! E6893 Big Data Analytics Lecture 9:! Linked Big Data Graph Computing (I)
|
|
|
- Ella Cathleen Mitchell
- 8 years ago
- Views:
Transcription
1 ! E6893 Big Data Analytics Lecture 9:! Linked Big Data Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big Data Analytics, IBM Watson Research Center October 30th, 2014

2 Course Structure Class Data Number Topics Covered 09/04/14 1 Introduction to Big Data Analytics 09/11/14 2 Big Data Analytics Platforms 09/18/14 3 Big Data Storage and Processing 09/25/14 4 Big Data Analytics Algorithms -- I 10/02/14 5 Big Data Analytics Algorithms -- II (recommendation) 10/09/14 6 Big Data Analytics Algorithms III (clustering) 10/16/14 7 Big Data Analytics Algorithms IV (classification) 10/23/14 8 Big Data Analytics Algorithms V (classification & clustering) 10/30/14 9 Linked Big Data Graph Computing I 11/06/14 10 Linked Big Data Graph Computing II 11/13/14 11 Hardware, Processors, and Cluster Platforms 11/20/14 12 Big Data Next Challenges IoT, Cognition, and Beyond 11/27/14 Thanksgiving Holiday 12/04/14 13 Final Projects Discussion (Optional) 12/11/14 & 12/12/ Two-Day Big Data Analytics Workshop Final Project Presentations 2
 12/11/14 &")
3 Forrester: Over 25% of enterprise will use Graph DB by 2017 TechRadar: Enterprise DBMS, Q12014 Graph DB is in the significant success trajectory, and with the highest business value in the upcoming DBs. System G Team 2014 IBM Corporation

4 4 Source: Dr. Toyotaro Suzumura, ICPE2014 E6893 Big keynote Data Analytics Lecture 9: Linked Big Data: Graph Computing

5 Graph Computation Step 1: Computations on graph structures / topologies Example converting Bayesian network into junction tree, graph traversal (BFS/DFS), etc. Characteristics Poor locality, irregular memory access, limited numeric operations! Step 2: Computations on graphs with rich properties Example Belief propagation: diffuse information through a graph using statistical models Characteristics Locality and memory access pattern depend on vertex models Typically a lot of numeric operations Hybrid workload Step 3: Computations on dynamic graphs Characteristics Poor locality, irregular memory access Operations to update a model (e.g., cluster, sub-graph) 3-core subgraph Hybrid workload 5

6 Parallel Inference Parallelism at Multiple Granularity Levels Absorb Marginalize Extend Multiply/Divide Marginalization 6

7 Large-Scale Graph Benchmark Graph IBM BlueGene or P775: 24 out of Top 30, except #4, #14, #22: Fujitsu (algorithm is from IBM) #6: Tianhe #15: Cray #24: HP
 #6: Tianhe #15: Cray #24:")
8 ScaleGraph algorithms (IBM System G s open source) made Top #1 in Graph 500 benchmark 8 Source: Dr. Toyotaro Suzumura, ICPE2014 keynote

9 RDF and SPARQL 9

10 RDF and SPARQL 10

11 Resource Description Format (RDF) A W3C standard sicne 1999 Triples Example: A company has nince of part p1234 in stock, then a simplified triple rpresenting this might be {p1234 instock 9}. Instance Identifier, Property Name, Property Value. In a proper RDF version of this triple, the representation will be more formal. They require uniform resource identifiers (URIs). 11

12 An example complete description 12

13 Advantages of RDF Virtually any RDF software can parse the lines shown above as self-contained, working data file. You can declare properties if you want. The RDF Schema standard lets you declare classes and relationships between properties and classes. The flexibility that the lack of dependence on schemas is the first key to RDF's value.! Split trips into several lines that won't affect their collective meaning, which makes sharding of data collections easy. Multiple datasets can be combined into a usable whole with simple concatenation.! For the inventory dataset's property name URIs, sharing of vocabulary makes easy to aggregate. 13

14 SPARQL Query Langauge for RDF The following SPQRL query asks for all property names and values associated with the fbd:s9483 resource: 14

15 The SPAQRL Query Result from the previous example 15

16 Another SPARQL Example What is this query for? Data 16

17 Open Source Software Apache Jena 17

18 Property Graphs 18

19 Reference 19

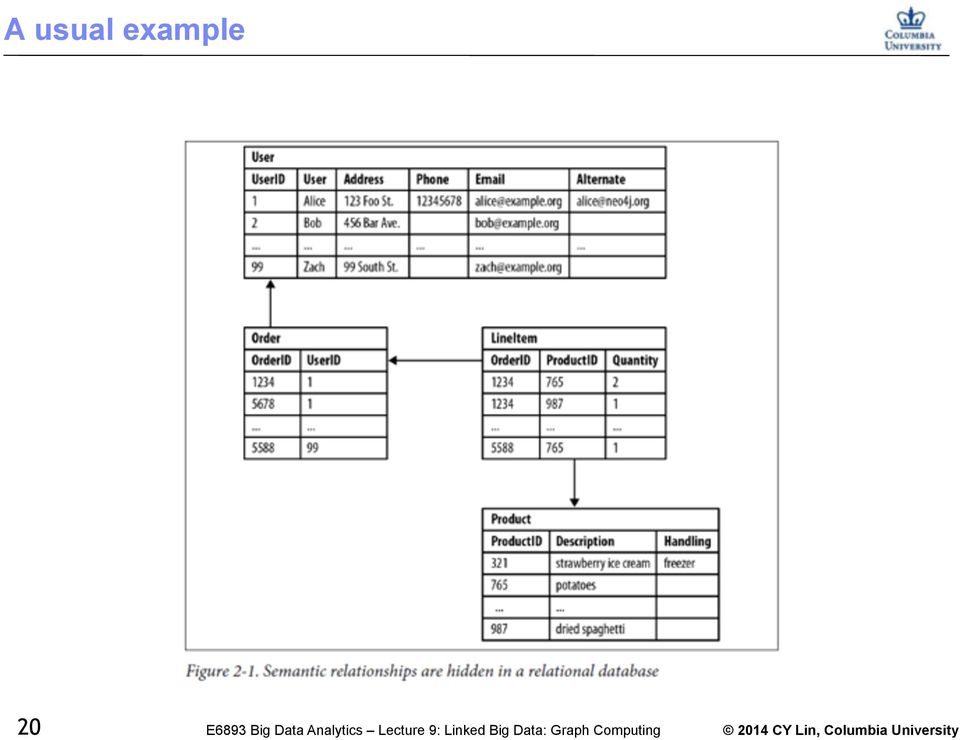
20 A usual example 20
21 Query Example I 21
22 Query Examples II & III 22 Computational intensive
23 Graph Database Example 23
24 Executation Time in the example of finding extended friends (by Neo4j) 24
25 Modeling Order History as a Graph 25
26 A query language on Property Graph Cypher 26
27 Cypher Example 27
28 Other Cypher Clauses 28
29 Property Graph Example Shakespheare 29
30 Creating the Shakespeare Graph 30
31 Query on the Shakespear Graph 31
32 Another Query on the Shakespear Graph 32
33 Chaining on the Query 33
34 Example Interaction Graph What's this query for? 34
35 Building Application Example Collaborative Filtering 35
36 How to make graph database fast? 36
37 Use Relationships, not indexes, for fast traversal 37
38 Storage Structure Example 38
39 Nodes and Relationships in the Object Cache 39
40 An Emerging Benchmark Test Set: data generator of full social media activity simulation of any number of users 40
41 TinkerPop Stack and choices of Open Source Graph DBs JVM API + Stack for Graph Includes: - Gremlin traversal language - - BluePrints JDBC of Graph DB s - BYO persistence graph store: - Growing community - Ex. Titan, Neo4J, InfiniteGraph! - But - It is still work in progress - - analytics (Furnace) are not yet implemented - - No support for pushing work to data nodes - - Big data support is not clear Titan by Aurelius Apache2 license Uses HBase, Berkeley DB, or Cassandra Includes Rexster, Frames, Gremlin, Blueprints Recently added: Faunus(M/R). RDF, bulk load Neo4J GraphDB GPLv3 or commercial license Fast Graph must fit on each cluster node 41
42 A recent experiment Dataset: 12.2 million edges, 2.2 million vertices Goal: Find paths in a property graph. One of the vertex property is call TYPE. In this scenario, the user provides either a particular vertex, or a set of particular vertices of the same TYPE (say, "DRUG"). In addition, the user also provides another TYPE (say, "TARGET"). Then, we need find all the paths from the starting vertex to a vertex of TYPE TARGET. Therefore, we need to 1) find the paths using graph traversal; 2) keep trace of the paths, so that we can list them after the traversal. Even for the shortest paths, it can be multiple between two nodes, such as: drug->assay->target, drug->moa->target First test (coldstart) Avg time (100 tests) Requested depth 5 traversal Requested full depth traversal IBM System G (NativeStore C++) 39 sec 3.0 sec 4.2 sec IBM System G (NativeStore JNI) 57 sec 4.0 sec 6.2 sec Java Neo4j (Blueprints 2.4) 105 sec 5.9 sec 8.3 sec Titan (Berkeley DB) 3861 sec 641 sec 794 sec Titan (HBase) 3046 sec 1597 sec 2682 sec 42 First full test - full depth 23. All data pulled from disk. Nothing initially cached. Modes - All tests in default modes of each graph implementation. Titan can only be run in transactional mode. Other implementations do not default to transactional mode.
43 IBM System G Native Store Overview System G Native store represents graphs in-memory and on-disk Organizing graph data for representing a graph that stores both graph structure and vertex properties and edge properties Caching graph data in memory in either batch-mode or on-demand from the on-disk streaming graph data Accepting graph updates and modifying graph structure and/or property data accordingly and incorperating time stamps Add edge, remove vertex, update property, etc. Persisting graph updates along with the time stamps from in-memory graph to on-disk graph Performing graph queries by loading graph structure and/or property data Find neighbors of a vertex, retrieve property of an edge, traverse a graph, etc.!!! Graph data Graph queries graph engine In-memory cached graph Time stamp control on-disk persistent graph 43
44 On-Disk Graph Organization Native store organizes graph data for representing a graph with both structure and the vertex properties and edge properties using multiple files in Linux file system Creating a list called ID Offset where each element translates a vertex (edge) ID into two offsets, pointing to the earliest and latest data of the vertex/edge, respectively Creating a list called Time_stamp Offset where each element has a time stamp, an offset to the previous time stamp of the vertex/edge, and a set of indices to the adjacent edge list and properties Create a list of chained block list to store adjacent list and properties! On-disk persistent graph: 44
45 Cache-Amenability of In-memory Data Structure Graph computations is notorious for highly irregularity in data access patterns, resulting in poor data locality for cache performance Data locality still exists in both graph structure and properties Should we leverage the limited data locality and organize the graph data layout accordingly? 45
46 Reducing Disk Accesses by Caching Cache graph data in memory either by: Caching in batch-mode leads to keep a chunk of the graph data files (lists) in memory for efficient data retrieval Caching on-demand loads elements from on-disk files into memory only when the vertices and/or edges are accessed Stitching elements from different data files together according to their VID or EID inmemory element, so as to increase data locality Behaving as a in-memory database when memory is sufficient to host all graph data In-memory graph data! Keep the offsets for write through 46 On-disk persistent graph files
47 Property Bundles Column Family The properties of a vertex (or an edge) can be stored in a set of property files, each called a property bundle, which consists of one or multiple properties that will be read/ write all together and therefore results in the following characteristics: Organizing properties that are usually used together into a single bundle for reducing disk IO Organizing properties not usually used together into different bundles for reducing disk band width Allowing dynamic all/delete properties to any property bundle 47
48 Impact from Storage Hardware Convert csv file (adams.csv 20G) to datastore Similar performance: 7432 sec versus 7806 sec CPU intensive Average CPU util.: 97.4 versus 97.2 I/O pattern Maximum read rate: 5.0 vs. 5.3 Maximum write rate: 97.7 vs Ratio HDD/SDD SSD offers consistently higher performance for both read and write TYPE1 TYPE2 TYPE3 TYPE Queries Type 1: find the most recent URL and PCID of a user Type 2: find all the URLs and PCIDs Type 3: find all the most recent properties Type 4: find all the historic properti 48
49 Impact from Storage Hardware 2 Dataset: IBM Knowledge Repository Nodes, Edges OS buffer is flushed before test Processing 320 queries in parallel In memory graph cache size: 4GB (System G default value) 49
50 Homework 3 1. Classification: 1.1: As introduced by TA in Demo Session 3, using the 20 newsgroups data, try various classification algorithms provided by Mahout, and discuss their performance 1.2: Do similar experiments as in 1.1 on the Wikipedia data that you downloaded in Homework 2.! 2. Graph Database: 2.1: Use the two datasets that you used in Homework #2, Item 1 Recommendation. Inject them into a graph database, e.g., Neo4j or ScaleGraph DB. Use the graph query language to get person-person recommendation and item-item recommendation. Compare results with Mahout. 2.2: (Optional) Use the URL links in the Wikipedia data that you downloaded. Create a knowledge graph. Inject it into a graph database. Try some queries to find relevant terms. This can serve as keyword expansion. 50
51 Questions? 51
Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing. October 29th, 2015
 E6893 Big Data Analytics Lecture 8: Spark Streams and Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing
E6893 Big Data Analytics Lecture 8: Spark Streams and Graph Computing (I) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph Computing
E6895 Advanced Big Data Analytics Lecture 4:! Data Store
 E6895 Advanced Big Data Analytics Lecture 4:! Data Store Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big Data Analytics,
E6895 Advanced Big Data Analytics Lecture 4:! Data Store Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big Data Analytics,
! E6893 Big Data Analytics Lecture 10:! Linked Big Data Graph Computing (II)
") E6893 Big Data Analytics Lecture 10: Linked Big Data Graph Computing (II) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
E6893 Big Data Analytics Lecture 10: Linked Big Data Graph Computing (II) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
! E6893 Big Data Analytics Lecture 5:! Big Data Analytics Algorithms -- II
 ! E6893 Big Data Analytics Lecture 5:! Big Data Analytics Algorithms -- II Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
! E6893 Big Data Analytics Lecture 5:! Big Data Analytics Algorithms -- II Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
Graph Database Proof of Concept Report
 Objectivity, Inc. Graph Database Proof of Concept Report Managing The Internet of Things Table of Contents Executive Summary 3 Background 3 Proof of Concept 4 Dataset 4 Process 4 Query Catalog 4 Environment
Objectivity, Inc. Graph Database Proof of Concept Report Managing The Internet of Things Table of Contents Executive Summary 3 Background 3 Proof of Concept 4 Dataset 4 Process 4 Query Catalog 4 Environment
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics
 E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
E6895 Advanced Big Data Analytics Lecture 3:! Spark and Data Analytics Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
How graph databases started the multi-model revolution
 How graph databases started the multi-model revolution Luca Garulli Author and CEO @OrientDB QCon Sao Paulo - March 26, 2015 Welcome to Big Data 90% of the data in the world today has been created in the
How graph databases started the multi-model revolution Luca Garulli Author and CEO @OrientDB QCon Sao Paulo - March 26, 2015 Welcome to Big Data 90% of the data in the world today has been created in the
E6893 Big Data Analytics Lecture 2: Big Data Analytics Platforms
 E6893 Big Data Analytics Lecture 2: Big Data Analytics Platforms Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big Data
E6893 Big Data Analytics Lecture 2: Big Data Analytics Platforms Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big Data
Cray: Enabling Real-Time Discovery in Big Data
 Cray: Enabling Real-Time Discovery in Big Data Discovery is the process of gaining valuable insights into the world around us by recognizing previously unknown relationships between occurrences, objects
Cray: Enabling Real-Time Discovery in Big Data Discovery is the process of gaining valuable insights into the world around us by recognizing previously unknown relationships between occurrences, objects
Big Graph Data Management
 maccioni@dia.uniroma3.it y d-b hel topic Antonio Maccioni email Big Data Course locatedin re whe 14 May 2015 is-a when affiliated Big Graph Data Management Rome this talk is about Graph Databases: models,
maccioni@dia.uniroma3.it y d-b hel topic Antonio Maccioni email Big Data Course locatedin re whe 14 May 2015 is-a when affiliated Big Graph Data Management Rome this talk is about Graph Databases: models,
Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software
 WHITEPAPER Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software SanDisk ZetaScale software unlocks the full benefits of flash for In-Memory Compute and NoSQL applications
WHITEPAPER Accelerating Enterprise Applications and Reducing TCO with SanDisk ZetaScale Software SanDisk ZetaScale software unlocks the full benefits of flash for In-Memory Compute and NoSQL applications
Integrating Apache Spark with an Enterprise Data Warehouse
 Integrating Apache Spark with an Enterprise Warehouse Dr. Michael Wurst, IBM Corporation Architect Spark/R/Python base Integration, In-base Analytics Dr. Toni Bollinger, IBM Corporation Senior Software
Integrating Apache Spark with an Enterprise Warehouse Dr. Michael Wurst, IBM Corporation Architect Spark/R/Python base Integration, In-base Analytics Dr. Toni Bollinger, IBM Corporation Senior Software
Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks
 WHITE PAPER July 2014 Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks Contents Executive Summary...2 Background...3 InfiniteGraph...3 High Performance
WHITE PAPER July 2014 Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks Contents Executive Summary...2 Background...3 InfiniteGraph...3 High Performance
bigdata Managing Scale in Ontological Systems
 Managing Scale in Ontological Systems 1 This presentation offers a brief look scale in ontological (semantic) systems, tradeoffs in expressivity and data scale, and both information and systems architectural
Managing Scale in Ontological Systems 1 This presentation offers a brief look scale in ontological (semantic) systems, tradeoffs in expressivity and data scale, and both information and systems architectural
A Performance Evaluation of Open Source Graph Databases. Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader
 A Performance Evaluation of Open Source Graph Databases Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader Overview Motivation Options Evaluation Results Lessons Learned Moving Forward
A Performance Evaluation of Open Source Graph Databases Robert McColl David Ediger Jason Poovey Dan Campbell David A. Bader Overview Motivation Options Evaluation Results Lessons Learned Moving Forward
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
E6893 Big Data Analytics Lecture 4: Big Data Analytics Algorithms -- I
 E6893 Big Data Analytics Lecture 4: Big Data Analytics Algorithms -- I Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
E6893 Big Data Analytics Lecture 4: Big Data Analytics Algorithms -- I Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and Big
SYSTAP / bigdata. Open Source High Performance Highly Available. 1 http://www.bigdata.com/blog. bigdata Presented to CSHALS 2/27/2014
 SYSTAP / Open Source High Performance Highly Available 1 SYSTAP, LLC Small Business, Founded 2006 100% Employee Owned Customers OEMs and VARs Government TelecommunicaHons Health Care Network Storage Finance
SYSTAP / Open Source High Performance Highly Available 1 SYSTAP, LLC Small Business, Founded 2006 100% Employee Owned Customers OEMs and VARs Government TelecommunicaHons Health Care Network Storage Finance
Towards Smart and Intelligent SDN Controller
 Towards Smart and Intelligent SDN Controller - Through the Generic, Extensible, and Elastic Time Series Data Repository (TSDR) YuLing Chen, Dell Inc. Rajesh Narayanan, Dell Inc. Sharon Aicler, Cisco Systems
Towards Smart and Intelligent SDN Controller - Through the Generic, Extensible, and Elastic Time Series Data Repository (TSDR) YuLing Chen, Dell Inc. Rajesh Narayanan, Dell Inc. Sharon Aicler, Cisco Systems
Why NoSQL? Your database options in the new non- relational world. 2015 IBM Cloudant 1
 Why NoSQL? Your database options in the new non- relational world 2015 IBM Cloudant 1 Table of Contents New types of apps are generating new types of data... 3 A brief history on NoSQL... 3 NoSQL s roots
Why NoSQL? Your database options in the new non- relational world 2015 IBM Cloudant 1 Table of Contents New types of apps are generating new types of data... 3 A brief history on NoSQL... 3 NoSQL s roots
Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy?
 HPC2012 Workshop Cetraro, Italy Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy? Bill Blake CTO Cray, Inc. The Big Data Challenge Supercomputing minimizes data
HPC2012 Workshop Cetraro, Italy Supercomputing and Big Data: Where are the Real Boundaries and Opportunities for Synergy? Bill Blake CTO Cray, Inc. The Big Data Challenge Supercomputing minimizes data
Complexity and Scalability in Semantic Graph Analysis Semantic Days 2013
 Complexity and Scalability in Semantic Graph Analysis Semantic Days 2013 James Maltby, Ph.D 1 Outline of Presentation Semantic Graph Analytics Database Architectures In-memory Semantic Database Formulation
Complexity and Scalability in Semantic Graph Analysis Semantic Days 2013 James Maltby, Ph.D 1 Outline of Presentation Semantic Graph Analytics Database Architectures In-memory Semantic Database Formulation
Graph Database Performance: An Oracle Perspective
 Graph Database Performance: An Oracle Perspective Xavier Lopez, Ph.D. Senior Director, Product Management 1 Copyright 2012, Oracle and/or its affiliates. All rights reserved. Program Agenda Broad Perspective
Graph Database Performance: An Oracle Perspective Xavier Lopez, Ph.D. Senior Director, Product Management 1 Copyright 2012, Oracle and/or its affiliates. All rights reserved. Program Agenda Broad Perspective
GRAPH DATABASE SYSTEMS. h_da Prof. Dr. Uta Störl Big Data Technologies: Graph Database Systems - SoSe 2016 1
 GRAPH DATABASE SYSTEMS h_da Prof. Dr. Uta Störl Big Data Technologies: Graph Database Systems - SoSe 2016 1 Use Case: Route Finding Source: Neo Technology, Inc. h_da Prof. Dr. Uta Störl Big Data Technologies:
GRAPH DATABASE SYSTEMS h_da Prof. Dr. Uta Störl Big Data Technologies: Graph Database Systems - SoSe 2016 1 Use Case: Route Finding Source: Neo Technology, Inc. h_da Prof. Dr. Uta Störl Big Data Technologies:
Apache Flink Next-gen data analysis. Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
G-SPARQL: A Hybrid Engine for Querying Large Attributed Graphs
 G-SPARQL: A Hybrid Engine for Querying Large Attributed Graphs Sherif Sakr National ICT Australia UNSW, Sydney, Australia ssakr@cse.unsw.edu.eu Sameh Elnikety Microsoft Research Redmond, WA, USA samehe@microsoft.com
G-SPARQL: A Hybrid Engine for Querying Large Attributed Graphs Sherif Sakr National ICT Australia UNSW, Sydney, Australia ssakr@cse.unsw.edu.eu Sameh Elnikety Microsoft Research Redmond, WA, USA samehe@microsoft.com
PERFORMANCE ANALYSIS OF KERNEL-BASED VIRTUAL MACHINE
 PERFORMANCE ANALYSIS OF KERNEL-BASED VIRTUAL MACHINE Sudha M 1, Harish G M 2, Nandan A 3, Usha J 4 1 Department of MCA, R V College of Engineering, Bangalore : 560059, India sudha.mooki@gmail.com 2 Department
PERFORMANCE ANALYSIS OF KERNEL-BASED VIRTUAL MACHINE Sudha M 1, Harish G M 2, Nandan A 3, Usha J 4 1 Department of MCA, R V College of Engineering, Bangalore : 560059, India sudha.mooki@gmail.com 2 Department
TITAN BIG GRAPH DATA WITH CASSANDRA #TITANDB #CASSANDRA12
 TITAN BIG GRAPH DATA WITH CASSANDRA #TITANDB #CASSANDRA12 Matthias Broecheler, CTO August VIII, MMXII AURELIUS THINKAURELIUS.COM Abstract Titan is an open source distributed graph database build on top
TITAN BIG GRAPH DATA WITH CASSANDRA #TITANDB #CASSANDRA12 Matthias Broecheler, CTO August VIII, MMXII AURELIUS THINKAURELIUS.COM Abstract Titan is an open source distributed graph database build on top
Software tools for Complex Networks Analysis. Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team
 Team") Software tools for Complex Networks Analysis Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team MOTIVATION Why do we need tools? Source : nature.com Visualization Properties extraction
Software tools for Complex Networks Analysis Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team MOTIVATION Why do we need tools? Source : nature.com Visualization Properties extraction
A Novel Cloud Based Elastic Framework for Big Data Preprocessing
 School of Systems Engineering A Novel Cloud Based Elastic Framework for Big Data Preprocessing Omer Dawelbeit and Rachel McCrindle October 21, 2014 University of Reading 2008 www.reading.ac.uk Overview
School of Systems Engineering A Novel Cloud Based Elastic Framework for Big Data Preprocessing Omer Dawelbeit and Rachel McCrindle October 21, 2014 University of Reading 2008 www.reading.ac.uk Overview
