The Hadoop Distributed File System
|
|
|
- Erika Cobb
- 10 years ago
- Views:
Transcription
1 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Presenter: Alex Hu

2 HDFS Introduction Architecture File I/O Operations and Replica Management Practice at YAHOO! Future Work Critiques and Discussion

3 Introduction and Related Work What is Hadoop? Provide a distributed file system and a framework Analysis and transformation of very large data set MapReduce

4 Introduction (cont.) What is Hadoop Distributed File System (HDFS)? File system component of Hadoop Store metadata on a dedicated server NameNode Store application data on other servers DataNode TCP-based protocols Replication for reliability Multiply data transfer bandwidth for durability

5 Architecture NameNode DataNodes HDFS Client Image Journal CheckpointNode BackupNode Upgrade, File System Snapshots

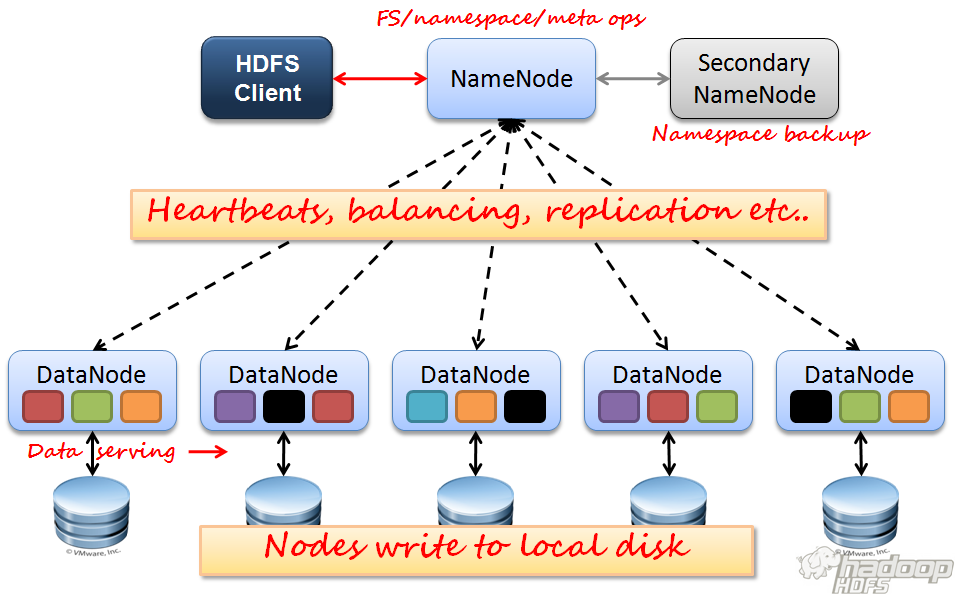
6 Architecture Overview

7 NameNode one per cluster Maintain The HDFS namespace, a hierarchy of files and directories represented by inodes Maintain the mapping of file blocks to DataNodes Read: ask NameNode for the location Write: ask NameNode to nominate DataNodes Image and Journal Checkpoint: native files store persistent record of images (no location)

8 DataNodes Two files to represent a block replica on DN The data itself length flexible Checksums and generation stamp Handshake when connect to the NameNode Verify namespace ID and software version New DN can get one namespace ID when join Register with NameNode Storage ID is assigned and never changes Storage ID is a unique internal identifier

9 DataNodes (cont.) - control Block report: identify block replicas Block ID, the generation stamp, and the length Send first when register and then send per hour Heartbeats: message to indicate availability Default interval is three seconds DN is considered dead if not received in 10 mins Contains Information for space allocation and load balancing Storage capacity Fraction of storage in use Number of data transfers currently in progress NN replies with instructions to the DN Keep frequent. Scalability

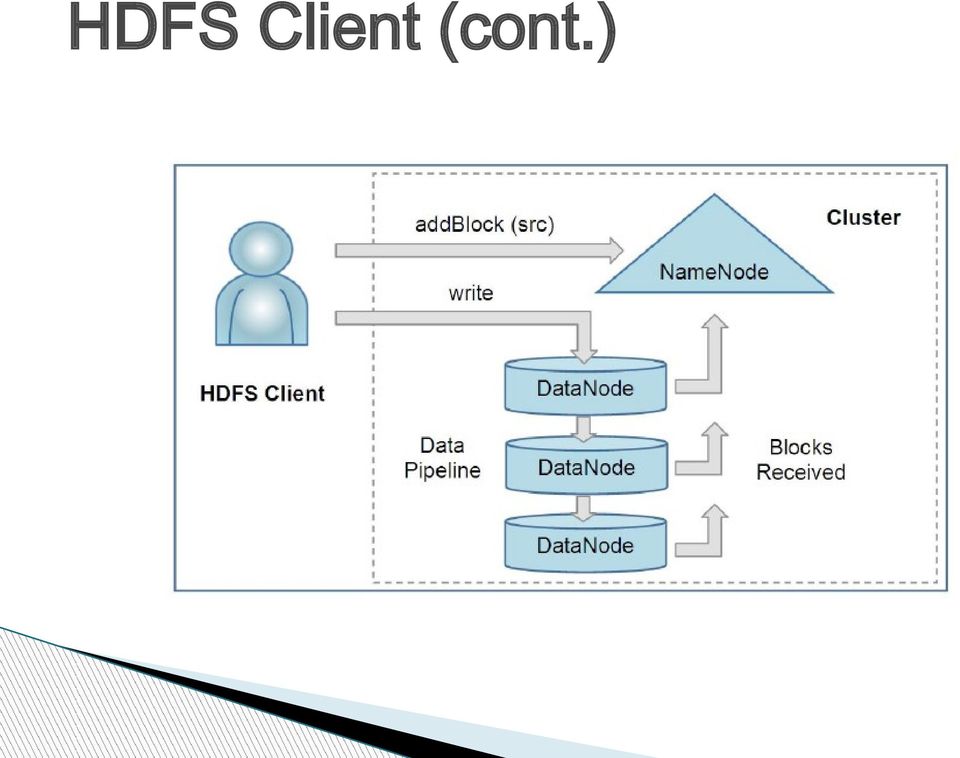
10 HDFS Client A code library exports HDFS interface Read a file Ask for a list of DN host replicas of the blocks Contact a DN directly and request transfer Write a file Ask NN to choose DNs to host replicas of the first block of the file Organize a pipeline and send the data Iteration Delete a file and create/delete directory Various APIs Schedule tasks to where the data are located Set replication factor (number of replicas)

11 HDFS Client (cont.)
12 Image and Journal Image: metadata describe organization Persistent record is called checkpoint Checkpoint is never changed, and can be replaced Journal: log for persistence changes Flushed and synched before change is committed Store in multiple places to prevent missing NN shut down if no place is available Bottleneck: threads wait for flush-and-sync Solution: batch

13 CheckpointNode CheckpointNode is NameNode Runs on different host Create new checkpoint Download current checkpoint and journal Merge Create new and return to NameNode NameNode truncate the tail of the journal Challenge: large journal makes restart slow Solution: create a daily checkpoint

14 BackupNode Recent feature Similar to CheckpointNode Maintain an in memory, up-to-date image Create checkpoint without downloading Journal store Read-only NameNode All metadata information except block locations No modification

15 Upgrades, File System and Snapshots Minimize damage to data during upgrade Only one can exist NameNode Merge current checkpoint and journal in memory Create new checkpoint and journal in a new place Instruct DataNodes to create a local snapshot DataNode Create a copy of storage directory Hard link existing block files

16 Upgrades, File System and Snapshots Rollback NameNode recovers the checkpoint DataNode resotres directory and delete replicas after snapshot is created The layout version stored on both NN and DN Identify the data representation formats Prevent inconsistent format Snapshot creation is all-cluster effort Prevent data loss

17 File I/O Operations and Replica Management File Read and Write Block Placement and Replication management Other features

18 File Read and Write Checksum Read by the HDFS client to detect any corruption DataNode store checksum in a separate place Ship to client when perform HDFS read Clients verify checksum Choose the closet replica to read Read fail due to Unavailable DataNode A replica of the block is no longer hosted Replica is corrupted Read while writing: ask for the latest length

19 File Read and Write (cont.) New data can only be appended Single-writer, multiple-reader Lease Who open a file for writing is granted a lease Renewed by heartbeats and revoked when closed Soft limit and hard limit Many readers are allowed to read Optimized for sequential reads and writes Can be improved Scribe: provide real-time data streaming Hbase: provide random, real-time access to large tables

20 Add Block and The hflush Unique block ID Perform write operation new change is not guaranteed to be visible The hflush hflush

21 Block Replacement Not practical to connect all nodes Spread across multiple racks Communication has to go through multiple switches Inter-rack and intra-rack Shorter distance, greater bandwidth NameNode decides the rack of a DataNode Configure script
22 Replica Replacement Policy Improve data reliability, availability and network bandwidth utilization Minimize write cost Reduce inter-rack and inter-node write Rule1: No Datanode contains more than one replica of any block Rule2: No rack contains more than two replicas of the same block, provided there are sufficient racks on the cluster
23 Replication management Detected by NameNode Under-replicated Priority queue (node with one replica has the highest) Similar to replication replacement policy Over-replicated Remove the old replica Not reduce the number of racks
24 Other features Balancer Balance disk space usage Bandwidth consuming control Block Scanner Verification of the replica Corrupted replica is not deleted immediately Decommissioning Include and exclude lists Re-evaluate lists Remove decommissioning DataNode only if all blocks on it are replicated Inter-Cluster Data Copy DistCp MapReduce job
25 Practice At Yahoo! 3500 nodes and 9.8PB of storage available Durability of Data Uncorrelated node failures Chance of losing a block during one year: <.5% Chance of node fail each month:.8% Correlated node failures Failure of rack or switch Loss of electrical power Caring for the commons Permissions modeled on UNIX Total space available

26 Benchmarks DFSIO benchmark DFSIO Read: 66MB/s per node DFISO Write: 40MB/s per node Production cluster Busy Cluster Read: 1.02MB/s per node Busy Cluster Write: 1.09MB/s per node Sort benchmark Operation Benchmark
27 Future Work Automated failover solution Zookeeper Scalability Multiple namespaces to share physical storage Advantage Isolate namespaces Improve overall availability Generalizes the block storage abstraction Drawback Cost of management Job-centric namespaces rather than cluster centric
28 Critiques and Discussion Pros Architecture: NameNode, DataNode, and powerful features to provide kinds of operations, detect corrupted replica, balance disk space usage and provide consistency. HDFS is easy to use: users don t have to worry about different servers. It can be used as local file system to provide various operations Benchmarks are sufficient. They use real data with large number of nodes and storage to provide kinds of experiments. Cons Fault tolerance is not very sophisticated. All the recoveries introduced are based on the assumption that NameNode is alive. No proper solution currently in this paper handles the failure of NameNode Scalability, especially the handling of replying heartbeats with instructions. If there are too many messages come in, the performance of NameNode is not proper measured in this paper The test of correlated failure is not provided. We can t get any information of the performance of HDFS after correlated failure is encountered.
29 Thank you very much
The Hadoop Distributed File System
 The Hadoop Distributed File System The Hadoop Distributed File System, Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, Yahoo, 2010 Agenda Topic 1: Introduction Topic 2: Architecture
The Hadoop Distributed File System The Hadoop Distributed File System, Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler, Yahoo, 2010 Agenda Topic 1: Introduction Topic 2: Architecture
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
The Hadoop Distributed File System
 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Abstract The Hadoop
The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Abstract The Hadoop
Distributed File Systems
 Distributed File Systems Alemnew Sheferaw Asrese University of Trento - Italy December 12, 2012 Acknowledgement: Mauro Fruet Alemnew S. Asrese (UniTN) Distributed File Systems 2012/12/12 1 / 55 Outline
Distributed File Systems Alemnew Sheferaw Asrese University of Trento - Italy December 12, 2012 Acknowledgement: Mauro Fruet Alemnew S. Asrese (UniTN) Distributed File Systems 2012/12/12 1 / 55 Outline
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,[email protected]
PERFORMANCE ANALYSIS OF A DISTRIBUTED FILE SYSTEM
 PERFORMANCE ANALYSIS OF A DISTRIBUTED FILE SYSTEM SUBMITTED BY DIBYENDU KARMAKAR EXAMINATION ROLL NUMBER: M4SWE13-07 REGISTRATION NUMBER: 117079 of 2011-2012 A THESIS SUBMITTED TO THE FACULTY OF ENGINEERING
PERFORMANCE ANALYSIS OF A DISTRIBUTED FILE SYSTEM SUBMITTED BY DIBYENDU KARMAKAR EXAMINATION ROLL NUMBER: M4SWE13-07 REGISTRATION NUMBER: 117079 of 2011-2012 A THESIS SUBMITTED TO THE FACULTY OF ENGINEERING
Distributed File Systems
 Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
HDFS Users Guide. Table of contents
 Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
HDFS Design Principles
 HDFS Design Principles The Scale-out-Ability of Distributed Storage SVForum Software Architecture & Platform SIG Konstantin V. Shvachko May 23, 2012 Big Data Computations that need the power of many computers
HDFS Design Principles The Scale-out-Ability of Distributed Storage SVForum Software Architecture & Platform SIG Konstantin V. Shvachko May 23, 2012 Big Data Computations that need the power of many computers
HDFS Under the Hood. Sanjay Radia. [email protected] Grid Computing, Hadoop Yahoo Inc.
 HDFS Under the Hood Sanjay Radia [email protected] Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
HDFS Under the Hood Sanjay Radia [email protected] Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
Hadoop Distributed File System. Dhruba Borthakur June, 2007
 Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Hadoop Distributed File System. Jordan Prosch, Matt Kipps
 Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
Hadoop Scalability at Facebook. Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011
 YaC, Moscow, September 19, 2011") Hadoop Scalability at Facebook Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
Hadoop Scalability at Facebook Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
Hadoop Distributed FileSystem on Cloud
 Hadoop Distributed FileSystem on Cloud Giannis Kitsos, Antonis Papaioannou and Nikos Tsikoudis Department of Computer Science University of Crete {kitsos, papaioan, tsikudis}@csd.uoc.gr Abstract. The growing
Hadoop Distributed FileSystem on Cloud Giannis Kitsos, Antonis Papaioannou and Nikos Tsikoudis Department of Computer Science University of Crete {kitsos, papaioan, tsikudis}@csd.uoc.gr Abstract. The growing
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
IJFEAT INTERNATIONAL JOURNAL FOR ENGINEERING APPLICATIONS AND TECHNOLOGY
 IJFEAT INTERNATIONAL JOURNAL FOR ENGINEERING APPLICATIONS AND TECHNOLOGY Hadoop Distributed File System: What and Why? Ashwini Dhruva Nikam, Computer Science & Engineering, J.D.I.E.T., Yavatmal. Maharashtra,
IJFEAT INTERNATIONAL JOURNAL FOR ENGINEERING APPLICATIONS AND TECHNOLOGY Hadoop Distributed File System: What and Why? Ashwini Dhruva Nikam, Computer Science & Engineering, J.D.I.E.T., Yavatmal. Maharashtra,
Distributed File Systems
 Distributed File Systems Paul Krzyzanowski Rutgers University October 28, 2012 1 Introduction The classic network file systems we examined, NFS, CIFS, AFS, Coda, were designed as client-server applications.
Distributed File Systems Paul Krzyzanowski Rutgers University October 28, 2012 1 Introduction The classic network file systems we examined, NFS, CIFS, AFS, Coda, were designed as client-server applications.
HDFS Reliability. Tom White, Cloudera, 12 January 2008
 HDFS Reliability Tom White, Cloudera, 12 January 2008 The Hadoop Distributed Filesystem (HDFS) is a distributed storage system for reliably storing petabytes of data on clusters of commodity hardware.
HDFS Reliability Tom White, Cloudera, 12 January 2008 The Hadoop Distributed Filesystem (HDFS) is a distributed storage system for reliably storing petabytes of data on clusters of commodity hardware.
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Big Data Technology Core Hadoop: HDFS-YARN Internals
 Big Data Technology Core Hadoop: HDFS-YARN Internals Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class Map-Reduce Motivation This class
Big Data Technology Core Hadoop: HDFS-YARN Internals Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class Map-Reduce Motivation This class
HADOOP MOCK TEST HADOOP MOCK TEST I
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
HDFS Federation. Sanjay Radia Founder and Architect @ Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
HDFS: Hadoop Distributed File System
 Istanbul Şehir University Big Data Camp 14 HDFS: Hadoop Distributed File System Aslan Bakirov Kevser Nur Çoğalmış Agenda Distributed File System HDFS Concepts HDFS Interfaces HDFS Full Picture Read Operation
Istanbul Şehir University Big Data Camp 14 HDFS: Hadoop Distributed File System Aslan Bakirov Kevser Nur Çoğalmış Agenda Distributed File System HDFS Concepts HDFS Interfaces HDFS Full Picture Read Operation
Highly Available Hadoop Name Node Architecture-Using Replicas of Name Node with Time Synchronization among Replicas
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 3, Ver. II (May-Jun. 2014), PP 58-62 Highly Available Hadoop Name Node Architecture-Using Replicas
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 3, Ver. II (May-Jun. 2014), PP 58-62 Highly Available Hadoop Name Node Architecture-Using Replicas
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
BookKeeper. Flavio Junqueira Yahoo! Research, Barcelona. Hadoop in China 2011
 BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
Master Thesis. Evaluating Performance of Hadoop Distributed File System
 MSc in Computer Science Master Thesis Evaluating Performance of Hadoop Distributed File System Supervisor Dott. Andrea Marin Author Luca Lorenzetto Student ID 840310 Ca Foscari Dorsoduro 3246 30123 Venezia
MSc in Computer Science Master Thesis Evaluating Performance of Hadoop Distributed File System Supervisor Dott. Andrea Marin Author Luca Lorenzetto Student ID 840310 Ca Foscari Dorsoduro 3246 30123 Venezia
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Processing of Hadoop using Highly Available NameNode
 Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
Sunita Suralkar, Ashwini Mujumdar, Gayatri Masiwal, Manasi Kulkarni Department of Computer Technology, Veermata Jijabai Technological Institute
 Review of Distributed File Systems: Case Studies Sunita Suralkar, Ashwini Mujumdar, Gayatri Masiwal, Manasi Kulkarni Department of Computer Technology, Veermata Jijabai Technological Institute Abstract
Review of Distributed File Systems: Case Studies Sunita Suralkar, Ashwini Mujumdar, Gayatri Masiwal, Manasi Kulkarni Department of Computer Technology, Veermata Jijabai Technological Institute Abstract
LOCATION-AWARE REPLICATION IN VIRTUAL HADOOP ENVIRONMENT. A Thesis by. UdayKiran RajuladeviKasi. Bachelor of Technology, JNTU, 2008
 LOCATION-AWARE REPLICATION IN VIRTUAL HADOOP ENVIRONMENT A Thesis by UdayKiran RajuladeviKasi Bachelor of Technology, JNTU, 2008 Submitted to Department of Electrical Engineering and Computer Science and
LOCATION-AWARE REPLICATION IN VIRTUAL HADOOP ENVIRONMENT A Thesis by UdayKiran RajuladeviKasi Bachelor of Technology, JNTU, 2008 Submitted to Department of Electrical Engineering and Computer Science and
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop: Embracing future hardware
 Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Sector vs. Hadoop. A Brief Comparison Between the Two Systems
 Sector vs. Hadoop A Brief Comparison Between the Two Systems Background Sector is a relatively new system that is broadly comparable to Hadoop, and people want to know what are the differences. Is Sector
Sector vs. Hadoop A Brief Comparison Between the Two Systems Background Sector is a relatively new system that is broadly comparable to Hadoop, and people want to know what are the differences. Is Sector
HADOOP MOCK TEST HADOOP MOCK TEST
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science [email protected] April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
CDH AND BUSINESS CONTINUITY:
 WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
WHITE PAPER CDH AND BUSINESS CONTINUITY: An overview of the availability, data protection and disaster recovery features in Hadoop Abstract Using the sophisticated built-in capabilities of CDH for tunable
Lecture 2 (08/31, 09/02, 09/09): Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015
: Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015") Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Apache Hadoop FileSystem Internals
 Apache Hadoop FileSystem Internals Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Storage Developer Conference, San Jose September 22, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem Internals Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Storage Developer Conference, San Jose September 22, 2010 http://www.facebook.com/hadoopfs
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ. Cloudera World Japan November 2014
 Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ Cloudera World Japan November 2014 WANdisco Background WANdisco: Wide Area Network Distributed Computing Enterprise ready, high availability
Non-Stop Hadoop Paul Scott-Murphy VP Field Techincal Service, APJ Cloudera World Japan November 2014 WANdisco Background WANdisco: Wide Area Network Distributed Computing Enterprise ready, high availability
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer [email protected] Alejandro Bonilla / Sales Engineer [email protected] 2 Hadoop Core Components 3 Typical Hadoop Distribution
A Survey of Distributed Database Management Systems
 Brady Kyle CSC-557 4-27-14 A Survey of Distributed Database Management Systems Big data has been described as having some or all of the following characteristics: high velocity, heterogeneous structure,
Brady Kyle CSC-557 4-27-14 A Survey of Distributed Database Management Systems Big data has been described as having some or all of the following characteristics: high velocity, heterogeneous structure,
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Detailed Outline of Hadoop. Brian Bockelman
 Detailed Outline of Hadoop Brian Bockelman Outline of Hadoop Before we dive in to an installation, I wanted to survey the landscape. HDFS Core Services Grid services HDFS Aux Services Putting it all together
Detailed Outline of Hadoop Brian Bockelman Outline of Hadoop Before we dive in to an installation, I wanted to survey the landscape. HDFS Core Services Grid services HDFS Aux Services Putting it all together
Storage Architectures for Big Data in the Cloud
 Storage Architectures for Big Data in the Cloud Sam Fineberg HP Storage CT Office/ May 2013 Overview Introduction What is big data? Big Data I/O Hadoop/HDFS SAN Distributed FS Cloud Summary Research Areas
Storage Architectures for Big Data in the Cloud Sam Fineberg HP Storage CT Office/ May 2013 Overview Introduction What is big data? Big Data I/O Hadoop/HDFS SAN Distributed FS Cloud Summary Research Areas
Hadoop Distributed File System (HDFS) Overview
 Overview") 2012 coreservlets.com and Dima May Hadoop Distributed File System (HDFS) Overview Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized
2012 coreservlets.com and Dima May Hadoop Distributed File System (HDFS) Overview Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized
Data Management in the Cloud
 Data Management in the Cloud Ryan Stern [email protected] : Advanced Topics in Distributed Systems Department of Computer Science Colorado State University Outline Today Microsoft Cloud SQL Server
Data Management in the Cloud Ryan Stern [email protected] : Advanced Topics in Distributed Systems Department of Computer Science Colorado State University Outline Today Microsoft Cloud SQL Server
Sujee Maniyam, ElephantScale
 Hadoop PRESENTATION 2 : New TITLE and GOES Noteworthy HERE Sujee Maniyam, ElephantScale SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member
Hadoop PRESENTATION 2 : New TITLE and GOES Noteworthy HERE Sujee Maniyam, ElephantScale SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member
The Google File System
 The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop
 Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop Kanchan A. Khedikar Department of Computer Science & Engineering Walchand Institute of Technoloy, Solapur, Maharashtra,
Role of Cloud Computing in Big Data Analytics Using MapReduce Component of Hadoop Kanchan A. Khedikar Department of Computer Science & Engineering Walchand Institute of Technoloy, Solapur, Maharashtra,
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Snapshots in Hadoop Distributed File System
 Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai [email protected] MapReduce is a parallel programming model
5 HDFS - Hadoop Distributed System
 5 HDFS - Hadoop Distributed System 5.1 Definition and Remarks HDFS is a file system designed for storing very large files with streaming data access patterns running on clusters of commoditive hardware.
5 HDFS - Hadoop Distributed System 5.1 Definition and Remarks HDFS is a file system designed for storing very large files with streaming data access patterns running on clusters of commoditive hardware.
Data Availability and Durability with the Hadoop Distributed File System
 Data Availability and Durability with the Hadoop Distributed File System ROBERT J. CHANSLER Robert J. Chansler is Senior Manager of Hadoop Infrastructure at LinkedIn. This work draws on Rob s experience
Data Availability and Durability with the Hadoop Distributed File System ROBERT J. CHANSLER Robert J. Chansler is Senior Manager of Hadoop Infrastructure at LinkedIn. This work draws on Rob s experience
Erlang Distributed File System (edfs)
") Indian Institute of Technology Bombay CS 492 : BTP Stage I Erlang Distributed File System (edfs) By: Aman Mangal (100050015) Coordinator: Prof. G. Sivakumar November 30, 2013 Contents Abstract 3 1 Introduction
Indian Institute of Technology Bombay CS 492 : BTP Stage I Erlang Distributed File System (edfs) By: Aman Mangal (100050015) Coordinator: Prof. G. Sivakumar November 30, 2013 Contents Abstract 3 1 Introduction
Implementation of Hadoop Distributed File System Protocol on OneFS Tanuj Khurana EMC Isilon Storage Division
 Implementation of Hadoop Distributed File System Protocol on OneFS Tanuj Khurana EMC Isilon Storage Division Outline HDFS Overview OneFS Overview HDFS protocol on OneFS HDFS protocol server implementation
Implementation of Hadoop Distributed File System Protocol on OneFS Tanuj Khurana EMC Isilon Storage Division Outline HDFS Overview OneFS Overview HDFS protocol on OneFS HDFS protocol server implementation
Running a Workflow on a PowerCenter Grid
 Running a Workflow on a PowerCenter Grid 2010-2014 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise)
Running a Workflow on a PowerCenter Grid 2010-2014 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise)
Big Data Trends and HDFS Evolution
 Big Data Trends and HDFS Evolution Sanjay Radia Founder & Architect Hortonworks Inc Page 1 Hello Founder, Hortonworks Part of the Hadoop team at Yahoo! since 2007 Chief Architect of Hadoop Core at Yahoo!
Big Data Trends and HDFS Evolution Sanjay Radia Founder & Architect Hortonworks Inc Page 1 Hello Founder, Hortonworks Part of the Hadoop team at Yahoo! since 2007 Chief Architect of Hadoop Core at Yahoo!
Cloudera Manager Health Checks
 Cloudera, Inc. 220 Portage Avenue Palo Alto, CA 94306 [email protected] US: 1-888-789-1488 Intl: 1-650-362-0488 www.cloudera.com Cloudera Manager Health Checks Important Notice 2010-2013 Cloudera, Inc.
Cloudera, Inc. 220 Portage Avenue Palo Alto, CA 94306 [email protected] US: 1-888-789-1488 Intl: 1-650-362-0488 www.cloudera.com Cloudera Manager Health Checks Important Notice 2010-2013 Cloudera, Inc.
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan [email protected] Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
High Availability on MapR
 Technical brief Introduction High availability (HA) is the ability of a system to remain up and running despite unforeseen failures, avoiding unplanned downtime or service disruption*. HA is a critical
Technical brief Introduction High availability (HA) is the ability of a system to remain up and running despite unforeseen failures, avoiding unplanned downtime or service disruption*. HA is a critical
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Implementing the Hadoop Distributed File System Protocol on OneFS Jeff Hughes EMC Isilon
 Implementing the Hadoop Distributed File System Protocol on OneFS Jeff Hughes EMC Isilon Outline Hadoop Overview OneFS Overview MapReduce + OneFS Details of isi_hdfs_d Wrap up & Questions 2 Hadoop Overview
Implementing the Hadoop Distributed File System Protocol on OneFS Jeff Hughes EMC Isilon Outline Hadoop Overview OneFS Overview MapReduce + OneFS Details of isi_hdfs_d Wrap up & Questions 2 Hadoop Overview
HDFS Space Consolidation
 HDFS Space Consolidation Aastha Mehta*,1,2, Deepti Banka*,1,2, Kartheek Muthyala*,1,2, Priya Sehgal 1, Ajay Bakre 1 *Student Authors 1 Advanced Technology Group, NetApp Inc., Bangalore, India 2 Birla Institute
HDFS Space Consolidation Aastha Mehta*,1,2, Deepti Banka*,1,2, Kartheek Muthyala*,1,2, Priya Sehgal 1, Ajay Bakre 1 *Student Authors 1 Advanced Technology Group, NetApp Inc., Bangalore, India 2 Birla Institute
Introduction to HDFS. Prasanth Kothuri, CERN
 Prasanth Kothuri, CERN 2 What s HDFS HDFS is a distributed file system that is fault tolerant, scalable and extremely easy to expand. HDFS is the primary distributed storage for Hadoop applications. Hadoop
Prasanth Kothuri, CERN 2 What s HDFS HDFS is a distributed file system that is fault tolerant, scalable and extremely easy to expand. HDFS is the primary distributed storage for Hadoop applications. Hadoop
Big Data Testbed for Research and Education Networks Analysis. SomkiatDontongdang, PanjaiTantatsanawong, andajchariyasaeung
 Big Data Testbed for Research and Education Networks Analysis SomkiatDontongdang, PanjaiTantatsanawong, andajchariyasaeung Research and Education Networks ThaiREN is a specialized Internet Service Provider
Big Data Testbed for Research and Education Networks Analysis SomkiatDontongdang, PanjaiTantatsanawong, andajchariyasaeung Research and Education Networks ThaiREN is a specialized Internet Service Provider
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,[email protected]
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Roadmap for Applying Hadoop Distributed File System in Scientific Grid Computing
 Roadmap for Applying Hadoop Distributed File System in Scientific Grid Computing Garhan Attebury 1, Andrew Baranovski 2, Ken Bloom 1, Brian Bockelman 1, Dorian Kcira 3, James Letts 4, Tanya Levshina 2,
Roadmap for Applying Hadoop Distributed File System in Scientific Grid Computing Garhan Attebury 1, Andrew Baranovski 2, Ken Bloom 1, Brian Bockelman 1, Dorian Kcira 3, James Letts 4, Tanya Levshina 2,
Hypertable Architecture Overview
 WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
Michael Thomas, Dorian Kcira California Institute of Technology. CMS Offline & Computing Week
 Michael Thomas, Dorian Kcira California Institute of Technology CMS Offline & Computing Week San Diego, April 20-24 th 2009 Map-Reduce plus the HDFS filesystem implemented in java Map-Reduce is a highly
Michael Thomas, Dorian Kcira California Institute of Technology CMS Offline & Computing Week San Diego, April 20-24 th 2009 Map-Reduce plus the HDFS filesystem implemented in java Map-Reduce is a highly