Automatic Tuning of HPC Applications for Performance and Energy Efficiency. Michael Gerndt Technische Universität München
|
|
|
- Camron Lang
- 7 years ago
- Views:
Transcription
1 Automatic Tuning of HPC Applications for Performance and Energy Efficiency. Michael Gerndt Technische Universität München

, 3")
2 SuperMUC: 3 Petaflops (3*10 15 =quadrillion), 3 MW 2

3 TOP 500 List TOTAL #1 #500 3

4 TOP 5 Systems: Linear Extens for Exascale *19 = 340 MW *36 = 302 MW *50 = 390 MW *89 = 1115 MW *100 = 394 MW 4

5 Project overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism for Energy-efficient exascale Computing Funding: European Commission Horizon 2020 grant agreement


6 Project partners Technische Universität Dresden (Coordinator), Germany Norwegian University of Science and Technology, Norway Innovations National Supercomputing Center, Czech Republic Technische Universität München, Germany Intel Exascale Centre, France GNS Braunschweig, Germany National University of Ireland Galway, Ireland 6

7 Motivation Challenges Energy consumption Extreme scale Dynamism Awareness Ability Effort Problems Solution Dynamism Automatic tuning Design-/Run-time 7

8 General idea HPC Automatic Tuning Embedded System Scenarios

9 Systems Scenario based Methodology 9

10 Outline Static Tuning with the Periscope Tuning Framework Dynamic Tuning with the READEX Tool Suite and Methodology 10

11 Periscope Tuning Framework Automatic application analysis & tuning Tune performance and energy (statically) Plug-in-based architecture Evaluate alternatives online Scalable and distributed framework Support variety of parallel paradigms MPI, OpenMP, OpenCL, Parallel pattern Developed in the AutoTune EU-FP7 project 11


12 Score-P Scalable Performance Measurement Infrastructure for Parallel Codes Common instrumentation and measurement infrastructure 12


13 ENOPT Library for Energy Measurements

14 Tuning Plugin Interface Search Space Exploration Tuning Step Scenario execution Plugin Periscope Frontend Tuning actions Application with Monitor Analysis strategies

15 Tuning Plugins MPI parameters Eager Limit, Buffer space, collective algorithms Application restart or MPIT Tools Interface DVFS Frequency tuning for energy delay product Model-based prediction of frequency Region level tuning Parallelism capping Thread number tuning for energy delay product Exhaustive and curve fitting based prediction

16 Tuning Plugins Master/worker Partition factor and number of workers Prediction through performance model based on data measured in preanalysis Parallel Pattern Tuning replication and buffers between pipeline stages Based on component distribution via StarPU OpenCL tuning Compiler flags for offline compilation NDRange tuning

17 Tuning Plugins MPI IO Tuning data sieving and number of aggregators Exhaustive and model based Compiler Flag Selection Automatic recompilation and execution Selective recompilation based on pre-analysis Exhaustive and individual search Scenario analysis for significant routines Combination with Pathway


18 Plugin Evaluation

19 Variation of Energy Measurements 19
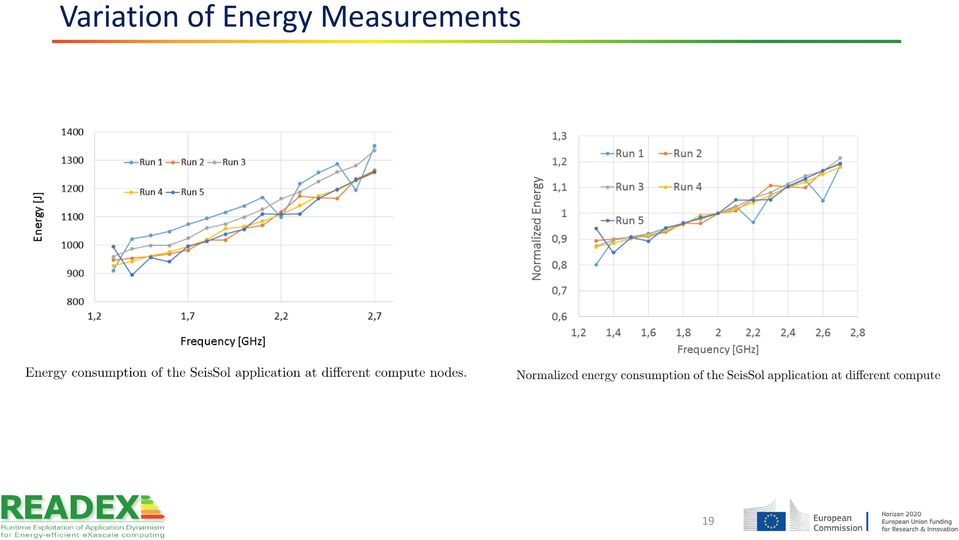
20 Predicted vs Measured Time for Seissol 20

21 Tuning with the Persicope Tuning Framework 21
22 Application Dynamism: Beyond Static Tuning 22

23 Inter-phase Dynamism All-to-all Performance 2048 phases PEPC Benchmark of the DEISA Benchmark Suite 23
24 Scenario-Based Tuning Design Time Analysis Periscope Tuning Framework (PTF) Tuning Model Runtime Tuning READEX Runtime Library (RRL) 24

25 Design Time Analysis Tuning Model Scenarios: set of runtime situations (rts) Classifiers: RTS S Selector: Context CFG Tuning cylces Captures intra-phase dynamism Creates phase TM Sequence of tuning cycles Captures inter-phase dynamism Creates inter-phase TM DTA for multiple inputs Captures input dynamism Creates application TM 25
26 Runtime Tuning with the READEX Runtime Library Enter phase: Capture phase identifiers Enter significant region: Classify rts; apply selector; perform switching Exit significant region: Save objective value Exit phase: Perform calibration
27 RRL Architecture Score-P RRL Parameter Control Online Access Interface Substrate Plugin Interface Scenario Switching Calibration RRL Substrate Plugin Scenario Detection Tuning Plugin Service MPI OpenMP Metrics Compiler Region Identifier Input Identifier Application Tuning Model 27