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Quick History of Data Management 4000 B C Manual recording From tablets to papyrus to paper A. Payberah 2014 2
YarcData urika Technical White Paper
 YarcData urika Technical White Paper 2012 Cray Inc. All rights reserved. Specifications subject to change without notice. Cray is a registered trademark, YarcData, urika and Threadstorm are trademarks
YarcData urika Technical White Paper 2012 Cray Inc. All rights reserved. Specifications subject to change without notice. Cray is a registered trademark, YarcData, urika and Threadstorm are trademarks
CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University](/thumbs/26/8135278.jpg "CS555: Distributed Systems [Fall 2015] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Streaming Significance of minimum delays? Interleaving
Lecture Data Warehouse Systems
 Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Review of Graph Databases for Big Data Dynamic Entity Scoring
 Review of Graph Databases for Big Data Dynamic Entity Scoring M. X. Labute, M. J. Dombroski May 16, 2014 Disclaimer This document was prepared as an account of work sponsored by an agency of the United
Review of Graph Databases for Big Data Dynamic Entity Scoring M. X. Labute, M. J. Dombroski May 16, 2014 Disclaimer This document was prepared as an account of work sponsored by an agency of the United
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Oracle BI EE Implementation on Netezza. Prepared by SureShot Strategies, Inc.
 Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Semantic Stored Procedures Programming Environment and performance analysis
 Semantic Stored Procedures Programming Environment and performance analysis Marjan Efremov 1, Vladimir Zdraveski 2, Petar Ristoski 2, Dimitar Trajanov 2 1 Open Mind Solutions Skopje, bul. Kliment Ohridski
Semantic Stored Procedures Programming Environment and performance analysis Marjan Efremov 1, Vladimir Zdraveski 2, Petar Ristoski 2, Dimitar Trajanov 2 1 Open Mind Solutions Skopje, bul. Kliment Ohridski
An empirical comparison of graph databases
 An empirical comparison of graph databases Salim Jouili Eura Nova R&D 1435 Mont-Saint-Guibert, Belgium Email: salim.jouili@euranova.eu Valentin Vansteenberghe Universite Catholique de Louvain 1348 Louvain-La-Neuve,
An empirical comparison of graph databases Salim Jouili Eura Nova R&D 1435 Mont-Saint-Guibert, Belgium Email: salim.jouili@euranova.eu Valentin Vansteenberghe Universite Catholique de Louvain 1348 Louvain-La-Neuve,
DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION
 DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION A DIABLO WHITE PAPER AUGUST 2014 Ricky Trigalo Director of Business Development Virtualization, Diablo Technologies
DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION A DIABLO WHITE PAPER AUGUST 2014 Ricky Trigalo Director of Business Development Virtualization, Diablo Technologies
Seeking Fast, Durable Data Management: A Database System and Persistent Storage Benchmark
 Seeking Fast, Durable Data Management: A Database System and Persistent Storage Benchmark In-memory database systems (IMDSs) eliminate much of the performance latency associated with traditional on-disk
Seeking Fast, Durable Data Management: A Database System and Persistent Storage Benchmark In-memory database systems (IMDSs) eliminate much of the performance latency associated with traditional on-disk
Unified Big Data Processing with Apache Spark. Matei Zaharia @matei_zaharia
 Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
Unified Big Data Processing with Apache Spark Matei Zaharia @matei_zaharia What is Apache Spark? Fast & general engine for big data processing Generalizes MapReduce model to support more types of processing
InfiniteGraph: The Distributed Graph Database
 A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
Big Data, Fast Data, Complex Data. Jans Aasman Franz Inc
 Big Data, Fast Data, Complex Data Jans Aasman Franz Inc Private, founded 1984 AI, Semantic Technology, professional services Now in Oakland Franz Inc Who We Are (1 (2 3) (4 5) (6 7) (8 9) (10 11) (12
Big Data, Fast Data, Complex Data Jans Aasman Franz Inc Private, founded 1984 AI, Semantic Technology, professional services Now in Oakland Franz Inc Who We Are (1 (2 3) (4 5) (6 7) (8 9) (10 11) (12
PUBLIC Performance Optimization Guide
 SAP Data Services Document Version: 4.2 Support Package 6 (14.2.6.0) 2015-11-20 PUBLIC Content 1 Welcome to SAP Data Services....6 1.1 Welcome.... 6 1.2 Documentation set for SAP Data Services....6 1.3
SAP Data Services Document Version: 4.2 Support Package 6 (14.2.6.0) 2015-11-20 PUBLIC Content 1 Welcome to SAP Data Services....6 1.1 Welcome.... 6 1.2 Documentation set for SAP Data Services....6 1.3
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM
 Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Maximizing Hadoop Performance and Storage Capacity with AltraHD TM Executive Summary The explosion of internet data, driven in large part by the growth of more and more powerful mobile devices, has created
Parallel Replication for MySQL in 5 Minutes or Less
 Parallel Replication for MySQL in 5 Minutes or Less Featuring Tungsten Replicator Robert Hodges, CEO, Continuent About Continuent / Continuent is the leading provider of data replication and clustering
Parallel Replication for MySQL in 5 Minutes or Less Featuring Tungsten Replicator Robert Hodges, CEO, Continuent About Continuent / Continuent is the leading provider of data replication and clustering
Microblogging Queries on Graph Databases: An Introspection
 Microblogging Queries on Graph Databases: An Introspection ABSTRACT Oshini Goonetilleke RMIT University, Australia oshini.goonetilleke@rmit.edu.au Timos Sellis RMIT University, Australia timos.sellis@rmit.edu.au
Microblogging Queries on Graph Databases: An Introspection ABSTRACT Oshini Goonetilleke RMIT University, Australia oshini.goonetilleke@rmit.edu.au Timos Sellis RMIT University, Australia timos.sellis@rmit.edu.au
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control
 Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Developing Scalable Smart Grid Infrastructure to Enable Secure Transmission System Control EP/K006487/1 UK PI: Prof Gareth Taylor (BU) China PI: Prof Yong-Hua Song (THU) Consortium UK Members: Brunel University
Performance and Scalability Overview
 Performance and Scalability Overview This guide provides an overview of some of the performance and scalability capabilities of the Pentaho Business Analytics platform. PENTAHO PERFORMANCE ENGINEERING
Performance and Scalability Overview This guide provides an overview of some of the performance and scalability capabilities of the Pentaho Business Analytics platform. PENTAHO PERFORMANCE ENGINEERING
The Synergy Between the Object Database, Graph Database, Cloud Computing and NoSQL Paradigms
 ICOODB 2010 - Frankfurt, Deutschland The Synergy Between the Object Database, Graph Database, Cloud Computing and NoSQL Paradigms Leon Guzenda - Objectivity, Inc. 1 AGENDA Historical Overview Inherent
ICOODB 2010 - Frankfurt, Deutschland The Synergy Between the Object Database, Graph Database, Cloud Computing and NoSQL Paradigms Leon Guzenda - Objectivity, Inc. 1 AGENDA Historical Overview Inherent
Oracle Big Data Spatial and Graph
 Oracle Big Data Spatial and Graph Oracle Big Data Spatial and Graph offers a set of analytic services and data models that support Big Data workloads on Apache Hadoop and NoSQL database technologies. For
Oracle Big Data Spatial and Graph Oracle Big Data Spatial and Graph offers a set of analytic services and data models that support Big Data workloads on Apache Hadoop and NoSQL database technologies. For
Storage and Retrieval of Large RDF Graph Using Hadoop and MapReduce
 Storage and Retrieval of Large RDF Graph Using Hadoop and MapReduce Mohammad Farhan Husain, Pankil Doshi, Latifur Khan, and Bhavani Thuraisingham University of Texas at Dallas, Dallas TX 75080, USA Abstract.
Storage and Retrieval of Large RDF Graph Using Hadoop and MapReduce Mohammad Farhan Husain, Pankil Doshi, Latifur Khan, and Bhavani Thuraisingham University of Texas at Dallas, Dallas TX 75080, USA Abstract.
Apache Spark 11/10/15. Context. Reminder. Context. What is Spark? A GrowingStack
 Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Apache Spark Document Analysis Course (Fall 2015 - Scott Sanner) Zahra Iman Some slides from (Matei Zaharia, UC Berkeley / MIT& Harold Liu) Reminder SparkConf JavaSpark RDD: Resilient Distributed Datasets
Performance and Scalability Overview
 Performance and Scalability Overview This guide provides an overview of some of the performance and scalability capabilities of the Pentaho Business Analytics Platform. Contents Pentaho Scalability and
Performance and Scalability Overview This guide provides an overview of some of the performance and scalability capabilities of the Pentaho Business Analytics Platform. Contents Pentaho Scalability and
Analytics March 2015 White paper. Why NoSQL? Your database options in the new non-relational world
 Analytics March 2015 White paper Why NoSQL? Your database options in the new non-relational world 2 Why NoSQL? Contents 2 New types of apps are generating new types of data 2 A brief history of NoSQL 3
Analytics March 2015 White paper Why NoSQL? Your database options in the new non-relational world 2 Why NoSQL? Contents 2 New types of apps are generating new types of data 2 A brief history of NoSQL 3
TE's Analytics on Hadoop and SAP HANA Using SAP Vora
 TE's Analytics on Hadoop and SAP HANA Using SAP Vora Naveen Narra Senior Manager TE Connectivity Santha Kumar Rajendran Enterprise Data Architect TE Balaji Krishna - Director, SAP HANA Product Mgmt. -
TE's Analytics on Hadoop and SAP HANA Using SAP Vora Naveen Narra Senior Manager TE Connectivity Santha Kumar Rajendran Enterprise Data Architect TE Balaji Krishna - Director, SAP HANA Product Mgmt. -
Oracle Big Data SQL Technical Update
 Oracle Big Data SQL Technical Update Jean-Pierre Dijcks Oracle Redwood City, CA, USA Keywords: Big Data, Hadoop, NoSQL Databases, Relational Databases, SQL, Security, Performance Introduction This technical
Oracle Big Data SQL Technical Update Jean-Pierre Dijcks Oracle Redwood City, CA, USA Keywords: Big Data, Hadoop, NoSQL Databases, Relational Databases, SQL, Security, Performance Introduction This technical
Big Data: Using ArcGIS with Apache Hadoop. Erik Hoel and Mike Park
 Big Data: Using ArcGIS with Apache Hadoop Erik Hoel and Mike Park Outline Overview of Hadoop Adding GIS capabilities to Hadoop Integrating Hadoop with ArcGIS Apache Hadoop What is Hadoop? Hadoop is a scalable
Big Data: Using ArcGIS with Apache Hadoop Erik Hoel and Mike Park Outline Overview of Hadoop Adding GIS capabilities to Hadoop Integrating Hadoop with ArcGIS Apache Hadoop What is Hadoop? Hadoop is a scalable
NoSQL Performance Test In-Memory Performance Comparison of SequoiaDB, Cassandra, and MongoDB
 bankmark UG (haftungsbeschränkt) Bahnhofstraße 1 9432 Passau Germany www.bankmark.de info@bankmark.de T +49 851 25 49 49 F +49 851 25 49 499 NoSQL Performance Test In-Memory Performance Comparison of SequoiaDB,
bankmark UG (haftungsbeschränkt) Bahnhofstraße 1 9432 Passau Germany www.bankmark.de info@bankmark.de T +49 851 25 49 49 F +49 851 25 49 499 NoSQL Performance Test In-Memory Performance Comparison of SequoiaDB,
Pulsar Realtime Analytics At Scale. Tony Ng April 14, 2015
 Pulsar Realtime Analytics At Scale Tony Ng April 14, 2015 Big Data Trends Bigger data volumes More data sources DBs, logs, behavioral & business event streams, sensors Faster analysis Next day to hours
Pulsar Realtime Analytics At Scale Tony Ng April 14, 2015 Big Data Trends Bigger data volumes More data sources DBs, logs, behavioral & business event streams, sensors Faster analysis Next day to hours
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
urika! Unlocking the Power of Big Data at PSC
 urika! Unlocking the Power of Big Data at PSC Nick Nystrom Director, Strategic Applications Pittsburgh Supercomputing Center February 1, 2013 nystrom@psc.edu 2013 Pittsburgh Supercomputing Center Big Data
urika! Unlocking the Power of Big Data at PSC Nick Nystrom Director, Strategic Applications Pittsburgh Supercomputing Center February 1, 2013 nystrom@psc.edu 2013 Pittsburgh Supercomputing Center Big Data
ABSTRACT 1. INTRODUCTION. Kamil Bajda-Pawlikowski kbajda@cs.yale.edu
 Kamil Bajda-Pawlikowski kbajda@cs.yale.edu Querying RDF data stored in DBMS: SPARQL to SQL Conversion Yale University technical report #1409 ABSTRACT This paper discusses the design and implementation
Kamil Bajda-Pawlikowski kbajda@cs.yale.edu Querying RDF data stored in DBMS: SPARQL to SQL Conversion Yale University technical report #1409 ABSTRACT This paper discusses the design and implementation
Big Systems, Big Data
 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
NoSQL systems: introduction and data models. Riccardo Torlone Università Roma Tre
 NoSQL systems: introduction and data models Riccardo Torlone Università Roma Tre Why NoSQL? In the last thirty years relational databases have been the default choice for serious data storage. An architect
NoSQL systems: introduction and data models Riccardo Torlone Università Roma Tre Why NoSQL? In the last thirty years relational databases have been the default choice for serious data storage. An architect
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Big Data Analytics - Accelerated. stream-horizon.com
 Big Data Analytics - Accelerated stream-horizon.com Legacy ETL platforms & conventional Data Integration approach Unable to meet latency & data throughput demands of Big Data integration challenges Based
Big Data Analytics - Accelerated stream-horizon.com Legacy ETL platforms & conventional Data Integration approach Unable to meet latency & data throughput demands of Big Data integration challenges Based
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
SAP HANA PLATFORM Top Ten Questions for Choosing In-Memory Databases. Start Here
 PLATFORM Top Ten Questions for Choosing In-Memory Databases Start Here PLATFORM Top Ten Questions for Choosing In-Memory Databases. Are my applications accelerated without manual intervention and tuning?.
PLATFORM Top Ten Questions for Choosing In-Memory Databases Start Here PLATFORM Top Ten Questions for Choosing In-Memory Databases. Are my applications accelerated without manual intervention and tuning?.
Big RDF Data Partitioning and Processing using hadoop in Cloud
 Big RDF Data Partitioning and Processing using hadoop in Cloud Tejas Bharat Thorat Dept. of Computer Engineering MIT Academy of Engineering, Alandi, Pune, India Prof.Ranjana R.Badre Dept. of Computer Engineering
Big RDF Data Partitioning and Processing using hadoop in Cloud Tejas Bharat Thorat Dept. of Computer Engineering MIT Academy of Engineering, Alandi, Pune, India Prof.Ranjana R.Badre Dept. of Computer Engineering
Big Graph Analytics on Neo4j with Apache Spark. Michael Hunger Original work by Kenny Bastani Berlin Buzzwords, Open Stage
 Big Graph Analytics on Neo4j with Apache Spark Michael Hunger Original work by Kenny Bastani Berlin Buzzwords, Open Stage My background I only make it to the Open Stages :) Probably because Apache Neo4j
Big Graph Analytics on Neo4j with Apache Spark Michael Hunger Original work by Kenny Bastani Berlin Buzzwords, Open Stage My background I only make it to the Open Stages :) Probably because Apache Neo4j
Big Graph Processing: Some Background
 Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН
 Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН Zettabytes Petabytes ABC Sharding A B C Id Fn Ln Addr 1 Fred Jones Liberty, NY 2 John Smith?????? 122+ NoSQL Database
Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН Zettabytes Petabytes ABC Sharding A B C Id Fn Ln Addr 1 Fred Jones Liberty, NY 2 John Smith?????? 122+ NoSQL Database
Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing
 /35 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
/35 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
Realtime Apache Hadoop at Facebook. Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens
 Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
H2O on Hadoop. September 30, 2014. www.0xdata.com
 H2O on Hadoop September 30, 2014 www.0xdata.com H2O on Hadoop Introduction H2O is the open source math & machine learning engine for big data that brings distribution and parallelism to powerful algorithms
H2O on Hadoop September 30, 2014 www.0xdata.com H2O on Hadoop Introduction H2O is the open source math & machine learning engine for big data that brings distribution and parallelism to powerful algorithms
Big Data, Cloud Computing, Spatial Databases Steven Hagan Vice President Server Technologies
 Big Data, Cloud Computing, Spatial Databases Steven Hagan Vice President Server Technologies Big Data: Global Digital Data Growth Growing leaps and bounds by 40+% Year over Year! 2009 =.8 Zetabytes =.08
Big Data, Cloud Computing, Spatial Databases Steven Hagan Vice President Server Technologies Big Data: Global Digital Data Growth Growing leaps and bounds by 40+% Year over Year! 2009 =.8 Zetabytes =.08
1-Oct 2015, Bilbao, Spain. Towards Semantic Network Models via Graph Databases for SDN Applications
 1-Oct 2015, Bilbao, Spain Towards Semantic Network Models via Graph Databases for SDN Applications Agenda Introduction Goals Related Work Proposal Experimental Evaluation and Results Conclusions and Future
1-Oct 2015, Bilbao, Spain Towards Semantic Network Models via Graph Databases for SDN Applications Agenda Introduction Goals Related Work Proposal Experimental Evaluation and Results Conclusions and Future
Large-Scale Data Processing
 Large-Scale Data Processing Eiko Yoneki eiko.yoneki@cl.cam.ac.uk http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Large-Scale Data Processing Eiko Yoneki eiko.yoneki@cl.cam.ac.uk http://www.cl.cam.ac.uk/~ey204 Systems Research Group University of Cambridge Computer Laboratory 2010s: Big Data Why Big Data now? Increase
Data sharing in the Big Data era
 www.bsc.es Data sharing in the Big Data era Anna Queralt and Toni Cortes Storage System Research Group Introduction What ignited our research Different data models: persistent vs. non persistent New storage
www.bsc.es Data sharing in the Big Data era Anna Queralt and Toni Cortes Storage System Research Group Introduction What ignited our research Different data models: persistent vs. non persistent New storage
SAP HANA SAP s In-Memory Database. Dr. Martin Kittel, SAP HANA Development January 16, 2013
 SAP HANA SAP s In-Memory Database Dr. Martin Kittel, SAP HANA Development January 16, 2013 Disclaimer This presentation outlines our general product direction and should not be relied on in making a purchase
SAP HANA SAP s In-Memory Database Dr. Martin Kittel, SAP HANA Development January 16, 2013 Disclaimer This presentation outlines our general product direction and should not be relied on in making a purchase
Performance And Scalability In Oracle9i And SQL Server 2000
 Performance And Scalability In Oracle9i And SQL Server 2000 Presented By : Phathisile Sibanda Supervisor : John Ebden 1 Presentation Overview Project Objectives Motivation -Why performance & Scalability
Performance And Scalability In Oracle9i And SQL Server 2000 Presented By : Phathisile Sibanda Supervisor : John Ebden 1 Presentation Overview Project Objectives Motivation -Why performance & Scalability
MyOra 3.5. User Guide. SQL Tool for Oracle. Kris Murthy
 MyOra 3.5 SQL Tool for Oracle User Guide Kris Murthy Contents Features... 4 Connecting to the Database... 5 Login... 5 Login History... 6 Connection Indicator... 6 Closing the Connection... 7 SQL Editor...
MyOra 3.5 SQL Tool for Oracle User Guide Kris Murthy Contents Features... 4 Connecting to the Database... 5 Login... 5 Login History... 6 Connection Indicator... 6 Closing the Connection... 7 SQL Editor...
In Memory Accelerator for MongoDB
 In Memory Accelerator for MongoDB Yakov Zhdanov, Director R&D GridGain Systems GridGain: In Memory Computing Leader 5 years in production 100s of customers & users Starts every 10 secs worldwide Over 15,000,000
In Memory Accelerator for MongoDB Yakov Zhdanov, Director R&D GridGain Systems GridGain: In Memory Computing Leader 5 years in production 100s of customers & users Starts every 10 secs worldwide Over 15,000,000
Semantic Modeling with RDF. DBTech ExtWorkshop on Database Modeling and Semantic Modeling Lili Aunimo
 DBTech ExtWorkshop on Database Modeling and Semantic Modeling Lili Aunimo Expected Outcomes You will learn: Basic concepts related to ontologies Semantic model Semantic web Basic features of RDF and RDF
DBTech ExtWorkshop on Database Modeling and Semantic Modeling Lili Aunimo Expected Outcomes You will learn: Basic concepts related to ontologies Semantic model Semantic web Basic features of RDF and RDF
! E6893 Big Data Analytics Lecture 11:! Linked Big Data Graphical Models (II)
") E6893 Big Data Analytics Lecture 11: Linked Big Data Graphical Models (II) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
E6893 Big Data Analytics Lecture 11: Linked Big Data Graphical Models (II) Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Mgr., Dept. of Network Science and
LDIF - Linked Data Integration Framework
 LDIF - Linked Data Integration Framework Andreas Schultz 1, Andrea Matteini 2, Robert Isele 1, Christian Bizer 1, and Christian Becker 2 1. Web-based Systems Group, Freie Universität Berlin, Germany a.schultz@fu-berlin.de,
LDIF - Linked Data Integration Framework Andreas Schultz 1, Andrea Matteini 2, Robert Isele 1, Christian Bizer 1, and Christian Becker 2 1. Web-based Systems Group, Freie Universität Berlin, Germany a.schultz@fu-berlin.de,
OntoDBench: Ontology-based Database Benchmark
 OntoDBench: Ontology-based Database Benchmark Stéphane Jean, Ladjel Bellatreche, Géraud Fokou, Mickaël Baron, and Selma Khouri LIAS/ISAE-ENSMA and University of Poitiers BP 40109, 86961 Futuroscope Cedex,
OntoDBench: Ontology-based Database Benchmark Stéphane Jean, Ladjel Bellatreche, Géraud Fokou, Mickaël Baron, and Selma Khouri LIAS/ISAE-ENSMA and University of Poitiers BP 40109, 86961 Futuroscope Cedex,
In-Memory Data Management for Enterprise Applications
 In-Memory Data Management for Enterprise Applications Jens Krueger Senior Researcher and Chair Representative Research Group of Prof. Hasso Plattner Hasso Plattner Institute for Software Engineering University
In-Memory Data Management for Enterprise Applications Jens Krueger Senior Researcher and Chair Representative Research Group of Prof. Hasso Plattner Hasso Plattner Institute for Software Engineering University
Rackspace Cloud Databases and Container-based Virtualization
 Rackspace Cloud Databases and Container-based Virtualization August 2012 J.R. Arredondo @jrarredondo Page 1 of 6 INTRODUCTION When Rackspace set out to build the Cloud Databases product, we asked many
Rackspace Cloud Databases and Container-based Virtualization August 2012 J.R. Arredondo @jrarredondo Page 1 of 6 INTRODUCTION When Rackspace set out to build the Cloud Databases product, we asked many
A Survey on: Efficient and Customizable Data Partitioning for Distributed Big RDF Data Processing using hadoop in Cloud.
 A Survey on: Efficient and Customizable Data Partitioning for Distributed Big RDF Data Processing using hadoop in Cloud. Tejas Bharat Thorat Prof.RanjanaR.Badre Computer Engineering Department Computer
A Survey on: Efficient and Customizable Data Partitioning for Distributed Big RDF Data Processing using hadoop in Cloud. Tejas Bharat Thorat Prof.RanjanaR.Badre Computer Engineering Department Computer
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
imgraph: A distributed in-memory graph database
 imgraph: A distributed in-memory graph database Salim Jouili Eura Nova R&D 435 Mont-Saint-Guibert, Belgium Email: salim.jouili@euranova.eu Aldemar Reynaga Université Catholique de Louvain 348 Louvain-La-Neuve,
imgraph: A distributed in-memory graph database Salim Jouili Eura Nova R&D 435 Mont-Saint-Guibert, Belgium Email: salim.jouili@euranova.eu Aldemar Reynaga Université Catholique de Louvain 348 Louvain-La-Neuve,
FastForward I/O and Storage: ACG 6.6 Demonstration
 FastForward I/O and Storage: ACG 6.6 Demonstration NOTICE: THIS MANUSCRIPT HAS BEEN AUTHORED BY INTEL UNDER ITS SUBCONTRACT WITH LAWRENCE LIVERMORE NATIONAL SECURITY, LLC WHO IS THE OPERATOR AND MANAGER
FastForward I/O and Storage: ACG 6.6 Demonstration NOTICE: THIS MANUSCRIPT HAS BEEN AUTHORED BY INTEL UNDER ITS SUBCONTRACT WITH LAWRENCE LIVERMORE NATIONAL SECURITY, LLC WHO IS THE OPERATOR AND MANAGER
Accelerating Cassandra Workloads using SanDisk Solid State Drives
 WHITE PAPER Accelerating Cassandra Workloads using SanDisk Solid State Drives February 2015 951 SanDisk Drive, Milpitas, CA 95035 2015 SanDIsk Corporation. All rights reserved www.sandisk.com Table of
WHITE PAPER Accelerating Cassandra Workloads using SanDisk Solid State Drives February 2015 951 SanDisk Drive, Milpitas, CA 95035 2015 SanDIsk Corporation. All rights reserved www.sandisk.com Table of
A Practical Approach to Process Streaming Data using Graph Database
 A Practical Approach to Process Streaming Data using Graph Database Mukul Sharma Research Scholar Department of Computer Science & Engineering SBCET, Jaipur, Rajasthan, India ABSTRACT In today s information
A Practical Approach to Process Streaming Data using Graph Database Mukul Sharma Research Scholar Department of Computer Science & Engineering SBCET, Jaipur, Rajasthan, India ABSTRACT In today s information
Mining Large Datasets: Case of Mining Graph Data in the Cloud
 Mining Large Datasets: Case of Mining Graph Data in the Cloud Sabeur Aridhi PhD in Computer Science with Laurent d Orazio, Mondher Maddouri and Engelbert Mephu Nguifo 16/05/2014 Sabeur Aridhi Mining Large
Mining Large Datasets: Case of Mining Graph Data in the Cloud Sabeur Aridhi PhD in Computer Science with Laurent d Orazio, Mondher Maddouri and Engelbert Mephu Nguifo 16/05/2014 Sabeur Aridhi Mining Large
KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS
 ABSTRACT KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS In many real applications, RDF (Resource Description Framework) has been widely used as a W3C standard to describe data in the Semantic Web. In practice,
ABSTRACT KEYWORD SEARCH OVER PROBABILISTIC RDF GRAPHS In many real applications, RDF (Resource Description Framework) has been widely used as a W3C standard to describe data in the Semantic Web. In practice,