Data Warehouse Overview. Namit Jain
|
|
|
- Ashley Charles
- 10 years ago
- Views:
Transcription
1 Data Warehouse Overview Namit Jain

2 Agenda Why data? Life of a tag for data infrastructure Warehouse architecture Challenges Summarizing

3 Data Science peace.facebook.com Friendships on Facebook

4 Data Science - facebook.com/data Gross National Happiness

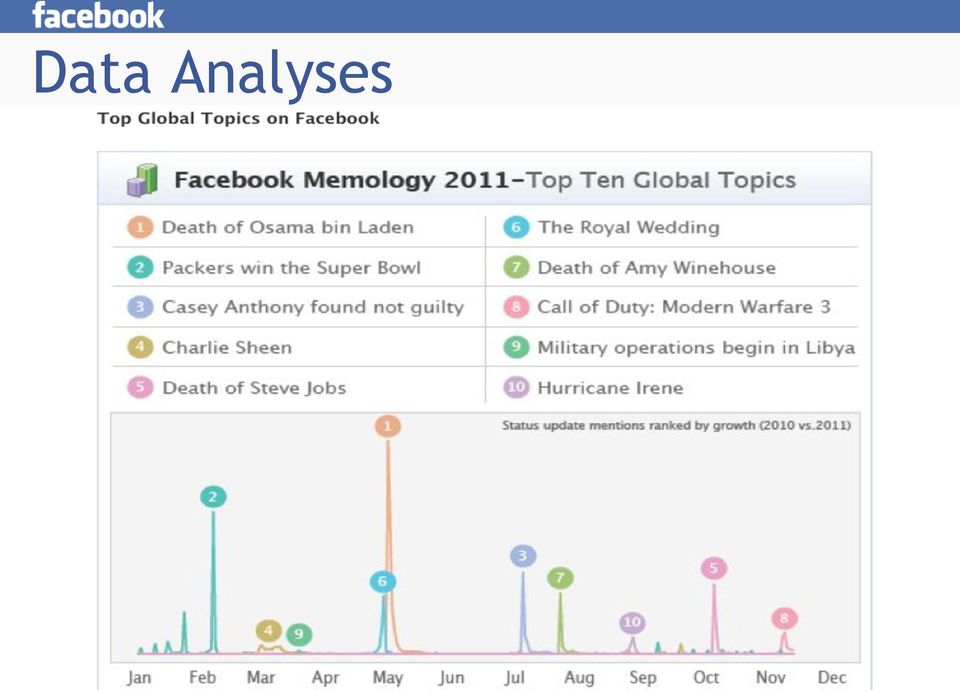
5 Data Analyses
6 Data-enhanced Products People You May Know (PYMK) Newsfeed ranking Ads optimization Index building for search

7 External Reporting Social Plugin Insights

8 Internal Reporting Product Insights Data-driven product development Allows products to iterate quickly by observing user behavior

9 Life of a tag for data infrastructure

10 Facebook Architecture (Simplified)
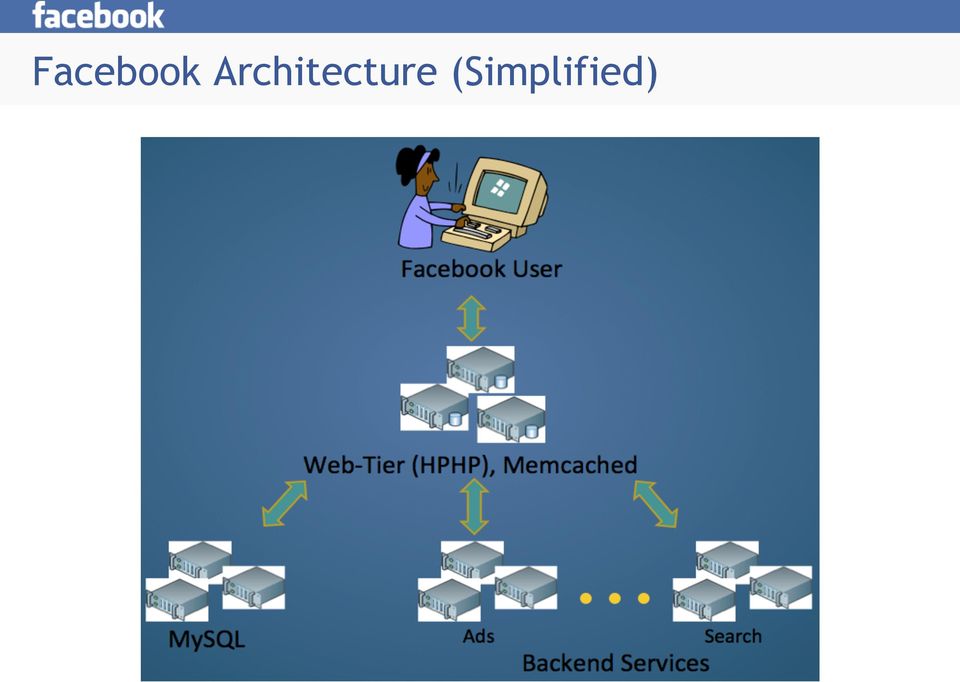
11 Facebook Architecture Data Sources Log Data (facts) Web-tier user activity logs View/click of an ad, liking a story, fanning a page, status update, Backend Services - Search, Newsfeed, Ads Facebook-Site related Data (dimensions) MySQL Descriptions of ads User demographics
 MySQL Descriptions of ads")
12 Life of a tag for data infrastructure Periodic Analysis Adhoc Analysis Daily report on count of photo tags by country (1day) nocron hipal Count photos tagged by females age yesterday Scrapes Warehouse User info reaches Warehouse (1day) MySql copier/loader Log line reaches warehouse (1hr) User tags a photo Real?me Analy?cs Count users tagging photos in the last hour (1min) puma Scribe Log Storage Log line reaches Scribeh (1s) Log line generated: <user_id, photo_id>
 puma Scribe Log Storage Log line reaches Scribeh (1s) www.facebook.")
13 Takeaways Log collection Realtime analysis Batch analysis Periodic analysis Interactive analysis

14 Takeaways Scribe/Calligraphus Puma/HBase Hive/Hadoop Databee/Chronos
15 Takeaways Open Source Scribe HBase Hive/Hadoop

16 Scribe Open Source, simple and scalable log collection system Web Tier Mid- Tier Warehouse

17 Challenges: Choosing the right stack? Hadoop/ Hive Oracle/ AsterData Sharded MySQL Cost Availability Scalability Performance ACID Ease of Use

