UML Domain Class Diagram). More specific data models used for describing relational databases Structured Data conforms to a pre-defined data model or is organized according to a pre-defined structural data model

18 Bigdata: Structured vs unstructured data Structured data is often represented by a Table, and implemented in a relational database Employee Department Salary J Jones Sales M Smith Sales I Walsh Admin (have datatypes with well-defined sets of values, ranges of values) 18

19 Bigdata: Structured vsunstructured data Unstructured Data: refers to information that either does not have a pre-defined data model or is not organized in a pre-defined manner. typical examples: natural language text, audio, images, video Semi-structured data: some structure associated with most data, e.g. sender, time-stamp, hashtags of tweet; logfile structure


20 SAP example: analysingtext

21 Bigdata: Structured vsunstructured data In natural language text analysis Need to often Find structural elements Do some keyword queries including operators Map to some sophisticated concept queries e.g., find all tweets referring to illness
22 Bigdata: Structured vsunstructured data Organisations like International Data Corporation (IDC)and MerrilLynch estimate that 80-90% of data is now unstructured, and that in 2014 almost 90% of data storage bought will be for unstructured data Storing and analysing big-data involves both traditional relational databases (RDBs) and the newer MapReduce/Hadoop paradigm
23 Computing over Big Data Sets Google s MapReduce See Google tutorial
24 MapReduce Overview MapReduce Framework for parallel computing Programmers get simple API Framework handles parallelization data distribution load balancing fault tolerance Works with sharding to allow parallel processing of large (terabytes and petabytes) datasets
25 MapReduceframework overview
26 Framework Map user supplied function gets called for each chunk of input; sort and partition output Reduce user supplied function gets called to combine/aggregate the results
27 MapReduce Main Implementations Google s original MapReduce Apache Hadoop MapReduce Standard open-source implementation Amazon Elastic MapReduce Uses Hadoop MapReduce running on Amazon EC2
28 MapReduce/HadoopSimple Example (IBM MapReduceoverview) The simple problem is to take lots of temperature records for cities around the world (e.g. hourly samples over a year), and do some simple analysis such as maximum in each city over that extended period. This could be implemented with a RDB using a simple table with 2 columns but the data and analysis are much simpler than that implemented by a RDB, and can be done more efficiently without the overhead of a RDB Each piece of data can be represented as a key-value pair, where city is the key and temperature is the value.
29 Dublin, 17 New York, 22 Rome, 32 Toronto, 4 Rome, 33 Dublin, 15 New York, 24 Rome, 32 Toronto, 4 Rome, 30 New York, 18 Toronto, 8 Key-value pairs model
30 Simple Example The MapReduce/Hadoopparadigm is optimized for this kind of key-value pair data analysis, where we can efficiently analysis these files in parallel, and then collect the intermediate results to produce the final result From all the data we have collected, we want to find the maximum temperature for each city across all of the data files (note that each file might have the same city represented multiple times). Assume we split the data into a number of files (for this example, 5), and each file contains two columns that represent a city and the corresponding temperature recorded in that city for the various measurement days.
31 Map tasks Using the MapReduce/Hadoopframework, let s break this down into five map tasks, where each mapperworks on one of the five files and the mappertask goes through the data and returns the maximum temperature for each city. For example, the intermediate results produced from one mapper task for one file: (Toronto, 20) (Dublin, 25) (New York, 22) (Rome, 33)
32 Reduce tasks Let s assume the five mappertasks produce the following intermediate results: (Toronto, 20) (Dublin, 25) (New York, 22) (Rome, 33) (Toronto, 18) (Dublin, 27) (New York, 32) (Rome, 37) (Toronto, 32) (Dublin, 20) (New York, 33) (Rome, 38) (Toronto, 22) (Dublin, 19) (New York, 20) (Rome, 31) (Toronto, 31) (Dublin, 22) (New York, 19) (Rome, 30) All five of these output streams would be fed into the reduce tasks, which combine the input results and output a single value for each city, producing a final result set as follows: (Toronto, 32) (Dublin, 27) (New York, 33) (Rome, 38)
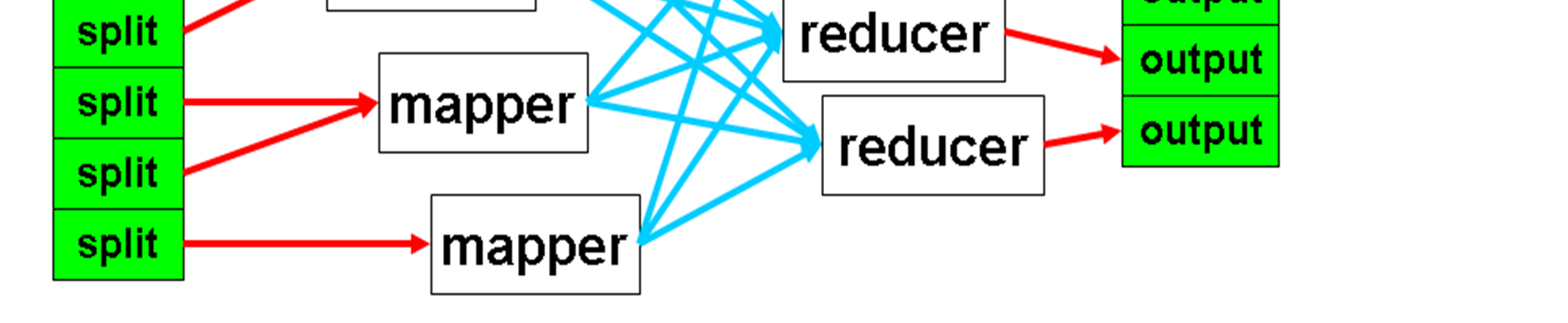
33 MapReduceframework overview
34 Map and Reduce in Functional Programming Map(function, set of values) Applies function to each value in the set Examples map length ((a b) (a) (a b) (a b c)) ( ) map (\x. x*2) ( ) ( ) Reduce(function, set of values) Combines all the values using a binary function (e.g., +) reduce # + 0 ( )) 30 First application is (0 + 16), the result of that then combined with next value, 1, (16 + 1), then (17 + 9) (26 + 4) reduce # * 1 ( )) 12
35 Big data Issues include Size and nature of data Structured/Unstructured data Database bottleneck Sharding of data/memcaching NoSQLalternatives to traditional relational database solutions More efficient computation over large data sets, for example, MapReduce
36 nano- n 10-9* -- micro- m 10-6* -- milli- m 10-3* -- centi- c 10-2* -- deci- d 10-1* -- (none) deka- D 10 1 * -- hecto- h 10 2 * -- kilo- k or K ** mega- M giga- G tera- T peta- P exa- E * 2 60 zetta- Z * 2 70 yotta- Y * 2 80 ** k = 10 3 and K = 2 10
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
INTRODUCTION TO CASSANDRA
 INTRODUCTION TO CASSANDRA This ebook provides a high level overview of Cassandra and describes some of its key strengths and applications. WHAT IS CASSANDRA? Apache Cassandra is a high performance, open
INTRODUCTION TO CASSANDRA This ebook provides a high level overview of Cassandra and describes some of its key strengths and applications. WHAT IS CASSANDRA? Apache Cassandra is a high performance, open
Big Data Buzzwords From A to Z. By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012
 Big Data Buzzwords From A to Z By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012 Big Data Buzzwords Big data is one of the, well, biggest trends in IT today, and it has spawned a whole new generation
Big Data Buzzwords From A to Z By Rick Whiting, CRN 4:00 PM ET Wed. Nov. 28, 2012 Big Data Buzzwords Big data is one of the, well, biggest trends in IT today, and it has spawned a whole new generation
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect
 Huibert Aalbers Senior Certified Executive IT Architect") The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Benchmarking and Analysis of NoSQL Technologies
 Benchmarking and Analysis of NoSQL Technologies Suman Kashyap 1, Shruti Zamwar 2, Tanvi Bhavsar 3, Snigdha Singh 4 1,2,3,4 Cummins College of Engineering for Women, Karvenagar, Pune 411052 Abstract The
Benchmarking and Analysis of NoSQL Technologies Suman Kashyap 1, Shruti Zamwar 2, Tanvi Bhavsar 3, Snigdha Singh 4 1,2,3,4 Cummins College of Engineering for Women, Karvenagar, Pune 411052 Abstract The
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
SQL VS. NO-SQL. Adapted Slides from Dr. Jennifer Widom from Stanford
 SQL VS. NO-SQL Adapted Slides from Dr. Jennifer Widom from Stanford 55 Traditional Databases SQL = Traditional relational DBMS Hugely popular among data analysts Widely adopted for transaction systems
SQL VS. NO-SQL Adapted Slides from Dr. Jennifer Widom from Stanford 55 Traditional Databases SQL = Traditional relational DBMS Hugely popular among data analysts Widely adopted for transaction systems
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
Lecture Data Warehouse Systems
 Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
A COMPARATIVE STUDY OF NOSQL DATA STORAGE MODELS FOR BIG DATA
 A COMPARATIVE STUDY OF NOSQL DATA STORAGE MODELS FOR BIG DATA Ompal Singh Assistant Professor, Computer Science & Engineering, Sharda University, (India) ABSTRACT In the new era of distributed system where
A COMPARATIVE STUDY OF NOSQL DATA STORAGE MODELS FOR BIG DATA Ompal Singh Assistant Professor, Computer Science & Engineering, Sharda University, (India) ABSTRACT In the new era of distributed system where
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Keywords Big Data; OODBMS; RDBMS; hadoop; EDM; learning analytics, data abundance.
 Volume 4, Issue 11, November 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Analytics
Volume 4, Issue 11, November 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Analytics
Big Data Storage, Management and challenges. Ahmed Ali-Eldin
 Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Big Data Storage, Management and challenges Ahmed Ali-Eldin (Ambitious) Plan What is Big Data? And Why talk about Big Data? How to store Big Data? BigTables (Google) Dynamo (Amazon) How to process Big
Data Modeling for Big Data
 Data Modeling for Big Data by Jinbao Zhu, Principal Software Engineer, and Allen Wang, Manager, Software Engineering, CA Technologies In the Internet era, the volume of data we deal with has grown to terabytes
Data Modeling for Big Data by Jinbao Zhu, Principal Software Engineer, and Allen Wang, Manager, Software Engineering, CA Technologies In the Internet era, the volume of data we deal with has grown to terabytes
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: bdg@qburst.com Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
these three NoSQL databases because I wanted to see a the two different sides of the CAP
 Michael Sharp Big Data CS401r Lab 3 For this paper I decided to do research on MongoDB, Cassandra, and Dynamo. I chose these three NoSQL databases because I wanted to see a the two different sides of the
Michael Sharp Big Data CS401r Lab 3 For this paper I decided to do research on MongoDB, Cassandra, and Dynamo. I chose these three NoSQL databases because I wanted to see a the two different sides of the
NoSQL Databases. Institute of Computer Science Databases and Information Systems (DBIS) DB 2, WS 2014/2015
 DB 2, WS 2014/2015") NoSQL Databases Institute of Computer Science Databases and Information Systems (DBIS) DB 2, WS 2014/2015 Database Landscape Source: H. Lim, Y. Han, and S. Babu, How to Fit when No One Size Fits., in CIDR,
NoSQL Databases Institute of Computer Science Databases and Information Systems (DBIS) DB 2, WS 2014/2015 Database Landscape Source: H. Lim, Y. Han, and S. Babu, How to Fit when No One Size Fits., in CIDR,
Can the Elephants Handle the NoSQL Onslaught?
 Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Cluster Computing. ! Fault tolerance. ! Stateless. ! Throughput. ! Stateful. ! Response time. Architectures. Stateless vs. Stateful.
 Architectures Cluster Computing Job Parallelism Request Parallelism 2 2010 VMware Inc. All rights reserved Replication Stateless vs. Stateful! Fault tolerance High availability despite failures If one
Architectures Cluster Computing Job Parallelism Request Parallelism 2 2010 VMware Inc. All rights reserved Replication Stateless vs. Stateful! Fault tolerance High availability despite failures If one
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Map Reduce / Hadoop / HDFS
 Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
NoSQL Databases. Nikos Parlavantzas
 !!!! NoSQL Databases Nikos Parlavantzas Lecture overview 2 Objective! Present the main concepts necessary for understanding NoSQL databases! Provide an overview of current NoSQL technologies Outline 3!
