Big Data Management and NoSQL Databases
|
|
|
- Dominic Simmons
- 10 years ago
- Views:
Transcription
1 NDBI040 Big Data Management and NoSQL Databases Lecture 8. Graph databases Doc. RNDr. Irena Holubova, Ph.D.

2 Graph Databases Basic Characteristics To store entities and relationships between these entities Node is an instance of an object Nodes have properties e.g., name Edges have directional significance Edges have types e.g., likes, friend, Nodes are organized by relationships Allow to find interesting patterns e.g., Get all nodes employed by Big Co that like NoSQL Distilled

3 Example:

4 Graph Databases RDBMS vs. Graph Databases When we store a graph-like structure in RDBMS, it is for a single type of relationship Who is my manager Adding another relationship usually means schema changes, data movement etc. In graph databases relationships can be dynamically created / deleted There is no limit for number and kind In RDBMS we model the graph beforehand based on the Traversal we want If the Traversal changes, the data will have to change We usually need a lot of join operations In graph databases the relationships are not calculated at query time but persisted Shift the bulk of the work of navigating the graph to inserts, leaving queries as fast as possible

5 Graph Databases Representatives FlockDB

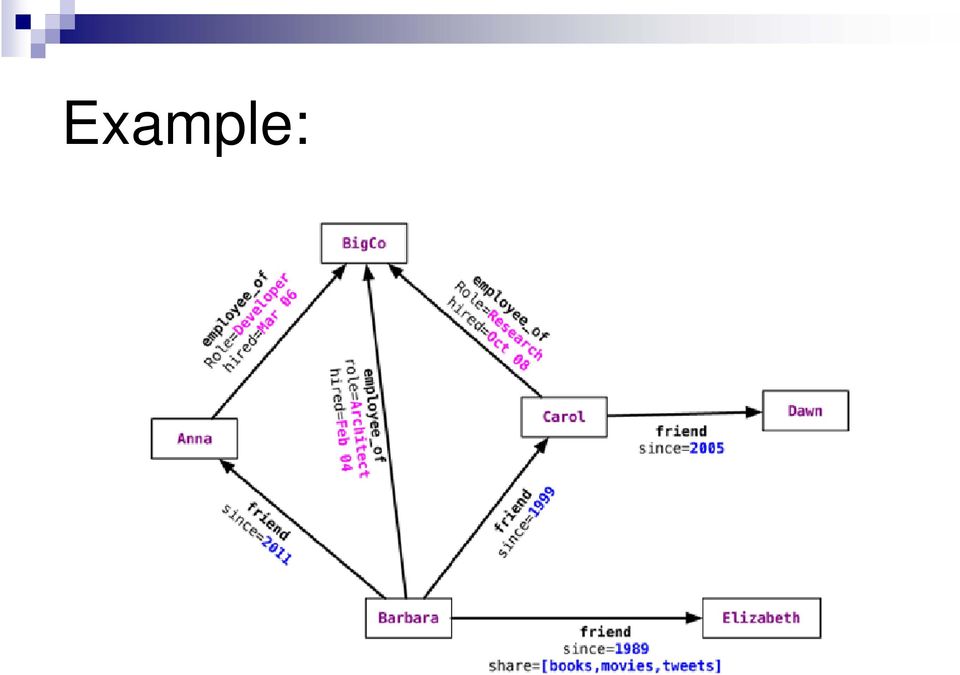
6 Graph Databases Basic Characteristics Nodes can have different types of relationships between them To represent relationships between the domain entities To have secondary relationships Category, path, time-trees, quad-trees for spatial indexing, linked lists for sorted access, There is no limit to the number and kind of relationships a node can have Relationships have type, start node, end node, own properties e.g., since when did they become friends

7 Example:
8 Example: Neo4J Node martin = graphdb.createnode(); martin.setproperty("name", "Martin"); Node pramod = graphdb.createnode(); pramod.setproperty("name", "Pramod"); martin.createrelationshipto(pramod, FRIEND); pramod.createrelationshipto(martin, FRIEND); We have to create a relationship between the nodes in both directions Nodes know about INCOMING and OUTGOING relationships
; We have to create a relationship between the nodes in")
9 adding nodes Graph Databases Query Properties of a node/edge can be indexed Indexes are queried to find the starting node to begin a traversal Transaction transaction = graphdb.begintx(); try { creating index Index<Node> nodeindex = graphdb.index().fornodes("nodes"); nodeindex.add(martin, "name", martin.getproperty("name")); nodeindex.add(pramod, "name", pramod.getproperty("name")); transaction.success(); } finally { transaction.finish(); } retrieving a node Node martin = nodeindex.get("name", "Martin").getSingle(); allrelationships = martin.getrelationships(); getting all its relationships
; } finally { transaction.finish(); } retrieving a node Node martin = nodeindex.get(\"name\", \"Martin\").getSingle(); allrelationships = martin.")
10 Graph Databases Query finding paths We are interested in determining if there are multiple paths, finding all of the paths, the shortest path, Node barbara = nodeindex.get("name", "Barbara").getSingle(); Node jill = nodeindex.get("name", "Jill").getSingle(); PathFinder<Path> finder1 = GraphAlgoFactory.allPaths( Traversal.expanderForTypes(FRIEND,Direction.OUTGOING), MAX_DEPTH); Iterable<Path> paths = finder1.findallpaths(barbara, jill); PathFinder<Path> finder2 = GraphAlgoFactory.shortestPath( Traversal.expanderForTypes(FRIEND,Direction.OUTGOING), MAX_DEPTH); Iterable<Path> paths = finder2.findallpaths(barbara, jill);
; PathFinder<Path> finder2 = GraphAlgoFactory.shortestPath( Traversal.expanderForTypes(FRIEND,Direction.")
11 Graph Databases Suitable Use Cases Connected Data Social networks Any link-rich domain is well suited for graph databases Routing, Dispatch, and Location-Based Services Node = location or address that has a delivery Graph = nodes where a delivery has to be made Relationships = distance Recommendation Engines your friends also bought this product when invoicing this item, these other items are usually invoiced

12 Graph Databases When Not to Use When we want to update all or a subset of entities Changing a property on all the nodes is not a straightforward operation e.g., analytics solution where all entities may need to be updated with a changed property Some graph databases may be unable to handle lots of data Distribution of a graph is difficult or impossible

13 Graph Databases A bit of theory Data: a set of entities and their relationships e.g., social networks, travelling routes, We need to efficiently represent graphs Basic operations: finding the neighbours of a node, checking if two nodes are connected by an edge, updating the graph structure, We need efficient graph operations G = (V, E) is commonly modelled as set of nodes (vertices) V set of edges E n = V, m = E Which data structure should be used?
 is commonly modelled as set of nodes (vertices) V set of edges E n = V, m")
14 Adjacency Matrix Bi-dimensional array A of n x n Boolean values Indexes of the array = node identifiers of the graph The Boolean junction A ij of the two indices indicates whether the two nodes are connected Variants: Directed graphs Weighted graphs

15 Adjacency Matrix Pros: Adding/removing edges Checking if two nodes are connected Cons: Quadratic space with respect to n We usually have sparse graphs lots of 0 values Addition of nodes is expensive Retrieval of all the neighbouring nodes takes linear time with respect to n

16 Adjacency List A set of lists where each accounts for the neighbours of one node A vector of n pointers to adjacency lists Undirected graph: An edge connects nodes i and j => the list of neighbours of i contains the node j and vice versa Often compressed Exploitation of regularities in graphs, difference from other nodes,

17 Adjacency List Pros: Obtaining the neighbours of a node Cheap addition of nodes to the structure More compact representation of sparse matrices Cons: Checking if there is an edge between two nodes Optimization: sorted lists => logarithmic scan, but also logarithmic insertion

18 Incidence Matrix Bi-dimensional Boolean matrix of n rows and m columns A column represents an edge Nodes that are connected by a certain edge A row represents a node All edges that are connected to the node

19 Incidence Matrix pros: For representing hypergraphs, where one edge connects an arbitrary number of nodes Cons: Requires n x m bits

20 Laplacian Matrix Bi-dimensional array of n x n integers Diagonal of the Laplacian matrix indicates the degree of the node The rest of positions are set to -1 if the two vertices are connected, 0 otherwise

21 Laplacian Matrix Pros: Allows analyzing the graph structure by means of spectral analysis Calculates the eigenvalues
22 Graph Traversals Single Step Single step traversal from element i to element j, where i, j (V E) Expose explicit adjacencies in the graph e out : traverse to the outgoing edges of the vertices e in : traverse to the incoming edges of the vertices v out : traverse to the outgoing vertices of the edges v in : traverse to the incoming vertices of the edges e lab : allow (or filter) all edges with the label : get element property values for key r e p : allow (or filter) all elements with the property s for key r = : allow (or filter) all elements that are the provided element
23 Graph Traversals Composition Single step traversals can compose complex traversals of arbitrary length e.g., find all friends of Alberto Traverse to the outgoing edges of vertex i (representing Alberto), then only allow those edges with the label friend, then traverse to the incoming (i.e. head) vertices on those friend-labeled edges. Finally, of those vertices, return their name property.
24 Improving Data Locality Idea: take into account computer architecture in the data structures to reach a good performance The way data is laid out physically in memory determines the locality to be obtained Spatial locality = once a certain data item has been accessed, the nearby data items are likely to be accessed in the following computations e.g., graph traversal Strategy: in graph adjacency matrix representation, exchange rows and columns to improve the cache hit ratio
25 Breadth First Search Layout (BFSL) Trivial algorithm Input: sequence of vertices of a graph Output: a permutation of the vertices which obtains better cache performance for graph traversals BFSL algorithm: 1. Selects a node (at random) that is the origin of the traversal 2. Traverses the graph following a breadth first search algorithm, generating a list of vertex identifiers in the order they are visited 3. Takes the generated list and assigns the node identifiers sequentially Pros: optimal when starting from the selected node Cons: starting from other nodes
26 Bandwidth of a Matrix Graphs matrices Locality problem = minimum bandwidth problem Bandwidth of a row in a matrix = the maximum distance between nonzero elements, with the condition that one is on the left of the diagonal and the other on the right of the diagonal Bandwidth of a matrix = maximum of the bandwidth of its rows Matrices with low bandwidths are more cache friendly Non zero elements (edges) are clustered across the diagonal Bandwidth minimization problem (BMP) is NP hard For large matrices (graphs) the solutions are only approximated
27
28 Cuthill-McKee (1969) Popular bandwidth minimization technique for sparse matrices Re-labels the vertices of a matrix according to a sequence, with the aim of a heuristically guided traversal Algorithm: 1. Node with the first identifier (where the traversal starts) is the node with the smallest degree in the whole graph 2. Other nodes are labeled sequentially as they are visited by BFS traversal In addition, the heuristic prefers those nodes that have the smallest degree
29 Graph Partitioning Some graphs are too large to be fully loaded into the main memory of a single computer Usage of secondary storage degrades the performance of graph applications Scalable solution distributes the graph on multiple computers We need to partition the graph reasonably Usually for particular (set of) operation(s) The shortest path, finding frequent patterns, BFS, spanning tree search,
30 One and Two Dimensional Graph Partitioning Aim: partitioning the graph to solve BFS more efficiently Distributed into shared-nothing parallel system Partitioning of the adjacency matrix 1D partitioning Matrix rows are randomly assigned to the P nodes (processors) in the system Each vertex and the edges emanating from it are owned by one processor
31
32 One and Two Dimensional Graph Partitioning BSF with 1D partitioning Input: starting node s having level 0 Output: every vertex v becomes labeled with its level, denoting its distance from the starting node 1. Each processor has a set of frontier vertices F At the beginning it is node s where the BFS starts 2. The edge lists of the vertices in F are merged to form a set of neighbouring vertices N Some owned by the current processor, some by others 3. Messages are sent to all other processors to (potentially) add these vertices to their frontier set F for the next level A processor may have marked some vertices in a previous iteration => ignores messages regarding them
33 One and Two Dimensional Graph Partitioning 2D partitioning Processors are logically arranged in an R x C processor mesh Adjacency matrix is divided C block columns and R x C block rows Each processor owns C blocks Note: 1D partitioning = 2D partitioning with C = 1 (or R = 1) Consequence: each node communicates with at most R + C nodes instead of all P nodes In step 2 a message is sent to all processors in the same row In step 3 a message is sent to all processors in the same column
34 Partitioning of vertices: Processor (i, j) owns vertices corresponding to block row (j 1) x R + i = block owned by processor (i,j)
35 Types of Graphs Single-relational Edges are homogeneous in meaning e.g., all edges represent friendship Multi-relational (property) graphs Edges are typed or labeled e.g., friendship, business, communication Vertices and edges in a property graph maintain a set of key/value pairs Representation of non-graphical data (properties) e.g., name of a vertex, the weight of an edge
36
37 Graph Databases A graph database = a set of graphs Types of graphs: Directed-labeled graphs e.g., XML, RDF, traffic networks Undirected-labeled graphs e.g., social networks, chemical compounds Types of graph databases: Non-transactional = few numbers of very large graphs e.g., Web graph, social networks, Transactional = large set of small graphs e.g., chemical compounds, biological pathways, linguistic trees each representing the structure of a sentence
38 Transactional Graph Databases Types of Queries Sub-graph queries Searches for a specific pattern in the graph database A small graph or a graph, where some parts are uncertain e.g., vertices with wildcard labels More general type: sub-graph isomorphism Super-graph queries Searches for the graph database members of which their whole structures are contained in the input query Similarity (approximate matching) queries Finds graphs which are similar, but not necessarily isomorphic to a given query graph Key question: how to measure the similarity
39
40 sub-graph: q 1 : g 1, g 2 q 2 : super-graph: q 1 : q 2 :g 3
41 Sub-graph Query Processing Non Mining-Based Graph Indexing Techniques Focus on indexing whole constructs of the graph database Instead of indexing only some selected features Cons: Can be less effective in their pruning (filtering) power May need to conduct expensive structure comparisons in the filtering process Pros: Can handle graph updates with less cost Do not rely on the effectiveness of the selected features Do not need to rebuild whole indexes
42 Non Mining-Based Techniques GraphGrep (2002) For each graph, it enumerates all paths up to a certain maximum length and records the number of occurrences of each path Path index table: Row = path Column = graph Entry in the table = number of occurrences of the path in the graph Query processing: candidate search 1. Path index is used to find candidate graphs G 1, G N which 1. contain paths in the query q and 2. counts of such paths are beyond threshold specified in query q 2. Each G 1, G N is examined by sub-graph isomorphism to obtain the final results verification
43 Non Mining-Based Techniques GraphGrep Pros: The indexing process of paths with limited lengths is usually fast Cons: The size of the indexed paths could drastically increase with the size of graph database The filtering power of paths is limited Verification cost can be very high due to the large size of the candidate set
44 Non Mining-Based Techniques GString (2007) Considers the semantics of the graph Models graph objects in the context of organic chemistry using basic structures Line = series of vertices connected end to end Cycle = series of vertices that form a closed loop Star = core vertex directly connected to several vertexes Order of identification of objects: cycles, stars, lines Graphs and queries are represented as string sequences Sub-graph search problem = subsequence string-matching domain Suffix tree-based index structure for the string representations is created
45 Collapsing of basic structures into single nodes
46 Non Mining-Based Techniques GString Basic structure has: Type Size Line/Cycle = number of vertices Star = fan-out of the central vertex Edits = set of annotations
47 Non Mining-Based Techniques GString Cons: Converting can be inefficient for large graphs Suitable for, e.g., chemical compounds but not in general
48 Sub-graph Query Processing Mining-Based Graph Indexing Techniques Idea: if features of query graph q do not exist in data graph G, then G cannot contain q as its sub-graph Graph-mining methods extract selected features (sub-structures) from the graph database members An inverted index is created for each feature Answering a sub-graph query q: 1. Identifying the set of features of q 2. Using the inverted index to retrieve all graphs that contain the same features of q Cons: Effectiveness depends on the quality of mining techniques to effectively identify the set of features Quality of the selected features may degrade over time (after lots of insertions and deletions) Re-identification and re-indexing must be done
49 Mining-Based Techniques GIndex (2004) Indexing unit = sub-graphs (of labeled undirected graph) Pros: improves query performance (higher filtering power) Cons: number of graph structures can be large GIndex considers only frequent discriminative sub-graphs Frequent: its support > threshold Support threshold is progressively increased as the graph grows Discriminative (distinctive): presence cannot be predicted by the set of all their frequently occurring subgraphs Among similar fragments with the same support only the smallest common fragment is indexed Query processing: given a query graph q 1. If q is a frequent sub-graph, the exact set of query answers containing q can be retrieved directly q is indexed 2. Otherwise, q probably has a frequent sub-graph f whose support maybe close to the support threshold q is infrequent => the sub-graph is only contained in a small number of graphs = small number of candidates to verify
50 (1) Carbon chains upto length 3 are present path-based approach cannot prune (a) and (b) Motivation from indexing text: Vocabulary size is small index phrases rather than individual words
51 Mining-Based Techniques TreePI (2007) Indexing unit = frequent sub-trees Observations: Tree data structures are more complex patterns than paths Trees can preserve almost equivalent amount of structural information as arbitrary sub-graph patterns The frequent sub-tree mining process is easier than general frequent sub-graph mining process. Mining: 1. Mining a frequent tree on the graph database 2. Selecting a set of frequent trees as index patterns Query processing: given a query graph q 1. Frequent sub-trees in q are identified and matched with the set of indexing features to obtain a candidate set 2. Candidates are verified
52 Super-graph Query Processing cindex (2007) not so extensively considered in literature Idea: If a feature f (sub-graph) is not in q, then the graphs having f are pruned The saving will be significant when f is a sub-graph of many graphs in the database. Indexing unit = contrast sub-graphs (features) = sub-graphs contained by a lot of graphs in database, but unlikely contained by a query graph Extracted from the database based on their rare occurrence in historical query graphs Pros: index is small Cons: query logs may frequently change index maybe outdated often Needs to be recomputed to stay effective
53 graph database: features: graph-feature matrix: query graph: - g a and g b can be pruned based on f 2 - f 1 has a low pruning (filtering) power
54 Super-graph Query Processing GPTree (2009) Similar idea, different approach to identification of frequent sub-graphs Based on approach for compact organization of graph database members (GPTree) All of the graph database members are stored into one graph Common sub-graphs are stored only once Complexity: Optimal construction is NP-complete => approximation algorithm Indexing unit = frequent sub-graphs Determination is based on the containment feature from the representation Exact + approximate algorithm
55
56 Graph Similarity Queries Find sub-graphs in the database that are similar to query q Allows for node mismatches, node gaps, structural differences, Usage: when graph databases are noisy or incomplete Approximate graph matching query-processing techniques can be more useful and effective than exact matching Key question: how to measure the similarity?
57 Graph Similarity Queries Grafil (2005) Feature-based structural filtering algorithm Models each query graph as a set of features Feature = can be any structure indexed in a graph database e.g., elementary structures, paths, frequent structures, Feature-graph matrix to compute the difference in the number of features between q and graphs in the database Column = graph in the graph database Row = feature being indexed Entry = number of embeddings of a feature in a graph
58 query graph q: features: feature-graph matrix: for some graphs G i in the database edge-feature matrix: for q and features f a, f b, f c Example: no match for q in our database which has 7 embeddings of f a, f b, f c => we relax one edge (e 1, e 2, or e 3 ), we still have at least 3 embeddings (we may miss at most 4 embeddings) we can discard graphs that do not involve at least 3 embeddings
59 Graph Similarity Queries Grafil Query processing: 1. Feature-graph matrix is used to calculate the difference in number of features between each graph database member and q 2. If the difference is greater than a threshold T, then it is discarded The remaining graphs constitute a candidate answer set 3. Substructure similarity (verification) is calculated for each candidate to prune the false positives candidates Many existing approaches not considered in Grafil Extension: Edge-feature matrix used to compute the maximum allowed feature misses (T) based on a query relaxation ratio (r) Row = an edge Column = embedding of a feature Entry = feature embedding involves the edge
60 Graph Similarity Queries Grafil Graph relaxation = allowing feature misses = approximation Feature miss in q = edge deletion/relabeling Inspiration: n-grams in approximate string matching Feature miss estimation problem: Given a query graph q and a set of features contained in q, if the relaxation ratio is r, what is the maximum number of features that can be missed (T)? i.e., the maximum number of columns that can be hit by k = r. G rows in the edge-feature matrix Maximum coverage problem NP-complete Approximated by a greedy algorithm Percentage of edges we relax
61 Graph Similarity Queries Closure Tree (CTree) (2006) For both similarity and sub-graph queries Similar to the R-tree indexing mechanism Extended to support graph-matching queries Each node in the tree contains information about its descendants To facilitate effective pruning (filtering) Closure of a set of vertices = generalized vertex whose attribute is the union of the attribute values of the vertices Closure of a set of edges = generalized edge whose attribute is the union of the attribute values of the edges Closure of two graphs g 1 and g 2 under a mapping M = generalized graph (V, E) V is the set of vertex closures of the corresponding vertices E is the set of edge closures of the corresponding edges
62 CTree
63 Graph Similarity Queries CTree CTree: Each node is a graph closure of its children The children of an internal node are nodes The children of a leaf node are database graphs Each node has at least m children unless it is root, m 2 Each node has at most M children, (M+1)/2 m Insertion/splitting/deletion take polynomial time Query evaluation: 1. Traverse the CTree, pruning (filtering) nodes based on pseudo sub-graph isomorphism A candidate answer set is returned 2. Verify each candidate answer for exact sub-graph isomorphism
64 Graph Query Languages Idea: need for a suitable language to query and manipulate graph data structures Some common standard Like SQL, XQuery, OQL, Classification: General Special-purpose (= special types of graphs) Inspired by existing query languages
65 PQL = Pathway Query Language (2005) Special purpose graph query language for biological networks Targets retrieving specific parts of large, complex networks Declarative Syntax is similar to SQL Queries match arbitrary sub-graphs in the database based on node properties and paths between nodes SELECT sub-graph-specification FROM node-variables WHERE node-condition-set
66 PQL Data model: Set of nodes and directed edges A node is either an interaction or a molecule The graphs need not be connected
67 PQL Basic Structures Constants (in double quotes ) Operators prefix, binary infix, and function calls with arguments in parentheses and, union, =, <>, like, Logical quantifiers (for all, exists) SELECT * has this name FROM A, B WHERE A.name = 3-Isopropylmalate AND B.name = EC has this type a path exists SELECT * FROM B, C, D WHERE D.name = L-Lactaldehyde AND B ISA Enzyme AND B[-*]C[-*]D AND C.name = Lactaldehyde
68 PQL Query Evaluation Node variables are bound to nodes of the database graph s.t. all node-conditions in the WHERE clause evaluate to TRUE All possible assignments of the variable to nodes of the graph are determined Node variables are equally assigned to molecules and interactions Query result is constructed from these variable bindings according to the sub-graph specification of the SELECT clause SQL works on tables and returns tables PQL works on graphs and returns graphs
69 GraphQL (2008) General graph query and manipulation language Supports arbitrary attributes on nodes, edges, and graphs Represented as a tuple Graphs are considered as the basic unit of information Query manipulates one or more collections of graphs Graph pattern = graph motif and a predicate on attributes of the graph Simple vs. complex graph motifs Concatenation, disjunction, repetition Predicate = combination of Boolean or arithmetic comparison expressions FLWR expressions
70 aliases
71 edges are unified if their nodes are unified
72 recursion = path itself + new edge declare a new node and unify with a nested one simple path = edge examples of repetition (Kleene star)
73 a root node v 0 arbitrary repetition as a child node of v 0
74 predicate pairs of authors co-authorship graph extract pairs of co-authors FLWR expression construct the graph each author occurs only once
75 Other Graph Query Languages GraphLog (1990) graphical query language for graph databases GOQL (1999) and GOOD (1994) extensions of OQL Object-oriented graph data model BPMN-Q (2007) determining whether a given business process model graph is structurally similar to a query graph Nodes, edges, wildcards, paths, negative paths SPARQL (2008) W3C recommendation for querying RDF graph data Describes a directed labeled graph by a set of triples
76 BPMN-Q Example Variables
77 BPMN-Q Example Paths
78 BPMN-Q Example Excluding
79 References Pramod J. Sadalage - Martin Fowler: NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence Eric Redmond - Jim R. Wilson: Seven Databases in Seven Weeks: A Guide to Modern Databases and the NoSQL Movement Sherif Sakr - Eric Pardede: Graph Data Management: Techniques and Applications
IE 680 Special Topics in Production Systems: Networks, Routing and Logistics*
 IE 680 Special Topics in Production Systems: Networks, Routing and Logistics* Rakesh Nagi Department of Industrial Engineering University at Buffalo (SUNY) *Lecture notes from Network Flows by Ahuja, Magnanti
IE 680 Special Topics in Production Systems: Networks, Routing and Logistics* Rakesh Nagi Department of Industrial Engineering University at Buffalo (SUNY) *Lecture notes from Network Flows by Ahuja, Magnanti
Subgraph Patterns: Network Motifs and Graphlets. Pedro Ribeiro
 Subgraph Patterns: Network Motifs and Graphlets Pedro Ribeiro Analyzing Complex Networks We have been talking about extracting information from networks Some possible tasks: General Patterns Ex: scale-free,
Subgraph Patterns: Network Motifs and Graphlets Pedro Ribeiro Analyzing Complex Networks We have been talking about extracting information from networks Some possible tasks: General Patterns Ex: scale-free,
Querying Large Graph Databases
 Querying Large Graph Databases Yiping Ke Chinese Univ. of Hong Kong [email protected] James Cheng Nanyang Technological Univ. [email protected] Jeffrey Xu Yu Chinese Univ. of Hong Kong [email protected]
Querying Large Graph Databases Yiping Ke Chinese Univ. of Hong Kong [email protected] James Cheng Nanyang Technological Univ. [email protected] Jeffrey Xu Yu Chinese Univ. of Hong Kong [email protected]
G-SPARQL: A Hybrid Engine for Querying Large Attributed Graphs
 G-SPARQL: A Hybrid Engine for Querying Large Attributed Graphs Sherif Sakr National ICT Australia UNSW, Sydney, Australia [email protected] Sameh Elnikety Microsoft Research Redmond, WA, USA [email protected]
G-SPARQL: A Hybrid Engine for Querying Large Attributed Graphs Sherif Sakr National ICT Australia UNSW, Sydney, Australia [email protected] Sameh Elnikety Microsoft Research Redmond, WA, USA [email protected]
Database Design Patterns. Winter 2006-2007 Lecture 24
 Database Design Patterns Winter 2006-2007 Lecture 24 Trees and Hierarchies Many schemas need to represent trees or hierarchies of some sort Common way of representing trees: An adjacency list model Each
Database Design Patterns Winter 2006-2007 Lecture 24 Trees and Hierarchies Many schemas need to represent trees or hierarchies of some sort Common way of representing trees: An adjacency list model Each
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 4. Basic Principles Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ NoSQL Overview Main objective:
NDBI040 Big Data Management and NoSQL Databases Lecture 4. Basic Principles Doc. RNDr. Irena Holubova, Ph.D. [email protected] http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ NoSQL Overview Main objective:
Distance Degree Sequences for Network Analysis
 Universität Konstanz Computer & Information Science Algorithmics Group 15 Mar 2005 based on Palmer, Gibbons, and Faloutsos: ANF A Fast and Scalable Tool for Data Mining in Massive Graphs, SIGKDD 02. Motivation
Universität Konstanz Computer & Information Science Algorithmics Group 15 Mar 2005 based on Palmer, Gibbons, and Faloutsos: ANF A Fast and Scalable Tool for Data Mining in Massive Graphs, SIGKDD 02. Motivation
Why? A central concept in Computer Science. Algorithms are ubiquitous.
 Analysis of Algorithms: A Brief Introduction Why? A central concept in Computer Science. Algorithms are ubiquitous. Using the Internet (sending email, transferring files, use of search engines, online
Analysis of Algorithms: A Brief Introduction Why? A central concept in Computer Science. Algorithms are ubiquitous. Using the Internet (sending email, transferring files, use of search engines, online
9.1. Graph Mining, Social Network Analysis, and Multirelational Data Mining. Graph Mining
 9 Graph Mining, Social Network Analysis, and Multirelational Data Mining We have studied frequent-itemset mining in Chapter 5 and sequential-pattern mining in Section 3 of Chapter 8. Many scientific and
9 Graph Mining, Social Network Analysis, and Multirelational Data Mining We have studied frequent-itemset mining in Chapter 5 and sequential-pattern mining in Section 3 of Chapter 8. Many scientific and
Home Page. Data Structures. Title Page. Page 1 of 24. Go Back. Full Screen. Close. Quit
 Data Structures Page 1 of 24 A.1. Arrays (Vectors) n-element vector start address + ielementsize 0 +1 +2 +3 +4... +n-1 start address continuous memory block static, if size is known at compile time dynamic,
Data Structures Page 1 of 24 A.1. Arrays (Vectors) n-element vector start address + ielementsize 0 +1 +2 +3 +4... +n-1 start address continuous memory block static, if size is known at compile time dynamic,
Physical Data Organization
 Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
CSE 326, Data Structures. Sample Final Exam. Problem Max Points Score 1 14 (2x7) 2 18 (3x6) 3 4 4 7 5 9 6 16 7 8 8 4 9 8 10 4 Total 92.
 2 18 (3x6) 3 4 4 7 5 9 6 16 7 8 8 4 9 8 10 4 Total 92.") Name: Email ID: CSE 326, Data Structures Section: Sample Final Exam Instructions: The exam is closed book, closed notes. Unless otherwise stated, N denotes the number of elements in the data structure
Name: Email ID: CSE 326, Data Structures Section: Sample Final Exam Instructions: The exam is closed book, closed notes. Unless otherwise stated, N denotes the number of elements in the data structure
GRAPH DATABASE SYSTEMS. h_da Prof. Dr. Uta Störl Big Data Technologies: Graph Database Systems - SoSe 2016 1
 GRAPH DATABASE SYSTEMS h_da Prof. Dr. Uta Störl Big Data Technologies: Graph Database Systems - SoSe 2016 1 Use Case: Route Finding Source: Neo Technology, Inc. h_da Prof. Dr. Uta Störl Big Data Technologies:
GRAPH DATABASE SYSTEMS h_da Prof. Dr. Uta Störl Big Data Technologies: Graph Database Systems - SoSe 2016 1 Use Case: Route Finding Source: Neo Technology, Inc. h_da Prof. Dr. Uta Störl Big Data Technologies:
Protein Protein Interaction Networks
 Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Graph Mining and Social Network Analysis
 Graph Mining and Social Network Analysis Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
Graph Mining and Social Network Analysis Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
DATA STRUCTURES USING C
 DATA STRUCTURES USING C QUESTION BANK UNIT I 1. Define data. 2. Define Entity. 3. Define information. 4. Define Array. 5. Define data structure. 6. Give any two applications of data structures. 7. Give
DATA STRUCTURES USING C QUESTION BANK UNIT I 1. Define data. 2. Define Entity. 3. Define information. 4. Define Array. 5. Define data structure. 6. Give any two applications of data structures. 7. Give
Problem Set 7 Solutions
 8 8 Introduction to Algorithms May 7, 2004 Massachusetts Institute of Technology 6.046J/18.410J Professors Erik Demaine and Shafi Goldwasser Handout 25 Problem Set 7 Solutions This problem set is due in
8 8 Introduction to Algorithms May 7, 2004 Massachusetts Institute of Technology 6.046J/18.410J Professors Erik Demaine and Shafi Goldwasser Handout 25 Problem Set 7 Solutions This problem set is due in
Social Media Mining. Graph Essentials
 Graph Essentials Graph Basics Measures Graph and Essentials Metrics 2 2 Nodes and Edges A network is a graph nodes, actors, or vertices (plural of vertex) Connections, edges or ties Edge Node Measures
Graph Essentials Graph Basics Measures Graph and Essentials Metrics 2 2 Nodes and Edges A network is a graph nodes, actors, or vertices (plural of vertex) Connections, edges or ties Edge Node Measures
DATA ANALYSIS II. Matrix Algorithms
 DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
DATA ANALYSIS II Matrix Algorithms Similarity Matrix Given a dataset D = {x i }, i=1,..,n consisting of n points in R d, let A denote the n n symmetric similarity matrix between the points, given as where
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Introduction
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Introduction
How To Improve Performance In A Database
 Some issues on Conceptual Modeling and NoSQL/Big Data Tok Wang Ling National University of Singapore 1 Database Models File system - field, record, fixed length record Hierarchical Model (IMS) - fixed
Some issues on Conceptual Modeling and NoSQL/Big Data Tok Wang Ling National University of Singapore 1 Database Models File system - field, record, fixed length record Hierarchical Model (IMS) - fixed
NoSQL Databases. Nikos Parlavantzas
 !!!! NoSQL Databases Nikos Parlavantzas Lecture overview 2 Objective! Present the main concepts necessary for understanding NoSQL databases! Provide an overview of current NoSQL technologies Outline 3!
!!!! NoSQL Databases Nikos Parlavantzas Lecture overview 2 Objective! Present the main concepts necessary for understanding NoSQL databases! Provide an overview of current NoSQL technologies Outline 3!
Graph Database Proof of Concept Report
 Objectivity, Inc. Graph Database Proof of Concept Report Managing The Internet of Things Table of Contents Executive Summary 3 Background 3 Proof of Concept 4 Dataset 4 Process 4 Query Catalog 4 Environment
Objectivity, Inc. Graph Database Proof of Concept Report Managing The Internet of Things Table of Contents Executive Summary 3 Background 3 Proof of Concept 4 Dataset 4 Process 4 Query Catalog 4 Environment
System Interconnect Architectures. Goals and Analysis. Network Properties and Routing. Terminology - 2. Terminology - 1
 System Interconnect Architectures CSCI 8150 Advanced Computer Architecture Hwang, Chapter 2 Program and Network Properties 2.4 System Interconnect Architectures Direct networks for static connections Indirect
System Interconnect Architectures CSCI 8150 Advanced Computer Architecture Hwang, Chapter 2 Program and Network Properties 2.4 System Interconnect Architectures Direct networks for static connections Indirect
Asking Hard Graph Questions. Paul Burkhardt. February 3, 2014
 Beyond Watson: Predictive Analytics and Big Data U.S. National Security Agency Research Directorate - R6 Technical Report February 3, 2014 300 years before Watson there was Euler! The first (Jeopardy!)
Beyond Watson: Predictive Analytics and Big Data U.S. National Security Agency Research Directorate - R6 Technical Report February 3, 2014 300 years before Watson there was Euler! The first (Jeopardy!)
Oracle8i Spatial: Experiences with Extensible Databases
 Oracle8i Spatial: Experiences with Extensible Databases Siva Ravada and Jayant Sharma Spatial Products Division Oracle Corporation One Oracle Drive Nashua NH-03062 {sravada,jsharma}@us.oracle.com 1 Introduction
Oracle8i Spatial: Experiences with Extensible Databases Siva Ravada and Jayant Sharma Spatial Products Division Oracle Corporation One Oracle Drive Nashua NH-03062 {sravada,jsharma}@us.oracle.com 1 Introduction
A Fast Algorithm For Finding Hamilton Cycles
 A Fast Algorithm For Finding Hamilton Cycles by Andrew Chalaturnyk A thesis presented to the University of Manitoba in partial fulfillment of the requirements for the degree of Masters of Science in Computer
A Fast Algorithm For Finding Hamilton Cycles by Andrew Chalaturnyk A thesis presented to the University of Manitoba in partial fulfillment of the requirements for the degree of Masters of Science in Computer
Practical Graph Mining with R. 5. Link Analysis
 Practical Graph Mining with R 5. Link Analysis Outline Link Analysis Concepts Metrics for Analyzing Networks PageRank HITS Link Prediction 2 Link Analysis Concepts Link A relationship between two entities
Practical Graph Mining with R 5. Link Analysis Outline Link Analysis Concepts Metrics for Analyzing Networks PageRank HITS Link Prediction 2 Link Analysis Concepts Link A relationship between two entities
SMALL INDEX LARGE INDEX (SILT)
") Wayne State University ECE 7650: Scalable and Secure Internet Services and Architecture SMALL INDEX LARGE INDEX (SILT) A Memory Efficient High Performance Key Value Store QA REPORT Instructor: Dr. Song
Wayne State University ECE 7650: Scalable and Secure Internet Services and Architecture SMALL INDEX LARGE INDEX (SILT) A Memory Efficient High Performance Key Value Store QA REPORT Instructor: Dr. Song
Discuss the size of the instance for the minimum spanning tree problem.
 3.1 Algorithm complexity The algorithms A, B are given. The former has complexity O(n 2 ), the latter O(2 n ), where n is the size of the instance. Let n A 0 be the size of the largest instance that can
3.1 Algorithm complexity The algorithms A, B are given. The former has complexity O(n 2 ), the latter O(2 n ), where n is the size of the instance. Let n A 0 be the size of the largest instance that can
Chapter 13: Query Processing. Basic Steps in Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Approximation Algorithms
 Approximation Algorithms or: How I Learned to Stop Worrying and Deal with NP-Completeness Ong Jit Sheng, Jonathan (A0073924B) March, 2012 Overview Key Results (I) General techniques: Greedy algorithms
Approximation Algorithms or: How I Learned to Stop Worrying and Deal with NP-Completeness Ong Jit Sheng, Jonathan (A0073924B) March, 2012 Overview Key Results (I) General techniques: Greedy algorithms
FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT MINING SYSTEM
 International Journal of Innovative Computing, Information and Control ICIC International c 0 ISSN 34-48 Volume 8, Number 8, August 0 pp. 4 FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT
International Journal of Innovative Computing, Information and Control ICIC International c 0 ISSN 34-48 Volume 8, Number 8, August 0 pp. 4 FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT
5. A full binary tree with n leaves contains [A] n nodes. [B] log n 2 nodes. [C] 2n 1 nodes. [D] n 2 nodes.
![5. A full binary tree with n leaves contains [A] n nodes. [B] log n 2 nodes. [C] 2n 1 nodes. [D] n 2 nodes.](/thumbs/40/21353779.jpg "5. A full binary tree with n leaves contains [A] n nodes. [B] log n 2 nodes. [C] 2n 1 nodes. [D] n 2 nodes.") 1. The advantage of.. is that they solve the problem if sequential storage representation. But disadvantage in that is they are sequential lists. [A] Lists [B] Linked Lists [A] Trees [A] Queues 2. The
1. The advantage of.. is that they solve the problem if sequential storage representation. But disadvantage in that is they are sequential lists. [A] Lists [B] Linked Lists [A] Trees [A] Queues 2. The
Part 2: Community Detection
 Chapter 8: Graph Data Part 2: Community Detection Based on Leskovec, Rajaraman, Ullman 2014: Mining of Massive Datasets Big Data Management and Analytics Outline Community Detection - Social networks -
Chapter 8: Graph Data Part 2: Community Detection Based on Leskovec, Rajaraman, Ullman 2014: Mining of Massive Datasets Big Data Management and Analytics Outline Community Detection - Social networks -
Krishna Institute of Engineering & Technology, Ghaziabad Department of Computer Application MCA-213 : DATA STRUCTURES USING C
 Tutorial#1 Q 1:- Explain the terms data, elementary item, entity, primary key, domain, attribute and information? Also give examples in support of your answer? Q 2:- What is a Data Type? Differentiate
Tutorial#1 Q 1:- Explain the terms data, elementary item, entity, primary key, domain, attribute and information? Also give examples in support of your answer? Q 2:- What is a Data Type? Differentiate
2. (a) Explain the strassen s matrix multiplication. (b) Write deletion algorithm, of Binary search tree. [8+8]
![2. (a) Explain the strassen s matrix multiplication. (b) Write deletion algorithm, of Binary search tree. [8+8]](/thumbs/40/21097758.jpg "2. (a) Explain the strassen s matrix multiplication. (b) Write deletion algorithm, of Binary search tree. [8+8]") Code No: R05220502 Set No. 1 1. (a) Describe the performance analysis in detail. (b) Show that f 1 (n)+f 2 (n) = 0(max(g 1 (n), g 2 (n)) where f 1 (n) = 0(g 1 (n)) and f 2 (n) = 0(g 2 (n)). [8+8] 2. (a)
Code No: R05220502 Set No. 1 1. (a) Describe the performance analysis in detail. (b) Show that f 1 (n)+f 2 (n) = 0(max(g 1 (n), g 2 (n)) where f 1 (n) = 0(g 1 (n)) and f 2 (n) = 0(g 2 (n)). [8+8] 2. (a)
Chapter 6: Episode discovery process
 Chapter 6: Episode discovery process Algorithmic Methods of Data Mining, Fall 2005, Chapter 6: Episode discovery process 1 6. Episode discovery process The knowledge discovery process KDD process of analyzing
Chapter 6: Episode discovery process Algorithmic Methods of Data Mining, Fall 2005, Chapter 6: Episode discovery process 1 6. Episode discovery process The knowledge discovery process KDD process of analyzing
NoSQL storage and management of geospatial data with emphasis on serving geospatial data using standard geospatial web services
 NoSQL storage and management of geospatial data with emphasis on serving geospatial data using standard geospatial web services Pouria Amirian, Adam Winstanley, Anahid Basiri Department of Computer Science,
NoSQL storage and management of geospatial data with emphasis on serving geospatial data using standard geospatial web services Pouria Amirian, Adam Winstanley, Anahid Basiri Department of Computer Science,
NoSQL systems: introduction and data models. Riccardo Torlone Università Roma Tre
 NoSQL systems: introduction and data models Riccardo Torlone Università Roma Tre Why NoSQL? In the last thirty years relational databases have been the default choice for serious data storage. An architect
NoSQL systems: introduction and data models Riccardo Torlone Università Roma Tre Why NoSQL? In the last thirty years relational databases have been the default choice for serious data storage. An architect
KEYWORD SEARCH IN RELATIONAL DATABASES
 KEYWORD SEARCH IN RELATIONAL DATABASES N.Divya Bharathi 1 1 PG Scholar, Department of Computer Science and Engineering, ABSTRACT Adhiyamaan College of Engineering, Hosur, (India). Data mining refers to
KEYWORD SEARCH IN RELATIONAL DATABASES N.Divya Bharathi 1 1 PG Scholar, Department of Computer Science and Engineering, ABSTRACT Adhiyamaan College of Engineering, Hosur, (India). Data mining refers to
2. Basic Relational Data Model
 2. Basic Relational Data Model 2.1 Introduction Basic concepts of information models, their realisation in databases comprising data objects and object relationships, and their management by DBMS s that
2. Basic Relational Data Model 2.1 Introduction Basic concepts of information models, their realisation in databases comprising data objects and object relationships, and their management by DBMS s that
An Introduction to APGL
 An Introduction to APGL Charanpal Dhanjal February 2012 Abstract Another Python Graph Library (APGL) is a graph library written using pure Python, NumPy and SciPy. Users new to the library can gain an
An Introduction to APGL Charanpal Dhanjal February 2012 Abstract Another Python Graph Library (APGL) is a graph library written using pure Python, NumPy and SciPy. Users new to the library can gain an
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Mining Social-Network Graphs
 342 Chapter 10 Mining Social-Network Graphs There is much information to be gained by analyzing the large-scale data that is derived from social networks. The best-known example of a social network is
342 Chapter 10 Mining Social-Network Graphs There is much information to be gained by analyzing the large-scale data that is derived from social networks. The best-known example of a social network is
Interconnection Networks. Interconnection Networks. Interconnection networks are used everywhere!
 Interconnection Networks Interconnection Networks Interconnection networks are used everywhere! Supercomputers connecting the processors Routers connecting the ports can consider a router as a parallel
Interconnection Networks Interconnection Networks Interconnection networks are used everywhere! Supercomputers connecting the processors Routers connecting the ports can consider a router as a parallel
Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing. October 29th, 2015
 E6893 Big Data Analytics Lecture 8: Spark Streams and Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing
E6893 Big Data Analytics Lecture 8: Spark Streams and Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing
So today we shall continue our discussion on the search engines and web crawlers. (Refer Slide Time: 01:02)
") Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Data Structure [Question Bank]
![Data Structure [Question Bank]](/thumbs/40/21355705.jpg "Data Structure [Question Bank]") Unit I (Analysis of Algorithms) 1. What are algorithms and how they are useful? 2. Describe the factor on best algorithms depends on? 3. Differentiate: Correct & Incorrect Algorithms? 4. Write short note:
Unit I (Analysis of Algorithms) 1. What are algorithms and how they are useful? 2. Describe the factor on best algorithms depends on? 3. Differentiate: Correct & Incorrect Algorithms? 4. Write short note:
Network (Tree) Topology Inference Based on Prüfer Sequence
 Topology Inference Based on Prüfer Sequence") Network (Tree) Topology Inference Based on Prüfer Sequence C. Vanniarajan and Kamala Krithivasan Department of Computer Science and Engineering Indian Institute of Technology Madras Chennai 600036 [email protected],
Network (Tree) Topology Inference Based on Prüfer Sequence C. Vanniarajan and Kamala Krithivasan Department of Computer Science and Engineering Indian Institute of Technology Madras Chennai 600036 [email protected],
CHAPTER-24 Mining Spatial Databases
 CHAPTER-24 Mining Spatial Databases 24.1 Introduction 24.2 Spatial Data Cube Construction and Spatial OLAP 24.3 Spatial Association Analysis 24.4 Spatial Clustering Methods 24.5 Spatial Classification
CHAPTER-24 Mining Spatial Databases 24.1 Introduction 24.2 Spatial Data Cube Construction and Spatial OLAP 24.3 Spatial Association Analysis 24.4 Spatial Clustering Methods 24.5 Spatial Classification
COMP3420: Advanced Databases and Data Mining. Classification and prediction: Introduction and Decision Tree Induction
 COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs
 CSE599s: Extremal Combinatorics November 21, 2011 Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs Lecturer: Anup Rao 1 An Arithmetic Circuit Lower Bound An arithmetic circuit is just like
CSE599s: Extremal Combinatorics November 21, 2011 Lecture 15 An Arithmetic Circuit Lowerbound and Flows in Graphs Lecturer: Anup Rao 1 An Arithmetic Circuit Lower Bound An arithmetic circuit is just like
EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES
 ABSTRACT EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES Tyler Cossentine and Ramon Lawrence Department of Computer Science, University of British Columbia Okanagan Kelowna, BC, Canada [email protected]
ABSTRACT EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES Tyler Cossentine and Ramon Lawrence Department of Computer Science, University of British Columbia Okanagan Kelowna, BC, Canada [email protected]
ML for the Working Programmer
 ML for the Working Programmer 2nd edition Lawrence C. Paulson University of Cambridge CAMBRIDGE UNIVERSITY PRESS CONTENTS Preface to the Second Edition Preface xiii xv 1 Standard ML 1 Functional Programming
ML for the Working Programmer 2nd edition Lawrence C. Paulson University of Cambridge CAMBRIDGE UNIVERSITY PRESS CONTENTS Preface to the Second Edition Preface xiii xv 1 Standard ML 1 Functional Programming
Composite Data Virtualization Composite Data Virtualization And NOSQL Data Stores
 Composite Data Virtualization Composite Data Virtualization And NOSQL Data Stores Composite Software October 2010 TABLE OF CONTENTS INTRODUCTION... 3 BUSINESS AND IT DRIVERS... 4 NOSQL DATA STORES LANDSCAPE...
Composite Data Virtualization Composite Data Virtualization And NOSQL Data Stores Composite Software October 2010 TABLE OF CONTENTS INTRODUCTION... 3 BUSINESS AND IT DRIVERS... 4 NOSQL DATA STORES LANDSCAPE...
Distributed Dynamic Load Balancing for Iterative-Stencil Applications
 Distributed Dynamic Load Balancing for Iterative-Stencil Applications G. Dethier 1, P. Marchot 2 and P.A. de Marneffe 1 1 EECS Department, University of Liege, Belgium 2 Chemical Engineering Department,
Distributed Dynamic Load Balancing for Iterative-Stencil Applications G. Dethier 1, P. Marchot 2 and P.A. de Marneffe 1 1 EECS Department, University of Liege, Belgium 2 Chemical Engineering Department,
Oracle 10g PL/SQL Training
 Oracle 10g PL/SQL Training Course Number: ORCL PS01 Length: 3 Day(s) Certification Exam This course will help you prepare for the following exams: 1Z0 042 1Z0 043 Course Overview PL/SQL is Oracle's Procedural
Oracle 10g PL/SQL Training Course Number: ORCL PS01 Length: 3 Day(s) Certification Exam This course will help you prepare for the following exams: 1Z0 042 1Z0 043 Course Overview PL/SQL is Oracle's Procedural
A Serial Partitioning Approach to Scaling Graph-Based Knowledge Discovery
 A Serial Partitioning Approach to Scaling Graph-Based Knowledge Discovery Runu Rathi, Diane J. Cook, Lawrence B. Holder Department of Computer Science and Engineering The University of Texas at Arlington
A Serial Partitioning Approach to Scaling Graph-Based Knowledge Discovery Runu Rathi, Diane J. Cook, Lawrence B. Holder Department of Computer Science and Engineering The University of Texas at Arlington
! E6893 Big Data Analytics Lecture 9:! Linked Big Data Graph Computing (I)
") ! E6893 Big Data Analytics Lecture 9:! Linked Big Data Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
! E6893 Big Data Analytics Lecture 9:! Linked Big Data Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
Oracle BI EE Implementation on Netezza. Prepared by SureShot Strategies, Inc.
 Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Clustering & Visualization
 Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
One last point: we started off this book by introducing another famously hard search problem:
 S. Dasgupta, C.H. Papadimitriou, and U.V. Vazirani 261 Factoring One last point: we started off this book by introducing another famously hard search problem: FACTORING, the task of finding all prime factors
S. Dasgupta, C.H. Papadimitriou, and U.V. Vazirani 261 Factoring One last point: we started off this book by introducing another famously hard search problem: FACTORING, the task of finding all prime factors
Chapter 13 File and Database Systems
 Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems
 Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Completing the Big Data Ecosystem:
 Completing the Big Data Ecosystem: in sqrrl data INC. August 3, 2012 Design Drivers in Analysis of big data is central to our customers requirements, in which the strongest drivers are: Scalability: The
Completing the Big Data Ecosystem: in sqrrl data INC. August 3, 2012 Design Drivers in Analysis of big data is central to our customers requirements, in which the strongest drivers are: Scalability: The
10CS35: Data Structures Using C
 CS35: Data Structures Using C QUESTION BANK REVIEW OF STRUCTURES AND POINTERS, INTRODUCTION TO SPECIAL FEATURES OF C OBJECTIVE: Learn : Usage of structures, unions - a conventional tool for handling a
CS35: Data Structures Using C QUESTION BANK REVIEW OF STRUCTURES AND POINTERS, INTRODUCTION TO SPECIAL FEATURES OF C OBJECTIVE: Learn : Usage of structures, unions - a conventional tool for handling a
DBMS / Business Intelligence, SQL Server
 DBMS / Business Intelligence, SQL Server Orsys, with 30 years of experience, is providing high quality, independant State of the Art seminars and hands-on courses corresponding to the needs of IT professionals.
DBMS / Business Intelligence, SQL Server Orsys, with 30 years of experience, is providing high quality, independant State of the Art seminars and hands-on courses corresponding to the needs of IT professionals.
Outline. NP-completeness. When is a problem easy? When is a problem hard? Today. Euler Circuits
 Outline NP-completeness Examples of Easy vs. Hard problems Euler circuit vs. Hamiltonian circuit Shortest Path vs. Longest Path 2-pairs sum vs. general Subset Sum Reducing one problem to another Clique
Outline NP-completeness Examples of Easy vs. Hard problems Euler circuit vs. Hamiltonian circuit Shortest Path vs. Longest Path 2-pairs sum vs. general Subset Sum Reducing one problem to another Clique
KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS
 ABSTRACT KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS In many real applications, RDF (Resource Description Framework) has been widely used as a W3C standard to describe data in the Semantic Web. In practice,
ABSTRACT KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS In many real applications, RDF (Resource Description Framework) has been widely used as a W3C standard to describe data in the Semantic Web. In practice,
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
In-Memory Databases Algorithms and Data Structures on Modern Hardware. Martin Faust David Schwalb Jens Krüger Jürgen Müller
 In-Memory Databases Algorithms and Data Structures on Modern Hardware Martin Faust David Schwalb Jens Krüger Jürgen Müller The Free Lunch Is Over 2 Number of transistors per CPU increases Clock frequency
In-Memory Databases Algorithms and Data Structures on Modern Hardware Martin Faust David Schwalb Jens Krüger Jürgen Müller The Free Lunch Is Over 2 Number of transistors per CPU increases Clock frequency
MapReduce. MapReduce and SQL Injections. CS 3200 Final Lecture. Introduction. MapReduce. Programming Model. Example
 MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
MapReduce MapReduce and SQL Injections CS 3200 Final Lecture Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System Design
Lecture Data Warehouse Systems
 Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
DATABASE DESIGN - 1DL400
 DATABASE DESIGN - 1DL400 Spring 2015 A course on modern database systems!! http://www.it.uu.se/research/group/udbl/kurser/dbii_vt15/ Kjell Orsborn! Uppsala Database Laboratory! Department of Information
DATABASE DESIGN - 1DL400 Spring 2015 A course on modern database systems!! http://www.it.uu.se/research/group/udbl/kurser/dbii_vt15/ Kjell Orsborn! Uppsala Database Laboratory! Department of Information
Query Optimization for Distributed Database Systems Robert Taylor Candidate Number : 933597 Hertford College Supervisor: Dr.
 Query Optimization for Distributed Database Systems Robert Taylor Candidate Number : 933597 Hertford College Supervisor: Dr. Dan Olteanu Submitted as part of Master of Computer Science Computing Laboratory
Query Optimization for Distributed Database Systems Robert Taylor Candidate Number : 933597 Hertford College Supervisor: Dr. Dan Olteanu Submitted as part of Master of Computer Science Computing Laboratory
Files. Files. Files. Files. Files. File Organisation. What s it all about? What s in a file?
 Files What s it all about? Information being stored about anything important to the business/individual keeping the files. The simple concepts used in the operation of manual files are often a good guide
Files What s it all about? Information being stored about anything important to the business/individual keeping the files. The simple concepts used in the operation of manual files are often a good guide
Efficient Data Structures for Decision Diagrams
 Artificial Intelligence Laboratory Efficient Data Structures for Decision Diagrams Master Thesis Nacereddine Ouaret Professor: Supervisors: Boi Faltings Thomas Léauté Radoslaw Szymanek Contents Introduction...
Artificial Intelligence Laboratory Efficient Data Structures for Decision Diagrams Master Thesis Nacereddine Ouaret Professor: Supervisors: Boi Faltings Thomas Léauté Radoslaw Szymanek Contents Introduction...
GRAPH THEORY LECTURE 4: TREES
 GRAPH THEORY LECTURE 4: TREES Abstract. 3.1 presents some standard characterizations and properties of trees. 3.2 presents several different types of trees. 3.7 develops a counting method based on a bijection
GRAPH THEORY LECTURE 4: TREES Abstract. 3.1 presents some standard characterizations and properties of trees. 3.2 presents several different types of trees. 3.7 develops a counting method based on a bijection
Load balancing in a heterogeneous computer system by self-organizing Kohonen network
 Bull. Nov. Comp. Center, Comp. Science, 25 (2006), 69 74 c 2006 NCC Publisher Load balancing in a heterogeneous computer system by self-organizing Kohonen network Mikhail S. Tarkov, Yakov S. Bezrukov Abstract.
Bull. Nov. Comp. Center, Comp. Science, 25 (2006), 69 74 c 2006 NCC Publisher Load balancing in a heterogeneous computer system by self-organizing Kohonen network Mikhail S. Tarkov, Yakov S. Bezrukov Abstract.
COMBINATORIAL PROPERTIES OF THE HIGMAN-SIMS GRAPH. 1. Introduction
 COMBINATORIAL PROPERTIES OF THE HIGMAN-SIMS GRAPH ZACHARY ABEL 1. Introduction In this survey we discuss properties of the Higman-Sims graph, which has 100 vertices, 1100 edges, and is 22 regular. In fact
COMBINATORIAL PROPERTIES OF THE HIGMAN-SIMS GRAPH ZACHARY ABEL 1. Introduction In this survey we discuss properties of the Higman-Sims graph, which has 100 vertices, 1100 edges, and is 22 regular. In fact
USE OF EIGENVALUES AND EIGENVECTORS TO ANALYZE BIPARTIVITY OF NETWORK GRAPHS
 USE OF EIGENVALUES AND EIGENVECTORS TO ANALYZE BIPARTIVITY OF NETWORK GRAPHS Natarajan Meghanathan Jackson State University, 1400 Lynch St, Jackson, MS, USA [email protected] ABSTRACT This
USE OF EIGENVALUES AND EIGENVECTORS TO ANALYZE BIPARTIVITY OF NETWORK GRAPHS Natarajan Meghanathan Jackson State University, 1400 Lynch St, Jackson, MS, USA [email protected] ABSTRACT This
SPARQL: Un Lenguaje de Consulta para la Web
 SPARQL: Un Lenguaje de Consulta para la Web Semántica Marcelo Arenas Pontificia Universidad Católica de Chile y Centro de Investigación de la Web M. Arenas SPARQL: Un Lenguaje de Consulta para la Web Semántica
SPARQL: Un Lenguaje de Consulta para la Web Semántica Marcelo Arenas Pontificia Universidad Católica de Chile y Centro de Investigación de la Web M. Arenas SPARQL: Un Lenguaje de Consulta para la Web Semántica
131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10
![131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10](/thumbs/25/4963058.jpg "131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10") 1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
ALLIED PAPER : DISCRETE MATHEMATICS (for B.Sc. Computer Technology & B.Sc. Multimedia and Web Technology)
") ALLIED PAPER : DISCRETE MATHEMATICS (for B.Sc. Computer Technology & B.Sc. Multimedia and Web Technology) Subject Description: This subject deals with discrete structures like set theory, mathematical
ALLIED PAPER : DISCRETE MATHEMATICS (for B.Sc. Computer Technology & B.Sc. Multimedia and Web Technology) Subject Description: This subject deals with discrete structures like set theory, mathematical
root node level: internal node edge leaf node CS@VT Data Structures & Algorithms 2000-2009 McQuain
 inary Trees 1 A binary tree is either empty, or it consists of a node called the root together with two binary trees called the left subtree and the right subtree of the root, which are disjoint from each
inary Trees 1 A binary tree is either empty, or it consists of a node called the root together with two binary trees called the left subtree and the right subtree of the root, which are disjoint from each
Oracle Database: SQL and PL/SQL Fundamentals
 Oracle University Contact Us: 1.800.529.0165 Oracle Database: SQL and PL/SQL Fundamentals Duration: 5 Days What you will learn This course is designed to deliver the fundamentals of SQL and PL/SQL along
Oracle University Contact Us: 1.800.529.0165 Oracle Database: SQL and PL/SQL Fundamentals Duration: 5 Days What you will learn This course is designed to deliver the fundamentals of SQL and PL/SQL along
A Comparison of Database Query Languages: SQL, SPARQL, CQL, DMX
 ISSN: 2393-8528 Contents lists available at www.ijicse.in International Journal of Innovative Computer Science & Engineering Volume 3 Issue 2; March-April-2016; Page No. 09-13 A Comparison of Database
ISSN: 2393-8528 Contents lists available at www.ijicse.in International Journal of Innovative Computer Science & Engineering Volume 3 Issue 2; March-April-2016; Page No. 09-13 A Comparison of Database
1) The postfix expression for the infix expression A+B*(C+D)/F+D*E is ABCD+*F/DE*++
 The postfix expression for the infix expression A+B*(C+D)/F+D*E is ABCD+*F/DE*++") Answer the following 1) The postfix expression for the infix expression A+B*(C+D)/F+D*E is ABCD+*F/DE*++ 2) Which data structure is needed to convert infix notations to postfix notations? Stack 3) The
Answer the following 1) The postfix expression for the infix expression A+B*(C+D)/F+D*E is ABCD+*F/DE*++ 2) Which data structure is needed to convert infix notations to postfix notations? Stack 3) The
Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries
 Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries Shin Morishima 1 and Hiroki Matsutani 1,2,3 1Keio University, 3 14 1 Hiyoshi, Kohoku ku, Yokohama, Japan 2National Institute
Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries Shin Morishima 1 and Hiroki Matsutani 1,2,3 1Keio University, 3 14 1 Hiyoshi, Kohoku ku, Yokohama, Japan 2National Institute
Understanding Web personalization with Web Usage Mining and its Application: Recommender System
 Understanding Web personalization with Web Usage Mining and its Application: Recommender System Manoj Swami 1, Prof. Manasi Kulkarni 2 1 M.Tech (Computer-NIMS), VJTI, Mumbai. 2 Department of Computer Technology,
Understanding Web personalization with Web Usage Mining and its Application: Recommender System Manoj Swami 1, Prof. Manasi Kulkarni 2 1 M.Tech (Computer-NIMS), VJTI, Mumbai. 2 Department of Computer Technology,
Big Data, Fast Data, Complex Data. Jans Aasman Franz Inc
 Big Data, Fast Data, Complex Data Jans Aasman Franz Inc Private, founded 1984 AI, Semantic Technology, professional services Now in Oakland Franz Inc Who We Are (1 (2 3) (4 5) (6 7) (8 9) (10 11) (12
Big Data, Fast Data, Complex Data Jans Aasman Franz Inc Private, founded 1984 AI, Semantic Technology, professional services Now in Oakland Franz Inc Who We Are (1 (2 3) (4 5) (6 7) (8 9) (10 11) (12
Using Object Database db4o as Storage Provider in Voldemort
 Using Object Database db4o as Storage Provider in Voldemort by German Viscuso db4objects (a division of Versant Corporation) September 2010 Abstract: In this article I will show you how
Using Object Database db4o as Storage Provider in Voldemort by German Viscuso db4objects (a division of Versant Corporation) September 2010 Abstract: In this article I will show you how
Data Warehousing und Data Mining
 Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
Data Warehousing und Data Mining Multidimensionale Indexstrukturen Ulf Leser Wissensmanagement in der Bioinformatik Content of this Lecture Multidimensional Indexing Grid-Files Kd-trees Ulf Leser: Data
Analysis of Algorithms, I
 Analysis of Algorithms, I CSOR W4231.002 Eleni Drinea Computer Science Department Columbia University Thursday, February 26, 2015 Outline 1 Recap 2 Representing graphs 3 Breadth-first search (BFS) 4 Applications
Analysis of Algorithms, I CSOR W4231.002 Eleni Drinea Computer Science Department Columbia University Thursday, February 26, 2015 Outline 1 Recap 2 Representing graphs 3 Breadth-first search (BFS) 4 Applications
Vector storage and access; algorithms in GIS. This is lecture 6
 Vector storage and access; algorithms in GIS This is lecture 6 Vector data storage and access Vectors are built from points, line and areas. (x,y) Surface: (x,y,z) Vector data access Access to vector
Vector storage and access; algorithms in GIS This is lecture 6 Vector data storage and access Vectors are built from points, line and areas. (x,y) Surface: (x,y,z) Vector data access Access to vector
Index Terms Domain name, Firewall, Packet, Phishing, URL.
 BDD for Implementation of Packet Filter Firewall and Detecting Phishing Websites Naresh Shende Vidyalankar Institute of Technology Prof. S. K. Shinde Lokmanya Tilak College of Engineering Abstract Packet
BDD for Implementation of Packet Filter Firewall and Detecting Phishing Websites Naresh Shende Vidyalankar Institute of Technology Prof. S. K. Shinde Lokmanya Tilak College of Engineering Abstract Packet
Yousef Saad University of Minnesota Computer Science and Engineering. CRM Montreal - April 30, 2008
 A tutorial on: Iterative methods for Sparse Matrix Problems Yousef Saad University of Minnesota Computer Science and Engineering CRM Montreal - April 30, 2008 Outline Part 1 Sparse matrices and sparsity
A tutorial on: Iterative methods for Sparse Matrix Problems Yousef Saad University of Minnesota Computer Science and Engineering CRM Montreal - April 30, 2008 Outline Part 1 Sparse matrices and sparsity