18 Warehouse Architecture

19 Warehouse Architecture Storage (HDFS)

20 Warehouse Architecture Compute (MapReduce) Storage (HDFS)
")
21 Warehouse Architecture Compute (MapReduce) Storage (HDFS) Hadoop
22 Warehouse Architecture Query (Hive) Compute (MapReduce) Storage (HDFS) Hadoop
23 Warehouse Architecture Workflow (Nocron) Query (Hive) Compute (MapReduce) Storage (HDFS) Hadoop
24 What is Hadoop: Open Source Apache project Framework for running applications on large clusters of commodity hardware Scale: petabytes of data on thousands of nodes Hadoop layers: Storage layer: HDFS Processing layer: MapReduce Characteristics: Uses clusters of commodity computers Supports moving computation close to data Single storage + compute cluster vs. Separate clusters Scalable, fault tolerant, and easily managed But, not easy to program compared to databases(sql)
25 HDFS Data Model Data is logically organized into files and directories Files are divided into uniform-sized blocks Blocks are distributed across the nodes of the cluster and are replicated to handle hardware failure HDFS keeps checksums of data for corruption detection and recovery HDFS exposes block placement so that computation can be migrated to data 25
26 HDFS Architecture Client Metadata ops Namenode Metadata ops Metadata (Name, #replicas, ): /users/foo/data, 3, Block ops Read Datanodes Datanodes Replication Blocks Rack 1 Write Rack 2 Client 26
27 MapReduce Review - WordCount
28 Warehouse Hadoop Storage/Compute
29 Hive Aim to simplify usage of Hadoop A system for managing and querying structured and semistructured data built on top of Hadoop Map-Reduce for execution HDFS for storage Metadata on HDFS files Key Building Principles SQL is a familiar language Extensibility Types, Functions, Formats, Scripts Performance
30 Hive Simplifying usage of Hadoop hive> select key, count(1) from kv1 where key > 100 group by key; vs. $ cat > /tmp/reducer.sh uniq -c awk '{print $2"\t"$1} $ cat > /tmp/map.sh awk -F '\001' '{if($1 > 100) print $1} $ bin/hadoop jar contrib/hadoop-0.23-dev-streaming.jar -input / user/hive/warehouse/kv1 -mapper map.sh -file /tmp/reducer.sh - file /tmp/map.sh -reducer reducer.sh -output /tmp/largekey - numreducetasks 1 $ bin/hadoop dfs cat /tmp/largekey/part*
31 Hive Architecture
32 Hive Data/Query Model Looks and behaves almost like a regular database Data Model Tables with typed columns Flexible types and storage formats Query Model Flavor of SQL for analytics queries Extensible via user defined functions and custom map/reduce scripts
33 Data Model Hive Entity Sample Metastore Entity Sample HDFS Location Table T /wh/t Partition date=d1 /wh/t/date=d1 Bucketing column External Table userid extt /wh/t/date=d1/part-0000 /wh/t/date=d1/part-1000 (hashed on userid) /wh2/existing/dir (arbitrary location)
34 Data Model Tables Analogous to tables in relational DBs Each table has corresponding directory in HDFS Example Page views table name: pvs HDFS directory /wh/pvs
35 Data Model Partitions Analogous to dense indexes on partition columns Nested sub-directories in HDFS for each combination of partition column values Example Partition columns: ds, ctry HDFS subdirectory for ds = , ctry = US /wh/pvs/ds= /ctry=us HDFS subdirectory for ds = , ctry = CA /wh/pvs/ds= /ctry=ca
36 Data Model Buckets Split data based on hash of a column - mainly for parallelism One HDFS file per bucket within partition sub-directory Example Bucket column: user into 32 buckets HDFS file for user hash 0 /wh/pvs/ds= /ctry=us/part HDFS file for user hash bucket 20 /wh/pvs/ds= /ctry=us/part-00020
37 Data Model External Tables Point to existing data directories in HDFS Can create tables and partitions partition columns just become annotations to external directories Example: create external table with partitions CREATE EXTERNAL TABLE pvs(userid int, pageid int, ds string, ctry string) PARTITIONED ON (ds string, ctry string) STORED AS textfile LOCATION /path/to/existing/table Example: add a partition to external table ALTER TABLE pvs ADD PARTITION (ds= , ctry= US ) LOCATION /path/to/existing/partition
38 Example Application Status updates table: status_updates(userid int, status string, ds string) Load the data from log files: LOAD DATA LOCAL INPATH /logs/status_updates INTO TABLE status_updates PARTITION (ds= ) User profile table profiles(userid int, school string, gender int)
39 Example Query Plan (Filter) Filter status updates containing michael jackson SELECT * FROM status_updates WHERE status LIKE michael jackson
40 Example Query Plan (Aggregation) Figure out total number of status_updates in a given day SELECT COUNT(1) FROM status_updates WHERE ds =
41 Hive Query Language Extensibility Pluggable Map-reduce scripts Pluggable User Defined Functions Pluggable User Defined Types Complex object types: List of Maps Pluggable Data Formats Apache Log Format Columnar Storage Format
42 Hive Evolution Originally: a way for Hadoop users to express queries in a high-level language without having to write map/reduce programs Now more and more: A parallel SQL DBMS which happens to use Hadoop for its storage and execution architecture Nearly 100% of hadoop jobs in the warehouse go through Hive. TRANSFORM scripts (any language) Serialization+IPC overhead Pre/Post Hooks (Java) Statement validation/execution Example uses: auditing, replication, authorization, multiple clusters
43 Hive is an open system Different on-disk data formats Text File, Sequence File, Different in-memory data formats Java Integer/String, Hadoop IntWritable/Text User-provided map/reduce scripts In any language, use stdin/stdout to transfer data User-defined Functions Substr, Trim, From_unixtime User-defined Aggregation Functions Sum, Average
44 File Format Example CREATE TABLE mylog ( user_id BIGINT, page_url STRING, unix_time INT) STORED AS TEXTFILE; LOAD DATA INPATH '/user/myname/log.txt' INTO TABLE mylog;
45 Existing File Formats TEXTFILE SEQUENCEFILE RCFILE Data type text only text/binary text/binary Internal Storage order Row-based Row-based Column-based Compression File-based Block-based Block-based Splitable* YES YES YES Splitable* after compression NO YES YES * Splitable: Capable of splitting the file so that a single huge file can be processed by multiple mappers in parallel.
46 SerDe Examples CREATE TABLE mylog ( user_id BIGINT, page_url STRING, unix_time INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; CREATE table mylog_rc ( user_id BIGINT, page_url STRING, unix_time INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.columnar.columnarserde' STORED AS RCFILE;
47 SerDe SerDe is short for serialization/deserialization. It controls the format of a row. Serialized format: Delimited format (tab, comma, ctrl-a ) Thrift Protocols Deserialized (in-memory) format: Java Integer/String/ArrayList/HashMap Hadoop Writable classes User-defined Java Classes (Thrift)
48 Map/Reduce Scripts Examples add file page_url_to_id.py; add file my_python_session_cutter.py; FROM (SELECT TRANSFORM(user_id, page_url, unix_time) USING 'page_url_to_id.py' AS (user_id, page_id, unix_time) FROM mylog DISTRIBUTE BY user_id SORT BY user_id, unix_time) mylog2 SELECT TRANSFORM(user_id, page_id, unix_time) USING 'my_python_session_cutter.py' AS (user_id, session_info);
49 Comparison of UDF/UDAF v.s. M/R scripts UDF/UDAF M/R scripts language Java any language data format in-memory objects serialized streams 1/1 input/output supported via UDF supported n/1 input/output supported via UDAF supported 1/n input/output supported via UDTF supported Speed faster Slower
50 Common Join Task A Table X Common Join Task Table Y Mapper Mapper Mapper Mapper Mapper Mapper Shuffle Reducer
51 Join in Map Reduce page_view key value key value pageid userid time 111 <1,1> 111 <1,1> :08: :08: <1,2> 111 <1,2> :08:14 user Map 222 <1,1> Shuffle Sort 111 <2,25> Reduce userid age gender key value key value female male 111 <2,25> 222 <2,32> 222 <1,1> 222 <2,32>
52 Auto Map-Join
53 Auto Map-Join
54 Auto Map-Join
55 Bucketized Map-Join
56 Sort Merge Bucket Map-Join
57 Hive but is not Enough! Workflow specification, schedule and execution framework Workflows are DAGS Nodes are data transfers and transformations Edges are dependencies between nodes Reporting and Dashboard Tools HiveQuery/Workflow Authoring Tools Warehouse management Track space and cpu usage of the cluster Capacity planning for growth
58 Warehouse Challenges
59 Warehouse Challenges Growth Data, data, and more data
60 Growth Numbers Facebook Users (million) Queries/ Day Scribe Data GB/ Day Nodes Size TB (Total) March 2008 March 2012 Growth 14X 60X 250X 260X 2500X
61 HDFS Normal Deployment NameNode Data Node 1 Data Node 2 Data Node 3
62 First Attempts Concatenate old tables/partitions Alter table partition <p> concatenate No need to compress/uncompress the data for RCFile Hadoop Archive File Needed for bucketed files Upgrade Namenode
63 HDFS Hacked Federation NN1 NN2 DN1 DN1 DN2 DN2 DN3 DN3
64 HDFS - Federated Deployment NameNode1 NameNode2 Data Node 1 Data Node 2 Data Node 3
65 HDFS Layout NEW Map Reduce HDFS Cluster with mul?ple Name Nodes
66 Corona Hive Query Task Tracker M Hive CLI + Job Client Job Tracker heartbeat Task Tracker Task Tracker R
67 Hadoop Corona Split the current Job Tracker Cluster Manager to manage resources/nodes One Corona Job Tracker per job Corona Job Tracker requests resources from Cluster Manager Small amount of state in Cluster Manager Can restart
68 Corona Hive Query Cluster Manager Task Tracker M Hive CLI + Job Client + Job Tracker heartbeat Task Tracker Task Tracker R
69 Warehouse Challenges Growth Isolation Space Isolation Compute Isolation Failure Isolation
70 Isolation - Now Hardware isolation Platinum cluster & Silver cluster Partial compute isolation Pools Pool1 Pool2 Pool3 Map Reduce Cluster HDFS Cluster
71 Challenges: Isolation Replica?on Pla3num Silver
72 Isolation Pools FIFO within each pool
73 TEAM Minimum Slots ADS BI COEFFICIENT GROWTH SCRAPING INSIGHTS NETEGO PLATFORM
