Naveen Muralimanohar Rajeev Balasubramonian Norman P Jouppi
|
|
|
- Lee Jones
- 8 years ago
- Views:
Transcription
1 Optimizing NUCA Organizations and Wiring Alternatives for Large Caches with CACTI 6.0 Naveen Muralimanohar Rajeev Balasubramonian Norman P Jouppi University of Utah & HP Labs 1

2 Large Caches Cache hierarchies will dominate chip area 3D stacked processors with an entire die for on-chip cache could be common Intel Montecito Cache Cache Montecito has two private 12 MB L3 caches (27MB including L2) Long global wires are required to transmit data/address University of Utah 2
 Long global wires are required to transmit data/address")
3 Wire Delay/Power Wire delays are costly for performance and power Latencies of 60 cycles to reach ends of a chip at 32nm (@ 5 GHz) 50% of dynamic power is in interconnect switching (Magen et al. SLIP 04) CACTI* access time for 24 MB cache is 90 5GHz, 65nm Tech *version 4 University of Utah 3
 CACTI* access time for 24 MB cache is 90 cycles @ 5GHz, 65nm Tech")
4 Contribution Support for various interconnect models Improved design space exploration Support for modeling Non-Uniform Cache Access (NUCA) University of Utah 4
")
5 Cache Design Basics Bitlines Input address Wordline rray Tag a Deco oder Data array Column muxes Sense Amps Comparators Output driver Valid output? Mux drivers Data output Output driver University of Utah 5

6 Existing Model - CACTI Wordline & bitline delay Decoder delay Wordline & bitline delay Decoder delay Cache model with 4 sub-arrays Cache model with 16 sub-arrays Decoder delay = H-tree delay + logic delay University of Utah 6

7 Power/Delay Overhead of Wires H-tree delay increases with cache size H-tree power continues to dominate Bitlines are other major contributors to total power 70% 60% 50% 40% 30% 20% 10% 0% H-tree delay percentage H-tree power percentage CacheSize(MB) 7

8 Motivation The dominant role of interconnect t is clear Lack of tool to model interconnect in detail can impede progress Current solutions have limited wire options Orion, CACTI - Weak wire model - No support for modeling Multi-megabyte caches University of Utah 8

9 CACTI 6.0 Enhancements Incorporation of Different wire models Different router models Grid topology for NUCA Shared bus for UCA Contention values for various cache configurations Methodology to compute optimal NUCA organization Improved interface that enables trade-off analysis Validation analysis University of Utah 9

10 Full-swing Wires Z X Y University of Utah 10

11 Full-swing Wires II 10% Delay Three different design points penalty 20% Delay penalty 30% Delay penalty Repeater size Caveat: Repeater sizing and spacing cannot be controlled precisely all the time University of Utah 11

12 Full-Swing Wires Fast and simple Delay proportional to sqrt(rc) as against RC High bandwidth Can be pipelined - Requires silicon area - High energy - Quadratic dependence on voltage 12

13 Low-swing wires 400mV 50mV raise 400mV 400mV Differential wires 50mV drop University of Utah 13

14 Differential Low-swing + Very low-power, can be routed over other modules - Relatively slow, low-bandwidth bandwidth, high area requirement, requires special transmitter and receiver Bitlines are a form of low-swing wire Optimized for speed and area as against power Driver and pre-charger employ full Vdd voltage University of Utah 14

15 Delay Characteristics Quadratic increase in delay University of Utah 15

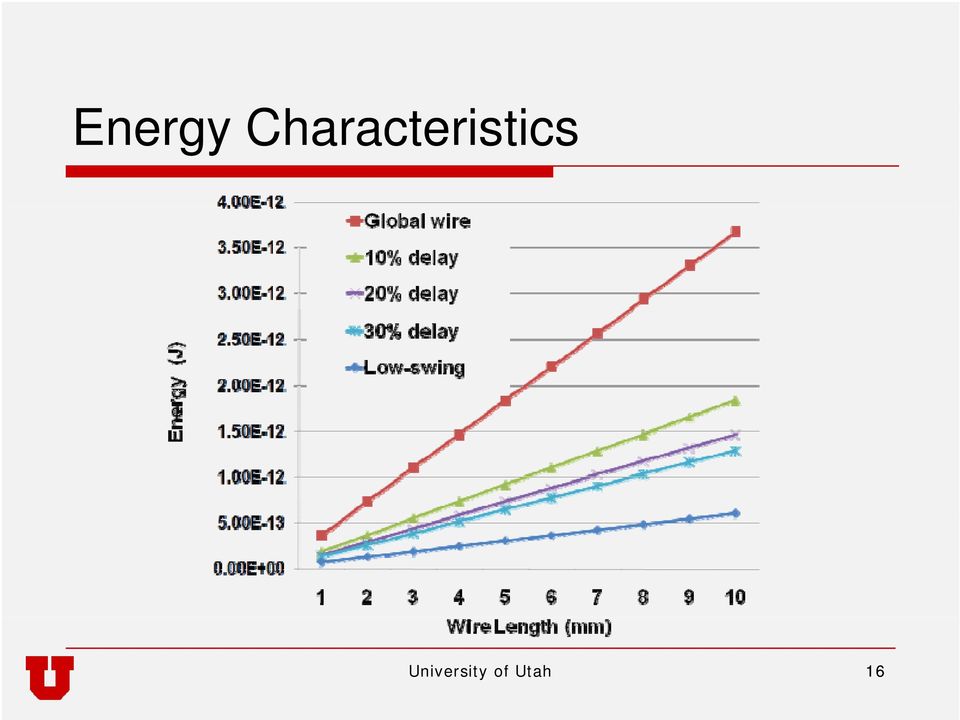
16 Energy Characteristics University of Utah 16
17 Search Space of CACTI-5 Design space with global wires optimized for delay University of Utah 17

18 Search Space of CACTI-6 Low-swing 30% Delay Penalty Least Delay Design space with global and low-swing wires University of Utah 18

19 CACTI Another Limitation Access delay is equal to the delay of slowest subarray Very high hit time for large caches Potential solution NUCA Extend CACTI to model NUCA Employs a separate bus for each cache bank for multi-banked caches Not scalable Exploit different wire types and network design choices to improve the search space University of Utah 19

20 Non-Uniform Cache Access (NUCA)* Large cache is broken into a number of small banks Employs on-chip network for communication CPU & L1 Access delay α (distance between bank and cache controller) *(Kim et al. ASPLOS 02) Cache banks University of Utah 20
 *(Kim et al.")
21 Extension to CACTI On-chip network Wire model based on ITRS 2005 parameters Grid network 3-stage speculative router pipeline Network latency vs Bank access latency tradeoff Iterate t over different bank sizes Calculate the average network delay based on the number of banks and bank sizes Consider contention values for different cache configurations Similarly we also consider power consumed for each organization University of Utah 21
22 Trade-off Analysis (32 MB Cache) Latency (c cycles) Core CMP Total No. of Cycles Network Latency Bank access latency Network contention Cycles No. of Banks 22
23 Effect of Core Count Conten ntion Cycles core 8-core 4-core Bank Count 23
24 Power Centric Design (32MB Cache) Ene ergy J 1.E-08 9.E-09 8.E-09 7.E-09 6.E-09 5.E-09 4.E-09 3.E-09 2.E-09 1.E-09 0.E+00 Total Energy Bank Energy Network Energy Power Optimal Point Bank Count University of Utah 24
25 Validation HSPICE tool Predictive Technology Model (65nm tech.) Analytical model that employs PTM parameters compared against HSPICE Distributed wordlines, bitlines, low-swing transmitters, wires, receivers Verified to be within 12% University of Utah 25
26 Case Study: Heterogeneous D-NUCA Dynamic-NUCA Reduces access time by dynamic data movement Near-by banks are accessed more frequentlyentl Heterogeneous Banks Near-by banks are made smaller and hence faster Access to nearby banks consume less power Other banks can be made larger and more power efficient 26
27 Access Frequency % % 80.00% 60.00% 40.00% 20.00% 0.00% 32,768 3,309,568 6,586,368 9,863,168 13,139,968 16,416,768 19,693,568 22,970,368 26,247,168 29,523,968 32,800,768 % request satisfied by x KB of cache 27
28 Few Heterogeneous Organizations Considered by CACTI Model 1 Model 2 University of Utah 28
29 Other Applications Exposing wire properties Novel cache pipelining Early lookup, Aggressive lookup (ISCA 07) Flit-reservation flow control (Peh et al., HPCA 00) Novel topologies Hybrid network (ISCA 07) 29
30 Conclusion Network parameters and contention play a critical role in deciding NUCA organization Wire choices have significant impact on cache properties CACTI 6.0 can identify models that reduce power by a factor of three for a delay penalty of 25%
ARCHITECTING EFFICIENT INTERCONNECTS FOR LARGE CACHES
 ... ARCHITECTING EFFICIENT INTERCONNECTS FOR LARGE CACHES WITH CACTI 6.0... INTERCONNECTS PLAY AN INCREASINGLY IMPORTANT ROLE IN DETERMINING THE POWER AND PERFORMANCE CHARACTERISTICS OF MODERN PROCESSORS.
... ARCHITECTING EFFICIENT INTERCONNECTS FOR LARGE CACHES WITH CACTI 6.0... INTERCONNECTS PLAY AN INCREASINGLY IMPORTANT ROLE IN DETERMINING THE POWER AND PERFORMANCE CHARACTERISTICS OF MODERN PROCESSORS.
CACTI 6.0: A Tool to Model Large Caches
 CACTI 6.0: A Tool to Model Large Caches Naveen Muralimanohar, Rajeev Balasubramonian, Norman P. Jouppi HP Laboratories HPL-2009-85 Keyword(s): No keywords available. Abstract: Future processors will likely
CACTI 6.0: A Tool to Model Large Caches Naveen Muralimanohar, Rajeev Balasubramonian, Norman P. Jouppi HP Laboratories HPL-2009-85 Keyword(s): No keywords available. Abstract: Future processors will likely
Optimizing NUCA Organizations and Wiring Alternatives for Large Caches With CACTI 6.0
 Optimizing NUCA Organizations and Wiring Alternatives for Large Caches With CACTI 6.0 Naveen Muralimanohar, Rajeev Balasubramonian, Norm Jouppi School of Computing, University of Utah Hewlett-Packard Laboratories
Optimizing NUCA Organizations and Wiring Alternatives for Large Caches With CACTI 6.0 Naveen Muralimanohar, Rajeev Balasubramonian, Norm Jouppi School of Computing, University of Utah Hewlett-Packard Laboratories
On-Chip Interconnection Networks Low-Power Interconnect
 On-Chip Interconnection Networks Low-Power Interconnect William J. Dally Computer Systems Laboratory Stanford University ISLPED August 27, 2007 ISLPED: 1 Aug 27, 2007 Outline Demand for On-Chip Networks
On-Chip Interconnection Networks Low-Power Interconnect William J. Dally Computer Systems Laboratory Stanford University ISLPED August 27, 2007 ISLPED: 1 Aug 27, 2007 Outline Demand for On-Chip Networks
How to Optimize 3D CMP Cache Hierarchy
 3D Cache Hierarchy Optimization Leonid Yavits, Amir Morad, Ran Ginosar Department of Electrical Engineering Technion Israel Institute of Technology Haifa, Israel yavits@tx.technion.ac.il, amirm@tx.technion.ac.il,
3D Cache Hierarchy Optimization Leonid Yavits, Amir Morad, Ran Ginosar Department of Electrical Engineering Technion Israel Institute of Technology Haifa, Israel yavits@tx.technion.ac.il, amirm@tx.technion.ac.il,
Power Reduction Techniques in the SoC Clock Network. Clock Power
 Power Reduction Techniques in the SoC Network Low Power Design for SoCs ASIC Tutorial SoC.1 Power Why clock power is important/large» Generally the signal with the highest frequency» Typically drives a
Power Reduction Techniques in the SoC Network Low Power Design for SoCs ASIC Tutorial SoC.1 Power Why clock power is important/large» Generally the signal with the highest frequency» Typically drives a
Light NUCA: a proposal for bridging the inter-cache latency gap
 Light NUCA: a proposal for bridging the inter-cache latency gap Darío Suárez, Teresa Monreal, Fernando Vallejo, Ramón Beivide, and Víctor Viñals gaz-diis-i3a ATC Universidad de Zaragoza, Spain Universidad
Light NUCA: a proposal for bridging the inter-cache latency gap Darío Suárez, Teresa Monreal, Fernando Vallejo, Ramón Beivide, and Víctor Viñals gaz-diis-i3a ATC Universidad de Zaragoza, Spain Universidad
Memory Architecture and Management in a NoC Platform
 Architecture and Management in a NoC Platform Axel Jantsch Xiaowen Chen Zhonghai Lu Chaochao Feng Abdul Nameed Yuang Zhang Ahmed Hemani DATE 2011 Overview Motivation State of the Art Data Management Engine
Architecture and Management in a NoC Platform Axel Jantsch Xiaowen Chen Zhonghai Lu Chaochao Feng Abdul Nameed Yuang Zhang Ahmed Hemani DATE 2011 Overview Motivation State of the Art Data Management Engine
Performance Evaluation of 2D-Mesh, Ring, and Crossbar Interconnects for Chip Multi- Processors. NoCArc 09
 Performance Evaluation of 2D-Mesh, Ring, and Crossbar Interconnects for Chip Multi- Processors NoCArc 09 Jesús Camacho Villanueva, José Flich, José Duato Universidad Politécnica de Valencia December 12,
Performance Evaluation of 2D-Mesh, Ring, and Crossbar Interconnects for Chip Multi- Processors NoCArc 09 Jesús Camacho Villanueva, José Flich, José Duato Universidad Politécnica de Valencia December 12,