!!!! NoSQL Databases Nikos Parlavantzas Lecture overview 2 Objective! Present the main concepts necessary for understanding NoSQL databases! Provide an overview of current NoSQL technologies Outline 3!
An Approach to Implement Map Reduce with NoSQL Databases
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN: 2319-7242 Volume 4 Issue 8 Aug 2015, Page No. 13635-13639 An Approach to Implement Map Reduce with NoSQL Databases Ashutosh
www.ijecs.in International Journal Of Engineering And Computer Science ISSN: 2319-7242 Volume 4 Issue 8 Aug 2015, Page No. 13635-13639 An Approach to Implement Map Reduce with NoSQL Databases Ashutosh
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
InfiniteGraph: The Distributed Graph Database
 A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
A survey of big data architectures for handling massive data
 CSIT 6910 Independent Project A survey of big data architectures for handling massive data Jordy Domingos - jordydomingos@gmail.com Supervisor : Dr David Rossiter Content Table 1 - Introduction a - Context
CSIT 6910 Independent Project A survey of big data architectures for handling massive data Jordy Domingos - jordydomingos@gmail.com Supervisor : Dr David Rossiter Content Table 1 - Introduction a - Context
Big Data: Study in Structured and Unstructured Data
 Big Data: Study in Structured and Unstructured Data Motashim Rasool 1, Wasim Khan 2 mail2motashim@gmail.com, khanwasim051@gmail.com Abstract With the overlay of digital world, Information is available
Big Data: Study in Structured and Unstructured Data Motashim Rasool 1, Wasim Khan 2 mail2motashim@gmail.com, khanwasim051@gmail.com Abstract With the overlay of digital world, Information is available
A Novel Cloud Based Elastic Framework for Big Data Preprocessing
 School of Systems Engineering A Novel Cloud Based Elastic Framework for Big Data Preprocessing Omer Dawelbeit and Rachel McCrindle October 21, 2014 University of Reading 2008 www.reading.ac.uk Overview
School of Systems Engineering A Novel Cloud Based Elastic Framework for Big Data Preprocessing Omer Dawelbeit and Rachel McCrindle October 21, 2014 University of Reading 2008 www.reading.ac.uk Overview
Associate Professor, Department of CSE, Shri Vishnu Engineering College for Women, Andhra Pradesh, India 2
 Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
 wow CPSC350 relational schemas table normalization practical use of relational algebraic operators tuple relational calculus and their expression in a declarative query language relational schemas CPSC350
wow CPSC350 relational schemas table normalization practical use of relational algebraic operators tuple relational calculus and their expression in a declarative query language relational schemas CPSC350
Big Data: Opportunities & Challenges, Myths & Truths 資 料 來 源 : 台 大 廖 世 偉 教 授 課 程 資 料
 Big Data: Opportunities & Challenges, Myths & Truths 資 料 來 源 : 台 大 廖 世 偉 教 授 課 程 資 料 美 國 13 歲 學 生 用 Big Data 找 出 霸 淩 熱 點 Puri 架 設 網 站 Bullyvention, 藉 由 分 析 Twitter 上 找 出 提 到 跟 霸 凌 相 關 的 詞, 搭 配 地 理 位 置
Big Data: Opportunities & Challenges, Myths & Truths 資 料 來 源 : 台 大 廖 世 偉 教 授 課 程 資 料 美 國 13 歲 學 生 用 Big Data 找 出 霸 淩 熱 點 Puri 架 設 網 站 Bullyvention, 藉 由 分 析 Twitter 上 找 出 提 到 跟 霸 凌 相 關 的 詞, 搭 配 地 理 位 置
NoSQL Systems for Big Data Management
 NoSQL Systems for Big Data Management Venkat N Gudivada East Carolina University Greenville, North Carolina USA Venkat Gudivada NoSQL Systems for Big Data Management 1/28 Outline 1 An Overview of NoSQL
NoSQL Systems for Big Data Management Venkat N Gudivada East Carolina University Greenville, North Carolina USA Venkat Gudivada NoSQL Systems for Big Data Management 1/28 Outline 1 An Overview of NoSQL
How To Handle Big Data With A Data Scientist
 III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
NoSQL Database Options
 NoSQL Database Options Introduction For this report, I chose to look at MongoDB, Cassandra, and Riak. I chose MongoDB because it is quite commonly used in the industry. I chose Cassandra because it has
NoSQL Database Options Introduction For this report, I chose to look at MongoDB, Cassandra, and Riak. I chose MongoDB because it is quite commonly used in the industry. I chose Cassandra because it has
Hadoop. http://hadoop.apache.org/ Sunday, November 25, 12
 Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
Hadoop http://hadoop.apache.org/ What Is Apache Hadoop? The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Study concluded that success rate for penetration from outside threats higher in corporate data centers
 Auditing in the cloud Ownership of data Historically, with the company Company responsible to secure data Firewall, infrastructure hardening, database security Auditing Performed on site by inspecting
Auditing in the cloud Ownership of data Historically, with the company Company responsible to secure data Firewall, infrastructure hardening, database security Auditing Performed on site by inspecting
A programming model in Cloud: MapReduce
 A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
NoSQL systems: introduction and data models. Riccardo Torlone Università Roma Tre
 NoSQL systems: introduction and data models Riccardo Torlone Università Roma Tre Why NoSQL? In the last thirty years relational databases have been the default choice for serious data storage. An architect
NoSQL systems: introduction and data models Riccardo Torlone Università Roma Tre Why NoSQL? In the last thirty years relational databases have been the default choice for serious data storage. An architect
Analytics in the Cloud. Peter Sirota, GM Elastic MapReduce
 Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Keywords Big Data, NoSQL, Relational Databases, Decision Making using Big Data, Hadoop
 Volume 4, Issue 1, January 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Transitioning
Volume 4, Issue 1, January 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Transitioning
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
NoSQL. Thomas Neumann 1 / 22
 NoSQL Thomas Neumann 1 / 22 What are NoSQL databases? hard to say more a theme than a well defined thing Usually some or all of the following: no SQL interface no relational model / no schema no joins,
NoSQL Thomas Neumann 1 / 22 What are NoSQL databases? hard to say more a theme than a well defined thing Usually some or all of the following: no SQL interface no relational model / no schema no joins,
Development of nosql data storage for the ATLAS PanDA Monitoring System
 Development of nosql data storage for the ATLAS PanDA Monitoring System M.Potekhin Brookhaven National Laboratory, Upton, NY11973, USA E-mail: potekhin@bnl.gov Abstract. For several years the PanDA Workload
Development of nosql data storage for the ATLAS PanDA Monitoring System M.Potekhin Brookhaven National Laboratory, Upton, NY11973, USA E-mail: potekhin@bnl.gov Abstract. For several years the PanDA Workload
Market Basket Analysis Algorithm on Map/Reduce in AWS EC2
 Market Basket Analysis Algorithm on Map/Reduce in AWS EC2 Jongwook Woo Computer Information Systems Department California State University Los Angeles jwoo5@calstatela.edu Abstract As the web, social networking,
Market Basket Analysis Algorithm on Map/Reduce in AWS EC2 Jongwook Woo Computer Information Systems Department California State University Los Angeles jwoo5@calstatela.edu Abstract As the web, social networking,
Slave. Master. Research Scholar, Bharathiar University
 Volume 3, Issue 7, July 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper online at: www.ijarcsse.com Study on Basically, and Eventually
Volume 3, Issue 7, July 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper online at: www.ijarcsse.com Study on Basically, and Eventually
Finding Insights & Hadoop Cluster Performance Analysis over Census Dataset Using Big-Data Analytics
 Finding Insights & Hadoop Cluster Performance Analysis over Census Dataset Using Big-Data Analytics Dharmendra Agawane 1, Rohit Pawar 2, Pavankumar Purohit 3, Gangadhar Agre 4 Guide: Prof. P B Jawade 2
Finding Insights & Hadoop Cluster Performance Analysis over Census Dataset Using Big-Data Analytics Dharmendra Agawane 1, Rohit Pawar 2, Pavankumar Purohit 3, Gangadhar Agre 4 Guide: Prof. P B Jawade 2
Referential Integrity in Cloud NoSQL Databases