28 Validation and project goals Goal: Validate the effect of READEX using real-world applications Co-design process: Hand-tune selected applications Compare results with automatic static and dynamic tuning Energy measurements using HDEEM infrastructure 28
29 Conclusion Energy-efficiency at exascale Application developers and users will have to care Lack of capabilities Awareness Expertise Resources Proposed solution READEX: Exploit dynamism Detect at design time, exploit at run-time Tools-aided autotuning methodology 29

30 Thank you! Questions? 30
Recent Advances in Periscope for Performance Analysis and Tuning
 Recent Advances in Periscope for Performance Analysis and Tuning Isaias Compres, Michael Firbach, Michael Gerndt Robert Mijakovic, Yury Oleynik, Ventsislav Petkov Technische Universität München Yury Oleynik,
Recent Advances in Periscope for Performance Analysis and Tuning Isaias Compres, Michael Firbach, Michael Gerndt Robert Mijakovic, Yury Oleynik, Ventsislav Petkov Technische Universität München Yury Oleynik,
Recent and Future Activities in HPC and Scientific Data Management Siegfried Benkner
 Recent and Future Activities in HPC and Scientific Data Management Siegfried Benkner Research Group Scientific Computing Faculty of Computer Science University of Vienna AUSTRIA http://www.par.univie.ac.at
Recent and Future Activities in HPC and Scientific Data Management Siegfried Benkner Research Group Scientific Computing Faculty of Computer Science University of Vienna AUSTRIA http://www.par.univie.ac.at
Unified Performance Data Collection with Score-P
 Unified Performance Data Collection with Score-P Bert Wesarg 1) With contributions from Andreas Knüpfer 1), Christian Rössel 2), and Felix Wolf 3) 1) ZIH TU Dresden, 2) FZ Jülich, 3) GRS-SIM Aachen Fragmentation
Unified Performance Data Collection with Score-P Bert Wesarg 1) With contributions from Andreas Knüpfer 1), Christian Rössel 2), and Felix Wolf 3) 1) ZIH TU Dresden, 2) FZ Jülich, 3) GRS-SIM Aachen Fragmentation
Part I Courses Syllabus
 Part I Courses Syllabus This document provides detailed information about the basic courses of the MHPC first part activities. The list of courses is the following 1.1 Scientific Programming Environment
Part I Courses Syllabus This document provides detailed information about the basic courses of the MHPC first part activities. The list of courses is the following 1.1 Scientific Programming Environment
Search Strategies for Automatic Performance Analysis Tools
 Search Strategies for Automatic Performance Analysis Tools Michael Gerndt and Edmond Kereku Technische Universität München, Fakultät für Informatik I10, Boltzmannstr.3, 85748 Garching, Germany gerndt@in.tum.de
Search Strategies for Automatic Performance Analysis Tools Michael Gerndt and Edmond Kereku Technische Universität München, Fakultät für Informatik I10, Boltzmannstr.3, 85748 Garching, Germany gerndt@in.tum.de
HPC enabling of OpenFOAM R for CFD applications
 HPC enabling of OpenFOAM R for CFD applications Towards the exascale: OpenFOAM perspective Ivan Spisso 25-27 March 2015, Casalecchio di Reno, BOLOGNA. SuperComputing Applications and Innovation Department,
HPC enabling of OpenFOAM R for CFD applications Towards the exascale: OpenFOAM perspective Ivan Spisso 25-27 March 2015, Casalecchio di Reno, BOLOGNA. SuperComputing Applications and Innovation Department,
MAQAO Performance Analysis and Optimization Tool
 MAQAO Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Evaluation Team, University of Versailles S-Q-Y http://www.maqao.org VI-HPS 18 th Grenoble 18/22
MAQAO Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Evaluation Team, University of Versailles S-Q-Y http://www.maqao.org VI-HPS 18 th Grenoble 18/22
Parallel Programming at the Exascale Era: A Case Study on Parallelizing Matrix Assembly For Unstructured Meshes
 Parallel Programming at the Exascale Era: A Case Study on Parallelizing Matrix Assembly For Unstructured Meshes Eric Petit, Loïc Thebault, Quang V. Dinh May 2014 EXA2CT Consortium 2 WPs Organization Proto-Applications
Parallel Programming at the Exascale Era: A Case Study on Parallelizing Matrix Assembly For Unstructured Meshes Eric Petit, Loïc Thebault, Quang V. Dinh May 2014 EXA2CT Consortium 2 WPs Organization Proto-Applications
for High Performance Computing
 Technische Universität München Institut für Informatik Lehrstuhl für Rechnertechnik und Rechnerorganisation Automatic Performance Engineering Workflows for High Performance Computing Ventsislav Petkov
Technische Universität München Institut für Informatik Lehrstuhl für Rechnertechnik und Rechnerorganisation Automatic Performance Engineering Workflows for High Performance Computing Ventsislav Petkov
Data Structure Oriented Monitoring for OpenMP Programs
 A Data Structure Oriented Monitoring Environment for Fortran OpenMP Programs Edmond Kereku, Tianchao Li, Michael Gerndt, and Josef Weidendorfer Institut für Informatik, Technische Universität München,
A Data Structure Oriented Monitoring Environment for Fortran OpenMP Programs Edmond Kereku, Tianchao Li, Michael Gerndt, and Josef Weidendorfer Institut für Informatik, Technische Universität München,
Petascale Software Challenges. William Gropp www.cs.illinois.edu/~wgropp
 Petascale Software Challenges William Gropp www.cs.illinois.edu/~wgropp Petascale Software Challenges Why should you care? What are they? Which are different from non-petascale? What has changed since
Petascale Software Challenges William Gropp www.cs.illinois.edu/~wgropp Petascale Software Challenges Why should you care? What are they? Which are different from non-petascale? What has changed since
Application Performance Analysis Tools and Techniques
 Mitglied der Helmholtz-Gemeinschaft Application Performance Analysis Tools and Techniques 2012-06-27 Christian Rössel Jülich Supercomputing Centre c.roessel@fz-juelich.de EU-US HPC Summer School Dublin
Mitglied der Helmholtz-Gemeinschaft Application Performance Analysis Tools and Techniques 2012-06-27 Christian Rössel Jülich Supercomputing Centre c.roessel@fz-juelich.de EU-US HPC Summer School Dublin
CRESTA DPI OpenMPI 1.1 - Performance Optimisation and Analysis
 Version Date Comments, Changes, Status Authors, contributors, reviewers 0.1 24/08/2012 First full version of the deliverable Jens Doleschal (TUD) 0.1 03/09/2012 Review Ben Hall (UCL) 0.1 13/09/2012 Review
Version Date Comments, Changes, Status Authors, contributors, reviewers 0.1 24/08/2012 First full version of the deliverable Jens Doleschal (TUD) 0.1 03/09/2012 Review Ben Hall (UCL) 0.1 13/09/2012 Review
PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions. Outline. Performance oriented design
 PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions Slide 1 Outline Principles for performance oriented design Performance testing Performance tuning General
PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions Slide 1 Outline Principles for performance oriented design Performance testing Performance tuning General
Performance analysis with Periscope
 Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München September 2010 Outline Motivation Periscope architecture Periscope performance analysis
Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München September 2010 Outline Motivation Periscope architecture Periscope performance analysis
IBM WebSphere DataStage Online training from Yes-M Systems
 Yes-M Systems offers the unique opportunity to aspiring fresher s and experienced professionals to get real time experience in ETL Data warehouse tool IBM DataStage. Course Description With this training
Yes-M Systems offers the unique opportunity to aspiring fresher s and experienced professionals to get real time experience in ETL Data warehouse tool IBM DataStage. Course Description With this training
A Multi-layered Domain-specific Language for Stencil Computations
 A Multi-layered Domain-specific Language for Stencil Computations Christian Schmitt, Frank Hannig, Jürgen Teich Hardware/Software Co-Design, University of Erlangen-Nuremberg Workshop ExaStencils 2014,
A Multi-layered Domain-specific Language for Stencil Computations Christian Schmitt, Frank Hannig, Jürgen Teich Hardware/Software Co-Design, University of Erlangen-Nuremberg Workshop ExaStencils 2014,
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Network for Sustainable Ultrascale Computing (NESUS) www.nesus.eu
 www.nesus.eu") Network for Sustainable Ultrascale Computing (NESUS) www.nesus.eu Objectives of the Action Aim of the Action: To coordinate European efforts for proposing realistic solutions addressing major challenges
Network for Sustainable Ultrascale Computing (NESUS) www.nesus.eu Objectives of the Action Aim of the Action: To coordinate European efforts for proposing realistic solutions addressing major challenges
Performance Analysis and Optimization Tool
 Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Analysis Team, University of Versailles http://www.maqao.org Introduction Performance Analysis Develop
Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Analysis Team, University of Versailles http://www.maqao.org Introduction Performance Analysis Develop
User-level Power Monitoring and Application Performance on Cray XC30 Supercomputers
 User-level Power Monitoring and Application Performance on Cray XC30 Supercomputers Alistair Hart, Harvey Richardson Cray Exascale Research Initiative Europe King s Buildings Edinburgh, UK {ahart,harveyr}@cray.com
User-level Power Monitoring and Application Performance on Cray XC30 Supercomputers Alistair Hart, Harvey Richardson Cray Exascale Research Initiative Europe King s Buildings Edinburgh, UK {ahart,harveyr}@cray.com
Auto-Tuning TRSM with an Asynchronous Task Assignment Model on Multicore, GPU and Coprocessor Systems
 Auto-Tuning TRSM with an Asynchronous Task Assignment Model on Multicore, GPU and Coprocessor Systems Murilo Boratto Núcleo de Arquitetura de Computadores e Sistemas Operacionais, Universidade do Estado
Auto-Tuning TRSM with an Asynchronous Task Assignment Model on Multicore, GPU and Coprocessor Systems Murilo Boratto Núcleo de Arquitetura de Computadores e Sistemas Operacionais, Universidade do Estado
Parallel Computing. Benson Muite. benson.muite@ut.ee http://math.ut.ee/ benson. https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage
 Parallel Computing Benson Muite benson.muite@ut.ee http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
Parallel Computing Benson Muite benson.muite@ut.ee http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
Agenda. HPC Software Stack. HPC Post-Processing Visualization. Case Study National Scientific Center. European HPC Benchmark Center Montpellier PSSC
 HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
FAKULTÄT FÜR INFORMATIK. Automatic Characterization of Performance Dynamics with Periscope
 FAKULTÄT FÜR INFORMATIK DER TECHNISCHEN UNIVERSITÄT MÜNCHEN Dissertation Automatic Characterization of Performance Dynamics with Periscope Yury Oleynik Technische Universität München FAKULTÄT FÜR INFORMATIK
FAKULTÄT FÜR INFORMATIK DER TECHNISCHEN UNIVERSITÄT MÜNCHEN Dissertation Automatic Characterization of Performance Dynamics with Periscope Yury Oleynik Technische Universität München FAKULTÄT FÜR INFORMATIK
David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems
 David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems About me David Rioja Redondo Telecommunication Engineer - Universidad de Alcalá >2 years building and managing clusters UPM
David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems About me David Rioja Redondo Telecommunication Engineer - Universidad de Alcalá >2 years building and managing clusters UPM
Automating Big Data Benchmarking for Different Architectures with ALOJA
 www.bsc.es Jan 2016 Automating Big Data Benchmarking for Different Architectures with ALOJA Nicolas Poggi, Postdoc Researcher Agenda 1. Intro on Hadoop performance 1. Current scenario and problematic 2.
www.bsc.es Jan 2016 Automating Big Data Benchmarking for Different Architectures with ALOJA Nicolas Poggi, Postdoc Researcher Agenda 1. Intro on Hadoop performance 1. Current scenario and problematic 2.
Performance Tools for System Monitoring
 Center for Information Services and High Performance Computing (ZIH) 01069 Dresden Performance Tools for System Monitoring 1st CHANGES Workshop, Jülich Zellescher Weg 12 Tel. +49 351-463 35450 September
Center for Information Services and High Performance Computing (ZIH) 01069 Dresden Performance Tools for System Monitoring 1st CHANGES Workshop, Jülich Zellescher Weg 12 Tel. +49 351-463 35450 September
Energy-aware job scheduler for highperformance
 Energy-aware job scheduler for highperformance computing 7.9.2011 Olli Mämmelä (VTT), Mikko Majanen (VTT), Robert Basmadjian (University of Passau), Hermann De Meer (University of Passau), André Giesler
Energy-aware job scheduler for highperformance computing 7.9.2011 Olli Mämmelä (VTT), Mikko Majanen (VTT), Robert Basmadjian (University of Passau), Hermann De Meer (University of Passau), André Giesler
Pros and Cons of HPC Cloud Computing
 CloudStat 211 Pros and Cons of HPC Cloud Computing Nils gentschen Felde Motivation - Idea HPC Cluster HPC Cloud Cluster Management benefits of virtual HPC Dynamical sizing / partitioning Loadbalancing
CloudStat 211 Pros and Cons of HPC Cloud Computing Nils gentschen Felde Motivation - Idea HPC Cluster HPC Cloud Cluster Management benefits of virtual HPC Dynamical sizing / partitioning Loadbalancing
Score-P A Unified Performance Measurement System for Petascale Applications
 Score-P A Unified Performance Measurement System for Petascale Applications Dieter an Mey(d), Scott Biersdorf(h), Christian Bischof(d), Kai Diethelm(c), Dominic Eschweiler(a), Michael Gerndt(g), Andreas
Score-P A Unified Performance Measurement System for Petascale Applications Dieter an Mey(d), Scott Biersdorf(h), Christian Bischof(d), Kai Diethelm(c), Dominic Eschweiler(a), Michael Gerndt(g), Andreas
A Case Study - Scaling Legacy Code on Next Generation Platforms
 Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
A Flexible Cluster Infrastructure for Systems Research and Software Development
 Award Number: CNS-551555 Title: CRI: Acquisition of an InfiniBand Cluster with SMP Nodes Institution: Florida State University PIs: Xin Yuan, Robert van Engelen, Kartik Gopalan A Flexible Cluster Infrastructure
Award Number: CNS-551555 Title: CRI: Acquisition of an InfiniBand Cluster with SMP Nodes Institution: Florida State University PIs: Xin Yuan, Robert van Engelen, Kartik Gopalan A Flexible Cluster Infrastructure
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Distributed communication-aware load balancing with TreeMatch in Charm++
 Distributed communication-aware load balancing with TreeMatch in Charm++ The 9th Scheduling for Large Scale Systems Workshop, Lyon, France Emmanuel Jeannot Guillaume Mercier Francois Tessier In collaboration
Distributed communication-aware load balancing with TreeMatch in Charm++ The 9th Scheduling for Large Scale Systems Workshop, Lyon, France Emmanuel Jeannot Guillaume Mercier Francois Tessier In collaboration
Networking Virtualization Using FPGAs
 Networking Virtualization Using FPGAs Russell Tessier, Deepak Unnikrishnan, Dong Yin, and Lixin Gao Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Massachusetts,
Networking Virtualization Using FPGAs Russell Tessier, Deepak Unnikrishnan, Dong Yin, and Lixin Gao Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Massachusetts,
Multi-GPU Load Balancing for Simulation and Rendering
 Multi- Load Balancing for Simulation and Rendering Yong Cao Computer Science Department, Virginia Tech, USA In-situ ualization and ual Analytics Instant visualization and interaction of computing tasks
Multi- Load Balancing for Simulation and Rendering Yong Cao Computer Science Department, Virginia Tech, USA In-situ ualization and ual Analytics Instant visualization and interaction of computing tasks
Incorporating Multicore Programming in Bachelor of Science in Computer Engineering Program
 Incorporating Multicore Programming in Bachelor of Science in Computer Engineering Program ITESO University Guadalajara, Jalisco México 1 Instituto Tecnológico y de Estudios Superiores de Occidente Jesuit
Incorporating Multicore Programming in Bachelor of Science in Computer Engineering Program ITESO University Guadalajara, Jalisco México 1 Instituto Tecnológico y de Estudios Superiores de Occidente Jesuit
A Parallel Server for Adaptive Geoinformation
 SIAM GS 2013 CP2 High Performance Computing A Parallel Server for Adaptive Geoinformation S. Rettenberger, A. Breuer, O. Meister, M. Bader Technische Universität München June 17, 2013 SIAM GS 2013 CP2
SIAM GS 2013 CP2 High Performance Computing A Parallel Server for Adaptive Geoinformation S. Rettenberger, A. Breuer, O. Meister, M. Bader Technische Universität München June 17, 2013 SIAM GS 2013 CP2
Building an energy dashboard. Energy measurement and visualization in current HPC systems
 Building an energy dashboard Energy measurement and visualization in current HPC systems Thomas Geenen 1/58 thomas.geenen@surfsara.nl SURFsara The Dutch national HPC center 2H 2014 > 1PFlop GPGPU accelerators
Building an energy dashboard Energy measurement and visualization in current HPC systems Thomas Geenen 1/58 thomas.geenen@surfsara.nl SURFsara The Dutch national HPC center 2H 2014 > 1PFlop GPGPU accelerators
End-user Tools for Application Performance Analysis Using Hardware Counters
 1 End-user Tools for Application Performance Analysis Using Hardware Counters K. London, J. Dongarra, S. Moore, P. Mucci, K. Seymour, T. Spencer Abstract One purpose of the end-user tools described in
1 End-user Tools for Application Performance Analysis Using Hardware Counters K. London, J. Dongarra, S. Moore, P. Mucci, K. Seymour, T. Spencer Abstract One purpose of the end-user tools described in
How To Build A Supermicro Computer With A 32 Core Power Core (Powerpc) And A 32-Core (Powerpc) (Powerpowerpter) (I386) (Amd) (Microcore) (Supermicro) (
 And A 32-Core (Powerpc) (Powerpowerpter) (I386) (Amd) (Microcore) (Supermicro) (") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 7 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 7 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
MPI / ClusterTools Update and Plans
 HPC Technical Training Seminar July 7, 2008 October 26, 2007 2 nd HLRS Parallel Tools Workshop Sun HPC ClusterTools 7+: A Binary Distribution of Open MPI MPI / ClusterTools Update and Plans Len Wisniewski
HPC Technical Training Seminar July 7, 2008 October 26, 2007 2 nd HLRS Parallel Tools Workshop Sun HPC ClusterTools 7+: A Binary Distribution of Open MPI MPI / ClusterTools Update and Plans Len Wisniewski
Tools for Analysis of Performance Dynamics of Parallel Applications
 Tools for Analysis of Performance Dynamics of Parallel Applications Yury Oleynik Fourth International Workshop on Parallel Software Tools and Tool Infrastructures Technische Universität München Yury Oleynik,
Tools for Analysis of Performance Dynamics of Parallel Applications Yury Oleynik Fourth International Workshop on Parallel Software Tools and Tool Infrastructures Technische Universität München Yury Oleynik,
Application Performance Tools @ NERSC. David Skinner, Richard Gerber, Nick Wright, Karl Fuerlinger and 4000 others
 Application Performance Tools @ NERSC David Skinner, Richard Gerber, Nick Wright, Karl Fuerlinger and 4000 others User demographics at NERSC Large scale parallelism and data needs of science teams Large
Application Performance Tools @ NERSC David Skinner, Richard Gerber, Nick Wright, Karl Fuerlinger and 4000 others User demographics at NERSC Large scale parallelism and data needs of science teams Large
Managing and Using Millions of Threads
 Managing and Using Millions of Threads A ew Paradigm for Operating/Runtime Systems Hans P. Zima Jet Propulsion Laboratory California Institute of Technology, Pasadena, California Today s High End Computing
Managing and Using Millions of Threads A ew Paradigm for Operating/Runtime Systems Hans P. Zima Jet Propulsion Laboratory California Institute of Technology, Pasadena, California Today s High End Computing
GEDAE TM - A Graphical Programming and Autocode Generation Tool for Signal Processor Applications
 GEDAE TM - A Graphical Programming and Autocode Generation Tool for Signal Processor Applications Harris Z. Zebrowitz Lockheed Martin Advanced Technology Laboratories 1 Federal Street Camden, NJ 08102
GEDAE TM - A Graphical Programming and Autocode Generation Tool for Signal Processor Applications Harris Z. Zebrowitz Lockheed Martin Advanced Technology Laboratories 1 Federal Street Camden, NJ 08102
FLOW-3D Performance Benchmark and Profiling. September 2012
 FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
Online Performance Observation of Large-Scale Parallel Applications
 1 Online Observation of Large-Scale Parallel Applications Allen D. Malony and Sameer Shende and Robert Bell {malony,sameer,bertie}@cs.uoregon.edu Department of Computer and Information Science University
1 Online Observation of Large-Scale Parallel Applications Allen D. Malony and Sameer Shende and Robert Bell {malony,sameer,bertie}@cs.uoregon.edu Department of Computer and Information Science University
The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud.
 White Paper 021313-3 Page 1 : A Software Framework for Parallel Programming* The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud. ABSTRACT Programming for Multicore,
White Paper 021313-3 Page 1 : A Software Framework for Parallel Programming* The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud. ABSTRACT Programming for Multicore,
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it
 Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
A Pattern-Based Approach to. Automated Application Performance Analysis
 A Pattern-Based Approach to Automated Application Performance Analysis Nikhil Bhatia, Shirley Moore, Felix Wolf, and Jack Dongarra Innovative Computing Laboratory University of Tennessee (bhatia, shirley,
A Pattern-Based Approach to Automated Application Performance Analysis Nikhil Bhatia, Shirley Moore, Felix Wolf, and Jack Dongarra Innovative Computing Laboratory University of Tennessee (bhatia, shirley,
Data-Flow Awareness in Parallel Data Processing
 Data-Flow Awareness in Parallel Data Processing D. Bednárek, J. Dokulil *, J. Yaghob, F. Zavoral Charles University Prague, Czech Republic * University of Vienna, Austria 6 th International Symposium on
Data-Flow Awareness in Parallel Data Processing D. Bednárek, J. Dokulil *, J. Yaghob, F. Zavoral Charles University Prague, Czech Republic * University of Vienna, Austria 6 th International Symposium on
Big Data Visualization on the MIC
 Big Data Visualization on the MIC Tim Dykes School of Creative Technologies University of Portsmouth timothy.dykes@port.ac.uk Many-Core Seminar Series 26/02/14 Splotch Team Tim Dykes, University of Portsmouth
Big Data Visualization on the MIC Tim Dykes School of Creative Technologies University of Portsmouth timothy.dykes@port.ac.uk Many-Core Seminar Series 26/02/14 Splotch Team Tim Dykes, University of Portsmouth
The Design and Implementation of Scalable Parallel Haskell
 The Design and Implementation of Scalable Parallel Haskell Malak Aljabri, Phil Trinder,and Hans-Wolfgang Loidl MMnet 13: Language and Runtime Support for Concurrent Systems Heriot Watt University May 8,
The Design and Implementation of Scalable Parallel Haskell Malak Aljabri, Phil Trinder,and Hans-Wolfgang Loidl MMnet 13: Language and Runtime Support for Concurrent Systems Heriot Watt University May 8,
Kashif Iqbal - PhD Kashif.iqbal@ichec.ie
 HPC/HTC vs. Cloud Benchmarking An empirical evalua.on of the performance and cost implica.ons Kashif Iqbal - PhD Kashif.iqbal@ichec.ie ICHEC, NUI Galway, Ireland With acknowledgment to Michele MicheloDo
HPC/HTC vs. Cloud Benchmarking An empirical evalua.on of the performance and cost implica.ons Kashif Iqbal - PhD Kashif.iqbal@ichec.ie ICHEC, NUI Galway, Ireland With acknowledgment to Michele MicheloDo
PRIMERGY server-based High Performance Computing solutions
 PRIMERGY server-based High Performance Computing solutions PreSales - May 2010 - HPC Revenue OS & Processor Type Increasing standardization with shift in HPC to x86 with 70% in 2008.. HPC revenue by operating
PRIMERGY server-based High Performance Computing solutions PreSales - May 2010 - HPC Revenue OS & Processor Type Increasing standardization with shift in HPC to x86 with 70% in 2008.. HPC revenue by operating
A Performance Study of Load Balancing Strategies for Approximate String Matching on an MPI Heterogeneous System Environment
 A Performance Study of Load Balancing Strategies for Approximate String Matching on an MPI Heterogeneous System Environment Panagiotis D. Michailidis and Konstantinos G. Margaritis Parallel and Distributed
A Performance Study of Load Balancing Strategies for Approximate String Matching on an MPI Heterogeneous System Environment Panagiotis D. Michailidis and Konstantinos G. Margaritis Parallel and Distributed
Proactive, Resource-Aware, Tunable Real-time Fault-tolerant Middleware
 Proactive, Resource-Aware, Tunable Real-time Fault-tolerant Middleware Priya Narasimhan T. Dumitraş, A. Paulos, S. Pertet, C. Reverte, J. Slember, D. Srivastava Carnegie Mellon University Problem Description
Proactive, Resource-Aware, Tunable Real-time Fault-tolerant Middleware Priya Narasimhan T. Dumitraş, A. Paulos, S. Pertet, C. Reverte, J. Slember, D. Srivastava Carnegie Mellon University Problem Description
Metrics for Success: Performance Analysis 101
 Metrics for Success: Performance Analysis 101 February 21, 2008 Kuldip Oberoi Developer Tools Sun Microsystems, Inc. 1 Agenda Application Performance Compiling for performance Profiling for performance
Metrics for Success: Performance Analysis 101 February 21, 2008 Kuldip Oberoi Developer Tools Sun Microsystems, Inc. 1 Agenda Application Performance Compiling for performance Profiling for performance
Big Data Management in the Clouds and HPC Systems
 Big Data Management in the Clouds and HPC Systems Hemera Final Evaluation Paris 17 th December 2014 Shadi Ibrahim Shadi.ibrahim@inria.fr Era of Big Data! Source: CNRS Magazine 2013 2 Era of Big Data! Source:
Big Data Management in the Clouds and HPC Systems Hemera Final Evaluation Paris 17 th December 2014 Shadi Ibrahim Shadi.ibrahim@inria.fr Era of Big Data! Source: CNRS Magazine 2013 2 Era of Big Data! Source:
benchmarking Amazon EC2 for high-performance scientific computing
 Edward Walker benchmarking Amazon EC2 for high-performance scientific computing Edward Walker is a Research Scientist with the Texas Advanced Computing Center at the University of Texas at Austin. He received
Edward Walker benchmarking Amazon EC2 for high-performance scientific computing Edward Walker is a Research Scientist with the Texas Advanced Computing Center at the University of Texas at Austin. He received
Scalability evaluation of barrier algorithms for OpenMP
 Scalability evaluation of barrier algorithms for OpenMP Ramachandra Nanjegowda, Oscar Hernandez, Barbara Chapman and Haoqiang H. Jin High Performance Computing and Tools Group (HPCTools) Computer Science
Scalability evaluation of barrier algorithms for OpenMP Ramachandra Nanjegowda, Oscar Hernandez, Barbara Chapman and Haoqiang H. Jin High Performance Computing and Tools Group (HPCTools) Computer Science
High Performance Computing in the Multi-core Area
 High Performance Computing in the Multi-core Area Arndt Bode Technische Universität München Technology Trends for Petascale Computing Architectures: Multicore Accelerators Special Purpose Reconfigurable
High Performance Computing in the Multi-core Area Arndt Bode Technische Universität München Technology Trends for Petascale Computing Architectures: Multicore Accelerators Special Purpose Reconfigurable
Performance Analysis for GPU Accelerated Applications
 Center for Information Services and High Performance Computing (ZIH) Performance Analysis for GPU Accelerated Applications Working Together for more Insight Willersbau, Room A218 Tel. +49 351-463 - 39871
Center for Information Services and High Performance Computing (ZIH) Performance Analysis for GPU Accelerated Applications Working Together for more Insight Willersbau, Room A218 Tel. +49 351-463 - 39871
Energy Efficient MapReduce
 Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
A Review of Customized Dynamic Load Balancing for a Network of Workstations
 A Review of Customized Dynamic Load Balancing for a Network of Workstations Taken from work done by: Mohammed Javeed Zaki, Wei Li, Srinivasan Parthasarathy Computer Science Department, University of Rochester
A Review of Customized Dynamic Load Balancing for a Network of Workstations Taken from work done by: Mohammed Javeed Zaki, Wei Li, Srinivasan Parthasarathy Computer Science Department, University of Rochester
Objectives. Distributed Databases and Client/Server Architecture. Distributed Database. Data Fragmentation
 Objectives Distributed Databases and Client/Server Architecture IT354 @ Peter Lo 2005 1 Understand the advantages and disadvantages of distributed databases Know the design issues involved in distributed
Objectives Distributed Databases and Client/Server Architecture IT354 @ Peter Lo 2005 1 Understand the advantages and disadvantages of distributed databases Know the design issues involved in distributed
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing
 Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing Innovation Intelligence Devin Jensen August 2012 Altair Knows HPC Altair is the only company that: makes HPC tools
Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing Innovation Intelligence Devin Jensen August 2012 Altair Knows HPC Altair is the only company that: makes HPC tools
Data Analytics at NERSC. Joaquin Correa JoaquinCorrea@lbl.gov NERSC Data and Analytics Services
 Data Analytics at NERSC Joaquin Correa JoaquinCorrea@lbl.gov NERSC Data and Analytics Services NERSC User Meeting August, 2015 Data analytics at NERSC Science Applications Climate, Cosmology, Kbase, Materials,
Data Analytics at NERSC Joaquin Correa JoaquinCorrea@lbl.gov NERSC Data and Analytics Services NERSC User Meeting August, 2015 Data analytics at NERSC Science Applications Climate, Cosmology, Kbase, Materials,
Petascale Software Challenges. Piyush Chaudhary piyushc@us.ibm.com High Performance Computing
 Petascale Software Challenges Piyush Chaudhary piyushc@us.ibm.com High Performance Computing Fundamental Observations Applications are struggling to realize growth in sustained performance at scale Reasons
Petascale Software Challenges Piyush Chaudhary piyushc@us.ibm.com High Performance Computing Fundamental Observations Applications are struggling to realize growth in sustained performance at scale Reasons
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Equalizer. Parallel OpenGL Application Framework. Stefan Eilemann, Eyescale Software GmbH
 Equalizer Parallel OpenGL Application Framework Stefan Eilemann, Eyescale Software GmbH Outline Overview High-Performance Visualization Equalizer Competitive Environment Equalizer Features Scalability
Equalizer Parallel OpenGL Application Framework Stefan Eilemann, Eyescale Software GmbH Outline Overview High-Performance Visualization Equalizer Competitive Environment Equalizer Features Scalability
Workshop on Parallel and Distributed Scientific and Engineering Computing, Shanghai, 25 May 2012
 Scientific Application Performance on HPC, Private and Public Cloud Resources: A Case Study Using Climate, Cardiac Model Codes and the NPB Benchmark Suite Peter Strazdins (Research School of Computer Science),
Scientific Application Performance on HPC, Private and Public Cloud Resources: A Case Study Using Climate, Cardiac Model Codes and the NPB Benchmark Suite Peter Strazdins (Research School of Computer Science),
Project Convergence: Integrating Data Grids and Compute Grids. Eugene Steinberg, CTO Grid Dynamics May, 2008
 Project Convergence: Integrating Data Grids and Compute Grids Eugene Steinberg, CTO May, 2008 Data-Driven Scalability Challenges in HPC Data is far away Latency of remote connection Latency of data movement
Project Convergence: Integrating Data Grids and Compute Grids Eugene Steinberg, CTO May, 2008 Data-Driven Scalability Challenges in HPC Data is far away Latency of remote connection Latency of data movement
Studying Code Development for High Performance Computing: The HPCS Program
 Studying Code Development for High Performance Computing: The HPCS Program Jeff Carver 1, Sima Asgari 1, Victor Basili 1,2, Lorin Hochstein 1, Jeffrey K. Hollingsworth 1, Forrest Shull 2, Marv Zelkowitz
Studying Code Development for High Performance Computing: The HPCS Program Jeff Carver 1, Sima Asgari 1, Victor Basili 1,2, Lorin Hochstein 1, Jeffrey K. Hollingsworth 1, Forrest Shull 2, Marv Zelkowitz
VALAR: A BENCHMARK SUITE TO STUDY THE DYNAMIC BEHAVIOR OF HETEROGENEOUS SYSTEMS
 VALAR: A BENCHMARK SUITE TO STUDY THE DYNAMIC BEHAVIOR OF HETEROGENEOUS SYSTEMS Perhaad Mistry, Yash Ukidave, Dana Schaa, David Kaeli Department of Electrical and Computer Engineering Northeastern University,
VALAR: A BENCHMARK SUITE TO STUDY THE DYNAMIC BEHAVIOR OF HETEROGENEOUS SYSTEMS Perhaad Mistry, Yash Ukidave, Dana Schaa, David Kaeli Department of Electrical and Computer Engineering Northeastern University,
Trends in High-Performance Computing for Power Grid Applications
 Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
ST810 Advanced Computing
 ST810 Advanced Computing Lecture 17: Parallel computing part I Eric B. Laber Hua Zhou Department of Statistics North Carolina State University Mar 13, 2013 Outline computing Hardware computing overview
ST810 Advanced Computing Lecture 17: Parallel computing part I Eric B. Laber Hua Zhou Department of Statistics North Carolina State University Mar 13, 2013 Outline computing Hardware computing overview
PRACE: access to Tier-0 systems and enabling the access to ExaScale systems Dr. Sergi Girona Managing Director and Chair of the PRACE Board of
 PRACE: access to Tier-0 systems and enabling the access to ExaScale systems Dr. Sergi Girona Managing Director and Chair of the PRACE Board of Directors PRACE aisbl, a persistent pan-european supercomputing
PRACE: access to Tier-0 systems and enabling the access to ExaScale systems Dr. Sergi Girona Managing Director and Chair of the PRACE Board of Directors PRACE aisbl, a persistent pan-european supercomputing
Computational Engineering Programs at the University of Erlangen-Nuremberg
 Computational Engineering Programs at the University of Erlangen-Nuremberg Ulrich Ruede Lehrstuhl für Simulation, Institut für Informatik Universität Erlangen http://www10.informatik.uni-erlangen.de/ ruede
Computational Engineering Programs at the University of Erlangen-Nuremberg Ulrich Ruede Lehrstuhl für Simulation, Institut für Informatik Universität Erlangen http://www10.informatik.uni-erlangen.de/ ruede
Universität Karlsruhe (TH)
") Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Working group meeting Software engineering for parallel systems Leipzig, Germany May 11, 2008 Dr. Victor Pankratius http://www.multicore-systems.org/separs
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Working group meeting Software engineering for parallel systems Leipzig, Germany May 11, 2008 Dr. Victor Pankratius http://www.multicore-systems.org/separs
The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
 WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
Data Centric Systems (DCS)
") Data Centric Systems (DCS) Architecture and Solutions for High Performance Computing, Big Data and High Performance Analytics High Performance Computing with Data Centric Systems 1 Data Centric Systems
Data Centric Systems (DCS) Architecture and Solutions for High Performance Computing, Big Data and High Performance Analytics High Performance Computing with Data Centric Systems 1 Data Centric Systems
BSC vision on Big Data and extreme scale computing
 BSC vision on Big Data and extreme scale computing Jesus Labarta, Eduard Ayguade,, Fabrizio Gagliardi, Rosa M. Badia, Toni Cortes, Jordi Torres, Adrian Cristal, Osman Unsal, David Carrera, Yolanda Becerra,
BSC vision on Big Data and extreme scale computing Jesus Labarta, Eduard Ayguade,, Fabrizio Gagliardi, Rosa M. Badia, Toni Cortes, Jordi Torres, Adrian Cristal, Osman Unsal, David Carrera, Yolanda Becerra,
Multi-Channel Clustered Web Application Servers
 THE AMERICAN UNIVERSITY IN CAIRO SCHOOL OF SCIENCES AND ENGINEERING Multi-Channel Clustered Web Application Servers A Masters Thesis Department of Computer Science and Engineering Status Report Seminar
THE AMERICAN UNIVERSITY IN CAIRO SCHOOL OF SCIENCES AND ENGINEERING Multi-Channel Clustered Web Application Servers A Masters Thesis Department of Computer Science and Engineering Status Report Seminar
Four Keys to Successful Multicore Optimization for Machine Vision. White Paper
 Four Keys to Successful Multicore Optimization for Machine Vision White Paper Optimizing a machine vision application for multicore PCs can be a complex process with unpredictable results. Developers need
Four Keys to Successful Multicore Optimization for Machine Vision White Paper Optimizing a machine vision application for multicore PCs can be a complex process with unpredictable results. Developers need
Debugging in Heterogeneous Environments with TotalView. ECMWF HPC Workshop 30 th October 2014
 Debugging in Heterogeneous Environments with TotalView ECMWF HPC Workshop 30 th October 2014 Agenda Introduction Challenges TotalView overview Advanced features Current work and future plans 2014 Rogue
Debugging in Heterogeneous Environments with TotalView ECMWF HPC Workshop 30 th October 2014 Agenda Introduction Challenges TotalView overview Advanced features Current work and future plans 2014 Rogue
Programming models for heterogeneous computing. Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga
 Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster
 Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster Gabriele Jost and Haoqiang Jin NAS Division, NASA Ames Research Center, Moffett Field, CA 94035-1000 {gjost,hjin}@nas.nasa.gov
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster Gabriele Jost and Haoqiang Jin NAS Division, NASA Ames Research Center, Moffett Field, CA 94035-1000 {gjost,hjin}@nas.nasa.gov
OpenACC 2.0 and the PGI Accelerator Compilers
 OpenACC 2.0 and the PGI Accelerator Compilers Michael Wolfe The Portland Group michael.wolfe@pgroup.com This presentation discusses the additions made to the OpenACC API in Version 2.0. I will also present
OpenACC 2.0 and the PGI Accelerator Compilers Michael Wolfe The Portland Group michael.wolfe@pgroup.com This presentation discusses the additions made to the OpenACC API in Version 2.0. I will also present
Parallel file I/O bottlenecks and solutions
 Mitglied der Helmholtz-Gemeinschaft Parallel file I/O bottlenecks and solutions Views to Parallel I/O: Hardware, Software, Application Challenges at Large Scale Introduction SIONlib Pitfalls, Darshan,
Mitglied der Helmholtz-Gemeinschaft Parallel file I/O bottlenecks and solutions Views to Parallel I/O: Hardware, Software, Application Challenges at Large Scale Introduction SIONlib Pitfalls, Darshan,
Kriterien für ein PetaFlop System
 Kriterien für ein PetaFlop System Rainer Keller, HLRS :: :: :: Context: Organizational HLRS is one of the three national supercomputing centers in Germany. The national supercomputing centers are working
Kriterien für ein PetaFlop System Rainer Keller, HLRS :: :: :: Context: Organizational HLRS is one of the three national supercomputing centers in Germany. The national supercomputing centers are working
Parallel Ray Tracing using MPI: A Dynamic Load-balancing Approach
 Parallel Ray Tracing using MPI: A Dynamic Load-balancing Approach S. M. Ashraful Kadir 1 and Tazrian Khan 2 1 Scientific Computing, Royal Institute of Technology (KTH), Stockholm, Sweden smakadir@csc.kth.se,
Parallel Ray Tracing using MPI: A Dynamic Load-balancing Approach S. M. Ashraful Kadir 1 and Tazrian Khan 2 1 Scientific Computing, Royal Institute of Technology (KTH), Stockholm, Sweden smakadir@csc.kth.se,
How To Monitor Infiniband Network Data From A Network On A Leaf Switch (Wired) On A Microsoft Powerbook (Wired Or Microsoft) On An Ipa (Wired/Wired) Or Ipa V2 (Wired V2)
 On A Microsoft Powerbook (Wired Or Microsoft) On An Ipa (Wired/Wired) Or Ipa V2 (Wired V2)") INFINIBAND NETWORK ANALYSIS AND MONITORING USING OPENSM N. Dandapanthula 1, H. Subramoni 1, J. Vienne 1, K. Kandalla 1, S. Sur 1, D. K. Panda 1, and R. Brightwell 2 Presented By Xavier Besseron 1 Date:
INFINIBAND NETWORK ANALYSIS AND MONITORING USING OPENSM N. Dandapanthula 1, H. Subramoni 1, J. Vienne 1, K. Kandalla 1, S. Sur 1, D. K. Panda 1, and R. Brightwell 2 Presented By Xavier Besseron 1 Date:
Overlapping Data Transfer With Application Execution on Clusters
 Overlapping Data Transfer With Application Execution on Clusters Karen L. Reid and Michael Stumm reid@cs.toronto.edu stumm@eecg.toronto.edu Department of Computer Science Department of Electrical and Computer
Overlapping Data Transfer With Application Execution on Clusters Karen L. Reid and Michael Stumm reid@cs.toronto.edu stumm@eecg.toronto.edu Department of Computer Science Department of Electrical and Computer
- Behind The Cloud -
 - Behind The Cloud - Infrastructure and Technologies used for Cloud Computing Alexander Huemer, 0025380 Johann Taferl, 0320039 Florian Landolt, 0420673 Seminar aus Informatik, University of Salzburg Overview
- Behind The Cloud - Infrastructure and Technologies used for Cloud Computing Alexander Huemer, 0025380 Johann Taferl, 0320039 Florian Landolt, 0420673 Seminar aus Informatik, University of Salzburg Overview