74 Isolation - Future Logical namespace per team Namespace encompasses Transport capacity (scribe) Realtime analytics capacity (puma) Storage capacity (hive tables) Compute capacity (periodic/adhoc analyses) Resource accountability per namespace Pools computed dynamically
75 Isolation - Future NEW NS1 NS2 NS3 Pool1 Pool2 Pool3 Map Reduce Cluster HDFS Cluster
76 Challenges: Testing Shadow testing with multiple DFS and MR clusters SILVER BRONZE DFS1 DFS5 DFSTEMP
77 Testing Snapshot cluster Queries for a day Track cpu/byte for top 100 queries
78 Warehouse Challenges Growth Isolation Multiple Regions Hadoop picky about new capacity requirements Need to use any capacity in any location Need to share data between regions
79 Multi Region Hive1 Map Reduce Replica?on HDFS
80 Project Prism Hive1 NS1 NS2 NS3 Replica?on Pool1 Pool2 Pool3 HDFS Cluster Central Namespace Server Replica?on Replica?on
81 Interactive Query - Peregrine
82 Peregrine Fast Approximate results Memory bound No Join/sub-query support
83 Open Source Hadoop Facebook has its internal branch Releases to github periodically Hive Development is in apache Pulls into internal branch periodically
84 Hive Open Projects Testing Benchmark Data Generator
85 Hive Open Projects Performance Materialized Views Cost-based optimizer for Hive Index Joins Better skew handling techniques Map-reduce-reduce-reduce* Hash without sort on map-reduce boundary
86 Questions?
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop
 Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
Hive User Group Meeting August 2009
 Hive User Group Meeting August 2009 Hive Overview Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 5+TB(compressed) raw data per day today What is HIVE?» A system
Hive User Group Meeting August 2009 Hive Overview Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 5+TB(compressed) raw data per day today What is HIVE?» A system
Hadoop and Hive Development at Facebook. Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009
 Hadoop and Hive Development at Facebook Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009 Hadoop @ Facebook Who generates this data? Lots of data
Hadoop and Hive Development at Facebook Dhruba Borthakur Zheng Shao {dhruba, zshao}@facebook.com Presented at Hadoop World, New York October 2, 2009 Hadoop @ Facebook Who generates this data? Lots of data
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 Hadoop Ecosystem Overview of this Lecture Module Background Google MapReduce The Hadoop Ecosystem Core components: Hadoop
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 Hadoop Ecosystem Overview of this Lecture Module Background Google MapReduce The Hadoop Ecosystem Core components: Hadoop
Hadoop and its Usage at Facebook. Dhruba Borthakur [email protected], June 22 rd, 2009
 Hadoop and its Usage at Facebook Dhruba Borthakur [email protected], June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Hadoop and its Usage at Facebook Dhruba Borthakur [email protected], June 22 rd, 2009 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed on Hadoop Distributed File System Facebook
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,[email protected]
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Hadoop Architecture and its Usage at Facebook
 Hadoop Architecture and its Usage at Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Microsoft Research, Seattle October 16, 2009 Outline Introduction
Hadoop Architecture and its Usage at Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Microsoft Research, Seattle October 16, 2009 Outline Introduction
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc [email protected]
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc [email protected] What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP)
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, XLDB Conference at Stanford University, Sept 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP)
Hive Development. (~15 minutes) Yongqiang He Software Engineer. Facebook Data Infrastructure Team
 Yongqiang He Software Engineer. Facebook Data Infrastructure Team") Hive Development (~15 minutes) Yongqiang He Software Engineer Facebook Data Infrastructure Team Agenda 1 Introduction 2 New Features 3 Future What is Hive? A system for managing and querying structured
Hive Development (~15 minutes) Yongqiang He Software Engineer Facebook Data Infrastructure Team Agenda 1 Introduction 2 New Features 3 Future What is Hive? A system for managing and querying structured
Big Data. Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich
 Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce The Hadoop
Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce The Hadoop
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, UC Berkeley, Nov 2012
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, UC Berkeley, Nov 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics data 4
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, UC Berkeley, Nov 2012 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics data 4
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Realtime Apache Hadoop at Facebook. Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens
 Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Realtime Apache Hadoop at Facebook Jonathan Gray & Dhruba Borthakur June 14, 2011 at SIGMOD, Athens Agenda 1 Why Apache Hadoop and HBase? 2 Quick Introduction to Apache HBase 3 Applications of HBase at
Alternatives to HIVE SQL in Hadoop File Structure
 Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System [email protected] Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Real-time Analytics at Facebook: Data Freeway and Puma. Zheng Shao 12/2/2011
 Real-time Analytics at Facebook: Data Freeway and Puma Zheng Shao 12/2/2011 Agenda 1 Analytics and Real-time 2 Data Freeway 3 Puma 4 Future Works Analytics and Real-time what and why Facebook Insights
Real-time Analytics at Facebook: Data Freeway and Puma Zheng Shao 12/2/2011 Agenda 1 Analytics and Real-time 2 Data Freeway 3 Puma 4 Future Works Analytics and Real-time what and why Facebook Insights
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Impala: A Modern, Open-Source SQL Engine for Hadoop. Marcel Kornacker Cloudera, Inc.
 Impala: A Modern, Open-Source SQL Engine for Hadoop Marcel Kornacker Cloudera, Inc. Agenda Goals; user view of Impala Impala performance Impala internals Comparing Impala to other systems Impala Overview:
Impala: A Modern, Open-Source SQL Engine for Hadoop Marcel Kornacker Cloudera, Inc. Agenda Goals; user view of Impala Impala performance Impala internals Comparing Impala to other systems Impala Overview:
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
HIVE. Data Warehousing & Analytics on Hadoop. Joydeep Sen Sarma, Ashish Thusoo Facebook Data Team
 HIVE Data Warehousing & Analytics on Hadoop Joydeep Sen Sarma, Ashish Thusoo Facebook Data Team Why Another Data Warehousing System? Problem: Data, data and more data 200GB per day in March 2008 back to
HIVE Data Warehousing & Analytics on Hadoop Joydeep Sen Sarma, Ashish Thusoo Facebook Data Team Why Another Data Warehousing System? Problem: Data, data and more data 200GB per day in March 2008 back to
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
Operations and Big Data: Hadoop, Hive and Scribe. Zheng Shao @ 铮 9 12/7/2011 Velocity China 2011
 Operations and Big Data: Hadoop, Hive and Scribe Zheng Shao @ 铮 9 12/7/2011 Velocity China 2011 Agenda 1 Operations: Challenges and Opportunities 2 Big Data Overview 3 Operations with Big Data 4 Big Data
Operations and Big Data: Hadoop, Hive and Scribe Zheng Shao @ 铮 9 12/7/2011 Velocity China 2011 Agenda 1 Operations: Challenges and Opportunities 2 Big Data Overview 3 Operations with Big Data 4 Big Data
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM
 HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
CitusDB Architecture for Real-Time Big Data
 CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
CitusDB Architecture for Real-Time Big Data CitusDB Highlights Empowers real-time Big Data using PostgreSQL Scales out PostgreSQL to support up to hundreds of terabytes of data Fast parallel processing
Introduction to Hadoop
 Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Introduction to Hadoop Miles Osborne School of Informatics University of Edinburgh [email protected] October 28, 2010 Miles Osborne Introduction to Hadoop 1 Background Hadoop Programming Model Examples
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Hadoop Distributed File System. Jordan Prosch, Matt Kipps
 Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
COSC 6397 Big Data Analytics. 2 nd homework assignment Pig and Hive. Edgar Gabriel Spring 2015
 COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Hadoop Introduction. Olivier Renault Solution Engineer - Hortonworks
 Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
HDFS Federation. Sanjay Radia Founder and Architect @ Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Spring,2015. Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE
 Spring,2015 Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE Contents: Briefly About Big Data Management What is hive? Hive Architecture Working
Spring,2015 Apache Hive BY NATIA MAMAIASHVILI, LASHA AMASHUKELI & ALEKO CHAKHVASHVILI SUPERVAIZOR: PROF. NODAR MOMTSELIDZE Contents: Briefly About Big Data Management What is hive? Hive Architecture Working
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Beyond Web Application Log Analysis using Apache TM Hadoop. A Whitepaper by Orzota, Inc.
 Beyond Web Application Log Analysis using Apache TM Hadoop A Whitepaper by Orzota, Inc. 1 Web Applications As more and more software moves to a Software as a Service (SaaS) model, the web application has
Beyond Web Application Log Analysis using Apache TM Hadoop A Whitepaper by Orzota, Inc. 1 Web Applications As more and more software moves to a Software as a Service (SaaS) model, the web application has
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
The Hadoop Distributed File System
 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Big Data Weather Analytics Using Hadoop
 Big Data Weather Analytics Using Hadoop Veershetty Dagade #1 Mahesh Lagali #2 Supriya Avadhani #3 Priya Kalekar #4 Professor, Computer science and Engineering Department, Jain College of Engineering, Belgaum,
Big Data Weather Analytics Using Hadoop Veershetty Dagade #1 Mahesh Lagali #2 Supriya Avadhani #3 Priya Kalekar #4 Professor, Computer science and Engineering Department, Jain College of Engineering, Belgaum,
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems
 Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Hadoop: The Definitive Guide
 FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
Hadoop Scalability at Facebook. Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011
 YaC, Moscow, September 19, 2011") Hadoop Scalability at Facebook Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
Hadoop Scalability at Facebook Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Big Data: Using ArcGIS with Apache Hadoop. Erik Hoel and Mike Park
 Big Data: Using ArcGIS with Apache Hadoop Erik Hoel and Mike Park Outline Overview of Hadoop Adding GIS capabilities to Hadoop Integrating Hadoop with ArcGIS Apache Hadoop What is Hadoop? Hadoop is a scalable
Big Data: Using ArcGIS with Apache Hadoop Erik Hoel and Mike Park Outline Overview of Hadoop Adding GIS capabilities to Hadoop Integrating Hadoop with ArcGIS Apache Hadoop What is Hadoop? Hadoop is a scalable
Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam [email protected]
 Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam [email protected] Agenda The rise of Big Data & Hadoop MySQL in the Big Data Lifecycle MySQL Solutions for Big Data Q&A
Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam [email protected] Agenda The rise of Big Data & Hadoop MySQL in the Big Data Lifecycle MySQL Solutions for Big Data Q&A
HDFS Under the Hood. Sanjay Radia. [email protected] Grid Computing, Hadoop Yahoo Inc.
 HDFS Under the Hood Sanjay Radia [email protected] Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
HDFS Under the Hood Sanjay Radia [email protected] Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
America s Most Wanted a metric to detect persistently faulty machines in Hadoop
 America s Most Wanted a metric to detect persistently faulty machines in Hadoop Dhruba Borthakur and Andrew Ryan dhruba,[email protected] Presented at IFIP Workshop on Failure Diagnosis, Chicago June
America s Most Wanted a metric to detect persistently faulty machines in Hadoop Dhruba Borthakur and Andrew Ryan dhruba,[email protected] Presented at IFIP Workshop on Failure Diagnosis, Chicago June
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology [email protected] Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Extending Hadoop beyond MapReduce
 Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Apache Hadoop: The Pla/orm for Big Data. Amr Awadallah CTO, Founder, Cloudera, Inc. [email protected], twicer: @awadallah
 Apache Hadoop: The Pla/orm for Big Data Amr Awadallah CTO, Founder, Cloudera, Inc. [email protected], twicer: @awadallah 1 The Problems with Current Data Systems BI Reports + Interac7ve Apps RDBMS (aggregated
Apache Hadoop: The Pla/orm for Big Data Amr Awadallah CTO, Founder, Cloudera, Inc. [email protected], twicer: @awadallah 1 The Problems with Current Data Systems BI Reports + Interac7ve Apps RDBMS (aggregated
Online Content Optimization Using Hadoop. Jyoti Ahuja Dec 20 2011
 Online Content Optimization Using Hadoop Jyoti Ahuja Dec 20 2011 What do we do? Deliver right CONTENT to the right USER at the right TIME o Effectively and pro-actively learn from user interactions with
Online Content Optimization Using Hadoop Jyoti Ahuja Dec 20 2011 What do we do? Deliver right CONTENT to the right USER at the right TIME o Effectively and pro-actively learn from user interactions with
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
<Insert Picture Here> Big Data
 Big Data Kevin Kalmbach Principal Sales Consultant, Public Sector Engineered Systems Program Agenda What is Big Data and why it is important? What is your Big
Big Data Kevin Kalmbach Principal Sales Consultant, Public Sector Engineered Systems Program Agenda What is Big Data and why it is important? What is your Big
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 PART 2 PART 3 BIG DATA PATTERNS...253 PART 4 BEYOND MAPREDUCE...385
 brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 1 Hadoop in a heartbeat 3 2 Introduction to YARN 22 PART 2 DATA LOGISTICS...59 3 Data serialization working with text and beyond 61 4 Organizing and
brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 1 Hadoop in a heartbeat 3 2 Introduction to YARN 22 PART 2 DATA LOGISTICS...59 3 Data serialization working with text and beyond 61 4 Organizing and
The Hadoop Eco System Shanghai Data Science Meetup
 The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related