 Referential Integrity in Cloud NoSQL Databases by Harsha Raja A thesis submitted to the Victoria University of Wellington in partial fulfilment of the requirements for the degree of Master of Engineering
Referential Integrity in Cloud NoSQL Databases by Harsha Raja A thesis submitted to the Victoria University of Wellington in partial fulfilment of the requirements for the degree of Master of Engineering
nosql and Non Relational Databases
 nosql and Non Relational Databases Image src: http://www.pentaho.com/big-data/nosql/ Matthias Lee Johns Hopkins University What NoSQL? Yes no SQL.. Atleast not only SQL Large class of Non Relaltional Databases
nosql and Non Relational Databases Image src: http://www.pentaho.com/big-data/nosql/ Matthias Lee Johns Hopkins University What NoSQL? Yes no SQL.. Atleast not only SQL Large class of Non Relaltional Databases
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
NoSQL Data Base Basics
 NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
NoSQL Data Base Basics Course Notes in Transparency Format Cloud Computing MIRI (CLC-MIRI) UPC Master in Innovation & Research in Informatics Spring- 2013 Jordi Torres, UPC - BSC www.jorditorres.eu HDFS
BRAC. Investigating Cloud Data Storage UNIVERSITY SCHOOL OF ENGINEERING. SUPERVISOR: Dr. Mumit Khan DEPARTMENT OF COMPUTER SCIENCE AND ENGEENIRING
 BRAC UNIVERSITY SCHOOL OF ENGINEERING DEPARTMENT OF COMPUTER SCIENCE AND ENGEENIRING 12-12-2012 Investigating Cloud Data Storage Sumaiya Binte Mostafa (ID 08301001) Firoza Tabassum (ID 09101028) BRAC University
BRAC UNIVERSITY SCHOOL OF ENGINEERING DEPARTMENT OF COMPUTER SCIENCE AND ENGEENIRING 12-12-2012 Investigating Cloud Data Storage Sumaiya Binte Mostafa (ID 08301001) Firoza Tabassum (ID 09101028) BRAC University
SEAIP 2009 Presentation
 SEAIP 2009 Presentation By David Tan Chair of Yahoo! Hadoop SIG, 2008-2009,Singapore EXCO Member of SGF SIG Imperial College (UK), Institute of Fluid Science (Japan) & Chicago BOOTH GSB (USA) Alumni Email:
SEAIP 2009 Presentation By David Tan Chair of Yahoo! Hadoop SIG, 2008-2009,Singapore EXCO Member of SGF SIG Imperial College (UK), Institute of Fluid Science (Japan) & Chicago BOOTH GSB (USA) Alumni Email:
Composite Data Virtualization Composite Data Virtualization And NOSQL Data Stores
 Composite Data Virtualization Composite Data Virtualization And NOSQL Data Stores Composite Software October 2010 TABLE OF CONTENTS INTRODUCTION... 3 BUSINESS AND IT DRIVERS... 4 NOSQL DATA STORES LANDSCAPE...
Composite Data Virtualization Composite Data Virtualization And NOSQL Data Stores Composite Software October 2010 TABLE OF CONTENTS INTRODUCTION... 3 BUSINESS AND IT DRIVERS... 4 NOSQL DATA STORES LANDSCAPE...
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Testing 3Vs (Volume, Variety and Velocity) of Big Data
 of Big Data") Testing 3Vs (Volume, Variety and Velocity) of Big Data 1 A lot happens in the Digital World in 60 seconds 2 What is Big Data Big Data refers to data sets whose size is beyond the ability of commonly used
Testing 3Vs (Volume, Variety and Velocity) of Big Data 1 A lot happens in the Digital World in 60 seconds 2 What is Big Data Big Data refers to data sets whose size is beyond the ability of commonly used
Chapter 6 8/12/2015. Foundations of Business Intelligence: Databases and Information Management. Problem:
 Foundations of Business Intelligence: Databases and Information Management VIDEO CASES Chapter 6 Case 1a: City of Dubuque Uses Cloud Computing and Sensors to Build a Smarter, Sustainable City Case 1b:
Foundations of Business Intelligence: Databases and Information Management VIDEO CASES Chapter 6 Case 1a: City of Dubuque Uses Cloud Computing and Sensors to Build a Smarter, Sustainable City Case 1b:
NoSQL Database Systems and their Security Challenges
 NoSQL Database Systems and their Security Challenges Morteza Amini amini@sharif.edu Data & Network Security Lab (DNSL) Department of Computer Engineering Sharif University of Technology September 25 2
NoSQL Database Systems and their Security Challenges Morteza Amini amini@sharif.edu Data & Network Security Lab (DNSL) Department of Computer Engineering Sharif University of Technology September 25 2
Infrastructures for big data
 Infrastructures for big data Rasmus Pagh 1 Today s lecture Three technologies for handling big data: MapReduce (Hadoop) BigTable (and descendants) Data stream algorithms Alternatives to (some uses of)
Infrastructures for big data Rasmus Pagh 1 Today s lecture Three technologies for handling big data: MapReduce (Hadoop) BigTable (and descendants) Data stream algorithms Alternatives to (some uses of)
Cloud Scale Distributed Data Storage. Jürmo Mehine
 Cloud Scale Distributed Data Storage Jürmo Mehine 2014 Outline Background Relational model Database scaling Keys, values and aggregates The NoSQL landscape Non-relational data models Key-value Document-oriented
Cloud Scale Distributed Data Storage Jürmo Mehine 2014 Outline Background Relational model Database scaling Keys, values and aggregates The NoSQL landscape Non-relational data models Key-value Document-oriented
How To Use Big Data For Telco (For A Telco)
") ON-LINE VIDEO ANALYTICS EMBRACING BIG DATA David Vanderfeesten, Bell Labs Belgium ANNO 2012 YOUR DATA IS MONEY BIG MONEY! Your click stream, your activity stream, your electricity consumption, your call
ON-LINE VIDEO ANALYTICS EMBRACING BIG DATA David Vanderfeesten, Bell Labs Belgium ANNO 2012 YOUR DATA IS MONEY BIG MONEY! Your click stream, your activity stream, your electricity consumption, your call
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Scalable Architecture on Amazon AWS Cloud
 Scalable Architecture on Amazon AWS Cloud Kalpak Shah Founder & CEO, Clogeny Technologies kalpak@clogeny.com 1 * http://www.rightscale.com/products/cloud-computing-uses/scalable-website.php 2 Architect
Scalable Architecture on Amazon AWS Cloud Kalpak Shah Founder & CEO, Clogeny Technologies kalpak@clogeny.com 1 * http://www.rightscale.com/products/cloud-computing-uses/scalable-website.php 2 Architect
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Evaluation of NoSQL databases for large-scale decentralized microblogging
 Evaluation of NoSQL databases for large-scale decentralized microblogging Cassandra & Couchbase Alexandre Fonseca, Anh Thu Vu, Peter Grman Decentralized Systems - 2nd semester 2012/2013 Universitat Politècnica
Evaluation of NoSQL databases for large-scale decentralized microblogging Cassandra & Couchbase Alexandre Fonseca, Anh Thu Vu, Peter Grman Decentralized Systems - 2nd semester 2012/2013 Universitat Politècnica
Introduction to NOSQL
 Introduction to NOSQL Université Paris-Est Marne la Vallée, LIGM UMR CNRS 8049, France January 31, 2014 Motivations NOSQL stands for Not Only SQL Motivations Exponential growth of data set size (161Eo
Introduction to NOSQL Université Paris-Est Marne la Vallée, LIGM UMR CNRS 8049, France January 31, 2014 Motivations NOSQL stands for Not Only SQL Motivations Exponential growth of data set size (161Eo
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Big Data Database Revenue and Market Forecast, 2012-2017
 Wikibon.com - http://wikibon.com Big Data Database Revenue and Market Forecast, 2012-2017 by David Floyer - 13 February 2013 http://wikibon.com/big-data-database-revenue-and-market-forecast-2012-2017/
Wikibon.com - http://wikibon.com Big Data Database Revenue and Market Forecast, 2012-2017 by David Floyer - 13 February 2013 http://wikibon.com/big-data-database-revenue-and-market-forecast-2012-2017/
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
The NoSQL Ecosystem, Relaxed Consistency, and Snoop Dogg. Adam Marcus MIT CSAIL marcua@csail.mit.edu / @marcua
 The NoSQL Ecosystem, Relaxed Consistency, and Snoop Dogg Adam Marcus MIT CSAIL marcua@csail.mit.edu / @marcua About Me Social Computing + Database Systems Easily Distracted: Wrote The NoSQL Ecosystem in
The NoSQL Ecosystem, Relaxed Consistency, and Snoop Dogg Adam Marcus MIT CSAIL marcua@csail.mit.edu / @marcua About Me Social Computing + Database Systems Easily Distracted: Wrote The NoSQL Ecosystem in
Big Data JAMES WARREN. Principles and best practices of NATHAN MARZ MANNING. scalable real-time data systems. Shelter Island