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Memory Hierarchy. Arquitectura de Computadoras. Centro de Investigación n y de Estudios Avanzados del IPN. adiaz@cinvestav.mx. MemoryHierarchy- 1
 Hierarchy Arturo Díaz D PérezP Centro de Investigación n y de Estudios Avanzados del IPN adiaz@cinvestav.mx Hierarchy- 1 The Big Picture: Where are We Now? The Five Classic Components of a Computer Processor
Hierarchy Arturo Díaz D PérezP Centro de Investigación n y de Estudios Avanzados del IPN adiaz@cinvestav.mx Hierarchy- 1 The Big Picture: Where are We Now? The Five Classic Components of a Computer Processor
Architectural Level Power Consumption of Network on Chip. Presenter: YUAN Zheng
 Architectural Level Power Consumption of Network Presenter: YUAN Zheng Why Architectural Low Power Design? High-speed and large volume communication among different parts on a chip Problem: Power consumption
Architectural Level Power Consumption of Network Presenter: YUAN Zheng Why Architectural Low Power Design? High-speed and large volume communication among different parts on a chip Problem: Power consumption
Intel Labs at ISSCC 2012. Copyright Intel Corporation 2012
 Intel Labs at ISSCC 2012 Copyright Intel Corporation 2012 Intel Labs ISSCC 2012 Highlights 1. Efficient Computing Research: Making the most of every milliwatt to make computing greener and more scalable
Intel Labs at ISSCC 2012 Copyright Intel Corporation 2012 Intel Labs ISSCC 2012 Highlights 1. Efficient Computing Research: Making the most of every milliwatt to make computing greener and more scalable
Photonic Networks for Data Centres and High Performance Computing
 Photonic Networks for Data Centres and High Performance Computing Philip Watts Department of Electronic Engineering, UCL Yury Audzevich, Nick Barrow-Williams, Robert Mullins, Simon Moore, Andrew Moore
Photonic Networks for Data Centres and High Performance Computing Philip Watts Department of Electronic Engineering, UCL Yury Audzevich, Nick Barrow-Williams, Robert Mullins, Simon Moore, Andrew Moore
Thread level parallelism
 Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
Thread level parallelism ILP is used in straight line code or loops Cache miss (off-chip cache and main memory) is unlikely to be hidden using ILP. Thread level parallelism is used instead. Thread: process
A Comprehensive Memory Modeling Tool and its Application to the Design and Analysis of Future Memory Hierarchies
 International Symposium on Computer Architecture A Comprehensive Memory Modeling Tool and its Application to the Design and Analysis of Future Memory Hierarchies Shyamkumar Thoziyoor, Jung Ho Ahn, Matteo
International Symposium on Computer Architecture A Comprehensive Memory Modeling Tool and its Application to the Design and Analysis of Future Memory Hierarchies Shyamkumar Thoziyoor, Jung Ho Ahn, Matteo
I. INTRODUCTION. TABLE I REPRESENTATIVE PROCESSOR SAMPLES OF CURRENT HIGH-END SOCS (40 45 nm). SHADED CELLS SHOW THE LAST LEVEL CACHE (LLC)
. SHADED CELLS SHOW THE LAST LEVEL CACHE (LLC)") 1510 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 20, NO. 8, AUGUST 2012 LP-NUCA: Networks-in-Cache for High- Performance Low-Power Embedded Processors Darío Suárez Gracia, Student
1510 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 20, NO. 8, AUGUST 2012 LP-NUCA: Networks-in-Cache for High- Performance Low-Power Embedded Processors Darío Suárez Gracia, Student
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
McPAT: An Integrated Power, Area, and Timing Modeling Framework for Multicore and Manycore Architectures
 McPAT: An Integrated Power, Area, and Timing Modeling Framework for Multicore and Manycore Architectures Sheng Li, Junh Ho Ahn, Richard Strong, Jay B. Brockman, Dean M Tullsen, Norman Jouppi MICRO 2009
McPAT: An Integrated Power, Area, and Timing Modeling Framework for Multicore and Manycore Architectures Sheng Li, Junh Ho Ahn, Richard Strong, Jay B. Brockman, Dean M Tullsen, Norman Jouppi MICRO 2009
Power-Aware High-Performance Scientific Computing
 Power-Aware High-Performance Scientific Computing Padma Raghavan Scalable Computing Laboratory Department of Computer Science Engineering The Pennsylvania State University http://www.cse.psu.edu/~raghavan
Power-Aware High-Performance Scientific Computing Padma Raghavan Scalable Computing Laboratory Department of Computer Science Engineering The Pennsylvania State University http://www.cse.psu.edu/~raghavan
Lecture 18: Interconnection Networks. CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012)
") Lecture 18: Interconnection Networks CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Project deadlines: - Mon, April 2: project proposal: 1-2 page writeup - Fri,
Lecture 18: Interconnection Networks CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Project deadlines: - Mon, April 2: project proposal: 1-2 page writeup - Fri,
Static-Noise-Margin Analysis of Conventional 6T SRAM Cell at 45nm Technology
 Static-Noise-Margin Analysis of Conventional 6T SRAM Cell at 45nm Technology Nahid Rahman Department of electronics and communication FET-MITS (Deemed university), Lakshmangarh, India B. P. Singh Department
Static-Noise-Margin Analysis of Conventional 6T SRAM Cell at 45nm Technology Nahid Rahman Department of electronics and communication FET-MITS (Deemed university), Lakshmangarh, India B. P. Singh Department
Multi-core and Linux* Kernel
 Multi-core and Linux* Kernel Suresh Siddha Intel Open Source Technology Center Abstract Semiconductor technological advances in the recent years have led to the inclusion of multiple CPU execution cores
Multi-core and Linux* Kernel Suresh Siddha Intel Open Source Technology Center Abstract Semiconductor technological advances in the recent years have led to the inclusion of multiple CPU execution cores
Intel Itanium Quad-Core Architecture for the Enterprise. Lambert Schaelicke Eric DeLano
 Intel Itanium Quad-Core Architecture for the Enterprise Lambert Schaelicke Eric DeLano Agenda Introduction Intel Itanium Roadmap Intel Itanium Processor 9300 Series Overview Key Features Pipeline Overview
Intel Itanium Quad-Core Architecture for the Enterprise Lambert Schaelicke Eric DeLano Agenda Introduction Intel Itanium Roadmap Intel Itanium Processor 9300 Series Overview Key Features Pipeline Overview
HP ProLiant Gen8 vs Gen9 Server Blades on Data Warehouse Workloads
 HP ProLiant Gen8 vs Gen9 Server Blades on Data Warehouse Workloads Gen9 Servers give more performance per dollar for your investment. Executive Summary Information Technology (IT) organizations face increasing
HP ProLiant Gen8 vs Gen9 Server Blades on Data Warehouse Workloads Gen9 Servers give more performance per dollar for your investment. Executive Summary Information Technology (IT) organizations face increasing
What is a System on a Chip?
 What is a System on a Chip? Integration of a complete system, that until recently consisted of multiple ICs, onto a single IC. CPU PCI DSP SRAM ROM MPEG SoC DRAM System Chips Why? Characteristics: Complex
What is a System on a Chip? Integration of a complete system, that until recently consisted of multiple ICs, onto a single IC. CPU PCI DSP SRAM ROM MPEG SoC DRAM System Chips Why? Characteristics: Complex
Making Multicore Work and Measuring its Benefits. Markus Levy, president EEMBC and Multicore Association
 Making Multicore Work and Measuring its Benefits Markus Levy, president EEMBC and Multicore Association Agenda Why Multicore? Standards and issues in the multicore community What is Multicore Association?
Making Multicore Work and Measuring its Benefits Markus Levy, president EEMBC and Multicore Association Agenda Why Multicore? Standards and issues in the multicore community What is Multicore Association?
Computer Systems Structure Main Memory Organization
 Computer Systems Structure Main Memory Organization Peripherals Computer Central Processing Unit Main Memory Computer Systems Interconnection Communication lines Input Output Ward 1 Ward 2 Storage/Memory
Computer Systems Structure Main Memory Organization Peripherals Computer Central Processing Unit Main Memory Computer Systems Interconnection Communication lines Input Output Ward 1 Ward 2 Storage/Memory
Chapter 5 :: Memory and Logic Arrays
 Chapter 5 :: Memory and Logic Arrays Digital Design and Computer Architecture David Money Harris and Sarah L. Harris Copyright 2007 Elsevier 5- ROM Storage Copyright 2007 Elsevier 5- ROM Logic Data
Chapter 5 :: Memory and Logic Arrays Digital Design and Computer Architecture David Money Harris and Sarah L. Harris Copyright 2007 Elsevier 5- ROM Storage Copyright 2007 Elsevier 5- ROM Logic Data
Computer Architecture
 Computer Architecture Random Access Memory Technologies 2015. április 2. Budapest Gábor Horváth associate professor BUTE Dept. Of Networked Systems and Services ghorvath@hit.bme.hu 2 Storing data Possible
Computer Architecture Random Access Memory Technologies 2015. április 2. Budapest Gábor Horváth associate professor BUTE Dept. Of Networked Systems and Services ghorvath@hit.bme.hu 2 Storing data Possible
Resource Efficient Computing for Warehouse-scale Datacenters
 Resource Efficient Computing for Warehouse-scale Datacenters Christos Kozyrakis Stanford University http://csl.stanford.edu/~christos DATE Conference March 21 st 2013 Computing is the Innovation Catalyst
Resource Efficient Computing for Warehouse-scale Datacenters Christos Kozyrakis Stanford University http://csl.stanford.edu/~christos DATE Conference March 21 st 2013 Computing is the Innovation Catalyst
Infrastructure Matters: POWER8 vs. Xeon x86
 Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
This Unit: Caches. CIS 501 Introduction to Computer Architecture. Motivation. Types of Memory
 This Unit: Caches CIS 5 Introduction to Computer Architecture Unit 3: Storage Hierarchy I: Caches Application OS Compiler Firmware CPU I/O Memory Digital Circuits Gates & Transistors Memory hierarchy concepts
This Unit: Caches CIS 5 Introduction to Computer Architecture Unit 3: Storage Hierarchy I: Caches Application OS Compiler Firmware CPU I/O Memory Digital Circuits Gates & Transistors Memory hierarchy concepts
Interconnection technologies
 Interconnection technologies Ron Ho VLSI Research Group Sun Microsystems Laboratories 1 Acknowledgements Many contributors to the work described here > Robert Drost, David Hopkins, Alex Chow, Tarik Ono,
Interconnection technologies Ron Ho VLSI Research Group Sun Microsystems Laboratories 1 Acknowledgements Many contributors to the work described here > Robert Drost, David Hopkins, Alex Chow, Tarik Ono,
Interconnection Networks. Interconnection Networks. Interconnection networks are used everywhere!
 Interconnection Networks Interconnection Networks Interconnection networks are used everywhere! Supercomputers connecting the processors Routers connecting the ports can consider a router as a parallel
Interconnection Networks Interconnection Networks Interconnection networks are used everywhere! Supercomputers connecting the processors Routers connecting the ports can consider a router as a parallel
SOC architecture and design
 SOC architecture and design system-on-chip (SOC) processors: become components in a system SOC covers many topics processor: pipelined, superscalar, VLIW, array, vector storage: cache, embedded and external
SOC architecture and design system-on-chip (SOC) processors: become components in a system SOC covers many topics processor: pipelined, superscalar, VLIW, array, vector storage: cache, embedded and external
FREE-p: Protecting Non-Volatile Memory against both Hard and Soft Errors
 FREE-p: Protecting Non-Volatile Memory against both Hard and Soft Errors Doe Hyun Yoon Naveen Muralimanohar Jichuan Chang Parthasarathy Ranganathan Norman P. Jouppi Mattan Erez Electrical and Computer
FREE-p: Protecting Non-Volatile Memory against both Hard and Soft Errors Doe Hyun Yoon Naveen Muralimanohar Jichuan Chang Parthasarathy Ranganathan Norman P. Jouppi Mattan Erez Electrical and Computer
Performance Impacts of Non-blocking Caches in Out-of-order Processors
 Performance Impacts of Non-blocking Caches in Out-of-order Processors Sheng Li; Ke Chen; Jay B. Brockman; Norman P. Jouppi HP Laboratories HPL-2011-65 Keyword(s): Non-blocking cache; MSHR; Out-of-order
Performance Impacts of Non-blocking Caches in Out-of-order Processors Sheng Li; Ke Chen; Jay B. Brockman; Norman P. Jouppi HP Laboratories HPL-2011-65 Keyword(s): Non-blocking cache; MSHR; Out-of-order
8 Gbps CMOS interface for parallel fiber-optic interconnects
 8 Gbps CMOS interface for parallel fiberoptic interconnects Barton Sano, Bindu Madhavan and A. F. J. Levi Department of Electrical Engineering University of Southern California Los Angeles, California
8 Gbps CMOS interface for parallel fiberoptic interconnects Barton Sano, Bindu Madhavan and A. F. J. Levi Department of Electrical Engineering University of Southern California Los Angeles, California
Outline. Introduction. Multiprocessor Systems on Chip. A MPSoC Example: Nexperia DVP. A New Paradigm: Network on Chip
 Outline Modeling, simulation and optimization of Multi-Processor SoCs (MPSoCs) Università of Verona Dipartimento di Informatica MPSoCs: Multi-Processor Systems on Chip A simulation platform for a MPSoC
Outline Modeling, simulation and optimization of Multi-Processor SoCs (MPSoCs) Università of Verona Dipartimento di Informatica MPSoCs: Multi-Processor Systems on Chip A simulation platform for a MPSoC
18-548/15-548 Associativity 9/16/98. 7 Associativity. 18-548/15-548 Memory System Architecture Philip Koopman September 16, 1998
 7 Associativity 18-548/15-548 Memory System Architecture Philip Koopman September 16, 1998 Required Reading: Cragon pg. 166-174 Assignments By next class read about data management policies: Cragon 2.2.4-2.2.6,
7 Associativity 18-548/15-548 Memory System Architecture Philip Koopman September 16, 1998 Required Reading: Cragon pg. 166-174 Assignments By next class read about data management policies: Cragon 2.2.4-2.2.6,
Binary search tree with SIMD bandwidth optimization using SSE
 Binary search tree with SIMD bandwidth optimization using SSE Bowen Zhang, Xinwei Li 1.ABSTRACT In-memory tree structured index search is a fundamental database operation. Modern processors provide tremendous
Binary search tree with SIMD bandwidth optimization using SSE Bowen Zhang, Xinwei Li 1.ABSTRACT In-memory tree structured index search is a fundamental database operation. Modern processors provide tremendous
Communicating with devices
 Introduction to I/O Where does the data for our CPU and memory come from or go to? Computers communicate with the outside world via I/O devices. Input devices supply computers with data to operate on.
Introduction to I/O Where does the data for our CPU and memory come from or go to? Computers communicate with the outside world via I/O devices. Input devices supply computers with data to operate on.
Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand
 Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand P. Balaji, K. Vaidyanathan, S. Narravula, K. Savitha, H. W. Jin D. K. Panda Network Based
Exploiting Remote Memory Operations to Design Efficient Reconfiguration for Shared Data-Centers over InfiniBand P. Balaji, K. Vaidyanathan, S. Narravula, K. Savitha, H. W. Jin D. K. Panda Network Based
PowerPC Microprocessor Clock Modes
 nc. Freescale Semiconductor AN1269 (Freescale Order Number) 1/96 Application Note PowerPC Microprocessor Clock Modes The PowerPC microprocessors offer customers numerous clocking options. An internal phase-lock
nc. Freescale Semiconductor AN1269 (Freescale Order Number) 1/96 Application Note PowerPC Microprocessor Clock Modes The PowerPC microprocessors offer customers numerous clocking options. An internal phase-lock
路 論 Chapter 15 System-Level Physical Design
 Introduction to VLSI Circuits and Systems 路 論 Chapter 15 System-Level Physical Design Dept. of Electronic Engineering National Chin-Yi University of Technology Fall 2007 Outline Clocked Flip-flops CMOS
Introduction to VLSI Circuits and Systems 路 論 Chapter 15 System-Level Physical Design Dept. of Electronic Engineering National Chin-Yi University of Technology Fall 2007 Outline Clocked Flip-flops CMOS
White Paper. Requirements of Network Virtualization
 White Paper on Requirements of Network Virtualization INDEX 1. Introduction 2. Architecture of Network Virtualization 3. Requirements for Network virtualization 3.1. Isolation 3.2. Network abstraction
White Paper on Requirements of Network Virtualization INDEX 1. Introduction 2. Architecture of Network Virtualization 3. Requirements for Network virtualization 3.1. Isolation 3.2. Network abstraction
The Quest for Speed - Memory. Cache Memory. A Solution: Memory Hierarchy. Memory Hierarchy
 The Quest for Speed - Memory Cache Memory CSE 4, Spring 25 Computer Systems http://www.cs.washington.edu/4 If all memory accesses (IF/lw/sw) accessed main memory, programs would run 20 times slower And
The Quest for Speed - Memory Cache Memory CSE 4, Spring 25 Computer Systems http://www.cs.washington.edu/4 If all memory accesses (IF/lw/sw) accessed main memory, programs would run 20 times slower And
Table Of Contents. Page 2 of 26. *Other brands and names may be claimed as property of others.
 Technical White Paper Revision 1.1 4/28/10 Subject: Optimizing Memory Configurations for the Intel Xeon processor 5500 & 5600 series Author: Scott Huck; Intel DCG Competitive Architect Target Audience:
Technical White Paper Revision 1.1 4/28/10 Subject: Optimizing Memory Configurations for the Intel Xeon processor 5500 & 5600 series Author: Scott Huck; Intel DCG Competitive Architect Target Audience:
CS250 VLSI Systems Design Lecture 8: Memory
 CS250 VLSI Systems esign Lecture 8: Memory John Wawrzynek, Krste Asanovic, with John Lazzaro and Yunsup Lee (TA) UC Berkeley Fall 2010 CMOS Bistable 1 0 Flip State 0 1 Cross-coupled inverters used to hold
CS250 VLSI Systems esign Lecture 8: Memory John Wawrzynek, Krste Asanovic, with John Lazzaro and Yunsup Lee (TA) UC Berkeley Fall 2010 CMOS Bistable 1 0 Flip State 0 1 Cross-coupled inverters used to hold
361 Computer Architecture Lecture 14: Cache Memory
 1 361 Computer Architecture Lecture 14 Memory cache.1 The Motivation for s Memory System Processor DRAM Motivation Large memories (DRAM) are slow Small memories (SRAM) are fast Make the average access
1 361 Computer Architecture Lecture 14 Memory cache.1 The Motivation for s Memory System Processor DRAM Motivation Large memories (DRAM) are slow Small memories (SRAM) are fast Make the average access
COMPUTER HARDWARE. Input- Output and Communication Memory Systems
 COMPUTER HARDWARE Input- Output and Communication Memory Systems Computer I/O I/O devices commonly found in Computer systems Keyboards Displays Printers Magnetic Drives Compact disk read only memory (CD-ROM)
COMPUTER HARDWARE Input- Output and Communication Memory Systems Computer I/O I/O devices commonly found in Computer systems Keyboards Displays Printers Magnetic Drives Compact disk read only memory (CD-ROM)
CACTI 3.0: An Integrated Cache Timing, Power, and Area Model
 A U G U S T 0 0 WRL Research Report 0/ CACTI 3.0: An Integrated Cache Timing, Power, and Area Model Premkishore Shivakumar and Norman P. Jouppi Western Research Laboratory 50 University Avenue Palo Alto,
A U G U S T 0 0 WRL Research Report 0/ CACTI 3.0: An Integrated Cache Timing, Power, and Area Model Premkishore Shivakumar and Norman P. Jouppi Western Research Laboratory 50 University Avenue Palo Alto,
Deploying in a Distributed Environment
 Deploying in a Distributed Environment Distributed enterprise networks have many remote locations, ranging from dozens to thousands of small offices. Typically, between 5 and 50 employees work at each
Deploying in a Distributed Environment Distributed enterprise networks have many remote locations, ranging from dozens to thousands of small offices. Typically, between 5 and 50 employees work at each
Empowering Developers to Estimate App Energy Consumption. Radhika Mittal, UC Berkeley Aman Kansal & Ranveer Chandra, Microsoft Research
 Empowering Developers to Estimate App Energy Consumption Radhika Mittal, UC Berkeley Aman Kansal & Ranveer Chandra, Microsoft Research Phone s battery life is critical performance and user experience metric
Empowering Developers to Estimate App Energy Consumption Radhika Mittal, UC Berkeley Aman Kansal & Ranveer Chandra, Microsoft Research Phone s battery life is critical performance and user experience metric
Industrial Ethernet How to Keep Your Network Up and Running A Beginner s Guide to Redundancy Standards
 Redundancy = Protection from Network Failure. Redundancy Standards WP-31-REV0-4708-1/5 Industrial Ethernet How to Keep Your Network Up and Running A Beginner s Guide to Redundancy Standards For a very
Redundancy = Protection from Network Failure. Redundancy Standards WP-31-REV0-4708-1/5 Industrial Ethernet How to Keep Your Network Up and Running A Beginner s Guide to Redundancy Standards For a very
Use-it or Lose-it: Wearout and Lifetime in Future Chip-Multiprocessors
 Use-it or Lose-it: Wearout and Lifetime in Future Chip-Multiprocessors Hyungjun Kim, 1 Arseniy Vitkovsky, 2 Paul V. Gratz, 1 Vassos Soteriou 2 1 Department of Electrical and Computer Engineering, Texas
Use-it or Lose-it: Wearout and Lifetime in Future Chip-Multiprocessors Hyungjun Kim, 1 Arseniy Vitkovsky, 2 Paul V. Gratz, 1 Vassos Soteriou 2 1 Department of Electrical and Computer Engineering, Texas
Digital Design for Low Power Systems
 Digital Design for Low Power Systems Shekhar Borkar Intel Corp. Outline Low Power Outlook & Challenges Circuit solutions for leakage avoidance, control, & tolerance Microarchitecture for Low Power System
Digital Design for Low Power Systems Shekhar Borkar Intel Corp. Outline Low Power Outlook & Challenges Circuit solutions for leakage avoidance, control, & tolerance Microarchitecture for Low Power System
On-Chip Communications Network Report
 On-Chip Communications Network Report ABSTRACT This report covers the results of an independent, blind worldwide survey covering on-chip communications networks (OCCN), defined as is the entire interconnect
On-Chip Communications Network Report ABSTRACT This report covers the results of an independent, blind worldwide survey covering on-chip communications networks (OCCN), defined as is the entire interconnect
Clocking. Figure by MIT OCW. 6.884 - Spring 2005 2/18/05 L06 Clocks 1
 ing Figure by MIT OCW. 6.884 - Spring 2005 2/18/05 L06 s 1 Why s and Storage Elements? Inputs Combinational Logic Outputs Want to reuse combinational logic from cycle to cycle 6.884 - Spring 2005 2/18/05
ing Figure by MIT OCW. 6.884 - Spring 2005 2/18/05 L06 s 1 Why s and Storage Elements? Inputs Combinational Logic Outputs Want to reuse combinational logic from cycle to cycle 6.884 - Spring 2005 2/18/05
Interconnection Network of OTA-based FPAA
 Chapter S Interconnection Network of OTA-based FPAA 5.1 Introduction Aside from CAB components, a number of different interconnect structures have been proposed for FPAAs. The choice of an intercmmcclion
Chapter S Interconnection Network of OTA-based FPAA 5.1 Introduction Aside from CAB components, a number of different interconnect structures have been proposed for FPAAs. The choice of an intercmmcclion
Energy-Efficient, High-Performance Heterogeneous Core Design
 Energy-Efficient, High-Performance Heterogeneous Core Design Raj Parihar Core Design Session, MICRO - 2012 Advanced Computer Architecture Lab, UofR, Rochester April 18, 2013 Raj Parihar Energy-Efficient,
Energy-Efficient, High-Performance Heterogeneous Core Design Raj Parihar Core Design Session, MICRO - 2012 Advanced Computer Architecture Lab, UofR, Rochester April 18, 2013 Raj Parihar Energy-Efficient,
what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored?
 Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Inside the CPU how does the CPU work? what operations can it perform? how does it perform them? on what kind of data? where are instructions and data stored? some short, boring programs to illustrate the
Unit A451: Computer systems and programming. Section 2: Computing Hardware 1/5: Central Processing Unit
 Unit A451: Computer systems and programming Section 2: Computing Hardware 1/5: Central Processing Unit Section Objectives Candidates should be able to: (a) State the purpose of the CPU (b) Understand the
Unit A451: Computer systems and programming Section 2: Computing Hardware 1/5: Central Processing Unit Section Objectives Candidates should be able to: (a) State the purpose of the CPU (b) Understand the
Inter-socket Victim Cacheing for Platform Power Reduction
 In Proceedings of the 2010 International Conference on Computer Design Inter-socket Victim Cacheing for Platform Power Reduction Subhra Mazumdar University of California, San Diego smazumdar@cs.ucsd.edu
In Proceedings of the 2010 International Conference on Computer Design Inter-socket Victim Cacheing for Platform Power Reduction Subhra Mazumdar University of California, San Diego smazumdar@cs.ucsd.edu
DEPLOYING AND MONITORING HADOOP MAP-REDUCE ANALYTICS ON SINGLE-CHIP CLOUD COMPUTER
 DEPLOYING AND MONITORING HADOOP MAP-REDUCE ANALYTICS ON SINGLE-CHIP CLOUD COMPUTER ANDREAS-LAZAROS GEORGIADIS, SOTIRIOS XYDIS, DIMITRIOS SOUDRIS MICROPROCESSOR AND MICROSYSTEMS LABORATORY ELECTRICAL AND
DEPLOYING AND MONITORING HADOOP MAP-REDUCE ANALYTICS ON SINGLE-CHIP CLOUD COMPUTER ANDREAS-LAZAROS GEORGIADIS, SOTIRIOS XYDIS, DIMITRIOS SOUDRIS MICROPROCESSOR AND MICROSYSTEMS LABORATORY ELECTRICAL AND
Vorlesung Rechnerarchitektur 2 Seite 178 DASH
 Vorlesung Rechnerarchitektur 2 Seite 178 Architecture for Shared () The -architecture is a cache coherent, NUMA multiprocessor system, developed at CSL-Stanford by John Hennessy, Daniel Lenoski, Monica
Vorlesung Rechnerarchitektur 2 Seite 178 Architecture for Shared () The -architecture is a cache coherent, NUMA multiprocessor system, developed at CSL-Stanford by John Hennessy, Daniel Lenoski, Monica
Solving Network Challenges
 Solving Network hallenges n Advanced Multicore Sos Presented by: Tim Pontius Multicore So Network hallenges Many heterogeneous cores: various protocols, data width, address maps, bandwidth, clocking, etc.
Solving Network hallenges n Advanced Multicore Sos Presented by: Tim Pontius Multicore So Network hallenges Many heterogeneous cores: various protocols, data width, address maps, bandwidth, clocking, etc.
SRAM Scaling Limit: Its Circuit & Architecture Solutions
 SRAM Scaling Limit: Its Circuit & Architecture Solutions Nam Sung Kim, Ph.D. Assistant Professor Department of Electrical and Computer Engineering University of Wisconsin - Madison SRAM VCC min Challenges
SRAM Scaling Limit: Its Circuit & Architecture Solutions Nam Sung Kim, Ph.D. Assistant Professor Department of Electrical and Computer Engineering University of Wisconsin - Madison SRAM VCC min Challenges
COMP 422, Lecture 3: Physical Organization & Communication Costs in Parallel Machines (Sections 2.4 & 2.5 of textbook)
") COMP 422, Lecture 3: Physical Organization & Communication Costs in Parallel Machines (Sections 2.4 & 2.5 of textbook) Vivek Sarkar Department of Computer Science Rice University vsarkar@rice.edu COMP
COMP 422, Lecture 3: Physical Organization & Communication Costs in Parallel Machines (Sections 2.4 & 2.5 of textbook) Vivek Sarkar Department of Computer Science Rice University vsarkar@rice.edu COMP
Scalability and Classifications
 Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Lecture 23: Interconnection Networks. Topics: communication latency, centralized and decentralized switches (Appendix E)
") Lecture 23: Interconnection Networks Topics: communication latency, centralized and decentralized switches (Appendix E) 1 Topologies Internet topologies are not very regular they grew incrementally Supercomputers
Lecture 23: Interconnection Networks Topics: communication latency, centralized and decentralized switches (Appendix E) 1 Topologies Internet topologies are not very regular they grew incrementally Supercomputers
Networking Virtualization Using FPGAs
 Networking Virtualization Using FPGAs Russell Tessier, Deepak Unnikrishnan, Dong Yin, and Lixin Gao Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Massachusetts,
Networking Virtualization Using FPGAs Russell Tessier, Deepak Unnikrishnan, Dong Yin, and Lixin Gao Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Massachusetts,
e.g. τ = 12 ps in 180nm, 40 ps in 0.6 µm Delay has two components where, f = Effort Delay (stage effort)= gh p =Parasitic Delay
= gh p =Parasitic Delay") Logic Gate Delay Chip designers need to choose: What is the best circuit topology for a function? How many stages of logic produce least delay? How wide transistors should be? Logical Effort Helps make
Logic Gate Delay Chip designers need to choose: What is the best circuit topology for a function? How many stages of logic produce least delay? How wide transistors should be? Logical Effort Helps make
The Orca Chip... Heart of IBM s RISC System/6000 Value Servers
 The Orca Chip... Heart of IBM s RISC System/6000 Value Servers Ravi Arimilli IBM RISC System/6000 Division 1 Agenda. Server Background. Cache Heirarchy Performance Study. RS/6000 Value Server System Structure.
The Orca Chip... Heart of IBM s RISC System/6000 Value Servers Ravi Arimilli IBM RISC System/6000 Division 1 Agenda. Server Background. Cache Heirarchy Performance Study. RS/6000 Value Server System Structure.
Efficient Big Data Analytics Computing: A Research Challenge
 Efficient Big Data Analytics Computing: A Research Challenge Wilfred Pinfold Director, Extreme Scale Programs 1 Agenda Intel Big Data Context Overview Key Research Areas Challenges Partnerships 2 Meeting
Efficient Big Data Analytics Computing: A Research Challenge Wilfred Pinfold Director, Extreme Scale Programs 1 Agenda Intel Big Data Context Overview Key Research Areas Challenges Partnerships 2 Meeting
A Study on the Scalability of Hybrid LS-DYNA on Multicore Architectures
 11 th International LS-DYNA Users Conference Computing Technology A Study on the Scalability of Hybrid LS-DYNA on Multicore Architectures Yih-Yih Lin Hewlett-Packard Company Abstract In this paper, the
11 th International LS-DYNA Users Conference Computing Technology A Study on the Scalability of Hybrid LS-DYNA on Multicore Architectures Yih-Yih Lin Hewlett-Packard Company Abstract In this paper, the
Why the Network Matters
 Week 2, Lecture 2 Copyright 2009 by W. Feng. Based on material from Matthew Sottile. So Far Overview of Multicore Systems Why Memory Matters Memory Architectures Emerging Chip Multiprocessors (CMP) Increasing
Week 2, Lecture 2 Copyright 2009 by W. Feng. Based on material from Matthew Sottile. So Far Overview of Multicore Systems Why Memory Matters Memory Architectures Emerging Chip Multiprocessors (CMP) Increasing
Why Latency Lags Bandwidth, and What it Means to Computing
 Why Latency Lags Bandwidth, and What it Means to Computing David Patterson U.C. Berkeley patterson@cs.berkeley.edu October 2004 Bandwidth Rocks (1) Preview: Latency Lags Bandwidth Over last 20 to 25 years,
Why Latency Lags Bandwidth, and What it Means to Computing David Patterson U.C. Berkeley patterson@cs.berkeley.edu October 2004 Bandwidth Rocks (1) Preview: Latency Lags Bandwidth Over last 20 to 25 years,
In-Memory Databases Algorithms and Data Structures on Modern Hardware. Martin Faust David Schwalb Jens Krüger Jürgen Müller
 In-Memory Databases Algorithms and Data Structures on Modern Hardware Martin Faust David Schwalb Jens Krüger Jürgen Müller The Free Lunch Is Over 2 Number of transistors per CPU increases Clock frequency
In-Memory Databases Algorithms and Data Structures on Modern Hardware Martin Faust David Schwalb Jens Krüger Jürgen Müller The Free Lunch Is Over 2 Number of transistors per CPU increases Clock frequency
- Nishad Nerurkar. - Aniket Mhatre
 - Nishad Nerurkar - Aniket Mhatre Single Chip Cloud Computer is a project developed by Intel. It was developed by Intel Lab Bangalore, Intel Lab America and Intel Lab Germany. It is part of a larger project,
- Nishad Nerurkar - Aniket Mhatre Single Chip Cloud Computer is a project developed by Intel. It was developed by Intel Lab Bangalore, Intel Lab America and Intel Lab Germany. It is part of a larger project,
Emerging storage and HPC technologies to accelerate big data analytics Jerome Gaysse JG Consulting
 Emerging storage and HPC technologies to accelerate big data analytics Jerome Gaysse JG Consulting Introduction Big Data Analytics needs: Low latency data access Fast computing Power efficiency Latest
Emerging storage and HPC technologies to accelerate big data analytics Jerome Gaysse JG Consulting Introduction Big Data Analytics needs: Low latency data access Fast computing Power efficiency Latest
Scalable Internet Services and Load Balancing
 Scalable Services and Load Balancing Kai Shen Services brings ubiquitous connection based applications/services accessible to online users through Applications can be designed and launched quickly and
Scalable Services and Load Balancing Kai Shen Services brings ubiquitous connection based applications/services accessible to online users through Applications can be designed and launched quickly and
A Generic Network Interface Architecture for a Networked Processor Array (NePA)
") A Generic Network Interface Architecture for a Networked Processor Array (NePA) Seung Eun Lee, Jun Ho Bahn, Yoon Seok Yang, and Nader Bagherzadeh EECS @ University of California, Irvine Outline Introduction
A Generic Network Interface Architecture for a Networked Processor Array (NePA) Seung Eun Lee, Jun Ho Bahn, Yoon Seok Yang, and Nader Bagherzadeh EECS @ University of California, Irvine Outline Introduction
 More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
The Internet of Things: Opportunities & Challenges
 The Internet of Things: Opportunities & Challenges What is the IoT? Things, people and cloud services getting connected via the Internet to enable new use cases and business models Cloud Services How is
The Internet of Things: Opportunities & Challenges What is the IoT? Things, people and cloud services getting connected via the Internet to enable new use cases and business models Cloud Services How is
Distance-Aware Round-Robin Mapping for Large NUCA Caches
 Distance-Aware Round-Robin Mapping for Large NUCA Caches Alberto Ros, Marcelo Cintra, Manuel E. Acacio and José M.García Departamento de Ingeniería y Tecnología de Computadores, Universidad de Murcia,
Distance-Aware Round-Robin Mapping for Large NUCA Caches Alberto Ros, Marcelo Cintra, Manuel E. Acacio and José M.García Departamento de Ingeniería y Tecnología de Computadores, Universidad de Murcia,
Measuring Cache and Memory Latency and CPU to Memory Bandwidth
 White Paper Joshua Ruggiero Computer Systems Engineer Intel Corporation Measuring Cache and Memory Latency and CPU to Memory Bandwidth For use with Intel Architecture December 2008 1 321074 Executive Summary
White Paper Joshua Ruggiero Computer Systems Engineer Intel Corporation Measuring Cache and Memory Latency and CPU to Memory Bandwidth For use with Intel Architecture December 2008 1 321074 Executive Summary
High Performance Computing. Course Notes 2007-2008. HPC Fundamentals
 High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
The Reduced Address Space (RAS) for Application Memory Authentication
 for Application Memory Authentication") The Reduced Address Space (RAS) for Application Memory Authentication David Champagne, Reouven Elbaz and Ruby B. Lee Princeton University, USA Introduction Background: TPM, XOM, AEGIS, SP, SecureBlue want
The Reduced Address Space (RAS) for Application Memory Authentication David Champagne, Reouven Elbaz and Ruby B. Lee Princeton University, USA Introduction Background: TPM, XOM, AEGIS, SP, SecureBlue want
Symmetric Multiprocessing
 Multicore Computing A multi-core processor is a processing system composed of two or more independent cores. One can describe it as an integrated circuit to which two or more individual processors (called
Multicore Computing A multi-core processor is a processing system composed of two or more independent cores. One can describe it as an integrated circuit to which two or more individual processors (called
Design-space exploration of flash augmented architectures
 Design-space exploration of flash augmented architectures Thanumalayan S 1, Vijay Chidambaram V 1, Ranjani Parthasarathi 2 College of Engineering, Guindy, Anna University Abstract Flash technologies are
Design-space exploration of flash augmented architectures Thanumalayan S 1, Vijay Chidambaram V 1, Ranjani Parthasarathi 2 College of Engineering, Guindy, Anna University Abstract Flash technologies are
OC By Arsene Fansi T. POLIMI 2008 1
 IBM POWER 6 MICROPROCESSOR OC By Arsene Fansi T. POLIMI 2008 1 WHAT S IBM POWER 6 MICROPOCESSOR The IBM POWER6 microprocessor powers the new IBM i-series* and p-series* systems. It s based on IBM POWER5
IBM POWER 6 MICROPROCESSOR OC By Arsene Fansi T. POLIMI 2008 1 WHAT S IBM POWER 6 MICROPOCESSOR The IBM POWER6 microprocessor powers the new IBM i-series* and p-series* systems. It s based on IBM POWER5
Removing The Linux Routing Cache
 Removing The Red Hat Inc. Columbia University, New York, 2012 Removing The 1 Linux Maintainership 2 3 4 5 Removing The My Background Started working on the kernel 18+ years ago. First project: helping
Removing The Red Hat Inc. Columbia University, New York, 2012 Removing The 1 Linux Maintainership 2 3 4 5 Removing The My Background Started working on the kernel 18+ years ago. First project: helping
Introduction to Exploration and Optimization of Multiprocessor Embedded Architectures based on Networks On-Chip
 Introduction to Exploration and Optimization of Multiprocessor Embedded Architectures based on Networks On-Chip Cristina SILVANO silvano@elet.polimi.it Politecnico di Milano, Milano (Italy) Talk Outline
Introduction to Exploration and Optimization of Multiprocessor Embedded Architectures based on Networks On-Chip Cristina SILVANO silvano@elet.polimi.it Politecnico di Milano, Milano (Italy) Talk Outline
EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES
 ABSTRACT EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES Tyler Cossentine and Ramon Lawrence Department of Computer Science, University of British Columbia Okanagan Kelowna, BC, Canada tcossentine@gmail.com
ABSTRACT EFFICIENT EXTERNAL SORTING ON FLASH MEMORY EMBEDDED DEVICES Tyler Cossentine and Ramon Lawrence Department of Computer Science, University of British Columbia Okanagan Kelowna, BC, Canada tcossentine@gmail.com
2010 Ingres Corporation. Interactive BI for Large Data Volumes Silicon India BI Conference, 2011, Mumbai Vivek Bhatnagar, Ingres Corporation
 Interactive BI for Large Data Volumes Silicon India BI Conference, 2011, Mumbai Vivek Bhatnagar, Ingres Corporation Agenda Need for Fast Data Analysis & The Data Explosion Challenge Approaches Used Till
Interactive BI for Large Data Volumes Silicon India BI Conference, 2011, Mumbai Vivek Bhatnagar, Ingres Corporation Agenda Need for Fast Data Analysis & The Data Explosion Challenge Approaches Used Till
HETEROGENEOUS SYSTEM COHERENCE FOR INTEGRATED CPU-GPU SYSTEMS
 HETEROGENEOUS SYSTEM COHERENCE FOR INTEGRATED CPU-GPU SYSTEMS JASON POWER*, ARKAPRAVA BASU*, JUNLI GU, SOORAJ PUTHOOR, BRADFORD M BECKMANN, MARK D HILL*, STEVEN K REINHARDT, DAVID A WOOD* *University of
HETEROGENEOUS SYSTEM COHERENCE FOR INTEGRATED CPU-GPU SYSTEMS JASON POWER*, ARKAPRAVA BASU*, JUNLI GU, SOORAJ PUTHOOR, BRADFORD M BECKMANN, MARK D HILL*, STEVEN K REINHARDT, DAVID A WOOD* *University of
Router Architectures
 Router Architectures An overview of router architectures. Introduction What is a Packet Switch? Basic Architectural Components Some Example Packet Switches The Evolution of IP Routers 2 1 Router Components
Router Architectures An overview of router architectures. Introduction What is a Packet Switch? Basic Architectural Components Some Example Packet Switches The Evolution of IP Routers 2 1 Router Components
LaPIe: Collective Communications adapted to Grid Environments
 LaPIe: Collective Communications adapted to Grid Environments Luiz Angelo Barchet-Estefanel Thesis Supervisor: M Denis TRYSTRAM Co-Supervisor: M Grégory MOUNIE ID-IMAG Laboratory Grenoble - France LaPIe:
LaPIe: Collective Communications adapted to Grid Environments Luiz Angelo Barchet-Estefanel Thesis Supervisor: M Denis TRYSTRAM Co-Supervisor: M Grégory MOUNIE ID-IMAG Laboratory Grenoble - France LaPIe: