Online Content Optimization Using Hadoop. Jyoti Ahuja Dec
|
|
|
- Scot Lawson
- 10 years ago
- Views:
Transcription
1 Online Content Optimization Using Hadoop Jyoti Ahuja Dec

2 What do we do? Deliver right CONTENT to the right USER at the right TIME o Effectively and pro-actively learn from user interactions with content that are displayed to maximize our objectives A new scientific discipline at the interface of o Large scale Machine Learning and Statistics o Multi-objective optimization in the presence of uncertainty o User understanding o Content understanding

3 Relevance at Yahoo! People 10s of Items Important Editors Popular Personal / Social Science Millions of Items

4 Ranking Problems Most Popular Most engaging overall based on objective metrics Most Popular + Per User History Engaging overall, and aware of what I ve already seen Light Personalization More relevant to me based on my age, gender and property usage Deep Personalization Most relevant to me based on my deep interests X Y Related Items Behavioral Affinity: People who did X, did Y Real-time Dashboard Business Optimization

5 Recommendation: A Match-making Problem Recommendation problems Search: Web, Vertical Online advertising Item Inventory Articles, web page, ads, Use an automated algorithm to select item(s) to show Opportunity Users, queries, pages, Get feedback (click, time spent,..) Refine the models Repeat (large number of times) Measure metric(s) of interest (Total clicks, Total revenue, )
 Refine the models Repeat (large number of times) Measure metric(s) of interest (Total")
6 Recommendation - match making problem Content optimization example 1 o I have an important module on my page, content inventory is obtained from a third part source which is further refined through editorial oversight. Can I algorithmically recommend content on this module? I want to drive up total CTR on this module Content optimization example 2 o I got X% lift in CTR. But I have additional information on other downstream utilities (e.g. dwell time). Can I increase downstream utility without losing too many clicks 6

7 Problem Characteristics : Today module Traffic obtained from a controlled randomized experiment Things to note: a) Short lifetimes b) temporal effects c) often breaking news story
 temporal effects c) often")
8 Bird s eye view 8
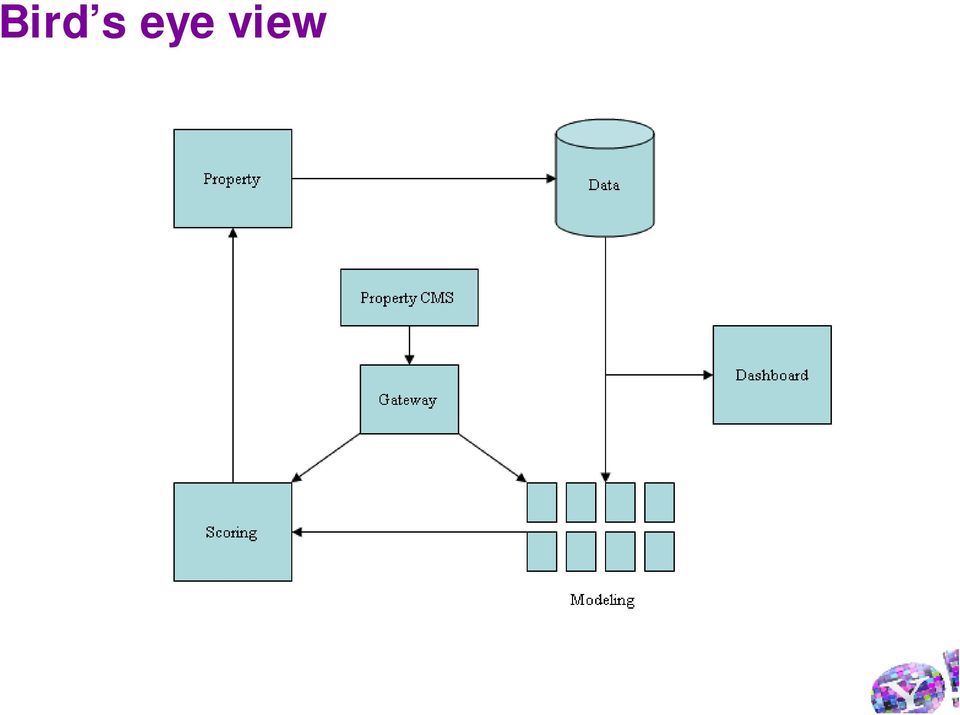


9 Flow Content feed with biz rules Optimization Engine Rules Engine Content Metadata Real-time Feedback Explore ~1% Exploit ~99% Real-time Insights Dashboard Optimized Module

10 Technology Stack Analytics and Debugging 10

11 Hadoop Framework for running applications on large clusters built of commodity hardware Lets one easily write and run applications that process vast amounts of data (petabytes) Distributed File System o Modeled on GFS Distributed Processing Framework o Using map-reduce metaphor Scheduler/Resource Management Open source Written in java with client apps in various languages

12 Hbase Supports random reads and writes HBase is a storage system that is o Distributed o Column oriented o Multi-dimensional o High availability o High-performance You must be OK with RDBMS anti-schema o Denormalized data o Wide and sparsely populated tables

13 Hive SQL like query engine o Enables ad-hoc querying, summarization, analysis of large volumes of data o Allows MR programmers to plugin their custom logic Hive is not o Comparable to real time processing systems like Oracle o Tend to have latency in mins o Not designed for online transaction processing Extensively used at o Facebook, Yahoo!, Digg, CNET, Last.fm, Rocket Fuel etc

14 Grid Edge Services Keeps MR jobs lean and mean Provides ability to control non-gridifyable solutions to be deployed easily Have different scaling characteristics (E.g. Memory, CPU) Provide gateway for accessing external data sources in M/R Map and/or Reduce step interact with Edge Services using standard client Examples o Categorization o Geo Tagging o Feature Transformation 14
 Provide gateway for accessing external data sources in M/R Map and/or Reduce step")
15 How it happens? Additional Content & User Feature Generation Feature Generation Item BASE M F ATTR CAT_Sports id id User Events At time t User u (user attr: age, gen, loc) interacted with Content id at Position o Property/Site p Section - s Module m International - i Content id Has associated metadata meta meta = {entity, keyword, geo, topic, category} Modeling Item Metadata 5 min latency ITEM Model Request Ranking B-Rules SLA 50 ms 200 ms 5 30 min latency USER Model STORE: PNUTS Item BASE M F ATTR CAT_Sports u u

16 Models USER x CONTENT FEATURES USER MODEL : Tracks User interest in terms of Content Features ITEM x USER FEATURES ITEM MODEL : Tracks behavior of Item across user features USER FEATURES x CONTENT FEATURES USER x USER PRIORS : Tracks interactions of user features with content features ITEM x ITEM CLUSTERING : Looks at User-User Affinity based on the feature vectors CLUSTERING : Looks at Item-Item Affinity based on item feature vectors 16

17 Scale Million events per second Hundreds of GB per run Million of stories in pool Tens of Thousands of Features (Content and/or User) 17
")
18 Modeling Framework Global state provided by HBase A collection of PIG UDFs Flow for modeling or stages assembled in PIG o OLR o Clustering o Affinity o Regression Models Configuration based behavioral changes for stages of modeling o Type of Features to generated o Type of joins to perform User / Item / Feature Input : DFS and/or HBase Output: DFS and/or Hbase 18

19 HBase ITEM Table o Stores item related features o Stores ITEM x USER FEATURES model o Stores parameters about item like view count, click count, unique user count. o 10 of Millions of Items o Updated every 5 minutes USER Model o Store USER x CONTENT FEATURES model for each individual user by Unique ID o Stores summarized user history Essential for Modeling in terms of item decay o Millions of profiles o Updated every 5 to 30 minutes TERM Model o Inverts the Item Table and stores statistics for the terms. o Used to find the trending features and provide baselines for user features o Millions of terms and hundreds of parameters tracked o Updates every 5 minutes 19

20 Analytics and Debugging Provides ability to debug modeling issues near-real time Run complex queries for analysis Easy to use interface PM, Engineers, Research use this cluster to get near-real time insights 100s of Modeling monitoring and Reporting queries every 5 minute Output fed to (near) real time dashboard We use HIVE 20
 real time dashboard We use")
21 Learnings PIG & HBase has been best combination so far o Made it simple to build different kind of science models o Point lookup using HBase has proven to be very useful o Modeling = Matrices HBase provides a natural way to represent and access them Edge Services o Have provided simplicity to whole stack o Management (Upgrades, Outage) has been easy HIVE has provided us a great way for analyzing the results o PIG was also considered 21
22 Q & A
23 Questions?
How To Handle Big Data With A Data Scientist
 III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
W H I T E P A P E R. Deriving Intelligence from Large Data Using Hadoop and Applying Analytics. Abstract
 W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Big data blue print for cloud architecture
 Big data blue print for cloud architecture -COGNIZANT Image Area Prabhu Inbarajan Srinivasan Thiruvengadathan Muralicharan Gurumoorthy Praveen Codur 2012, Cognizant Next 30 minutes Big Data / Cloud challenges
Big data blue print for cloud architecture -COGNIZANT Image Area Prabhu Inbarajan Srinivasan Thiruvengadathan Muralicharan Gurumoorthy Praveen Codur 2012, Cognizant Next 30 minutes Big Data / Cloud challenges
Managing Big Data with Hadoop & Vertica. A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database
 Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Application and practice of parallel cloud computing in ISP. Guangzhou Institute of China Telecom Zhilan Huang 2011-10
 Application and practice of parallel cloud computing in ISP Guangzhou Institute of China Telecom Zhilan Huang 2011-10 Outline Mass data management problem Applications of parallel cloud computing in ISPs
Application and practice of parallel cloud computing in ISP Guangzhou Institute of China Telecom Zhilan Huang 2011-10 Outline Mass data management problem Applications of parallel cloud computing in ISPs
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
NoSQL for SQL Professionals William McKnight
 NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
NoSQL for SQL Professionals William McKnight Session Code BD03 About your Speaker, William McKnight President, McKnight Consulting Group Frequent keynote speaker and trainer internationally Consulted to
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Oracle Big Data SQL Technical Update
 Oracle Big Data SQL Technical Update Jean-Pierre Dijcks Oracle Redwood City, CA, USA Keywords: Big Data, Hadoop, NoSQL Databases, Relational Databases, SQL, Security, Performance Introduction This technical
Oracle Big Data SQL Technical Update Jean-Pierre Dijcks Oracle Redwood City, CA, USA Keywords: Big Data, Hadoop, NoSQL Databases, Relational Databases, SQL, Security, Performance Introduction This technical
So What s the Big Deal?
 So What s the Big Deal? Presentation Agenda Introduction What is Big Data? So What is the Big Deal? Big Data Technologies Identifying Big Data Opportunities Conducting a Big Data Proof of Concept Big Data
So What s the Big Deal? Presentation Agenda Introduction What is Big Data? So What is the Big Deal? Big Data Technologies Identifying Big Data Opportunities Conducting a Big Data Proof of Concept Big Data
An Oracle White Paper November 2010. Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics
 An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Bringing Big Data into the Enterprise
 Bringing Big Data into the Enterprise Overview When evaluating Big Data applications in enterprise computing, one often-asked question is how does Big Data compare to the Enterprise Data Warehouse (EDW)?
Bringing Big Data into the Enterprise Overview When evaluating Big Data applications in enterprise computing, one often-asked question is how does Big Data compare to the Enterprise Data Warehouse (EDW)?
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
GigaSpaces Real-Time Analytics for Big Data
 GigaSpaces Real-Time Analytics for Big Data GigaSpaces makes it easy to build and deploy large-scale real-time analytics systems Rapidly increasing use of large-scale and location-aware social media and
GigaSpaces Real-Time Analytics for Big Data GigaSpaces makes it easy to build and deploy large-scale real-time analytics systems Rapidly increasing use of large-scale and location-aware social media and
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
America s Most Wanted a metric to detect persistently faulty machines in Hadoop
 America s Most Wanted a metric to detect persistently faulty machines in Hadoop Dhruba Borthakur and Andrew Ryan dhruba,[email protected] Presented at IFIP Workshop on Failure Diagnosis, Chicago June
America s Most Wanted a metric to detect persistently faulty machines in Hadoop Dhruba Borthakur and Andrew Ryan dhruba,[email protected] Presented at IFIP Workshop on Failure Diagnosis, Chicago June
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
The Internet of Things and Big Data: Intro
 The Internet of Things and Big Data: Intro John Berns, Solutions Architect, APAC - MapR Technologies April 22 nd, 2014 1 What This Is; What This Is Not It s not specific to IoT It s not about any specific
The Internet of Things and Big Data: Intro John Berns, Solutions Architect, APAC - MapR Technologies April 22 nd, 2014 1 What This Is; What This Is Not It s not specific to IoT It s not about any specific
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Azure Data Lake Analytics
 Azure Data Lake Analytics Compose and orchestrate data services at scale Fully managed service to support orchestration of data movement and processing Connect to relational or non-relational data
Azure Data Lake Analytics Compose and orchestrate data services at scale Fully managed service to support orchestration of data movement and processing Connect to relational or non-relational data
Comprehensive Analytics on the Hortonworks Data Platform
 Comprehensive Analytics on the Hortonworks Data Platform We do Hadoop. Page 1 Page 2 Back to 2005 Page 3 Vertical Scaling Page 4 Vertical Scaling Page 5 Vertical Scaling Page 6 Horizontal Scaling Page
Comprehensive Analytics on the Hortonworks Data Platform We do Hadoop. Page 1 Page 2 Back to 2005 Page 3 Vertical Scaling Page 4 Vertical Scaling Page 5 Vertical Scaling Page 6 Horizontal Scaling Page
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics
 Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at [email protected].
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at [email protected].
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
www.pwc.com/oracle Next presentation starting soon Business Analytics using Big Data to gain competitive advantage
 www.pwc.com/oracle Next presentation starting soon Business Analytics using Big Data to gain competitive advantage If every image made and every word written from the earliest stirring of civilization
www.pwc.com/oracle Next presentation starting soon Business Analytics using Big Data to gain competitive advantage If every image made and every word written from the earliest stirring of civilization
Native Connectivity to Big Data Sources in MSTR 10
 Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Native Connectivity to Big Data Sources in MSTR 10 Bring All Relevant Data to Decision Makers Support for More Big Data Sources Optimized Access to Your Entire Big Data Ecosystem as If It Were a Single
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
A Scalable Data Transformation Framework using the Hadoop Ecosystem
 A Scalable Data Transformation Framework using the Hadoop Ecosystem Raj Nair Director Data Platform Kiru Pakkirisamy CTO AGENDA About Penton and Serendio Inc Data Processing at Penton PoC Use Case Functional
A Scalable Data Transformation Framework using the Hadoop Ecosystem Raj Nair Director Data Platform Kiru Pakkirisamy CTO AGENDA About Penton and Serendio Inc Data Processing at Penton PoC Use Case Functional
Big Data Explained. An introduction to Big Data Science.
 Big Data Explained An introduction to Big Data Science. 1 Presentation Agenda What is Big Data Why learn Big Data Who is it for How to start learning Big Data When to learn it Objective and Benefits of
Big Data Explained An introduction to Big Data Science. 1 Presentation Agenda What is Big Data Why learn Big Data Who is it for How to start learning Big Data When to learn it Objective and Benefits of
Scaling Up 2 CSE 6242 / CX 4242. Duen Horng (Polo) Chau Georgia Tech. HBase, Hive
 Chau Georgia Tech. HBase, Hive") CSE 6242 / CX 4242 Scaling Up 2 HBase, Hive Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 2 HBase, Hive Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
Hadoop Big Data for Processing Data and Performing Workload
 Hadoop Big Data for Processing Data and Performing Workload Girish T B 1, Shadik Mohammed Ghouse 2, Dr. B. R. Prasad Babu 3 1 M Tech Student, 2 Assosiate professor, 3 Professor & Head (PG), of Computer
Hadoop Big Data for Processing Data and Performing Workload Girish T B 1, Shadik Mohammed Ghouse 2, Dr. B. R. Prasad Babu 3 1 M Tech Student, 2 Assosiate professor, 3 Professor & Head (PG), of Computer
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
Fast Data in the Era of Big Data: Twitter s Real-
 Fast Data in the Era of Big Data: Twitter s Real- Time Related Query Suggestion Architecture Gilad Mishne, Jeff Dalton, Zhenghua Li, Aneesh Sharma, Jimmy Lin Presented by: Rania Ibrahim 1 AGENDA Motivation
Fast Data in the Era of Big Data: Twitter s Real- Time Related Query Suggestion Architecture Gilad Mishne, Jeff Dalton, Zhenghua Li, Aneesh Sharma, Jimmy Lin Presented by: Rania Ibrahim 1 AGENDA Motivation
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Customer Case Study. Sharethrough
 Customer Case Study Customer Case Study Benefits Faster prototyping of new applications Easier debugging of complex pipelines Improved overall engineering team productivity Summary offers a robust advertising
Customer Case Study Customer Case Study Benefits Faster prototyping of new applications Easier debugging of complex pipelines Improved overall engineering team productivity Summary offers a robust advertising
Aligning Your Strategic Initiatives with a Realistic Big Data Analytics Roadmap
 Aligning Your Strategic Initiatives with a Realistic Big Data Analytics Roadmap 3 key strategic advantages, and a realistic roadmap for what you really need, and when 2012, Cognizant Topics to be discussed
Aligning Your Strategic Initiatives with a Realistic Big Data Analytics Roadmap 3 key strategic advantages, and a realistic roadmap for what you really need, and when 2012, Cognizant Topics to be discussed
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System [email protected] Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Scaling Up HBase, Hive, Pegasus
 CSE 6242 A / CS 4803 DVA Mar 7, 2013 Scaling Up HBase, Hive, Pegasus Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 A / CS 4803 DVA Mar 7, 2013 Scaling Up HBase, Hive, Pegasus Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Similarity Search in a Very Large Scale Using Hadoop and HBase
 Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
Similarity Search in a Very Large Scale Using Hadoop and HBase Stanislav Barton, Vlastislav Dohnal, Philippe Rigaux LAMSADE - Universite Paris Dauphine, France Internet Memory Foundation, Paris, France
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
End to End Solution to Accelerate Data Warehouse Optimization. Franco Flore Alliance Sales Director - APJ
 End to End Solution to Accelerate Data Warehouse Optimization Franco Flore Alliance Sales Director - APJ Big Data Is Driving Key Business Initiatives Increase profitability, innovation, customer satisfaction,
End to End Solution to Accelerate Data Warehouse Optimization Franco Flore Alliance Sales Director - APJ Big Data Is Driving Key Business Initiatives Increase profitability, innovation, customer satisfaction,
ISSN: 2320-1363 CONTEXTUAL ADVERTISEMENT MINING BASED ON BIG DATA ANALYTICS
 CONTEXTUAL ADVERTISEMENT MINING BASED ON BIG DATA ANALYTICS A.Divya *1, A.M.Saravanan *2, I. Anette Regina *3 MPhil, Research Scholar, Muthurangam Govt. Arts College, Vellore, Tamilnadu, India Assistant
CONTEXTUAL ADVERTISEMENT MINING BASED ON BIG DATA ANALYTICS A.Divya *1, A.M.Saravanan *2, I. Anette Regina *3 MPhil, Research Scholar, Muthurangam Govt. Arts College, Vellore, Tamilnadu, India Assistant
SEO 360: The Essentials of Search Engine Optimization INTRODUCTION CONTENTS. By Chris Adams, Director of Online Marketing & Research
 SEO 360: The Essentials of Search Engine Optimization By Chris Adams, Director of Online Marketing & Research INTRODUCTION Effective Search Engine Optimization is not a highly technical or complex task,
SEO 360: The Essentials of Search Engine Optimization By Chris Adams, Director of Online Marketing & Research INTRODUCTION Effective Search Engine Optimization is not a highly technical or complex task,
Beyond Web Application Log Analysis using Apache TM Hadoop. A Whitepaper by Orzota, Inc.
 Beyond Web Application Log Analysis using Apache TM Hadoop A Whitepaper by Orzota, Inc. 1 Web Applications As more and more software moves to a Software as a Service (SaaS) model, the web application has
Beyond Web Application Log Analysis using Apache TM Hadoop A Whitepaper by Orzota, Inc. 1 Web Applications As more and more software moves to a Software as a Service (SaaS) model, the web application has
How To Use Big Data For Telco (For A Telco)
") ON-LINE VIDEO ANALYTICS EMBRACING BIG DATA David Vanderfeesten, Bell Labs Belgium ANNO 2012 YOUR DATA IS MONEY BIG MONEY! Your click stream, your activity stream, your electricity consumption, your call
ON-LINE VIDEO ANALYTICS EMBRACING BIG DATA David Vanderfeesten, Bell Labs Belgium ANNO 2012 YOUR DATA IS MONEY BIG MONEY! Your click stream, your activity stream, your electricity consumption, your call
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon [email protected] [email protected] XLDB
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon [email protected] [email protected] XLDB
Hadoop Beyond Hype: Complex Adaptive Systems Conference Nov 16, 2012. Viswa Sharma Solutions Architect Tata Consultancy Services
 Hadoop Beyond Hype: Complex Adaptive Systems Conference Nov 16, 2012 Viswa Sharma Solutions Architect Tata Consultancy Services 1 Agenda What is Hadoop Why Hadoop? The Net Generation is here Sizing the
Hadoop Beyond Hype: Complex Adaptive Systems Conference Nov 16, 2012 Viswa Sharma Solutions Architect Tata Consultancy Services 1 Agenda What is Hadoop Why Hadoop? The Net Generation is here Sizing the
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
KNIME & Avira, or how I ve learned to love Big Data
 KNIME & Avira, or how I ve learned to love Big Data Facts about Avira (AntiVir) 100 mio. customers Extreme Reliability 500 employees (Tettnang, San Francisco, Kuala Lumpur, Bucharest, Amsterdam) Company
KNIME & Avira, or how I ve learned to love Big Data Facts about Avira (AntiVir) 100 mio. customers Extreme Reliability 500 employees (Tettnang, San Francisco, Kuala Lumpur, Bucharest, Amsterdam) Company
Big Data Analytics Platform @ Nokia
 Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Ubuntu and Hadoop: the perfect match
 WHITE PAPER Ubuntu and Hadoop: the perfect match February 2012 Copyright Canonical 2012 www.canonical.com Executive introduction In many fields of IT, there are always stand-out technologies. This is definitely
WHITE PAPER Ubuntu and Hadoop: the perfect match February 2012 Copyright Canonical 2012 www.canonical.com Executive introduction In many fields of IT, there are always stand-out technologies. This is definitely
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
... ... PEPPERDATA OVERVIEW AND DIFFERENTIATORS ... ... ... ... ...
 ..................................... WHITEPAPER PEPPERDATA OVERVIEW AND DIFFERENTIATORS INTRODUCTION Prospective customers will often pose the question, How is Pepperdata different from tools like Ganglia,
..................................... WHITEPAPER PEPPERDATA OVERVIEW AND DIFFERENTIATORS INTRODUCTION Prospective customers will often pose the question, How is Pepperdata different from tools like Ganglia,
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
WHAT S NEW IN SAS 9.4
 WHAT S NEW IN SAS 9.4 PLATFORM, HPA & SAS GRID COMPUTING MICHAEL GODDARD CHIEF ARCHITECT SAS INSTITUTE, NEW ZEALAND SAS 9.4 WHAT S NEW IN THE PLATFORM Platform update SAS Grid Computing update Hadoop support
WHAT S NEW IN SAS 9.4 PLATFORM, HPA & SAS GRID COMPUTING MICHAEL GODDARD CHIEF ARCHITECT SAS INSTITUTE, NEW ZEALAND SAS 9.4 WHAT S NEW IN THE PLATFORM Platform update SAS Grid Computing update Hadoop support
Hadoop Scalability at Facebook. Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011
 YaC, Moscow, September 19, 2011") Hadoop Scalability at Facebook Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
Hadoop Scalability at Facebook Dmytro Molkov ([email protected]) YaC, Moscow, September 19, 2011 How Facebook uses Hadoop Hadoop Scalability Hadoop High Availability HDFS Raid How Facebook uses Hadoop Usages
ANALYTICS CENTER LEARNING PROGRAM
 Overview of Curriculum ANALYTICS CENTER LEARNING PROGRAM The following courses are offered by Analytics Center as part of its learning program: Course Duration Prerequisites 1- Math and Theory 101 - Fundamentals
Overview of Curriculum ANALYTICS CENTER LEARNING PROGRAM The following courses are offered by Analytics Center as part of its learning program: Course Duration Prerequisites 1- Math and Theory 101 - Fundamentals
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected]
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee [email protected] [email protected] Hadoop, Why? Need to process huge datasets on large clusters of computers
ASAM ODS, Peak ODS Server and openmdm as a company-wide information hub for test and simulation data. Peak Solution GmbH, Nuremberg
 ASAM, and as a company-wide information hub for test and simulation data Peak Solution GmbH, Nuremberg Overview ASAM provides for over a decade a standard, that has proven itself as a reliable basis for
ASAM, and as a company-wide information hub for test and simulation data Peak Solution GmbH, Nuremberg Overview ASAM provides for over a decade a standard, that has proven itself as a reliable basis for
Big Data on Microsoft Platform
 Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data? Definition # 1: Big Data Definition Forrester Research
 Big Data Big Data? Definition # 1: Big Data Definition Forrester Research Big Data? Definition # 2: Quote of Tim O Reilly brings it all home: Companies that have massive amounts of data without massive
Big Data Big Data? Definition # 1: Big Data Definition Forrester Research Big Data? Definition # 2: Quote of Tim O Reilly brings it all home: Companies that have massive amounts of data without massive
Talend Real-Time Big Data Sandbox. Big Data Insights Cookbook
 Talend Real-Time Big Data Talend Real-Time Big Data Overview of Real-time Big Data Pre-requisites to run Setup & Talend License Talend Real-Time Big Data Big Data Setup & About this cookbook What is the
Talend Real-Time Big Data Talend Real-Time Big Data Overview of Real-time Big Data Pre-requisites to run Setup & Talend License Talend Real-Time Big Data Big Data Setup & About this cookbook What is the
COSC 6397 Big Data Analytics. 2 nd homework assignment Pig and Hive. Edgar Gabriel Spring 2015
 COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
COSC 6397 Big Data Analytics 2 nd homework assignment Pig and Hive Edgar Gabriel Spring 2015 2 nd Homework Rules Each student should deliver Source code (.java files) Documentation (.pdf,.doc,.tex or.txt
Intel HPC Distribution for Apache Hadoop* Software including Intel Enterprise Edition for Lustre* Software. SC13, November, 2013
 Intel HPC Distribution for Apache Hadoop* Software including Intel Enterprise Edition for Lustre* Software SC13, November, 2013 Agenda Abstract Opportunity: HPC Adoption of Big Data Analytics on Apache
Intel HPC Distribution for Apache Hadoop* Software including Intel Enterprise Edition for Lustre* Software SC13, November, 2013 Agenda Abstract Opportunity: HPC Adoption of Big Data Analytics on Apache
CRITEO INTERNSHIP PROGRAM 2015/2016
 CRITEO INTERNSHIP PROGRAM 2015/2016 A. List of topics PLATFORM Topic 1: Build an API and a web interface on top of it to manage the back-end of our third party demand component. Challenge(s): Working with
CRITEO INTERNSHIP PROGRAM 2015/2016 A. List of topics PLATFORM Topic 1: Build an API and a web interface on top of it to manage the back-end of our third party demand component. Challenge(s): Working with
Cloud Platforms, Challenges & Hadoop. Aditee Rele Karpagam Venkataraman Janani Ravi
 Cloud Platforms, Challenges & Hadoop Aditee Rele Karpagam Venkataraman Janani Ravi Cloud Platform Models Aditee Rele Microsoft Corporation Dec 8, 2010 IT CAPACITY Provisioning IT Capacity Under-supply
Cloud Platforms, Challenges & Hadoop Aditee Rele Karpagam Venkataraman Janani Ravi Cloud Platform Models Aditee Rele Microsoft Corporation Dec 8, 2010 IT CAPACITY Provisioning IT Capacity Under-supply
BIG DATA TECHNOLOGY. Hadoop Ecosystem
 BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
Advanced Big Data Analytics with R and Hadoop
 REVOLUTION ANALYTICS WHITE PAPER Advanced Big Data Analytics with R and Hadoop 'Big Data' Analytics as a Competitive Advantage Big Analytics delivers competitive advantage in two ways compared to the traditional
REVOLUTION ANALYTICS WHITE PAPER Advanced Big Data Analytics with R and Hadoop 'Big Data' Analytics as a Competitive Advantage Big Analytics delivers competitive advantage in two ways compared to the traditional
Oracle Big Data Spatial & Graph Social Network Analysis - Case Study
 Oracle Big Data Spatial & Graph Social Network Analysis - Case Study Mark Rittman, CTO, Rittman Mead OTN EMEA Tour, May 2016 [email protected] www.rittmanmead.com @rittmanmead About the Speaker Mark
Oracle Big Data Spatial & Graph Social Network Analysis - Case Study Mark Rittman, CTO, Rittman Mead OTN EMEA Tour, May 2016 [email protected] www.rittmanmead.com @rittmanmead About the Speaker Mark
ORACLE DATABASE 10G ENTERPRISE EDITION
 ORACLE DATABASE 10G ENTERPRISE EDITION OVERVIEW Oracle Database 10g Enterprise Edition is ideal for enterprises that ENTERPRISE EDITION For enterprises of any size For databases up to 8 Exabytes in size.
ORACLE DATABASE 10G ENTERPRISE EDITION OVERVIEW Oracle Database 10g Enterprise Edition is ideal for enterprises that ENTERPRISE EDITION For enterprises of any size For databases up to 8 Exabytes in size.
Unified Batch & Stream Processing Platform
 Unified Batch & Stream Processing Platform Himanshu Bari Director Product Management Most Big Data Use Cases Are About Improving/Re-write EXISTING solutions To KNOWN problems Current Solutions Were Built
Unified Batch & Stream Processing Platform Himanshu Bari Director Product Management Most Big Data Use Cases Are About Improving/Re-write EXISTING solutions To KNOWN problems Current Solutions Were Built
Cisco Data Preparation
 Data Sheet Cisco Data Preparation Unleash your business analysts to develop the insights that drive better business outcomes, sooner, from all your data. As self-service business intelligence (BI) and
Data Sheet Cisco Data Preparation Unleash your business analysts to develop the insights that drive better business outcomes, sooner, from all your data. As self-service business intelligence (BI) and
Analytics on Spark & Shark @Yahoo
 Analytics on Spark & Shark @Yahoo PRESENTED BY Tim Tully December 3, 2013 Overview Legacy / Current Hadoop Architecture Reflection / Pain Points Why the movement towards Spark / Shark New Hybrid Environment
Analytics on Spark & Shark @Yahoo PRESENTED BY Tim Tully December 3, 2013 Overview Legacy / Current Hadoop Architecture Reflection / Pain Points Why the movement towards Spark / Shark New Hybrid Environment
Virtualizing Apache Hadoop. June, 2012
 June, 2012 Table of Contents EXECUTIVE SUMMARY... 3 INTRODUCTION... 3 VIRTUALIZING APACHE HADOOP... 4 INTRODUCTION TO VSPHERE TM... 4 USE CASES AND ADVANTAGES OF VIRTUALIZING HADOOP... 4 MYTHS ABOUT RUNNING
June, 2012 Table of Contents EXECUTIVE SUMMARY... 3 INTRODUCTION... 3 VIRTUALIZING APACHE HADOOP... 4 INTRODUCTION TO VSPHERE TM... 4 USE CASES AND ADVANTAGES OF VIRTUALIZING HADOOP... 4 MYTHS ABOUT RUNNING
L1: Introduction to Hadoop
 L1: Introduction to Hadoop Feng Li [email protected] School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
L1: Introduction to Hadoop Feng Li [email protected] School of Statistics and Mathematics Central University of Finance and Economics Revision: December 1, 2014 Today we are going to learn... 1 General
The Future of Data Management
 The Future of Data Management with Hadoop and the Enterprise Data Hub Amr Awadallah (@awadallah) Cofounder and CTO Cloudera Snapshot Founded 2008, by former employees of Employees Today ~ 800 World Class
The Future of Data Management with Hadoop and the Enterprise Data Hub Amr Awadallah (@awadallah) Cofounder and CTO Cloudera Snapshot Founded 2008, by former employees of Employees Today ~ 800 World Class
White Paper. How to Achieve Best-in-Class Performance Monitoring for Distributed Java Applications
 White Paper How to Achieve Best-in-Class Performance Monitoring for Distributed Java Applications July / 2012 Introduction Critical Java business applications have been deployed for some time. However,
White Paper How to Achieve Best-in-Class Performance Monitoring for Distributed Java Applications July / 2012 Introduction Critical Java business applications have been deployed for some time. However,
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/