 Big Data Principles and best practices of scalable real-time data systems NATHAN MARZ JAMES WARREN II MANNING Shelter Island contents preface xiii acknowledgments xv about this book xviii ~1 Anew paradigm
Big Data Principles and best practices of scalable real-time data systems NATHAN MARZ JAMES WARREN II MANNING Shelter Island contents preface xiii acknowledgments xv about this book xviii ~1 Anew paradigm
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM
 Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
extensible record stores document stores key-value stores Rick Cattel s clustering from Scalable SQL and NoSQL Data Stores SIGMOD Record, 2010
 System/ Scale to Primary Secondary Joins/ Integrity Language/ Data Year Paper 1000s Index Indexes Transactions Analytics Constraints Views Algebra model my label 1971 RDBMS O tables sql-like 2003 memcached
System/ Scale to Primary Secondary Joins/ Integrity Language/ Data Year Paper 1000s Index Indexes Transactions Analytics Constraints Views Algebra model my label 1971 RDBMS O tables sql-like 2003 memcached
R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5
 Distributed data processing in heterogeneous cloud environments R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5 1 uskenbaevar@gmail.com, 2 abu.kuandykov@gmail.com,
Distributed data processing in heterogeneous cloud environments R.K.Uskenbayeva 1, А.А. Kuandykov 2, Zh.B.Kalpeyeva 3, D.K.Kozhamzharova 4, N.K.Mukhazhanov 5 1 uskenbaevar@gmail.com, 2 abu.kuandykov@gmail.com,
Big Data and Transactional Databases Exploding Data Volume is Creating New Stresses on Traditional Transactional Databases
 Big Data and Transactional Databases Exploding Data Volume is Creating New Stresses on Traditional Transactional Databases Introduction The world is awash in data and turning that data into actionable
Big Data and Transactional Databases Exploding Data Volume is Creating New Stresses on Traditional Transactional Databases Introduction The world is awash in data and turning that data into actionable
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Big Data Are You Ready? Thomas Kyte http://asktom.oracle.com
 Big Data Are You Ready? Thomas Kyte http://asktom.oracle.com The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Big Data Are You Ready? Thomas Kyte http://asktom.oracle.com The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
How To Improve Performance In A Database
 Some issues on Conceptual Modeling and NoSQL/Big Data Tok Wang Ling National University of Singapore 1 Database Models File system - field, record, fixed length record Hierarchical Model (IMS) - fixed
Some issues on Conceptual Modeling and NoSQL/Big Data Tok Wang Ling National University of Singapore 1 Database Models File system - field, record, fixed length record Hierarchical Model (IMS) - fixed
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
Accelerating Hadoop MapReduce Using an In-Memory Data Grid
 Accelerating Hadoop MapReduce Using an In-Memory Data Grid By David L. Brinker and William L. Bain, ScaleOut Software, Inc. 2013 ScaleOut Software, Inc. 12/27/2012 H adoop has been widely embraced for
Accelerating Hadoop MapReduce Using an In-Memory Data Grid By David L. Brinker and William L. Bain, ScaleOut Software, Inc. 2013 ScaleOut Software, Inc. 12/27/2012 H adoop has been widely embraced for
Big Data: Tools and Technologies in Big Data
 Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Big Data: Tools and Technologies in Big Data Jaskaran Singh Student Lovely Professional University, Punjab Varun Singla Assistant Professor Lovely Professional University, Punjab ABSTRACT Big data can
Entering the Zettabyte Age Jeffrey Krone
 Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Entering the Zettabyte Age Jeffrey Krone 1 Kilobyte 1,000 bits/byte. 1 megabyte 1,000,000 1 gigabyte 1,000,000,000 1 terabyte 1,000,000,000,000 1 petabyte 1,000,000,000,000,000 1 exabyte 1,000,000,000,000,000,000
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh miles@inf.ed.ac.uk October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh miles@inf.ed.ac.uk October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples