Apache Cassandra Present and Future. Jonathan Ellis
|
|
|
- Nickolas Gray
- 10 years ago
- Views:
Transcription
1 Apache Cassandra Present and Future Jonathan Ellis

2 History Bigtable, 2006 Dynamo, 2007 OSS, 2008 Incubator, 2009 TLP, , October 2011

3 Why people choose Cassandra Multi-master, multi-dc Linearly scalable Larger-than-memory datasets High performance Full durability Integrated caching Tuneable consistency

4 Cassandra users Financial Social Media Advertising Entertainment Energy E-tail Health care Government

5 Road to 1.0 Storage engine improvements Specialized replication modes Performance and other real-world considerations Building an ecosystem

6 Compaction Size-Tiered Leveled

7 Differences in Cassandra s leveling ColumnFamily instead of key/value Multithreading (experimental) Optional throttling (16MB/s by default) Per-sstable bloom filter for row keys Larger data files (5MB by default) Does not block writes if compaction falls behind
 Does not block writes if compaction")
8 Column ( secondary ) indexing cqlsh> CREATE INDEX state_idx ON users(state); cqlsh> INSERT INTO users (uname, state, birth_date) VALUES ( bsanderson, UT, 1975) users state_idx state birth_date bsanderson UT 1975 UT bsanderson htayler prothfuss WI 1973 WI prothfuss htayler UT 1968

9 Querying cqlsh> SELECT * FROM users WHERE state='ut' AND birth_date > 1970 ORDER BY tokenize(key);

10 More sophisticated indexing? Want to: Support more operators Support user-defined ordering Support high-cardinality values But: Scatter/gather scales poorly If it s not node local, we can t guarantee atomicity If we can t guarantee atomicity, doublechecking across nodes is a huge penalty

11 Other storage engine improvements Compression Expiring columns Bounded worst-case reads by re-writing fragmented rows

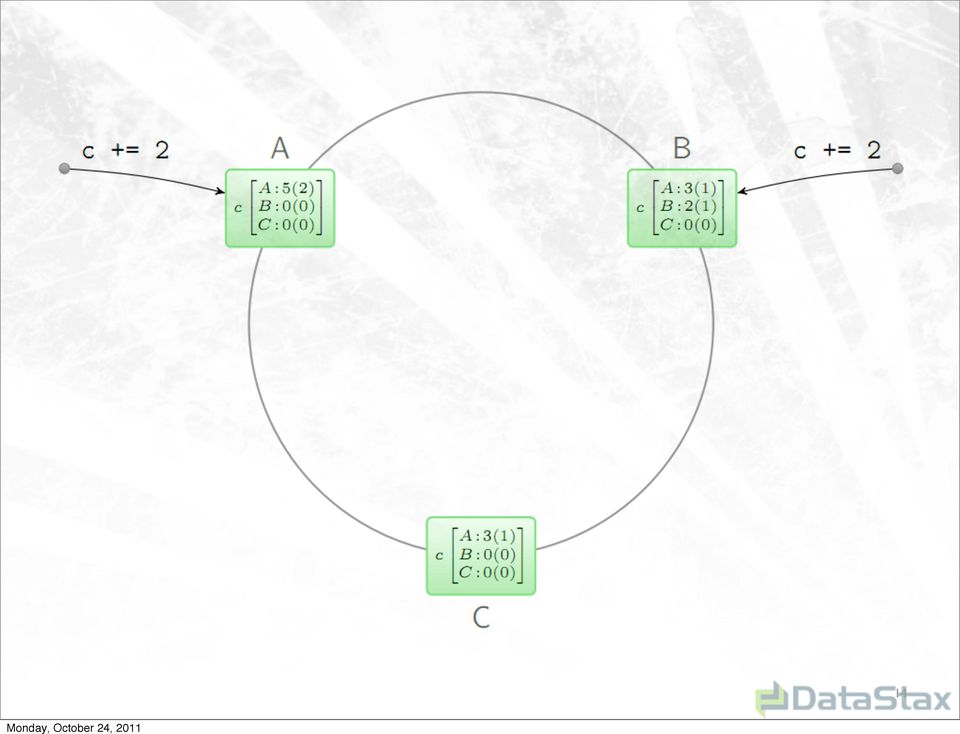
12 Eventually-consistent counters Counter is partitioned by replica; each replica is master of its own partition

13 13

14 14
15 15

16 16

17 The interesting parts Tuneable consistency Avoiding contention on local increments Store increments, not full value; merge on read + compaction Renewing counter id to deal with data loss Interaction with tombstones

18 (What about version vectors?) Version vectors allow detecting conflict, but do not give enough information to resolve it except in special cases In the counters case, we d need to hold onto all previous versions until we can be sure no new conflict with them can occur Jeff Darcy has a longer discussion at wordpress/?p=2601

19 Performance A single four-core machine; one million inserts + one million updates

20 Dealing with the JVM JNA mlockall() posix_fadvise() link() Memory Move cache off-heap In-heap arena allocation for memtables, bloom filters Move compaction to a separate process?

21 The Cassandra ecosystem Replication into Cassandra Gigaspaces Drizzle Solandra: Cassandra + Solr search DataStax Enterprise: Cassandra + Hadoop analytics
22 DataStax Enterprise
23 Operations Vanilla Hadoop 8+ services to setup, monitor, backup, and recover (NameNode, SecondaryNameNode, DataNode, JobTracker, TaskTracker, Zookeeper, Metastore,...) Single points of failure Can't separate online and offline processing DataStax Enterprise Single, simplified component Peer to peer JobTracker failover No additional cassandra config
24 What s next Ease Of Use CQL: Native transport, prepared statements Triggers Entity groups Smarter range queries enabling Hive predicate pushdown Blue sky: streaming / CEP
25 Questions? DataStax is hiring! ~15 engineers (35 employees), want to double in 2012 Austin, Burlingame, NYC, France, Japan, Belarus 100+ customers $11M Series B funding
HADOOP MOCK TEST HADOOP MOCK TEST I
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Facebook: Cassandra. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
Certified Big Data and Apache Hadoop Developer VS-1221
 Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
Introduction to Cassandra
 Introduction to Cassandra DuyHai DOAN, Technical Advocate Agenda! Architecture cluster replication Data model last write win (LWW), CQL basics (CRUD, DDL, collections, clustering column) lightweight transactions
Introduction to Cassandra DuyHai DOAN, Technical Advocate Agenda! Architecture cluster replication Data model last write win (LWW), CQL basics (CRUD, DDL, collections, clustering column) lightweight transactions
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Big Data Development CASSANDRA NoSQL Training - Workshop. March 13 to 17-2016 9 am to 5 pm HOTEL DUBAI GRAND DUBAI
 Big Data Development CASSANDRA NoSQL Training - Workshop March 13 to 17-2016 9 am to 5 pm HOTEL DUBAI GRAND DUBAI ISIDUS TECH TEAM FZE PO Box 121109 Dubai UAE, email training-coordinator@isidusnet M: +97150
Big Data Development CASSANDRA NoSQL Training - Workshop March 13 to 17-2016 9 am to 5 pm HOTEL DUBAI GRAND DUBAI ISIDUS TECH TEAM FZE PO Box 121109 Dubai UAE, email training-coordinator@isidusnet M: +97150
Apache Cassandra for Big Data Applications
 Apache Cassandra for Big Data Applications Christof Roduner COO and co-founder [email protected] Java User Group Switzerland January 7, 2014 2 AGENDA Cassandra origins and use How we use Cassandra Data
Apache Cassandra for Big Data Applications Christof Roduner COO and co-founder [email protected] Java User Group Switzerland January 7, 2014 2 AGENDA Cassandra origins and use How we use Cassandra Data
The Apache Cassandra storage engine
 The Apache Cassandra storage engine Sylvain Lebresne ([email protected]) FOSDEM 12, Brussels 1. What is Apache Cassandra 2. Data Model 3. The storage engine 1. What is Apache Cassandra 2. Data Model 3. The
The Apache Cassandra storage engine Sylvain Lebresne ([email protected]) FOSDEM 12, Brussels 1. What is Apache Cassandra 2. Data Model 3. The storage engine 1. What is Apache Cassandra 2. Data Model 3. The
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
Distributed Systems. Tutorial 12 Cassandra
 Distributed Systems Tutorial 12 Cassandra written by Alex Libov Based on FOSDEM 2010 presentation winter semester, 2013-2014 Cassandra In Greek mythology, Cassandra had the power of prophecy and the curse
Distributed Systems Tutorial 12 Cassandra written by Alex Libov Based on FOSDEM 2010 presentation winter semester, 2013-2014 Cassandra In Greek mythology, Cassandra had the power of prophecy and the curse
Practical Cassandra. Vitalii Tymchyshyn [email protected] @tivv00
 Practical Cassandra NoSQL key-value vs RDBMS why and when Cassandra architecture Cassandra data model Life without joins or HDD space is cheap today Hardware requirements & deployment hints Vitalii Tymchyshyn
Practical Cassandra NoSQL key-value vs RDBMS why and when Cassandra architecture Cassandra data model Life without joins or HDD space is cheap today Hardware requirements & deployment hints Vitalii Tymchyshyn
MapReduce with Apache Hadoop Analysing Big Data
 MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside [email protected] About Journey Dynamics Founded in 2006 to develop software technology to address the issues
MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside [email protected] About Journey Dynamics Founded in 2006 to develop software technology to address the issues
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Highly available, scalable and secure data with Cassandra and DataStax Enterprise. GOTO Berlin 27 th February 2014
 Highly available, scalable and secure data with Cassandra and DataStax Enterprise GOTO Berlin 27 th February 2014 About Us Steve van den Berg Johnny Miller Solutions Architect Regional Director Western
Highly available, scalable and secure data with Cassandra and DataStax Enterprise GOTO Berlin 27 th February 2014 About Us Steve van den Berg Johnny Miller Solutions Architect Regional Director Western
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Realtime Apache Hadoop at Facebook. Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens
 Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Qsoft Inc www.qsoft-inc.com
 Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
NETWORK TRAFFIC ANALYSIS: HADOOP PIG VS TYPICAL MAPREDUCE
 NETWORK TRAFFIC ANALYSIS: HADOOP PIG VS TYPICAL MAPREDUCE Anjali P P 1 and Binu A 2 1 Department of Information Technology, Rajagiri School of Engineering and Technology, Kochi. M G University, Kerala
NETWORK TRAFFIC ANALYSIS: HADOOP PIG VS TYPICAL MAPREDUCE Anjali P P 1 and Binu A 2 1 Department of Information Technology, Rajagiri School of Engineering and Technology, Kochi. M G University, Kerala
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming. by Dibyendu Bhattacharya
 Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Near Real Time Indexing Kafka Message to Apache Blur using Spark Streaming by Dibyendu Bhattacharya Pearson : What We Do? We are building a scalable, reliable cloud-based learning platform providing services
Cassandra. Jonathan Ellis
 Cassandra Jonathan Ellis Motivation Scaling reads to a relational database is hard Scaling writes to a relational database is virtually impossible and when you do, it usually isn't relational anymore The
Cassandra Jonathan Ellis Motivation Scaling reads to a relational database is hard Scaling writes to a relational database is virtually impossible and when you do, it usually isn't relational anymore The
Hadoop Scalability at Facebook. Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011
 YaC, Moscow, September 19, 2011") Hadoop Scalability at Facebook Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
Hadoop Scalability at Facebook Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
HadoopRDF : A Scalable RDF Data Analysis System
 HadoopRDF : A Scalable RDF Data Analysis System Yuan Tian 1, Jinhang DU 1, Haofen Wang 1, Yuan Ni 2, and Yong Yu 1 1 Shanghai Jiao Tong University, Shanghai, China {tian,dujh,whfcarter}@apex.sjtu.edu.cn
HadoopRDF : A Scalable RDF Data Analysis System Yuan Tian 1, Jinhang DU 1, Haofen Wang 1, Yuan Ni 2, and Yong Yu 1 1 Shanghai Jiao Tong University, Shanghai, China {tian,dujh,whfcarter}@apex.sjtu.edu.cn
Big Data : Experiments with Apache Hadoop and JBoss Community projects
 Big Data : Experiments with Apache Hadoop and JBoss Community projects About the speaker Anil Saldhana is Lead Security Architect at JBoss. Founder of PicketBox and PicketLink. Interested in using Big
Big Data : Experiments with Apache Hadoop and JBoss Community projects About the speaker Anil Saldhana is Lead Security Architect at JBoss. Founder of PicketBox and PicketLink. Interested in using Big
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon [email protected] [email protected] XLDB
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon [email protected] [email protected] XLDB
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems
 Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Where is Hadoop Going Next?
 Where is Hadoop Going Next? Owen O Malley [email protected] @owen_omalley November 2014 Page 1 Who am I? Worked at Yahoo Seach Webmap in a Week Dreadnaught to Juggernaut to Hadoop MapReduce Security
Where is Hadoop Going Next? Owen O Malley [email protected] @owen_omalley November 2014 Page 1 Who am I? Worked at Yahoo Seach Webmap in a Week Dreadnaught to Juggernaut to Hadoop MapReduce Security
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
HBase Schema Design. NoSQL Ma4ers, Cologne, April 2013. Lars George Director EMEA Services
 HBase Schema Design NoSQL Ma4ers, Cologne, April 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera ConsulFng on Hadoop projects (everywhere) Apache Commi4er HBase and Whirr
HBase Schema Design NoSQL Ma4ers, Cologne, April 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera ConsulFng on Hadoop projects (everywhere) Apache Commi4er HBase and Whirr
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Apache Cassandra Query Language (CQL)
") REFERENCE GUIDE - P.1 ALTER KEYSPACE ALTER TABLE ALTER TYPE ALTER USER ALTER ( KEYSPACE SCHEMA ) keyspace_name WITH REPLICATION = map ( WITH DURABLE_WRITES = ( true false )) AND ( DURABLE_WRITES = ( true
REFERENCE GUIDE - P.1 ALTER KEYSPACE ALTER TABLE ALTER TYPE ALTER USER ALTER ( KEYSPACE SCHEMA ) keyspace_name WITH REPLICATION = map ( WITH DURABLE_WRITES = ( true false )) AND ( DURABLE_WRITES = ( true
BIG DATA HADOOP TRAINING
 BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
LARGE-SCALE DATA STORAGE APPLICATIONS
 BENCHMARKING AVAILABILITY AND FAILOVER PERFORMANCE OF LARGE-SCALE DATA STORAGE APPLICATIONS Wei Sun and Alexander Pokluda December 2, 2013 Outline Goal and Motivation Overview of Cassandra and Voldemort
BENCHMARKING AVAILABILITY AND FAILOVER PERFORMANCE OF LARGE-SCALE DATA STORAGE APPLICATIONS Wei Sun and Alexander Pokluda December 2, 2013 Outline Goal and Motivation Overview of Cassandra and Voldemort
HDB++: HIGH AVAILABILITY WITH. l TANGO Meeting l 20 May 2015 l Reynald Bourtembourg
 HDB++: HIGH AVAILABILITY WITH Page 1 OVERVIEW What is Cassandra (C*)? Who is using C*? CQL C* architecture Request Coordination Consistency Monitoring tool HDB++ Page 2 OVERVIEW What is Cassandra (C*)?
HDB++: HIGH AVAILABILITY WITH Page 1 OVERVIEW What is Cassandra (C*)? Who is using C*? CQL C* architecture Request Coordination Consistency Monitoring tool HDB++ Page 2 OVERVIEW What is Cassandra (C*)?
Ankush Cluster Manager - Hadoop2 Technology User Guide
 Ankush Cluster Manager - Hadoop2 Technology User Guide Ankush User Manual 1.5 Ankush User s Guide for Hadoop2, Version 1.5 This manual, and the accompanying software and other documentation, is protected
Ankush Cluster Manager - Hadoop2 Technology User Guide Ankush User Manual 1.5 Ankush User s Guide for Hadoop2, Version 1.5 This manual, and the accompanying software and other documentation, is protected
Hadoop Evolution In Organizations. Mark Vervuurt Cluster Data Science & Analytics
 In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
No-SQL Databases for High Volume Data
 Target Conference 2014 No-SQL Databases for High Volume Data Edward Wijnen 3 November 2014 The New Connected World Needs a Revolutionary New DBMS Today The Internet of Things 1990 s Mobile 1970 s Mainfram
Target Conference 2014 No-SQL Databases for High Volume Data Edward Wijnen 3 November 2014 The New Connected World Needs a Revolutionary New DBMS Today The Internet of Things 1990 s Mobile 1970 s Mainfram
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Non-Stop for Apache HBase: Active-active region server clusters TECHNICAL BRIEF
 Non-Stop for Apache HBase: -active region server clusters TECHNICAL BRIEF Technical Brief: -active region server clusters -active region server clusters HBase is a non-relational database that provides
Non-Stop for Apache HBase: -active region server clusters TECHNICAL BRIEF Technical Brief: -active region server clusters -active region server clusters HBase is a non-relational database that provides
Real-Time Big Data in practice with Cassandra. Michaël Figuière @mfiguiere
 Real-Time Big Data in practice with Cassandra Michaël Figuière @mfiguiere Speaker Michaël Figuière @mfiguiere 2 Ring Architecture Cassandra 3 Ring Architecture Replica Replica Replica 4 Linear Scalability
Real-Time Big Data in practice with Cassandra Michaël Figuière @mfiguiere Speaker Michaël Figuière @mfiguiere 2 Ring Architecture Cassandra 3 Ring Architecture Replica Replica Replica 4 Linear Scalability
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Introduction to Apache Cassandra
 Introduction to Apache Cassandra White Paper BY DATASTAX CORPORATION JULY 2013 1 Table of Contents Abstract 3 Introduction 3 Built by Necessity 3 The Architecture of Cassandra 4 Distributing and Replicating
Introduction to Apache Cassandra White Paper BY DATASTAX CORPORATION JULY 2013 1 Table of Contents Abstract 3 Introduction 3 Built by Necessity 3 The Architecture of Cassandra 4 Distributing and Replicating
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS)
 with the Cassandra File System (CFS)") Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) White Paper BY DATASTAX CORPORATION August 2013 1 Table of Contents Abstract 3 Introduction 3 Overview of HDFS 4
Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) White Paper BY DATASTAX CORPORATION August 2013 1 Table of Contents Abstract 3 Introduction 3 Overview of HDFS 4
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
CitusDB Architecture for Real-Time Big Data
 CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
low-level storage structures e.g. partitions underpinning the warehouse logical table structures
 DATA WAREHOUSE PHYSICAL DESIGN The physical design of a data warehouse specifies the: low-level storage structures e.g. partitions underpinning the warehouse logical table structures low-level structures
DATA WAREHOUSE PHYSICAL DESIGN The physical design of a data warehouse specifies the: low-level storage structures e.g. partitions underpinning the warehouse logical table structures low-level structures
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam [email protected]
 Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam [email protected] Agenda The rise of Big Data & Hadoop MySQL in the Big Data Lifecycle MySQL Solutions for Big Data Q&A
Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam [email protected] Agenda The rise of Big Data & Hadoop MySQL in the Big Data Lifecycle MySQL Solutions for Big Data Q&A
Hadoop and its Usage at Facebook. Dhruba Borthakur [email protected], June 22 rd, 2009
 Hadoop and its Usage at Facebook Dhruba Borthakur [email protected], June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Hadoop and its Usage at Facebook Dhruba Borthakur [email protected], June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Big Table A Distributed Storage System For Data
 Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) WHITE PAPER
 with the Cassandra File System (CFS) WHITE PAPER") Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) WHITE PAPER By DataStax Corporation September 2012 Contents Introduction... 3 Overview of HDFS... 4 The Benefits
Comparing the Hadoop Distributed File System (HDFS) with the Cassandra File System (CFS) WHITE PAPER By DataStax Corporation September 2012 Contents Introduction... 3 Overview of HDFS... 4 The Benefits
So What s the Big Deal?
 So What s the Big Deal? Presentation Agenda Introduction What is Big Data? So What is the Big Deal? Big Data Technologies Identifying Big Data Opportunities Conducting a Big Data Proof of Concept Big Data
So What s the Big Deal? Presentation Agenda Introduction What is Big Data? So What is the Big Deal? Big Data Technologies Identifying Big Data Opportunities Conducting a Big Data Proof of Concept Big Data
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Getting Started with Hadoop. Raanan Dagan Paul Tibaldi
 Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Getting Started with Hadoop Raanan Dagan Paul Tibaldi What is Apache Hadoop? Hadoop is a platform for data storage and processing that is Scalable Fault tolerant Open source CORE HADOOP COMPONENTS Hadoop
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan [email protected] Abstract Every day, we create 2.5 quintillion
Hypertable Architecture Overview
 WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
Study and Comparison of Elastic Cloud Databases : Myth or Reality?
 Université Catholique de Louvain Ecole Polytechnique de Louvain Computer Engineering Department Study and Comparison of Elastic Cloud Databases : Myth or Reality? Promoters: Peter Van Roy Sabri Skhiri
Université Catholique de Louvain Ecole Polytechnique de Louvain Computer Engineering Department Study and Comparison of Elastic Cloud Databases : Myth or Reality? Promoters: Peter Van Roy Sabri Skhiri
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1
 How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
How to Install and Configure EBF15328 for MapR 4.0.1 or 4.0.2 with MapReduce v1 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
DataStax Enterprise Reference Architecture
 DataStax Enterprise Reference Architecture DataStax Enterprise Reference Architecture 7.8.15 1 Table of Contents ABSTRACT... 3 INTRODUCTION... 3 DATASTAX ENTERPRISE... 3 ARCHITECTURE... 3 OPSCENTER: EASY-
DataStax Enterprise Reference Architecture DataStax Enterprise Reference Architecture 7.8.15 1 Table of Contents ABSTRACT... 3 INTRODUCTION... 3 DATASTAX ENTERPRISE... 3 ARCHITECTURE... 3 OPSCENTER: EASY-
NOSQL DATABASES AND CASSANDRA
 NOSQL DATABASES AND CASSANDRA Semester Project: Advanced Databases DECEMBER 14, 2015 WANG CAN, EVABRIGHT BERTHA Université Libre de Bruxelles 0 Preface The goal of this report is to introduce the new evolving
NOSQL DATABASES AND CASSANDRA Semester Project: Advanced Databases DECEMBER 14, 2015 WANG CAN, EVABRIGHT BERTHA Université Libre de Bruxelles 0 Preface The goal of this report is to introduce the new evolving
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
The Hadoop Eco System Shanghai Data Science Meetup
 The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
HDFS Users Guide. Table of contents
 Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Lecture 2 (08/31, 09/02, 09/09): Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015
: Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015") Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop