Proactive, Resource-Aware, Tunable Real-time Fault-tolerant Middleware
|
|
|
- Mervyn Moody
- 10 years ago
- Views:
Transcription
1 Proactive, Resource-Aware, Tunable Real-time Fault-tolerant Middleware Priya Narasimhan T. Dumitraş, A. Paulos, S. Pertet, C. Reverte, J. Slember, D. Srivastava Carnegie Mellon University

2 Problem Description CORBA is increasingly used for applications, where dependability and quality of service are important The Real-Time CORBA (RT-CORBA) standard The Fault-Tolerant CORBA (FT-CORBA) standard But Neither of the two standards addresses its interaction with the other Either real-time support or fault-tolerant support, but not both Applications that need both RT and FT are left out in the cold Focus of MEAD Why real-time and fault tolerance do not make a good marriage Overcoming these issues to build support for CORBA applications that require both real-time and fault tolerance 2

3 Real-Time Systems Requires a priori knowledge of events Operations ordered to meet task deadlines RT-Determinism Bounded predictable temporal behavior Multithreading for concurrency and efficient task scheduling Use of timeouts and timer-based mechanisms Fault-Tolerant Systems No advance knowledge of when faults might occur Operations ordered to preserve data consistency (across replicas) FT-Determinism Coherent state across replicas for every input FT-Determinism prohibits the use of multithreading FT-Determinism prohibits the use of local processor time 3

4 Technology Development Trade-offs between RT and FT for specific scenarios Effective ordering of operations to meet both RT and FT requirements Proactive fault-tolerance to meet both RT and FT requirements Impact of fault-tolerance and real-time on each other Impact of faults/restarts on real-time behavior Replication of scheduling/resource management components Scheduling (and bounding) recovery to avoid missing deadlines Additional features Tools for (re-)configuring fault-tolerance in an resource-aware manner Tools for the structured injection of different kinds of faults Metrics (and measurement techniques) for objectively evaluating fault-tolerance 4
 for objectively")
5 MEAD Architectural Overview Use replication to protect Application objects Scheduler and global resource manager Special RT-FT scheduler Real-time resource-aware scheduling service Fault-tolerant-aware to decide when to initiate recovery Hierarchical resource management framework Local resource managers feed into a replicated global resource manager Global resource manager coordinates with RT-FT scheduler Ordering of operations Keeps replicas consistent in state despite faults, missed deadlines, recovery and non-determinism in the system 5

6 Fault Model for MEAD Crash faults Hardware and/or OS crashes in isolation Process and/or Object crashes Communication faults Message loss and message corruption Network partitioning Resource-exhaustion faults Running out of memory, CPU, bandwidth Fault Model Kinds of faults that MEAD is designed to tolerate Omission faults Missed deadline in a real-time system Malicious faults (commission/byzantine) not in current version Processor/process/object maliciously subverted 6
 not in current version Processor/process/object maliciously subverted 6")
7 7
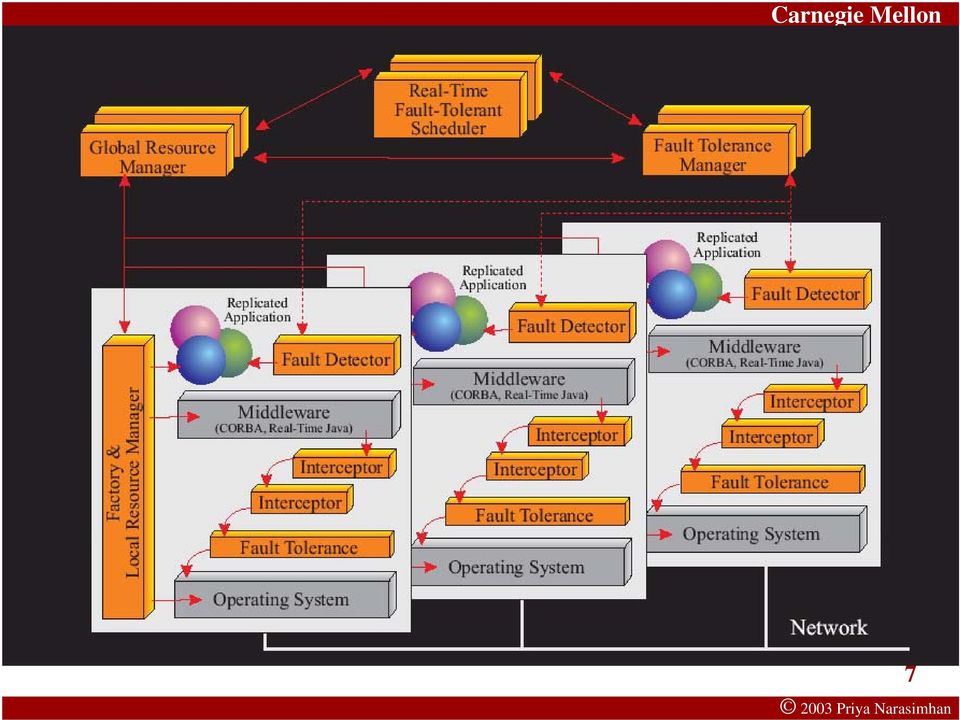
8 MEAD Interceptors for Transparency Interceptor - User-level extension to add new capabilities; works with Unmodified operating systems Intercepted Middleware Process Unmodified ORBs and JVMs Unmodified applications MEAD employs interception to Plug in fault-tolerance at run-time Profile application for patterns of communication and resource usage Provide run-time support for different aspects of FT and RT Mix-and-match serial and parallel interceptors, at run-time, to achieve specific goals MEAD Interceptor Original Library Operating System Modified Functionality 8

9 Proactive Fault-Tolerance: Overview Carnegie Mellon Involves predicting, with some confidence, when a failure might occur, and compensating for the failure even before it occurs For instance, if we knew that a processor had an 80% chance of failing within the next 5 minutes, we could perform process-migration Our goal in MEAD is to Lower the impact faults have on real time schedules Implement proactive dependability in a transparent manner Proactive dependability has two aspects: Fault prediction: Reducing the unpredictable nature of faults Proactive recovery: Reducing fail-over times and number of failures experienced at the application-level (primary focus in MEAD) Complements, but does not replace, the classical reactive faulttolerance schemes since we cannot predict every fault 9
 Complements, but does not replace, the classical reactive faulttolerance schemes since we cannot predict every")
10 Experimental Results Carnegie Mellon Setup: Run on 5 PC850 Emulab nodes (100 Mbps LAN and UAV-RHL73-STD operating system) 4 server replicas,1 client Warm passive replication with memory leak fault Used round robin algorithm for failover Recovery schemes At Client Reactive recovery at client (with and without cached object references) At Interceptor On abrupt failure, client contacts group for next server reference Proactive failover (i.e. failover when resource usage < 100%) send either: GIOP LOCATION_FORWARD message Custom MEAD message that causes client to reconnect to next replica transparently at client 10
 At Interceptor On abrupt failure, client contacts group for next server reference Proactive failover (i.e. failover when resource usage")
11 Summarized Results Recovery in Client App (No cache) Carnegie Mellon Proactive Recovery with MEAD message (Failover at 60%) RTT (in m icroseconds) Runs RTT(in m icroseconds) Runs Overhead in fault-free runs: GIOP LOCATION_FORWARD: 61%, MEAD message Overhead: 5% Approximate failover times: Reactive recovery at client app (no cache) 9400 µs (COMM_FAILUREs) Proactive recovery with GIOP message: µs Proactive recovery with MEAD message: 3400 µs Failures: None visible at the client side in proactive schemes Reactive schemes have 1:1 correspondence between client and server side 11

12 Benefits for Operational Scenarios Provides a framework for proactive recovery that is transparent to the client application Proactive recovery can: Significantly reduce failover times, lowering the impact of a failure on real-time schedules Reduce the number of failures experienced at the application level Provide advance warning of failures to other servers further down the line (multi-tiered applications) Request the recovery manager to launch new replicas so that a consistent number of replicas are retained in the group (useful for active replication where a certain number of servers are required to reach agreement) Caveat Not applicable to every kind of fault, of course 12
 Caveat Not applicable to every kind of fault, of")
13 Versatile Dependability CPU usage Bandwidth Energy / Power Memory usage Number of nodes Storage space Strength of fault-model Group communication style FT granularity No. of faults tolerated Frequency of failures Window of vulnerability Overhead of FT Fault detection latency Replica launch latency Fault-recovery latency No. of missed deadlines Scheduling algorithms 13

14 Resource-Aware RT-FT Scheduling Carnegie Mellon Requires ability to predict and to control resource usage Example: Virtual memory is too unpredictable/unstable for real-time usage RT-FT applications that use virtual memory need better support Needs input from the local and global resource managers Resources of interest: load, memory, network bandwidth Parameters: resource limits, current resource usage, usage history profile Uses resource usage input for Proactive action Predict and perform new resource allocations Migrate resource-hogging objects to idle machines before they start executing Reactive action Respond to overload conditions and transients Migrate replicas of offending objects to idle machines even as they are executing invocations 14

15 Versatile Dependability: System Architecture Design goals One infrastructure, multiple knobs Quantifiable trade-offs: FT vs. RT. vs. resources (benchmarking) Dynamic adaptation to working conditions Transparency 15

16 Versatile Dependability: Overheads Fault-tolerance overhead varies Active replication has less overhead than warm passive replication Comparing the application with and without replication Overheads are currently in the range of 200% Most of the overhead comes from using a group communication system underneath we are looking at configuring this better Not yet optimized Resource usage (e.g. bandwidth) varies too Active Uniformly distributed across replicas Warm passive Not uniform Primary is worse than backups Experiments on reactive recovery 16

17 Resource Usage Experiments Server Replicas Client Server Replicas Client 17

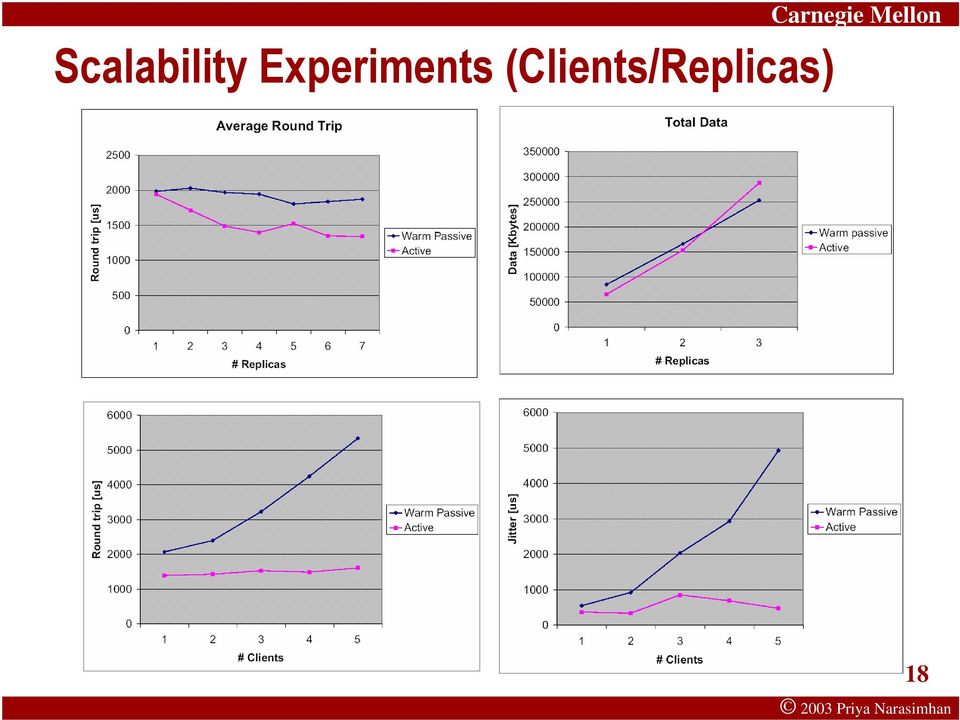
18 Scalability Experiments (Clients/Replicas) Carnegie Mellon 18
19 Reactive Fault-Tolerance Experiments 19

20 Fault-Tolerance Advisor Middleware Application Application characteristics (size of state, invocation patterns, etc.) Reliability requirements Recovery time Faults to tolerate Run-time profile of resource usage Fault Tolerance Advisor RT-FT Schedule Number of replicas Locations of replicas Replication style Checkpointing rate Fault detection rate Operating system, Network speed/type, Configuration, Workstation speed/type 20

21 Fault-Tolerance Advisor Fault-tolerance configuration of reliable applications is often ad-hoc, done by hand with little or no optimization Reliability and performance can be greatly improved by tuning the fault-tolerance parameters Replication style, checkpointing rate, fault-detection rate, number of replicas, locations of replicas Static fault-tolerance configurations quickly go out of tune as systems change Dynamic re-tuning can adapt to changing system characteristics Varying fault rates, system load, resource availability, reliability requirements The Fault-Tolerance Advisor gives deployment-time and run-time advice to tune fault-tolerant applications running over MEAD 21
22 Fault-Tolerance Advisor Architecture MEAD Manager components enforce FT configuration Factory Fault detector Resource monitor / interceptor library Fault-tolerance advisor interface Fault-Tolerance Advisor Dynamically tunes fault-tolerance configuration Decentralized architecture No single point-of-failure Managers are symmetrically replicated on all nodes Synchronized view of system state via Spread group communication bus Managers take local action without requiring coordination Faster recovery, better scalability 22
23 Fault-Tolerance Advisor Architecture 23
24 Resource Monitoring Results Tested the scalability of resource monitoring software Measured round-trip time of batch image transfers Observed good scaling of Advisor s monitoring overhead Linear as advising-update frequency increases Linear as number of nodes increases Linear as network traffic increases 24
25 Fault-Tolerance Advising Results Carnegie Mellon Tested the use of interceptor libraries for network monitoring Monitor library intercepted network system calls Monitored incoming and outgoing network traffic for each process Measured round-trip time of batch image transfers Low performance impact Minimal increase of average round-trip time (~4%) Minimal increase in jitter 25
26 Offline Program Analysis Application may contain RT vs. FT conflicts Application may be non-deterministic Multi-threading Direct access to I/O devices Local timers Program analyzer sifts interactively through application code To pinpoint sources of conflict between real-time and fault-tolerance To determine size of state, and to estimate recovery time To determine the appropriate points in the application for the incremental checkpointing of the application To highlight, and to compensate for, sources of non-determinism Offline program analyzer feeds its recovery-time estimates to the Fault-Tolerance Advisor 26
27 Summary Resolving trade-offs between real-time and fault tolerance Bounding fault detection and recovery times in asynchronous environment Estimating worst-case performance in fault-free, faulty and recovery cases MEAD s RT-FT middleware support Tolerance to crash, communication and timing faults Proactive dependability framework Fault-tolerance advisor to take the guesswork out of configuring reliability Release of MEAD on Emulab Active and warm passive replication for CORBA Uses the Spread group communication system for underlying transport Ongoing work with fault-tolerant CCM with active replication 27
28 For More Information on MEAD Priya Narasimhan Assistant Professor of ECE and CS Carnegie Mellon University Pittsburgh, PA Tel:
Performance tuning policies for application level fault tolerance in distributed object systems
 Journal of Computational Methods in Sciences and Engineering 6 (2006) S265 S274 IOS Press S265 Performance tuning policies for application level fault tolerance in distributed object systems Theodoros
Journal of Computational Methods in Sciences and Engineering 6 (2006) S265 S274 IOS Press S265 Performance tuning policies for application level fault tolerance in distributed object systems Theodoros
SCALABILITY AND AVAILABILITY
 SCALABILITY AND AVAILABILITY Real Systems must be Scalable fast enough to handle the expected load and grow easily when the load grows Available available enough of the time Scalable Scale-up increase
SCALABILITY AND AVAILABILITY Real Systems must be Scalable fast enough to handle the expected load and grow easily when the load grows Available available enough of the time Scalable Scale-up increase
Huang-Ming Huang and Christopher Gill. Bala Natarajan and Aniruddha Gokhale
 Replication Strategies for Fault-Tolerant Real-Time CORBA Services Huang-Ming Huang and Christopher Gill Washington University, St. Louis, MO {hh1,cdgill}@cse.wustl.edu Bala Natarajan and Aniruddha Gokhale
Replication Strategies for Fault-Tolerant Real-Time CORBA Services Huang-Ming Huang and Christopher Gill Washington University, St. Louis, MO {hh1,cdgill}@cse.wustl.edu Bala Natarajan and Aniruddha Gokhale
LinuxWorld Conference & Expo Server Farms and XML Web Services
 LinuxWorld Conference & Expo Server Farms and XML Web Services Jorgen Thelin, CapeConnect Chief Architect PJ Murray, Product Manager Cape Clear Software Objectives What aspects must a developer be aware
LinuxWorld Conference & Expo Server Farms and XML Web Services Jorgen Thelin, CapeConnect Chief Architect PJ Murray, Product Manager Cape Clear Software Objectives What aspects must a developer be aware
Fault Tolerance in the Internet: Servers and Routers
 Fault Tolerance in the Internet: Servers and Routers Sana Naveed Khawaja, Tariq Mahmood Research Associates Department of Computer Science Lahore University of Management Sciences Motivation Client Link
Fault Tolerance in the Internet: Servers and Routers Sana Naveed Khawaja, Tariq Mahmood Research Associates Department of Computer Science Lahore University of Management Sciences Motivation Client Link
Distributed Systems LEEC (2005/06 2º Sem.)
") Distributed Systems LEEC (2005/06 2º Sem.) Introduction João Paulo Carvalho Universidade Técnica de Lisboa / Instituto Superior Técnico Outline Definition of a Distributed System Goals Connecting Users
Distributed Systems LEEC (2005/06 2º Sem.) Introduction João Paulo Carvalho Universidade Técnica de Lisboa / Instituto Superior Técnico Outline Definition of a Distributed System Goals Connecting Users
- An Essential Building Block for Stable and Reliable Compute Clusters
 Ferdinand Geier ParTec Cluster Competence Center GmbH, V. 1.4, March 2005 Cluster Middleware - An Essential Building Block for Stable and Reliable Compute Clusters Contents: Compute Clusters a Real Alternative
Ferdinand Geier ParTec Cluster Competence Center GmbH, V. 1.4, March 2005 Cluster Middleware - An Essential Building Block for Stable and Reliable Compute Clusters Contents: Compute Clusters a Real Alternative
Agenda. Enterprise Application Performance Factors. Current form of Enterprise Applications. Factors to Application Performance.
 Agenda Enterprise Performance Factors Overall Enterprise Performance Factors Best Practice for generic Enterprise Best Practice for 3-tiers Enterprise Hardware Load Balancer Basic Unix Tuning Performance
Agenda Enterprise Performance Factors Overall Enterprise Performance Factors Best Practice for generic Enterprise Best Practice for 3-tiers Enterprise Hardware Load Balancer Basic Unix Tuning Performance
Evaluating the Performance of Middleware Load Balancing Strategies
 Evaluating the Performance of Middleware Load Balancing Strategies Jaiganesh Balasubramanian, Douglas C. Schmidt, Lawrence Dowdy, and Ossama Othman fjai,schmidt,[email protected] and [email protected]
Evaluating the Performance of Middleware Load Balancing Strategies Jaiganesh Balasubramanian, Douglas C. Schmidt, Lawrence Dowdy, and Ossama Othman fjai,schmidt,[email protected] and [email protected]
Cluster Computing. ! Fault tolerance. ! Stateless. ! Throughput. ! Stateful. ! Response time. Architectures. Stateless vs. Stateful.
 Architectures Cluster Computing Job Parallelism Request Parallelism 2 2010 VMware Inc. All rights reserved Replication Stateless vs. Stateful! Fault tolerance High availability despite failures If one
Architectures Cluster Computing Job Parallelism Request Parallelism 2 2010 VMware Inc. All rights reserved Replication Stateless vs. Stateful! Fault tolerance High availability despite failures If one
Client/Server Computing Distributed Processing, Client/Server, and Clusters
 Client/Server Computing Distributed Processing, Client/Server, and Clusters Chapter 13 Client machines are generally single-user PCs or workstations that provide a highly userfriendly interface to the
Client/Server Computing Distributed Processing, Client/Server, and Clusters Chapter 13 Client machines are generally single-user PCs or workstations that provide a highly userfriendly interface to the
Microsoft SQL Server on Stratus ftserver Systems
 W H I T E P A P E R Microsoft SQL Server on Stratus ftserver Systems Security, scalability and reliability at its best Uptime that approaches six nines Significant cost savings for your business Only from
W H I T E P A P E R Microsoft SQL Server on Stratus ftserver Systems Security, scalability and reliability at its best Uptime that approaches six nines Significant cost savings for your business Only from
LBPerf: An Open Toolkit to Empirically Evaluate the Quality of Service of Middleware Load Balancing Services
 LBPerf: An Open Toolkit to Empirically Evaluate the Quality of Service of Middleware Load Balancing Services Ossama Othman Jaiganesh Balasubramanian Dr. Douglas C. Schmidt {jai, ossama, schmidt}@dre.vanderbilt.edu
LBPerf: An Open Toolkit to Empirically Evaluate the Quality of Service of Middleware Load Balancing Services Ossama Othman Jaiganesh Balasubramanian Dr. Douglas C. Schmidt {jai, ossama, schmidt}@dre.vanderbilt.edu
How To Understand The Concept Of A Distributed System
 Distributed Operating Systems Introduction Ewa Niewiadomska-Szynkiewicz and Adam Kozakiewicz [email protected], [email protected] Institute of Control and Computation Engineering Warsaw University of
Distributed Operating Systems Introduction Ewa Niewiadomska-Szynkiewicz and Adam Kozakiewicz [email protected], [email protected] Institute of Control and Computation Engineering Warsaw University of
Red Hat Enterprise linux 5 Continuous Availability
 Red Hat Enterprise linux 5 Continuous Availability Businesses continuity needs to be at the heart of any enterprise IT deployment. Even a modest disruption in service is costly in terms of lost revenue
Red Hat Enterprise linux 5 Continuous Availability Businesses continuity needs to be at the heart of any enterprise IT deployment. Even a modest disruption in service is costly in terms of lost revenue
System Models for Distributed and Cloud Computing
 System Models for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Classification of Distributed Computing Systems
System Models for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Classification of Distributed Computing Systems
Managing Mobile Devices Over Cellular Data Networks
 Managing Mobile Devices Over Cellular Data Networks Best Practices Document Best Practices Document www.soti.net We Manage Mobility TABLE OF CONTENTS UNIQUE CHALLENGES OF MANAGING DEVICES OVER CELLULAR
Managing Mobile Devices Over Cellular Data Networks Best Practices Document Best Practices Document www.soti.net We Manage Mobility TABLE OF CONTENTS UNIQUE CHALLENGES OF MANAGING DEVICES OVER CELLULAR
Client/Server and Distributed Computing
 Adapted from:operating Systems: Internals and Design Principles, 6/E William Stallings CS571 Fall 2010 Client/Server and Distributed Computing Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Traditional
Adapted from:operating Systems: Internals and Design Principles, 6/E William Stallings CS571 Fall 2010 Client/Server and Distributed Computing Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Traditional
Virtual machine interface. Operating system. Physical machine interface
 Software Concepts User applications Operating system Hardware Virtual machine interface Physical machine interface Operating system: Interface between users and hardware Implements a virtual machine that
Software Concepts User applications Operating system Hardware Virtual machine interface Physical machine interface Operating system: Interface between users and hardware Implements a virtual machine that
EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications
 ECE6102 Dependable Distribute Systems, Fall2010 EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications Deepal Jayasinghe, Hyojun Kim, Mohammad M. Hossain, Ali Payani
ECE6102 Dependable Distribute Systems, Fall2010 EWeb: Highly Scalable Client Transparent Fault Tolerant System for Cloud based Web Applications Deepal Jayasinghe, Hyojun Kim, Mohammad M. Hossain, Ali Payani
Replication on Virtual Machines
 Replication on Virtual Machines Siggi Cherem CS 717 November 23rd, 2004 Outline 1 Introduction The Java Virtual Machine 2 Napper, Alvisi, Vin - DSN 2003 Introduction JVM as state machine Addressing non-determinism
Replication on Virtual Machines Siggi Cherem CS 717 November 23rd, 2004 Outline 1 Introduction The Java Virtual Machine 2 Napper, Alvisi, Vin - DSN 2003 Introduction JVM as state machine Addressing non-determinism
Chapter 7: Distributed Systems: Warehouse-Scale Computing. Fall 2011 Jussi Kangasharju
 Chapter 7: Distributed Systems: Warehouse-Scale Computing Fall 2011 Jussi Kangasharju Chapter Outline Warehouse-scale computing overview Workloads and software infrastructure Failures and repairs Note:
Chapter 7: Distributed Systems: Warehouse-Scale Computing Fall 2011 Jussi Kangasharju Chapter Outline Warehouse-scale computing overview Workloads and software infrastructure Failures and repairs Note:
Evaluation Methodology of Converged Cloud Environments
 Krzysztof Zieliński Marcin Jarząb Sławomir Zieliński Karol Grzegorczyk Maciej Malawski Mariusz Zyśk Evaluation Methodology of Converged Cloud Environments Cloud Computing Cloud Computing enables convenient,
Krzysztof Zieliński Marcin Jarząb Sławomir Zieliński Karol Grzegorczyk Maciej Malawski Mariusz Zyśk Evaluation Methodology of Converged Cloud Environments Cloud Computing Cloud Computing enables convenient,
Introduction to CORBA. 1. Introduction 2. Distributed Systems: Notions 3. Middleware 4. CORBA Architecture
 Introduction to CORBA 1. Introduction 2. Distributed Systems: Notions 3. Middleware 4. CORBA Architecture 1. Introduction CORBA is defined by the OMG The OMG: -Founded in 1989 by eight companies as a non-profit
Introduction to CORBA 1. Introduction 2. Distributed Systems: Notions 3. Middleware 4. CORBA Architecture 1. Introduction CORBA is defined by the OMG The OMG: -Founded in 1989 by eight companies as a non-profit
Principles and characteristics of distributed systems and environments
 Principles and characteristics of distributed systems and environments Definition of a distributed system Distributed system is a collection of independent computers that appears to its users as a single
Principles and characteristics of distributed systems and environments Definition of a distributed system Distributed system is a collection of independent computers that appears to its users as a single
Copyright www.agileload.com 1
 Copyright www.agileload.com 1 INTRODUCTION Performance testing is a complex activity where dozens of factors contribute to its success and effective usage of all those factors is necessary to get the accurate
Copyright www.agileload.com 1 INTRODUCTION Performance testing is a complex activity where dozens of factors contribute to its success and effective usage of all those factors is necessary to get the accurate
Tools Page 1 of 13 ON PROGRAM TRANSLATION. A priori, we have two translation mechanisms available:
 Tools Page 1 of 13 ON PROGRAM TRANSLATION A priori, we have two translation mechanisms available: Interpretation Compilation On interpretation: Statements are translated one at a time and executed immediately.
Tools Page 1 of 13 ON PROGRAM TRANSLATION A priori, we have two translation mechanisms available: Interpretation Compilation On interpretation: Statements are translated one at a time and executed immediately.
Petascale Software Challenges. Piyush Chaudhary [email protected] High Performance Computing
 Petascale Software Challenges Piyush Chaudhary [email protected] High Performance Computing Fundamental Observations Applications are struggling to realize growth in sustained performance at scale Reasons
Petascale Software Challenges Piyush Chaudhary [email protected] High Performance Computing Fundamental Observations Applications are struggling to realize growth in sustained performance at scale Reasons
MOSIX: High performance Linux farm
 MOSIX: High performance Linux farm Paolo Mastroserio [[email protected]] Francesco Maria Taurino [[email protected]] Gennaro Tortone [[email protected]] Napoli Index overview on Linux farm farm
MOSIX: High performance Linux farm Paolo Mastroserio [[email protected]] Francesco Maria Taurino [[email protected]] Gennaro Tortone [[email protected]] Napoli Index overview on Linux farm farm
HRG Assessment: Stratus everrun Enterprise
 HRG Assessment: Stratus everrun Enterprise Today IT executive decision makers and their technology recommenders are faced with escalating demands for more effective technology based solutions while at
HRG Assessment: Stratus everrun Enterprise Today IT executive decision makers and their technology recommenders are faced with escalating demands for more effective technology based solutions while at
PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions. Outline. Performance oriented design
 PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions Slide 1 Outline Principles for performance oriented design Performance testing Performance tuning General
PART IV Performance oriented design, Performance testing, Performance tuning & Performance solutions Slide 1 Outline Principles for performance oriented design Performance testing Performance tuning General
SOFT 437. Software Performance Analysis. Ch 5:Web Applications and Other Distributed Systems
 SOFT 437 Software Performance Analysis Ch 5:Web Applications and Other Distributed Systems Outline Overview of Web applications, distributed object technologies, and the important considerations for SPE
SOFT 437 Software Performance Analysis Ch 5:Web Applications and Other Distributed Systems Outline Overview of Web applications, distributed object technologies, and the important considerations for SPE
B) Using Processor-Cache Affinity Information in Shared Memory Multiprocessor Scheduling
 Using Processor-Cache Affinity Information in Shared Memory Multiprocessor Scheduling") A) Recovery Management in Quicksilver 1) What role does the Transaction manager play in the recovery management? It manages commit coordination by communicating with servers at its own node and with transaction
A) Recovery Management in Quicksilver 1) What role does the Transaction manager play in the recovery management? It manages commit coordination by communicating with servers at its own node and with transaction
Performance Management for Cloudbased STC 2012
 Performance Management for Cloudbased Applications STC 2012 1 Agenda Context Problem Statement Cloud Architecture Need for Performance in Cloud Performance Challenges in Cloud Generic IaaS / PaaS / SaaS
Performance Management for Cloudbased Applications STC 2012 1 Agenda Context Problem Statement Cloud Architecture Need for Performance in Cloud Performance Challenges in Cloud Generic IaaS / PaaS / SaaS
IMCM: A Flexible Fine-Grained Adaptive Framework for Parallel Mobile Hybrid Cloud Applications
 Open System Laboratory of University of Illinois at Urbana Champaign presents: Outline: IMCM: A Flexible Fine-Grained Adaptive Framework for Parallel Mobile Hybrid Cloud Applications A Fine-Grained Adaptive
Open System Laboratory of University of Illinois at Urbana Champaign presents: Outline: IMCM: A Flexible Fine-Grained Adaptive Framework for Parallel Mobile Hybrid Cloud Applications A Fine-Grained Adaptive
Distribution One Server Requirements
 Distribution One Server Requirements Introduction Welcome to the Hardware Configuration Guide. The goal of this guide is to provide a practical approach to sizing your Distribution One application and
Distribution One Server Requirements Introduction Welcome to the Hardware Configuration Guide. The goal of this guide is to provide a practical approach to sizing your Distribution One application and
Fault Tolerant Servers: The Choice for Continuous Availability on Microsoft Windows Server Platform
 Fault Tolerant Servers: The Choice for Continuous Availability on Microsoft Windows Server Platform Why clustering and redundancy might not be enough This paper discusses today s options for achieving
Fault Tolerant Servers: The Choice for Continuous Availability on Microsoft Windows Server Platform Why clustering and redundancy might not be enough This paper discusses today s options for achieving
Distributed System Principles
 Distributed System Principles 1 What is a Distributed System? Definition: A distributed system consists of a collection of autonomous computers, connected through a network and distribution middleware,
Distributed System Principles 1 What is a Distributed System? Definition: A distributed system consists of a collection of autonomous computers, connected through a network and distribution middleware,
Performance Prediction, Sizing and Capacity Planning for Distributed E-Commerce Applications
 Performance Prediction, Sizing and Capacity Planning for Distributed E-Commerce Applications by Samuel D. Kounev ([email protected]) Information Technology Transfer Office Abstract Modern e-commerce
Performance Prediction, Sizing and Capacity Planning for Distributed E-Commerce Applications by Samuel D. Kounev ([email protected]) Information Technology Transfer Office Abstract Modern e-commerce
System types. Distributed systems
 System types 1 Personal systems that are designed to run on a personal computer or workstation Distributed systems where the system software runs on a loosely integrated group of cooperating processors
System types 1 Personal systems that are designed to run on a personal computer or workstation Distributed systems where the system software runs on a loosely integrated group of cooperating processors
OpenMosix Presented by Dr. Moshe Bar and MAASK [01]
![OpenMosix Presented by Dr. Moshe Bar and MAASK [01]](/thumbs/24/2169062.jpg "OpenMosix Presented by Dr. Moshe Bar and MAASK [01]") OpenMosix Presented by Dr. Moshe Bar and MAASK [01] openmosix is a kernel extension for single-system image clustering. openmosix [24] is a tool for a Unix-like kernel, such as Linux, consisting of adaptive
OpenMosix Presented by Dr. Moshe Bar and MAASK [01] openmosix is a kernel extension for single-system image clustering. openmosix [24] is a tool for a Unix-like kernel, such as Linux, consisting of adaptive
High Performance Cluster Support for NLB on Window
 High Performance Cluster Support for NLB on Window [1]Arvind Rathi, [2] Kirti, [3] Neelam [1]M.Tech Student, Department of CSE, GITM, Gurgaon Haryana (India) [email protected] [2]Asst. Professor,
High Performance Cluster Support for NLB on Window [1]Arvind Rathi, [2] Kirti, [3] Neelam [1]M.Tech Student, Department of CSE, GITM, Gurgaon Haryana (India) [email protected] [2]Asst. Professor,
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
Distributed Software Development with Perforce Perforce Consulting Guide
 Distributed Software Development with Perforce Perforce Consulting Guide Get an overview of Perforce s simple and scalable software version management solution for supporting distributed development teams.
Distributed Software Development with Perforce Perforce Consulting Guide Get an overview of Perforce s simple and scalable software version management solution for supporting distributed development teams.
CHAPTER 1: OPERATING SYSTEM FUNDAMENTALS
 CHAPTER 1: OPERATING SYSTEM FUNDAMENTALS What is an operating? A collection of software modules to assist programmers in enhancing efficiency, flexibility, and robustness An Extended Machine from the users
CHAPTER 1: OPERATING SYSTEM FUNDAMENTALS What is an operating? A collection of software modules to assist programmers in enhancing efficiency, flexibility, and robustness An Extended Machine from the users
Segmentation in a Distributed Real-Time Main-Memory Database
 Segmentation in a Distributed Real-Time Main-Memory Database HS-IDA-MD-02-008 Gunnar Mathiason Submitted by Gunnar Mathiason to the University of Skövde as a dissertation towards the degree of M.Sc. by
Segmentation in a Distributed Real-Time Main-Memory Database HS-IDA-MD-02-008 Gunnar Mathiason Submitted by Gunnar Mathiason to the University of Skövde as a dissertation towards the degree of M.Sc. by
The Methodology Behind the Dell SQL Server Advisor Tool
 The Methodology Behind the Dell SQL Server Advisor Tool Database Solutions Engineering By Phani MV Dell Product Group October 2009 Executive Summary The Dell SQL Server Advisor is intended to perform capacity
The Methodology Behind the Dell SQL Server Advisor Tool Database Solutions Engineering By Phani MV Dell Product Group October 2009 Executive Summary The Dell SQL Server Advisor is intended to perform capacity
EMC VPLEX FAMILY. Continuous Availability and data Mobility Within and Across Data Centers
 EMC VPLEX FAMILY Continuous Availability and data Mobility Within and Across Data Centers DELIVERING CONTINUOUS AVAILABILITY AND DATA MOBILITY FOR MISSION CRITICAL APPLICATIONS Storage infrastructure is
EMC VPLEX FAMILY Continuous Availability and data Mobility Within and Across Data Centers DELIVERING CONTINUOUS AVAILABILITY AND DATA MOBILITY FOR MISSION CRITICAL APPLICATIONS Storage infrastructure is
Preview of Oracle Database 12c In-Memory Option. Copyright 2013, Oracle and/or its affiliates. All rights reserved.
 Preview of Oracle Database 12c In-Memory Option 1 The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any
Preview of Oracle Database 12c In-Memory Option 1 The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any
CA ARCserve Family r15
 CA ARCserve Family r15 Rami Nasser EMEA Principal Consultant, Technical Sales [email protected] The ARCserve Family More than Backup The only solution that: Gives customers control over their changing
CA ARCserve Family r15 Rami Nasser EMEA Principal Consultant, Technical Sales [email protected] The ARCserve Family More than Backup The only solution that: Gives customers control over their changing
Performance Management for Cloud-based Applications STC 2012
 Performance Management for Cloud-based Applications STC 2012 1 Agenda Context Problem Statement Cloud Architecture Key Performance Challenges in Cloud Challenges & Recommendations 2 Context Cloud Computing
Performance Management for Cloud-based Applications STC 2012 1 Agenda Context Problem Statement Cloud Architecture Key Performance Challenges in Cloud Challenges & Recommendations 2 Context Cloud Computing
Dynamic Load Balancing in a Network of Workstations
 Dynamic Load Balancing in a Network of Workstations 95.515F Research Report By: Shahzad Malik (219762) November 29, 2000 Table of Contents 1 Introduction 3 2 Load Balancing 4 2.1 Static Load Balancing
Dynamic Load Balancing in a Network of Workstations 95.515F Research Report By: Shahzad Malik (219762) November 29, 2000 Table of Contents 1 Introduction 3 2 Load Balancing 4 2.1 Static Load Balancing
Cloud Based Application Architectures using Smart Computing
 Cloud Based Application Architectures using Smart Computing How to Use this Guide Joyent Smart Technology represents a sophisticated evolution in cloud computing infrastructure. Most cloud computing products
Cloud Based Application Architectures using Smart Computing How to Use this Guide Joyent Smart Technology represents a sophisticated evolution in cloud computing infrastructure. Most cloud computing products
Container-based operating system virtualization: a scalable, high-performance alternative to hypervisors
 Container-based operating system virtualization: a scalable, high-performance alternative to hypervisors Soltesz, et al (Princeton/Linux-VServer), Eurosys07 Context: Operating System Structure/Organization
Container-based operating system virtualization: a scalable, high-performance alternative to hypervisors Soltesz, et al (Princeton/Linux-VServer), Eurosys07 Context: Operating System Structure/Organization
CHAPTER 7 SUMMARY AND CONCLUSION
 179 CHAPTER 7 SUMMARY AND CONCLUSION This chapter summarizes our research achievements and conclude this thesis with discussions and interesting avenues for future exploration. The thesis describes a novel
179 CHAPTER 7 SUMMARY AND CONCLUSION This chapter summarizes our research achievements and conclude this thesis with discussions and interesting avenues for future exploration. The thesis describes a novel
Chapter 18: Database System Architectures. Centralized Systems
 Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Eloquence Training What s new in Eloquence B.08.00
 Eloquence Training What s new in Eloquence B.08.00 2010 Marxmeier Software AG Rev:100727 Overview Released December 2008 Supported until November 2013 Supports 32-bit and 64-bit platforms HP-UX Itanium
Eloquence Training What s new in Eloquence B.08.00 2010 Marxmeier Software AG Rev:100727 Overview Released December 2008 Supported until November 2013 Supports 32-bit and 64-bit platforms HP-UX Itanium
Application Performance Testing Basics
 Application Performance Testing Basics ABSTRACT Todays the web is playing a critical role in all the business domains such as entertainment, finance, healthcare etc. It is much important to ensure hassle-free
Application Performance Testing Basics ABSTRACT Todays the web is playing a critical role in all the business domains such as entertainment, finance, healthcare etc. It is much important to ensure hassle-free
SAN Conceptual and Design Basics
 TECHNICAL NOTE VMware Infrastructure 3 SAN Conceptual and Design Basics VMware ESX Server can be used in conjunction with a SAN (storage area network), a specialized high speed network that connects computer
TECHNICAL NOTE VMware Infrastructure 3 SAN Conceptual and Design Basics VMware ESX Server can be used in conjunction with a SAN (storage area network), a specialized high speed network that connects computer
Maximum Availability Architecture
 Oracle Data Guard: Disaster Recovery for Sun Oracle Database Machine Oracle Maximum Availability Architecture White Paper April 2010 Maximum Availability Architecture Oracle Best Practices For High Availability
Oracle Data Guard: Disaster Recovery for Sun Oracle Database Machine Oracle Maximum Availability Architecture White Paper April 2010 Maximum Availability Architecture Oracle Best Practices For High Availability
Tuning Tableau Server for High Performance
 Tuning Tableau Server for High Performance I wanna go fast PRESENT ED BY Francois Ajenstat Alan Doerhoefer Daniel Meyer Agenda What are the things that can impact performance? Tips and tricks to improve
Tuning Tableau Server for High Performance I wanna go fast PRESENT ED BY Francois Ajenstat Alan Doerhoefer Daniel Meyer Agenda What are the things that can impact performance? Tips and tricks to improve
Fault-Tolerant Computer System Design ECE 695/CS 590. Putting it All Together
 Fault-Tolerant Computer System Design ECE 695/CS 590 Putting it All Together Saurabh Bagchi ECE/CS Purdue University ECE 695/CS 590 1 Outline Looking at some practical systems that integrate multiple techniques
Fault-Tolerant Computer System Design ECE 695/CS 590 Putting it All Together Saurabh Bagchi ECE/CS Purdue University ECE 695/CS 590 1 Outline Looking at some practical systems that integrate multiple techniques
Mixed-Criticality Systems Based on Time- Triggered Ethernet with Multiple Ring Topologies. University of Siegen Mohammed Abuteir, Roman Obermaisser
 Mixed-Criticality s Based on Time- Triggered Ethernet with Multiple Ring Topologies University of Siegen Mohammed Abuteir, Roman Obermaisser Mixed-Criticality s Need for mixed-criticality systems due to
Mixed-Criticality s Based on Time- Triggered Ethernet with Multiple Ring Topologies University of Siegen Mohammed Abuteir, Roman Obermaisser Mixed-Criticality s Need for mixed-criticality systems due to
Performance Tuning and Optimizing SQL Databases 2016
 Performance Tuning and Optimizing SQL Databases 2016 http://www.homnick.com [email protected] +1.561.988.0567 Boca Raton, Fl USA About this course This four-day instructor-led course provides students
Performance Tuning and Optimizing SQL Databases 2016 http://www.homnick.com [email protected] +1.561.988.0567 Boca Raton, Fl USA About this course This four-day instructor-led course provides students
ARC VIEW. Stratus High-Availability Solutions Designed to Virtually Eliminate Downtime. Keywords. Summary. By Craig Resnick
 ARC VIEW OCTOBER 23, 2014 Stratus High-Availability Solutions Designed to Virtually Eliminate Downtime By Craig Resnick Keywords Virtualization, High Availability, Fault Tolerant, Critical Process, Real-time
ARC VIEW OCTOBER 23, 2014 Stratus High-Availability Solutions Designed to Virtually Eliminate Downtime By Craig Resnick Keywords Virtualization, High Availability, Fault Tolerant, Critical Process, Real-time
IBM WebSphere Distributed Caching Products
 extreme Scale, DataPower XC10 IBM Distributed Caching Products IBM extreme Scale v 7.1 and DataPower XC10 Appliance Highlights A powerful, scalable, elastic inmemory grid for your business-critical applications
extreme Scale, DataPower XC10 IBM Distributed Caching Products IBM extreme Scale v 7.1 and DataPower XC10 Appliance Highlights A powerful, scalable, elastic inmemory grid for your business-critical applications
Why Standardize on Oracle Database 11g Next Generation Database Management. Thomas Kyte http://asktom.oracle.com
 Why Standardize on Oracle Database 11g Next Generation Database Management Thomas Kyte http://asktom.oracle.com Top Challenges Performance Management Change Management Ongoing Administration Storage Backup
Why Standardize on Oracle Database 11g Next Generation Database Management Thomas Kyte http://asktom.oracle.com Top Challenges Performance Management Change Management Ongoing Administration Storage Backup
White Paper on NETWORK VIRTUALIZATION
 White Paper on NETWORK VIRTUALIZATION INDEX 1. Introduction 2. Key features of Network Virtualization 3. Benefits of Network Virtualization 4. Architecture of Network Virtualization 5. Implementation Examples
White Paper on NETWORK VIRTUALIZATION INDEX 1. Introduction 2. Key features of Network Virtualization 3. Benefits of Network Virtualization 4. Architecture of Network Virtualization 5. Implementation Examples
The International Journal Of Science & Technoledge (ISSN 2321 919X) www.theijst.com
 www.theijst.com") THE INTERNATIONAL JOURNAL OF SCIENCE & TECHNOLEDGE Efficient Parallel Processing on Public Cloud Servers using Load Balancing Manjunath K. C. M.Tech IV Sem, Department of CSE, SEA College of Engineering
THE INTERNATIONAL JOURNAL OF SCIENCE & TECHNOLEDGE Efficient Parallel Processing on Public Cloud Servers using Load Balancing Manjunath K. C. M.Tech IV Sem, Department of CSE, SEA College of Engineering
Web Email DNS Peer-to-peer systems (file sharing, CDNs, cycle sharing)
") 1 1 Distributed Systems What are distributed systems? How would you characterize them? Components of the system are located at networked computers Cooperate to provide some service No shared memory Communication
1 1 Distributed Systems What are distributed systems? How would you characterize them? Components of the system are located at networked computers Cooperate to provide some service No shared memory Communication
CS550. Distributed Operating Systems (Advanced Operating Systems) Instructor: Xian-He Sun
 Instructor: Xian-He Sun") CS550 Distributed Operating Systems (Advanced Operating Systems) Instructor: Xian-He Sun Email: [email protected], Phone: (312) 567-5260 Office hours: 2:10pm-3:10pm Tuesday, 3:30pm-4:30pm Thursday at SB229C,
CS550 Distributed Operating Systems (Advanced Operating Systems) Instructor: Xian-He Sun Email: [email protected], Phone: (312) 567-5260 Office hours: 2:10pm-3:10pm Tuesday, 3:30pm-4:30pm Thursday at SB229C,
Distributed RAID Architectures for Cluster I/O Computing. Kai Hwang
 Distributed RAID Architectures for Cluster I/O Computing Kai Hwang Internet and Cluster Computing Lab. University of Southern California 1 Presentation Outline : Scalable Cluster I/O The RAID-x Architecture
Distributed RAID Architectures for Cluster I/O Computing Kai Hwang Internet and Cluster Computing Lab. University of Southern California 1 Presentation Outline : Scalable Cluster I/O The RAID-x Architecture
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CHAPTER 5 WLDMA: A NEW LOAD BALANCING STRATEGY FOR WAN ENVIRONMENT
 81 CHAPTER 5 WLDMA: A NEW LOAD BALANCING STRATEGY FOR WAN ENVIRONMENT 5.1 INTRODUCTION Distributed Web servers on the Internet require high scalability and availability to provide efficient services to
81 CHAPTER 5 WLDMA: A NEW LOAD BALANCING STRATEGY FOR WAN ENVIRONMENT 5.1 INTRODUCTION Distributed Web servers on the Internet require high scalability and availability to provide efficient services to
Recommendations for Performance Benchmarking
 Recommendations for Performance Benchmarking Shikhar Puri Abstract Performance benchmarking of applications is increasingly becoming essential before deployment. This paper covers recommendations and best
Recommendations for Performance Benchmarking Shikhar Puri Abstract Performance benchmarking of applications is increasingly becoming essential before deployment. This paper covers recommendations and best
TIBCO ActiveSpaces Use Cases How in-memory computing supercharges your infrastructure
 TIBCO Use Cases How in-memory computing supercharges your infrastructure is a great solution for lifting the burden of big data, reducing reliance on costly transactional systems, and building highly scalable,
TIBCO Use Cases How in-memory computing supercharges your infrastructure is a great solution for lifting the burden of big data, reducing reliance on costly transactional systems, and building highly scalable,
Configuring Apache Derby for Performance and Durability Olav Sandstå
 Configuring Apache Derby for Performance and Durability Olav Sandstå Database Technology Group Sun Microsystems Trondheim, Norway Overview Background > Transactions, Failure Classes, Derby Architecture
Configuring Apache Derby for Performance and Durability Olav Sandstå Database Technology Group Sun Microsystems Trondheim, Norway Overview Background > Transactions, Failure Classes, Derby Architecture
DISTRIBUTED SYSTEMS [COMP9243] Lecture 9a: Cloud Computing WHAT IS CLOUD COMPUTING? 2
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 9a: Cloud Computing WHAT IS CLOUD COMPUTING? 2](/thumbs/27/10009660.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 9a: Cloud Computing WHAT IS CLOUD COMPUTING? 2") DISTRIBUTED SYSTEMS [COMP9243] Lecture 9a: Cloud Computing Slide 1 Slide 3 A style of computing in which dynamically scalable and often virtualized resources are provided as a service over the Internet.
DISTRIBUTED SYSTEMS [COMP9243] Lecture 9a: Cloud Computing Slide 1 Slide 3 A style of computing in which dynamically scalable and often virtualized resources are provided as a service over the Internet.
Real Time Network Server Monitoring using Smartphone with Dynamic Load Balancing
 www.ijcsi.org 227 Real Time Network Server Monitoring using Smartphone with Dynamic Load Balancing Dhuha Basheer Abdullah 1, Zeena Abdulgafar Thanoon 2, 1 Computer Science Department, Mosul University,
www.ijcsi.org 227 Real Time Network Server Monitoring using Smartphone with Dynamic Load Balancing Dhuha Basheer Abdullah 1, Zeena Abdulgafar Thanoon 2, 1 Computer Science Department, Mosul University,
Cloud Computing Disaster Recovery (DR)
") Cloud Computing Disaster Recovery (DR) Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Need for Disaster Recovery (DR) What happens when you
Cloud Computing Disaster Recovery (DR) Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Need for Disaster Recovery (DR) What happens when you
Distributed Operating Systems
 Distributed Operating Systems Prashant Shenoy UMass Computer Science http://lass.cs.umass.edu/~shenoy/courses/677 Lecture 1, page 1 Course Syllabus CMPSCI 677: Distributed Operating Systems Instructor:
Distributed Operating Systems Prashant Shenoy UMass Computer Science http://lass.cs.umass.edu/~shenoy/courses/677 Lecture 1, page 1 Course Syllabus CMPSCI 677: Distributed Operating Systems Instructor:
A Taxonomy and Survey of Energy-Efficient Data Centers and Cloud Computing Systems
 A Taxonomy and Survey of Energy-Efficient Data Centers and Cloud Computing Systems Anton Beloglazov, Rajkumar Buyya, Young Choon Lee, and Albert Zomaya Present by Leping Wang 1/25/2012 Outline Background
A Taxonomy and Survey of Energy-Efficient Data Centers and Cloud Computing Systems Anton Beloglazov, Rajkumar Buyya, Young Choon Lee, and Albert Zomaya Present by Leping Wang 1/25/2012 Outline Background
A SWOT ANALYSIS ON CISCO HIGH AVAILABILITY VIRTUALIZATION CLUSTERS DISASTER RECOVERY PLAN
 A SWOT ANALYSIS ON CISCO HIGH AVAILABILITY VIRTUALIZATION CLUSTERS DISASTER RECOVERY PLAN Eman Al-Harbi [email protected] Soha S. Zaghloul [email protected] Faculty of Computer and Information
A SWOT ANALYSIS ON CISCO HIGH AVAILABILITY VIRTUALIZATION CLUSTERS DISASTER RECOVERY PLAN Eman Al-Harbi [email protected] Soha S. Zaghloul [email protected] Faculty of Computer and Information
Unification of Transactions and Replication in Three-Tier Architectures Based on CORBA
 Unification of Transactions and Replication in Three-Tier Architectures Based on CORBA Wenbing Zhao, L. E. Moser and P. M. Melliar-Smith Index Terms: Fault tolerance, transaction processing, replication,
Unification of Transactions and Replication in Three-Tier Architectures Based on CORBA Wenbing Zhao, L. E. Moser and P. M. Melliar-Smith Index Terms: Fault tolerance, transaction processing, replication,