Data-Flow Awareness in Parallel Data Processing
|
|
|
- Teresa Stanley
- 10 years ago
- Views:
Transcription
1 Data-Flow Awareness in Parallel Data Processing D. Bednárek, J. Dokulil *, J. Yaghob, F. Zavoral Charles University Prague, Czech Republic * University of Vienna, Austria 6 th International Symposium on Intelligent Distributed Computing September 24-26, 2012, Calabria


2 Problem Processing large data collections (GB, TB) unstructured data, BigData data streams Cloud Computing Hadoop Map-Reduce paradigm not sufficient for nonlinear computations matrix inversion, fluid dynamics equations, data joins

3 Problem Parallel processing Threading Building Blocks shared memory parallel processing OpenMP mathematical computations MPI distributed computing Significant knowledge required synchronization, cache hierarchy, technical details


4 Bobox Framework for parallel programming Main goal: simplify writing parallel programs Targeted to data-intensive applications Technical details handled by the framework Data connection Box computing unit

5 Data flow awareness Data-flow awareness in parallel data processing Explicit specification of data flow part of the application algorithm gives the task scheduler more precise info improves the quality of task scheduling better performance

6 Scheduler Scheduler - selection of the next task TBB, OpenMP, or MPI no information on data flow difficult to optimize their strategy Bobox model abstraction of data flow known to the scheduler decisions are data-flow aware box - basic computational component zero or more inputs and outputs in the pipeline via - one link in the pipeline connects one output to one or more inputs of other boxes envelope - the smallest unit of data

7 Scheduling in Bobox Fixed number of threads Separate scheduler for each thread one central task scheduler would create a bottleneck immediate queue tasks to be scheduled immediately data are hot in cache stealing queue tasks which are not tightly bound to the thread Scheduling algorithm execute the first task in the immediate queue if empty - head of the stealing queue if empty - steals tasks from another scheduler

8 Task enqueueing Task enqueueing immediate task - head of the immediate queue relaxed task - end of the stealing queue hard-wired into a box and via framework Main reason: cache-awareness of the framework head of the immediate queue should be scheduled immediately by the same thread on the same CPU the data bound to the task is hot in the cache number of memory accesses is minimized relaxed task is placed on the tail since the data are not needed to be hot

9 Scheduling example
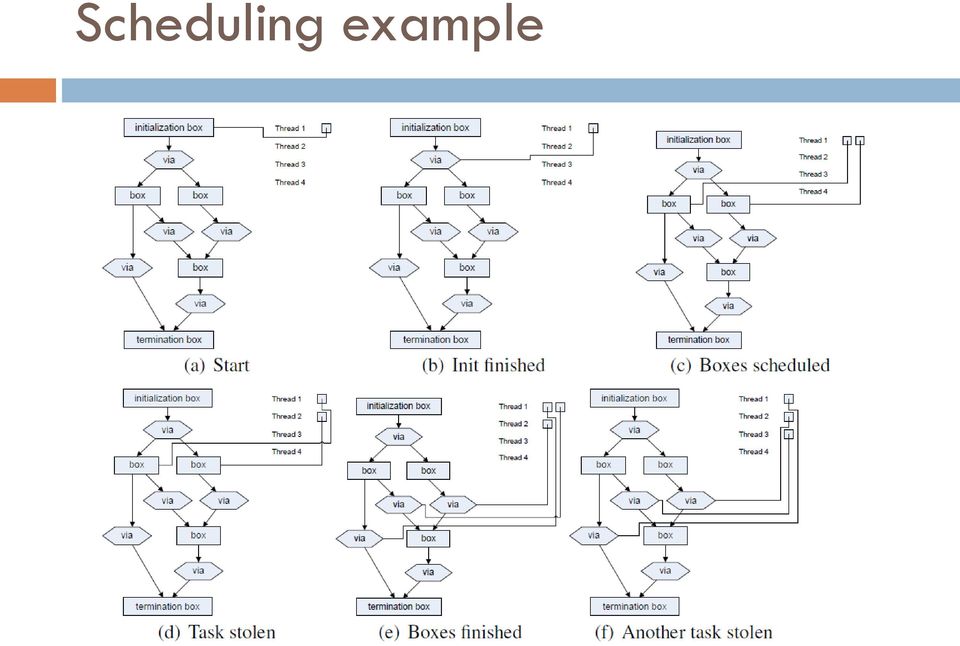
10 1. start Bobox model - pipeline 4 threads, task queues initial box is enqueued

11 2. initialization finished box produces data sends it to the first via enqueues the via

12 3. boxes scheduled the via duplicates data sends it to the boxes enqueues them


13 4. task stolen thread 2 steals one task both tasks are invoked boxes produce their results


14 5. boxes finished newly created tasks enqueued with the same thread

15 6. another task stolen one task stolen by the thread 3

16 Performance DFA and non-dfa (referential) scheduler Performance is affected by envelope (data) size data larger than cache performance decreases several levels of caches several drops Number of threads CPU: 4 cores w/ hyperthreading 2 to 4 threads significantly better than single-threaded best results: 7 threads


17 time (ms) Performance / envelope size envelope size

18 time (ms) Performance / number of threads number of threads

19 Related projects Bobox is used in several related projects SPARQL compiler model visualization (graph drawing) semantic processing query optimization data stream processing (astro-informatics) Participating universities Charles University Prague (cz) Comenius University Bratislava (sk) University of Vienna (at)
 Comenius University Bratislava (sk) University of")
20 Conclusions We have demonstrated the impact of supplying dataflow information to a scheduler Advantage of Bobox architecture data-flow information is a part of the application code Data-awareness significant performance improvement DFA scheduler required appx. 30% less time

21 The End Thank you for your attention
22 Bobox runtime architecture
23 Performance / envelope size 2K 4K 8K 16K 32K 64K 128K 256K DFA ref
24 Bobox Box computation unit basic paradigms task parallelism, non-linear pipeline high-performance messaging communication, synchronization technical details handled by the framework NUMA, cache hierarchy, CPU architecture
Task Scheduling in Data Stream Processing. Task Scheduling in Data Stream Processing
 Task Scheduling in Data Stream Processing Task Scheduling in Data Stream Processing Zbyněk Falt and Jakub Yaghob Zbyněk Falt and Jakub Yaghob Department of Software Engineering, Charles University, Department
Task Scheduling in Data Stream Processing Task Scheduling in Data Stream Processing Zbyněk Falt and Jakub Yaghob Zbyněk Falt and Jakub Yaghob Department of Software Engineering, Charles University, Department
Data Store Interface Design and Implementation
 WDS'07 Proceedings of Contributed Papers, Part I, 110 115, 2007. ISBN 978-80-7378-023-4 MATFYZPRESS Web Storage Interface J. Tykal Charles University, Faculty of Mathematics and Physics, Prague, Czech
WDS'07 Proceedings of Contributed Papers, Part I, 110 115, 2007. ISBN 978-80-7378-023-4 MATFYZPRESS Web Storage Interface J. Tykal Charles University, Faculty of Mathematics and Physics, Prague, Czech
A Novel Cloud Based Elastic Framework for Big Data Preprocessing
 School of Systems Engineering A Novel Cloud Based Elastic Framework for Big Data Preprocessing Omer Dawelbeit and Rachel McCrindle October 21, 2014 University of Reading 2008 www.reading.ac.uk Overview
School of Systems Engineering A Novel Cloud Based Elastic Framework for Big Data Preprocessing Omer Dawelbeit and Rachel McCrindle October 21, 2014 University of Reading 2008 www.reading.ac.uk Overview
Parallel Compression and Decompression of DNA Sequence Reads in FASTQ Format
 , pp.91-100 http://dx.doi.org/10.14257/ijhit.2014.7.4.09 Parallel Compression and Decompression of DNA Sequence Reads in FASTQ Format Jingjing Zheng 1,* and Ting Wang 1, 2 1,* Parallel Software and Computational
, pp.91-100 http://dx.doi.org/10.14257/ijhit.2014.7.4.09 Parallel Compression and Decompression of DNA Sequence Reads in FASTQ Format Jingjing Zheng 1,* and Ting Wang 1, 2 1,* Parallel Software and Computational
Big Data, Fast Data, Complex Data. Jans Aasman Franz Inc
 Big Data, Fast Data, Complex Data Jans Aasman Franz Inc Private, founded 1984 AI, Semantic Technology, professional services Now in Oakland Franz Inc Who We Are (1 (2 3) (4 5) (6 7) (8 9) (10 11) (12
Big Data, Fast Data, Complex Data Jans Aasman Franz Inc Private, founded 1984 AI, Semantic Technology, professional services Now in Oakland Franz Inc Who We Are (1 (2 3) (4 5) (6 7) (8 9) (10 11) (12
Parallel Computing. Benson Muite. [email protected] http://math.ut.ee/ benson. https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage
 Parallel Computing Benson Muite [email protected] http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
Parallel Computing Benson Muite [email protected] http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
MapReduce and Hadoop Distributed File System V I J A Y R A O
 MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
Scheduling Task Parallelism" on Multi-Socket Multicore Systems"
 Scheduling Task Parallelism" on Multi-Socket Multicore Systems" Stephen Olivier, UNC Chapel Hill Allan Porterfield, RENCI Kyle Wheeler, Sandia National Labs Jan Prins, UNC Chapel Hill Outline" Introduction
Scheduling Task Parallelism" on Multi-Socket Multicore Systems" Stephen Olivier, UNC Chapel Hill Allan Porterfield, RENCI Kyle Wheeler, Sandia National Labs Jan Prins, UNC Chapel Hill Outline" Introduction
Analysis and Modeling of MapReduce s Performance on Hadoop YARN
 Analysis and Modeling of MapReduce s Performance on Hadoop YARN Qiuyi Tang Dept. of Mathematics and Computer Science Denison University [email protected] Dr. Thomas C. Bressoud Dept. of Mathematics and
Analysis and Modeling of MapReduce s Performance on Hadoop YARN Qiuyi Tang Dept. of Mathematics and Computer Science Denison University [email protected] Dr. Thomas C. Bressoud Dept. of Mathematics and
A Performance Evaluation of Open Source Graph Databases. Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader
 A Performance Evaluation of Open Source Graph Databases Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader Overview Motivation Options Evaluation Results Lessons Learned Moving Forward
A Performance Evaluation of Open Source Graph Databases Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader Overview Motivation Options Evaluation Results Lessons Learned Moving Forward
Benchmark Study on Distributed XML Filtering Using Hadoop Distribution Environment. Sanjay Kulhari, Jian Wen UC Riverside
 Benchmark Study on Distributed XML Filtering Using Hadoop Distribution Environment Sanjay Kulhari, Jian Wen UC Riverside Team Sanjay Kulhari M.S. student, CS U C Riverside Jian Wen Ph.D. student, CS U
Benchmark Study on Distributed XML Filtering Using Hadoop Distribution Environment Sanjay Kulhari, Jian Wen UC Riverside Team Sanjay Kulhari M.S. student, CS U C Riverside Jian Wen Ph.D. student, CS U
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy?
 HPC2012 Workshop Cetraro, Italy Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy? Bill Blake CTO Cray, Inc. The Big Data Challenge Supercomputing minimizes data
HPC2012 Workshop Cetraro, Italy Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy? Bill Blake CTO Cray, Inc. The Big Data Challenge Supercomputing minimizes data
Storage and Retrieval of Large RDF Graph Using Hadoop and MapReduce
 Storage and Retrieval of Large RDF Graph Using Hadoop and MapReduce Mohammad Farhan Husain, Pankil Doshi, Latifur Khan, and Bhavani Thuraisingham University of Texas at Dallas, Dallas TX 75080, USA Abstract.
Storage and Retrieval of Large RDF Graph Using Hadoop and MapReduce Mohammad Farhan Husain, Pankil Doshi, Latifur Khan, and Bhavani Thuraisingham University of Texas at Dallas, Dallas TX 75080, USA Abstract.
Scalability evaluation of barrier algorithms for OpenMP
 Scalability evaluation of barrier algorithms for OpenMP Ramachandra Nanjegowda, Oscar Hernandez, Barbara Chapman and Haoqiang H. Jin High Performance Computing and Tools Group (HPCTools) Computer Science
Scalability evaluation of barrier algorithms for OpenMP Ramachandra Nanjegowda, Oscar Hernandez, Barbara Chapman and Haoqiang H. Jin High Performance Computing and Tools Group (HPCTools) Computer Science
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2015/16 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
MapReduce and Hadoop Distributed File System
 MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) [email protected] http://www.cse.buffalo.edu/faculty/bina Partially
MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) [email protected] http://www.cse.buffalo.edu/faculty/bina Partially
A Pattern-Based Approach to. Automated Application Performance Analysis
 A Pattern-Based Approach to Automated Application Performance Analysis Nikhil Bhatia, Shirley Moore, Felix Wolf, and Jack Dongarra Innovative Computing Laboratory University of Tennessee (bhatia, shirley,
A Pattern-Based Approach to Automated Application Performance Analysis Nikhil Bhatia, Shirley Moore, Felix Wolf, and Jack Dongarra Innovative Computing Laboratory University of Tennessee (bhatia, shirley,
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Spring 2011 Prof. Hyesoon Kim Today, we will study typical patterns of parallel programming This is just one of the ways. Materials are based on a book by Timothy. Decompose Into tasks Original Problem
Big Data and Transactional Databases Exploding Data Volume is Creating New Stresses on Traditional Transactional Databases
 Big Data and Transactional Databases Exploding Data Volume is Creating New Stresses on Traditional Transactional Databases Introduction The world is awash in data and turning that data into actionable
Big Data and Transactional Databases Exploding Data Volume is Creating New Stresses on Traditional Transactional Databases Introduction The world is awash in data and turning that data into actionable
Data-intensive HPC: opportunities and challenges. Patrick Valduriez
 Data-intensive HPC: opportunities and challenges Patrick Valduriez Big Data Landscape Multi-$billion market! Big data = Hadoop = MapReduce? No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard,
Data-intensive HPC: opportunities and challenges Patrick Valduriez Big Data Landscape Multi-$billion market! Big data = Hadoop = MapReduce? No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard,
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Surfing the Data Tsunami: A New Paradigm for Big Data Processing and Analytics
 Surfing the Data Tsunami: A New Paradigm for Big Data Processing and Analytics Dr. Liangxiu Han Future Networks and Distributed Systems Group (FUNDS) School of Computing, Mathematics and Digital Technology,
Surfing the Data Tsunami: A New Paradigm for Big Data Processing and Analytics Dr. Liangxiu Han Future Networks and Distributed Systems Group (FUNDS) School of Computing, Mathematics and Digital Technology,
HPC and Big Data. EPCC The University of Edinburgh. Adrian Jackson Technical Architect [email protected]
 HPC and Big Data EPCC The University of Edinburgh Adrian Jackson Technical Architect [email protected] EPCC Facilities Technology Transfer European Projects HPC Research Visitor Programmes Training
HPC and Big Data EPCC The University of Edinburgh Adrian Jackson Technical Architect [email protected] EPCC Facilities Technology Transfer European Projects HPC Research Visitor Programmes Training
Parallel Computing for Data Science
 Parallel Computing for Data Science With Examples in R, C++ and CUDA Norman Matloff University of California, Davis USA (g) CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint
Parallel Computing for Data Science With Examples in R, C++ and CUDA Norman Matloff University of California, Davis USA (g) CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU
 Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
DBpedia German: Extensions and Applications
 DBpedia German: Extensions and Applications Alexandru-Aurelian Todor FU-Berlin, Innovationsforum Semantic Media Web, 7. Oktober 2014 Overview Why DBpedia? New Developments in DBpedia German Problems in
DBpedia German: Extensions and Applications Alexandru-Aurelian Todor FU-Berlin, Innovationsforum Semantic Media Web, 7. Oktober 2014 Overview Why DBpedia? New Developments in DBpedia German Problems in
Snapshots in Hadoop Distributed File System
 Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications. Jürgen Primsch, SAP AG July 2011
 SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications Jürgen Primsch, SAP AG July 2011 Why In-Memory? Information at the Speed of Thought Imagine access to business data,
SAP HANA - Main Memory Technology: A Challenge for Development of Business Applications Jürgen Primsch, SAP AG July 2011 Why In-Memory? Information at the Speed of Thought Imagine access to business data,
Part I Courses Syllabus
 Part I Courses Syllabus This document provides detailed information about the basic courses of the MHPC first part activities. The list of courses is the following 1.1 Scientific Programming Environment
Part I Courses Syllabus This document provides detailed information about the basic courses of the MHPC first part activities. The list of courses is the following 1.1 Scientific Programming Environment
Module 14: Scalability and High Availability
 Module 14: Scalability and High Availability Overview Key high availability features available in Oracle and SQL Server Key scalability features available in Oracle and SQL Server High Availability High
Module 14: Scalability and High Availability Overview Key high availability features available in Oracle and SQL Server Key scalability features available in Oracle and SQL Server High Availability High
Recent and Future Activities in HPC and Scientific Data Management Siegfried Benkner
 Recent and Future Activities in HPC and Scientific Data Management Siegfried Benkner Research Group Scientific Computing Faculty of Computer Science University of Vienna AUSTRIA http://www.par.univie.ac.at
Recent and Future Activities in HPC and Scientific Data Management Siegfried Benkner Research Group Scientific Computing Faculty of Computer Science University of Vienna AUSTRIA http://www.par.univie.ac.at
Informatica Ultra Messaging SMX Shared-Memory Transport
 White Paper Informatica Ultra Messaging SMX Shared-Memory Transport Breaking the 100-Nanosecond Latency Barrier with Benchmark-Proven Performance This document contains Confidential, Proprietary and Trade
White Paper Informatica Ultra Messaging SMX Shared-Memory Transport Breaking the 100-Nanosecond Latency Barrier with Benchmark-Proven Performance This document contains Confidential, Proprietary and Trade
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
An efficient Join-Engine to the SQL query based on Hive with Hbase Zhao zhi-cheng & Jiang Yi
 International Conference on Applied Science and Engineering Innovation (ASEI 2015) An efficient Join-Engine to the SQL query based on Hive with Hbase Zhao zhi-cheng & Jiang Yi Institute of Computer Forensics,
International Conference on Applied Science and Engineering Innovation (ASEI 2015) An efficient Join-Engine to the SQL query based on Hive with Hbase Zhao zhi-cheng & Jiang Yi Institute of Computer Forensics,
MIDeA: A Multi-Parallel Intrusion Detection Architecture
 MIDeA: A Multi-Parallel Intrusion Detection Architecture Giorgos Vasiliadis, FORTH-ICS, Greece Michalis Polychronakis, Columbia U., USA Sotiris Ioannidis, FORTH-ICS, Greece CCS 2011, 19 October 2011 Network
MIDeA: A Multi-Parallel Intrusion Detection Architecture Giorgos Vasiliadis, FORTH-ICS, Greece Michalis Polychronakis, Columbia U., USA Sotiris Ioannidis, FORTH-ICS, Greece CCS 2011, 19 October 2011 Network
Performance Characteristics of Large SMP Machines
 Performance Characteristics of Large SMP Machines Dirk Schmidl, Dieter an Mey, Matthias S. Müller [email protected] Rechen- und Kommunikationszentrum (RZ) Agenda Investigated Hardware Kernel Benchmark
Performance Characteristics of Large SMP Machines Dirk Schmidl, Dieter an Mey, Matthias S. Müller [email protected] Rechen- und Kommunikationszentrum (RZ) Agenda Investigated Hardware Kernel Benchmark
Operatin g Systems: Internals and Design Principle s. Chapter 10 Multiprocessor and Real-Time Scheduling Seventh Edition By William Stallings
 Operatin g Systems: Internals and Design Principle s Chapter 10 Multiprocessor and Real-Time Scheduling Seventh Edition By William Stallings Operating Systems: Internals and Design Principles Bear in mind,
Operatin g Systems: Internals and Design Principle s Chapter 10 Multiprocessor and Real-Time Scheduling Seventh Edition By William Stallings Operating Systems: Internals and Design Principles Bear in mind,
Load Balancing MPI Algorithm for High Throughput Applications
 Load Balancing MPI Algorithm for High Throughput Applications Igor Grudenić, Stjepan Groš, Nikola Bogunović Faculty of Electrical Engineering and, University of Zagreb Unska 3, 10000 Zagreb, Croatia {igor.grudenic,
Load Balancing MPI Algorithm for High Throughput Applications Igor Grudenić, Stjepan Groš, Nikola Bogunović Faculty of Electrical Engineering and, University of Zagreb Unska 3, 10000 Zagreb, Croatia {igor.grudenic,
Big Systems, Big Data
 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
How To Get A Computer Science Degree At Appalachian State
 118 Master of Science in Computer Science Department of Computer Science College of Arts and Sciences James T. Wilkes, Chair and Professor Ph.D., Duke University [email protected] http://www.cs.appstate.edu/
118 Master of Science in Computer Science Department of Computer Science College of Arts and Sciences James T. Wilkes, Chair and Professor Ph.D., Duke University [email protected] http://www.cs.appstate.edu/
Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012
 Author: Motti Beck, Mellanox Technologies Date: March 27, 2012") Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012 1 Market Trends Big Data Growing technology deployments are creating an exponential increase in the volume
Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012 1 Market Trends Big Data Growing technology deployments are creating an exponential increase in the volume
GeoGrid Project and Experiences with Hadoop
 GeoGrid Project and Experiences with Hadoop Gong Zhang and Ling Liu Distributed Data Intensive Systems Lab (DiSL) Center for Experimental Computer Systems Research (CERCS) Georgia Institute of Technology
GeoGrid Project and Experiences with Hadoop Gong Zhang and Ling Liu Distributed Data Intensive Systems Lab (DiSL) Center for Experimental Computer Systems Research (CERCS) Georgia Institute of Technology
Talend Real-Time Big Data Sandbox. Big Data Insights Cookbook
 Talend Real-Time Big Data Talend Real-Time Big Data Overview of Real-time Big Data Pre-requisites to run Setup & Talend License Talend Real-Time Big Data Big Data Setup & About this cookbook What is the
Talend Real-Time Big Data Talend Real-Time Big Data Overview of Real-time Big Data Pre-requisites to run Setup & Talend License Talend Real-Time Big Data Big Data Setup & About this cookbook What is the
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Stream Processing on GPUs Using Distributed Multimedia Middleware
 Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
EMC XtremSF: Delivering Next Generation Storage Performance for SQL Server
 White Paper EMC XtremSF: Delivering Next Generation Storage Performance for SQL Server Abstract This white paper addresses the challenges currently facing business executives to store and process the growing
White Paper EMC XtremSF: Delivering Next Generation Storage Performance for SQL Server Abstract This white paper addresses the challenges currently facing business executives to store and process the growing
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems
 Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Professor and Director, Division of Biological Sciences & Computation Institute, University of Chicago
 Dr. Robert Grossman Professor and Director, Division of Biological Sciences & Computation Institute, University of Chicago Dr. Xian-He Sun Chair and Professor, Computer Science, Illinois Institute of Technology
Dr. Robert Grossman Professor and Director, Division of Biological Sciences & Computation Institute, University of Chicago Dr. Xian-He Sun Chair and Professor, Computer Science, Illinois Institute of Technology
<Insert Picture Here> Oracle and/or Hadoop And what you need to know
 Oracle and/or Hadoop And what you need to know Jean-Pierre Dijcks Data Warehouse Product Management Agenda Business Context An overview of Hadoop and/or MapReduce Choices, choices,
Oracle and/or Hadoop And what you need to know Jean-Pierre Dijcks Data Warehouse Product Management Agenda Business Context An overview of Hadoop and/or MapReduce Choices, choices,
Data Modeling for Big Data
 Data Modeling for Big Data by Jinbao Zhu, Principal Software Engineer, and Allen Wang, Manager, Software Engineering, CA Technologies In the Internet era, the volume of data we deal with has grown to terabytes
Data Modeling for Big Data by Jinbao Zhu, Principal Software Engineer, and Allen Wang, Manager, Software Engineering, CA Technologies In the Internet era, the volume of data we deal with has grown to terabytes
Multi-GPU Load Balancing for Simulation and Rendering
 Multi- Load Balancing for Simulation and Rendering Yong Cao Computer Science Department, Virginia Tech, USA In-situ ualization and ual Analytics Instant visualization and interaction of computing tasks
Multi- Load Balancing for Simulation and Rendering Yong Cao Computer Science Department, Virginia Tech, USA In-situ ualization and ual Analytics Instant visualization and interaction of computing tasks
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Architecture of Hitachi SR-8000
 Architecture of Hitachi SR-8000 University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 Most of the slides from Hitachi Slide 2 the problem modern computer are data
Architecture of Hitachi SR-8000 University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 Most of the slides from Hitachi Slide 2 the problem modern computer are data
Cloud Computing. and Scheduling. Data-Intensive Computing. Frederic Magoules, Jie Pan, and Fei Teng SILKQH. CRC Press. Taylor & Francis Group
 Cloud Computing Data-Intensive Computing and Scheduling Frederic Magoules, Jie Pan, and Fei Teng SILKQH CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint of the Taylor
Cloud Computing Data-Intensive Computing and Scheduling Frederic Magoules, Jie Pan, and Fei Teng SILKQH CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint of the Taylor
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
An Oracle White Paper November 2010. Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics
 An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
Big-data Analytics: Challenges and Opportunities
 Big-data Analytics: Challenges and Opportunities Chih-Jen Lin Department of Computer Science National Taiwan University Talk at 台 灣 資 料 科 學 愛 好 者 年 會, August 30, 2014 Chih-Jen Lin (National Taiwan Univ.)
Big-data Analytics: Challenges and Opportunities Chih-Jen Lin Department of Computer Science National Taiwan University Talk at 台 灣 資 料 科 學 愛 好 者 年 會, August 30, 2014 Chih-Jen Lin (National Taiwan Univ.)
Big Data Are You Ready? Thomas Kyte http://asktom.oracle.com
 Big Data Are You Ready? Thomas Kyte http://asktom.oracle.com The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
Big Data Are You Ready? Thomas Kyte http://asktom.oracle.com The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated
PERFORMANCE MODELS FOR APACHE ACCUMULO:
 Securely explore your data PERFORMANCE MODELS FOR APACHE ACCUMULO: THE HEAVY TAIL OF A SHAREDNOTHING ARCHITECTURE Chris McCubbin Director of Data Science Sqrrl Data, Inc. I M NOT ADAM FUCHS But perhaps
Securely explore your data PERFORMANCE MODELS FOR APACHE ACCUMULO: THE HEAVY TAIL OF A SHAREDNOTHING ARCHITECTURE Chris McCubbin Director of Data Science Sqrrl Data, Inc. I M NOT ADAM FUCHS But perhaps
Architecture Support for Big Data Analytics
 Architecture Support for Big Data Analytics Ahsan Javed Awan EMJD-DC (KTH-UPC) (http://uk.linkedin.com/in/ahsanjavedawan/) Supervisors: Mats Brorsson(KTH), Eduard Ayguade(UPC), Vladimir Vlassov(KTH) 1
Architecture Support for Big Data Analytics Ahsan Javed Awan EMJD-DC (KTH-UPC) (http://uk.linkedin.com/in/ahsanjavedawan/) Supervisors: Mats Brorsson(KTH), Eduard Ayguade(UPC), Vladimir Vlassov(KTH) 1
Intro to GPU computing. Spring 2015 Mark Silberstein, 048661, Technion 1
 Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
Performance Counters. Microsoft SQL. Technical Data Sheet. Overview:
 Performance Counters Technical Data Sheet Microsoft SQL Overview: Key Features and Benefits: Key Definitions: Performance counters are used by the Operations Management Architecture (OMA) to collect data
Performance Counters Technical Data Sheet Microsoft SQL Overview: Key Features and Benefits: Key Definitions: Performance counters are used by the Operations Management Architecture (OMA) to collect data
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
Testing 3Vs (Volume, Variety and Velocity) of Big Data
 of Big Data") Testing 3Vs (Volume, Variety and Velocity) of Big Data 1 A lot happens in the Digital World in 60 seconds 2 What is Big Data Big Data refers to data sets whose size is beyond the ability of commonly used
Testing 3Vs (Volume, Variety and Velocity) of Big Data 1 A lot happens in the Digital World in 60 seconds 2 What is Big Data Big Data refers to data sets whose size is beyond the ability of commonly used
CPET 581 Cloud Computing: Technologies and Enterprise IT Strategies
 CPET 581 Cloud Computing: Technologies and Enterprise IT Strategies Lecture 8 Cloud Programming & Software Environments Part 1 of 2 Spring 2013 A Specialty Course for Purdue University s M.S. in Technology
CPET 581 Cloud Computing: Technologies and Enterprise IT Strategies Lecture 8 Cloud Programming & Software Environments Part 1 of 2 Spring 2013 A Specialty Course for Purdue University s M.S. in Technology
~ Greetings from WSU CAPPLab ~
 ~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
Making Multicore Work and Measuring its Benefits. Markus Levy, president EEMBC and Multicore Association
 Making Multicore Work and Measuring its Benefits Markus Levy, president EEMBC and Multicore Association Agenda Why Multicore? Standards and issues in the multicore community What is Multicore Association?
Making Multicore Work and Measuring its Benefits Markus Levy, president EEMBC and Multicore Association Agenda Why Multicore? Standards and issues in the multicore community What is Multicore Association?
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
Big Data Challenges in Bioinformatics
 Big Data Challenges in Bioinformatics BARCELONA SUPERCOMPUTING CENTER COMPUTER SCIENCE DEPARTMENT Autonomic Systems and ebusiness Pla?orms Jordi Torres [email protected] Talk outline! We talk about Petabyte?
Big Data Challenges in Bioinformatics BARCELONA SUPERCOMPUTING CENTER COMPUTER SCIENCE DEPARTMENT Autonomic Systems and ebusiness Pla?orms Jordi Torres [email protected] Talk outline! We talk about Petabyte?
BEYOND MAP REDUCE: THE NEXT GENERATION OF BIG DATA ANALYTICS
 WHITE PAPER Abstract Co-Authors Brian Hellig ET International, Inc. [email protected] Stephen Turner ET International, Inc. [email protected] Rich Collier ET International, Inc. [email protected]
WHITE PAPER Abstract Co-Authors Brian Hellig ET International, Inc. [email protected] Stephen Turner ET International, Inc. [email protected] Rich Collier ET International, Inc. [email protected]
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
CS 575 Parallel Processing
 CS 575 Parallel Processing Lecture one: Introduction Wim Bohm Colorado State University Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5
CS 575 Parallel Processing Lecture one: Introduction Wim Bohm Colorado State University Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5
Seeking Opportunities for Hardware Acceleration in Big Data Analytics
 Seeking Opportunities for Hardware Acceleration in Big Data Analytics Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto Who
Seeking Opportunities for Hardware Acceleration in Big Data Analytics Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto Who
Introduction to DISC and Hadoop
 Introduction to DISC and Hadoop Alice E. Fischer April 24, 2009 Alice E. Fischer DISC... 1/20 1 2 History Hadoop provides a three-layer paradigm Alice E. Fischer DISC... 2/20 Parallel Computing Past and
Introduction to DISC and Hadoop Alice E. Fischer April 24, 2009 Alice E. Fischer DISC... 1/20 1 2 History Hadoop provides a three-layer paradigm Alice E. Fischer DISC... 2/20 Parallel Computing Past and
Building an energy dashboard. Energy measurement and visualization in current HPC systems
 Building an energy dashboard Energy measurement and visualization in current HPC systems Thomas Geenen 1/58 [email protected] SURFsara The Dutch national HPC center 2H 2014 > 1PFlop GPGPU accelerators
Building an energy dashboard Energy measurement and visualization in current HPC systems Thomas Geenen 1/58 [email protected] SURFsara The Dutch national HPC center 2H 2014 > 1PFlop GPGPU accelerators
GeoImaging Accelerator Pansharp Test Results
 GeoImaging Accelerator Pansharp Test Results Executive Summary After demonstrating the exceptional performance improvement in the orthorectification module (approximately fourteen-fold see GXL Ortho Performance
GeoImaging Accelerator Pansharp Test Results Executive Summary After demonstrating the exceptional performance improvement in the orthorectification module (approximately fourteen-fold see GXL Ortho Performance
BSPCloud: A Hybrid Programming Library for Cloud Computing *
 BSPCloud: A Hybrid Programming Library for Cloud Computing * Xiaodong Liu, Weiqin Tong and Yan Hou Department of Computer Engineering and Science Shanghai University, Shanghai, China [email protected],
BSPCloud: A Hybrid Programming Library for Cloud Computing * Xiaodong Liu, Weiqin Tong and Yan Hou Department of Computer Engineering and Science Shanghai University, Shanghai, China [email protected],
Kafka & Redis for Big Data Solutions
 Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
Kafka & Redis for Big Data Solutions Christopher Curtin Head of Technical Research @ChrisCurtin About Me 25+ years in technology Head of Technical Research at Silverpop, an IBM Company (14 + years at Silverpop)
How In-Memory Data Grids Can Analyze Fast-Changing Data in Real Time
 SCALEOUT SOFTWARE How In-Memory Data Grids Can Analyze Fast-Changing Data in Real Time by Dr. William Bain and Dr. Mikhail Sobolev, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 T wenty-first
SCALEOUT SOFTWARE How In-Memory Data Grids Can Analyze Fast-Changing Data in Real Time by Dr. William Bain and Dr. Mikhail Sobolev, ScaleOut Software, Inc. 2012 ScaleOut Software, Inc. 12/27/2012 T wenty-first