Big Data Storage
|
|
|
- Nicholas Goodwin
- 3 years ago
- Views:
Transcription

1 HBase IntroductionandNewDevelopments AndrewPurtell
2 Outline BigDataandCloudComputing HBaseIntroduction NewFeatures ACIDGuarantees MultiDataCenterReplication Security Coprocessors WrapUp
3 BigDataandCloudComputing
ofdatavolume Google encountered Big Data in their operations and devisedarchitecturalsolutionsforit,includingbigtable BigTableistheinspirationforHBase TheBigDataAge")
4 BigData BigDatadefined Scale beyond the limits of conventional data storage solutions today either in terms of capacity or of the sustainablecostofthesolution Trillions(10^12)ofdataitems Petabytes(10^15bytes)ofdatavolume Google encountered Big Data in their operations and devisedarchitecturalsolutionsforit,includingbigtable BigTableistheinspirationforHBase TheBigDataAge Accordingtooneestimate,globally the world created 150 exabytes of datain2005 This year, the world may create morethan1,500exabytesofdata
5 MediumData What about Medium Data? We like to say that Facebook doesn t run Hadoop because it has a lot of data, but that Facebook has a lot of data because it runs Hadoop. Businesses that use Hadoop find that keeping data is worthwhile because Hadoop helps themprocessitinnewways. MikeOlson,CEO,Cloudera Manybusiness,evensmallones,duringthecourseof their normal operations can generate petabytes of dataperyear Iftheyretainit,theycanmineitandgaininsights Open source analytics enablers like the Hadoop software ecosystem of which HBase is a part makethisanemergingreality
6 CloudComputing "Internet based access to highly scalable pay per use ITcapabilities" YnemaMangum,SUNMicrosystems Anevolutionofnetworkcomputing Describesinfrastructure as a service(iaas)prettywelll Workstation Network Grid Cloud Cloudcomputingisclient servercomputingthatabstracsthe detailsoftheserveraway Scalefree Resourcesanywhere/everywhere Looselycoupledcomputing Decentralized,openstandards Opentechnologies Newownershipmodel
7 CloudComputing Scalefreecomputing A limitless pool of on demand resources is a game changer Paybyuseinsteadofprovisioningforpeak Elasticscalingupanddown,scaleupverylarge Optimizecoststoactualservicedemand Worry only about the application or service, not about infrastructure Capacity Capacity Demand Demand Time Time Staticdatacenter Datacenterinthecloud Unusedresources
8 Convergence As we enter the age of Big Data we have the scale (and scale free computational nature) of the Cloud to manageit TheCloudisadriverofBigDataevenasitisameans todealwithit HadoopandHBaseareCloudscalearchitectures ContainerforBig(andMedium)Data Scalefreecomputationalframeworkfor managingit
9 HBase(andHadoop)Introduction
in62seconds")
10 HadoopThePlatform Atransparentlyscalablecomputingplatform Cloudscale griddataprocessing 2009GraySortwinner:0.578terabytes/minute,anew worldrecord 10Knodes,100millionfiles,10petabytes Sortaterabyte(1,000,000,000,000bytes)in62seconds Sortapetabyte(1,000,000,000,000,000bytes)in16.25hours
11 HadoopTheEcosystem RDBMS BI,ETL ETL Sqoop Hive Pig MapReduce(Computation) HBase(DistributedMap) HDFS (HadoopDistributedFileSystem) Avro(Serialization) MapReduceframework(Core) Pluggableclustertaskscheduler(Core) Distributedreplicatedfaulttolerantfilesystem(HDFS) Horizontallyscalabledistributedfaulttolerantdatabase (HBase) Various value adds: Add on packages (analytics, management),distributions,dashboards,etc. Zookeepr(Coordination)
seekandreplace(RDBMS) Transferdominant:sort/merge(MapReduce,Bigtable) Seekisinefficientcomparedtotransferatscale Given: Updating1%ofentries(100,000,000)takes: 10MB/secondtransferbandwidth")
12 SeekVersusSortandMerge Atscale,disktimedominatesstorageandcomputation Twodatabaseparadigms CPU,RAM,anddisksizedoubleevery18 24months Seektimeremainsnearlyconstant(~5%peryear) Seekdominant:Indexed(B Tree)seekandreplace(RDBMS) Transferdominant:sort/merge(MapReduce,Bigtable) Seekisinefficientcomparedtotransferatscale Given: Updating1%ofentries(100,000,000)takes: 10MB/secondtransferbandwidth 10millisecondsdiskseektime 100bytesperentry(10billionentries) 10kBperpage(1billionpages) 1,000dayswithrandomB Treeupdates 100dayswithbatchedB Treeupdates 1daywithsortandmerge Logstructureddataaccessonstreamingfilesystem
13 HBaseTheHadoopDatabase Apersistentdistributedhashmap...andseparatenamespaces Tables...andanindex Rows...andlocalityofI/Oreferences Columnfamilies...andtimeranges Timestamps
14 HBaseTheHadoopDatabase Google: BigTable is a distributed storage system for managingstructureddatathatisdesignedtoscaletoa verylargesize:petabytesofdataacrossthousandsof commodityservers Goal: Store billions of rows * millions of columns * thousandsofversions An open source version of BigTable, enhanced with additionalfeaturesdevelopedbythecommunity FastfaultrecoveryviaZookeeper Querypushdownviaserversidequeryandscannerfilters Optimizationsforrealtimequeries Rollingrestarts PushmetricstologfilesorGanglia( Valuetimetolives(TTLs) AdministrativeGUIandcommandlineshell AHadoopsubproject TheusualASFthingsapply(license,JIRA,etc)
15 HBaseTheHadoopDatabase Designed,liketheHadoopplatform,forBigData To handle Big Data, we discard transactions and relationaldatamodels Nodistributedtransactions Nocomplexlocking Nowaitsordeadlocks Updatethroughsortandmergeinsteadofseekandreplace Incontrast,RDBMSsystems Distributedtransactions,complexlocking Seekandreplaceupdatestrategy Waits and deadlocks rise non linearly with transaction size andconcurrency Squareofconcurrency Thirdpoweroftransactionsize Relationalfeaturesareabandonedatscaleanyway Applicationlevelshardingasalastresortisnotasolution

16 DataModel Distributedpersistentsparsemap Multidimensionalkeys <row>,<column>:<qualifier>,<timestamp> Keysarearbitrarystrings Datagroupedbycolumns Accesstorowdataisatomic Multiversioning and timestamps avoid edit conflicts causedbyconcurrentdecoupledprocesses

17 GroupedbyColumns? Notaspreadsheet Instead,thinkoftags Valuesofanylength,nopredefinednamesorwidths
intocolumnstoretofindany matchingrow Thenscantheblocktofindvalueswith matchingqualifiers Valuesarestoredinsortedorder Optionalfilelevelcompression")
18 ColumnOrientedStores Atableconsistsofoneormore columnfamilies Columnnamesmayhaveanoptional qualifier family:qualifier Qualifiersareadditionallevelofindexing Eachfamilyinseparatestorefiles First,binarysearchoverindex(memory resident)intocolumnstoretofindany matchingrow Thenscantheblocktofindvalueswith matchingqualifiers Valuesarestoredinsortedorder Optionalfilelevelcompression (GZIP,LZO) Lexiographicallysimilarvaluesare packedadjacenttoeachotherfor goodlocalityofi/o;itisfastandcheap toscanadjacentrowsandcolumns

19 TablesAndRegions Rowsarestoredinbyte lexographicsortedorder Tablesaredynamicallysplitintoregions Regionsarehostedonanumberofregionservers As regions grow, they are split and distributed evenly amongthestorageclustertolevelload Splitsare almost instantaneous Finegrainedloadbalancing Regionsaremigratedawayfromhighly loadednodes Enablesfastrecovery Masterrapidlyredeploysregionsfrom failednodestoothers
 P:PartitionTolerance Writesarevisibletoall readersatthesametime A:Availability Brewer,2000 Strongconsistencywithfault(partition)tolerance")
20 "StrongC"(Consistency) CAPTheorem Simplifieddefinitions: C:Consistency Thesystemcanhandle thefailureofsome nodesandlossofsome messages HBase (BigTable) Youcanhaveonly2of3 BigTableisa"CP"architecture Thesystemalways returnsananswer (immediately) P:PartitionTolerance Writesarevisibletoall readersatthesametime A:Availability Brewer,2000 Strongconsistencywithfault(partition)tolerance Valuestorageiscanonical:Everyvalueappearsinoneregiononlyand eachregionisassignedtoonlyoneregionserveratatime
21 MoreonConsistency HBaseisstronglyconsistent In comparison with other "NoSQL" systems, HBase hasworkableatomicprimitives Rowlocks Atomic compareandset (CAS) and increment/decrement operators Allmutationsareatomicintherow Multiversioning and timestamps can help with applicationlayerconsistencyconcerns Every value appears in one region only, within the appropriateboundary[startkey,endkey]foritsrowkey Eachregionisassignedtoonlyoneregionserveratatime All edits are timestamped and the storage system supports storageandretrievalofmultipleversionsofavalue Applications can query for the latest version according to timestamp, time range, or most recent N versions, dependingonrequirements
22 MoreonConsistency Versionpool Asynchronousprocessesupdatetableindependently Microsecond resolution timestamps make edit conflicts unlikely UsedinconjunctionwithNTPclocksynchronization,providesglobal ordering Crosssitereplicationpreservestimestamps ApplicationcanqueryNversionsorbytimestamprangefor independentlystorededitsandmergeorresolvethem CURRENT O (O,t2) O (O,t1) O VERSION POOL (Olderversions thatmaybe useful)
23 IntegrationwithHadoop WithHDFS WithZooKeeper HBase relies on DFS replication for data durability and availability WALusesappendfeature WithoutHDFS,regionscouldnotbemigrated HBase compaction interacts faviorably with HDFS block placement Trackclustermembershipanddetectdeadservers Supports master election and recovery in multi master deployments AutomaticMasterfailover Rollingupgradesofpointreleases Modifysomeclusterconfigurationwithoutfullclusterrestart

24 IntegrationwithHadoop WithMapReduce TableInputFormat TableOutputFormat SplitscorrespondtoregionsforoptimalI/O TasksscheduledonRegionServershostingthetableregions Thisisfirstclass integrationintothe Hadoopstack Imagecredit:LarsGeorge
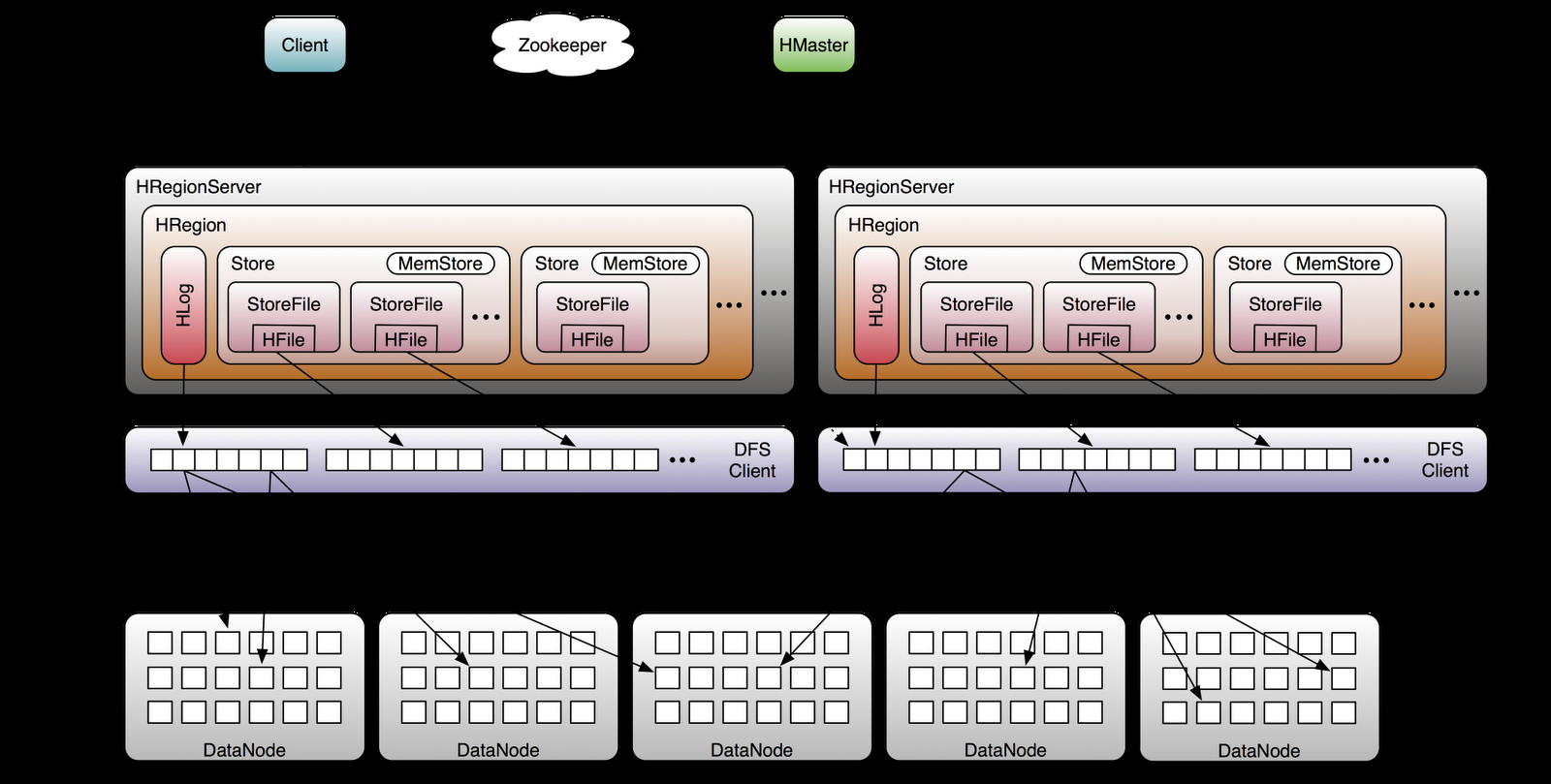
25 IntegrationwithHadoop Imagecredit:LarsGeorge

26 MoreDetail:WritePath Whenawriteoccurs Itiswrittentoawriteaheadlog Itisbufferedinmemory("memstore") Deletesarejustanotherkindofwrite,adeletemarker Periodically,thecacheiswrittentodisk,creatinganewfileineachstore forthecolumnsbeingflushed A compaction occurs when the number of files in an store exceeds a threshold:allstoresaremergesortedintoasinglenewstorefile Deletedandexpiredvaluesaregarbagecollectedduringcompactions Compactionsaredonein thebackground Periodically,thelogfile isclosedandanewone created Oldlogfilesaregarbage collected Updatingviarewritingis 100x1000xfasterthan updateviaseekand replaceatlargescale
![MoreDetail:ReadPath Whenareadoccurs Checkfordatainmemstore Lookfordatainpersisteddata,fromnewesttooldest Stopbackwardssearchforagiven{table,row,column,[timestamp]} coordinateifadeletemarkerisfound](/docs-images/30/14486661/images/27-0.png "Stop search if enough versions have been found to satisfy the search criteria Ignore expired values if TTLs are configured on the relevant column families Expired values will be garbage collected at")
27 MoreDetail:ReadPath Whenareadoccurs Checkfordatainmemstore Lookfordatainpersisteddata,fromnewesttooldest Stopbackwardssearchforagiven{table,row,column,[timestamp]} coordinateifadeletemarkerisfound Stop search if enough versions have been found to satisfy the search criteria Ignore expired values if TTLs are configured on the relevant column families Expired values will be garbage collected at next compaction, just like deletes
28 NewFeatures DataDurabilityandACIDGuarantees
29 ACIDGuarantees ACID Atomicity Consistency Isolation Durability Up to now, the ACID guarantees that HBase has providedhavenotbeenwellenumerated,butwenow haveaspecification In JavaDocin HBASE 2294 ( 2294) Many of these guarantees have always been informallyprovided Somehavebeenclarifiedforthisrelease Next: Additions to the unit test suite to continuously validatetheimplementationandtestforregressions
30 ACIDGuarantees Allmutationsareatomicwithinarow The checkandput API happens atomically like the typicalcompareandset(cas)operation The order of mutations is seen to happen in a well definedorderforeachrow,withnointerleaving All rows returned via any access API will consist of a completerowthatexistedatsomepoint Thisistrueacrosscolumnfamilies A scan is not a consistent view of a table; scans do notexhibitsnapshotisolation;instead: Anyputwilleithertotallysucceedortotallyfail APIsthatmutateseveralrowswillnotbeatomicacrossthe multiplerows Anyrowreturnedbythescanwillbeaconsistentview Ascanwillalwaysreflectaviewofthedataatleastasnew asthebeginningofthescan
31 ACIDGuarantees When a client receives a success response for any mutation, that mutation is immediately visible to both thatclientandanyotherclient Arowwillneverexhibit"time travel"properties A series of mutations moves a row sequentially through a seriesofstates Anysequenceofconcurrentreadswillreturnasubsequence Anyversionofacellthathasbeenreturnedtoaread operationisguaranteedtobedurablystored
32 DataDurability HDFS Aworkingappend This feature is critical for HBase to be able to guaranteetoclientsthatwriteshavebeenpersistedto disk(inthewriteaheadlog) Normally not a problem but there are some narrow failurecasesremaining HDFS 200 provides working append and HBase has supportforitwhichsolvestheproblem In Developed Intesting About1 2monthsaway HBase with a Hadoop release including HDFS 200 willinsurethatifastoresucceedsthedataisguaranteedto bepersisted
33 NewFeatures MultiDataCenterReplication
34 MultiDataCenterReplication Logshipping Lazy/asynchronous Updateeverywhere ConvergencewithmultiversioninginsteadofACID Use column and/or table descriptor attributes to specify the scopeofdataitemsstoredthere Supportsarbitrarytopologies:mesh,spoke and wheel,tree, pipeline,etc. RegionServersdothework Local:Donotreplicate Global:Replicateeverywhere Onlyreplicategloballyscopedcells Scopeisspecifiedasanintegertoenablemorecomplexpoliciesas theyaredevelopedinthefuture Replicationispeertopeer(cluster) In A subset of RS nominate themselves via ZK to act as endpointsforinter clusterreplication Shiplogsbetweenthemselvesinthebackground
DeleteWALoncealleditsareacked")
35 MultiDataCenterReplication 2)Sendeditstopeerclusters 3)DeleteWALoncealleditsareacked 1)CollectglobaleditsfromnewlyrolledWAL LogBackup
36 NewFeatures SecureHBase
37 SecureHBase Isolationguarantees Auditsupport,authentication,authorization NewsecurityfeaturesinHadoopfromY! AddrolebasedaccesscontrolmodeltoHBase Kerberosstrongauthentication DataisolationattheHDFSlayer SecureRPC GetHBaseworkingonthissubstratebottomup LeverageKerberostoestablishuseridentity Manageametatablethatassociatesuserswithroles ACLsontables,possiblyalsooncolumnfamilies Superuserprivilegeforadministration IntegratethisintoHBasetopdown IntegratewithHDFSlayersecurity? Meetefficientlyandeffectivelyinthemiddle
 SecureRPC AuditTrace Zookeeper")
38 SecureHBase Motiviations Multitenant cloud platforms and hosted services based (in part)onhbaseandhdfs Weneedtobeabletoreasonaboutuserisolationanddata integritycontrolsforcertification,e.g.sas 70 Isolationand Integrity DataAccessLayer HBase HDFS (HadoopDistributedFileSystem) SecureRPC AuditTrace Zookeeper
39 SecureHBase AuthenticationandAuthorization HBase Master krb(user) krb(user) blocktoken Clients (Servicefront ends) krb(user) krb(hdfs) blocktoken blocktoken HBase RegionServer HDFS NameNode HDFS DataNode Authentication Server(AS) LDAP Bootstrap DB TicketGranting Server(TGS) LDAP blocktoken KerberosKDC ClientsaccessHDFSandHBaseservicesindependently AllactionsrequiresavalidHDFSblocktokenacquiredviakrbauthenticationtoNameNode HDFSDataNodeswillnotservereadsandwritesunlessgivenvalidblocktokenforblock(s) AllRPCissecure(SASL+GSSAPI)
 HDFS HDFS DataNode MRtasks DataNode ChukwaLog4JAppender LogaggregationsolutionproposalbasedonApacheChukwa")
40 SecureHBase Audit HBase Master HBase HBase RegionServer RegionServer HDFS NameNode HDFS HDFS HDFS DataNode DataNode DataNode HDFS HDFS DataNode ZooKeeper DataNode JobTracker HDFS HDFS DataNode TaskTrackers DataNode Clients (Servicefront ends) HDFS HDFS DataNode MRtasks DataNode ChukwaLog4JAppender LogaggregationsolutionproposalbasedonApacheChukwa SubsetofplatformresourcesmustbereservedforprivateChukwa/MRcluster
41 NewFeatures Coprocessors
42 Coprocessors In0.21 AnewBigTableFeature NewSinceOSDI'06 Arbitrarycodethatrunsrunnexttoeachtabletintable As tablets split and move, coprocessor code automatically splits/movestoo High levelcallinterfaceforclients Callsaddressedtorowsorrangesofrows "Veryflexiblemodelforbuildingdistributedservices" "Automaticscaling,loadbalancing,requestrouting" ExampleCoprocessorUses Coprocessorclientlibraryresolvestoactuallocations Calls across multiple rows automatically split into multiple parallelizedrpcs ScalablemetadatamanagementforColossus Distributed language model serving for machine translation system Distributedqueryprocessingforfull textindexingsupport Regularexpressionsearchsupportforcoderepository
43 HBaseCoprocessors InspiredbyBigTableCoprocessors Genericextensionmechanism Coprocessorsareassociatedwithtablesviaatableattribute Tableattributeisapath(e.g.HDFSURI)tojarfile Jar is loaded into the regionservers when table regions are openedandnewfunctionbecomespartoftheregionserver Motiviation Currently extending HBase means HRegionServerandHRegionInterface Basic Hadoop architectural computationwithdata Resultingextensionsaremutuallyexclusive principle subclassing of colocating Computationherecanbe Calculationofaggregatesoverregiondata:count(),sum(),etc. Managementofsecondaryindices Dynamicindexing MorecomplexdatamodelslayeredonHBaseforscalability Querypushdownwitharbitrarilycomplexpredicates
44 HBaseCoprocessors RegionObserver If the coprocessor implements this interface, it will be interposedinallregionactionsviaupcalls Chainingofmultipleobservers(bypriority) Canmediate(veto)actions ManyextensionscanbebuiltontopofRegionObserver If the coprocessor implements this interface, it can receive arbitrarymethodinvocationsfromclients Combine RegionObserver and CommandTarget to extendhbaseinarbitraryways Secondaryindexes Filters Propagationconstraints? CommandTarget Enablessecuritypolicyextensions Mediatorscanbechainedaheadofobservers Mappinglayers,e.g.ORMs NativeRDFtuplestore Cloudfilesystem
45 HBaseCoprocessors MapReduce Ifthecoprocessorimplementsthisinterface,clientscancall uptoitexecuteparallelmapreduceoverthehbasecluster Runsconcurrentlyonallregionsofthetable LikeHadoopMapReduce Mappers,reducers,partitioners,intermediates UnlikeHadoopMapReduce NottableMapReduce,parallelregionMapReduce Sharedmemory Multithreaded(workerpools) Concurrencyofmappersandreducersisspecifiedseparately Scannerlikeinterfacetoretrieveresults Usesleases Forefficientimplementationofaggregatingfunctions Ajobisonlyaliveaslongasithasalease Forlongrunningjobstheclientmustperiodicallypollstatustokeepit alive;jobswithoutinterestwillbecancelled Retrievalby"scanner"willalsorenewthelease
46 WrapUp
47 ForMoreInformation HBaseWebsiteandWiki MailingList #hbaseonfreenode Committers and core contributors are here on a regular basis MoreactivethantheHadoopforums FollowHBaseonTwitter! IRCChannel
48 TheEnd Q&A Contactinfo: AndrewPurtell
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Storage of Structured Data: BigTable and HBase. New Trends In Distributed Systems MSc Software and Systems
 Storage of Structured Data: BigTable and HBase 1 HBase and BigTable HBase is Hadoop's counterpart of Google's BigTable BigTable meets the need for a highly scalable storage system for structured data Provides
Storage of Structured Data: BigTable and HBase 1 HBase and BigTable HBase is Hadoop's counterpart of Google's BigTable BigTable meets the need for a highly scalable storage system for structured data Provides
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Qsoft Inc www.qsoft-inc.com
 Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
How to Hadoop Without the Worry: Protecting Big Data at Scale
 How to Hadoop Without the Worry: Protecting Big Data at Scale SESSION ID: CDS-W06 Davi Ottenheimer Senior Director of Trust EMC Corporation @daviottenheimer Big Data Trust. Redefined Transparency Relevance
How to Hadoop Without the Worry: Protecting Big Data at Scale SESSION ID: CDS-W06 Davi Ottenheimer Senior Director of Trust EMC Corporation @daviottenheimer Big Data Trust. Redefined Transparency Relevance
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Getting Started with Hadoop. Raanan Dagan Paul Tibaldi
 Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Infomatics. Big-Data and Hadoop Developer Training with Oracle WDP
 Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
HBase A Comprehensive Introduction. James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367
 CIT 367") HBase A Comprehensive Introduction James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367 Overview Overview: History Began as project by Powerset to process massive
HBase A Comprehensive Introduction James Chin, Zikai Wang Monday, March 14, 2011 CS 227 (Topics in Database Management) CIT 367 Overview Overview: History Began as project by Powerset to process massive
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Google Bing Daytona Microsoft Research
 Google Bing Daytona Microsoft Research Raise your hand Great, you can help answer questions ;-) Sit with these people during lunch... An increased number and variety of data sources that generate large
Google Bing Daytona Microsoft Research Raise your hand Great, you can help answer questions ;-) Sit with these people during lunch... An increased number and variety of data sources that generate large
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Hadoop Scalability at Facebook. Dmytro Molkov (dms@fb.com) YaC, Moscow, September 19, 2011
 YaC, Moscow, September 19, 2011") Hadoop Scalability at Facebook Dmytro Molkov (dms@fb.com) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
Hadoop Scalability at Facebook Dmytro Molkov (dms@fb.com) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Introduction to Big data. Why Big data? Case Studies. Introduction to Hadoop. Understanding Features of Hadoop. Hadoop Architecture.
 Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Big Data Hadoop Administration and Developer Course This course is designed to understand and implement the concepts of Big data and Hadoop. This will cover right from setting up Hadoop environment in
Certified Big Data and Apache Hadoop Developer VS-1221
 Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop
 Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop Kanchan A. Khedikar Department of Computer Science & Engineering Walchand Institute of Technoloy, Solapur, Maharashtra,
Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop Kanchan A. Khedikar Department of Computer Science & Engineering Walchand Institute of Technoloy, Solapur, Maharashtra,
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Scaling Up 2 CSE 6242 / CX 4242. Duen Horng (Polo) Chau Georgia Tech. HBase, Hive
 Chau Georgia Tech. HBase, Hive") CSE 6242 / CX 4242 Scaling Up 2 HBase, Hive Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 2 HBase, Hive Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
 Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
HBase. Lecture BigData Analytics. Julian M. Kunkel. julian.kunkel@googlemail.com. University of Hamburg / German Climate Computing Center (DKRZ)
") HBase Lecture BigData Analytics Julian M. Kunkel julian.kunkel@googlemail.com University of Hamburg / German Climate Computing Center (DKRZ) 11-12-2015 Outline 1 Introduction 2 Excursion: ZooKeeper 3 Architecture
HBase Lecture BigData Analytics Julian M. Kunkel julian.kunkel@googlemail.com University of Hamburg / German Climate Computing Center (DKRZ) 11-12-2015 Outline 1 Introduction 2 Excursion: ZooKeeper 3 Architecture
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
ITG Software Engineering
 Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Introduction to Apache Hadoop Course ID: Page 1 Last Updated 12/15/2014 Introduction to Apache Hadoop Course Overview: This 5 day course introduces the student to the Hadoop architecture, file system,
Communicating with the Elephant in the Data Center
 Communicating with the Elephant in the Data Center Who am I? Instructor Consultant Opensource Advocate http://www.laubersoltions.com sml@laubersolutions.com Twitter: @laubersm Freenode: laubersm Outline
Communicating with the Elephant in the Data Center Who am I? Instructor Consultant Opensource Advocate http://www.laubersoltions.com sml@laubersolutions.com Twitter: @laubersm Freenode: laubersm Outline
MapReduce Job Processing
 April 17, 2012 Background: Hadoop Distributed File System (HDFS) Hadoop requires a Distributed File System (DFS), we utilize the Hadoop Distributed File System (HDFS). Background: Hadoop Distributed File
April 17, 2012 Background: Hadoop Distributed File System (HDFS) Hadoop requires a Distributed File System (DFS), we utilize the Hadoop Distributed File System (HDFS). Background: Hadoop Distributed File
Big Data and Scripting Systems build on top of Hadoop
 Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform interactive execution of map reduce jobs Pig is the name of the system Pig Latin is the
Big Data and Scripting Systems build on top of Hadoop 1, 2, Pig/Latin high-level map reduce programming platform interactive execution of map reduce jobs Pig is the name of the system Pig Latin is the
HDFS Federation. Sanjay Radia Founder and Architect @ Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
Lecture 2 (08/31, 09/02, 09/09): Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015
: Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015") Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН
 Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН Zettabytes Petabytes ABC Sharding A B C Id Fn Ln Addr 1 Fred Jones Liberty, NY 2 John Smith?????? 122+ NoSQL Database
Вовченко Алексей, к.т.н., с.н.с. ВМК МГУ ИПИ РАН Zettabytes Petabytes ABC Sharding A B C Id Fn Ln Addr 1 Fred Jones Liberty, NY 2 John Smith?????? 122+ NoSQL Database
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Introduction to Apache Cassandra
 Introduction to Apache Cassandra White Paper BY DATASTAX CORPORATION JULY 2013 1 Table of Contents Abstract 3 Introduction 3 Built by Necessity 3 The Architecture of Cassandra 4 Distributing and Replicating
Introduction to Apache Cassandra White Paper BY DATASTAX CORPORATION JULY 2013 1 Table of Contents Abstract 3 Introduction 3 Built by Necessity 3 The Architecture of Cassandra 4 Distributing and Replicating
BIG DATA & HADOOP DEVELOPER TRAINING & CERTIFICATION
 FACT SHEET BIG DATA & HADOOP DEVELOPER TRAINING & CERTIFICATION BIGDATA & HADOOP CLASS ROOM SESSION GreyCampus provides Classroom sessions for Big Data & Hadoop Developer Certification. This course will
FACT SHEET BIG DATA & HADOOP DEVELOPER TRAINING & CERTIFICATION BIGDATA & HADOOP CLASS ROOM SESSION GreyCampus provides Classroom sessions for Big Data & Hadoop Developer Certification. This course will
From Relational to Hadoop Part 1: Introduction to Hadoop. Gwen Shapira, Cloudera and Danil Zburivsky, Pythian
 From Relational to Hadoop Part 1: Introduction to Hadoop Gwen Shapira, Cloudera and Danil Zburivsky, Pythian Tutorial Logistics 2 Got VM? 3 Grab a USB USB contains: Cloudera QuickStart VM Slides Exercises
From Relational to Hadoop Part 1: Introduction to Hadoop Gwen Shapira, Cloudera and Danil Zburivsky, Pythian Tutorial Logistics 2 Got VM? 3 Grab a USB USB contains: Cloudera QuickStart VM Slides Exercises
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
 Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2016 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2016 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Hadoop Evolution In Organizations. Mark Vervuurt Cluster Data Science & Analytics
 In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
Hadoop 101. Lars George. NoSQL- Ma4ers, Cologne April 26, 2013
 Hadoop 101 Lars George NoSQL- Ma4ers, Cologne April 26, 2013 1 What s Ahead? Overview of Apache Hadoop (and related tools) What it is Why it s relevant How it works No prior experience needed Feel free
Hadoop 101 Lars George NoSQL- Ma4ers, Cologne April 26, 2013 1 What s Ahead? Overview of Apache Hadoop (and related tools) What it is Why it s relevant How it works No prior experience needed Feel free
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com
 REPORT Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com The content of this evaluation guide, including the ideas and concepts contained within, are the property of Splice Machine,
REPORT Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com The content of this evaluation guide, including the ideas and concepts contained within, are the property of Splice Machine,
So What s the Big Deal?
 So What s the Big Deal? Presentation Agenda Introduction What is Big Data? So What is the Big Deal? Big Data Technologies Identifying Big Data Opportunities Conducting a Big Data Proof of Concept Big Data
So What s the Big Deal? Presentation Agenda Introduction What is Big Data? So What is the Big Deal? Big Data Technologies Identifying Big Data Opportunities Conducting a Big Data Proof of Concept Big Data
Virtualizing Apache Hadoop. June, 2012
 June, 2012 Table of Contents EXECUTIVE SUMMARY... 3 INTRODUCTION... 3 VIRTUALIZING APACHE HADOOP... 4 INTRODUCTION TO VSPHERE TM... 4 USE CASES AND ADVANTAGES OF VIRTUALIZING HADOOP... 4 MYTHS ABOUT RUNNING
June, 2012 Table of Contents EXECUTIVE SUMMARY... 3 INTRODUCTION... 3 VIRTUALIZING APACHE HADOOP... 4 INTRODUCTION TO VSPHERE TM... 4 USE CASES AND ADVANTAGES OF VIRTUALIZING HADOOP... 4 MYTHS ABOUT RUNNING
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
MySQL and Hadoop. Percona Live 2014 Chris Schneider
 MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Apache Cassandra Present and Future. Jonathan Ellis
 Apache Cassandra Present and Future Jonathan Ellis History Bigtable, 2006 Dynamo, 2007 OSS, 2008 Incubator, 2009 TLP, 2010 1.0, October 2011 Why people choose Cassandra Multi-master, multi-dc Linearly
Apache Cassandra Present and Future Jonathan Ellis History Bigtable, 2006 Dynamo, 2007 OSS, 2008 Incubator, 2009 TLP, 2010 1.0, October 2011 Why people choose Cassandra Multi-master, multi-dc Linearly
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
Apache Hadoop: Past, Present, and Future
 The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) WHITE PAPER
 with the Cassandra File System (CFS) WHITE PAPER") Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) WHITE PAPER By DataStax Corporation September 2012 Contents Introduction... 3 Overview of HDFS... 4 The Benefits
Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) WHITE PAPER By DataStax Corporation September 2012 Contents Introduction... 3 Overview of HDFS... 4 The Benefits
Scaling Up HBase, Hive, Pegasus
 CSE 6242 A / CS 4803 DVA Mar 7, 2013 Scaling Up HBase, Hive, Pegasus Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 A / CS 4803 DVA Mar 7, 2013 Scaling Up HBase, Hive, Pegasus Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Introduction to Hbase Gkavresis Giorgos 1470
 Introduction to Hbase Gkavresis Giorgos 1470 Agenda What is Hbase Installation About RDBMS Overview of Hbase Why Hbase instead of RDBMS Architecture of Hbase Hbase interface Summarise What is Hbase Hbase
Introduction to Hbase Gkavresis Giorgos 1470 Agenda What is Hbase Installation About RDBMS Overview of Hbase Why Hbase instead of RDBMS Architecture of Hbase Hbase interface Summarise What is Hbase Hbase
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
HDFS Under the Hood. Sanjay Radia. Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc.
 HDFS Under the Hood Sanjay Radia Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
HDFS Under the Hood Sanjay Radia Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS)
 with the Cassandra File System (CFS)") Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) White Paper BY DATASTAX CORPORATION August 2013 1 Table of Contents Abstract 3 Introduction 3 Overview of HDFS 4
Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) White Paper BY DATASTAX CORPORATION August 2013 1 Table of Contents Abstract 3 Introduction 3 Overview of HDFS 4
Distributed storage for structured data
 Distributed storage for structured data Dennis Kafura CS5204 Operating Systems 1 Overview Goals scalability petabytes of data thousands of machines applicability to Google applications Google Analytics
Distributed storage for structured data Dennis Kafura CS5204 Operating Systems 1 Overview Goals scalability petabytes of data thousands of machines applicability to Google applications Google Analytics
Study and Comparison of Elastic Cloud Databases : Myth or Reality?
 Université Catholique de Louvain Ecole Polytechnique de Louvain Computer Engineering Department Study and Comparison of Elastic Cloud Databases : Myth or Reality? Promoters: Peter Van Roy Sabri Skhiri
Université Catholique de Louvain Ecole Polytechnique de Louvain Computer Engineering Department Study and Comparison of Elastic Cloud Databases : Myth or Reality? Promoters: Peter Van Roy Sabri Skhiri
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani
 A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
A Tour of the Zoo the Hadoop Ecosystem Prafulla Wani Technical Architect - Big Data Syntel Agenda Welcome to the Zoo! Evolution Timeline Traditional BI/DW Architecture Where Hadoop Fits In 2 Welcome to
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Integration of Apache Hive and HBase
 Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 About Me User and committer of Hadoop since 2007 Contributor to Apache Hadoop, HBase, Hive and Gora Joined
Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 About Me User and committer of Hadoop since 2007 Contributor to Apache Hadoop, HBase, Hive and Gora Joined
Ankush Cluster Manager - Hadoop2 Technology User Guide
 Ankush Cluster Manager - Hadoop2 Technology User Guide Ankush User Manual 1.5 Ankush User s Guide for Hadoop2, Version 1.5 This manual, and the accompanying software and other documentation, is protected
Ankush Cluster Manager - Hadoop2 Technology User Guide Ankush User Manual 1.5 Ankush User s Guide for Hadoop2, Version 1.5 This manual, and the accompanying software and other documentation, is protected
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
MapReduce with Apache Hadoop Analysing Big Data
 MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside gavin.heavyside@journeydynamics.com About Journey Dynamics Founded in 2006 to develop software technology to address the issues
MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside gavin.heavyside@journeydynamics.com About Journey Dynamics Founded in 2006 to develop software technology to address the issues
Big Data : Experiments with Apache Hadoop and JBoss Community projects
 Big Data : Experiments with Apache Hadoop and JBoss Community projects About the speaker Anil Saldhana is Lead Security Architect at JBoss. Founder of PicketBox and PicketLink. Interested in using Big
Big Data : Experiments with Apache Hadoop and JBoss Community projects About the speaker Anil Saldhana is Lead Security Architect at JBoss. Founder of PicketBox and PicketLink. Interested in using Big
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Big Data in a Relational World Presented by: Kerry Osborne JPMorgan Chase December, 2012
 Big Data in a Relational World Presented by: Kerry Osborne JPMorgan Chase December, 2012 whoami Never Worked for Oracle Worked with Oracle DB Since 1982 (V2) Working with Exadata since early 2010 Work
Big Data in a Relational World Presented by: Kerry Osborne JPMorgan Chase December, 2012 whoami Never Worked for Oracle Worked with Oracle DB Since 1982 (V2) Working with Exadata since early 2010 Work
HADOOP MOCK TEST HADOOP MOCK TEST I
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
A Scalable Data Transformation Framework using the Hadoop Ecosystem
 A Scalable Data Transformation Framework using the Hadoop Ecosystem Raj Nair Director Data Platform Kiru Pakkirisamy CTO AGENDA About Penton and Serendio Inc Data Processing at Penton PoC Use Case Functional
A Scalable Data Transformation Framework using the Hadoop Ecosystem Raj Nair Director Data Platform Kiru Pakkirisamy CTO AGENDA About Penton and Serendio Inc Data Processing at Penton PoC Use Case Functional
BIG DATA TECHNOLOGY. Hadoop Ecosystem
 BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
Hadoop. MPDL-Frühstück 9. Dezember 2013 MPDL INTERN
 Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Chukwa, Hadoop subproject, 37, 131 Cloud enabled big data, 4 Codd s 12 rules, 1 Column-oriented databases, 18, 52 Compression pattern, 83 84
 Index A Amazon Web Services (AWS), 50, 58 Analytics engine, 21 22 Apache Kafka, 38, 131 Apache S4, 38, 131 Apache Sqoop, 37, 131 Appliance pattern, 104 105 Application architecture, big data analytics
Index A Amazon Web Services (AWS), 50, 58 Analytics engine, 21 22 Apache Kafka, 38, 131 Apache S4, 38, 131 Apache Sqoop, 37, 131 Appliance pattern, 104 105 Application architecture, big data analytics
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Criteria to Compare Cloud Computing with Current Database Technology
 Criteria to Compare Cloud Computing with Current Database Technology Jean-Daniel Cryans, Alain April, and Alain Abran École de Technologie Supérieure, 1100 rue Notre-Dame Ouest Montréal, Québec, Canada
Criteria to Compare Cloud Computing with Current Database Technology Jean-Daniel Cryans, Alain April, and Alain Abran École de Technologie Supérieure, 1100 rue Notre-Dame Ouest Montréal, Québec, Canada
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
The Hadoop Distributed File System
 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software. 22 nd October 2013 10:00 Sesión B - DB2 LUW
 Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
Session: Big Data get familiar with Hadoop to use your unstructured data Udo Brede Dell Software 22 nd October 2013 10:00 Sesión B - DB2 LUW 1 Agenda Big Data The Technical Challenges Architecture of Hadoop
NoSQL for SQL Professionals William McKnight
 NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
Hadoop: Distributed Data Processing. Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010
 Hadoop: Distributed Data Processing Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010 Outline Scaling for Large Data Processing What is Hadoop? HDFS and MapReduce
Hadoop: Distributed Data Processing Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010 Outline Scaling for Large Data Processing What is Hadoop? HDFS and MapReduce
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM
 HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
Big Data Analytics: Hadoop-Map Reduce & NoSQL Databases
 Big Data Analytics: Hadoop-Map Reduce & NoSQL Databases Abinav Pothuganti Computer Science and Engineering, CBIT,Hyderabad, Telangana, India Abstract Today, we are surrounded by data like oxygen. The exponential
Big Data Analytics: Hadoop-Map Reduce & NoSQL Databases Abinav Pothuganti Computer Science and Engineering, CBIT,Hyderabad, Telangana, India Abstract Today, we are surrounded by data like oxygen. The exponential
There's Plenty of Room in the Cloud
 There's Plenty of Room in the Cloud [Shameless reference to Feynman s talk from 1959] Lecturer: Zoran Dimitrijevic Altiscale, Inc. Spring 2015 CS290B -- Cloud Computing 50 Years of Moore
There's Plenty of Room in the Cloud [Shameless reference to Feynman s talk from 1959] Lecturer: Zoran Dimitrijevic Altiscale, Inc. Spring 2015 CS290B -- Cloud Computing 50 Years of Moore
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind